
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The extraction of roads from UAV images is challenged by lighting, noise, occlusions, and similar non-road objects, making high-quality road extraction difficult. To addressing these issues, this study proposes an enhanced U-Net network to automate the extraction and 3D modeling of real road scenes using UAV imagery. Initially, a cascaded atrous spatial pyramid module was integrated into the encoder to capitalize on global context information, thereby refining the fuzzy segmentation outcomes. Subsequently, a module for augmenting road feature extraction was added within the channel, and a spatial attention mechanism was introduced in the decoder to enhance edge clarity. Experimental results demonstrated that this model captures more road information compared to mainstream networks and effectively incorporates topological structure perception for road extraction in complex scenarios, thus improving road connectivity. The model achieved an F1 score and mean Intersection over Union (mIoU) of 85.6% and 81.2%, respectively, on UAV images of road scenes – marking improvements of 3.9% and 3.4% over the traditional U-Net model, thereby exhibiting superior automatic road extraction capabilities. Ultimately, the model facilitated refined modeling and visual analysis of road scenes, achieving high overall accuracy and detailed local restoration of the actual scene.
1. Introduction
Traffic management, disaster management, and public health all rely on road information (Guan et al. Citation2016; Liu, Yang, and Gu Citation2023). Meanwhile, as unmanned aerial vehicles (UAVs) become more widely used (Fan et al. Citation2020; Altuntabak and Ata Citation2022), UAV remote sensing (RS) plays a vital role in fine-tuning surface attachment measurements such as roads and three-dimensional reconstruction of urban buildings (Liu et al. Citation2024). Currently, UAV images are being used to extract geospatial road information. Traditional methods for extracting roads from high-resolution images are time-consuming and labor-intensive, and the study of automatic extraction method will effectively improve the efficiency of road acquisition and update. The UAV is small in size, easy to carry and low in ground support requirements, which greatly reduces the operation and maintenance costs of the UAV (Wang et al. Citation2014; Hastaoğlu, Göğsu, and Yavuz Citation2022). Compared with road information acquisition methods such as vehicle-mounted cameras, the road information acquisition method based on UAV images has obvious advantages, and effectively solves the problems of small information acquisition area, low image resolution and poor mobility (Samad et al. Citation2013; Akay and Ozcan Citation2021). However, it is very difficult to analyze a large amount of road RS-data obtained by UAV using traditional methods (Olson and Anderson Citation2021; Qin et al. Citation2022; Wang et al. Citation2023), including spectrographic analysis (Gomez Citation2002), threshold segmentation (Singh and Garg Citation2013), knowledge model (Shen et al. Citation2008), etc. Due to the frequent necessity for manual intervention, these methods entail a substantial workload, proving both time-consuming and labor-intensive. Consequently, they fall short of achieving automated road extraction, particularly when compared with traditional methodologies. This reliance on manual processes significantly hampers efficiency and scalability in road mapping applications (Xu et al. Citation2018).
In recent years, after many scholars adopt convolutional neural networks (CNNs) to realize image recognition (Wang et al. Citation2022; Li et al. Citation2021), deep learning (DL) methods have gained more and more applications in RS image’s information extraction (Zhang et al. Citation2016; Liu et al. Citation2021). Minh and Hinton first applied DL method to extract road edges, using restricted Boltzmann machines to detect road in high-resolution RS images and achieved good results (Mnih and Hinton Citation2010; Liu et al. Citation2023). Li et al. (Citation2016) predicted the probability graph of pixels belonging to road regions in RS images using CNNs, and then smoothed it by using linear integral convolution algorithm to retain the road edge information. Wang et al. (Wang et al. Citation2020) proposed a new coordinate convolution module to acquire multi-level spatial data. These path extraction methodologies predominantly concentrate on developing deeper network architectures or enhancing functional capabilities to optimize classifier construction. The global context awareness module stands as a pivotal element within these models, enabling the extraction of semantic information from the global context. This module facilitates the integration of this information to produce higher-level feature maps, thereby enriching the model's ability to discern and interpret complex scenes.
U-Net is currently one of the most effective approaches to semantic segmentation (Oktay et al. Citation2018). U-Net model uses two convolution layers in the encoder part for feature extraction and an average pooling layer for subsampling. Compared with this method, the ResNet model deepens the number of layers of the training model by adding a shortcut mechanism, which effectively avoids gradient disappearance and accelerates network convergence (He et al. Citation2016). In the process of using RS images to extract road context information, there have been studies that propose multi-scale and multi-level features for combining pixel category and spatial information (Chen et al. Citation2022; Liu et al. Citation2023). For example, PSPNet used the spatial pyramid module to gather multi-level features as context information (Zhao et al. Citation2017). Later, some studies used extended convolution to enlarge the receiving field to obtain context information. DeepLab v2 combined extended convolution with different expansion rates to propose an extended convolution module, which can capture a large range of multi-scale context information without increasing the computational burden (Chen et al. Citation2018). This method, however, does not adequately consider the overall geometry of the road, nor does it fully utilize contextual information. Throughout the down-sampling process, there is a progressive decline in image resolution, resulting in the loss of critical spatial information which proves challenging to recover. Consequently, this loss adversely affects the clarity of the extracted road edges, diminishing the precision of the segmentation outcome. By introducing the space void pyramid module into U-Net model, many scholars could acquire more global context information by integrating image feature information of different sizes (Fan et al. Citation2022; Liu, Su, and Lv Citation2022; Bayramoğlu and Melis Citation2023). Some studies also put forward an improved U-Net algorithm with improved attention mechanisms to promote the feature extraction of road edges and improve segmentation accuracy (Han et al. Citation2021; Su et al. Citation2022). Road extraction research can benefit from the above improved ideas.
In addition, cross-entropy loss function is often adopted for DL-based models (Tao et al. Citation2019). As a result, the loss caused in the process of obtaining information about curves such as roads and complex topologies is local, and the same penalty is applied to all errors, without considering the influence of geometric topological factors (Neven et al. Citation2018). However, road information in RS images often has a tiny pixel share and a strong topological structure. Therefore, this loss function is not optimal for road segmentation. During model training, the feature map encoded by the encoder will contain more feature information (He et al. Citation2019), including boundary, texture and spatial structure. However, the pooling operations employed during the encoding process inevitably led to a loss of semantic information and the generation of additional background noise. Conversely, feature maps that have not undergone encoding retain a greater amount of semantic information, which could potentially enhance the overall quality of the image analysis (Liu et al. Citation2019). The combination of un-coded and encoded feature images is very helpful for feature localization and noise suppression.
