
ABSTRACT
In this paper, we address two challenging issues underlying spatial simulation using software agents immersed in virtual geographic environments (VGE). First, the way to describe virtual VGE models using accurate spatial decomposition approaches structured using graph theory techniques. Second, the use of graph abstraction techniques to support realistic and advanced navigation and path planning capabilities for software agents considering the VGE's characteristics. In order to illustrate our contributions to the growing field of spatial simulations, we present and discuss a case study involving an urban VGE model populated with agents who autonomously and differently interact with multiple abstractions of the same physical environment.
1. Introduction
During the last decade, the multi-agent geo-simulation (MAGS) approach has attracted a growing interest from researchers and practitioners to simulate phenomena in a variety of domains including traffic simulation, crowd simulation, urban dynamics, and changes of land use and cover (Benenson and Torrens Citation2004). Such approaches are used to study phenomena (i.e. car traffic, mobile robots, sensor deployment, crowd behaviors, etc.) involving a large number of simulated actors (implemented as software agents) of various kinds evolving in, and interacting with, an explicit description of the geographic environment called the virtual geographic environment (VGE) (Lin and Batty Citation2009).
A critical step towards the development of a MAGS is the creation of a VGE, using appropriate representations of the geographic space and of the objects contained in it, in order to efficiently support the agents' situated reasoning (Li et al. Citation2015). Since a geographic environment may be complex and large scale, the creation of a VGE is difficult and needs large quantities of geometrical data originating from the environment characteristics (terrain elevation, location of objects and agents, etc.) as well as semantic information that qualifies space (building, road, park, etc.) (Winde and Hoffmann Citation2015).
In order to yield realistic MAGSs, a VGE must precisely represent the geometrical information which corresponds to geographic features. It must also integrate several semantic notions about various geographic features (Moore and Bricker Citation2015). To this end, we propose to enrich the VGE data structure with semantic information that is associated with the geographic features. Moreover, we propose to abstract this semantically enriched and geometrically precise VGE description in order to enable large-scale and complex geographic environments modeling.
In this paper, we present a novel approach that addresses these challenges toward the creation of such a semantically enriched and geometrically accurate VGE, which we call an Informed VGE (IVGE). We also detail our abstraction technique to support large-scale and complex geographic environments. The rest of the paper is organized as follows: Section 2 provides an overview of related works. Section 3 introduces our IVGE computation model. Section 4 presents the proposed abstraction approach which is composed of the three processes: (1) geometric abstraction, (2) topologic abstraction, and (3) semantic abstraction. Section 5 presents a case study involving model software agents who autonomously and differently interact with each other and within an urban informed VGE model. Section 6 discusses the proposed abstraction approach. Finally, Section 7 concludes and presents the future perspectives of this work.
2. Related works
Virtual environments and spatial representations have been used in several application domains. For example, Farenc et al. proposed a virtual scene for virtual humans representing a part of a city for graphic animation purposes (Citation1999). Thomas and Donikian proposed a modeling system that is able to produce a multi-level database of virtual urban environments devoted to driving simulations (Citation2003). More recently, Shao and Terzopoulos proposed a virtual environment representing the New York City's Pennsylvania Train Station populated by autonomous virtual pedestrians in order to simulate the movement of people (Citation2005). Paris, Donikian, and Bonvalet also proposed a virtual environment representing a train station populated by autonomous virtual passengers in order to characterize the levels of services inside exchange areas (Citation2006). However, since the focus of these approaches is computer animation and virtual reality, the virtual environment usually plays the role of a simple background scene in which agents mainly deal with geometric characteristics (Lü et al. Citation2015). Indeed, the description of the virtual environment is often limited to the geometric level, though it should also contain topological and semantic information for other types of applications using advanced agent-based simulations. Current virtual environment models do not support large-scale and complex geographic environments and fail to capture real-world physical environments' characteristics.
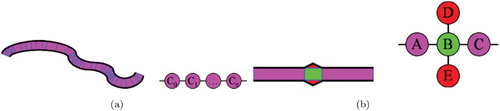
When dealing with large-scale and complex geographic environments, the spatial subdivision which can be either exact or approximate produces a large number of cells (Fehler, Franziska, and Neumann Citation2005). The topologic approach allows the representation of such a spatial subdivision using a graph structure and to take advantage of efficient algorithms provided by the graph theory (Paris, Donikian, and Bonvalet Citation2006). However, the graph size may still remain large when dealing with geographic environments with dense geographic features (Fehler, Franziska, and Neumann Citation2005). Moreover, geographic features with curved geometries () produce a large number of triangles since they are initially represented by a large number of segments.
Figure 1. Cells resulting from curved geometries (a) and alignment anomalies (b) (Paris, Donikian, and Bonvalet Citation2006).
An environment abstraction is a process used to better organize the information obtained at the time of spatial subdivision of the geographic environment. The unification process is addressed principally in two ways: (1) a pure topological (Lamarche and Donikian Citation2004) unification which associates the subdivision cells according to their number of connexions and (2) a more conceptual unification which introduces a semantical definition of the environment, like with the IHT-graph structure (Thomas and Donikian Citation2003). Lamarche and Donikian proposed a topologic abstraction approach that assigns to each node of the graph resulting from the space decomposition a topological qualification according to the number of connected edges given by its arity (Citation2004). The topologic abstraction algorithm aims to generate an abstraction tree by merging interconnected cells while trying to preserve topological properties (Lamarche and Donikian Citation2004). When merging several cells into a single one, the composition of cells is stored in a graph structure in order to generate the abstraction tree. The topologic abstraction proposed by Lamarche and Donikian relies on the topological properties of the cells and reduces the size of the graph that represents the space subdivision (Citation2004). However, the topological characteristics are not sufficient to abstract a virtual environment when dealing with a large-scale and complex environment involving areas with various qualifications (buildings, roads, parks, sidewalks, etc.).
Not much research has been done on semantic integration in the description of a virtual environment. The Computer Animation and Behavioral Animation research fields provide a few attempts to integrate the semantic information in order to assist agents interacting with their environments. Semantic information has been used for different purposes, including the simulation of inhabited cities (Farenc et al. Citation1999), computer animation (Kallmann Citation2001), and simulation of virtual humans (Garcia Rojas Martinez Citation2009). Farenc has first used the notion of Informed Environments (Farenc et al. Citation1999). She defined informed environments as a database that represents urban environments with semantic information representing urban knowledge (Farenc et al. Citation1999). An informed environment is thus characterized as a place where information (semantic and geometrical) is dense, and can be structured and organized using rules (Farenc et al. Citation1999). Building an informed environment as presented by Farenc consists of adding a semantic layer onto a core corresponding to a classical scene (a set of graphical objects) modeled using graphical software for computer animation purposes (Farenc et al. Citation1999).
Smart objects introduced by Kallmann and coworkers allow easy reusability of already defined objects located within the virtual environment (Kallmann Citation2001). This property stems from the fact that the smart objects are self-contained and the animation control is decentralized, alleviating the need for complex updates of the agents in the simulation whenever a new object is added to the virtual environment (). Unfortunately, the smart objects are strictly targeted towards animation – the semantic information contained within them is animation-oriented and geometric in nature. Hence, semantic information is not available for agents to reason about them.
Figure 2. An agent representing a human operating a smart object – a drawer (Kallmann Citation2001).

The Improv system described by Perlin and Goldberg consists of an Animation Engine, used for the motion generation aspects, and a Behavior Engine, used for describing the decision-making process through rules (Citation1996). The Behavior Engine allows scripting in a language close to normal English, making it accessible for the non-programmers as well. Parametrized action representation by Badler et al. describes an action by specifying information about the pre-conditions and post-conditions of an action, its execution steps and which objects are concerned by it. The actions can prescribe chaining of the actions allowing for complex behaviors. The actions come in two forms: uninstantiated (UPAR) and instantiated (IPAR). The uninstantiated actions do not specify the virtual character nor the objects involved in the action, essentially representing the whole class of possible actions. Instantiated actions are essentially UPARs extended with the references to the virtual character, objects involved and termination conditions. Collection of UPARs represents all the actions possible in the system.
