Abstract
While significant progress has been made to implement the Digital Earth vision, current implementation only makes it easy to integrate and share spatial data from distributed sources and has limited capabilities to integrate data and models for simulating social and physical processes. To achieve effectiveness of decision-making using Digital Earth for understanding the Earth and its systems, new infrastructures that provide capabilities of computational simulation are needed. This paper proposed a framework of geospatial semantic web-based interoperable spatial decision support systems (SDSSs) to expand capabilities of the currently implemented infrastructure of Digital Earth. Main technologies applied in the framework such as heterogeneous ontology integration, ontology-based catalog service, and web service composition were introduced. We proposed a partition-refinement algorithm for ontology matching and integration, and an algorithm for web service discovery and composition. The proposed interoperable SDSS enables decision-makers to reuse and integrate geospatial data and geoprocessing resources from heterogeneous sources across the Internet. Based on the proposed framework, a prototype to assist in protective boundary delimitation for Lunan Stone Forest conservation was implemented to demonstrate how ontology-based web services and the services-oriented architecture can contribute to the development of interoperable SDSSs in support of Digital Earth for decision-making.
1. Introduction
The concept of Digital Earth as a mechanism for integrating data from multiple sources has been put forward for more than 10 years (Gore Citation1998), and significant progress has been made to implement the Digital Earth systems (Guo Citation1999; Citation2008, Ehlers Citation2008, Foresman Citation2008, Yang et al. Citation2008, Nativi and Domenico Citation2009). For example, in China a variety of prototype systems of Digital Earth have been implemented (Cheng et al. Citation2000, Li Citation2001, Li and Lin Citation2001, Chen and Wu Citation2003, Guo et al. Citation2009). The recently available geo-browsers such as Google Earth, NASA World Wind, Microsoft Virtual Earth, and ESRI ArcGIS Explorer have got spatial and non-spatial data into the hands of millions of citizens, NGOs, businesses, and governments, with a friendly graphic interface. The Digital Earth prowess has spread to a variety of applications such as disaster predictions, environmental monitoring and assessments (Guo et al. Citation2009). Although the advances in computer architecture and network design as well as the growth of the World Wide Web (WWW) now permit the share and management of gigabytes to terabytes of data for Digital Earth, the currently implemented infrastructure of Digital Earth has limited capabilities to provide model/simulation functions to scientists, decision-makers, and the general public for understanding the Earth and its physical, natural, and social science knowledge systems. Thus the ambitious vision of Digital Earth concerning the simulation of social and environmental phenomena remains almost entirely unrealized (Goodchild Citation2008).
However, it is possible to allow modeling and simulation to be implemented in the Digital Earth system to help solve a semi-structured spatial decision problem, and it is also possible to implement the mechanisms that would allow users to search for, access, and execute suitable data and simulation models to support effectiveness of decision-making (Crosier et al. Citation2003). The objective of this paper is to propose a framework of geospatial semantic web-based spatial decision support system (SDSS) in support of Digital Earth to access and share geospatial data and simulation models for tackling complex and ill-defined spatial decision problems. Besides the data sharing and integration capabilities, the proposed framework adds modeling and analytic capabilities, which are almost completely absent in currently implemented Digital Earth systems. The proposed framework is based on Geospatial Semantic Web technologies and the previous work on SDSS in GIS literature. In fact, many spatial decision support systems (SDSSs) have been developed for environmental and natural resource decision-making (e.g. Armstrong Citation1993, Jankowski et al. Citation1997; Citation2001). However, an important limitation of the SDSS applications is that they are not interoperable (Casey and Austin Citation2002, Rinner Citation2003, Ostländer Citation2004, Wang et al. Citation2004, Bhargava et al. Citation2007) and many developed SDSSs are not easily reusable (Goodchild and Glennon Citation2008).
Although in IT and internet GIS fields, automatic web service discovery and composition for geospatial data sharing have been explored in literature using geospatial semantic technology, most of the studies focus on discovering semantically annotated data (e.g. Zhang et al. Citation2007; Citation2009, Zhao et al. Citation2008). According to our knowledge, no paper has been published about how to design and implement a workable interoperable SDSS based on geospatial semantic technologies for decision-making. Although many projects have been funded for semantically enabled SDSSs, such as the SWING project (http://www.swing-project.org) and its predecessors – the DIP project (http://dip.semanticweb.org/) and SEKT project (http://www.sekt-project.com/), semantically enabled SDSSs are still at the initial research stage. Practical and novel techniques, methods, and systems for spatial data and geoprocessing sharing at the semantic level are needed. This paper proposed an interoperable SDSS based on geospatial semantic web technologies in support of Digital Earth for better decision-making and policy formulation. The proposed framework should enable decision-makers to reuse and integrate geospatial data and geoprocessing for Digital Earth from heterogeneous sources across the Internet. Based on the proposed framework, a prototype has been implemented to demonstrate how geospatial semantic technologies contribute to the development of interoperable SDSSs in support of Digital Earth for informing and engaging the public to participate effectively in the decision-making process and helping authorities to make better decisions. The implemented prototype addressed how to find and integrate existing heterogeneous data at the semantic level from diverse sources.
2. Proposed framework
A framework of an interoperable SDSS based on the geospatial semantic web technologies for Digital Earth is proposed as shown in . The main objectives of the framework are: (a) to enable geospatial data and geoprocessing sharing at the semantic level over the web; (b) to maximize productivity and efficiency with geospatial data and geoprocessing sharing; (c) to overcome data duplication and data maintenance problems; and (d) to make it easy to integrate with other SDSS applications. The framework is based on independent geospatial semantic web services and the service-oriented architecture (SOA). The SOA-based framework is composed of four elements: service provider, service broker, service client, and ontology server. illustrates the four components of the proposed framework in the logic universe. Service provider supplies heterogeneous geoprocessing and geospatial data from disparate sources via OGC Web Processing Services (WPS) and data services such as Web Feature Services (WFS), Web Map Services (WMS), and Web Coverage Services (WCS). The decision geoprocessing services and data services can be chained to build specific spatial decision support services. Service client helps decision-makers display and manage data services and access decision processing services to generate and evaluate alternative solutions to semi-structured spatial problems. Service broker provides a registry for available services. Service broker uses ontology-based semantic Catalog Services (CS) to register and manage the data and processing services and to allow users to search for these services at the semantic level. The ontology server ensures the semantic interoperability of the ontologies of service clients and providers. The web services are connected via Web Service Description Language (WSDL) and OWL-S among the service provider, the service broker and the service client. The Simple Object Access Protocol (SOAP) binding over HTTP is employed for communication between web services via the Internet. In the following sections, we introduce the main advanced technologies applied in the framework such as heterogeneous ontology integration, ontology-based catalog services, and web service composition.
Figure 1. Framework of the proposed interoperable SDSS based on geospatial semantic technologies.
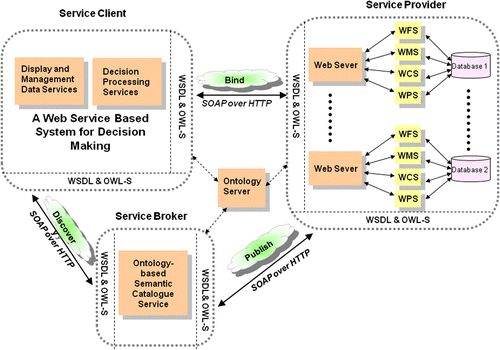
Figure 2. Service components of geospatial semantic Web in the logic universe.