Besides, road model reconstruction using multi-angle images collected by UAVs has been widely used (Knyaz et al. Citation2020; Kalacska et al. Citation2020). In the process of 3D automatic modeling, the quality of the model is not only affected by various factors such as resolution and overlapping map, but also greatly affected by moving objects on the road, which often cause serious distortion and dislocation of the texture of the road model (Murtiyoso et al. Citation2020). Among the various factors affecting the model, the deformation caused by moving vehicles on the road is particularly significant. Therefore, it is crucial to focus on the fine modeling and visual management of road UAV images to address these dynamic changes effectively and enhance the accuracy of the representation.
In response to the analysis of the structural characteristics and limitations of the traditional U-Net network, an enhanced U-Net architecture is proposed. This revised network incorporates an Atrous Spatial Pyramid Pooling (ASPP) module at the juncture between the encoder and decoder to enhance segmentation accuracy. Additionally, a coordinate attention mechanism is integrated within the channel part to augment the capability of information extraction. Moreover, spatial attention is introduced in the decoder to improve the clarity of model segmentation. Ultimately, sophisticated 3D modeling software and a visualization platform are employed to accurately reconstruct the road scene.
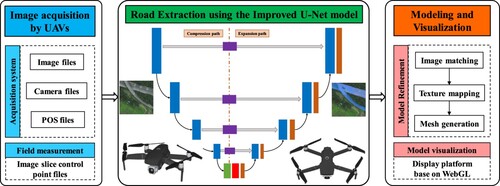
As shown in , Section 2 describes the image acquisition and preprocessing method. The road extraction method based on the improved U-Net model is given in Section 3. Then, Section 4 elaborated the modeling and visualization process of road scenes. Section 5 summarizes the experimental results and findings. Finally, Section 6 concludes this study.
Figure 1. Flowchart of the automatic extraction and 3D modeling of real road scenes.
2. Data preparation and preprocessing
The DJI Matrice M600 Pro hexacopter UAV was used as the image collection platform in this study, with a single photo resolution set to 7952 × 5304. Other hardware specifications are shown in .
Table 1. Hardware specifications for UAV road image collection.
As presented in , two image sets were used for the model. ) shows a self-made UAV image set of a road collected in November 2022, and the shooting area is the North Ring road section of G312 National Highway in Wuxi, China. The image resolution is 0.1 m, which makes its size larger after stitching. Due to the use of large-size training images, the requirements for computer performance are higher, and the training phase will be more extended. This results in 1800 images, in which the training image is divided into 1024 × 1024 pixels blocks.
Figure 2. Road in remote sensing images and its annotation: (a) UAV-acquired, (b) DeepGlobe dataset, and (c) labels.

) shows the DeepGlobe road extraction dataset derived from DeepGlobe 2018 (Demir et al. Citation2018). The training data for the Road Challenge consists of 6,226 RGB satellite images (1024 × 1024 pixels). The image has a 0.5 m resolution and was collected by Digital Globe’s satellites. One thousand two hundred of these samples were used in this study. In addition, the original images of all regions and the corresponding label images are arranged according to disorder and stored in different folders to avoid over-adapting to image features of a specific region during training stages.
Finally, 3000 data sets were established and randomly divided according to the ratio of 8:1:1, and 300 data sets were used for testing and result evaluation: path road and highway road, as shown in ). Labeling is divided into two labels according to different road characteristics: path road (road-P) and highway road (road-H). As a result, the dataset and labels information of roads in UAV images is given in .
Table 2. Road dataset information in UAV images.
3. Road extraction using the improved U-Net model
3.1. U-Net network
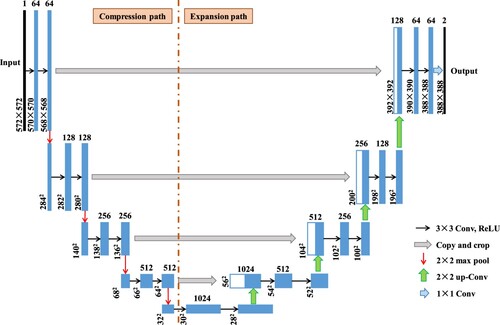
U-Net network structure comprises an encoder and a decoder with an encoder symmetry structure to realize down-sampling and up-sampling, respectively. describes its network structures. The encoder, also known as the compression path, is mainly used to extract image features. The compression path consists of four blocks, each of which uses three effective convolution and 1 maximum pooled down-sampling. Traditional sampling will reduce the resolution of the image. The decoder, also known as the extension path, is also composed of four blocks, each of which restores the size of the feature map by deconvolution and then merges it with the corresponding feature map of the encoder to form a new feature map. U-Net network, as a variant of FCN, has the advantage of full-CNN feature expression, and it solves the problem of rough feature maps extracted by FCN by reusing low-level semantic information through jumping connections.
Figure 3. Network structure of the original U-Net model.
3.2. Improved U-Net network
However, road extraction using U-Net would likely fail because that in RS images is complex and may be blocked. To enhance its anti-blocking ability, this study introduced the ASPP and fusion attention modules to improve the segmentation effect. illustrates the detail structure of improved model, which includes coding and decoding networks.
Figure 4. Network structure of the improved U-Net model.
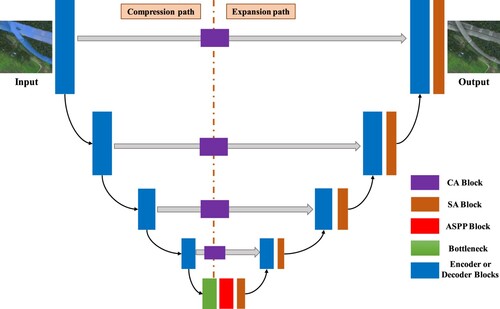
The first part is the encoder part, which introduces a channel attention module in each channel to make the model channel relationship and adjust the weight of the channel dimension. The improved ASPP module is used to connect the bottom of encoder and decoder. Its purpose is to obtain multi-scale image context information using cavity convolution with different expansion rates, improve decoder classification accuracy, and increase model detail expression ability.
