?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
To enable machines to understand human-centric images and videos, they need the capability to detect human–object interactions. This capability has been studied using various approaches, but previous research has mainly focused only on recognition accuracy using widely used open datasets. Given the need for advanced machine-learning systems that provide spatial analysis and services, the recognition model should be robust to various changes, have high extensibility, and provide sufficient recognition speed even with minimal computational overhead. Therefore, we propose a novel method that combines the skeletal method with object detection to accurately predict a set of human, verb, object
triplets in a video frame considering the robustness, extensibility, and lightweight of the model. Training a model with similar perceptual elements to those of humans produces sufficient accuracy for advanced social systems, even with only a small training dataset. The proposed model is trained using only the coordinates of the object and human landmarks, making it robust to various situations and lightweight compared with deep-learning methods. In the experiment, a scenario in which a human is working on a desk is simulated and an algorithm is trained on object-specific interactions. The accuracy of the proposed model was evaluated using various types of datasets.
1. Introduction
Human–object interaction recognition is an important capability that will enable machine-learning algorithms to assist society in understanding the real world. If a computer could understand spatial information as humans do, it could provide superior assistance to humans when needed. The intelligent space (iSpace) concept was created to support people informatively and physically through computer-vision analysis of spaces. iSpaces are rooms or other areas that are equipped with sensors that enable the spaces to perceive and understand what is happening inside them. With such features, people and systems in the iSpace can apply additional functions afforded by the technology. They are expected to have a broad range of applications in homes, offices, factories, and other spaces [Citation1–8]. We proposed a platform that recognizes human states and maps them to an environmental map [Citation9]. By mapping and storing the human state in the environmental map, iSpace can learn information such as user interest and utilization of space and provide improved robot control and information for users. In this study, we verified that the proposed method could apply as a social application with additional experiments in various recognition conditions.
The task of recognizing human–object interaction has been mainly defined as detecting human, verb, object
triplets in an image [Citation10]. The existing recognition method mainly focused on the recognition accuracy and speed against a still image and video. Several deep-learning approaches have been proposed to predict and classify human–object interactions [Citation11–18], and most learn their spatial relationships by applying object-based image segmentation [Citation11,Citation12]. The accuracy of such label-trained approaches depends on human attributes in the training dataset, which include nationality, age, height, and others. To reduce false positives in the predictions, the transferable interactiveness network [Citation13] learns the various types of interactions using multiple datasets. To represent human–object interactions, graph convolutional networks (GCNs) have been used with some success. Spatial–temporal GCN [Citation14] uses pose estimation results as input and learns the relationships of position landmarks related to each action. Graph parsing neural network [Citation15] learns the graph structure of an adjacency matrix filled with node labels that represent object detection classes. PoseConv3D [Citation16] generates a three-dimensional (3D) heatmap from a two-dimensional (2D) human pose to develop robustness in recognizing actions regardless of pose estimation noise. Human–object interaction transformer [Citation17] applies an adapted transformer architecture for object bounding-box regression to provide fast and accurate interaction recognition.
These methods have achieved sufficient performance in image and video recognition accuracy, but in terms of the iSpace concept, their robustness, extensibility, and recognition speed remain insufficient. iSpace aims to support people while providing user-centric services by learning information like characteristics of user behaviours and space utilization through real-time computer-vision recognition in a distributed sensor network with cameras and other devices. Our main concerns with respect to this concept as it relates to human–object interaction recognition are as follows: (1) Recognition robustness of humans (e.g. gender, age, and nationality), camera settings (angle and frame size), and environments (e.g. lighting conditions and background); (2) Model extensibility in terms of ability to quickly train new classes for prediction; (3) Lightweight model that provides real-time recognition speeds with minimized computational overhead.