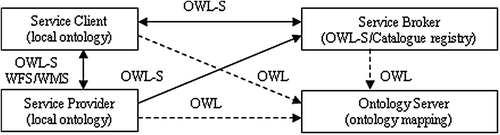
2.1 Heterogeneous ontology integration
Unlike traditional web services, our service clients and providers must maintain local ontology at both the client side and the provider side to ensure the semantic interoperability. Local ontology at the service client refers to semantics used by the client user or client applications, while local ontology at the service provider refers to semantics used by the service providers. These local ontologies may address geospatial relations such as topological relations (e.g. connectivity, adjacency, and intersection among geospatial objects), cardinal directions (e.g. east, west, and northeast), and proximity relations (e.g. the geographical distances among objects). The client ontology must be able to communicate with the provider ontology. However, the ontologies created by the client and the provider may not match well, thus heterogeneity problems may arise. Moreover, a service client may need to access multiple providers to complete a task. Thus, it is necessary to create mappings of equivalent or related classes and properties in the local ontologies. The ontology server is used to realize this function and it keeps a taxonomy of geospatial terminologies and maintains consistency for different local ontologies. The local ontologies developed by the clients and providers have to be mapped to the ontologies in the ontology server.
The state-of-the-art of ontology and schema alignment methodologies was recently surveyed by Shvaiko and Euzenat (Citation2005). Many software tools have been developed for merging ontologies such as Chimaera (McGuinness et al. Citation2000), Falcon-AO (Jian et al. Citation2005), MapOnto (An et al. Citation2005). Although in IT literature, algorithms and tools have been proposed to resolve the problem of heterogeneous ontology integration (e.g. Doan et al. Citation2004, Noy Citation2004, Ashpole et al. Citation2005, Giunchiglia et al. Citation2005; Citation2008, Castano et al. Citation2006, Tang et al Citation2006, Hu et al. Citation2008), they are not developed for dealing with spatial data. Some solutions to the geographic ontology matching problem haven been suggested recently (Cruz et al. Citation2007, Euzenat and Shvaiko Citation2007, Cruz and Sunna Citation2008, Janowicz et al. Citation2008, Vaccari et al. Citation2009). Hess et al. (Citation2006; Citation2007a; Citation2007b) recently proposed the G-Match algorithm for geographic ontology integration. To match and integrate two different geographic ontologies, the G-algorithm measures overall similarity Sim(C 1, C 2) of their concepts by combining similarity measure of concept names, attributes, taxonomies, and conventional as well as topological relationships in a weighted sum. The G-Algorithm rejects a matching of two ontology classes if the overall similarity measure is below a predetermined threshold. One problem with this approach is that classes or properties with very similar names could be considered equivalent even though they are not in reality or they are not compatible in structure so that translation is impossible. Also, this approach does not consider the range types of relations in computing their similarity. In the proposed SDSS framework, we developed a partition-refinement algorithm for mapping local ontology and server ontology.
Definition 1. An ontology consists of a set of classes and properties. A property can be a datatype property with the range of a primitive type or an object property that relates two class instances.
Given two ontologies – local ontology O 1 and sever ontology O 2 , ontology mapping is defined as for each concept C 1 =(T 1 , A 1 , R 1 ) in local ontology O 1 , finding a corresponding concept C 2 =(T 2 , A 2 , R 2 ), which has the same or similar semantics, in sever ontology O 2 where C i is the class (or concept) in ontology O i , T i is the name of C i , A i is the set of datatype properties (or attributes) of C i , R i is the set of object properties (or relations) of C i including spatial relations, and i=1, 2.
When comparing two ontologies for similar classes and properties, we do not have to distinguish which ontology the classes and properties belong to. So in the proposed partition-refinement algorithm, first we pool all classes and properties from the two ontologies together to form equivalence partition P={p1, p2,…, pn}, where pi is a set of concepts or properties that are considered equivalent. Then we compute equivalence relation based on similarity measures. Because a partition usually contains classes or properties that are similar but not exactly equivalent, we will adjust the similarity measure to refine the partition if necessary. Our similarity measure uses a structural equivalence as defined below.
Definition 2. Ontology classes C 1 and C 2 are structurally equivalent if there is a one-to-one correspondence of structurally equivalent datatype properties between attr(C 1 ) and attr(C 2 ), and there is one-to-one correspondence of structurally equivalent object properties between rel(C 1 ) and rel(C 2 ), where attr(C i ) is the set of datatype properties of C i and rel(C i ) is the set of object properties of C i , for i=1, 2.
A datatype property a1 is structurally equivalent to another datatype property a2 if they have the same range type.
An object property r1 is structurally equivalent to another object property r2 if there is a one-to-one correspondence of structurally equivalent classes between range(r1) and range(r2), where range(ri) is the set of range types of ri, for i=1, 2.
Since there are only a few primitive types, many datatype properties could have the same range types. Name similarity measure is applied to distinguish different datatype properties. Name similarity can be computed with the help of WordNet to find synonyms. Name similarity can be considered for object properties and classes as well but in this case we need to find structurally equivalent object properties and classes first, and then apply the name similarity measure if too many equivalent classes or properties are found.
Our name similarity measure is based on a reduced form of the string comparison measure (Stoilos et al. Citation2005). The similarity of two strings s1 and s2 is Sim(s1, s2)=Comm(s1, s2)-Diff(s1, s2), where Comm(s1, s2) measures the total length of the maximum common substrings of s1 and s2 divided by the total length of s1 and s2, and Diff(s1, s2) is a function of the length of unmatched substrings of s1 and s2 scaled by the length of s1 and s2, respectively. Comm(s1, s2) and Diff(s1, s2) range between 0 and 1. Thus, the similarity value ranges from −1 and 1. The threshold of accepting similar pairs of names can be chosen between 0 and 1 but it needs to be adjusted based on actual data.
We also consider the spatial characteristics of ontology classes to find initial partitions. In particular, we infer the geometry type of an ontology class to determine whether it is Point, LineString, Polygon, MultiPoint, MultiPolygon, or GeomCollection. Given a geometry ontology class and its instances, it is possible to distinguish its geometry type based on its spatial contents. For example, a Point class has at most a pair of x, y coordinates while other geometries have multiple pairs of such coordinates. LineString and MultiPoint geometries are different from Polygon because the latter one must form a closed loop. MultiPolygon and GeomCollection are different from the rest because they must use delimiters to contain multiple geometries while MultiPolygon contains only one type of geometries and GeomCollection includes various kinds of geometries. Only LineString and MultiPoint cannot be easily distinguished since both contai n a sequence of points. So they are assigned to the same initial partition and need to be separated using partition refinement algorithm. Another kind of spatial characteristics that we consider is spatial relations that include within, overlap, contain, touch, intersect, disjoint, cross, and equal. Though the spatial relations may be computed, sometimes they are specified in ontology as well to improve performance. In ontology, these relations are treated as object properties. To identify them, we use name comparison and also utilize spatial constraints to eliminate properties that cannot be spatial related. For example, if we let P be point, L be line, and A be polygon, then the within relation applies to P/L, P/A, L/L, L/A, and A/A groups of relationships and the cross relation applies to P/L, P/A, L/L, and L/A situations. Once we identified spatial relations, we replace within relation with within-1 by switching its domain and range. The notation within-1 represents a property similar to within but with its domain and range reversed and it is considered equivalent to contain. Also, since intersect is more general than overlap, we allow them to be matched in ontology alignment.
