Abstract
Geospatial simulation models can help us understand the dynamic aspects of Digital Earth. To implement high-performance simulation models for complex geospatial problems, grid computing and cloud computing are two promising computational frameworks. This research compares the benefits and drawbacks of both in Web-based frameworks by testing a parallel Geographic Information System (GIS) simulation model (Schelling's residential segregation model). The parallel GIS simulation model was tested on XSEDE (a representative grid computing platform) and Amazon EC2 (a representative cloud computing platform). The test results demonstrate that cloud computing platforms can provide almost the same parallel computing capability as high-end grid computing frameworks. However, cloud computing resources are more accessible to individual scientists, easier to request and set up, and have more scalable software architecture for on-demand and dedicated Web services. These advantages may attract more geospatial scientists to utilize cloud computing for the development of Digital Earth simulation models in the future.
1. Introduction
The advancement of computational science has enabled researchers to solve complex geospatial problems using a Geographic Information System (GIS) and computational models. Nevertheless, GIS model developers are facing many computational challenges (including data intensity, computing intensity, concurrent intensity, and spatiotemporal intensity) while building various GIS applications (Yang et al. Citation2011a). In many cases, the ‘computational complexity’ of models and ‘poor performance’ of local computers have been major obstacles during the development of GIS models (Armstrong Citation2000). Most traditional GIS models built on local desktop computers are limited to solving only simple geospatial problems. However, many geospatial problems are not intrinsically trivial, and require the utilization of high-performance computing to process complex and advanced GIS models (e.g. urban growth, population change, or weather simulation/forecasting).
GIS simulation using high-performance computing is an important research agenda of Digital Earth (Goodchild Citation2008). Grid computing and cloud computing are two promising frameworks for providing high-performance computing resources, tackling complex geospatial problems, and enhancing the performance of GIS models (Cui, Wu, and Zhang Citation2010; Tang et al. Citation2011b; Tsou and Kim Citation2011; Wang and Armstrong Citation2009; Yang et al. Citation2011b; Zhang and Tsou Citation2009). This paper provides an overview comparison of both grid and cloud computing frameworks in the context of GIS simulation models, and discusses the benefits and drawbacks of their implementation procedures, performances, and scalability for the Digital Earth framework.
Although both cloud and grid computing frameworks can provide high-performance computing resources for Digital Earth simulation models, their system architectures, resource management procedures, and accessibility are very different. Grid computing originated from a distributed computing infrastructure for advanced science and engineering (Foster, Kesselman, and Tuecke 2001) and is focused on the integration of distributed high-performance computing power (such as clusters or supercomputers). Cloud computing is in general provided by the private sector (such as Amazon, Google, and Microsoft) for commercial services (Foster et al. Citation2008). Computing resources in a grid computing framework are shared based on a prioritized queuing system, in which job requests are submitted by multiple users asking for available resources (such as CPU numbers and memory quota). On the other hand, cloud computing can provide dedicated, encapsulated, and on-demand services for multiple users. Although computing resources in a cloud computing environment are shared, users can purchase dedicated virtual machines and disk space for their immediate computation tasks without waiting in a queue. In this article, we highlight the major differences between cloud computing and grid computing and compare the performances of both under different system settings.
This research implemented a parallel Web GIS simulation model (Schelling's residential segregation model) as a case study to compare the computational performances and system requirements in cloud computing and grid computing environments. Schelling's segregation model is a residential segregation model designed by Thomas C. Schelling (Citation1971). We applied Schelling's model to San Diego County using real-world datasets including Decennial Census data and residential land use data. This simulation model converted the total population (2.8 million residents as of 2000) of San Diego County into 2.8 million agents in the GIS simulation model. The GIS model then needs to compute individual movements based on their preferences and behavior rules. The massive number of agents leads to both the data intensity and computing intensity required by this GIS simulation model.
Schelling's segregation model was implemented as a parallel agent-based model to simulate the spatiotemporal pattern changes in the residential segregation in San Diego County. We conducted only one iteration step of the GIS simulation model. The simulation results may help us understand the dynamics of a local urban structure (in terms of ethnic group segregation).
The parallel GIS simulation model was created inside a geospatial Web portal with a friendly Web-based user interface. Users can easily submit their GIS simulation model requests through their Web browser. The grid-enabled GIService framework was implemented on XSEDE (formerly TeraGrid, http://portal.xsede.org). XSEDE is comprised of distributed supercomputer resources across the United States. The cloud-enabled GIService framework was implemented on Amazon Elastic Compute Cloud (EC2, http://aws.amazon.com/ec2/), which is one of the most popular cloud computing environments available. By combining multiple computing instances on Amazon EC2, we built virtual clusters as test-beds. A visualization of the simulation results was developed using the Google Earth Application Programming Interface (API) and Keyhole Markup Language (KML). Based on the experiments on cloud and grid computing, this paper mainly discusses the benefits and drawbacks of two computing frameworks for high-performance GIS models.
2. Internet GIServices and parallel computing
Many researchers have discussed the great opportunities made available when using parallel computing under various GIS models, such as terrain triangulation (Puppo et al. Citation1994), local spatial interpolation (Armstrong and Marciano Citation1996), Douglas line simplification (Mower Citation1996), terrain analysis (Kidner, Rallings, and Ware Citation1997), cellular automata (Guan and Clarke Citation2010), and agent-based models (Tacng, Bennett, and Wang Citation2011a; Tang and Wang Citation2009; Tang et al. Citation2011b). However, parallel computing tools and high-performance GIS models need to be more accessible and friendly to individual scientists and researchers. Internet GIServices with Web-based user interfaces may provide a good platform for the utilization of parallel GIS models.
An Internet GIService is a powerful platform used to deploy geospatial data, Web maps, and online geospatial services for studying Digital Earth (Peng and Tsou Citation2003). Internet GIServices can be categorized into three levels of service: (1) data archiving and searches (sharing data), (2) information displays and queries (sharing information), and (3) spatial analyzes and GIS modeling services (sharing knowledge) (Tsou Citation2004). Most Internet GIServices have focused on sharing data and visualizing information. To date, however, very few Internet GIServices have been developed for knowledge sharing, including spatial analysis and spatial models. Computing intensity can be a major obstacle to implementing complex and large-scale simulation models (Lei et al. Citation2005; Stevens and Dragicevic Citation2007; Tang and Wang Citation2009).
