
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Region-based classification of PolSAR data can be effectively performed by seeking for the assignment that minimizes a distance between prototypes and segments. Silva et al. [“Classification of segments in PolSAR imagery by minimum stochastic distances between wishart distributions.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 6 (3): 1263–1273] used stochastic distances between complex multivariate Wishart models which, differently from other measures, are computationally tractable. In this work we assess the robustness of such approach with respect to errors in the training stage, and propose an extension that alleviates such problems. We introduce robustness in the process by incorporating a combination of radial basis kernel functions and stochastic distances with Support Vector Machines (SVM). We consider several stochastic distances between Wishart: Bhatacharyya, Kullback-Leibler, Chi-Square, Rényi, and Hellinger. We perform two case studies with PolSAR images, both simulated and from actual sensors, and different classification scenarios to compare the performance of Minimum Distance and SVM classification frameworks. With this, we model the situation of imperfect training samples. We show that SVM with the proposed kernel functions achieves better performance with respect to Minimum Distance, at the expense of more computational resources and the need of parameter tuning. Code and data are provided for reproducibility.
1. Introduction
The availability of Polarimetric Synthetic Aperture Radar (PolSAR) sensors has increased as a consequence of the technological advances in Remote Sensing. Compared to conventional SAR sensors, PolSAR is able to acquire the amplitude, phase, and orientation of the electromagnetic waves reflected from targets in different transmission and reception polarizations. The use of these images is challenging, among other reasons, because of the data structure (complex matrices in each pixel), their properties (the Gaussian additive noise is not valid), and the signal-to-noise ratio (typically very low). Bearing these characteristics in mind, several specific methods have been developed for PolSAR image processing and classification.
PolSAR image classification has been intensively investigated. The notion that more information on the same area leads to better classification is intuitive. Lee, Grunes, and Kwok (Citation1994) and Cloude and Pottier (Citation1997) proposed two pioneer approaches for PolSAR data classification. While the former develops a pixel-based method based on the Maximum Likelihood Classifier under the Complex Multivariate Wishart distribution, the latter is an unsupervised classification through the eigenvalue analysis of coherency matrices.
Several PolSAR data classification approaches have been proposed since then. Frery, Correia, and Freitas (Citation2007) used specific probability density functions for PolSAR intesity data in the classic Maximum Likelihood Classifier method. Ersahin, Cumming, and Ward (Citation2010) based their approach for segmentation and classification of PolSAR data with on spectral graph partitioning. Du et al. (Citation2014) used a Kernel Extreme Learning Machine with multiple polarimetric and spatial features. Tao et al. (Citation2015) proposed a feature extraction method based on Independent Component Analysis and tensor decomposition. Recently, Hou et al. (Citation2017) proposed a semi-supervised method able to learn even when the training data quality and quantity are both poor.
Silva et al. (Citation2013) investigated the use of stochastic distances between Complex Multivariate Wishart distributions on a region-based approach. The performance of using the Kullback-Leibler, Bhattacharyya, Hellinger, Rényi, and Chi-Square stochastic distances was assessed, providing evidence that such leads to better results when compared to the Maximum Likelihood Classifier using the Complex Multivariate Wishart distribution for pixel-based PolSAR classification as proposed in Lee, Grunes, and Kwok (Citation1994). Furthermore, the Kullback-Leibler, Bhattacharyya, and Rényi distances are more indicated than Hellinger and Chi-Square.
Adopting stochastic distance between Complex Multivariate Wishart models and a hypothesis test derived from this kind of measure, Negri, Silva, and Mendes (Citation2016) presented a new version of K-Means algorithm for region-based classification of PolSAR data. Similarly, Negri et al. (Citation2016) verified the use of Bhattacharyya distance with a Support Vector Machine (SVM) through kernel functions for region-based classification of SAR data. However, to the best of the authors' knowledge, there is still room for investigating other distances and specific distributions for PolSAR images.
This study aims at analyzing the use of a number of stochastic distances as inputs for an SVM with kernel functions for PolSAR region-based classification. Additionally, it presents comparisons with the Minimum Distance Classifier framework investigated by Silva et al. (Citation2013). Such comparisons are conducted on PolSAR images, both simulated and from operational sensors, and different classification scenarios. Such scenarios include an analysis of the often encountered situation of using imperfect, i.e. contaminated, training samples.
The remainder of this article is organized as follows. Fundamental concepts regarding statistical PolSAR modeling, and the use of stochastic distances for region-based classification are presented in Section 2. In Section 3, these concepts are applied in two case studies. Conclusions are presented in Section 4.
2. Statistical region-based PolSAR classification
2.1. Statistical PolSAR modeling
The backscatter signal measured by a PolSAR sensor can be represented through the complex scattering vector . Each component of
is a complex number that carries the amplitude and phase of a polarization combination. The polarizations are indicated by the subscripts in
, where, for example, hv denotes the signal recorded with vertical polarization from a signal initially emitted with horizontal polarization. Considering the reciprocity of an atmospheric medium, which makes
similar to
, the scattering vector is simplified to
(Frery, Correia, and Freitas, Citation2007).
