
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This paper proposes a novel data indexing scheme, the distributed access pattern R-tree (DAPR-tree), for spatial data retrieval in a distributed computing environment. As compared to traditional distributed indexing schemes, the DAPR-tree introduces the data access patterns during the indexing utilization stage so that a more balanced indexing structure can be provided for spatial applications (e.g. Digital Earth data warehouse). In this new indexing scheme, (a) an indexing penalty matrix is proposed by considering the balance of data number, topology and access load between different indexing nodes; (b) an ‘access possibility’ element is integrated to a classic ‘Master-Client’ structure for a distributed indexing environment; and (c) indexing algorithm for the DAPR-tree is provided for index implementations. By using a duplication of official GEOSS Clearinghouse system as a case study, the DAPR-tree was evaluated in a number of scenarios. The results show that our indexing schemes generally outperform (around 9%) traditional distributed indices with the utilization of data access patterns. Finally, we discuss the applicability of the DARP-tree and document DARP-tree shortcomings to encourage researchers pursuing related topics in Big Data indexing for Digital Earth and other geospatial initiatives.
1. Introduction
With the rapid advancement of Digital Earth and observation technologies, satellite, ground-based cameras, smartphones, and even human sensors produce spatial Big Data with high spatial and temporal resolution (Huang et al. Citation2017; Nativi et al. Citation2015; Guo, Zhang, and Zhu Citation2015,). Spatial data have been accumulated at a global scale with an unprecedented fast rate. How to fast produce ‘Big Value' from ‘Big Data' has become one of the most critical research questions for the science domain (Siddiqa et al. Citation2016; LaValle et al. Citation2011,). To tackle this challenge, the fast access to Big Data is a key. (Xia, Yang, and Li Citation2018; Boyd and Crawford Citation2011; Wu et al. Citation2014).
Data indexing is one of the most widely used mechanisms to provide fast data access against a large dataset by constituting a better logical data organization. Typically, a spatial index significantly improves spatial data accessing performance by leveraging spatial relationships (e.g. topology) among data (Bereuter and Weibel Citation2013). A spatial index fast supports a variety of operators such as range queries, spatial queries, and trajectory queries. Efficient implementation of these basic operators is essential for accessing required data records from a big dataset so that the ‘Big Value' can be fast explored. Therefore, a variety of indexing schemes have been proposed and widely used in various scientific models, database management systems, and National Spatial Data Infrastructure (NSDI) (Gaede and Günther Citation1998; Guttman Citation1984; Beckmann et al. Citation1990; Ji et al. Citation2014; Mehrotra, Majhi, and Gupta Citation2010; Feng et al. Citation2018).
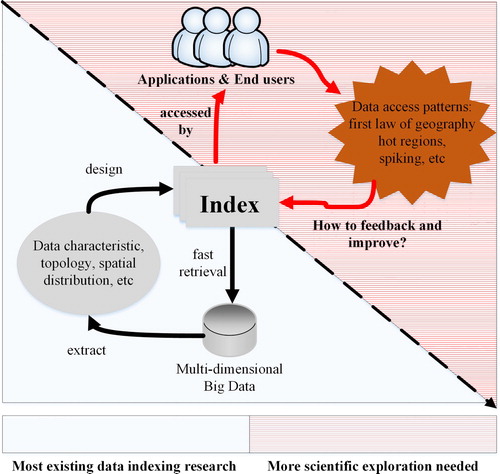
Due to the limited scalability, traditional data indexing schemes often become a major bottleneck for the retrieval of explosively growing data (Wang, Chen, and Liu Citation2013). However, distribution and parallelization have become two essential strategies for Big Data handling in the Big Data era. Large problems are partitioned into smaller sub-problems so that these sub-problems can be processed in parallel by scalable computer clusters. Targeting on this challenge, a substantial amount of works have been done to exploit spatial data indexing schemes in a distributed computing environment (Hsu et al. Citation2012; Cary et al. Citation2010; Wang, Chen, and Liu Citation2013). However, even at a time when so many indexing schemes are available to use, we still know little about how different data accessing patterns may impact the performance of these indices and change the way we index data (). Specifically, a research question still needs to be answered: how we can utilize different data access patterns to better design a distributed data indexing scheme? This research question provides the primary motivation of our research where a novel indexing scheme is provided by integrating patterns of data access in a distributed computing environment.
Figure 1. More scientific exploration is needed on how data access patterns impact and improve the existing data indexing scheme.
In this paper, Section 2 provides a review of the relevant literature regarding existing indexing challenges. Section 3 introduces the design of our indexing scheme with detailed indexing penalty matrix, indexing structure, and indexing algorithm. Section 4 presents experimental results across a variety of problem scenarios, and Section 5 provides conclusions and suggestions for future research.
2. Related work
2.1. Data indexing in a distributed environment
The advancement of distributed computing offers an emerging computing paradigm for managing spatial Big Data. A substantial amount of research has been conducted to exploit parallel data indexing. The Parallel R-tree extended the classic R-tree index capabilities from single-disk to multi-disk environment (Kamel and Faloutsos Citation1992). With the support of multi-disk and parallel algorithms, concurrent I/O performance is scientifically improved during the data retrieval process. Hoel and Samet (Citation1994) explored the strategies of using the multi-processors environment to support a variety of operations such as data structure build, polygonization, and join. To extend to data indexing capabilities from single-workstation to multi-workstation, Wang et al.(Citation1999) designed a distributed R-tree in a distributed shared virtual memory (DSVM) environment. This DSVM-based R-tree can utilize both distributed processors and disks and facilitates data management with a global memory address space for data retrieval. The Master-Client R-tree (Schnitzer and Leutenegger Citation1999) was proposed to index spatial data in a shared-nothing parallel system. Compared to single-workstation index and DSVM index, the shared-nothing index is more scalable and cost-effective. The shared-nothing computing environment can be built on a large number of low-cost commodity computers, each of which has its own computing processors, memory, and disk. The Master-Client R-tree distributes data across to computer clients and utilizes a master server to manage the entire index. Nam and Sussman (Citation2005) improved this Master-Client index schemes by employing a replication protocol to improve indexing scalability. Wan et al. (Citation2019) designed a distributed data index for internet of things (IoT) environment. A Voronoi-based approach was used to provide more efficient routing in distributed IoT applications.