Depending on the recognition environment, the target people and camera positions may greatly differ. Thus, approaches that rely too heavily on training datasets will probably not satisfy the iSpace concept. In addition, each environment has unique activities or behaviours that need to be recognized. For example, in a factory setting, recognizing the picking of items from shelves may be important for inventory management. In an office setting, recognizing desk work such as typing on a keyboard and using a mouse may be useful for monitoring employee productivity. Therefore, the model should easily extend its prediction classes when necessary. Deep-learning methods require excessive time and data to train the original set of prediction classes. Methods with complex architectures and large datasets also lead to slow speeds that preclude real-time recognition. To overcome these limitations, the proposed human–object interaction model considers the three elements listed above.
Additionally, there has been little discussion in the literature regarding target-object recognition error reductions in detected human–object relationships. To accurately estimate interactions, the model must identify similar actions that are object-agnostic. Human posture is a useful cue for recognizing behaviours in the context of human–object interactions. However, deep-learning methods that rely solely on human skeletal information may not be sufficient, as they can predict the wrong action label from the training dataset even if the ground-truth label is different. This problem has been widely recognized in the research community. An approach is proposed that combines temporal information using optical flow and spatial appearance features for accurate human pose estimation and action recognition in videos [Citation18]. Our approach to addressing these problems is to consider the object type, distance between the human and the object, and shape of the object in predictions. This helps to determine the interactional objects and classify the label accurately. Ordinarily, when training a deep-learning model, one must prepare large numbers of annotated images and video datasets, which requires a huge amount of labour. Our hypothesis in this study is that training a model using a set of similar interaction recognition elements will provide sufficient accuracy, with less training data and less effort. We also hypothesize that the recognition model trained in this fashion will be robust to the diversity of humans, camera settings, and environments by simply relying on coordinates for model training. Additionally, iSpace aims to recognize human–object interactions with lightweight, distributed, and low-computing-power devices. To achieve this, existing lightweight but accurate detection models are adopted as our baseline.
2. Method
In this section, the proposed method of human–object interaction recognition is explained. Each component of the feature extraction process, model training, and inference is discussed. Our objective is to predict triplets of human, verb, object
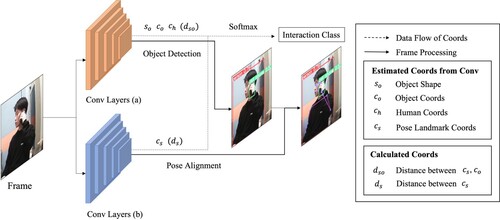
from each video frame as human–object interactions. To predict human–object interactions, the YOLOv5 object detection network [Citation19] is used to extract features of the object shape, and the MediaPipe [Citation20] landmark estimation algorithm is employed to extract features of human posture. Unlike typical deep learning methods that utilize many symbols in an image for feature learning, the proposed model employs logistic regression to extract only necessary symbols, enabling it to quickly capture features. Specifically, using only the coordinates of objects and human position landmarks, the proposed model can learn how humans interact with objects without the need to prepare a large dataset. Therefore, it can easily extend the original action classes. Furthermore, prediction by using only coordinates leads to robust change recognition. To predict human actions, the model is trained using multinomial logistic regression. The dataset consists of prediction class labels and their explanatory variables related to the extracted coordinates about human and object features. In the recognition process, the proposed model calculates the prediction probability of each interaction class, and the final output is the class of maximum probability within each class. Figure illustrates each process and model component. Video frames are passed to the convolution layers. The convolution layer (a) estimates object bounding-box coordinates, including the object shape so, position co, and human position ch, as well as their classes, and the convolution layer (b) estimates human posture landmark cs. The proposed model also calculates the moving distance of each landmark from the previous frame ds and the distance between objects and each landmark dso using the coordinates estimated by the convolution layers. On the softmax layer, the proposed model classifies the interaction class using these coordinates.
Figure 1. Overview of the proposed human–object interaction.
2.1. Feature extraction
2.1.1. Object detection
For the object detection task, the YOLOv5 network is used. The detection object classes depend on the dataset. In this study, the COCO dataset [Citation21] was used for network training. If objects are detected, the object detection branch outputs a bounding-box width and height, so, and the corresponding class label, co and ch.