The second part is the decoder part, which introduces the spatial attention mechanism into the sampling module of each layer to help decoder recover the original feature map’s resolution. Thus, it could extract more and more complete road information.
3.2.1. Fusion attention mechanism module
| (1) | Channel attention mechanism | ||||
Figure 5. Network structure of coordinate attention mechanism.
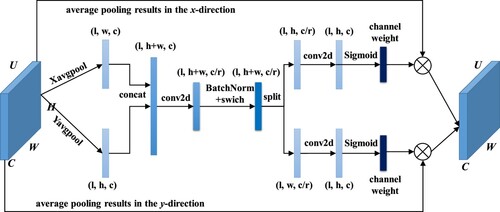
First, a feature graph U (H × W × C) is input into CA mode. After average pooling in the X and Y directions, a new feature graph (1× (H + W) ×C) is generated by splicing in the channel dimension. C/r is number of convolutional compression channels, r is the attenuation rate. Then, the nonlinear transformation operation is carried out by using the convolutional transformation function BN and the swich activation function. Feature graphs are then separated into above two feature graphs of size 1×H × C and 1×W × C and activated by the Sigmoid function to generate a pair of weights along and horizontally for each feature channel of the original input. Last, A new output feature graph U’ is created by multiplying learned weights with inputted feature graphs, then U’ has richer semantic information. The calculation process of this network is shown in EquationEquation (1(1)
(1) ).
(1)
(1) where, U and U’ are the input and out feature maps, respectively. σ1 and σ2 are channel weight along vertical and horizontal directions, respectively.
| (2) | Spatial attention (SA) mechanism | ||||
Channels combine the high-level and low-level feature maps recovered by the decoder. At the same time, the original encoder part adopts traditional convolution method to extract features. There is a potential for interference from extraneous information, such as noise in the extracted feature maps, which can rapidly result in issues like edge blurring and road disconnection in road segmentation. To enhance the segmentation quality, an SA fusion module is incorporated into the decoder section of the model. This addition aims to concentrate on road features, improve their extraction, restore the continuity of roads, and enhance the clarity of their edges. Network structure of SA module is illustrated in .
Figure 6. Network structure of SA module.
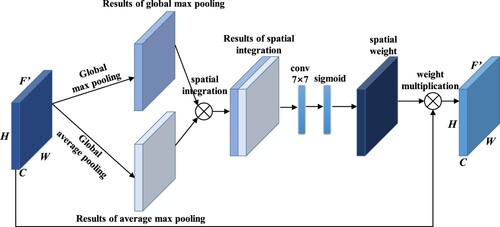
Firstly, pooling operations at the global maximum and average levels are carried out on feature graphs F, following spatial fusion, and then feature extraction is enhanced by a 7 × 7 convolution kernel, and the spatial weight value is obtained by Sigmoid activation function and multiplied with the original image pixel by pixel to get a new feature graph F’, as calculated in EquationEquation (2(2)
(2) ).
(2)
(2) where Ms(F) denotes the spatial weight value, σ represents the activation function, and f7 × 7 denotes a 7 × 7 convolution operation.
3.2.2. ASPP module
Encoder outputs the most decadent semantic features in the last feature map. To enhance the feature utilization rate, an ASPP module is inserted following the feature map. This module utilizes dilated convolutions at various dilation rates to extract features, thereby capturing multi-scale contextual information. Additionally, it expands the receptive field without the addition of extra parameters, enabling the acquisition of a broader spectrum of feature information while preserving the original resolution. Different expansion rates can increase the filter's receptive field, as given in EquationEquation (3(3)
(3) ).
(3)
(3) where r is the expansion rate and k is the length of the filter. However, ASPP also has some shortcomings. It lacks mutual dependence in the results of a certain layer obtained by hollow convolution, which will cause local information loss and affect the classification results. Thus, ASPP module structure was improved by changing it from the original independent branch method to serial structure to realize more intensive pixel sampling, expand the receptive field, improve feature extraction ability, and avoid local information inconsistency. describes this improved ASPP module.
Figure 7. Network structure of the improved ASPP module.
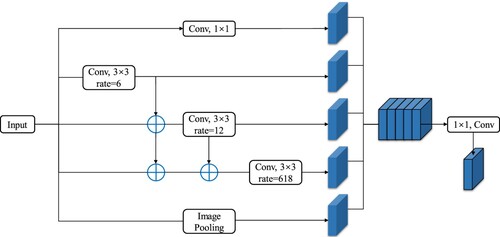
The convolution of two voids can result in a larger receptive field. EquationEquation (4(4)
(4) ) further gives the receptive field size after superposition:
(4)
(4) where S1 and S2 are the respective receptive field sizes convolved by two voids. According to Equations (Equation3
(3)
(3) ) and (Equation4
(4)
(4) ), the maximum receptive field of the original ASPP module is 37, and that of the improved ASPP module is 73. The enhanced module facilitates information sharing via skip-layer connections, while the use of dilated convolutions with varying dilation rates complements one another, thereby broadening the receptive field. This integration effectively increases the scope of feature detection and contributes to a more comprehensive understanding of the spatial context.
3.2.3. Loss function
It is a pixel-by-pixel classification issue for the DL-based model to determine whether a pixel is a road or a background. The proportion of roads in UAV images to the overall area of the image is small, and there are better choices than cross-entropy loss for such tasks. Thus, Dice coefficient (Ldice) and cross-entropy (Lcross) loss functions are combined to calculate loss function for this model. EquationEquation (5(5)
(5) ) shows how to calculate Lcross for binary classification (Mosinska et al. Citation2018; Liu et al. Citation2024).
(5)
(5) where y represents the corresponding real road label, ‘0’ and ‘1’ represent the pixel value of background and road, respectively. f is used to represent the parameterized form, then the output image output is y’ = f(x); N represents the number of pixel points.
EquationEquation (6(6)
(6) ) further shows how Ldice calculated (Liu et al. Citation2022).
(6)
(6) where X and Y, respectively represent the predicted graph and the actual label. |X∩Y| denotes the intersection between labels and prediction, |X| and |Y| indicate the number of labeled and predicted elements, respectively.
Thus, the final loss function Lloss is calculated in EquationEquation (7(7)
(7) ).