In general, the distributed data indexing strategy is more compatible with the modern computing frameworks and paradigms (e.g. Hadoop, spark, and cloud computing). A-tree (Papadopoulos and Katsaros Citation2011) is proposed to optimize a distributed index in cloud computing environments. Hadoop GIS (Aji et al. Citation2013) is a spatial data warehousing system in Hadoop system that also supports a variety of indexing schemas. By using the Hadoop environment, a tile-based spatial index is designed for fast Lidar data retrieval (Li, Hodgson, and Li Citation2018). Geospark (Yu, Wu, and Sarwat Citation2015) and Locationspark (Tang et al. Citation2016) are similar systems in spark environment. Wang et al. Citation2016 designed a distributed spatial index for massive remote sensing image metadata retrieval under spark. Hu et al. Citation2020 optimized a 3-layer indexing schema to optimize Apache Spark for raster datasets. A well-known challenge with distributed data indexing is the balance of data distribution. By distributing the data to different computing nodes, the data retrieval path often skews on certain computing nodes, which is a bottleneck of the entire retrieval process (Mondal et al. Citation2001). In order to balance the workload in different computing nodes, optimizations have been proposed to distribute data based on their spatiotemporal relationships (e.g. Schnitzer and Leutenegger Citation1999; Wang, Chen, and Liu Citation2013). A good distribution scheme can be determined at the index construction stage by balancing the spatiotemporal coverage of data retrieval paths at different computing nodes. However, a limitation of previous methods is that the data access pattern is rarely considered in the index design, which may also significantly impact the retrieval path in a distributed indexing environment.
2.2. Utilizing spatiotemporal patterns for data indexing
Social and natural phenomena evolve in a four-dimensional (3D+1D) world with specific spatiotemporal patterns (Yang et al. Citation2011). The spatiotemporal pattern of phenomenon plays a key role in various scientific studies. For example, the spatiotemporal patterns of the dust storm process were utilized to optimize computing resource scheduling for forecasting tasks, which improve dust storm event forecasting performance by over 20% (Huang et al. Citation2013). Li et al. (Citation2013) analysed the spatiotemporal dynamics of landscape metrics in the Shanghai metropolitan area from 1989 to 2005 to better understand the urbanization process and urban morphology for Shanghai city. The spatiotemporal patterns of moose-vehicles collision were analysed for better design of transportation facilities in the United States (Mountrakis and Gunson Citation2009).
Big Data is produced at different spatiotemporal scales and end-users interact with Big Data with various spatiotemporal patterns during the index usage stages. A typical example is that end-users are more likely to access the data related to their geographical locations (Xia, Yang, and Li Citation2018). However, how to utilize these spatiotemporal patterns for better data indexing is still an open question. Hadjieleftheriou et al. (Citation2005) provided a pioneer study on introducing spatiotemporal patterns to indexing structures and supported a novel type of query: spatiotemporal pattern (STP) queries. In STP queries, users can specify temporal order constraints on the fulfillment of predicates and it can be efficiently supported by the STP index. However, the spatiotemporal pattern of data access is not considered in the STP index. Xia et al. (Citation2014) introduced the index usage patterns to the R*-tree structure for global user accesses. The Access possibility R-tree (APR-tree) optimized traditional R*-tree structure by considering the access possibilities of features by end-users from different regions. The APR-tree demonstrated a great potential of utilizing spatiotemporal patterns for index optimizations on a stand-alone computer environment. However, due to the limited scalability, stand-alone-based indexing scheme often fails to meet the requirement of large-scale Big Data indexing. But, the distributed data indexing scheme offers a great scalability to meet such requirements. However, how to utilize spatiotemporal data access pattern in a distributed data indexing scheme is still an open question. This limitation motivates the research presented here, where a distributed index mechanism considering data access patterns is provided.
3. Methodologies
3.1. Indexing with access patterns
In a distributed computing environment, the key of fast data retrieval is the balance of index structure and workload parallelization among multiple back-end computing nodes. A well-balanced index structure can reduce the data retrieval complexity by tracing along the index tree with the utilization of spatiotemporal relationships among data. However, well-balanced data distribution and workload parallelization can maximize computing resource utilization and avoid a single computing node becoming the bottleneck of the entire data retrieval process. Therefore, the following indexing strategies should be considered:
Data balance
The amount of data and the number of index nodes in each computing node should be balanced. If a computing node has much more data or index nodes than others, this computing node is likely to become a bottleneck of the entire data retrieval process. This strategy helps improve parallelization.
Topology balance
The topology of a single index structure should be balanced. Between different computing nodes, the union of spatial minimum bounding rectangles (MBRs) for the entire dataset (coverage) in each computing node should be similar. The spatial penalty metrics (e.g. ‘overlap', perimeter and ‘dead-space', Beckmann et al. Citation1990) between index nodes should be minimized. These strategies produce a well-balanced index structure for fast data retrievals.
