
Abstract
Deep learning techniques are increasingly used to automate categorization and identification tasks for large datasets of digital photographs. For rasterized images formats, such as JPEGs, GIFs, and PNGs, the analysis happens on the level of individual pixels. Given this, digital images used in deep learning applications are typically restricted to relatively low-resolution formats to conform to the standards of popular pre-trained neural networks. Using Hito Steyerl’s conception of the ‘poor image’ as a theoretical frame, this article investigates the use of these relatively low-resolution images in automated analysis, exploring the ways in which they may be deemed preferable to higher-resolution images for deep learning applications. The poor image is rich in value in this context, as it limits the undesirable ‘noise’ of too much detail. In considering the case of automated art authentication, this article argues that a notion of authenticity is beginning to emerge that raises questions around Walter Benjamin’s often-cited definition in relation to mass image culture. Copies or reproductions are now forming the basis for a new model of authenticity, which exists latently in the formal properties of a digital image.
Trade-offs between detail and accessibility have long been a factor in popular uptake of competing photographic practices. In the early days of photography, negative-to-positive printing techniques, such as the calotype, could not match the detail of direct-positive photographic processes like daguerreotype, but what they lacked in detail they made up for in accessibility since they were easier to copy and less fragile.Footnote1 In a similar vein, early adoption of digital photography in the 1990s and early 2000s was driven by ease of use and speed of reproducibility/distribution, even when weighed against the superior detail of 35 mm film photography at that time. In the digital era, detail has become synonymous with quality. For digital photography, the more pixels — the more detail — the better. As digital camera manufacturers release higher and higher megapixel capabilities, however, the necessity for compromise is rapidly diminishing.
The level of detail captured in a photograph is affected by a number of different factors. For film photography, these include the size of the film, lens techniques, issues related to chemical exposure time, and camera movement. To this mix, digital photography added sensor size, processing power, and pixilation, the latter of which is a reflection of the underlying structure of information in digital images as picture elements, i.e. pixels. To say an image is ‘pixelated’ is shorthand for saying that the image is composed of too few pixels for the human viewer to see smooth curves or relatively high levels of detail.Footnote2 As the digital photograph is downsampled, meaning the amount of information provided to constitute the photo is decreased, the image is made up of fewer pixel squares and details are lost. The image or portions of the image can thus be rendered a rectilinear abstraction within a few clicks, which has fascinated contemporary artists such as Thomas Ruff, Angela Bulloch, Thomas Hirschhorn, and Hito Steyerl, among many others.
In 2009 Steyerl published the influential essay ‘In Defense of the Poor Image,’ where she outlines her theory of the poor image as the digital copy of a copy unmoored from its original, circulating quickly on the internet. The essay is a rebuke to resolution fetishists, who value higher levels of detail above all else. In describing the poor image, Steyerl uses a variety of negatively-loaded words: ‘bad’, ‘substandard’, ‘bastard’, ‘degraded’, ‘dilapidated’, ‘debris’.Footnote3 Steyerl’s defense, therefore, proceeds from the popular assumption that such images are unquestionably deficient in comparison to their higher-resolution cousins, that they are defined by what they lack. However, this does not reflect how digital images are first and foremost machine-readable packets of information. They are the code for processes that produce visual appearance as an end product. Needless to say, computers ‘see’ and ‘judge’ images in ways that are different from humans, despite the biological metaphors often used to describe their perceptual capabilities.Footnote4 Therefore, Steyerl’s poor images might be deemed superior — from a computational point of view — to bulky, rich images precisely because of what they lack: excess or un-needed information.
In recent times, deep learning techniques that use neutral networks have enriched the process of sorting and analyzing images (particularly photographic images) for a range of applications, including facial recognition, road-obstacle detection, and medical imaging. Popular pre-trained convolutional neural networks (CNNs) for deep learning, such as ResNet-50, VGG-16, and Inception-v3, are typically implemented with images that are downscaled and cropped to a resolution of just 224 × 224 pixels. In this article, I investigate the use of these relatively low-resolution images in the context of training datasets for deep learning, where the poor image is actually rich in value as it limits the undesirable ‘noise’ of too much detail for object recognition tasks. Looking at the case of automated art authentication, I argue that a notion of authenticity is beginning to emerge in deep learning applications that raises questions around Walter Benjamin’s classic conception of authenticity and aura.
Although image and screen resolutions have increased since the time Steyerl’s essay was published, there remains a sizeable wealth gap between the lowest and highest classes of digital images. This wealth gap is often disguised or hidden from view, as both super rich and very poor images are automatically processed by contemporary software to be more palatable. Unlike in the early days of the internet and personal computing, the software that mediates what is posted online today automates the downsampling process for very high-resolution images so that one almost never has to think about it or experience slow image loading while browsing online. In other words, when a photograph is uploaded to most popular social media platforms or content management systems, it will be automatically scaled to an optimal size for web-viewing. Additionally, most desktop software for viewing digital photographs now has automatic anti-aliasing, which smooths the jagged edges in lower resolution or pixelated images. This means that one rarely encounters disparities of resolution or the visible pixel. Exposed pixels were a hallmark of the millennial period, as digital photography and the internet grew up together, but they are less common in today’s digital landscape — at least for human viewers.
This is not the case for machine ‘viewers’, however. Machine learning techniques, commonly referred to as artificial intelligence (AI), are increasingly used to automate categorization and identification tasks for large digital image datasets. For rasterized images, such as JPEGs, GIFs, and PNGs, the analysis happens on the level of individual pixels.Footnote5 In these applications, low-resolution images are the norm. Given that a digital photograph is constituted programmatically, its resolution and the processing power that instantiates and handles it are relative to one another. Heavy, big images are ‘rich’ in detail but move slowly. Light, small images are fast but of ‘poor’ quality. However, there is no absolute measure of what high and low resolution are or what constitutes fast processing. Behind the scenes, a calculation between processing power and image size determines how digital images are perceived and analyzed.
