
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Sheep are a primary species in animal husbandry. Accurate sheep population counts are vital for managing husbandry practices and preventing grassland overgrazing. Current methods using UAV images are time-consuming and costly. The small size of sheep and complex backgrounds in large-scale areas make accurate extraction challenging. We propose the Small Object Extraction Net (SOENet), a semantic segmentation model with an encoder–decoder structure. The SOENet encoder resizes the original images to three resolutions to extract multi-scale sheep features. A Multi-resolution Context Enhancement (MCE) module is proposed to extract complicated contextual features of sheep by concatenating different scales of feature maps to reduce the possibility of commission errors. To minimize omission errors, a Multi-resolution Feature Fusion (MFF) module is proposed by introducing more scales of features to the encoder, facilitating the sharing and exchange of multi-scale sheep features. Our model outperforms nine deep learning models, with a 7.9% improvement in precision and a 1.2% increase in mIoU. SOENet provides an effective solution for large-scale sheep extraction from various ground objects.
1. Introduction
Sheep are the most prevalent type of grazing livestock and currently account for the largest population of livestock in animal husbandry (Xiao et al. Citation2023). Livestock monitoring plays a crucial role in regulating grazing activities and ensuring the protection of grassland environments. Accurately determining the location distribution and scale of the sheep population is crucial for maintaining a balance between grassland areas and the economic development of livestock. Traditional sheep counting methods, which rely on local sampling and Unmanned Aerial Vehicle (UAV) imagery (Kellenberger, Volpi, and Tuia Citation2017), are costly and inefficient. Limited research has focused on automatic sheep extraction from high-resolution remote sensing images (Peng et al. Citation2020). Due to the rapid development of remote sensing technology (Cracknell Citation2018), an increasing number of high spatial resolution images are available (Chen et al. Citation2023; Li et al. Citation2023; Yu et al. Citation2023; Yu et al. Citation2023b), which can accurately identify sheep even in complex scenes. Compared to using UAV for sheep extraction, the utilization of high-resolution remote sensing images can effectively decrease the cost of sheep monitoring and greatly enhance estimation efficiency.
Traditional methods of sheep extraction from remote sensing images rely on manual visual interpretation, a process that is labor intensive and not feasible on a large scale (Xiao et al., Citation2023). Moreover, manual visual interpretation poses difficulties for practical application in a large-scale area. In addition, there has been some research on automating sheep extraction from remote sensing images. Rognlien (Rognlien and Tran Citation2018) and Hollings (Hollings et al. Citation2018) successfully extracted sheep based on a threshold segmentation method, which has been widely used as a typical image segmentation technique (Cai et al. Citation2014). However, such methods are susceptible to interference from background objects with similar spectral features, often resulting in inaccurate extraction and a consequent reduction in extraction accuracy. In order to address the issue, machine learning methods have been adopted to extract sheep by automatically learning the thresholds from designed features using training samples (Li, Ma, and Xin Citation2017). Rey et al. used a support vector machine (SVM) to extract animals, including sheep, based on UAV images (Rey et al. Citation2017). However, designing features for machine learning methods relies heavily on the researcher’s expertise (Chen et al. Citation2022); inexperienced researchers may find it difficult to optimize the model parameters, impacting prediction accuracy.
In order to automate feature learning, deep learning frameworks, especially semantic segmentation frameworks, have been adopted for sheep extraction; these frameworks have achieved significant improvement in extraction performance. Sarwar et al. proposed an improved U-Net network and achieved a high precision and recall of 99% and 98%, respectively, in extracting sheep from UAV images (Sarwar et al. Citation2021). Xiao et al. implemented U-Net to extract sheep from Gaofen-2 remote sensing images after enhancement by a bilateral filtering algorithm to suppress noise (Xiao et al., Citation2023). Both of the above methods are modified from UNet (Guan et al. Citation2020), a typical model of semantic segmentation. However, continuous convolution and pooling layers in UNet lead to feature loss of small-scale sheep, resulting in large quantities of sheep omission errors. UGTransformer, a model with a CNN-based encoder and a transformer-based decoder, proposed by Wang et al. (Wang et al. Citation2024a), showed a 1.8% improvement in mean Intersection over Union (mIoU) for sheep extraction from high-resolution images. Moreover, Xu et al. proposed a multi-scale residual visual information fusion Network (MRVIFNet) for sheep extraction, but it also contains continuous convolution and pooling layers. This leads to an enormous loss of sheep pixels and is not practical for sheep extraction from large-scale remote sensing images (Xu et al. Citation2022).
