
Abstract
Metadata are the information about and description of data. In Digital Earth, metadata become variant and heterogeneous with many uncertainties. This paper studies uncertain features in the generation and application of metadata, and two types of uncertainties (incomplete and imprecise) are described based on semantic quantitative measurement method semantic relationship quantitative measurement based on possibilistic logic and probability statistic (SRQ-PP). Moreover, in the case study, we apply two types of quantitative measurements based on SRQ-PP to describe incomplete (uncertain) knowledge and imprecise (vague) information separately in spatial data service retrieval, which in turn is helpful to identify additional potential data resources and provide a quantitative analysis of the results.
1. Introduction
In Digital Earth, users can obtain large and variant spatial data from networks of all kinds of fields. Distributed computing, grid computing, and cloud computing are adopted to realize resource sharing and cooperative computing based on big data in distributed environment (Kim and Tsou Citation2013). Up to now, these efforts have achieved great success.
To dispatch and interoperate every network service, metadata are used to give a basic description of the service and resources (NISO Citation2010). This type of description method describes the service from the viewpoint of resource usage and function and can help to realize the standardization of resource descriptions (Percivall Citation2010). However, this type of standardization method and traditional lexical match cannot resolve the problem of semantic heterogeneity (Zhang, Zhao, and Li Citation2010), which poses many challenges in the improvement of network service and resource retrieval. The motivation of our work is the desire to solve these semantic heterogeneities based on ontology and so that the metadata of each service can be inter-comprehended.
This paper is intended to present some research works of metadata description and resource retrieval based on a semantic ontology in big data time. Based on the characteristic analysis of variant semantic heterogeneities, two main types of uncertainties (incomplete and imprecise) in metadata are analyzed and quantitatively described based on the SRQ-PP method. Finally, this type of quantitative semantic measurement is applied in the retrieval process of spatial data service and shows its effectiveness.
2. Related works
The research on big data has gradually developed and become a focus of attention for many domains. Looking more specifically at big geo-referenced data, the vast multi-dimensional and multi-perspective geo-data have proved to be extremely useful in assisting humans to better understand the Earth and to help policy-makers take certain actions to begin solving some of our most pressing problems. In many ways, Digital Earth, as a collection of technologies that has matured over the years, could be seen as a successful example of big data, Digital Earth integrates the huge and valuable geo-data resources into a digital representation of the planet (Guo Citation2014). There are large-scale geo-data in Digital Earth systems, how to providing an effective and efficient way to find required data on demand is a challenge.
Metadata (or metacontent) are defined as the data providing information about one or more aspects of data (Sicilia Citation2006). In the fields of information management, information science, information technology, librarianship and graphic information system (GIS), this term has been widely adopted. This type of data structure and function description can help users to retrieve and obtain required resources in networks (Batcheller Citation2008). However, when so many types of metadata have emerged, how to enable these metadata to be inter-comprehended with each other is essential.
On the one hand, some researchers have proposed many metadata specifications and tried to standardize all metadata. In the field of spatial data service in Digital Earth, ISO19115 is a content standard for Digital Geospatial Metadata (Chen, Zhu, and Du Citation2008), Web Service Description Language (WSDL) is used to describe functions and interfaces of Web service (Wu Citation2012), Web Feature Service (Vretanos Citation2005), Web Coverage Service (Whiteside and Evans Citation2008), and Web Map Service (Beaujardiere Citation2006) provide specifications for Open Geospatial Consortium (OGC) Web services (Florczyk et al. Citation2012), and Web Processing Service (Schut Citation2007) can normalize computing resource as Web services implemented with a standard-based interface (Trilles et al. Citation2012). This type of method describes net services in the viewpoint of resource usage and function and can help to realize the standardization of resource descriptions. However, this type of metadata normalization is impractical and cannot resolve the problem of semantic heterogeneity, such as concept heterogeneity and structure heterogeneity. These problems are very common in Digital Earth application (Zhang, Zhao, and Li Citation2010), which makes it hard to implement this method in big data environment.