Terms like detail and resolution can be difficult to define in relation to digital images and digital photography, as they tend to signal judgement of quality. For John Szarkowski, ‘the detail’ signals the truth content of photography and thus, he argues, creates the conditions for its narrative incoherence.Footnote6 Although ‘detail’ may imply meaningful information, it is simply defined as a piece or a component part of the whole, stemming from the French détailler (to cut apart).Footnote7 This means that individual details are not necessarily unique or materially different from one another in a given image. If we accept that a pixel can be defined as a detail, fewer pixels mean fewer details in a digital photograph. Resolution, on the other hand, is the effect of rendering component parts or details into a distinguishable whole.Footnote8 High resolution thus means that more details are distinguishable or resolved. One might speak of suitably high resolution for human perception, but this does not translate to suitable resolution for automated machine analysis.
Object recognition
The vast majority of machine learning applications for photographic image datasets have been concerned not with the photograph as a whole, as an object or picture with aesthetic qualities, but rather what information it contains or indexes. In other words, most computational processing is concerned with who or what is depicted in the photograph — object recognition.Footnote9 The camera becomes, in a manner of speaking, the machinic eye of the computational system and the images it produces are what filmmaker Harun Farocki calls ‘operative images,’ which allow the computer to ‘see’ and understand the world in its own particular way.Footnote10 Although the photographs in large-scale training datasets like ImageNetFootnote11 and Google’s Open Images DatasetFootnote12 were initially intended for human viewers (scraped from photo-sharing websites like Flickr), their compilation for the purposes of machine learning have rendered them operative.
Indeed, all digital images have the potential to be operative, given their constitution in quantifiable parameters. However, in addition to these native attributes, training datasets often provide segmentation information, which means objects depicted within a given image are identified and labeled. This data is then used to train the system to identify objects in any new images encountered. Foundational labels such as these, which bridge the so-called ‘semantic gap’, need to be created manually through crowdsourcing.Footnote13 AI researchers today have access to vast pools of human labor through online platforms, whether they are volunteers on wikis/institutional platforms or low-paid workers on taskwork sites like Amazon’s Mechanical Turk. One of the early quandaries for computer scientists compiling datasets was how to reconcile the need for large datasets with the massive amount of labor it would take to hand-label them.Footnote14 While crowdsourcing has helped solve this issue for researchers, the ethics of such practices are questionable.Footnote15
Used for the purposes of object recognition, a photograph becomes merely a collection of component parts to be compared and classed by similarity with those in other photographs. This is not unlike the systematic method of analyzing artworks developed by Giovanni Morelli in the mid-nineteenth century, where the style in which ears or hands were depicted by particular artists is taken as telltale signs of authorship and authenticity [.Footnote16 In a similar vein, one can browse the Google Open Images Dataset with the class ‘human ear’ identified within the photographs [ and see a variety of ears highlighted in isolation from the rest of the body or face. Both Morelli’s drawings and the Open Images Dataset separate the ear from the individual. Ears become generalized objects divorced from their context as not only part of the human body but part of a particular person’s body. This fragmented manner of reading an image produces a very narrow understanding of what an image is.
Fig. 1. Illustration for Italian Painters (1892) by Giovanni Morelli. Source: Wikimedia Commons, public domain.
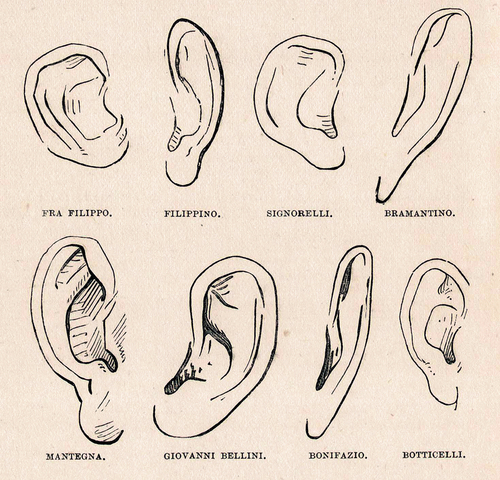
Fig. 2. Screen capture of Google Open Images Dataset (https://storage.googleapis.com/openimages/web/visualizer/index.html). Source: Google.

Human and machine can only really communicate with one another via these fragmented operations, however. By breaking the photograph into labeled objects, the machine is able to create a translation between the information constituted as the image and how a human might see the image. Machine learning systems can only determine patterns in pixels, they do not know what, for example, a dog is without a human-given label. This is why training is necessary. The more patterns of dogs labeled in the training data, the more likely it is the computer can begin labeling new images on its own and recognize the variety of patterns a human might identify as a dog. Once again, though, the machine’s capacity is seemingly limited by the collective human labelers’ ability to recognize a particular object in an image. This tangled web of object, representation, and understanding is reminiscent of René Magritte’s famous semiotic puzzle in La Trahison des Images (1929), where images, words, and the things they represent are flattened in our comprehension. For a machine looking at an image, the collection of pixels is ‘dog’, but it has no comprehension of the concept of a dog beyond that, given the limited scope of its operations.
Object recognition exercises in machine learning also highlight the importance of what James Elkins calls ‘the surround’ in photography. Elkins uses this term to differentiate between background, which he associates with painting and describes as intentional, and the incidental nature of what is depicted in a photograph besides the intended subject.Footnote17 A human might differentiate between a photograph of a dog and a photograph that merely has a dog in it. Training data makes no such distinctions. For example, when browsing the Google Open Images Dataset category of dog, I hit upon a photograph that struck me as peculiar. In the photo [, four people are pictured holding up signs protesting the Iraq War. The man on the far right is accompanied by a dog, sitting in the grass beside him. Given that the dataset identifies the dog in the photo, it is segmented and called up within that category [, even though the presence of the dog is incidental. By labeling every recognizable object or element in a photograph, machine learning training sets understand the photograph in what might be termed a highly democratized way. It is flattened into a collection of objects to label, rather than a cohesive whole or a composition with relational meaning. Google Open Images Dataset does provide some relational data for the objects in any given photograph but, at present, it is nothing more complicated than ‘woman playing guitar’ or ‘table is wooden’.Footnote18 Highly subjective determinations, such as my assertion that the dog in the protest photo is not very important to the scene as a whole, would be difficult for a dataset to codify other than through taking a survey of people’s opinions.