The following are the partition-refinement algorithm we developed for mapping local ontology and server ontology in the proposed SDSS framework:
Partition-refinement Algorithm:
Input: A set of classes, datatype properties, and object properties.
Output: Partitions of classes P C , object properties P R , and datatype properties P A , where each partition in P C contains equivalent classes and each partition in P A (P R ) contains equivalent datatype (object) properties.
Step 1, initialization:
-
Divide the set of datatype properties into P A where each partition in P A contains datatype properties with similar names and the same range type.
-
Put the set of object properties into P R with only one partition.
-
Divide the set of classes into P C such that C 1, C 2 is in a partition in P C if and only if for each partition P in P A ,|p⋂ attr(C 1)| = |P ⋂ attr(C 2)|, where |P ⋂ attr (Ci )|, is the size of the set P ⋂ attr (Ci ).
Step 2, partition refinement:
-
Refine P R such that r 1, r 2 are in a partition in P R , if and only if for each partition P in P C, |P ⋂ range(r 1)| = |P ⋂ range(r 2)|.
-
Refine P C such that C 1, C 2 are in a partition in P C , if and only if for each partition P in P R , |P ⋂ rel(C 1)| = |P ⋂ rel(C 2)|.
Step 3, repeat Step 2 until P R and P C stabilize.
Step 4, refine P C and P R even further based on the name similarity of the classes and object properties. If this step results in any changes, then go back to Step 2.
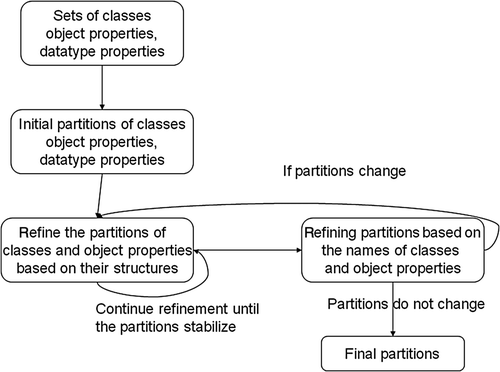
illustrates the process of finding equivalent ontology classes and properties according to the algorithm shown above. First, we pool all sets of classes, object properties, and datatype properties from both local and server ontologies. Then we initialize partitions of classes, object properties, datatype properties to form equivalence partition. After that we first refine the partitions of classes and object properties based on their structure. If too many equivalent classes and object properties are found, we refine the partitions based on names of classes and object properties. The refinement process will be continued until the partitions become stable. Finally we obtain the final stable partitions, which will not change and are considered to be equivalent ontology classes and properties.
Figure 3. The process of finding equivalent ontology classes and properties through partitioning refinement.
The above algorithm always terminates since each iteration splits at least one set in the partitions of classes or object properties. This problem is similar to finding structurally equivalent recursive types for object-oriented programming languages and the time complexity was shown to be N log N, where N is the total number of classes and properties (Jha et al. Citation2002).
Note that the partition refinement step can be adjusted to allow a partition to include more (or less) similar classes or properties. For example, instead of requiring |P ⋂ rel (C 1)| = |P ⋂ rel (C 2)| for the refinement of class partitions, we can require only |P ⋂ rel (C 1)| ≈ |P ⋂ rel (C 2)|, where ≈ is approximately equal so that two classes are structurally equivalent if they contain approximately the same number of equivalent object properties (e.g. within 1 or 2).
The main advantage of the proposed partition refinement algorithm over G-Algorithm is that it finds matching ontology classes and properties based on their structures. Unlike the G-Algorithm that heavily relies on string-based similarity measure, the partition-refinement algorithm makes full use of the structures of the ontologies being mapped. Thus, it allows translation of instances between local ontology and server ontology. Further, the partition-refinement algorithm can deal with recursive structure efficiently while G-Algorithm cannot. We know that ontology classes may form recursive data structure where, for example, a class A may have object property with range of another class B, which may include a property that points back to class A. While the partition-refinement algorithm can find matching classes with this recursive structure efficiently, G-Algorithm is unable to deal with recursively defined ontology classes. This is due to the fact that G-Algorithm uses a top-down approach to compute similarity scores between two classes (or concepts) using their names, datatype properties (attributes), and object properties (relations). Because G-Algorithm needs to compute the similarity for object properties first before deciding whether classes can be matched, thus it is unable to deal with recursively defined ontology classes. Another problem with the G-Algorithm approach is that the threshold values are hard to determine and so are the weights assigned to different components of the score. If the weight for name similarity is too high, then it is likely that the matched ontology classes could be semantically different but they just have similar names by accident while classes with different names but similar semantics are not matched. Thus, the G-Algorithm fails to discover some correct mappings when the mapped ontologies are syntactically dissimilar. Our algorithm, however, can overcome this shortcoming and may discover meaningful and syntactically unidentifiable mappings. Note that our algorithm also considers names, especially for datatype properties since their range types are very limited. However, the class and object property names are secondary to their structures. The names can be used when too many matches are found.
2.2 Ontology-based catalog services
The service broker uses the ontology server to map the standard OGC catalog services to ontology-based catalog services. By binding the diverse systems together in a common ontology through defining a common semantic meaning of web services, the ontology-based catalog can explicitly specify traditional web services at semantic level and supports automatic discovery, composition, invocation, and orchestration of these data services. Unlike the traditional service broker such as the OGC catalog service that enables discovery and retrieval of metadata, the ontology-based catalog service in the framework provides searchable repositories of service descriptions at semantic level and allows users directly searching and accessing geospatial information based on semantic content. Thus, instead of providing resource-based metadata that describes services and data sets, the ontology-based catalog service can allow users to directly locate, access, and make use of geospatial services and data sets in an open, distributed system.
To facilitate querying the enhanced semantic web services, the ontology-based catalog service build up a knowledge base for automatic service matching using a DL-based reasoner and inference rules. Description Logics are a well-known family of knowledge representation formalisms. They are based on the notion of concepts (unary predicates, classes) and roles (binary relations), and are mainly characterized by constructors that allow complex concepts and roles to be built from atomic ones. The main benefit from using the DL-based reasoner is that it can solve the subsumption (subconcept/superconcept) and satisfiability (consistency) problems that often exist in the presenting data. A DL reasoner can check whether two concepts equal, satisfy (consist) or subsume each other. Based on the decision-making problem and goals of the SDSS and the available web services, a set of inference rules are defined and linked to classes and properties in OWL ontologies. The inference rules are built on top of OWL and offer enhanced representation and reasoning capabilities. They play an important role in ontology-based catalog service and can be used to further deduce knowledge and combine information, e.g. derive object properties based on the datatype properties.
One of the characteristics of the DL-based reasoner and inference rules is that it enables systems built on it to infer implicitly represented knowledge from the knowledge that is explicitly contained in the knowledge base. To infer implicitly represented knowledge, the following two axioms are applied:
Terminological axioms. C, D are concepts and R, S are roles, C⊆D (R⊆S) is called an inclusion axiom, which means that concept C is more specific than D, e.g. C subsumes D, and C≡D (R≡S) is called an equivalence axiom, which means C and D are equivalent and is an abbreviation of the pair of axioms C⊆D and C⊇D.
