
ABSTRACT
The uncontrolled proliferation of natural roads in arid regions has exacerbated regional land degradation and desertification, presenting substantial challenges to their accurate mapping owing to their dynamic and obscure features. Moreover, the high cost of data annotation restricts the availability of comprehensively labelled datasets, which are essential for advanced remote sensing processing and natural road detection. This study dedicated to implement a semi-supervised deep learning method for dirty road extraction in southern Mongolia. A new thematic semantic segmentation dataset of natural roads was established firstly to address scarcity of annotation datasets this region. A semi-supervised UniMatch structure was designed consequently. Operating with high-resolution GaoFen-2 images, this approach minimises the need for extensive manual annotation, achieving an IOU of 73.51% and MIOU of 86.37%. This method significantly reduces labour and time costs associated with manual and fully supervised methods. These observations provide a valuable data source and methodology for addressing natural road expansion in arid regions. They can aid governments in evaluating transportation infrastructure in remote areas, and analysing dirty road traffic impact on environment.
1. Introduction
The Mongolian Plateau locates inland in Asia, which is a delicate natural ecosystem that is highly susceptible to human activity. Over three-quarters of Mongolian terrestrial ecosystems experience varying degrees of desertification. Bordered by China, southern Mongolia is a significant source of dust storms in East Asia (Shao and Dong Citation2006). Off-road vehicles prevail in this region, which has no public transportation infrastructure. This has resulted in numerous unplanned natural roads known as dirty or natural roads. The arbitrary driving of vehicles affects the fragile surface ecosystem and stability of arid and semiarid areas. It easily leads to soil degradation such as desertification and dust storms, disturbing the ecological balance, and posing threats to rare species and biodiversity.
The road infrastructure in Mongolia predominantly comprises asphalt, gravel, and unpaved natural roads with inadequate hardening (Davaadorj, Byambabayar, and Oyunkhand Citation2016). Natural roads in Mongolia have proliferated because the exponential increase in vehicles has significantly outpaced the construction capacity of hardened roadways. The number of vehicles in Mongolia increased from 43,792 in 1990 to 81,693 in 2000, since the economic and social transition in early 1990s (MNEM Citation1999). In local perspective, South Gobi Province in Southern Mongolia has numerous coal and gold mines. High demand for mining and transportation has expedited the development of natural roadways. However, information on the natural highways in Mongolia remains insufficient. There is neither a mature training dataset nor a method for facilitating the systematic extraction of natural roads in arid and semiarid regions. Their availability would enable subsequent efforts to analyse the impact of human activities on the uncontrolled expansion of natural roads and implement measures to control their environmental effects.
With the advent of high-resolution quantitative remote sensing, the capabilities of remote sensing data acquisition and information services have rapidly developed. High-resolution images provide new opportunities for improved extraction accuracy (Abdollahi, Pradhan, and Alamri Citation2011). Numerous studies have used high-resolution remote-sensing image (HRSIs) datasets as a new data source. These include variation detection (Li et al. Citation2021; Lv et al. Citation2022), specific target recognition (Wang and Tian Citation2021; Yin et al. Citation2023), and semantic segmentation (Chen et al. Citation2022; Hang et al. Citation2022; Khan, Alarabi, and Basalamah Citation2023b). With the rapid development of various high-resolution remote sensing satellites, such as QuickBird, GeoEy, and the Gaofen series, HRSIs have become the primary data source for road extraction in remote sensing research. This is due to their remarkable spatial, spectral, and temporal resolutions (Ma et al. Citation2015; Panteras and Cervone Citation2018). Extraction of roads from the HRSIs is crucial for urban planning, transportation management, and disaster response.
Depending on automation level of road extraction, it can be classified into semi-automatic extraction using conventional methods and fully automatic extraction employing deep-learning theories. In semi-automatic human–computer interaction approaches, a prevalent method involves extracting road information based on prior knowledge from pixel, geometric, photometric, structural, and textural information (Chen et al. Citation2022). Semiautomatic methods employ simple classifiers such as decision trees and hidden Markov models. Li et al. (Citation2016) proposed a binary partitioning tree (BPT) method for extracting roads in densely populated urban areas from VHR satellite images. Maboudi et al. (Citation2016) proposed a multistage approach that integrated structural, spectral, textural, and contextual object information to extract road networks from VHR satellite images. However, basic classifier algorithms contain numerous parameters and are less robust. Conventional techniques are focused on specific regions. This limits their generalisability to complex or larger geographical units. In contrast, automatic extraction using deep-learning principles has the potential to rapidly and accurately obtain road data from HRSIs, because of their robust feature extraction capabilities (Pi, Nath, and Behzadan Citation2020).
The maturation of deep-learning semantic segmentation algorithms has resulted in significant advancements in computer vision and image processing (Farabet et al. Citation2012; Park and Hong Citation2018; Zhang, Liu, and Kim Citation2024). Deep learning algorithms’ popularity has surpassed conventional methods, particularly in road information extraction from remote-sensing images. Deep learning techniques, particularly convolutional neural networks (CNNs), are pivotal in automating road extraction tasks. CNNs leverage the hierarchical features within HRSIs and capture intricate patterns and variations in road structures. A seminal study by Mnih and Teh (Citation2012) introduced a multicolumn CNN architecture that enhanced the capability of the model to learn complex spatial features. Long, Shelhamer, and Darrell (Citation2015) refined this approach using fully convolutional networks (FCNs). This enabled end-to-end learning and pixel-wise road extraction without manual postprocessing. The U-Net architecture, introduced by Ronneberger, Fischer, and Brox (Citation2015), features a contracting path for context extraction and an expansive path for precise localisation. This method was demonstrated to be highly effective for road extraction. Zhang, Liu, and Wang (Citation2018) proposed a novel approach using a deep residual U-Net for road extraction from high-resolution remote sensing images. It leverages deep learning to learn hierarchical features automatically. Khan, Alarabi, and Basalamah (Citation2023a) and Khan, Singh, et al. (Citation2023) introduced DSMSA-Net for high-resolution road extraction using spatial, multiscale attention, and Quantum Dilated CNNs, enhancing accuracy in complex environments. Singh and Garg (Citation2013, Citation2014) improved road extraction in urban settings using a two-stage feature-focused approach. Cira et al. (Citation2020) developed a model for mapping secondary roads, handling irregularities through hybrid segmentation and integrating the results with geographic data for extensive mapping.
