
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
In this paper, we have worked with some of the most popular models to fit the lactation curve. Lactation curves have received considerable attention in modelling dairy cattle milk production. These curves express the evolution over time of a cattle head’s milk yield. Observations of milk production over a cycle have usually been carried out periodically (i.e. daily, weekly or monthly). Optimal experiment design allows one to know the times when a herd’s milk production must be recorded. An experiment design is optimal when it achieves the best parameter estimates for the curve model. This work aims to study optimal designs for certain models such as quadratic polynomial, hyperbolic, exponentials and Wilmink models (WMs). Designs are observed to depend on models and must be compared to get to know if a design for a specific model has a good behaviour with another model. Design efficiency is the tool used for this comparison. Efficiency is a value between 0 and 1 – a design is good if its efficiency is close to 1. The WM designs perform well and are an improvement on those designs that are routinely used in daily observations.
Optimal experiment design allows one to know the times when a herd‘s milk production must be recorded.
The use of optimal design methodology greatly reduces the number of instances when dairy production has to be recorded.
Optimal designs reduce the costs of experimentation by allowing parameters to be estimated with fewer experimental runs.
Highlights
Introduction
A lactation curve represents the evolution over time of a herd’s milk production during a specific lactation cycle. This cycle is the period from lactation onset after calving until the cow’s milk dries up. Lactation curves generally reach their peak yield after calving and then decrease steadily from then until drying up (Figure ).
Figure 1. Standard shape of the lactation curve for dairy cattle. The plot shows the milk production as function of the weeks after the parturation.
Lactation curves allow the evaluation of important milk production characteristics such as maximum production and times to maximum production (Gipson and Grossman, Citation1990) or persistency (Gengler, Citation1996). These curves can help in herd management, particularly in assessing cattle heads’ nutritional and health status (Dudouet, Citation1982). These curves are also useful in predicting a cattle head’s total milk yield when only early lactation cycle observations are known.
Multiple statistical models have been used to describe lactation curves. Quintero et al. (Citation2007), Cankaya et al. (Citation2011), Macciotta et al. (Citation2011), Graesbøll et al. (Citation2016), Hossein-Zadeh (Citation2016) and Melzer et al. (Citation2017) reported on different lactation curve models, which are compared for dairy cattle. These papers show some models that can generally be expressed as where
stands for milk yield at week or day
of lactation, and time
is on a time interval
. Here
is a vector which contains the unknown model parameters to be estimated from data. Function
can be either linear or nonlinear on
. Some of the models used to fit lactation curve data are: linear (LM)
, quadratic (QM)
, hyperbolic (HM)
, inverse quadratic (IM)
, exponential (EM)
or exponential with constant term (EMC)
.
This paper is focussed on the Wilmink model (WM), which is one of the most popular models used for lactation curve description. It is expressed as where parameter
is associated with the level of production,
with the production decrease after peak yield,
with the production increase prior to peak yield, and
is a parameter associated with the time of peak yield. Cankaya et al. (Citation2011) characterised peak yield and the maximum production time. In Wilmink (Citation1987) and many subsequent papers, parameter
is fixed at
. Nevertheless, Torshizi et al. (Citation2011) used values of
,
, and
for
. The WM has three parameters when
is fixed. Olori et al. (Citation1999) concluded that the WM is the best three-parameter model for predicting mean herd yield. If
is an unknown parameter, the WM has four parameters,
being a nonlinear parameter and is called the Wilmink extended model (WEM).
Some papers dealing with lactation models researched the use of several models to estimate the data and compared them using the coefficient of determination. Different conclusions were drawn regarding the best model for lactation period modelling. Figure shows the plot of some of these functions.
Figure 2. Plot for some lactation models: QM (dashed line), HM (dotted line), IM (dot-dashed line) and WEM (solid line).
