
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Efficiently recognizing Activities of Daily Living (ADLs) requires overcoming challenges in collecting datasets through innovative approaches. Simultaneously, it involves adapting to the demand for interpreting human activities amidst temporal sequences of actions and interactions with objects, considering real-life scenarios and resource constraints. This study investigates the potential of generating synthetic training data for ADLs recognition using the VirtualHome2KG framework. Furthermore, we investigate the transformative potential of simulating activities in virtual spaces, as evidenced by our survey of real-world activity datasets and exploration of synthetic datasets in virtual environments. Our work explicitly simulates activities in the 3D Unity platform, affording seamless transitions between environments and camera perspectives. Furthermore, we meticulously construct scenarios not only for regular daily activities but also for abnormal activities to detect risky situations for independent living, ensuring the incorporation of critical criteria. We incorporate one contemporary method for abnormal activity detection to demonstrate the efficacy of our simulated activity data. Our findings suggest that our activity scenario preparation accomplishes the intended research objective while paving the way for an interesting research avenue.
1. Introduction
The significance of human activity datasets cannot be overlooked in enhancing the quality of life for an ageing society and promoting independent living. The core objective of identifying risks in daily living activities to ensure the safety of older adults in their home hinges on access to these vital datasets. As we navigate the Fourth Industrial Revolution (4IR), marked by advancements in virtual reality (VR), robotics, and machine automation, the integration of health-assistive technologies takes centre stage. While household robots with monitoring capabilities hold immense potential for safeguarding older adults against maltreatment and supporting their independence, the data forms the bedrock of these advancements. Envisioning a future where AI assistants or robots can undertake myriad complex tasks, from meal preparation [Citation1] to assist in accident recovery [Citation2], underscores the pressing need for comprehensive datasets. These datasets enable AI assistants to interpret human instructions and interact with their environment effectively. As the primary sensory tool, the camera is pivotal in data acquisition, driving processes such as object detection [Citation3], and detailed environmental analysis. Given the increasing demand for deep analytics and recognition tasks, the critical question arises: Where can we source the diverse dataset necessary to train these household robots and establish intelligent monitoring systems? In answering this question, we can unlock the potential of the transformative technologies, such as simulating synthetic data, to enhance the safety and well-being of older adults in their homes.
Indeed, the progress in the realm of human action recognition owes much to the dynamic development of benchmark datasets, as reflected in several commendable research efforts [Citation4–7]. These datasets serve as the foundational pillars that underpin vision-based systems, offering a glimpse into human actions within real-life settings, mirroring the way people naturally go about their daily routines. Nevertheless, there persist constraints in terms of human resources, time, and budget, which hinder the creation of complete home-like environments with multiple sensors and furnishings. Moreover, the intrinsic challenge lies in understanding behaviour as a coherent sequence of continuous actions – a feature found in only select existing datasets. Even seemingly simple activities, such as “making and enjoying a cup of coffee,” comprise a multitude of discrete steps. These steps involve intricate processes like “preparing a coffee maker,” “grinding coffee beans,” “boiling water,” and “pouring coffee into a cup.” Often, unrelated actions are intertwined with the core activity, and temporal gaps or omissions may occur in the recorded time series. Hence, the ability to synthesize these diverse actions into a unified understanding, such as “making and enjoying a cup of coffee,” becomes pivotal for comprehending a scene fully. To achieve this level of understanding, it is imperative to discern primary postures and movements in relation to the environment over a temporal continuum. Leveraging concepts like affordance and situational awareness, researchers are actively working on creating virtual human representations in virtual spaces, replicating the intricacies of daily household tasks. This innovative approach not only offers a promising avenue for training robots but also holds great potential for enhancing monitoring systems, ultimately contributing to the safety and well-being of individuals in their living spaces [Citation8].
In this paper, we present two profound contributions. First, we conduct a comprehensive survey aimed at integrating knowledge from real-life ADLs datasets, shedding light on their existing limitations. This survey serves as a valuable guide for creating informative synthetic datasets. Synthetic data, which refers to artificially generated data that replicates the properties and patterns of real-world data related to human activity but does not contain information about actual individuals or entities, plays a crucial role in supporting activity recognition tasks and advancing robotics applications. We also explore how synthetic data has proven instrumental in these domains. Our second contribution involves an extensive review of active activity datasets in virtual spaces. Building upon this survey, we present meticulously designed scenarios for ADLs, complete with critical criteria, to facilitate the generation of activity datasets using the VirtualHome2KG [Citation9,Citation10] framework.
