
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
We propose the Jaccard matrix (JM) and the Jaccard cell (JC), define them as the extended concepts of the Jaccard index, and theoretically and numerically analyze them. The data on the Euclidean plane can derive the JM as a sparse matrix. We show the JC inherits the feature of similarity of the Jaccard index as the exponential function of mutual information. We theoretically and numerically confirm that the local correlation coefficient of the data on the Euclidean plane relates the JC to the mutual information. Although one could potentially select an arbitrary cell size of the grid to make the JM, the knowledge we can obtain from the matrix decreases if the cell size is too big or too small to distinguish the data clusters appropriately. Therefore, the JM needs a computational procedure to determine the cell size within the appropriate scale. Maximizing the variance of the JCs supports determining the unique cell size, which value locates in the middle range of the parabolic function of the cell-size parameter. The JM could derive an index extracting nonlinear correlation of the data. The maximized standard deviation of the JCs as such an index is a decreasing function of the noise scale of the data under the constraint conditions. The ability to determine the homogeneous rectangular grid pattern of the JM might be a significant feature for finding nonlinear correlation. We would summarize this study as that of a nonlinear filter working as an efficient component of explainable AI and statistics.
1. Introduction
Discovering functionality between two variables is a significant task of data mining. Pearson correlation coefficient (PCC) [Citation1], a measure of linearity between two variables, is a classical tool for the task, but it cannot detect a general association, such as a nonlinear function with random noise. Such an association not to be measured adequately by PCC is called nonlinear correlation [Citation2]. The maximum information coefficient (MIC) is a measure proposed by Reshef et al. [Citation3] of the nonlinear correlation between two variables. MIC is the maximum value of mutual information (MI) calculated for the divided two-dimensional spaces into various grid patterns. As the recent studies on MIC, for instance, there is a new algorithm to optimize it [Citation4] and is an extension to apply to multi-dimensional data [Citation5]. MIC is one of the excellent practices in advanced applications of MI as a well-known measure. We are interested in developing a method to create an index of nonlinear correlation by aggregating a canonical measure modified appropriately, inspired by the procedure of MIC.
On the other hand, as the context from a general view of mathematical formulation, we pay attention to mathematical operability and analyzability. A general association of data of two variables, including nonlinear correlation, can be regarded as a binary relation R defined as a subset of a direct product of data sets A and B. A function is a binary relation such that any element of A is in a relation with one and only one element of B. In this sense, data mining for two variables implies knowledge discovery of binary relations or functions from observed data with random noises. The studies on machine learning to estimate such relations or functions suggest the effectivity of matrix representation in terms of operability and analyzability for the mathematical models. The rectangles of the grids of MIC are not congruent to each other, and it might have a disadvantage in terms of mathematical formulation and operation via matrix representation.
Moreover, several experimental sciences have developed indices of similarity between two sets. Jaccard index is proposed as a measure of the similarity in plant biology [Citation6]. It has several versions coming from different disciplines, such as Tanimoto coefficient [Citation7] in computer science, Tversky index [Citation8] in psychology, pARIs [Citation9–12] in cognitive science. These indices have almost the same forms defined as a quotient of dividing a meet of two sets by a join of them. Especially, pARIs based on the research of causal inference [Citation13] including causal induction has interesting backgrounds in terms of detection of general association. Causal induction is a cognitive feature of humans finding a causality from the co-occurrence of two kinds of events [Citation14]. In this context, the indices give non-parametric statistic models as the strength of recognizing causality. The two kinds of events of the models can be assigned to Bernoulli variables when we regard the models as functions with random variables in probability theory. pARIs is an index of the causal induction well reflecting human cognitive features, although why the index well fits human behaviour is not known. It also has the same mathematical form as the Jaccard index.
As the introduction of the present article, we gave the above overview of the three contexts, i.e. data mining of nonlinear correlation, operability and analyzability of mathematical method, and the indices of similarity of sets originated from the experimental sciences. At the junction of the above three contexts, we propose the concepts of the Jaccard cell and the Jaccard matrix. Jaccard matrix is defined as multi-dimensional Jaccard indices by one of the authors of the present article. The first idea of that appeared as pARIX in 2014 [Citation15], and the name of the Jaccard matrix appeared in 2016 [Citation16]. The Jaccard matrix as a component of statistical informatics let be independent of pARIs and pARIX connected to cognitive sciences in the description of this article. This concept in this article is well defined and analysed mathematically, but that in these previous studies sufficiently had been not yet. Concretely, we think that the idea of monotonicity in the previous studies was too rough to analyse the results. The mathematical improvements in this study promote an understanding of the meaning of aggregation of the Jaccard index and of the mechanism of nonlinear correlation derived from it theoretically and numerically.