Access balance
The index node access workload at different computing nodes should be balanced. For example, if two index nodes are frequently accessed by certain data access patterns during the utilization stage, two index nodes should be distributed to two separated computing nodes. This strategy introduces the dynamics of index utilization to improve computing resource utilization so that more computing resources can be activated for various data retrieval tasks.
provides a general evaluation of different indexing strategies with an example dataset. In the ‘Space Partitions’ column, the black rectangles represent the MBRs of the data to be indexed. The rectangles in red color represent the MBRs of indexing nodes. By tracking data access logs, the access possibilities of data and indexing nodes are calculated and demonstrated as red numbers in the ‘Indexing Structure’ column. For each indexing structure, the penalty matrixes are calculated as , where Penalty represents the data penalty, topology penalty, access penalty or overall penalty. Penalty ranges from 0 to 1.
represents the data number, topology area or accumulated access possibility of an indexing node; N presents the total number of indexing nodes in the same tree level;
is the mean value of
.
Figure 2. Data balance, topology balance and access balance strategies for data indexing in a distributed computing environment (numbers in data structure represent the access possibility of data node or index node).

As demonstrates, by adopting the first three indexing strategies, different indexing structures are built with various penalty matrixes. For example, the access balance strategy aims to minimize the difference of historical data access workload between different indexing nodes. Therefore, Feature 1(F1), F2, F3 and F6 are indexed to Node 1(N1), and F4, F5 are indexed to N2. In this case, N1 and N2 have the similar node access possibility (49.9% and 50.1%). By assigning N1 and N2 to two computing nodes in a distributed environment, the access penalty of the entire index is minimized (0.002). However, minimizing the access balance penalty may also increase data penalty (0.33) and topology penalty (0.6), which result in unbalanced data distributions and poor topology discrimination data structure. Therefore, balancing the three penalty matrixes for an overall balance () is needed for better data indexing in a distributed computing environment, and we present an implementation (section 3.2 and section 3.3) for doing so.
3.2. Indexing structure
To balance the data penalty, topology penalty and access penalty in a distributed index, we propose the distributed access pattern R-tree (DAPR-tree). The DAPR-tree data structure is derived from the classic ‘Master-Client' structure, while the data access pattern is integrated (). It adopts a global distributed R-tree indexing scheme that consists of three tiers: the master-tier is the global index entrance and maintains data partitions for the sub-tier; the sub-tier builds a number of sub-tree indices for different data partitions; the data and computing-tier provide data and computing resources to support DAPR-tree operations.
Figure 3. Distributed access pattern R-tree (DAPR-tree) introduces the data access possibility to traditional distributed indexing structure.
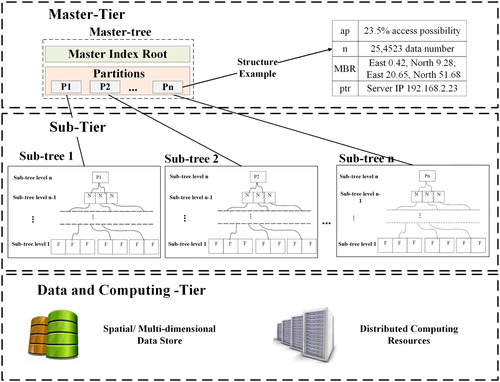
The master-tier is implemented by a master-tree. The master-tree divides the entire dataset into several partitions using our novel indexing strategies (Section 3.1). A data structure {ap, n, MBR, ptr} is used to maintain the metadata of each data partitions, where (a) ap is the access possibilities for each data partition under the index usage stage, (b) n is the data number, (c) MBR is the coverage (minimum bounding rectangle) that completely encloses all data within the partition, and (d) ptr is the pointer to location of a data partition in the distributed environment. The master-tree also serves as the index entrance and maintains global information such as the index size, global index coverage and update schedule. In a distributed computing environment, we recommend using a dedicated computing node (a master node) to maintain the master-tree life cycle.
The sub-tier stores the actual data by a number of sub-trees. With several partitions from the master-tier, a sub-tree is built for each partition, and this sub-tree is responsible for the data organization and data retrieval inside the partition with a balanced tree structure. Each sub-tree and the corresponding data partition are assigned to a client computing node for distributed spatial Big Data management and parallel indexing. The sub-tree index adopts a traditional R-tree, R*-tree or an APR-tree (Xia et al. Citation2014). Compared to R-tree or R*-tree, the APR-tree not only maintains the spatial relationship between data, but also implements the access possibilities in the sub-tier. The access possibility element is stored at APR-tree leaf node and non-leaf node so that the data access patterns inside a computing node can be integrated.
Such a three-tier indexing structure manages the data access status in each feature, index node and computing node so that the indexing structure can be adapted to various data access patterns. In addition, the ‘top-down' distributed structure helps overcome the scalability challenge by operating the index life cycle in parallel with a large number of back-end computing clients.
3.3. Indexing algorithm
3.3.1. DAPR-tree construction
The DAPR-tree index construction generally includes three stages. The first stage analyses user access patterns by conducting system-log mining. The second phase builds the master-tier index by partitioning the entire n-dimensional space into several partitions. The third phase builds the sub-tier index structures by constructing local indices (sub-trees) for each partition and computing nodes in parallel.
Access pattern mining collects historical index and data access records (e.g. system log-file) and calculates data access possibilities for each data (Xia et al. Citation2014).
Pre-processing produces an overview of the entire dataset such as calculating record number, extracting spatiotemporal coverage (e.g., 45°S, 120°W to 90°N, 180°E; Nov 1 2019) and retrieving data access possibilities from historical records. In addition, this step calculates the number of total index partitions in the entire distributed environment. For a distributed indexing environment with one master node and n computing nodes, the partition number n is usually recommended.
Sampling (optional) is recommended to reduce the computational complexity of DAPR-tree construction for a large dataset. This step produces a random sample dataset for the next step (partitioning) instead of using the entire dataset. Currently, we are adopting a ‘simple random sampling' in the implementation.