With the small size of sheep in high spatial resolution images, the advent of deep learning frameworks for small object extraction can be adapted to sheep extraction. Ma et al. proposed FactSeg to specifically improve the extraction of small targets (Ma et al. Citation2022). It is a two-branch encoder–decoder network for multi-scale feature extraction and more detailed contextual feature extraction. Peng et al. proposed CFNet by adding a channel attention refinement block and a cross-fusion block to enlarge the receptive field of low-level feature maps and enhance more significant features (Peng et al. Citation2022). Dong et al. proposed DenseU-Net to improve small object extraction by enhancing the connection of feature maps at different levels in the encoder and decoder (Dong, Pan, and Li Citation2019). Learning more detailed feature maps is essential, especially for small objects. Li et al. proposed TANet with an auxiliary branch in the encoder, resulting in a 0.7% improvement in mIoU in small object extraction (Li et al. Citation2021). Some land classification methods can accurately identify the correct category of some small targets, such as the Multiscale Interactive Fusion Network (Wang et al. Citation2022; Wang et al. Citation2023), Graph-feature-enhanced selective assignment network (Li et al. Citation2022), Intermediate Domain Prototype Contrastive Adaptation (Zhao et al. Citation2024), and S2PNet (Gao et al. Citation2024), such methods can serve as inspiration for research on sheep extraction. The attention mechanism in latest works can promote deep learning models to focus on small-scale objects, which are instructive for the extraction of sheep (Zhang, Liu, and Kim Citation2024; Zhou et al. Citation2023). Khan et al. used multiple region proposal networks to achieve higher precision in object detection across universal multi-class geo-spatial objects; the structure of the multi-scale object proposals was conducive to small object extraction, helping to improve the efficacy of sheep extraction from images (Khan, Alarabi, and Basalamah Citation2022).
Drawing inspiration from these advancements, we propose the Small Object Extraction Net (SOENet), an encoder–decoder semantic segmentation framework for detailed sheep feature retention from high-resolution remote sensing images. Current studies on sheep extraction are limited and focused on UAV image-based methods. They are difficult to apply to sheep extraction from large-scale remote sensing images due to sheep having similar spectral characteristics to certain background objects, such as stones. In order to deal with such issues, our study proposes a Multi-resolution Context Enhancement (MCE) module to enhance the contextual feature distinguishing capability, enabling sheep to be identified in images with complicated background objects. Moreover, to extract more details of sheep, we propose a Multi-resolution Feature Fusion (MFF) module to fuze multi-dimensional features of sheep to avoid sheep omission errors. In addition, to retain more detailed sheep features, a Feature Enhancement module (FE) is deployed between the encoder and decoder to assign higher weights to detailed feature maps, thus reducing omission and commission errors in the extracted sheep. The main contributions of the study are as follows: (1) Proposal of an encoder–decoder semantic segmentation framework, SOENet, to extract sheep from images with a high spatial resolution. This technique outperforms the widely used network structures for sheep extraction. (2) Proposal of MCE and MFF modules to enhance feature fusion and contextual capacity. (3) Proposal of an FE module to enhance the learning capability of detailed features.
2. Methodology
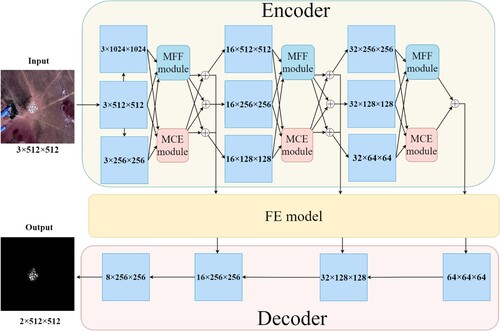
Our proposed model, as depicted in , comprises three main components: the encoder, the decoder, and the FE module connecting the encoder and decoder. Initially, the encoder resizes the original image to images of three varying dimensions. The three images can be used to learn different scales of features. Both MCE and MFF modules in the encoder take the resized three images as input to learn multi-scale features. The extracted features from the encoder are transferred to the FE module for further feature enhancement by assigning higher weights to more detailed feature maps. Finally, the decoder gradually restores the feature maps from the FE module by bilinear upsampling to the original input image size, outputting a binary sheep extraction result.
Figure 1. Model structure of our proposed SOENet.
2.1. Encoder
As shown in , the encoder of our proposed SOENet is a three-branch network to enhance the variability of the feature scales. It resizes the input image from a 512×512 pixel resolution to a lower resolution of 256×256 pixels via max pooling and a higher resolution of 1024×1024 pixels through bilinear upsampling. These varying resolutions allow for the extraction of diverse scales of sheep features for the model to learn from. The MCE and MFF modules are then introduced to synthesize the feature maps from different scales more effectively, thereby enhancing the contextual feature extraction and feature fusion capabilities.
