Abstract
An optimal validation of a thematic map would ideally require in-situ observations of a large sample of units specifically conceived for the map under validation. This is often not possible due to budget limitations. The alternative can be using photo-interpretation of high or very high resolution images instead of in-situ observations or using available data sets that do not fully comply with the ideal characteristics: unit size, reference date or sampling plan. This paper illustrates some examples of use of available data in the European Union. For land cover maps, the best existing data set is probably Land Use/Cover Area-frame Survey (LUCAS) that has been conducted by Eurostat on four occasions since 2001. Because LUCAS is based on systematic sampling, advantages and limitations of systematic sampling are discussed. A fine-scale population density map is presented as an example of a situation in which reference data on a statistical sample cannot be collected.
Introduction
The amount of thematic maps derived from satellite images has dramatically increased in the last decades, and accuracy assessment and validation have become critical. There are two related but different concepts referring to the goodness of a land cover map: quality control and accuracy assessment or validation (Carfagna and Marzialetti Citation2009). Quality control ensures that the product is close to the best we could produce given its specifications and the available tools; for example, image photo-interpretation made by a large team may be compared with photo-interpretation by highly skilled staff. Accuracy assessment or validation measures the difference between the land cover map and reality; in practice it is performed by comparison with more accurate data. Both quality control and validation require a sample of locations.
The validation of categorical GIS layers, in particular land cover maps, has been more widely studied than quantitative maps in the remote sensing literature. Congalton and Green (Citation1999) classify in three stages the historical evolution of accuracy assessment for image classification: (1) it looks nice; (2) the area classified in each class in a given region seems correct; and (3) confusion matrices. The first stage is obviously not very scientific. The second stage (we get approximately the expected area for each class) is generally unacceptable, but it can give a partial idea of the needed improvement: the agreement of total areas for each class does not guarantee that the map is correct, but a strong disagreement may give hints on the classification bias, taking into account in any case that the total area in each class may be scale dependent (Moody and Woodcock Citation1994). Confusion matrices are the key tool for accuracy assessment of classified images or land cover maps in general. The concept of confusion matrix is simple at first sight: an array of values A gc that correspond to the area that belongs to class g on the ground and has been classified into class c. The estimated confusion matrix is an array of a gc that estimates each A gc . Thus, the estimation of a confusion matrix can be seen as a problem of area estimation, although in practice it becomes more complex for several reasons: relative mislocation of images, mixed pixels, unclear definition of categories and errors in the reference data can lead to pessimistic assessments (Foody Citation2008). The accuracy reported by a confusion matrix can be summarised into a single index (for example, overall accuracy, Kappa, etc.) or class-level indexes (for example, commission and omission errors); Liu et al. (Citation2007) make an interesting comparison of a wide range of indexes that have been proposed in the literature to summarise a confusion matrix.
Additional difficulties appear for soft image classification, in which a pixel is not attributed to a single category; a number of generalisations of the accuracy indicators for fuzzy classifications have been proposed (Woodcock and Gopal Citation2000, Hagen Citation2003, Fritz and See Citation2005, Gómez et al. Citation2008). The adaptation of the confusion matrix depends on the conceptual basis of the ‘softness’: probabilistic, fuzzy or area share (Pontius and Cheuk Citation2006). In the probabilistic conception, each pixel belongs to a class with a certain probability. The fuzzy conception corresponds to a vague relationship between the class and the pixel; it is very attractive for classes with an unclear definition, but difficult to use for area estimation. In the area-share conception, classes have a sharp definition and the classification algorithm estimates the part x ik of pixel i that belongs to class k. Gopal and Woodcock (1994) also give a method to measure accuracy of a crisp (non-fuzzy) image classification with a fuzzy reference data set.
Examples of quantitative maps to be validated include vegetation indexes (Elmore et al. Citation2000), leaf area index (Verger et al. Citation2009), tree height (Persson et al. Citation2002) or population density (Harvey Citation2002). The most frequently used index for the comparison is the root mean square error (RMSE); however, the mean absolute error (MAE) is more robust than RMSE in the presence of outliers (Legates and McCabe Citation1999, Willmott and Matsuura Citation2005).