It is worth noting that this study builds upon our previous work [Citation11] with more notable enhancements. Firstly, we expand our survey to encompass a wider array of synthetic datasets, enabling us to simulate a new ADLs dataset with a richer and more diverse set of data, free from the limitations inherent in real-life datasets. Secondly, we delve into the changing landscape of research tasks in human activity recognition and robotics, reflecting the evolving nature of these fields over time. Lastly, we leverage the insights gained from our survey to craft activity scenarios, which in turn inform the creation of the activity dataset through the application of the VirtualHome2KG framework. To validate the effectiveness of our simulated activity data, we employ one comprehensive method for abnormal activity detection. Our findings not only demonstrate the successful accomplishment of our research objectives but also pave the way for intriguing avenues of future research in this dynamic and transformative domain.
The rest of this paper is organized as follows: Section 2 provides the related works; Section 3 presents the surveys of benchmark activity datasets in real-world environment and synthetic datasets with embodied AI simulators; Section 4 describes the preparation of activity scenarios for the data simulation and generation processes; Section 5 examines the effectiveness of the generated datasets in improving abnormal activity detection; and finally, Section 6 includes the conclusions of this paper.
2. Related work
Reflecting on the extensive body of research in this domain, it is evident that the development of benchmark datasets for human action recognition has been a dynamic endeavour [Citation12–14]. Beddiar et al. [Citation12] undertook the task of cataloguing publicly available datasets, categorizing them into five action-level datasets (e.g. jogging, walking, jumping), three behaviour-level datasets (e.g. meeting with others, leaving a package in a public place, window shopping), nine interaction-level datasets (e.g. drinking, eating, reading), and nine group activities-level datasets (e.g. boxing, punching including multiple persons). Their focus was to assist researchers in selecting datasets pertinent to their specific research areas. However, this effort primarily addresses dataset availability and usage rather than a detailed description of the specific requirements of each dataset, a critical foundation for recognition tasks. There remains a scarcity of guidance on the real-life activities that should be incorporated into such datasets. Similarly, Sharma et al. [Citation13] provided an extensive overview of deep learning-based algorithms applied to 13 prominent activity datasets spanning the period from January 2011 to May 2021. In line with [Citation12], this work predominantly outlines dataset features, yet may benefit from a more detailed analysis. More recently, Olugbade et al. [Citation14] highlighted limitations in activity datasets concerning data size and interdisciplinary applicability. While existing reviews emphasize dataset strengths, this work underscored the necessity for a comprehensive study that amalgamates dataset features. The authors analysed 704 datasets spanning diverse fields, including human–computer interaction, machine learning, human activity recognition, disability innovation, clinical psychology, affective computing, and movement neuroscience. In our previous study [Citation11], we scrutinized nine real and synthetic ADLs datasets spanning from 2016 to 2021, discerning essential criteria for activity datasets. This comparison yielded pivotal insights that could catalyse future research challenges. Firstly, we describe the problem of determining continuous actions, defining them as activities, and structuring these activities into daily episodes. Secondly, we explore the potential of simulating virtual agents to surmount privacy constraints inherent in vision-based monitoring systems. Lastly, we advocate the utilization of knowledge graphs to harness copious semantic information for enhanced visualization of daily activities. Semantic information in the context of human daily activities represents the meaningful and contextually rich details that describe not only the actions being performed but also the relationships, intentions, and significance behind those actions. This integration of semantic information enhances the visualization of daily activities.
Recent years have witnessed significant attention towards developing simulated activity video data involving avatars in cyberspace. This attention stems from the potential advantages these advancements offer, particularly in enhancing embodied AI system’s ability to identify everyday hazards that pose challenges for detection [Citation15]. One notable framework in this realm is the VirtualHome2KG framework [Citation9,Citation10], proposed by Egami et al., which revolves around creating Knowledge Graphs (KGs) that depict daily life activities within virtual environments. Its primary objective is to streamline the generation of virtual environments teeming with avatars engaged in a spectrum of daily activities. These synthetic KGs serve as a contextual representation for simulated activity video data, empowering researchers to analyse human behaviour in virtual domains. Egami et al. [Citation8] demonstrated the potential of VirtualHome2KG by showcasing its ability to learn and interpret daily life activities in virtual spaces. Beyond serving as a valuable resource for behaviour recognition research, this framework opens doors for exploring diverse AI techniques to tackle real-world challenges, such as detecting fall risks among older adults. In our research, we leverage the VirtualHome2KG framework to generate daily activity data to detect and identify risks associated with daily activities.
Concurrently, machine learning techniques have found widespread application in human activity recognition (HAR) and anomaly detection. These methodologies harness the computational prowess of algorithms and statistical models to delve into data patterns, facilitating the automated identification and categorization of human activities, as well as the detection of abnormal behaviour. For example, our prior research [Citation16] emphasized detecting abnormal events, particularly within the context of human posture analysis and decision-making processes. In this paper, we employed our previously proposed method [Citation17] for detecting simulated abnormal activities. This approach serves as a compelling showcase of the effectiveness of our simulated activity data in a comprehensive manner.
