
Abstract
With growing demand on multi-purpose or multi-modal navigation, the route calculation needs to traverse semantically enriched road networks for different transportation modes. Currently, operational route planning algorithms reveal rather limited performances or their potential for comprehensive applications are constrained by the unavailable or insufficient interoperation among the underlying geo-data that are separately maintained in different spatial databases. To overcome this limitation, a novel approach has been proposed to integrate the routing-relevant information from different data sources, which involves three processes: (1) automatic matching to identify the corresponding road objects between different datasets; (2) interaction to refine the automatic matching result; and (3) transferring the routing-relevant information from one data-set to another. In process (1), the Delimited Stroke Oriented algorithm is employed to achieve the automatic data matching between different datasets, which has revealed a high matching rate and certainty. However uncertain matching problems occur in areas where topological conditions are too complicated or inconsistent. The remaining unmatched or wrongly matched objects are treated in process (2), with the help of a series of interaction tools. On the basis of refined matching results after the interaction, process (3) is dedicated to automatic integration of the routing-relevant information from different data sources.
1. Introduction
As a key element of the Intelligent Transportation Systems, route planning based on geospatial databases is gaining a growing importance for safer and more efficient traffic with less congestion, pollution and other negative environmental impacts. With the rapid improvement of geospatial data acquisition and processing techniques, a series of routing-capable spatial databases covering the same geographic space have become readily available from various public or private organisations. These datasets can complement one another in terms of geometry, accuracy, actuality and functional emphasis. In the recent years, users are getting more and more fastidious about route-planning services. Instead of being confined to a shortest-route function, they have begun to seek more comprehensive optimal ways that should involve different routing modes (e.g. pacer + car) or satisfy multiple criteria such as time, cost, energy consumption, carbon emissions, convenience and comfort, scenic spot, etc. (Fawcett and Robinson Citation2000, Lozano and Storchi Citation2002, Marathe Citation2002, Liu and Meng Citation2009). Consequently, the study of integrating the routing-relevant information from different datasets becomes increasingly demanding because in most cases the ‘best’ route does not exist in a single data source.
For instance, as one of the most well-known routing-capable database in the world, the data-set of Tele Atlas cannot meet the increasing requirements of multi-modal routing/navigation due to the data acquisition ways. In Tele Atlas, the road networks were captured primarily by GPS-supported equipments on cars, that is a lot of pedestrian ways which are prohibited to motor vehicles in some public parks or mountain areas are hardly available in the data-set of Tele Atlas. On the contrary, the DLM De data from German Mapping Agency were captured through map digitisation in combination with semiautomatic object extraction from aerial imagery and thereby completely covers all of the pedestrian areas. On the other hand, however, the DLM De data-set itself is either not capable for multi-modal routing/navigation applications although it involves both motor and pedestrian ways, because the attributes are not completely covered with values, especially those routing-relevant information that is rarely included in this data-set. To overcome such limitation, the routing-relevant information from DLM De and Tele Atlas can be integrated. Clearly, one cannot rely on manual works to accomplish this task, because the area of interest could be anywhere in the world, and data processing on large-region(s) manually (e.g. the whole Germany) is very time consuming and error-prone. Hence, automatic methods are desirable for the integration of such multi-sourced geospatial datasets.
The automatic integration of different geospatial datasets firstly became a reality in the mid-1980s through a project initiated by the United States Geological Survey (USGS) and the Bureau of Census to consolidate the digital vector maps of both organisations (Rosen and Saalfeld Citation1985). The initial focus was to remove geometric inconsistency between heterogeneous overlapped geospatial datasets. From then on a lot of new ideas and technologies have been promoted in this area. Cobb et al. (Citation1998) put forward a complete matching approach for the conflation of attributed vector data such as the Vector Product Format (VPF) datasets produced and disseminated by the National Imagery and Mapping Agency (NIMA). The data integration approach presented here utilises both spatial and non-spatial information associated with data, including attribute information such as feature codes from standardised set, associated data quality information of varying levels, and topology, as well as more traditional measures of geometry and proximity. In Butenuth et al. (Citation2007), two generic cases including novel integration algorithms are described, one is the integration of two heterogeneous vector datasets, and the other is the integration of raster and vector data. Both algorithms are linked to a federated database, which allows for integrating heterogeneous datasets via a global schema and provides a uniform interface for global applications. In this article, the involved data consist of the vector data from topography and geosciences as well as the raster data of multi-spectral imageries. Balsters et al. (Citation2010) point out that the geospatial data integration has a profound meaning for both the government and the commercial companies. For government, geo-data is crucial for space use in an intelligent and sustainable manner. For commercial parties, such as mobile providers, handset manufactures, apps developers and media companies, geo-spatial data integration can be a valuable strategic asset to provide new and better GIS-related services. On the basis of Object Role Modeling (ORM) language, the authors have provided a case study and a design method for real-time integration of geo-databases.