Fig. 3. Photograph of protestors at “Atlanta Veto Rally” on May 2, 2007. Photo: Mike Schinkel via Flickr, CC by 2.0.

Fig. 4. Screen capture of Google Open Images Dataset (https://storage.googleapis.com/openimages/web/visualizer/index.html). Source: Google.

Although it may seem self-evident to a human viewer, the undifferentiated nature of machine vision at the pixel level means that machine learning may not grasp the concept of foreground and background (or subject and surround). There is a popular urban legend in AI circles, known as the tank classifier problem, that illustrates this point.Footnote19 As the story goes, US government researchers training a neural network to categorize different types of US and Soviet tanks found that they had accidentally categorized all the tanks pictured on cloudy days together and all those on sunny days in a different category. It turned out that the neural net was classifying based on background weather conditions rather than the tanks themselves. While this story may be apocryphal, there are plenty of documented cases where neural nets have classified images by incidental details or even by the photographic or imaging equipment rather than the image itself. For example, researchers reviewing recent AI applications on medical imaging designed to detect COVID-19 cases were using healthy lung scans of children to train their AI and therefore ended up categorizing by children versus adults rather than cases of COVID-19.Footnote20 Another study, meanwhile, found that the labels and background detail (produced by the imaging equipment) in the image of lung scans could skew COVID-19 detection.Footnote21 This highlights how, apart from confusions between image background and foreground, as a human might define it, there are issues of classification by production methods that a human may not be aware of. For example, a classifier may find more commonalities at the pixel level between pictures taken with the same camera in the same format than those with the same or similar objects taken on different devices.Footnote22
Machine vision is thus highly indiscriminate. Given both the composition and the context implied by the Iraq War protesters and their signs in , a human may barely note the presence of a dog. The computer, on the other hand, will treat all objects the same if it is asked to complete an object recognition task. It will merely recognize each and every collection of pixels in the photograph that it has been trained to ‘see’ as objects. It does not make any differentiation whether some are more important than others — unless it has been guided to do so by humans in the process of training.
The fact that photography, a seemingly dispassionate mechanical procedure, captured both relevant and incidental details of a particular object of observation raised questions regarding its utility for scientific illustration in the nineteenth century.Footnote23 Clarifying drawings or diagrams were sometimes needed to make sense of early scientific photography, which might also be clouded by artifacts from the technical process.Footnote24 The understanding of photographs as both too indiscriminate and too specific was thus a facet of debates in the sciences around the adoption of photography.Footnote25 Scientific drawing traditionally depicts a generalized exemplar of the subject matter at hand, distilled from its most common characteristics. For example, a drawing of a flower of a particular species of plant would need to be generalized to reflect the entire species rather than one particular plant. Given this, photographs were deemed less useful at first since they only showed one plant in highly specific detail, not a generalized prototypical plant.Footnote26 According to Lorraine Daston and Peter Galison, ‘Failure to discriminate between essential and accurate detail’ would have been taken ‘as signs of incompetence’ for atlas makers in the eighteenth century, whereas the indiscriminate quality of photography later became a sought-after ideal.Footnote27
It could be said that, like the atlas makers, machine learning algorithms create generalized models for object identification. When there is not enough training data, a model may be in danger of overfitting, meaning that not enough generalizations are made between different individuals of a similar type and, so, each individual is isolated in a category of its own. For example, if the system does not have enough dog training data, a Saint Bernard and a Chihuahua may be classed as separate objects rather than two dogs. In order to provide ‘accurate’ generalizations, photographs must be broken up or fragmented into component objects and these objects must be simple enough to avoid overfitting. In other words, the detail that might satisfy a human viewer may be nothing other than distracting noise for the machine. Too much detail might make each image too different from one another and therefore not sufficiently generalizable. For this reason, downsampled images often perform better in classification tasks than highly detailed images.
Information and connoisseurship
A photograph from 1955 shows art historian Bernard Berenson holding up a magnifying glass with his face pressed close to a painting in the Borghese Gallery in Rome [. The methods of analysis that look to stylistic details of artworks to ascertain their authenticity or attribution are now known in the field of art history as connoisseurship, named for those early amateurs of art who sought to understand artworks through close inspection and comparison. The aforementioned techniques of Giovanni Morelli were some of the most influential methods of connoisseurship, widely used by art historians in the nineteenth and early twentieth century. Although direct viewing of the works was, of course, important for Berenson, he also relied heavily on photographic reproductions to conduct his research [ and maintained an extensive photographic archive.Footnote28
Fig. 5. Bernard Berenson looking at a painting with a magnifying glass at the Borghese Gallery, Rome, Italy, 1955. Photo: David Seymour/Magnum Photos.

Fig. 6. Bernard Berenson (1865–1959), 1957. Photo: David Lees Photography Archive/Bridgeman Images.

Berenson’s methods of art analysis are not dissimilar from the way machine learning systems analyze the details of a digital photograph, attending to one small area at a time. A scholar like Berenson would have trained his brain, through viewing as many artworks as possible, to recognize certain patterns and characteristics as belonging to a certain artist or school. When he approached a new artwork or — more likely — a photographic reproduction of an artwork, he would be able to recall this training and make a judgement regarding authenticity or attribution based on his previous experience. Likewise, deep learning systems must be trained to understand the patterns that identify a particular artwork as attributable to a certain artist or school before they can then identify a new photographic reproduction of an artwork as belonging to a known category. Despite these similarities, however, there are key differences between connoisseurship, exemplified by Berenson’s close viewing, and the way machine vision operates.