3. Research efforts in vision-based activity datasets
As vision-based ADLs datasets must provide challenges to be applied in practical applications, the essential criteria for preparing such datasets have already been presented in our previous work [Citation11]. This work gives more extensive examples of those criteria and datasets obtained in real-life. We conducted a survey of the most influential research published between 2016 and 2023 by searching for the keywords “Activity recognition datasets, synthetic datasets” on Google Scholar. Our selection process focused on identifying popular datasets relevant to our targeted research tasks.
3.1. Benchmark activity datasets in read-world settings
In human activity recognition datasets, the criteria of context awareness, spontaneous acting, framing techniques, and cross-scene cross-view are crucial, as they collectively shape the depth and authenticity of our understanding of real-world activities [Citation11]. Context Awareness plays a pivotal role in interpreting a scene, enabling us to derive meaningful insights from it. This context encompasses a wide range of information, including the environment depicted in an image, the arrangement of surrounding objects, their physical attributes, and the circumstances surrounding a human subject within that environment. It takes various forms, including knowledge of the individual’s identity, the activity being performed, the location, the time of day, and the reasons behind the actions. For instance, consider an image from the HOMAGE [Citation7] dataset as illustrated in Figure , where we observe a young man, approximately 25 years old, searching for something in a kitchen cabinet around noon. Examining this scene reveals critical elements. Firstly, it presents a realistic depiction of a household, complete with furniture, and showcases items like the stove, kitchen cabinet, and kitchen table, providing unmistakable evidence that this space is indeed a kitchen. Secondly, to fully comprehend the situation and recognize that a 25-year-old man is conducting this activity, it is imperative to focus on the individual participant, considering factors such as his age, gender, and background. Moreover, the Spontaneous Acting of the young man extends beyond mere postures and movements. It encompasses the natural interaction between humans and objects within the kitchen. This level of detail is crucial for understanding the depth and authenticity of the depicted activity. Furthermore, Framing Techniques employed in capturing this scene must facilitate a comprehensive view. Close-up shots focusing solely on the person could limit the context provided, whereas broader, low-framing techniques offer a more encompassing view of the person’s actions within the kitchen. To complete the contextual scenery, it is necessary to consider Cross-Scene Cross-View aspects. It is a feature that allows a dataset to integrate information from different perspectives and points of view using multiple cameras. This criterion is crucial for datasets that provide a continuous view of a person’s activities and capture activities from various angles and locations. It ensures that the dataset can offer a comprehensive view of human activities in different environmental conditions and scenarios, enhancing the dataset’s utility for research and analysis.
Figure 1. Example context related to human household activities, behaviour, or kitchen usage patterns.
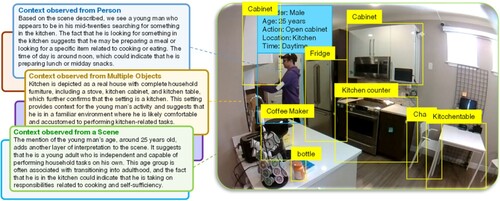
In our survey of Activities of Daily Living (ADLs) datasets, we emphasize the above pivotal criteria that collectively contribute to the authenticity and utility of these datasets in understanding human activities. We explore the datasets that align with these criteria to provide a holistic perspective on human activity recognition in real-world settings. CLAD dataset [Citation18] is proposed to make complex scenarios into long-range activity videos. However, recording video is limited by the environmental context because human activity can only be recorded in a specific research lab, not in a home residential setting. Similarly, in the DAHLIA dataset [Citation19], the activities were recorded in a real residential environment, but only one kitchen room was utilized. Thus, assuming that the context was rich enough isn’t easy. Instead of filming video footage in a research lab, the Charades [Citation4], Toyota SmartHome [Citation5], and HOMAGE [Citation7] datasets capture activity videos from typical homes complete with bedrooms, kitchens, living rooms, and bathrooms using a large number of participants and different ages. Moreover, the NTU RGB+D dataset [Citation6] also captures activity data to provide a variable atmosphere under 96 different environmental conditions to become a qualitative dataset. Moreover, 106 participants of varying gender, age, and cultures were used to perform daily household activities. This way, contextual information is freed from bias as much as possible.
Another related criterion here is spontaneous acting, which allows the participants to do the activities freely without giving specific instructions. Even in the time cycle of a day, a person can do numerous and complex activities. Since there are no limitations for people to perform daily tasks at will, it should be natural to perform activities in preparing ADLs dataset or activity recognition tasks used in practice. In order to get a truly unbiased view of natural activities, Toyota SmartHome [Citation5] consisted of 18 older adults aged 60–80 who were videotaped for 8 h a day from morning to afternoon without any pre-defined scripts. Similarly, the HOMAGE [Citation7] dataset also allowed the 27 participants to act as naturally as possible without time and actions, allowing them to do as they desired.