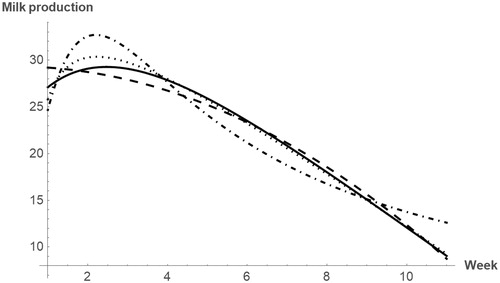
The WM is a modification of the Cobby–Le Du model (see Cobby and Le Du, Citation1978). This model includes particularity that post-peak milk yield is modelled as a linear decline function and combines exponential and linear models. Both models are related to a model proposed by Wood (Citation1967), which is expressed as . The Wood model is widely used for lactation curve descriptions in dairy cattle and lactation predictions in cows and goats. Nonetheless, the results from the Wood model are improved by the WM.
To estimate these models’ parameters, the researcher requires certain observations; namely, a sample of and
values. The optimal design of experiments methodology can be applied because it aims to find the best
values where variable
is to be observed (i.e. the days or weeks when milk production must be registered). In general, model estimation includes several steps in which the researcher can control the independent variable
. Firstly, given a theoretical model, one attempts to find ‘optimum’ values for the design variable,
, in the range of experimental interest,
. This search is carried out with respect to an optimality criterion which is chosen according to the final analysis goal – parameter estimation or hypothesis testing. Secondly, variable
is observed in the optimum
allocations given by the optimum design. Finally, the model is estimated using these observations.
Optimal designs have been applied to a wide range of fields such as biomedicine (Campos-Barreiro and López-Fidalgo, Citation2013), pharmacokinetics and pharmacodynamics (Kitsos and Kolovos, Citation2013), and agricultural studies (Martínez-López et al., Citation2009).
This paper researches optimal experimental designs for lactation curves. However, these designs depend on the particular model and the optimality criterion. Therefore, several lactation models are considered in the paper. With the objective of estimating the model parameters, a commonly adopted criterion is D-optimality, which obtains D-optimal designs. By using such designs, the best estimates for a model’s unknown coefficients (parameters) are achieved.
Material and methods
The statistical regression model is expressed as: where
is the response variable,
is the independent variable, and
is a vector of
unknown parameters that we have to estimate from the observations. The
term stands for the random errors with zero mean and constant variance.
Some definitions of optimal experimental design theory
An experimental design is a collection of
values where
is to be observed. The design is made-up of
different support points
,
,
,
, and their respective weights
,
,
,
(relative frequencies,
). A weight,
, is the proportion of the total observations taken at time
, and this can be considered as a probability measure (Kiefer, Citation1974). If we want
observations to estimate the model, then we round up the
values to know the number of observations at points
.
An optimal design, , includes the best points and weights with respect to an optimality criterion. Of the different criteria in the literature, we are going to consider the D-optimality criterion because it relates to the estimation quality of the model parameters.
The advantage of using optimal designs is that we control the times when the observations are taken, leading to the best possible parameter estimation. The accuracy of an estimator is measured by its variance, and this is part of a matrix known as the information matrix. This matrix is the main tool when looking for optimal designs.
When the function is differentiable with a continuous derivative for every parameter,
, with
as its gradient vector, the information matrix is defined by
The inverse of the information matrix is asymptotically proportional to the covariance matrix of the parameter estimators. For this reason, many optimality criteria are formulated in terms of this matrix; for example, the D-optimality criterion is related to the determinant of the information matrix. A D-optimal design maximises this determinant, which is equivalent to minimising that of the covariance matrix, so D-optimal designs minimise the volume of the confidence region of the regression parameter vector,
.
The General Equivalence Theorem is a useful tool to check whether a design is optimal. This theorem states that a design is D-optimal if and only if
for all values of
in
, with
being the number of model parameters. Furthermore, the maxima of
occur at the
support points. Function
is called the variance function.
For non-linear models, the variance function and the information matrix depend on unknown parameters. The simplest way to deal with this problem is by using a single prior guess for the unknown parameters, obtaining locally optimal designs. Such knowledge is often available from preliminary studies. Optimal designs will depend on this initial information.
Results
The results of this study are the optimal experimental designs for the Wilmink lactation curves. These designs contain the times when observations must to be recorded. The D-optimality criterion is used. The optimal designs are presented in several tables.