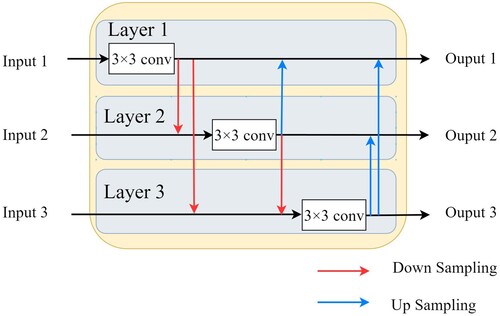
2.1.1. MFF module
The MFF module is structured with three inputs and three output feature maps. The three input feature maps are derived from the three different resolution images in the encoder. The MFF module is designed to fuze the three feature maps. As illustrated in , the structure of the MFF module consists of three layers. The feature maps of the first layer are fuzed with the second and third layers by addition. Similarly, the feature maps of layer 2 and layer 3 are fuzed with the other two feature maps in the same way. The fusion of different scales of features can enhance the feature extraction capability of encoders to reduce sheep omission errors. The proposed MFF module is organized with a similar structure to Res2Net, but with three scales of feature maps as input instead of the one in Res2Net to enhance the feature fusion capacity.
Figure 2. MFF module structure.
2.1.2. MCE module
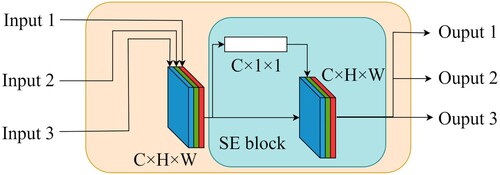
Similar to the MFF module, our proposed MCE module is also structured with three inputs and three output feature maps. It fuzes three feature maps into one by concatenation to enhance the contextual features, which is an effective structure inspired by PSPNet. In contrast to PSPNet, our MCE module has three input feature maps with three different resolutions, which are fuzed directly without pooling layers. In this way, more sheep features can be retained. Furthermore, as shown in , we use a Squeeze-and-Excitation (SE) block (Hu, Shen, and Sun Citation2018) in our proposed MCE module; this automatically learns weights for significant feature enhancement, thereby enhancing the sheep extraction capacity.
Figure 3. MCE module structure: the notation C in the figure represents the number of channels of the feature map; H and W indicate the height and width of the feature map.
2.2. Feature enhancement module (FE module)
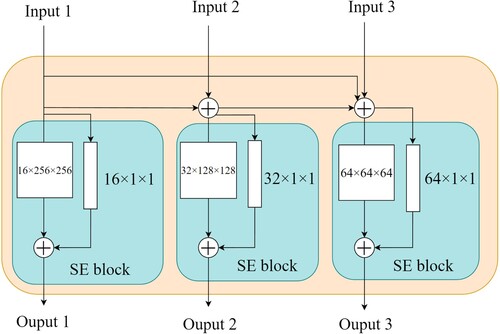
The feature maps from the MCE and MFF modules are integrated into one by addition and transferred to the FE module. The FE module is proposed to retain the detailed features of sheep to avoid feature loss caused by continuous convolution and pooling operations. As shown in , the sizes of the three feature maps from the encoder are 256×256 pixels, 128×128 pixels, and 64×64 pixels. In order to retain more sheep features, the more detailed feature maps (256×256 pixels) are fuzed with the remaining feature maps (128×128 pixels and 64×64 pixels) by addition. This step increases the weight of the more detailed feature maps, enabling the retention of more sheep features. Next, the feature maps in the FE module are extracted by a Squeeze-and-Excitation block (SE block), which can further enhance significant features by assigning higher weights.
Figure 4. FE module structure.
2.3. Decoder
As shown in , the three feature maps received by the decoder as input from the FE module are sized 256×256 pixels, 128×128 pixels, and 64×64 pixels. Among them, the 64×64 pixel feature map is resized by bilinear upsampling and restored to 128×128 pixels, and it is then fuzed with the 128×128 pixel input feature map by concatenation. The fuzed feature map is resized to 256×256 pixels by bilinear upsampling and fuzed with the 256×256 pixel input feature map. Finally, the fuzed feature map is restored to 512×512 pixels by binary extraction as the output.
3. Experiment and results
3.1. Study area and dataset preparation
The research area is situated in New Barag West County, Hulunbeier City, Inner Mongolia, China (as shown in ). It is a typical grassland area with flat terrain and numerous lakes. High spatial resolution (0.5 m) remote sensing images taken by the Beijing-3 satellite were adopted to extract sheep in this study. Eight images with a size of 26,900×12,000 pixels were collected in the year 2022 to cover the study area. As shown in , our dataset contains multiple types of background features, such as lakes, snow layers, roads, and rocks. The sheep were visually interpreted by two experienced experts, supplemented by a field survey. The collected remote sensing images and the corresponding ground truth images were uniformly cropped to image patches with a size of 512×512 pixels, and a total of 8,000 image patches were generated. Data augmentation was applied to enhance the effectiveness of the model training, with implemented strategies of image flip, image rotation, and noise addition. With the dataset augmented, 12,000 images were produced, with 2,400 image patches containing instances of sheep instances and 9,600 patches containing background objects only. We randomly selected 80% of the image patches containing background objects only and all of the images containing instances of sheep, and then mixed the two types of images to obtain the dataset for the study. A total of 7,056 image patches were used for training, and 3,024 image patches were used for testing.
Figure 5. Scope of the study area.