On the other hand, people try to link different metadata and create relationships among them. In 2002, Max introduced a new framework of Semantic Geospatial Web (Egenhofer Citation2002), which enables users to retrieve more precisely the data they need based on the semantics associated with these data. World Wide Web Consortium (W3C) also sets a standard Ontology Web Language for Service (OWL-S) for Web service semantic descriptions (Martin, Burstein, and Hobbs Citation2004) that enables users and software agents automatically to discover, invoke, compose, and monitor Web resources offering services under specified constraints. Vaccari, Shvaiko, and Marchese (Citation2009) proposed an approach (structure to preserving semantic matching) to enable service providers to share explicit knowledge of the interactions in which their services are engaged, and these models of interaction are used operationally as the anchor for describing the semantics of the interaction.
The research works mentioned above mainly focused on two aspects: service meta-info semantic description and the service discovery semantic process. Moreover, the semantic description is the basis of semantic retrieval, but these works did not pay much attention to the semantic analysis and match of different service description specifications (Chena et al. Citation2011). Furthermore, in the background of big data, there are many types of uncertainty and fuzziness, which cannot be settled by a traditional ontology model (which requires the completeness and precision of knowledge and information; Maue Citation2008). These problems all limit the application of semantic analysis and comprehension in big data and their solutions face many challenges.
3. The solutions of uncertainty description and mapping among metadata
Based on the method mentioned above, different metadata can be linked by means of semantic relevancy (Li, Goodchild, and Raskin Citation2014), which can help in implementing inter-comprehension and interoperation among metadata. However, in realistic applications, there are many uncertain features in these semantic relations (mainly incompleteness and fuzziness). The emergence of these uncertainties leads to the obstacle of former semantic retrieval and inference, especially in the application environment which full of great mount of fuzzy, vague, imprecise, and incomplete (De Tré et al. Citation2010). Handling uncertainty and vagueness has started to play an important role in the research on the application of ontology (Lukasiewicz Citation2009). In upfront research (Sun Citation2013), a novel description method of uncertain semantic relations based on the combination of possibilistic logic (Dubois, Mengin, and Prade Citation2006) and probability statistic (Qi, Pan, and Ji Citation2007) was proposed. We named this method a semantic relationship quantitative measurement based on possibilistic logic and probability statistics (SRQ-PP for short). This section uses the SRQ-PP method to describe two main types of uncertainties and demonstrates how this method works in the measurement of various kinds of uncertainties in the background of big data.
The reasons for uncertainty mainly lie in two factors: incomplete (uncertain) knowledge and imprecise (vague) information (Haase and Volker Citation2008). Knowledge imperfection leads to an incomplete and partial description of events, and information inaccuracy results in multi-value or imprecision of characters. Therefore, there are mainly two types of uncertainties in the ontology as discussed below.
3.1. The incomplete description of concept's semantic properties
Because of the limitations of recognition in the real world, the description of concepts in ontology is often incomplete, which affects the complete comprehension of concepts. In the process of semantic retrieval or inference, the absence of some description properties may result in the termination of process in classical logic, default intolerance, and the overlooking of possible results (Grau et al. Citation2012). The solution for this type of uncertainty can enable the process to continue as usual in the case of the absence of a few unessential properties values.
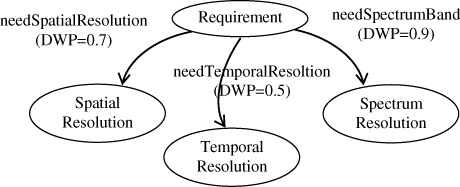
Therefore, we need to measure the degree of importance of properties to concepts. When adding a property to a concept using meta-relation ‘hasProperty’ we set the default weight of the property (DWP; range 0–1 and default value is 1). The higher the DWP value of a semantic relation is, the more crucial this property is to the corresponding concept in common sense. If the DWP of one absent property is below a threshold T, then this property can be ignored and regarded as a satisfied condition (this property can be absent); otherwise, this property must a have value for judgment.
The value of DWP can be set by experts based on experiments or it can be obtained automatically based on the statistic of possibility degree related on this concept's instances and certain property. The relations among concept, instance, and property are shown in .