2.1.2. Pose landmark detection
For the pose landmark detection task, MediaPipe which outputs 33 coordinates was used. BlazePose is a lightweight pose estimation model of MediaPipe [Citation22], which enables high-speed human pose estimation. The pose landmark detection branch outputs relative human pose landmark coordinates based on the pose landmark, cs, and the moving distance of each landmark between frames, ds.
2.1.3. Interaction feature extraction
In human–object recognition, understanding several perceptual elements (e.g. actions, object reactions, and reaching motions [Citation23]) simultaneously leads to the improvement of recognition accuracy. InteractNet [Citation10] learns the action-specific probability density for the target region based on the appearance of the detected person. SP(3 + 1)D (spatially part-based (3 + 1) dimensions) [Citation24] considers the area of interest as the “human intention.” IPNet [Citation25] determines the most likely interaction class using the interaction point and a vector. The ability to recognize elements other than human–object relationships also helps improve accuracy. When recognizing interactions with objects, humans primarily consider factors such as human posture, object type, the distance between the human and the object, and the shape of the object. To account for these factors, the interaction model is trained by extracting the elements representing them from the outputs of the object detection and pose landmark detection models in the proposed method. For the interaction feature, the posture and object features are extracted using MediaPipe (i.e. cs and ds) and YOLOv5 (i.e. so, co, and ch). The proposed model outputs these variables and the distance between the central coordinate of each object and the pose landmark, dso, as calculated by (1).
(1)
(1)
2.2. Training
Human–object interaction recognition requires various perceptual elements. Thus, as explanatory variables, so, co, ch, cs, ds, and dso are extracted from the model. Variables ds and dso are key to robust recognition in terms of humans, camera angles, and environments. These variables are used to predict human–object interactions. Human–object interaction classes, yitr, and action classes, yat, which do not interact with objects, are defined. Multinomial logistic regression (2) is used for model training.
(2)
(2) In (2), µitr and µat represent the log-odds of yitr and yat, respectively. The coefficients βi (where i ranges from 1 to 9) represent the weights of each explanatory variable. The term α in both equations represents the intercept. The term θ represents the predicted probability distribution over the classes, and it is obtained by passing the log-odds µ through the softmax function. Finally, the notation y ∼ Cat(θ) represents the assumption that the observed class labels y are generated from a categorical distribution with probability θ. The variable θ in the equation includes θitr and θat, obtained by applying the softmax function to µitr and µat. The variable y represents the observed class labels generated from a categorical distribution that includes yitr and yat.
2.3. Inference
During the inference process, the final output action class, Cat, and interaction class, Citr, are simultaneously predicted alongside their probabilities. The prediction class is the maximum probability in the Sclass of each interaction model excluding the “none” class (3). To account for interactions with multiple objects, if multiple interactions are predicted with probabilities greater than 80%, they are recognized simultaneously. The proposed model is built to consider the need for privacy protection; thus, the proposed model outputs only class labels.
(3)
(3)
3. Experiments
To verify the proposed recognition model, we conducted experiments on recognition accuracy. In terms of the iSpace concept, our first concern was the recognition robustness of humans, camera settings, and environment. We hypothesized that the coordinates of human posture, object shape, and their relationship could contribute to robust recognition of the elements of our concern. To confirm this, we performed experiments in a variety of situations and verified the contributions of each model element. Using only 2D image coordinates to determine whether a human is truly interacting with an object is challenging. Thus, we also conducted the experiment using multiple cameras for complementary recognition accuracy. Since action classes to be recognized differed based on the situations of their use, a model that could easily extend recognition classes was needed. Hence, we also experimented with model extensibility. To show the versatility independent of the computing resources, we also tested the recognition speeds. The validation dataset in all the experiment except for validation of robustness was the set of recognition log against the video frames that include real-time continuous activity and changing actions. The activity assuming the desk-working was done in the various situations considering elements related to robustness.
