
Abstract
Geospatial Semantic Web promises better retrieval geospatial information for Digital Earth systems by explicitly representing the semantics of data through ontologies. It also promotes sharing and reuse of geospatial data by encoding it in Semantic Web languages, such as RDF, to form geospatial knowledge base. For many applications, rapid retrieval of spatial data from the knowledge base is critical. However, spatial data retrieval using the standard Semantic Web query language – Geo-SPARQL – can be very inefficient because the data in the knowledge base are no longer indexed to support efficient spatial queries. While recent research has been devoted to improving query performance on general knowledge base, it is still challenging to support efficient query of the spatial data with complex topological relationships. This research introduces a query strategy to improve the query performance of geospatial knowledge base by creating spatial indexing on-the-fly to prune the search space for spatial queries and by parallelizing the spatial join computations within the queries. We focus on improving the performance of Geo-SPARQL queries on knowledge bases encoded in RDF. Our initial experiments show that the proposed strategy can greatly reduce the runtime costs of Geo-SPARQL query through on-the-fly spatial indexing and parallel execution.
1. Introduction
Digital Earth as a mechanism for integrating data from multiple sources has been put forward for more than 10 years (Gore Citation1998), and significant progress has been made to implement the Digital Earth systems (Guo Citation1999; Guo et al. Citation2009). Semantic interoperability is a core research topic for integrating, interlinking, and retrieving vast geo-referenced, multi-perspective geospatial knowledge through the Digital Earth systems. Geospatial Semantic Web offers the support of semantic interoperability to the Digital Earth systems and extends the Digital Earth vision from a data archive and infrastructure to a knowledge engine, which enables more powerful reasoning and information retrieving from heterogeneous and contradicting conceptual models and scientific data in Digital Earth systems. Geospatial Semantic Web promises better retrieval geospatial information for the Digital Earth systems by explicitly representing the semantics of data through ontologies, which can be understood and processed by computers. It also promotes sharing and reuse of spatial data for a wide variety of applications by using standardized Semantic Web languages such as RDF to encode spatial data. However, representing structured geospatial data in these languages can result in inefficient data access. One of the main obstacles that prevent efficient and distributed query on geospatial knowledge base is the lack of indexing on spatially related data objects. This problem is inherent in the RDF representation of spatial data, which consists of loosely connected data objects related by object properties. Even if spatial objects are originally stored in related database tables, once they are transformed to RDF objects, the spatial indices are lost. It is possible to recreate indices for RDF objects with spatial attributes. However, pre-computing spatial indices does not guarantee performance improvement since the RDF queries are much more flexible than database queries and it is difficult to predict which spatial objects should be indexed and how. Thus, it is necessary to implement suitable extensions of the RDF query engine to take advantage of the creating spatial indexing on-the-fly.
The Geo-SPARQL protocol was proposed by Open Geospatial Consortium (OGC) as an extension of SPARQL for querying geographic RDF data. Geo-SPARQL queries are dominated by spatial join operations due to the fine-grained nature of RDF data model. Lack of spatial indices causes additional performance problems for Geo-SPARQL queries. One reason for the poor performance problems is caused by the way that spatial attributes are stored in RDF datasets. Spatial attributes are usually stored as string literals that conform to certain formats such as WKT or GML. The Geo-SPARQL query engine that implements spatial operators and filter functions has to parse these strings to recover the spatial coordinates for spatial computation. A naïve implementation of a spatial operator or a filter function in Geo-SPARQL treats its spatial inputs as plain strings and has to parse the strings to retrieve spatial contents such as x and y coordinates. Repeated parsing of the spatial inputs imposes a very large runtime overhead. The second reason for the poor performance problems is due to lack of parallelization. Since spatial objects are not indexed, Geo-SPARQL query engine cannot partition ontology data into subsets to be processed in parallel. As a result, Geo-SPARQL query can only be processed as a single-threaded program. Even with pre-computed spatial indices, partitioning spatial ontology data is not easy since the targeted data may not be evenly distributed in the indices.
This research introduces a new parallel approach for improving the query performance of geospatial ontology in a Geo-SPARQL query by separating spatial and non-spatial components. In fact, different parallel approaches have been widely used for improving the query performance for a long time in literature. However, past research on improving query performance using parallelization has been centered on relational databases (e.g. Boral et al. Citation1990; DeWitt et al. Citation1986; Kitsuregawa et al. Citation1983). Optimizing techniques for parallel relational databases do not specialize on the triple model of RDF and triple patterns of SPARQL queries for query engines based on the RDF- and SPARQL-specific properties (Groppe and Groppe Citation2011). Although there are studies to query heterogeneous relational databases using SPARQL and parallel algorithms (e.g. Miao and Wang Citation2009; Castagna, Seaborne, and Dollin Citation2009; Karjalainen Citation2009), parallel relational databases have inherent limitations such as scalability. SPARQL query can be parallelized by treating each triple statement in the query as a parallel task and the results of all the triple statement sub-queries can be joined together after all the parallel tasks have completed (Groppe and Groppe Citation2011). Unfortunately, this approach does not work efficiently when spatial predicates exist in the triple sta0tements. There are also studies to propose methods for efficiently parallelizing joint query of RDF data using Map-Reduce systems (e.g. Ravindra, Kim, and Anyanwu 2011; Kim, Ravindra, and Anyanwu Citation2011; Anyanwu Citation2013). However, to the best of our knowledge, there is no study to deal with parallelizing spatial join computations to support efficient spatial RDF query, which is an important issue for the development of a Geospatial Semantic Web (Zhang, Li, and Zhao Citation2007; Zhao et al. Citation2008, Citation2010b; Zhang, Zhao, and Li Citation2010a, Citation2010c, Citation2013;).