Whether we want to perform an accuracy assessment or a quality control, whether we are dealing with categorical layers (such as land cover) or with quantitative maps, we need to select a sample. Many sampling strategies are possible for accuracy assessment: the sampling units can be points, transects (lines of a certain length) or polygons. If we sample polygons, the sampling units can be regularly shaped (e.g. square tiles) or the irregular polygons that constitute the land cover map under validation. The three categories are not clearly different in practice, for example, long and thin polygons (e.g. 100×1 km low altitude flights) can be seen as transects; points are often defined in practice as small polygons (a pixel for example). Stehman (Citation2009) gives an overview of the statistical sampling techniques for accuracy assessment, including random sampling and systematic sampling with a random starting point. In both cases, we can introduce a number of additional features: stratification, two-stage (cluster) sampling, two-phase sampling, etc. Carfagna and Marzialetti (Citation2009) analyse the use of sequential sampling for the accuracy assessment of land cover maps, although some care is needed on the operational implications of an approach that may require knowing the results at step n–1 before selecting the nth sample element or deciding if it will be observed. More sophisticated approaches, such as balanced sampling (Deville and Tillé Citation2004), or simulated annealing (Van Groenigen and Stein Citation1998) are also options to consider, but there is little experience on their application to the validation of thematic maps.
Non-optimal (but cheap) strategies to validate thematic maps
Ideally, the validation of a thematic map should be based on a sample of very accurate data, possibly in-situ observations, and the sampling protocol (including size of sampling units and observation mode) should be specifically conceived for the map that is being validated. In practice, optimal approaches with a sufficient sample size are often difficult to apply because of budget limitations and the theoretical conditions need to be softened. Some of the possible alternative strategies are:
| • | Using existing sample data, even if they do not perfectly correspond to the requirements. For example, using point sample data even if a proper validation would require a specific observation of the neighbourhood. | ||||
| • | Using indirect observations; for example, substituting ground observations with high resolution satellite images. | ||||
| • | Using purposive data sets instead of statistical samples. For example, to validate a land cover map of the European Union (EU), we may try to collect more detailed maps in specific regions, urban areas and environmentally protected areas. Purposive sampling was widely used at the beginning of the 20th century (Jensen Citation1928) and is still frequently used in social sciences when replies are difficult to obtain in a random sampling, for example, in drug dependence studies (Topp et al. Citation2004). The method proposed by Cihlar et al. (Citation2000) can be seen as a purposive sample with constraints: a set of images is selected with the restriction that the land cover profile of the sample in an existing land cover map behaves close to the population profile. Non-random or purposive sampling methods are generally model based. The validity of the results depends on a given model that defines the random structure, even if the model is often implicit. | ||||
Major land cover data layers in the European Union (EU)
The examples presented in this paper are strongly linked with land cover. We introduce in this section some EU land cover layers that may be considered as standard products for the EU: CORINE Land Cover (CLC) and a soil sealing layer(SSL) that we will treat as layers to be validated and Land Use/Cover Area-frame Survey (LUCAS), a major reference data source for validation.
CORINE Land Cover 2000 (CLC2000)
CLC2000 has been produced by photo-interpretation of Image2000, a coverage of Landsat ETM+images (Multispectral + Panchromatic) resampled with 12.5 m resolution (JRC-EEA Citation2005). The nomenclature of CLC2000 has 44 classes. The photo-interpretation was conducted separately in each country but the rules were the same in all countries. The minimum mapping unit is 25 ha; smaller units are included in the dominant land cover type around or grouped in polygons labelled as heterogeneous. The class ‘heterogeneous’ is important (>10% of the total area) because of the coarse scale of the map. CLC2000 is a patchwork of nearly 1.9 million polygons. To validate CLC2000, we could think of using these polygons as sampling units, but this choice is not practical because of their very heterogeneous size. For example, 519 polygons (0.03% of the total) are larger than 50,000 ha; they represent more than 24% of the overall area. Two raster layers (with resolutions of 100 m and 250 m) have been produced to facilitate spatial analysis operations.
There is a previous version of CLC, sometimes called CLC90, with a reference date that is very roughly around 1990 (it ranges between 1986 and 1994) and has a smaller geographical coverage (UK, Sweden and Finland not covered). Both CLC2000 and CLC90 can be downloaded from the EEA data service (http://www.eea.europa.eu/data-and-maps/data). CLC2006 has had some delay and is not fully available to users at the time of writing this paper.