Deep learning systems trained on digital images ‘see’ the image as the measurable characteristics of its pixels. From within this pixel information, ‘features’ are extracted, for example, color, luminance, gradients, edges, textures, etc. What makes deep learning deep is the relative number of layers in the system, some of which extract low-level features (for example, edges of an object) that then contribute to the extraction of higher-level features (for example, different looking objects that are all called ‘apple’). In other words, deep learning produces more sophisticated analysis of images automatically, as higher-level features are learned based on lower-level features. This saves the computer programmer time trialing different ‘hand-crafted’ feature extraction methods to suit the task at hand.
Additionally, machine learning analyzes the characteristics of the digital image first, not the qualities of the artwork. In other words, unlike Berenson, the machine does not know that the image is a photographic reproduction of, for example, a painted altarpiece and it cannot extrapolate the material qualities of the object from the photograph. It only knows that it is a digital image. This is an important distinction to make, as deep learning systems are often trained on and operate using low resolution images, so the distance of the representation from the object it represents is exaggerated. The readily visible surface and design characteristics of a painting or drawing are preserved but other aspects of its materiality are largely lost. Higher resolution images can only be analyzed piecemeal as small samplings of the larger image composition, whereas lower resolution images capture more of the overall pattern. To illustrate this, shows a 10 × 10 pixel segment of an image — a common convolutional layer size — extracted from an image of the same artwork (a portrait of King Henry VIII of England) scaled to 16 × 16 pixels and 224 × 224 pixels. As evident, the former sample includes much more of the general compositional form of the image, while the latter only shows a detail of Henry VIII’s mustache.
Fig. 7. A 10 x 10 pixel segment from a 16 x 16 pixel image, a 10 x 10 pixel segment from a 224 x 224 pixel image, Portrait of Henry VIII (16th century) by the circle of Hans Holbein the Younger. Images: author, Photo: Wikimedia Commons, public domain.

This is a simplified example, of course, since the feature detection (and eventual object recognition) tasks performed by a deep CNN depend on the size of the receptive field, which is the area within that input image that help define or produce a particular feature.Footnote29 A feature is a characteristic of the image that is automatically determined by the neural network based on a certain area of the image, so it would be helpful to know exactly how much of the image the neural net is looking at. According to Araujo et. al., the larger the receptive field, the more accurate the classification task: ‘large receptive fields are necessary for high-level recognition tasks, but with diminishing rewards.’Footnote30 This means that an expanded receptive field, which effectively includes all the input pixels in the output feature map, may not have that much or, indeed, any advantage over a smaller one.
In essence, most image-based applications of deep learning will have a sweet spot for ideal resolution which is not equivalent to the highest resolution possible. More pixels after this point do not produce better results. Sabbottke et. al., in investigating the best performing resolution for radiography, explain:
Achieving better model performance with lower input image resolutions might initially seem paradoxical, but, in various machine learning paradigms, a reduced number of inputs or features is desirable as a means of lowering the number of parameters that must be optimized, which in turn diminishes the risk of model overfitting.Footnote31
As their study shows, for the disease diagnostic applications they investigate, performance plateaus at around 224 × 224 pixel images. Of course, resolution and receptive field are not the only factors in determining deep learning performance, but it is important to note that there is a perceptual ceiling above which more information, i.e. more detail, just becomes noise.
In the late 1940s, Claude E. Shannon published his groundbreaking mathematical theory of communication, wherein he theorized the quantification of information using a unit of measurement called the bit.Footnote32 Among many other important aspects of Shannon’s work, it demonstrates the gap between information and meaning. In a noteworthy passage of his article, Shannon describes how one can generate English language text based on the relationship between letters and their frequency to one another at higher orders (using so-called n-grams). Although the text that he produced consisted of English words, it was complete nonsense to read. That is, the text produced was just a collection of words, not a sequence with meaning.Footnote33 Warren E. Weaver surmised in relation to Shannon’s theory, ‘One has the vague feeling that information and meaning may prove to be something like a pair of canonically conjugate variables in quantum theory, they being subject to some joint restriction that condemns a person to the sacrifice of the one as he insists on having much of the other.’Footnote34 In the communication systems Shannon described, noise is also a quantity of information and, so, in order for something to be meaningful, it may actually require less information, i.e. less noise.Footnote35 The more noise, the more information, and therefore the more difficulty in understanding the meaning of the message.
Given that, as noted, the vast majority of machine learning application on images were developed for recognizing objects in photographs, it makes sense that lower resolution images would function just as well if not better than more detailed higher resolution images. The simplified forms of lower resolution images may show all the information necessary to identify, for example, an apple or a dog. As applications of deep learning on images move away from classic object recognition tasks in standard photographic images, however, the optimal resolution remains an open question.
Learnings from object recognition tasks are regularly applied to a variety of contexts. This is known as ‘transfer learning’. In the case of medical imaging, for instance, smaller details may be necessary for diagnosing illness but are often left out.Footnote36 As stated in the above-cited review of COVID-19 research, ‘Many publications used the same resolutions such as 224-by-224 or 256-by-256 for training, which are often used for ImageNet classification, indicating that the pre-trained model dictated the image rescaling used rather than clinical judgement.’Footnote37 Transfer learning is similarly influenced by pre-trained models when applied to photographic reproductions of artworks.
Art authentication using deep learning not only presents an issue in terms of the difference in image content/image type but also in terms of task. Although reproduced as digital photographs, images of artworks have a general appearance that is not indexical in relation to the motif or contents of the work itself.Footnote38 In the absence of material analysis, given the digital nature of the images, authenticity of artworks via deep learning can only be determined by its formal properties. A machine must therefore be taught how to detect style. Object recognition in the traditional sense does not aid in authenticating artworks, but certain details of a work of art — and their recognition — may tip off an automated system as to whether the work is genuine, just as the details of an ear were the telltale sign of authorship for Morelli.