In this study, we propose a new approach to optimize and parallelize spatial joins in Geo-SPARQL queries. The novel idea of the proposed parallel approach is to separate spatial and non-spatial components in a Geo-SPARQL query. Instead of pre-computing spatial indices for geospatial ontology and implementing spatial extensions of a query engine to use the indices, we propose a strategy for a query engine implementation by separating spatial components from non-spatial components in a Geo-SPARQL query and processing spatial sub-query after non-spatial sub-queries have been completed. The main benefit of this approach is that a smaller set of ontology objects can be obtained after non-spatial sub-queries so that their spatial attributes can be cached for subsequent spatial computation including on-the-fly spatial indexing and spatial joins. Since the parsed spatial attributes are cached, the overhead caused by repeatedly parsing of spatial literal strings can be avoided. We expect that the results of this research will facilitate the access to spatial ontology information for multiple users through highly intensive geo-computation processes over a Geospatial Semantic Web, particularly for time-critical applications such as disaster response.
2. A framework for improving Geo-SPARQL query performance
The proposed approach focuses on improving the performance of spatial computations in Geo-SPARQL queries. Geo-SPARQL is a geographic query language for RDF that extends SPARQL with a standard vocabulary for spatial information, query functions for spatial computation, and query rewriting rules to expand feature-feature query to geometry query. In our framework, we separate the spatial and non-spatial components of a query. Based on the spatial component of a query, we construct spatial indices for the spatial objects returned from the non-spatial component of the query. For parallel processing, we partition the spatial objects based on the indices and process spatial operations in parallel for each data partition. The results of the parallel computation are compiled as the final result of the original query.
shows the detailed query procedure using the proposed approach. There are four major components that play important roles in the query procedure: a parser, a static analyzer, a query optimizer, and a spatial query parallelizer. Geo-SPARQL is used as a query language to search the needed geospatial information from heterogeneous data sources over the Web. The parser converts a Geo-SPARQL query to an abstract syntax tree form, which is checked by the static analyzer for potential errors. A Geo-SPARQL query itself usually is just a few lines. We use the SPARQL query engine of an ontology library, Jena, to parse a Geo-SPARQL query to an abstract syntax tree (AST) form. The static analyzer checks the AST for any potential errors programmatically.
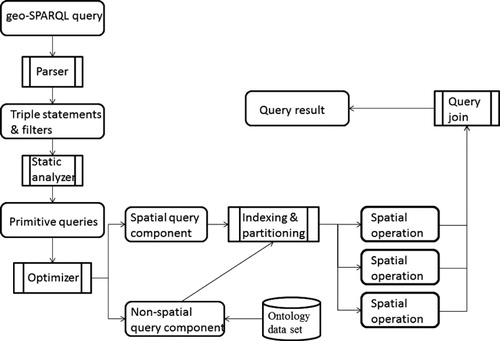
The result of the static analyzer is an ordered collection of primitive sub-queries that will be processed by the optimizer so that the sub-queries can be processed more efficiently. The optimizer divides sub-queries into spatial and non-spatial queries. The non-spatial query component will be answered first since they are usually less time consuming and the non-spatial results will be the inputs for answering the spatial query component. The spatial queries are potentially computational intensive. Therefore, they will be parallelized based on spatial indices. The spatial queries are parallelized by splitting them into disjoint parallel query tasks, which are answered independently. In the end, the results of the parallel query tasks are integrated to form the final answer to the original Geo-SPARQL query.
We extend the Jena library's implementation of SPARQL query engine by processing filtering operations on spatial objects in parallel fashion. While the strategy of parallelization by splitting data using spatial index is not new, the idea of adopting this strategy to support efficient Geo-SPARQL query is never done before.
The main advantage of this framework is that it improves the runtime performance of Geo-SPARQL queries by caching the spatial attributes parsed from ontology literals, on-the-fly indexing, and parallel spatial joins. The overall goal is to increase the efficiency of Geo-SPARQL queries so that applications of a Geospatial Semantic Web can process the spatial queries within a reasonable amount of time.
In the following sections, we introduce the primary technologies applied in the framework. These include Geo-SPARQL and query rewriting and parallelization.
2.1. Geo-SPARQL
In our framework, we use the OGC Geo-SPARQL (OGC11-052r4 Citation2012) protocol for querying geospatial data on a Geospatial Semantic Web. Geo-SPARQL represents geospatial data using RDF (Resource Description Framework) representation. It queries geospatial data by extending the general SPARQL query language to process geospatial data (Battle and Kolas Citation2012). illustrates the major components of Geo-SPARQL. The core component defines top-level RDFS/OWL (RDF Schema/ Web Ontology Language) classes for spatial objects. The Geometry component describes the geometry vocabulary and non-topological query functions for geometry objects. The Topological vocabulary component expresses RDF properties for asserting topological relations between spatial objects. The Geometry topology component identifies topological query functions. The Query rewrite component defines transformation rules for computing spatial relations between spatial objects based on their associated geometries. Finally, the RDFS entailment component introduces a mechanism for matching implicit RDF triples that are derived based on RDF and RDFS semantics.
