
Abstract
The hypermap concept was introduced in 1992 as a way to hyperlink geospatial features to text, multimedia or other geospatial features. Since then, the concept has been used in several applications, although it has been found to have some limitations. On the other hand, Spatial Data Infrastructures (SDIs) adopt diverse and heterogeneous service oriented architectures (SOAs). They are developed by different standard bodies and are generally disconnected from mass market web solutions. This work expands the hypermap concept to overcome its limitations and harmonise it with geospatial resource oriented architecture (ROA), connecting it to the semantic web and generalising it to the World Wide Hypermap (WWH) as a tool for building a single ‘Digital Earth’. Global identifiers, dynamic links, link purposes and resource management capabilities are introduced as a solution that orchestrates data, metadata and data access services in a homogeneous way. This is achieved by providing a set of rules using the current Internet paradigm formalised in the REpresentational State Transfer (REST) architecture and combining it with existing Open Geospatial Consortium (OGC) and International Organization for Standardization (ISO) standards. A reference implementation is also presented and the strategies needed to implement the WWH, which mainly consist in a set of additions to current Geographic Information System (GIS) products and a RESTful server that mediates between the Internet and the local GIS applications.
1. Introduction
Hyperstructure refers to a form of communication that goes beyond or over the linear style so that the reader is able to jump from one content to another through links in a non-linear way (Laurini and Thompson Citation1992). In fact, in 1967, Douglas C. Engelbart filled a US patent form on a ‘x-y position indicator’ that was later known as computer mouse (Engelbart Citation1967) and on 9 December 1968, he publicly demonstrated that a computer mouse could be used to control a networked computer system using hypertext linking among other precursor technologies we use today, from personal computing to social networking (Engelbart and English Citation1968). The hypertext concept was extended to digital maps and the hypermap concept was established in 1990 by Laurini and Milleret-Raffort (Citation1990) just before Berners-Lee proposed the World Wide Web and the hypertext markup language (HTML). Hypermaps are geo-referenced multimedia systems that can hyperstructure individual components with respect to each other and to the map (Kraak and Driel Citation1997); thus, features on a map can be linked to information of any kind (text documents, pictures, sounds, videos and other multimedia content) through hyperlinks. These links are represented on the screen by buttons appearing as icons/pictograms or typographical enrichments in text, etc. (Boursier and Mainguenaud Citation1992).
The hyperrelated elements in a hypermap are called resources, and the connections are possible because each resource has an identifier (Laurini and Thompson Citation1992). The hypermap concept has been implemented in some Geographic Information System (GIS) applications, such as ArcView 3.0 and MiraMon, which evolved from linking to a proprietary data hierarchical structure (Kraak and Driel Citation1997) to a more flexible link to any document in the computer or over the Internet, including other hypermaps (Pons Citation2002).
Hypermaps have been used with several purposes: raster images resulting from finite element simulations on urban networks (in which pixels represent identifiers to videos or hypertext) (Saugy et al. Citation1995), in the atlas metaphor (Kraak and Driel Citation1997), in urban geography and planning learning environments (Thompson et al. Citation1997), in geological studies (Voisard Citation1998), in intelligent transport systems with geo-referenced video frames (Kim et al. Citation2000) and in tourist maps (Proll Citation2002). Since the hypermap is closer to a naive user's way of thinking, most of these applications have been developed for the general public in interactive terminals (Boursier and Mainguenaud Citation1992).
The largest limitation of the hypermap is that all queries must be previously defined and ‘prepared’, i.e. links must be established between entities and users can only follow those particular paths (Boursier and Mainguenaud Citation1992). In addition, resources are linked to other resources by pairing local identifiers, and thus limit the scope of their relationships (Yuan et al. Citation2000). Another criticism is that the underlying data model is extremely poor, as it only includes the concept of hyperlinks among entities (Boursier and Mainguenaud Citation1992, Voisard Citation1998) and has no semantics that identifies the purpose of each hyperlink. Moreover, hypermaps are limited to retrieving resources (Voisard Citation1998) and are not able to create, update or delete resources.
Indeed, Al Gore (Citation1998), in the famous speech about the ‘Digital Earth’ vision, recognises the need for combining simple users way of thinking to navigate and search geospatial information with a digital globe database maintained by thousands of different producer organisations interconnected by the web, interlinking the information about the planet in a single system. In the past 20 years, new technologies have emerged that are used here to overcome the hypermap limitations and to extend it to a distributed environment for Internet GIS (Yuan et al. Citation2000). In fact, hyperlinks are recognised as a needed functionality for data store interconnection and as user interface navigation elements to build the ‘Digital Earth’ (Grossner et al. Citation2008). Taking the concept to the extreme, there is only one giant hypermap that links all spatial data in a World Wide Hypermap (WWH). In the present paper, Section 2 covers the technological context that makes the WWH possible, Section 3 describes how these technologies can be applied in the WWH, and Section 4 describes the development of a reference software and some details of its implementation.
2. Technological methodologies
In the introduction, four limitations of the original hypermap concept have been enumerated. This chapter describes four technologies that are useful to extend the hypermap concept, and to evolve it to a WWH and that have been applied to overcome the four limitations identified earlier.
2.1. Geospatial web services and dynamically generated hyperlinks
The original hypermap concept relied on a predefined set of static links; however, this limitation no longer exists thanks to web services. Just sit at your Internet browser and type ‘hypermap’ in Google search, for instance. You immediately get about 51,000 results (June 2011) in the form of HTML pages with hyperlinks that were dynamically created on the fly by the web service search engine. Similarly, mass market map search engines, like geocommons.com, or catalogues compliant with the Open Geospatial Consortium (OGC) Catalogue Service for the Web (CSW) return collections of dynamically generated links to geospatial data-sets. Indeed, the Internet in general, but particularly the web, has made it possible to share cartographic resources globally. Organisations involved in producing and using cartographical resources have organised themselves into Spatial Data Infrastructures (SDIs), and have eventually created a global community (Coleman and McLaulghlin Citation1997). SDI implementations are based on web services that make it possible to discover data (web catalogue services), display data (web visualisation services), share data (web downloading services) and even manipulate data (web processing services [WPS]). Classical cartographic products and data-sets are merged with sensor data (remote and in situ sensors) and with Volunteered Geographic Information (VGI) (Longueville et al. Citation2010). Distributed services make it possible to build complex systems that rely on smaller pieces or individual corporative services. The European SDI, promoted by the INSPIRE directive (INSPIRE Citation2008), is an example of a multilevel architecture, and the Global Earth Observations System of Systems (GEOSS) is an example of a more decentralised and diversely composed structure (Butterfield et al. Citation2008).