Model of authenticity
AI has been hyped as a game-changing new tool in the art authenticator’s toolbox.Footnote39 In light of this, a notion of authenticity is beginning to emerge that raises questions around Walter Benjamin’s often-cited definition of authenticity in relation to mass image culture. For Benjamin, the authenticity of a work of art is tied to the ‘here and now of the original’ whereas the films and photographs (including reproductions of artworks) circulating in his time were cut loose from this spaciotemporal mooring.Footnote40 Following from Steyerl’s concept of the poor image, however, one could say that the low-resolution digital images used for deep learning today are divorced from the here and now to, perhaps, an even greater extent than the reproductions of Benjamin’s time. Nevertheless, these copies or reproductions are now forming the basis for a new model of authenticity, which exists latently in the formal properties of a digital image. Authenticity, therefore, is divined from the pool of data and emerges from masses of images rather than from the aura of a singular original.
Authenticity in the age of deep learning must be quantitatively verified rather than qualitatively felt. Benjamin argued that authenticity ‘eludes technological — and of course not only technological — reproduction.’Footnote41 Deep learning raises the specter of authenticity as manifested in not only reproductions but poor reproductions. While the statistical turn of modernity did not go unnoted by Benjamin, he could not have foreseen the emergence of another notion of the divine and another kind of aura emerging from masses of reproductions.Footnote42 There is a growing sense that the algorithmic processes that digest our digital data trails can predict our wants and needs before we have even thought of them ourselves. Somehow ‘the algorithms’ seem to divine a reality, an authenticity that is deeper than our conscious thoughts, almost as if they reveal an underlying truth beyond perception. Benjamin coined the term ‘optical unconscious’ to describe a mechanical process (photography) that reveals something outside of the ‘normal spectrum of sense impressions.’Footnote43 Although he did not extensively develop this term, other scholars have subsequently expanded on his proposition that photography helps reveal the imperceptible.Footnote44 Just as Benjamin spoke of an optical unconscious, there seems to be a growing belief in an algorithmic unconscious manifest in contemporary machine learning applications.Footnote45 For Benjamin, the loss of art’s aura and authenticity was a positive development — it could be freed from its ‘parasitic subservience to ritual.’Footnote46 The rise of computational methods in the study of art, however, introduces a new concept of aura in the form of machine divination.
How deep learning comes to the conclusions it does is often not known, i.e. it is a black box. Typically, one can only determine the ‘accuracy’ of the results not the how or why those conclusions were reached. Given the methods of data analysis at our disposal and the mass digitization projects that have thus far been completed, the alignment of ‘reality’ or ‘truth’ with the masses has been augmented to such an extent that it disappears. We feel that we need to sift the data to rediscover the reality embedded in it and, for that, we depend on automated sorting processes. Deep learning models for analysis of art and its authenticity proceed as if artworks are like flowers of the same species, both of which have a generalized form. In other words, to be authentic is to be average. The unique original is effectively invisible. Of course, neither a generalized flower nor a generalized artwork exists. Indeed, generalizations as applied to human beings have had consequences ranging from cruel to catastrophically evil.Footnote47 Nevertheless, aura may be lost in a single reproduction but a new aura — a new concept of authenticity — is in the masses. The here and now is thus latent in these countless poor images, which otherwise seem so distant from their origins.
Further complicating matters, the rasterization of digital images has created an inbuilt fragmentation of whatever is reproduced or represented photographically. This fragmentation is often noted as an essential quality of digital media, which sets it apart from the supposed continuity of analog media.Footnote48 However, within the black box of the artificial neural network, there is additional unseen fragmentation as pieces of the image are attached to neurons and ‘carried’ through the processing layers. As is the case in the above example, it would be useful to know exactly what the system is basing its categorization on. Feature visualizations are one tool that has been develop to try to understand this.Footnote49 What feature visualizations often reveal is that the image in deep learning is never understood as a whole, even if it seems to enter the system that way. Images fragments are grabbed and scrambled in a way that makes sense to the system in delivering its output, and these rarely reflect how humans understand the same image. Categorization, though it may address the whole, never therefore truly comprehends or synthesizes the entirety of an image but rather treats granular, incidental, and fragmented elements.
Conclusion
By treating images as operative, deep learning applications expose the digital image for what it is: functional, quantitative information. Digital images are not continuous wholes or self-contained objects, as humans are wont to perceive them, but rather fragmented data that is continually reconstituted. As human viewers crave ever-higher resolution for digital images and screens, it is worth reflecting on how additional resolution or detail may just be noise to the growing number of machine ‘viewers’ dealing with these images. Benjamin’s optimism regarding the political potential of reproductive media, particularly film, which banishes aura and ritual to the past, is echoed in Steyerl’s conception of the poor image as politically radical. Just as Benjamin’s reproductions are freed from ritual function, Steyerl’s poor images are freed from their status as mere copies: ‘The poor image is no longer about the real thing — the original original. Instead it is about its own real conditions of existence […] In short: it is about reality.’Footnote50 Reduced to mere reproduction, seen as a shadow of something like an artwork, the poor image is by definition a poor replacement, a substandard stand-in. However, digital images — chief among them photographic images — are rapidly being turned over to a purely operative role. Machines are taking over image interpretation due to the sheer volume we seek to order and understand. Understood as machinic divination, AI places aura within the mass of data and the poor image thus becomes the information or the quantification of the world that the original lacks.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Amanda Wasielewski
Amanda Wasielewski is Associate Senior Lecturer of Digital Humanities and Associate Professor (Docent) of Art History at Uppsala University. Her writing and research investigate the use of digital technology in relation to art/visual culture and spatial practice. Her recent focus has been on the use of artificial intelligence techniques for the analysis and creation of art and other visual media. She is in the Metadata Culture research group at Stockholm University as part of the project “Sharing the Visual Heritage: Metadata, Reuse, and Interdisciplinary Research.” Wasielewski is the author of three monographs: Made in Brooklyn: Artists, Hipsters, Makers, Gentrifiers (Zero, 2018), From City Space to Cyberspace: Art, Squatting, and Internet Culture in the Netherlands (Amsterdam University Press, 2021), and Computational Formalism: Art History and Machine Learning (MIT Press, 2023).