(7)
(7)
3.2.4. Experimental design and evaluation index
In this work, the training hardware configuration was A40 GPU, and the software configuration was PyTorch environment under Windows. For training models, the hyperparameters are set as below: The gradient descent method with the minimum batch of 4 was used for training. The initial learning rate is set to 0.00002, momentum is 0.9, and attenuation coefficient is 0.0001. The maximum batch is set to 200 (Liu et al. Citation2024c). Subsequently, the experiment employed the adaptive moment estimation (Adam) optimizer (Şen and Özkurt Citation2020) to adjust the model parameters and update the network weights, iterating 100 times. The learning rate was progressively decreased as the number of training iterations increased. To prevent the imbalance between positive and negative samples, a hybrid loss function as specified in EquationEquation (7(7)
(7) ) was utilized.
To quantitatively compare the results, the evaluation indexes of Equations (8)–(11) (Liu et al. Citation2022; Liu et al. Citation2022; Liu, et al. Citation2024e) were adopted, which were precision (P), recall rate (R), F1 score, average precision (AP), IoU, and mean IoU (mIoU), respectively.
(8)
(8)
(9)
(9)
(10)
(10)
(11)
(11) where: TP represents correctly predicted pixels; FP represents pixels’ number whose predicted results are inconsistent with the real ones. FN represents pixels’ number that are not predicted. The values of the above indicators are all within the range of [0,1]. Road segmentation performs better when the value is close to 1.
4. 3D modeling of real road scenes
4.1. 3D modeling
To build the 3D model of the highway real scene, ContextCapture software was used to semi-automatically process the initial data of oblique photography and establish the 3D model of a multi-format real scene, and the preliminary results of the 3D model of the highway were obtained. ContextCapture software is one of the world's most commonly used 3D modeling software, which can semi-automatically generate high-quality, high-resolution 3D models based on high-definition images (the ground sampling resolution was 2.0 cm) (Cui and Wang Citation2023). It can generate geographic 3D models in any coordinate system and even in the custom plane system suitable for GIS applications. Authentic projective images and digital surface models that are compatible with all standard GIS tools can also be generated.
To optimize third-party visualization and analysis software for accurate 3D models, an open scene graph binary (OSGB) data format was selected. As shown in , the oblique photography model of OSGB format also includes Data files and XML files composed of multiple sub-files. Each sub-file is an OSGB format file organized in a tree structure.
Figure 8. OSGB data format: (a) file structures and (b) organizational form.
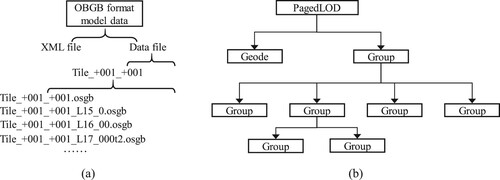
The Data file adopts the PagedLOD mechanism based on OSG, which manages the 3D model data by establishing a top-down hierarchical pyramid structure. The PagedLOD organization form consists of Geode nodes and Group nodes. Leaf nodes are mainly used to store coordinates, textures, indexes, and other information for rendering and no longer contain child nodes. Group nodes can include any number of child nodes, and child nodes can also continue to distribute nodes, forming a large and orderly organization data structure, significantly improving rendering performances.
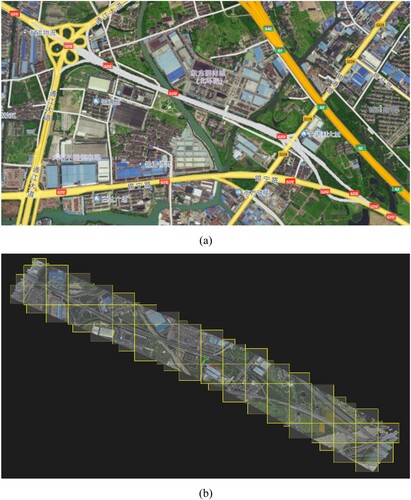
As shown in ), Context Capture software was used to process it and obtain the OSGB real 3D model data format based on the oblique photography data (WGS84 coordinate system) collected on the road section (the gray part), which was used for subsequent refinement, visualization and analysis software optimization. The tile set of production results contains 72 tiles (each tile includes approximately nine images), and ) shows its basic division rule. Starting from the top view of the model, it was divided equidistantly in the horizontal and vertical directions, respectively, to form several regular square tiles and rectangular tiles with edges and corners. In the tile file naming convention, the initial three digits represent the number of columns, while the subsequent set indicates the number of rows, ordered from bottom to top. This systematic naming facilitates the rapid identification and location of the 3D model corresponding to each tile.
Figure 9. 3D modeling process.
The third-party software SuperMap GIS can display the preliminary results of oblique photography models in OSGB format obtained by Context Capture software. Detailed steps are as follows:
The 3D slice cache layer of the oblique photography model was obtained through the generate profile function. The source path selects the Data file ‘Data,’ and the object path was consistent. The model reference point and projection settings were edited according to the < SRSOrigin > and < SRS > lines in the XML file. Click OK to get the 3D layer stored in SCP format (named ‘Config’);
Once the profile is complete, it can browse the tilt photography 3D model using the SuperMap iDesktopX software. A new spherical scene was created, and the newly generated Config 3D slice cache layer was inserted to show the preliminary results of the actual highway model in the scene.
4.2. Model refinement
In practical scenarios, the accuracy of 3D model results is often compromised due to interference from flight conditions, climatic environments, time of acquisition, and the image processing algorithms used. These factors can introduce flaws and defects into the 3D models. Consequently, it is necessary to modify and replace the preliminary models to achieve a refined and more accurate representation. This refinement process is crucial for enhancing the reliability and utility of the 3D models in practical applications.
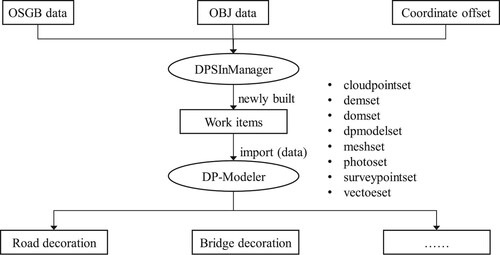
As shown in , DP-Modeler was selected as the refinement software. Before using DP-Modeler to repair the model, it is necessary to use DPSInManager software to create a new project, import OBJ format and OSGB format oblique photography data into the Mesh local model modification, and set the offset value according to the XML file. Import the JAS format file into DP-Modeler, and then it can start the local modification work of the model, such as road safety devices and bridge opening modification.