3.1. Datasets
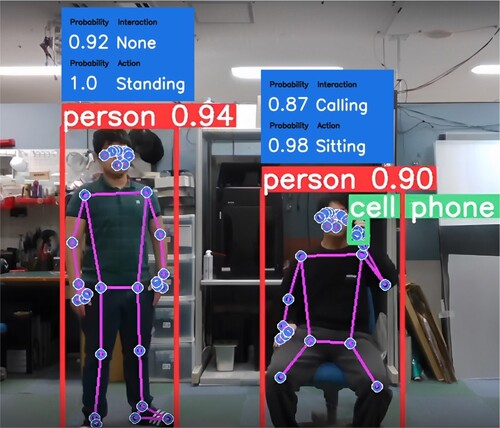
A new dataset consisting of prediction class labels and their explanatory variables was built. As the prediction classes, actions that include human–object interactions that occur during desk work were defined. The interaction classes of four objects from the COCO dataset were defined (i.e. mobile phone (holding, calling, and none), keyboard (working on a computer and none), book (holding, reading, and none), and bottle (holding, drinking, and none)). For human actions, three classes were also defined (i.e. walking, standing, and sitting). The size of each dataset was 900 frames. Figures and show the human pose and object shape of each interaction class and action class.
Figure 2. Human–object interaction class examples recognized by the proposed method.

Figure 3. Action class examples recognized by the proposed method.

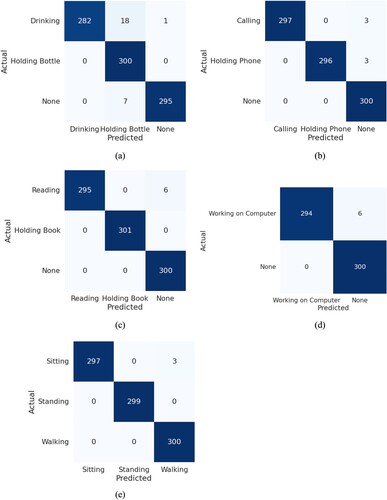
Figure 4. Model accuracies of the proposed method: (a) bottle, (b) mobile phone, (c) book, (d) keyboard, and (e) actions (no interaction).
3.2. Robustness
The robustness of the proposed model was evaluated. As shown in Figure , the recognition accuracy of the proposed model was first tested by using a validation dataset from the same situational domain as the training dataset. The validation set included 300 frames of data per interaction and was classified with high accuracy.
To verify the robustness of the proposed human–object interaction recognition method, the recognition result for the video dataset of mobile phone was set as the baseline in Table because of its high accuracy. The unification of recognition conditions except for the target element also leads to suitable validation. Human–object interactions were then recognized by changing each human, camera angle, camera frame size, and experiment environment. As shown in Table , there was no significant observed degradation in prediction accuracy from the base result. The results indicate that the proposed model provides robust recognition under various and changing conditions. Each result in Table reflects the average score for each experimental component. Table shows the results for four subjects who differed in terms of gender, nationality, and personal accessories. We also conducted experiments to evaluate the effect of changing the camera angle on recognition accuracy and the results are shown in Table . A constant angle difference was selected considering real-world recognition situations. Each angle in Table represents vertical camera angle variations. We defined negative angles as rotations in the downward vertical direction and positive angles as rotations in the upward vertical direction. Table lists the different camera frame-size results. In selecting these sizes, we took into account the commonly used aspect ratios (i.e. 1:1, 3:2, 4:3, and 16:9). Table demonstrates the effect of experimental environments on the recognition accuracy. The experimental environment for clean space refers to an area where only objects that are relevant to the recognition task are present. Messy space represents the space where objects that are not relevant to the interaction task, such as bookshelves, are present. The narrow space and wide space are 1.2 × 2.5 m and 4.5 × 4.7 m, respectively.
3.3. Ablation study
The evaluations of the performance contributions of the different components of the proposed method are listed in Table . The considered factors included object features co and so, the moving distance of each pose landmark between frames ds, and the distance between the central coordinate of the object and each pose landmark dso. Each component contributed to the improvement of recognition accuracy. Furthermore, our hypothesis that the object shape is an important component of human–object interaction recognition was verified. The proposed method improved the accuracy by 10% better than that using only human pose coordinates.