Partition and distribution partitions the entire n-dimensional space by assigning all simple data into different partitions. The spatiotemporal coverage of each partition must enclose all data inside this partition. The partition algorithm is detailed in section 3.3.2. After virtual partitioning, all partitions are physically distributed to corresponding back-end computing nodes in the distributed environment.
Sub-tier indexing adopts R-tree indexing algorithm (Guttman Citation1984), R*-tree indexing algorithm (Beckmann et al. Citation1990) or APR-tree indexing algorithm (Xia et al. Citation2014) to build local indices in parallel for each partition at back-end computing nodes. When all computing nodes finish their sub-tree constructions, a message will be passed to the master-tree, and the entire distributed index will be activated.
3.3.2. Space partitioning
Space partition and data distribution are keys for the balance of the entire distributed index. Ideally, three indexing balance strategies (data balance, topology balance and access balance) should be considered and the overall indexing penalties should be minimized during the partition process. We define the objective of the partitioning algorithm as minimizing the DAPR-tree penalty matrix (the sum of data penalty, topology penalty and access penalty). To achieve this objective, methods of enumeration and linear programming can be used for seeking the optimal partitions. However, for a large dataset problem, conducting enumeration or linear programming is highly combinatorially complex. It often fails to find optimal partitions due to extremely high computing cost or limited solving time.
A practical application of DAPR-tree construction will certainly benefit from the implementation of heuristic procedures. Therefore, we design a greedy heuristic algorithm for fast DAPR-tree partitions. Algorithm 1 shows the general workflow for the partition process using a classic two-dimensional space as an example. The major idea of this algorithm is to slice the space into the different rectangular region (strips) for each dimension until the entire partitions are generated. In this slicing process, topologies and access possibilities between different strips are considered. Take the two-dimensional space as an example, the algorithm first determines vertical and horizontal slices number: , where r is the sample data size and n is the partition number. Then, the algorithm slices the entire space into different vertical strips. Finally, each vertical strip is further sliced into horizontal strips for the final partitioning result.
Table
For each ‘slice' action, a greedy strategy is applied by assigning the data into a strip to partition with the minimum cost. Currently, we adopt a naive approach for penalty measurement by equally weighting the data penalty, topology penalty and access penalty. Although localized optimum solutions are achieved at every slice action, this strategy usually cannot produce the optimal partition result. Nonetheless, an optimized partition result can be found in a reasonable time as compared to optimal solution procedures.
3.3.3. Data accessing
Data accessing in a DAPR-tree is identical to a traditional distributed index data access algorithm. The master-tier first handles various query requests and passes the requests to corresponding sub-tresses based on the spatial coverage of different partitions. At the sub-tier level, each sub-tree locates the data corresponding to this query request by conducting a top-down tracing process along the tree structure. Finally, all results from different computing nodes are returned to the master-tier and a merge operation is used to produce the final result set.
4. Results and discussions
4.1. Implementation and experiment environment
A prototype of the DAPR-tree is implemented with Java. The distributed computing environment is supported by the Amazon Web Services (AWS). The AWS cloud instance type was m4.large with 8 GiB Memory, 2 vCPU (Intel Xeon E5 2.4 GHz) and Elastic Block Store (EBS) storage.
4.2. Case study and experimental data
We evaluated our novel indexing approach using the Global Earth Observation System of Systems (GEOSS) as a case study. In 2002 World-Summit Group-of Eight (G8), the Group on Earth Observation (GEO, Withee, Smith, and Hales Citation2004) was proposed as a voluntary partnership of government for international collaboration to Earth observation systems. Targeting on this aim, the GEO proposed a ten-year plan – the GEOSS ecosystem (Nativi et al. Citation2015). As one of the four principal components in the GEOSS (Butterfield, Pearlman, and Vickroy Citation2008), the GEOSS Clearinghouse (Huang et al. Citation2010; Christian Citation2008,) serves as the data/metadata warehouse and the search engine for the entire infrastructure. By 2015, the GEOSS Clearinghouse has received over two million end-user requests from 140+ countries worldwide.
To analyse data access patterns, we collected the daily system operation log-files of GEOSS Clearinghouse from the official operational server (the traditional blade-server from 2010 to 2011 and AWS cloud computing server from 2011 to 2012). These log-files recorded various request information including but not limited to access location, access time, requested data identifier, data coverage (both spatial and temporal) and data theme. These log-files were analysed with a variety of data mining technologies to calculate historical data access possibilities (Xia et al. Citation2014).
For the indexing datasets, we collected about 0.13 million records from the GEOSS Clearinghouse through private Open Geospatial Consortium (OGC) Catalog Service for the Web (CSW) protocols. The distribution and spatial coverage of this dataset is demonstrated in . In order to evaluate data indexing performance with larger datasets, we generated 1.2 billion synthetic data based on the distribution of 0.13 million true data. To avoid duplicated data records, we randomly shifted the synthetic data coverage from −0.001 degree to +0.001 degree. provides a summary of our experimental data.
Figure 4. The distribution and spatial overage of GEOSS Clearinghouse true dataset (base map provided by NASA ‘Blue Marble’ through OGC: Web Map Service).
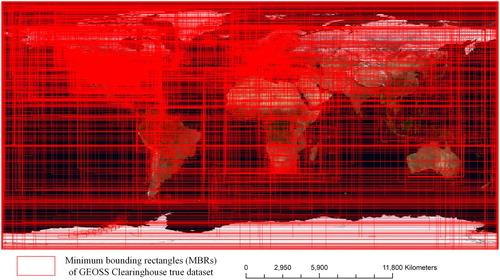
Table 1. A summary of experimental data.
