
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
In recent years, the deep learning-based semantic segmentation for point clouds has demonstrated remarkable capabilities in processing 3D urban scenes for applications such as three-dimensional reconstruction, semantic modeling, and augmented reality. However, research on grottoes scenes is very limited. It is currently unclear how existing neural architectures for point cloud semantic segmentation perform in grotto scenes, and how to effectively incorporate the unique characteristics of grotto scenes to enhance the performance of deep neural networks. This study proposed a method for point cloud semantic segmentation of grotto scenes, combining knowledge with deep learning approaches. The method adopted knowledge to guide the creation of benchmark datasets, the design of a neural network called GSS-Net, and the correction of segmentation errors in the results of deep learning. The results show that the proposed method outperforms four existing mainstream models without the correction of segmentation results. Moreover, a set of ablation studies verified the effectiveness of each proposed module. This method not only improves the accuracy of point cloud semantic segmentation in grotto scenes but also enhances the interpretability of network designs. It provides new insights into the application of knowledge-guided deep learning models in grotto scenes.
1. Introduction
Grottoes, as cultural treasures with immense historical and artistic significance, embody a wealth of historical details and cultural connotations (Li Citation2023; Runze Citation2023). Some are recognized as the World Heritage by the United Nations Educational, Scientific, and Cultural Organization (UNESCO), such as the Longmen Grottoes,Footnote1 Yungang Grottoes,Footnote2 and Dazu Rock Carvings.Footnote3 The intricate Buddha sculptures and delicate geometric patterns are carved into cliffs at these grottoes, narrating Buddhist tales, historical events, and slices of social life. Consequently, the three-dimensional (3D) digital documentation of these invaluable grottoes has become integral to cultural heritage preservation. Photogrammetry and 3D laser scanning technologies are extensively employed to capture the sophisticated geometry of the grottoes (Ahn and Wohn Citation2015; Diao et al. Citation2019; Keqina et al. Citation2008). However, unstructured point clouds consist of spatial coordinates with limited attributes (e.g. color and reflectivity), and are lack of semantic information for scene representation. This makes it difficult to be directly used for applications and services beyond visualization (Camuffo, Mari, and Milani Citation2022; Weinmann Citation2016). Semantic segmentation assigns meaningful semantic labels to each point, enabling the transformation of point clouds from visual formats into interpretable resources (Malinverni et al. Citation2019; Xie, Tian, and Zhu Citation2020; Yang, Hou, and Li Citation2023). Point cloud semantic segmentation has become a fundamental step in 3D reconstruction with semantics, scene interpretation and knowledge sharing (Colucci et al. Citation2021; Croce et al. Citation2020; Croce, Caroti, De Luca et al. Citation2021; Moyano et al. Citation2022). Furthermore, the semantic segmentation of basic geometric primitives in point clouds, coupled with the integration of relevant cultural heritage information, significantly enhances the expression of 3D models (Moyano et al. Citation2021; Poux, Neuville, Hallot et al. Citation2017; Poux, Neuville, Van Wersch et al. Citation2017). Therefore, semantic segmentation is essential in transforming raw point cloud data into semantically rich 3D models in the 3D reconstruction process (Apollonio, Gaiani, and Sun Citation2013; Croce, Caroti, Piemonte et al. Citation2021). A notable implementation is its application in Scan to Building Information Modeling (BIM) processes (Bosché et al. Citation2015; Brumana et al. Citation2020; Rocha et al. Citation2020).
In this study, the grotto scene is classified into ten classes, including cliff wall, cliff wall footing, niche eaves, Buddha statues, small niches, pedestals, steles, cement pavements, railings and low vegetation. Since mountains are blanketed by low vegetation, they are considered as the same class (Yang and Hou Citation2023; Yang, Hou, and Fan Citation2024). Due to the limited research, the semantic segmentation of grotto scenes still relies on manual processing, which is often time-consuming and labor-intensive. In recent years, data-driven deep learning methods have made remarkable advancements in point cloud semantic segmentation, particularly in large-scale urban and indoor scenes (Liu et al. Citation2019; Zhang et al. Citation2019; Zhang et al. Citation2023). To evaluate the performance of these methods, many point cloud benchmark datasets such as Semantic3D (Hackel et al. Citation2017), Toronto-3D (Tan et al. Citation2020), Stanford Large-Scale 3D Indoor Spaces (S3DIS) (Armeni et al. Citation2016), SemanticKITTI (Behley et al. Citation2019), and SensatUrban (Hu, Yang, Khalid et al. Citation2021) have been available to the public. Moreover, 3D semantic segmentation has been focused on specific urban sub-scenes and industrial scenarios, such as agricultural landscapes (Chen et al. Citation2021), bridge and railway infrastructures (Grandio et al. Citation2022; Lee, Park, and Ryu Citation2021; Xia, Yang, and Chen Citation2022), shield tunnels (Li et al. Citation2023), and architectural façades (Maru et al. Citation2023). In the field of cultural heritage, most of the point cloud semantic segmentation-related studies place focus on historical buildings (Grilli and Remondino Citation2019; Matrone et al. Citation2020; Morbidoni et al. Citation2020; Pierdicca et al. Citation2020). However, significant differences exist between the grotto scenes and the afore-mentioned scenes. In the grotto scene, geometric primitives with the same semantics vary in shape, such as the size, posture, and the appearance of different Buddha statues, which are often neglected by existing deep learning methods. Therefore, the performance of existing deep learning methods in the grotto scenes is unclear. Additionally, how to modify the existing network modules to improve segmentation accuracy in grotto scenes remains a problem that needs to be solved.
To address the above-mentioned problems, we proposed a method for point cloud semantic segmentation of grotto scenes through combining knowledge with deep neural network. The proposed method first summarized the point clouds characteristics, color characteristics, local geometric features, global spatial distribution patterns, the threshold for the size of grotto components and grotto components (referred to as class labels in grotto scenes) as knowledge. The knowledge is used to guide the production of benchmark dataset, design network modules, and correct incorrect segmentation results. With regard to the neural network design, we proposed a K-random neighbors method (called K-R method in this paper) based on K-Nearest Neighbors (KNN) approach to select neighboring points, addressing the issue of uneven distribution of point clouds in multiple directions. A total of six eigen-features were then used to build the point cloud attribute extension module. Through adopting the multi-layer perceptron (MLP) as the fundamental unit, we developed the local spatial hybrid encoding (LSHE) module, the parallel attention pooling (PAP) module, and the local-global feature aggregation (LGFA) module. These modules were integrated through concatenation and stacking to implement the Grotto Semantic Segmentation Network (GSS-Net). Additionally, the spatial distribution patterns and the size threshold of grotto components were used as constraint conditions to correct segmentation results. The performance of our model was further validated through comparative experiments which took four classical methods as baselines. A series of ablation studies demonstrated the effectiveness of the proposed modules.
The main contributions of this work are as follows:
The knowledge of grotto scenes is summarized, laying foundation for building benchmark dataset, customizing neural network and improving the results through knowledge guidance.
A neural network model specific for grottoes scenes is developed under the knowledge guidance, thereby enhancing the interpretability of the model design.
We quantitatively evaluate the performance of our proposed method by comparing it with four classical deep learning-based methods across five distinct grotto scenes. The results demonstrate the superior effectiveness of our method.
The rest of this paper is organized as follows. Section 2 reviews related work in this field. Section 3 elaborates on the proposed methods. Section 4 presents experiment design, benchmark dataset, and the experiment results. In Section 5, the influence and effect of each module of the proposed method and some limitations are discussed. The conclusion of this work is finally summarized in Section 6.
2. Related work
Deep learning-based methods can be categorized into projection-based (Boulch et al. Citation2018; Lawin et al. Citation2017), voxel-based (Huang and You Citation2016), and point-based methods (Hu, Yang, Khalid et al. Citation2021; Qi, Su et al. Citation2017). To capture the geometric details in grotto scenes, the point clouds usually have a high density with a large number of points, making them highly suitable for point-based methods. These methods process raw point cloud data directly and avoid the loss of geometric fidelity inherent in the viewpoint selection or voxelization processes, which are limitations observed in projection-based and voxel-based approaches. Consequently, we mainly focus on reviewing the point-based methods in the following.
2.1. Point-based semantic segmentation
Point-based methods can be grouped into four types, including pointwise MLP (Chen et al. Citation2019; Engelmann et al. Citation2018; Hu, Yang, Xie et al. Citation2021; Jiang et al. Citation2018; Qi, Su et al. Citation2017; Qi, Yi et al. Citation2017; Xie et al. Citation2018; Yang et al. Citation2019; Yin et al. Citation2023; Zeng and Gevers Citation2018; Zhang, Hua, and Yeung Citation2019; Zhao et al. Citation2019), point convolution (Engelmann, Kontogianni, and Leibe Citation2020; Hua, Tran, and Yeung Citation2018; Li et al. Citation2018; Li et al. Citation2022; Ma et al. Citation2019; Park et al. Citation2023; Thomas et al. Citation2019; Wang, Suo et al. Citation2018), RNN-based (Engelmann et al. Citation2017; Huang, Wang, and Neumann Citation2018; Ye et al. Citation2018), and graph-based methods (Du, Ye, and Cao Citation2022; Jiang et al. Citation2019; Landrieu and Simonovsky Citation2018; Liang et al. Citation2019; Pan, Chew, and Lee Citation2020; Wang et al. Citation2019). The pointwise MLP method, which uses shared MLP as the units of the artificial neural network, is suitable for integrating with other networks such as pooling layers or feature aggregation layers. This facilitates the construction of network architectures for specific tasks (Guo et al. Citation2020).
PointNet (Qi, Su et al. Citation2017) pioneers the pointwise MLPs by directly processing point clouds. It employs MLPs to extract features, addresses point cloud permutation invariance using a symmetric function, and aggregates point features through max-pooling. However, PointNet is limited in capturing local contextual information. Qi, Yi et al. (Citation2017) subsequently proposed PointNet++, which uses PointNet as a foundational module for hierarchical feature extraction. This method allows the network to capture multi-scale information within the local neighborhood of the point cloud, thereby improving its capability to express local contextual information. Inspired by the 2D shape descriptor Scale-Invariant Feature Transform (SIFT), Jiang et al. (Citation2018) developed the PointSIFT module. This module constructs directional encoding units in eight directions and stacks them for comprehensive feature representation. Zhao et al. (Citation2019) proposed the PointWeb approach with an Adaptive Feature Adjustment (AFA) module for efficient local contextual feature extraction, though its edge segmentation capabilities remain limited. Hu, Yang, Xie et al. (Citation2021) proposed RandLA-Net, a cost-effective and lightweight network for large-scale point cloud segmentation. It utilizes random point sampling to enhance computational efficiency and incorporates advanced residual network modules to effectively capture multi-scale geometric features, thus compensating for the potential information loss that is typically associated with random sampling. Point Attention Transformers (PATs) (Yang et al. Citation2019) process points by taking the absolute and relative positions of points into consideration and employ MLPs for high-dimensional feature learning. The DCNet (Yin et al. Citation2023) presents novel local feature aggregation schemes to further improve local contextual feature aggregation.