3.2. Evaluation metrics
To present a comprehensive performance evaluation of our proposed model for sheep extraction, four widely used metrics were adopted: mIoU (mean Intersection over Union), precision, recall, and F1 score (Huang et al. Citation2015). IoU (Intersection over Union) calculates the overlapping area ratio of the predicted sheep and the ground truth sheep to measure the alignment of the model’s predictions with the ground truth sheep. mIoU is the average IoU across multiple evaluation cases, presenting a comprehensive assessment. Precision quantifies the proportion of correctly identified sheep pixels among the model’s predictions. Recall is the ratio between the number of correctly identified sheep pixels and that of the ground truth sheep pixels. The F1 score provides a comprehensive assessment of the model’s performance by considering both precision and recall. A higher F1 score indicates superior model competency in balancing accuracy and comprehensiveness in sheep extraction. The above evaluation metrics were calculated according to Equations (1)–(4).
(1)
(1)
(2)
(2)
(3)
(3)
(4)
(4) wherein TP (True Positive) represents the number of accurately extracted ground truth sheep pixels. FP (False Positive) represents the number of background pixels that are incorrectly predicted as sheep pixels. FN (False Negative) represents the number of sheep pixels that are incorrectly predicted as background pixels. TN (True Negative) represents the number of accurately classified background pixels.
3.3. Implementation details
The experiments in this study were conducted using the RTX 3090 GPU device, equipped with 24 GB of memory in a Linux environment. Our proposed model was implemented using the PyTorch framework, and its parameters were optimized using the Adam optimization algorithm (Khan et al. Citation2020). This adaptively adjusted the learning rate as the training epochs progressed, with an initial learning rate set at 0.001 and a weight decay of 0.001, following the strategy employed in previous studies (Wang et al. Citation2024b). The batch size was set to 8 in the training process. With 80 training epochs, our proposed model was optimized to its best performance. We completed three times of the same training on SOENet. The average value of each metrics is shown in , and the standard deviation of mIoU is 0.013, which indicates the stability of the output of our model. The widely used Binary Cross Entropy Loss (BCELoss) (Su et al. Citation2021) was adopted as a loss function in this study. It quantified the divergence between the probability distribution predicted by the model and the actual labels, which was calculated according to Equation (5):
(5)
(5) wherein yi refers to the ground truth category of each pixel (0: background, 1: sheep) and p(yi) indicates the prediction probability of each pixel being from a sheep. In addition, for the sake of public comparison and application, the implementation code of our proposed model will be released publicly when the paper is accepted for publication.
3.4. Ablation study
To evaluate the effectiveness of our proposed modules, namely the MFF module, MCE module, and FE module, we modified our proposed SOENet framework by excluding each module individually. Comparative analysis was conducted of the performance of the three modified models and the original SOENet framework, and the experimental results are presented in .
Table 1. Evaluation statistics of models with the removal of the MCE, MFF, and FE modules.
As indicated in , after removing the MCE module from SOENet, the model experienced a decrease of 2.8% in precision and 3.7% in recall. This shows that the MCE module makes a significant contribution to reducing the omission and commission errors of sheep, and it also indicates the efficiency of the MCE module in enhancing contextual features for sheep extraction. As depicted in , the removal of the MFF module resulted in a 2% decrease in the model’s mIoU. It shows the significance of the MFF module in enhancing feature fusion capacity by integrating different scales of features.
As the size of the feature map decreases, sheep features are more susceptible to loss. In order to address this problem, the FE module is designed to retain more sheep features by assigning higher weights to feature maps with more details and fuzing feature maps of different scales. As indicated in , the removal of the FE module led to a decrease in mIoU and precision by 0.5% and 1.1%, respectively. This shows that enhancing feature maps with more details is effective in improving sheep extraction performance.
3.5. Comparison with different methods
In order to evaluate the performance of our proposed model in sheep extraction, it was compared with nine recently proposed deep learning frameworks: U-Net, PSPNet (Zhu et al. Citation2021), DeeplabV3+ (Wang et al. Citation2022), Bisenet (Yu et al. Citation2021), U-Net++ (Zhao et al. Citation2022), SiNet (Hu et al. Citation2019), SegNet (Badrinarayanan, Kendall, and Cipolla Citation2017), Res2-UNet (Chen et al. Citation2022), and UGTransformer (Wang et al. Citation2024a). To present a fair comparison, all the models were trained and evaluated using the same dataset in this study, and the corresponding evaluation statistics of different models are listed in . In addition, to visualize the differences in sheep extraction results by different methods, five test images with sheep were randomly selected and the corresponding extracted results by different methods are listed in .
Figure 6. Visual results of the sheep extraction, where (*).1 indicates the optical remote sensing image patches used for testing; (*).2 is the ground truth images;(*).3. results from Res2-UNet; (*).4. results from SegNet; (*).5. results from SiNet; (*).6. results from UNet++; (*).7. results from U-Net; (*).8. results from UGTransformer; (*).9. results from SOENet.