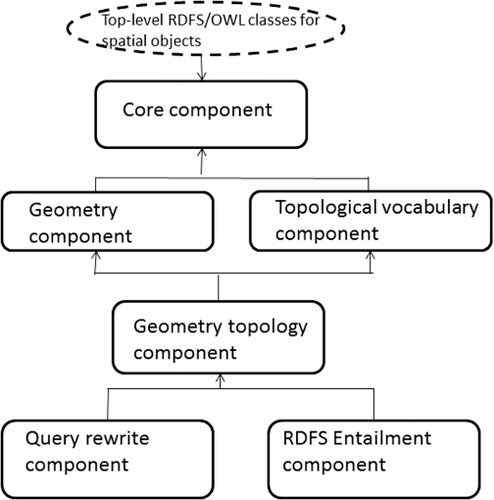
Geo-SPARQL defines a small ontology to represent features and geometries. Specifically, geo:SpatialObject and geo:Feature are the two main classes that represent geospatial features. The single root geometry class called geo:Geometry or the properties geo:hasGeometry and geo:defaultGeometry that associate with geospatial features are used for encoding geometry information. Geo-SPARQL also defines a number of topological and non-topological query predicates and functions to support geospatial data queries. Geo-SPARQL includes a set of terms for topological relations such as geo:equals, geo:disjoint, geo:intersects, geo:touches, geo:crosses, geo:within, geo:contains, geo:overlaps, which allow users to perform geospatial reasoning and formulate queries based on topological relations between spatial objects. Geospatial reasoning is critical for a Geospatial Semantic Web application such as disaster response. For example, in disaster response when concerned with damages around a given town, for example, Mansfield, this allows questions such as ‘Which residential homes are contained within the damaged area of Mansfield?’ to be answered efficiently. This query requires a topological comparison between the geometries of the residential homes and the geometries of the damaged area of Mansfield. The property geo:hasGeometry can be used to connect the features to their geometries, and the topology function geo:within can be used to evaluate the topological relationships. The following lists some sample codes to carry out the example query:


2.2. Query rewriting and parallelization
To illustrate our query processing framework, we consider a restricted form of SPARQL query with the syntax shown in .

A query Q consists of a set of selection variables v and a triple pattern P, which is a conjunction of a set of triple statements. A triple statement consists of a subject s, a predicate p, and an object o. The subject is either a variable or a URI, and a predicate is a URI, while an object can be a URI, a variable, or a literal. A URI includes a prefix and a short name to identify an ontology resource. In this framework, we only consider the URI that refers to an ontology class or a property. The answer to the query is a set of functions, where a function σ maps each variable to a literal or a URI ().
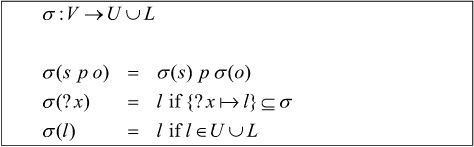
The query to a triple statement P returns a set of σ such that the knowledge base (denoted by K below) entails σ(P).
The function F ensures that the two solutions to a query are consistent.
Thus, we redefine the query solution as below to use the solution query (Pn) to non-spatial query Pn to restrict the set of solutions to each spatial triple spso and then join the results of spatial triples as the final solution. The solution for a spatial triple is defined by .
The inefficiency comes from several sources. One is due to the fact that geometries of spatial objects are stored in as string literals so that each time the objects are passed to the extension function, the geometry literal has to be parsed. This is very costly for spatial joins. For example, if we want to find out pairs of objects that touch each other and there are N objects, then we have to make calls to fgeo : touches and the same N geometry literals are parsed
times. The extension function itself is stateless and it is unable to cache the literal that it has parsed. Thus, to avoid this source of inefficiency, we need to avoid passing geometry literals to the extension function altogether. Instead, we cache the parsed values of the geometry literals, which may be used as inputs to the spatial functions that only pass the parsed values.
Another source of inefficiency is due to the way RDF query is processed. In calculating the entailment of a knowledge base, the query engine will conduct an exhaustive search to find the triples that are answers to a triple query statement. A spatial index is not a consideration in SPARQL queries. For a Geo-SPARQL query, it is possible to have pre-computed spatial indices for certain spatial objects so that the extension functions can take advantage of the indices to avoid a linear search. For example, if we have indexed the geo-names in a knowledge base using an R-tree, then a query such as ? x geo : nearby (43, −88) can be answered by searching the index much more efficiently. However, this pre-computed spatial index approach only works in limited cases. For example, it can be used when the object of the triple query is a literal. For a query such as ? x geo : nearby ? y, the index may not be useful if the knowledge base contains multiple types of spatial objects. The reason is that the definition of nearby relation depends on the geometries that are being compared while the available indices may be suitable for locating objects nearby a point but not a line or a polygon. To allow more efficient query and yet remain flexible, we will create on-the-fly spatial indexing for spatial objects. The actual indexing will be dependent on the spatial predicates and the geometry types of the spatial objects. For instance, if we are going to find out the nearby streets of several high schools, we can index the streets based on x-coordinates so that streets are indexed to the closest high school based on the x-coordinates. After indexing, we can greatly reduce the number of calls to fgeo : nearby. Since our indexing is on-the-fly and specific to each spatial predicate, we can implement it as a pre-processing function associated with fgeo : nearby. The knowledge base itself does not need to include any spatial indices. Note that even though the current experiment had defined a specific indexing strategy for lines nearby points, we can generalize this for every combination of extension functions and their input types.
The last source of inefficiency is the lack of parallelism in processing Geo-SPARQL queries. Even though we can answer triple statements in parallel and join their results, the performance gain is not significant since the runtime of the triple queries is often very uneven and in some cases, answering all triple statements sequentially may be faster than answering each triple statement in parallel if the triple statements are highly correlated. Thus, in this framework, we will answer the non-spatial queries first and use their solutions to trim the solution space for the spatial queries.
We focus on performance improvement for each spatial triple. Given a triple s pso, if either s or o is a literal, then the query can be answered efficiently without parallelization. In the case when both s and o are variables, we first create indices for the spatial objects that are in any potential solution σ to s and o, then we partition the solutions into k portions σ1, σ2,…, σk, and finally we compute in parallel based on the partitions. The results of the parallel threads are then aggregated to form the final solution to s pso. For multiple spatial triple statements, we can execute them in parallel as well and join the results of each individual query. However, performance gain will be query dependent and is not as predictable as parallelizing the query of an individual triple statement.
