
Abstract
Abundant sensor data are now available online from a wealth of sources, which greatly enhance research efforts on the Digital Earth. The combination of distributed sensor networks and expanding citizen-sensing capabilities provides a more synchronized image of earth's social and physical landscapes. However, it remains difficult for researchers to use such heterogeneous Sensor Webs for scientific applications since data are published by following different standards and protocols and are in arbitrary formats. In this paper, we investigate the core challenges faced when consuming multiple sources for environmental applications using the Linked Data approach. We design and implement a system to achieve better data interoperability and integration by republishing real-world data into linked geo-sensor data. Our contributions include presenting: (1) best practices of re-using and matching the W3C Semantic Sensor Network (SSN) ontology and other popular ontologies for heterogeneous data modeling in the water resources application domain, (2) a newly developed spatial analysis tool for creating links, and (3) a set of RESTful OGC Sensor Observation Service (SOS) like Linked Data APIs. Our results show how a Linked Sensor Web can be built and used within the integrated water resource decision support application domain.
Introduction
The Digital Earth research motivates the need for integrating and interlinking vast and complex datasets from different domains to make an overall digital representation of the planet, which has been greatly propelled by the advances in Sensor & Observation technologies (Janowicz and Hitzler Citation2012). The past few years have seen remarkable progress in the Sensor Web standardization effort sponsored by the Open Geospatial Consortium (OGC), as highlighted in a recent paper (Bröring et al. Citation2011). Such continuous standardization efforts reflect the common vision of the Sensor Web community that interoperability and standardization are critical to build viable large-scale sensor-driven solutions for solving many grand scientific problems such as water sustainability and climate change. Success stories have already been reported in the literature on using the OGC Sensor Web Enablement (SWE) standards for environmental applications (Conover et al. Citation2010).
In the meantime, the Sensor Web community has also started to witness an emerging paradigm shift on building sensor data infrastructure by following using Linked Data and W3C Semantic Web standards, most recently discussed in a paper (Keßler and Janowicz Citation2010), among many others (Heath and Bizer Citation2011). Different names of Linked Data have been used in the Sensor Web context such as Linked Sensor Data (Barnaghi, Presser, and Moessner Citation2010), Linked Streaming Data (Barbieri and Valle Citation2010, Le-Phuoc, Parreira, and Hauswirth Citation2010), LinkedGeoData (Auer, Lehmann, and Hellmann Citation2009), and GeoLinkedData (Lopez-Pellicer et al. Citation2010). Linked Data suggests using the Hypertext Transfer Protocol (HTTP) dereferenceable Universal Resource Identifiers (URIs) to locate and access data and the Resource Description Framework (RDF) as the data model for encoding and understanding data with the help of semantics. Janowicz et al. (Citation2010) has speculated that a micro-Spatial Data Infrastructure (µSDI) based on Linked Data principles might co-exist with the full-fledged OGC SWE infrastructure, which consists of simplified and light-weight OGC services and can be directly embedded into Web pages and applications. An example of such a system can be seen being implemented in various map services embedded in web pages to provide location and transportation information instead of plain text descriptions. With the underlying ontologies, Linked Data is becoming a driving force making the Digital Earth as a distributed knowledge engine (Janowicz and Hitzler Citation2012). However, there is no published literature to show how a µSDI might be established and what challenges and added value one would encounter or obtain in terms of improving data integration and interoperability.
In this paper, we study the usage of the Linked Data approach to build a Linked Sensor Web in the context of integrated water resource decision support (IWRDS), including flooding control and emergency management. Given the interdisciplinary nature of environmental and water resource problems, integrating data and knowledge over multiple disciplines including hydro-geo-meteorological science, social science, and engineering are often necessary for solving practical water management problems (Braden et al. Citation2009; Cai Citation2008). From this perspective, the Sensor Web is inherently a heterogeneous one at its current form and will continue to be in the foreseeable future. For example, water resources data from various sources continue to become available on the Web. These sources include environmental monitoring networks and databases owned by local, state, and federal government agencies (e.g. United States Geological Survey [USGS], National Oceanic and Atmospheric Administration [NOAA]); research sensor testbeds; and citizen sensing sources such as geo-tagged microblogs from Twitter. Data examples include the USGS's National Map project, which not only publishes shapefile data but also starts to publish selected vector and raster data in RDF (http://cegis.usgs.gov/ontology.html). The Consortium of Universities for the Advancement of Hydrologic Science, Inc. (CUAHSI) Hydrologic Information System (HIS) (Maidment Citation2008) has produced the WaterML 1.1 encoding format, which has been adopted by USGS to publish point-based water-related measurements, although it is currently migrating to the OGC-based WaterML 2.0 encoding and related OGC SWE and other services standards (Bermudez and Arctur Citation2011).
Given that using the Linked Data approach is a paradigm shift for the Sensor Web infrastructure, it is our intention to share our experiences in a real-world heterogeneous data integration study. Furthermore, we would like to shed some light on how one would design and build a µSDI for a specific project or even for a large-scale data integration effort. Specifically, the contributions of this paper are as follows:
We design and develop an end-to-end data integration solution that is capable of linking geospatial vector data, time-series sensor data, citizen twitter data, etc. from heterogeneous data sources using different protocols within the IWRDS scientific domain.
We present the best practices of re-using the W3C Semantic Sensor Network (SSN) ontology (http://purl.oclc.org/NET/ssnx/ssn) and other existing ontologies such as the Semantic Web for Earth and Environmental Terminology (SWEET: http://sweet.jpl.nasa.gov/2.2/) ontology for modeling heterogeneous Sensor Web data.
We develop a set of methods and tools for creating links among the linked datasets. These include a spatial analysis tool that can create spatial links between entities in the RDF models based on the geometric relations of their spatial attributes and using the Extensible Stylesheet Language Transformation (XSLT) to generate owl:same links to external datasets such as DBPedia.
We adopt the Linked Data API (LDA) to develop a set of RESTful SOS-like linked data services that are far more flexible than existing implementations such as the 52North RESTful SOS implementation (http://tinyurl.com/3hun5hk) since we can fully leverage the power of Linked Data. LDA specifically refers to RESTful services that can serve the linked data in a Resource-oriented Architecture (ROA).
