Abstract
The ultimate goal of much current research in earth science informatics is to enable more efficient discovery and use of environmental data. Large-scale efforts are underway at regional and global levels. For instance the European INSPIRE Directive (2007/2/EC) and international GEOSS initiative will both provide unprecedented catalogues of earth observation and environmental data, with links to online services providing direct access to digital data repositories. While the motivation for these emerging infrastructures is clear (e.g. understanding global change), it is less obvious how they might be implemented. Standards will play a major role and considerable effort is currently being devoted to their development by bodies like the International Organisation for Standardisation and the Open Geospatial Consortium. Internet search engines are amongst the most popular websites visited today. Using the metaphor of a web search portal, we review the potential of new geospatial standards to provide an advanced, user-friendly approach to discovery and use of climate-science data.
Introduction
Web search engines consistently rank among the most highly visited internet sites; for instance, at the time of writing, the top five most-visited websites according to alexa.com Footnote1 includes three search engines (google.com, yahoo.com and live.com), a video-sharing site (youtube.com) and a social networking site (facebook.com). The need to find and access digital information is at the heart of the new economy. Likewise, in order to understand and respond to the most pressing environmental problems of the modern world, access to data and information is central. For scientific researchers, the complex, interconnected nature of the global earth system demands access to a wide spectrum of data types that cross traditional research discipline boundaries. For policymakers, the pressure to adopt evidence-based approaches means that access to environmental data must be at the heart of decision-making.
It is for these reasons that there is a surge in the development of large-scale environmental data-sharing initiatives. Various regional spatial data infrastructures (SDIs) are under development. Examples include the Infrastructure for Spatial Information in Europe (INSPIRE, Directive 2007/2/EC) and the US National Spatial Data Infrastructure. At global level, the Global Earth Observing System of Systems (GEOSS) aims to achieve ‘coordinated, comprehensive and sustained Earth observations’ (GEOSS Citation2005) for a number of societal benefit areas.
The multi-purpose nature of the demands being placed on environmental data requires an unprecedented level of ‘interoperability’ – an ability to share information regardless of where or how it is stored and free of vendor-specific technology constraints. Interoperability, in turn, requires a commitment to open standards. For exchange of environmental data, there is now considerable momentum behind the de jure Footnote2 standards being developed by ISO Technical Committee 211 on Geographic information and Geomatics, and the de facto standards being developed by the Open Geospatial Consortium Inc (OGC) (a non-profit body with members across academia, government and industry).
This paper examines the potential of these emerging standards for new data-sharing capability in the climate sciences. Due to its ubiquity and success, the metaphor of a web search portal is adopted in order to identify the core functionality required by users and to examine the potential of standards in meeting these requirements. While an extensive requirements analysis is beyond the scope of this paper, it seems clear that a simple search interface of this type is sufficient for many users – most major geo/environmental data portals (e.g. the GEOSS Clearinghouse prototypes, the INSPIRE prototype Geo-portal, etc.) already offer some kind of free-text search capability. Moreover, the link from discovery to access is implemented differently in different geo-portals and so in the absence of an agreed best practice the web portal analogy seems as useful as any other. In addition, while the vision of a future Digital Earth is some way from being realised, it is clear that standards for the interoperable discovery and navigation of geospatial information also lie at its core (Gore Citation1998).
The architecture of SDIs is often factored into three complementary elements: metadata for discovery, data models for structuring content and network services for access. This corresponds well to the typical use of a web search portal (): first, a user is presented with a summary list of matching web pages (metadata); these are a projection of the more complex structured content of a page (data); finally, the user retrieves the content from a remote web server (service). This architectural perspective is also adopted in the analysis below.
Figure 1. Web search analogy to SDI components (metadata, data and services).
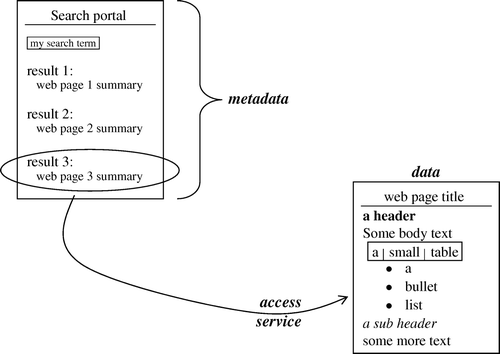
As well as these three ‘SDI components’, metadata for ‘evaluation’ and ‘use’ are sometimes identified as additional important elements which overlap and link the others (see, for example, the European INSPIRE Directive 2007/2/EC Art. 3(6)); they incorporate controlled vocabularies, constraints on access and use, dataset resolution, etc. In reality, of course, there is a continuum of levels at which a data resource may be described and a myriad description axes. Any given application will have its own, specific, data concerns – it would be naïve to imagine there could ever be a universal ‘SDI client’ tool. A less ambitious task is confronted here, aiming only to provide a useful level of generic data discovery, passing over in a standardised and controlled manner to a user application for evaluation and access. Validating the utility of today's standards to navigate the required spectrum of (meta)data granularity will never be possible whilst ever new applications are imagined. However, it seems likely that new standards requirements will continue to be identified. It will remain the job of applications to exploit the richness of these standards to their maximum benefit.