We can look at CLC2000 as reference data for local validation of coarser global land cover maps (Caetano and Araújo Citation2005), but in this paper we only consider it as a land cover map to be validated with more detailed data.
The Global Monitoring for Environment and Security, Fast Track Service Precursor (GMES-FTSP) soil sealing layer (SSL)
IMAGE2006 is a mosaic of SPOT 4/5 and IRS-LISSIII images (Müller et al. Citation2007); it is the basis for the production of CLC2006, and has also been used for additional thematic maps; one of them is the SSL, produced in the framework of Global Monitoring for Environment and Security, Fast Track Service Precursor (GMES-FTSP) and distributed by the EEA data service as a quantitative grid (integer values from 0 to 100%) with 100 m resolution (EEA Citation2009). Each country was analysed separately, but the approach to produce this layer was mainly based on automatic image analysis (initially with 20 m resolution and later generalised). Therefore the international coordination effort was lighter than for CLC and for LUCAS (that required local photo-interpreters and local surveyors).
Land Use/Cover Area-frame Survey (LUCAS)
LUCAS was carried out in 2001 and 2003 in the 15 countries that were member states of the EU in 2001 and Hungary, Estonia and Slovenia. The sampling scheme had a two-stage systematic design (Gallego and Delincé Citation2010). Primary Sampling Units (PSU) were selected with a grid of 18 km without stratification. Each PSU is a cluster of 10 points following a 5×2 rectangular pattern with a 300 m step. The point is conceived as a circle of 3 m diameter.
In 2006, a two-phase sampling scheme was used instead. In the first phase, a systematic 2 km grid on EU25 was photo-interpreted for stratification. Each stratum was subsampled with a different rate for the ground survey. In 2006, the ground survey was carried out in 11 countries (2.3 million km2) with a sample of 169,000 points. LUCAS has been carried out again in 2009 covering the whole EU25.
LUCAS has a double nomenclature: land cover (57 classes in 2001 and 68 classes in 2009) and land use (14 classes). The LUCAS nomenclature is quite detailed for crops (35 classes in 2001) and relatively coarse for other land cover classes (Bettio et al. Citation2002).
Landscape pictures were taken for a large number of points: in 2001 and 2003 pictures were taken from one point of each cluster (towards N, S, E and W), except when the point could not be reached and had to be observed from some distance. In 2006, landscape pictures were taken from more than 100,000 points. These pictures are available at http://www.eea.europa.eu/themes/landuse/clc-lucas and improve the usability of LUCAS for the validation of land cover maps.
Systematic sampling
Because LUCAS uses a variant of systematic sampling, we discuss here with more detail the use of systematic sampling. When we compute a confusion matrix or summary indicators derived from it, we would like the estimators to have a number of properties:
| 1. | Each element a gc of the estimated confusion matrix should be an unbiased estimator of the corresponding value A gc in the unknown theoretical matrix. | ||||
| 2. | The variance V(a gc ) should be as low as possible. | ||||
| 3. | It should be possible to compute an estimator | ||||
| 4. | The estimator | ||||
A practical limitation highlighted by Stehman (Citation2009) for a simple systematic sample is that the sampling scheme is not very flexible to adapt to a smaller sample for budget problems: it is easy to reduce the sample by 50% or by 75%, but it is more difficult to reduce it in a nearly continuous way. To reduce this rigidity LUCAS has used a system based on a pattern of replicates in relatively large blocks (9×9 points) that allow subsampling in each stratum with any rate between 1/81 and 1, keeping a good homogeneity of the spatial layout.
For sensitive issues, i.e. when different stakeholders have an interest to get a certain result, the most important advantage of systematic sampling is the traceability. If a team has produced a thematic map and the same team makes an accuracy assessment, they probably want to show that the map is compliant with the specifications. If a random sample is adopted, the team may be honest and respect the sample selected at the first attempt, but it will be very difficult to demonstrate to an external observer that the sample has not been manipulated to obtain the desired result. In systematic sampling, the possibilities of manipulation are more limited; this improves the trust of an external observer.