On the animation front, virtual human–object interaction techniques were specifically addressed in the Object-Specific Reasoner (OSR) (Libby and Norman Citation1994). The primary aim of this work was to bridge the gap between high-level AI planners and the low-level actions for objects based on the observation that objects can be categorized with respect to how they are to be manipulated (Levison Citation1996). OSR differs from the work presented in this document in that Levison uses a top-down approach (Levison Citation1996). Generic actions are gradually refined by the agent using object taxonomies into executable actions. The agent classifies the object into a category (e.g. a crate belongs to the containers category) and then uses that information to decide what to do with it (e.g. containers can be opened by hands).
Finally, Vosinakis and Panayotopoulos have introduced the Task Definition Language and aimed at filling the gap between higher-level decision processes and an agent's interaction with the environment (Citation2003). This language supports complex high-level task descriptions through a combination of parallel, sequential and conditionally executed sequences of primitive actions. The primitive actions can be of two types; either pre-defined with fixed duration or goal-oriented, where the termination condition is given for the action. Although the TDF approach allows one to describe complex and high-level agent behaviors, it does not support spatial.
Despite the multiple designs and implementations of virtual environment frameworks and systems, the creation of geometrically accurate and semantically enriched geographic content is still an open issue. Indeed, research has focused almost exclusively on the geometric and topologic characteristics of the VGE. However, the structure of the virtual environment description, the optimization of this description to support large-scale and complex geographic environments, the meaning of the geographic features contained in the environment, as well as the ways to interact with them have received less attention.
The work done towards the representation of semantic information in virtual environments has been mostly carried out at a geometric level (Garcia Rojas Martinez Citation2009). An enriched representation of virtual environments has been proposed by Gutiuerez Alonso for computer animation and user interface purposes (Guterrez Alonso Citation2005). This approach addresses the lack of flexibility of virtual objects within a virtual environment. It mainly refers to the need for adaptive entities, from the perspectives of the geometric representation and the user interface. Gutiuerez Alonso proposes a semantic model that aims to represent the meaning and functionality of objects in a virtual scene (Citation2005). However, since the purpose of Gutiuerez Alonso 's approach is computer animations, the semantic information integration is located at the object description level rather than enriching the description the geographic environments.
Virtual environments are usually created as computer graphics applications, with minimal consideration given to the semantic information (Guterrez Alonso Citation2005). The typical data are a convex mesh representing some geometric shapes. There is a gap between geometry and semantic information in current VGE models. Only a few works have attempted to integrate semantic information into a VGE's description (Yersin Citation2009). Moreover, semantic information has been used in an ad hoc way without any standard formalism. Indeed, semantic information integration into a VGE's description is by nature a knowledge representation problem. A suitable and standard knowledge representation formalism should be used to integrate semantic information in the VGE's description (Chen Citation2013) and (Yu et al. Citation2015).
3. Computation of IVGE
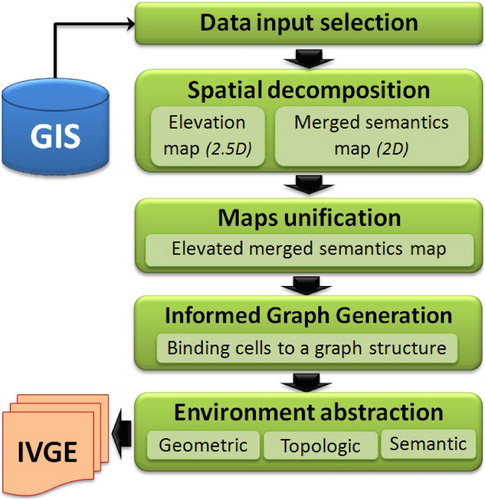
In this section, we briefly present our automated approach to compute the IVGE data using vector GIS data. This approach is based on four stages: input data selection, spatial decomposition, maps unification, and finally the generation of the informed topologic graph (Mekni and Moulin Citation2009; Mekni Citation2013).
GIS input data selection: The first step of our approach consists of selecting the different vector data sets which are used to build the IVGE. The input data can be organized into two categories. First, elevation layers contain geographical marks indicating absolute terrain elevations. As we consider 2.5D IVGE, a given coordinate cannot have two different elevations, making it impossible to represent tunnels for example. Multiple elevation layers can be specified, and if this limitation is respected, the model can merge them automatically. Second, semantic layers are used to qualify various types of data in space. Each layer indicates the physical or virtual limits of a given set of features with identical semantics in the geographic environment, such as roads or buildings. The limits can overlap between two layers, and our model is able to merge the information.
Spatial decomposition: The second step consists of obtaining an exact spatial decomposition of the input data into cells. First, an elevation map is computed using the constrained Delaunay triangulation (CDT) technique. All the elevation points of the layers are injected into a 2D triangulation, the elevation being considered as an attribute of each node. Second, a merged semantics map is computed, corresponding to a constrained triangulation of the semantic layers. Indeed, each segment of a semantic layer is injected as a constraint which keeps track of the original semantic data by using an additional attribute for each semantic layer. The obtained map is then a constrained triangulation merging all input semantics where each constraint represents as many semantics as the number of input layers containing it ( and ).
Figure 3. Various semantic layers related to Quebec City (Canada): (a) road network, (b) old city wall, (c) marina, (d) governmental buildings, and (e) houses.
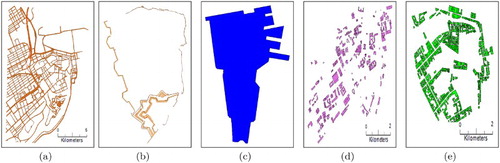
Figure 4. The two processed maps (a, b) and the unied map (c).
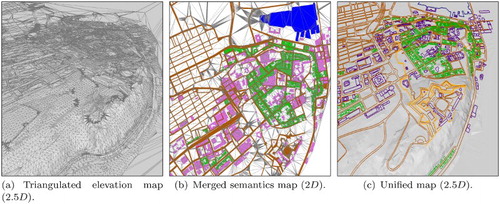
Map unification: The third step to obtain our IVGE consists of unifying the two maps previously obtained. As we consider 2.5D IVGE, a given coordinate cannot have two different elevations, making it impossible to represent tunnels for example. This phase can be depicted as mapping the merged semantic map onto the 2.5D elevation map in order to obtain the final 2.5D elevated merged semantics map. First, preprocessing is carried out on the merged semantics map in order to preserve the elevation precision inside the unified map. Indeed, all the points of the elevation map are injected into the merged semantics triangulation, creating new triangles. Then, a second process elevates the merged semantics map. The elevation of each merged semantics point P is computed by retrieving the corresponding triangle T inside the elevation map, i.e. the triangle whose
projection contains the coordinates of P. Once T is obtained, the elevation is simply computed by projecting P on the plane defined by T using the Z axis. When P is outside the convex hull of the elevation map then no triangle can be found and the elevation is computed using the average height of the points of the convex hull which are visible from P.
Informed topologic graph: The resulting unified map now contains all the semantic information of the input layers, along with the elevation information. This map can be used as an Informed topologic graph (ITG), where each node corresponds to the map's triangles, and each arc corresponds to the adjacency relations between these triangles. Then, common graph algorithms can be applied to this topological graph, and graph traversal algorithms in particular. One of these algorithms retrieves the node, and therefore the triangle, corresponding to given coordinates. Once this node is obtained, it is possible to extract the data corresponding to the position, such as the elevation from the 2.5D triangle, and the semantics from its additional attributes. Several other algorithms can be applied, such as path planning or graph abstraction, but they are out of the scope of this paper and will not be detailed here.