To summarize, in this framework, we introduce improvements to an ontology query engine by (1) separating the non-spatial queries from the spatial queries, (2) caching the inputs to spatial extension functions to avoid repeatedly parsing of geometry literals, (3) creating indices for certain inputs of spatial extensions on-the-fly, and (4) parallelizing the spatial joins using data partitioned based on the spatial indices, where a spatial join is represented by a triple of the form s pso in the query and ps is a predicate corresponding to a topological relation. We report some of the experimental results of our preliminary implementation in the next section.
3. Performance evaluation
To share the heterogeneous data of GIS databases at the semantic level, we published the original formats of GIS data in Shapefiles using WFS services across different sources. We then converted spatial features from the WFS services into JSON (JavaScript Object Notation) files. The JSON files were then converted through our Java-based converter into RDF files, which were loaded into memory through Jena library API, to share the heterogeneous of GIS databases at the semantic level.
Under this environment we conducted a limited set of experiments on parallelizing the Geo-SPARQL queries using the RDF files. The experiments were run on a workstation with a dual Intel Core i5-3320M CPU at 2.6 GHz with 4 hyper-threads. The allocated memory of the workstation is 2 GB. The queries were executed both sequentially and in parallel using a Java program. The standard JDK threading library was used to develop the parallel programs. The parallel program used a shared memory model where all threads have access to the same memory so that the experiments were run on a single machine. To use clustered machines, distributed memory model such as Map-Reduce has to be used. This is achievable but not necessary to demonstrate the speed-up of our experiments in this study.
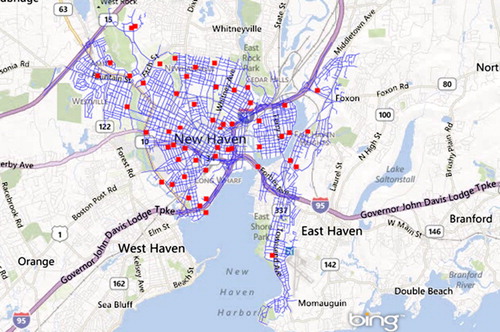
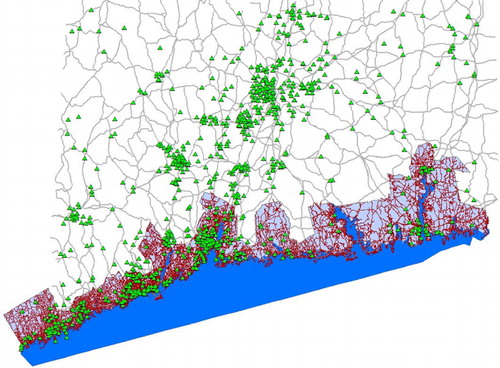
Here we show some of the evaluation results of two experiments that we conducted based on two different sizes of datasets: a small dataset for New Haven, CT and a larger dataset for the coastal region of Connecticut. The first experiment was conducted on the small dataset, which consists of two map layers, one for schools and one for streets, as illustrated in . It contains 54 schools, shown as red squares, and 3449 streets, shown as blue lines.
In both experiments, we executed the query Q1 to select the nearby streets of each school.

The workflow of query rewriting and parallelization is illustrated in , where the static analyzer rewrites the original query to expand some triple statements to more primitive triple and filter statements using the pre-defined query rewriting rules. The primitive queries are grouped into spatial and non-spatial sub-queries. The solutions to the non-spatial sub-queries are indexed and partitioned for answering the spatial sub-queries in parallel. The query rewriting rules are pre-defined logic inference rules, with each rule consisting of a head and a set of conditions. For example, the rewriting rule for the nearby relation is defined as follows:

To parallelize the query, we group the query statements into two sub-queries: the first sub-query consists of the triple statements such as ‘?school rdf:type ct:school’ and the second sub-query consists of the filter statements. In this experiment, the first sub-query was executed in parallel by sending triples of the same subject variable to the same thread. The final results of the triple threads were aggregated as a set of solutions to the variables (?school, ?g1, ?street, ?g2). The results from the triple sub-queries were used for processing the filter sub-query.
We executed the filter sub-query in parallel by dividing the inputs into equal proportions and sending them to each thread. For this sub-query, we divided the inputs to p equally sized blocks where each block contains N/p number of streets and N is the total number of streets and p is the number of threads. While the number of threads to execute a triple sub-query is bounded by the number of the subject variables involved, the number of threads to execute the filter sub-query is not bounded. We observed that the runtime of the Geo-SPARQL query may be dominated by the filter sub-query. Therefore, it is possible to reduce the execution time of a query by increasing the number of threads for executing the filter functions. The performance gain of the parallel execution is limited by underlying parallel architecture and the overhead of threading.
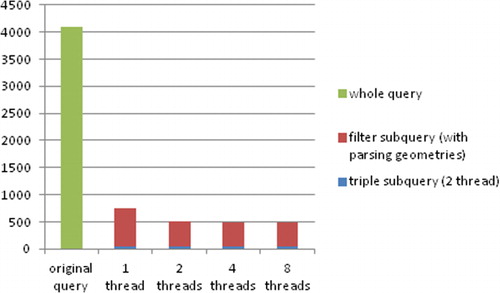
shows the runtime statistics of the query Q1, where the sequential query time is over 4 seconds. If we divided the query into a sub-query of triple statements and a sub-query of filter statements and executed the two sub-queries in sequence, then the total runtime was reduced substantially to 488–759 ms (milliseconds) depending on the number of threads used to run the filter statement. We explain the two components of the runtime cost:
The triple sub-queries were run on two threads only and it took 56 ms in total. Since the number of schools is much smaller than the number of streets, the thread for querying streets took 54 ms while the thread for querying schools only took 6 ms.