The reported work so far has doubtlessly paved way to the development of more comprehensive systems of geo-spatial data integration. In the domain of road networks, currently available methods are focused on the improvement of geometric quality (Siriba Citation2011) and transferring the individual attributes that directly describe the underlying road objects (Cobb et al. Citation1998, Walter and Fritsch Citation1999, Thakkar et al. Citation2007, Zhang and Meng Citation2007). More complicated relationships between the road geometries and meaningful network attributes have not yet been considered. For this reason, further research works have to be conducted for the comprehensive information transferring and/or exchange between two comparable roads datasets, especially for the special purposes of routing and navigation applications.
2. Investigated datasets
Two datasets which are to be investigated in this work are (a) DLM De and (b) Tele Atlas.
The DLM De data-set was captured by German Mapping Agency through map digitisation in combination with semi-automatic object extraction from imagery data. The data structure is defined in accordance with the Official Topographic Cartographic Information System (ATKIS). DLM De is a general topographic data-set that stores data of different topographic object categories. It is not targeted to a certain application domain; rather it serves as framework data-set containing different topographic object categories with which application-dependent data can be combined (Volz Citation2006). The road layer in DLM De is composed of geometries and general-purposed attributes of road lines (middle axes) which were captured through map digitisation in combination with semi-automatic object extraction from imagery data. It reveals an accuracy of ±3m at important positions. However the attributes are not completely covered with values, especially the routing-relevant information is rarely considered in this data-set.
Tele Atlas company is one of the most important data suppliers for the routing of motor vehicles. Its product Tele Atlas is a high-end database comprising detailed street network, water features, parks and landmarks, county, city and civil divisions, ZIP codes, urbanised area codes and census tracts. The Tele Atlas road network contains geometries and navigation-oriented attributes of road lines (middle axes) which were captured through map digitisation, GPS-supported field measurement and dynamic supervision of traffic information. Among, the navigation-oriented or routing-relevant attributes are street name, Functional Road Class (FRC), Form of Way (FOW), turning restrictions and maneuvers, signpost information, Points of Interest (POIs), etc. One of major assets of the Tele Atlas database is the fully and detailed attribution of its road elements that constitute the transportation network, which is very important for the routing calculations.
3. Methodology
As depicted in , the flow diagram of enriching the DLM De with the routing-relevant information from Tele Atlas can be characterised by three processes: (1) automatic matching to identify the corresponding road objects between different datasets; (2) interaction to refine the automatic matching result; and (3) transferring the routing-relevant information from Tele Atlas to DLM De. In Sections 3.1–3.3, the three processes are introduced in detail.
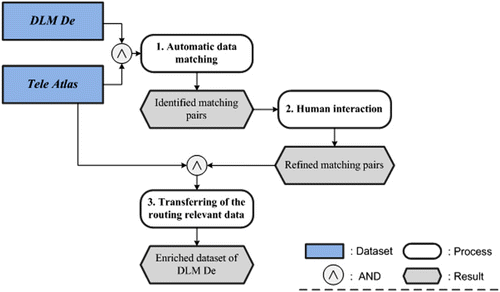
3.1. Automatic data matching
A true data integration is much more than just overlaying data in a geographic information system (GIS) as it must set up the explicit relations between individual objects in different datasets (Butenuth et al. Citation2007), which indicates that the integration of routing-relevant information from various data sources requires the identification of the corresponding road objects, namely data matching, between different road networks.
As the road network plays a significant role in geospatial databases, street matching has been intensively and extensively researched during the recent decades. Despite other approaches, two of the most popular and well-known matching algorithms reported in literature hitherto are Buffer Growing (BG) (Walter Citation1996, Mantel and Lipeck Citation2004, Zhang and Meng Citation2007) and Iterative Closest Point (ICP) (Besl and McKay Citation1992, Gösseln and Sester Citation2004, Gösseln Citation2005, Volz Citation2006). So far a majority of the developed matching approaches based on BG, ICP or combination of them have revealed high matching rate and efficiency on certain data types of selected test areas. However, most of these methods were developed as specialised solutions with limited reusability. Their matching performance might drop dramatically either in areas where the context conditions are too complicated or when one of the datasets contains little or no meaningful semantic information at all. It has been generally assumed that better matching result can be reached with more context information (Stigmar Citation2006, Mustiẻre Citation2006). developed an innovative matching algorithm for road networks, namely Delimited Stroke Oriented (DSO) algorithm to achieve the more robust matching between different datasets (ref. Zhang and Meng Citation2008).