2.2. Knowledge-guided semantic segmentation
Combining knowledge with deep learning for point cloud semantic segmentation has shown promising results. Weinmann et al. (Citation2015) demonstrated that incorporating common local geometric features into model training enhanced the accuracy of semantic segmentation in point clouds. As using too many features can be counterproductive for the deep learning algorithm (Weinmann and Weinmann Citation2019), González-Collazo et al. (Citation2024) explored the use of 1D Convolutional Neural Networks (1D CNNs) for the semantic segmentation of urban point clouds gathered through mobile laser scanning, utilizing local geometric features for training. Grilli et al. (Citation2023) proposed a knowledge-enhanced neural network that added local geometric features and logical knowledge as a new layer into Transformer architecture (Zhao et al. Citation2021), but it did not change the network structure and modules. Maru et al. (Citation2023) segmented building facades based on RandLA-Net, which applied corrected laser intensity as an additional attribute. Xia, Yang, and Chen (Citation2022) developed a local geometric feature descriptor for bridge structural components, providing novel insights for small sample learning. Ballouch et al. (Citation2022) employed image classification as prior knowledge, and then mapped these raster values onto point clouds, expanding the attributes in point clouds. Ponciano et al. (Citation2021) compared the performance of deep learning-based method and knowledge-based method in urban scenes of point cloud semantic segmentation. The deep learning-based proved more effective for processing those elements with complex, non-standard geometric features, while the knowledge-based method excelled in segmenting the elements with regular geometric shapes. In order to improve semantic segmentation results using a knowledge-based approach, extensive and precise knowledge sets need to be predefined.
Currently, the performance of existing point cloud semantic segmentation methods in grotto scenes remains uncertain. Therefore, this study aims to summarize the characteristics of grotto scenes into knowledge for guiding neural network design and employ additional constraints to improve the deep learning results. To accomplish this objective, we build a point cloud benchmark dataset comprising five grotto scenes and selected four deep learning methods as baselines. Subsequently, we proposed a knowledge-guided deep learning approach to elevate the accuracy of point cloud semantic segmentation in grotto scenes.
3. Methodology
This section begins with an overview of the overall research approach. Accordingly, the details of the neural network modules are highlighted, following which the results based on knowledge constraint are introduced.
3.1. Overall research approach
The overall research framework is depicted in . Firstly, knowledge of grotto scenes is summarized to guide the deep learning-based semantic segmentation process. The knowledge includes point cloud density knowledge, visual color knowledge, local geometric feature knowledge, global spatial distribution knowledge, threshold for the size of grotto components knowledge and grotto components knowledge. Guided by the above-mentioned knowledge, a benchmark dataset is constructed, addressing the challenge faced by data processors who are not in the field of cultural heritage and find it difficult to understand class labels in grottoes. Subsequently, a neural network taking the characteristics knowledge of grotto scenes into account is designed, trained, verified and tested with the benchmark dataset. Finally, the erroneously segmented areas are corrected by applying the constraints derived from the afore-mentioned knowledge. More details regarding how the summarized knowledge guides semantic segmentation of point clouds in grotto scenes are elaborated in the following.
Figure 1. The overall research approach of semantic segmentation using the knowledge-guided deep learning method.
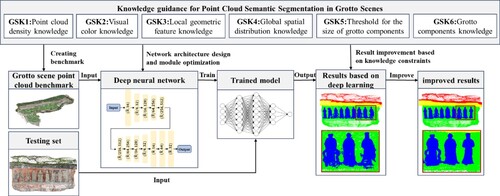
The grotto scene knowledge (GSK) is summarized below.
GSK 1: Point cloud density knowledge applied for grotto scenes
In scenarios with uneven point cloud density, it is crucial to select nearest neighbor points that encompass information from multiple directions. This approach better represents local geometric features. The variations in the proportions of different components within the point clouds can result in insufficient learning for those classes with smaller sample size, such as stone tablets, railings in the scene.
GSK 2: Visual color knowledge applied for grotto scenes
Color variations are notably significant among different components in grotto scenes. For example, vegetation typically appears green, while the ground is usually cementing gray. The color of cliff walls varies depending on the type of rock. For instance, in the Dazu Rock Carvings, the predominantly red sandstone results in red-colored cliff walls. These obvious color differences among grotto components aid in distinguishing various classes.
GSK 3: Local geometric feature knowledge applied for grotto scenes
Different components within grotto scenes possess unique local geometric shapes. For example, the ground and niche eave are relatively flat and oriented horizontally, and cliff walls are nearly vertical with minimal local curvature changes. The geometric shapes of Buddha statues are complex with significant curvature variations. Additionally, the sizes and orientations of the Buddha statues vary. Thus, the rotation as well as the scale-invariant local geometric feature descriptors are essential for their description.
GSK 4: Global spatial distribution knowledge applied for grotto scenes
The types of components in grotto scenes are closely associated with their relative elevations within the scene. There is a distinct vertical stratification, with components arranged from the lowest to the highest, i.e. the ground, the cliff wall footing, pedestal, the cliff wall and Buddha statue, niche eave, and the mountain and vegetation. Consequently, the relative height can effectively serve as a constraint for identifying and categorizing global features.
GSK 5: Threshold for the size of grotto components knowledge
The actual size range of various components in grottoes and the size of segmentation results can be used to identify erroneously segmented regions. Therefore, the threshold for the size of grotto components can be used to improve results.
GSK 6: Grotto components knowledge
Accurate identification of semantic categories (i.e. labeling classes) within grotto scenes requires expertise in cultural heritage, which plays as basis for the construction of point cloud benchmarks dataset.
In the following subsections, we provide an exploration of how knowledge guides the design of modules as listed in . Furthermore, we have conducted ablation studies to validate the effectiveness of each module. The correspondences among GSKs, network modules, and ablation studies are also illustrated in .
Table 1. The correspondence between module, grotto scene knowledge, and ablation study.
3.2. Knowledge-guided point cloud semantic segmentation of grotto scene
3.2.1. Neighborhood selection
In order to describe the local geometric features of a given point with its surrounding nearest neighborhood in the point clouds, several neighborhood definition methods include the spherical approach (Lee and Schenk Citation2002), the cylindrical approach (Filin and Pfeifer Citation2005), and the K-Nearest Neighbors (KNN) method (Connor and Kumar Citation2010) have been commonly used. The spherical and cylindrical approaches require predefined parameters, such as radius or cylinder height, which highly depend on the density of the point cloud. In contrast, the KNN method, which relies on a fixed number of neighboring points
, is independent of point cloud specifics.
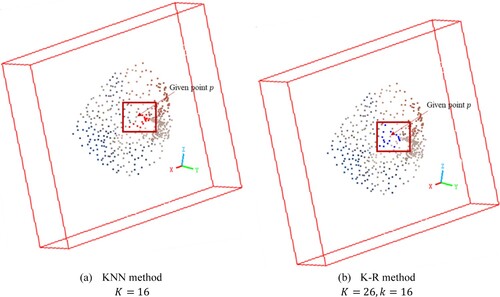
As described in GSK 1, the KNN method may not ensure the inclusion of neighboring points from a variety of directions in point clouds with uneven distribution, potentially leading to imprecise representation of local geometric features. This limitation is particularly noticeable in high-density point clouds with a smaller value. To address this, we proposed the K-random neighbors method (K-R method) for selecting nearest neighbors in the point clouds. The K-R method initially expands the neighborhood by increasing
to include a broader range of points and then selects
points through random sampling. shows the results of the KNN method and the K-R method in selecting neighbor points to the given point
. The red points in (a) and the blue points in (b) are the neighbor points selected by the two methods The K-R method considers neighbor points in various directions relative to the given point, thereby enhancing the ability to discern local geometric features.
Figure 2. Comparison of KNN and K-R method.
3.2.2. Point cloud attribute extension
The integration of the local features of point clouds as extended attributes into the neural network has been shown to enhance the performance of semantic segmentation (Grilli et al. Citation2023; Maru et al. Citation2023; Weinmann et al. Citation2015). Guided by GSK2 and GSK3, the Point Cloud Attribute Extension (PCAE) module extends a new scalar field for each point, which is composed of color features and eigen-features (Lin et al. Citation2014; Weinmann, Jutzi, and Mallet Citation2014).
The covariance matrix is a fundamental statistical tool that captures the spatial variance of a set of points in 3D space, reflecting the spread and orientation of the data. We used the weighted principal component analysis (PCA) method with geometric median (Lin et al. Citation2014) to extract local neighborhood eigen-features for each point. The covariance matrix is formulated as
(1)
(1) where
is the point
belongs to point set
and
is the weight of point
with respect to the geometric median
.
The calculation of the covariance matrix presents three non-negative eigenvalues, denoted as . Upon normalizing these eigenvalues, a set of features is computed by formula (2)-(7) to describe the local geometric characteristics of a point cloud and indicate the 2D planarity, 3D divergence, surface variation, and the order or disorder of 3D points within the local 3D neighborhood. The eigen-features selected in this study include planarity
, scattering
, omnivariance
, anisotropy
, eigenentropy
, and change of curvature
. Those formulas are as follows:
(2)
(2)
(3)
(3)
(4)
(4)
(5)
(5)
(6)
(6)
(7)
(7)
3.2.3. Local spatial hybrid encoding
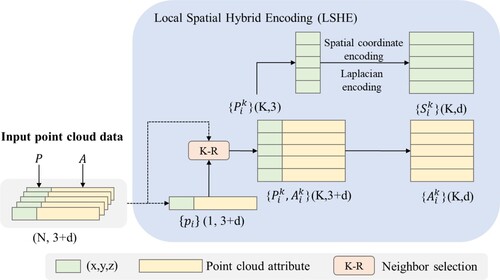
Effective local spatial feature encoding can represent the spatial patterns and the structure of points related to their neighbors, thereby providing improved contextual information to the neural network (Chen et al. Citation2022; Fan et al. Citation2021; Huang, Xu, and Stilla Citation2021; Li et al. Citation2020). Guided by GSK3, we adopt a hybrid approach that combines the Euclidean distance in Cartesian coordinates with the Laplacian (Laplace operator) in differential coordinates (Sorkine Citation2005) to construct the local spatial hybrid encoding (LSHE) module. The design details of this module are shown in .
Figure 3. The local spatial hybrid encoding module.