Hypothetical use case: a standards-powered climate data search portal
The following discussion analyses the capabilities available through a hypothetical search portal (Geogle) for climate-science data, with functionality derived from the use of ISO and OGC standards being proposed as the basis of infrastructures like INSPIRE. In part, this is an attempt to evaluate what might be possible in a familiar paradigm using existing and emerging standards. The visual appearance and use of the hypothetical portal is modelled on existing web search portals (). The initial access point presents a simple text entry box, into which a hypothetical user enters a search for ‘temperature’.
Figure 2. Geogle portal with ‘temperature’ search.

Discovery metadata: what data is available?
Metadata, by definition, is data about data; it represents a summary description of available data in a form that simplifies comparison and evaluation following an initial search. Conventional web search engines incorporate three main functionalities in their implementation of web-page searching (Brin and Page Citation1998). Firstly, they ‘crawl’ websites through systematic automated visits by agents. Secondly, they summarise and categorise found content into a structured index. Finally, efficient searches against this index are provided through a defined interface. These three elements are also implemented in the hypothetical climate-science data portal, Geogle.
An analogue to the search engine ‘crawler’ is found in the notion of ‘metadata harvesting’. Early models of federated metadata search, e.g. z39.50 (ISO Citation1998), performed live queries across a collection of distributed catalogues. These are only as capable as the weakest element and inevitably suffer from poor network connections and unreliable remote catalogue services. More recent architectures have adopted a harvesting approach (Lawrence et al. Citation2004) similar to the web crawling of search engines, where remote catalogues are periodically visited and snapshots cached locally by the discovery portal. The Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) (Lagoze et al. Citation2002) is a lightweight protocol that has proven very successful for this purpose. Developed initially by the digital library community, it has been adopted in a number of earth- and climate-science metadata catalogues, for instance: NERC DataGrid (Latham et al. Citation2009), NASA Langley Research Center (Chu et al. Citation2006), World Data Center for Climate (Lautenschlager et al. Citation2006) and the Collaborative Climate Community Grid (Schindler et al. Citation2007).
The analogy between web search engine ‘crawling’ and metadata ‘harvesting’ is not exact. In fact, the latter requires a register of metadata providers in order to seed the harvesting procedure, while the former relies on ad-hoc cross-linkages between ‘crawled’ web resources. While citation and linkingFootnote3 of datasets is in its infancy (Brase et al. Citation2009, www.linkeddata.org), it is intriguing to imagine that web crawling techniques could one day also be applied directly to datasets, offering the tantalising prospect also of hyperlink-based dataset ranking (Kleinberg Citation1999).
In order to facilitate efficient indexing and searching, harvested metadata must conform to a structured standard ‘metadata format’. Just as a web crawler is able to parse web-pages conforming to HTML (identifying title, headers, links, etc.), so a metadata harvesting catalogue is able to identify key elements summarising dataset characteristics. Various metadata formats may be found in use across the climate-science community, e.g. the Global Change Master Directory (GCMD) Directory Interchange Format (DIF), the ‘GEO profile’ of z39.50, Dublin Core, FGDC Content Standard for Digital Metadata; however, we focus here on the recent standard ISO 19115 (ISO Citation2003) which is being widely adopted. In the climate-science domain, profiles of ISO 19115 are being considered both by the World Meteorological OrganisationFootnote4 and the International Oceanographic Commission.Footnote5
For initial evaluation purposes, a search engine displays just the barest summary of matching web pages. Similarly, the climate-science data search portal displays only the most basic characteristics of matching datasets, drawing on key elements of the ISO 19115 metadata standard ().
Figure 3. Results of search for ‘temperature’, based on ISO 19115 metadata elements.

Where and when: EX_Extent
A fundamental property of almost any climate-science data is its location in time and/or space. In-situ measurements are always taken somewhere, and at some time, and simulations usually correspond to a real-world location at some time in the past or future. An exception is process studies (e.g. numerical simulation of instability with idealised topography/stratification, or meridional circulation under global warming scenarios) but even in these cases a ‘location’ or ‘time’ descriptor may be relevant (e.g. a latitude corresponding to a specific Coriolis parameter, or a future year under a specific CO2 emissions scenario).
The metadata standard, ISO 19115, includes elements providing an array of possibilities for describing the spatial and temporal extent of a dataset. The basic metadata element (EX_Extent) allows any number of horizontal, vertical and temporal location descriptors to be aggregated together for an overall description of dataset extent. A horizontal extent descriptor may take the form of a rectangular latitude/longitude bounding box, a more general bounding polygon or a geographic identifier (e.g. a place name from a gazetteer). Some examples include:
-
polygons corresponding to swath limits of one or more passes of an earth-orbiting satellite;
-
a series of geographic names for the locations of automatic weather stations managed by some authority; and
-
a rectangular latitude–longitude box providing the boundaries of a limited-area nested forecast model.
Temporal extent descriptors may be given through any number of temporal ‘primitives’ defined by (ISO Citation2002) (Temporal schema). These include time instants and periods, both of which may be defined against a variety of temporal reference systems:
-
calendars and clocks;
-
‘coordinate systems’ using a temporal offset with respect to a reference date–time origin; and
-
‘ordinal’ systems using a hierarchical structure of eras (e.g. for geological time).
Figure 4. Visual presentation of ISO 19115 spatiotemporal extent (EX_Extent) elements.
What: MD_Keywords
The use of keywords has proven successful in characterising datasets for human evaluation at a very summarised level. ISO 19115 allows any number of descriptive keywords to be assigned to a dataset (through the MD_Keywords element). Moreover, in order to maximise the interoperability of keywords, they may be taken from specified controlled vocabularies, also known as thesauri ().