Background and Motivation
Interoperability and Virtual Environmental Observatories
In Oct. 2010, a US National Science Foundation-sponsored workshop was held on creating ‘Scientific Software Innovation Institute (S2I2) for Environmental Observatories’ (http://www.renci.org/s2i2workshop). One of the major findings of this workshop was about achieving interoperability among data, tools, and models, or, as some workshop attendees described it, ‘the grand challenge.’ The intriguing promise of Linked Data for Web-scale data integration motivates us to perform this research.
The vision of creating a Virtual Environmental Observatory (VEO) is to provide seamless access to heterogeneous data as well as other advanced modeling, analysis, visualization, and decision support services (Liu Citation2010). The current prevailing approach for water data discovery and retrieval is through catalogue services. Integrated access, discovery and query of both time-series observation data, and geospatial map layers are also a challenge (Huang, Maidment, and Tian Citation2011). Since IWRDS requires data from so many different areas, a catalogue service is inherently an Achilles' heel of such architecture, as pointed out recently by Keßler and Janowicz (Citation2010). For example, at the University of Illinois at Urbana-Champaign Illinois, researchers have been working on adaptive sensing and management for an agricultural environmental observatory testbed, where rainfall-triggered execution of an agricultural model needs data streams from multiple data sources including hydrological, meteorological, as well as geospatial data from locally deployed sensors and sensors owned by agencies. Another collaboration with the South Florida Water Management District works on the integration of multiple infrastructure sensing, citizen sensing, and satellite data for improving situational awareness and emergency management during frequent urban flash flooding scenarios (http://sensorweb.ncsa.uiuc.edu/msrproject/).
Our previous work already started to implement the vision of virtual environmental observatories, although previous examples only show single data type processing (i.e. radar data) with complex computational workflows that require model-based data interpolation and transformation (Liu et al. Citation2010). We show how to use the Linked Data approach for data integration in this paper, from a data consumer's perspective.
Open data, Linked Data, OData, ROA, and related variants
There exists some debate in terms of the relationship among Linked Data, open data, and RDF (http://tinyurl.com/3vxewq9). A five-star rating system (http://lab.linkeddata.deri.ie/2010/lod-badges/) added by Tim Berners-Lee in 2010 explains that as long as data are online and in a non-proprietary format such as CSV with an open license, they can be considered as three-star open data. There exist considerable efforts of promoting open data using the philosophy of the Linked Data, but not necessarily using RDF directly. For example, the Open Data Protocol (OData: http://www.odata.org/) is a Web protocol for querying and updating data usually locked in a relational database or file system. It does not explicitly use any RDF but does have the extensibility to allow annotations of OData feeds using shared vocabularies. The Open Graph Protocol (http://ogp.me/) is another initiative that uses RDFa (RDF in–attributes: http://www.w3.org/TR/xhtml-rdfa-primer/). In this paper, we adopt the so-called ‘Hard Semantic Technologies (HST)’ notation (Tiropanis et al. Citation2009), where HST uses RDF that allows machine reasoning. Thus, the Linked Data approach used in this paper is the official Linked RDF Data. Note that there is also a Linked Open Data (LOD) project (http://lod-cloud.net/). We believe that Linked Data can be public (i.e. publishing to the LOD) or private (i.e. my Linked Data). In this paper, the re-published Linked Data are linked to the DBPedia dataset in the LOD.
ROA was proposed based on Service-oriented Architecture (SOA) by leveraging the RESTFul standard (Richardson and Ruby Citation2007). It defines resources as directly accessible distributed components through standard interface (mostly via HTTP protocol), which is one of the principles of Linked Data. It is appropriate for linking components in sensor network (Usländer Citation2009). Our research combines the ROA with RDF by associating the URI defined in RDF with their RESTFul services. This consistency will facilitate the exploration of the Web of Things (WoT).
Challenges and architecture
Challenge
In order to use the Linked Data approach for data integration in a heterogeneous Sensor Web, we needed to address the following challenges.
How do we re-publish existing plain data to semantically linked data? In other words, what semantics/ontologies should we leverage in a domain? In addition, it is likely that we need to use several ontologies, where concepts from different ontologies need to be aligned and related to each other.
How to meet the ‘Cool URIs’ requirement of the semantic web? There are two basic challenges that make the Cool URI principle necessary: (1) to make differentiations between the URIs of resources that represent the real physical world from the common web documents such that they improve the interoperability between independent systems and (2) to make the URIs as consistent as possible to reduce the dangling links on the semantic web.
How do we make potentially ‘linkable data’ actually link together and enable complex queries in a heterogeneous Sensor Web? The essence of Linked Data is to allow data to connect to each other (i.e. a data network). Guéret et al. (Citation2010) have also shown that about 80% of all triples within the LOD cloud point to URIs either in the same namespace, blank nodes, or literals.
How do we serve data in a programmable web-compliant way so that more users can use the data? The current prevailing way to refer to resources online is through ROA, where each resource can be referred by a single URL through RESTful APIs. However, the majority of Linked Data are currently served through SPARQL endpoints, which require users to be familiar with the domain ontologies to query the data.
How do we track the provenance of Linked Data? Since a re-publishing process will publish existing data sources into Linked RDF data, there is a need to trace where the data came from and what tools were used for such a transformation.
System architecture and design
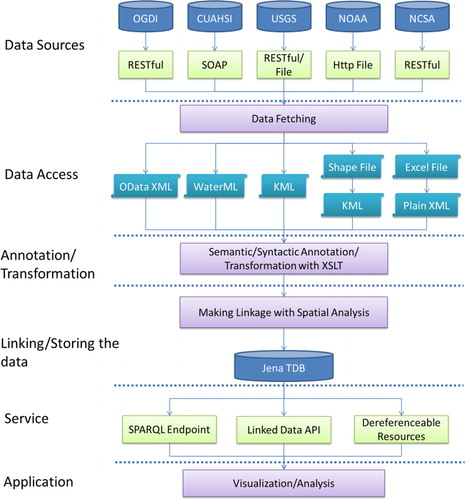
A six-layer end-to-end prototype system is designed to facilitate our data integration study in this paper as shown in . We explain the architecture starting from the sources to the application layer below.
Data Sources: For our prototype implementation, data sources are selected from Open Government Data Initiative (OGDI: http://ogdisdk.cloudapp.net/), CUAHSI, USGS, NOAA, and NCSA. Each source has different Web APIs or Web accessible datasets. More sources can be added if needed.
Data Access: Data are fetched or downloaded from different sources and then converted to a XML serialization format if the original data are not already in XML.