The Laplacian is defined as the divergence () of the gradient (
). This operator exhibits rotational invariance, scale invariance, making it effective for describing the difference between the function value of a point and the average value of its neighborhood. It can be used to approximately express the local geometry shape based on the nearest neighbor in a simple, efficient and accurate way (Cao et al. Citation2010; Liang et al. Citation2012; Sharp and Crane Citation2020), which is very important for point cloud processing. The Laplacian (
) corresponding to any twice-differentiable function
can be expressed as:
(8)
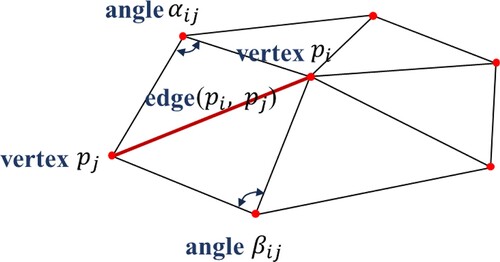
(8) Given that point clouds are spatially discrete, this module uses the discretization of the cotangent Laplace operator to express local geometric feature around a point. As shown in , one-ring triangles are constructed with the given point
and its nearest neighbors
is selected by the K-R method. The value of Laplacian (i.e. differential coordinate vector) with the cotangent weighting is calculated as follows (Bunge et al. Citation2020; Sorkine Citation2006).
(9)
(9) where
is the given point,
is the total number of neighboring points,
is one of the neighboring points, and
and
are denoted as the two angles opposite of edge (
).
Figure 4. Cotangent discretization of the Laplacian operator.
Finally, spatial encoding is performed for each point set formed by K-R neighbors. The formula for spatial encoding is as follows.
(10)
(10) where
represents the Laplacian operator of the given point
, and
are the absolute coordinates of the point cloud in the Euclidean coordinate system,
denotes the concatenation operation, and
is the Euclidean distance between the central point and its neighbors.
is the spatial encoding of discrete spatial coordinate points, which is used for local feature learning.
3.2.4. Parallel attention pooling
The pooling layers are used to select prominent features from the high-dimensional feature vectors of neighbor points (Er et al. Citation2016; Lu et al. Citation2022; Wang et al. Citation2023). Features within each neighborhood are aggregated using methods such as maximum pooling (Qi, Su et al. Citation2017), average pooling (Wang, Zhang et al. Citation2018), or combination of both (Li et al. Citation2023). However, these pooling approaches are limited to capturing partial information, ignoring other valuable features (Yang et al. Citation2020). The attention scores are gained through adopting a ‘scoring method’ to assign attention to features rather than simply ignoring some of them. In order to minimize the loss of feature selection, we use MLP transformation on the input, calculate Softmax scores, and ultimately multiply the input features. Considering that new scalar fields have been expanded in the PCAE module, there exist a risk that the premature mixing of point cloud attribute information with spatial encoding information leads to the loss of significant features. As shown in , this study develops a parallel attention pooling (PAP) module, which computes different attention scores for spatial information and extended attributes. Subsequently, the two sets of features are concatenated and combined through weighted summation, with feature aggregation achieved using the shared MLP.
Figure 5. The parallel attention pooling module.
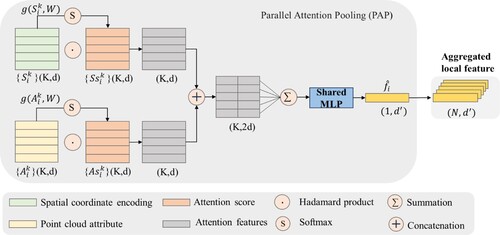
The PAP module computes attention scores separately for spatial encoding and attribute features
based on a shared function
, ensuring that the sum of attention scores in each row equals to 1. The function
consists of a shared MLP followed by a Softmax operation. The formula is as follows.
(11)
(11) where
represents the learnable weights of the shared MLP, and
and
are the attention scores of spatial encoding and attributes, respectively.
Subsequently, it adopts attention scores as weights of feature selection for features aggregation to enhance important features while weakening irrelevant features. The pooled feature for each point is determined by the weighted sum of its local features. The result is represented by a feature vector that encapsulates the enhanced and aggregated features, which is computed as follows.
(12)
(12) where
denotes the Hadamard product, which is the element-wise multiplication of two vectors, forming a new vector of the same size as the original vectors.
The PAP module captures the most salient features from neighboring points, enabling the model to handle complex spatial dependencies effectively. Therefore, for a given point in point cloud
, its geometric patterns and attributes in a local area are expressed by the vector
after learning with the LSHE and PAP modules. This vector encapsulates all the important features about one point and its neighbors.
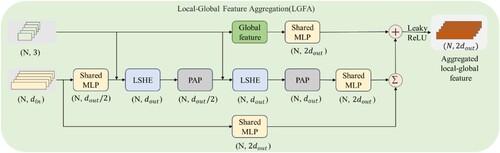
3.2.5. Local-global feature aggregation
The feature aggregation integrates an extensive range of local and global contextual information, thereby enriching each point with a comprehensive set of features (Xie et al. Citation2024; Zhou, Huang, and Fang Citation2021). In accordance with GSK4, the global features are obtained through computing a global pattern by multiplying the horizontal projection density of local point sets with their relative elevation
. The formula for this process is as follows:
(13)
(13) where
denotes the spatial coordinates of points within the point cloud,
represents the projection density of the point set in the local neighborhood on the horizontal plane, and
signifies the relative elevation of the point within the aggregate point cloud.
By stacking the LSHE and PAP modules twice, the local features across multiple spatial scales are incorporated. The fusion of global and local features forms the Local-Global Feature Aggregation (LGFA) module, which is inspired by the residual module principles in ResNet (He et al. Citation2016) and RandLA-Net (Hu, Yang, Xie et al. Citation2021). The proposed LGFA unit consists of the following steps as depicted in .
Figure 6. The local-global feature aggregation module.
3.2.6. Network architecture
As illustrated in , the GSS-Net adopts the Encoder-Decoder architecture with skip connections. The input of this network is point cloud data composed points. Each point with
-dimensional
consists of spatial coordinates, color information, and extended attributes. Initially, a Fully Connected (FC) layer is utilized to expand the feature dimension to
. The encoding phase involves stacking four layers. Each layer comprises a LGFA module and a random sampling operation. After each encoding step, the number of points is down sampled to 25% of the previous layer, while the feature dimensions are increased to 32, 128, 256, and 512, respectively. This down-sampling strategy, based on random sampling (Hu, Yang, Xie et al. Citation2021), is complemented by the LGFA module, which aims to mitigate potential information loss incurred during the process.
Figure 7. The architecture of GSS-Net. FC: Fully Connect layer, LGFA: Local-Global Feature Aggregation Module, RS: Random Sampling, US: Up-sampling, MLP: shared Multi-Layer Perceptron, DP: Dropout.

In the decoding layers, the nearest neighbor interpolation is employed for up-sampling, progressively restoring the point cloud to its original size. Meanwhile, the feature dimension of each layer is gradually reduced. The features generated in each decoding layer are aligned and concatenated with those from the corresponding LGFA modules in the encoding layers. This ensures continuity and prevents information loss during the up-sampling. Finally, the network concludes with three FC layers that generate the prediction results. The network outputs point clouds comprising points, where each point is labeled with a 1-dimensional class label
.
The implementation details of the shared MLP in this work can be represented as
(14)
(14) where
represents the activation function,
denotes batch normalization,
refers to a convolution operation with a 1 × 1 kernel, and
is the input for the
.
In addition, guided by GSK1 and GSK6, the weighted cross-entropy loss function (Ho and Wookey Citation2019) is used to handle unbalanced datasets in classification tasks. This approach assigns different weights to various categories, which not only addresses the imbalance but also accelerates the convergence speed in the model training process.
3.3. Results improvement with knowledge constraints
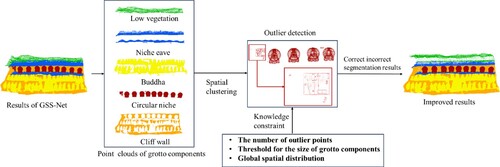
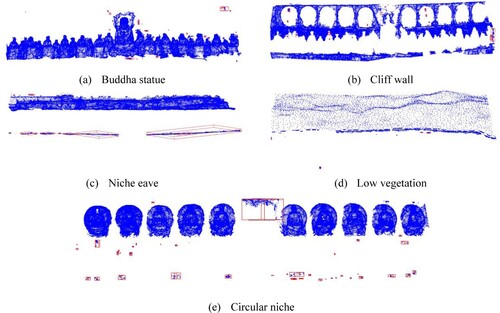
The process of improving segmentation results with knowledge constraints is shown in . After processing by GSS-Net, the point clouds are divided into different semantic categories according to semantic labels. With regard to the same labels, the spatial clustering algorithm based on Euclidean distance is used to cluster and constitute multiple point cloud patches. Under the constraints of GSK4, GSK5 and the number of outlier points, each point cloud patch is assessed to determine whether it is an outlier (i.e. a set of points that is not segmented correctly). For example, regarding the detection of outlier points in , the number and the size of point set in the red box are obviously different from the circular Buddhist niche, so it is judged to be the incorrect area for segmentation. In such cases, the boundary of the outlier points is calculated using the alpha-shape operator (Wei Citation2008). The outlier points are merged into the semantic label with which they share the most boundaries.
Figure 8. The method of improving results with knowledge constraints.
3.4. Evaluation metrics
Currently, there is a lack of point cloud benchmark datasets for grotto scenes in the field of cultural heritage. To facilitate a quantitative evaluation of the method proposed in this work, we use CloudCompare softwareFootnote4 to manually segment and assign semantic labels to point cloud of five grotto scenes. GSK 6 provides knowledge guidance for manually adding class labels when making benchmark datasets. The description of the ten classes is provided in detail in .
Table 2. The class labels in grotto scenes.
In this study, three quantitative indicators are used to evaluate the experimental results, which include the Overall Accuracy (OA), Intersection-over-Union (IoU) for each class, and mean Intersection-over-Union (mIoU). Among them, OA is the ratio of the number of correctly predicted points to the total number of points. The formulas for calculating IoU and mIoU are as follows.
(15)
(15)
(16)
(16) where
is the number of correctly predicted points for class
,
represents the number of points that belong to class
but are misclassified as class
, and
indicates the number of points that belong to class
but are misclassified as class
.
is the total number of classes.
represents the IoU for class
.
4. Experiments and results
4.1. Experiment design
In this section, two sets of experiments were designed to verify the effectiveness of the proposed method. A total of four classical point-based deep learning models for point cloud semantic segmentation were selected as baselines to compare with our proposed method for performance validation based on the benchmark dataset of grotto scenes. presents the detailed experimental design, including grotto scene datasets used in different experiments, the division of the grotto scenes for training, validation and testing, and the comparative experiments for each experimental configuration.
Figure 9. The design of experiments.