Figure 5. Thesaurus terms referenced from ISO 19115 keywords.
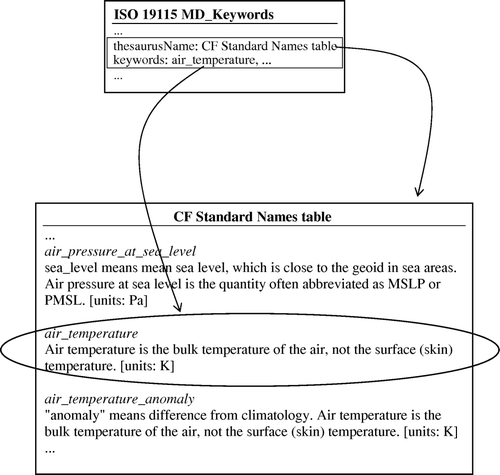
Best practice for assigning keywords to datasets would suggest that they should always be taken from a controlled vocabulary, rather than being free-form text. Several such thesauri are becoming available for use in the climate sciences. The Standard Names Table of the ‘NetCDF Climate and Forecast (CF) Metadata Convention’ (Eaton et al. Citation2009) contains nearly two thousand terms describing physical parameters across the climate-sciences (atmospheric and ocean dynamics, chemistry, radiation, sea-ice, etc.). A similar number of terms are available in the list of ‘GCMD Science keywords’ (Olsen et al. Citation2007). For the ocean sciences, the extensive ‘BODC Parameter Dictionary’Footnote6 (Lowry Citation1998) contains over 20,000 terms for physical, chemical, biological and geological parameters. For use within INSPIRE, a ‘Feature Concept Dictionary’ is being developed.Footnote7
Common to any controlled vocabulary is a requirement to apply well-defined content management and governance rules – a user of a term needs to have some assurance that it will continue to have a defined meaning into the future, that versioning will not affect the availability of definitions and that the thesaurus itself is being managed by a competent authority on a sustainable basis. ISO 19135 (ISO Citation2005d) lays out a set of procedures for managing controlled terms within ‘registers’; requests for change may be made by ‘submitting organisations’, and are decided by a group of technical experts (the ‘control body’). In addition, a registered item (e.g. a term in a controlled vocabulary) has a number of defined attributes; most important of these is a name and definition, but they also include lifetime dates (acceptance, modification), and status (valid, retired, etc.), amongst others. All the abovementioned controlled vocabularies follow the principles of ISO 19135 to some degree, though only the INSPIRE Feature Concept Dictionary does so rigorously.
Relevant keywords for a dataset are displayed prominently for the user within the Geogle search portal (). They include a link to their entry within the relevant thesaurus to ensure their correct interpretation by the user.
Figure 6. ISO 19115 descriptive keywords and coordinate reference systems displayed in search portal.

Reference systems
As mentioned above, ISO 19115 metadata allows the spatial extent of a dataset to be described. Any spatial reference with coordinates must be against a defined coordinate reference system – examples include the well-known WGS-84 system (NIMA Citation1984), but also ETRS-89Footnote8 for Europe and NAD-83 (Schwarz Citation1989) for North America. These ‘geodetic coordinate reference systems’ use latitude and longitude coordinates together with a reference ellipsoid (the datum). Different ellipsoids will correspond more or less accurately to the actual Earth surface at different locations.
In traditional geodesy, vertical positions are normally represented as length-based heights or depths (e.g. with respect to a reference ellipsoid or hydrographic sea surface, such as Lowest Astronomical Tide). However, in the climate sciences, a range of alternative vertical coordinate systems are used. Atmospheric or oceanographic pressure is often used as a proxy for vertical position with in-situ measurements (e.g. weather balloons or ocean soundings) and numerical models may be formulated in vertical layers that follow the terrain of the earth (so-called ‘sigma coordinates’). The ISO standard 19111 (ISO Citation2007a) deals with the definition of coordinate reference systems for traditional geodetic applications, but not with the ‘parametric’ systems widely used for vertical referencing in the climate sciences. However, a very recent extension, ISO 19111-2 (ISO Citation2008) to the standard is being approved, enabling such systems to be described in a standards-compliant manner. This activity has been driven directly by members of the climate-science community (Woolf et al. Citation2005).
ISO 19115 allows details of coordinate reference systems to be provided (through the element MD_ReferenceSystem) using both an identifying code and a responsible authority. Thus, the climate-science community now has the opportunity to develop agreed descriptions of relevant vertical coordinate reference systems (in accordance with ISO 19111-2) and to reference them from within metadata descriptions of datasets. A process similar to that used for managing controlled vocabularies (described above) could be used for maintaining lists of these coordinate reference systems.
The Geogle portal lists the coordinate reference systems used in datasets, with a link to the authority that maintains the definition of the system ().
Data models: how is the data structured?
The focus so far has been on those metadata aspects of a dataset description that concern high-level summary information. However, a user will also want to know details of the internal structure of a dataset – does it contain a set of point in-situ measurements of atmospheric temperature or rather gridded fields from a numerical simulation? If the latter, on what kind of a grid is it discretised? And if the former, is it a timeseries from an automatic weather station, or a series of vertical profiles from daily radiosonde releases?