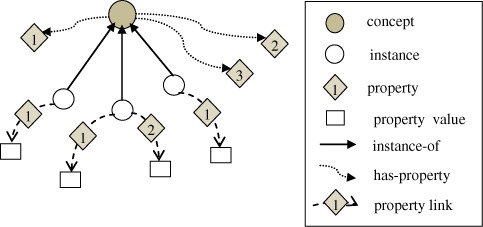
In the instances of a certain concept, the contribution statistic of property values can reflect the degree of importance of each property to the concept, thus helping in judging which property is more necessary to the concept. All instances of a concept with valid values of a property indicate that this property is necessary to the concept. In contrast, a property that has been defined but never assigned a value indicates that this property is not essential to the concept.
This method sets the DWP value based on the statistic of the possibility degree and gives a rough reference of the incomplete description of concept's semantic properties.
3.2. The multi-value of concept's semantic properties
When adding instances of concepts to the ontology, the semantic property values need to be set. In most situations, the property value is not singular or certain, and there are several choices of the same property (Truong and Nguyen Citation2012). However, these multi-values have different semantic strengths and possibilities, as well as varying effects on the inference results.
An ontology based on typical description logic can only describe semantic properties in Boolean logic (qualitative analysis), which cannot distinguish among the semantic difference of these property values. This means in that the retrieval of an inference results cannot determine the priority relation among these outcomes. Therefore, we need a quantification method to describe the differences among these semantic linkages and to improve the precision of ontology retrieval and inference.
When adding and setting a data type property or an object property for an instance, we also set a possibility of the property value (PPV) for this property value, shown in Equation 2. This value reflects the possibility degree of this semantic value. Moreover, we can obtain the necessity of the property value (NPV) based on the statistic of PPV, shown in Equation 3. The NPV reflects the dependence degree of this semantic value to this instance (in other words, the relevance degree from this semantic value to the instance, indicating the semantic characteristic of the instance). This type of measurements of PPV and NPV can assist in the processes of broad retrieval and the exact choice of ontology knowledge.
As mentioned above, the computation of NPV depends on the statistic operation in the whole knowledge space, whose effect relies on the scale of the knowledge base. The larger and richer the knowledge base is, more precise and efficacious the NPV is. However, when the scale of knowledge base reaches a high degree, the computation of NPV will consume a vast amount of time. Moreover, this computation process needs to be executed once the related PPV is updated. Therefore, this method is more suitable to the application scene of a small knowledge base system (knowledge has greater completeness). We can select several key instances as observation objects based on the task, but not all of them, which can lower the consumption of computation time.
This section has presented how to measure two typical kind of uncertain semantic relationships based on SRQ-PP. And the quantitatively measurement of these uncertainties in the ontology can help to describe and comprehend uncertain semantic more completely.
4. The example of uncertain query and inference in spatial data service retrieval
In spatial data service retrieval, common interface needs to search data by the conditions of spatial location, temporal range, and spectrum characters. The first and second conditions can be easily obtained from users, but the settings of spectrum conditions are quite difficult for laymen. However, there are some potential relationships between users' requirements and suitable remote sensing data. This type of relationship can be described based on a semantic ontology and inferred based on reasoning rules, which are briefly described in .
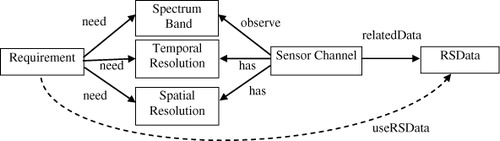
In , ‘need,’ ‘has,’ and ‘relatedData’ are semantic properties which can be described by domain experts, and ‘useRSData’ is semantic link which need to be inferred based on reasoning rules according to the existent semantic description. We describe the reasoning rules in form of IF…THEN… production rules as below.
app2data:
{?app=ns:RSApplication,?channel=ns:SensorWaveBand,?data=?channel.ns:relatedDataProduct}
IF (?app.ns:needSpectrumBand=?channel.ns:observeSpectrumBand) AND (?app.ns:neeSpatialResolution=?channel.ns:hasSpatialResolution) AND
(?app.ns:needTemporalResolution=?channel.ns:hasTemporalResolution)
THEN (?app.ns:useRSData=?data)
In this semantic relationship, there are also some uncertainties in the semantic property descriptions and inference rules. According to a certain remote sensing application and observation task, there are several candidates of characteristic spectrums (with different degrees of satisfaction), so users can have several choices of remote sensing data. Moreover, in inference rule ‘app2data’ not all the conditions of spectrum characters have to be satisfied and matched equivalently with the same weight. A few mismatches or the missing of weak conditions may satisfy users' requirements too (this type of inclusiveness of inference rules can help to get more possible results).