Although deep-learning methods have significantly advanced road extraction from HRSIs, challenges still persist. This is particularly evident in scenarios with limited labelled data. Model performance can be affected by scenarios with limited or noisy data. Additionally, the computational requirements for training deep models are substantial. Current general road semantic segmentation datasets fail to incorporate pertinent information on natural roads. However, researches on this topic are scarce. Hence, it is imperative to study automated and intelligent extraction of natural roads while generating annotated specialised road datasets encompassing natural road characteristics. The semi-supervised semantic segmentation of remote sensing images has been demonstrated to be an effective approach for reducing manual annotation costs and leveraging available unlabelled data to improve segmentation performance (Berthelot et al. Citation2019; Chen et al. Citation2023; Yang, Qi, et al. Citation2023; Zhang et al. Citation2023). The semi-supervised semantic segmentation method was suitable for this study due to the deficiency of thematic natural road datasets and the high cost of manually labelling natural roads.
This study addresses issue of numerous dirty roads affecting the regional ecological environment of Mongolia. This study was conducted in Gurvantes Sumu, South Gobi Province. First, an off-road thematic dataset was established. Subsequently, a semi-supervised deep-learning method was proposed to automatically extract natural roads using a smaller dataset comprising 288 labelled and 1008s unlabelled images. This study proposes an effective method for extracting dirty roads from high-resolution images. It is expected to provide a crucial data source and methodology for governments to evaluate and improve off-road transportation infrastructures in arid and semiarid regions, analyse related environmental impacts.
2. Materials and methods
Python 3 + PyTorch was selected as the experimental environment for this study. An NVIDIA TITAN X graphics card with 12 GB memory was used. We trained the model using a semi-supervised UniMatch network combined with a DeepLabv3 + architecture (ResNet-101 backbone-based). We also used a coincident-supervised DeepLabv3 + architecture (ResNet-101 backbone-based) for performance comparison.
2.1. Data pre-processing
Dirty road annotation datasets are scarce in public database, such as iSAID, ISPRS Potsdam, and ISPRS Vaihingen. They do not include the features of natural roads. Therefore, we propose a manual annotation method for high-quality HRSIs to construct a special natura l road training dataset. The selected training dataset was obtained from Gurvantes Sumu in South Gobi Province, Mongolia. Gurvantes Sumu is rich in mineral resources, with large underground coking coal and Cu reserves. Many natural roads have been formed in Gurvantes Sumu to improve transportation conditions, owing to the direct crushing of grasslands by transportation vehicles.
The selected satellite is GaoFen-2(GF-2). It is the second satellite in China's Gaofen project and can provide panchromatic image data with a width of 45 km. It provides panchromatic and multispectral image data at a spatial resolution of 0.8 and 3.2 m, respectively. GF-2 images from September to December in 2019 and 2020 were selected. We used the nearest neighbour diffusion (NNDiffuse) pan sharpening algorithm to combine a 0.8 m panchromatic image with a 3.2 m multispectral image to obtain a 1 m multispectral image as our original training dataset. The fusion results effectively preserved colour, spectral, and textural information.
Before the annotation step, we cut each pre-processed remote sensing image into 512 × 512 PNG files for subsequent road target annotation. Semantic segmentation in image processing is a pixel-wise image classification task. The goal is to assign an identical classification label to pixels belonging to the same category of objects in an image. This enables the classification of all objects in the image. Before enabling a machine to automatically classify objects in images, it is necessary to inform the machine of the categories to which the various object samples belong. Therefore, the initial step involved annotating the object categories in image samples. We used the Labelme annotation tool (an open-source image annotation software developed by the Massachusetts Institute of Technology Computer Science and Artificial Intelligence Laboratory). Consequently, a thematic dataset of trainable natural off-road roads is obtained.
2.2. Data annotation and training
The annotation files generated by the Labelme tool were in JSON format. This facilitates the rapid generation of source data files for semantic segmentation tasks in this format. However, further steps are required to convert each JSON file into a dataset folder for the convenience of the subsequent segmentation network data input. The training dataset included the original remote sensing image in PNG format, an expanded road annotation PNG file, and a text file with annotated names. These were organised within a dataset folder.
Our dataset comprises 288 annotated and 1008 unlabelled high-resolution images (512 × 512) from Gaofen-2 satellite. The high cost of dataset annotation makes extensive labelled datasets scarce, particularly in specialised fields, such as remote sensing for natural road detection. This study completed a recognition task with high accuracy based on small-labelled samples. It demonstrated the effectiveness of semi-supervised learning techniques, particularly in scenarios constrained by the high costs and logistical challenges of extensive manual annotations. Furthermore, this study set the unannotated dataset to 571 and 1008 images, ensuring a broader base for training our models with different ratios of annotated to unannotated data (approximately 1:2 and 1:3).
The selection of a 70:30 split for our training and validation sets was designed to maximise the utility of the available data while maintaining rigorous validation standards. The original and labelled images of the samples are shown in . We annotated our dataset into two categories: the red class represents the background, and the green class corresponds to the target class (road category). Our dataset presented a sample imbalance problem: the proportion of pixels in the background class was significantly higher than in the target class. As shown in (a) and (c), the target road class characteristics were misperceived as those of the background (barren land, wadis, mountain ridges, and clouds). The annotation criteria were based on spectral, textural, and contextual information. Specifically, the following criteria were employed for the data annotation process:
Spectral Criteria: The image colour and brightness pattern were examined. Natural roads typically exhibit a more uniform colouration, contrasting distinctly with the varied hues characteristic of mountain ridges. This spectral difference initially helped distinguish between these two features.
Textural Standard: Roads generally exhibit a smoother texture than mountain ridges’ rugged, irregular surfaces. Using these textural characteristics, this study recognises and differentiates natural road entities from background entities.
Contextual Analysis: The contextual information surrounding the features is crucial. Roads are often linear and connect points of interest, such as settlements or mining areas, whereas mountain ridges do not exhibit these patterns. We assessed the linearity and connectivity of the paths that suggested roads. In contrast, mountain ridges that lacked connectivity and purposeful alignment were categorised separately.
Figure 1. The visualisation results of the training dataset by Labelme annotation tool, presenting original images (a, c) and labelled images (b, d) of certain samples.

The spectral analysis focuses on colour patterns, whereas textural standards distinguish between surface smoothness. The contextual analysis assesses the geographical alignment and connectivity of roads. These criteria are meticulously applied to ensure annotation accuracy, thereby allowing the semi-supervised model to effectively learn the most distinguishing features.