The DSO algorithm consists of five routines: (1) data pre-processing to reduce the noise of irrelevant details and eliminate topologic ambiguities in the datasets to be matched; (2) construction of the ‘graph’ to record the relationships between conjoint objects; (3) connection of the Delimited Strokes; (4) matching of the Delimited Strokes; and (5) treatment of fragmental matching areas. According to the DSO algorithm, the conjoint edges to a Delimited Stroke can be easily brought together with the help of the ‘graph’ that records the conjoint objects. The corresponding network is then treated as an integral unit in the matching process, that is the DSO algorithm will lead to a network-based matching. As compared with point- or line-based matching, such as the ICP algorithm and BG, the network-based matching is able to implement topologic information more thoroughly, which allows a context-related topologic analysis and thus helps to improve the results of geometric or semantic matching. The experiments conducted in the work of Zhang and Meng (Citation2008) have confirmed the considerably improved matching performance of DSO algorithm in terms of computing speed, matching rate, Matching Certainty and robustness (see some detailed descriptions in Section 3.1). Due to its ‘robustness’ and ‘generic’ nature, the DSO matching algorithm has been successfully implemented to automatically identify corresponding road objects between DLM De and Tele Atlas, despite the unfavourable conditions that in one of the datasets (namely DLM De) the road attributes are not completely covered with values, especially the street names which are essential clues for the matching are only sporadically available.
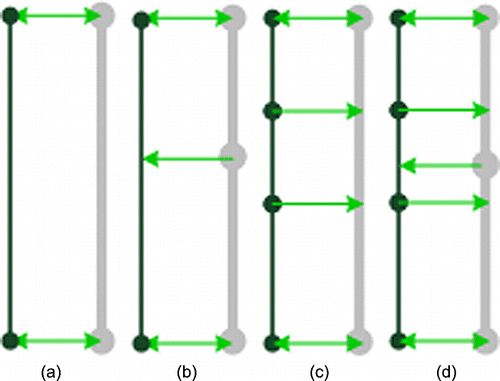
To emphasise that with the DSO algorithm, not only the matching pairs with one-to-one relationship, that is one DLM De road object is corresponding to one object in Tele Atlas, but also the matching pairs with one-to-many, many-to-one and many-to-many relationships can be identified (cf. ).
3.2. Interaction to refine the automatic matching result
In spite of the apparent progresses of the DSO algorithm, a completely automatic road matching between different datasets with 100% matching rate or accuracy is still difficult to reach. The automatic matching algorithm may suffer some limitations in case that (1) the datasets to be matched reveal a substantial topological inconsistency; and/or (2) the objects in the data-set are highly fragmental (Walter and Fritsch Citation1999, Xiong and Sperling Citation2004, Volz Citation2006, Zhang and Meng Citation2008).
However, the integration of the routing-relevant information requires a comprehensive and accurate matching between different datasets. Hence, the human operators should be provided with some interactive tools to evaluate and refine the results of automatic data-matching processes.
In practice, the matching errors are much more intractable than the unmatched objects. This can be explained by the fact that, for the time being, the unmatched objects can be very easily marked as doubtful, whereas the process to detect the errors is time consuming and labour intensive, because erroneous matches need to be analysed one by one. Moreover, even if a match is visually correct, it is still coupled with a degree of uncertainty. Hence, in order to minimise the costs of human interaction, the matching quality is accessed by classifying the matching results into different certainty levels, where the measurement of Matching Certainty is defined by the ‘MCertainty’ in Equation (Equation1).
Using the DSO matching approach in three different experiments with the total matching area of ca. 1400 km2, more than 19,000 objects from the reference data-set are matched to their corresponding objects in the target data-set, among which 101 matching errors are detected manually, including mismatch and false positive match. Then, we conducted a Matching Certainty analysis on the overall matched pairs and the falsely matched pairs, respectively. On the basis of statistical work, the distribution of MCertainty (Matching Certainty) as well as its classification is illustrated in and .
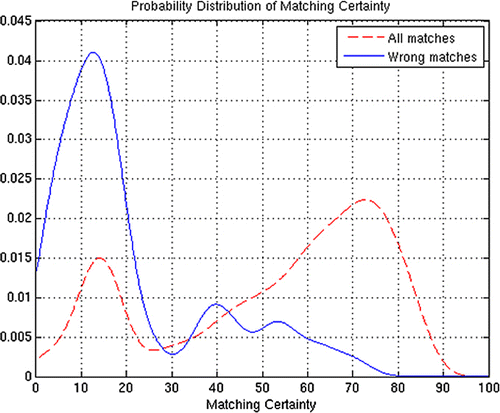
Table 1. Distribution of Matching Certainty.