Figure 10. Workflow of the model refinement.
4.3. Model visualization
For GIS, the Web GIS development platform is commonly used as a 3D graphics engine to publish GIS spatial data and further realize the functions of retrieval, query, cartographic output and editing. Cesium uses the most advanced WebGL technology to achieve hardware acceleration (Liu et al. Citation2021), which can achieve smooth operation on HTML5 browsers without plug-ins and is suitable for displaying and simulating dynamic data on GIS layers. Thus, it was used for model visualization analysis.
ContextCapture Web View 2.0 is a Cesium-based custom Web application that enables user interface customization and real-world data display. By calling the HTML code of the 3D model, the URL can be generated, and the 3D model can be published on the web page. Any device running Cesium through a Node.js server can open the published highway 3D model visualizations directly from the web address without tilt photography data files.
5. Results and discussions
5.1. Automatic extraction results of roads
5.1.1. Results of road extraction
To verify the model performance, U-Net, FCNs, and Mask R-CNN networks were used for segmentation processing using the same testing dataset. Experimental results are shown in .
Figure 11. Diagram of the detection results of road extraction for each model.

The distribution of roads is mainly straight lines or cross lines. Among them, the types of ground objects around the ‘road-H’ label are relatively consistent, and the prominence is somewhat apparent. The ‘road-P’ label is rather indistinct from the surrounding land because of its small area. In the figure, the yellow box indicates missed detection, and the red box indicates false detection. Compared with FCNs model, Mask R-CNN, U-Net, and improved U-Net models all showed better road segmentation effects. However, both the Mask R-CNN and U-Net models exhibited significant instances of missed and false detections, particularly at road intersections and with the ‘road-P’ label. In contrast, the improved U-Net model demonstrated substantially fewer missed and false detections, as well as a smaller erroneous pixel area, compared to other models. This indicates a more effective separation of the road-covered parts from the rest of the road, underscoring the superiority of the enhanced U-Net model in maintaining the integrity and accuracy of road segmentation.
5.1.2. Contrast analysis
To analyze the segmentation results more intuitively, the evaluation results of each segmentation model are calculated. The U-Net1 model refers to the introduction of CA and SA modules into the original U-Net architecture, while U-Net2 further incorporates an improved ASPP module to analyze the impact of the proposed improvements on the detection results.
gives the segmentation results of different models. From the table, F1 score, AP, and mIoU of improved U-Net network reached 85.6%, 82.9%, and 81.2%, respectively. Among these models, the proposed model’s IoU is 8.4% higher than the FCNs, 5.5% higher than the Mask R-CNN, and 3.4% higher than the U-Net models. F1 score of improved U-Net model improved by 3.9% compared to original U-Net model, 5.5% compared to the Mask R-CNN model, and 10.1% compared to the FCNs model. AP of the improved U-Net model also improved by 5.6%.
Table 3. Comparisons of the testing results of four road extraction models.
Specifically, the indexes of the ‘road-H’ label were higher than those of the ‘road-P’ label because the road features of highways are more regular and the scope is broader, so the segmentation is more accurate. In addition, although the index of the ‘road-P’ label was not as good as that of ‘road-H,’ improved U-Net performance on the ‘road-P’ label was still satisfactory, with the P of the ‘road-H’ label reaching 90.1% and the P of ‘road-P’ label exceeding 80%, achieving the highest value among these models. Quantitative comparison results of these indicators suggested that improved U-Net network had improved road extraction accuracy from UAV images. The main reason is that by introducing CA, SA and improved ASPP modules in the improved U-Net model, the segmented road structure is more complete, more road information can be obtained, and the accuracy rate of road segmentation can be improved. A more detailed analysis revealed that the U-Net1 model offers the most significant improvement over the original U-Net model, with an increase in AP of about 4%. The subsequent U-Net2 model and the final improved U-Net model showed less than a 1% improvement, indicating that the uneven scale of road labels has the greatest impact on network detection performance.
In terms of the detection speed, although the FCNs model boasted the fastest detection speed among the experimental models, its segmentation accuracy failed to meet the required standards. The Mask R-CNN model exhibited the slowest testing speed. The improved U-Net model increased the detection time by only 1.14 ms per image (3.22%) compared to the original model, but the detection accuracy of the improved model has significantly increased. Taking everything into consideration, the model designed in this study offers the most balanced segmentation performance for road scene images captured from UAVs.
In addition, the improved model demonstrates excellent automatic road extraction capabilities on a mixed dataset (comprising both proprietary and public datasets), indicating that the proposed model adapts well to datasets from various sources. However, due to significant scale variations among different road types, some errors still occur in the extraction of images of roads on a smaller scale. Therefore, future research should focus on optimizing the algorithm and utilizing data sources from different platforms to achieve better application.
5.2. Results of 3D modeling of real road scenes
5.2.1. 3D models of road
presents the preliminary modeling results of the highway. It can be seen that the outline of the primary model coincides with the actual road and is relatively smooth. Still, the modeling effect of the area with vehicles was poor, indicating the need for local fine processing.
Figure 12. 3D model renderings: (a) global top view and (c) to (d) local details.

5.2.2. Model refinement
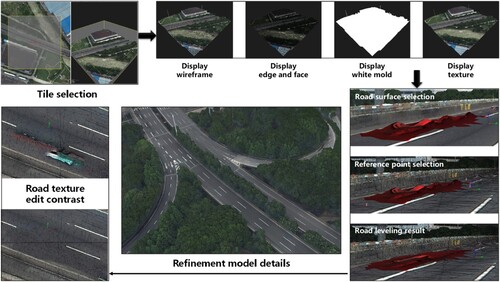
describes the model refinement process and the final result. It can be seen that after modifying the local details, the abnormal undulation of the road surface had been smoothed out. The overall model was smoother and closer to the actual situation than the preliminary model.
Figure 13. 3D model renderings: (a) global top view and (c) to (d) local details.