One possible solution is to adopt a distributed computing framework, such as the distributed GIService architecture (Tsou and Buttenfield Citation2002) or Distributed Geospatial Information Processing (DGIP) (Yang and Raskin Citation2009; Yang et al. Citation2008). For distributed computing, some frameworks integrating both grid and cloud computing have been presented for distributed high-performance computing. For instance, Zentner et al. (Citation2011) discussed the utilization of cloud computing for nanoHub.org, which is a science gateway based on grid computing. Mateescu, Gentzsch, and Ribbens (Citation2011) demonstrated a hybrid-architecture utilizing both grid and cloud computing. Behzad et al. (Citation2011) illustrated the CyberGIS Gateway, including grid (XSEDE) and cloud (Microsoft Azure) computing. Thus, to better utilize both computing methods, it is important to know the different benefits of each.
2.1. Simulation modeling for parallel computing
Parallel computing is the utilization of multiple processors to solve a computational problem (Foster Citation1995). Parallel computing can be categorized into ‘shared memory’ and ‘distributed memory’ based on how the processors access the memory (Sawyer Citation1998). In parallel computing with shared memory, any memory location can be accessed by any processor. On the other hand, in parallel computing with distributed memory, a memory location can be accessed by only one processor exclusively. For parallel programming, OpenMP (Open Multiprocessing) and MPI (Message Passing Interface) are widely used to implement parallel processing models with shared and distributed memory respectively.
For simulation modeling approaches in GIS, Cellular Automata (CA) and Agent Based Models (ABM) are recent popular trends in simulation modeling, and both are widely used to simulate complex geospatial phenomena with a bottom-up approach. These two simulation modeling approaches are computationally intensive, and some researchers have made an effort to utilize parallel computing to address the computing intensity issue. Guan and Clarke (Citation2010) developed a general-purpose parallel raster processing programming library, which they tested for SLEUTH, a popular CA model for urban growth and land use changes. Li et al. (Citation2010) also implemented a parallel CA model for land use change simulations. For ABM, Tang, Bennett, and Wang (Citation2011a) implemented an agent-based model for the formation of large-scale land use opinions by utilizing parallel computing. Each of these parallel simulation models was constructed based on distributed memory parallel programming using an MPI.
Although such efforts have attracted the attention of researchers, parallel computing has still not been widely adopted by most geospatial scientists. There are two main reasons for this: an ‘inaccessibility of HPC resources’ and ‘the lack of a parallel GIS algorithm’ (Clematis, Mineter, and Marciano Citation2003; Guan and Clarke Citation2010). In general, local clusters are unavailable to most geospatial scientists. Distributed high-performance computing, such as grid or cloud computing, can therefore be a solution for the ‘inaccessibility of HPC resources,’ as such computing can be accessed through the Internet. This paper demonstrates how grid and cloud computing can each contribute to the utilization of parallel computing (high-performance computing) for geospatial scientists implementing GIS simulation models.
2.2. Parallel computing using grid computing
Grid computing is the integration of powerful distributed computing resources through high-speed networks (Baker, Buyya, and Laforenza Citation2002). Grid computing is generally used to solve ‘large-scale computational and data intensive problems’ (Baker, Buyya, and Laforenza Citation2002). In addition, according to Foster, Kesselman, and Tuecke (Citation2001) grid computing is ‘resource sharing and problem solving in dynamic, multi-institutional virtual organizations.’ Grid computing has provided geospatial scientists with parallel computing environments to solve complex spatial analytical problems. To date, most Web-based parallel GIS models have been implemented through grid computing (Tsou and Kim Citation2011; Wang Citation2010; Wang and Liu Citation2009; Zhang and Tsou Citation2009).
One grid-enabled GIService framework for the development of a geospatial cyberinfrastructure was illustrated by Zhang and Tsou (Citation2009). To enable high-performance GIS models, the authors proposed a four-tier framework for a grid-enabled Internet GIService. This framework is composed of (1) a presentation tier, which offers user interfaces to clients through a spatial Web portal; (2) a logic tier, which constitutes traditional map services and coordinates grid-enabled GIServices; (3) a service tier, which provides grid-enabled Web services; and (4) a grid tier, which accesses grid computing resources. Both data and computing intensity issues are tackled by utilizing parallel computing in the grid tier. In this framework, the logic tier and service tier are designed as spatial middleware to link Internet GIServices to the grid middleware in the grid tier.
2.3. Parallel computing using cloud computing
Cloud computing is a recent trend in Internet services for sharing both diverse and high-performance computing resources. Cloud computing provides users with the software, platform, and infrastructure as services from a private computing environment to third-party data centers over the Internet (Armbrust et al. Citation2009; Armbrust et al. Citation2010; Buyya, Pandey, and Vecchiola Citation2009). These services are referred to as (1) software as a service (SaaS), (2) platform as a service (PaaS), and (3) infrastructure as a service (IaaS) (Buyya, Pandey, and Vecchiola Citation2009). Collectively, these cloud computing services are referred to as ‘XaaS.’
Through the utilization of high-performance computing resources available in cloud computing, large amounts of data and computationally intensive models can be handled. Research on implementing high-performance cloud computing through the use of virtual clusters has been conducted (Ekanayake et al. Citation2010; Vecchicola, Pandey, and Buyya Citation2009, Zhai et al. Citation2011). While virtual clusters have shown a lower performance compared to other high-performance computing resources, cloud computing vendors currently offer other high-performance computing resources (e.g. Cluster Compute Instances and Cluster GPU Instances on Amazon EC2). Since Amazon EC2 began providing high-performance computing instances (Mateescu, Gentzsch, and Ribbens Citation2011, Zhai et al. Citation2011), performance improvements in cloud computing have been reported.