Using Land Use/Cover Area-frame Survey (LUCAS) to validate CLC2000
One of the applications of LUCAS 2001 has been the validation of CLC2000 (EEA Citation2006). A simple overlay of LUCAS on CORINE gives a misleadingly high disagreement (Gallego and Bamps Citation2008). The main reason is the different spatial resolution: 25 ha minimum mapping unit for CLC and 3 m for LUCAS observations. reports the result of a simple overlay with a grouped nomenclature; it may look like a confusion matrix, but there are a few conceptual differences, in particular the matrix is not square because the class ‘heterogeneous’ is important in CLC and is not foreseen in LUCAS; this is one of the consequences of the different spatial resolution. If we want to compute a synthetic accuracy indicator, such as the overall accuracy, we can consider that the whole row ‘heterogeneous’ is off-diagonal and therefore wrongly classified.
Table 1. Overlay matrix of LUCAS 2001 point observations with CLC2000.
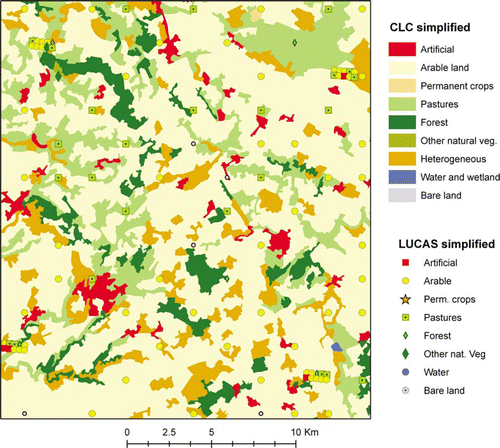
We would estimate the overall accuracy at 67.3%, but this would be strongly unfair. A better solution would be excluding the class ‘heterogeneous’ from the assessment; this would lead to an estimate of the overall accuracy 75.5%, but this is still pessimistic: a LUCAS observation labelled ‘artificial’ or ‘forest’ may be correctly included in a CLC polygon ‘arable land’ if it corresponds to an isolated house or a small forest patch surrounded by arable land. illustrates the overlay of LUCAS points on CLC in a small area in France. Most of the apparent disagreement cases are due to scale (isolated buildings or small forest patches), but some of them correspond to photo-interpretation mistakes (e.g. areas mapped as arable land should have been labelled as pastures).
Figure 1. Scale differences between CLC and LUCAS in a mixed area in Central France.
Exploiting the landscape pictures taken by surveyors allows a better validation. The same satellite images used to produce CLC2000 were interpreted again with the additional information provided by LUCAS. Now the photo-interpreter focuses the attention on one point and decides if it is possible to delineate a polygon with a dominant land cover class or one of the heterogeneous classes should be considered. Focusing the attention on one point is an additional element of improvement, but it would rather correspond to the idea of quality control if no additional information is used. With the information provided by LUCAS (land cover code, land use code and above all landscape pictures) the procedure becomes a proper validation (EEA 2006). In LUCAS 2001, the number of points that could be physically reached by the surveyor to take the landscape pictures was 8231 out of the theoretical maximum of approximately 9800 points (one per PSU); thus there is a significant amount of missing pictures. Taking into account missing data required procedures with some simplifying assumptions, thus improvements of the procedure are possible; nevertheless LUCAS data allowed a proper validation at a reasonable cost. The estimated overall accuracy was 87.0±0.8% with the 44 class nomenclature. Commission and omission errors could be estimated with a sufficient accuracy only for half of the classes; for the other 22 classes the sample size was too small.
Looking at the Global Monitoring for Environment and Security, Fast Track Service Precursor (GMES-FTSP) soil sealing layer (SSL) with Land Use/Cover Area-frame Survey (LUCAS) data
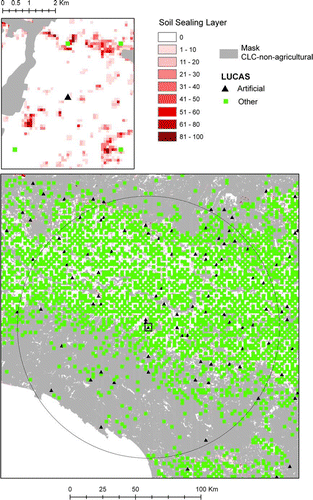
Using LUCAS to validate SSL has the same limitation found for the validation of CLC; If a LUCAS point i falls on a 100 m cell that has been mapped as 50% built-up (SSL i =0.5), the 0–1 information from LUCAS (L i =1 if i is built-up) cannot be directly used to build a confusion matrix. An alternative approach could be an operation similar to the CLC validation described above: photo-interpretation on the IMAGE2006 mosaic for the LUCAS 2006 points (or a subsample) with the help of the landscape photographs. This process has not been undertaken at the moment, but some indications have been obtained with a simple analysis presented here.