4.1. The description of uncertainties based on SRQ-PP
In this example, based on the SRQ-PP method, we use PPV to describe the possibility degree of semantic properties, multi-values, and DWP to describe the weight differences of semantic properties in the semantic retrieval and inference process.
4.1.1. The possibility degree of multi-value properties in semantic description
When setting the property value of the semantic link ‘needSpectrumBand’ between a remote sensing application and a spectrum band, different spectrum bands have different weights, reflecting the strength of semantic associations. Based on domain knowledge, we learn that, in the remote sensing of suspended sand detection the most suitable spectrum band is near infrared (NIR) and next is green and blue; therefore, we can set the PPV values of these ‘needSpectrumBand’ semantic links as shown in .
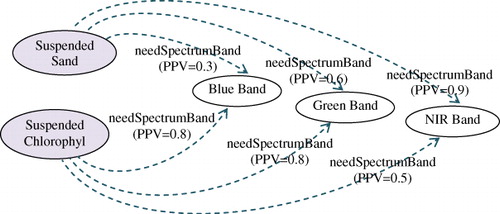
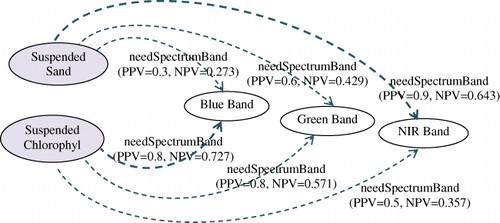
The value of PPV measures the possibility degree of semantic association from the remote sensing application to a spectrum band, which is the weight reference of semantic retrieval and inference. The higher the value of PPV is, the closer the semantic linkage is. In SRQ-PP, NPV is another measurement based on PPV that measures the necessity degree of semantic association from the destination to the source of semantic linkage. In this example, the NPV value of the semantic link ‘needSpectrumBand’ reflects the strength of reversed semantic association. According to Equation 3, we gain the values of NPV as shown in .
4.1.2. The weight differences of semantic properties in the inference process
The previous section solves the uncertainty of the multi-value problem, and this section introduces how to solve the uncertainty problem of similar matching in the inference process. Based on existing domain knowledge and semantic information, when we try to undertake some semantic retrieval or inference, the state of complete matching based on Boolean logic is not always satisfied. The reasons mainly lie in inadequate initial conditions, incomplete descriptions of resources, overly strict matching laws, and so on. The problem of inadequate initial conditions can be solved by interaction with users or by the semantic extension of initial conditions. However, the solutions to the other problems require improvement in the inclusiveness and flexibility of the semantic retrieval and inference process, extending the hunting zone, and obtaining more possible results.
Based on SRQ-PP, we can use DWP to measure the importance degree of each semantic property to the corresponding class. The value of DWP can be used as the reference for the condition match judgment, and we can set a threshold T to adjust the tolerance degree of semantic matching.
In the example shown as , there are three semantic properties corresponding to ‘Requirement’ and they have different DWP values to indicate their weights. If we set T = 0.7, based on DWP values in , we can judge (DWP ≥ T) that the value of the property ‘needSpatialResolution’ and ‘needSpectrumBand’ is required and need to be matched. In contrast, the value of the property ‘needTemproalResolution’ may be missing, and the mismatch of this property can be tolerant as a possible result. In extreme case, T = 0.0 (minimum value) means that the tolerance degree is 0 and all conditions must be fully matched (classical logic with no uncertainty), and T = 1.0 (upper bound) means that the tolerance degree is unlimited and all resources can match each condition (no meaning in practical application). Moreover, DWP = 1.0 (maximum value) means that this property is a necessary property to corresponding class, and DWP = 0.0 (lower bound) means that this property is meaningless to the corresponding class and can be ignored in semantic retrieval and inference.