In the framework of the ISO and OGC standards on which this paper is focussed, the logical structure and semantic content of a dataset is defined by a so-called ‘application schema’. ISO 19109 (ISO Citation2005a) outlines rules for application schema, the most important of which is that a dataset should contain discrete identifiable objects called ‘features’. The notion of a feature is very general – in the climate sciences it may represent a four-dimensional grid of simulated model output or it may represent salinity measurements along the trajectory of a ship-towed CTD (Conductivity-Temperature-Depth) instrument. The important thing is that all relevant ‘feature types’ are known and defined and that a metadata description of a dataset should reference those feature types present in the dataset. This is possible using the ISO 19115 metadata standard through the MD_ContentInformation element.
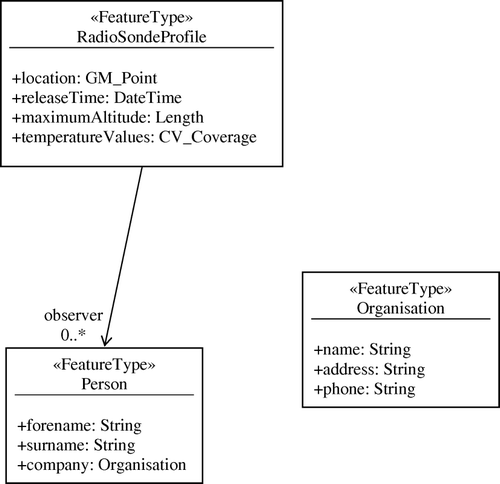
In slightly more detail, the ‘feature type’ model follows an object-modelling approach: feature types are completely defined by their properties and relationships. For this reason, an object-based modelling framework (the ‘Unified Modelling Language’ (ISO Citation2009c)) is used to formalise the definition of feature types ().
Figure 7. Following ISO 19109, UML is used as the formal model for defining feature types. In this case a RadioSondeProfile is defined by attributes for location, time of release, maximum altitude, and measured temperature values. It is released by one or more observers who have a name, and work for some organisation.
Merely describing the contents of a dataset in terms of formalised feature types, however, does not help a user interpret the dataset once it has been retrieved. They may download a dataset file and know that it contains a ‘gridded model timeseries’, but without additional knowledge will not be able to relate the bits and bytes to the feature they expect within. The standards framework therefore specifies a ‘canonical encoding’ for datasets: an XML-based representation that corresponds one-to-one with the associated feature types. The ISO standard 19136 (ISO Citation2007b) specifies an XML language (the Geography Markup Language) as the canonical encoding for feature types.
A common pattern across several aspects of the standards framework mentioned so far has been the notion of a competent authority with the remit to manage concepts on behalf of a community. Keywords should be based on a controlled vocabulary managed by some authority; coordinate reference systems should be defined by an authority and referenced by dataset providers. Similarly, feature types used within a community should be defined and referenced; this aids the interpretation and understanding of shared data and maximises the possibility of re-usable software and tools. The ISO standard 19110 (ISO Citation2005b) introduces a ‘feature catalogue’ for managing re-usable feature type definitions.
As mentioned earlier, the ISO 19115 metadata standard allows a dataset description to include a reference (through the MD_ContentInformation element) to those feature types that are to be found within the dataset. This description may include a reference to the feature catalogue that defines those feature types, thus enabling the user to obtain as much detail as necessary about the structure of dataset features. The hypothetical search portal, Geogle, lists for discovered datasets those feature types that are present, with a link to their definition within a feature catalogue ().
Figure 8. List of feature types, with link to relevant feature catalogue.

There is a major opportunity available to the climate-science community to develop and adopt standard feature type models to describe the contents of their datasets. This will lead to unprecedented data exchange possibilities and facilitate the development of widely reusable software tools. An early attempt at doing this is the Climate Science Modelling LanguageFootnote9 (CSML, Woolf et al. Citation2006) which has defined formalised feature-type models for a range of climate-science data types (point timeseries, grids, profiles, trajectories, etc.). A prototype feature catalogue for CSML has also been shown to provide benefits for re-use (Millard et al. Citation2007).
Access services: how do I get the data?
Having performed a search and evaluated available datasets, a user finally will wish to access data. In the networked world of online digital content, the standard technology for this is web services – remote services that provide defined functionality (e.g. downloading or rendering data) and may be invoked by sending messages via HTTP (Fielding et al. Citation1999) or SOAP (Gudgin et al. Citation2007). If services implement agreed standardised interfaces, then they may be accessed on the user's computer desktop by a range of familiar tools that incorporate client-side support for those interfaces.
It is worth noting in the discussion that follows that the ease with which different scenarios may be implemented depends on implementation choices – in many cases a HTTP ‘RESTful’ approach to services will simplify interactive workflow construction, compared with SOAP bindings.
Within the ISO 19115 metadata standard, a link to an associated online service may be provided for a dataset (through the CI_OnlineResource element). Such a service might implement the functionality for download, viewing, ordering, etc. A number of specific elements must be known in order for a user to access a service reliably. These include the service ‘endpoint’ (network address at which it is available), the service type (i.e. what interfaces are implemented), the connection protocol, whether a specialised profile of a standard service type is used, etc. While the ‘online resource’ metadata element contains properties that could be used for all of these, a consensus has yet to emerge within the climate science community on how best to do it.Footnote10
It is assumed that such ambiguities have been resolved within the implementation of the Geogle search portal: the dataset title doubles as a link to the endpoint of an associated data download service. Using the familiar ‘right-click/copy’ action, the user is able to paste the link into client softwareFootnote11 in order to access the service directly within their desktop tools of choice ().
Figure 9. Copying data access endpoint to client software.
