
Abstract
Many progresses have been made since the Digital Earth notion was envisioned thirteen years ago. However, the mechanism for integrating geographic information into the Digital Earth is still quite limited. In this context, we have developed a process to generate, integrate and publish geospatial Linked Data from several Spanish National data-sets. These data-sets are related to four Infrastructure for Spatial Information in the European Community (INSPIRE) themes, specifically with Administrative units, Hydrography, Statistical units, and Meteorology. Our main goal is to combine different sources (heterogeneous, multidisciplinary, multitemporal, multiresolution, and multilingual) using Linked Data principles. This goal allows the overcoming of current problems of information integration and driving geographical information toward the next decade scenario, that is, ‘Linked Digital Earth.’
1. Introduction
In 1999, the Digital Earth was envisioned as a multiresolution, three-dimensional representation of the planet that would make it possible to find, visualize and make sense of vast amounts of geo-referenced information on physical and social environments.Footnote1 Such a system would allow users to navigate through space and time, accessing historical data as well as future predictions (based for example on environmental models), and would support its use by scientists, policy-makers and children alike (Gore Citation1999). Hence, The Digital Earth was motivated by the insight that complex questions cannot be answered from within one domain alone but span over multiple disciplines ranging from the natural and earth sciences to the social sciences, information sciences, and engineering (Janowicz and Hitzler Citation2012).
In these 13 years, many progresses have been made toward this vision, by defining standards, implementing prototypes, popularizing industry products, and building applications through several initiatives around the world (Yang et al. Citation2010). Many of the elements of Digital Earth are not only available but also used daily by hundreds of millions of people worldwide; thanks to innovative ways to organize and present the data and rapid technological advancements (Craglia et al. Citation2008).
Nevertheless, the notion of Digital Earth as a mechanism for integrating and reusing data from multiple and heterogeneous sources, the primary motivation for Gore's first reference to it (Gore Citation1992), is still quite limited. Taking it into account, as well as other limitations, several research challenges have been identified as needed to achieve the next-generation Digital Earth vision (Craglia et al. Citation2008, Citation2012) including data structures, semantic integration, etc.
These challenges are a direct consequence of the growing availability of information and existing difficulties to reuse and integrate associated data, because they are strictly separated from the others in most cases, that is, they use distinct data models and are encoded using ad-hoc vocabularies, and they are sometimes being published in non-standard formats. This situation is the cultural heritage of the Geospatial Community that is associated with previous Digital Earth vision. This vision has been successful in addressing syntactic and structural interoperability; however, semantic interoperability, which may solve problems related to reusing and integration, remains a major challenge (Kuhn Citation2009; Janowicz et al. Citation2010).
Linked Data (http://linkeddata.org) may allow addressing some of these challenges, by proposing best practices for exposing, sharing, and integrating data via dereferenceable URIs on the Web (Heath and Bizer Citation2011). These best practices are being adopted by an increasing number of data providers, leading to the creation of a global data space containing billions of assertions – the Web of Data (Heath and Bizer Citation2011). In the geospatial context, the concept of geolinked data appears (OGC Citation2004) to refer to geographically related data, where geometry is not directly stored within the attribute data. Instead, a geographic identifier is used, which refers to a geometric feature in a separate geospatial data-set. The transformation and publication of geographical data as Linked Data has been pioneered by initiatives from OpenStreetMap (Auer, Lehmann, and Hellmann Citation2009) and Ordnance Survey (Goodwin, Dolbear, and Hart Citation2009). However, these proposals only publish Linked Data of specific data sources (for instance, Ordnance Survey has published three separate Linked Data resources) and they do not perform an integration process with different data-sets.
The main contribution of this paper is the provision of a case study where diverse geographical information sources are semantically integrated. These sources belong to different National producers and are characterized by different heterogeneity issues. This integration process is performed according to Linked Data principles. Herein, we describe the process for generating geographical Linked Data from four Infrastructure for Spatial Information in the European Community (INSPIRE) (European Commission Citation2007) themes, and the main lessons learnt that could be extrapolated to similar integration processes of geographical information. Additionally, an important innovation of this work is that we pay attention to geometries, so that spatial data can be retrieved and interlinked on an unprecedented level of granularity. This is not common yet in the context of other linked GeoData initiatives.
This paper is structured as follows. We start providing a description of a case study of ‘Linked Digital Earth.’ In Section 3, we present a brief overview of the Linked Data initiative and related work. The process for integrating geographical information in the ‘Linked Digital Earth’ is described in Section 4, covering specification (Section 4.1), ontology network modeling (Section 4.2), Resource Description Framework (RDF) generation (Section 4.3), links generation (Section 4.4), publication (Section 4.5), and exploitation (Section 4.6). Section 5 presents the discussion and several lessons learnt. Finally, we summarize some conclusions and identify future work in Section 6.
2. A case study of Linked Digital Earth
With the advancement of the Digital Earth vision the volume of data is increasing continuously, but these data have a strong legacy of specialized formats managed and processed by disconnected applications. Likewise, most contemporary problems require a cross-disciplinary approach, but existing data sources are locked in silos and cannot be easily shared and integrated across organizations and communities. Instead, users spend a lot of time installing and learning a variety of software on local machines, searching for and collecting the geospatial data from a variety of sources, and preprocessing and analyzing the data on local machines (Zhao, Foerster, and Yue Citation2012). Thus, according to the Geographic Information Panel (Citation2008), current users of geographic information spend 80% of their time collating and managing the information and only 20% analyzing it to solve problems and generate benefits.
Driven by this scenario, we present a case study, where heterogeneous National geographical information sources are reused and semantically integrated in order to connect data, domains and communities. These data sources are created and maintained by diverse Spanish National Agencies, such as: National Mapping Agency (Instituto Geográfico Nacional de España – IGN-E), National Statistics Institute (Instituto Nacional de Estadística – INE) and National Meteorological Agency (Agencia Estatal de Meteorología – AEMET), and are related to four INSPIRE themes, specifically with Administrative units, Hydrography, Statistical units, and Meteorology. This diversity of producers and topics entails different issues related to heterogeneity of data-sets (multithematic, multiresolution, multitemporal, multilingual, and multiformat). Further details about these data-sets are described in Section 4. Hence the main challenges of this case study are associated with how to deal with data heterogeneity (formats, data models, and so on) of different data-sets and how to establish information flow between different agencies that produce and use geographic information in various areas for facilitating the reuse of this information.