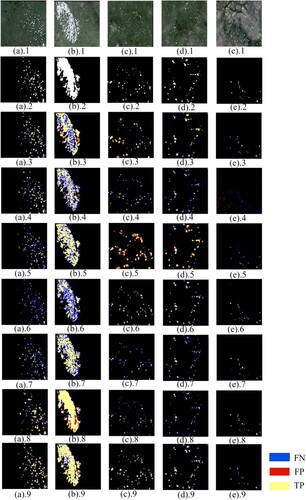
Table 2. Comparison of evaluation statistics from different methods.
As shown in , our proposed SOENet achieved significant improvement in sheep extraction with at least a 7.9% increase in precision and a 3% increase in F1-score compared to the other models. The precision values of the typical U-shaped network structures Unet, Res2-UNet, PSPNet, DeepLabV3+, and Sinet are generally lower than 56%, with PSPNet and DeepLabV3+ even having a precision of lower than 25% due to detailed feature loss caused by continuous convolutions. In addition, Unet and Segnet achieved a lower recall, of only 39.1% and 49.3%, respectively. They are prone to omit sheep due to their inadequate feature fusion capabilities, while model structures with stronger feature fusion capability, such as Unet++, Segnet, and our proposed SOENet all achieved a precision of higher than 62%. The clear precision gap between the two groups of models indicates the effectiveness of feature fusion in reducing omission errors, especially the proposed MFF and FE modules in our proposed SOENet. This can be further visually validated in the images of (a), (b), and (d), with Unet, Res2-UNet, and Sinet omitting more sheep than Unet++, SegNet, and SOENet.
The enhancement of contextual features is crucial for differentiating sheep from background elements in complex remote sensing imagery. It should be pointed out that both PSPNet and DeeplabV3+ have special contextual enhancement modules, but they failed to extract sheep in most cases due to detailed feature loss by continuous convolutions. Segnet and Unet achieved a recall of lower than 50%, while Sinet, BiseNet, UGTransformer, and our proposed SOENet achieved a recall of higher than 56%. The main reason for such a clear difference in recall is that enhanced contextual features can reduce the commission errors in sheep extraction, which further confirms the effectiveness of the MCE module in our SOENet at enhancing contextual features. This can be further visually validated in the images of (c) and (e), with Unet and Segnet making more commission errors of sheep as background objects.
Our dataset covers a diverse range of sheep. As shown in , both clustered sheep ((b)) and scattered sheep ((a)) were considered. In addition, the proposed MCE module enables simultaneous extraction of sheep and contextual information by effectively fuzing features of different dimensions through concatenation. The MFF module further enhances multi-dimensional feature fusion by adding feature maps of different resolutions, promoting feature sharing among the encoder’s three feature maps. To reduce omission and commission errors in the extraction result, a Feature Enhancement module (FE) is incorporated between the encoder and decoder, assigning higher weight to more detailed feature maps to retain finer details of the sheep. As shown in the final visualization result ((b)), our proposed SOENet can accurately identify sheep with different distribution patterns, including clustering and scattering distribution patterns.
3.6. Sheep number estimation
The number of sheep is estimated based on the extracted image result. Since sheep are likely to be clustered in distribution, it is difficult to estimate sheep numbers by quantifying the number of extracted binary sheep contours. Our proposed SOENet is a semantic segmentation method, which can extract pixel-level sheep from the remote sensing images and estimate the corresponding area. Stemming from the statistical relationship between sheep area and number by Wang et al (Wang et al. Citation2024a), we can generally estimate the number of sheep based on the experienced relationship, as calculated in Equation (6). The notation of S is the area of a single pixel in the remote sensing image, which is 0.25 m2 in this study. The notation Npixel represents the number of extracted sheep pixels in the image result, and k represents the actual area occupied by a sheep.
(6)
(6) In the image results of the testing dataset, the extracted sheep cover an area of 5057m2. Correspondingly, the number of sheep is estimated to be 3,201, referring to Equation (6).
4. Discussion
A sheep is usually 0.8–1.2 meters long (Riva et al. Citation2004), which occupies only 4–6 pixels in a remote sensing image taken by the Beijing-3 satellite with a spatial resolution of 0.5 meters. Such a small size makes it difficult for deep learning models to extract detailed features of sheep. Continuous convolution and pooling operations mean that it is easy to lose features of sheep. Moreover, it is easy to confuse sheep with stones and other interferences, resulting in obvious omission and commission errors in images with complicated background objects.
Since Unet++ has a higher precision than Unet, enhancing the feature fusion capability of the model is significant for reducing omission errors. The proposed MFF and FE modules have demonstrated effectiveness in fuzing varying scales of feature maps by reducing omission errors in the ablation study. In addition, contextual feature enhancement is significant for reducing commission errors. Due to a lack of texture features of sheep, more contextual features are required. The pooling pyramid module of PSPNet is a typical structure used to enhance contextual features, but its continuous convolution and pooling operations are likely to omit sheep in the extraction. Inspired by the pooling pyramid module, our proposed MCE has shown efficiency in contextual feature learning for sheep extraction by concatenating different scales of feature maps without pooling operations.