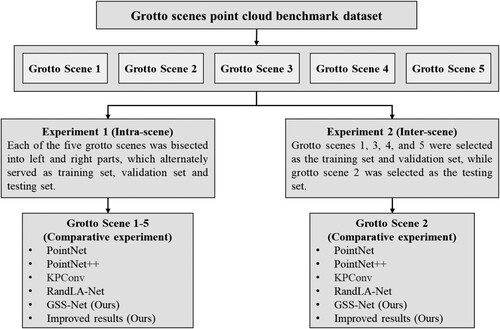
In Experiment 1, each of the five grotto scenes was bisected into left and right sections, which alternately served as training set, validation set and testing set. A two-fold cross-validation approach was used to validate the methods proposed in this study. For example, when the left side of scene 1 is used for training and validation, the right side is used for testing, and then the left and right sides are swapped again. Grotto scenes 1–5 are selected for the comparative analysis in the intra-scene by using four baseline approaches: PointNet (Qi, Su et al. Citation2017), PointNet++ (Qi, Yi et al. Citation2017), KPConv (Thomas et al. Citation2019), and RandLA-Net (Hu, Yang, Xie et al. Citation2021).
Experiment 2 is to verify the performance in the inter-scene. The number of points, the number of semantic labels and the complexity of grotto scene 2 are moderate among the five scenes. As such, grotto scenes 1, 3, 4, and 5 were selected as the training set and validation set, while grotto scene 2 was selected as the testing set. As there exist different number of labels in the five grotto scenes, these experiments focused on using five types of class labels: Buddha statues, cliff walls, niche eaves, low vegetation, and circular niches, which are almost included in each scene.
The hardware environment for these experiments consisted of a 13th i7-13700KF 3.40 GHz processor and a RTX 4070Ti GPU with 12G of memory. The software environment included Ubuntu 22.04, the TensorFlow 2.0 deep learning framework, CUDA 12.2, CUDNN 8.3.0, and Python 3.6. An Adam optimizer with default settings was also used. The initial learning rate was set as 0.01, with a 5% reduction after each epoch. The batch size for the experiments was configured at 4. The K-R method initially set 32 nearest neighbors, and then randomly selected 16 points. The impact of different values on experiments is shown in Section 5.1.5. The code employed for the comparative experiments was obtained from the open-source repositories hosted on GitHub, as shown in . All source codes were adapted to the TensorFlow 2.0 framework without other adjustments. The network architecture and implementation proposed in this work was referred to the code of RandLA-Net.
Table 3. The code source of comparative experiments.
4.2. Point cloud benchmark dataset of grotto scenes
The benchmark dataset includes five distinct grotto scenes located in Baoding Mountain, a part of the Dazu Rock Carvings in Chongqing, China. illustrates the point clouds of the five scenes with class labels. From scene 1 to scene 5, it exhibits a progressive increase in the semantic categories and complexity of grotto components, showcasing a range of geometric structure that evolves from simple to intricate forms. The point clouds were generated by intensive image matching between the UAV oblique photography and close-up photos in the Context Capture software. To be specific, the drone was DJI mini 4 Pro, of which the image sensor was 1/1.3-inch CMOS with 48 million effective pixels. The SONY A7R4 camera was used to take supplementary photos closer to the grottoes, with a lens resolution of 62 megapixels and a 35 mm full-frame Exmor R CMOS backlit image sensor. provides the detailed information of the number of points across various semantics (i.e. ten labeled classes) within each scene.
Figure 10. The visualization of the grotto scenes point clouds.
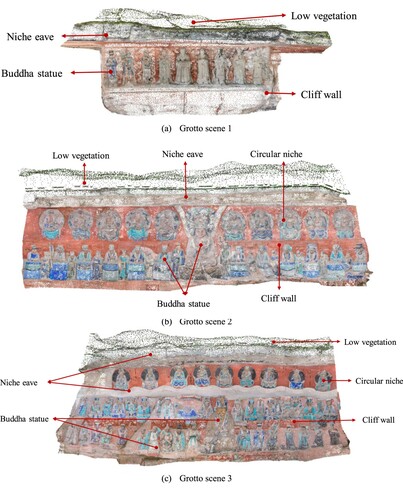
Table 4. The number of points of each element in the grotto scene point cloud benchmark dataset (Bud.sta.: Buddha statue, cli. wal.: cliff wall, nic. eav.: niche eave, low veg.: low vegetation, cir.nic.: circular niche, c. w. foo.: cliff wall footing, cem.pav.: cement pavement, rai.: railing, ped.: pedestal, ste.: stele).
The characteristics and details of each scene are as follows.
Grotto scene 1 features simple semantic categories with orderly arranged components. The scene spans approximately 4.5 meters in height and 10.7 meters in length. It features a Buddha statue approximately 1.6 meters tall, with a total number of points of 724,275.
Grotto scene 2 is more complex compared to scene 1, which features circular niches and Buddha statues of various geometric shapes. It spans approximately 20 meters in length and 7.3 meters in height. The central Buddha statue is approximately 4 meters tall, with other statues averaging around 1.6 meters in height. The circular niches are about 1.8 meters high and 1.4 meters wide. The total number of points in this scene is 2,735,811.
Grotto scene 3 extends about 20 meters in length and approximately 10 meters in height, characterized by its double-layered niche eaves which divide the cliff wall into upper and lower sections. The upper section predominantly consists of circular niches, each measuring approximately 1.5 meters by 1.7 meters. The lower section displays small Buddha statues approximately 1.6 meters tall and a central large statue about 4 meters in height. The total number of points in this scene is 4,168,480.
Grotto scene 4, approximately 14 meters high and 18 meters long, features a 4.5-meter-tall half-body Buddha statue and various smaller statues scattered around. The classes are expanded to include cliff wall footing, railings, and cement pavement. This scene encompasses a total of 3,560,818 points.
Grotto scene 5, stretching approximately 16 meters in length and about 14.5 meters in height, encompasses the most diverse range of 10 classes. This scene features three prominent Buddha statues, each standing 6 meters tall. The cliff walls adorned with circular niches approximately 0.75 meters in diameter. The total number of points in this scene reaches 3,761,198.
4.3. Results and analysis
Experiment 1 – grotto scene 1
illustrated the quantitative results from OA, mIoU and IoU of grotto scene 1, including the results obtained by the four baseline methods, the results of our proposed GSS-Net method, and the results of adding knowledge constraints on the GSS-Net results. The RGB colored input point clouds, ground truth, the results obtained by the GSS-Net and the improved results with knowledge constraints are visualized in . Overall, it obtained excellent results in scenarios with fewer types of classes and regularly arranged Buddha statues. The result of GSS-Net segmentation achieved OA of 95% and mIoU of 90.23%. After improving the segmentation results with knowledge constraints (see (c) and (d)), the OA increased by 1.59%, and the mIoU improved by 0.7%.
| (2) | Experiment 1 – grotto scene 2 | ||||
Figure 11. The visualization results of segmentation in grotto scene 1.
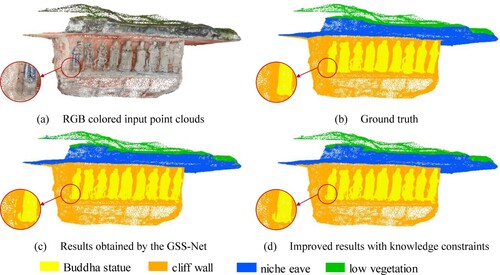
Table 5. The results of OA, mIoU and IoU of different approaches in grotto scene 1.
In grotto scene 2, it was challenging to segment the main Buddha statue, particularly at its boundary area, due to its distinctive shape. As shown in (c and d), the improved results with knowledge constraints effectively corrected errors in the boundaries of Buddha statues, circular niches, and niche eave. Furthermore, those areas with relatively regular geometric features, such as circular niches, achieved good segmentation results. The mIoU of the GSS-Net in this scene reached 86.98%. After the improvement, there was a notable enhancement in segmentation results, with the OA increasing by 1.2% and the mIoU increasing by 0.76%, as detailed in .
| (3) | Experiment 1 – grotto scene 3 | ||||
Figure 12. The visualization results of segmentation in grotto scene 2.
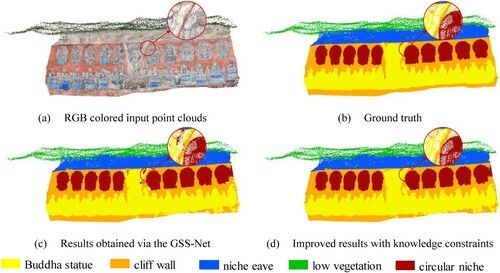
Table 6. The results of OA, mIoU and IoU of different approaches in grotto scene 2
In grotto scene 3, the mIoU for the Buddha statue and niche eave was relatively low. This was primarily attributed to their complex geometric shapes, leading to some horizontal areas being mistakenly identified as niche eave. A notable example was observed on the left side of the experimental area, where a large section part of the cliff wall was erroneously classified as circular niches (see (c and d)). Since the number of points and the size of these misclassified areas did not correspond with actual circular niches, the improvement process was able to reclassify these areas into cliff wall, particularly focusing on the sections with the most boundary contact. The visualized segmentation results for grotto scene 3 are depicted in . The detailed quantitative results are shown in .
| (4) | Experiment 1 – grotto scene 4 | ||||
Figure 13. The visualization results of segmentation in grotto scene 3.
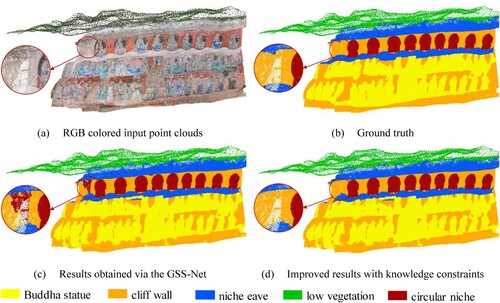
Table 7. The results of OA, mIoU and IoU of different approaches in grotto scene 3.
In grotto scene 4, the Buddha statues were distributed more sporadically across the cliff wall and varied in posture, while the shape of the cliff wall footing was irregular. These factors contributed to lower segmentation results for the Buddha statues, cliff wall, and cliff wall footing, compared to other classes. The visualization and quantitative segmentation results for this scene are illustrated in and , respectively. It is noted that the mIoU of segmenting railings, which own regular geometric shapes, achieved 95.09%.
Figure 14. The visualization results of segmentation in grotto scene 4.
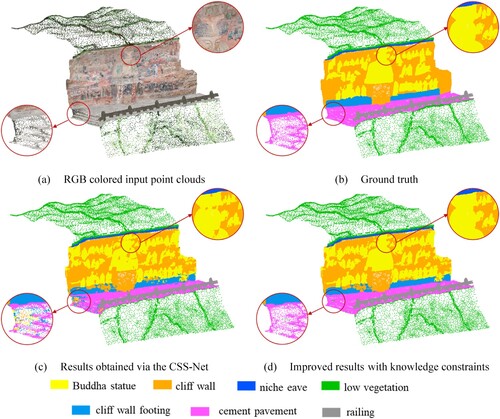
Table 8. The results of OA, mIoU and IoU of different approaches in grotto scene 4.