Annotation and Transformation: We transformed the XML files from the previous step to semantically annotated RDF (in a XML serialization format) using XSLT. This is important because, as many previous literatures point out, simply transforming to a RDF format without adding ontological concepts and relationship does not add any value to the Linked Data world (Janowicz et al. Citation2011; Jain et al. Citation2010). We added formally defined concepts from ontologies by using RDF/OWL predicates such as rdf:type, owl:sameAs, etc. This allows a third party (such as a data consumer) to add annotations beyond what the original data providers can supply and then re-publish the data as a new linked dataset.
Linking and Storing: A spatial analysis is performed to create links among datasets produced from the previous step. In this prototype, Geotools APIs are used to develop a tool to perform the analysis. The relations are represented by spatial predicates from GeoSPARQL (http://www.opengeospatial.org/standards/geosparql), an OGC candidate standard. Note that the relations are between entities (watersheds, sensors, etc.) that are related to spatial geometric objects (polygon, line, etc.) rather than between the geometric objects themselves. For the spatial data encoding, we currently support KML and Well Known Text (WKT) encodings for 2D geometries as well as W3C Geo Vocabulary (http://www.w3.org/2003/01/geo) for points. All links are also written into RDF/XML and then loaded into a centralized RDF repository (a Jena TDB) together with the transformed RDF data.
Services: We used Joseki (an open source SPARQL server: http://www.joseki.org/) to set up a query interface on top of our RDF repository. To lower the barrier for the usage of Linked Data, we used Elda (a specific LDA implementation: http://www.epimorphics.com/web/tools/linked-data-api.html, which was used for the sensor system by Australian Bureau of Meteorology) (Lefort et al. Citation2012) to develop RESTful query services for data collection and dereferenceable URI services for each resource. Data are served in formats such as RDF/XML, JSON, and HTML. By using the LDA, spatiotemporal observation data can be filtered and ordered as various streams and served as a RESTful SOS-like linked data services, similar to a RESTful Proxy for SOS (Janowicz et al. Citation2011) but without using any actual OGC SWE SOS services in the backend.
Applications: An application can consume services using the Linked Data APIs. In this paper, we show an observation data visualization using World Wide Telescope (WWT: http://www.worldwidetelescope.org) ∣ Earth, which can use the query results and show spatiotemporal dynamics of the sensor observation data.
Implementation and experiments
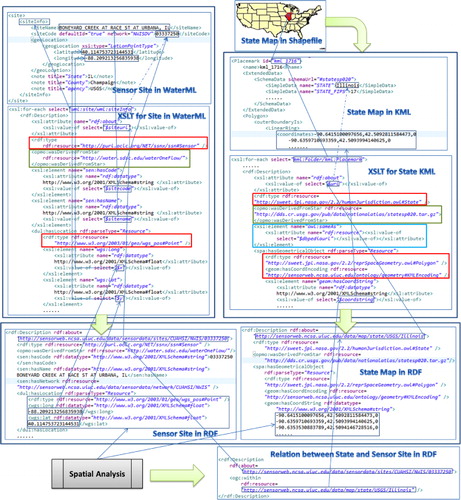
To facilitate our discussion, a data integration example is shown in and used throughout this section when needed, where two datasets (the national state map and a USGS sensor site) are processed and annotated with semantics in XSLT and then transformed to RDF. A link between them is constructed by a spatial analysis. The related technical issues are discussed in the rest of this section.
Use of multiple ontologies
As can been seen from the two XSLT files in , there are some annotations such as rdf:type, spa:hasGeometryObject, wgs:long, etc., which are defined in existing ontologies. They need to be well investigated prior to usage. Although everyone can create proprietary ontology, we chose to reuse existing ontologies to facilitate the data integration and discovery, as there are many previous studies in this area (Janowicz and Compton Citation2010). Multiple ontologies (including SWEET v2.2, SSN, W3C Basic Geo, W3C Time, and OGC GeoSPARQL) are used in this paper since none of them can serve our needs alone. Instead, they complement each other. Ontology matching is needed when using multiple ontologies for the following reasons:
Multiple ontologies contain the same or similar concepts. For example, both SSN and SWEET contain sensors, which can be aligned using owl:EquivalentClass. SSN has the concept ‘UnitofMeasure’ while SWEET has the concept ‘Unit,’ which can be aligned with owl:subClassof.
One ontology contains more detailed information about a concept than another one. For example, the observedProperty in SSN is used to specify the relationship between an observation and the properties observed. SSN itself has a very limited set of properties, while SWEET has many. Also, the FeatureOfInterest in SSN is a very broad concept, while we prefer to use more concrete terms in SWEET such as Tornado, Hail, etc.
Some concepts from a particular ontology are not easy to instantiate. For example, there are no predicates in SWEET to add coordinates to a geometric object such as a point, a line, or a polygon, while W3C Geo Vocabulary provides predicates such as long, lat, elevation, etc. We also created predicates (such as geom:hasCoordString and geom:hasCoordEncoding) to store the coordinate strings in RDF and specify their encoding formats. The domains and ranges of those predicates are matched to those concepts.
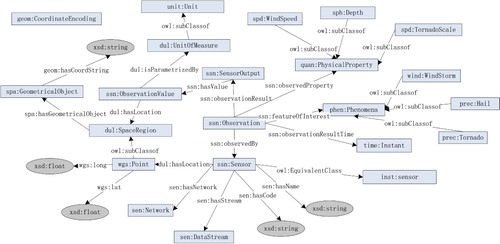
Table 1. Ontology namespaces used in this paper.
Creating linked spatiotemporal RDF data
For the data integration in this paper, we used the datasets in . Note that we used the CUAHSI WaterOneFlow Web service to get sensor site information and then used the USGS NWIS (National Water Information System) RESTful Web service to get real-time water observation data. The ‘Sensor Sites in WaterML’ in shows an instance of the sensor site in the WaterML format. Because the current USGS National Map project's published RDF data only cover six watersheds, two urban areas, and one costal area, we had to download shapefile datasets directly from their website for this study. NCSA's data stream service harvests citizen sensing resources such as Twitter feeds, which we integrated with other data. The OGDI provides government data via the OData protocol; however, while the OGDI database covers a wide range of topics, most data do not cover many areas in the United States. For our purpose, we only fetched OGDI data about educational facilities in the District of Columbia.
Table 2. Data sources, formats, and descriptions.
Four steps are needed to turn these data into semantically linked RDF data after the previous semantic modeling using multiple ontologies is completed.