An N-looks covariance matrix is the average of N backscatter measurements in a neighborhood:(1)
(1) where ⋆ and T represent the conjugate and transposed operators, respectively. The diagonal elements of
are nonnegative numbers that represent the intensity of the signal measured on a specific polarization.
Assuming that follows a zero-mean Complex Gaussian distribution (cf. Goodman, Citation1963), it is possible to obtain the distribution of
, the scaled Complex Multivariate Wishart law, which is characterized by the following probability density function:
(2)
(2) where
.
The parameters N and are the number of looks and the target mean covariance matrix. The determinant, inversion and trace operators are denoted
,
and
, respectively.
The scaled Complex Multivariate Wishart model is valid in textureless areas. Target variability can be included by one or more additional parameters; the reader is referred to the work by Deng et al. (Citation2017) for a comprehensive survey of models for PolSAR data.
2.2. Stochastic distances between Complex Multivariate Wishart distributions
A divergence is a measure of the difficulty of discriminating between two models. Csiszár (Citation1967) proposed the φ divergence family, providing a formally organized framework to analytically obtain divergence measures between distributions. Salicru et al. (Citation1994) proposed a more general class of divergences, the divergence, through the adoption of an additional function (h).
Consider the random variables X and Y defined on the same support with distributions characterized by the densities
and
, respectively, where
and
are parameters. The
divergence between X and Y is given by:
(3)
(3) where
is a convex function and
is a strictly increasing function with
and
for all
. Several well-known divergence measures can be obtained by choosing h and φ, but they are not necessarily symmetric.
The symmetrization allows to obtain distances measures from any divergence
. This leads to the following properties:
Non-negativity:
;
Identity (of indiscernible):
Symmetry:
Additionally, if a distance has the following property, then it is a metric:
Triangle inequality:
where X, Y and Z have the same support . It is noteworthy that Bathacharrya, Kullback-Leibler, Rényi, Hellinger and Chi-Square distances are not metrics since the triangle inequality is not fulfilled.
Nascimento, Cintra, and Frery (Citation2010) computed the Bathacharrya, Kullback-Leibler, Rényi (of order β), Hellinger, Jensen-Shannon, Arithmetic-Geometric, Triangular and Harmonic Mean stochastic distances between distributions. These distances were successfully used to evaluate contrast differences among regions in intensity Synthetic Aperture Radar (SAR) images.
Frery, Nascimento, and Cintra (Citation2014) developed analytic expressions for the first four aforementioned stochastic distances between scaled Complex Multivariate Wishart distributions. Previously, the Chi-Square stochastic distance between Complex Multivariate Wishart distributions was presented in Frery, Nascimento, and Cintra (Citation2011). These distances were used by Silva et al. (Citation2013) in PolSAR imagery classification by a minimum distance criterion.
Let X and Y be two random variables modeled by scaled Complex Multivariate Wishart distributions and
. The Bathacharrya, Kullback-Leibler, Rényi (order
) and Hellinger stochastic distances expressions between scaled Complex Multivariate Wishart distributions, according to Frery, Nascimento, and Cintra (Citation2014), are given by:
(4)
(4)
(5)
(5)
(6)
(6)
(7)
(7)
(8)
(8) where
returns the modulus of a real number.
2.3. Region-based PolSAR image classification
Let be an image defined on the grid
whose pixels are elements of the attribute space
. We use the notation
to represent that a pixel
of
has attribute
. The image support can be partitioned in
disjoint subsets
, such that
.
A region-based classification process consists of associating a class from a set of c possible classes Ω to all the pixels that comprise the region
. A supervised region-based decision rule is built trough information available from a set of labeled regions
. The notation
indicates that
is assigned to the class
.
Silva et al. (Citation2013) adopt the Minimum Distance Classifier framework using stochastic distances as a measure to compare the similarity between classes and unlabeled regions. We refer to this method as Minimum Stochastic Distance Classifier (MSDC). The pixel values in an unlabeled region are used to estimate a probability distribution. This region is then assigned to the closest class in distribution, according to an stochastic distance. The class distributions are modeled based on information from .
Formally, let be an unlabeled region and let
be a stochastic distance between distributions estimated from the attributes of the pixels in
and the class
. An assignment
is made when the following rule is satisfied:
(9)
(9) In Equation (Equation9
(9)
(9) ),
is estimated with all the pixels assigned to
in
.
Other methods can be adopted to perform region-based classification beyond the MSDC as, for instance, Support Vector Machines (SVMs). SVMs have received great attention because of their excellent generalization ability, their independence of data distribution and their robustness with respect to the Hughe's phenomenon (Bruzzone and Persello, Citation2009).
The use of kernel functions, , is a common strategy to improve SVM classification performance on nonlinearly separable patterns. Kernel functions also allow the application of SVMs in problems where patterns cannot be represented as vectors.
A kernel function is symmetric and conforms to the Mercer theorem conditions (Theodoridis and Koutroumbas, Citation2008). However, as such verification may be not trivial there are alternative ways to develop such functions. For example, adopting the radial basis function model (Schölkopf and Smola, Citation2002):
(10)
(10) where
is a strictly positive real function and
is a metric.