In fact, current web services implicitly try to extend the hypermap concept. In the SDI, cartographic resources can be immediately interconnected to others. By doing so we are creating a single huge WWH that reuses the hypermap concept but overcomes its main limitations. Current SDIs build an integrated network based on International Organization for Standardization (ISO) and OGC web service (OWS) standards (Percivall Citation2010), which have helped the development of the SDIs enormously. Web services are distributed applications that manage resources so that the user software no longer accesses the data directly but rather makes requests to remote computer applications. Remote applications obtain a subset of the data and transform it into a suitable format. During this extraction, it is possible to encode hyperlinks to other subsets of the data or to other cartographic resources that were not encoded in the original data; therefore, the hyperlinks are no longer static but rather are constantly created by web services.
Nevertheless, 15 years of using geospatial web services have revealed some practical limitations. One of the main problems is the metadata catalogues and the difficulties involved in generating federated catalogues, resulting in the metadata being replicated in several harvested catalogues that are disconnected from the actual data (Craglia et al. Citation2007). A common SDI has at least two catalogues: one for metadata about data and another for metadata about services. If a user needs some data and makes a query in an SDI search engine, he/she obtains a set of metadata about data that is very often poorly connected to the data and services (data and services are maintained and stored by the data provider itself); or the user receives metadata about data services that often do not have enough information about which data they contain. So even if the user is able to discover the existence of an interesting data-set, he/she will have problems getting it as a file or as a service response. Instead of building a WWH in which the focus is centred on resources, SDIs build infrastructures based on catalogues, which inadvertently confuse users. Furthermore, many current web service standards do not have the transactional extensions to allow them to do more than just access data, but also create and update data. Even if some data standards, such as Geography Markup Language (GML), have the ability to hyperlink geospatial objects, current web services provide poor direct access to hyper-references and do not provide operations for creating new ones. There is also no uniform interface for addressing resources; instead, current standards provide different protocols for the address access to a diversity of resource types, making data exchanges more challenging.
This paper provides a different perspective in which web services are almost invisible in favour of providing immediate access to resources and their associations. Service catalogues are no longer needed for data discovery and access, and only play a role in providing distributed data processing and metadata discovery.
2.2. Global geo-identifiers
Only resources that have a unique identifier can be referenced and indicated by hyper-references in a hypermap. Classic hypermaps use local identifiers to relate internal resources. Replacing local identifiers with global identifiers is the logical solution, but the problem is that global identifiers need a resolver application to find the actual resource that each identifier indicates (Bishr Citation1999). These resolution systems are too dependent on specific and centralised resolver components. The Internet offers an alternative for identifying geo-resources directly, i.e. Hypertext Transfer Protocol (HTTP) Uniform Resource Identifier (URI), which provide a global addressing space for resource and service discovery. The advantage of HTTP URIs is that they encapsulate all the information required to identify and locate a resource in a global addressing space without needing a centralised registry. This is a simple solution that relies on technological components that have existed for many years, and indeed, make the Web work.
Hypertext Transfer Protocol Uniform Resource Identifiers have some important advantages: They can be used with the current Internet infrastructure and they do not require an extra catalogue component to be maintained. URI can be bookmarked, exchanged via hyperlinks and, given their readability, even advertised (Pautasso et al. Citation2008). These identifiers can be used directly on a REpresentational State Transfer (REST) architecture in REST oriented services (zur Muehlen et al. Citation2005). However, there are some disadvantages (Bishr Citation1999): Since the system relies on the Internet Protocol (the context in which HTTP URIs are valid), URI cannot work directly on other networks. In addition, it has been argued that the use of URI is too sensitive to the specific location of the server, which can change over time. This problem can be overcome by using Domain Name Servers (DNS) to translate addresses, and thus it is only necessary to configure the networking infrastructure properly (Pautasso et al. Citation2008).
2.3. Hyperlinks with purpose
A classic hypermap link can serve different purposes, but there is no way to express and store these purposes, which is one of the reasons why some people consider the hypermap model to be extremely poor. In the following we give some examples of different purposes described in scientific papers:
To link resources that are semantically related (Laurini and Milleret-Raffort Citation1990).
To link resources to the time when they were created in a way that allows version dependencies to be defined (Voisard Citation1998, Sargent Citation1999).
To link resources with the evidence describing the phenomenon, such as previous documentation, scientific papers, etc. (Voisard Citation1998).
To link resources that exist only if other objects exist, such as topological dependencies (Voisard Citation1998).
To link multiple representations of the same object in different data-sets or at different scales (Friis-Christensen and Jensen Citation2005).
To allow incremental discovery of resources (Pautasso et al. Citation2008).
To assign a coordinate reference system (CRS) and to define CRS dependencies with a datum ellipsoid, etc., like the GML does (Portele Citation2007).
In an XML document, the xlink arcrole attribute can store the role or purpose of the target resource in relation to the present resource, given as a URI.
In an HTML page, the Resource Description Framework in attributes (RDFa) allows rel and rev attributes to be added to express the meaning of a direct or reverse relationship between two resources.
2.4. RESTful web services
Classical hypermaps are limited to retrieving resources. Retrieving resources is only a subset of what Internet architecture can do as it was formalised in the REST (Fielding Citation2000). Fielding defines a set of REST principles that can be applied to more generic Resource Oriented Architecture (ROA), a flourishing kind of web services, and particularly geo-services (Richardson and Ruby Citation2007). REST is an architectural style for building large-scale distributed hypermedia systems (Pautasso et al. Citation2008). It is the perfect environment in which the WWH can grow and break the individual data-set barriers.