It should be pointed out that in complex scenes, especially those with a lot of interference in the background, our proposed SOENet also interprets stones in the background as sheep, as illustrated in (e.9). These deficiencies need to be improved by expanding the number of datasets with complex scenes and optimizing the model with the advanced network structure for better contextual feature enhancement in future studies. In addition, while the three-branch encoder of our proposed SOENet can extract more numerous scales of sheep features, it also introduces additional parameters. The FPS of our proposed SOENet can be recognized as acceptable, with a speed 0.2f/s lower than the widely used DeepLabv3+, as illustrated in . With the highest mIoU and F1 scores, SOENet has a satisfactory capacity for practical sheep extraction. In addition, in our future studies, we will implement more strategies to optimize our proposed framework.
5. Conclusion
To enhance grassland environmental protection and facilitate sheep husbandry monitoring, we propose an end-to-end deep learning framework, SOENet, for extracting sheep from high-resolution remote sensing images. Existing methods of sheep extraction have the deficiency of making omission and commission errors in complex scenes. To deal with this problem, we propose a novel model called SOENet that can significantly reduce omission and commission errors. In order to enhance the feature extraction capability of the model, we propose an MFF module introducing more scales of features in the encoder to share and exchange features. To enhance the contextual feature extraction capability, we propose an MCE module to extract complicated contextual features of sheep by concatenating different scales of feature maps. The feature maps extracted by the encoder are transferred to the FE module to retain more detailed features of sheep by assigning higher weights on feature maps with more details.
In a comparison with nine recently proposed deep learning models (U-Net, PSPNet, DeeplabV3+, bisenet, Unet++, SiNet, SegNet, Res2-UNet, and UGTransformer), our model showed a notable improvement of 7.9% and 3% in precision and F1 metrics, respectively. This indicates that our model has superior sheep extraction performance and has higher potential for practical application.
Acknowledgments
The authors thank the anonymous reviewers for their valuable comments.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Badrinarayanan, V., A. Kendall, and R. Cipolla. 2017. “SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation.” IEEE Transactions on Pattern Analysis and Machine Intelligence 39 (12): 2481–2495. https://doi.org/10.1109/TPAMI.2016.2644615.
- Cai, H., Z. Yang, X. Cao, W. Xia, and X. Xu. 2014. “A New Iterative Triclass Thresholding Technique in Image Segmentation.” IEEE Transactions on Image Processing 23 (3): 1038–1046. https://doi.org/10.1109/TIP.2014.2298981.
- Chen, F., J. Wang, B. Li, A. Yang, and M. Zhang. 2023. “Spatial Variability in Melting on Himalayan Debris-Covered Glaciers from 2000 to 2013.” Remote Sensing of Environment 291: 113560. https://doi.org/10.1016/j.rse.2023.113560.
- Chen, F., N. Wang, B. Yu, and L. Wang. 2022. “Res2-Unet, a New Deep Architecture for Building Detection from High Spatial Resolution Images.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 15: 1494–1501. https://doi.org/10.1109/JSTARS.2022.3146430.
- Cracknell, A. P. 2018. “The Development of Remote Sensing in the Last 40 Years.” International Journal of Remote Sensing 39 (23): 8387–8427. https://doi.org/10.1080/01431161.2018.1550919.
- Dong, R., X. Pan, and F. Li. 2019. “DenseU-Net-based Semantic Segmentation of Small Objects in Urban Remote Sensing Images.” IEEE Access 7: 65347–65356. https://doi.org/10.1109/ACCESS.2019.2917952.
- Gao, Y., W. Li, J. Wang, M. Zhang, and R. Tao. 2024. “Relationship Learning from Multisource Images Via Spatial-Spectral Perception Network.” IEEE Transactions on Image Processing 33: 3271–3284. https://doi.org/10.1109/TIP.2024.3394217.
- Guan, S., A. A. Khan, S. Sikdar, and P. V. Chitnis. 2020. “Fully Dense UNet for 2-D Sparse Photoacoustic Tomography Artifact Removal.” IEEE Journal of Biomedical and Health Informatics 24 (2): 568–576. https://doi.org/10.1109/JBHI.2019.2912935.
- Hollings, T., M. Burgman, M. van Andel, M. Gilbert, T. Robinson, and A. Robinson. 2018. “How do you Find the Green Sheep? A Critical Review of the use of Remotely Sensed Imagery to Detect and Count Animals.” Methods in Ecology and Evolution 9 (4): 881–892. https://doi.org/10.1111/2041-210X.12973
- Hu, J., L. Shen, and G. Sun. 2018. “Squeeze-and-Excitation Networks.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7132–7141.