5.2.3. Model visualization
illustrates the real-world 3D model of a highway on the Website published by Cesium. The toolbar on the left was divided into a browsing view editing plate, an operation editing plate, and a model measurement plate. For the 3D model of the actual highway scene, the utility of distance and coordinate measurements within the model was substantiated. Distance measurement facilitates the determination of the distance and elevation difference between any two points in the model, while coordinate measurement provides the longitude, latitude, and elevation of any point in the model. This enhances the model's applicability in real-world spatial analysis and precision mapping. Furthermore, this platform provides embedded semantic segmentation networks from the research, enabling online model training, testing, and evaluation. It accomplishes road recognition and extraction from drone aerial imagery and serves as a basis for further understanding of road scenes.
Figure 14. Web-based 3D real-scene highway model using Cesium.

6. Conclusions
This research provides a method for automatic extraction and 3D modeling of real road scenes using UAV imagery and the improved U-Net model. The main conclusions are drawn as follows:
Compared to the conventional network utilized for road information extraction, the enhanced training model demonstrated a superior capability to capture more detailed road data. The feasibility of incorporating an improved ASPP module to extract roads in complex environments was confirmed. Additionally, the CA and SA modules effectively mitigated issues related to missed and false detections, thereby enhancing the overall accuracy and reliability of the model.
he F1 score and IoU of the improved U-Net model for road extraction from UAV imagery reached 85.6% and 81.2%, respectively. These metrics signify a notable enhancement over other network models, demonstrating the improved model's superior performance. This model effectively reconstructs the actual road layout, showcasing its exceptional capability for automatic road extraction. This improvement in performance indices highlights the model's advanced ability to capture and delineate road features accurately in diverse aerial scenarios.
The ContextCapture, DP-Modeler, and Cesium software platforms were employed to facilitate the preliminary modeling, fine modeling, and visual analysis of road scenes. The model demonstrated high overall accuracy and effectively restored local details to closely replicate the actual scene. Additionally, the web-based model incorporated functionalities for coordinate and distance measurement, enhancing its utility for detailed spatial analysis and accurate geographical assessments.
However, this work only realizes the segmentation of road images. A further research topic will use a more optimized model to segment diverse objects in remote-sensing images, especially for the analysis of factors such as land, urban buildings, and rivers.
Acknowledgements
This research was funded by the Key Science and Technology Research Project of Jinhua, China, grant number 2022-3-056.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
Data in ) are publicly available and the DeepGlobe road extraction dataset derived from DeepGlobe 2018 (https://www.kaggle.com/datasets/balraj98/deepglobe-road-extraction-dataset). Data in ) were privately acquired and are available on request from the corresponding author.
Additional information
Funding
References
- Akay, Semih Sami, and Orkan Ozcan. 2021. “Assessing the Spatial Accuracy of UAV-Derived Products Based on Variation of Flight Altitudes.” Turkish Journal of Engineering 5 (1): 35–40. https://doi.org/10.31127/tuje.653631.
- Altuntabak, Hazal, and Ercenk Ata. 2022. “Investigation of Accuracy of Detailed Verified by Unmanned Aerial Vehicles with RTK System; The Example of Ortakent-Bodrum Area.” Review of. Advanced UAV 2 (1): 1–10.
- Bayramoğlu, Zeynep, and Uzar Melis. 2023. “Performance Analysis of Rule-Based Classification and Deep Learning Method for Automatic Road Extraction.” International Journal of Engineering and Geosciences 8 (1): 83–97. https://doi.org/10.26833/ijeg.1062250.
- Chen, Yihan, Xingyu Gu, Zhen Liu, and Jia Liang. 2022. “A Fast Inference Vision Transformer for Automatic Pavement Image Classification and Its Visual Interpretation Method.” Remote Sensing 14 (8): 1877. https://doi.org/10.3390/rs14081877.
- Chen, Liang-Chieh, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. 2018. “Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs.” IEEE Transactions on Pattern Analysis and Machine Intelligence 40 (4): 834–848. https://doi.org/10.1109/TPAMI.2017.2699184.
- Cui, Bingyan, and Hao Wang. 2023. “Analysis and Prediction of Pipeline Corrosion Defects Based on Data Analytics of In-Line Inspection.” Journal of Infrastructure Preservation and Resilience 4 (1): 14. https://doi.org/10.1186/s43065-023-00081-w.
- Demir, Ilke, Krzysztof Koperski, David Lindenbaum, Guan Pang, Jing Huang, Saikat Basu, Forest Hughes, Devis Tuia, and Ramesh Raskar. 2018. “Deepglobe 2018: A Challenge to Parse the Earth Through Satellite Images.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops.
- Fan, Bangkui,, Yun Li, Ruiyu Zhang, and Qiqi Fu. 2020. “Review on the Technological Development and Application of UAV Systems.” Chinese Journal of Electronics 29 (2): 199–207. https://doi.org/10.1049/cje.2019.12.006.
- Fan, Xiangsuo, Chuan Yan, Jinlong Fan, and Nayi Wang. 2022. “Improved U-net Remote Sensing Classification Algorithm Fusing Attention and Multiscale Features.” Remote Sensing 14 (15): 3591. https://doi.org/10.3390/rs14153591.
- Gomez, Richard B. 2002. “Hyperspectral Imaging: A Useful Technology for Transportation Analysis.” Optical Engineering 41 (9): 2137–2143. https://doi.org/10.1117/1.1497985.
- Guan, Haiyan, Jonathan Li, Shuang Cao, and Yongtao Yu. 2016. “Use of Mobile LiDAR in Road Information Inventory: A Review.” International Journal of Image and Data Fusion 7 (3): 219–242. https://doi.org/10.1080/19479832.2016.1188860.
- Han, Gujing, Min Zhang, Wenzhao Wu, Min He, Kaipei Liu, Liang Qin, and Xia Liu. 2021. “Improved U-Net Based Insulator Image Segmentation Method Based on Attention Mechanism.” Review of. Energy Reports 7: 210–217.
- Hastaoğlu, Kemal Özgür, Sinan Göğsu, and GÜL Yavuz. 2022. “Determining the Relationship Between the Slope and Directional Distribution of the UAV Point Cloud and the Accuracy of Various IDW Interpolation.” International Journal of Engineering and Geosciences 7 (2): 161–173. https://doi.org/10.26833/ijeg.940997.