Converting to XML
We first converted all non-XML data to XML to enable the annotation process. For example, USGS national maps were converted to KML using ArcGIS version 9.3, while the NOAA event data in CSV were converted to XML using Microsoft Excel 2010.
Minting URIs
Each data record must be globally and uniquely identified by a URI. Some systems use a Universally Unique Identifier (UUID) for each data record. However, this does not meet the requirement of the ‘cool URI’ principle, which requires a URI to be easily recognized and remembered. Thus, we designed the following pattern for minting (creating) URIs: http://{host}/data/{categories}[1..n]/{source}/{localKey}
In this study, the host name is always ‘sensorweb.ncsa.uiuc.edu’, which is the host that serves two types of resources (linked data API and dereferenceable resources [i.e. data]). There can be more than one item in the ‘categories’ section (e.g. event/tornado). The ‘source’ can be the original data provider's name such as USGS, NOAA, OGDI, etc., and a sub-dataset name can also be attached to its tail (e.g. NWIS can be the network name for a USGS sensor site). A local key is specific to each dataset. For example, a state name is the local key for a state map, while a county name plus a state name is the local key for a county map. Note that in the dash lines indicate that one data element is derived from another but with some additional processing (not shown). The URI minting is a typical case for that, that is, to mint a URI by adding a prefix before a local identifier such as a ‘SiteCode’ for a sensor site.
Sometimes it is better to use a blank node (i.e. a URI is not given for an RDF resource) rather than creating a random URI. For example, for geometries attached to spatial features (such as a building), it is better to use blank nodes rather than UUID (Schandl and Popitsch Citation2010) or other random numbers (see examples in LinkedGeodata). In our system, we treat all the geometric objects as blank nodes. The rdf:parseType=“Resource” is the symbol to declare an element as a blank node (see ).
Annotating with Ontological Concepts
For each newly created instance for a data record, we added semantic annotation in the XSLT style sheets using the ontologies discussed in the previous section to indicate the rdf:type information as shown in . The XSLT files can be reused for the same kind of data and modified for similar data sources. For example, XSLT files for the state, county, and watershed maps from USGS are similar but are annotated with different ontological types, which are defined in SWEET ontology such as humj:State, humj:County, and flu:Watershed.
Creating Links
Currently, we have created two kinds of links based on the thematic and geospatial properties of data entities.
A thematic link is an outgoing link pointing to DBPedia. State and county URIs are linked to DBPedia using owl:sameAs by following the same naming schema recommended by Bizer, Heath, and Berners-Lee (Citation2009). For example, the following N-triples show that the ‘Illinois state’ and ‘Champaign County, Illinois’ in our dataset are the same as the ones in DBPedia:
<http://sensorweb.ncsa.uiuc.edu/data/map/state/USGS/Illinois> owl:sameAs <http://dbpedia.org/resource/Illinois>
<http://sensorweb.ncsa.uiuc.edu/data/map/county/USGS/Champaign_County,_IL> owl:sameAs <http://dbpedia.org/resource/Champaign_County,_IL>
A spatial link is computed using a newly developed spatial analysis tool so that a data entity can be linked to its topologically related entities, for example, a sensor is linked to a county or a watershed and vice versa. (Note that there is another set of spatial relations in GeoSPARQL, such as ogc:sf-within, which applies to simple features such as points, lines, and polygons.). RDF links generated by the spatial analysis tool represent the linked spatial attributes (relations between two spatial entities), rather than spatial relations between two geometric objects (e.g. a point within a polygon). As can be seen in , the spatial analysis component makes use of the spatial information of two RDF datasets and then generates a statement with the ogc:within predicate. The steps are as follows: (1) selecting all the points from one RDF model and all the polygons from the other RDF model; (2) using GeoTools API to create objects of class com.vividsolutions.jts.geom.Point and com.vividsolutions.jts.geom.Polygon to load the results from the previous step; (3) determining if the point is within the polygon. If true, the result is written back to the dataset as a link. We currently support three topological relations (within, intersects, and overlaps) and a point-to-point relation indicated by geom:near which is associated with a distance value (also see for a schematic view of creating spatial links).
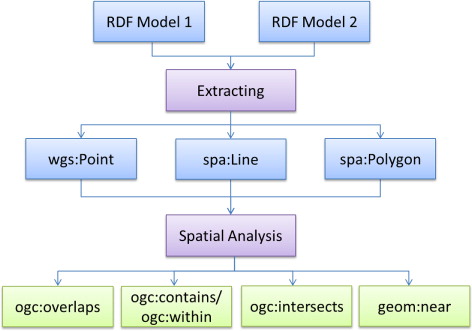
In this paper, we do not use temporal information for creating links. However, it might be useful for linking two spatiotemporal datasets. For example, it is reasonable to link a tornado event to an observation about wind if they are spatially related and happened at the same time. Currently we can query two datasets within the same temporal range but they are not linked directly through RDF links.
Linked Data APIs for sensor observations
Linked Data API is in fact a collection of RESTFul services that provide RDF-compliant content when the URLs are dereferenced. Elda is used in this paper to design and develop the following two sets of services.
Services to provide descriptions for a single resource
Each single URI created in this system should be dereferenceable via a HTTP-GET request. The result includes all the triples where the subject is the URI of interest. For example, the URI ‘http://sensorweb.ncsa.uiuc.edu/data/map/state/USGS/Illinois’ returns the following results (note the subject is omitted):
rdf:type <http://sweet.jpl.nasa.gov/2.2/humanJurisdiction.owl#State> spa:hasGeometricalObject <coordinate string>;
……
ogc:intersects <http://sensorweb.ncsa.uiuc.edu/data/event/Hail/NOAA/2010/10877_2010-12-31T10:57:00>;
……
owl:sameAs <http://dbpedia.org/resource/Illinois>.
RESTful APIs to query a collection of data
Currently we have data collections such as events, national maps, sensor sites, and time-series water observation data. Also, predefined filters can be applied to constrain the query. The predefined keywords are translated to full URIs when a query is performed on the SPARQL endpoint. Examples in the ‘Experiments’ section show how the data collection query APIs work.