Equation (Equation10(10)
(10) ) gives a hint to develop suitable kernel functions for PolSAR region-based image classification. A sensible choice for g is the negative exponential function, and m, as a measure of similarity between the input data, a metric based on stochastic distances between distributions. It is noteworthy that Equations (Equation4
(4)
(4) ) to (Equation8
(8)
(8) ) will not produce valid kernel functions since they do not attain the triangle inequality.
However, if is a stochastic distance with
such that
for
, the following expression provides a metric:
(11)
(11) The identity property of m stems from (Equation11
(11)
(11) ). Non-negativity and symmetry are inherited from
, which is a distance, since adding a positive constant will not invalidate such proprieties. Finally, the triangle inequality is fulfilled since the following relations are satisfied:
once we have that
. The constant τ can be chosen as the largest distance measured by
in the classification problem. illustrates this procedure.
Figure 1. Schema of the construction of a kernel function K between regions and
.
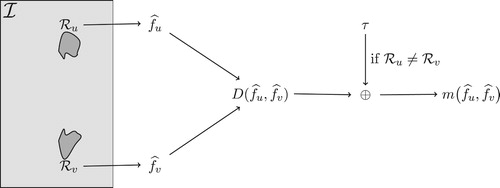
We can thus define kernel functions for PolSAR region-based image classification using the model from Equation (Equation10(10)
(10) ), the expression from Equation (Equation11
(11)
(11) ) and considering the substitution of
by a stochastic distance given by Equations (Equation4
(4)
(4) ) to (Equation8
(8)
(8) ):
(12)
(12) where
is a user-adjusted parameter. We denote the kernel functions obtained from the Bathacharrya, Kullback-Leiber, Hellinger, Rényi e Chi-Square distances as
,
,
,
and
, respectively.
We make clear that denotes a kernel function between estimates of distributions
and
computed with the observations in regions
and
.
3. Experiments and results
In this section, we present studies of region-based image classification of actual and simulated PolSAR data using the stochastic distances presented in Section 2.2 by both MSDC (i.e. ,
,
,
and
) and through the kernel functions, defined in Section 2.3 (i.e.
,
,
,
and
).
The first study (Section 3.1) consists of the classification of simulated images generated with basis on parameters estimated from targets in an actual image. The second case study (Section 3.2) focuses on the classification of the PolSAR image used to extract the parameters. The results are compared by accuracy measures and hypothesis tests.
The scenarios considered in both studies allow a robustness analysis. Specifically, the results from simulated data are assessed through the overall accuracy, while the actual data are verified with the kappa coefficient of agreement (Congalton and Green, Citation2009).
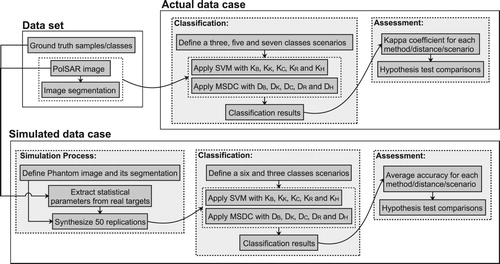
presents an overview of the experiment design, whereas the specifics are discussed in the following sections.
Figure 2. The experiment design overview.
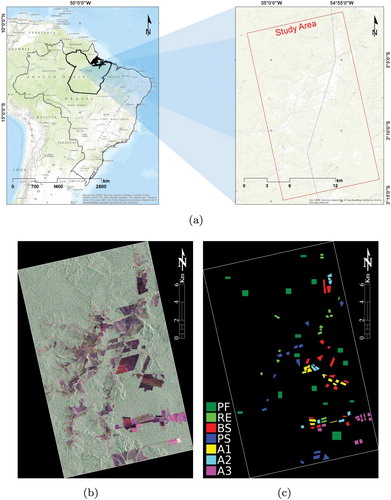
The actual PolSAR data belongs to an image acquired on 2009 March 13 by the ALOS-PALSAR sensor with approximately resolution after a
multi-look process. This image, with center near to
South and
West, corresponds to a region near the Tapajós National Forest, State of Pará, Brazil.
A field work campaign conducted in September 2009 identified the following land use and land cover (LULC) types: Primary Forest (PF), Regeneration (RE), Pasture (PS), Bare Soil (BS), and three types of Agriculture (A1, A2 and A3). These agricultural classes differ on the crop type or growing stage. (a), (b) and (c) present the study area location, a color composition of the ALOS-PALSAR image and the LULCs, respectively.
Figure 3. The study area, actual PolSAR image and the spatial distribution of the LULC samples used in the study. (a) Study area location, (b) ALOS-PALSAR image in RGB color composition (HH, HV, VV) and (c) LULC samples.
The experiments run on a computer with an Intel Core i7 processor, and 16 GB of RAM running the Debian Linux version 8.1 operating system. The platform was the IDL (Interactive Data Language) version 7.1 programming platform.