The knowledge constraints played a crucial role in refining and improving the segmentation results. A significant portion of the main Buddha statue, which was initially misclassified as part of the cliff wall, was correctly classified as Buddha statue after applying the knowledge constraints. Such correction improved the segmentation results of the main Buddha statue. Consequently, as shown in , the OA increased by 0.96% and the mIoU increased by 0.6%.
| (5) | Experiment 1 – grotto scene 5 | ||||
In grotto scene 5, the comparative results of the proposed method in this study against the other four baseline methods are depicted in . presents the quantitative results comparing our proposed method with others. These results demonstrate that the GSS-Net outperforms the second best in four baselines in both OA and mIoU, with improvements of 0.18% and 1.65%. The Buddha statue, niche eave, low vegetation, cliff wall footing and stele achieved the best IoU scores. After improving the results with knowledge constraints, the OA and mIoU reached 93.69% and 85.41%.
| (6) | Experiment 2 | ||||
Figure 15. Comparison of different approaches in grotto scene 5.
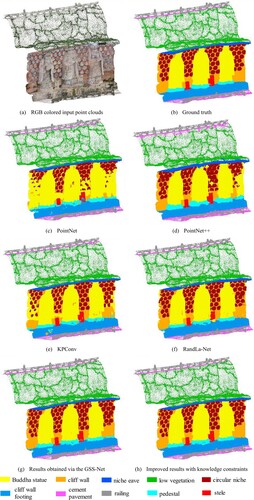
Table 9. The results of OA, mIoU and IoU of different approaches in grotto scene 5.
In experiment 2 that compared our method with four baseline methods, our proposed method also achieved convincing result as shown in and . It can be observed that, without optimization, GSS-Net achieved the best performance in OA and mIoU. Buddha statues, low vegetation, and circular niches achieved the higher IoU scores. The differences in shapes among various Buddha statues pose a segmentation challenge. However, GSS-Net is able to consider the characteristics of grotto scenes in feature expression and aggregation, our method achieved an IoU of 77.76% for Buddha statues, which is an improvement of 2.85% over the second-best method.
Figure 16. Comparison of different methods in grotto scene 2.
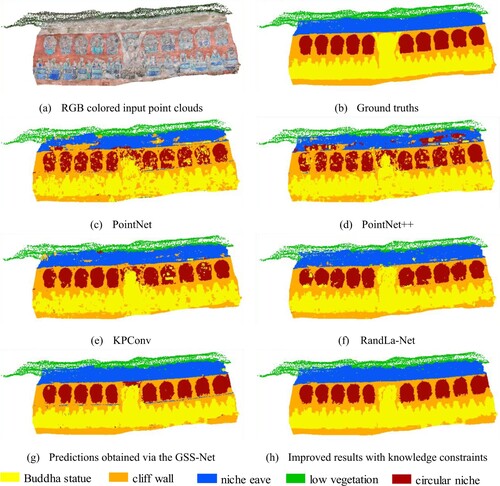
Table 10. The results of OA, mIoU and IoU of different methods in grotto scene 2.
Our method showed weaker performance in segmenting niche eaves and cliff walls. It is potentially because there is a small horizontal protrusion in the middle of the cliff wall, which was intended to differentiate the lower layer of Buddha statues from the upper layer of circular niches. Our method misclassified it as niche eaves, leading to numerous incorrectly segmented points. However, guided by the GSK5 of relative height, these areas were correctly reclassified as part of the cliff wall in the improvement process. illustrates the incorrectly segmented areas that were identified through spatial clustering. These areas were corrected under the constraints of relative height and the threshold for the size of grotto components.
Figure 17. The identification of incorrectly segmented areas in grotto scene 2 (red boxes indicate incorrectly segmented areas).
5. Discussion
5.1. Ablation studies
We design the following ablation studies to illustrate the effectiveness of each sub-module in GSS-Net designed under the knowledge guidance and its influence on the segmentation results. For these ablation studies, grotto scene 1, 3, 4, and 5 were chosen as the training and validation set, while grotto scene 2 was selected as the testing set. The mIoU score was selected as the metric to validate the comparison results in ablation studies, since it can reflect the segmentation effect of all class labels in the grottoes.
5.1.1. Ablation of the overall framework
The network architecture of GSS-Net comprises several key modules, including the local spatial hybrid encoding (LSHE) module, the parallel attention pooling (PAP), and the local-global feature aggregation (LGFA) module. To evaluate the individual contribution of each sub-module to the overall performance of the framework, six ablation studies were conducted. These studies involved adjusting the network by selectively disabling or modifying certain modules to assess their impact on the network performance. shows the details of each ablation study and presents the mIoU scores for all the adjusted networks compared to the full implementation of GSS-Net.
Table 11. mIoU for different module ablation studies in the overall framework.
From , the findings of this ablation study revealed the following results.
Impact of Simplifying the LGFE Module: The simplification of this module hindered its ability to aggregate multi-scale spatial features and global features of local areas by increasing the receptive field. This limitation led to a significant decrease in segmentation effectiveness. Hence, establishing a local neighborhood that encompasses multi-scale spatial context and effectively linking it with global information is essential for semantic segmentation.
Removal of the LSHE Module: The LSHE module had the second most significant impact on the overall performance of the model. The LSHE module is primarily responsible for the representation of local geometric pattern. Without this module, the subsequent network modules are difficult to effectively learn and interpret the context of each point.
Replacement of the Attention Pooling Module: The PAP module assigns a weighted attention score to different features, facilitating a more careful feature selection. Alternative methods used in place of attention pooling did not provide clear weight interpretation, resulting in less detailed attention to different feature channels.
5.1.2. Ablation of point cloud attribute extension
The point cloud attribute extension module conducted four ablation experiments to examine the impact of various combinations of spatial coordinates, color information and eigen-features. The different combinations of attributes and mIoU results are shown in .
Table 12. The mIoU scores of different point cloud attributes for ablation studies.
The experimental findings demonstrate the effectiveness of incorporating color information and expanding point cloud attributes in the point cloud semantic segmentation of grotto scenes. Within these scenes, some components exhibit pronounced color patterns, such as ground, vegetation, and cliff walls. The integration of color information into the model provides more distinctive features, aiding in the differentiation between various classes. Additionally, through inputting eigen-features as additional attributes into the network, the representation of local geometry around each point is significantly enhanced. This enhancement is particularly noticeable when comparing the uniform geometric shapes of the ground and cliff walls with the more varied curvature found in Buddha statues. The point cloud attribute extension module improves the network to accurately identify the local geometric characteristics of different objects, resulting in an increase of segmentation accuracy.
5.1.3. Ablation of local spatial encoding
In this work, we introduced a novel spatial encoding method that integrates the Laplacian operator , the relative position between a given point and its neighboring points
, as well as the Euclidean distance
. To assess the impact of different types of spatial information on the spatial encoding units, we tested seven distinct combinations of these encoding units. The results in indicate that, among the three sub-encoding methods, the relative position information between a given point and its neighbors contributes most to the model. This is because this information intuitively provides the local geometric pattern of the point. Although the Laplacian operator was also used to describe local geometric features, it was designed resist to rotation and scale variations in an implicit manner. The contribution of the Euclidean distance is the least. The potential reason is that it fails to capture the subtle differences in local geometric shapes. Ultimately, combining these three sub-encoding methods together achieved the best performance.
Table 13. The mIoU scores of different spatial coding for ablation studies.
5.1.4 Ablation of local-global feature aggregation
The role of the local-global feature aggregation module is to encompass global geometric features while increasing the receptive field. To evaluate the impact of LSHE, PAP and the concatenation of global feature representations on the overall network, we designed four ablation studies as shown in .
Table 14. The mIoU scores of ablated LGFA.
As indicated by the results in , one set of the LSHE module concatenated with the PAP module fails to effectively increase the receptive field, leading to insufficient model performance in perceiving local multi-scale spatial context. Meanwhile, stacking three sets of LSHE and PAP modules increases the network complexity, but it requires more samples and longer training time for model convergence and is prone to overfitting, thus reducing its generalization ability. This explains why the performance of three stacked sets is inferior to two stacked sets. Moreover, integrating global features into the LGFA module enhances segmentation performance. This is mainly due to the correlation between different components in grotto scenes and their relative heights.
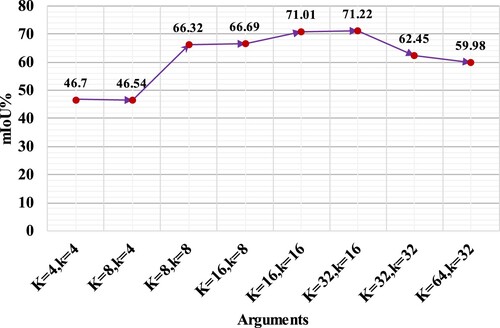
5.1.5. Ablation of the K-R method for selecting neighbor points
To compare the effectiveness of the K-R method with the KNN method, and the impact of the values of and
on segmentation results, eight ablation studies with different parameter settings were conducted. As illustrated in , the K-R method influences the effectiveness of semantic segmentation. However, selecting a larger value of
can lead to overfitting issues due to the over broad selection area. Conversely, a too small value of
may not sufficiently represent local geometric patterns. In this study, the best segmentation results were achieved when
and
. This is because the K-R method considers more directions when selecting neighbor points and performs a dropout operation through random sampling to prevent overfitting caused by involving all points in the calculation. It is important to note that the optimal values for
and
are closely related to the density of the point clouds.
Figure 18. The influence of different parameter on mIoU by using the K-R method.
5.2. Limitations
Although extensive experimentation has demonstrated the superior efficacy of the proposed method in point cloud semantic segmentation for grotto scenes, there are still limitations to be addressed. The purpose of point cloud semantic segmentation of grotto scenes is modeling grottoes in 3D with semantic information for knowledge dissemination, which requires higher precision of segmentation and is less sensitive to segmentation efficiency. Therefore, compared with the segmentation accuracy, the computational efficiency of network modules is seldom considered in this study. In the expression of geometric patterns, local information often proves more crucial than global spatial information. The effective representation of point cloud contextual information significantly enhances the results of semantic segmentation. This is because global features are more likely to be affected by application scenarios. Therefore, based on existing semantic segmentation models, incorporating more global features to enhance the perception of global patterns can improve the segmentation accuracy in certain scenes. Additionally, it is effective to adopt knowledge as guidance to improve the segmentation results after deep learning. This approach requires the predefined knowledge specific to grotto scenes, such as the threshold for the size of grotto components and relative elevation. Such strategy holds the potential to evolve into an independent and more universal module for improving the segmentation results, and is applicable as a post-processing step in deep learning as well. Lastly, grottoes are not solely man-made artistic creations, but their geometric shapes are also influenced by natural environment. Therefore, the applicability and performance of our proposed method across different types of grottoes require further validation.