In order to face these challenges, progress on Linked Data, ontologies and geospatial semantics (Kuhn Citation2005) are considered in this case study, due to the fact that they provide the decisive glue between models, data and users (Janowicz and Hitzler Citation2012). Thus, we take different geospatial data-sets from IGN-E and (semantically) interconnect these data with statistical and meteorological data from INE and AEMET. In this process, we transform unstructured original data into machine-processable (structured) data and integrate current data silos in a unified view according to recommendations and best practices of the aforementioned research areas. After integrating data of Spanish National Agencies, we enrich this integration with other sources of the Web of Data, such as: GeoNames, DBpedia (a community effort to extract structured information from Wikipedia and to make this information available on the Web of Data), and GDAM (a spatial database of the location of the world's administrative areas for use in GIS and similar software).
In short, this proposal allows performing a process to generate, integrate and publish geospatial Linked Data from the aforementioned Spanish National agencies and allows building a semantic mashup in which original and unexpected value emerges from reuse of data. Hence, from our viewpoint, this work may contribute to overcome current problems of information integration and driving geographical information toward the next decade scenario, that is, ‘Linked Digital Earth,’ because it allows overcoming the traditional concept of layers overlapping as the integrating procedure, in order to reach semantic interoperability at the level data.
3. Background and related work
In this section, we provide a brief introduction to the Linked Data initiative and describe existing approaches related to other efforts in a similar direction.
3.1. An overview of the Linked Data initiative
Since the representation and publication of geospatial data as Linked Data is only being recently addressed, as described in the introduction, we first provide some background on the Linked Data initiative. The principles of Linked Data were first outlined by Berners-Lee (Citation2006) using the following four guidelines:
Use URIs as names for things.
Use HTTP URIs so that people can look up those names.
When someone looks up a URI, provide useful information, using standards, such as: RDF and SPARQL Query Language for RDF (SPARQL). Details about these standards can be found in the W3C Specifications: www.w3.org/RDF/ and http://www.w3.org/TR/rdf-sparql-query/, respectively.
Include links to other URIs, so that they can discover more things.
Technically, in the context of Linked Data the RDF language is used to describe resources in the form of triples (subject-predicate-object), which can provide additional links (URIs in the object position of the triples), what allows connecting data between different data sources. The HTTP protocol is used to handle the interactions between Linked Data clients and publishers. Further details about sets of rules for publishing data on the Web are shown in (Berners-Lee Citation2006).
3.2. Related work
One relevant work is the Linked Data life cycles ( http://linked-data-life-cycles.info/ ) proposed by Hausenblas and colleagues. In this work, the authors identify involved parties and fundamental phases for several Linked Data life cycles, and examples of methods, tools or evaluations for the phases. The authors assume that the process follows a linear life cycle, and do not say anything about how to maintain the Linked Data afterward.
Another general relevant work is (Heath and Bizer Citation2011). This book gives an overview of the principles of Linked Data, and presents a set of patterns for publishing Linked Data. However, it is not based on geospatial information; neither there is a report of having applied them into real case scenarios.
In the geographical context, shows the existing efforts for publishing geographical data. The Ordnance Survey and OpenStreetMap initiatives, as the main linked GeoData providers to date, just manage geometry of each resource like points, lines and polygons, and these proposals offer geometrical information as Geography Markup Language (GML) (Ordnance Survey) or Well-Known Text (WKT), mainly.
Table 1. Characteristics of different geospatial Linked Data.
With respect to the vocabulary used, we can see that the ontologies that are used in all approaches are diverse, using own vocabularies in some cases, and that all approaches use the WGS84 Geo Positioning vocabulary. Finally, the data-sets that are used are different for each approach, and the English language is predominant, although DBpedia and GeoNames provide different languages, for instance, Spanish, Italian, French, etc.
In the context of statistics, there are some data-sets that are exposed as Linked Data, by using the RDF Data Cube Vocabulary ( http://www.w3.org/TR/vocab-data-cube/ ), such as COINS 2006–2007 ( http://data.gov.uk/resources/coins ), Eurostat-Real GDP growth rate ( http://estatwrap.ontologycentral.com/ ), and the CIA World Factbook ( https://www.cia.gov/library/publications/the-world-factbook/ ), which covers history, people, government, etc.
Finally, regarding Semantic Sensor Web, which is directly related to meteorological data context, there are several previous works that have proposed combining both sensor data and Linked Data. Patni, Henson, and Sheth (Citation2010) present a framework for publishing the sensor data on the Linked Open Data Cloud. The proposed framework converts raw sensor observations to RDF and links with other data-sets on the Linking Open Data. Phuoc and Hauswirth (Citation2009) introduce SensorMasher, an infrastructure that makes sensor available following the Linked Open Data principles and enables the integration of such data into mashups. SensorMasher allows users to semantically describe raw sensor readings, and then the descriptions can be exploited in mashups. Finally, Page et al. (Citation2009) present a prototype API for exposing data from Channel Coastal Observatory in the UK. The prototype supports Semantic Web clients, OGC GML clients, and hybrid applications by combining REST and Linked Data principles.
4. A process for integrating geographical information in the Linked Digital Earth
In this section we describe our refined process for generating, integrating and publishing geospatial data according to Linked Data principles. This process (see ) was inspired by existing methodological guidelines (Villazón-Terrazas et al. Citation2011), which propose an iterative incremental life cycle model where data gets continuously improved and extended. It consists of the following steps: (1) specification, (2) modeling, (3) RDF generation, (4) links generation, (5) publication, and (6) exploitation. We illustrate it with examples and lessons learnt from our case.
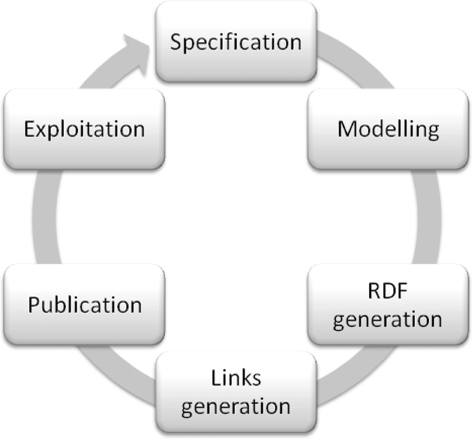
4.1. Specification
As any other project, aimed at the implementation and further development of IT solutions, the first activity is the drawing up of a detailed specification of requirements. When a geospatial Linked Data application is being developed, Linked Data requirements should be identified in addition to the application ones. Our experience in the publication of Linked Data in several contexts has showed that, the efficient and precise identification of the geospatial Linked Data requirements was more critical than the capturing software/application requirements. Next, in this activity we identify and analyze the data sources to transform and design the URIs to generate.