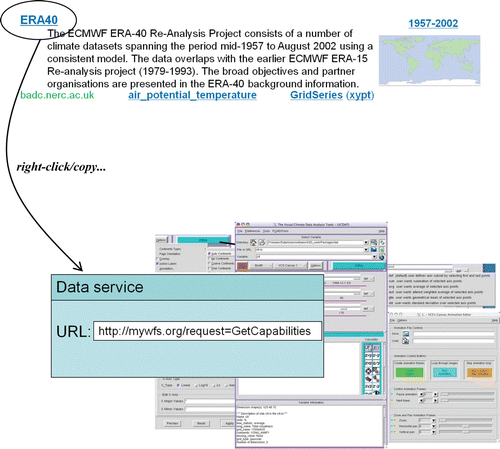
We consider now available standards-based network services that may be used for downloading climate-science data. Two major service types have been developed by the OGC: the Web Feature Service (WFS) for accessing features within a dataset (Vretanos Citation2005) and the Web Coverage Service (WCS) for subsetting gridded features (Whiteside and Evans Citation2008). Whereas the WFS has almost completed standardisation as ISO 19142 (ISO Citation2009a), the WCS is still under active development. In addition, the WFS is likely to be adopted as the mandated download service within INSPIRE; and so the focus here is on its applicability for accessing climate-science data.
The WFS effectively acts as a query interface onto a dataset regarded as an opaque ‘feature store’. Individual dataset features may be requested by identifier or by matching specified filter criteria (ISO 19143, (ISO Citation2009b)). Filter selection predicates may be constructed using a range of comparison, logical, spatial and temporal operators applied against specified feature properties. Thus, a request could be formulated for individual radiosonde features that lie within some defined geographical area, were collected within certain date windows and where the maximum altitude was greater than 30 km. Clearly, a powerful set of queries may be used with the WFS; there are no obvious a-priori limitations that unduly restrict its use for querying and retrieving climate-science data. Indeed, the mechanism offers significant benefits over other download mechanisms that do not allow subselection of individual dataset components (e.g. retrieving a complete netCDF file from an ftp server).
At first glance, it appears that a major limitation on the use of WFS might be its restriction to returning entire feature instances. Thus, if a numerical simulation is described by a feature type representing a four-dimensional grid of data (as with the CSML ‘GridSeriesFeature’) the WFS is limited, in principle, to retrieving the entire four-dimensional grid – a data volume that could easily amount to Terabytes with the latest atmospheric or oceanographic models. By comparison, the non-standards-based OPeNDAP protocol (Gallagher et al. Citation2007) widely used in the climate-science community allows subsets of data objects to be requested. (Note that subsetting a single feature instance is different from filtering one from a set of features, as described above for WFS.) However, an additional capability of the newly standardised ISO 19142 version of WFS provides an intriguing possibility that appears to support subsetting individual feature instances. As well as selecting features for download based on complex filter queries, the WFS offers the possibility to return features based on the result of executing predefined ‘stored queries’ against a dataset. Stored queries may be associated to individual return feature types and require additional query parameters in a WFS request. Thus, a stored query could accept geographic bounding box and time window parameters, and extract from a large simulation dataset a gridded feature subset within those spatiotem-poral bounds. In principle, this would be a new feature instance, but for all practical purposes it is simply a subset of the original (possibly tera-scale) four-dimensional gridded dataset feature, delivered through a standard WFS request. Early experiments using this functionality with climate-science datasets have been performed with promising results (Lowe and Woolf Citation2008).
The WFS endpoint available by ‘right-clicking’ in the Geogle search portal may be copied to WFS-enabled client software (a desktop climate-data analysis package, for instance) and the full richness of the WFS capabilities may be invoked. Such a package could, for instance, provide drop-down menus for directly invoking well-known feature subsetting operations on the server – e.g. selecting a temperature timeseries at a given location from a reanalysis run to verify against an equivalent record from an automatic weather station.
While the WFS interface and GML may be used in principle for climate-science data as described above, we examine below two additional issues that are the subject of specific ongoing debate within the climate-science community: binary content and irregular grids.
Binary encoding formats
The standard encoding format for WFS was noted earlier to be based on the XML dialect, Geography Markup Language. Even with a WFS feature subsetting capability, data volumes, at least for numerical simulation datasets, would be prohibitive if converted from native binary formats (e.g. netCDF, GRIB, HDF) to GML. Thus it needs to be determined whether binary encodings may be used together with WFS in a standards-compliant manner. Fortunately, preliminary experiments appear to suggest this is the case (INSPIRE Citation2008, Woolf Citation2009).
GML employs a ‘by-reference’ pattern that enables content to be referenced ‘out-of-band’ rather than included inline. This is achieved using the W3C xlink specification, allowing the complete xlink semantics to be incorporated within GML. While most uses of xlink with GML will refer to external documents also containing GML, this need not be the case. The xlink specification allows the following properties to be specified in the context of a reference to a target resource:
-
href: the location of a target resource, as a URL (which may include a ‘fragment identifier’ denoting a subsection of the resource, e.g. a particular variable within a netCDF file);
-
role: the nature of the target resource, e.g. a mime-type for the file format; and
-
arcrole: how the target resource should be interpreted with respect to the source xlink element, e.g. providing the logical content for a child GML element.
Figure 10. Using xlink to replace in-line GML with an ‘interoperability layer’ over a binary file.