6. Conclusion
In this study, we proposed a method of point cloud semantic segmentation of grotto scenes with good performance, which is based on knowledge guidance and a deep learning model. The knowledge, including point cloud density knowledge, visual color knowledge, local geometric feature knowledge, global spatial distribution knowledge, threshold for the size of grotto components and grotto components knowledge, guided the construction of the grotto scene point cloud benchmark dataset, the design and improvement of neural network, and the improvement of segmentation results. With the guidance of these knowledge and the reference of RandLA-Net, we built a deep learning model named GSS-NET to make it more suitable for grotto scenes. This model more effectively captures the local and global spatial geometric patterns in grotto scenes and incorporates neural network modules for efficient selection and aggregation of point clouds contextual information. The comparative experiments with four deep learning models on our self-constructed point cloud benchmark dataset demonstrate the advanced performance of our proposed method. The knowledge constraints further improve the segmentation results. In the inter-scene experiment, it achieved an OA of 83.53% and a mIoU of 71.22% with the GSS-Net. Through applying knowledge constraints for result improvement, the OA and the mIoU increased to 90.28% and 76.47%. A set of ablation studies reveal the effectiveness of model design and improvement under knowledge guidance, aiding explain the contribution of each module to the entire deep neural architecture for point cloud sematic segmentation. The GSS-Net proposed in this study adopts Pointwise MLP as the basic unit. The spatial coding layer, pooling layer, and feature aggregation layer as sub-modules in our proposed model can be used in other MLP-Based methods. For example, the Laplace operator is capable of representing the local geometric properties of the point clouds. The parallel attention pooling can capture contextual information in a soft way. The global features enable the neural network to perceive the spatial distribution of features. In addition, the first four of the six GSKs we summarized in this study are applicable to grotto scenes and have certain generalization to deal with those scenes that have similar features, such as complex geometry, uneven density distribution, color being important, and relative height being correlated with category. In the future, our goal is to expand the benchmark dataset of grotto scenes to evaluate the generalizability of this method across a broader range of grotto scenes.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The point cloud used in the study cannot be shared publicly due to restrictions.
Additional information
Funding
Notes
1 https://whc.unesco.org/en/list/1003/ (accessed on 15 December 2023).
2 https://whc.unesco.org/en/list/1039/ (accessed on 15 December 2023).
3 https://whc.unesco.org/en/list/912/ (accessed on 15 December 2023).
4 https://www.cloudcompare.org/ (accessed on 14 January 2024).
References
- Ahn, J., and K. y. Wohn. 2015. “Lessons Learned from Reconstruction of a Virtual Grotto - From Point Cloud to Immersive Virtual Environment.” Paper Presented at the 2015 Digital Heritage, 28 Sept.–2 Oct. 2015.
- Apollonio, Fabrizio I, Marco Gaiani, and Zheng Sun. 2013. “3D Modeling and Data Enrichment in Digital Reconstruction of Architectural Heritage.” The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 40:43–48. https://doi.org/10.5194/isprsarchives-XL-5-W2-43-2013.
- Armeni, Iro, Ozan Sener, Amir R Zamir, Helen Jiang, Ioannis Brilakis, Martin Fischer, and Silvio Savarese. 2016. “3D Semantic Parsing of Large-Scale Indoor Spaces.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Ballouch, Zouhair, Rafika Hajji, Florent Poux, Abderrazzaq Kharroubi, and Roland Billen. 2022. “A Prior Level Fusion Approach for the Semantic Segmentation of 3D Point Clouds Using Deep Learning.” Remote Sensing 14 (14): 3415. https://doi.org/10.3390/rs14143415.
- Behley, Jens, Martin Garbade, Andres Milioto, Jan Quenzel, Sven Behnke, Cyrill Stachniss, and Jurgen Gall. 2019. “Semantickitti: A Dataset for Semantic Scene Understanding of Lidar Sequences.” Paper Presented at the Proceedings of the IEEE/CVF International Conference on Computer Vision.
- Bosché, Frédéric, Mahmoud Ahmed, Yelda Turkan, Carl T Haas, and Ralph Haas. 2015. “The Value of Integrating Scan-to-BIM and Scan-vs-BIM Techniques for Construction Monitoring Using Laser Scanning and BIM: The Case of Cylindrical MEP Components.” Automation in Construction 49:201–213. https://doi.org/10.1016/j.autcon.2014.05.014.
- Boulch, Alexandre, Joris Guerry, Bertrand Le Saux, and Nicolas Audebert. 2018. “SnapNet: 3d Point Cloud Semantic Labeling with 2D Deep Segmentation Networks.” Computers & Graphics 71:189–198. https://doi.org/10.1016/j.cag.2017.11.010.
- Brumana, Raffaella, Daniela Oreni, Luigi Barazzetti, Branka Cuca, Mattia Previtali, and Fabrizio Banfi. 2020. “Survey and Scan to BIM Model for the Knowledge of Built Heritage and the Management of Conservation Activities.” In Digital Transformation of the Design, Construction and Management Processes of the Built Environment, edited by Bruno Daniotti, Marco Gianinetto, and Stefano Della Torre, 391–400. Cham: Springer International Publishing.
- Bunge, Astrid, Philipp Herholz, Misha Kazhdan, and Mario Botsch. 2020. “Polygon Laplacian made Simple.” Paper Presented at the Computer Graphics Forum.
- Camuffo, Elena, Daniele Mari, and Simone Milani. 2022. “Recent Advancements in Learning Algorithms for Point Clouds: An Updated Overview.” Sensors 22 (4): 1357. https://doi.org/10.3390/s22041357.
- Cao, J., A. Tagliasacchi, M. Olson, H. Zhang, and Z. Su. 2010. “Point Cloud Skeletons via Laplacian Based Contraction.” Paper Presented at the 2010 Shape Modeling International Conference, 21–23 June 2010.
- Chen, Jiaxuan, Shuang Chen, Xiaoxian Chen, Yuan Dai, and Yang Yang. 2022. “CSR-Net: Learning Adaptive Context Structure Representation for Robust Feature Correspondence.” IEEE Transactions on Image Processing 31:3197–3210.
- Chen, Lin-Zhuo, Xuan-Yi Li, Deng-Ping Fan, Kai Wang, Shao-Ping Lu, and Ming-Ming Cheng. 2019. “LSANet: Feature learning on point sets by local spatial aware layer.” arXiv preprint arXiv:1905.05442. https://doi.org/10.48550/arXiv.1905.05442.
- Chen, Yi, Yingjun Xiong, Baohua Zhang, Jun Zhou, and Qian Zhang. 2021. “3D Point Cloud Semantic Segmentation Toward Large-Scale Unstructured Agricultural Scene Classification.” Computers and Electronics in Agriculture 190:106445. https://doi.org/10.1016/j.compag.2021.106445.
- Colucci, Elisabetta, Xufeng Xing, Margarita Kokla, Mir Abolfazl Mostafavi, Francesca Noardo, and Antonia Spanò. 2021. “Ontology-based Semantic Conceptualisation of Historical Built Heritage to Generate Parametric Structured Models from Point Clouds.” Applied Sciences 11 (6): 2813. https://doi.org/10.3390/app11062813.
- Connor, Michael, and Piyush Kumar. 2010. “Fast Construction of k-Nearest Neighbor Graphs for Point Clouds.” IEEE Transactions on Visualization and Computer Graphics 16 (4): 599–608.
- Croce, Valeria, Gabriella Caroti, Livio De Luca, Kévin Jacquot, Andrea Piemonte, and Philippe Véron. 2021. “From the Semantic Point Cloud to Heritage-Building Information Modeling: A Semiautomatic Approach Exploiting Machine Learning.” Remote Sensing 13 (3): 461. https://doi.org/10.3390/rs13030461.
- Croce, Valeria, Gabriella Caroti, Livio De Luca, Andrea Piemonte, and Philippe Véron. 2020. “Semantic Annotations on Heritage Models: 2D/3D Approaches and Future Research Challenges.” International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 43 (B2): 829–836. https://doi.org/10.5194/isprs-archives-XLIII-B2-2020-829-2020.
- Croce, Valeria, Gabriella Caroti, Andrea Piemonte, and Marco Giorgio Bevilacqua. 2021. “From Survey to Semantic Representation for Cultural Heritage: The 3D Modeling of Recurring Architectural Elements.” ACTA IMEKO 10 (1): 98–108. https://doi.org/10.21014/acta_imeko.v10i1.842.
- Diao, Changyu, Zhirong Li, Zhuo Zhang, Bo Ning, and Yong He. 2019. “To Achieve Real Immersion: The 3D Virtual and Physical Reconstruction of Cave 3 and Cave 12 of Yungang Grottoes.” The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 42:297–303. https://doi.org/10.5194/isprs-archives-XLII-2-W9-297-2019.
- Du, Zijin, Hailiang Ye, and Feilong Cao. 2022. “A Novel Local-Global Graph Convolutional Method for Point Cloud Semantic Segmentation.” IEEE Transactions on Neural Networks and Learning Systems 35:4798–4812. https://doi.org/10.1109/TNNLS.2022.3155282.
- Engelmann, Francis, Theodora Kontogianni, Alexander Hermans, and Bastian Leibe. 2017. “Exploring Spatial Context for 3D Semantic Segmentation of Point Clouds.” Paper Presented at the Proceedings of the IEEE International Conference on Computer Vision Workshops.
- Engelmann, Francis, Theodora Kontogianni, and Bastian Leibe. 2020. “Dilated Point Convolutions: On the Receptive Field Size of Point Convolutions on 3D Point Clouds.” Paper Presented at the 2020 IEEE International Conference on Robotics and Automation (ICRA).
- Engelmann, Francis, Theodora Kontogianni, Jonas Schult, and Bastian Leibe. 2018. “Know What Your Neighbors Do: 3D Semantic Segmentation of Point Clouds.” Paper Presented at the Proceedings of the European Conference on Computer Vision (ECCV) Workshops.
- Er, Meng Joo, Yong Zhang, Ning Wang, and Mahardhika Pratama. 2016. “Attention Pooling-Based Convolutional Neural Network for Sentence Modelling.” Information Sciences 373:388–403.
- Fan, Siqi, Qiulei Dong, Fenghua Zhu, Yisheng Lv, Peijun Ye, and Fei-Yue Wang. 2021. “SCF-Net: Learning Spatial Contextual Features for Large-Scale Point Cloud Segmentation.” Paper Presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Filin, Sagi, and Norbert Pfeifer. 2005. “Neighborhood Systems for Airborne Laser Data.” Photogrammetric Engineering & Remote Sensing 71 (6): 743–755. https://doi.org/10.14358/PERS.71.6.743.
- González-Collazo, S. M., N. Canedo-González, E. González, and J. Balado. 2024. “Semantic Point Cloud Segmentation in Urban Environments with 1D Convolutional Neural Networks.” International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences XLVIII-4/W9-2024:205–211. https://doi.org/10.5194/isprs-archives-XLVIII-4-W9-2024-205-2024.