4.1.1. Identification and analysis of geospatial data sources
As aforementioned, we work with data sources from three national institutions: IGN-E, INE, and AEMET. They are national providers of official Spanish geographical, statistical and meteorological data, respectively.
The geospatial data-sets provided by IGN-E have information at various granularity levels, associated with the scales and formats of data collection and visualization (1:1 million; 1:200,000; 1:50,000; and 1:25,000).
On the one hand, we work with different relational databases (BTN25, BCN200, NOMGEO, and NGCE) that contain data about Spanish geographical features (rivers, motorways, administrative boundaries, airports, etc.). These databases are available at different scales (from 1:25,000 to 1:1 million), and use distinct vocabularies. They also contain multilingual information in the official languages of Spain (Castilian, Galician, Catalan, and Basque). There are two main features that distinguish these databases from the previous ones:
Geometrical information, represented as geometrical points or in Binary Large Objects (BLOB) records (A BLOB is a database data type that can hold up to 4 GB of data). In the first case the information appears as records of latitude/longitude, and in the second case the information is encoded as a set of points, e.g.<41.93035 −7.48711; 41.93086 −7.48707; 41.93105 −7.48703; 41.93114 −7.48701 … >.
Scale factor. Different scales normally present different geographical features and geometries for the same feature, e.g. one village may be represented as a point (X,Y) or as an area (a collection of {Xn,Yn}).
On the other hand, we work with a set of files (shapefiles) that contain municipal boundaries (centroids, single boundary lines between two municipalities, and polygons). Besides, these shapefiles provide official and alternative names of each municipality and its reference scale is 1:50,000.
Statistical data-sets, which are available as spreadsheets, are obtained from the INE website. The data-sets selected contain data about population, unemployment, and industry. Data are available in Spanish, organized by administrative regions (municipalities, provinces and autonomous regions), and within time intervals (years).
The meteorological data selected from AEMET are the ones generated by its 250 automatic weather stations, which register pressure, temperature, humidity, precipitation and wind data every 10 minutes throughout Spain. These data are provided in CSV files, one per station, which are updated every hour and kept for seven days in the AEMET FTP server.
4.1.2. URI design
The goal of the Linked Data initiative is to promote a vision of the Web as a global database, and interlink data in the same way as Web documents. In this global database, it is necessary to identify a resource on the Internet, and precisely URIs are thought for that purpose. Hence, one of the main decisions to be taken in the generation process of Linked Data is the template with which identifiers (URIs) will be generated. URIs are key for the alignment of heterogeneous resources coming from different data sources. In addition, INSPIRE requires the provision of unique and interoperable identifiers of spatial-objects.
According to Sauermann et al. (Citation2008) URIs should be designed to be simple, stable and manageable. We follow general guidelines for URI design (e.g. Sauermann et al. Citation2008; Davidson Citation2009; Montiel-Ponsoda et al. Citation2011), adding some geospatial-specific considerations and guidance collected by (Cabinet Office Citation2011) and (Drafting Team Data Specifications Citation2010). Taking into account the aforementioned guidelines and our experience, we propose the following URI design decisions for this work (examples provided in and ):
Sector. Include the name of the sector under which a concept and its related reference data-sets are governed. We use the general domain http://linkeddata.es/ with subdomains http://geo.linkeddata.es/, http://estadistica.linkeddata.es/, and http://aemet.linkeddata.es/. Note that it may also be possible to refer to organization-related schemes like http://datos.ign.es, http://datos.ine.es, http://datos.aemet.es, etc.
Data-set. Append the data-set name to the base URI structure to include a ‘key’ that allows distinguishing geographical features (and their characteristics) in a particular data-set. We also generate data-set-agnostic identifiers, which point through owl:sameAs statements to all those corresponding URIs available in data-sets.
Schema. Append the word ontology to the base URI structure to refer to ontology concepts and properties.
Resource and type. Append the term resource to the base URI to distinguish resources (instances) from ontology concepts and properties; and include the type of resource afterward to prevent URI clashes, since names are commonly shared among different geospatial features. For instance, there is a province, municipality and autonomous region in Spain called Madrid.
Name. The name associated with a geospatial resource, when possible, must be clear and understandable (e.g. http://dbpedia.org/resource/Madrid), and avoid including IDs (e.g. http://data.ordnancesurvey.co.uk/id/50kGazetteer/218013 - Southampton URI created by Ordnance Survey). That is, we propose using non-opaque URIs.
Observation. Observations related to meteorological features. They follow a ‘composite’ pattern, where the local ID is formed by several interconnected pieces of information related to the resource being identified.
Geometry. We create a hash to identify a complex geometry associated with a geographical feature. This hash collects different points (X, Y) that compose a LineString or Polygon. These are the only opaque URIs that we use.
Table 2. Pattern used for models (ontologies).
Table 3. Pattern used for resources (instances).
Besides this URI pattern, we recommend to use the main official language of the data when generating URIs. In our case, we had to fix errors like unescaped characters and encoding problems, caused by the use of Spanish, which has some special characters (e.g. á, é, ñ). Considering this encoding issue (e.g. geores:Provincia/M%C3%A1laga), we provide ‘clean information’ in the rdfs:label (in this example, Málaga). These recommendations are supported by the essence of geographical features: a feature may change some characteristics and/or its representation in a map; however it rarely changes its name.
4.2. Ontology modeling
After the specification activity, we need to determine the ontology to be used for modeling different themes of those data sources. An ontology is ‘a formal, explicit specification of a conceptualization’ (Gruber Citation1993) that provides a common and shared vocabulary for a knowledge domain and defines the meaning of the terms and the relations between them. By this way, ontologies allow the making of the explicit meaning of concepts in the used data-sets, creating a harmonized model for considered data-sets (using common and shared vocabularies) and making it easier to search and access geospatial information.