In the following second section of the present article, we induce the Jaccard cell and Jaccard matrix from the Jaccard index and pARIs. In the third section, we mathematically define the Jaccard cell and Jaccard matrix for the data on the Euclidean plane and show their computational procedure. In the fourth section, we study the mathematical features of the Jaccard cell, which is approximated locally by the exponential function of MI. In the fifth section, we study a simple model of the variance of the Jaccard cells induced from the approximated equation and show that maximizing the variance of the Jaccard cells supports determining the unique cell size. In the sixth section, by the simulations, we numerically analyse the features of the Jaccard cell and Jaccard matrix theoretically shown in the previous sections. Finally, we briefly discuss the maximized standard deviation of the Jaccard cells as a decreasing function of the noise scale of the data in terms of nonlinear correlation and summarize this study as that of a nonlinear filter.
2. Jaccard cell and Jaccard matrix
In this section, we define the Jaccard cell and Jaccard matrix. Their names inherit from the Jaccard index, known as the first one of the affiliated indices. We introduce them as a generalization of a statistical index of causal induction, pARIs, which is one of such indices, The explanation might make our acceptance of their following calculation procedures easy.
2.1. pARIs and Jaccard index
In the quantitative studies of causal induction, the counting information of co-occurrence events is given by a form so-call contingency table [Citation14]. Let C and E be events that correspond to causes and effects. Let a, b, c, d be frequency of occurrence of the events,
,
,
,
, where ¬ be the negation. Then the
contingency table is given as Table .
Table 1. contingency table.
Note that Table is the transposed contingency table of [Citation14]; i.e. we swap the row and column of Table to be easier to associate the row and column of the table with that of the matrix and with the horizontal x-axis and vertical y-axis of
in the following sections. In addition, even not to distinguish rows with columns of Table and the following Table does not make trouble in our study, since the Jaccard cell and pARIs are symmetric to swapping rows with columns. Although pARIs is an index of causal induction, it has no asymmetricity between cause and effect.
Table 2. contingency table.
Given information of the contingency table, we can define pARIs as a statistical index of causal induction [Citation9, Citation11] by the following:
(1)
(1) where it satisfies
for all
. Jaccard index is defined as
, where
and
are sets, and
is the number of elements of the set S. pARIs (Equation1
(1)
(1) ) has the same mathematical form as the Jaccard index. For N: = a + b + c + d, we obtain the relative frequency on
and
, a/N and
. If these are replaced by occurrence probabilities
and
, then we obtain pARIs as a model of strength of human causal inference:
(2)
(2)
2.2. Definition of Jaccard cell and Jaccard matrix
In this section, we define the Jaccard cell and Jaccard matrix. Let X and Y be Bernoulli random variables . First, we define an index ψ as the following:
(3)
(3) Equation (Equation3
(3)
(3) ) is the same mathematical form as the Jaccard index and pARIs. It is a model for the Jaccard index and pARIs in probability theory.
Secondly, we define Jaccard cell as a generalization of the index ψ in (Equation3
(3)
(3) ) to that of multi-dimensional Bernoulli random vectors. Let
and
be one-hot vectors following the categorical distributions,
(4)
(4) where the one-hot encoding or 1-of-K encoding, like
, is well known in machine learning. A categorical distribution
, also called a generalized Bernoulli distribution, is a particular case of the multi-nomial distribution [Citation17]. Given the above
and
, we define Jaccard cell
as the following:
(5)
(5) The given
and
equal
following the Bernoulli random variables under the condition,
(6)
(6) Consequently, the Jaccard cell (Equation5
(5)
(5) ) is a natural extension of the index (Equation3
(3)
(3) ) that is equivalent to the Jaccard index and pARIs. Moreover, we define the Jaccard matrix as the following matrix:
(7)
(7) given by aggregating the Jaccard cell (Equation5
(5)
(5) ).
Let us be back to the context of pARIs. The extension to the Jaccard cell means that “the event occurs or not” is replaced by “the event indexed by i occurs.” In this sense, the contingency table as Table is also extended to
contingency table as Table , where
is the number of data on event occurrence of
. Table derives a frequency distribution on event occurrence:
(8)
(8) and
(9)
(9) where
is the data size. Consequently, Equations (Equation5
(5)
(5) ), (Equation8
(8)
(8) ), and (Equation9
(9)
(9) ) derive the following Jaccard cell given statistically:
(10)
(10) The denominator of Jaccard cell (Equation10
(10)
(10) ) implies the total number of the local cross-shaped region of
contingency table.
In this section, we defined the Jaccard cell and Jaccard matrix. of Equation (14) in [Citation15] is mathematically equivalent to the Jaccard cell
defined in Equation (Equation5
(5)
(5) ), except for the insignificant difference about the indices,
. Now, it is reasonable to construct their concept strictly and to give the starting point afresh to research this theme as mathematics for information systems away from the context of cognitive sciences, including pARIs and pARIX.
3. Jaccard matrix induced from the data on the Euclidean plane
In this section, we induce the Jaccard matrix from the data on the Euclidean plane and give the representations to compute it. See Figure to understand the following definitions briefly.