By using the DL and inference rules, the proposed SDSS framework facilitates knowledge sharing and reuse via automatic machine processing. With the knowledge reasoning based on DL and inference rules, SDSS programs can understand the meaning or relationship of spatial web services and automatically process them. Through sufficiently detailed definitions and captured semantics of web services, the proposed framework can serve as a basis for detecting semantically similar information and support complex decision-making.
2.3 Web service composition
To utilize web services effectively, users have to analyze service features and evaluate their applicability to the task at hand dynamically. Sometimes they may need to dynamically bind component services or invoke these component services in a certain sequence at run-time to complete a personal need. The dynamic nature of the availability of web services, the large number of alternative combinations of service choices, and real-time requirements on service composition make the development of an integrated framework for the web service-based SDSS a formidable task. In the proposed framework, two steps are needed in facilitating dynamic service composition: first, based on the user's request, locate possible services based on adequate descriptions. The rich semantics added to web service descriptions by OWL-S enable semantic composition by matching service capability descriptions at semantic level to requirements. Second, based on the necessary control and data flow constraints among services, develop a service plan to invoke the execution among the services in the correct order. The service plan can be created and updated dynamically and is based on the centralized broker that manages the service composition process. The service plan needs to determine which service requests can be feasibly processed and which requests cannot be fulfilled. When one service cannot satisfy a user's request, the service plan will communicate and cooperate to other services to finish the composition service for the request. Thus, the proposed web service-based interoperable SDSS exhibits the systemic characteristics such as self-organization, evolution, scalability, and adaptability, although each of the web services is not designed to do so.
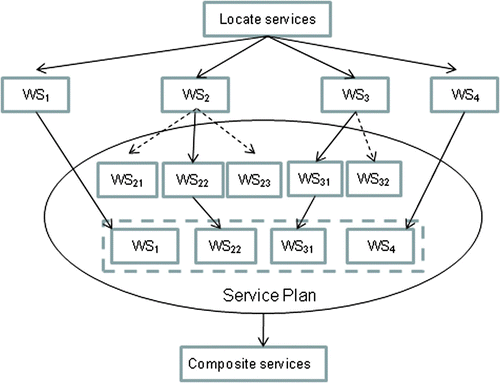
illustrates the web services composition process. It is based on two processes – service discovery process and service composition process. Service discovery is based on semantic service description, and it automatically determines data services and processing services that will precisely fulfill the decision-making needs. If the single data service and processing service cannot be found, the SDSS will search for two or more services that can be composed to synthesize the required service. This is called service composition. The discovery and composition algorithm proposed in the proposed SDSS is illustrated as follows:
Figure 4. Web services composition process.
Algorithm: Service discovery and composition
Input:
SDSS web services that require spatial feature data and provide evaluation results for spatial decision support.
WFS services that provide spatial features
Ontology services that provide ontology definitions for spatial features and criteria for SDSS
A service query Q of spatial decision support
Output: a combination of WFS, ontology web services, and SDSS web services.
Step 1: Take service query Q and consult ontology web services to find the names of SDSS web services that can fulfill the requests of spatial decision.
Step 2: Query SDSS web services to find the spatial features required by the services to compute spatial decision
Step 3: Consult ontology web services again to find the names of the WFS services and their spatial features that are required by the SDSS web services
Step 4: Match the ontology definitions for the spatial features required by SDSS and provided by WFS services.
Step 5: Translate the spatial features provided by WFS services into forms acceptable to SDSS web services
Step 6: Query SDSS web services with the transformed WFS spatial features to obtain results.
As an example, consider a SDSS web service Σ that needs spatial data to compute score function for a spatial feature r based on a number of other spatial features f 1, f 2,…, f n that serve as the decision criteria. We can formulate this web service as a process that accepts spatial features of certain types T 1, T 2,…, T n and return values as a function of another type of spatial feature T r . Assume that an ontology server Ω maintains ontology for these spatial features of the types T 1, T 2,…, T n and T r . Also assume that there are a number of web service providers which can fulfill WFS requests on web features of these types. Then, a service client X interested in spatial decision involving feature type related to T r can search Ω to find compatible ontology classes and use that information to consult web service registries in the ontology-based catalog services to find SDSS web services such as Σ. Also, after learning the spatial feature types needed by Σ, the service client X will need to consult Ω again to find compatible ontology classes for T 1, T 2,…, T n . Then X will query web service registries for services that can provide spatial features needed by Σ. After these spatial features are retrieved, they need to be transformed to types T 1, T 2,…, T n and sent as inputs to Σ. The output of Σ is for the spatial feature type T r , which may also be transformed to a format needed by X.
The SDSS uses domain knowledge to guide the service composition process. The domain knowledge is available from experienced decision-makers or domain experts and is modeled in the formal ontology language OWL. The domain-related OWL ontologies provide an explicit shared conceptualization of the SDSS domain and serve as a conceptual backbone to underpin the service composition framework. The automation of service composition is realized via the service plan. The service plan is domain-specific and problem-dependent. Both semantic service descriptions and domain-specific knowledge are essential for developing the service plan in the SDSS. Semantic service descriptions support effective service discovery, seamless service integration. Domain-specific knowledge can suggest that what should be done next during a service composition process and which service should be chosen once a number of services are discovered. The exact nature of the decision-making problem in the SDSS, the SDSS problem-solving goals, and the performances of the services available decide the selection of a service. The domain-specific knowledge provides advice and guidance with respect to the selection, sequencing and correct configuration of services as part of construction of a workflow specification for the service plan. The service plan is developed dynamically by taking into consideration the characteristics of the complex spatial decision-making problem, service performances and previous computation results.
For example, as illustrated in the SDSS will need four web services – WS1, WS2, WS3, and WS4 to be put together to obtain the desired web service. Using the discovery engine, individual web services that make up the composed service first are selected by using logic-based inference, which relies mainly on concept hierarchies as a means for providing approximately matched web services and ensuring semantic compatibility. Then the found individual web services are split into different parts or kept as a whole service (if the service is the specific parts of the queried service and has hyponym relation with the queried service). Finally, these different parts are integrated into one composed web service, which is the SDSS needed. The service plan determines the workflow of these different parts. In the example shown in , the composite SDSS service is synthesized from a set of available partially matched specific web services – WS1 and WS4, and the split web services – WS22, WS31, which come from the available partially matched generic web services – WS2 and WS3 (has hyponym relation with the queried service).
3. Prototype implementation
3.1 Prototype
The Lunan Stone Forest, or Shilin, is the World's premier pinnacle karst landscape. Located among the plateau karstlands of Yunnan Province, in southwest China, it is widely recognized as the type example of pinnacle karst, demonstrating greater evolutionary complexity and containing a wider array of karren morphologies than any other example (Zhang et al. Citation2005). The area is designated as a national park covering a protected Shilin area of 350 km2, and is organized into three zones with different protection levels. But, not much evaluation work was done when the protected-area boundaries were delimited in 1984. The designation of these boundaries are mainly based on the scenery beautiful values of the Stone Forest Landscape, and it has no relationship with the karst landscape itself or its natural values. Further the boundaries are drawn on a small-scale (1:1,000,000) geological map. They almost have no relationship with the topography characteristics such as road, river, topography line, or geological character. Thus, to a great extent it is even difficult for the administrative officials to know the direction of the boundaries and to find out their exact location, not to say for the public and local residents. This brings difficulty in carrying out the according conservation regulations.