Linked Data can be generated with or without the use of a specific vocabulary (note that along this paper we use vocabulary and ontology without distinction). Nevertheless, just transforming data to RDF does not add any semantics, as pointed out by Jain et al. (Citation2010). For the modeling of the information contained in the aforementioned data-sets we have created an ontology network, which is a collection of ontologies joined together through a variety of different relationships such as mapping, modularization, version, and dependency relationships (Haase et al. Citation2006). This network has been developed following the NeOn methodology (Suárez-Figueroa Citation2010), by reusing existing ontologies and vocabularies.
We have reused five vocabularies associated with different domains:
RDF Data Cube Vocabulary enables statistical information to be represented using the W3C (World Wide Web Consortium) RDF standard and published, following the principles of Linked Data. The model underpinning the Data Cube vocabulary is compatible with the cube model that underlies SDMX (Statistical Data and Metadata eXchange), an ISO standard for exchanging and sharing statistical data and metadata among organizations.
hydrOntology (Vilches-Blázquez et al. Citation2009) is an OWL ontology that attempts to cover most of the concepts of the hydrographical domain (rivers, lakes, etc.). Its main goal is to harmonize heterogeneous information sources coming from several cartographic agencies and other international resources. This ontology is available in www.oeg-upm.net/index.php/en/ontologies/107-hydrontology and it has concepts in Spanish, English, and French.
Regarding the time information we chose the Time ontology (http://www.w3.org/TR/owl-time/), an ontology for temporal concepts developed into the context of W3C. This ontology, available in English, provides a vocabulary for expressing facts about topological relations among instants and intervals, together with information about durations, and about date-time information.
Semantic Sensor Network Ontology (SSN), which is developed by the W3C SSN incubator group, supports the description of the physical and processing structure of sensors, that is, weather stations and their observations, and related concepts. This ontology is available in http://www.w3.org/2005/Incubator/ssn/ssnx/ssn.
PhenomenOntology. This is a topographic ontology (http://www.oeg-upm.net/index.php/en/ontologies/152-phenomenontology) that contains geographical features present in Spanish territory. The development of this ontology is based on different heterogeneous geospatial information resources that belong to IGN-E. We have reused this ontology to consider more relevant concepts related to means of transport (e.g. airport, railway station, highway, etc.).
We have also extended the FAO geopolitical ontology (http://www.fao.org/countryprofiles/geoinfo.asp?lang=en). This OWL ontology includes information about continents, countries, etc. in English. We have extended the original ontology to cover the main characteristics of the Spanish administrative division.
Finally, we have developed two ontologies: Geometry and Weather observations.
Geometry. This ontology is based on the GML ontology, which is an OWL ontology for the representation of information structured according to the OGC Geography Markup Language – GML v3.0-); and on the WGS84 vocabulary, which is a basic RDF vocabulary, published by the W3C Semantic Web Interest Group, that provides a namespace for representing lat(itude), long(itude) and other information about spatially located things, using WGS84 as a reference datum).
Weather observations. This ontology, which is available in http://aemet.linkeddata.es/files/aemetontologynetworkv2.rar, models the knowledge related to meteorological observations. Main concepts modeled in this ontology are reused from the SSN ontology. As part of the customization of SSN to our work, the concept ssn:Property has been extended and populated according to the properties that meteorological data gather in their observations.
depicts a detailed view of the conceptual model through main classes of the aforementioned ontologies. This figure shows how statistical, geographical (and geometrical), temporal, and meteorological information is represented in our ontology network.
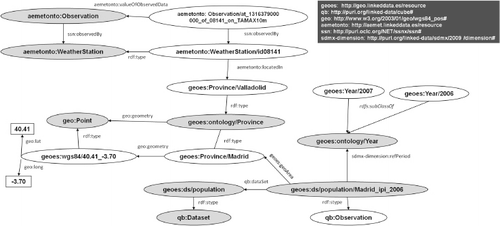
To sum up, this modeling activity allows sharing common understanding of dealt data-sets and improving communication between Spanish Agencies and the Geospatial Community. This is a real case where ontologies are understood as a communication and exchange layer.
4.3. RDF generation
We decided to use RDF as the normal form for the data-sets to be published, due to the fact that we want to harmonize different formats of our data-sets (databases, shapefiles, spreadsheets, and CSV files), to avoid using proprietary formats, and because we are pursuing a Linked Data approach. As described in Section 3, RDF is one of the standard languages in which information has to be made available, according to the Linked Data principles. The reason for this is that it offers several advantages, such as provision of an extensible schema, dereferenceable URIs, and as RDF links are typed, safe merging (linking) of different data-sets (Omitola et al. Citation2010). Therefore, in this activity we have to take the data sources selected in the specification activity (see Section 4.1), and transform them to RDF according to the vocabulary mentioned in the modeling activity (see Section 4.2).
Several tools provide technological support to this task ( http://www.w3.org/wiki/ConverterToRdf ). Given the different non-standard formats in which the selected data-sets were available, we used five systems to convert our data-sets into RDF:
We use different systems to transform geospatial features from aforementioned data-sets into RDF. Next we describe some details of both of them:
Features (without geometry) stored in the relational databases of IGN-E was transformed with NeOn Toolkit, specifically with ODEMapster+ plugin (http://www.oeg-upm.net/index.php/downloads/9-r2o-odempaster). This plugin provides a rich graphical user interface for creating mappings between relational database schemas and ontologies.
Features (with geometry) stored in the relational databases was transformed with geometry2RDF (http://geo.linkeddata.es/web/guest/geometry2rdf). This tool transforms first the geometrical information (GEOMETRY column) of each feature into geo-standard formats GML and WKT. This can be done in two ways, depending on the DataBase Management System (DBMS) that stores this data. In this case, we only support Oracle and MySQL, since these were the DBMSs used by IGN-E. However, our tool can be extended to other spatial DBMS, for instance, PostGIS.
For Oracle databases, where information is stored using BLOB records, we use the Oracle SDO UTIL package for the transformation into GML.
For MySQL spatial databases, we use WKT to extract (lat)itude and (long)itude. This is created with GeoTools library.
The next step is to convert the generated GML or WKT into RDF. The GML and WKT are manipulated with GeoTools in order to retrieve the geometry and to perform coordinate transformation if necessary. Finally, we generate the geospatial RDF according to our geometry model.
Data of administrative boundaries (municipalities) stored in shapefiles were transformed with shp2RDF. This tool parses shapefiles using GeoTools library in order to retrieve the associated geometric and alphanumeric data, and generate the geospatial RDF according to our geometry model.