3.4. Multi-camera complementarity
A 2D interaction model cannot accurately recognize the location relationship between humans and objects owing to occlusions and unrecognizable depths of the field. A multi-camera configuration can overcome this problem. Thus, the recognition accuracy was verified using several test cases, including target-object occlusion and various pose interactions, by setting up two cameras. The performance of the proposed model with one or two cameras is shown in Table .
Table 1. Robustness experiment.
Table 2. Robustness with various subjects.
Table 3. Robustness with various camera angles.
Table 4. Robustness with various camera frame sizes.
Table 5. Robustness in various environments.
Table 6. Ablation study on the explanatory variables in the proposed method.
Table 7. Comparison of accuracy on consideration of multi-camera complementarity.
Table 8. Effect of accuracy on changing the size of training dataset.
Table 9. Effect of accuracy on changing the number of recognized interaction models.
Table 10. Recognition speed experiment on various processor.
3.5. Model extensibility
By using similar perceptual elements of human–object interaction to humans, the proposed model captured the relationship between human and object even with a small dataset. To test the accuracy, the proposed model was trained with different dataset sizes as shown in Table . The accuracy of action recognition in cases involving actions characterized by similar postures is influenced by the number of interaction models that can be recognized. For instance, when detecting the action of drinking, calling class also has a similar posture. However, our model also uses object class information, which addresses this problem. Table shows the effect of the number of interactions to predict a 30-second video which includes the action of the bottle model (holding, drinking, and none).
3.6. Recognition speed
Table demonstrates that the proposed model achieved recognition speeds of 10 FPS or higher on various types of processors. In this experimental study, we utilized two computing devices (no GPU), NUC5i7RYH (Intel® Core™ i7-5557U processor) and the NUC11PAHi7 (Intel® Core™ i7-1165G7 processor), and a desktop computer equipped with a GPU (GeForce RTX 3080 Ti) and a CPU (Intel® Core™ i7-10700 processor). These computing resources were employed in a scenario involving the provision of services through distributed sensors in a spatial context. Small-scale computers such as the aforementioned NUC models are particularly suitable as edge devices in this context. Consequently, we conducted an evaluation of recognition speeds for both CPU and GPU resources. The findings from this experimental investigation demonstrate that the proposed model can achieve speeds adequate to meet real-time requirements for recognizing human-object interactions, even when utilizing edge-computing resources.
4. Discussion
It was confirmed that robustness to changes in the person, camera frame size, and the environment was achieved because only human posture and object features were used as explanatory variables for human–object interaction prediction. Additionally, because the posture moving distance between frames was considered, the recognition was also made robust to changes in the camera angle. In our results, no significant degradation in prediction accuracy was observed. This indicates that the proposed model provides robust recognition under a variety of changes, which makes it more generalizable than most. The environment in which human–object interactions take place may also be key to recognizing the interaction. Thus, discrete environmental features might also be considered explanatory variables in the future. The results related to dataset size indicate that the proposed model can be trained with smaller datasets in general, and the recognition speed results show that the proposed model can handle real-time social performance needs.
5. Conclusions
In this study, we proposed a human–object interaction recognition method for practical social use that only uses pose and object coordinates. The high efficacy of the proposed method in terms of robust recognition of person, camera setting, and the environment was demonstrated by the experiment. The proposed method is superior to methods that use only posture information, and the concatenation of object features and the relationship between human and object leads to a more accurate recognition. In the ablation study, we found that the object shape was an important cue for human–object interaction recognition. Multi-camera complementarity reduces recognition errors (e.g. occlusion and similar behaviours). Through experiments, it was also demonstrated that the proposed model was easily extensible to the new prediction classes and provided sufficient recognition speed even with minimal computational overhead. In future work, we plan to develop applications that learn spatial utilization and user characteristics using the proposed method.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
Haruhiro Ozaki
Haruhiro Ozaki received his B.E. from Ritsumeikan University, Japan in 2022. He is currently a master’s student at the Graduate School of Information Science and Engineering, Ritsumeikan University. His main research interests include intelligent space, computer vision, and machine learning.