We ran the filter sub-query using 1, 2, 4, and 8 threads and the average runtime of each thread decreased as expected and the total runtime of the sub-query is 703, 460, 432, and 434 ms, respectively. The lack of performance gain after 4 threads may be due to the fact that the experiment was run on a CPU with 2 cores and 4 hyper threads. As we increased the number of Java threads, the runtime per thread decreased as expected but there was no larger performance gain after the number of threads exceeded four. The reason that we ran the filter sub-query using one thread is that we want to obtain a measure on the overhead associated with parallel execution of the filter sub-query. Note that in all parallel runs, the triple sub-queries have been done in parallel and the parsed geometries of streets and schools are cached. Thus, even with a single thread, the query ran much faster than it did before optimization.
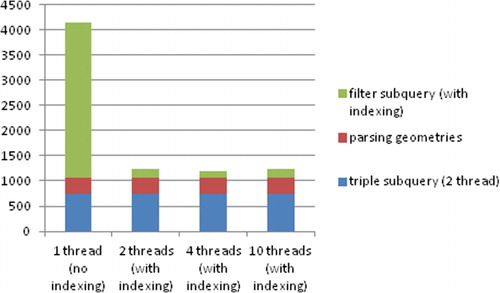
This experiment demonstrated the dramatic difference between the original Geo-SPARQL query and the optimized query. shows the runtime statistics of the query Q1, where the original Geo-SPARQL query took about 365,797 ms (or over 6 minutes). If we divided the query into a sub-query of triple statements and a sub-query of filter statements and executed the two sub-queries in sequence, then the total runtime was reduced substantially to 1119–4157 ms depending on the number of threads used for the filter statement. We summarize the components of the runtime cost below:
The triple sub-queries were run on two threads only and it took 756 ms in total.
The cost of parsing the outputs of the triple sub-queries is 314 ms.
The filter sub-query was run on 1, 2, 4, and 10 threads and the total runtime of the sub-query is 3097, 172, 139, and 179 ms, respectively. The cost of on-the-fly indexing (if applicable) is included in this cost component. Note that the total costs go up slightly when we use 10 threads and this is due to the constraint of the 4 physical threads.
The extension function for calculating object distances needs to parse the geometry literals into coordinates. In the optimized implementation, the literals were parsed only once and then cached in object arrays. In the original query engine, the geometry literal had to be parsed each time the distance function was called. The overhead of parsing is one of the reasons for the poor performance of the original implementation. Note that even though we can represent the geometries of streets and schools as RDF instances with their coordinates as typed literals, which may reduce the cost of parsing, it is difficult to define an extension function to operate on these RDF instances with a lower runtime overhead.
When we calculated the distance between every pair of schools and streets using one thread, the runtime of the filter sub-query, as shown in , is 3097 ms. However, not all pairs of schools and streets need to be compared since we only need to check the schools and streets that are relatively close to each other. Thus, we only applied the spatial indexing to the inputs of the filter sub-query so that the inputs could be divided in a way that results in a more efficient parallel execution.
We first divided the schools into several sets based on their x-coordinates. For each street s, we checked if the x-coordinate of s falls into the range of the x-coordinates of all schools in a set (we extended the range with a buffer on each end to include all possible nearby streets). If it did, then we calculated the distances between s with each school in the set. In this experiment, we divided the schools into 10 sets, where each set contains schools that are close to each other. This roughly reduced the number of comparisons between schools and streets by a factor of 10. In fact, the runtime statistics shows that the filter sub-query time is 172 ms with 2 threads and 139 ms with 4 threads. When we increased the number of threads further, the performance decreased slightly. When we increased the number of sets of schools, the overhead of dividing up the sets and partitioning the streets became significant and we did not have much performance gain.
Lastly, the total runtime of the query with on-the-fly indexing was dominated by the triple sub-queries, which could not be improved further without partitioning the RDF model. We plan to examine how to improve the performance of the triple sub-queries in the future study.
4. Discussion
In the experiments, the ontology data were parsed by the Jena library when they were loaded. However, the data loading was just one time and once data were loaded as ontology model (as a memory model in the experiments), there was no more parsing on the original data. One problem with ontology representation of spatial data is that there is no good way of representing spatial objects such as line strings as ontology instances. For example, if a street has many segments and each segment is a line, then we were faced with the choice of representing the street as a typed literal (e.g. a sequence of line objects) or just as an un-parsed string. The application programming interface support for composite and typed liberal is poor in SPARQL engines such as Jena library, and there are no suitable ways to go through the individual elements on a literal with a complex structure. Thus, we were forced to represent the street objects as string literals, which required a repeatedly parsing each time a spatial join was applied to streets.
The results are limited since they were based on the use of a small- and a medium-sized spatial dataset. Nevertheless, we are able to gain some insights into how the execution of Geo-SPARQL queries can be improved through a parallel processing. Note that the purpose of our experiments is to evaluate the performance gain of the proposed optimization algorithms rather than evaluate a particular parallel platform. The proposed algorithm in this study could be used on different architectures, which include not only the shared memory architecture (as in our case) but also the distributed memory architecture (such as Map-Reduce on clusters or Amazon Web Services). Increasing memory size, using persistent RDF models, or adopting a distributed memory model could accommodate much larger datasets used in the experiments. The current experiments, however, still have sufficiently demonstrated that the proposed strategy is able to drastically improve performance of Geo-SPARQL queries.
From the runtime statistics, we learned that the biggest performance gain was achieved by separating the triple statements from the filtering statements that involved spatial computations, which tended to be very costly. A spatial indexing can help partition the inputs to the filter functions for parallel processing. This provided an additional performance gain since the inputs to the filter functions are often Cartesian products of several sets of geometries, which can be very large. Partitioning the inputs to the filter functions can reduce the input size and runtime costs significantly.
We also learned that performance of answering the triple statements may be improved with parallelization though the performance gain may not be significant as compared to that of the filter statements. By spatial indexing and by increasing the number of threads used in processing the filter statements, we were able to reduce the total runtime subjected to the limitation of the underlying architecture. In this experiment, the CPU has four hyper threads, which limited the performance gain to that of four threads. When we increased the number of threads to more than four, the average runtime per thread was reduced but the total runtime remained stable. However, this is not the performance bottleneck because after we reduced the runtime cost of the filter sub-query, the runtime of the triple sub-queries dominated the total runtime again. It is not straightforward to increase performance of the triple sub-queries through parallelization since we are only able to assign at most one thread to one triple statement. To further improve performance of the triple sub-queries, we need to partition the RDF model, which is an issue needed for further research.