- He, Hao, Dongfang Yang, Shicheng Wang, Shuyang Wang, and Yongfei Li. 2019. “Road Extraction by Using Atrous Spatial Pyramid Pooling Integrated Encoder-Decoder Network and Structural Similarity Loss.” Remote Sensing 11 (9): 1015. https://doi.org/10.3390/rs11091015.
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Identity Mappings in Deep Residual Networks. Paper Presented at the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part IV 14.
- Hou, Qibin, Daquan Zhou, and Jiashi Feng. 2021. “Coordinate Attention for Efficient Mobile Network Design.” Paper Presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Kalacska, Margaret, Oliver Lucanus, J. Pablo Arroyo-Mora, Étienne Laliberté, Kathryn Elmer, George Leblanc, and Andrew Groves. 2020. “Accuracy of 3D Landscape Reconstruction Without Ground Control Points Using Different UAS Platforms.” Drones 4 (2): 13. https://doi.org/10.3390/drones4020013.
- Knyaz, Vladimir A., Vladimir V. Kniaz, Fabio Remondino, Sergey Y. Zheltov, and Armin Gruen. 2020. “3D Reconstruction of a Complex Grid Structure Combining UAS Images and Deep Learning.” Remote Sensing 12 (19): 3128. https://doi.org/10.3390/rs12193128.
- Li, Shuwei, Xingyu Gu, Xiangrong Xu, Dawei Xu, Tianjie Zhang, Zhen Liu, and Qiao Dong. 2021. “Detection of Concealed Cracks from Ground Penetrating Radar Images Based on Deep Learning Algorithm.” Construction and Building Materials 273: 121949. https://doi.org/10.1016/j.conbuildmat.2020.121949.
- Li, Peikang, Yu Zang, Cheng Wang, Jonathan Li, Ming Cheng, Lun Luo, and Yao Yu. 2016. “Road Network Extraction via Deep Learning and Line Integral Convolution.” Paper Presented at the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS).
- Liu, Zhen, Yihan Chen, Xingyu Gu, Justin KW Yeoh, and Qipeng Zhang. 2022aaa. “Visibility Classification and Influencing-Factors Analysis of Airport: A Deep Learning Approach.” Atmospheric Environment 278: 119085. https://doi.org/10.1016/j.atmosenv.2022.119085.
- Liu, Qian, Bingyan Cui, and Zhen Liu. 2024. “Air Quality Class Prediction Using Machine Learning Methods Based on Monitoring Data and Secondary Modeling.” Atmosphere 15 (5): 553. http://dx.doi.org/10.3390/atmos15050553.
- Liu, Zhen, Bingyan Cui, Qifeng Yang, and Xingyu Gu. 2024a. “Sensor-Based Structural Health Monitoring of Asphalt Pavements with Semi-Rigid Bases Combining Accelerated Pavement Testing and a Falling Weight Deflectometer Test.” Sensors 24 (3): 994. https://doi.org/10.3390/s24030994.
- Liu, Zhen, Xingyu Gu, Jiaqi Chen, Danyu Wang, Yihan Chen, and Lutai Wang. 2023aa. “Automatic Recognition of Pavement Cracks from Combined GPR B-Scan and C-Scan Images Using Multiscale Feature Fusion Deep Neural Networks.” Automation in Construction 146: 104698. https://doi.org/10.1016/j.autcon.2022.104698.
- Liu, Zhen, Xingyu Gu, Qiao Dong, Shanshan Tu, and Shuwei Li. 2021a. “3D Visualization of Airport Pavement Quality Based on BIM and WebGL Integration.” Journal of Transportation Engineering, Part B: Pavements 147 (3): 04021024. https://doi.org/10.1061/JPEODX.0000280.
- Liu, Z., X. Y. Gu, W. X. Wu, X. Y. Zou, Q. Dong, and L. T. Wang. 2022baa. “GPR-based Detection of Internal Cracks in Asphalt Pavement: A Combination Method of DeepAugment Data and Object Detection.” Measurement 197: 111281. https://doi.org/10.1016/j.measurement.2022.111281.
- Liu, Z., X. Gu, H. Yang, L. Wang, Y. Chen, and D. Wang. 2022bba. “Novel YOLOv3 Model with Structure and Hyperparameter Optimization for Detection of Pavement Concealed Cracks in GPR Images.” IEEE Transactions on Intelligent Transportation Systems 23 (11): 22258–22268. https://doi.org/10.1109/TITS.2022.3174626.
- Liu, Huafeng, Xiaofeng Han, Xiangrui Li, Yazhou Yao, Pu Huang, and Zhenmin Tang. 2019. “Deep Representation Learning for Road Detection Using Siamese Network.” Multimedia Tools and Applications 78: 24269–24283. https://doi.org/10.1007/s11042-018-6986-1.
- Liu, Zhixin, Boning Su, and Fang Lv. 2022bbb. “Intelligent Identification Method of Crop Species Using Improved U-Net Network in UAV Remote Sensing Image.” Review of Scientific Programming 2022: 1–9.
- Liu, Zhen, Siqi Wang, Xingyu Gu, Danyu Wang, Qiao Dong, and Bingyan Cui. 2024. “Intelligent Assessment of Pavement Structural Conditions: A Novel FeMViT Classification Network for GPR Images.” IEEE Transactions on Intelligent Transportation Systems: 1–13. http://dx.doi.org/10.1109/TITS.2024.3403144.
- Liu, Zhen, Wenxiu Wu, Xingyu Gu, Shuwei Li, Lutai Wang, and Tianjie Zhang. 2021b. “Application of Combining YOLO Models and 3D GPR Images in Road Detection and Maintenance.” Remote Sensing 13 (6): 1081. https://doi.org/10.3390/rs13061081.
- Liu, Zhen, Qifeng Yang, and Xingyu Gu. 2023ba. “Assessment of Pavement Structural Conditions and Remaining Life Combining Accelerated Pavement Testing and Ground-Penetrating Radar.” Remote Sensing 15 (18): 4620. https://doi.org/10.3390/rs15184620.
- Liu, Zhen, Qifeng Yang, Anlue Wang, and Xingyu Gu. 2024b. “Vehicle Driving Safety of Underground Interchanges Using a Driving Simulator and Data Mining Analysis.” Infrastructures 9 (2): 28. https://doi.org/10.3390/infrastructures9020028.