Figure 1. A sketch of the two-dimensional rectangular space to define the Jaccard matrix and the cruciform region
to calculate the Jaccard cell.
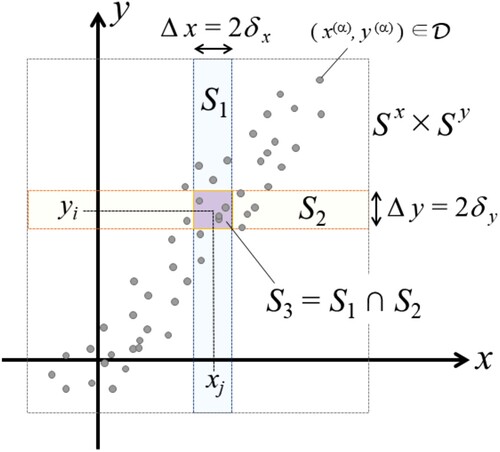
Assume a two-dimensional rectangular space . Let us divide
into the grid as the direct sums of subspaces,
and
, where
are the number of the sections of the rows and columns.
expresses a small rectangular cell in the grid.
and
express the centre points of the cells at the bottom left and top right in
. Consequently the size of each cell is
and
, thus
is concretely expressed by
, and the centre point is
.
Assume that data are observed. We can calculate an index j of the range
by
, where
. Since
, thus
. We can also calculate
for data
in the same way, where
.
Based on the above procedure, we count the number of the data observed in each cell
, which corresponds to
in Figure . It derives a
matrix of non-negative integers,
(11)
(11) which corresponds to a
contingency table.
Let us adjust some matrix representations for GPU programming. Defining by a n-dimensional column vector that has 1 as all of the elements, i.e.
, we obtain the relationship between the matrix C and the data size
as the following:
(12)
(12) On the other hand, defining
by the
matrix that has 1 as all of the elements, i.e.
, we obtain the following
matrix H:
(13)
(13) The element of H,
, is the denominator of the Jaccard cell
, as well as
is the numerator of it, since Equation (Equation13
(13)
(13) ) derives
(14)
(14) The region to count these data corresponds to the cruciform one of
in Figure . Equation (Equation14
(14)
(14) ) has the other representation, i.e.
(15)
(15) For all i, j,
thus
. Therefore,
. Consequently,
Jaccard matrix Ψ is given by an element-wise quotient of the matrices C and H as the following:
(16)
(16) where
(17)
(17) The mean of
,
, is calculated by
(18)
(18) The variance of
,
, is calculated by
(19)
(19) where ° is Hadamard product or element-wise product defined by
.
For instance, of the concrete values of the above, we can calculate the following example: assume and
, then we obtain six cells of the grid in the space. If observed data are given as
, they derive the following matrix:
(20)
(20) then
, and then
means that we observed three data in the grid,
. For the matrix C, we obtain the matrix H and the Jaccard matrix Ψ as the following:
(21)
(21) It is not rare that the matrix C is sparse. The above procedure is inefficient when C is a sparse matrix, although it helps the programming of GPU computing for them. Indeed, the data based on an ordinary function
can derive a sparse matrix C by sufficiently small
. Therefore, we can use the list including only the non-zero elements of C, such as the format of COO or CSR [Citation18, Citation19], for effective programming. For instance, the COO format of the matrix (Equation20
(20)
(20) ) is given as the following:
(22)
(22)
4. Mathematical analyses of the Jaccard cell and Jaccard matrix
In this section, we analyse the mathematical features of the Jaccard cell derived from data on .
4.1. Jaccard cell depending on the cell-size parameters
The value of the Jaccard cell depends on the size of the cell . Therefore, we construct a representation of the Jaccard cell explicitly integrated with cell-size parameters, i.e. we replace the number of the data discretely counted in Equation (Equation10
(10)
(10) ) by the probability density function of them continuously integrated as the following:
(23)
(23)
(24)
(24)
(25)
(25) where
are the cell-size parameters, and
is the probability density function of data observed in the point
. Let us write the regions of the integrals
,
, and
as
,
, and
.
means the probability of data observed in
. Figure represents the regions
.
is a local cruciform region, and
is the rectangular region of the centre of the former. Using Equations (Equation23
(23)
(23) )–(Equation25
(25)
(25) ) and replacing the sum on
with the integral on
, we obtain the Jaccard cell depending on the continuous variables
and the cell-size parameters
,
(26)
(26) Since
, thus generally
(27)
(27) as well as pARIs and the Jaccard cell
in (Equation10
(10)
(10) ). If we divide
into
rectangular cells by the procedure of the previous section, then
(28)
(28) for Equations (Equation10
(10)
(10) ) and (Equation26
(26)
(26) ).
4.2. Jaccard cell approximated by the exponential function of MI
Correlation coefficient and MI are well-known measures for an association between two random variables. In this section, we study the mathematical relationship between the Jaccard cell (Equation26(26)
(26) ) and these measures.