The overlay is limited to the 11 countries covered by LUCAS 2006 (). In this area the average value of SSL is 3.15%, while the estimated proportion of built-up area from LUCAS is 5.7%. This means that SSL generally underestimates the soil sealing level. If we stratify per values of SSL we get additional information (): most of the underestimation seems to come from areas with a low degree of soil sealing that is not detected (SSL = 0). In the moderate to high SSL intervals, the mean values of LUCAS and SSL do not appear to be very different. However, the zoning for is misleading: it is obvious that the average SSL is 0 in the row defined by the Condition ‘SSL = 0’, and it is equally obvious that this underestimates the soil sealing proportion estimated by LUCAS.
Table 2. Proportion of built area estimated with LUCAS 2006 in areas defined by the soil sealing layer values.
A more reasonable zoning is provided by CLC2000 with a simplified nomenclature (). The underestimation is moderate in CLC-mapped artificial areas, and is particularly severe in areas where forest is dominant, although most of the total underestimation comes from areas classified as agricultural or heterogeneous in CLC. Heterogeneous areas are part of the agricultural domain in the CLC nomenclature, but they have been considered separately in because of the higher soil sealing proportion.
Table 3. Proportion of built area estimated with LUCAS 2006 in areas defined by main CLC classes.
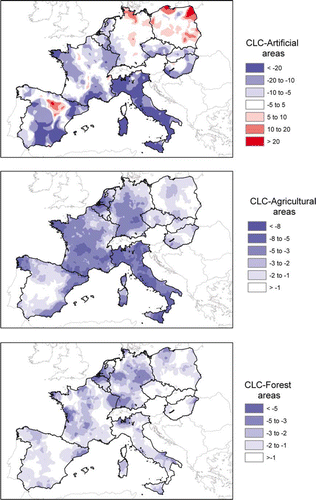
We can make a further step identifying areas where the underestimation is stronger for each of the most important CLC classes. Mapping the disagreement can be as important and sometimes more informative than quantifying it with a summary index (Fritz and See Citation2008). illustrates the computation of the indicator we have used. In the upper square we can see an example of LUCAS point that falls in the CLC class ‘agriculture’ and has been observed on the ground as artificial. SSL reports 8% soil sealing for the corresponding pixel. This is not necessarily a mistake and we cannot build a confusion matrix on this basis.
Figure 2. Illustration of the indicator used to map overestimation and underestimation of SSL.
We have looked around instead of using a 100 km radius circle. We call the weighted average of SSL in the CLC-agricultural areas (the weight is a decreasing function of the distance to the central pixel i).
is the proportion LUCAS points with an artificial land cover in the same neighbourhood and with the same weights.
provides a measure of the local overestimation or underestimation of SSL expressed as proportion on the total area of each CLC class. shows the result for three major CLC classes: in CLC-artificial areas, we can see a strong underestimation in Italy and other Mediterranean areas and some overestimation, for example, in Baltic areas; in CLC-agricultural areas, including heterogeneous classes that turned out to have a similar pattern, stronger underestimation appears again in Italy and some areas of France, Germany, Belgium, the Netherlands and Spain; for the CLC class ‘forest and woodland’, underestimation seems to be more important in more densely populated areas. Notice that gives the impression of a less important underestimation in CLC-forest areas than in CLC agriculture because the chosen indicator was
, and both
and
are small in CLC-forest areas; for example, if SSL estimates a soil sealing rate of 1% of the total area mapped as forest by CLC, but the rate is estimated to be 4% from ground data, the map reports −3%.
Figure 3. Underestimation and overestimation of the soil sealing layer for three major CLC classes in percentage of the total area of the corresponding CLC class.