4.3. Experiment result
4.3.1. DAPR-tree performance
In this section, we present a comparison between the DAPR-tree, Master-Client R-tree (MC-tree) and traditional R*-tree (single computing node only) for data retrieval. Both DAPR-tree and MC-tree are configured with one master node and four computing nodes, while the R*-tree has one computing node only. Both master and computing nodes are implemented with the AWS cloud instance (m4.large instance type). The performance was measured by the real data retrieval response time. The message passing time inside the GEOSS Clearinghouse was excluded to eliminate to network quality impact. The response time mean value was calculated by repeating the experiment 50 times to reduce the impact of noise. To better compare the performance of different indexing structures, the following three data query scenarios are used:
Real-world data queries
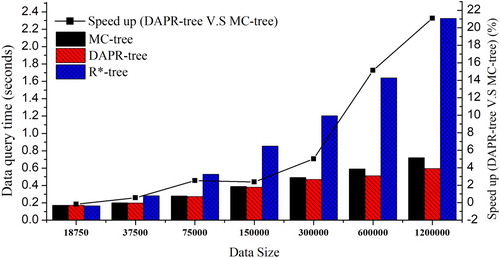
The ‘real-world data queries' scenario performs a batch of historical data queries (extracted from the GEOSS Clearinghouse) against three different indices. demonstrates the comparison results with different data sizes (from around 18.75 thousand to 1.2 million). The following trends are observed: (1) with the increase of data size, the distributed indexing structures (DAPR-tree and MC-tree) significantly outperform the R*-tree (average 94% speedup). However, when the data size is less than 37 thousand, the R*-tree with one computing node only could be a better option because it avoids distribution overhead and saves computing cost; (2) the DAPR-tree outperforms the MC-tree with an about 9% performance gain. The gains also experience the growth with the increase of data size. The major reason for this gain is the improved index balance in the distributed computing environment. By utilizing ‘real-world' data access pattern in GEOSS Clearinghouse, the access balance in DAPR-tree is significantly improved as compared to other distributed indices. Although the topology balance and data balance of the DAPR-tree were gently sacrificed, the huge improvement of access balance helps the DAPR-tree achieve a better over all balance, thereby improving the overall data access performance. However, this access balance improvement may largely rely on the regularity of data query patterns. DAPR-tree performance under unregular access patterns is explored in the following experimental scenarios.
Random data queries
Figure 5. Data query performance with real-world queries.
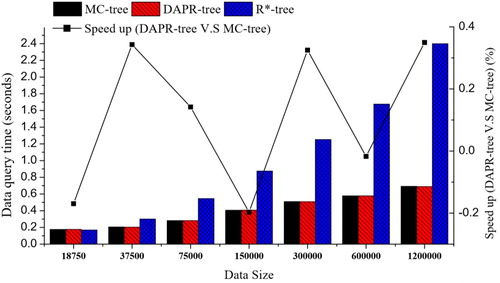
This scenario simulates a batch of completely random data queries (from 90oS, 180oW to 90oN, 180oE) against three indexing structures. As shown in , the performance of three indices generally decreased under this scenario. The reason is that the random queries tend to generate larger queries regions than real-world queries, which results in more active query path inside the indexing structure. More importantly, the DAPR-tree produced approximately 5% overheads against the MC-tree when completely random data queries were performed. The major reason for this is the decrease of overall balance in DAPR-tree under completely random data queries. In general, the topology balance of the DAPR-tree needs to be sacrificed to achieve an overall balance (section 3.1). However, under completely random queries, the DAPR-tree gains no benefit from historical access patterns for the access balance. That is why DAPR-tree may introduce performance overheads and the applicability of the DAPR-tree should currently limited to those applications that have relatively stable data access patterns during system operation.
Mixed data queries
Figure 6. Data query performance with random data queries.
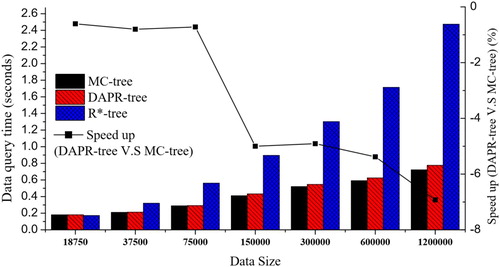
Mixed data queries are produced by the combination of 50% real-world queries and 50% random queries. With this data query scenario, the speedups of the DAPR-tree against the MC-tree range from −0.2% to 0.34% with different data size problem instances (). In addition, there was no linear relation between the DAPR-tree speed up and data size. In general, DAPR-tree and MC-tree tend to provide similar data query performance under this mixed data query scenario.
Figure 7. Data query performance with mixed data queries (50% real-world queries + 50% random queries).
4.3.2. Local indexing
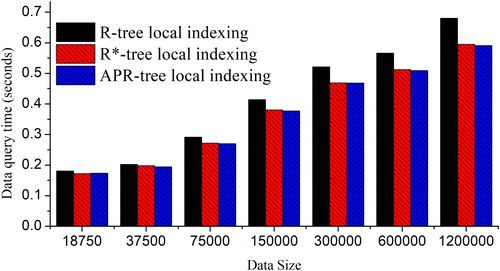
In this section, we compare three different DAPR-tree local indexing approaches: R-tree, R*-tree and APR-tree. We use the same experiment configuration (one master node + four computing nodes) as section 4.3.1. During the stage of local indexing, different indexing approaches were implemented and the data retrieval results are shown in .