Provenance tracing
Provenance information makes it clear where the data came from and how they were produced. Provenance can be tracked at different granularities, for example, provenance for dataset, data entity, or even a single statement in RDF. For example, DBPedia has published an N-Quads version of their linked data where the fourth item indicates the Wikipedia page from which this statement was extracted. However, we think common users are more interested in knowing the provenance of data entity as a whole instead of a single statement's history. In our current system, the provenance information is added to each data instance as an additional statement, which uses the predicate opmo:wasDerivedFromStar from the Open Provenance Model (OPM: http://openprovenance.org/) vocabulary. An example of the annotation in XSLT is as follows:
<opmo:wasDerivedFromStar rdf:resource=“http://dds.cr.usgs.gov/pub/data/nationalatlas/countyp020.tar.gz”></opmo:wasDerivedFromStar>.
Experiments
We conducted the following experiments to evaluate and test our prototype system.
Query a collection of datasets. By following the URI convention discussed previously, the collection query URI is http://{host}/api/{super_categories}[0...n]/{leaf_category_plural}. For example, the collection of Hail events can be accessed via the URI http://sensorweb.ncsa.uiuc.edu/api/event/hails The last part of the URI is the ‘leaf category,’ which should be plural to indicate it as a collection. Each URI returns data in different formats by adding different suffix (e.g. hails.json returns the data in JSON format). The default format is html.
Query events that happened in Illinois. If an event's path intersects with Illinois geographically, then this event will be returned in the query result. The tornados can be accessed using the following URI: http://sensorweb.ncsa.uiuc.edu/api/event/tornados?intersects=http://sensorweb.ncsa.uiuc.edu/data/map/state/USGS/Illinois
Query all sensor sites in Illinois. It is similar to the previous query but the predicate is changed to ‘within’: http://sensorweb.ncsa.uiuc.edu/api/sensordata/sites?within=http://sensorweb.ncsa.uiuc.edu/data/map/state/USGS/Illinois URIs from DBPedia can also be used for this query: http://sensorweb.ncsa.uiuc.edu/api/sensordata/sites?within.sameAs=http://dbpedia.org/resource/Illinois
Query all observations that were generated by sensors. The URI for querying all the observations generated by sensors in Illinois is: http://sensorweb.ncsa.uiuc.edu/api/sensordata/observations?observedBy.within=http://sensorweb.ncsa.uiuc.edu/data/map/state/USGS/Illinois ‘observedBy.within’ means the observation is observed by a sensor, which is within the specified area.
Query an observation stream by a time window. The previous query actually generates a temporal data stream, which can be ordered by time. It is also possible to filter the stream with a time frame, such ashttp://sensorweb.ncsa.uiuc.edu/api/sensordata/observations?observedBy.within=http://sensorweb.ncsa.uiuc.edu/data/map/state/USGS/Illinois&_sort=observationResultTime.inXSDDateTime&min-observationResultTime.inXSDDateTime=2011-05-01T00:00:00-05:00&_page=0&max-observationResultTime.inXSDDateTime=2011-05-03T00:00:00-05:00&observedProperty=http://sensorweb.ncsa.uiuc.edu/data/property/USGS/NWIS:UnitValues/00065
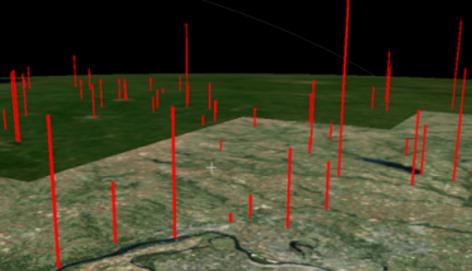
It is evident that these services can be used in a similar way as the OGC SOS service since they allow queries of sensors, observation, observation streams, and features of interest, similar to those services provided by the 52North RESTful SOS Service. However, the Linked Data APIs provide better flexibility by leveraging the power of SPARQL, which means one can add unlimited parameters by following the links between those resources. An animation was developed with WWT to visualize the change of the water level over time according to result from query 5, a snapshot of which is shown in . WWT is a space exploratory tool developed by Microsoft. We used its standalone version for Windows to develop the animation.
Related work and lessons learned
Related work
To the best of our knowledge, this is the first attempt of using the Linked Data approach for Sensor Web data integration based on sources from multiple real-world geospatial, time-series, and event data sources in the context of IWRDS. However, similar efforts in the broad Sensor Web community have been undertaken in the past few years.
For example, Barnaghi, Presser, and Moessner (Citation2010) developed a prototype system called ‘Sense2Web’ to allow users to publish linked sensor data by considering spatial, temporal, and thematic attributes. However, their work only publishes sensor site information but not observation time-series data or provenance information. Patni, Henson, and Sheth (Citation2010) published the first set of Linked Sensor data and Linked meteorological observation data with provenance on the LOD cloud but no discussions of Linked Data APIs were presented. In addition, no geospatial data were published and linked as part of the Linked Sensor Data. Furthermore, their approach was to convert sensor observation data to OGC Observation and Measurement Markup Language and then to RDF, rather than reusing W3C SSN ontology and other existing ontologies. Several early linked streaming data papers were only presented as position papers or proposals without any concrete implementation (Barbieri and Valle Citation2010; Le-Phuoc, Parreira, and Hauswirth Citation2010). Stasch et al. (Citation2011) argues that the external links from one of the original observations can be preserved for the aggregation, which is modeled on top of Stimulus Sensor Observation (SSO) ontology. Although aggregation is not the focus in this paper, it should be an essential function of the Linked Data API.
In two of their papers, Omitola et al. (Citation2010a, Citation2010b) present a case study of data integration using UK government public datasets (mostly statistical records about crime, hospital waiting time, mortality rates, geographic data, etc.). One of the major challenges they encountered is the lack of suitable tools and user interfaces to allow linked data consumers to find and view the integrated data (Dadzie, Rowe, and Petrelli Citation2011). Since we deal with a broadly defined Sensor Web concept, we follow the Sensor Observation Service to build RESTful Linked Data APIs for the data consumers to find and consume the data.
Omitola et al. (Citation2011) used a Vocabulary for Data and Dataset Provenance (voidP: http://www.enakting.org/provenance/voidp/) for provenance tracing when producing linked data, while we currently only use a single OPM predicate to denote the derivation history.
Our research was, at the time, one of the few experiments that tried to apply the latest W3C SSNO (updated in June 2011) for linked sensor data. We expect that the GeoSPARQL standardization will further promote the shared ontology usage in the geospatial Sensor Web community, as the geospatial ontology for Linked Data is an active research area.