- Liu, Zhen, Justin KW Yeoh, Xingyu Gu, Qiao Dong, Yihan Chen, Wenxiu Wu, Lutai Wang, and Danyu Wang. 2023bb. “Automatic Pixel-Level Detection of Vertical Cracks in Asphalt Pavement Based on GPR Investigation and Improved Mask R-CNN.” Automation in Construction 146: 104689. https://doi.org/10.1016/j.autcon.2022.104689.
- Mnih, Volodymyr, and Geoffrey E Hinton. 2010. Learning to Detect Roads in High-Resolution Aerial Images. Paper Presented at the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, September 5-11, 2010, Proceedings, Part VI 11.
- Mosinska, Agata, Pablo Marquez-Neila, Mateusz Koziński, and Pascal Fua. 2018. “Beyond the Pixel-Wise Loss for Topology-Aware Delineation.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Murtiyoso, Arnadi, Mirza Veriandi, Deni Suwardhi, Budhy Soeksmantono, and Agung Budi Harto. 2020. “Automatic Workflow for Roof Extraction and Generation of 3D CityGML Models from Low-Cost UAV Image-Derived Point Clouds.” ISPRS International Journal of Geo-Information 9 (12): 743. https://doi.org/10.3390/ijgi9120743.
- Neven, Davy, Bert De Brabandere, Stamatios Georgoulis, Marc Proesmans, and Luc Van Gool. 2018. “Towards end-to-end Lane Detection: An Instance Segmentation Approach.” Paper Presented at the 2018 IEEE Intelligent Vehicles Symposium (IV).
- Oktay, Ozan, Jo Schlemper, Loic Le Folgoc, Matthew Lee, Mattias Heinrich, Kazunari Misawa, Kensaku Mori, Steven McDonagh, Nils Y Hammerla, and Bernhard Kainz. 2018. “Attention u-net: Learning Where to Look for the Pancreas.” Review of. arXiv preprint arXiv:1804.03999.
- Olson, Daniel, and James Anderson. 2021. “Review on Unmanned Aerial Vehicles, Remote Sensors, Imagery Processing, and Their Applications in Agriculture.” Agronomy Journal 113 (2): 971–992. https://doi.org/10.1002/agj2.20595.
- Qin, Jianxin, Wenjie Yang, Tao Wu, Bin He, and Longgang Xiang. 2022. “Incremental Road Network Update Method with Trajectory Data and UAV Remote Sensing Imagery.” ISPRS International Journal of Geo-Information 11 (10): 502. https://doi.org/10.3390/ijgi11100502.
- Samad, Abd Manan, Nazrin Kamarulzaman, Muhammad Asyraf Hamdani, Thuaibatul Aslamiah Mastor, and Khairil Afendy Hashim. 2013. The Potential of Unmanned Aerial Vehicle (UAV) for Civilian and Mapping Application. Paper Presented at the 2013 IEEE 3rd International Conference on System Engineering and Technology.
- Şen, Sena Yağmur, and Nalan Özkurt. 2020. Convolutional Neural Network Hyperparameter Tuning with Adam Optimizer for ECG Classification. Paper Presented at the 2020 Innovations in Intelligent Systems and Applications Conference (ASYU).
- Shen, Jing, Xiangguo Lin, Yunfei Shi, and Cheng Wong. 2008. “Knowledge-based Road Extraction from High Resolution Remotely Sensed Imagery.” Paper Presented at the 2008 Congress on Image and Signal Processing.
- Singh, Pankaj Pratap, and Rahul D Garg. 2013. “Automatic Road Extraction from High Resolution Satellite Image Using Adaptive Global Thresholding and Morphological Operations.” Journal of the Indian Society of Remote Sensing 41: 631–640. https://doi.org/10.1007/s12524-012-0241-4.
- Su, Huifeng, Xiang Wang, Tao Han, Ziyi Wang, Zhongxiao Zhao, and Pengfei Zhang. 2022. “Research on a U-Net Bridge Crack Identification and Feature-Calculation Methods Based on a CBAM Attention Mechanism.” Buildings 12 (10): 1561. https://doi.org/10.3390/buildings12101561.
- Tao, Chao, Ji Qi, Yansheng Li, Hao Wang, and Haifeng Li. 2019. “Spatial Information Inference Net: Road Extraction Using Road-Specific Contextual Information.” ISPRS Journal of Photogrammetry and Remote Sensing 158: 155–166. https://doi.org/10.1016/j.isprsjprs.2019.10.001.
- Wang, Danyu, Zhen Liu, Xingyu Gu, and Wenxiu Wu. 2023. “Feature Extraction and Segmentation of Pavement Distress Using an Improved Hybrid Task Cascade Network.” International Journal of Pavement Engineering 24 (1): 2266098. https://doi.org/10.1080/10298436.2023.2266098.
- Wang, Danyu, Zhen Liu, Xingyu Gu, Wenxiu Wu, Yihan Chen, and Lutai Wang. 2022. “Automatic Detection of Pothole Distress in Asphalt Pavement Using Improved Convolutional Neural Networks.” Remote Sensing 14 (16): 3892. https://doi.org/10.3390/rs14163892.
- Wang, Pei, Xiwen Luo, Zhiyan Zhou, Ying Zang, and Lian Hu. 2014. “Key Technology for Remote Sensing Information Acquisitionbased on Micro UAV.” Review of Transactions of the Chinese Society of Agricultural Engineering 30 (18): 1–12.
- Wang, Shuai, Hui Yang, Qiangqiang Wu, Zhiteng Zheng, Yanlan Wu, and Junli Li. 2020. “An Improved Method for Road Extraction from High-Resolution Remote-Sensing Images That Enhances Boundary Information.” Sensors 20 (7): 2064. https://doi.org/10.3390/s20072064.
- Xu, Yongyang, Zhong Xie, Yaxing Feng, and Zhanlong Chen. 2018. “Road Extraction from High-Resolution Remote Sensing Imagery Using Deep Learning.” Remote Sensing 10 (9): 1461. https://doi.org/10.3390/rs10091461.
- Zhang, Liangpei, Gui-Song Xia, Tianfu Wu, Liang Lin, and Xue Cheng Tai. 2016. “Deep Learning for Remote Sensing Image Understanding.” Review of Journal of Sensors 2016:7954154.
- Zhao, Hengshuang, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. 2017. Pyramid Scene Parsing Network. Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.