Statistical data was transformed with NOR2O (Villazón-Terrazas, Suárez-Figueroa, and Gómez-Pérez Citation2010) software library. This library performs an Extract, Transform, and Load (ETL) process of the legacy data sources, transforming these non-ontological resources (NORs) (Villazón-Terrazas, Suárez-Figueroa, and Gómez-Pérez Citation2010) into ontology instances. We have decided to use this tool because it provides facilities for transforming bidimensional tables coming from statistical spreadsheets. There are other tools that convert spreadsheets to RDF such as RDF Extension for Google Refine, XLWrap, and RDF123, but none of them provides a straightforward transformation from bidimensional tables.
Meteorological data was transformed with ad-hoc Python scripts that were executed in two steps: (1) generation of static RDF data about automatic stations, and (2) generation of dynamic RDF data about meteorological observations. The decision of using these ad-hoc scripts is due the meteorological data is stored in very complex CSVs.
In short, this RDF generation process allows transforming data of dealt data-sets into structured and non-proprietary data. Besides, RDF data are generated according to a common and shared vocabulary (developed ontology network) and, therefore, they are semantically interoperable. On the other hand, we share with the Geospatial Community the different developed tools for generating RDF of geospatial, statistical and meteorological data. These tools are freely available in our website ( http://www.oeg-upm.net/index.php/en/technologies ).
4.4. Links generation
Following the fourth Linked Data Principle, ‘Include links to other URIs, so that they can discover more things,’ the next task is to create links between our data-sets and other external data-sets in order to integrate and enrich our data with other data of the Web of Data. This allows setting relationships between multiple data-sets, incorporating additional descriptions to original data and increasing their navigability in the aforementioned Web. So, this task involves the discovery of (owl:sameAs) relationships between data items. In order to discover these relationships, there are several tools available, such as SILK ( http://www4.wiwiss.fu-berlin.de/bizer/silk/ ) or LIMES ( http://aksw.org/Projects/limes ).
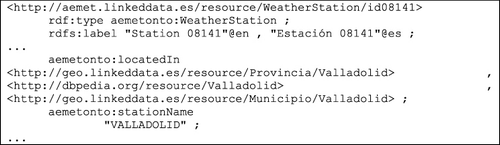
In this work we interconnected our data (RDF) in three levels: connecting intra-agency data-sets, inter-agency data-sets, and linking the data-sets with Linking Open Data data-sets. First, we performed a process of aligning the data-sets from the same agency, the IGN-E. The process of alignment was done setting links between the two aforementioned layers. We used SILK for that purpose because we had better results. This interconnection allowed us (1) to integrate information of different data-sets (e.g. there are 1.806 URIs related to lakes in data sources of IGN-E), (2) to identify the data-set of a given resource from its URI (e.g. there are 38 lakes in NGCE, 1.416 in NOMGEO, and 406 in BCN200), and (3) to complete information of data-sets. Next, we present an example of this alignment process from IGN-E data that is displayed in the Turtle format.


4.5. Publication
Every day, governments and government agencies publish more data on the Internet. Sharing these data enables greater transparency; delivers more efficient public services; and encourages greater public and commercial use and re-use of government information (Bennett and Harvey Citation2009). Following these principles, we publish results of semantic integration process in order to help Spanish Agencies for opening, sharing, and structuring their data, and also making easy for the public to find and use these data.
With respect to technical issues, we have published our data-sets using state-of-the-art systems, such as Virtuoso Universal Server ( http://virtuoso.openlinksw.com/ ) and Pubby ( http://www4.wiwiss.fu-berlin.de/pubby/ ). Besides, we used VoID ( http://www.w3.org/TR/void/ ), which allows expressing metadata about RDF data-sets, and covers general metadata, access metadata, structural metadata, and description of links between data-sets. Likewise, we created its corresponding entry in the Data Hub of CKAN (a community-run catalog of useful sets of data on the Internet – http://ckan.org/ ), and submitted the sitemap files, that is, XML files that lists URLs for a site along with additional metadata about each URL so that search engines can more intelligently crawl the site, generated by sitemap4rdf ( http://lab.linkeddata.deri.ie/2010/sitemap4rdf/ ), to web search engines, such as Google and Sindice ( http://sindice.com/ ). This enables effective discovery and synchronization of the data-sets published.
4.6. Exploitation
As we said previously, we integrate different geospatial data-sets from diverse Spanish National Agencies, which produce geospatial (IGN-E), statistical (INE) and meteorological (AEMET) data, and connect these official data with other sources of the Web of Data (such as: GeoNames, DBpedia and GDAM). The final goal of opening these data is that users are able to absorb data in ways that can be readily found via search, visualized and absorbed programmatically. Therefore, applications are needed on top of the geospatial Linked Data that exploit these data and provide rich graphical user interfaces to users.
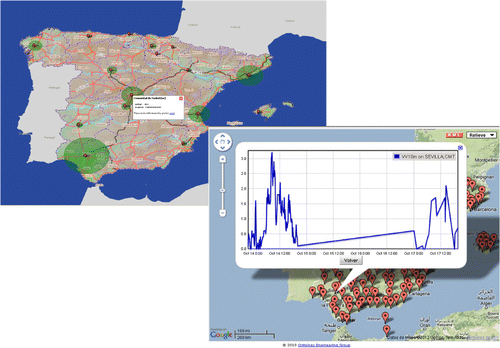
Thus, we have developed a web-based application, map4rdf (De León et al. Citation2012), to enhance the visualization of the integrated information. This interface combines the faceted browsing paradigm (Oren, Delbru, and Decker Citation2006) with map-based visualization using the Google Maps API and OpenLayers. This allows displaying the generated RDF on Google Map, OpenStreetMap, and on the Web Map Service (WMS) of the Spanish Spatial Data Infrastructure (IDEE - http://www.idee.es ).
We developed map4rdf because there was no tool that fitted our needs of visualizing complex geospatial information in RDF. The application is able to render on the map geometrical representation such as points (for instance, they show provinces’ centroids), lineStrings (for instance, these shapes depict hydrographical features such as: rivers, roads, etc.), or polygons (for instance, they show administrative boundaries, reservoirs, etc.). Besides, the application allows integrating resources from statistical data-sets (e.g. level of unemployment in Spanish provinces) (see , on the left side) or displaying the evolution of a meteorological variable (e.g. temperature) (see , on the right side) like a semantic mashup, where original information is integrated using Linked Data principles.