We developed a spatial analysis component to generate spatially meaningful links among datasets. An alternative way for pre-generating spatial links is to run spatial queries every time when a resource is accessed, which is more flexible and always provide up-to-date information given that nowadays many triple stores are able to support spatial query. It is suitable for real-time systems, which usually require high performance backend to support a huge amount of concurrent accesses. Comparatively, our approach is suitable for distributed web resources. Once a link is discovered, it persists and becomes accessible without a backend support. This echoes the aforementioned µSDI where resources are distributed over the web and linked to each other. Similar research has been conducted by Isele, Jentzsch, and Bizer (Citation2010), who proposed a ‘Silk Server’ to add missing links among Linked Data, which could be a next step for us to further extend the data network effect.
Lessons learned
As a recent paper (Janev and Vraneš Citation2011) pointed out, Semantic Web technologies are slowly entering mainstream applications. Building a µSDI using the Linked Data approach is certainly achievable, as shown in this paper. However, we did encounter a few difficulties and gained some valuable lessons during our data integration study in this paper, as shared below.
URI minting is important and the Cool URL guideline is acceptable but not robust enough
First, we realize that having knowledge about a data source is very important for URI minting. To make a URI both globally unique and meaningful is critical. For example, the NOAA dataset does not provide unique keys for the event data because there could be multiple observations about the same event. Thus we added a time stamp to each of them. Second, a URI in the Linked Data should be identical to the service that will provide the resource. Some projects do not follow this, such as the 52 North RESTful service that provides this result:
<rdf:type rdf:resource=“http://v-swe.uni-muenster.de:8080/52nRESTfulSOS/miniOnM.owl#Sensor”/>
Publishing ‘at source’ is different from re-publishing for reuse and data integration
Many Sensor Web papers assume the publishing of sensor data is ‘at source’, that is, the owner of the sensor publishes the sensor data. However, this paper focuses on the data integration and data reuse issue, thus requiring re-publishing and adding user/domain-specific annotations into the sensor streams. A flexible XLST mechanism to allow non-original data providers to add new meaning to the data for further data reuse and sharing is valuable.
Re-using existing ontologies is critical for the success of Linked Data in the Sensor Web context
Because data from different providers are available in arbitrary formats, it takes major efforts to develop XSLT files to re-publish them into Linked RDF Data. There are efforts in the literature proposing Linked Data services that provide wrapper services around existing Web APIs so that they can provide RDF dynamically (Speiser and Harth Citation2011). However, even if we already have RDF data formats, it is not enough if we do not resolve ontology alignment and matching issues, which require human intervention at this moment, although fully automatic approach may (Millard et al. Citation2010).
Providing Linked Data in a RESTful way is the way to go
Composing a SPARQL query is very difficult for common users, even though many tools are dedicated to providing a friendly user interface (e.g. Virtuoso: http://virtuoso.openlinksw.com/). The barrier is the complexity of the underlying ontologies. We should not expect users to master those ontologies. Hiding the complexity is needed and is adopted in this paper by using Linked Data APIs. This is also consistent with the emerging RESTful SOS accessing methods in OGC SWE.
Provenance is critical
Currently, we only use a simplified approach to record provenance using OPM vocabularies. Such provenance traces are needed, especially when we scale from a µSDI to a Web-scale spatiotemporal Linked Sensor Web.
Conclusion and future work
This paper presents a Linked Data study in the context of IWRDS. We identified challenges, proposed and implemented our solution, and shared our experiences and lessons learned. The Linked Data approach is a viable way to build a Linked Sensor Web, albeit with on-going challenges (Corcho and García-Castro Citation2010). Our future research directions are as follows:
Moving towards Linked Geostreaming Data: Our previous work designed Time-Annotated RDF (Rodriguez et al. Citation2009) to represent time-series data in RDF. We plan to leverage that to move towards Linked Geostreaming data (unbounded geo-referenced data streams), instead of just Linked Datasets. As a data stream is defined as ‘real time, continuous sequence of items’ (Golab and Özsu Citation2003), there should be additional semantics for modeling the streams as well as backend support, for example, a ‘push’ model LDA.
Providing data processing as services: Processing modules such as aggregation and interpolation are widely used for the raw observation data to better meet the requirements from applications (Stasch et al. Citation2011). They could also be provided as linked APIs, which hold provenance information as links. A typical use case is the ‘virtual sensor’ system (Liu et al. Citation2010), where complex computational workflows are used. All the provenance information from such a heterogeneous system need to be captured through an end-to-end Web-scale mashup.
Improving query and storage performance: Given the verbose nature of Linked Data, the size of Linked Data can grow very quickly. We already witness a significant storage challenge and query performance issues in our current study (not discussed in this paper). Reference (Haase, Mathäß, and Ziller Citation2010) has done a benchmark study on Linked Data query performance in a logically distributed environment. Following such suggestions, we plan to investigate how we can perform distributed query and storage for continuously arriving Linked GeoStreaming Data.
Moving towards searching and crawling of Linked data: As the growth of Linked Data in the Sensor Web community continues, a searching and crawling service of Linked Data might be needed (Hogan et al. Citation2011). We plan to investigate this topic for its usage in building VEOs.
Investigating the ontology matching for semantic Sensor Web. Although following standard ontologies have been recognized as the best practise for semantic web, there are still many proprietary ontologies invented by applications. Architecting the ontologies in a hierarchical structure can help this process (Moodley and Tapamo Citation2011).
Acknowledgement
This research was performed when both authors were full-time employees in NCSA. The authors thank Singapore-MIT Alliance for Research and Technology for the support to the first author for revising this paper.
Funding
The authors thank Microsoft Research and the Institute for Advanced Computing Applications and Technologies at the University of Illinois at Urbana-Champaign for partially funding this work
Additional information
Funding
References
- Auer, S., J. Lehmann, and S. Hellmann. 2009. “LinkedGeoData: Adding a Spatial Dimension to the Web of Data.” Lecture Notes in Computer Science (LNCS) 5823: 731–746. doi:10.1007/978-3-642-04930-9_46.
- Barbieri, D. F., and E. D. Valle. 2010. “A Proposal for Publishing Data Streams as Linked Data. Linked Data on the Web Workshop.” In Proceedings of the Linked Data on the Web Workshop (LDOW2010). CEUR Workshop Proceedings, Raleigh, NC, April 27. ceur-ws.org/Vol-628/ldow2010_paper11.pdf.
- Barnaghi, P., M. Presser, and K. Moessner. 2010. “Publishing Linked Sensor Data.” In Proceedings of the 3rd International Workshop on Semantic Sensor Networks, CEUR Workshop Proceedings, Shanghai, China, November 7. ceur-ws.org/Vol-668/paper2.pdf.