Dinh Tuan Tran
Dinh Tuan Tran is currently an associate professor at the College of Information Science and Engineering, Ritsumeikan University, Japan. His main research interests include machine learning, computer vision, image processing, and robotics.
Joo-Ho Lee
Joo-Ho Lee is currently a professor at the College of Information Science and Engineering, Ritsumeikan University, Japan. His main research interests include intelligent space, robotics, artificial intelligence, and human interface.
References
- Lee J-H, Hashimoto H. Intelligent space–concept and contents. Adv Robot. 2002;16:265–280. doi:10.1163/156855302760121936.
- Maegawa K, Shiotani T, Iwamoto K, et al. Ubiquitous display 2.0: development of new prototype and software modules for improvement. 10th International Conference on Ubiquitous Robots and Ambient Intelligence; 2013 Oct 30–Nov 2; Jeju, South Korea, p. 102–107. doi:10.1109/URAI.2013.6677483.
- Park J, Lee J-H. Reconfigurable intelligent space, R+iSpace, and mobile module, MoMo. IEEE/RSJ International Conference on Intelligent Robots and Systems; 2012 Oct 7–12; Vilamoura-Algarve, Portugal, p. 3865–3866. doi:10.1109/IROS.2012.6386282.
- Itsuka T, Song M, Kawamura A, et al. Development of ROS2 -TMS: new software platform for informationally structured environment. Robomech J. 2022;9:1. doi:10.1186/s40648-021-00216-2
- Murakami K, Tsuji T, Hasegawa T, et al. Object tracking system by integrating multi-sensored data. IECON 2016 - 42nd Annual Conference of the IEEE Industrial Electronics Society; 2016 Oct 23–26; Florence, Italy, p. 747–754. doi:10.1109/IECON.2016.7793355
- Pyo Y, Hasegawa T, Tanaka M, et al. Measurement and estimation of indoor human behavior of everyday life based on floor sensing with minimal invasion of privacy. 2013 IEEE International Conference on Robotics and Biomimetics; 2013 Dec 12–14; Shenzhen, China, p. 2170–2176. doi:10.1109/ROBIO.2013.6739791
- Niitsuma M, Kobayashi H, Shiraishi A. Enhancement of spatial memory for applying to sequential activity. Acta Polytech Hung. 2012;9:121–137.
- Irie K, Wakamura N, Umeda K. Construction of an intelligent room based on gesture recognition: operation of electric appliances with hand gestures. IEEE/RSJ International Conference on Intelligent Robots and Systems; 2004 Sept 28–Oct 2; Sendai, Japan, 193–198. doi:10.1109/IROS.2004.1389351
- Ozaki H, Tran DT, Lee J-H. Human state recognition method in intelligent space. 2023 International Symposium on System Integration; 2023 Jan 17–20; Atlanta, GA, USA.
- Gkioxari G, Girshick R, Dollár P, et al. Detecting and recognizing human–object interactions. 2018 IEEE/CVF Conference on Computer Vision and pattern Recognition; 2018 Jun 18–23; Salt Lake City, UT, USA, p. 8359–8367. doi:10.1109/CVPR.2018.00872
- Chao Y-W, Liu Y, Liu X, et al. Learning to detect human–object interactions. 2018 IEEE Winter Conference on Applications of Computer Vision; 2018 Mar 12–15; Lake Tahoe, NV, USA, p. 381–389.
- Wang T, Anwer RM, Khan MH, et al. Deep contextual attention for human–object interaction detection. In: 2019 IEEE/CVF International Conference on Computer Vision, 2019 Oct 27–Nov 2, Seoul, Korea, p. 5693–5701. doi:10.1109/ICCV.2019.00579
- Li Y-L, Zhou S, Huang X, et al. Transferable interactiveness knowledge for human–object interaction detection. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2019 Jun 15–20; Long Beach, CA, USA, p. 3580–3589. doi:10.1109/CVPR.2019.00370
- Yan S, Xiong Y, Lin D. Spatial temporal graph convolutional networks for skeleton-based action recognition. The 32nd AAAI Conference on Artificial Intelligence; 2018 Feb 2–7; New Orleans, LA, USA, p. 1–9.