4. Abstraction of IVGE
In this section, we describe the abstraction process that optimizes the description of the IVGE. Section 4.1 presents the first enhancement which is related to the qualification of terrain. We propose a novel approach of information extrapolation using a one-time spatial reasoning process based on a geometric abstraction. This approach can be used to fix input elevation errors, as well as to create new qualitative data relative to elevation variations. These data are stored as additional semantics bound to the graph nodes, which can subsequently be used for spatial reasoning. Section 4.2 introduces the second enhancement which optimizes the size of the informed graph structure using a topological abstraction process. This process aims at building a hierarchical topologic graph structure in order to deal with large-scale VGEs. Section 4.3 details the third enhancement technique which propagates qualitative input information from the arcs of the graph to the nodes, which allows deduction of the internal parts of features such as buildings or roads in addition to their boundaries. Moreover, this technique uses conceptual graphs (CG) (Sowa Citation2000), a standard formalism for the representation of semantic information. illustrates the abstracted IVGE generation model.
Figure 5. The IVGE global architecture of IVGE generation including the environment abstraction process.
4.1. Geometric abstraction
Spatial decomposition subdivides the environment into convex cells. Such cells encapsulate various quantitative geometric data which are suitable for precise computations. Since geographic environments are seldom flat, it is important to consider the terrain's elevation and shape. While elevation data are stored in a quantitative way which is suitable for exact calculations, spatial reasoning often needs to manipulate qualitative information. Indeed, when considering a slope, it is obviously simpler and faster to qualify it using an attribute with ordinal values such as gentle and steep rather than using numerical values. However, when dealing with large-scale geographic environments, handling the terrain's elevation, including its light variations, may be a complex task. To this end, we propose an abstraction process that uses geometric data to extract the average terrain's elevation information from spatial areas. The objectives of this geometric abstraction are threefold. First, it aims to reduce the amount of data used to describe the environment. Second, it helps for the detection of anomalies, deviations, and aberrations in elevation data. Third, the geometric abstraction enhances the environment description by integrating qualitative information characterizing the terrain shape. In this section, we first present the algorithm which computes the geometric abstraction. Then, we describe two processes which use the geometric abstraction, namely filtering elevation anomalies and extracting elevation semantics.
4.1.1. Geometric abstraction algorithm
The geographic environment generated by our IVGE model is subdivided into cells of different shapes and sizes. The algorithm takes advantage of the graph structure obtained from the IVGE extraction process. A cell corresponds to a node in the topological graph. A node represents a triangle generated by the CDT spatial decomposition technique. A cell is characterized by its boundaries, its neighboring cells, its surface, as well as its normal vector which is a vector perpendicular to its plane.
Now, we introduce the notion of a group, which is a collection of adjacent cells. The grouping strategy is based on a coplanarity criterion which is assessed by computing the difference between the normal vectors of two neighboring cells or groups of cells. Since a group is basically composed of adjacent cells, it is obvious to characterize a group by its boundaries, its neighboring groups, its surface, as well as its normal vector. However, the normal vector of a group must rely on an interpretation of the normal vectors of its composing cells. In order to compute the normal vector of a group, we adopt the area-weight normal vector (Sheng-Gwo and Jyh-Yang Citation2005) which takes into account the unit normal vectors of its composing cells as well as their respective surfaces. Let denote the surface area of the cell and
be its unit normal vector. Let
be the area-weight normal vector of the group gr. The formula to compute
is:
(1) Let
denote the surface area of a cell c and
be its unit normal vector. The area-weight normal vector
of a group G is computed as follows:
(2) The geometric abstraction algorithm uses two input parameters: (1) a set of starting cells which act as access points to the graph structure and (2) a Δ parameter which corresponds to the maximal allowed difference between cells' gradients. Two adjacent cells are considered coplanar, and hence grouped, when the angle between their normal vectors is lesser than Δ. The recursive geometric abstraction algorithm is composed of five steps:
For each cell c of the starting cells, create a new group G and do step 2.
For each neighbouring group or cell n of G, if the neighbour has already been processed, do step 3, else do step 5.
If angle
, then do step 4. Otherwise do step 5.
Merge n in group G, then evaluate
If n is an unprocessed cell, create a new group G with n and do step 2.
The algorithm starts by visiting all the cells of the virtual environment. For each visited cell , a new group
is created and the cell is registered as a member (line 2). The area-weighted normal vector of
is computed using Equation (Equation2
(2) ). Besides, the algorithm tests the coplanarity of
with its neighbouring cells (
belonging to
) using Equation (Equation2
(2) ) and to decide whether to include these neighbours in the group
to which
belongs. Next, the algorithm explores and processes the neighbouring cells of
. For each neighbour, if it is visited for the first time, a new group is created and the neighbour cell is registered as its first member.
Afterwards, the algorithm computes the angles resulting from the merging of and
groups. The area-weighted normal vector resulting from the integration of
's elements in the
group is computed. The algorithm goes on by computing the angle between the new (after the merge) and the previous (before the merge) area-weighted normal vectors. The angle is given by the scalar product of the two normalised vectors
and
. If this angle respects the input parameter Δ (line 9), then merging is performed (line 10).
In the proposed algorithm, the geometric abstraction produces coherent groups whose cells are coplanar and with respect to the Δ threshold. The geometric abstraction process abstracts a higher order topologic graph and produces a new graph with fewer nodes which helps to enhance the performance of spatial reasoning mechanisms.
The analysis of the resulting groups helps to identify anomalies in elevation data. Such anomalies need to be fixed in order to build a realistic VGE. Furthermore, the average terrain slope which characterizes each group is a quantitative datum described using area-weighted normal vectors. Such quantitative data are too precise to be used by qualitative spatial reasoning. Hence, a qualification process would greatly simplify spatial reasoning mechanisms. Thus, the geometric abstraction can improve IVGE by filtering the elevation anomalies, qualifying the terrain slope using semantics and integrating such semantics in the description of the geographic environment.
4.1.2. Filtering elevation anomalies
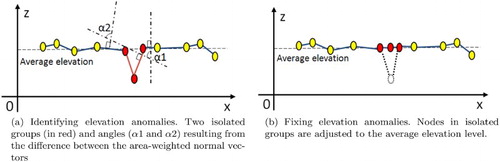
Analysis of the geometric abstraction may reveal an isolated group which is totally surrounded by another single coherent group. These groups are characterized by a large difference between their respective area-weighted normal vectors. Such isolated groups are often characterized by their small surface areas and can usually be considered as anomalies, deviations, or aberrations in the initial elevation data. MAGS users may verify if such groups correspond to real pits or depressions, or substantial mounds or heaps on the landscape. The geometric abstraction process helps to identify them and can help to automatically filter such anomalies using a two-phase process. First, isolated groups are identified ((a)). The identification of isolated groups is based on two key parameters: (1) the ratio between the surface areas of the surrounded and surrounding groups and (2) the difference between the area-weighted normal vectors of the surrounded and surrounding groups. Second, these isolated groups are adjusted to the average level of elevation of the surrounding ones ((b)). The lowest and the highest elevation (,
) of the surrounding group (
) are computed. Then, the elevation of all the vertices of the isolated group (
) is adjusted using the average between
and
. As a consequence, we obtain more coherent groups in which anomalies of elevation data are corrected.
Figure 6. Profile section of anomalous Isolated Groups adjusted to the average elevation of the surrounding ones.