- Hu, X., X. Xu, Y. Xiao, H. Chen, S. He, J. Qin, and P. A. Heng. 2019. “SINet: A Scale-Insensitive Convolutional Neural Network for Fast Vehicle Detection.” IEEE Transactions on Intelligent Transportation Systems 20 (3): 1010–1019. https://doi.org/10.1109/TITS.2018.2838132.
- Huang, H., H. Xu, X. Wang, and W. Silamu. 2015. “Maximum F1-Score Discriminative Training Criterion for Automatic Mispronunciation Detection.” IEEE/ACM Transactions on Audio, Speech, and Language Processing 23 (4): 787–797. https://doi.org/10.1109/TASLP.2015.2409733.
- Kellenberger, B., M. Volpi, and D. Tuia. 2017. “Fast Animal Detection in UAV Images Using Convolutional Neural Networks.” Paper presented at the. International Geoscience and Remote Sensing Symposium (IGARSS), 866–869.
- Khan, S. D., L. Alarabi, and S. Basalamah. 2022. “A Unified Deep Learning Framework of Multi-Scale Detectors for geo-Spatial Object Detection in High-Resolution Satellite Images.” Arabian Journal for Science and Engineering 47 (8): 9489–9504. https://doi.org/10.1007/s13369-021-06288-x
- Khan, A. H., X. Cao, S. Li, V. N. Katsikis, and L. Liao. 2020. “BAS-ADAM: An ADAM Based Approach to Improve the Performance of Beetle Antennae Search Optimizer.” IEEE/CAA Journal of Automatica Sinica 7 (2): 461–471. https://doi.org/10.1109/JAS.2020.1003048.
- Li, C., F. Chen, N. Wang, B. Yu, and L. Wang. 2023. “SDGSAT-1 Nighttime Light Data Improve Village-Scale Built-up Delineation.” Remote Sensing of Environment 297: 113764. https://doi.org/10.1016/j.rse.2023.113764
- Li, Z., X. Ma, and H. Xin. 2017. “Feature Engineering of Machine-Learning Chemisorption Models for Catalyst Design.” Catalysis Today 280: 232–238. https://doi.org/10.1016/j.cattod.2016.04.013.
- Li, W., J. Wang, Y. Gao, M. Zhang, R. Tao, and B. Zhang. 2022. “Graph-Feature-Enhanced Selective Assignment Network for Hyperspectral and Multispectral Data Classification.” IEEE Transactions on Geoscience and Remote Sensing 60: 1–14. https://doi.org/10.1109/TGRS.2022.3166252.
- Li, Y., H. Zhao, X. Qi, L. Wang, Z. Li, J. Sun, and J. Jia. 2021. “Fully Convolutional Networks for Panoptic Segmentation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 214–223.
- Ma, A., J. Wang, Y. Zhong, and Z. Zheng. 2022. “FactSeg: Foreground Activation-Driven Small Object Semantic Segmentation in Large-Scale Remote Sensing Imagery.” IEEE Transactions on Geoscience and Remote Sensing 60: 1–16. https://doi.org/10.1109/TGRS.2021.3097148.
- Peng, J., D. Wang, X. Liao, Q. Shao, Z. Sun, H. Yue, and H. Ye. 2020. “Wild Animal Survey Using UAS Imagery and Deep Learning: Modified Faster R-CNN for Kiang Detection in Tibetan Plateau.” ISPRS Journal of Photogrammetry and Remote Sensing 169: 364–376. https://doi.org/10.1016/j.isprsjprs.2020.08.026
- Peng, C., K. Zhang, Y. Ma, and J. Ma. 2022. “Cross Fusion Net: A Fast Semantic Segmentation Network for Small-Scale Semantic Information Capturing in Aerial Scenes.” IEEE Transactions on Geoscience and Remote Sensing 60: 1–13. https://doi.org/10.1109/TGRS.2021.3053062.
- Rey, N., M. Volpi, S. Joost, and D. Tuia. 2017. “Detecting Animals in African Savanna with UAVs and the Crowds.” Remote Sensing of Environment 200: 341–351. https://doi.org/10.1016/j.rse.2017.08.026.
- Riva, J., R. Rizzi, S. Marelli, and L. G. Cavalchini. 2004. “Body Measurements in Bergamasca Sheep.” Small Ruminant Research 55 (1-3): 221–227. https://doi.org/10.1016/j.smallrumres.2003.12.010.
- Rognlien, E. A., and T. Q. Tran. 2018. “Detecting Location of Free Range Sheep-Using Unmanned Aerial Vehicles and Forward Looking Infrared Images.” (Master’s thesis). NTNU.
- Sarwar, F., A. Griffin, S. U. Rehman, and T. Pasang. 2021. “Detecting Sheep in UAV Images.” Computers and Electronics in Agriculture 187: 106219. https://doi.org/10.1016/j.compag.2021.106219.