- Bermudez, L., and D. Arctur. 2011. Engineering Report: Water Information Services Concept Development Study. Open Geospatial Consortium (OGC), OGC 11-013r6. portal.opengeospatial.org/files/?artifact_id=44834.
- Bizer, C., T. Heath, and T. Berners-Lee. 2009. “Linked Data – The Story So far.” International Journal on Semantic Web and Information Systems 5 (3): 1–22. doi:10.4018/jswis.2009081901.
- Braden, J. B., D. G. Brown, J. Dozier, P. Gober, S. M. Hughes, D. R. Maidment, S. L. Schneider, et al. 2009. “Social Science in a Water Observing System.” Water Resources Research 45. doi:10.1029/2009WR008216.
- Bröring, A., J. Echterhoff, S. Jirka, I. Simonis, T. Everding, C. Stasch, S. Liang, and R. Lemmens. 2011. “New Generation Sensor Web Enablement.” Sensors 11: 2652–2699. doi:10.3390/s110302652.
- Cai, X. 2008. “Implementation of Holistic Water Resources-Economic Optimization Models for River Basin Management - Reflective Experiences.” Environmental Modelling and Software 23 (1): 2–18. doi:10.1016/j.envsoft.2007.03.005.
- Calbimonte, J. P., H. Jeung, O. Corcho, and K. Aberer. 2011. “Semantic Sensor Data Search in a Large-Scale Federated Sensor Network.” In Proceedings: 4th International Workshop on Semantic Sensor Networks. CEUR Workshop Proceedings, Bonn. ceur-ws.org/Vol-839/calbimonte.pdf.
- Conover, H., G. Berthiau, M. Botts, H. M. Goodman, X. Li, Y. Lu, M. Maskey, K. Regner, and B. Zavodsky. 2010. “Using Sensor Web Protocols for Environmental Data Acquisition and Management.” Ecological Informatics 5 (1): 32–41. doi:10.1016/j.ecoinf.2009.08.009.
- Corcho, O., and R. García-Castro. 2010. “Five Challenges for the Semantic Sensor Web.” Semantic Web 1 (1): 121–125. http://www.semantic-web-journal.net/content/five-challenges-semantic-sensor-web.
- Dadzie, A. S., M. Rowe, and D. Petrelli. 2011. “Hide the Stack: Toward Usable Linked Data.” Lecture Notes in Computer Science 6643: 93–107. doi:10.1007/978-3-642-21034-1_7.
- Golab, L., and T. M. Özsu. 2003. “Issues in Data Stream Management.” ACM SIGMOD Record 32 (2): 5–14. doi:10.1145/776985.776986.
- Guéret, C., P. Groth, F. V. Harmelen, and S. Schlobach. 2010. “Finding the Achilles Heel of the Web of Data: Using Network Analysis for Link-recommendation.” Lecture Notes in Computer Science 6496: 289–304. doi:10.1007/978-3-642-17746-0_19.
- Haase, P., T. Mathäß, and M. Ziller. 2010. “An Evaluation of Approaches to Federated Query Processing Over Linked Data.” In Proceedings of the 6th International Conference on Semantic Systems. ACM Digital Library. doi:10.1145/1839707.1839713.
- Heath, T., and C. Bizer. 2011. Linked Data: Evolving the Web into a Global Data Space. San Rafael, CA: Morgan & Claypool.
- Hogan, A., A. Harth, J. Umbrich, S. Kinsella, A. Polleres, and S. Decker. 2011. “Searching and Browsing Linked Data with SWSE: The Semantic Web Search Engine.” Web Semantics: Science, Services and Agents on the World Wide Web 9 (4): 365–401. http://dx.doi.org/10.1016/j.websem.2011.06.004.
- Huang, M., D. R. Maidment, and Y. Tian. 2011. “Using SOA and RIAs for Water Data Discovery and Retrieval.” Environmental Modelling and Software 26: 1309–1324. doi:10.1016/j.envsoft.2011.05.008.
- Isele, R., A. Jentzsch, and C. Bizer. 2010. “Silk Server – Adding Missing Links While Consuming Linked Data.” 1st International Workshop on Consuming Linked Data (COLD 2010). CEUR Workshop Proceedings. Shanghai, August 13. http://ceur-ws.org/Vol-665/IseleEtAl_COLD2010.pdf.
- Jain, P., P. Hitzler, P. Yeh, K. Verma, and A. Sheth. 2010. “Linked Data Is Merely More Data.” In Linked Data Meets Artificial Intelligence, edited by D. Brickley, V. Chaudhri, H. Halpin, and D. McGuinness, 82–86. Menlo Park, CA: AAAI Press, Technical Report SS-10-07.
- Janev, V., and S. Vraneš. 2011. “Applicability Assessment of Semantic Web Technologies.” Information Processing and Management 47: 507–517. doi:10.1016/j.ipm.2010.11.002.
- Janowicz, K., A. Bröring, C. Stasch, S. Schade, T. Everding, and A. Llaves. 2011. “A RESTful Proxy and Data Model for Linked Sensor Data.” International Journal of Digital Earth 6 (3): 233–254. http://dx.doi.org/10.1080/17538947.2011.614698. doi:10.1080/17538947.2011.614698
- Janowicz, K., and M. Compton. 2010. “The Stimulus-Sensor-Observation Ontology Design Pattern and Its Integration into the Semantic Sensor Network Ontology.” In Proceedings of the 3rd International Workshop on Semantic Sensor Networks (SSN10). CEUR Workshop Proceedings, Shanghai, China, November 7. http://ceur-ws.org/Vol-668/paper12.pdf.
- Janowicz, K., and P. Hitzler. 2012. “The Digital Earth as Knowledge Engine.” Semantic Web Journal 3 (3): 213–221. http://www.semantic-web-journal.net/content/digital-earth-knowledge-engine.
- Janowicz, K., S. Schade, A. Bröring, C. Keßler, P. Maué, and C. Stasch. 2010. “Semantic Enablement for Spatial Data Infrastructures.” Transactions in GIS 14 (2): 111–129. doi:10.1111/j.1467-9671.2010.01186.x.
- Keßler, C, and K. Janowicz. 2010. “Linking Sensor Data – Why, to What, and How?” In Proceedings of the 3rd International Workshop on Semantic Sensor Networks. CEUR Workshop Proceedings, Shanghai, China, November 1–11. http://ceur-ws.org/Vol-668/paper9.pdf.