2.3. Deeplabv3 + network backbone
After selecting HRSIs and annotating classification entities, DeepLabv3 + (based on the ResNet-101 network) was selected as the backbone network to train the model files and output final predictions. This study built semi-supervised (UniMatch) and fully supervised models using the DeepLabv3 + architecture, incorporating ResNet-101 as its backbone. The essential distinction between semi-and fully supervised approaches lies in their data handling and training strategies. Whereas the fully supervised model utilises datasets that are fully annotated for various land cover classes, the semi-supervised UniMatch method integrates a mix of annotated and unannotated data, enhancing the model performance with reduced labelling requirements. Both approaches were implemented on the same foundational network architecture, DeepLabv3+, with ResNet-101 to facilitate a fair comparison of their effectiveness.
Semantic segmentation is a fundamental task in computer vision field. Intricate architectures are required for accurate pixel-wise predictions. This section discusses the proposed DeepLabv3 + methodology based on the ResNet-101 backbone. The DeepLabv3 + backbone plays a pivotal role in endowing our model with the capability to detect complex visual hierarchies, which is essential for achieving state-of-the-art (SOTA) performance in semantic segmentation tasks (Chen et al. Citation2018). The DeepLabv3 + network backbone structure is illustrated in .
Figure 2. The DeepLabv3 + network backbone structure is usinged in both semi-supervised (UniMatch) and fully supervised models.
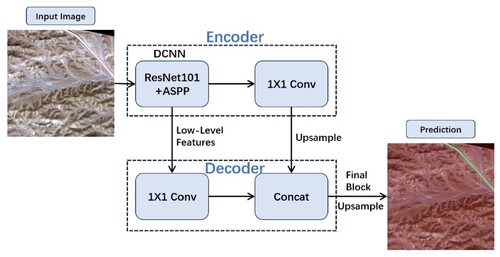
The DeepLabv3 + architecture is an evolution of the DeepLab series, renowned for its highly effective semantic segmentation. The core of DeepLabv3 + is an atrous spatial pyramid pooling (ASPP) module. This is a critical component for capturing contextual information at multiple scales. The ASPP module employs dilated convolution at different rates. This enabled the network to perceive objects and structures at various resolutions. This adaptability is particularly advantageous in scenarios where objects exhibit diverse scales and sizes. The encoder-decoder structure further enhanced the capability of DeepLabv3 + to capture both global and local contextual information. The encoder employed a ResNet backbone for feature extraction, whereas the decoder employed bilinear upsampling to refine the spatial resolution of the feature maps. This dual-branch architecture enables the model to balance a broad contextual understanding and detailed feature localisation.
The ResNet-101 backbone forms the foundation of the network architecture. ResNet-101 introduces the innovative concept of residual learning, thereby addressing the challenge of training exceptional deep neural networks. The introduction of residual blocks mitigates the vanishing gradient problem. This enabled the network to learn more effectively. With 101 layers, ResNet-101 excelled in capturing hierarchical features. This enables the proposed model to discriminate intricate patterns crucial for semantic segmentation. The residual learning mechanism facilitates the generation of skip connections, thereby enabling the network to bypass certain layers during forward and backward passes. This accelerates the training and promotes the development of a highly discriminative feature hierarchy. Consequently, ResNet-101 functioned as a robust feature extractor, enabling our model to understand and interpret complex visual contexts.
2.4. Semi-supervised semantic segmentation framework
Semi-supervised semantic segmentation is an essential task in the field of computer vision. Unlike fully supervised approaches, which rely on annotated data, or purely semi-supervised methods, which are deficient in labelled samples, semi-supervised techniques leverage a combination of labelled and unlabelled data for training. This paradigm significantly reduced the annotation load while maintaining high segmentation accuracy.
The seminal work by Pathak, Krahenbuhl, and Darrell (Citation2015) introduced the concept of self-supervision through context prediction. By training a CNN to predict the missing parts of an image, their approach effectively utilised unlabelled data to enhance feature learning. Tarvainen and Valpola (Citation2017) proposed a method based on entropy minimisation that made the model's predictions more accurate for labelled and unlabelled samples. This entropy minimisation technique has become a fundamental component of many semi-supervised frameworks. Furthermore, Laine and Aila’s (Citation2022) introduction of consistency regularisation is pivotal in semi-supervised learning.
This study employed the DeepLabv3 + architecture with a ResNet-101 backbone for both semi-and fully supervised segmentation models. The primary difference between semi-supervised and fully supervised methods is their data utilisation and training approaches. Specifically, the fully supervised model was trained using completely annotated datasets covering diverse land-cover types. In contrast, the semi-supervised approach combined labelled and unlabelled data, effectively minimising the need for extensive labelling. We used a unified dual-stream perturbation approach (UniMatch) network as our semi-supervised framework to generate the final prediction. The architectures of the semi-supervised framework (UniMatch) and the fully supervised framework are shown in .
Figure 3. Architecture of fully supervised framework (a) and semi-supervised framework (UniMatch) (b).
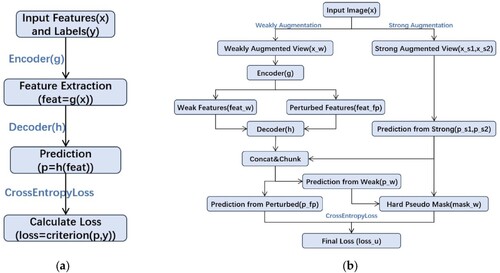
The UniMatch Network (2023) was introduced by Yang, You, et al. (Citation2023). It re-examines the ‘strong–weak consistency’ approach in semi-supervised semantic segmentation. The FixMatch network (2020) proposed by Sohn et al. (Citation2020) fundamentally enforces strong–weak consistency constraints. Therefore, it achieves a performance comparable to that of the current SOTA. Inspired by this, the UniMatch network enhanced the perturbation method by unifying image-level and feature-level perturbations. They introduced a dual-stream perturbation technique that effectively utilises image-level perturbations. These two components significantly improved the baseline. The final UniMatch method yields impressive results in various scenarios.