- Su, J., Z. Liu, J. Zhang, V. S. Sheng, Y. Song, Y. Zhu, and Y. Liu. 2021. “DV-Net: Accurate Liver Vessel Segmentation via Dense Connection Model with D-BCE Loss Function.” Knowledge-Based Systems 232: 107471. https://doi.org/10.1016/j.knosys.2021.107471.
- Wang, L., C. Chen, F. Chen, N. Wang, C. Li, H. Zhang, Y. Wang, and B. Yu. 2024a. “UGTransformer: A Sheep Extraction Model from Remote Sensing Images for Animal Husbandry Management.” IEEE Transactions on Geoscience and Remote Sensing 62: 1–14. https://doi.org/10.1109/TGRS.2024.3355925.
- Wang, J., W. Li, Y. Gao, M. Zhang, R. Tao, and Q. Du. 2023. “Hyperspectral and SAR Image Classification via Multiscale Interactive Fusion Network.” IEEE Transactions on Neural Networks and Learning Systems 34 (12): 10823–10837. https://doi.org/10.1109/TNNLS.2022.3171572.
- Wang, Z., J. Wang, K. Yang, L. Wang, F. Su, and X. Chen. 2022. “Semantic Segmentation of High-Resolution Remote Sensing Images Based on a Class Feature Attention Mechanism Fused with Deeplabv3+.” Computers and Geosciences 158: 104969. https://doi.org/10.1016/j.cageo.2021.104969.
- Wang, L., C. Ye, F. Chen, N. Wang, C. Li, H. Zhang, Y. Wang, and B. Yu. 2024b. “CG-CFPANet: A Multi-Task Network for Built-up Area Extraction from SDGSAT-1 and Sentinel-2 Remote Sensing Images.” International Journal of Digital Earth 17 (1), https://doi.org/10.1080/17538947.2024.2310092.
- Xiao, R., J. Gao, A. Liu, P. Hou, W. Zhang, Y. Yang, Y. Li, et al. 2023. “Remote Sensing Monitoring Method of Livestock in Grassland Based on Multi-Scale Features and Multi-Models Fusion.” National Remote Sensing Bulletin 27 (10): 2383–2394. https://doi.org/10.11834/jrs.20222099.
- Xu, J., W. Liu, Y. Qin, and G. Xu. 2022. “Sheep Counting Method Based on Multiscale Module Deep Neural Network.” IEEE Access 10: 128293–128303. https://doi.org/10.1109/ACCESS.2022.3221542.
- Yu, B., F. Chen, N. Wang, L. Wang, and H. Guo. 2023. “Assessing Changes in Nighttime Lighting in the Aftermath of the Turkey-Syria Earthquake Using SDGSAT-1 Satellite Data.” The Innovation 4 (3): 100419. https://doi.org/10.1016/j.xinn.2023.100419
- Yu, B., F. Chen, C. Ye, Z. Li, Y. Dong, N. Wang, and L. Wang. 2023b. “Temporal Expansion of the Nighttime Light Images of SDGSAT-1 Satellite in Illuminating Ground Object Extraction by Joint Observation of NPP-VIIRS and Sentinel-2A Images.” Remote Sensing of Environment 295: 113691. https://doi.org/10.1016/j.rse.2023.113691
- Yu, C., C. Gao, J. Wang, G. Yu, C. Shen, and N. Sang. 2021. “BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation.” International Journal of Computer Vision 129 (11): 3051–3068. https://doi.org/10.1007/s11263-021-01515-2.
- Zhang, H., H. Liu, and C. Kim. 2024. “Semantic and Instance Segmentation in Coastal Urban Spatial Perception: A Multi-Task Learning Framework with an Attention Mechanism.” Sustainability 16 (2): 833. https://doi.org/10.3390/su16020833.
- Zhao, C., R. Shuai, L. Ma, W. Liu, and M. Wu. 2022. “Segmentation of Skin Lesions Image Based on U-Net + +.” Multimedia Tools and Applications 81 (6): 8691–8717. https://doi.org/10.1007/s11042-022-12067-z.
- Zhao, B., M. Zhang, W. Li, X. Song, Y. Gao, Y. Zhang, and J. Wang. 2024. “Intermediate Domain Prototype Contrastive Adaptation for Spartina Alterniflora Segmentation Using Multitemporal Remote Sensing Images.” IEEE Transactions on Geoscience and Remote Sensing 62: 1–14. https://doi.org/10.1109/TGRS.2024.3350691.
- Zhou, G., Y. Tang, W. Zhang, W. Liu, Y. Jiang, E. Gao, and Y. Bai. 2023. “Shadow Detection on High-Resolution Digital Orthophoto Map Using Semantic Matching.” IEEE Transactions on Geoscience and Remote Sensing 61, https://doi.org/10.1109/TGRS.2023.3294531.
- Zhu, X., Z. Cheng, S. Wang, X. Chen, and G. Lu. 2021. “Coronary Angiography Image Segmentation Based on PSPNet.” Computer Methods and Programs in Biomedicine 200: 105897. https://doi.org/10.1016/j.cmpb.2020.105897.