Based on the high-performance computing capability of cloud computing, data as a service (DaaS) (Yang et al. Citation2011a) and knowledge as a service (KaaS) (Raskin Citation2011) can function as two additional cloud computing service types. According to Raskin (Citation2011), KaaS is used to share memories and experiences through cloud computing. The experience and knowledge obtained from high-performance Web-based GIS simulation models can be shared with other users. The KaaS concept is closely related to third-level (knowledge sharing) Internet GIServices. Parallel GIS models can be implemented from Spatial Cloud Computing (SCC) as Internet GIServices. Users can share their experiences obtained by GIS models through the Internet. In this sense, parallel GIS simulation models on SCC can be provided as KaaS.
2.4. Cloud computing vs. grid computing
Cloud computing and grid computing are related but different. Both computing frameworks provide distributed computing resources that are shared to reduce the costs of computing, increase flexibility, and handle large datasets (Foster et al. Citation2008).
Grid computing technology can be utilized as the backbone of cloud computing (Foster et al. Citation2008). Cloud computing evolved from grid computing (Foster et al. Citation2008), and provides a ‘shared pool’ of computing resources (Yang et al. Citation2011a). However, there are some differences between grid computing and cloud computing, including architecture and resource management (Foster et al. Citation2008). Cloud computing is based on virtualization more than grid computing (Foster et al. Citation2008). Grid computing technology has been mainly utilized by the science community (Yang et al. Citation2011a) and has facilitated scientific research rather than business applications. Grid computing has adopted standard protocols (e.g. Grid Security Architecture, Grid Remote Procedure Call, and Grid FTP) for the interoperability of distributed computing resources (Foster et al. Citation2008). Grid computing resources are shared based on a queuing method such as the Portable Batch System (PBS). For example, a PBS script for a job request can be submitted to the queuing system, which means that a waiting period is needed until the other queues are processed. Grid computing resources are therefore not generally subordinated to an Internet GIService. On the other hand, cloud computing resources are widely used by both Web service providers and businesses. Once virtual machines (compute instances) are created on a cloud computing infrastructure, the virtual machines become similar to computers, allowing users remote access at any time, and can be dedicated to a particular Internet GIService.
Differences in resource allocations also exist between grid and cloud computing. It is more difficult to access grid computing resources. To obtain a resource allocation from grid computing, a research proposal should be submitted (Vecchiola, Pandey, and Buyya Citation2009). For XSEDE (which is a representative grid computing resource), a research proposal should be submitted through the XSEDE Web portal. The review of such a research proposal may take two to three weeks for a small allocation request, which is called a start-up allocation. Overall, it may therefore take almost one month to obtain the grid computing resources, including the proposal preparation and review procedures. A large allocation request, called a research allocation, can be obtained through rigorous review procedures, which generally take three months to complete. Including the proposal preparation, the entire request can take more than three months. In addition, the allocation of XSEDE is basically limited to ‘a researcher or an educator at a US academic or non-profit research institution’ (https://www.xsede.org/web/guest/allocation-policies#uses:eligibility).
Conversely, elasticity and on-demand services make cloud computing a more accessible computing resource for individual researchers or short-term projects. Once users pay for cloud computing resources, they can use online resources immediately without a review process. Users can then have full permission to control their virtual machines (Vecchicola, Pandey, and Buyya Citation2009). Scientists can select their preferred operating systems (Windows or Linux) to implement their models through Remote Desktop for Windows or SSH for Linux. In addition, powerful Application Programming Interface (API) tools are provided by cloud computing vendors (e.g. Amazon Web Service API Tools for Amazon EC2). Using these API tools, users can implement tools to automatically manage cloud computing resources.
Given the costs, commercial cloud computing can be useful for moderate-scale high-performance computing and as test-beds before using grid computing. Once grid computing resources are allocated, researchers can utilize free large-scale high-performance computing resources. Owing to these advantages of cloud and grid computing, a hybrid high-performance computing framework that includes both grid and cloud computing can provide more elasticity and flexibility.
In the geospatial science domain, Behzad et al.(Citation2011) demonstrated an Internet GIService framework encompassing grid and cloud computing. Through this framework, they illustrated how cloud computing can address the scalability issues of Internet GIServices. Our framework is also based on a hybrid framework. However, we focused on how cloud computing can be utilized to handle the data and computing intensity issues of a parallel GIS simulation model, compared to grid computing.
3. Implementation of a parallel Web GIS simulation model
This section will illustrate how the performance test-beds for Web-based GIS simulation models were implemented. illustrates the implementation architecture of the GIS simulation model for both cloud and grid computing. A geospatial Web portal prototype was designed to utilize both grid and cloud computing through the OGCE (Open Grid Computing Environment) toolkit. The OGCE toolkit is a package used to build a grid-enabled Web portal to enable users to utilize grid computing resources. In this research, the OGCE toolkit was customized to include functions to utilize cloud computing resources. To access grid computing, Grid Security Infrastructure Secure Shell (GSISSH) and Grid Security Infrastructure Secure Copy (GSISCP) of Globus Toolkit were utilized. For Amazon EC2 (cloud computing), Amazon Web Service (AWS) EC2 API Tools were used to control the instances on Amazon EC2.
Figure 1. Architecture of a parallel Web GIS simulation model.
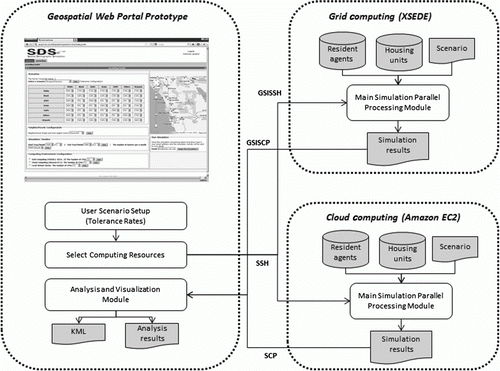
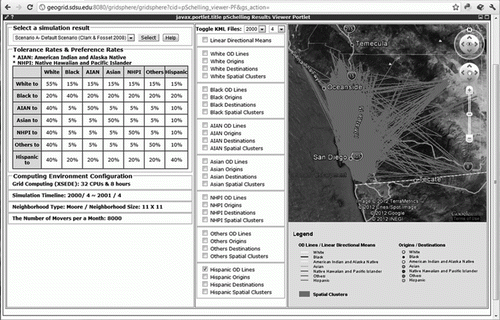
and show the Web-based user interfaces. Users can set up the parameters of the parallel Schelling model (such as the tolerance rates, time periods, and number of moving agents), and select grid or cloud computing for high-performance use (). After the simulation model is generated, the simulation results are downloaded to the server. The users can then investigate the simulation results overlaid over the Google Earth API ().