Notes
1. Frizot, “1839–1840 Photographic Developments,” 27–28; Trachtenberg, Classic Essays on Photography, 27–28.
2. A digital photograph of any resolution is, of course, pixelated, i.e. composed of individual picture elements (pixels). However, the term ‘pixelated’ is now synonymous with visible pixels.
3. Steyerl, “In Defense of the Poor Image,” 1.
4. Cobb, The Idea of the Brain; Lindsay, Models of the Mind. It should be noted that the distinctions drawn between human and machine vision here are not meant to signal an absolute binary division between man and machine more generally. The human and nonhuman are, of course, deeply intertwined. See Grusin, The Nonhuman Turn.
5. Palmer, “The Rhetoric of the JPEG.”
6. Szarkowski, The Photographer’s Eye, 8–9.
7. “Detail, v.1.”
8. “Resolution, n.1.”
9. For a longer discussion of object recognition tasks in relation to artworks, including a discussion of facial recognition tasks, see Wasielewski, Computational Formalism: Art History and Machine Learning.
10. Farocki, “Phantom Images”; Ehmann and Eshun, “A to Z of HF or: 26 Introductions to HF,” 211.
11. “ImageNet.”
12. “Open Images V6.”
13. Howe, “The Rise of Crowdsourcing.”
14. Colombo, Del Bimbo, and Pala, “Semantics in Visual Information Retrieval,” 38.
15. Terranova, “Free Labor”; Crawford and Paglen, “Excavating AI.”
16. Morelli, Italian Painters. For commentary on Morellian methods from the point of view of digital humanities methods, see Langmead et al., “Leonardo, Morelli, and the Computational Mirror.”
17. Elkins, What Photography Is, 116–17.
18. “Open Images V6 - Description.”
19. Branwen, “The Neural Net Tank Urban Legend.”
20. Roberts et al., “Common Pitfalls and Recommendations,” 211.
21. Maguolo and Nanni, “A Critic Evaluation of Methods for COVID-19.”
22. Noord, Hendriks, and Postma, “Toward Discovery of the Artist’s Style,” 53.
23. Daston and Galison, Objectivity, 109.
24. Tucker, Nature Exposed, 233.
25. This is not to mention the conflicting opinions over whether early photography was more art or science, given on one hand the lack of color and ability to capture movement and, on the other, the detail captured. See Batchen, Burning with Desire: The Conception of Photography, 137–38.
26. Daston and Galison, Objectivity, 109.
27. Daston and Galison, 186.
28. Israëls, “The Berensons, Photography, and the Discovery of Sassetta’; Pagliarulo, ‘Photographs to Read: Berensonian Annotations.”
29. Araujo, Norris, and Sim, “Computing Receptive Fields of Convolutional Neural Networks.”
30. Ibid.
31. Sabottke and Spieler, “The Effect of Image Resolution on Deep Learning in Radiography,’ 1.
32. Shannon, “The Mathematical Theory of Communication,” 32.
33. Ibid., 43–44.
34. Weaver, “Recent Contributions to the Mathematical Theory of Communication,” 27.
35. Ibid., 19.
36. Geras et al., “High-Resolution Breast Cancer Screening,” 2.
37. Roberts et al., “Common Pitfalls,” 210.
38. For a discussion of how digital images problematize the indexicality of photography, see Rubenstein and Sluis, “The Digital Image in Photographic Culture.”
39. Batycka, “We Were Blown Away.”
40. Benjamin, “The Work of Art in the Age of Its Technological Reproducibility,” 21.
41. Ibid., 21.
42. Ibid., 24.
43. Benjamin, “The Work of Art in the Age of Its Technological Reproducibility” and “Little History of Photography,” 37–28, 278.
44. Krauss, The Optical Unconscious; Smith and Sliwinski, eds., Photography and the Optical Unconscious.
45. For a psychoanalytical perspective on this idea, see Possati, “Algorithmic Unconscious: Why Psychoanalysis Helps in Understanding AI.” This naturally raises questions around what, then, is algorithmic consciousness. One must exercise caution in this realm, however. As Emily M. Bender argues, machine learning language systems are designed to ‘abuse our empathy’ and lead us to believe they are conscious or sentient.
46. Ibid., 24.
47. Tagg and Sekula famously explored the relationship between photography and (state) power, particularly as an aid to the racist and eugenics classification of human beings.
48. Lunenfeld, “Introduction: Screen Grabs,” xv.
49. Zhang and Zhu, “Visual Interpretability for Deep Learning”; Offert, “Images of Image Machines”; Gonthier, Gousseau, and Ladjal, “An Analysis of the Transfer Learning of Convolutional Neural Networks for Artistic Images.”
50. Steyerl, “In Defense of the Poor Image,” 8.
Bibliography
- Albadarneh, Israa Abdullah, and Ashraf Ahmad. “Machine Learning Based Oil Painting Authentication and Features Extraction.” International Journal of Computer Science and Network Security 17, no. 1 (January 30, 2017): 8–17.
- Araujo, André, Wade Norris, and Jack Sim. “Computing Receptive Fields of Convolutional Neural Networks.” Distill 4, no. 11, (November 4, 2019): e21. doi:10.23915/distill.00021.
- Batchen, Geoffrey. Burning with Desire: The Conception of Photography. Cambridge, MA: The MIT Press, 1999.