FixMatch is a lightweight semi-supervised classification method. It begins by employing a model trained on labelled data to predict weakly augmented unlabelled images, thereby generating pseudo labels. The pseudo-labels were retained only when the model produced highly confident predictions for a given image. Subsequently, the model is trained to predict the pseudo labels on a strongly augmented version of the same input image. This straightforward process yielded results comparable to those of recent SOTA studies when applied to segmentation scenarios. However, the success of FixMatch relies significantly on strong manually designed data augmentation. UniMatch network addresses the limitations of the FixMatch network by introducing an auxiliary feature perturbation stream. This expanded the perturbation space at the feature level. To thoroughly evaluate the enhancements at the original image level, UniMatch proposes a dual-stream perturbation technique that enables two strong views to be guided simultaneously by a common weak view (similar to increasing the number of strong augmentation branches in FixMatch). Building on FixMatch, UniMatch unifies image- and feature-level perturbations into separate streams to evaluate a more extensive perturbation space. It employs a dual-stream perturbation strategy to thoroughly investigate a predefined image-level perturbation space and leverages the advantages of contrastive learning to acquire distinctive representations. FixMatch optimises only the image level. UniMatch extends further by injecting perturbations at the feature level of weakly perturbed images, thereby constructing a broader perturbation space. UniMatch has been demonstrated to be simple and effective. It yielded significantly superior results compared with previous methods in diverse domains, including natural images (Pascal VOC, Cityscapes, and COCO), variation detection in remote sensing imagery (WHU-CD and LEVIR-CD), and medical imaging (ACDC).
3. Results
3.1. Model training and validation
Considering complex features of natural road entities, the maximum number of training epochs was set to 1500. The batch size was set to eight for both model training processes. Sample imbalance problem in our training dataset: the pixel proportion of the background class (shown in red in the labelled image) is significantly larger than that of the target road class (shown in green in ). Therefore, to enable the model to learn more feature information from our target class, we increased the weight loss of the road class and set the weight loss ratio of the background class to the target class as 1:10. shows the loss-value curve of the entire process during the two training processes (supervised resnet101 based DeepLabv3 + and the UniMatch method with 1008 unlabelled images). The loss value is essential to evaluate the training quality of the results.
Figure 4. Numerical variation diagram of loss values in the supervised natural road training process (a) and semi-supervised natural road training process (b).
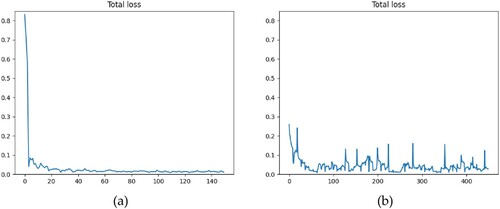
The two curves exhibited flat, low-level loss values. This indicated the superior accuracy of both models (). In model training processes, the pre-trained backbone ‘Resnet101.pth’ was used for conventional pre-training model operation.
As UniMatch training progresses, shown in (b), the loss curve fluctuates, which denotes the confrontation of the model with more nuanced patterns within the data. These variations are characteristic of semi-supervised learning, where the model is trained on a labelled dataset and attempts to make sense of the unlabelled data by generating pseudo-labels. This process is less stable because the model navigates uncertainties within the unlabelled data. The periodic spikes observed in the graph may correspond to the points where the model encounters particularly challenging batches of data, which momentarily increase the loss. Troughs followed these peaks as the model adapted and improved its predictions. These patterns also indicate the robustness of the model in learning from complex data distributions and its ability to recover and continue learning effectively. It is also noteworthy that by design, the semi-supervised approach incorporates elements of uncertainty. The UniMatch method introduces controlled noise through data augmentation and feature perturbations to improve the model's generalisation to unseen data. The slight upward trends observed sporadically along the curve can be attributed to this methodology, as the model learned to stabilise its predictions in the face of these perturbations. Finally, the generally decreasing trend towards the end of the training process signifies the model’s convergence, albeit with expected minor oscillations, as it fine-tunes its parameters on the intricate details of the training dataset. The overall loss fluctuated within a constant low range.
In semantic segmentation studies, evaluation metrics such as the intersection over union (IOU) and mean intersection over union (MIOU) are crucial for assessing the accuracy and performance of segmentation models in this domain. The IOU metric quantifies the accuracy of the pixel-level predictions by measuring the overlap between the predicted and ground-truth regions. This was calculated as the intersection of these regions divided by their union, yielding a score between zero and one. Here, one indicates a complete match. The IOU provides an intuitive understanding of how effectively the model captures the spatial extent of each class. The MIOU extends the assessment beyond individual classes by computing the average IOU across all the classes. This metric comprehensively evaluates the model's overall performance, considering its capability to segment various classes accurately. In remote sensing imagery, where diverse land cover types and objects should be identified, the MIOU is a key indicator of the segmentation model's effectiveness across the entire spectrum of classes.
In remote sensing semantic segmentation tasks, achieving high IOU and MIOU values is critical for accurate classification. These metrics function as valuable tools for assessing the reliability and robustness of segmentation models. The model recognition performance was superior, with high IOU and MIOU scores ranging from 0 to 1. Our model was set to calculate IOU and MIOU every 30 epochs. Therefore, 50 model evaluation indices are used in the training process.
3.2. Evaluation metrics and recognition visualisation
and present the numerical results of the evaluation indices (the values are rounded to four decimal places). The MIOU indices for both the models exceeded 85%. However, the UniMatch semi-supervised network model exhibited a superior IOU index of 0.7351 (). UniMatch leverages labelled and unlabelled data to train the model, achieving substantial performance improvements with reduced annotation effort. The effectiveness of this approach compared with a fully supervised model that uses only labelled data is demonstrated in , which shows the benefits of incorporating unlabelled data in training. Because natural roads and Gobi entities have similar characteristics, the detection performance for the target class was satisfactory. Although we increased the number of training epochs in the training process by 1500, the IOU index of the natural class remained low. This indicates that natural road entities remain complex. For the HRSIs, the proportion of pixels in the background class was significantly higher than in the target natural road class. This presents a sample-imbalance problem. Therefore, it is difficult to distinguish between the target entities. These interferences affect the recognition performance of the proposed model. shows several predicted recognition diagrams obtained using the UniMatch semi-supervised training model. This study evaluated models based on the Intersection over Union (IOU) for the target class and the Mean Intersection over Union (MIOU) across classes. Two backbone architectures are used: Xception and ResNet-101.
Figure 5. Numerical variation diagram of IOU and MIOU values in the supervised resnet101 -based DeepLabv3 training process (a,c) and semi-supervised UniMatch training process with 1008 unlabelled images (b,d).