As shown in and , among the falsely matched objects, around 80% have a Matching Certainty of less than 0.2, whilst nearly none of them reveals a Matching Certainty greater than 0.70, which indicates: (1) a wrong match can be associated with a very small Matching Certainty (≤0.2; (2) a match with a Matching Certainty of above 0.70 can be confirmed as a correct match.
According to this rule, the author suggests to classify the matching results into three certainty levels (see ):
Table 2. Classification of the Matching Certainty.
Level 1 contains all the matching pairs with the Matching Certainty less than 0.20. Approximately 18% of all matching pairs of the test areas and 80% of the wrong matching pairs are within this class, which indicates most of the matching errors are falling inside this class with the Matching Certainty ≤0.20. Therefore the matching pairs within this class are classified as ‘possible’.
Level 2 contains all the matching pairs which have the Matching Certainty between 0.20 and 0.70. This class contains approximately 53% of all matching pairs which are classified as ‘good’. Wrong matches are very few but still appear in this class – the matching accuracy is about 99.8% (1-20/10,174 = 99.8%).
Level 3 contains the remaining 29% of all matching pairs which have the Matching Certainty higher than 0.70. These matching pairs are treated as ‘perfect’ matches due to the fact that among the 19,126 matched pairs as mentioned in , there is only one error detected within this class. The accuracy of the matching pairs within this class exceeds 99.98% (1-1/5498 = 99.98%).
As illustrated above, the definition of the Matching Certainty and the concomitant classification of the matching results can simplify the process of detecting the matching errors as most of the matching errors are concealed at the certainty level of ‘possible’. Thus, the tedious manual work to interactively detect the matching errors could be highly reduced (Zhang and Meng Citation2007).
On the basis of such a classification, a series of Plug-Ins (extensions) in Arc GIS 9.x have been developed which have the availability to visualise the identified corresponding objects between different datasets and then allow the users to interactively add new matching pairs or correct the falsely matched ones, so that a more desirable matching result can be achieved. On the basis of the refined matching results, the process 2.3 is eligible to automatic integration of the routing-relevant information from different data sources.
3.3. Transferring routing-relevant information from Tele Atlas to DLM De
Depending on the relationship to the road objects, the routing-relevant information in Tele Atlas can be categorised into three groups: (1) attributes of the road itself; (2) attributes at the intersections; and (3) POIs bound to the road objects. Different data groups will call upon different methodologies to transfer the routing-relevant information.
3.3.1. Attributes of the road itself
In Tele Atlas, the routing-relevant information of the road itself consists of street name, street width, direction restriction, speed limitation, FRC, FOW, etc.
While attribute transfer is a relatively trivial task if a one-to-one correspondence exists between the datasets of DLM De and Tele Atlas (ref. (a)), such ideal cases are rare (Song et al. Citation2006, Zhang and Meng Citation2008). In the real world, many other scenarios arise, e.g. the matching pairs with many-to-one, one-to-many or many-to-many. In order to deal with the general cases of m:n (m≥1, n≥1) matchings consentaneously, the matching pairs with 1:n/m relationship are identified – one object from the DLM De is matched to a cluster of connected objects or object-parts in Tele Atlas. For instance, for each reference road object v of DLM De, its corresponding counterpart in Tele Atlas can be represented as:
k is the number of the Tele Atlas road objects which are corresponded or partially corresponded to the reference road object v.
represents a portion of the road object
If the reference road object v does not have any counterpart, then k = 0.
If the reference object v is relevant to two or more road objects of Tele Atlas, namely k>1, then
Once the matching pairs with 1:n/m relationship are identified, it is possible to transfer the routing-relevant attributes of the road itself from Tele Atlas to DLM De. If one object from DLM De is related to more than one object in Tele Atlas, the attributes of the different objects in Tele Atlas must be firstly generalised and then transferred to the DLM De object. In this process, the generalisation of attribute values is guided by a knowledge base, that is the generalisation of attribute values should be triggered by a set of rules such as: (1) keep the same attribute, for example street name can be directly transferred to another data-set; (2) transfer the maximum or minimum value, for example maximally allowed speed of the vehicles on the streets, or minimum bridge height over a road; (3) transfer the sum of attribute values of the object or object parts, for example the travel time of the streets; and (4) transfer the average attribute value, for example CO2 emission value of the vehicles on the streets; (5) transfer the directional attributes, for example the property of one-way road and house number range, etc. For the attributes which cannot be generalised to a single value, such as the one-way directions or street names which are in conflict, the DLM De object can be split into several parts according to the amount and length of its related objects of Tele Atlas. After the splitting, one object-part of DLM De is only related to one Tele Atlas, so that the attributes of the Tele Atlas objects can be straightforwardly transferred without the generalisation processing. Meanwhile, the attributes of this DLM Object have to be re-calculated and assigned to each object part.