Let X and Y be the random variables following the two-dimensional normal distribution with correlation coefficient ρ as the parameter of it:
(29)
(29) Assume that the observed data for the Jaccard cell (Equation26
(26)
(26) ) follows the distribution (Equation29
(29)
(29) ) in the local cell
, and the centre of the local cell is located on the expected values
. This assumption probabilistically expresses observed data have a linear functional structure around the local space where the Jaccard cell is defined, although the spatial pattern of the data might be nonlinear globally. The strength of the linear functional structure corresponds to the correlation coefficient, and the data are normally distributed around the linear function. By the calculation in Appendix, we obtain the approximated Jaccard cell as the following:
(30)
(30) In the following two cases under different conditions, we show that the Jaccard cells are locally approximated by the exponential of MI.
Case 1: the condition of the cell-size parameters that are proportional to the standard deviations of the data distribution
Let us set a sufficiently small value of δ as
(31)
(31) and set the cell-size parameters,
and
, as
(32)
(32) Substituting the above conditions for Equation (Equation30
(30)
(30) ), we obtain the value of the approximated Jaccard cell (AJC) as the following:
(33)
(33) A MI
of two normal random variables X and Y following (Equation29
(29)
(29) ) generally depends on only the correlation coefficient ρ of them; i.e.
(34)
(34) Therefore, if δ is sufficiently small as
, then we obtain the value of the approximated Jaccard cell using the mutual information (JCMI) as the following:
(35)
(35) We compare the value of (Equation33
(33)
(33) ) with that of (Equation35
(35)
(35) ) numerically in Section 6.1.
Studying the mathematical features of the Jaccard cell based on the approximated equations, we should pay attention to the intrinsic constraint conditions of the parameters, δ and ρ. The Jaccard cell (Equation26(26)
(26) ) satisfies the condition (Equation27
(27)
(27) ) exactly, therefore we generally obtain
(36)
(36) Substituting Equations (EquationA5
(A5)
(A5) ), (EquationA6
(A6)
(A6) ), (EquationA8
(A8)
(A8) ) in Appendix and the conditions (Equation31
(31)
(31) ) and (Equation32
(32)
(32) ) for inequation (Equation36
(36)
(36) ), we obtain
(37)
(37) and then, since
,
(38)
(38)
Case 2: the condition of the two cell-size parameters that have the same small value
If we set the cell-size parameters, and
, as the same small value
(39)
(39) then, by the calculation of the Appendix, we obtain the approximated value of the Jaccard cell (Equation26
(26)
(26) ) as the following:
(40)
(40) Assuming
(i.e.
), we obtain
(41)
(41) Equation (Equation41
(41)
(41) ) derives Equation (Equation35
(35)
(35) ) under the condition
. We analyse a simple model of the above approximated Jaccard cell (Equation40
(40)
(40) ) in the following section.
5. A simple model of the approximated Jaccard cells and the cell-size parameter determined uniquely
In this section, we study a simple model of the variance of the Jaccard cells (Equation19(19)
(19) ) induced from the approximated Equation (Equation40
(40)
(40) ). As we know in the previous section, the Jaccard cell and Jaccard matrix depend on the cell-size parameters. We select the value of the cell-size parameter derived by a computable procedure to determine the Jaccard matrix uniquely. The analysis of the model in this section supports the unique determination of the Jaccard matrix and its cell-size parameter.
5.1. A simple model of the Jaccard cell
Let be a function of σ that is a standard deviation as a scale of the noise of observed data. For instance, in Equation (Equation40
(40)
(40) ),
(42)
(42) which is a part of the denominator of that. In this view, we study the following equation as a model of the Jaccard cell (Equation40
(40)
(40) ):
(43)
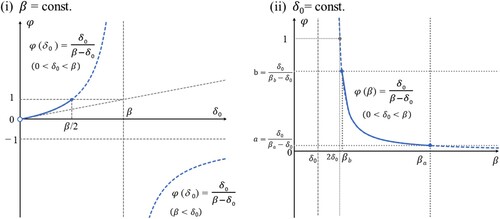
(43) The solid lines of (i) and (ii) in Figure show sketches of the graphs of (Equation43
(43)
(43) ) in the cases that β or
is fixed as each constant value.
Figure 2. The solid lines of (i) and (ii) show sketches of the graphs of the simple model of the Jaccard cell, Equation (Equation43(43)
(43) ), in the cases where β or
is fixed as each constant value.