4.1.3. Qualification of terrain shape
The geometric abstraction algorithm computes quantitative geometric data which precisely describe the terrain. However, handling and exploiting quantitative data is a complex task as the range of values may be too large and calculations or analysis methods may be too costly. Therefore, we propose to interpret the quantitative data representing the terrain shape by qualifying the terrain characteristics. Semantic labels, which are called the shape semantics, are associated with quantitative intervals of values that represent the terrain's shape. In order to obtain the shape's semantics, we propose a two-step process taking advantage of the geometric abstraction: (1) calculation of the inclination, or the angle α between the weighted normal vector of a group grp and the horizontal plane and (2) assigning to each discrete value a semantic category which qualifies it. The discretisation process can be done in two ways: a customised and an automated approach.
The customised approach requires that the user provides a complete specification of the discretisation to qualify the range of slopes. Indeed, the user needs to specify a list of inclination intervals as well as their associated semantic labels. The algorithm iterates over the groups obtained by the geometric abstraction. For each group grp, it calculates the inclination value I. Then, this process checks the interval bounds and determines in which one the inclination value I falls. Finally, the customized discretisation extracts the semantic shape label from the selected slope interval and assigns it to the group grp. For example, let us consider the following inclination interval and the associated semantic label: . Such a customized specification associates the semantic label gentle slope to inclination values included in the interval
and the semantic label steep slope to inclination values included in the interval
.
The automated approach only relies on a list of semantic shape labels representing the slope qualifications. Let N be the number of elements of this list, and T be the total number of groups obtained by the geometric abstraction algorithm. First, the automated discretisation order groups based on their terrain inclination. Then, it iterates over the ordered groups and associates a uniform number of groups, T/N, to each semantic label from the semantic set, each T/N processed groups. For example, let us consider the following semantic slope labels: , and an ordered set S of groups denoted as follows:
with the following respective slope values:
. For every 2 groups (as T = 6 and N = 3,
), the automated discretisation assigns a new semantic slope label:
.
Let us compare these two discretisation approaches. On the one hand, the customized discretisation process allows one to freely specify the qualification of the slopes, choosing ranges that match the problem domain. However, qualifications resulting from such a flexible approach deeply rely on the correctness of the interval bounds' values. Therefore, the customized discretisation method requires to have a good knowledge of the terrain characteristics in order to guarantee a valid specification of inclination intervals. On the other hand, the automated discretisation process is also able to qualify slopes without the need to specify interval bounds. This method also guarantees that all the specified semantic attributes will be assigned to the groups without a prior knowledge of the environment characteristics. However, the resulting intervals may have no relation to the problem domain.
4.1.4. Improving the geometric abstraction
Thanks to the extraction of slope semantics, terrain shape is qualified using semantic attributes and associated with groups and with their cells. Because of the nature of the classification intervals, adjacent groups with different area-weighted normal vectors may obtain the same semantic slope label. In order to improve the results provided by the geometric abstraction, we propose a process that merges adjacent groups which share the same semantic slope. This process starts by iterating over groups. Every time it finds a set of adjacent groups sharing an identical semantic slope, it creates a new group. Next, cells composing the adjacent groups are registered as members of the new group. Finally, the area-weighted normal vector is computed for the new group. Hence, this process guarantees that every group is only surrounded by groups which have different semantic slopes.
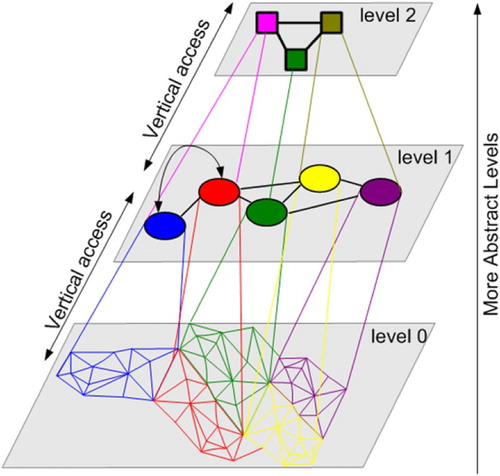
4.2. Topological abstraction
In Section 3, we presented our work on the generation of informed VGEs using an exact spatial decomposition scheme which subdivides the environment into convex cells organized in a topological graph structure. However, inside large-scale and complex geographic environments (such as a city for example), such topological graphs can become very large. The size of such a topological graph has a direct effect on paths' computation time for path-finding. In order to optimize the performance of path computation, we need to reduce the size of the topological graph representing the IVGE. The aim of the topological abstraction is to provide a compact representation of the topological graph that is suitable for situated reasoning and enables fast path planning. However, in contrast to the geometric abstraction which only enhances the description of the IVGE with terrain semantics, the topological abstraction extends the topological graph with new layers. In each layer (except for the initial layer which is called level 0), a node corresponds to a single or a group of nodes in the immediate lower level (). The topological abstraction simplifies the IVGE description by combining cells (triangles) in order to obtain convex groups of cells. Such a hierarchical structure evolves the concept of hierarchical topologic graph in which cells are fused into groups and edges are abstracted in boundaries. To do so, convex hulls are computed for every node of the topological graph. Then, the coverage ratio of the convex hull is evaluated as the surface of the hull divided by the actual surface of the node. The topological abstraction finally performs groupings of a set of connected nodes if and only if the group ratio is equal or close to one depending on the problem domain. Let C be the convexity rate and be the convex hull of the polygon corresponding to gr. C is computed as follows:
(3) The convex property of each group's hull needs to be preserved after the topological abstraction. This ensures that an entity can move freely inside a given cell (or group of cells), and that there exists a straight path linking edges belonging to the same cell (or group of cells).
Figure 7. The topological graph extraction from space decomposition and extension into different levels using the topological abstraction.
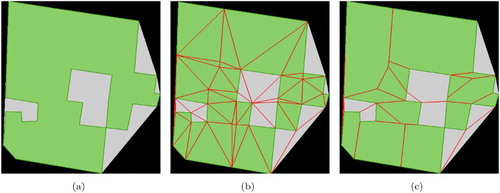
illustrates an example of the topological abstraction process and the way it reduces the number of cells representing the environment. In (a), we present the initial vector format GIS data of a complex building. (b) depicts the initial exact spatial decomposition which yields 63 triangular cells. (c) presents 28 convex polygons generated by the topological abstraction algorithm. The abstraction rate of the number of cells representing the environment is around . This rate is computed using the ratio of the initial number of cells produced by the space decomposition techniques (63) by the number of convex polygons (28) obtained using the topologic abstraction technique with a convexity rate equal to 1
Figure 8. Illustration of the topological abstraction process with a strict convex property (): (a) the GIS data of a complex building, (b) the exact space decomposition using CDT techniques (63 triangular cells), and (c) the topological abstraction (28 convex polygons).
To conclude, we described in this section a topologic abstraction process in order to enhance the performance of the exploration of the IVGE's description. This process aims to simplify large informed graphs corresponding to large-scale and complex geographic environments. Our topologic abstraction approach reduces the number of convex cells by overlaying the informed graph with a topologically abstracted graph. The resulting IVGE is hence based on a hierarchical graph whose lowest level corresponds to the informed graph initially produced by the spatial decomposition. In the following section, we show how we use a well-known knowledge representation formalism to represent the semantic information in order to further enhance the IVGE description with respect to agents' and the environment's characteristics (Lokka and Çöltekin Citation2016).
4.3. Semantic abstraction
Two kinds of information can be stored in the description of an IVGE. Quantitative data are stored as numerical values which are generally used to depict geometric properties (like a path's width of 2 m) or statistical values (like a density of 2.5 persons per square meter). Qualitative data are introduced as identifiers which can range from a word with a given semantics, called a label, to a reference to an external database or to a specific knowledge representation. Such semantic information can be used to qualify an area (like a road or a building) or to interpret a quantitative value (like a narrow passage or a crowded place) (Jia et al. Citation2016). An advantage of interpreting quantitative data is to reduce a potentially infinite set of inputs to a discrete set of values, which is particularly useful to condense information in successive abstraction levels to be used for reasoning purposes. Furthermore, the semantic information enhances the description of the IVGE, which in turn extends the agents' knowledge about their environment. However, the integration of the semantic information raises the issue of its representation. Therefore, we need a standard formalism that allows for precisely representing the semantic information which qualifies space and which is computationally tractable in order to be used by spatial reasoning algorithms used by agents. In the following subsection, we present the (CGs) formalism which we use to represent the semantic information in the IVGE. Next, we introduce the semantic abstraction process which takes advantage of both the CGs representation and the hierarchical topological graph. This semantic abstraction aims to extract a specialized view of the IVGE which takes into account the characteristics of the involved agent archetypes, the performed actions, and the locations where these actions occur.