The judgment rules of the process of semantic retrieval or inference based on DWP set are as follows:
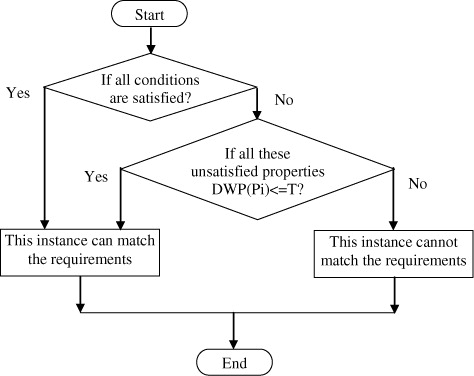
If the condition of a semantic property is satisfied, then the corresponding instance is selected.
If the condition of a semantic property is not satisfied but the DWP value of this semantic property is no greater than T (which means that this semantic property is not a required property of the corresponding concept), then the corresponding instance is a possible result.
If the condition of a semantic property is not satisfied and the DWP value of the semantic property is greater than T (which means that the semantic property is a required property of the corresponding concept and must be satisfied), then this corresponding instance can be rejected.
The flowchart of this judgment process is shown in .
Based on the measurements of PPV (or NPV) and DWP from SRQ-PP, we describe two kinds of uncertainties in the domain of spatial information services. In next section, an example will show how to integrate these measurements in the application of spatial data service retrieval.
4.2. The application of spatial data service retrieval with uncertainty measurements
In the semantic retrieval of spatial information, based on the purpose of observation task from users, the remote sensing data requirements can be obtained, and related usable spatial data resource can be found. This semantic analysis process includes semantic retrieval and inference steps. The following part shows an example of mud-rock flow detection to explain this semantic analysis process further. In spatial data search interface, user inputs the query request ‘last year the mud-rock flow in north China.’
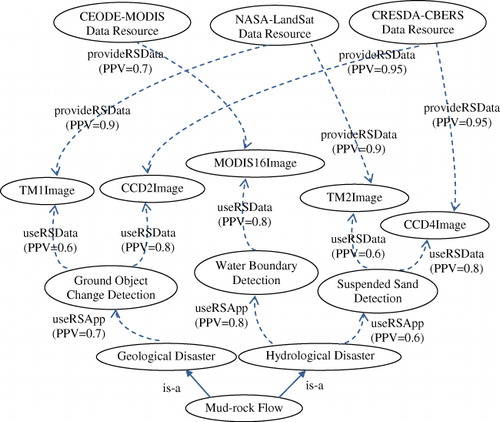
Step 1. Obtain the users' requirement and analyze the purpose of data usage. From the users' query request, we obtain the keyword ‘mud-rock flow.’ Then, based on the taxonomy relationship of concepts in the ontology, we gain the parent concepts ‘hydrological disaster’ and ‘geological disaster’ of ‘mud-rock flow.’ This hierarchical structure of concepts can help us to determine the relationship among concepts and extend the semantic width and depth of query.
Step 2. Based on the purpose of the data usage to search related remote sensing applications. From concepts ‘geological disaster’ and ‘hydrological disaster,’ based on the semantic relation ‘useRSApp’ we find related remote sensing applications. The ‘RSApp’ related to ‘hydrological disasters’ includes ‘water boundary detection,’ ‘suspended sand detection,’ and so on. The related ‘RSApp’ with ‘geological disaster’ includes ‘ground object change detection,’ ‘tectonic movement analysis,’ and so on. Each property ‘useRSApp’ (from source ‘disaster’ to destination ‘RSApp’) has its PPV to indicate the different strength of the semantic linkage, as shown in .