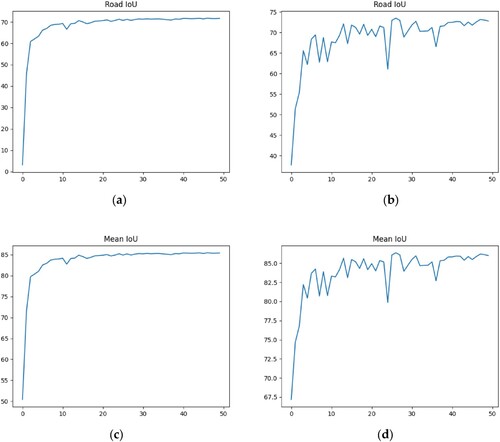
Figure 6. Several sample recognition result images were obtained using the training model of UniMatch semi-supervised network (a, b).

Table 1. Best evaluation indexes of generated model files by supervised and UniMatch semi-supervised network.
In a supervised learning context with an Xception backbone, the model achieved an IOU of 0.6907 and MIOU of 0.8410 using 288 labelled images. By switching the backbone to ResNet-101 in a supervised context, we observed a performance increase with an IOU of 0.7178 and an MIOU of 0.8548. The ResNet-101 backbone performed better than the Xception network.
Shifting to a semi-supervised UniMatch approach, using DeepLabv3 + network architecture with a ResNet-101 backbone, a notable improvement has been achieved in both the IOU and MIOU indices. With the same amount of labelled data (288 images) and an additional 571 unlabelled data points, the model achieved an IOU of 0.7322 and an MIOU of 0.8621, signifying its efficacy in leveraging unlabelled data to enhance performance. This result indicates that the semi-supervised approach is beneficial when unlabelled data are used. Further performance enhancement was observed when unlabelled data reached 1008, an approximately 3:1 ratio of labelled data to unlabelled data. The IOU marginally increased to 0.7351 and the MIOU to 0.8637, underscoring the effectiveness of the UniMatch semi-supervised learning strategy in handling larger sets of unlabelled data and signifying the robustness of the UniMatch method in integrating unlabelled data to improve training capabilities.
In summary, the UniMatch semi-supervised strategy outperforms fully supervised approach when additional unlabelled data are incorporated into the training process. These results demonstrate the potential of semi-supervised methods for semantic segmentation tasks, especially in scenarios where labelled data are scarce or expensive.
We first cut each GF-2 HRSI into 512 × 512 PNG files for the subsequent prediction task. This study obtained all sample recognition result images 512 × 512 predicted by the UniMatch semi-supervised network in different GF-2 images. We then added and stitched all predicted images to obtain each GF-2 high-resolution remote sensing image's panoramic image. Projection information from the original TIFF GF-2 images was added to the stitched images. shows several GF-2 panoramic predictions for Gurvantes Sumu in the South Gobi Province, Mongolia.
Figure 7. (a,c) presents several GF-2 panoramic prediction results in Gurvantes Sumu, Mongolia; (b,d) presents prediction results superimposed on the original GF-2 images.
4. Discussion
4.1. Advanced model structure
This study selected the DeepLabv3 + architecture with a ResNet-101 backbone and UniMatch strategy as our semi-supervised framework to output the final prediction. The effectiveness of DeepLabv3 + and ResNet-101 for semantic segmentation has been validated in several studies. Chen et al. (Citation2018) demonstrated the superior performance of DeepLabv3+, and He et al. (Citation2016) highlighted the feature learning capabilities of ResNet-101. Our backbone architecture integrated DeepLabv3 + with ResNet-101 to form a synergistic model with several advantages. The ASPP module captures contextual information at varying scales, enhancing object recognition. ResNet-101 enables a model with rich feature representations to identify the intricate details. ResNet-101 residual learning ensured stable training and facilitated efficient convergence. Skip connections aid the gradient flow, enabling the effective learning of hierarchical features. This combination of the ASPP and ResNet-101 components makes our model a highly effective tool for nuanced semantic segmentation. This is particularly true in contexts that require a sophisticated understanding of visual scenarios.
In remote-sensing semantic segmentation tasks, the annotation process is generally expensive and challenging owing to the requirement of accurately outlining the object margins in mask annotation. Semi-supervised deep learning techniques exhibit significant advantages in extracting roads from high-resolution remote sensing photographs. These approaches produce competitive results and reduce the need for manual annotation by successfully leveraging labelled and unlabelled data. Expanding on the FixMatch approach, the semi-supervised UniMatch framework used in this study integrates image- and feature-level perturbations into separate streams. This broadened the perturbation space. UniMatch thoroughly evaluates predefined image-level perturbations and utilises contrastive learning for distinctive representations by employing a dual-stream perturbation strategy. Unlike FixMatch, which only optimises at the image level, UniMatch introduces perturbations at the feature level for weakly perturbed images. Therefore, a more comprehensive perturbation space is generated. UniMatch is characterised by its simplicity and effectiveness. It outperformed previous methods in various domains.
This study introduces a novel semi-supervised deep learning framework tailored for natural road extraction in the arid and semi-arid regions of the southern Mongolian Plateau, utilising a dataset of 288 annotated and 1008 unlabelled high-resolution images (512 × 512) from the Gaofen-2 satellite. To validate the performance of our proposed model, this study compared the MIOU values with those of recent state-of-the-art methods in . By establishing the first thematic semantic segmentation dataset specifically for natural roads, this study leveraged a balanced set of images to efficiently reduce the annotation burden and time costs while achieving superior IOU and MIOU indicators of 73.51% and 86.37%, respectively. DeepLabv3 models (Xception and ResNet-101) serve as benchmarks, with MIOU values of 84.10% and 85.48% respectively, providing a reference for evaluating semi-supervised methods. ResNet-101 demonstrates greater effectiveness as a backbone compared to Xception, further confirming its superiority across various settings. The UniMatch model, using semi-supervised strategy, achieve MIOU values of 86.21% and 86.37%, indicating a significant improvement in performance by leveraging additional unlabeled data. With more unlabeled data input, there is a clear trend of improving MIOU scores from 86.21% to 86.37%, as shown in , highlighting the advantages of semi-supervised strategies in enhancing model performance. The semi-supervised method significantly outperforms traditional fully supervised approaches using the same DeepLabv3 + backbone. It demonstrates high performance among deep learning networks, substantiating the statistical superiority of the model's predictions in enhancing road extraction accuracy and effectiveness.