- Batycka, Dorian. “‘We Were Blown Away’: How New A.I. Research is Changing the Way Conservators and Collectors Think About Attribution.” Artnet News. Accessed January 10, 2022. https://news.artnet.com/art-world/ai-research-changing-attributions-2057023
- Bender, Emily M. “Human-Like Programs Abuse Our Empathy – Even Google Engineers Aren’t Immune.” The Guardian, Accessed June 14, 2022, sec. Opinion. https://www.theguardian.com/commentisfree/2022/jun/14/human-like-programs-abuse-our-empathy-even-google-engineers-arent-immune
- Benjamin, Walter. “Little History of Photography.” In The Work of Art in the Age of Its Technological Reproducibility, and Other Writings on Media, edited by Michael William Jennings, Brigid Doherty, and Thomas Y. Levin, translated by Edmund Jephcott, Rodney Livingstone, and Howard Eiland, 274–298. Cambridge, MA: Belknap Press of Harvard University Press, 2008.
- Benjamin, Walter. “The Work of Art in the Age of Its Technological Reproducibility.” In The Work of Art in the Age of Its Technological Reproducibility, and Other Writings on Media, edited by Michael William Jennings, Brigid Doherty, and Thomas Y. Levin, translated by Edmund Jephcott, Rodney Livingstone, and Howard Eiland, 19–55. Cambridge, MA: Belknap Press of Harvard University Press, 2008.
- Berezhnoy, Igor E., Eric O. Postma, and H. J. van den Herik. “Computerized Visual Analysis of Paintings.” International Conference Association for History and Computing 16, (2005): 28–32.
- Branwen, Gwern. “The Neural Net Tank Urban Legend,” September 20, 2011. https://www.gwern.net/Tanks.
- Cobb, Matthew. The Idea of the Brain: The Past and Future of Neuroscience. New York: Basic Books, 2020.
- Colombo, C., A. Del Bimbo, and P. Pala. “Semantics in Visual Information Retrieval.” IEEE MultiMedia 6, no. 3, (July, 1999): 38–53. doi:10.1109/93.790610.
- Crawford, Kate, and Trevor Paglen. “Excavating AI: The Politics of Images in Machine Learning Training Sets.” 2019. https://www.excavating.ai/
- Daston, Lorraine, and Peter Galison. Objectivity. New York: Zone Books, 2007.
- “Detail, V.1.” OED Online, Oxford University Press. Accessed April 22, 2022. http://www.oed.com/view/Entry/51169#eid7045768
- Dobbs, Todd, Aileen Benedict, and Zbigniew Ras. “Jumping into the Artistic Deep End: Building the Catalogue Raisonné.” AI & SOCIETY (January 9, 2022). doi:10.1007/s00146-021-01370-2.
- Ehmann, Antje, and Kodwo Eshun. “A to Z of HF Or: 26 Introductions to HF.” In Harun Farocki: Against What? Against Whom? edited by Antje Ehmann and Kodwo Eshun, 294–317. London: Koenig Books, 2009.
- Elgammal, Ahmed, Yan Kang, and Milko Den Leeuw. “Picasso, Matisse, or a Fake? Automated Analysis of Drawings at the Stroke Level for Attribution and Authentication.” Proceedings of the AAAI Conference on Artificial Intelligence 32, no. 1 (April 25, 2018). https://ojs.aaai.org/index.php/AAAI/article/view/11313
- Elkins, James. What Photography Is. New York: Routledge, 2011.
- Farocki, Harun. “Phantom Images.” Translated by Brian Poole. Public, Accessed January 1, 2004. https://public.journals.yorku.ca/index.php/public/article/view/30354
- Frizot, Michel. “1839-1840 Photographic Developments.” In A New History of Photography, edited by Michel Frizot, 23–31. Cologne: Könemann, 1998.
- Geras, Krzysztof J., Stacey Wolfson, Yiqiu Shen, S. Gene Kim Nan Wu, Eric Kim, Laura Heacock, Ujas Parikh, Linda Moy, and Kyunghyun Cho. “High-Resolution Breast Cancer Screening with Multi-View Deep Convolutional Neural Networks.” ArXiv:1703.07047 [Cs, Stat], Accessed June 27, 2018. http://arxiv.org/abs/1703.07047
- Gonthier, Nicolas, Yann Gousseau, and Saïd Ladjal. “An Analysis of the Transfer Learning of Convolutional Neural Networks for Artistic Images.” ArXiv:2011.02727 [Cs], Accessed November 24, 2020. http://arxiv.org/abs/2011.02727
- Grusin, Richard, edited by. The Nonhuman Turn. Minneapolis: University of Minnesota Press, 2015.
- Howe, Jeff. “The Rise of Crowdsourcing.” Wired. Accessed June 14, 2006. https://www.wired.com/2006/06/crowds/
- “ImageNet.” Accessed March 23, 2022. https://image-net.org/
- Israëls, Machtelt. “The Berensons, Photography, and the Discovery of Sassetta.” In Photo Archives and the Photographic Memory of Art History, edited by Constanza Caraffa, 157–168. Munich: Deutscher Kunstverlag, 2011.
- Krauss, Rosalind E. The Optical Unconscious. Cambridge, MA: MIT Press, 1993.
- Langmead, Alison, Christopher J. Nygren, Paul Rodriguez, and Alan Craig. “Leonardo, Morelli, and the Computational Mirror.“ Digital Humanities Quarterly 15, no. 1 (March 5, 2021). http://www.digitalhumanities.org/dhq/vol/15/1/000540/000540.html
- Lindsay, Grace. Models of the Mind: How Physics, Engineering and Mathematics Have Shaped Our Understanding of the Brain. London: Bloomsbury Sigma, 2021.
- Lunenfeld, Peter. “Introduction: Screen Grabs: The Digital Dialectic and New Media Theory.” In The Digital Dialectic: New Essays on New Media, edited by Peter Lunenfeld, xiv–xxi. Cambridge, MA: MIT Press, 1999.