For DAPR-tree local indexing, R*-tree and APR-tree provided better data retrieval performance than the R-tree. The major reason for this improvement is that R*-tree and APR-tree adopted more comprehensive indexing penalty matrix (e.g. perimeter and ‘dead space') to reduce data retrieval path length. As a result, the data retrieval performance is enhanced, while the index construction times were also significantly increased.
Although APR-tree utilizes data access patterns at the local indexing level (sub-tier), it did not achieve expected performance gains against the R*-tree. A potential reason is that the local index coverage from the DAPR-tree is significantly different from the APR-tree original design. In addition, there was a 13% overhead for APR-tree construction as compared to R*-tree. Therefore, R*-tree seems to be a better option than the APR-tree for DAPR-tree local indexing regarding the data size and the computing environment in our experiment. This result implies that the benefit of utilizing data access pattern is more effective at the global indexing level (master-tier), rather than local indexing level (sub-tier).
Figure 8. DAPR-tree performances using different local indexing schemes.
4.4. Discussions
As demonstrated in our experiment results, a DAPR-tree utilizes the benefit of historical data access pattern to improve the overall balance (data balance, topology balance and access balance) of its distributed indexing structure. However, the DAPR-tree performance also largely depends on the regularity of data queries. When data queries are highly regular, the DAPR-tree provides approximately 9% performance gains against a classic MC-tree. However, DAPR-tree could also result in overheads if data queries tend to be random. Therefore, the applicability of the DAPR-tree is currently limited to those applications that have relatively stable data access patterns.
The predictability of data queries is another key for the DAPR-tree applicability. With the increasing awareness and the better understanding of human behaviors in cyber-space, how to predict ‘user-data' interactions has become a hot research topic. Combining multi-source Big Data (e.g. public interests from social metadata), latest machine learning technologies and various cyber-user behavior theories, we have an increasing potential to better predict user queries in the near future. Such opportunity requires current data indexing structures to be dynamically adjustable to different ‘user-data' interactions, but most existing indexing structure lacks the element of data access patterns at indexing strategies, structures, algorithms and implementations levels. On the other hand, the DAPR-tree keep tracking the data access at the data structure level and provide a corresponding indexing algorithm with data access pattern integrated. With our increasing understanding of ‘user-data' interactions, the benefit of DAPR-tree might be better utilized with more applicability and different application scenarios. We also expect this initial exploration may help catalyze future research in relating topics. For example, exploring ‘user-data' interactions in Digital Earth and other global geospatial initiatives.
5. Conclusion and future work
In this paper, we proposed a novel indexing approach for spatial data retrieval in a distributed computing environment: the DARP-tree. From the existing literature, we know that data indexing is an essential technology to improve the performance the data access, thereby enhancing the important transformation from ‘Big Data’ to ‘Big Value’. However, we still know little about how the data access pattern could impact the design of our indexing scheme. This research provides a tentative exploration for this research question, and our key contribution includes: (a) we present a novel indexing penalty matrix by introducing the data access element to the balance of data index; (b) we design the DARP-tree structure and algorithm for spatial data indexing in a distributed computing environment; (c) we experimentally evaluate the DAPR-tree using the GEOSS Clearinghouse system as a case study. The DARP-tree is compared with other classic indexing schemes under a number of evaluation scenarios. The experimental results show that the DARP-tree provides approximately 9% and 94% performance gains against a classic MC-tree (5 nodes) and R*-tree (1 node), respectively, using data queries from the GEOSS Clearinghouse; (d) we discuss the applicability of the DARP-tree and document our shortcoming as a mechanism to encourage researchers pursuing these and other problems regarding data indexing using data access patterns.
To further enhance the access to spatial Big Data, many challenges remain to be addressed, and future research is desired:
Index caching with access pattern: the current DARP-tree indexing mechanism is desired to be combined with data caching technologies. A data caching mechanism could pre-fetched frequently accessed index nodes into the computer memory, which significantly reduces the data retrieval time.
Dynamic indexing: in section 4.4, we discussed the importance of dynamically adapting index structure to near future data queries patterns. Although the current DARP-tree structure provides such a potential, more adaptive data structure and dynamic indexing algorithm need to be designed. Computing resource scheduling mechanisms are also needed to support dynamic data access.
Spatial sampling: in section 3.3.1, we used a ‘simple random sampling’ method in DAPR-tree implementation. However, due to the spatially autocorrelation and spatial heterogeneity, traditional sampling methods may not be the best choice for data sampling in DAPR-tree. We plan to look into how different spatial sampling methods (Wang et al. Citation2012; Van Groenigen and Stein Citation1998; Tucker Citation1993) impact DAPR-tree performance.
Comprehensive evaluations: besides the GEOSS Clearinghouse case study, we plan to apply the DAPR-tree indexing scheme to more real-world Digital Earth applications and scenarios. Only by exposing the DAPR-tree to the true population of Big Data users, more issues of DAPR-tree from different natures can be detected, which provides future motivations for catalyzing more comprehensive research regarding this topic.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Aji, A., F. Wang, H. Vo, R. Lee, Q. Liu, X. Zhang, and J. Saltz. 2013. “Hadoop Gis: A High Performance Spatial Data Warehousing System Over Mapreduce.” Proceedings of the VLDB Endowment 6 (11): 1009–1020. doi: 10.14778/2536222.2536227
- Beckmann, N., H. P. Kriegel, R. Schneider, and B. Seeger. 1990. “The R*-tree: An Efficient and Robust Access Method for Points and Rectangles.” Proceedings of the 1990 ACM SIGMOD International Conference on Management of data, 322–331. Chicago.
- Bereuter, P., and R. Weibel. 2013. “Real-time Generalization of Point Data in Mobile and Web Mapping Using Quadtrees.” Cartography and Geographic Information Science 40 (4): 271–281. doi: 10.1080/15230406.2013.779779
- Boyd, D., and K. Crawford. 2011. “Six Provocations for Big Data.” In A Decade in Internet Time: Symposium on the Dynamics of the Internet and Society. Oxford: Oxford Internet Institute. doi:10.2139/ssrn.1926431.