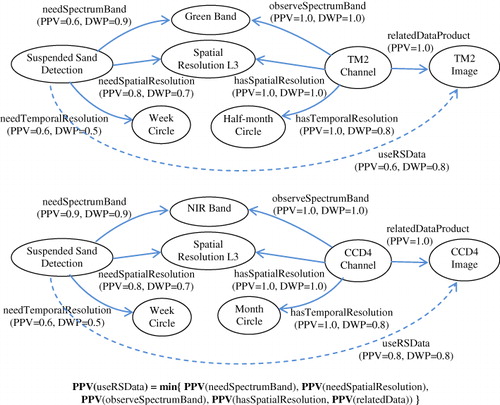
Step 3. Based on remote sensing applications, find suitable remote sensing data. Different remote sensing application tasks observe different ground objects based on characteristic spectrums. This domain knowledge can be described as reasoning rules, as mentioned at the beginning of this section. We can modify threshold T to adjust the tolerance degree of this semantic analysis process (in this example, we set T = 0.7), and based on this reasoning rule, we obtain the results of ‘useRSData’ inference with the possibility degree, shown in .
The calculation and transfer rules of PPV are shown as . In this inference process, both conditions for the temporal resolution of ‘TM2 Channel’ and ‘CCD4 Channel’ cannot be satisfied, and based on traditional inference methods, they cannot be found as possible results. However, when we take DWP into consideration, DWP(needTemporalResolution) = 0.5 < T = 0.7 means that this property is not a required condition in inference, and these two sensor channels are possible results with the possibility PPV. The calculation rule is:
Step 4. Based on remote sensing data, find satisfactory data resources. A data resource is the gathering place of data. From the description profile of a data resource, we can determine what kind of data it can provide, as well as the spatial dimension and the temporal range of data collections. In spatial information ontologies, the semantic relation ‘provideRSData’ is used to describe the linkages between remote sensing data and data resources. Because there are different services capabilities for certain types of data, this semantic linkage also has the quantitative measurement of PPV to describe the strength of this semantic relationship. Based on the analytical results for the data requirements in the next step, we can find all usable data resources, shown in .
The satisfaction measurement of final results depends on the uncertainty degree of all the semantic links in the searching route and the calculation rule is:
In this equation, dr is a data resource found by the semantic retrieval process from the initial requirements of s, and mi is medium nodes that are involved in the searching route. The satisfaction measurement of the final data resource is the minimum PPV value of all the semantic links involved in the semantic retrieval chain of this data resource.
The complete semantic retrieval chains are shown in . In this process, there are two types of uncertainty measurements: PPV gives the quantitative measurement of the semantic link strength in this semantic retrieval chain and DWP gives a judgment reference for the semantic inference results. Both of them can describe and solve some uncertainties in the semantic retrieval process. These quantitative measurements can extend the semantic retrieval results and measure the satisfaction degree of each result.
At present, this type of spatial service and data retrieval with uncertainty has been applied in the prototype of the Spatial Information Grid. In the query portal when user inputs the natural query language ‘The flood situations of Beijing region in last year’ in Chinese, this query sentence will be analyzed and extracted the details about time, location and query intention (reflects the observation task).
Then based on the matching process of remote sensing application and spectrum channel as above, user can find all of the possible data sources which meet his requirements of flood observation task. Based on the SRQ-PP method, user could find more possible results than before. This matching and retrieval process can tolerant some uncertainty (weak linkage or fuzzy relationship) and help user to obtain more useful data resources.
This SRQ-PP method measures uncertainty in the ontology based on possibilistic logic and probabilistic statistics. It has the features of fewer constraints, low arithmetic complexity from possibilistic logic, objective measurement, and dynamic adaptability from probabilistic statistics. Based on these measurements from SRQ-PP, we gain higher effective semantic analysis capabilities: (1) the inclusivity of the semantic inference procedure, (2) the metrizability of the semantic retrieval process, and (3) the comparability of semantic retrieval results. To some degree, they enhance the flexibility and imprecision of semantic analysis based on ontology.
5. Conclusions
Ontology has emerged recently as a knowledge representation infrastructure for the provision of shared semantics to metadata, which essentially forms the basis of the vision of the Semantic Web. The combination of metadata description techniques and ontology engineering defines a new landscape for information engineering with specific challenges and promising applications. Especially in age of big data, with the abundance of various data, the metadata of this data have become more different and heterogeneous. The problem of structural heterogeneity and semantic uncertainty are particularly prominent.