Ontology data allow flexible query but an ontology query is very inefficient because of the lack of indexing. Indexing cannot be easily done on loosely connected ontology data without knowing what the query is. A big portion of performance gain in the experiments was actually from the spatial indexing itself, which does not require parallelization. The indexing was done on-the-fly and not before. Note that the ontology contains a collection of triples and there is no good way to index them before knowing what the query is. While the ideas of data parallel execution and partitioning spatial objects based on spatial indices are not new, there is no study to apply these strategies to spatial ontology data for efficient spatial ontology query in the literature. Moreover, although there is similarity between SQL filters and SPARQL filters, the ways that the filters are implemented are quite different. This study is the first explorative study on this issue.
4.1. Other query processing strategies
Query answering with large spatial datasets represented in Semantic Web languages consumes a large amount of physical memory and is computational intensive. As a result, distributed query processing strategies such as those using Map-Reduce frameworks to improve query performance become attractive options. Map-Reduce framework is a programming model for processing and generating large datasets (Dean and Ghemawat Citation2004). In the Map-Reduce model, programs written in functional style are automatically parallelized and executed on a large cluster of commodity machines. Map-Reduce concept was first proposed by Google to support its large distributed computing across a large number of machines on its huge databases (Dean and Ghemawat Citation2004). Recently, a number of studies have addressed the implementation of distributed SPARQL query engines using the Map-Reduce implementations such as the Hadoop framework (e.g. Husain et al. Citation2009; Choi et al. Citation2009; Kulkarni Citation2010).
Hadoop is one of the most popular implementations of Map-Reduce model. Although Hadoop provides a simple and powerful mechanism to implement distributed applications while hiding details such as instantiation of jobs in cluster, fault tolerance, or data distribution, the binary relational operators such as join, Cartesian product, and set operations are difficult to implement in a pure Hadoop framework (Mazumdar Citation2011). Currently, Hadoop supports only partition parallelism in which a single operator executes on different partitions of data across the nodes. As a result, the existing Hadoop-based systems with the relational style join operators translate multi-join query plans into a linear execution plan with a sequence of multiple Map-Reduce cycles. This significantly increases the overall communication and I/O overhead involved in RDF graph processing on Map-Reduce platforms (Ravindra, Kim, and Anyanwu Citation2011). In addition, files on Hadoop now cannot be modified randomly, which may limit many features such as update operation for RDF applications (Sun and Jin Citation2010).
Increasingly, distributed systems such as Cloud Computing (Cui, Wu, and Zhang Citation2010; Liu et al. Citation2009; Yang et al. Citation2011a, Citation2011b; Yang, Xu, and Nebert Citation2013; Liu et al. Citation2013; Huang et al. Citation2013; Wen et al. Citation2013; Kim and Tsou Citation2013; Yue et al. Citation2013), cyber-GIS (Wang Citation2010; Wang et al. Citation2013), or spatial cyber-infrastructure (Wright and Wang Citation2011) have been suggested as a solution to overcome the scalability and performance problems of the Web-based GIS systems. Cloud computing is a recent paradigm developed to search, access, and utilize large volumes of geospatial data for many geospatial science applications. Hadoop, as an emerging cloud computing tool, is supported by many cloud service providers such as Amazon.
The proposed parallel query processing strategy may be adapted to run in a Map-Reduce framework. The non-spatial query component of a query can be readily executed as data parallel map tasks, the results of which can be aggregated as a reduce task. After indexing and partitioning of the results of the non-spatial queries, the spatial query component can be executed as data parallel map tasks as well. Using a Map-Reduce framework, we should be able to overcome the restriction of limited memory in shared memory platforms so that we can handle much larger datasets. However, the potential performance improvement remains to be investigated considering the overhead of a Map-Reduce framework.
Lastly, the technology of GPU (Graphic Processing Unit) computing is not a good choice for our experiments because of the difficulty in interacting with GPU model (copying back and forth between global CPU memory and GPU memory). In addition, GPU memory is also too limited for each GPU unit to handle the parallel tasks of spatial queries.
4.2. Advantages
Geospatial data are increasingly being made available on a Geospatial Semantic Web using the Resource Description Framework (RDF). The OGC Geo-SPARQL aims to access and query geospatial data represented by RDF over Geospatial Semantic Web. While the Geo-SPARQL enables users to retrieve more precisely the data they needed based on the semantics associated with these data, slow performance is an important issue for retrieving data from big geospatial datasets. To facilitate real-time spatial queries over Geospatial Semantic Web, we proposed a new optimization strategy for improving the runtime performance of Geo-SPARQL queries, which can accurately retrieve the data by explicitly representing semantics of data during the search process. The proposed approach has several advantages.
Firstly, by separating spatial from non-spatial query components, we are able to reduce the size of the input dataset for the spatial query component, which tends to be time consuming. A naive implementation of ontology query engine would process the triple statements in sequence, which may cause spatial queries to run on an unnecessarily large dataset.
Secondly, by caching the geometries that are inputs to the spatial extension functions to the query engine, we are able to drastically reduce the cost associated with parsing geometry literals. This cost is significant in queries that involve spatial joins of large sets of spatial objects.
Finally, by creating index for spatial objects on-the-fly, we are able to greatly reduce the sets of geometry inputs to the spatial extension functions of the ontology query engine. This means that we are able to answer a computation-intensive spatial ontology query in a reasonable amount of time.