The REST architectural style is defined by the following rules: client-server interaction, stateless interaction, cache support, chaining of services, code on demand and uniform interface (Mazzetti et al. Citation2009). In the REST approach, a client performs a request and a server provides a response (client-server interaction) in the form of a document of a particular media type that can sometimes include new code that can be executed on the client (code on demand). No session is established (stateless interaction) and only the information in the request message is used to provide the response (no previous requests from the same client are considered); therefore, the responses can be cached by intermediate elements of the protocol and reused anytime (cache support). Servers can act as clients of other servers, which allows service chaining (chaining of services).
In REST, the client and server interaction is based on exchanging resource representations. Communication of resource representations is possible because each resource has its own resource identifier that can be used in a request (what is known as the addressability principle). A resource representation is a document of some sort (expressed in a particular media type), and some documents contain hyperlinks to other resource identifiers that can be followed to manipulate other resources so that Hypermedia is The Engine Of the Application State (property sometimes referred to with the acronym of HATEOAS). This last property is the same paradigm that Laurini and Milleret-Raffort (Citation1990) used to define the hypermap two decades ago, where a user click on a map feature brings up information and it is a link that can be followed to discover new information that was not directly available. The term RESTful was introduced to indicate ‘REST oriented approach’ (Richardson and Ruby Citation2007).
Combining different RESTful requests we can manipulate interrelated resources using resource identifiers without needing previous predefined links. We can also create resources, retrieve representations and update or delete resources, and thus overcome the historical limitations of the classical hypermap.
In this context, the most important characteristic of the REST architectural style is probably the uniform interface. The only mandatory requirement for a RESTful web service is to adopt URI addressing. However, the HTTP application-level protocol is very common. In this case, the HTTP 1.0 methods (sometimes called verbs) (Berners-Lee and Fielding Citation1996) define the action to be performed on the target resource (GET = retrieve; POST = create; PUT = update; DELETE = delete) (Mazzetti et al. Citation2009). In addition, HTTP 1.0 defines HEAD, and HTTP 1.1 (Fielding et al. Citation1999) adds three additional methods, TRACE, OPTIONS and CONNECT, that can be associated with new actions of the target resource (Pautasso et al. Citation2008). For instance, HEAD can be used to obtain metadata about the resource without retrieving the complete representation of the resource itself, and OPTIONS lists the methods supported by a particular resource (Richardson and Ruby Citation2007). GET is the most commonly used method on the Web. In fact, we use it many times a day to retrieve web pages on a web browser or to download a PDF file. The POST operation is used sometimes when we fill in a form on a web page and submit it. Although PUT and DELETE are not used in common web browsing, they are well defined and ready to use for the indicated purposes.
Currently, SDI web services are based on a different architectural style that is called Remote Procedure Call–Service Oriented Architecture (RPC–SOA) (Booth Citation2004, Whiteside Citation2005). However, the web 2.0 geo-community is currently pushing the geospatial standard organisations to introduce RESTful styles because they find them simpler to implement. Some RESTful standards based on RDF Site Summary (RSS) and Atom have been extremely successful in the VGI community.
The OCG has recently taken some measures to bring web services closer to the REST style:
It was recognised that some mass market applications use RESTful services, such as GeoRSS and Keyhole Markup Language (KML) (Percivall Citation2008).
A draft for the Integration of ROA Concepts into the OGC Reference Model was proposed (Usländer Citation2008).
A RESTful interface for the Workflows and Sensor Web Enablement groups of standards was considered in interoperability experiments, such as the OGC OWS-5 initiative (Werling Citation2008), tested in the OWS-6 initiative (Cappelaere Citation2009).
Open Geospatial Consortium policies mandate that any new OGC standard or new revision of a previous standard must evaluate a ROA style.
The Web Map Tile Service (WMTS) is the first OGC approved standard that includes an explicitly RESTful interface (Masó et al. Citation2009) (tested in the OGC OWS-6 initiative).
3. How to implement the WWH
The four technologies presented earlier are not new but the contribution of this paper is to apply them together in a single system to overcome the four main drawbacks of the old hypermap concept, and make it possible to extend the hypermap so it becomes a WWH. This section describes the essential elements needed to implement them.
If you imagine a permanent collection of data-sets (with all their different components) that represents an immutable world that considers all aspects imaginable, it is easy to generate a set of global identifiers in a centralised way, and then encode the logical links between them. But in the real world, data-sets are generated progressively and frequently updated. A data-set is updated by creating new features or modifying some of the previous ones. However, applications in GIS analysis currently generate new derived data-sets. This process can be carried out in local GIS applications but also in distributed environments either by professional or VGI communities.
In a ROA the first step is to identify the resources available in the problem and provide a logic that guarantees that each resource has its own global identifier. Resources that are part of the WWH are information such as feature collections (e.g. vector cartographic series), feature instances, feature attributes (textual, multimedia, etc.), coverage collections (e.g. multiband rasters), simple coverages, etc. Previous efforts have been made to apply a ROA style to some of these resources (Mazzetti 2009); however, it is still necessary for a unified protocol to manage all these resources and a mechanism is required to generate and maintain a harmonised but decentralised global geospatial identifiers schema.
The solution presented in this paper proposes combining a new RESTful web service with slightly modified classical GIS applications to generate a seamless WWH environment in which common GIS processes can be carried out directly in a classical GIS application or in a distributed environment on the Web. describes how local GIS instances can access data directly, while external users of the Internet can access data by requesting it from a RESTful application. The following paragraphs explain the details of RESTful access to data and the implications of this approach.