3.1. Classification of simulated data
3.1.1. Image simulation
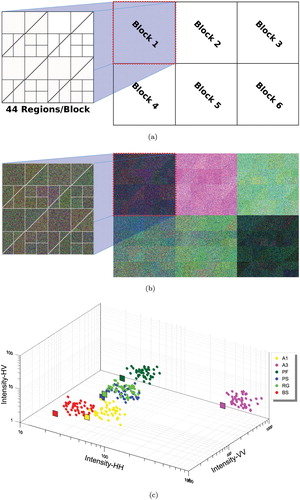
The process adopted for simulated images involves two primary steps. The first step consists of defining a ‘phantom image’ which is an idealized model for the spatial distribution of classes. The phantom is formed by six identical blocks of pixels. Each block represents a distinct class, which is partitioned into 44 segments of different dimension. (a) illustrates the phantom image and the structure inside the blocks.
Figure 4. Simulated data. (a) Phantom - Blocks, (b) Simulation example and (c) Mean covariance matrices (squares), and 44 perturbed covariance matrices (circles) in semilogarithmic scale.
The second step consists of simulating pixels values. For this purpose, we adopted a procedure based on Goodman (Citation1963). In order to obtain samples from the Wishart distribution with covariance matrix and L looks, we obtain L independent deviates from scattering vectors following a Complex Multivariate Gaussian distribution with zero mean and covariance matrix Θ:
(13)
(13) where
represents the imaginary unit and the covariance matrix of the Gaussian law is
We then apply Equation (Equation1
(1)
(1) ) to obtain an observation. Each class is modeled by a covariance matrix
obtained by averaging observations from the corresponding LULC.
We introduce intra-class variability to describe ‘imperfect’ samples and, with this, model plausible errors in the training stage. Frery, Ferrero, and Bustos (Citation2009) analyzed the effect of such errors in classification, and showed that incorporating context is a way of alleviating such problem.
Consider the (true, unobserved) covariance matrix Σ that describes a class. If it is estimated with perfect samples, i.e. with independent identically distributed observations from the hypothesized distribution, then its maximum likelihood estimate will be as close to Σ as the information in the sample permits. Errors in the training stage may lead to suboptimal estimates in terms of bias and variance. We model this situation by introducing random perturbations in
, as follows.
The user believes each class is characterized by Σ but, in fact, the data come from 44 slightly different models: . These models are built by adding random covariance matrices
to
, which is obtained estimating from actual data from a single class. Each perturbation covariance matrix is formed as
where
are independent uniform random variables on
, where
is the ij diagonal element of
, and
controls the perturbation. With this, each mean intensity
in
is a value in
, where
is the (wrongly assumed for the whole block) mean intensity, and
is the standard deviation of
.
Notice that the correct model for each class would be a mixture of 44 distributions, but the user will train each class with samples from 11 (typically slightly) different laws; cf. the colored squares in (a). With this, we assess how the classification techniques perform in the practical situation of using less classes for describing a complex truth, and not collecting samples from all the underlying classes. (c) shows, in logarithmic scale, the intensity of averaged covariance matrices as squares, and their respective 44 perturbed versions.
Figure 5. Simulated data. (a) Training samples – six classes case, (b) Ideal result for six classes, (c) Training samples – three classes case and (d) Ideal result for three classes.
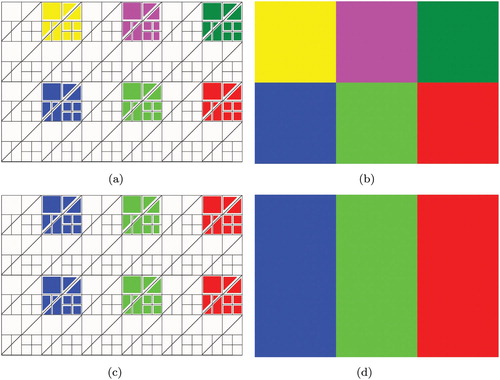
As can be seen from (c) we consider the following situations:
Classes that do not overlap, e.g. A1 and A3, A1 and PF, A1 and RG, A3 and all others, PF and BS, PS and BS, RG and BS
Classes with some overlap, e.g. A1 and PS, A1 and BS,
Classes that overlap, e.g. PS and RG.
This is corroborated by (14) below, which shows the Hellinger distances between the classes.
(b) presents a simulated image, where it is possible to identify the intra-class variability. The covariance matrices that plays the rule of in the simulation process, estimated from observed LULC samples shown in (c), are presented as Appendix.
3.1.2. Classification and results
A set of fifty images were simulated independently following the procedure described in Section 3.1.1 Each image was then classified using the MSDC and SVM methods. MSDC used the stochastic distances between Complex Multivariate Wishart distributions by plugging Equations (Equation4(4)
(4) ) to (Equation8
(8)
(8) ) in (Equation9
(9)
(9) ). SVM also employed these distances through the kernel functions in (Equation11
(11)
(11) ) and (Equation12
(12)
(12) ).
Furthermore, although the simulated images have six well-defined blocks of targets (regions), such objects where classified in two scenarios (i.e. classes configurations). The first scenario considers each block as a single class, the second scenario considers the blocks 1 and 4; 2 and 5; and 3 and 6 as three distinct classes. The second scenarios describes situations where the user specifies less classes than those actually present in the image. According to this organization, (a) and (b) present the training samples and the ideal results expected for the first scenario; similarly, (c) and (d) refer to the second scenario.