5.2. Determination of the cell-size parameter
Assume that there are various σ for the Jaccard cells, i.e. we regard σ as a random variable for each Jaccard cell. In other words, σ of given whole data is a fixed value, but the locally divided data by the Jaccard cells have the various σ. Note that σ of the whole given data might not even be a mean of σ of the locally divided data. Moreover, assume that β is proportional to σ (i.e. β is also a random variable), where (Equation42(42)
(42) ) satisfies this assumption. For simplicity, we assume β of Equation (Equation43
(43)
(43) ) is a continuous uniform random variable in
. We can regard Equation (Equation43
(43)
(43) ) as the inverse transformation sampling to make the random numbers of φ. Therefore, Equation (Equation43
(43)
(43) ) derives the probability density function of φ as the following:
(44)
(44) Equation (Equation44
(44)
(44) ) is a Pareto distribution cut off by a and b. When we substitute b and
for φ and β of Equation (Equation43
(43)
(43) ), we obtain
. The condition of the total probability
derives the equation
, which uniquely determines the ratio b/a, where
. Based on the distribution (Equation44
(44)
(44) ), we can calculate the mean of φ as
, where
, and the variance of φ as
, where
. Therefore, we obtain the following quadratic functions:
(45)
(45)
(46)
(46) and the maximum value of the variance
(47)
(47) We express the values of
and
in
as
(48)
(48) We assumed that β is a uniform random variable to express the existence of the various sigma of the Jaccard cells as the simple model. Consequently, this derived the procedure to determine the unique value of the cell-size parameter as Equation (Equation48
(48)
(48) ).
5.3. Relationship between the standard deviation of the Jaccard cells and that of the given data
Under the determined by (Equation48
(48)
(48) ), we regard β as a fixed value again (i.e. σ is the value of given data). We can regard the standard deviation
as the function of β,
(49)
(49) substituting
for
of Equation (Equation43
(43)
(43) ). Under the assumptions in which β is proportional to σ and
, Equation (Equation49
(49)
(49) ) derives
(50)
(50) The above relationship between the standard deviation of the Jaccard cells and that of the given data might look strange at first glance, but features of the Jaccard cell could make it available. If the Jaccard matrix also generally realizes the relationship in numerical calculations, we could use
as an index for nonlinear correlation.
6. Numerical simulation
6.1. Jaccard cell depending on the correlation coefficient
As the first of the numerical simulations, we investigate the feature of the Jaccard cell for the change of correlation coefficient ρ. Figure shows the graphs of AJC (Equation33(33)
(33) ) in
, JCMI (Equation35
(35)
(35) ) in
, MI (Equation34
(34)
(34) ), and the absolute value of the correlation coefficient
. By Figure , we can see that (Equation33
(33)
(33) ) is well-approximated by (Equation35
(35)
(35) ) based on MI in the small δ (i.e.
), but it is not so in
and 0.6. Moreover, the condition (Equation38
(38)
(38) ) on δ constrains (Equation33
(33)
(33) ) and (Equation35
(35)
(35) ). Solving (Equation38
(38)
(38) ) for ρ, we obtain the bound of ρ for (Equation33
(33)
(33) ) and (Equation35
(35)
(35) ) as the following:
(51)
(51) Thus, the bounds in Figure are
,
,
, and
. The values of the approximated Jaccard cells are flat in the range of the low and middle of
. It shows an abrupt increase in that of the high. Therefore, the Jaccard cell could strongly react to correlation locally formed in an appropriate small region.
Figure 3. The graphs of the Jaccard cells (JC) based on Equation (Equation33(33)
(33) ) in
, the approximation by (Equation35
(35)
(35) ) in
, the MI (Equation34
(34)
(34) ), and the absolute value of the correlation coefficient
.
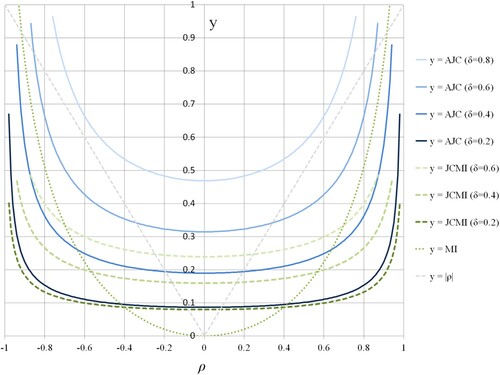
6.2. Jaccard matrix and the cell-size parameter uniquely determined by the standard deviation maximization
As the second of the numerical simulations, we investigate the mean , the variance
, and the standard deviation
of
Jaccard matrix, defined by (Equation18
(18)
(18) ) and (Equation19
(19)
(19) ). We express the numerical values of them as
,
, and
. The input data set
is generated by
(52)
(52) where u is a uniform random variable on an appropriately defined interval of real numbers and r is a noise defined as a normal random variable following
. Table expresses the instances of Equation (Equation52
(52)
(52) ) to generate data
. For each function f, we test the 30 data sets for the noise scales
(
). The data size of
is
.
Table 3. The instances of the function to generate test data.
Figure shows the typical behaviour of ,
, and
for n which defines
Jaccard matrix. These lines are generated by Equation (Equation52
(52)
(52) ) using the function Cos14x in Table and
. Figure shows the numerical tests for the theoretical model (Equation46
(46)
(46) ) expressing the estimation of the relationship between the mean and the variance of the Jaccard cells. The plotted dots of it are generated by the function Cos14x of
. The grey dashed line shows the parabolic function
, where
,
, and
, to approximate the dots of
phenomenologically. Although the values of Figures and are the results of the function Cos14x, all of the instances in Table show the behaviour qualitatively equivalent.