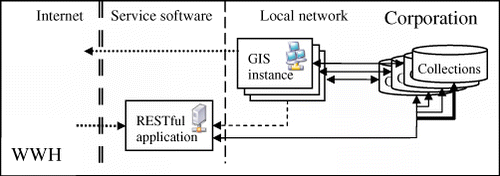
First, global identifiers (HTTP URI) have to be generated as soon as the resource is created. They also have to be maintained during the entire life cycle of these resources, even if elements are generated when the local GIS computer is off-line. This guarantees the uniqueness of the global identifiers and avoids missing links to resources. To make this possible in a decentralised environment, the HTTP URI structure is separated into levels (or namespaces). The first level of the HTTP URI identifies the organisation and is formed by the current URI of its main website followed by the fixed word ‘WWH’ (using URI template language (Gregorio Citation2008) this is expressed as http://{OrganizationServer}/WWH). The next level is the name assigned to the software instance used to generate the data (expressed as http://{OrganizationServer}/WWH/{SoftwareInstanceName}). The third level is the name of a geospatial set of entities (e.g. a feature or a coverage collection) (expressed as: http://{OrganizationServer}/WWH/{SoftwareInstance}/{GeospatialCollection}. The next levels can identify particular features, coverages or even feature attributes of the geospatial entities and so on as explained in .
Table 1 Basic geospatial URI templates in the WWH.
The uniqueness of the complete URI depends on three independent pieces of software that manage the first, second and further levels defined earlier. The uniqueness of the first level is provided by the HTTP naming authorities and mechanisms (mainly the DNS registration). The uniqueness of the second level is provided by a centralised RESTful application inside the corporative domain. The uniqueness of the following levels is provided by each GIS software instance.
Each GIS software instance in the corporation can manage their own resources. Creating a new geospatial collection resource implies creating a new identifier in the GIS software instance namespace. Next, an internal identifier (unique in the geospatial collection namespace) is associated with each feature created in the geospatial collection (several GIS software already do this).
Geospatial collections can be composed of internal entities that have identifiers in the geospatial collection namespace, or by external geospatial entities that have external geospatial identifiers in other namespaces that can be stored in the same corporation or in any other. Geospatial collections can contain vector, raster and tabular data in an integrated way. For vector data, a geospatial collection is a feature collection that has vector features (geospatial entities) which have attributes. Each attribute is associated with a feature (including the geometries) and receives a unique identifier (See ). This schema can go even deeper to geometry coordinates or types that are composed by complex attributes, but these are more advanced capabilities. For raster data the geospatial collection is formed by several raster layers, each describing a value distribution. In this case the atomic resource is the value of a cell of a single raster layer (coverage element). For tabular data, the geospatial collection is a database that is formed by record sets (tables or predefined queries). The atomic resource is the cell value of a particular field in a particular record.
Once identified, these elements can be hyperlinked to internal or external resources. In the WWH model, a hyperlink is a unidirectional relation between two resources of the WWH. Links use global identifiers, and a purpose for this relation can also be included. Yuan et al. (Citation2000) described some examples of purposes in hypermaps, such as ‘part and whole’, ‘generalization’, ‘more resolution’, ‘previous version’, and ‘new version’. These purposes can be combined with other exhaustive lists of types of links, such as the ones described by Kopak (Citation1999), and extended with concepts needed for the resource management system, such as ‘copied from’ and ‘moved to’, as it will be described later.
Following this schema, GIS software instances are able to interact directly with their resources in their usual way (binary file accessing, geodatabase querying, etc.) and are also able to interact with remote features using the RESTful requests to the corresponding corporative application by applying one of the four HTTP methods and a global resource identifier. The four HTTP methods in the REST architecture (POST, GET, PUT and DELETE) are associated with the four common actions of any computer system (create, retrieve, update and delete) for each resource type. To create a resource, you have to send it with a POST operation to the parent resource URI. The response of that request is the new resource URI. To update a resource, the new description of the resource has to be sent to the resource URI in a PUT operation. In a system with versioning, the previous version of the resource could be hyperlinked to the new one. To delete a resource, a DELETE operation has to be sent to the resource URI. Finally, a GET operation with the URI retrieves a description of the resource.
On the web, discovering resources is simple because the URI of any HTTP server has a single entry point. In the WWH, discovering resources in a corporation from a client that is external to it is also simple because there is also only one entry point to the corporative part of the WWH (http://{OrganizationServer}/WWH) that indicates the corporative RESTful application. A GET request to this URI returns a description of the service and also enumerates the public software instances that are present in this corporation. Then a GET operation to the http://{OrganizationServer}/WWH/{SoftwareInstance} enumerates the geospatial collections available in the service. A GET request to http://{OrganizationServer}/WWH/{SoftwareInstance}/{GeospatialCollection} enumerates the URIs of the geospatial entities available. lists some examples of possible operations that can be carried out on geospatial entities.
Table 2 Retrieval, creation, update and delete of geospatial entities.
uses Unified Modelling Language (UML) diagrams to provide a summary of resources and their operations, relations and URI templates in the WWH. To create these diagrams, we followed the rules described by Rauf (Citation2010).
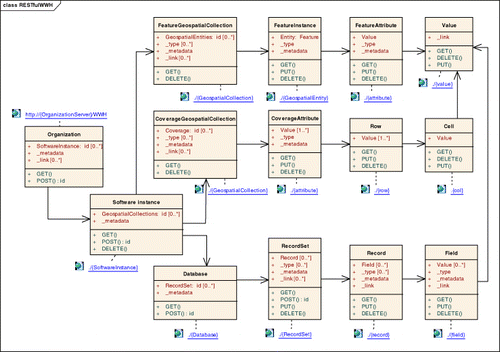
There are five special resources that can be used by adding the words;_metadata’, ‘_type’, ‘_link’, ‘_all’ and ‘_history’ to an appropriate resource. For instance, by adding _metadata to http://{OrganizationServer}/WWH we can refer to the RESTful service metadata in the ISO 19139 style with the list of its capabilities; or by adding it to http://{OrganizationServer}/WWH/{SoftwareInstance}/{GeospatialCollection} we obtain a data-set metadata document, also in the ISO 19139. By adding ‘_type’ to a vector geospatial collection URI we can access a description of the data model of geospatial entities mainly composed by attribute types that can be classified into spatial (geometrical), thematic (textual descriptions of properties, multimedia types, etc), and temporal types. These data models can be transmitted as GML application schemas or in ISO 19110 descriptions encoded in XML. By adding ‘_type’ to a multidimensional data coverage collection URI we obtain the data model describing the dimensions of the raster and the value types of each coverage element. In this case, only the methods PUT and GET (update and retrieve) apply since metadata are automatically associated with the geospatial collection during their creation and it makes no sense to delete them without deleting the collection itself. Adding ‘_link’ to any resource makes it possible to access a list of links for this resource. A link provides a target URI and an optional purpose for the link. We added another reserved word, ‘_all’, to indicate all child resources of a particular resource. This is needed in certain cases for specific purposes, for instance to obtain the data model description of a particular property for all feature instances of a geospatial collection using this URI http://{OrganizationServer}/WWH/{SoftwareInstance}/{GeospatialCollection}/_all/{attribute}/_type.