We will consider the general design space ,
, and two cases depending on parameter
. If
is a known value, we employ the usual WM, which has three parameters
. If
is an unknown parameter, we employ the WEM, which has four parameters
. Consequently, the optimal designs differ in each case.
Wilmink model
The D-optimal design, , for WM in the interval
, with
, is supported at exactly three points:
,
and
. The respective weights are
For the proof of the above results, we have taken into account the gradient vector and the results in Karlin and Studden (Citation1966). In this case the information matrix and the variance function do not depend on unknown parameters, so they can be denoted by
and
, respectively. Studying the maxima and minima of
, and applying the General Equivalence Theorem, we conclude that
,
and
is an interior point in
, which is the solution of
.
We can observe that interior support point tends to the midpoint of the interval
when
and
tends to
when
.
According to Wilmink (Citation1987), the lactation cycle length was days, making
. Consequently, the observations must to be recorded at days
,
and
. For
, considered in Wilmink (Citation1987), the optimal value of
is
. Nevertheless, in the Wilmink work milk production was observed on each of the 305 days; that is, a uniform design with
support points
was considered; this will be denoted by
.
We can compare designs and
through the determinant of the information matrix:
and
; the second determinant being greater than the first because it corresponds to the D-optimal design. Applying the D-optimality criterion, design
is better than design
because its determinant is greater as is the meaningful information. Therefore, the estimated parameters will be more precise if we use design
.
A measurement of a given design’s behaviour, , relative to the D-optimal design,
, is the D-efficiency, which is calculated as:
where
is the number of unknown parameters. This value is within
and
meaning that design
needs to double the total number of observations to perform as well as optimal design
. The D-efficiency of
is only 0.43, which is a very low value.
Torshizi et al. (Citation2011) considered other values for ; namely,
,
and
. For these values, the D-optimal designs in
are equally supported at three points – these are the ends of this interval and the points 46.9, 35.14, and 9.56, respectively.
Since D-optimal design depends on the value of , we need to analyse whether the D-optimal design for a given
value behaves well for another value. Table reports the D-efficiencies of the optimal design for
when it is used to estimate another model with a different value,
. For this, we considered the values of
in Torshizi et al. (Citation2011). For instance, the value
in Table implies that the D-optimal design for
behaves very well in estimating the WM with
. However, the D-optimal design for
does not behave well in estimating the model with
, because its D-efficiency is
. Table also includes the efficiencies of daily design
. We can see that the efficiencies for the various D-optimal designs are higher than for the daily design used in Wilmink (Citation1987).
TABLE 1. Efficiencies for WM D-optimal designs.
Wilmink extended model
Here, we consider that is another unknown parameter. The WEM is nonlinear with four parameters
. The information matrix depends on parameter
and is denoted by
. Locally D-optimal designs will be obtained because there is a need for prior information regarding
; for example, from previous experiments, this will be denoted by
.
The locally D-optimal design for WEM in
,
, and
is equally supported at exactly four points. Two of the support points are the boundary points of the interval (
and
). For the other points,
and
, we do not have an explicit expression but they are the solutions to the equations of
and
. Table reports the support points of locally D-optimal designs in
for WEM and the values of
in Torshizi et al. (Citation2011).
TABLE 2. Support points of WEM locally D-optimal designs in .
Table compares the behaviour of the different locally D-optimal designs in Table . Efficiencies for daily design are included. In this case, efficiencies are strongly influenced by parameter
. Significantly lower efficiency is obtained when
differs from the true
value. As in WM, the daily design efficiencies are very small.
TABLE 3. Efficiencies for WEM D-optimal designs.
In Table , we include the efficiencies of the locally D-optimal designs for WEM when they are used to estimate the WM. We can use a four-point optimal design for WEM to estimate a three-parameter WM but it is not possible to use an optimal design for a WM (three points) to estimate a WEM (four parameters).
TABLE 4. Efficiencies of locally D-optimal designs for WEM with respect to those for WM, for different values.