The findings of this research offer valuable data and methodologies that enable governments and policymakers to assess and enhance transportation infrastructure in remote regions, evaluate environmental consequences, and inform the strategic planning and management of land use and transportation systems.
4.2. Irregular shape segmentation problem
Natural roads in arid and semi-arid areas, characterised by their irregular shapes and contours, pose significant challenges for segmentation because it is difficult to define clear and consistent boundaries. The UniMatch framework is engineered to address these complexities.
The proposed framework incorporated an Atrous Spatial Pyramid Pooling (ASPP) module within the DeepLabv3 + architecture. This module is adept at capturing contextual information at various scales, essential for addressing the irregular geometries of natural roads. By employing convolutions at multiple rates, ASPP allows the network to adapt to these roads’ diverse sizes and forms. The entire model architecture then follows an encoder-decoder structure that includes skip connections. These connections are crucial for preserving high-resolution details throughout the network, ensuring that the finer aspects of road shapes are not lost during the downsampling and upsampling processes. This is particularly beneficial for maintaining the integrity of the irregular contours of segmented roads. Meanwhile, sophisticated data augmentation techniques have been applied, introducing a range of transformations, such as random rotations, flips, and scaling. These augmentations force the model to learn the invariant features of natural roads, thereby enhancing its ability to recognise and segment roads with irregular shapes under different orientations and scales.
In addition, model framework employs a dual-stream strategy to apply weak and strong data perturbations derived from the UniMatch network. This combination not only enforces consistent predictions across perturbations but also improves the model’s robustness against less obvious or incomplete features, which are common in images of natural roads.
Furthermore, to address the challenge posed by the varying prominence of road features, we implemented a weighted loss function by setting the loss weight ratio of the background class to the target class as 1:10. This approach prioritises feature learning from challenging and underrepresented road segments, thereby ensuring a balanced learning process.
Through these integrated strategies, our framework demonstrates a heightened capability to segment natural roads with irregular patterns and contours in arid and semiarid regions, enhancing its practical applicability in remote sensing and environmental monitoring.
4.3. Incorrect and missing classifications result
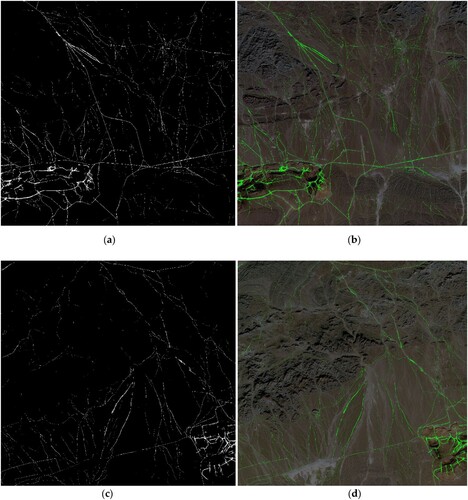
The spatial distribution data on natural road usage in specific regions can assist local governments in studying the relationship between the impact of natural roads formed by vehicles and land desertification in southern Mongolia. Understanding this relationship can help to prevent land desertification and balance regional development with ecological protection. This study conducted a preliminary attempt to identify natural roads in several GF-2 images of Gurvantes Sumu. The characteristics of certain roads were similar to those of the background classes in the Gobi area. The prediction model encountered incorrect and missing classifications in the prediction results for several images ().
Figure 8. (a–d) presents several sample images of entities misidentified during the semi-supervised predicting process; (a,b) presents the phenomenon of lacking classification; (c,d) presents a phenomenon of excessive and incorrect classification.

shows several sample images of the entities misidentified during the prediction process. The abovementioned phenomena occur because of the complex entity features contained in HRSIs and several imperfect conditions. These conditions include target entities occupying too few pixels to extract adequate features for training and interference from brightness, shadows, clouds, and other entities. Natural road entities have multiple types and patterns, and several shapes are severely deformed and distorted. These factors affect the performance of the algorithms in terms of feature recognition and function discrimination. Thus, the discriminant feature function obtained by the classifier is skewed during discriminant feature induction.
Moreover, the IOU index performance of the target natural road class remained low, as indicated by the indicators in the results section (). In these provided images (), we can see Examples of these issues are shown in . The green lines indicate the algorithm's attempt to identify and trace natural roads. The areas circled in red are likely points where the algorithm has either failed to continue tracing the road correctly because of the issues mentioned above or incorrectly identified a road where there is none.
4.4. Outlook
This approach enables the rapid, cost-effective, and efficient extraction of non-paved natural roads. By adopting a semi-supervised approach, we can train a classifier on a small amount of labelled data and then use the classifier to make predictions on the unlabelled data. Because these predictions are likely to be better than random estimations, unlabelled data predictions can be adopted as ‘pseudo-labels’ in the subsequent iterations of the classifier. Although there are many types of semi-supervised learning, this technique is called self-training. By effectively leveraging both labelled and unlabelled data, our semi-supervised natural road extraction method achieved competitive results while reducing the need for manual annotation. However, there are still many limitations that require further investigation.
The training dataset still needs to be optimized. Increasing the number of samples in training dataset still remains essential. However, defining a temporary road during labelling is inconvenient. Its characteristics are straightforwardly misperceived as those of the background (e.g. barren land, wadis, mountain ridges, and clouds). In the future, we will consider optimising the training dataset for better performance.
Model generalization ability needs to be enhanced. Although this semi-supervised natural road extraction method demonstrates substantial improvements in accuracy and efficiency, potential failure scenarios, including complex environmental conditions such as heavy cloud cover or extreme seasonal variations, may obscure road visibility in satellite images. This proposed semi-supervised method may struggle with sparse or fragmented road networks that do not provide sufficient continuous features for effective learning. The current training dataset may not fully represent all the types of natural road conditions encountered in arid and semiarid landscapes worldwide which could limit the generalisability of model to regions outside of the specific study area in southern Mongolia. In future research, a more extensive comparative analysis using state-of-the-art methods is planned to handle the model generalization ability problem.
Developing more robust and efficient natural road extractions algorithm. The extraction of the features of natural road entities remains complex and defective in HRSIs. Future studies addressing these complexities are crucial. This could involve the development of algorithms that can handle sparse pixel distributions more effectively, enhance feature extraction to be more robust against environmental noise, and train on a more diverse set of images that include a wide range of natural road conditions to improve the generalisability of the model.