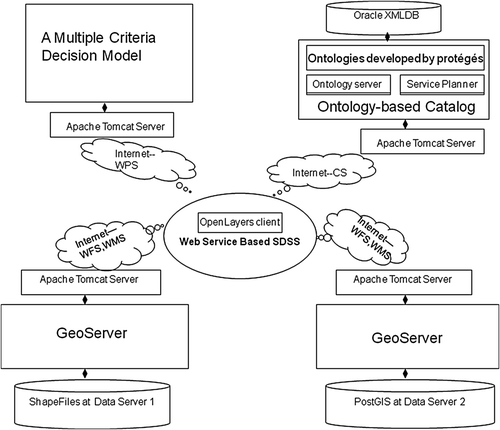
A web-based SDSS for Lunan Stone Forest Conservation has been developed to provide a way to establish rational protective boundaries based on a variety of environmental and social criteria and render the location of the boundaries clear to the public (Zhang et al. Citation2005). While the web-based SDSS has benefited in many ways from Web technologies such as platform-independent, remote, and distributed computation, the developed web-based SDSS was based on traditional Client–Server architecture and was implemented using traditional computer technologies such as Visual Basic 6.0, ESRI Mapobjects 2.1 and ESRI Mapobjects IMS 2.0 and ASP (Active Server Pages) (Zhang et al. Citation2005). Thus, it is not an interoperable SDSS and has limitations for share and reuse of geographical data and geoprocessing although it indeed increased public access to information and involvement in the decision-making processes for protective boundary designation decision-making processes. The objective of this case study is to develop an interoperable SDSS prototype to assist in protective boundary delimitation for Lunan Stone Forest Conservation based on the proposed framework shown in . The interoperable SDSS prototype should facilitate share and reuse of heterogeneous geographical data and geoprocessing over the web, and thus can increase the range and depth of information access and improve the solving of decision problems and the effectiveness of decision-making performance. The prototype covers several components in the proposed framework, such as using OGC WFS and WMS services to access the heterogeneous spatial data connected to legacy GISystems, using OGC WPS to access the multiple-criteria decision model for delimitation of the protected-area boundaries, using ontologies to describe the geographic information, using ontology-based semantic catalog services to register and discover the published WFS, WMS and WPS services, using partition-refinement algorithm to mapping local and server ontologies, and using the proposed discovery and composition algorithm to combine web services. illustrates the architecture of the prototype. The architecture consists of:
-
Data service providers:
-
ESRI ArcGIS and PostGIS, which provide different format spatial data;
-
Geoserver (http://geoserver.sourceforge.net/html/index.php), an open-source software which enables full implementation of the OGC WFS and WMS specifications and serves ShapeFile and PostGIS data using WFSs and WMSs;
-
Apache Tomcat, a Java Servlet container, which hosts the web application GeoServer.
-
-
Web processing service providers:
-
A Multiple Criteria Decision Model to incorporate the interacting biophysical and social-economic criteria such as geology, geomorphology into the delimitation of the protected-area boundaries, which is implemented as WPS using Java;
-
J2EE, the underlying developing environment for the Multiple Criteria Decision Model;
-
Apache Tomcat: a Java Servlet container, which provides access to WPS.
-
-
Service brokers:
-
An ontology server, which maintains consistency for different local ontolgoies and is developed based on Protégé software (http://protege.stanford.edu/).
-
An ontology-based semantic catalog and service planner, which are developed based on ebXML and Java API for XML registries (JAXR).
-
Oracle XMLDB, which provides capabilities for the storage and management of XML data for ontology-based catalog.
-
Apache Tomcat to act as container for the ontology-based catalog.
-
-
Service clients:
-
We implemented the client using OpenLayers library to provide a user-friendly interface for decision-makers to query and access to ontology-based web services such as ontology-based WFS, WMS, WCS, and WPS. OpenLayers is a JavaScript library for rendering maps and features from WFS/WMS servers and other map services from providers such as Google Map and Yahoo Map. Based on OpenLayers library, we implemented the client software. The implemented service client software provides functionalities of querying features from ontology-based WFS servers using OGC filters, retrieving the properties of features selected by mouse actions, and rendering ontology-based WMS maps based on customized style files. Moreover, the implemented service client software supports transactions on ontology-based WFS features that include addition, modification, and removal of features. In contrast to other WFS/WMS client software such as MapBuilder, the implemented client software provides better performance in map rendering and flexibility in editing geometries such as polygon.
-
Figure 5. Architecture of the implemented prototype.
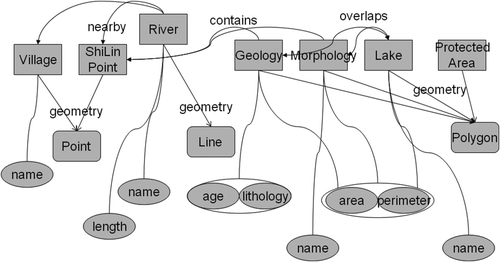
3.2 Ontology alignment
The prototype's ontologies describe the features of the stone forest region. illustrates part of these ontologies where Village and ShiLin_Point are point features; River is a line feature; and Geology, Morphology, Lake, and Protected_Area are polygon features. Most of the object properties are spatial relations such as nearby, contains, and overlaps. One object property – geometry relates spatial features to their geometries. There are a few datatype properties as well. The ranges of properties name, age, and lithology are string. The ranges of length, area, and perimeter are float.
Figure 6. Stone Forest Ontology: squares represent ontology classes, arrows between classes are object properties, ovals represent datatype properties.
There are many ways to define the local ontologies for our prototype. Thus, it is important that we can align similar local ontologies to ontology server automatically. To illustrate how our algorithm can achieve this, we consider a variation of the Stone Forest local ontologies shown in .
Figure 7. A variation of the Stone Forest Ontologies.
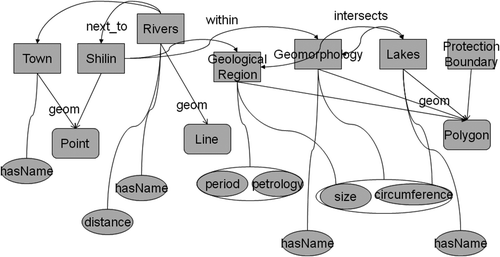
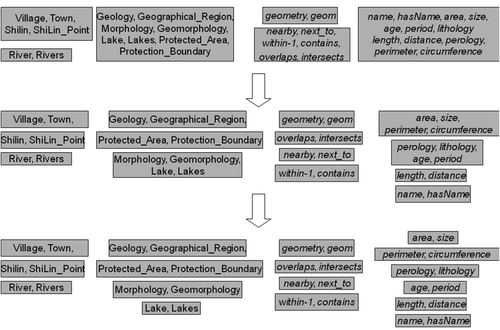
The differences between the two ontology definitions are mostly nominal – the class and property names are different. The object properties are also different by names except for within. Before we apply the partition-refinement algorithm, we reverse the domain and range of within and rename it to within-1. Note that the ontology classes for representing point, line, and polygon are assumed to be the same. We can apply the partition-refinement algorithm to the two ontology definitions as shown in . In the initial partitions, the ontology classes are separate from object properties and datatype properties. Also, ontology classes that refer to different types of geometries are separately into different partitions. After the first iteration of the algorithm, class partitions are split because of the number of the properties that they have. For example, the set of Village, Town, Shilin, and ShiLin_Point is split into two partitions, since Village and Town both have one more property than Shilin and ShiLin_Point. The sets of properties are split into smaller partitions because the domains or ranges of these properties are in different partitions. For example, nearby and next_to are separated from intersect and overlap since the former group has domains of River and Rivers (line features) while the latter has the domains that are polygon features. Also, datatype properties name and hasName are split from the rest because their ranges are string and they do not share domains with other datatype properties. After the second iteration of the algorithm, Morphology and Geomorphology are separated from Lake and Lakes since Morphology and Geomorphology have the properties contain and within-1, which are no longer in the same partition as intersect and overlap. Note that in the last iteration, the properties age and period have to be separated from lithology and perology by some other methods since we cannot tell them apart by domain or range information. We cannot rely on string comparison either since they are very different. In this case, a domain ontology for geographic concepts should be used to find related terms.