Likewise, the deployed architecture (see Section 4.5) allows performing geospatial queries on data. For instance, the next SPARQL query would get resources near the city of Madrid, at a distance of 10 Km (0.1) and with labels in Spanish:

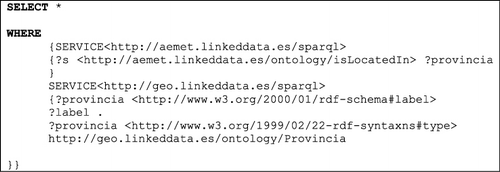
The query may be modified easily to provide the measurements from the weather stations close to a lake, river, beach, etc. Other potential uses of the generated data show off when we combine them with other data-sets in Linked Data. For example, the data can be used by exploiting its geospatial component through geoprocessing and spatial analysis (e.g. measure the wind speed in stations close to airports to analyze its relation to flight delay, check the temperature close to certain rivers, villages or provinces for biology studies, etc.).
This integration with other data-sets, thanks to the semantics provided by the links, is one of the main advantages of our proposal (‘Linked Digital Earth’). This makes easier to answer problems that require a cross-disciplinary approach and allows unlocking data silos facilitating their reuse across organizations and communities. Hence, reusing and integrating the data is easier as well, as compared with other formats or existing approaches in the original Digital Earth vision.
Furthermore, this work has had different social (i.e. non-technical) impacts; due to this approach it was part of various national and international events, such as: hackathons (Open Hack Day Data Bilbao 2012, Open Data Hackathon, European Data Forum 2012, etc.) and VoCamps (GeoVoCampSouthampton 2011, GeoVoCamp Madrid 2012, etc.). Likewise, numerous initiatives have started to utilize our geospatial Linked Data for different purposes (like acquisition, enrichment, disambiguation, etc.), such as: El Viajero ( http://webenemasuno.linkeddata.es/ ), DBpedia@es, OTALEX ( http://www.ideotalex.eu/ ) and so on. Finally, this work has also contributed to open, share and integrate data of evolved National Agencies, and these agencies started a first experience with semantic interoperability and diverse issues related to Linked Data.
5. Discussion and lessons learnt
The need for a semantic approach in the Digital Earth vision is acknowledged; however, crucial components to realize the next-generation Digital Earth vision are missing. In this sense, our work helps to provide solutions to (semantic) challenges described in (Craglia et al. 2008), and it is aligned with the proposal that the Digital Earth should be envisioned as a distributed knowledge engine (Janowicz and Hitzler Citation2012). This proposal (knowledge engine) attempts to go beyond mere data visualization and/or simple retrieval tasks.
Likewise, new challenges are coming due to the fact that the data volume is growing at a higher rate than our capacities for consuming, analyzing and long-term archiving. Facing this upcoming scenario, Linked Data and Big Data will become a part of the next-generation Digital Earth vision, where massive amounts of geospatial data will be available, connected and identifiable via URIs. Therefore, the Digital Earth must take account of the fact that new techniques and technologies (semantic modeling and reasoning, spatial cloud computing, etc.) are needed for the sustainable and socially balanced exploitation of huge data.
Next, we describe main lessons learnt performing this work. These lessons are related to data curation, ontologies, geometrical data, recommendations and good practices, and benefits for users.
Regarding data curation, even though the providers are national agencies and their data goes through strong quality checks, data still needs to be normalized and cleaned. We identified problems such as: some resources changed order of strings (Ebro, Río/Río Ebro) (River), official and alternative names appear in a same record (Abades/Abattes) (municipality), diverse languages appear within a same record, etc.
In this sense, the data transformation task is really useful for agencies, because this process helps them improve the quality and clean noise of their data. In the context of this work, after the generation of the RDF we identified the following errors that were corrected afterward: (1) Some resources, with the same name, were mixed; for example, Granada municipality belongs to Granada province, and La Granada municipality belongs to Barcelona Province; (2) Autonomous communities that only had one province, e.g. Murcia Region, missed some municipalities, but their corresponding provinces, e.g. Murcia Province, had the correct number of municipalities; (3) some hydrographical resources missed some parts of their geometrical information. These errors were in the original data sources. We reported these errors to the agencies and they were fixed.
With respect to ontologies, they are limited in the geospatial domain. Hence, the most important recommendation in this context is to reuse as much as possible available vocabularies (Bizer, Cyganiak, and Heath Citation2007) and/or non-ontological resources. This reuse-based approach speeds up ontology development, and therefore, time, effort and resources will be saved. Furthermore, we suggest that reused/extended/developed ontologies should be validated for domain experts and take into account the domain recommendations (geospatial specifications and standards). In our case, the modeling activity was supported by ontology engineers and members of different agencies, and took into account (OGC Citation2007, Citation2011), etc.
Regarding geometrical data, considering that geospatial domain experts deal with specific formats and RDF data are not common in that realm, we provide complex geometrical information of a resource in RDF, like a set of points (according to our geometry ontology), and in GML and WKT format.
With regard to recommendations and good practices, we highlight that our approach follows the Linked Data and the Open Government Data (http://www.opengovdata.org/home/8principles) principles. Hence, we offer primary (they are published as collected at the source), accessible (they are available to the widest range of users for the widest range of purposes), and structured (machine processable) data. Besides, these data are available in a non-proprietary format (we publish our data according to RDF standard). Likewise, we promote the use of standards and methodologies to publish geospatial data in the context of the ‘Linked Digital Earth’ (semantic interoperability).
Finally, this work provides different benefits for users. On the one hand, data silos are unlocked and users may interact with structured, non-proprietary and harmonized data. On the other hand, geospatial, statistical and meteorological data are semantically integrated as a unified view; therefore users may take potential advantage of integration for problems that require a cross-disciplinary approach. Besides, these results (vocabularies, data and developed tools) are freely available for the Geospatial Community. In short, these benefits help to facilitate reusing of this information, allow the public to use these data in new and innovative ways, improve the application of geospatial data in various domains and increase the geospatial knowledge available to society.
6. Conclusions and future work
In this paper we described the process followed to generate, integrate and publish geospatial Linked Data from several Spanish National data-sets, concretely data-sets related to four INSPIRE themes, specifically with Administrative units, Hydrography, Statistical units, and Meteorology. Our main goal was to allow combining different sources (heterogeneous, multidisciplinary, multitemporal, multiresolution, and multilingual), using Linked Data principles, for overcoming current problems of information integration and driving geographical information toward the next decade scenario, that is, ‘Linked Digital Earth.’ Additionally, we deal with the different geometrical information of geographical features [points, lines, polygons and more complex geometry (e.g. MultiLineString, MultiPolygon, etc.)], and offer geometrical information as GML and WKT.