- Qi S, Wang W, Jia B, et al. Learning human–object interactions by graph parsing neural networks. In: Ferrari V, Hebert M, Sminchisescu C, Weiss Y, editors. Computer vision- ECCV 2018. Lecture notes in computer science, Vol. 11213. Cham: Springer. doi:10.1007/978-3-030-01240-325
- Duan H, Zhao Y, Chen K, et al. Revisiting skeleton-based action recognition. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2022 Jun 19–24; New Orleans, LA, USA, p. 2959–2968. doi:10.1109/CVPR52688.2022.00298
- Kim B, Lee J, Kang J, et al. HOTR: End-to-end human–object interaction detection with transformers. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2021 Jun 20–25; Nashville, TN, USA, p. 74–83. doi:10.1109/CVPR46437.2021.00014
- Pfister T, Charles J, Zisserman A. Flowing convnets for human pose estimation in videos. 2015 IEEE International Conference on Computer Vision (ICCV). IEEE; 2015, p. 1913–1921.
- YOLOv5. [Cited 2023 Apr 10]. Available from: https://github.com/ultralytics/yolov5.
- MediaPipe. [Cited 2023 Apr 10]. Available from: https://google.github.io/mediapipe/.
- Lin T-Y, Maire M, Belongie S, et al. Microsoft COCO: common objects in context. In: Fleet D, Pajdla T, Schiele B, Tuytelaars T, editors. Computer vision- ECCV 2014: Lecture notes in computer science, vol 8693. Cham: Springer. doi:10.1007/978-3-319-10602-1
- Bazarevsky V, Grishchenko I, Raveendran K, et al. BlazePose: On-device real-time body pose tracking. arXiv preprint. 2020. doi:10.48550/arXiv.2006.10204
- Gupta A, Kembhavi A, Davis LS. Observing human–object interactions: using spatial and functional compatibility for recognition. IEEE Trans Pattern Anal Mach Intell. 2009;31:1775–1789. doi:10.1109/TPAMI.2009.83
- Fan H, Zhuo T, Yu X, et al. Understanding atomic hand-object interaction with human intention. IEEE Trans Circuits Syst Video Technol. 2022;32:275–285. doi:10.1109/TCSVT.2021.3058688
- Wang T, Yang T, Danelljan M, et al. Learning human-object interaction detection using interaction points. 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2020 Jun 14–19, Online, p. 4115–4124. doi:10.1109/CVPR42600.2020.00417
Appendices
Appendix 1: extension to 3D recognition
To recognize and understand where and how humans interact with objects in the space of a given environment, the coordinates of features need to be 3D, because interaction recognition using 2D coordinates cannot appropriately classify the interactions. Multi-camera calibration can be used to retrieve 3D coordinates, but doing so requires preconfiguring each scenario, and even slight camera movements can cause problems. Therefore, recognition using depth cameras was considered. Using RealSense, which estimates the distances of objects using parallax, the depth coordinates of objects and humans and the 3D distances between human pose and object central coordinates were considered in the prediction. Thus, the model can predict interactions more accurately than models using only 2D coordinates, as shown in Table .
Table A1. Comparison of accuracy on consideration of depth coordinates.
Appendix 2: extension to multi-person interaction recognition
Considering the social applications of recognizing human–object and human–human interactions, multiple pose estimation and tracking are required for the baseline model. We chose MediaPipe as the pose estimation model because it is lightweight. However, this model estimates only the pose of one person at a time. Several multi-pose estimation methods have been proposed, but they require computers with high computational performances. To verify that the proposed method works when extended to multi-person recognition tasks, the original recognition system was developed to estimate multiple poses. The YOLOv5 tensor corresponding to the person detection bounding box was used instead of the whole camera frame as the pose estimation input of the model. Relative human posture features and those of humans and objects were modelled. Therefore, if multiple poses are recognized, the proposed model can be easily adapted to multi-person prediction, as shown in Figure .
Figure A1. Multi-person interaction recognition.