Figure 4. The typical behaviour of ,
, and
for n which defines
Jaccard matrix. These lines are generated by Equation (Equation52
(52)
(52) ) using the function Cos14x in Table and
.
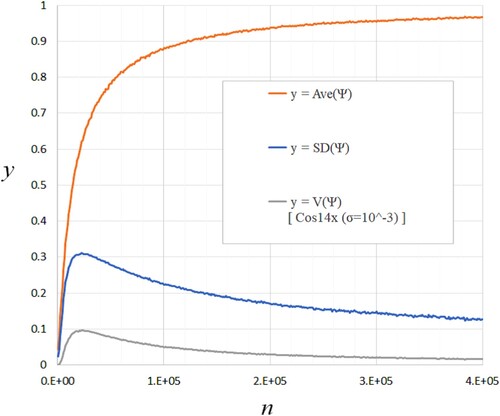
Figure 5. The numerical tests for the theoretical model (Equation46(46)
(46) ) expressing the estimation of the relationship between the mean and the variance of the Jaccard cells. The plotted dots are generated by the function Cos14x of
. The grey dashed line shows the parabolic function
, where
,
, and
, to approximate the dots of
phenomenologically.
=−(φ¯−ZV2ZE)2+ZV24ZE2(46) ) expressing the estimation of the relationship between the mean and the variance of the Jaccard cells. The plotted dots are generated by the function Cos14x of σr=10−3,10−2,10−1,10−0.1. The grey dashed line shows the parabolic function V(Ψ)=−α0(Ave(Ψ)−α1)2+α2, where α0=0.6, α1=0.61, and α2=0.096, to approximate the dots of σr=10−3 phenomenologically.](/cms/asset/4dc9c425-9edc-48a6-8908-9a6885bacb8d/tmsi_a_2194169_f0005_oc.jpg)
The variances have the stationary points in the numerical simulations, like the parabolic function of the theoretical model (Equation46
(46)
(46) ). Therefore, we can uniquely determine the value of the cell-size parameter and the Jaccard matrix not only in the theoretical model but also in the numerical calculation. Note that the results of simulations qualitatively correspond with that of the model but do not quantitively.
6.3. The standard deviation of the Jaccard cells as a nonlinear correlation
As the third of the numerical simulations, we investigate the relationship between the standard deviation of the Jaccard cells and that of the input data given by (Equation52(52)
(52) ), theoretically expressed by (Equation50
(50)
(50) ).
Figure shows the values of for the standard deviation
of the additional noise r of Equation (Equation52
(52)
(52) ). Note the irregular representation of axes in Figure , i.e. the horizontal axis is a logarithmic one for the value of
, and the vertical axis is a normal one for the value of
since the absolute value of the derivative of
is very small.
means the stationary point of
in Figure . All conditions of input data are the same as in the previous subsection. The horizontal dashed lines (RandomAve±s) in Figure show the mean ± standard deviation values of
generated by 30 data sets of i.i.d. normal random numbers,
. In Figure , we can see the proportional trend
(53)
(53) in the range of
. The red dashed line expresses
as the approximation of
in the range.
Figure 6. The values of for the standard deviation
of the additional noise r of Equation (Equation52
(52)
(52) ). The horizontal axis is a logarithmic one for the value of
, and the vertical axis is a normal one for the value of
.
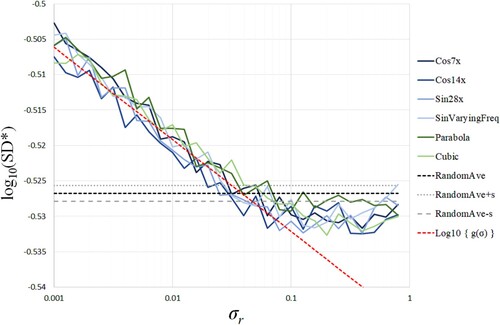
The simple theoretical model (Equation43(43)
(43) ) of the Jaccard cell predicts the relation (Equation50
(50)
(50) ) that corresponds to
in (Equation53
(53)
(53) ), but the numerical results show
. The trend of (Equation53
(53)
(53) ) suggests that
might be used as an index of nonlinear correlation by the qualitative correspondence between the theoretical prediction and the numerical results, although it has a quantitative difference between them.
7. Discussion
In this section, we discuss the implications of the theoretical and numerical results in the previous analyses and summarize the view of our study as nonlinear filter statistics.