- Grandio, Javier, Belén Riveiro, Mario Soilán, and Pedro Arias. 2022. “Point Cloud Semantic Segmentation of Complex Railway Environments Using Deep Learning.” Automation in Construction 141:104425. https://doi.org/10.1016/j.autcon.2022.104425.
- Grilli, Eleonora, Alessandro Daniele, Maarten Bassier, Fabio Remondino, and Luciano Serafini. 2023. “Knowledge Enhanced Neural Networks for Point Cloud Semantic Segmentation.” Remote Sensing 15 (10): 2590. https://doi.org/10.3390/rs15102590.
- Grilli, Eleonora, and Fabio Remondino. 2019. “Classification of 3D Digital Heritage.” Remote Sensing 11 (7): 847. https://doi.org/10.3390/rs11070847.
- Guo, Yulan, Hanyun Wang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun. 2020. “Deep Learning for 3d Point Clouds: A Survey.” IEEE Transactions on Pattern Analysis and Machine Intelligence 43 (12): 4338–4364. https://doi.org/10.1109/TPAMI.2020.3005434.
- Hackel, Timo, Nikolay Savinov, Lubor Ladicky, Jan D Wegner, Konrad Schindler, and Marc Pollefeys. 2017. “Semantic3d. Net: A New Large-Scale Point Cloud Classification Benchmark.” arXiv preprint arXiv:1704.03847.
- He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. “Deep Residual Learning for Image Recognition.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Ho, Yaoshiang, and Samuel Wookey. 2019. “The Real-World-Weight Cross-Entropy Loss Function: Modeling the Costs of Mislabeling.” IEEE Access 8:4806–4813. https://doi.org/10.1109/ACCESS.2019.2962617.
- Hu, Qingyong, Bo Yang, Sheikh Khalid, Wen Xiao, Niki Trigoni, and Andrew Markham. 2021. “Towards Semantic Segmentation of Urban-Scale 3D Point Clouds: A Dataset, Benchmarks and Challenges.” Paper Presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Hu, Qingyong, Bo Yang, Linhai Xie, Stefano Rosa, Yulan Guo, Zhihua Wang, Niki Trigoni, and Andrew Markham. 2021. “Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling.” IEEE Transactions on Pattern Analysis and Machine Intelligence 44 (11): 8338–8354. https://doi.org/10.1109/TPAMI.2021.3083288.
- Hua, Binh-Son, Minh-Khoi Tran, and Sai-Kit Yeung. 2018. “Pointwise Convolutional Neural Networks.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Huang, Qiangui, Weiyue Wang, and Ulrich Neumann. 2018. “Recurrent Slice Networks for 3d Segmentation of Point Clouds.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Huang, Rong, Yusheng Xu, and Uwe Stilla. 2021. “GraNet: Global Relation-Aware Attentional Network for Semantic Segmentation of ALS Point Clouds.” ISPRS Journal of Photogrammetry and Remote Sensing 177:1–20. https://doi.org/10.1016/j.isprsjprs.2021.04.017.
- Huang, Jing, and Suya You. 2016. “Point Cloud Labeling Using 3d Convolutional Neural Network.” Paper Presented at the 2016 23rd International Conference on Pattern Recognition (ICPR).
- Jiang, Mingyang, Yiran Wu, Tianqi Zhao, Zelin Zhao, and Cewu Lu. 2018. “Pointsift: A Sift-Like Network Module for 3d Point Cloud Semantic Segmentation.” arXiv preprint arXiv:1807.00652.
- Jiang, Li, Hengshuang Zhao, Shu Liu, Xiaoyong Shen, Chi-Wing Fu, and Jiaya Jia. 2019. “Hierarchical Point-Edge Interaction Network for Point Cloud Semantic Segmentation.” Paper Presented at the Proceedings of the IEEE/CVF International Conference on Computer Vision.
- Keqina, Zhou, Zhao Xub, Zhou Junzhaod, Wang Feia, and Hu Songd. 2008. “Application of Terrestrial Laser Scanning for Heritage Conservation in Yungang Grotto.” The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 37:337–340.
- Landrieu, Loic, and Martin Simonovsky. 2018. “Large-Scale Point Cloud Semantic Segmentation with Superpoint Graphs.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Lawin, Felix Järemo, Martin Danelljan, Patrik Tosteberg, Goutam Bhat, Fahad Shahbaz Khan, and Michael Felsberg. 2017. “Deep Projective 3D Semantic Segmentation.” Paper Presented at the Computer Analysis of Images and Patterns: 17th International Conference, CAIP 2017, Ystad, Sweden, August 22–24, 2017, Proceedings, Part I 17.
- Lee, Jun S, Jeongjun Park, and Young-Moo Ryu. 2021. “Semantic Segmentation of Bridge Components Based on Hierarchical Point Cloud Model.” Automation in Construction 130:103847. https://doi.org/10.1016/j.autcon.2021.103847.
- Lee, Impyeong, and Toni Schenk. 2002. “Perceptual Organization of 3D Surface Points.” International Archives of Photogrammetry Remote Sensing and Spatial Information Sciences 34 (3/A): 193–198.
- Li, Yu. 2023. “Analysis of the Relationship Between the Temporal and Spatial Evolution of Henan Grotto Temples and Their Geographical and Cultural Environment Based on GIS.” Heritage Science 11 (1): 216. https://doi.org/10.1186/s40494-023-01044-w.
- Li, Yangyan, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. 2018. “Pointcnn: Convolution on x-Transformed Points.” Proceedings of the 32nd International Conference on Neural Information Processing Systems (NIPS'18). Curran Associates Inc., Red Hook, NY, USA, 828–838. https://dl.acm.org/doi/10.5555/3326943.3327020.
- Li, Yong, Xu Li, Zhenxin Zhang, Feng Shuang, Qi Lin, and Jincheng Jiang. 2022. “DenseKPNET: Dense Kernel Point Convolutional Neural Networks for Point Cloud Semantic Segmentation.” IEEE Transactions on Geoscience and Remote Sensing 60:1–13. https://doi.org/10.1109/TGRS.2022.3162582.
- Li, Xiang, Lingjing Wang, Mingyang Wang, Congcong Wen, and Yi Fang. 2020. “DANCE-NET: Density-Aware Convolution Networks with Context Encoding for Airborne LiDAR Point Cloud Classification.” ISPRS Journal of Photogrammetry and Remote Sensing 166:128–139.
- Li, Jincheng, Zhenxin Zhang, Haili Sun, Si Xie, Jianjun Zou, Changqi Ji, Yue Lu, Xiaoxu Ren, and Liuzhao Wang. 2023. “GL-Net: Semantic Segmentation for Point Clouds of Shield Tunnel via Global Feature Learning and Local Feature Discriminative Aggregation.” ISPRS Journal of Photogrammetry and Remote Sensing 199:335–349. https://doi.org/10.1016/j.isprsjprs.2023.04.011.
- Liang, J., R. Lai, T. W. Wong, and H. Zhao. 2012. “Geometric Understanding of Point Clouds using Laplace-Beltrami Operator.” Paper Presented at the 2012 IEEE Conference on Computer Vision and Pattern Recognition, 16–21 June 2012.
- Liang, Zhidong, Ming Yang, Liuyuan Deng, Chunxiang Wang, and Bing Wang. 2019. “Hierarchical Depthwise Graph Convolutional Neural Network for 3D Semantic Segmentation of Point Clouds.” Paper Presented at the 2019 International Conference on Robotics and Automation (ICRA).
- Lin, Chao-Hung, Jyun-Yuan Chen, Po-Lin Su, and Chung-Hao Chen. 2014. “Eigen-feature Analysis of Weighted Covariance Matrices for LiDAR Point Cloud Classification.” ISPRS Journal of Photogrammetry and Remote Sensing 94:70–79. https://doi.org/10.1016/j.isprsjprs.2014.04.016.
- Liu, Weiping, Jia Sun, Wanyi Li, Ting Hu, and Peng Wang. 2019. “Deep Learning on Point Clouds and Its Application: A Survey.” Sensors 19 (19): 4188.
- Lu, Houhong, Yangyang Zhu, Ming Yin, Guofu Yin, and Luofeng Xie. 2022. “Multimodal Fusion Convolutional Neural Network with Cross-Attention Mechanism for Internal Defect Detection of Magnetic Tile.” IEEE Access 10:60876–60886.
- Ma, Lingfei, Ying Li, Jonathan Li, Weikai Tan, Yongtao Yu, and Michael A Chapman. 2019. “Multi-scale Point-Wise Convolutional Neural Networks for 3D Object Segmentation from LiDAR Point Clouds in Large-Scale Environments.” IEEE Transactions on Intelligent Transportation Systems 22 (2): 821–836. https://doi.org/10.3390/s19194188.
- Malinverni, Eva Savina, Roberto Pierdicca, Marina Paolanti, Massimo Martini, Christian Morbidoni, Francesca Matrone, and Andrea Lingua. 2019. “Deep Learning for Semantic Segmentation of 3D Point Cloud.” The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 42:735–742. https://doi.org/10.5194/isprs-archives-XLII-2-W15-735-2019.
- Maru, Michael Bekele, Yusen Wang, Hansun Kim, Hyungchul Yoon, and Seunghee Park. 2023. “Improved Building Facade Segmentation Through Digital Twin-Enabled RandLA-Net with Empirical Intensity Correction Model.” Journal of Building Engineering 78:107520. https://doi.org/10.1016/j.jobe.2023.107520.
- Matrone, Francesca, Eleonora Grilli, Massimo Martini, Marina Paolanti, Roberto Pierdicca, and Fabio Remondino. 2020. “Comparing Machine and Deep Learning Methods for Large 3D Heritage Semantic Segmentation.” ISPRS International Journal of Geo-Information 9 (9): 535. https://doi.org/10.3390/ijgi9090535.
- Morbidoni, Christian, Roberto Pierdicca, Marina Paolanti, Ramona Quattrini, and Raissa Mammoli. 2020. “Learning from Synthetic Point Cloud Data for Historical Buildings Semantic Segmentation.” Journal on Computing and Cultural Heritage 13 (4): 1–16. https://doi.org/10.1145/3409262.
- Moyano, Juan, Javier León, Juan E Nieto-Julián, and Silvana Bruno. 2021. “Semantic Interpretation of Architectural and Archaeological Geometries: Point Cloud Segmentation for HBIM Parameterisation.” Automation in Construction 130:103856. https://doi.org/10.1016/j.autcon.2021.103856.
- Moyano, Juan, Juan E Nieto-Julián, Lara M Lenin, and Silvana Bruno. 2022. “Operability of Point Cloud Data in an Architectural Heritage Information Model.” International Journal of Architectural Heritage 16 (10): 1588–1607. https://doi.org/10.1080/15583058.2021.1900951.
- Pan, Liang, Chee-Meng Chew, and Gim Hee Lee. 2020. “PointAtrousGraph: Deep Hierarchical Encoder-Decoder with Point Atrous Convolution for Unorganized 3D Points.” Paper Presented at the 2020 IEEE International Conference on Robotics and Automation (ICRA).