- Lefort, L., J. Bobruk, A. Haller, K. Taylor, and A. Woolf. 2012. “A Linked Sensor Data Cube for a 100 Year Homogenised Daily Temperature Dataset.” In Semantic Sensor Networks (SSN'12) November 2012. CEUR Workshop Proceedings, Bonn, Germany, October 23–27. http://ceur-ws.org/Vol-904/paper10.pdf.
- Le-Phuoc, D., J. X. Parreira, and M. Hauswirth. 2010. “Challenges in Linked Stream Data Processing: A Position Paper.” In Proceedings of the 3rd International Workshop on Semantic Sensor Networks (SSN). CEUR Workshop Proceedings, Shanghai, China, November 7–11. http://ceur-ws.org/Vol-668/paper10.pdf.
- Liu, Y. 2010. “Towards GeoS3Web-based Virtual Environmental Observatories.” In Microsoft Environmental Research Workshop. Microsoft Environmental Research Workshop, Redmond, Washington, July 14.
- Liu, Y., J. Futrelle, J. Myers, A. Rodriguez, and R. Kooper. 2010. “A Provenance-aware Virtual Sensor System Using the Open Provenance Model.” In 2010 International Symposium on Collaborative Technologies and Systems, Chicago, IL, May 17–21. 330–339.
- Lopez-Pellicer, F. J., M. J. Silva, M. Chaves, F. J. Zarazaga-Soria, and P. R. Muro-Medrano. 2010. “Geo Linked Data.” Lecture Notes in Computer Science (LNCS) 6261: 495–502. doi:10.1007/978-3-642-15364-8_42.
- Maidment, D. R. 2008. “Bringing Water Data Together.” Journal of Water Resources Planning and Management 134: 95–96. doi:10.1061/(ASCE)0733-9496(2008)134:2(95).
- Millard, I. C., H. Glaser, M. Salvadores, and N. Shadbolt. 2010. “Consuming Multiple Linked Data Sources: Challenges and Experiences.” In First International Workshop on Consuming Linked Data (COLD2010). CEUR Workshop Proceedings, Shanghai, China, November 8. http://ceur-ws.org/Vol-665/MillardEtAl_COLD2010.pdf.
- Moodley, D., and R. J. Tapamo. 2011. “A Semantic Infrastructure for a Knowledge Driven Sensor Web.” In The 4th International Workshop on Semantic Sensor Networks 2011 (SSN11), edited by K. Taylor, A. Ayyagari, and D. De Roure. CEUR Workshop Proceedings, Bonn, Germany, October 23–27. http://onlineceur-ws.org/Vol-839/moodley.pdf.
- Omitola, T., C. L. Koumenides, I. O. Popov, Y. Yang, M. Salvadores, G. Correndo, W. Hall, and N. Shadbolt. 2010a. Proceedings of the Workshop on Linked Data in the Future Internet at the Future Internet Assembly. CEUR Workshop Proceedings, Ghent, Belgium, December 16–17. http://ceur-ws.org/Vol-700/Paper8.pdf.
- Omitola, T., C. L. Koumenides, I. O. Popov, Y. Yang, M. Salvadores, M. Szomszor, T. Berners-Lee, et al. 2010b. “Put in Your Postcode, Out Comes the Data: A Case Study.” Lecture Notes in Computer Science 6088: 318–332. doi:10.1007/978-3-642-13486-9_22.
- Omitola, T., L. Zuo, C. Gutteridge, I. C. Millard, H. Glasher, N. Gibbins, and N. Shadbolt. 2011. “Tracing the Provenance of Linked Data Using voiD.” In Proceedings of the International Conference on Web Intelligence, Mining and Semantics (WIMS '11). New York, NY: ACM. Article 17, 7 p. http://doi.acm.org/10.1145/1988688.1988709.
- Patni, H., C. Henson, and A. Sheth. 2010. “Linked Sensor Data.” In 2010 International Symposium on Collaborative Technologies and Systems, CTS 2010, 362–370. Collaborative Technologies and Systems (CTS), Chicago, IL, May 17–21. doi:10.1109/CTS.2010.5478492.
- Patni, H., S. S. Sahoo, C. Henson, and A. Sheth. 2010. “Provenance Aware Linked Sensor Data.” 2nd Workshop on Trust and Privacy on the Social and Semantic Web. Co-located with ESWC, Heraklion Greece, May 30–June 3. http://knoesis.wright.edu/library/download/SPOT-Provenance_Aware_LSD.pdf.
- Richardson, L., and S. Ruby. 2007. RESTful Web Services. Sebastopol, CA: O'Reilly Media.
- Rodriguez, A., R. McGrath, Y. Liu, and J. Myers. 2009. “Semantic Management of Streaming Data.” 2nd International Workshop on Semantic Sensor Networks, a Workshop of the 8th International Semantic Web Conference (ISWC). CEUR Workshop Proceedings, Washington, DC, October 25–29. http://onlineceur-ws.org/Vol-522/p12.pdf.
- Schandl, B., and N. Popitsch. 2010. “Lifting File Systems into the Linked Data Cloud with TripFS.” Proceedings of the WWW 2010 Workshop on Linked Data on the Web, LDOW 2010. CEUR Workshop Proceedings, Raleigh, April 27. http://ceur-ws.org/Vol-628/ldow2010_paper02.pdf.
- Speiser, S., and A. Harth. 2011. “Integrating Linked Data and Services With Linked Data Services.” Lecture Notes in Computer Science (LNCS) 6643: 170–184. doi:10.1007/978-3-642-21034-1_12.
- Stasch, C., S. Schade, A. Llaves, K. Janowicz, and A. Bröring. 2011. “Aggregating Linked Sensor Data.” In Proceedings of the 4th International Workshop on Semantic Sensor Networks, edited by K. Taylor, A. Ayyagari, and D. De Roure. Bonn, Germany, October 23. http://ceur-ws.org/Vol-839/stasch.pdf.
- Tiropanis, T., H. Davis, D. Millard, and M. Weal. 2009. “Semantic Technologies for Learning and Teaching in the Web 2.0 era.” IEEE Intelligent Systems 24: 49–53. doi:10.1109/MIS.2009.121.
- Usländer, T. 2009. Specification of the Sensor Service Architecture (SensorSA). Open Geospatial Consortium Inc. Reference Number: OGC 09-132r1. http://opengeospatial.org/files/?artifact_id=35888?.