Reference grids to validate a population density map
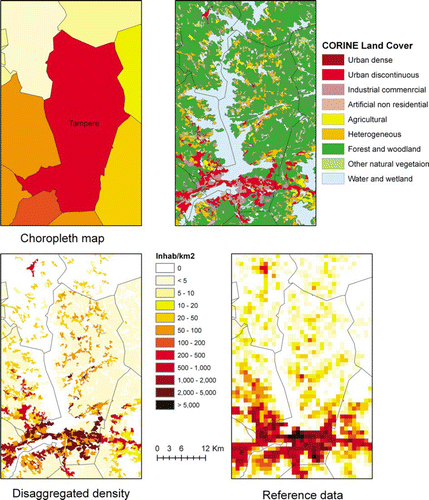
This paragraph describes an example in which the collection of reference data on a statistical sample is impossible, not only for budgetary reasons, but also for legal limitations. Harmonised population data in the EU from official sources are available at the level of the commune, and this may be insufficient for spatial analysis of events that hit areas that do not follow administrative boundaries, such as floods (Thieken et al. Citation2006). A disaggregated population dasymetric (density) map has been produced combining population per commune with CLC (Gallego Citation2010). The result, distributed by the EEA data service, is far from being a perfect representation of the reality, but it is substantially better than the choropleth map with a homogeneous density attributed to the whole commune. Two questions need to be answered: how much have we improved compared to the choropleth map? and which of the methods that have been tested so far for the disaggregation gives the best results?
A specific data acquisition for the validation of the disaggregated population density would have presented the two difficulties mentioned above (budget and time constraints) and an even more important one: due to privacy regulations, a very strong legal mandate would be necessary to acquire detailed data on the precise number of people who live in each point or small site of a sample. Fortunately, a number of National Statistical Institutes (Scandinavian countries, the Netherlands, Austria, Switzerland, Estonia, Slovenia and Northern Ireland) have provided reference grid data with 1 km2 resolution that have allowed assessing the accuracy of the disaggregated map. The reference data set is not a statistical sample and does not allow making any statistical inference valid for the whole EU, but it allowed making a simple descriptive analysis suggesting that the accuracy improvement between 40 and 70% for the best behaving method, quantified by the MAE. The improvement was quantified comparing the inaccuracy Δ d of the disaggregated map d and Δ ch of the choropleth map, computed as:
Figure 4. Illustration of the population density downscaling process in the area of Tampere (Finland).
Discussion, conclusions and way forward
Validating thematic maps, and land cover maps in particular, would ideally require a survey with characteristics that are specifically conceived for the map under validation, but this is often unfeasible because it is too expensive.
The LUCAS run by Eurostat, provides a major data source of georeferenced data that can be used to validate land cover maps. Individual LUCAS point data are directly available for all users, but files with a large amount of points are only delivered by Eurostat upon request for public interest non-commercial applications.
Automatic processing approaches of LUCAS data are often insufficient for a proper validation, but it can give in many cases valid indications on the type and location of the most important errors. Proper validation of land cover maps may require re-interpretation of images with the help of landscape pictures acquired during the LUCAS field work. Landscape pictures were acquired for only a few thousands of points in LUCAS 2001, but these pictures have allowed the EEA to make a proper validation of CLC2000 at a reasonable cost; the number of points with landscape pictures was significantly increased in 2006 to about 100,000.
The use of LUCAS to validate other thematic maps is enhanced in LUCAS 2009 with the observation of additional environmental parameters, such as the soil composition for a subsample of points, although the results of chemical analysis will still require some time.
For the SSL produced from the IMAGE2006 mosaic, only a preliminary analysis is presented in this paper that provides hints on the geographic layout of over/underestimation. A more specific validation for Slovakia has been undertaken by Hurbanek et al. (Citation2010).
We have also presented the example of population density maps obtained by downscaling commune-level data with CLC. The EU-wide validation with a statistical sample is not possible. It has been possible only for a few countries for which reference data are available. The accuracy indicators for this set of countries cannot be directly extrapolated to the whole EU because it is not a statistical sample. One of the forthcoming steps in this study is a more structured model-based validation, in which the inaccuracy is expressed as a function of parameters such as the rural–urban character of the area.
Note on contributor
Javier Gallego was born in 1953 in Spain. He graduated in Mathematics in 1975 and received a PhD in Statistics in 1979 from the University of Valladolid, as well as a ‘Doctorat de troisième cycle’ from the University of Paris VI in 1980. In 1983, he became Head of the Department of Statistics at the University of Valladolid, and full professor in 1986. In 1987, he moved to the European Commission, first in DG Agriculture and then since 1988 in the JRC, where he has worked mainly on the use of remote sensing for land cover area estimation and agricultural statistics, geographic sampling and downscaling techniques.