Discussion
A variety of different mathematical models have been used to research the lactation curve shape. Working with these models, a particular problem is collecting data to estimate the parameters as precisely as possible. To do this, it is necessary to design the experiment. There is relevant literature regarding D-optimal designs for regression models. We then set the results for those models applied to lactation – namely, the polynomial, hyperbolic, inverse quadratic and exponential models. Firstly, we offer the theoretical insight and, after that, the numerical results will be included in Table . Depending on the model, we will have to record the observations at different times, so we compare the behaviour of a model-specific D-optimal design when used to estimate another model. Finally, a web application is presented to obtain the optimal designs for this research.
TABLE 5. Support points for D-optimal designs for some lactation models.
Polynomial model
According to Karlin and Studden (Citation1966), the D-optimal design for the polynomial model of degree , on interval
, is equally supported at
points, which are the roots of the polynomial
, where
is the derivative of the Legendre polynomial of degree
. If
are the support points in
, then
are the support points on interval
. Both ends of the design space are always support points.
Hyperbolic model
The D-optimal design in , with
, is equally supported at
,
and
. In particular, the D-optimal design is equally supported at
for the interval
.
Inverse quadratic polynomial model
From Haines (Citation1992), the locally D-optimal design is equally supported at ,
and
, with
,
,
and
, for initial values
,
and
. If
or
are not included in the design interval, the support point is then fixed at the end of the interval and the other support points are calculated as shown in Haines (Citation1992).
Exponential model
Han and Chaloner (Citation2003) obtained the locally D-optimal design in interval is equally supported at two points:
and
, for
.
Exponential model with constant term
Han and Chaloner (Citation2003) also calculated the locally D-optimal design for the exponential model with a constant term in . For
it is equally supported at three points
,
and
.
Table reports the optimal designs for the above models in the interval considered by Landete-Castillejos and Gallego (Citation2000). This design space corresponds to monthly observations of lactation yield throughout a cycle. All designs in Table are equally supported. Some of the designs are locally optimal designs so they are obtained for initial parameter values found in Landete-Castillejos and Gallego (Citation2000). For example, EM(1) is the locally D-optimal design for the exponential model with
. IM(2) is the locally D-optimal design for the inverse quadratic polynomial model with
,
and
. Table also includes the locally D-optimal design for WEM with
and the locally D-optimal design for the Wood model (WDM) with
and
.
Table summarises the performances of the optimal designs in Table in terms of their efficiencies. We must emphasise the good performance of some of these designs for different lactation curves, with efficiencies close to , and the low efficiency always shown by the monthly design
.
TABLE 6. Efficiency study for optimal design for lactation models.
We have created a Web application with the R Shiny software. This application allows one to obtain the optimal design for any of the models discussed, and for an interval . We can estimate and draw the models for our experimental data. The Web application is available at https://imor.shinyapps.io/lactancy/
Conclusions
Milk yield over the course of the lactation cycle follows a curvilinear pattern, so a suitable function is required to model this curve. Eight functions (namely: linear, exponential, hyperbolic, inverse quadratic, exponential with constant term, quadratic, Wilmink and Wilmink extended) are investigated to model the lactation curve. The optimal designs for these models are studied in this paper.
The use of optimal design methodology greatly reduces the number of instances when dairy production has to be recorded. Consequently, milk production does not have to be observed every day or weekly. To obtain the best parameter estimates, one only has to study the days proposed by the optimal design. Optimal designs reduce the costs of experimentation by allowing parameters to be estimated with fewer experimental runs.
Efficiency was used to compare optimal design performance. This method allows one to compare models under different conditions. Table shows two groups within the 3-support-point D-optimal designs. The hyperbolic, the inverse quadratic polynomial and the Wood models show a similar behaviour and high efficiency. Another group includes the exponential model with constant term, the quadratic polynomial model, and the WM, which likewise share similar characteristics.
The results of this work support the idea that the WM provides good performance. Its efficiencies are high for the cases considered. It greatly improves the design with routinely used with daily observations. The main disadvantage of the WM is the importance of having an accurate parameter value for the exponent. Inappropriate specifications for this parameter can lead to low efficiencies.