5. Conclusion
Obtaining spatial information quickly from disparate sources is a critical need for a Geospatial Semantic Web application. Although advances in a Geospatial Semantic Web facilitate geospatial data sharing at semantic level, performance issues still hamper efficient and effective utilization of spatial information. This study proposes a new optimization strategy for improving query performance in the Geospatial Semantic Web. It uses on-the-fly spatial indexing to partition spatial objects referenced in an ontology knowledge base, followed by the parallel execution of spatial joins, thereby improving the performance of Geo-SPARQL queries.
The initial experimental results show that the proposed approach can greatly reduce the runtime cost of Geo-SPARQL queries compared with that of straightforward implementation of ontology query engine. As future work, we will extend the proposed strategy to distributed platforms using cloud-based web services and cluster platforms. Further study is needed to improve the proposed approach. For example, the current partitioning scheme does not consider the distribution of the spatial data. How are we able to produce a balanced partitioning for a skewed distribution of the data? Similarly, how can we build a cloud service or cyber-infrastructure based on the proposed framework? How scalable will the system be when we add different types of data? These are some examples of the challenges we face to further improve the proposed approach for the Geospatial Semantic Web applications.
Acknowledgment
Anselin's research was supported in part by award OCI-1047916, SI2-SSI from the US National Science Foundation.
References
- Anyanwu, K. 2013. “A Vision for SPARQL Multi-Query Optimization on Map-Reduce.” ICDE Workshops, pp. 25–26, Brisbane, Australia.
- Battle, R., and D. Kolas. 2012. “Enabling the Geospatial Semantic Web with Parliament and Geo-SPARQL.” http://www.semantic-web-journal.net/sites/default/files/swj176_3.pdf.
- Boral, H., W. Alexander, L. Clay, G. Copeland, S. Danforth, M. Franklin, B. Hart, M. Smith, and P. Valduriez. 1990. “Prototyping Budda: A Highly Parallel Database System.“ IEEE Transactions on Knowledge and Data Engineering, 2 (1): 4–24, March.
- Castagna P., A. Seaborne, and C. Dollin. 2009. “A parallel Processing Framework for RDF Design and Issues.” http://www.hpl.hp.com/techreports/2009/HPL-2009-346.pdf.
- Choi, H., J. Son, Y. Cho, M. K. Sung, and Y.D. Chung, 2009. “SPIDER: A System for Scalable, Parallel/Distributed Evaluation of Large-scale RDF Data.” Proceeding 18th ACM Conference on Information and Knowledge Management (CIKM 09), ACM, pp. 2087–2088. doi:10.1145/1645953.1646315.
- Cui, D., Y. Wu, and Q. Zhang. 2010. “Massive Spatial Data Processing Model Based on Cloud Computing Model.” In Proceedings of the Third International Joint Conference on Computational Sciences and Optimization, IEEE Computer Society, Los Alamitos, CA, pp. 347–350, 28–31. May. Anhui: Huangshan.
- Dean, J., and S. Ghemawat. 2004. “Map-Reduce: Simplified Data Processing on Large Clusters.” OSDI '04: 6th Symposium on Operating Systems Design and Implementation, pp. 137–149, Berkeley, CA. https://www.usenix.org/legacy/events/osdi04/tech/full_papers/dean/dean.pdf.
- DeWitt, D. J., R. H. Gerber, G. Graefe, M. L. Heytens, and K. B. Kumar. 1986. “GAMMA – A High Performance Dataflow Database Machine.” Kyoto: Very Large Data Bases (VLDB).
- Gore, A. 1998. “The Digital Earth: Understanding Our Planet in the 21st Century.” Presented at the Californian Science Center, Los Angeles, CA, January 31.
- Groppe J., and S. Groppe. 2011. “Parallelizing Join Computations of SPARQL Queries for Large Semantic Web Databases.” Proceeding SAC ‘11 Proceedings of the 2011 ACM Symposium on Applied Computing Pages 1681–1686. http://dl.acm.org/citation.cfm?doid=1982185.1982536.
- Grütter, R., and B. Bauer-Messmer. 2007. “Combining Owl with RCC for Spatioterminological Reasoning on Environmental Data.” http://sunsite.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-258/paper17.pdf.
- Guo, H. D. 1999. Earth observation and Digital Earth. Beijing: Chinese Science Press.
- Guo, H., X. Fan, and C. Wang. 2009. “A Digital Earth Prototype System: DEPS/CAS.” International Journal of Digital Earth 2 (1): 315.
- Huang, Q., C. Yang, K. Benedict, S. Chen, A. Rezgui, and J. Xie. 2013. “Utilize Cloud Computing to Support Dust Storm Forecasting.” International Journal of Digital Earth 6 (4): 338–355. doi:10.1080/17538947.2012.749949.
- Husain, M. F., P. Doshi, L. Khan, and B. Thuraisingham. 2009. “Storage and Retrieval of Large RDF Graph Using Hadoop and Map-Reduce.” In CloudCom 2009, Beijing, China, LNCS 5931, edited by M.G. Jaatun, G. Zhao, and C. Rong, 680–686.
- Karjalainen, M. 2009. “Uniform Query Processing in a Federation of RDFS and Relational Resources.” In Proceedings of the 2009 International Database Engineering and Applications Symposium, pp. 315–320. Calabria, Italy. http://dl.acm.org/citation.cfm?id=1620469.
- Kim, H., P. Ravindra, and K. Anyanwu. 2011. “From SPARQL to Map-Reduce: The Journey Using a Nested TripleGroup Algebra.” PVLDB 4 (12): 1426–1429.
- Kim, I.-H., and M.-H. Tsou. 2013. “Enabling Digital Earth Simulation Models Using Cloud Computing or Grid Computing – Two Approaches Supporting High-Performance GIS Simulation Frameworks.” International Journal of Digital Earth 6 (4): 383–403. doi:10.1080/17538947.2013.783125.