Acknowledgements
Pascal Jacques, Marjo Kasanko, Laura Martino and Alessandra Palmieri (Eurostat) provided LUCAS data. National Statisitcal Institutes involved in the European forum for Geostatistics provided reference population density data for validation. Stefan Jensen (EEA) provided the necessary information to exploit the soil sealing layer.
Related Research Data
References
- Bellhouse , D.R. , 1988 . Systematic sampling . In : P.R. Krisnaiah and C.R. Rao Handbook of statistics . Vol. 6 . North Holland Amsterdam , 125 – 146 .
- Bettio , M. , et al. , 2002 . Area frame surveys: aim, principals and operational surveys . J. Gallego Building agri-environmental indicators, focussing on the European area frame survey LUCAS . EC report EUR 20521 JRC Ispra 12 – 27
- Caetano , M. and Araújo , A. , 2005 . Comparing land cover products CLC2000 and MOD12Q1 for Portugal . Portugese Geographical Institute. Available from: http://www.igeo.pt/instituto/cegig/gdr/pdf/caetano2006c.pdf [Accessed 25 August 2010].
- Carfagna , E. and Marzialetti , J. 2009 . Sequential design in quality control and validation of land cover databases . Applied Stochastic Models in Business and Industry , 25 ( 2 ) : 195 – 205 .
- Cihlar , J. 2000 . Selecting representative high resolution sample images for land cover studies. Part 1: methodology . Remote Sensing of the Environment , 71 : 26 – 42 .
- Congalton , R.G. and Green , K. , 1999 . Assessing the accuracy of remotely sensed data: principles and practices . Boca Raton: Lewis Publishers , 137 pp.
- Deville , J. and Tillé , Y. 2004 . Efficient balanced sampling: the cube method . Biometrika , 91 ( 4 ) : 893 – 912 .
- EEA , 2006 . The thematic accuracy of Corine land cover 2000. Assessment using LUCAS (land use/cover area frame statistical survey) . Copenhagen: European Environment Agency, EEA technical report 7/2006. Available from: www.eea.europa.eu/publications/technical_report_2006_7 [Accessed 25 August 2010].
- EEA , 2009 . GMES fast track service precursor on land monitoring: high-resolution core land cover data built-up areas including degree of soil sealing . Updated delivery report; European Mosaic. Copenhagen: European Environment Agency. Available from: http://www.eea.europa.eu/data-and-maps/data/eea-fast-track-service-precursor-on-land-monitoring-degree-of-soil-sealing-100m[Accessed 25 August 2010].
- Elmore , A.J. 2000 . Quantifying vegetation change in semiarid environments: precision and accuracy of spectral mixture analysis and the normalized difference vegetation index . Remote Sensing of Environment , 73 ( 1 ) : 87 – 102 .
- Fattorini , L. , Marcheselli , M. and Pisani , C. 2004 . Two-phase estimation of coverages with second-phase corrections . Environmetrics , 15 ( 4 ) : 357 – 368 .
- Foody , G.M. 2008 . Harshness in image classification accuracy assessment . International Journal of Remote Sensing , 29 ( 11 ) : 3137 – 3158 .
- Fritz , S. and See , L. 2005 . Comparison of land cover maps using fuzzy agreement . International Journal of Geographical Information Science , 19 ( 7 ) : 787 – 807 .
- Fritz , S. and See , L. 2008 . Identifying and quantifying uncertainty and spatial disagreement in the comparison of global land cover for different applications . Global Change Biology , 14 : 1057 – 1075 .
- Gallego , F.J. 2010 . A population density map of the European Union . Population and Environment , 31 ( 6 ) : 460 – 473 .
- Gallego , F.J. and Delincé , J. , 2010 . The European land use and cover area-frame statistical survey (LUCAS) . In: R. Benedetti , M. Bee , G. Espa , and F. Piersimoni Agricultural survey methods . New York : John Wiley , 151 – 168 .
- Gallego , J. and Bamps , C. 2008 . Using CORINE Land Cover and the point survey LUCAS for area estimation . International Journal of Applied Earth Observation and Geoinformation , 10 : 467 – 475 .