- Butterfield, M. L., J. S. Pearlman, and S. C. Vickroy. 2008. “A System-of-Systems Engineering Geoss: Architectural Approach.” IEEE Systems Journal 2 (3): 321–332. doi: 10.1109/JSYST.2008.925973
- Cary, A., Y. Yesha, M. Adjouadi, and N. Rishe. 2010. “Leveraging Cloud Computing in Geodatabase Management.” Granular Computing (GrC), IEEE International Conference, 2010, 73–78. IEEE.
- Christian, E. J. 2008. “GEOSS Architecture Principles and the GEOSS Clearinghouse.” IEEE Systems Journal 2 (3): 333–337. doi: 10.1109/JSYST.2008.925977
- Feng, B., Q. Zhu, M. Liu, Y. Li, J. Zhang, X. Fu, Y. Zhou, M. Li, H. He, and W. Yang. 2018. “An Efficient Graph-Based Spatio-Temporal Indexing Method for Task-Oriented Multi-Modal Scene Data Organization.” ISPRS International Journal of Geo-Information 7 (9): 371. doi: 10.3390/ijgi7090371
- Gaede, V., and O. Günther. 1998. “Multidimensional Access Methods.” ACM Computing Surveys (CSUR) 30 (2): 170–231. doi: 10.1145/280277.280279
- Guo, H., L. Zhang, and L. Zhu. 2015. “Earth Observation Big Data for Climate Change Research.” Advances in Climate Change Research 6 (2): 108–117. doi: 10.1016/j.accre.2015.09.007
- Guttman, A. 1984. “R-Trees: A Dynamic Index Structure for Spatial Searching.” Proceedings of the ACM SIGMOD international conference on management of data, 47–57. Boston.
- Hadjieleftheriou, M., G. Kollios, P. Bakalov, and V. J. Tsotras. 2005. “Complex Spatio-temporal Pattern Queries.” Proceedings of the 31st international conference on Very large data bases, 877–888. VLDB Endowment.
- Hoel, E. G., and H. Samet. 1994. Performance of Data-Parallel Spatial Operations. Very Large Data Bases, 156–167.
- Hsu, Y. T., Y. C. Pan, L. Y. Wei, W. C. Peng, and W. C. Lee. 2012. “Key Formulation Schemes for Spatial Index in Cloud Data Managements.” Mobile Data Management (MDM), IEEE 13th International Conference, 2012, 21–26, IEEE.
- Hu, F., C. Yang, Y. Jiang, Y. Li, W. Song, D. Q. Duffy, J. L. Schnase, and T. Lee. 2020. “A Hierarchical Indexing Strategy for Optimizing Apache Spark with HDFS to Efficiently Query Big Geospatial Raster Data.” International Journal of Digital Earth 13 (3): 410–428. doi: 10.1080/17538947.2018.1523957
- Huang, C. S., M. F. Tsai, P. H. Huang, L. D. Su, and K. S. Lee. 2017. “Distributed Asteroid Discovery System for Large Astronomical Data.” Journal of Network and Computer Applications 93: 27–37. doi: 10.1016/j.jnca.2017.03.013
- Huang, Q., C. Yang, K. Benedict, A. Rezgui, J. Xie, J. Xia, and S. Chen. 2013. “Using Adaptively Coupled Models and High-Performance Computing for Enabling the Computability of Dust Storm Forecasting.” International Journal of Geographical Information Science 27 (4): 765–784. doi:10.1080/13658816.2012.715650.
- Huang, Q., C. Yang, D. Nebert, K. Liu, and H. Wu. 2010. “Cloud Computing for Geosciences: Deployment of GEOSS Clearinghouse on Amazon’s EC2.” In ACM Sigspatial International Workshop on High PERFORMANCE and Distributed Geographic Information Systems. Vol. 281, 35–38. San Jose, CA: ACM.
- Ji, C., Z. Li, W. Qu, Y. Xu, and Y. Li. 2014. “Scalable Nearest Neighbor Query Processing Based on Inverted Grid Index.” Journal of Network and Computer Applications 44: 172–182. doi: 10.1016/j.jnca.2014.05.010
- Kamel, I., and C. Faloutsos. 1992. “Parallel R-Trees.” In: Proceedings of the ACM SIGMOD International Conference on Management of Data, 195–204. San Diego. doi:10.1145/141484.130315.
- LaValle, S., E. Lesser, R. Shockley, M. S. Hopkins, and N. Kruschwitz. 2011. “Big Data, Analytics and the Path From Insights to Value.” MIT Sloan Management Review 52 (2): 21.
- Li, Z., M. E. Hodgson, and W. Li. 2018. “A General-Purpose Framework for Parallel Processing of Large-Scale LiDAR Data.” International Journal of Digital Earth 11 (1): 26–47. doi: 10.1080/17538947.2016.1269842
- Li, J., C. Li, F. Zhu, C. Song, and J. Wu. 2013. “Spatiotemporal Pattern of Urbanization in Shanghai, China Between 1989 and 2005.” Landscape Ecology 28 (8): 1545–1565. doi: 10.1007/s10980-013-9901-1
- Mehrotra, H., B. Majhi, and P. Gupta. 2010. “Robust Iris Indexing Scheme Using Geometric Hashing of SIFT Keypoints.” Journal of Network and Computer Applications 33 (3): 300–313. doi: 10.1016/j.jnca.2009.12.005
- Mondal, A., M. Kitsuregawa, B. C. Ooi, and K. Tan. 2001. “R-Tree-Based Data Migration and Self-Tuning Strategies in Shared-Nothing Spatial Databases.” Advances in Geographic Information Systems. 28–33.