Irregular grids
Assuming it is possible to combine binary encodings with GML, the question arises whether GML contains a sufficient set of elements to support the full-range of climate-science data types. Of course this depends in detail on the conceptual model and feature types adopted. However, one particular building block finds very wide applicability in the climate sciences. A ‘coverage’ is equivalent to a function that assigns values in its range to every location in its domain. Since, most of the climate-science data types are values of a physical quantity over some region of time and/or space, they may be regarded as coverages (Woolf Citation2008). ISO 19123 (ISO Citation2005c) distinguishes a number of coverage subtypes – discrete and continuous, and classified by the geometry of their domain (point, curve, grid, triangulated irregular network, etc.). GML provides representations of all the discrete coverage subtypes; except that in case of a discrete grid coverage,Footnote12 only regularly spacedFootnote13 and not general curvilinear,Footnote14 or irregular, grid domains are supported. Such grids are very widely used in the climate sciences. For instance, ocean models are often formulated on a mesh that follows the coastline and vertical discretisation is finer near pycnoclines. Limited area and nested atmospheric models may be ‘telescoped’ near a region of interest. The lack of a representation for irregular grids within GML currently is a significant limitation for its application to numerical simulations in the climate sciences. However, a change request is currently being considered for adoption in GML (Woolf et al. Citation2007) and it is almost certain that the next version will include support for irregular grids.
Summary and conclusions
We have adopted the metaphor of a web search portal for climate-science data to investigate the potential functionality that is available through the adoption of ISO and OGC standards. The metadata standard ISO 19115 appears to have capability to support advanced interaction sequences for climate-science data across the spectrum from discovery to evaluation, access and use.
It includes elements that allow an intuitive summary presentation of spatial and temporal extent of a dataset during evaluation of search results. Scoped keywords may reference authoritative thesauri or controlled vocabularies to provide an unambiguous summary of dataset contents. The coordinate reference systems on which a dataset is defined may be referenced in a similar manner, with recent developments supporting the range of complex vertical coordinate systems used in the climate sciences.
In order to characterise the internal logical structure and semantics of discovered datasets, the standards framework offers a rich ‘conceptual modelling’ methodology. Object-like conceptual models of data are developed using ‘feature types’ in UML. These provide a formal description of the structure of dataset components and can encapsulate a broad community consensus. They may be placed in ‘feature catalogues’ to facilitate interoperability and tools developed on the basis of these models offer the possibility of widespread re-use.
Finally, in order to access data, the standard ‘Web Feature Service’ appears to be effective for a range of climate-science datasets. For large binary gridded data files, GML may be used in a WFS response as a wrapper providing an interoperability layer. In addition, the ‘stored query’ capability of the newly standardised ISO 19142 version of WFS allows server-side subsetting to be performed. While irregular grids are not currently supported by GML, that is expected to change.
The metaphor of web search also indicates areas requiring additional work by the geospatial standards community. Web search is so successful because it works – users can find what they want from the myriad web resources available. In contrast, effective ranking of geospatial search results remains a work in progress. Despite the success of web search, it currently lacks a semantic foundation – a shortcoming being addressed by the ‘semantic web’ research community. Similar efforts are underway within the geospatial community, but at a very preliminary stage (see, for example, the new ISO project 19150 on ontologies). Finally, standardised and interoperable solutions to access control and rights management would benefit both the web and geospatial communities.
In summary, we conclude that the ISO and OGC standards framework offers excellent prospects for powerful new tools providing interoperable exchange of climate-science data. Such approaches will go a long way to meeting new requirements for sharing data beyond traditional discipline boundaries and for meeting the needs of decision-makers in a world of rapidly changing environmental pressures.
Notes on contributors
Andrew Woolf is leader of the STFC Environmental Informatics group. He is particularly interested in developing architectural approaches to standards-based environmental information management, advancing standards for environmental management and developing large-scale data-sharing infrastructures (INSPIRE, GMES and GEOSS).
Notes
1. alexa.com calculates website traffic on a rolling three-month cycle using a combination of measures described at http://www.alexa.com/help/traffic_learn_more
2. We adopt the terminology of the UK Association for Geographic Information in discriminating de jure and de facto geospatial standards (http://www.agi.org.uk/POOLED/articles/bf_trainart/view.asp?Q=bf_trainart_159658#types):
Four classes of standard can be recognised: proprietary, ad hoc, de facto and de jure. Proprietary standards are those of a particular organisation, usually a product vendor. Standards become ad hoc when they become more widely used than their originator intended. Standards are considered to be de facto when they become the property of Consortia that represent a wide range of interests. Relevant examples of de facto standards producers are the Open Geospatial Consortium Inc (OGC) and the Object Management Group (OMG). Standards are de jure when they are developed by standards bodies established under national or international laws. Relevant examples are the British Standards Institution (BSI), Comite European de Normalisation (CEN) and the International Standards Organisation (ISO). (Self-evidently, de jure standards may be developed at the national level, for Europe as a whole and for the whole world.)
3. Online cross-referencing is supported conceptually by the ISO 19115 CI_Citation class, and at the implementation level through xlink in both metadata (ISO 19139) and data (ISO 19136) encoding standards.