- Gómez , D. , Biging , G. and Montero , J. 2008 . Accuracy statistics for judging soft classification . International Journal of Remote Sensing , 29 ( 3 ) : 693 – 709 .
- Gopal , S. and Woodcock , C. 1994 . Theory and methods for accuracy assessment of thematic maps using fuzzy sets . Photogrammetric Engineering and Remote Sensing , 60 ( 2 ) : 181 – 188 .
- Hagen , A. 2003 . Fuzzy set approach to assessing similarity of categorical maps . International Journal of Geographical Information Science , 17 ( 3 ) : 235 – 249 .
- Harvey , J.T. 2002 . Population estimation models based on individual TM pixels . Photogrammetric Engineering and Remote Sensing , 68 ( 11 ) : 1181 – 1192 .
- Hurbanek , P. , et al. 2010 July . Accuracy of built-up area mapping in Europe at varying scales and thresholds . In: Accuracy 2010 , 20 – 23 Leicester (proceedings in preparation)
- Jensen , A. 1928 . Purposive selection . Journal of the Royal Statistical Society , 91 : 541 – 547 .
- JRC-EEA , 2005 . CORINE land cover updating for the year 2000: Image2000 and CLC2000 . In: V. Lima Products and methods . Report EUR 21757 EN . JRC-Ispra .
- Legates , D.R. and McCabe , G.J. Jr. 1999 . Evaluating the use of ‘Goodness-of-Fit’ measures in hydrologic and hydroclimatic model validation . Water Resources Research , 35 1 , 233 – 241 .
- Liu , C. , Frazier , P. and Kumar , L. 2007 . Comparative assessment of the measures of thematic classification accuracy . Remote Sensing of Environment , 107 ( 4 ) : 606 – 616 .
- Moody , A. and Woodcock , C. 1994 . Scale-dependent errors in the estimation of land cover proportions: implications for global land-cover datasets . Photogrammetric Engineering and Remote Sensing , 60 ( 5 ) : 585 – 594 .
- Müller , R. , et al. , 2007 Automatic production of a European orthoimage coverage within the GMES land fast track service using Spot 4/5 and IRS-P6 Liss III data . ISPRS conference proceedings , Vol. XXXXVI May 2007 Hannover 6 pp. Available from: http://www.isprs.org/proceedings/XXXVI/1-WS1/paper/papers.htm
- Persson , Å. , Holmgren , J. and Söderman , U. 2002 . Detecting and measuring individual trees using an airborne laser scanner . Photogrammetric Engineering and Remote Sensing , 68 ( 9 ) : 925 – 932 .
- Pontius , R.G. Jr. and Cheuk , M.L. , 2006 . A generalized cross-tabulation matrix to compare soft-classified maps at multiple resolutions . International Journal of Geographical Information Science , 20 1 , 1 – 30 .
- Stehman , S.V. 2009 . Sampling designs for accuracy assessment of land cover . International Journal of Remote Sensing , 30 ( 20 ) : 5243 – 5272 .
- Thieken , A. 2006 . Regionalisation of asset values for risk analyses . Natural Hazards and Earth System Sciences , 6 : 167 – 178 .
- Topp , L. , Barker , B. and Degenhardt , L. 2004 . The external validity of results derived from ecstasy users recruited using purposive sampling strategies . Drug and Alcohol Dependence , 73 : 33 – 40 .
- Van Groenigen , J.W. and Stein , A. 1998 . Constrained optimization of spatial sampling using continuous simulated annealing . Journal of Environmental Quality , 43 : 684 – 691 .
- Verger , A. 2009 . Accuracy assessment of fraction of vegetation cover and leaf area index estimates from pragmatic methods in a cropland area . International Journal of Remote Sensing , 30 ( 10 ) : 2685 – 2704 .
- Willmott , C.J. and Matsuura , K. 2005 . Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance . Climate Research , 30 ( 1 ) : 79 – 82 .
- Wolter , K.M. 1984 . An investigation of some estimators of variance for systematic sampling . Journal of the American Statistical Association , 79 ( 388 ) : 781 – 790 .
- Woodcock , C.E. and Gopal , S. 2000 . Fuzzy set theory and thematic maps: accuracy assessment and area estimation . International Journal of Geographical Information Science , 14 ( 2 ) : 153 – 172 .