First, one of the informatically significant meanings of the Jaccard cell is the behaviour as the exponential function of MI, which is shown by Equations (Equation35(35)
(35) ) and (Equation41
(41)
(41) ) theoretically and by Figure numerically. The local correlation coefficient of the data relates the Jaccard cell to the MI. Interestingly, as a result, the indicators our method aggregates, the Jaccard cells, are related to MI, like MIC. By the effect of the exponential function, the Jaccard cell could more strongly sharpen the x−y dependence of the two-dimensional data than just the MI.
Second, the standard deviation of the data affects the value of the Jaccard cell. The approximated Jaccard cell (Equation41(41)
(41) ) suggests elongating the data deviation to the direction of each axis decreases the value of the Jaccard cell. That means the localized data increase the value of the Jaccard cell more than the expanded data.
Third, we uniquely determine the Jaccard matrix depending on the cell-size parameters by selecting them as the stationary point of the variances , although we potentially could give the values of the cell-size parameters arbitrarily. The variances
have the stationary points in the numerical simulations, like the parabolic function of the theoretical model (Equation46
(46)
(46) ). Note that the results of simulations qualitatively correspond with that of the model but do not quantitively. Thus, we will need to improve the model to analyse the feature of the Jaccard cell in future research.
Fourth, at the stationary point determined by the above method is a decreasing function of the noise scale σ of the data under the constraint conditions. The proportionality (Equation50
(50)
(50) ) suggests it theoretically, and Figure and the proportionality (Equation53
(53)
(53) ) numerically. It means that we might be able to use
as an index of nonlinear correlation. MIC needs to vary the heterogeneous grid pattern on the computational procedure for each data. By contrast, the Jaccard matrix has a homogeneous rectangular grid pattern. The variance
of the Jaccard matrix shows unimodality and has a stationary point as the above. Thus, it has good features for finding a solution potentially. As with the stationary point analysis of the above, the difference between theoretical and numerical values is a matter for further study.
The structure of our method is abstractly similar to that of a convolutional neural network (CNN) composed of a convolution layer and a pooling layer. CNN extracts features of input data by a convolution layer called a filter and synthesizes them by a pooling layer. The first layer of our method, making the Jaccard matrix, affects the information derived from input data as a “nonlinear filter” extracting their features, but it is not a convolution operation. The second layer of that calculates an index of nonlinear correlation. We guess that could and should replace an alternative statistic to express nonlinear correlation better in future studies. The Jaccard matrix and the procedure of our method will have been effective yet in the case of the replaced index, since
has the determining ability of the cell-size parameters by the unimodality. It is significant to characterize features of numerical data as low-dimensional measures when humans understand and judge the structure and order of the data. In this sense, each AI and statistics have roles for themselves, although they are closely related to modern statistical machine learning. We think nonlinear filters like the Jaccard matrix might work as efficient components of explainable AI and statistics.
8. Conclusion
In this article, we proposed the Jaccard matrix and the Jaccard cell as the element of that, defined them as the extended concepts of the Jaccard index, and theoretically and numerically analysed them. The data on the Euclidean plane can derive the Jaccard matrix as a sparse matrix.
The Jaccard index is well known as a classical index of similarity between two sets and is derived from the table describing two binary classes. The Jaccard matrix has
(generally
) elements called the Jaccard cells. It is an extended concept of the classical Jaccard index and has the arbitrariness of the cell size to derive it from observed data on
. We showed the Jaccard cell inherits the feature of similarity as the exponential function of MI. We theoretically and numerically confirmed that the local correlation coefficient of the data on the Euclidean plane relates the Jaccard cell to the MI.
Although one could potentially select an arbitrary cell size of the grid to make the Jaccard matrix, the knowledge we can obtain from the matrix decreases if the cell size is too big or too small to distinguish the data clusters appropriately. Therefore, the Jaccard matrix needs a computational procedure to determine the cell size within the appropriate scale. Maximizing the variance of the Jaccard cells supports determining the unique cell size, which value locates in the middle range of the parabolic function of the cell-size parameter.
Moreover, the Jaccard matrix could derive an index extracting nonlinear correlation of the data. The maximized standard deviation of the Jaccard cells as such an index is a decreasing function of the noise scale of the data under the constraint conditions. The ability to determine the homogeneous rectangular grid pattern of the Jaccard matrix might be a significant feature for finding nonlinear correlation.
The structure of our method is abstractly similar to that of a convolutional neural network. The first layer making the Jaccard matrix affects the information derived from input data as a nonlinear filter extracting their features. The second layer calculates an index of nonlinear correlation. We would summarize this study as that of a nonlinear filter working as an efficient component of explainable AI and statistics.
Acknowledgments
We are grateful to the editors and anonymous reviewers for giving valuable and dedicated comments to improve this research.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Notes on contributors
Moto Kamiura
Moto Kamiura received B.Sc. in 2002 from Toho University, Japan; M.Sc. in 2004, and Ph.D. in Physics in 2007 from Kobe University, Japan. He was an assistant professor at Tokyo University of Science from 2008 to 2011; a Cooperative Researcher at the Research Institute of Electrical Communication, Tohoku University from 2010 to 2016; an assistant professor at Tokyo Denki University from 2011 to 2018; Co-Founder/Vice-President of Felixia Inc. in Japan from 2017 to the present. He is presently an associate professor at the Institute for Advanced Research and Education, Doshisha University, Japan.