Sometimes all the resources of a particular level have a common child resource. In this case, we use the reserved word all to obtain a URI that follows a common pattern but affects a group of resources. An example of this practice is when the value array of a particular cell of a coverage collection (a value for each coverage element) needs to be obtained: http://{OrganizationServer}/WWH/{SoftwareInstance}/{GeospatialCollection}/_all/{row}/{col}.
In a real system, some resources have to be updated due to a change in the real world or due to a better interpretation of the same phenomena. A resource identifier of an updated resource will be the same as the previous one. To access an old version of it, the reserved word ‘_history’ can be added to obtain a list of the previous versions and their identifiers that will follow the pattern _history/r1, _history/r2, etc. It will also be possible to obtain the version that was valid on a particular date by adding this URI fragment to the end of any resource: /_history?date={date}.
Moving or deleting resources is particularly critical in a distributed environment in which external resources might be linked to the ones that are moved or deleted. If a resource needs to be moved, it receives a new identifier in the target resource collection and a hyperlink is set on the source resource. The original identifier cannot be used in the target resource collection because the decentralised method of resolving identifiers is based on the actual hierarchy of the identifier itself. Moving a resource implies retrieving a resource representation in order to do three things: create a new resource in the target resource collection, create the hyperlink in the source with the ‘moved’ purpose and delete the original resource (keeping the hyperlink active). Therefore, any external link to the original resource is still valid. Deleting resources is not recommended and resource identifiers are never deleted. It is possible to delete the content of a resource but not the identifier itself because it could be the target of hyperlinks.
If a particular resource is copied to another software instance, it keeps its original resource identifier. The new software instance is capable of knowing that this is a copy of an external resource because resource identifiers do not share the same structure as internal objects. If any child resource is modified or created by the software instance, communication is established with the original corporative software to determine whether the original copy has been modified and to request that this resource collection is edited. If communication with it is possible, any modification in the source is updated in both copies. If communications are off-line the geospatial identifier changes to a new one under the software instance namespace. A link is set between both geospatial collections with the ‘copied from’ purpose. The unedited child resource still has its original identifier. Synchronisation procedures can be executed when communications are possible again.
Apart form retrieving a single object, a very common operation with feature collections is to extract a subset of them according to some spatial and/or thematic criteria. This functionality can be achieved by the RESTful encoding with a POST request by adding the words _SpatialSubset and/or _FilteredSubset to a geospatial collection URI that includes a spatial object description encoded in, for example, GML, or a reference to it (i.e. a direct reference or an OGC Web Feature Service [WFS] request that retrieves an object, typically a rectangular bounding box). The result is a URI of a new geospatial collection that can be retrieved later like any other.
3.1. Catalogues in the WWH
The proposed solution has several advantages over a classical approach based on RPC web services. It eliminates the need for specific data access web services as well as different identifiers or data, metadata and data services to the data. Actually, using a single identifier and a simple set of RESTful rules, users can indicate the data, obtain their metadata and gain access to the actual data. WWH also makes it completely unnecessary to catalogue data access services. OGC CSW metadata catalogues can be used to catalogue and search in metadata about data but it is also expected that common text searching web tools and crawlers will also be useful for discovering data in the WWH.
Most of the metadata catalogues cannot automatically discover new resources by themselves (except if they are harvesting another catalogue), and regular manual updates imply a large investment of time. In essence, the corporative RESTful application acts as an automatic corporative metadata catalogue and presents metadata and data simultaneously to the authorised users. Moreover, in the presented REST architecture, the current web crawlers are able to automatically discover by simply reading the HTTP GET response of http://{OrganizationServer}/WWH (a simple crawler could use the list of DNS names). The crawler can then follow the links to other resources and request descriptions recursively and catalogue resources automatically. Moreover, the existence of the ‘_link’ special resource allows links to other resources to be exposed. Therefore, crawlers can discover which resources are linked more frequently and thus gain some criteria with which to arrange the resources by relevance. This does not invalidate the existence of OGC CSW data catalogues; on the contrary, it provides a way that they can function more automatically and collect all the available information, filtering by any criteria. It also allows popular web search engines to include geospatial information and expand the availability and accessibility of geographic information to the general public.
Furthermore, catalogues can rely on the uniqueness of the original resource URI, so there is no need to generate their own local identifiers. The generation of different identifiers for the same resource is a problem that affects many current catalogues (Nebert Citation2004). Another advantage is that metadata catalogues use the data URI as the base identifier so the responses of the catalogue will immediately link to the actual data and users will know how to get them immediately.
3.2. Services in the WWH
Having an identifier for each geospatial resource from the moment the resource was created provides automatic access to any geospatial resource, and therefore there is no need for a specific feature or coverage service protocols. As the data access service is implicit in the WWH there is also no need to catalogue data access services anymore. Therefore, this solution replaces current OGC WFS, WFS Transactional (WFS-T) and Web Coverage Service (WCS) protocols and functionalities and makes use of diverse OGC format encodings to exchange information. In fact, encodings are used to communicate resource representations and GML, KML, GeoRSS (Wick and Becker Citation2007) and Filter Encoding language are excellent recommended encodings for geospatial representations in the WWH. However, map services, including the tiled ones, can be offered by each geospatial collection directly using the Web Map Service (WMS) (de la Beaujardiere Citation2004) or WMTS protocols, considering the geospatial collection URI as a root server of the OGC service and adding the WMS Key-Value Pair (KVP) specified parameters (KVP or REST for the WMTS).