3.3.2 Attributes at road intersections
As the DSO matching algorithm is able to match both the roads and their ending-nodes (Zhang and Meng Citation2008), it is possible to transfer the information at the road intersections from Tele Atlas to DLM De. In the data-set of Tele Atlas, the significant routing-relevant information at the road intersections, such as turning restrictions and manoeuvres, signpost information, traffic light, etc., are represented by the combination of the node (‘junction’) and its emanating edges (‘road objects’).
For instance, the ‘turning restrictions’ are stored in the way of ‘road object → junction → road object’ as shown in (a) and ; and the ‘signposts’ are described by relationships between junction and the relevant road objects, see (b) and .
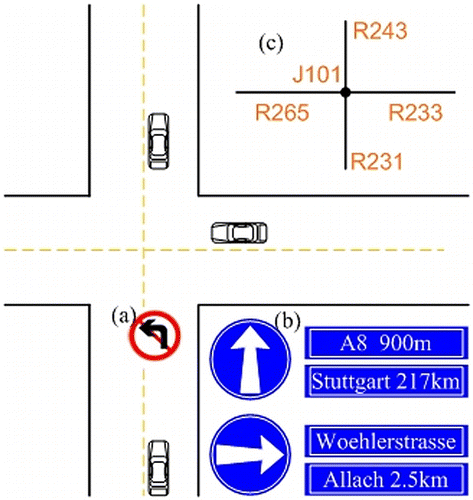
Table 3. ‘Left forbidden’ in Tele Atlas.
Table 4. ‘Signposts’ in Tele Atlas.
In order to transfer such kind of routing-relevant information from Tele Atlas to DLM De, it is necessary to identify the matching pairs with pseudo 1:1 relationship around the road intersections in spite of the fact that some of the matching pairs do not have one-to-one, but hold many-to-one, one-to-many or many-to-many corresponding relationships between different datasets. The matching pairs with pseudo 1:1 relationship could be generated from the matching pair with 1:n/m relationship, which are always recorded with the related corresponding node (junction) information. On the basis of matching pair of for instance, the road object v and
can be treated as pseudo 1:1 correspondence if and only if α(1) = 0 or 1 : α(1) = 0 indicates that the from-node of v is corresponded to the from-node of
while the α(1) = 1 means that ‘the from-node of v is corresponded to the to-node of
’. Likewise a pseudo 1:1 matching pair between v and
can be established as well if β(k)= 0 or 1.
The matching pairs with pseudo 1:1 relationship make it possible to transfer the routing-relevant information at road intersections between different datasets as the information of the corresponding nodes (junctions) are included.
3.3.3 POIs bound to the road objects
POIs are a series of point representations bound to the road lines, such as hotel, gas station, restaurant, showplace, beauty spot, etc. The POI information is also relevant for routing although it is not always used for the routing purposes. The transferring of the POI information from Tele Atlas to DLM De involves two steps.
Geometric displacement
Initially the individual POIs are stored as discrete points along the road features in Tele Atlas. In order to adapt the POIs position to the DLM De roads, it is necessary to establish the linkages between the shape points of matched road pairs by means of interpolation; with the availability of these links, the POIs can be automatically displaced from Tele Atlas to DLM De following the Rubber-Sheet principle (Gillman Citation1985). This process is illustrated in .
Semantic transferring
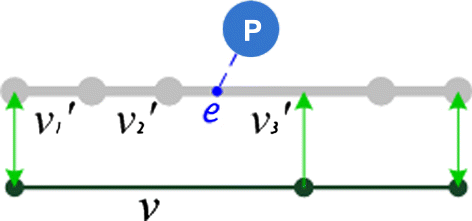
The incipient POIs are semantically related to the road objects of Tele Atlas. On the basis of identified matching pairs with 1:n/m relationship, the semantic relationships between the POIs and road objects in Tele Atlas can be also transferred to the data-set of DLM De.
In the example depicted in , the POI ‘P’ is related to a road object in Tele Atlas and its entry point is denoted as ‘e’. Given a matching pair with 1:n/m relationship, namely , if the entry point ‘e’ belongs to any
in this matching pair, a semantic connection between POI ‘P’ and the road object v should be appended in the data-set of DLM De.