4.3.1. Representation of semantic information using CGs
Several knowledge representation techniques can be used to structure semantic information and to represent knowledge in general such as frames (Minsky Citation1974), rules (Lewis, Skarek, and Varga Citation1995) (also called If–Then rules), tagging (Varlan Citation2010), and semantic networks (Sowa Citation2000) which have originated from theories of human information processing. Since knowledge is used to achieve intelligent behavior, the fundamental goal of knowledge representation is to represent knowledge in a manner that facilitates inferencing (i.e. drawing conclusions) from knowledge. In order to select a knowledge representation (and a knowledge representation system to logically interpret sentences in order to derive inferences from them), we have to consider the expressivity of the knowledge representation. The more expressive a knowledge representation technique is, the easier (and more compact) we can describe and qualify geographic features which characterize IVGE. Various artificial languages and notations have been proposed to represent knowledge. They are typically based on logic and mathematics and can be easily parsed for machine processing. However, Sowas' conceptual graphs (Sowa Citation2000) are widely considered an advanced standard logical notation for logic based on existential graphs proposed by Charles Sanders Peirce and on semantic networks. Conceptual Graph Interchange Format has been standardized in 2017 as a part of the ISO standard for Common Logic (ISO 24707). CGs are commonly accepted to be a powerful knowledge representation technique as they combine logic and computational linguistics (Haddad and Moulin Citation1995). We chose to use CGs in order to represent spatial semantic information for several reasons. First, CGs are known to express meaning in a form that is logically precise and computationally tractable (Sowa Citation2000). Second, CGs are proved to be efficient for spatial semantic information (spatial semantics) and geographic knowledge representation (Haddad and Moulin Citation1995). Third, with their direct mapping to natural language, CGs serve as an intermediate language to translate computer-oriented formalisms to and from natural language. With their graphic representation, CGs serve as a readable, but formal design and specification language. CGs are basically graphs which are analogous to the description of our IVGE model. As a consequence, nodes from CGs may be easily associated with nodes of the IVGE's description. Exploring and manipulating CGs also take advantage of the efficiency of algorithms from graph theory. Fourth, CGs provide extensible means to capture and represent real-world knowledge and have been implemented in a variety of applications for information retrieval (Hensman and Dunnion Citation2010), natural language processing (Chu and Cesnik Citation2001), and qualitative simulations (Haddad and Moulin Citation1995). However, our proposal to use CGs to represent spatial semantics in VGEs and to reason about them is an innovative issue. Indeed, VGEs integrating semantic information expressed using a standard formalism did not exist.
Syntactically, a CG is a network of concept nodes linked by relation nodes. Concept nodes are represented by the notation [Concept Type: Concept instance] and relation nodes by (Relationship-Name). A concept instance can be either a value, a set of values, or even a CG. The formalism can be represented in either graphical or character-based notations. In the graphical notation, concepts are represented by rectangles, relations by circles and the links between concept nodes and relation nodes by arrows. The most abstract concept type is called the universal type (or simply Universal) denoted by the symbol ⊥.
A MAGS usually involves a large number of situated agents of different types (human, animal, static, mobile, etc.) performing various actions (moving, perceiving, etc.) in virtual geographic spaces of various extents. Using CGs greatly simplifies the representation of complex situated interactions occurring at different locations and involving various agents of different types. In order to create models for MAGS, we consider three fundamental abstract concepts: (1) agents, (2) actions, and (3) locations.
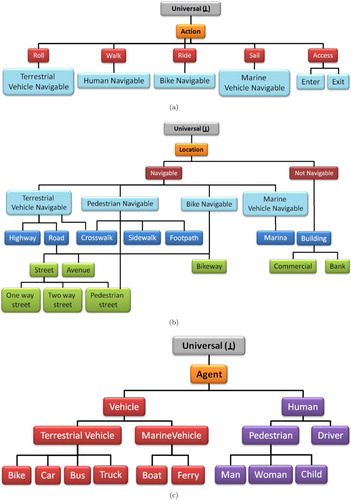
Taking advantage of the abstraction capabilities of the CGs formalism, through concept type lattice (CTL), instead of representing different situated interactions of various agents in distinct locations, we are able to represent abstract actions performed by agent archetypes in abstract locations. Concept types are organized in a hierarchy according to levels of generality. However, this hierarchy is not a tree, since some concept types may have more than one immediate supertype. Moreover, we first need to specify and characterize each of the abstract concepts. The CTL enables us to specialize each abstract concept in order to represent situated behaviors such as path planning of agents in space. presents the first level of the CTL refining the agent, action, and location concepts. (a), (b), and (c) present the expansion of the CTL presented in . (a) illustrates some situated actions that can be performed by agents in the IVGE such as sailing for maritime vehicles, rolling for terrestrial vehicles, walking for humans, and accessing for humans to enter or exit buildings (we assume that buildings are not navigable locations from the perspective of outdoor navigation). (b) depicts how the location concept may be specialized into Navigable and Not Navigable concepts. The Navigable concept may also be specialized into Terrestrial Vehicle Navigable, Pedestrian Navigable, Marine Vehicle Navigable, and Bike Navigable which are dedicated navigable areas with respect to agent archetypes and environmental characteristics as specified by the elementary semantics. (c) illustrates a few agent archetypes that are relevant to our geo-simulation including pedestrians, cars, trucks, and bikes.
Figure 9. Illustration of the action, agent, and location concepts using a concept type lattice.
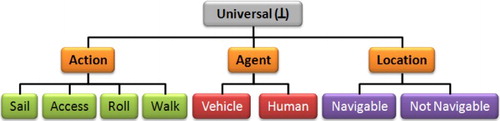
Figure 10. An example of a conceptual description of agents archetypes (a), actions performed (b), and locations situated in a geographic environment (c).
In order to show how powerful such a representation may be, let us consider the following example. We want to build a MAGS simulating the navigation of three human agents (a man, a woman, and a child), two bike riders (a man and a woman), and three vehicles (a car, a bus, and a boat) in a coastal city. The navigation behaviors of these different agent archetypes must respect the following constraints (or rules): (1) pedestrian agents can only move on sidewalks, on pedestrian streets, and eventually on crosswalks if needed; (2) vehicles can move on roads and highways; (3) boats sail on the river and stop at the harbour port; and (4) bikes move on bikeways, roads, and streets but not on pedestrian streets. Using standard programming languages, it might be difficult to represent or develop the functions related to such simple navigation rules which take into account both the agents' and the locations' characteristics. However, the representation of these navigation rules becomes an easy task when using CGs and our defined CTL. Here are their expressions in CGs:
[PEDESTRIAN:*p]<-(agnt)<-[WALK:*w1]->(loc)->[PEDESTRIAN NAVIGABLE:*pn]
[VEHICLE:*v]<-(agnt)<-[ROLL:*r1]->(loc)->[TERRESTRIAL NAVIGABLE:tn]
The arrows indicate the expected direction for reading the graph. For instance, the first example may be read: an agent *p which is a ‘ pedestrian’ walks on a location *pn which is ‘pedestrian navigable’. Since this expression involves the concepts Pedestrian, Walk and Pedestrian Navigable, this rule remains valid for every sub-type of these concepts. Therefore, thanks to CGs and the CTL, there is no need to specify the navigation rules for men, women, and children if they act as pedestrians in locations such as pedestrian streets, sidewalks, or crosswalk. Indeed, these agent archetypes are subtypes of the Pedestrian concept and pedestrian streets, sidewalks, and crosswalks are subtypes of the Pedestrian Navigable concept. To conclude, CGs offer a powerful formalism to easily describe different concepts involved in MAGS including agents, actions, and environments.