Performing ground truth verification of road network prediction. Due to the current scarcity of off-road datasets in Mongolia, high-resolution remote sensing images were used serving as the primary source for visual verification in this study. To ensure the accuracy of model predictions, we conduct cross-validation using these high-resolution remote sensing images. In the future, undertaking field surveys to collect ground truth data will contribute the data validation of the model prediction results.
5. Conclusion
Dirty roads are difficult to extract in arid and semi-arid regions. This study aims to complete a recognition task with high accuracy based on small-labelled samples and demonstrate the effectiveness of semi-supervised learning techniques, particularly in scenarios constrained by the high labour costs and challenges of extensive manual annotations. We proposed a unified dual-stream perturbation approach (UniMatch) network as a semi-supervised framework combined with the DeepLabv3 + architecture using the ResNet-101 backbone to automatically identify natural road entities in HRSIs. First, a thematic semantic segmentation dataset for natural roads is established. We efficiently extracted natural road information using a small dataset with 288 labelled and 1008 unlabelled images compared to conventional manual census methods and supervised methods with high labour and time costs. Prediction IOU (natural road class) and MIOU indexes exceeded 73.51% and 86.37% respectively. The integration of semi-supervised learning methods in this context has shown significant predictive potential. This approach leverages labelled and unlabelled data to reduce the annotation burden while maintaining high accuracy for road extraction. In summary, this study provides an important research data source and methodology for addressing the uncontrolled expansion of natural roads. This contributes substantially to the intelligent automation of natural road extraction and offers significant implications for policymaking and transportation infrastructure development in remote and environmentally sensitive areas.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
Data and model have been made available on the following GitHub link: https://github.com/wm-jessica/roadseg-back-up.
Funding
This research was supported by the National Key Research and Development Program (2022YFE0119200), Key R&D and Achievement Transformation Plan Project of the Inner Mongolia Autonomous Region (2023KJHZ0027), Key Project of Innovation LREIS (KPI006), and Construction Project of the China Knowledge Center for Engineering Sciences and Technology (CKCEST-2023-1-5).
References
- Abdollahi, Abolfazl, Biswajeet Pradhan, and Abdullah Alamri. 2011. “RoadVecNet: A new Approach for Simultaneous Road Network Segmentation and Vectorization from Aerial and Google Earth Imagery in a Complex Urban set-up.” GIScience & Remote Sensing 58 (7): 1151–1174. https://doi.org/10.1080/15481603.2021.1972713.
- Amit, Siti Nor Khuzaimah Binti, and Yoshimitsu Aoki. 2017. “Disaster Detection from Aerial Imagery with Convolutional Neural Network.” 2017 International Electronics Symposium on Knowledge Creation and Intelligent Computing (IES-KCIC). IEEE.
- Berthelot, David, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, and Colin A. Raffel. 2019. “Mixmatch: A Holistic Approach to Semi-Supervised Learning.” Advances in Neural Information Processing Systems 32.
- Chen, Hao, Zhenghong Li, Jiangjiang Wu, Wei Xiong, and Chun Du. 2023. “SemiRoadExNet: A Semi-Supervised Network for Road Extraction from Remote Sensing Imagery via Adversarial Learning.” ISPRS Journal of Photogrammetry and Remote Sensing 198:169–183. https://doi.org/10.1016/j.isprsjprs.2023.03.012.
- Chen, Jie, Jingru Zhu, Ya Guo, Geng Sun, Yi Zhang, and Min Deng. 2022. “Unsupervised Domain Adaptation for Semantic Segmentation of High-Resolution Remote Sensing Imagery Driven by Category-Certainty Attention.” IEEE Transactions on Geoscience and Remote Sensing 60:1–15.
- Chen, Liang-Chieh, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. 2018. “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation.” Proceedings of the European Conference on Computer Vision (ECCV).
- Cira, Calimanut-Ionut, Ramón Alcarria, Miguel-Ángel Manso-Callejo, and Francisco Serradilla. 2020. “A Deep Learning-Based Solution for Large-Scale Extraction of the Secondary Road Network from High-Resolution Aerial Orthoimagery.” Applied Sciences 10 (20): 7272. https://doi.org/10.3390/app10207272.
- Davaadorj, D., G. Byambabayar, and B. Oyunkhand. 2016. “Soil Erosion Assessment in Southern Mongolia: Case Study of Gurvates Soum.” Journal of Young Scientists 4:169–181.
- Farabet, Clement, Camille Couprie, Laurent Najman, and Yann LeCun. 2013. “Learning Hierarchical Features for Scene Labeling.” IEEE Transactions on Pattern Analysis and Machine Intelligence 35 (8): 1915–1929. https://doi.org/10.1109/TPAMI.2012.231.
- Hang, Renlong, Ping Yang, Feng Zhou, and Qingshan Liu. 2022. “Multiscale Progressive Segmentation Network for High-Resolution Remote Sensing Imagery.” IEEE Transactions on Geoscience and Remote Sensing 60:1–12.
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. “Deep Residual Learning for Image Recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
- Khan, Sultan Daud, Louai Alarabi, and Saleh Basalamah. 2023a. “DSMSA-Net: Deep Spatial and Multi-Scale Attention Network for Road Extraction in High Spatial Resolution Satellite Images.” Arabian Journal for Science and Engineering 48 (2): 1907–1920. https://doi.org/10.1007/s13369-022-07082-z.
- Khan, Sultan Daud, Louai Alarabi, and Saleh Basalamah. 2023b. “Segmentation of Farmlands in Aerial Images by Deep Learning Framework with Feature Fusion and Context Aggregation Modules.” Multimedia Tools and Applications 82 (27): 42353–42372. https://doi.org/10.1007/s11042-023-14962-5.
- Khan, Mohd Jawed, Pankaj Pratap Singh, Biswajeet Pradhan, Abdullah Alamri, and Chang-Wook Lee. 2023. “Extraction of Roads Using the Archimedes Tuning Process with the Quantum Dilated Convolutional Neural Network.” Sensors 23 (21): 8783. https://doi.org/10.3390/s23218783.
- Laine, Samuli, and Timo Aila. 2022. “Temporal Ensembling for Semi-Supervised Learning.” International Conference on Learning Representations.
- Li, Xinghua, Meizhen He, Huifang Lim, and Huanfeng Shen. 2021. “A Combined Loss-Based Multiscale Fully Convolutional Network for High-Resolution Remote Sensing Image Change Detection.” IEEE Geoscience and Remote Sensing Letters 19:1–5.