Figure 8. The application of the partition-refinement algorithm to the Stone Forest example. Each box represents a partition of classes or properties. The first group is the set of initial partitions. The second and the third groups are partitions after the first and the second iterations of the partition refinement algorithm.
3.3 Some experimental results
shows the interface of the implemented interoperable SDSS for Stone Forest conservation (http://jiangxi.cs.uwm.edu:8080/stone-forest/gis.html. Note: the SDSS works better with Mozilla Firefox than Internet Explorer). Through the prototype, decision-makers can delimit protective boundaries using the multiple-criteria decision model based on a variety of biophysical and social economic criteria by employing ontology-based WFS, WMS, WPS and CS. shows one scenario of two different level protection areas that was delimited by using the prototype system. Note: in the prototype, the criteria data are stored in two different format databases (Shapfile and PostGIS) on two remote servers (http://boyang.cs.uwm.edu:8080/geoserver; http://172.16.1.34). The multiple-criteria decision model and the ontology-based catalog software are held in the remote server (http://172.16.1.34).
Figure 9. The interface of the web service-based SDSS for Stone Forest conservation.
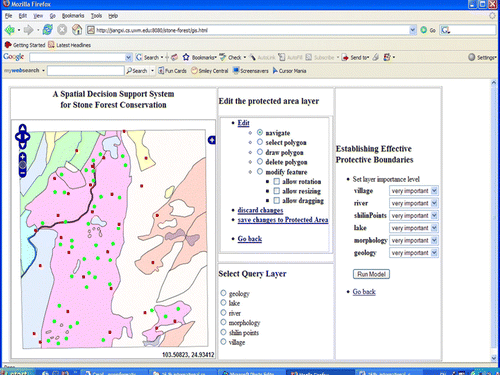
Figure 10. One scenario of two different level protection areas delimited using the prototype system.
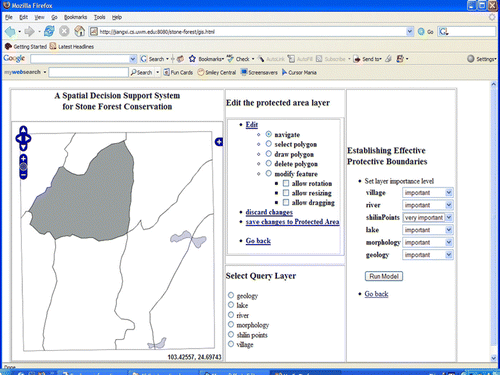
Using the implemented prototype, decision-makers can also render the location of the boundaries clear to the public by aligning them with conspicuous landscape features such as water bodies, roads or buildings via employing WFS, WMS, and CS. The following experimental results demonstrate some advantages of the web services-based prototype SDSS:
-
The prototype system provides decision-makers with the ability to access and analyze heterogeneous criteria data in order to make better decisions for protected-area delimitation. It allows the decision-makers to access the heterogeneous criteria data from a variety of sources on the Internet. The criteria data, such as geology, geomorphology, land use data, are stored in different databases with different formats on separate computers. However, decision-makers can directly access these heterogeneous data sources without having to know specifically who might provide the data and the format of the data. In the implemented prototype decision-makers can seamlessly and dynamically integrate geology data (original in Shapefile format) located at the data server http://boyang.cs.uwm.edu:8080/geoserver and village data (original in PostGIS databases) located at the data server http://172.16.1.34 by invoking the ontology-based WFS and WMS services with little or no knowledge about the heterogeneous environments of the data providers. By seamless data integration the web services-based system not only promotes remote access and potential collaborative decision support applications. It can also reduce development and maintenance costs and minimize data conflicts by avoiding redundant data.
-
The prototype system provides decision-makers with the ability of access and integrating geospatial data services at semantic level from distributed data sources. For example, the Shilin point spatial data used by the SDSS client is composed from two separate WFS web services: in one WFS web service the Shilin point feature is named Yunnan-Shilin, and in another WFS web service it is called StoneForest. Local ontology class Yunnan:Shilin has been created to Yunnan-Shilin for the first WFS web service, and ontology class Yunnan:StoneForest has been developed to StoneForest for the second WFS web service. To resolve the heterogeneous local ontology integration problem, the ontology server is used to matching Yunnan:Shilin ontology to Yunnan:StoneForest ontology by using the developed partition-refinement algorithm. After the ontology matching, the two semantically heterogeneous WFS web services are composed together into one Shilin point spatial data, which is required by the multiple-criteria decision model as one input parameter.
-
The prototype system allows decision-makers access to the multiple-criteria decision model across the web via ontology-based WPS. The ontology-based WPS dynamically conduct spatial data analysis, compute the evaluation value and pass the evaluation results as input to ontology-based WFS. The input and output data for the implemented WPS is in GML format, which are connected with WFS. In one scenario of the different level protected-area boundaries calculated by the WPS (shown in ), the first protection level (dark) covers almost all the limestone pinnacles and the lakes, which are considered by the karst scientist to be of great importance to the landscape; the second protection level (gray) contains less important protection targets including villages, farmlands, and tourism facilities, such as hotels, commercial stores, roads and parking lots. Since the multiple-criteria decision model is employed as web services, it provides the interoperable capability of cross-platform and cross-language and can be accessed and reused by other applications and organizations.
-
The web services-based prototype system facilitates decision-makers access to the most up-to-date criteria data. With the ontology-based WFS and WMS, data maintenance of the prototype system becomes easy. Because the criteria data reside in the original databases, they are always updated. Unlike traditional SDSSs the data updated from one source have to be delivered or downloaded manually to its applications to maintain the changed data, the web services-based prototype system automatically propagates the change or update of data. In addition, the web services-based prototype system also allows developers or decision-makers change or update criteria data or alternative solution maps remotely in disparate sources cross the web. They can create, delete, and update geographic features in a remote database over the web using ontology-based WFS. Changes to the protective boundaries are instantaneously relayed to other decision-makers and applications. This instant access to the most up-to-date information enables decision-makers avoid the tedious process of transferring data and facilitate the decision-making process. In this way inconsistencies generated by updates are minimized and enterprises collaboration for a specific joint project is supported.