5. Case study: human agents taking buses
In this section, we illustrate our contributions to the growing field of spatial simulations. We present and discuss a case study involving an urban VGE model populated with agents who autonomously and differently interact with multiple abstractions of the same physical environment. This case study aims to illustrate how spatial agents representing humans leverage the informed VGE we propose. In order to acquire knowledge about the environment and to reason about it, spatial agents apprehend the virtual environment and make decisions according to their types and capabilities and taking into account its characteristics. In this example, a few human agents representing students and workers interact with the IVGE in order to plan their bus commute to get to their destinations, the university and an office building, respectively. This case study also involves a few agents representing bus stations.
Let us consider three types of agents: Bus, Student, and Worker and several actions including STOP, GO, GETIN, WALK and ROLL. The Bus agent type represents the different kinds of buses including city buses, school buses, etc. The Student agent type includes schoolchildren, pupils, students, etc. The Worker agent type represents working persons.
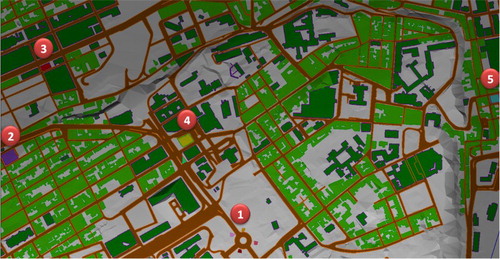
This case study involves an informed VGE representing a part of Quebec City (). In this IVGE, we first specified the different semantic information that qualify our virtual urban environment. Second, we specified the above introduced agent types namely, BUS, STUDENT, and WORKER. Two IVGE instances are specified: (1) HUMANNAV representing a view of the IVGE including the different geographic zones on which an agent of type human can move;(2) VEHICLENAV representing a view of the IVGE including the different geographic zones on which an agent of type vehicle can move.
Figure 11. The IVGE representing a part of Quebec city where the spatial behaviour simulation takes place with five geo-referenced locations.
Besides, we specify the following facts:
students and workers use buses to respectively reach universities and work places:
cg([STUDENT]
cg([WORKER]
cg([STUDENT]
cg([WORKER]
humans walk on human navigable zones:
cg([HUMAN]
vehicles roll on vehicle navigable zones:
cg([VEHICLE]
buses stop at stations:
cg([BUS]
In addition, two instances of buses, two instances of stations, and two instances of destinations are defined: Bus1, Bus2, Station1, Station2, w, and u . Bus1 which stops at station1 goes to workplace w. Bus2 which stops at station2 goes to the university u.
cg([BUS: Bus1]agnt-[GO]-loc
[WORKPLACE:w]).
cg([BUS: Bus2]agnt-[GO]-loc
[UNIVERSITY: u]).
cg([BUS: Bus1]agnt-[Stop]-loc
[STATION: Station1]).
cg([BUS: Bus2]agnt-[Stop]-loc
[STATION: Station2]).
Now that the agent types are specified, and the facts which characterize their instances are defined, we carry out the simulation in which two agents of type student and three agents of type worker interact with the IVGE evolving in order to localize the appropriate station from which they can catch the right bus to reach their final destinations. For simplification purposes, agents of type bus follow a pre-defined computed path ((b)). Agents of type student and worker start by identifying their own locations within the IVGE. Next, they interrogate the IVGE in order to determine which bus they should take in order to reach their final destinations ((a)). The student agent asks the following query which bus goes to the university?:
?- cg([?]
The answer provided by the IVGE is: x = Bus2;
Then, the student agent asks the following query: where does Bus2 stop at?:
?- cg([BUS: Bus2]
The answer provided by the IVGE is: x = Station2;
Figure 12. Stations, student and worker passengers, and buses: (a) 3 students and 2 workers agents; (b) 4 agents of type Bus approaching the stations. Agents either students, workers, or buses are associated with their respective perception fields.
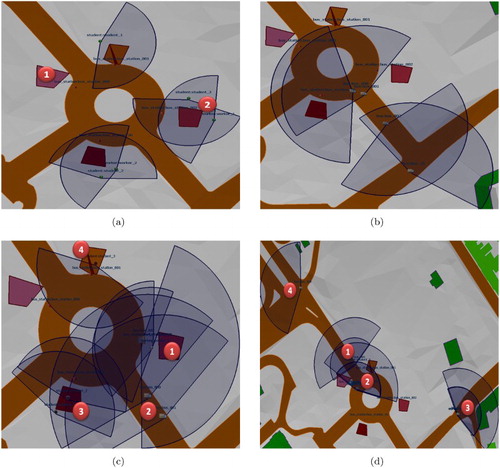
Once answers are provided, agents plan paths using this semantic description. Agents move towards the appropriate bus station, then wait for the bus ((b)). Since our agents are endowed with perception capabilities, they are able to detect when a bus arrives at the station. The agent bus is also endowed with the same spatial capabilities and waits at the station until all the agents are on broad.
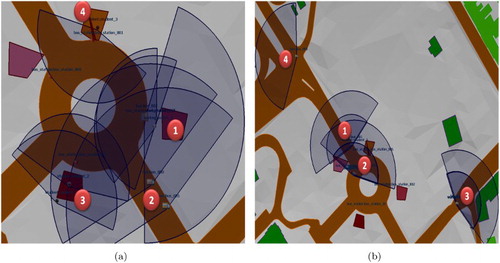
depicts the simulation of human agents representing the students and the workers taking the bus in order to get to their final destinations. In (c), (1) shows two passengers getting on the bus; (2) two buses approaching their specific stations; (3) and (4) human agents waiting for the bus. (d) highlights in (1), (2), and (3) the container-contained topologic relationship which involves the passengers and the bus; (4) shows an empty bus.
Figure 13. Simulation of human agents (students and workers) getting on the bus and moving towards their final destinations.
6. Discussion
Thomas and Donikian proposed an Informed Hierarchical Topologic (IHT) (Citation2003) graph representing a part of the city of Renne (France) for human behavior animation purposes. This graph is composed of three layers: (1) the Basic Topological layer which contains real urban objects modelled as simple spaces such as buildings and road sections; (2) the Composite Space layer which is composed of simple spaces or composite spaces of lesser importance; and (3) the Local Area layer which is the highest level of the IHT-graph and is composed of composite spaces. This hierarchical urban model allows manual abstraction of buildings into blocks and road sections and crossings into roads. The abstraction process is done by the user which constrains and considerably limits its application to real-world large-scale and complex geographic environments. Thomas' approach relies on a pre-defined decomposition of the virtual environment which is dedicated to urban environments. This decomposition is application dependent (urban environments) and does not take into account the topologic and the geometric characteristics of the environment (Min Citation2015).
In contrast with Thomas (Thomas and Donikian Citation2003) and Lamarche (Lamarche and Donikian Citation2004) approaches, our abstraction technique optimizes the representation of the geographic environment while taking into account the geometric, topologic, and semantic characteristics of the geographic environment. This abstraction approach relies on an exact space decomposition technique (CDT) in order to preserve the geometric and topologic characteristics of the geographic environment rather than on a pre-defined space decomposition. It also integrates semantic information associated with GIS data in order to enrich the description of the IVGE.