- Park, Jaehyun, Chansoo Kim, Soyeong Kim, and Kichun Jo. 2023. “PCSCNet: Fast 3D Semantic Segmentation of LiDAR Point Cloud for Autonomous car Using Point Convolution and Sparse Convolution Network.” Expert Systems with Applications 212:118815. https://doi.org/10.1016/j.eswa.2022.118815.
- Pierdicca, Roberto, Marina Paolanti, Francesca Matrone, Massimo Martini, Christian Morbidoni, Eva Savina Malinverni, Emanuele Frontoni, and Andrea Maria Lingua. 2020. “Point Cloud Semantic Segmentation Using a Deep Learning Framework for Cultural Heritage.” Remote Sensing 12 (6): 1005. https://doi.org/10.3390/rs12061005.
- Ponciano, Jean-Jacques, Moritz Roetner, Alexander Reiterer, and Frank Boochs. 2021. “Object Semantic Segmentation in Point Clouds—Comparison of a Deep Learning and a Knowledge-Based Method.” ISPRS International Journal of Geo-Information 10 (4): 256. https://doi.org/10.3390/ijgi10040256.
- Poux, Florent, Romain Neuville, Pierre Hallot, and Roland Billen. 2017. “Model for Semantically Rich Point Cloud Data.” ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences 4:107–115. https://doi.org/10.5194/isprs-annals-IV-4-W5-107-2017.
- Poux, Florent, Romain Neuville, Line Van Wersch, Gilles-Antoine Nys, and Roland Billen. 2017. “3D Point Clouds in Archaeology: Advances in Acquisition, Processing and Knowledge Integration Applied to Quasi-Planar Objects.” Geosciences 7 (4): 96. https://doi.org/10.3390/geosciences7040096.
- Qi, Charles R, Hao Su, Kaichun Mo, and Leonidas J Guibas. 2017. “Pointnet: Deep Learning on Point Sets for 3d Classification and Segmentation.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Qi, Charles Ruizhongtai, Li Yi, Hao Su, and Leonidas J Guibas. 2017. “Pointnet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space.” Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS'17). Curran Associates Inc., Red Hook, NY, USA, 5105–5114. https://dl.acm.org/doi/10.5555/3295222.3295263.
- Rocha, Gustavo, Luís Mateus, Jorge Fernández, and Victor Ferreira. 2020. “A Scan-to-BIM Methodology Applied to Heritage Buildings.” Heritage 3 (1): 47–67. https://doi.org/10.3390/heritage3010004.
- Runze, Yang. 2023. “A Study on the Spatial Distribution and Historical Evolution of Grotto Heritage: A Case Study of Gansu Province, China.” Heritage Science 11 (1): 165. https://doi.org/10.1186/s40494-023-01014-2.
- Sharp, Nicholas, and Keenan Crane. 2020. “A Laplacian for Nonmanifold Triangle Meshes.” Paper Presented at the Computer Graphics Forum.
- Sorkine, Olga. 2005. “Laplacian Mesh Processing.” In Eurographics 2005 - State of the Art Reports, edited by Yiorgos Chrysanthou and Marcus Magnor. The Eurographics Association. https://diglib.eg.org/items/f8479593-c041-46fe-bd44-3d529a5b9aeb/full.
- Sorkine, O. 2006. “Differential Representations for Mesh Processing.” Computer Graphics Forum 25 (4): 789–807. https://doi.org/10.1111/J.1467-8659.2006.00999.X.
- Tan, Weikai, Nannan Qin, Lingfei Ma, Ying Li, Jing Du, Guorong Cai, Ke Yang, and Jonathan Li. 2020. “Toronto-3D: A Large-Scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways.” Paper Presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops.
- Thomas, Hugues, Charles R Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, François Goulette, and Leonidas J Guibas. 2019. “Kpconv: Flexible and Deformable Convolution for Point Clouds.” Paper Presented at the Proceedings of the IEEE/CVF International Conference on Computer Vision.
- Wang, Jingxue, Huan Li, Zhenghui Xu, and Xiao Xie. 2023. “Semantic Segmentation of Urban Airborne LiDAR Point Clouds Based on Fusion Attention Mechanism and Multi-Scale Features.” Remote Sensing 15 (21): 5248.
- Wang, Yue, Yongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon. 2019. “Dynamic Graph CNN for Learning on Point Clouds.” ACM Transactions on Graphics (TOG) 38 (5): 1–12.
- Wang, Shenlong, Simon Suo, Wei-Chiu Ma, Andrei Pokrovsky, and Raquel Urtasun. 2018. “Deep Parametric Continuous Convolutional Neural Networks.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Wang, Zhen, Liqiang Zhang, Liang Zhang, Roujing Li, Yibo Zheng, and Zidong Zhu. 2018. “A Deep Neural Network with Spatial Pooling (DNNSP) for 3-D Point Cloud Classification.” IEEE Transactions on Geoscience and Remote Sensing 56 (8): 4594–4604.
- Wei, Shen. 2008. ““Building Boundary Extraction Based on Lidar Point Clouds Data.” Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 37:157–161.
- Weinmann, Martin. 2016. Reconstruction and Analysis of 3D Scenes. Vol. 1. Springer. http://doi.org/10.1007/978-3-319-29246-5.
- Weinmann, Martin, Boris Jutzi, Stefan Hinz, and Clément Mallet. 2015. “Semantic Point Cloud Interpretation Based on Optimal Neighborhoods, Relevant Features and Efficient Classifiers.” ISPRS Journal of Photogrammetry and Remote Sensing 105:286–304. https://doi.org/10.1016/j.isprsjprs.2015.01.016.
- Weinmann, M., B. Jutzi, and C. Mallet. 2014. “Semantic 3D Scene Interpretation: A Framework Combining Optimal Neighborhood Size Selection with Relevant Features.” ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information. II-3:181–188. https://doi.org/10.5194/isprsannals-II-3-181-2014.
- Weinmann, Martin, and Michael Weinmann. 2019. “Fusion of Hyperspectral, Multispectral, Color and 3D Point Cloud Information for the Semantic Interpretation of Urban Environments.” The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences 42:1899–1906.
- Xia, Tian, Jian Yang, and Long Chen. 2022. “Automated Semantic Segmentation of Bridge Point Cloud Based on Local Descriptor and Machine Learning.” Automation in Construction 133:103992.
- Xie, Saining, Sainan Liu, Zeyu Chen, and Zhuowen Tu. 2018. “Attentional Shapecontextnet for Point Cloud Recognition.” Paper Presented at the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Xie, Yuxing, Jiaojiao Tian, and Xiao Xiang Zhu. 2020. “Linking Points with Labels in 3D: A Review of Point Cloud Semantic Segmentation.” IEEE Geoscience and Remote Sensing Magazine 8 (4): 38–59. https://doi.org/10.1109/mgrs.2019.2937630.
- Xie, Tao, Li Wang, Ke Wang, Ruifeng Li, Xinyu Zhang, Haoming Zhang, Linqi Yang, Huaping Liu, and Jun Li. 2024. “FARP-Net: Local-Global Feature Aggregation and Relation-Aware Proposals for 3D Object Detection.” IEEE Transactions on Multimedia 26: 1027–1040.
- Yang, Su, and Miaole Hou. 2023. “Knowledge Graph Representation Method for Semantic 3D Modeling of Chinese Grottoes.” Heritage Science 11 (1): 266. https://doi.org/10.1186/s40494-023-01084-2.
- Yang, Su, Miaole Hou, and Hongchao Fan. 2024. “CityGML Grotto ADE for Modelling Niches in 3D with Semantic Information.” Heritage Science 12 (1): 135. https://doi.org/10.1186/s40494-024-01260-y.
- Yang, Su, Miaole Hou, and Songnian Li. 2023. “Three-Dimensional Point Cloud Semantic Segmentation for Cultural Heritage: A Comprehensive Review.” Remote Sensing 15 (3): 548. https://doi.org/10.3390/rs15030548.
- Yang, Bo, Sen Wang, Andrew Markham, and Niki Trigoni. 2020. “Robust Attentional Aggregation of Deep Feature Sets for Multi-View 3D Reconstruction.” International Journal of Computer Vision 128:53–73.
- Yang, Jiancheng, Qiang Zhang, Bingbing Ni, Linguo Li, Jinxian Liu, Mengdie Zhou, and Qi Tian. 2019. “Modeling Point Clouds with Self-Attention and Gumbel Subset Sampling.” Paper Presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and pattern Recognition.
- Ye, Xiaoqing, Jiamao Li, Hexiao Huang, Liang Du, and Xiaolin Zhang. 2018. “3d Recurrent Neural Networks with Context Fusion for Point Cloud Semantic Segmentation.” Paper Presented at the Proceedings of the European conference on computer vision (ECCV).
- Yin, Fukun, Zilong Huang, Tao Chen, Guozhong Luo, Gang Yu, and Bin Fu. 2023. “Dcnet: Large-Scale Point Cloud Semantic Segmentation with Discriminative and Efficient Feature Aggregation.” IEEE Transactions on Circuits and Systems for Video Technology 33 (8): 4083–4095.
- Zeng, Wei, and Theo Gevers. 2018. “3DContextNet: Kd Tree Guided Hierarchical Learning of Point Clouds Using Local and Global Contextual Cues.” Paper presented at the Proceedings of the European Conference on Computer Vision (ECCV) Workshops.
- Zhang, Zhiyuan, Binh-Son Hua, and Sai-Kit Yeung. 2019. “Shellnet: Efficient Point Cloud Convolutional Neural Networks Using Concentric Shells Statistics.” Paper Presented at the Proceedings of the IEEE/CVF International Conference on Computer Vision.
- Zhang, Rui, Yichao Wu, Wei Jin, and Xiaoman Meng. 2023. “Deep-Learning-Based Point Cloud Semantic Segmentation: A Survey.” Electronics 12 (17): 3642.
- Zhang, Jiaying, Xiaoli Zhao, Zheng Chen, and Zhejun Lu. 2019. “A Review of Deep Learning-Based Semantic Segmentation for Point Cloud.” IEEE Access 7:179118–179133.
- Zhao, Hengshuang, Li Jiang, Chi-Wing Fu, and Jiaya Jia. 2019. “Pointweb: Enhancing Local Neighborhood Features for Point Cloud Processing.” Paper Presented at the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Zhao, Hengshuang, Li Jiang, Jiaya Jia, Philip HS Torr, and Vladlen Koltun. 2021. “Point Transformer.” Paper Presented at the Proceedings of the IEEE/CVF International Conference on Computer Vision.
- Zhou, Ziyun, Hong Huang, and Binhao Fang. 2021. “Application of Weighted Cross-Entropy Loss Function in Intrusion Detection.” Journal of Computer and Communications 9 (11): 1–21.