Ryo Sekine
Ryo Sekine received B.Info. in 2016 and M.Info. in 2018 from Tokyo Denki University, Japan. He is presently an engineer at Japan Information Processing Service Co., Ltd., Japan.
References
- Pearson K. Notes on the history of correlation. Biometrika. 1920;13(1):25–45.
- Speed T. A correlation for the 21st century. Science. 2011;334(6062):1502–1503.
- Reshef DN, Reshef YA, Finucane HK, et al. Detecting novel associations in large data sets. Science. 2011;334(6062):1518–1524.
- Chen Y, Zeng Y, Luo F, et al. A new algorithm to optimize maximal information coefficient. PLoS ONE. 2016;11(6):e0157567.
- Zhang ZX, Hao W, Chen G, et al. An extension of MIC for multivariate correlation analysis based on interaction information. In: CSAI'18: Proceedings of the 2018 Second International Conference on Computer Science and Artificial Intelligence. 2018. p. 399–403. Shenzhen, China.
- Jaccard P. The distribution of the flora in the alpine zone. New Phytol. 1912;11(2):37–50.
- Tanimoto TT. An elementary mathematical theory of classification and prediction. IBM Internal; 1958. (Technical report).
- Tversky A. Features of similarity. Psychol Rev. 1977;84(4):327–352.
- Takahashi T, Kohno Y, Oyo K. Causal induction heuristics as proportion of assumed-tobe rare instances (pARIs). In: Proceedings of the Seventh International Conference on Cognitive Science. 2010. p. 361–362. Beijing, China.
- Kamiura M, Takahashi T. Informatics of a stochastic model for causal induction. In: Proceeding of the 27th Annual Conference of the Japanese Society for Artificial Intelligence. 2013. 1L5OS24c3 p. 1–3. Toyama, Japan.
- Takahashi T. Correlation detection with and without the theories of conditionals, in logic and uncertainty in the human mind: a tribute to David E. Over. New York, NY: Routledge; 2020. p. 207–226.
- Higuchi K, Oyo K, Takahashi T. Causal intuition in the indefinite world: meta-analysis and simulations. Biosystems. 2023;225:104842.
- Sloman SA, Lagnado D. Causality in thought. Annu Rev Psychol. 2015;66:223–247.
- Hattori M, Oaksford M. Adaptive non-interventional heuristics for covariation detection in causal induction: model comparison and rational analysis. Cogn Sci. 2007;31:765–814.
- Kamiura M. pARIX: an index for causal induction as extended pARIs/JACCARD index. In: Proceedings of the SICE Annual Conference 2014. p. 872–876. Sapporo, Japan.
- Kamiura M. Jaccard matrix supporting calculations of nonlinear correlation. In: Proceedings of the 21st International Symposium on Artificial Life and Robotics (AROB). 2016. OS14-3. Beppu, Japan.
- Murphy KP. Machine learning: a probabilistic perspective. Cambridge, Mass: MIT Press; 2012. p. 35.
- Saad Y. Iterative methods for sparse linear systems. Philadelphia, Penn: SIAM; 2003.
- Buluç A, Fineman JT, Frigo M, et al. Parallel sparse matrix-vector and matrix-transpose-vector multiplication using compressed sparse blocks. In: Proceedings of the 21st Annual Symposium on Parallelism in Algorithms and Architectures (SPAA09). 2009. p. 233–244. Calgary, Canada.
Appendix
In the Appendix, we show the procedures to calculate the approximations of the Jaccard cell (Equation26(26)
(26) ) under the conditions of small values for the cell-size parameters. By completing the square of the exponent of Equation (Equation29
(29)
(29) ), the two-dimensional normal distribution
with correlation coefficient ρ, we can transform it into the following:
(A1)
(A1) where
and
. Let us set the parts of Equation (EquationA1
(A1)
(A1) ) as
(A2)
(A2) then the integral of (EquationA1
(A1)
(A1) ) gives the marginal probability density
as the following:
(A3)
(A3) Assuming the cell-size parameter
is sufficiently small (i.e.
), we can obtain the following approximation of
around
:
(A4)
(A4) therefore we obtain
(A5)
(A5) By the same calculation based on the symmetry of x and y, assuming
is sufficiently small (i.e.
), we can obtain the following approximation of
around
:
(A6)
(A6) In addition, assuming
and
are sufficiently small, we obtain the following approximation of
around
:
(A7)
(A7) therefore we obtain
(A8)
(A8) Consequently, by Equations (EquationA5
(A5)
(A5) ), (EquationA6
(A6)
(A6) ), and (EquationA8
(A8)
(A8) ), we obtain the following approximation of the Jaccard cell (Equation30
(30)
(30) ).