Finally, the RESTful application can be extended to provide remote execution support for processes with internal or external data. Processes can be executed directly by the GIS application or can be executed by posting an OGC WPS execute document (Schut Citation2007) to the http://{OrganizationServer}/WWH/_SpatialOperation URI. The response is a WPS execute document with the result or results, which can be numeric values, texts, tables, or URIs of each geospatial result in the form of a geospatial collection in the http://{OrganizationServer}/WWH/_external namespace. A list of the URIs of the available processes in the server can be retrieved with a GET operation to the http://{OrganizationServer}/WWH/_SpatialOperation URI. The description of the processes can be retrieved in the same format described in the OGC WPS DescribeProcess operation, through a GET operation to http://{OrganizationServer}/WWH/_SpatialOperation/{Process}.
4. Implementation example
The implementation of the WWH requires some extra software that can run on top of the HTTP protocol. As a reference implementation this paper presents how it was implemented in an extended version of the MiraMon software. Here we used a file based implementation, but it is possible to implement it using other data systems, such as a geodatabase.
MiraMon is a GIS and Remote Sensing software that allows visualisation, query, edition and analysis of raster (remote sensing images, orthophotos, digital terrain models, conventional thematic maps with raster structure, etc.) and vector (topographic and thematic maps that contain points, lines or polygons) data-sets, and also connects to OGC services (e.g. WMS and WMTS). Attributes are stored in relational database tables. MiraMon is developed cooperatively by various members of the Consolidated Research Group GRUMETS of the Centre for Ecological Research and Forestry Applications (CREAF) and the Autonomous University of Barcelona (UAB) (Pons Citation2002).
MiraMon Map Server (MMS) is a component of this software that provides web services in protocols and standards established by the OGC like WMS, WMTS, WCS and WFS. The server application is a Common Gateway Interface (CGI) type executable, developed in C language, which can be directly installed on a web server for Windows (Internet Information Server, Apache, etc.).
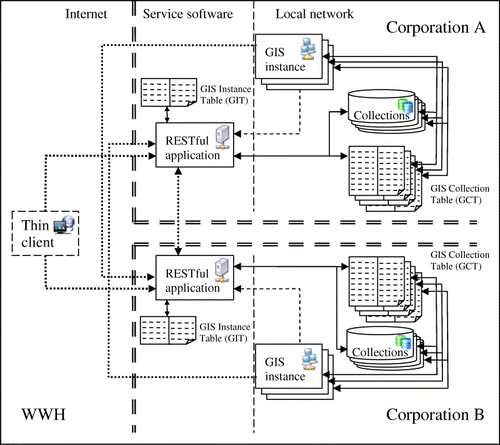
The extension of the MiraMon software can be explained as a set of modifications on the MiraMon GIS Professional software and the extension of MMS into a RESTful service. shows how a corporation uses a single instance of the RESTful application and a single entry port that can manage several GIS instances, and how two particular imaginary corporations are interconnected in the WWH. The two applications share a common core of functionalities but also have some particularities. In the common core, both applications are able to perform the maintenance of the internal data files directly and both can act as RESTful clients using HTTP. They are able to make requests like the ones listed in and and explained in Section 3.
4.1. Modifications in the GIS internal component
The main functionalities of the MiraMon software have not been altered, but small additions have been made. The internal file data model has been modified (keeping backwards compatibility) to allow the collection identifier (recorded as a metadata field) to be stored, and hyperlinks to geospatial collections (recorded as metadata fields) and to geospatial entities and attributes (stored in the attributes database). Support for references to external geospatial entities in geospatial collections has also been added. The ability to function as a RESTful client (and make a request to any other RESTful service in the WWH) has been added.
The MiraMon software uses the methodology previously described to access the URIs until it gets the list of geospatial collections available. The geospatial collections are then transferred and shown to the user. Another important modification is the addition of the geospatial collection table (GCT) that keeps track of the identifier of all the geospatial collections (data-sets) maintained by a particular GIS instance and the access method required for managing the data (e.g. a file path or the geodatabase access parameters).
4.2. Corporative RESTful server
This application is an HTTP CGI capable of responding to RESTful requests. It recognises the four HTTP methods and translates them into actions that have to be performed on the identified resources. It is able to recognise a global resource identifier, to find the GIS instance that keeps the data, discover where the actual resource is stored and to perform the requested operation directly on the data. To make this possible, it keeps a list of all GIS instances in the corporation (in a GIS instance table, GIT). When a new GIS software instance is set-up on a particular internal computer it also sets up its own GCT. In addition, it creates a resource identifier with a POST operation to the http://{OrganizationServer}/WWH URI sending information about how to access the GCT. This makes the RESTful service register the new GIS instance in the GIT.
When a corporate RESTful application receives a request for internal data it receives the global identifier. This identifier can be separated into three levels. The first level is used to identify the request as a URI to an internal resource. The second level allows it to identify the software instance and read the GIT to determine the way to access the GIS instance GCT table. The third level provides information about the geospatial collection requested; the GCT translates it to information on how to access the real data that can be accessed directly. The RESTful implementation can also act as a GIS software so that it has a reserved software instance identifier, http://{OrganizationServer}/WWH/_external, and also manages its own GCT for collections that are created from outside without any internal GIS software instance intervention, such as requests for spatial filters, thematic filters or process results, or by simply sending new data with a POST operation.
The proposed implementation of the WWH concept demonstrates that a RESTful approach provides a unified interface for discovering data as well as accessing it and executing processing services. Current systems use a diversity of standards to do so and current implementations fail to provide a global unified identification system, so that users can not easily visualise or download the data once discovered in metadata catalogues. Metadata producers are currently required to manually include references to map services and downloading services that are considered optional in ISO metadata model and they are usually left blank. The proposed WWH implementation implicitly and automatically connects all services together. Additionally, the system simplifies the metadata cataloguing process by relying on web crawlers instead of requiring specific geospatial metadata catalogues.