4. See the ‘WMO Core Profile’ of ISO 19115: http://wis.wmo.int/2006/metadata/WMO%20Core%20Metadata%20Profile%20(October%202006)/WMO%20Core%20Metadata%20Profile%20-%20documentation/wmo_core_metadata_profile_documentation.html
5. IOC is considering adoption of the ISO 19115 ‘Marine Community Profile’ developed by the Australian Ocean Data Centre Joint Facility: http://www.aodc.gov.au/files/MarineCommunityProfilev1.4.pdf
6. Full list available at http://vocab.ndg.nerc.ac.uk/list/P011/current, see also http://www.bodc.ac.uk/data/codes_and_formats/parameter_codes/
9. Current (CSML v2) User's Manual available at: http://proj.badc.rl.ac.uk/csml/export/4290/Documentation/trunk/CSMLUsersManual.pdf
10. See for example: http://home.badc.rl.ac.uk/lawrence/blog/2008/03/19/online_resources_in_iso19115_and_moles
11. In the case of a SOAP service binding, the link should reference a WSDL document for the service.
12. CV_DiscreteGridPointCoverage from ISO 19123.
13. CV_RectifiedGrid from ISO 19123.
14. CV_ReferenceableGrid from ISO 19123.
References
- Brase , J. , et al. , 2009 . Approach for a joint global registration agency for research data . Information Services and Use , 29 (1), 13–27. Available from: http://dx.doi.org/10.3233/ISU-2009-0595 [Accessed 22 February 2010] .
- Brin , S. and Page , L. 1998 . The anatomy of a large-scale hypertextual web search engine . Computer Networks and ISDN Systems , 30 ( 1–7 ) : 107 – 117 .
- Chu , C. , et al. , 2006 . OAI-PMH architecture for the NASA Langley Research Center Atmospheric Science Data Center, in ‘Research and Advanced technology for digital libraries’ . Lecture Notes in Computer Science , 4172, 524–527. Available from: http://dx.doi.org/10.1007/11863878_59 [Accessed 22 February 2010] .
- Eaton , B. , et al. 2009 . NetCDF climate and forecast (CF) metadata conventions, version 1.4 Available from: http://cf-pcmdi.llnl.gov/documents/cf-conventions/1.4/cf-conventions.pdf [Accessed 27 February 2009] .
- Fielding , R. , et al. , 1999 . Hypertext transfer protocol – HTTP/1.1, RFC 2616 . Available from: http://www.ietf.org/rfc/rfc2616.txt [Accessed 22 February 2010] .
- Gallagher , J. , et al. , 2007 . The data access protocol – DAP 2.0, NASA Earth Science Data Systems recommended standard ESE-RFC-004.1.1 . Available from: http://www.esdswg.org/spg/rfc/ese-rfc-004/ESE-RFC-004v1.1.pdf [Accessed 22 February 2010] .
- GEOSS , 2005 . The Global Earth Observation System of Systems (GEOSS) 10-year implementation plan, Group on Earth Observations . Available from: http://www.earthobservations.org/documents/10-Year%20Implementation%20Plan.pdf [Accessed 22 February 2010] .
- Gore , A. , 1998 . The digital earth: understanding our planet in the 21st century, speech given at the California Science Center, Los Angeles, CA, 31 January 1998. Available from: http://portal.opengeospatial.org/files/?artifact_id=6210 [Accessed 22 February 2010] .
- Gudgin , M. , et al. , 2007 . SOAP version 1.2 Part 1: messaging framework . W3C Recommendation. 2nd ed. Available from: http://www.w3.org/TR/soap12/ [Accessed 22 February 2010] .
- INSPIRE Drafting Team ‘Data Specifications’ , 2008 . D2.7: guidelines for the encoding of spatial data, Version 2.0 . Available from: http://inspire.jrc.ec.europa.eu/reports/ImplementingRules/DataSpecifications/inspire_dataspec_D2.7_v2.0.pdf [Accessed 22 February 2010] .
- ISO , 1998 . ISO 23950. Information and documentation – information retrieval (Z39.50) – application service definition and protocol specification . Geneva : International Organisation for Standardisation .
- ISO , 2002 . ISO 19108 . Geographic information – temporal schema . Geneva : International Organisation for Standardisation .
- ISO , 2003 . ISO 19115 . Geographic information – metadata . Geneva : International Organisation for Standardisation .
- ISO , 2005a . ISO 19109 . Geographic information – rules for application schema . Geneva : International Organisation for Standardisation .
- ISO , 2005b . ISO 19110 . Geographic information – methodology for feature cataloguing . Geneva : International Organisation for Standardisation .
- ISO , 2005c . ISO 19123 . Geographic information – schema for coverage geometry and functions . Geneva : International Organisation for Standardisation .
- ISO , 2005d . ISO 19135 . Geographic information – procedures for item registration . Geneva : International Organisation for Standardisation .
- ISO , 2007a . ISO 19111 . Geographic information – spatial referencing by coordinates . Geneva : International Organisation for Standardisation .
- ISO , 2007b . ISO 19136 . Geographic information – geography markup language (GML) . Geneva : International Organisation for Standardisation .
- ISO , 2008 . ISO19111-2 . Geographic information – spatial referencing by coordinates – part 2: extension for parametric values . ISO/DIS 19111-2 . Geneva : International Organisation for Standardisation .
- ISO , 2009a . ISO 19142 . Geographic information – web feature service . ISO/DIS 19142 . Geneva : International Organisation for Standardisation .
- ISO , 2009b . ISO 19143 . Geographic information – filter encoding . ISO/DIS 19143 . Geneva : International Organisation for Standardisation .
- ISO , 2009c . ISO/IEC 19505-1 . Information technology – OMG Unified Modeling Language (OMG UML) Version 2.1.2 – Part 1: infrastructure . Geneva : International Organisation for Standardisation .