- Kitsuregawa, M., H. Tanaka, and T. Motooka. 1983. “Application of Hash to Data Base Machine and Its Architecture.” New Generation Computing 1 (1), 63–74. doi:10.1007/BF03037022.
- Kulkarni, P. 2010. “Distributed SPARQL Query Engine Using Map-Reduce.” http://www.inf.ed.ac.uk/publications/thesis/online/IM100832.pdf.
- Liu, Y., W. Guo, W. Jiang, and J. Gong. 2009. “Research of Remote Sensing Service Based on Cloud Computing Mode.” Application Research of Computers 26 (9): 3428–3431.
- Liu, Y., A. Y. Sun, K. Nelson, and W. E. Hipke. 2013. “Cloud Computing for Integrated Stochastic Groundwater Uncertainty Analysis.” International Journal of Digital Earth 6 (4): 313–337. doi:10.1080/17538947.2012.687778.
- Mazumdar, P. 2011. “Complex SPARQL Query Engine for Hadoop Map-Reduce.” www.csi.ucd.ie/files/u1450/SM_Query_RDf.ps.
- Miao, Z., and J. Wang. 2009. “Querying Heterogeneous Relational Database Using SPARQL.” In Eighth IEEE/ACIS International Conference on Computer and Information Science, Shanghai, China.
- OGC 11-052r4. 2012. “OGC Geo-SPARQL – A Geographic Query Language for RDF Data.” http://www.opengis.net/doc/IS/Geo-SPARQL/1.0.
- Ravindra, P., H. Kim, and K. Anyanwu. 2011. “An Intermediate Algebra for Optimizing RDF Graph Pattern Matching on Map-Reduce.” http://link.springer.com/chapter/10.1007%2F978-3-642-21064-8_4.
- Sun, J., and Q. Jin, 2010. “Scalable RDF Store Based on HBase and Map-Reduce.” In Advanced Computer Theory and Engineering (ICACTE), 2010 3rd International Conference on, vol. 1, pp. V1-633, V1-636, August 20–22, Chengdu, China.
- Wang, S. 2010. “A Cyber GIS Framework for the Synthesis of Cyber Infrastructure, GIS, and Spatial Analysis.” Annals of the Association of American Geographers 100 (3): 535–557. doi:10.1080/00045601003791243.
- Wang, S., L. Anselin, B. Badhuri, C. Crosby, M. Goodchild, Y. Liu, and T. Nyerges. 2013. “Cyber GIS Software: A Synthetic Review and Integration Roadmap.” International Journal of Geographical Information Science 27 (11): 2122–2145. doi:10.1080/13658816.2013.776049.
- Wen, Y., M. Chen, G. Lu, H. Lin, L. He, and S. Yue. 2013. “Prototyping an Open Environment for Sharing Geographical Analysis Models on Cloud Computing Platform.” International Journal of Digital Earth 6 (4): 356–382. doi:10.1080/17538947.2012.716861.
- Wright, D. J., and S. Wang. 2011. “The Emergence of Spatial Cyber Infrastructure.” Proceedings of the National Academy of Sciences 108 (14): 5488–5491. doi:10.1073/pnas.1103051108.
- Yang, C., M. Goodchild, Q. Huang, D. Nebert, R. Raskin, Y. Xu, M. Bambacus, and D. Fay. 2011b. “Spatial Cloud Computing: How can the Geospatial Sciences Use and Help Shape Cloud Computing?” International Journal on Digital Earth 4 (4): 305–329. doi:10.1080/17538947.2011.587547.
- Yang, C., H. Wu, Q. Huang, Z. Li, and J. Li. 2011a. “Using Spatial Principles to Optimize Distributed Computing for Enabling the Physical Science Discoveries.” Proceedings of the National Academy of Sciences 108 (14): 5498–5503. doi:10.1073/pnas.0909315108.
- Yang, C., Y. Xu, and D. Nebert. 2013. “Redefining the Possibility of Digital Earth and Geosciences with Spatial Cloud Computing.” International Journal of Digital Earth 6 (4): 297–312. doi:10.1080/17538947.2013.769783.
- Yue P., H. Zhou, J. Gong, and L. Hu. 2013. “Geoprocessing in Cloud Computing Platforms – A Comparative Analysis.” International Journal of Digital Earth 6 (4): 404–425. doi:10.1080/17538947.2012.748847.
- Zhang, C., W. Li, and T. Zhao. 2007. “Geospatial Data Sharing Based on Geospatial Semantic Web Technologies.” Journal of Spatial Science 52 (2): 35–49. doi:10.1080/14498596.2007.9635121.
- Zhang, C., T. Zhao, and W. Li. 2010a. “Automatic Search of Geospatial Features for Disaster and Emergency Management.” International Journal of Applied Earth Observation and Geoinformation 12 (6): 409–418. doi:10.1016/j.jag.2010.05.004.
- Zhang, C., T. Zhao, and W. Li. 2010c. “A Framework for Geospatial Semantic Web Based Spatial Decision Support System.” International Journal of Digital Earth 3 (2): 111–134. doi:10.1080/17538940903373803.
- Zhang, C., T. Zhao, and W. Li. 2013. “Towards Improving Query Performance of Web Feature Services (WFS) for Disaster Response.” ISPRS International Journal of Geo-Information 2 (1): 67–81. doi:10.3390/ijgi2010067.
- Zhang, C., T. Zhao, W. Li, and J. P. Osleeb. 2010b. “Towards Logic-based Geospatial Feature Discovery and Integration using Web Feature Service and Geospatial Semantic Web.” International Journal of Geographical Information Science 24 (6): 903–923. doi:10.1080/13658810903240687.
- Zhao, T., C. Zhang, M. Wei, and Z.-R. Peng. 2008. “Ontology-Based Geospatial Data Query and Integration.” Lecture Notes in Computer Science LNCS5266: Geographic Information Science 5266: 370–392.