5. Conclusions
This paper demonstrates that the RESTful architecture can reproduce the hypermap concept defined two decades ago and overcome its original limitations. The ROA hides the complexity of the web services and unifies data, metadata and services, reusing simple principles that have been used in the web from the beginning. A network of dynamic hyperlinked geospatial resources is accessed using global URIs in a distributed environment that defines a single huge hypermap.
Current SDIs have implemented RPC–SOA style services based on OGC and ISO international standards for over 10 years, while mass market web services and VGI communities mainly use RESTful services. The WWH concept reconnects these two worlds again and lowers the entry barrier, providing a harmonised environment, adopting the semantic web and contributing to achieve the ‘Digital Earth vision’. GEOSS and INSPIRE are only two examples of large geospatial data systems composed by a distributed collection of data servers and systems that use heterogeneous data access standards and protocols to disseminate scientific and commercial data. By adopting many different standards, both improve interoperability but still face some difficulties. INSPIRE attempts to overcome these difficulties by defining guidelines and implementation rules, narrowing the standard set to a common profile for discovery under a common data access framework. Despite these efforts, none of these systems have an integrated mechanism for upgrading and maintaining new data. Implementations of the WWH proposed in this paper will provide a unified interface for discovering data as well as accessing data and services, and will interrelate knowledge by improving access to geospatial data and the results of scientific studies.
The proposed system combines common metadata catalogues with current search engine tools and makes cataloguing data access services unnecessary, as it provides an implicit way to access data. By adopting a simple set of rules, and based on current standard data formats and encodings, the system provides an interface that can also create and edit geospatial data remotely. Common functionalities, such as spatially or thematically filtering geospatial collections, generating maps, executing processes, etc., are also included in the RESTful approach, making data access services (such as WFS and WCS) unnecessary and integrating other web service standards such as WMS, WMTS and WPS.
Finally, the paper also presents a reference implementation that demonstrates that only minor extensions and modifications to a state-of-the-art GIS software are necessary so that it can be included in the WWH. A corporate RESTful CGI application acts as a broker, connecting local applications and files to the WWH. Future work will aim to implement secured access to selected resources and harmonise them with current sensor web protocols.
Acknowledgements
This paper was written with the support of the European Commission through the FP7-265178-GeoViQua (ENV.2010.4.1.2-2) and a grant to the Consolidated Research Groups given by the Catalan Government (2009 SGR 1511). Xavier Pons is recipient of an ICREA Acadèmia Excellence in Research grant (2011–2015).
References
- Berners-Lee, T. and Fielding, R., 1996. Hypertext Transfer Protocol -- HTTP/1.0. Available from: http://www.ietf.org/rfc/rfc1945.txt [Accessed 23 June 2011].
- Bishr, Y. 1999. A global unique persistent object ID for geospatial information sharing. In: A. Vckovski, K.E. Brassel, and H.-J. Schek, eds. Interoperating geographic information systems. Berlin: Springer Lecture Notes in Computer Science, No. 1580, 55–64.
- Bizer, C., Heath, T., and Berners-Lee, T., 2009. Linked data - the story so far. International Journal on Semantic Web and Information Systems, 5 (3), 1–22.
- Booth, D., et al., 2004. Web Services Architecture, W3C Working Group Note 11 February 2004. Available from: http://www.w3.org/TR/ws-arch/wsa.pdf [Accessed 23 June 2011].
- Boursier, P. and Mainguenaud, M. 1992. Spatial query languages; extended SQL vs visual languages vs hypermaps. In: Proceedings of the 5th International Symposium on Spatial Data Handling, August 1992, Charlestopn, VA, 242–295.
- Butterfield, M.L., Pearlman, J.S., and Vickroy, S.C., 2008. A system-of-systems engineering GEOSS; architectural approach. IEEE Systems Journal, 2 (3), 321–332.
- Cappelaere, P.G. 2009. OWS-6 RESTful Workflow Architecture ER. OGC. Available from: https://portal.opengeospatial.org/files/?artifact_id=33731 [Accessed 9 March 2012].
- Coleman, D. and McLaulghlin, J.D., 1997. Information access and network usage in the emerging spatial information marketplace. Journal of Urban and Regional Information Systems Association, 9 (1), 8–11.
- Craglia, M., et al., 2008. Next-generation Digital Earth. International Journal of Spatial Data Infrastructures Research, 3, 146–167.
- Craglia, M., Kanellopoulos, I., and Smits, P. 2007. Metadata where we are now, and where we should be going. 10th AGILE International Conference on Geographic Information Science. Aalborg University, Denmark, 1–7. Available from: http://people.plan.aau.dk/~enc/AGILE2007/PDF/93_PDF.pdf [Accessed 9 March 2012].
- de la Beaujardiere, J., 2004. OGC Web Map Service (WMS) Interface, Ver 1.3.0, OGC 03-109r1. Available from: http://portal.opengis.org/files/?artifact_id=5316 [Accessed 20 March 2010].
- Engelbart, D.C., 1967, X-Y Position Indicator for a Display System. US Patent 3541541. 17 November 1970.
- Engelbart, D.C. and English, W.K. 1968, A research center for augmenting human intellect. AFIPS Conference Proceedings of the 1968 Fall Joint Computer Conference, 9–11 December 1968, San Francisco, CA, 33, 395–410.
- Fielding, R.T., 2000. Architectural styles and the design of network-based software architectures. Thesis (PhD). University of California.
- Fielding, R.T., et al., 1999. Hypertext Transfer Protocol -- HTTP/1.1. Available from: http://www.ietf.org/rfc/rfc2616.txt [Accessed 23 June 2010].
- Friis-Christensen, A. and Jensen, C.S., 2005. A conceptual schema language for the management of multiple representations of geographic entities. Transactions in GIS, 9 (3), 345–380.
- Gore, A. 1998. The digital earth: understanding our planet in the 21st century. Available from http://www.nextspace.co.nz/wp-content/uploads/2010/08/Gore-Speech2.pdf [Accessed 4 February 2012].
- Gregorio, J., 2008. URI Template. Network Working Group Internet- Draft. Available from: http://tools.ietf.org/html/draft-gregorio-uritemplate-03 [Accessed 14 September 2011].