Figure 2. User interface for the parameter settings.
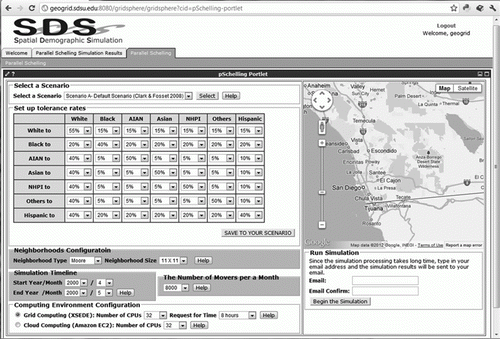
Figure 3. User interface for a visualization of the simulation results.
3.1. The utilization of grid computing
For grid computing resources, we obtained a research allocation from XSEDE. Although XSEDE is composed of over ten super computers in the USA, we could not access all resources on it. Instead, we obtained permission for only Trestles at the San Diego Supercomputer Center (SDSC). The system specifications of a Trestles node are 32 cores with a 2.4 GHz clock speed and 64 GB of memory. The GSISSH and GSISCP were used for the connection and data transfer between the geospatial Web portal prototype and grid computing. The job requests that were used to perform the simulation model were submitted through a Portable Batch System (PBS) on Trestles. The job request batch files were created automatically using shell scripts through the GSISSH.
3.2. The utilization of cloud computing
In this research, virtual clusters were built on Amazon EC2 for the utilization of high-performance computing resources. We installed a Linux operating system and MPICH2 on virtual machines for parallel processing. The pricing policy for Amazon EC2 computing instances is varying and flexible. shows a partial list of the different instance types and costs on Amazon EC2.
Table 1. A partial list of instance types and costs for Linux operating systems on Amazon EC2. The number of cores used for EC2 is based on the virtual cores.
High CPU Extra Large instances and Cluster Compute Quadruple Extra Large instances were used as the major test-beds of the virtual clusters. The cores of the Amazon EC2 instances are virtual cores rather than physical CPU cores. The shell scripts in the Web server were developed to automatically launch and control the virtual machines from Amazon Machine Images (AMIs). The shell scripts invoked EC2 API Tools. We created AMIs for parallel computing. Based on the ID of the AMI, we could then create the same multiple virtual instances through the shell scripts. Once the computing instances started, the shell scripts that are used to set up a virtual cluster, run the simulation model, and transfer the data were invoked using SSH and SCP.
4. Case study: Schelling's residential segregation model
In this research, a parallel agent-based model to simulate a population change in San Diego County was implemented. The population change simulation model is based on Schelling's residential segregation model, which illustrates that a considerable amount of tolerance for different ethnic groups can lead to residential segregation. Schelling's model is significant for an understanding of residential segregation and its effect on society. For this case study, Schelling's model was implemented for parallel processing, and applied to San Diego County. Since this research is focused on the performance tests of the parallel Schelling's model applied to grid and cloud computing, a more detailed technical implementation of the model is not discussed herein. However, this section briefly introduces the experimental configurations of the parallel Schelling's model.
4.1. Data processing
For data processing, the Decennial Census and land use datasets were obtained from the Websites of the Census Bureau and the San Diego Association of Governments (SANDAG) (). The Decennial Census datasets were processed using the Topologically Integrated Geographic Encoding and Referencing (TIGER) system boundary datasets. The spatial datasets were rasterized from the vector data format with a 30-m cell size.
Table 2. Datasets for the parallel Schelling's model.
Population, household, and housing unit categories were extracted from the 2000 Decennial Census. The population was then categorized into seven different ethnic groups: White, Black, American Indian and Alaska Native (AIAN), Asian, Native Hawaiian and Pacific Islander (NHPI), Other Races, and Hispanic. The housing units were randomly assigned to the residential land use cells in the same census block. The resident agents were then randomly assigned to the housing units in the same census block. During this procedure, the housing unit ID property of the resident agent was set to link the resident agent with the housing unit. The parallel Schelling's model was implemented to apply to the real world (San Diego County). Since 2.8 million agents were created (the total population of San Diego County in 2000), the GIS model was computationally intensive and data intensive.
4.2. Parallel agent-based model for population change
shows a diagram of the overall data decomposition. The spatial domain was partitioned and distributed to each parallel node. For neighborhood configurations, there were overlapped grid cells between parallel nodes. The grid cells are called ghost zones. shows the pseudo algorithm used for the parallel Schelling's model. The algorithm was constructed based on the parallel processing of distributed memory using MPI. For both grid and cloud computing, the same parallel algorithm was used and tested.
Figure 4. A diagram illustrating column-wise decomposition.
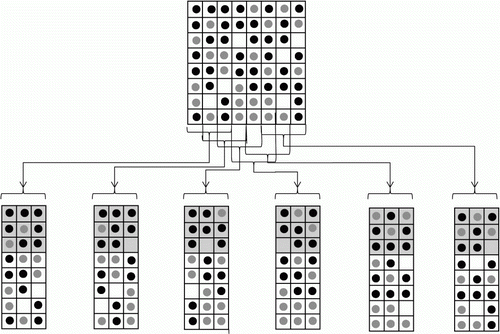
Figure 5. Parallel algorithm of the Schelling's model.