- Li, Mengmeng, Alfred Stein, Wietske Bijker, and Qingming Zhan. 2016. “Region-based Urban Road Extraction from VHR Satellite Images Using Binary Partition Tree.” International Journal of Applied Earth Observation and Geoinformation 44:217–225. https://doi.org/10.1016/j.jag.2015.09.005.
- Long, Jonathan, Evan Shelhamer, and Trevor Darrell. 2015. “Fully Convolutional Networks for Semantic Segmentation.” Proceedings of the IEEE Conference on Computer Vision and Pattern recognition.
- Lv, Zhiyong, Tongfei Liu, Robert Yu Wang, Jon Atli Benediktsson, and Sudipan Saha. 2022. “Simple Multiscale UNet for Change Detection with Heterogeneous Remote Sensing Images.” IEEE Geoscience and Remote Sensing Letters 19:1–5. https://doi.org/10.1109/LGRS.2020.3041409.
- Ma, Yan, Haiping Wu, Lizhe Wang, Bormin Huang, Rajiv Ranjan, Albert Zomaya, and Wei Jie. 2015. “Remote Sensing big Data Computing: Challenges and Opportunities.” Future Generation Computer Systems 51:47–60. https://doi.org/10.1016/j.future.2014.10.029.
- Maboudi, Mehdi, Jalal Amini, Michael Hahn, and Mehdi Saati. 2016. “Road Network Extraction from VHR Satellite Images Using Context Aware Object Feature Integration and Tensor Voting.” Remote Sensing 8 (8): 637. https://doi.org/10.3390/rs8080637.
- MNEM (The Ministry of Nature and Environment of Mongolia). 1999. “Country Report on Natural Disasters in Mongolia.” Ulaanbaatar: MNEM.
- Mnih, Andriy, and Yee Whye Teh. 2012. “A fast and simple algorithm for training neural probabilistic language models.” Proceedings of the 29th International Coference on International Conference on Machine Learning 419–426.
- Panteras, George, and Guido Cervone. 2018. “Enhancing the Temporal Resolution of Satellite-Based Flood Extent Generation Using Crowdsourced Data for Disaster Monitoring.” International Journal of Remote Sensing 39 (5): 1459–1474. https://doi.org/10.1080/01431161.2017.1400193.
- Park, Seong-Jin, and Ki-Sang Hong. 2018. “Video Semantic Object Segmentation by Self-Adaptation of DCNN.” Pattern Recognition Letters 112:249–255. https://doi.org/10.1016/j.patrec.2018.07.032.
- Pathak, Deepak, Philipp Krahenbuhl, and Trevor Darrell. 2015. “Constrained Convolutional Neural Networks for Weakly Supervised Segmentation.” Proceedings of the IEEE International Conference on Computer vision.
- Pi, Yalong, Nipun D. Nath, and Amir H. Behzadan. 2020. “Convolutional Neural Networks for Object Detection in Aerial Imagery for Disaster Response and Recovery.” Advanced Engineering Informatics 43:101009. https://doi.org/10.1016/j.aei.2019.101009.
- Ronneberger, Olaf, Philipp Fischer, and Thomas Brox. 2015. “U-net: Convolutional Networks for Biomedical Image Segmentation.” Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18. Springer International Publishing.
- Shao, Y., and C. H. Dong. 2006. “A Review on East Asian Dust Storm Climate, Modeling and Monitoring.” Global and Planetary Change 52 (1-4): 1–22. https://doi.org/10.1016/j.gloplacha.2006.02.011.
- Singh, Pankaj Pratap, and Rahul D. Garg. 2013. “Automatic Road Extraction from High Resolution Satellite Image Using Adaptive Global Thresholding and Morphological Operations.” Journal of the Indian Society of Remote Sensing 41 (3): 631–640. https://doi.org/10.1007/s12524-012-0241-4.
- Singh, Pankaj Pratap, and Rahul D. Garg. 2014. “A two-Stage Framework for Road Extraction from High-Resolution Satellite Images by Using Prominent Features of Impervious Surfaces.” International Journal of Remote Sensing 35 (24): 8074–8107. https://doi.org/10.1080/01431161.2014.978956.
- Sohn, Kihyuk, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A. Raffel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. 2020. “Fixmatch: Simplifying Semi-Supervised Learning with Consistency and Confidence.” Advances in Neural Information Processing Systems 33:596–608.
- Tarvainen, Antti, and Harri Valpola. 2017. “Mean Teachers are Better Role Models: Weight-Averaged Consistency Targets Improve Semi-Supervised Deep Learning Results.” Advances in Neural Information Processing Systems 30: 1195–1204.
- Wang, Zhengyang, and Shufang Tian. 2021. “Ground Object Information Extraction from Hyperspectral Remote Sensing Images Using Deep Learning Algorithm.” Microprocessors and Microsystems 87:104394. https://doi.org/10.1016/j.micpro.2021.104394.
- Yang, Lihe, Lei Qi, Litong Feng, Wayne Zhang, and Yinghuan Shi. 2023. “Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Yang, Zi-Xiong, Zhi-Hui You, Si-Bao Chen, Jin Tang, and Bin Luo. 2023. “Semi-supervised Edge-Aware Road Extraction via Cross Teaching Between CNN and Transformer.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 16: 8353–8362.
- Yin, Lirong, Lei Wang, Tingqiao Li, Siyu Lu, Zhengtong Yin, Xuan Liu, Xiaolu Li, and Wenfeng Zheng. 2023. “U-Net-STN: A Novel end-to-end Lake Boundary Prediction Model.” Land 12 (8): 1602. https://doi.org/10.3390/land12081602.
- Zhang, Huijie, Pu Li, Xiaobai Liu, Xianfeng Yang, and Li An. 2023. “An Iterative Semi-Supervised Approach with Pixel-Wise Contrastive Loss for Road Extraction in Aerial Images.” ACM Transactions on Multimedia Computing, Communications and Applications 20 (3): 1–21.
- Zhang, Hanwen, Hongyan Liu, and Chulsoo Kim. 2024. “Semantic and Instance Segmentation in Coastal Urban Spatial Perception: A Multi-Task Learning Framework with an Attention Mechanism.” Sustainability 16 (2): 833. https://doi.org/10.3390/su16020833.
- Zhang, Zhengxin, Qingjie Liu, and Yunhong Wang. 2018. “Road Extraction by Deep Residual u-Net.” IEEE Geoscience and Remote Sensing Letters 15 (5): 749–753. https://doi.org/10.1109/LGRS.2018.2802944.