Embedding the information directly in the environment allows the support of agents' spatial reasoning capabilities (Hui and Min Citation2015). However, the preparation of the fully augmented geometric model is very time-consuming and difficult due to the sheer amount of data (Lin et al. Citation2015). For example, a typical model of a city quarter as used by Farenc can contain several thousands of primitives of many types (such as polygons modeling sidewalk pieces, benches, trees, bus stops, etc.). Moreover, Farenc built the urban environment using data provided by Computer-Assisted Graphic Design systems since the purpose of the simulation is computer animation. However, when building VGEs representing large-scale and complex geographic environments based on reliable GIS data, Farenc's approach cannot be used since it is dedicated to exclusively represent urban environments. Indeed, the manual hierarchical space partitioning as proposed by Farenc is not feasible when dealing with geometrically complex environments. Moreover, the data structure of the urban environment's description as proposed by Farenc needs to be enhanced in order to manage a large amount of geometric and topologic data. Finally, the hierarchical structure should be built using the geographic environment 's characteristics rather than being defined a priori as Farenc proposed.
The work done towards representation of semantic information in virtual environments has been mostly carried out at a geometric level (Guterrez Alonso Citation2005; Garcia Rojas Martinez Citation2009). Gutiuerez Alonso proposed a semantic model which aims to represent the meaning, and functionality of objects in a virtual scene (Citation2005). However, since the purpose of Gutiuerez Alonso 's approach is computer animations, the semantic information integration is located at the object description level rather than enriching the description the geographic environments. Virtual environments are usually created as computer graphics applications, with minimal consideration given to the semantic information (Guterrez Alonso Citation2005; Li et al. Citation2015). Moreover, semantic information has been used in an ad hoc way without any standard formalism. There is a gap between geometry and semantic information in current VGE models.
Different investigations of data integration have proposed various solutions and examples in respective fields. Most researches are localized in the following three categories: data format interchange, direct data access, and spatial data standards. These categories belong to the conventional methods in multi-sourced heterogeneous spatial data integration (Chen Citation2013). These methods have their disadvantage in processing heterogeneous spatial data. First, data models vary with the understanding of spatial data in different GIS software which hampers the development of spatial data integration and interchange. Second, taking all heterogeneous data into one format disobeys the principle of distribution and independence for spatial data. Finally, in order to integrate multi-format data, the data access interface should be a common format used widely. It is not realistic in the near future. So, all the above three methods may have difficulty in representing heterogeneous spatial data. Since we believe semantic information integration into a VGE's description is by nature a knowledge representation problem, a suitable and standard knowledge representation formalism has been proposed to integrate semantic information in the VGE's description (Chen Citation2013; Liang, Gong, and Li Citation2015; Yu et al. Citation2015).
Moreover, the proposed model only focuses on geometry, topology, and semantic information in VGEs. Also, such virtual environments include other valuable information such as attributes, processes, and textures. This information is multidimensional, dynamic, and correlated. The proposed model will greatly benefit from harmoniously integrating this information while providing tools and algorithms to structure, organize, and analyze such information.
Finally, authors in Chen, Hui, and Guonian (Citation2017) and (Lü Citation2011) have presented VGEs as a workspace for computer-aided geographic experiments and a new generation of geographic analysis and computer-aided geographic experiment tools. Characterized by their support for geographic simulation (geo-simulation), geographic interaction (geo-interaction), and geographic collaboration (geo-collaboration), VGEs are developed with the objective of providing open, digital windows into geographic environments in the physical world and to allow users to feel it in person by a means for augmenting the senses. Also seeing it beyond reality through geographic phenomena simulation and collaborative geographic experiments. The proposed model is a basic foundation to build a geometric environment prepared for geo-simulation, which is a critical issue related to geographic research.
7. Conclusion and future works
In this paper, we introduced our IVGE model which automatically builds semantically enriched and geometrically accurate descriptions of informed VGEs. Since a geographic environment may be complex and large-scale, the creation of an VGE is difficult and needs large quantities of geometrical data originating from the environment characteristics (terrain elevation, location of objects and agents, etc.) as well as information that qualifies space (building, roads, parks, etc.) (Mekni Citation2015). Therefore, We also proposed an abstraction approach of the IVGE's description in order to support large-scale and complex geographic environments. First, we described a geometric abstraction process which enriches the IVGE description with terrain semantics. Moreover, the geometric abstraction process helps to detect and filter elevation anomalies and qualifies the terrain shape, specifically slope. Second, we detailed a topologic abstraction which builds a hierarchical topologic graph in order to deal with large-scale VGEs. This hierarchical structure reduces the size of the topological graph representing the IVGE. Third, we showed how the semantic abstraction process enhances the hierarchical topological graph using the CTL in order to build different views of the IVGE. The abstraction model we proposed provides a hierarchically structured graph-based description of IVGE which is suitable for the simulation of agents' spatial behaviors using spatial reasoning algorithms such as path planning and navigation. We are currently working leveraging of our enhanced IVGE model to support hierarchical path planning algorithms taking into account both the abstracted description of the IVGE and the agent type's characteristics.
Another shortcoming of our approach concerns the exact decomposition of geographic environments. This decomposition is a pre-process which generates a set of convex cells using reliable GIS data. The resulting convex cells' description is static and does evolve during the simulation process. However, when simulating dynamic phenomena, the spatial decomposition needs to be updated at least locally in order to take into account the occurring changes. For example, when simulating a flooding river due to heavy rain, the boundary of the river is expected to change as the simulation evolves. However, our IVGE model in its current version does not support such a dynamic spatial decomposition. A desirable extension of our IVGE model would be to compute a new spatial decomposition of the geographic environment at run time (i.e. during the simulation process) when such a need arises.
Computing a new spatial decomposition may be a complex process. When dealing with geometrically complex or large-scale geographic environments, such a process may suffer from high costs in both time and memory use. However, we might consider the computation of only parts of the IVGE where the dynamic phenomenon occurs.
Acknowledgements
The author would like to thank colleagues from the Department of Computer Science and Information Technology who provided insight and expertise that greatly assisted the research, although they may not agree with all of the interpretations/conclusions of this paper.
Disclosure statement
No potential conflict of interest was reported by the author.
ORCID
Mehdi Mekni http://orcid.org/0000-0002-5769-3501
References
- Benenson, Isaak, and Paul Torrens. 2004. Automata-Based Modeling of Urban Phenomena. London: John Wiley and Sons Inc.
- Chen, Chaomei. 2013. Information Visualisation and Virtual Environments. London: Springer Science Business Media.
- Chen, Min, Lin Hui, and Lu Guonian. 2017. Virtual Geographic Environments. The International Encyclopedia of Geography.
- Chen, Min, H. Lin, O. Kolditz, and C. Chen. 2015. “Developing Dynamic Virtual Geographic Environments (VGEs) for Geographic Research.” Environmental Earth Sciences 74 (10): 6975–6980. doi: 10.1007/s12665-015-4761-4
- Chu, Stephen, and Branko Cesnik. 2001. “Knowledge Representation and Retrieval using Conceptual Graphs and free Text Document Self-Organisation Techniques.” International Journal of Medical Informatics 62: 121–133. doi: 10.1016/S1386-5056(01)00156-3
- Farenc, Nathalie, S. R. Musse, Elsa Schweiss, Marcelo Kallmann, Olivier Aune, Ronan Boulic, and Daniel Thalmann. 1999. “A Paradigm for Controlling Virtual Humans in Urban Environment Simulations.” Applied Artificial Intelligence 14: 69–91. doi: 10.1080/088395100117160
- Fehler, Manuel, Külgl Franziska, and Michael Neumann. 2005. “Fourth International Joint Conference on Autonomous Agents & Multiagent Systems.” Utrecht University, The Netherlands, July.
- Garcia Rojas Martinez, Alejandra. 2009. “Semantics for Virtual Humans.” Ecole Polytechnique Federale de Lausanne, Lausanne.
- Guterrez Alonso, Mario. 2005. “Semantic Virtual Environments.” Ecole Polytechnique Federale de Lausanne, Lausanne.