Funding
This study was financially supported by Grant MTM2013-479879-C2-1-P Spanish Ministerio de Economía y Competitividad.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Campos-Barreiro S, López-Fidalgo J. 2013. Experimental designs for a Benign Paroxysmal Positional Vertigo model. Theor Biol Med Model. 10:1–14.
- Cankaya S, Unalan A, Soydan E. 2011. Selection of a mathematical model to describe the lactation curves of Jersey cattle. Archiv Fur Tierzucht. 54:27–35.
- Cobby JM, Le Du LP. 1978. Fitting curves to lactation data. Animal Prod. 26:127–134.
- Dudouet E. 1982. Courbe de lactation théorique de la chèvre et applications (Theoretical lactation curve of the goat and its applications). Point Vet. 14:53–61.
- Gengler N. 1996 Persistency of lactation yields: a review. Proceedings of the International Workshop on Genetic Improvement of Functional Traits in Cattle, Gembloux, Belgium. Interbull Bull. 12:87–96.
- Gipson TA, Grossman M. 1990. Lactation curves in dairy goats: a review. Small Ruminant Res. 3:383–396.
- Graesbøll K, Kirkeby C, Nielsen SS, Halasa T, Toft N, Christiansen LE. 2016. Models to estimate lactation curves of milk yield and somatic cell count in dairy cows at the herd level for the use in simulations and predictive models. Front Vet Sci. 3:115.
- Haines LM. 1992. Optimal design for inverse quadratic polynomials. South African Stat J. 26:25–41.
- Han C, Chaloner K. 2003. D- and c-optimal designs for exponential regression models used in pharmacokinetics and viral dynamics. J Stat Plan Inference. 115:585–601.
- Hossein-Zadeh NG. 2016. Modelling lactation curve for fat to protein ratio in Holstein cows. Animal Sci Papers Rep. 34:233–246.
- Karlin S, Studden WJ. 1966. Optimal experimental designs. Ann Math Stat. 37:783–815.
- Kiefer J. 1974. General equivalence theory for optimum designs. Approximate theory. Ann Stat. 2:849–879.
- Kitsos CP, Kolovos KG. 2013. A compilation of the D-optimal designs in chemical kinetics. Chem Eng Commun. 200:185–204.
- Landete-Castillejos T, Gallego L. 2000. Technical note: the ability of mathematical models to describe the shape of lactation curves. J Animal Sci. 78:3010–3013.
- Macciotta NPP, Dimauro C, Rassu SPG, Steri R, Pulina G. 2011. The mathematical description of lactation curves in dairy cattle. Ital J Animal Sci. 16:213–223.
- Martínez-López I, Ortiz-Rodríguez I, Rodríguez-Torreblanca C. 2009. Optimal designs for weighted rational models. Appl Math Lett. 22:1892–1895.
- Melzer N, Trißl S, Nürnberg G. 2017. Estimating lactation curves for highly inhomogeneous milk yield data of an F2 population (Charolais x German Holstein). J Dairy Sci. 100:9136–9142.
- Olori VE, Brotherstone S, Hill WG, McGuirk BJ. 1999. Fit of standard models of the lactation curve to weekly records of milk production of cows in a single herd. Livestock Prod Sci. 58:55–63.
- Quintero JC, Serna JI, Hurtado NA, Rosero Noguera R, Cerón-Muñoz MF. 2007. Modelos matemáticos para curvas de lactancia en ganado lechero. Rev Colom Cienc Pec. 20:149–156.
- Torshizi ME, Aslamenejad AA, Nassiri MR, Farhangfar H. 2011. Comparison and evaluation of mathematical lactation curve functions of Iranian primiparous Holsteins. South African J Animal Sci. 41:105–115.
- Wilmink J. 1987. Comparison of different methods of predicting 305-day milk yield means calculated from within herd lactation. Livestock Prod Sci. 17:1–17.
- Wood PDP. 1967. Algebraic model of the lactation curve in cattle. Nature. 216:164–165.