Using preliminary tests, the order of the Rényi distance (β) was set to 0.9 for both SVM and MSDC methods. The SVM penalty and kernel parameter were adjusted for each image, considering a fixed parameter space, through an exhaustive search for the configuration which produces the most accurate results with respect to testing samples. In this study, penalty ranges in and the kernel flexibility γ in
.
Two multiclass strategies were considered for SVM in order to assess relationships between strategies, scenarios, kernels and method performance: One-Against-All (OAA) and One-Against-One (OAO), denoted SVM-OAA and SVM-OAO respectively. Details about these strategies can be found in Webb and Copsey (Citation2011).
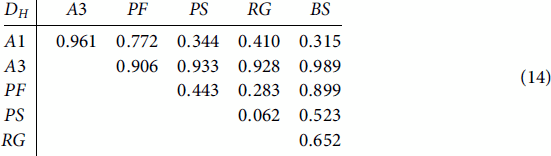
We measured the accuracy of each classification result by the number of correctly classified regions, without taking into account training regions. represents the classification accuracy achieved by each method for different configurations (i.e. stochastic distances/kernel and multiclass strategy for SVM). presents the p-values of a bilateral t-test to check the statistical equality between the accuracy values achieved by two distinct combinations of methods and distances. Further discussions about statistical equality are based on 95% of confidence.
Figure 6. The accuracy of classification results for the simulated data set. (a) Six classes classification and (b) Three classes classification.
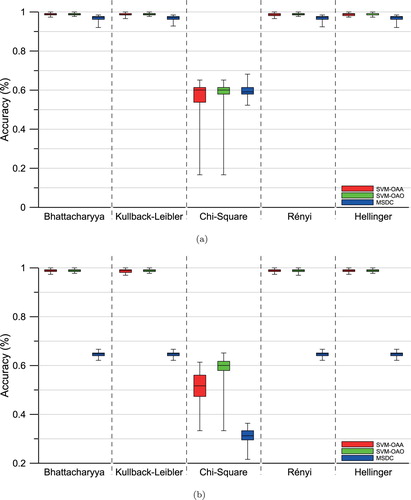
Table 1. Test statistic p-values for the t test that verifies that two classification techniques produce equivalent results. Values above (below) the diagonal correspond to the six (three, resp.) classes. Underlined values indicate equivalent coefficients at the 95% level.
In the following tables SA, SO and MS represent the SVM-OAA, SVM-OAO and MSDC methods, and B, K, C, R and H represent the Bhattacharyya, Kullback-Leibler, Chi-Square, Rényi and Hellinger stochastic distances in the kernel functions.
Focusing on the results of the first scenario (six classes), illustrated in (a), we obtain high accuracy values regardless the method or distance adopted, except for the Chi-Square distance. Six hundred classifications were produced by three methods (SVM-OAA, SVM-OAO and MSDC), four distances (Bhattacharyya, Kullback-Leibler, Rényi and Hellinger, except Chi-Square) and fifty synthetic images. The minimum and maximum values observed over the 600 classifications were 92% and 100% respectively.
The Chi-Square distance does not only produce lower accuracy, but also higher variation in comparison to the other distances/methods. Numerical problems with the Chi-square distance have been reported by Frery, Nascimento, and Cintra (Citation2011). Furthermore, the use of such distance in MSDC and SVM through (Equation8(8)
(8) ) provides statistically equal results.
SVM has better performance than MSDC in the second scenario. Usually, OAO multiclass strategy provides higher average accuracy compared to OAA, even though both strategies provide statistically equal results. Furthermore, we note that the methods are not influenced by the adopted distance, with exception of the Chi-Square distance, where the results are very similar. It is noteworthy that Batthacharyya, Rényi and Hellinger distances in SVM lead to accurate results and small deviations.
presents the computational time spent for training and performing the classification by each method. We observe that in the first scenario the MSDC method spends approximately 3 s, while SVM has a higher cost, specially when OAA strategy is adopted. The reason for this is the training stage, which although SVM with OAO strategy requires splitting the multiclass classification in fifteen binary problems, when OAA is adopted the SVM training needs to solve six large quadratic optimization problems (for details, see Theodoridis and Koutroumbas, Citation2008).
Figure 7. The computational of the analyzed methods in the expriment with synthetic data.

Additionally, we note that MSDC it is more expensive in the second scenario than in the first. Although the second scenario has fewer classes, the quantity of training regions is larger and, then, requires more time to estimate the parameters (i.e. the covariance matrix of each classes) of the probability distribution function that models the classes. With respect to SVM, in general it requires less time in comparison to the first scenario since there are less classes. OAA is still more expensive in the second scenario. Furthermore, the Kullback-Leibler kernel function requires the shortest average times SVM.
3.2. Classification of data from an actual sensor
This section presents classification results of the ALOS-PALSAR image shown in (b). In analogy to Section 3.1.2, we discuss a variety of classification scenarios.