- Lyu, S., D. Rockmore, and H. Farid. “A Digital Technique for Art Authentication.” Proceedings of the National Academy of Sciences of the United States of America 101, no. 49, (December 7, 2004): 17006–17010. doi:10.1073/pnas.0406398101.
- Maguolo, Gianluca, and Loris Nanni. “A Critic Evaluation of Methods for COVID-19 Automatic Detection from X-Ray Images.” ArXiv:2004.12823 [Cs, Eess], Accessed September 19, 2020. http://arxiv.org/abs/2004.12823
- Morelli, Giovanni. Italian Painters: Critical Studies of Their Works, Translated by Constance Jocelyn Ffoulkes London: John Murray, 1907.
- Offert, Fabian. ”Images of Image Machines. Visual Interpretability in Computer Vision for Art.” In Computer Vision – ECCV 2018 Workshops. ECCV 2018, edited by Leal-Taixé Laura, Roth Stefan, vol. 11130. Cham: Springer, 2019.
- “Open Images V6.” Accessed March 23, 2022. https://storage.googleapis.com/openimages/web/index.html
- “Open Images V6 - Description.” Accessed March 25, 2022. https://storage.googleapis.com/openimages/web/factsfigures.html
- Pagliarulo, Giovanni. “Photographs to Read: Berensonian Annotations.” In Photo Archives and the Photographic Memory of Art History, edited by Constanza Caraffa, 181–191. London: Deutscher Kunstverlag, 2011.
- Palmer, Daniel. “The Rhetoric of the JPEG.” In The Photographic Image in Digital Culture, edited by Martin Lister, 149–164. London: Taylor & Francis, 2013.
- Polatkan, Güngör, Sina Jafarpour, Andrei Brasoveanu, Shannon Hughes, and Ingrid Daubechies. “Detection of Forgery in Paintings Using Supervised Learning.” In 2009 16th IEEE International Conference on Image Processing (ICIP), 2921–2924. Cairo, Egypt: IEEE, 2009.
- Possati, Luca M. “Algorithmic Unconscious: Why Psychoanalysis Helps in Understanding AI.” Palgrave Communications 6, no. 1, (April 24, 2020): 1–13. doi:10.1057/s41599-020-0445-0.
- Roberts, Michael, Derek Driggs, Matthew Thorpe, Julian Gilbey, Michael Yeung, Stephan Ursprung, Angelica I. Aviles-Rivero, et al. “Common Pitfalls and Recommendations for Using Machine Learning to Detect and Prognosticate for COVID-19 Using Chest Radiographs and CT Scans.” Nature Machine Intelligence 3, no. 3 (March, 2021): 199–217. doi:10.1038/s42256-021-00307-0.
- Rubenstein, Daniel, and Katrina Sluis. “The Digital Image in Photographic Culture: Algorithmic Photography and the Crisis of Representation.” In The Photographic Image in Digital Culture, edited by Martin Lister, 22–40. London: Taylor & Francis, 2013.
- Sabottke, Carl F., and Bradley M. Spieler. “The Effect of Image Resolution on Deep Learning in Radiography.” Radiology: Artificial Intelligence 2, no. 1 (January 1, 2020): e190015. doi:10.1148/ryai.2019190015.
- Sekula, Allan. “The Body and the Archive.” 39 (October 1986): 3–64. doi:10.2307/778312.
- Shannon, Claude E. “The Mathematical Theory of Communication.” In The Mathematical Theory of Communication, edited by Claude E. Shannon and Warren Weaver, 29–125. Urbana: The University of Illinois Press, 1964.
- Smith, Shawn Michelle, and Sharon Sliwinski, edited by. Photography and the Optical Unconscious. Durham, NC: Duke University Press, 2017.
- Steyerl, Hito. “In Defense of the Poor Image.” E-Flux Journal, no. 10 (November 2009). https://www.e-flux.com/journal/10/61362/in-defense-of-the-poor-image/
- Szarkowski, John. The Photographer’s Eye. New York: Museum of Modern Art, 1966.
- Tagg, John. The Burden of Representation: Essays on Photographies and Histories. Minneapolis: University of Minnesota Press, 1993.
- Terranova, Tiziana. “Free Labor: Producing Culture for the Digital Economy.” Social Text 18, no. 2, (June 1 2000): 33–58. doi:10.1215/01642472-18-2_63-33.
- Trachtenberg, Alan. Classic Essays on Photography. New Haven: Leete’s Island Books, 1980.
- Tucker, Jennifer. Nature Exposed: Photography as Eyewitness in Victorian Science. Maryland: John Hopkins University Press, 2005.
- van Noord, Nanne, Ella Hendriks, and Eric Postma. “Toward Discovery of the Artist’s Style: Learning to Recognize Artists by Their Artworks.” IEEE Signal Processing Magazine 32, no. 4 (July 2015): 46–54. doi:10.1109/MSP.2015.2406955.
- Wasielewski, Amanda. Computational Formalism: Art History and Machine Learning. Cambridge, MA: MIT Press, 2023.
- Weaver, Warren. “Recent Contributions to the Mathematical Theory of Communication.” In The Mathematical Theory of Communication, edited by Claude E. Shannon and Warren Weaver, 1–28. Urbana: The University of Illinois Press, 1964.
- Yunfei, Fu, Yu Hongchuan, Chih-Kuo Yeh, Tong-Yee Lee, and Jian J. Zhang. “Fast Accurate and Automatic Brushstroke Extraction.” ACM Transactions on Multimedia Computing Communications and Applications 17, no. 2 (June 2021): 44. doi:10.1145/3429742.
- Zhang, Quan-shi, and Song-chun Zhu. “Visual Interpretability for Deep Learning: A Survey.” Frontiers of Information Technology & Electronic Engineering 19, no. 1 (January 1, 2018): 27–39. doi:10.1631/FITEE.1700808.