4. Experiments
4.1. Performance of automatic data matching
The DSO matching algorithm has been applied to a number of large test areas in Germany such as Hessen, Lower Saxony and Bavaria. The automatic matching performance can be summarised as follows:
4.1.1. Matching rate and accuracy
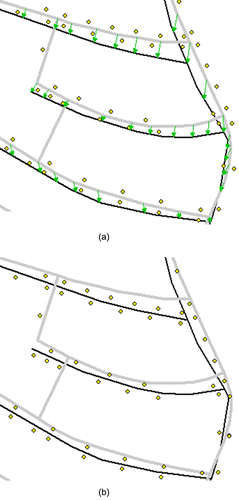
In a number of large test areas in Germany, the overall matching rate exceeds 97%; among the matched objects more than 99% are correct. With less than 3% unmatched objects and 1% matching errors in spite of data complexity and ambiguity, the employed DSO matching algorithm is highly successful. For example in the cases shown in , the automatic matching process reveals a nearly perfect matching accuracy. Not only the lines but also the nodes are accurately matched through the topological comparison.
Figure 7. Several matching cases (black lines: DLM De; grey lines: Tele Atlas; arrows: linkages).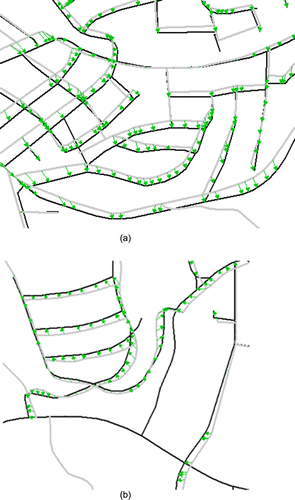
To the best of our experience, there are two causes that can lead to imperfections of the data matching performances: algorithm limitations and data ambiguity. In the conducted matching experiments, data ambiguity is the primary inducement to generate unfavourable matching results, for example the matching problems often occur in areas with completely different acquisition rules or when the topologic connections are too inconsistent.
4.1.2 Computing speed
In a test region of ca. 1200 km2, there are 10,959 objects in DLM De and 10,681 objects in Tele Atlas in total. To match all of them, our matching programme takes 22 seconds by a normal personal computer (PC), that is about 500 objects per second. If we assume that an experienced human operator is able to match 5–6 pairs in a minute (Walter and Fritsch Citation1999), the automatic approach can match the data thousands of times faster. Moreover, with the use of the grid-based spatial indexes for points and lines (Schimandl et al. Citation2009, Zhang et al. Citation2009), an increase in network size will not significantly slow down the matching speed.
4.2. Interactive of the automatic matching results
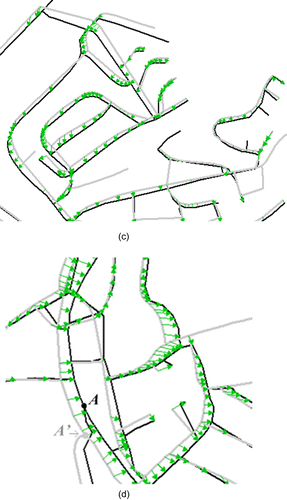
The automatic matching results cannot be always perfect. The node A in , for example, has its topological counterpart A'. Unfortunately these two nodes could not be matched together due to the large difference in branch orientation and a large distance (ca. 70 m). In addition, the topological inconsistency and fragmental geometries can also disturb the automatic matching approach. In the proposed approach, such negative matching results can be minimised by the human operators with the help of several interaction tools developed in Arc GIS 9.x. As most of the uncertain matching results are concealed in the certainty level of ‘possible’ (ref. Section 3.2), the tedious human interaction work to detect as well as correct the unfavourable matching pairs are dramatically reduced.
4.3. Data enrichment of DLM De with the routing-relevant information from Tele Atlas
As known, in the data-set of DLM De, the attributes are not completely covered with values, especially the routing applications are not yet considered. Following the methodologies defined in Section 3.3, all of the significant routing-relevant information can be transferred from Tele Atlas to DLM De.
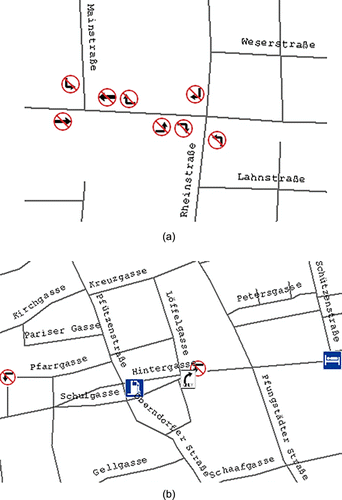
Figures and show the enriched DLM De with a few routing-relevant information from Tele Atlas, including street name, turning restrictions and maneuvers, and some POIs like park place, gas station, hospital, etc.; where it should be noted that not all road objects from DLM De can be enriched with the attributes from Tele Atlas because some kinds of roads (e.g. pedestrian ways in parks) only exist in DLM De, but not be captured in Tele Atlas, see examples in the lower-left and upper-right of . After the data enrichment, the DLM De has gained several capabilities for routing calculation, car navigation and many other web map services.