The first scenario uses all LULC classes identified in the study area; cf. . The union of the agriculture classes (i.e. A1, A2 and A3) defines the new class called Agricultural Areas (AA). A second scenario is created with the five classes AA, PF, PS, RG and BS. The last third scenario consists of three classes: Agricultural Areas, High Biomass (HB) and Low Biomass (LB). HB is obtained merging Primary Forest and Regeneration classes, LB comes from the union between Pasture and Bare Soil. We obtain the training and testing samples of AA, HB and LB classes by merging the sample polygons of the individual classes. These scenarios describe practical situations of users with different interests and knowledge of the area. The Appendix provides the sample covariance matrices from the six LULC classes.
Table 2. Summary of the land cover classes samples.
(a), (b) and (c) show the spatial distribution of training and testing samples of each scenario, while presents a summary of the LULC samples. The spatial distribution of these samples is also shown in (a), where training and test samples are shown in solid and empty polygons, respectively.
Figure 8. Spatial distribution of the samples on the different considered scenarios and the adopted segmentation. (a) Scenario 1, (b) Scenario 2, (c) Scenario 3 and (d) Segmentation.
The region-based classification requires a segmentation. It was performed using the region-growing method available in the Geographic Information System SPRING (Camara et al., Citation1996, freely available at http://www.dpi.inpe.br/spring/english/), choosing the segmentation parameter by visual inspection. (d) shows the segments contours.
We applied all possible combinations of methods, distances and multiclass strategies to the image and its segmentation. The SVM parameters were obtained following the same procedures and space searches described in Section 3.1.2. The data were spatially subsampled taking one every three pixels in both horizontal and vertical direction in order to reduce the spatial dependence. The accuracy was measured by the kappa agreement coefficient with respect to the test samples.
shows the kappa values along with their standard deviation. Additionally, present the p-values of a bilateral hypothesis test to check the statistical equality between kappa values achieved by two distinct combinations of methods and distances for each scenario. Further discussions about statistical equality are based on 95% of confidence.
Figure 9. Classification accuracy.
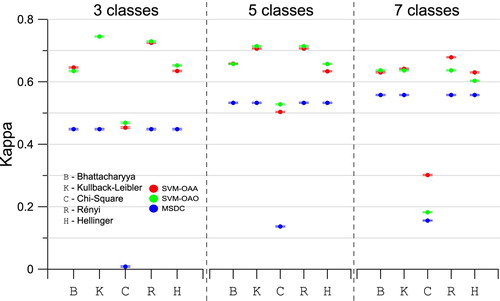
Table 3. p-values from hypothesis test for comparing methods and distances with seven classes. Underlined values indicate equivalent coefficients at the 95% level.
Table 4. p-values from hypothesis for comparing methods and distances with five classes. Underlined values indicate equivalent coefficients at the 95% level.
Table 5. p-values from hypothesis tests for comparing methods and distances with three classes. Underlined values indicate equivalent coefficients at the 95% level.
We observe that the Chi-Square distance produces low kappa values in both methods and with both multiclass strategies for SVM. This is due to the aforementioned numerical instabilities presented by this measure. While most of the considered distances ranged, in the experiments, from to
, the Chi-Square had its values approximately in 0 to
.
Results provided by MSDC using the Bhatacharyya, Kullback-Leibler, Rényi and Hellinger are statistically the same.
Similarly to the results presented in Section 3.1.2, the choice of a multiclass strategy does not have strong influence on the performance of SVM. Except when the Batthacharyya distance is used, the increased in intra-class variability, which occurs when the number of classes decrease, suggests the use of OAO strategy in SVM. Observing the SVM performance as function of the stochastic distance integrated in its kernel, the Rényi distance has the highest accuracy in the first scenario. Regarding the second and third scenarios, SVM performs better when the kernel functions are enhanced with Kullback-Leibler and Rényi distances.
The influence of the scenario is noteworthy. As the number of classes decreases, leading to increasing intra-class variability, the performance of MSDC also decreases. Converseley, the classification accuracy of SVM tends to increase while the number of classes decrease.
In summary, SVM presented better performance with respect to MSDC. Kullback-Leibler and Rényi distances are the preferred choice for defining radial basis kernel functions for the region-based classification with SVM.