This paper applies the SRQ-PP method (a novel method of semantic relationship quantitative measurement based on possibilistic logic and probabilistic statistics) to describe two types of uncertainties (incomplete and imprecise) in the description and generation of metadata based on two quantitative measurements, PPV and DWP. From the case study of spatial data retrieval, we find that the integrated application of PPV and DWP can improve the inclusivity and metrizability of the semantic retrieval process based on an ontology and enhance the flexibility and imprecision of metadata semantic analysis and mapping.
This initial research can be considered as a philosophical discussion with simple experiments. There remain some further works, such as the overall solution to metadata heterogeneity based on the Semantic Web to make metadata more comprehensible, the creation of a formal metadata language based on semantic ontology and the realistic application system of metadata retrieval, and interoperation based on semantic analysis, to be investigated. We hope that the combination of metadata and ontology will become more efficient and helpful.
Acknowledgments
The authors would like to thank the editors and anonymous reviewers for their valuable comments and insightful ideas.
Funding
The work in this paper is supported by the National Natural Science Foundation of China under grant no. [61303130] and the Natural Science Foundation of Hebei Province under grant no. [F2014203093].
Additional information
Funding
References
- Batcheller K. James. 2008. “Automating Geospatial Metadata Generation – An Integrated Data Management and Documentation Approach.” Computers & Geosciences 34 (4): 387–398. doi:10.1016/j.cageo.2007.04.001.
- Beaujardiere de la Jeff. 2006. OpenGIS Web Map Service Implementation Specification, version 1.3.0, OGC 06-042. Wayland, MA: Open Geospatial Consortium.
- Chen, Xu, Xinyan Zhu, and Daosheng Du. 2008. “Ontology Based Semantic Metadata for Imagery and Gridded Data.” The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences XXXVII: 743–748.
- Chena, Nengcheng, Zeqiang Chena, Chuli Hua, and Liping Di. 2011. “A Capability Matching and Ontology Reasoning Method for High Precision OGC Web Service Discovery.” International Journal of Digital Earth 4 (6): 449–470. doi:10.1080/17538947.2011.553688.
- De Tré, Guy, Antoon Bronselaer, Tom Matthé, Nico Van de Weghe, and Philippe De Maeyer. 2010. “Consistently Handling Geographical User Data.” Information Processing and Management of Uncertainty in Knowledge-Based Systems, Part II, CCIS 81: 85–94.
- Dubois, Didier, Jérôme Mengin, and Henri Prade. 2006. “Possibilistic Uncertainty and Fuzzy Features in Description Logic: A Preliminary Discussion.” Fuzzy Logic and the Semantic Web, Capture Intelligence 1: 101–114.
- Egenhofer, J. Max. 2002. “Toward the Semantic Geospatial Web.” In Proceedings of the 10th ACM International Symposium on Advances in Geographic Information Systems, 1–4. New York: ACM Press.
- Florczyk, Aneta Jadwiga, Francisco Javier López-Pellicer, Javier Nogueras-Iso, and Francisco Javier Zarazaga-Soria. 2012. “Automatic Generation of Geospatial Metadata for Web Resources.” International Journal of Spatial Data Infrastructures Research 7: 151–172.
- Grau, Cuenca Bernardo, Boris Motik, Giorgos Stoilos, and Ian Horrocks. 2012. “Completeness Guarantees for Incomplete Ontology Reasoners: Theory and Practice.” Journal of Artificial Intelligence Research 43: 419–476.
- Guo, Huadong. 2014. “Digital Earth: Big Earth Data.” International Journal of Digital Earth 7 (1): 1–2. doi:10.1080/17538947.2014.878969.
- Haase, Peter, and Johanna Volker. 2008. “Ontology Learning and Reasoning-Dealing with Uncertainty and Inconsistency.” Uncertainty Reasoning for the Semantic Web I, Lecture Notes in Computer Science 5327: 366–384. doi:10.1007/978354089765121.