The overall procedure of the parallel Schelling's model algorithm was as follows:
In a master node
| 1. | Distribute housing units based on a column-wise decomposition. | ||||
| 2. | Distribute resident agents into parallel partitions where the assigned housing units are located. | ||||
In each parallel node
| 1. | Check the satisfaction of each agent for its current neighborhood. | ||||
| 2. | Check for a vacant housing unit that can satisfy a particular ethnic group. | ||||
| 3. | Select a set of unsatisfied resident agents randomly. | ||||
| 4. | Select vacant housing units. | ||||
| 5. | Assign unsatisfied resident agents to vacant housing units selected in step 4. | ||||
| 6. | Move all selected agents to the parallel nodes where the housing units are located. | ||||
| 7. | In the case of multiple iterations, repeat from step 1. | ||||
In a master node
| 1. | Gather the resident agent information from all parallel nodes. | ||||
| 2. | Save the simulation results. | ||||
4.3. Simulation results
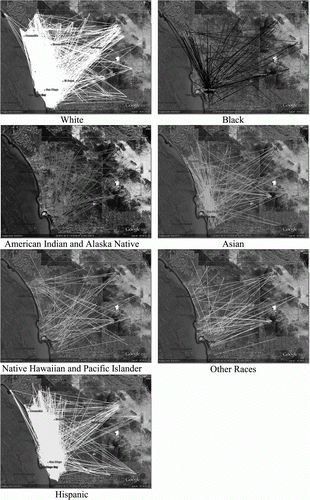
The simulation model used in this research was executed to illustrate the utility of parallel computing on both cloud and grid computing. For the performance testing, we conducted only a single iteration. Our primary concern here is the relative performance of cloud and grid computing, and all other simulation results will be discussed in further research. Various spatial statistics can be used to analyze the simulation results. Rather than using statistics, however, the simulation results from a single iteration were mapped using the Google Earth API (). The residential moving patterns are illustrated on the map. The coordinates of the origins and destinations of the moving agents are saved in data tables. To visualize the simulation results on the Google Earth API, the x and y coordinates in ESRI GRID format were converted into latitude and longitude in decimal degree. The KML files were created based on the decimal degree coordinates of the moving agents. Individual moving patterns could then be explored by selecting individual origin-destination lines on the Google Earth API.
Figure 6. Visualization of moving residents.
4.4. Performance comparison between cloud and grid computing
A performance test was conducted for both grid computing (XSEDE) and cloud computing (Amazon EC2) using the parallel Schelling's model. The grid computing resource used for XSEDE was Trestles at the SDSC. For the cloud computing resources, various Amazon EC2 instance types were tested. Although we tested four different computing instance types (High CPU Extra Large, Cluster Compute Quadruple Extra Large, Cluster Compute Eight Extra Large, and Micro), we focused on the performance results of the virtual clusters with High CPU Extra Large instances and Cluster Compute Quadruple Extra Large instances.
MPICH2 was utilized for the message communication among the computing instances in a virtual cluster. The same parallel algorithm was tested for both grid and cloud computing. In addition, the parallel algorithm was based on distributed memory parallel processing using the MPI library. illustrates the technical specifications of Trestles and the virtual clusters on Amazon EC2.
Table 3. The technical specifications of cloud and grid computing resources tested for the GIS simulation model. The number of cores of the EC2 instances is based on the virtual cores.
The performances of both cloud and grid computing were tested by increasing the number of cores. We calculated the turnaround time including the EC2 virtual machine launching time, XSEDE queuing time, data uploading and downloading times, and computing time. For EC2, since we did not turn the virtual machines on at all times, the virtual machine launching time was also included in the turnaround time. For XSEDE, the queuing time could also be considered. Because the resource requests of researchers are variable, the queuing time is generally not predictable. If there are more queue requests, an additional queuing time is expected. The network performance can also be variable when uploading and downloading data from San Diego State University to Trestles at SDSC of XSEDE (San Diego, CA) and Amazon EC2 (Virginia). The data-upload times of XSEDE were slightly faster than those of EC2. However, the data-download times of XSEDE were twice those of EC2.
Launching and initializing the EC2 instances consumed 2–4 min. For the XSEDE queuing time, we requested a small amount of parallel nodes and computing times (e.g. 4 nodes and 10 min). Our job requests could therefore be processed almost immediately. On average, 2 min were consumed as the queue waiting time. We also tested different job requests using the configurations of additional nodes and computing times (e.g. 128 nodes and 1 h). In this case, the queuing times varied considerably from 30 min to 1 day.
and illustrate a performance comparison of Trestles (grid computing) and the virtual cluster of High CPU Extra Large instances (cloud computing). The main difference in the turnaround times was caused by the computing times. Along with the increase in the number of cores, the turnaround and computing times declined. The performance results of this experiment show that grid computing is approximately twice as fast as the virtual cluster of High CPU Extra Large instances. For the computing times using 8 cores, Trestles (XSEDE) took 4,829 s, whereas the virtual cluster of High CPU Extra Large instances (Amazon EC2) took 10,240 s. These results might be because the Amazon High CPU Extra Large instance was not designed for high-performance computing. However, the performance gaps between the two computing platforms were reduced significantly when the number of cores increased.
Figure 7. A comparison of the turnaround (solid line) and computing (dashed line) times between grid (XSEDE) and cloud (Amazon EC2) computing. The virtual cluster for cloud computing was tested using High CPU Extra Large instances.
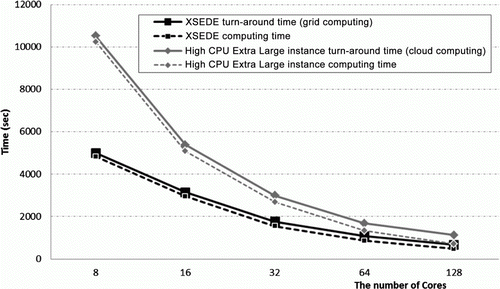
Table 4. A comparison of the turnaround times of grid (XSEDE) and cloud (Amazon EC2) computing. The virtual cluster for cloud computing was tested using High CPU Extra Large instances.