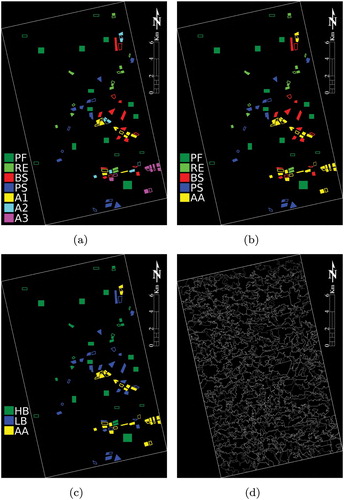
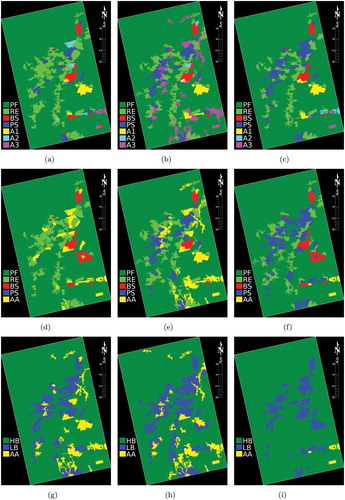
shows selected results. The first scenario, that considers seven classes, posses a difficult problem to both methods to discriminate the agricultural classes (i.e. A1, A2 and A3). With respect to the second scenario, while SVM with OAA strategy does not distinguish PS and MSDC often confuses AA with PS, the SVM with OAO strategy provides a better separation between such classes. In the last scenario MSDC was not apt to separating AA and LH classes, differently fom SVM. This last method, specially when using OAA strategy, provides a better classification of HB and LB areas; cf. the central region of the study area.
Figure 10. Actual data classification results. (a) SA/B – Scenario 1, (b) SO/K – Scenario 1, (c) MS/R – Scenario 1, (d) SA/H – Scenario 2, (e) SO/R – Scenario 2, (f) MS/K – Scenario 2, (g) SA/R – Scenario 3, (h) SO/K – Scenario 3 and (i) MS/H – Scenario 3.
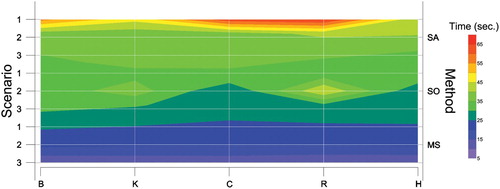
presents the computational time spent by the methods in the experiments with actual data. It can be noted a gradual increase in the processing time when dealing with scenarios with more classes. As previously observed in the first case study, the use of OAA strategy by SVM implies more processing time compared to OAO. MSDC is the least computational intensive method. Furthermore, the time execution is relatively insensitive to choices of distances.
Figure 11. Computational time of the analyzed methods in the experiment with actual data.
4. Conclusions
The objective of this study was to verify the performance of SVM for region-based classification of PolSAR image in comparison to MSDC. For this purpose, we adopted radial basis functions derived from stochastic distances between Complex Multivariate Wishart distributions: Bhatacharyya, Kullback-Leibler, Chi-Square, Rényi and Hellinger. We used simulated images and data from an operational sensor, and proposed a number of scenarios which describe different situations of ability to discriminate classes. These scenarios depict actual situations users encounter in practice.
It was found that SVM it is more robust than MSDC in both simulated and actual data sets because, depending on the adopted multiclass strategy, SVM has equal or superior performance on simple scenarios (first scenarios of simulated and actual data sets – (a) and ) and superior in more complex scenarios (second scenario of simulated and second and third scenarios with actual data sets – (b) and ).
The main drawbacks of SVM are its computational cost and the need to tuning the penalty and the kernel parameter.
As previously verified by Silva et al. (Citation2013), the Chi-Square distance is not indicated to perform classification through MSDC. Its numerical instabilities lead to relative poor performance.
Face to the exposed results, the SVM method presented a better performance compared to MSDC. With respect to radial basis kernel functions considered in this study for region-based classification with SVM, the preferred ones are Kullback-Leibler and Rényi distances. The use of distinct stochastic distances on MSDC does not lead to improved accuracy, so the choice should be based on computational execution time.
Underlying research materials
The underlying research materials for this article can be accessed at: https://github.com/rogerionegri/SVM-PolSAR.
Disclosure statement
There is no conflict of interest involving this research.
ORCID
Rogério G. Negri http://orcid.org/0000-0002-4808-2362
Alejandro C. Frery http://orcid.org/0000-0002-8002-5341
Wagner B. Silva http://orcid.org/0000-0002-5686-5105
Tatiana S. G. Mendes http://orcid.org/0000-0002-0421-5311
Luciano V. Dutra http://orcid.org/0000-0002-7757-039X
Additional information
Funding
Related Research Data
References
- Bruzzone, L., and C. Persello. 2009. “A Novel Context-Sensitive Semisupervised SVM Classifier Robust to Mislabeled Training Samples.” IEEE Transactions on Geoscience and Remote Sensing 47 (7): 2142–2154. doi: 10.1109/TGRS.2008.2011983
- Câmara, G., R. C. M. Souza, U. M. Freitas, and J. Garrido. 1996. “Spring: Integrating Remote Sensing And Gis By Object-oriented Data Modelling.” Computers & Graphics 20 (3): 395–403. doi: 10.1016/0097-8493(96)00008-8
- Cloude, S. R., and E. Pottier. 1997. “An Entropy based Classification Scheme for Land Applications of Polarimetric SAR.” IEEE Transactions on Geoscience and Remote Sensing 35 (1): 68–78. doi: 10.1109/36.551935
- Congalton, R. G., and K. Green. 2009. Assessing the Accuracy of Remotely Sensed Data. Boca Raton: CRC Press.
- Csiszár, I. 1967. “Information-type Measures of Difference of Probability Distributions and Indirect Observations.” Studia Scientiarum Mathematicarum Hungarica 2: 299–318.