Besides the different small test areas illustrated in , and , the proposed data-integration approach has been already tested on many other large areas of several federal states of Germany with the aim at constructing a routing-capable street database based on DLM De. The various conducted experiments proved that once the corresponding counterparts of road objects are accurately identified, the routing-relevant information can be properly and comprehensively transferred from one data-set to another based on the matched pairs with ‘1:n/m’ and ‘pseudo 1:1’ relationships.
5. Conclusion
This article proposes a three-step approach for the automatic enrichment of topographic road database (i.e. DLM De) with supplementary routing-relevant information from another data source (i.e. Tele Atlas). In the first step, the DSO algorithm is employed to automatically identify the corresponding road objects between different datasets. It takes advantage of the network-based matching strategy; the employed algorithm has revealed a high matching rate and certainty. Considering the uncertain matching problems in areas where topological conditions are too inconsistent to allow a reliable identification of matching pairs, the automatic matching results have been classified into three ‘certainty levels’: perfect, good and possible. The conducted statistic experiment demonstrates that most of the matching errors are concealed at the certainty level of possible. Such a categorisation can dramatically reduce the tedious and time-consuming manual work to detect/correct the unfavourable results of automatic matching. As the overall automatic matching rate exceeds 95% and the accompanied accuracy reaches 99.3%, the required interaction is kept very low. In the third step, three different methodologies have been developed to respectively transfer the routing-relevant attributes of the road itself, the attributes at the intersections as well as the POIs bound to the road objects from the data-set Tele Atlas to DLM De. After the data enrichment, the DLM De has gained several capabilities for the multi-modal routing and navigation.
From the scientific point of view, two main contributions are involved in the proposed approach:
First of all, the proposed approach provided a generic methodology for the attributes transfer and integration. Its ‘generic nature’ manifested in two aspects: (1) the attributes transferring between the corresponding feature chains essentially rely on comparisons of the geometries and topologies; therefore, the proposed approach is not sensitive to the availability of semantic information. This makes it applicable not only for the datasets of DLM De and Tele Atlas employed by the conducted experiments, but also for many other data resources, such as NAVTEQ, OpenStreetMap, U.S. Tiger. (2) In the proposed approach, the routing-relevant information has been categorised into three group: the attributes of the road itself, the attributes at the intersections and the elements (e.g. POIs) bound to the road objects. As a matter of fact, this kind of categorisation can also be utilised for all the other attributes of road networks. The ‘generic nature’ in the two aspects makes our approach possible for many other GIS applications to use the geometric elements that are represented in one of the datasets and meanwhile use semantic properties that are only represented in the other.
Moreover, the proposed approach defined brand-new concepts to represent the ‘matching pairs with 1:n/m relationship’ and ‘matching pairs with pseudo 1:1 relationship’. To the best of our knowledge, these two corresponding relationships between matched objects or object-chains have not yet been conceptualised in literatures published so far, while they are necessitated by a standardisation process for the comprehensive attributes exchange between different road networks.
In general, the proposed three-step approach in this article is committed to a generic and standardised strategy for the automatic attributes exchange and integration, which makes different geo-spatial datasets more interpretable and thereby can provide better data services for many applications in the fields of digital earth.
Acknowledgements
The research described in this article was funded by (1) German Federal Agency for Cartography and Geodesy (BKG) as part of the project ‘Development of a method for the construction of a routing-capable street database in medium-scale’; and (2) ‘the Fundamental Research Funds for the Central Universities’.
References
- Balsters, H., Klaver, C., and Huitema, G.B., 2010. Real-time integration of geo-data in ORM. Lecture Notes in Computer Science, 6428, 436–446.
- Besl, P. and McKay, N., 1992. A method for registration of 3-d shapes. Transactions on PAMI, 14 (2), 239–256.
- Butenuth, M., et al., 2007. Integration of heterogeneous geospatial data in a federated database. ISPRS Journal of Photogrammetry & Remote Sensing, 62, 328–346.
- Cobb, M.A., et al., 1998. A rule-based approach for the conflation of attributed vector data. Geoinformatica, 2 (1), 7–35.
- Fawcett, J. and Robinson, P., 2000. Adaptive routing for road traffic. Computer Graphics and Applications, 20 (3), 46–53.
- Gillman, D.W., 1985. Triangulations for rubber-sheeting. In: Proceeding of Auto-Carto 7, 11–14 March 1985, Washington, DC. Falls Church, VA: ACSM/ASP, 191–199.