- Mountrakis, G., and K. Gunson. 2009. “Multi-Scale Spatiotemporal Analyses of Moose–Vehicle Collisions: A Case Study in Northern Vermont.” International Journal of Geographical Information Science 23 (11): 1389–1412. doi:10.1080/13658810802406132.
- Nam, B., and A. Sussman. 2005. “Spatial Indexing of Distributed Multidimensional Datasets.” In CCGrid 2005. IEEE International Symposium on Cluster Computing and the Grid, 2005. Vol. 2, 743–750.
- Nativi, S., P. Mazzetti, M. Santoro, F. Papeschi, M. Craglia, and O. Ochiai. 2015. “Big Data Challenges in Building the Global Earth Observation System of Systems.” Environmental Modelling & Software 68: 1–26. doi: 10.1016/j.envsoft.2015.01.017
- Papadopoulos, A., and D. Katsaros. 2011. “A-Tree: Distributed Indexing of Multidimensional Data for Cloud Computing Environments.” In 2011 IEEE Third International Conference on Cloud Computing Technology and Science, 407–414. IEEE.
- Schnitzer, B., and S. T. Leutenegger. 1999. “Master-Client R-Trees: A New Parallel R-Tree Architecture.” In: Eleventh International Conference on Scientific and Statistical Database Management, 68–77. doi:10.1109/SSDM.1999.787622.
- Siddiqa, A., I. A. T. Hashem, I. Yaqoob, M. Marjani, S. Shamshirband, A. Gani, and F. Nasaruddin. 2016. “A Survey of Big Data Management: Taxonomy and State-of-the-Art.” Journal of Network and Computer Applications 71: 151–166. doi: 10.1016/j.jnca.2016.04.008
- Tang, M., Y. Yu, Q. M. Malluhi, M. Ouzzani, and W. G. Aref. 2016. “Locationspark: A Distributed in-Memory Data Management System for Big Spatial Data.” Proceedings of the VLDB Endowment 9 (13): 1565–1568. doi: 10.14778/3007263.3007310
- Tucker, D. M. 1993. “Spatial Sampling of Head Electrical Fields: The Geodesic Sensor Net.” Electroencephalography and Clinical Neurophysiology 87 (3): 154–163. doi: 10.1016/0013-4694(93)90121-B
- Van Groenigen, J. W., and A. Stein. 1998. “Constrained Optimization of Spatial Sampling Using Continuous Simulated Annealing.” Journal of Environmental Quality 27 (5): 1078–1086. doi: 10.2134/jeq1998.00472425002700050013x
- Wan, S., Y. Zhao, T. Wang, Z. Gu, Q. H. Abbasi, and K. K. R. Choo. 2019. “Multi-Dimensional Data Indexing and Range Query Processing Via Voronoi Diagram for Internet of Things.” Future Generation Computer Systems 91: 382–391. doi: 10.1016/j.future.2018.08.007
- Wang, L., B. Chen, and Y. Liu. 2013. “Distributed Storage and Index of Vector Spatial Data Based on HBase.” International Conference on Geoinformatics, 1–5. IEEE.
- Wang, B., H. Horinokuchi, K. Kaneko, and A. Makinouchi. 1999. “Parallel R-Tree Search Algorithm on DSVM.” In: Proceedings of 6th International Conference on Database Systems for Advanced Applications, 237–244. Kyoto. doi: 10.1109/DASFAA.1999.765757.
- Wang, J. F., A. Stein, B. B. Gao, and Y. Ge. 2012. “A Review of Spatial Sampling.” Spatial Statistics 2: 1–14. doi: 10.1016/j.spasta.2012.08.001
- Wang, F., X. Wang, W. Cui, X. Xiao, Y. Zhou, and J. Li. 2016. “Distributed Retrieval for Massive Remote Sensing Image Metadata on Spark.” In 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), 5909–5912. IEEE.
- Withee, G. W., D. B. Smith, and M. B. Hales. 2004. “Progress in Multilateral Earth Observation Cooperation: Ceos, Igos and the Ad Hoc Group on Earth Observations.” Space Policy 20 (1): 37–43. doi: 10.1016/j.spacepol.2003.12.001
- Wu, X., X. Zhu, G. Q. Wu, and W. Ding. 2014. “Data Mining with Big Data.” IEEE Transactions on Knowledge and Data Engineering 26 (1): 97–107. doi: 10.1109/TKDE.2013.109
- Xia, J., C. Yang, Z. Gui, K. Liu, and Z. Li. 2014. “, Optimizing an Index with Spatiotemporal Patterns to Support GEOSS Clearinghouse.” International Journal of Geographical Information Science 28 (7): 1459–1481. doi: 10.1080/13658816.2014.894195
- Xia, J., C. Yang, and Q. Li. 2018. “Using Spatiotemporal Patterns to Optimize Earth Observation Big Data Access: Novel Approaches of Indexing, Service Modeling and Cloud Computing.” Computers, Environment and Urban Systems 72: 191–203. doi: 10.1016/j.compenvurbsys.2018.06.010
- Yang, C., H. Wu, Q. Huang, Z. Li, and J. Li. 2011. “Using Spatial Principles to Optimize Distributed Computing for Enabling the Physical Science Discoveries.” Proceedings of the National Academy of Sciences 108 (14): 5498–5503. doi:10.1073/pnas.0909315108.
- Yu, J., J. Wu, and M. Sarwat. 2015. “Geospark: A Cluster Computing Framework for Processing Large-Scale Spatial Data.” In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, 70. ACM.