4. Discussion and conclusion
While progress has been made to develop the Digital Earth for sharing and integration of data from multiple sources over the Web, new methods are needed to allow decision makers to incorporate simulation decision models with the collected data to do spatial analysis and give new insights into these data. This paper proposed a framework of an interoperable SDSS using geospatial semantic technologies in support of Digital Earth to easily access decision models, databases, and analytical tools to conduct spatial data analysis and help decision-makers to employ web services to solve a specific task in geospatial decision-making. We expect that the proposed framework can increase both expert and public access to information/models for Digital Earth and involvement in decision-making, thus ensure the benefits derived from the use of Digital Earth. It provides new technologies for intelligent spatial search, access and use of Digital Earth and gives capabilities beyond mapping and query functions, thus may stimulate new achievements on using Digital Earth to application issues. The proposed framework not only resolves technical or syntactical interoperability via web services and standard interfaces and it also resolves semantic heterogeneity problem in composition of web services. By integration of web services and ontologies, the proposed framework can interpret messages exchanged by web services as well as understanding of the web service capabilities totally depending on the knowledge embedded in applications. Thus, it promises a new level of interoperability and offers a potential solution to the semantic heterogeneity problem in sharing spatial data and geoprocessing resources for decision-making. The proposed SDSS could combine data, decision models from multiple sources and deliver application specific solution support on the fly. Based on concise and unambiguous semantic description of web services, the proposed framework also facilitates automated handling of web services.
A prototype has been implemented to demonstrate how to build a workable interoperable SDSS using ontologies, WFS, WMS, and WPS. OGC WFS and WMS were used to access the heterogeneous spatial data and WPS were used to access the multiple-criteria decision model. Results from the implemented prototype showed that the proposed framework provides an environment for interoperability. Information from any source may serve as inputs to the decision-making process in such systems. Decision-makers can access necessary geospatial information no matter where it resides, what format it takes and how quickly it changes. By reusing existing heterogeneous data and geoprocessing plus update and maintenance of data remotely across the web, the web services-based interoperable system provides a potential way to alleviate duplication problem and reduce related costs.
The proposed framework is particularly useful for organizations with scarce resources such as limited time, expertise and finances to implement a SDSS. It is cost effective because SDSS developers can find, access, and use the information needed over the web. They no longer have to address the technical side of the SDSS to exploit its value because they do not need to develop and maintain whole databases and geoprocessing by themselves and can integrate existing geospatial data and functionalities into their custom applications online. This will greatly increase the use of Digital Earth.
Although the proposed framework offers the aforementioned advantages, it still has several issues which need further investigation. One issue is performance. The current version of the implemented client software based on OpenLayers library does not perform well when displaying a WFS layer with a large number of features (hundreds or more) and it works better with Mozilla Firefox than Internet Explorer. More research would greatly benefit from file compression algorithms and highly efficient parsing methods. In addition, considering that the amount of the available web services and the size of ontology models are huge, studies need to be done about improving the efficiency of location, negotiation, and composition of web services.
The second issue is automatic web service composition. Automatic web service composition is a far from trivial problem (Sycara et al. Citation2002; Citation2004). It deals with complex goals, temporal conditions, intricate preferences requirements, heterogeneous results provided by several services, and the partial observability of the services' internal status. Thus, it is difficult to find a totally automatic and dynamic composition approach to locate the best services for solving a particular problem and automatically compose the relevant services to build applications dynamically. In the implemented prototype, we only developed a module to automatically discover, split, and compose WFS data services. Further research is needed to automatically compose heterogeneous WPS. Further, the proposed framework is based on a centralized broker that manages the service composition process. The drawback of this approach is that if a huge number of users attempt to access an increasing number of various services distributed over the network, the broker will quickly become a bottleneck.
Except for the two major issues discussed above, other issues such as the security and privacy issues, reliability of systems, moral hazard problems, copyright issue, and the data quality issue also need further study.
Notes on contributors
Chuanrong Zhang is currently an assistant professor at the University of Connecticut and holds a joint appointment with the Department of Geography and the Center for Environmental Sciences and Engineering (CESE). She got her PhD degree in GIS from the University of Wisconsin, Milwaukee in 2004. She has several years of work experience in computer companies. Her current research interests include Internet GIS, geostatistics, and applications of these techniques in natural resource and environmental management.
Tian Zhao obtained his Ph.D. degree in Computer Science from Purdue University in 2002. He is currently an associate professor at the University of Wisconsin, Milwaukee. His research interests include programming languages, real-time programming, and geographic information systems.
Weidong Li is currently a professor in geospatial information engineering at Huazhong Agricultural University, and also a research professor at the University of Connecticut. He got a Master degree in computer science from Marquette University and obtained a PhD degree in soil and water science in 1995 from China Agricultural University. His research interest is focused on geostatistics and geoinformatics for natural resource management.
Acknowledgements
We thank the editor and the anonymous reviewers for their constructive comments on the manuscript. This research is partially supported by USA NSF grant No-0616957. Authors have the sole responsibility of all of the viewpoints presented in the paper.
References
- An Y. Borgida A. Mylopoulos J. 2005 Inferring complex semantic mappings between relational tables and ontologies from simple correspondences Lecture notes in computer science for OTM confederated international conferences (Part II) 3761 1152 1169
- Ashpole B. et al. 2005 The Integrating Ontologies Workshop at k-CAP 2005 B. Ashpole M. Ehrig J. Euzenat H. Stuckenschmidt Proceedings of the K-CAP 2005 workshop on integrating ontologies, Ban® 2 October 2005 Canada
- Armstrong , M.P. 1993 . Perspectives on the development of group decision support systems for locational problem solving . Geographical Systems , 1 : 69 – 81 .
- Bhargava , H.K. , Power , D.J. and Sun , D. 2007 . Progress in Web-based decision support technologies . Decision Support Systems , 43 : 1083 – 1095 .
- Carver , S.J. 1991 . Integrating multi-criteria evaluation with geographic information systems . International Journal of Geographical Information Systems , 5 : 321 – 339 .
- Casey M.J. Austin M.A. 2002 Semantic web methodologies for spatial decision support Proceedings of the international conference on decision support systems in the internet age – DSIAge2002 3–7 July 2002 Cork Ireland .
- Castano , S. , Ferrara , A. and Montanelli , S. 2006 . “ Matching ontologies in open networked systems: techniques and applications ” . In Data semantics V, Lecture notes in computer science , Edited by: Spaccapietra , S. , Atzeni , P. , Chu , W.W. , Catarci , T. and Sycara , K.P. 25 – 63 . Berlin : Springer .
- Chen , J. and Wu , L. 2003 . Geospatial fundamental framework of digital China , Beijing : China Science Press .
- Cheng , J.C. 2000 . Introduction to Digital Earth , Beijing : China Science Press .
- Crosier , S.J. 2003 . Developing an infrastructure for sharing environmental models . Environment and Planning B: Planning and Design , 30 : 487 – 501 .
- Cruz , I.F. and Sunna , W. 2008 . Structural alignment methods with applications to geospatial ontologies . Transactions in GIS , 12 : 683 – 711 .
- Cruz , I.F. 2007 . A visual tool for ontology alignment to enable geospatial interoperability . Journal of Visual Languages and Computing , 18 : 230 – 254 .
- Doan , A. 2004 . “ Ontology matching: a machine learning approach ” . In Handbook on ontologies, International handbooks on information systems , Edited by: Staab , S. and Studer , R. 385 – 404 . Berlin : Springer .
- Ehlers , M. 2008 . Geoinformatics and digital earth initiatives: a German perspective . International Journal of Digital Earth , 1 ( 1 ) : 17 – 30 .
- Euzenat , J. and Shvaiko , P. 2007 . Ontology matching , Berlin : Springer-Verlag .
- Foresman , T.W. 2008 . Evolution and implementation of the Digital Earth vision, technology and society . International Journal of Digital Earth , 1 ( 1 ) : 4 – 16 .