- Haddad, Hedi, and Bernard Moulin. 1995. “Using Cognitive Archetypes and Conceptual Graphs to Model Dynamic Phenomena in Spatial Environments.” Paper presented at the ICCS'07: Proceedings of the 15th International Conference on Conceptual Structures: Knowledge Architectures for Smart Applications, 69–82. London: Springer.
- Hensman, Svetlana, and John Dunnion. 2010. “Using Linguistic Resources to Construct Conceptual Graph Representation of Texts.” In Text, Speech and Dialogue, edited by P. Sojka, I. Kopecek, and K. Pala, 81–88. Berlin: Springer.
- Jia, Fenli, Xiong You, Jiangpeng Tian, Guomin Song, and Qing Xia. 2016. “Formal language for the Virtual Geographic Environment.” Environmental Earth Sciences 74 (10): 6981–7002. doi: 10.1007/s12665-015-4756-1
- Kallmann, Marcelo. 2001. “Object Interaction in Real-Time Virtual Environments.” Ecole Polytechnique Federale de Lausanne, Lausanne.
- Lamarche, Fabrice, and Stephane Donikian. 2004. “Crowds of Virtual Humans: A New Approach for Real Time Navigation in Complex and Structured Environments.” Computer Graphics Forum 23 (3): 509–518. doi: 10.1111/j.1467-8659.2004.00782.x
- Levison, Libby. 1996. “Connecting Planning and Acting via Object Specific Reasoning.” University of Pennsylvania, Philadelphia.
- Lewis, John, Peter Skarek, and Lawrence Varga. 1995. “A Rule-Based Consultant for Accelerator Beam Scheduling used in the CERNPS Complex.” Paper presented at the ICALEPCS'95: International Conference on Accelerator and Large Experimental Physics Control Systems, Chicago, IL.
- Li, Xiaoming, Zhihan Lv, Baoyun Zhang, Weixi Wang, Shengzhong Feng, and Jinxing Hu. 2015. Webvrgis based city bigdata 3d visualization and analysis. arXiv preprint arXiv:1504.01051.
- Liang, Jianming, Jianhua Gong, and Yi Li. 2015. “Realistic Rendering for Physically based Shallow Water Simulation in Virtual Geographic Environments (VGEs).” Annals of GIS 4: 301–312. doi: 10.1080/19475683.2015.1050064
- Libby, Levison, and Badler Norman. 1994. “How Animated Agents Perform Tasks: Connecting Planning and Manipulation Through Object-Specific Reasoning.” Paper presented at the Proceedings of Toward Physical Interaction and Manipulation, AAAI Spring Symposium Series. AAAI Spring Symposium, Palo Alto, CA, USA.
- Lin, Hui, and Michael Batty. 2009. Virtual Geographic Environments. Beigin: Science Press.
- Lin, Hui, Michael Batty, Sven E. Jørgensen, Bojie Fu, Milan Konecny, Alexey Voinov, Paul Torrens, et al. 2015. “Virtual Environments Begin to Embrace Process-based Geographic Analysis.” Transactions in GIS 19 (4): 493–498. doi: 10.1111/tgis.12167
- Lin, Hui, and Min Chen. 2015. “Managing and Sharing Geographic Knowledge in Virtual Geographic Environments (VGEs).” Annals of GIS 21 (4): 261–263. doi: 10.1080/19475683.2015.1099568
- Lokka, I, and A Çöltekin. 2016. “Simulating navigation with virtual 3D geovisualizations – A focus on memory related factors.” Paper presented at the ISPRS-International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 671–673, Prague.
- Lü, Guonian. 2011. “Geographic Analysis-Oriented Virtual Geographic Environment: Framework, Structure and Functions.” Science China. Earth Sciences 54 (5): 733. doi: 10.1007/s11430-011-4193-2
- Lü, Guonian, Zhaoyuan Yu, Liangchen Zhou, Mingguang Wu, Yehua Sheng, and Linwang Yuan. 2015. “Data Environment Construction for Virtual Geographic Environment.” Environmental Earth Sciences 74 (10): 7003–7013, doi: 10.1007/s12665-015-4736-5
- Mekni, Mehdi. 2013. “Using GIS Data to Build Informed Virtual Geographic Environments (IVGE).” Journal of Geographic Information System 5 (06): 548–558. doi: 10.4236/jgis.2013.56052
- Mekni, Mehdi. 2015. “Integration of GIS Data for Visualization of Virtual Geospatial Environments.” Paper presented at the Second International Conference on Mathematics and Computers in Sciences and in Industry (MCSI). IEEE, Sliema, Malta.
- Mekni, Mehdi, and Bernard Moulin. 2009. “Holonic Modelling of Large Scale Geographic Environments.” Paper presented at the Proceedings of the Fourth International Conference on Industrial Applications of Holonic and Multi-Agent Systems (HOLOMAS'09), Linz.
- Minsky, Marvin. 1974. “A Framework for Representing Knowledge.” Peter Winston, MIT-AI Laboratory.
- Moore, Antoni B., and Mike Bricker. 2015. “Mountains of Work: Spatialization of Work Projects in a Virtual Geographic Environment.” Annals of GIS 21 (4): 313–323. doi: 10.1080/19475683.2015.1057227
- Paris, Sébastien, Stéphane Donikian, and Nicolas Bonvalet. 2006. “Environmental Abstraction and Path Planning Techniques for Realistic Crowd Simulation.” Computer Animation and Virtual Worlds 17: 325–335. doi: 10.1002/cav.136
- Perlin, Ken, and Athomas Goldberg. 1996. “Improv: A System for Scripting Interactive Actors in Virtual Worlds.” Paper presented at the Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, 205–216. New Orleans, LA: ACM Press.
- Shao, Wei, and Demetri Terzopoulos. 2005. “Environmental Modeling for Autonomous Virtual Pedestrians.” Paper presented at the Digital Human Modeling for Design and Engineering Symposium, Iowa City, IA, USA.
- Sheng-Gwo, Chen, and Wu Jyh-Yang. 2005. “A Geometric Interpretation of Weighted Normal Vectors and its Improvements.” Paper presented at the Proceedings of the International Conference on Computer Graphics, Imaging and Vision: New Trends, 422–425, Beijing, China.
- Sowa, John. 2000. Knowledge Representation: Logical, Philosophical, and Computational Foundations. Course Technology. Boston: PWS Publishing.
- Thomas, Romain, and Stephane Donikian. 2003. “A model of hierarchical cognitive map and human memory designed for reactive and planned navigation.” Paper presented at the proceedings of the fourth international space syntax symposium, London, Vol. 1, 72–100.
- Varlan, Simona Elena. 2010. “Knowledge Representation in the Context of E-business Applications.” BRAND. Broad Research in Accounting, Negotiation, and Distribution 1 (1): 1–4.
- Vosinakis, Spyros, and Themis Panayotopoulos. 2003. “A Task Definition Language for Virtual Agents.” Journal of WSCG 11: 512–519.
- Winde, Frank, and Emile Hoffmann. 2015. “Virtual Geographical Environments as a tool to map human exposure to mining-related radionuclides.” In Proceeding of the 7th International Conference on Uranium Mining and Hydrogeology, Uranium-Past and Future Challenges, edited by Broder J. Merkel and Alireza Arab, 193–200. London: Springer.
- Yersin, Barbara. 2009. “Real-Time Motion Planning, Navigation, and Behavior for Large Crowds of Virtual Humans.” Ecole Polytechnique Federale de Lausanne, Swiss.
- Yu, Zhaoyuan, Wen Luo, Linwang Yuan, Yong Hu, A.-xing Zhu, and Guonian L”u. 2015. Geometric Algebra Model for Geometry-oriented Topological Relation Computation. Transactions in GIS, Wiley Online Library.