Amazon EC2 also provides high-performance computing resources, such as Cluster Compute instances (Cluster Compute Quadruple Extra Large instances and Cluster Compute Eight Extra Large instances) and Cluster GPU instances (http://aws.amazon.com/hpc-applications/). In this research, the virtual clusters of Cluster Compute instances were also tested for the parallel computing performance of cloud computing. The virtual clusters of the Cluster Compute instances in and show a performance similar to grid computing. Because of the virtualization technology of cloud computing, we expected that there would be a large difference between its performance and that of grid computing. Zhai et al. (Citation2011) also reported a high communication latency in EC2 Cluster Compute instances. In this research, however, the virtual cluster performance of the Cluster Compute instances was almost the same as or slightly better than that of grid computing. All datasets were distributed and gathered only when the parallel model started and ended. Thus, high communication latency was not a significant problem in this experiment. In addition, the virtual cluster performance of the Cluster Compute instances was much better than that of the High CPU Extra Large instances. These results indicate that researchers should consider which instance type in cloud computing is most efficient for their research, and that, like grid computing, cloud computing can provide high-performance computing resources.
Figure 8. A comparison of the turnaround (solid line) and computing (dashed line) times between grid (XSEDE) and cloud (Amazon EC2) computing. The virtual cluster for cloud computing was tested using Cluster Compute instances (Quadruple Extra Large instances).
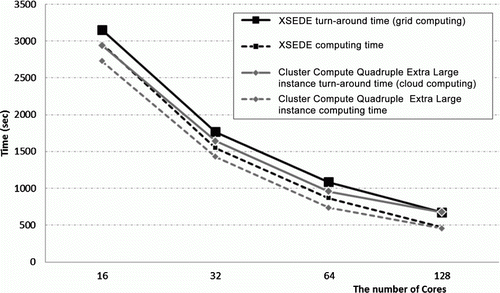
Table 5. A comparison of the turnaround times of grid (XSEDE) and cloud (Amazon EC2) computing. The virtual cluster for cloud computing was tested using Cluster Compute instances (Quadruple Extra Large instances).
Although we also tested the virtual clusters of Micro instances and Cluster Compute Eight Extra Large instances, we did not compare the performance results of the two computing instances for the following reasons: the virtual cluster performance of the Micro instances was very slow because their core was shared, and the virtual cluster of Cluster Compute Eight Extra Large instances showed similar performance results to Cluster Compute Quadruple Extra Large instances.
5. Conclusion and discussion
This research compared the benefits and drawbacks of both cloud and grid computing by testing a parallel Geographic Information System (GIS) simulation model and analyzing the performance test results under different system settings. High-end cloud computing platforms showed similar performance results compared to grid computing platforms. In comparison, non-high-performance computing instances for cloud computing (e.g. High CPU Extra Large instances on Amazon EC2) showed lower performance results. However, the performance gaps between the two platforms became smaller when the number of cores used in the GIS model increased.
Based on our testing results, cloud computing is a promising framework for developing high-performance parallel GIS models and resolving computing and data intensity issues in complex GIS simulation tasks. This research compared various cloud computing performance results with different instance types and system settings on Amazon EC2. The virtual cluster of Cluster Compute Quadruple Extra Large instances showed better performances than that of High CPU Extra Large instances for parallel GIS models. For non-parallel GIS models, High CPU Extra Large instances might be a better solution at lower cost. Different types of GIS models (parallel vs. non-parallel algorithms) will therefore require different types of cloud computing resources.
Cloud computing also has better accessibility, flexibility, and scalability compared to grid computing. To date, grid computing frameworks have not been widely used by geospatial scientists, which might be due to the idea that it is very difficult for geospatial scientists to learn complicated system protocols and unique development tools. On the other hand, cloud computing resources can be accessed easily in popular system environments, such as Windows or Linux virtual machines. The accessibility of cloud computing resources will encourage more geospatial scientists to utilize parallel computing and develop high-performance GIS simulation models for Digital Earth. Additionally, grid computing has a lack of flexibility, and the operating systems and resource management systems used in grid computing are configured and fixed by the system administrators. Users cannot select different operating systems or modify the resource management systems. In the case of cloud computing (Amazon EC2), users can select their preferred operating systems and install various program libraries needed for their own models. Cloud computing has better scalability because users can increase the available computing resources (different combinations of virtual machines, memory, and disk space) dynamically based on their needs.
Although we focused on a discussion on the benefits of cloud computing in terms of its high performance, users should keep in mind some important concerns when utilizing cloud computing. Armbrust et al. (Citation2009) listed some obstacles such as the service availability (e.g. outages and DDoS attacks) and data confidentiality and auditability. A cloud computing vendor can experience a system failure, interrupting the use of cloud computing resources. In addition, unlike in grid computing, the virtual machines used in cloud computing are managed by individual users, and can be vulnerable to computer security. Data security is also an important concern (Yang et al. Citation2011a). Basically, most users cannot know where their data are located, and may worry whether their data are properly secured. In addition, commercial cloud computing costs are a major concern.
For this research, we did not discern which of the two computing methods is better. However, it is important to acknowledge that cloud computing has been improved and has become a useful high-performance computing resource. For this reason, some grid computing environments have made plans for adopting cloud computing (https://cloudsurvey.cac.cornell.edu/). To take advantage of both grid and cloud computing, the framework used for Digital Earth can integrate both computing methods.
To simulate the dynamics of Digital Earth, GIScientists will require high-performance computing resources to construct complex GIS models. Both grid and cloud computing are promising frameworks for supporting next-generation high-performance GIS models. In our study, we found that cloud computing frameworks are more accessible to researchers, easier to request and set up, and have a more scalable and flexible software architecture for on-demand and dedicated Web services. These advantages may attract more geospatial scientists to utilize cloud computing for the development of Digital Earth simulation models and to facilitate the advancement of GIScience and geospatial knowledge.
Acknowledgements
This work used the Extreme Science and Engineering Discovery Environment (XSEDE), which is supported by National Science Foundation grant number OCI-1053575. The first author expresses the appreciation of funds received from the National Science Foundation (Award #CNS-1028177), and support from San Diego State University.