- Giunchiglia , F. , Shvaiko , P. and Yatskevich , M. 2005 . “ S-match: an algorithm and an implementation of semantic matching ” . In Semantic interoperability and integration , Edited by: Kalfoglou , Y. , Schorlemmer , W.M. , Sheth , A.P. , Staab , S. and Uschold , M. Vol. 04391 , Schloss Dagstuhl, , Germany : IBFI .
- Giunchiglia F. et al. 2008 Approximate structure-preserving semantic matching In: Proceedings of the seventh conference on ontologies, databases, and applications of semantics (ODBASE) 11–13 November 2008 Monterey Mexico 1234 1253
- Goodchild , M.F. 2008 . The use cases of digital earth . International Journal of Digital Earth , 1 ( 1 ) : 31 – 42 .
- Goodchild , M.F. and Glennon , A. 2008 . “ Representation and computation of geographic dynamics ” . In Understanding dynamics of geographic domains , Edited by: Hornsby , K.S. and Yuan , M. 13 – 30 . Boca Raton, FL : CRC Press .
- Gore A. 1998 The Digital Earth: understanding our planet in the 21st Century Presented at the Californian Science Center 31 January Los Angeles California
- Guo , H. , Fan , X. and Wang , C. 2009 . A digital earth prototype system: DEPS/CAS . International Journal of Digital Earth , 2 ( 1 ) : 3 – 15 .
- Guo H. 2008 Digital Earth Science Platform: DESP/CAS. The international archives of the photogrammetry, remote sensing and spatial information sciences XXXVII Part B2 Beijing ISPRS (International Society for Photogrammetry and Remote Sensing)
- Guo , H.D. 1999 . Earth observation and Digital Earth , Beijing : Chinese Science Press .
- Hess G.N. Iochpe C. Castano S. 2006 An algorithm and implementation for GeoOntologies integration [online] GEOINFO 2006 , Campos do Jordão Brazil Available from: http://www.geoinfo.info/geoinfo2006/papers/p46.pdf [Accessed 6 May 2009]
- Hess , G.N. , Iochpe , C. and Castano , S. 2007a . Geographic ontology matching with iG-Match . Lecture Notes in Computer Science: Advances in Spatial and Temporal Databases , 4605 : 185 – 202 .
- Hess G.N. et al. Towards effective geographic ontology matching Lecture notes in computer science: The second international conference on geospatial semantics (GeoS 2007) 2007b 4853 51 65
- Hu , W. , Qu , Y. and Cheng , G. 2008 . Matching large ontologies: a divide-and-conquer approach . Data & Knowledge Engineering , 67 : 140 – 160 .
- Jankowski , P. 1997 . Spatial group choice: a SDSS tool for collaborative spatial decision making . International Journal of Geographic Information Science , 11 : 577 – 602 .
- Jankowski , P. , Andrienko , G.L. and Andrienko , N.V. 2001 . Map-centered exploratory approach to multiple criteria spatial decision making . International Journal of Geographical Information Science , 15 : 101 – 127 .
- Janowicz , K. , Wilkes , M. and Lutz , M. 2008 . Similarity-based information retrieval and its role within spatial data infrastructures . Lecture Notes in Computer Science: Geographic Information Science , 5266 : 151 – 167 .
- Jha S. Palsberg J. Zhao T. 2002 Efficient type matching Proceedings of FOSSACS'02, foundations of software science and computation structures 6–14 April Grenoble France
- Jian N. et al. 2005 FalconAO: aligning ontologies with Falcon B. Ashpole M. Ehrig J. Euzenat H. Stuckenschmidt Proceedings of the K-CAP 2005 workshop on integrating ontologies, Ban 2 October 2005 Canada
- Li , D. 2001 . Function of digital province and digital city in territorial planning and urban construction. Engineering . Journal of Wuhan University , 34 : 47 – 59 .
- Li Q. Lin S. 2001 Research on digital city framework architecture Proceedings of ICII 2001 29 October – 1 November 2001 Beijing China 1 30 36
- Malczewski , J. 1996 . A GIS-based approach to multiple criteria group decision-making . International Journal of Geographical Information Systems , 10 : 955 – 971 .
- Malczewski , J. 2000 . On the use of weighted linear combination method in GIS: common and best practice approaches . Transactions in GIS , 4 : 5 – 22 .
- McGuinness D.L. et al. An environment for merging and testing large ontologies Seventh international conference on principles of knowledge representation and reasoning (KR 2000) 2000 483 493
- Nativi , S. and Domenico , B. 2009 . Enabling interoperability for Digital Earth: earth science coverage access services . International Journal of Digital Earth , 2 ( 1 ) : 79 – 104 .
- Noy N.F. Tools for mapping and merging ontologies Handbook on ontologies. International handbooks on information systems for the international semantic web conference 2005 Staab S. Studer R. Springer Berlin 2004 365 384
- Ostländer N. 2004 Interoperable services for Web-based spatial decision support [online]. Available from: http://plone.itc.nl/agile_old/Conference/greece2004/papers/P-13_Ostlander.pdf [Accessed 6 May 2009]
- Rinner , C. 2003 . Web-based spatial decision support: status and research directions . Journal of Geographic Information and Decision Analysis , 7 : 14 – 31 .
- Shvaiko , P. and Euzenat , J. 2005 . A survey of schema-based matching approaches . In: Lecture Notes in Computer Science: Journal of the Data Semantics IV , 3730 : 146 – 171 .
- Stoilos , G. , Stamou , G. and Kollias , S. 2005 . “ A string metric for ontology alignment ” . In ISWC 2005, Lecture notes in computer science , Edited by: Gil , Y. Vol. 3729 , 624 – 637 . Berlin : Springer-Verlag .
- Sycara , K. , Klusch , M. and Lu , J. 2002 . LARKS: dynamic matchmaking among heterogeneous software agents in cyberspace . Autonomous Agents and Multi-Agent Systems , 5 : 173 – 203 .
- Sycara , K. 2004 . Dynamic discovery and coordination of agent-based Semantic Web services . IEEE Internet Computing , 8 ( 3 ) : 66 – 73 .
- Tang , J. 2006 . Using Bayesian decision for ontology mapping . Journal of Web Semantics , 4 ( 4 ) : 243 – 262 .
- Vaccari , L. , Shvaiko , P. and Marchese , M. 2009 . A geo-service semantic integration in spatial data infrastructures . International Journal of Spatial Data Infrastructures Research , 4 : 24 – 51 .
- Wang , M. 2004 . A Web-service agent-based decision support system for securities exception management . Expert Systems with Applications , 27 : 439 – 450 .
- Yang , C. 2008 . Distributed geospatial information processing: sharing distributed geospatial resources to support Digital Earth . International Journal of Digital Earth , 1 ( 3 ) : 259 – 278 .
- Zhang C. et al. in press Towards logic-based geospatial feature discovery and integration using web feature service and geospatial semantic web International Journal of Geographical Information Science
- Zhang , C. , Li , W. and Zhao , T. 2007 . Geospatial data sharing based on geospatial semantic web technologies . Journal of Spatial Science , 52 ( 2 ) : 35 – 49 .
- Zhang , C. , Li , W. and Day , M. 2005 . Towards establishing effective protective boundaries for the Lunan Stone Forest using an online spatial decision support system . Acta Carsologica , 34 : 178 – 193 .
- Zhao T. et al. Ontology-based geospatial data query and integration Lecture notes in computer science for the fifth international conference on geographic information science , 5266 2008 2008 370 392