- Deng, X., C. López-Martínez, J. Chen, and P. Han. 2017. “Statistical Modeling of Polarimetric SAR Data: A Survey and Challenges.” Remote Sensing 9 (4): 348. doi: 10.3390/rs9040348
- Du, P., A. Samat, P. Gamba, and X. Xie. 2014. “Polarimetric SAR Image Classification by Boosted Multiple-Kernel Extreme Learning Machines with Polarimetric and Spatial Features.” International Journal of Remote Sensing 35 (23): 7978–7990. doi: 10.1080/2150704X.2014.978952
- Ersahin, K., I. G. Cumming, and R. K. Ward. 2010. “Segmentation and Classification of Polarimetric SAR Data Using Spectral Graph Partitioning.” IEEE Transactions on Geoscience and Remote Sensing 48 (1): 164–174. doi: 10.1109/TGRS.2009.2024303
- Frery, A. C., A. H. Correia, and C. C. Freitas. 2007. “Classifying Multifrequency Fully Polarimetric Imagery With Multiple Sources of Statistical Evidence and Contextual Information.” IEEE Transactions on Geoscience and Remote Sensing 45: 3098–3109. doi: 10.1109/TGRS.2007.903828
- Frery, A. C., S. Ferrero, and O. H. Bustos. 2009. “The Influence of Training Errors, Context and Number of Bands in the Accuracy of Image Classification.” International Journal of Remote Sensing 30 (6): 1425–1440. doi: 10.1080/01431160802448919
- Frery, A. C., A. D. C. Nascimento, and R. J. Cintra. 2011. “Information Theory and Image Understanding: An Application to Polarimetric SAR Imagery.” Chilean Journal of Statistics 2 (2): 81–100.
- Frery, A. C., A. D. C Nascimento, and R. J. Cintra. 2014. “Analytic Expressions for Stochastic Distances Between Relaxed Complex Wishart Distributions.” IEEE Transactions on Geoscience and Remote Sensing 52 (2): 1213–1226. doi: 10.1109/TGRS.2013.2248737
- Goodman, N. R. 1963. “Statistical Analysis Based on a Certain Multivariate Complex Gaussian Distribution (An Introduction).” The Annals of Mathematical Statistics 34 (1): 152–177. doi: 10.1214/aoms/1177704250
- Hou, B., Q. Wu, Z. Wen, and L. Jiao. 2017. “Robust Semisupervised Classification for PolSAR Image With Noisy Labels.” IEEE Transactions on Geoscience and Remote Sensing 55 (11): 6440–6455. doi: 10.1109/TGRS.2017.2728186
- Lee, J. S., M. R. Grunes, and R. Kwok. 1994. “Classification of Multi-look Polarimetric SAR Imagery based on Complex Wishart Distribution.” International Journal of Remote Sensing 15 (11): 2299–2311. doi: 10.1080/01431169408954244
- Nascimento, A. D. C., R. J. Cintra, and A. C. Frery. 2010. “Hypothesis Testing in Speckled Data With Stochastic Distances.” IEEE Transactions on Geoscience and Remote Sensing 48 (1): 373–385. doi: 10.1109/TGRS.2009.2025498
- Negri, R. G., L. V. Dutra, S. J. S. Sant'Anna, and D. Lu. 2016. “Examining Region-based Methods for Land Cover Classification using Stochastic Distances.” International Journal of Remote Sensing 37 (8): 1902–1921. doi: 10.1080/01431161.2016.1165883
- Negri, R. G., W. B. Silva, and T. S. G. Mendes. 2016. “K-means Algorithm based on Stochastic Distances for Polarimetric Synthetic Aperture Radar Image Classification.” Journal of Applied Remote Sensing10 (4): 045005–045005. doi: 10.1117/1.JRS.10.045005
- Salicru, M., D. Morales, M. L. Menendez, and L. Pardo. 1994. “On the Applications of Divergence Type Measures in Testing Statistical Hypotheses.” Journal of Multivariate Analysis 51 (2): 372–391. doi: 10.1006/jmva.1994.1068
- Schölkopf, B., and A. J. Smola (2002). Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond. Adaptive computation and machine learning. Cambridge, MA: MIT Press.
- Silva, W. B., C. C. Freitas, S. J. S. Sant'Anna, and A. C. Frery. 2013. “Classification of Segments in PolSAR Imagery by Minimum Stochastic Distances between Wishart Distributions.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 6 (3): 1263–1273. doi: 10.1109/JSTARS.2013.2248132
- Tao, M., F. Zhou, Y. Liu, and Z. Zhang. 2015. “Tensorial Independent Component Analysis-based Feature Extraction for Polarimetric SAR Data Classification.” IEEE Transactions on Geoscience and Remote Sensing 53 (5): 2481–2495. doi: 10.1109/TGRS.2014.2360943
- Theodoridis, S., and K. Koutroumbas. 2008. Pattern Recognition. 4th ed. San Diego: Academic Press.
- Webb, A. R., and K. D. Copsey. 2011. Statistical Pattern Recognition. 3rd ed. Chichester: John Wiley & Sons.