- Grossner, K.E., Goodchild, M.F., and Clarke, K.C., 2008. Defining a Digital Earth System. Transactions in GIS, 12 (1), 145–160.
- INSPIRE, 2008. Directive of the European Parliament and of the Council Establishing an Infrastructure for Spatial Information in the Community (INSPIRE).
- Kim, Y.I., Pyeon, M.W., and Eo, Y.D., 2000. Development of hypermap database for ITS and GIS. Computers, Environment and Urban Systems, 24, 45–60.
- Kopak, R.W., 1999. Functional link typing in hypertext. ACM Computing Surveys, 31 (4es), 1–5.
- Kraak, M.J. and Driel, R.V., 1997. Principles of hypermaps. Computers and Geosciences, 23 (4), 451–464.
- Laurini, R. and Milleret-Raffort, F., 1990. Principles of geomatic hypermaps. Proc. 4th Intern. Symposium on Spatial Data handling. Zurich, 2, 642–655.
- Laurini, R. and Thompson, D. 1992. Fundamentals of spatial information systems. London: Academic Press, 680, Chapter 16.
- Longueville, B. de, et al., 2010. Digital Earth's Nervous System for crisis events: real-time Sensor Web Enablement of Volunteered Geographic Information. International Journal of Digital Earth, 3 (3), 242–259.
- Lucchi, R., Millot, M., and Elfers, C. 2008. Resource Oriented Architecture and REST. Assessment of impact and advantages on INSPIRE. EUR 23397 EN – 2008.
- Masó, J., Pomakis, K., and Julià, N. 2009. OGC Web Map Tile Service (WMTS) Implementation Standard, Ver 1.0.0, OGC 07-057r7. Available from: http://portal.opengeospatial.org/files/?artifact_id=35326 [Accessed 7 January 2011].
- Mazzetti, P., Nativi, S., and Caron, J., 2009. RESTful implementation of geospatial services for Earth and Space Science applications. International Journal of Digital Earth, 2 (1), 40–61.
- Nebert, D.D. 2004. The SDI Cookbook. Available from: http://www.gsdi.org/docs2004/Cookbook/cookbookV2.0.pdf [Accessed 20 March 2010].
- Pautasso, C., Zimmermann, O., and Leymann, F. 2008. RESTful Web Services vs. Big Web Services; Making the Right Architectural Decision. WWW 2008, Beijing, China, 21–25 April.
- Percivall, G. 2008. OGC Reference Model. OGC 08-062r4. Available from: http://portal.opengeospatial.org/files/?artifact_id=31112 [Accessed 12 December 2009].
- Percivall, G., 2010. The application of open standards to enhance the interoperability of geoscience information. International Journal of Digital Earth, 3 (S1), 14–30.
- Pons, X. 2002. MiraMon. Geographic Information System and Remote Sensing software. Centre de Recerca Ecològica i Aplicacions Forestals, CREAF. Bellaterra. ISBN: 84-931323-5-7.
- Portele, C. 2007. OpenGIS® Geography Markup Language (GML) Encoding Standard. Ver 3.2.1, OGC 07-036. Available from: http://portal.opengeospatial.org/files/?artifact_id=20509 [Accessed 14 September 2011].
- Proll, B. 2002. Exploring Hypermedia Design Patterns in Web-based Tourism Information Systems. Proceedings of the 6th World Multiconference on Systemics, Cybernetics and Informatics (SCI 2002), Orlando, USA, 14–18 July.
- Rauf, I., et al., 2010. Modeling a Composite RESTful Web Service with UML. Proceedings of the Fourth European Conference on Software Architecture ECSA. Companion Volume. University of Copenhagen. 23–26 August.
- Richardson, L. and Ruby, S., 2007. RESTful web services. Sebastopol, CA: O'Reilly Media.
- Sargent, P., 1999. Features identities, descriptors and handles. In: A. Vckovski, K.E. Brassel, and H.J. Schek, eds. Interoperating geographic information systems. Berlin: Springer Lecture Notes in Computer Science No. 1580, 41–53
- Saugy, B., et al., 1995. GigaView and Hypermaps for Finite Elements Based Urban Networks and System Managers. Computers, Environment and Urban Systems, 19 (3), 151–160.
- Schut, P. 2007, OGC Web Processing Service (WPS), Ver 1.0.0, OGC 05-007r7. Available from: http://portal.opengeospatial.org/files/?artifact_id=24151 [Accessed 20 March 2010].
- Thompson, D., et al., 1997. Towards a framework for learning with GIs; The case of UrbanWorld, a hypermap learning environment based on GIS. Transactions in GIS, 2 (2), 151–167.
- Usländer, T., 2008. Integration of Resource-Oriented Architecture Concepts into the OGC Reference Model. OGC 07-156r1 internal draft document.
- Voisard, A. 1998. Geologic hypermaps are more than clickable maps. Proceedings of the 6th ACM international symposium on Advances in GIS. Washington, DC, 14–19.
- Werling, M. 2008. OWS-5 GeoProcessing Workflow Architecture Engineering Report. Ver 0.1.0. OGC 07-138r1. Available from: http://portal.opengeospatial.org/files/?artifact_id=30065&version=1 [Accessed 12 December 2009].
- Whiteside, A. 2005. OpenGIS web services architecture description. OGC 05-042r2 Best Practices Paper.
- Wick, M. and Becker, T., 2007. Enhancing RSS feeds with extracted geospatial information for further processing and visualization. In: A. Scharl, and K. Tochtermann eds. The Geospatial Web. How Geobrowsers, Social Software and the Web 2.0 are Shaping the Network Society. Berlin: Springer, 105–115
- Yuan, X., Chen, N., and Gong, J., 2000. A distributed hypermap model for Internet GIS. Geo-Spatial Information Science, 3 (4), 9–15.
- zur Muehlen, M., Nickerson, J.V., and Swenson, K.D., 2005. Developing web services choreography standards—the case of REST vs. SOAP. Decision Support Systems, 40, 9–29.