As we have demonstrated with our case study, our efforts effectively contribute toward realization of the Digital Earth vision for the next decade. Based on that, we can conclude that there is a narrow relationship between our approach and some of the key features that the aforementioned vision should have. Paraphrasing (Craglia et al. Citation2012), this work allows sharing information and improving our collective understanding of the complex relationships of geographical information, making possible to navigate across multiple data sources, connecting global issues to local ones.
Future work will focus on identifying and interlinking other geographical features with knowledge bases belonging to the Linked Open Data Initiative. We will also continue publishing geospatial Linked Data for other domains and providers (e.g. biodiversity, environmental indicators, etc.), and improve our faceted browser. Furthermore, we plan to support the extension to GeoSPARQL (this new OGC standard is a vocabulary for representing geospatial data in RDF, and it defines an extension to the SPARQL query language for processing geospatial data) and NeoGeo vocabulary.
Finally, we identified some limitations of tools available (SILK and LIMES) for dealing with co-reference problems in the geospatial context. For instance, the available metrics to deal with complex geometry and metrics for comparing coordinates (X, Y) are limited. However, in these tools, metrics to compare strings are common. Hence, we plan to develop metrics that take into account domain-dependent and domain-independent considerations in order to increase the accuracy of these tools.
Acknowledgements
This work has been supported by the PlanetData (FP7-257641) and myBigData (TIN2010-17060) projects. We would like to kindly thank all OEG members involved in the Linked Data initiatives.
Notes
1. Boris Villazón-Terrazas is now working at iSOCO.
References
- Auer, S., J. Lehmann, and S. Hellmann. 2009. “LinkedGeoData – Adding a Spatial Dimension to the Web of Data.” In Lecture Notes in Computer Science. 5823, edited by A. Bernstein, D. R Karger, T. Heath, L. Feigenbaum, D. Maynard, E. Motta, and K. Thirunarayan, 731–746. Berlin: Springer.
- Bennett, D., and A. Harvey. 2009. “Publishing Open Government Data.” W3C Working Draft 8 September 2009, W3C. Accessed December 20, 2012. http://www.w3.org/TR/gov-data/
- Berners-Lee, T. 2006. “Linked Data – Design Issues.” W3C. Accessed December 20 2012. http://www.w3.org/DesignIssues/LinkedData.html.
- Bizer, C., R. Cyganiak, and T. Heath. 2007. “How to Publish Linked Data on the Web.” Accessed December 20, 2012. http://wifo5-03.informatik.uni-mannheim.de/bizer/pub/LinkedDataTutorial/
- Cabinet Office – Chief Technology Officer Council. 2011. “Designing URI Sets for Location.” Accessed December 20, 2012. http://location.defra.gov.uk/wp-content/uploads/2010/04/Designing_URI_Sets_for_Location-Ver0.5.pdf.
- Craglia, M., K. De Bie, D. Jackson, M. Pesaresi, G. Remetey-Fülöpp, C. Wang, A. Annoni, et al. 2012. “Digital Earth 2020: Towards the Vision for the Next Decade.” International Journal of Digital Earth 5 (1): 4–21. doi:10.1080/17538947.2011.638500.
- Craglia, M., M. F. Goodchild, A. Annoni, G. Camara, M. Gould, W. Kuhn, D. Mark, et al. 2008. “Next-generation Digital Earth. A position paper from the Vespucci Initiative for the Advancement of Geographic Information Science.” International Journal of Spatial Data Infrastructure Research 3: 146–167. http://ijsdir.jrc.ec.europa.eu/index.php/ijsdir/article/viewFile/119/99.
- Davidson, P. 2009. “Designing URI Sets for the UK Public Sector.” UK Chief Technology Officer Council. Accessed December 20, 2012. http://www.cabinetoffice.gov.uk/sites/default/files/resources/designing-URI-sets-uk-public-sector.pdf.
- De León, A., F. Wisniewki, B. Villazón-Terrazas, and O. Corcho. 2012. “Map4rdf – Faceted Browser for Geospatial Datasets.” Using Open Data. W3C Workshop. http://www.w3.org/2012/06/pmod/pmod2012_submission_33.pdf.
- Drafting Team Data Specifications – INSPIRE. 2010. “D2.5: Generic Conceptual Model, Version 3.3.” Accessed December 12, 2012. http://inspire.jrc.ec.europa.eu/documents/Data_Specifications/D2.5_v3_3.pdf.
- European Commission. 2007. Directive 2007/2/EC of the European Parliament and of the Council of 14 March 2007 establishing an Infrastructure for Spatial Information in the European Community (INSPIRE).
- Geographic Information Panel. 2008. “Place Matters: The Location Strategy for the United Kingdom.” London. Accessed December 20, 2012. http://location.defra.gov.uk/wp-content/uploads/2009/12/uk-location-strategy.pdf.
- Goodwin, J., C. Dolbear, and G. Hart. 2009. “Geographical Linked Data: The Administrative Geography of Great Britain on the Semantic Web.” Transaction in GIS 12 (1): 19–30. http://onlinelibrary.wiley.com/doi/10.1111/j.1467-9671.2008.01133.x/abstract.
- Gore, A. 1992. Earth in the Balance: Ecology and the Human Spirit. Boston: Houghton Mifflin.
- Gore, A. 1999. “The Digital Earth: Understanding Our Planet in the 21st Century.” Photogrammetric Engineering and Remote Sensing 65 (5): 528.
- Gruber, T. R. 1993. “A Translation Approach to Portable Ontology Specification.” Knowledge Acquisition 5 (2): 199–220. doi:10.1006/knac.1993.1008.
- Haase, P., S. Rudolph, Y. Wang, S. Brockmans, R. Palma, J. Euzenat, and M. d'Aquin. 2006. “NeOn Deliverable D1.1.1.” Networked Ontology Model. Available at: http://www.neonproject.org/.
- Heath, T. and C. Bizer. 2011. Linked Data: Evolving the Web into a Global Data Space. Vol. 1. San Rafael, CA: Morgan & Claypool.