References
- Armbrust , M. , A. Fox , R. Griffith , A. D. Joseph , R. Katz , A. Konwinski , G. Lee , et al. , 2009 . Above the Clouds: A Berkeley View of Cloud Computing . Dept. of Electrical Engineering and Computer Sciences, University of California, Berkeley, Tech. Rep. UCB/EECS , 28 .
- Armbrust , M. , Fox , A. , Griffith , R. , Joseph , A. D. , Katz , R. , Konwinski , A. Lee , G. 2010 . A View of Cloud Computing . Communications of the ACM , 53 ( 4 ) : 50 – 58 . doi: 10.1145/1721654.1721672
- Armstrong , M. P. 2000 . Geography and Computational Science . Annals of the Association of American Geographers , 90 ( 1 ) : 146 – 156 . doi: 10.1111/0004-5608.00190
- Armstrong , M. P. and Marciano , R. J. 1996 . Local Interpolation Using a Distributed Parallel Supercomputer . International Journal of Geographical Information Systems , 10 ( 6 ) : 713 – 729 . doi: 10.1080/02693799608902106
- Baker , M. , Buyya , R. and Laforenza , D. 2002 . Grids and Grid Technologies for Wide-area Distributed Computing . Software: Practice and Experience , 32 ( 15 ) : 1437 – 1466 . doi: 10.1002/spe.488
- Behzad , B. , A. Padmanabhan , Y. Liu , Y. Liu , and S. Wang . 2011 . “ Integrating CyberGIS Gateway with Windows Azure: A Case Study on MODFLOW Groundwater Simulation .” In Proceedings of the ACM SIGSPATIAL Second International Workshop on High Performance and Distributed Geographic Information Systems , S. Wang and N. Wilkins-Diehr , 26 – 29 . Chicago , IL : ACM .
- Buyya , R. , Pandey , S. and Vecchiola , C. 2009 . “ Cloudbus Toolkit for Market-oriented Cloud Computing ” . In Cloud Computing , Edited by: Jaatun , M. , Zhao , G. and Rong , C. 24 – 44 . Berlin/Heidelberg : Springer .
- Clematis , A. , Mineter , M. and Marciano , R. 2003 . High Performance Computing with Geographical Data . Parallel Computing , 29 ( 10 ) : 1275 – 1279 . doi: 10.1016/j.parco.2003.07.001
- Cui , D. , Y. Wu , and Q. Zhang . 2010 . “ Massive Spatial Data Processing Model Based on Cloud Computing Model .” In : Proceedings of the Third International Joint Conference on Computational Sciences and Optimization , L. Yu , Y. Song , W. K. Ching , S. Wang , and K. K. Lai , 347 – 350 . Huangshan , Anhui : IEEE .
- Ekanayake , J. , Qiu , X. , Gunarathne , T. , Beason , S. and Fox , G. 2010 . “ High-performance Parallel Computing with Cloud and Cloud Technologies ” . In Cloud Computing and Software Services: Theory and Techniques , Edited by: Ahson , S.A. and Ilyas , M. 275 – 308 . Boca Raton , FL : CRC Press, Inc .
- Foster , I. 1995 . Designing and Building Parallel Programs , Reading , MA : Addison-Wesley .
- Foster , I. , Kesselman , C. and Tuecke , S. 2001 . The Anatomy of the Grid: Enabling Scalable Virtual Organizations . International Journal of High Performance Computing Applications , 15 ( 3 ) : 200 – 222 . doi: 10.1177/109434200101500302
- Foster , I. , Z. Yong , I. Raicu , and S. Lu . 2008 . “ Cloud Computing and Grid Computing 360-degree Compared .” In Grid Computing Environments Workshop, 2008 . GCE'08 , 1 – 10 . Austin , TX : IEEE .
- Goodchild , M. F. 2008 . The Use Cases of Digital Earth . International Journal of Digital Earth , 1 ( 1 ) : 31 – 42 . doi: 10.1080/17538940701782528
- Guan , Q. and Clarke , K. C. 2010 . A General-purpose Parallel Raster Processing Programming Library Test Application Using a Geographic Cellular Automata Model . International Journal of Geographical Information Science , 24 ( 5 ) : 695 – 722 . doi: 10.1080/13658810902984228
- Kidner , D. B. , Rallings , P. J. and Ware , J. A. 1997 . Parallel Processing for Terrain Analysis in GIS: Visibility as a Case Study . Geoinformatica , 1 ( 2 ) : 183 – 207 . doi: 10.1023/A:1009740712769
- Lei , Z. , Pijanowski , B. C. , Alexandridis , K. T. and Olson , J. 2005 . Distributed Modeling Architecture of a Multi-agent-based Behavioral Economic Landscape (MABEL) Model . Simulation , 81 ( 7 ) : 503 – 515 . doi: 10.1177/0037549705058067
- Li , X. , Zhang , X. , Yeh , A. and Liu , X. 2010 . Parallel Cellular Automata for Large-scale Urban Simulation Using Load-balancing Techniques . International Journal of Geographical Information Science , 24 ( 6 ) : 803 – 820 . doi: 10.1080/13658810903107464
- Mateescu , G. , Gentzsch , W. and Ribbens , C. J. 2011 . Hybrid Computing—Where HPC Meets Grid and Cloud Computing . Future Generation Computer Systems , 27 ( 5 ) : 440 – 453 . doi: 10.1016/j.future.2010.11.003
- Mower , J. E. 1996 . Developing Parallel Procedures for Line Simplification . International Journal of Geographical Information Systems , 10 ( 6 ) : 699 – 712 . doi: 10.1080/02693799608902105
- Peng , Z. R. and Tsou , M. H. 2003 . Internet GIS: Distributed Geographic Information Services for the Internet and Wireless Network , New Jersey : John Wiley and Sons .