- Gösseln, G.v., 2005. A matching approach for the integration, change detection and adaptation of heterogeneous vector data sets. In: XXII international cartography conference 2005 [online], 11–16 July 2005, A Coruna. Available from: http://www.ikg.uni-hannover.de/fileadmin/ikg/staff/publications/Konferenzbeitraege_abstract_review/Goesseln_ica2005.pdf [Accessed 7 June 2011].
- Gösseln, G.v. and Sester, M., 2004. Integration of geoscientific data sets and the German digital map using a matching approach. In: XXth ISPRS Congress 2004, 12–23 July 2004, Istanbul, 1249–1254.
- Liu, L. and Meng, L., 2009. Algorithms of multi-modal route planning based on the concept of switch point. Photogrammetrie Fernerkundung Geoinformation, 2009 (5), 431–444.
- Lozano, A. and Storchi, G., 2002. Shortest viable hyperpath in multimodal networks. Transportation Research Part B: Methodological, 36 (10), 853–874.
- Mantel, D. and Lipeck, U., 2004. Matching cartographic objects in spatial databases. In: ISPRS Vol. XXXV, ISPRS Congress, Commission, 2004 [online], 12–23 July 2004, Istanbul. Available from: http://www.isprs.org/proceedings/XXXV/congress/comm4/papers/336.pdf [Accessed 7 June 2011].
- Marathe, M.V., 2002. Routing in very large multi-modal time dependent networks: theory and practice. Electronic Notes in Theoretical Computer Science, 66 (6), 1–7.
- Mustiẻre, S., 2006. Results of experiments of automated matching of networks at different scales. In: XXXVI. ISPRS Workshop - multiple representation and interoperability of spatial data, 2006 [online]. Available from: http://www.isprs.org/proceedings/XXXVI/2-W40/92_XXXVI-2-W40.pdf [Accessed 7 June 2011].
- Rosen, B. and Saalfeld, A., 1985. Match criteria for automatic alignment. In: Proceeding of Auto-Carto VII, 1985, 11–14 March 1985, Washington, DC, 456–462.
- Schimandl, F., et al., 2009. Real time application for traffic state estimation based on large sets of floating car data. In: International scientific conference on mobility and transport - ITS for larger cities, 12–13 May 2009, Munich, Germany.
- Siriba, D.N., 2011. Conflation of provisional cadastral and topographical datasets. Thesis (PhD). Techniche Universität München. ISBN 978-3-7696-5085-3.
- Song, W., Haithcoat, T.L. and Keller, J.M., 2006. A snake-based approach for TIGER road data conflation. Cartography and Geographic Information Science, 33 (4), 287–298.
- Stigmar, H., 2006. Some aspects of mobile map services. Thesis (Licentiate Dissertation). Lund University.
- Thakkar, S., Knoblock, C.A. and Ambite, J.L., 2007. Quality-driven geospatial data integration. In: 15th annual ACM international symposium on advances in geographic information systems, 2007 [online], 7–9 November 2007, Seattle, Washington. Available from: http://portal.acm.org/citation.cfm?id=1341034 [Accessed 7 June 2011].
- Volz, S., 2006. An iterative approach for matching multiple representations of street data. In: ISPRS Vol. XXXVI, ISPRS Workshop - multiple representation and interoperability of spatial data, 2006 [online], 22–24 February 2006, Hannover, 101–110. Available from: http://www.ikg.uni-hannover.de/isprs/workshop2006/Paper/6006/2-Workshop_Hannover_Volz.pdf [Accessed 7 June 2011].
- Walter, V., 1996. Zuordnung von raumbezogenen Daten - am Beispiel der Datenmodelle ATKIS und GDF [Matching of spatial data - with the example of the dataset ATKIS]. Thesis (PhD). University of Stuttgart.
- Walter, V. and Fritsch, D., 1999. Matching spatial data sets: a statistical approach. International Journal for Geographical Information Science, 13 (5), 445–473.
- Xiong, D. and Sperling, J., 2004. Semiautomated matching for network database integration. ISPRS Journal of Photogrammetry and Remote Sensing, Special Issue on Advanced Techniques for Analysis of Geo-spatial Data, 59 (1–2), 35–46.
- Zhang, M. and Meng, L., 2007. An iterative road-matching approach for the integration of postal data. Computers, Environment and Urban Systems, 31 (5), 598–616.
- Zhang, M. and Meng, L., 2008. Delimited stroke oriented algorithm-working principle and implementation for the matching of road networks. Journal of Geographic Information Sciences, 14 (1), 44–53.
- Zhang, M., et al., 2009. A grid-based spatial index for matching between moving vehicles and road-network in a real-time environment. In: Proceeding of the XXIV international cartographic conference (ICC), 15–21 November 2009, Santiago.