- Jain, P., P. Hitzler, P. Z. Yeh, K. Verma, and A. P. Sheth. 2010. “Linked Data is Merely More Data.” In AAAI Spring Symposium ‘Linked Data Meets Artificial Intelligence’, edited by Dan Brickley, Vinay K. Chaudhri, Harry Halpin, and Deborah McGuinness, 82–86. Menlo Park, CA: AAAI Press.
- Janowicz, K., and P. Hitzler. 2012. “The Digital Earth as Knowledge Engine” (editorial). Semantic Web Journal 3 (3): 213–221. http://iospress.metapress.com/content/15532q7438635g50/.
- Janowicz, K., S. Schade, A. Bröring, C. Keßler, P. Maué, and C. Stasch. 2010. “Semantic Enablement for Spatial Data Infrastructures.” Transactions in GIS 14 (2): 111–129. doi:10.1111/j.1467-9671.2010.01186.x.
- Kuhn, W. 2005. “Geospatial Semantics: Why, of What, and How?” In Journal on Data Semantics III, vol. 3534 of Lecture Notes in Computer Science, edited by S. Spaccapietra and E. Zimányi, 1–24. Berlin: Springer. http://link.springer.com/chapter/10.1007%2F11496168_1?LI=true.
- Kuhn, W. 2009. “Semantic Engineering.” In Research Trends in Geographic Information Science, Lecture Notes in Geoinformation and Cartography, edited by G. Navratil, 63–76. Berlin: Springer.
- Montiel-Ponsoda, E., D. Vila-Suero, B. Villazón-Terrazas, G. Dunsire, E. E. Rodríguez, and A. Gómez-Pérez. 2011. “Style Guidelines for Naming and Labeling Ontologies in the Multilingual Web.” In Proceedings of the 2011 International Conference on Dublin Core and Metadata Applications, 105 –115.The Netherlands:The Hague.
- OGC. 2004. Open Geospatial Consortium, Geolinked Data Access Service (GDAS), Version: 0.9.1. Wayland, MA: OGC.
- OGC. 2007. Open Geospatial Consortium, Geography Markup Language (GML), Encoding Standard. v3.2.1, Open Geospatial Consortium, http://www.opengeospatial.org/standards/gml.
- OGC. 2011. Open Geospatial Consortium, Implementation Standard for Geographic Information – Simple feature access – Part 1: Common architecture. Open Geospatial Consortium. http://www.opengeospatial.org/standards/sfa
- Omitola, T., C. L. Koumenides, I. O. Popov, Y. Yang, M. Salvadores, M. Szomszor, T. Berners-Lee, et al. 2010. “Put in Your Postcode, Out Comes the Data: A Case Study.” In 7th Extended Semantic Web Conference, Lecture Notes in Computer Science, Vol. 6088. Subseries: Information Systems and Applications, incl. Internet/Web, and HCI, edited by L. Aroyo, G. Antoniou, E. Hyvönen, A. ten Teije, H. Stuckenschmidt, L. Cabral, and T. Tudorache,318–332.Berlin: Springer.
- Oren, E., R. Delbru, and S. Decker. 2006. “Extending faceted navigation for RDF data.” In Proceedings of 5th ISWC, Lecture Notes in Computer Science, Vol. 4273. Part I, edited by I. Cruz, S. Decker, D. Allemang, C. Preist, D. Schwabe, P. Mika, M. Uschold and L. Aroyo, 559–572. Berlin: Springer.
- Page, K., D. D. Roure, K. Martinez, J. Sadler, and O. Y. Kit. 2009. “Linked Sensor Data: Restfully Serving RDF and GML.” In Proceedings of the 2nd International Workshop on Semantic Sensor Networks (SSN09) at ISWC 2009, volume 522, edited by Kerry Taylor, Arun Ayyagari, and David De Roure, 49–63. CEUR Workshop Proceedings. http://ceur-ws.org/Vol-522/.
- Patni, H., C. Henson, and A. Sheth. 2010. “Linked Sensor Data.” In 2010 International Symposium on Collaborative Technologies and Systems, 362–370. Chicago, IL: IEEE. May 17–21.
- Phuoc, D. L., and M. Hauswirth. 2009. “Linked open data in sensor data mashups.” In Proceedings of the 2nd International Workshop on Semantic Sensor Networks (SSN09) ISWC 2009, edited by A. A. Kerry Taylor, and D. D. Roure, Vol. 522, 1–16. Washington, DC: CEUR Workshop Proceedings.
- Sauermann, L., R. Cyganiak, D. Ayers, and M. Volkel. 2008. “Cool URIs for the Semantic Web.” W3C - Interest Group Note 20080331. Accessed December 12, 2012. http://www.w3.org/TR/cooluris/.
- Suárez-Figueroa, M. C. 2010. “NeOn Methodology for Building Ontology Networks: Specification, Scheduling and Reuse.” PhD diss., Universidad Politécnica de Madrid.
- Vilches-Blázquez, L. M., J. A. Ramos, F. J. López-Pellicer, O. Corcho, and J. Nogueras-Iso. 2009. “An Approach to Comparing Different Ontologies in the Context of Hydrographical Information.” In IF&GIS'09. LNG&C, edited by Vasily V. Popovich, Christophe Claramunt, Manfred Schrenk, and Kyrill V., Korolenko P.E, 193–207. St. Petersburg: Springer.
- Villazón-Terrazas, B., M.C. Suárez-Figueroa, and A. Gómez-Pérez. 2010. “A Pattern-Based Method for Re-Engineering Non-Ontological Resources into Ontologies.” International Journal on Semantic Web and Information Systems 6 (4): 27–63. http://www.igi-global.com/article/pattern-based-method-engineering-non/50498.
- Villazón-Terrazas, B., L. M. Vilches-Blázquez, O. Corcho, and A. Gómez-Pérez. 2011. “Methodological Guidelines for Publishing Government Linked Data.” In Linking Government Data, edited by D. Wood, 27–49, Springer. http://www.springer.com/computer/database+management+%26+information+retrieval/book/978-1-4614-1766-8.
- Yang, C., R. Raskin, M. Goodchild, and M. Gahegan. 2010. “Geospatial Cyberinfrastructure: Past, Present, and Future.” Computers, Environment and Urban Systems 34 (4): 264–277. doi:10.1016/j.compenvurbsys.2010.04.001.
- Zhao, P., T. Foerster, and P. Yue. 2012. “The Geoprocessing Web.” Computers and Geosciences 47, 3–12. doi:10.1016/j.cageo.2012.04.021.