- Puppo , E. , Davis , L. , De Menthon , D. and Teng , Y. A. 1994 . Parallel Terrain Triangulation . International Journal of Geographical Information Systems , 8 ( 2 ) : 105 – 128 . doi: 10.1080/02693799408901989
- Raskin , R. 2011 . “ Knowledge as a Service (KaaS) .” Accessed June 11, 2012. http://cisc.gmu.edu/scc/presentation/CloudRaskin.pdf
- Sawyer , M. 1998 . “ The Development of Hardware for Parallel Processing ” . In Parallel Processing Algorithms for GIS , Edited by: Healey , R. , Dowers , S. , Gittings , B. and Mineter , M. 13 – 31 . London : Taylor and Francis .
- Schelling , T. C. 1971 . Dynamic Models of Segregation . Journal of Mathematical Sociology , 1 ( 2 ) : 143 – 186 . doi: 10.1080/0022250X.1971.9989794
- Stevens , D. and Dragicevic , S. 2007 . A GIS-based Irregular Cellular Automata Model of Land-use Change . Environment and Planning B: Planning and Design , 34 ( 4 ) : 708 – 724 . doi: 10.1068/b32098
- Tang , W. , Bennett , D. A. and Wang , S. 2011a . A Parallel Agent-based Model of Land Use Opinions . Journal of Land Use Science , 6 ( 2,3 ) : 121 – 135 . doi: 10.1080/1747423X.2011.558597
- Tang , W. and Wang , S. 2009 . HPABM: A Hierarchical Parallel Simulation Framework for Spatially-explicit Agent-based Models . Transactions in GIS , 13 ( 3 ) : 315 – 333 . doi: 10.1111/j.1467-9671.2009.01161.x
- Tang , W. , Wang , S. , Bennett , D. A. and Liu , Y. 2011b . Agent-based Modeling within a Cyberinfrastructure Environment: A Service-oriented Computing Approach . International Journal of Geographical Information Science , 25 ( 9 ) : 1323 – 1346 . doi: 10.1080/13658816.2011.585342
- Tsou , M.-H. 2004 . Integrating Web-based GIS and Image Processing Tools for Environmental Monitoring and Natural Resource Management . Journal of Geographical Systems , 6 ( 2 ) : 155 – 174 . doi: 10.1007/s10109-004-0131-6
- Tsou , M.-H. and Kim , I.-H. 2011 . “ Creating GIS Simulation Models on a TeraGrid-enabled Geospatial Web Portal: A Demonstration of Geospatial Cyberinfrastructure ” . In Advances in Web-based GIS, Mapping Services and Applications , Edited by: Li , S. , Dragicevic , S. and Veenendaal , B. 55 – 70 . London : Taylor & Francis Group .
- Tsou , M.-H. and Buttenfield , B. P. 2002 . A Dynamic Architecture for Distributing Geographic Information Services . Transactions in GIS , 6 ( 4 ) : 355 – 381 . doi: 10.1111/1467-9671.00118
- Vecchiola , C. , S. Pandey , and R. Buyya . 2009 . “ High-performance Cloud Computing: A View of Scientific Applications .” In 10th International Symposium on Pervasive Systems, Algorithms, and Networks (ISPAN) , 4 – 16 . Kaohsiung , , Taiwan : IEEE Computer Society .
- Wang , S. 2010 . A CyberGIS Framework for the Synthesis of Cyberinfrastructure, GIS, and Spatial Analysis . Annals of the Association of American Geographers , 100 ( 3 ) : 535 – 557 . doi: 10.1080/00045601003791243
- Wang , S. and Armstrong , M. P. 2009 . A Theoretical Approach to the Use of Cyberinfrastructure in Geographical Analysis . International Journal of Geographical Information Science , 23 ( 2 ) : 169 – 193 . doi: 10.1080/13658810801918509
- Wang , S. and Liu , Y. 2009 . TeraGrid GIScience Gateway: Bridging Cyberinfrastructure and GIScience . International Journal of Geographical Information Science , 23 ( 5 ) : 631 – 656 . doi: 10.1080/13658810902754977
- Yang , C. , Goodchild , M. , Huang , Q. , Nebert , D. , Raskin , R. , Xu , Y. , Bambacus , M. and Fay , D. 2011a . Spatial Cloud Computing: How Can the Geospatial Sciences Use and Help Shape Cloud Computing? . International Journal of Digital Earth , 4 ( 4 ) : 305 – 329 . doi: 10.1080/17538947.2011.587547
- Yang , C. , Li , W. , Xie , J. and Zhou , B. 2008 . Distributed Geospatial Information Processing: Sharing Distributed Geospatial Resources to Support Digital Earth . International Journal of Digital Earth , 1 ( 3 ) : 259 – 278 . doi: 10.1080/17538940802037954
- Yang , C. and Raskin , R. 2009 . Introduction to Distributed Geographic Information Processing Research . International Journal of Geographical Information Science , 23 ( 5 ) : 553 – 560 . doi: 10.1080/13658810902733682
- Yang , C. , H. Wu , Q. Huang , Z. Li , J. Li , and W. Li . 2011b . “ WebGIS Performance Issues and Solutions .” In Advances in Web-based GIS, Mapping Services and Applications , S. Li , S. Dragicevic , and B. Veenendaal , 121 – 138 . London : Taylor & Francis Group .
- Zentner , L. K. , S. M. Clark , P. M. Smith , S. Shivarajapura , V. Farnsworth , K. P. C. Madhavan , and G. Klimeck . 2011 . “ Practical Considerations in Cloud Utilization for the Science Gateway NanoHUB.org .” In Utility and Cloud Computing (UCC), 2011 Fourth IEEE International Conference on , R. Buyya , S. Pallickara , and G. Fox , 287 – 292 . Melbourne : IEEE .
- Zhai , Y. , M. Liu , J. Zhai , X. Ma , and W. Chen . 2011 . “ Cloud Versus In-house Cluster: Evaluating Amazon Cluster Compute Instances for Running MPI Applications .” State of the Practice Reports Seattle , Washington : ACM , 1 – 10 .
- Zhang , T. and Tsou , M.-H. 2009 . Developing a Grid-enabled Spatial Web Portal for Internet GIServices and Geospatial Cyberinfrastructure . International Journal of Geographical Information Science , 23 ( 5 ) : 605 – 630 . doi: 10.1080/13658810802698571