- Kleinberg , J.M. 1999 . Authoritative sources in a hyperlinked environment . Journal of the ACM , 46 ( 5 ) : 604 – 632 .
- Lagoze , C. , et al. 2002 . The open archives initiative protocol for metadata harvesting. Open Archives Initiative . Available from: http://www.openarchives.org/OAI/openarchivesprotocol.html [Accessed 22 February 2010] .
- Latham , S. , et al. , 2009 . The NERC DataGrid services . Philosophical Transactions of the Royal Society A , 367 (1890), 1015–1019. Available from: http://dx.doi.org/10.1098/rsta.2008.0238 [Accessed 22 February 2010] .
- Lautenschlager , M. , Thiemann , H. Toussaint , F. , 2006 . World DataCenter Climate: status and portal integration . Presented at ‘Fifth GO-ESSP community workshop’ , 19–21 June 2006, Lawrence Livermore National Laboratory, Livermore, CA, USA. Available from: http://www.mad.zmaw.de/fileadmin/extern/Publications/GO-ESSP-WS-LLNL-190606.pdf [Accessed 22 February 2010] .
- Lawrence , B. , et al. , 2004 . The NERC DataGrid: ‘Googling’ Secure Data . Proceedings of the UK e-Science All Hands Conference 2004 , 91–99, EPSRC. Available from: http://www.allhands.org.uk/2004/proceedings/papers/76.pdf [Accessed 22 February 2010] .
- Lowe , D. Woolf , A. , 2008 . What's this ‘coverage vs. feature’ nonsense? Presented at OGC Technical Committee meeting , 1–5 December 2008 Valencia. Available from: http://epubs.cclrc.ac.uk/work-details?w=49662 [Accessed 22 February 2010] .
- Lowry , R. 1998 . “ The BODC parameter dictionary ” . In Proceedings of the Ocean Data Symposium 1997 , Edited by: Cahill , B. Dublin, , Ireland : Irish Marine Data Centre, Marine Institute .
- Millard , K. , et al. , 2007 . Developing feature types and related catalogues for the marine community-lessons from the MOTIIVE project . International Journal of Spatial Data Infrastructures Research , 2 , 132 162 . Available from: http://ijsdir.jrc.ec.europa.eu/index.php/ijsdir/article/view/31/53 [Accessed 22 February 2010] .
- NIMA , 1984 . Department of Defense World Geodetic System 1984: its definition and relationships with local geodetic systems. Technical Report 8350.2, National Imagery and Mapping Agency, USA. Available from: http://earth-info.nga.mil/GandG/publications/tr8350.2/wgs84fin.pdf [Accessed 22 February 2010] .
- Olsen , L. , et al. , 2007 . NASA/Global Change Master Directory (GCMD) earth science keywords . Version 6.0.0.0.0. Available from: http://gcmd.nasa.gov/Resources/valids/archives/keyword_list.html [Accessed 22 February 2010] .
- Schindler , U. , Bräuer , B. Diepenbroek , M. , 2007 . Data information service based on open archives initiative protocols and Apache Lucene . Proceedings of the German e-Science conference 2007 . Available from: http://hdl.handle.net/10013/epic.26667
- Schwarz , C. 1989 . The North American Datum of 1983 . NOAA Professional Paper NOS 2, National Geodetic Survey , Rockville .
- Vretanos , P. , 2005 . Web feature service implementation specification . OGC document 04-094. Available from: http://portal.opengeospatial.org/files/?artifact_id=8339 [Accessed 22 February 2010] .
- Whiteside , A. Evans , J.D. , 2008 . Web coverage service (WCS) implementation standard . OGC document 07-067r5. Available from: http://portal.opengeospatial.org/files/?artifact_id=27297 [Accessed 22 February 2010] .
- Woolf , A. , 2008 . Next steps to interoperability: functions, observations and other things . Presented at ‘Workshop on the use of GIS/OGC standards in meteorology’ , ECMWF, 24–26 November 2008, Reading, UK. Available from: http://epubs.cclrc.ac.uk/bitstream/3475/ECMWF-Nov2008-Woolf.ppt [Accessed 22 February 2010] .
- Woolf , A. , 2009 . An approach to interoperability for file-based coverage data . Presented at Coverages Domain Working Group, OGC Technical Committee meeting , Boston, USA. Available from: http://epubs.stfc.ac.uk/bitstream/3850/CoveragesDWG-Boston-Woolf.ppt [Accessed 22 February 2010] .
- Woolf , A. , Lake , R. Burggraf , D. , 2007 . Add implementation of ISO 19123 CV_ReferenceableGrid to GML. OGC document 07-112. Available from: http://epubs.cclrc.ac.uk/bitstream/1854/07-112_GML_Change_Request_for_ReferenceableGrid.doc [Accessed 22 February 2010] .
- Woolf , A. , et al. , 2006 . Data integration with the climate science modelling language . Advances in Geosciences , 8, 83–90. Available from: http://www.adv-geosci.net/8/83/2006/ [Accessed 22 February 2010] .
- Woolf , A. , et al. , 2005 . European developments in GIS standards for met/ocean data . Proceedings of European Geosciences Union, General Assembly 2005 , 24–29 April 2005, Vienna, Austria. Geophysical Research Abstracts, 7, 08919. Available from: http://www.cosis.net/abstracts/EGU05/08919/EGU05-J-08919.pdf [Accessed 22 February 2010] .