- Kim, Ick-Hoi, and Ming-Hsiang Tsou. 2013. “Enabling Digital Earth Simulation Models Using Cloud Computing or Grid Computing – Two Approaches Supporting High-Performance GIS Simulation Frameworks.” International Journal of Digital Earth 6 (4): 383–403. doi:10.1080/17538947.2013.783125.
- Li, Wenwen, Michael F. Goodchild, and Robert Raskin. 2014. “Towards Geospatial Semantic Search: Exploiting Latent Semantic Relations in Geospatial Data.” International Journal of Digital Earth 7 (1): 17–37. doi:10.1080/17538947.2012.674561.
- Lukasiewicz, Thomas. 2009. “Uncertainty in the Semantic Web.” In Proceedings of the 3rd International Conference on Scalable Uncertainty Management, SUM'09, edited by L. Godo and A. Pugliese, 2–11. Berlin, Heidelberg: Springer. Lecture Notes in Computer Science, 5785.
- Martin, David, Mark Burstein, and Jerry Hobbs. 2004. “OWL-S: Semantic Markup for Web Services.” Accessed October 11. http://www.w3.org/Submission/OWL-S/
- Maue, Patrick. 2008. “An Extensible Semantic Catalogue for Geospatial Web Services.” International Journal of Spatial Data Infrastructures Research 3: 68–191.
- NISO. 2010. Understanding Metadata. Bethesda: NISO Press. ISBN 1-880124-62-9.
- Percivall, G. 2010. “The Application of Open Standards to Enhance the Interoperability of Geoscience Information.” International Journal of Digital Earth 3 (sup1): 14–30. doi:10.1080/17538941003792751.
- Qi, Guilin, Jeff Z. Pan, and Qiu Ji. 2007. “Extending Description Logics with Uncertainty Reasoning in Possibilistic Logic.” In ECSQARU 2007, edited by K. Mellouli, 828–839. Heidelberg: Springer.
- Schut, Peter. 2007. OpenGIS Web Processing Service, version: 1.0.0, OGC 05-007r7. Wayland, MA: Open Geospatial Consortium.
- Sicilia, Miguel-Angel. 2006. “Metadata, Semantics, and Ontology: Providing Meaning to Information Resources.” International Journal of Metadata, Semantics and Ontologies 1 (1): 83–86. doi:10.1504/IJMSO.2006.008773.
- Sun, Shengtao. 2013. “A Novel Semantic Quantitative Description Method Based on Possibilistic Logic.” Journal of Intelligent & Fuzzy Systems 25 (4): 931–940.
- Trilles, Sergio, Jose Gil, Laura Diaz, and Joquin Huerta. 2012. “Assisted Generation and Publication of Geospatial Metadata.” Proceedings of the AGILE'2012 International Conference on Geographic Information Science, 24–27. Avignon: Springer-Verlag New York.
- Truong, Hai Bang, and Ngoc Thanh Nguyen. 2012. “A Multi-Attribute and Multi-Valued Model for Fuzzy Ontology Integrationon Instance Level.” Intelligent Information and Database Systems, Lecture Notes in Computer Science 7196: 187–197. doi:10.1007/978364228487819.
- Vaccari, Lorenzino, Pavel Shvaiko, and Maurizio Marchese. 2009. “A Geo-Service Semantic Integration in Spatial Data Infrastructures.” International Journal of Spatial Data Infrastructures Research 4: 24–51.
- Vretanos, Panagiotis A. 2005. OpenGIS Web Feature Service Implementation Specification, version 1.1.0, OGC 04-094. Wayland, MA: Open Geospatial Consortium.
- Whiteside, Arliss, and John D. Evans. 2008. Web Coverage Service Implementation Standard, version 1.1.2, OGC 07-067r5. Wayland, MA: Open Geospatial Consortium.
- Wu, Chen. 2012. “WSDL Term Tokenization Methods for IR-Style Web Services Discovery.” Science of Computer Programming 77 (3): 355–374. doi:10.1016/j.scico.2011.08.001.
- Zhang, Chuanrong, Tian Zhao, and Weidong Li. 2010. “The Framework of a Geospatial Semantic Web-based Spatial Decision Support System for Digital Earth.” International Journal of Digital Earth 3 (2): 111–134. doi:10.1080/17538940903373803.