Video recording techniques are also needed to significantly include context in every video frame sequence. Most existing datasets: Charades [Citation4], NTU RGB+D [Citation6], CLAD [Citation18], DAHLIA [Citation19] only focus on action with the intention of action recognition. Thus, they tend to shoot close-ups to see the person clearly. In other words, the scene is limited by framing techniques. For example, let’s say that the recording scene performs the eating activity. A person enters the scene, sits in front of a simulated kitchen table to have a meal, and serves the activity of eating. In that scene, the participant can provide the context of interaction with the object. However, it cannot give a richer context since the background is too specific. The person’s movement can only be done in the same place and cannot change in a time series. It is because the distance between the camera and the participant is close, and a background setting of a broader range cannot be provided. Such a kind of video recording technique is defined as high framing. A low-framing technique that can capture the entire room is necessary to keep a continuous view of a person’s activities. However, in practice, it is difficult to capture the scene of a whole room in a residential home using a single camera. Thus, multiple cameras are installed in places where activities are needed to capture.
The ability to integrate information from different points of view using multiple cameras is defined as shooting with a cross-scene cross-view setting [Citation20]. Data samples in these benchmark ADLs datasets: Toyota SmartHome [Citation5], NTU RGB+D [Citation6], HOMAGE [Citation7] were considerably acquired from multiple camera views to include synchronized video streams from multiple perspectives with low-level action and high-level activity interpretation. Table describes consistent features observed among the real-world activity datasets.
Table 1. Consistent features observed among the real-world activity datasets.
3.2. Synthetic activity datasets with embodied AI simulators
Synthetic datasets are widely adopted for several key reasons. They serve to replicate intricate activity scenarios over time, which can be challenging to acquire through actual data collection. These synthetic datasets are instrumental in bolstering the volume of training data required for intelligent monitoring systems in robotics. Moreover, they help circumvent the privacy concerns associated with collecting real-world data for human activity recognition while striving to minimize biases inherent in such datasets. In this section, we offer an overview of five synthetic activity datasets that have emerged between 2018 and 2023. These datasets have been meticulously crafted using AI simulators to mimic various purposes and support a range of research tasks. The datasets under discussion include VirtualHome [Citation21], ElderSim [Citation22], SIMS4ACTION [Citation23], iGibson [Citation24], and AI2THOR [Citation25]. This comprehensive survey delves into the features of these datasets, illustrating how they effectively simulate the intricate realities of complex daily activities.
3.2.1. Features in simulating synthetic activity dataset
Over the past two decades, there has been a rapid emergence of action datasets collected from real-world settings. However, these datasets often fall short when it comes to providing scenarios that perform satisfactorily in real-world vision-based recognition applications. Typically, these datasets are collected under idealized conditions.
To address this limitation, VirtualHome [Citation21] was introduced as a platform for simulating household activities and enabling interaction among multiple agents using high-level directives. It uses a game-based scene method with a Python API and 3D assets to create a rich environment across seven apartments. Agents can manipulate objects and engage in various activities, with a focus on interactive objects and multi-agent support. The platform offers over 150 cameras in each scene, providing top, first-person, and third-person views for analysing human postures and motions. It includes 75 atomic actions in 12 categories to train robots for common home activities.
Hwang et al. [Citation22] introduced ElderSim to address the deficiency of existing synthetic datasets for action recognition and elderly care applications. ElderSim, built using Unreal Engine 4® (UE4)Footnote1 and Autodesk Maya®,Footnote2 features 13 agents specializing in older adults’ activities. The simulation closely mimics daily living environments, utilizing 40 markers and 16 motion capture (MoCap) cameras for realistic motion. It includes 55 activity classes, 35 with human-object interaction and 28 object classes. An important feature is the real-time sunlight change effect, making it practical for various applications.
While the Toyota Smarthome dataset [Citation5] was designed for recognizing older adults’ activities, Roitberg et al. [Citation23] identified challenges in expanding this dataset to include new scenarios, movements, environments, and actors of different ages. The SIMS4ACTION dataset [Citation23] is a video game-based activity simulation that addresses various challenges. It focuses on simulating virtual subjects, replicating human behaviours, and creating virtual environments for these subjects. Unlike other datasets that mainly consider appearances and demographics, SIMS4ACTION excels in simulating detailed personalization, including traits, emotions, and walking styles. It covers 10 common household activities and numerous atomic actions, providing a wide range of behaviour recognition capabilities. Notably, it enhances the simulation duration for activities like cooking and eating, offers insights into room-specific activity locations, and specifies camera types and placements in the virtual environment.
The iGibson dataset [Citation24] was introduced in contemporary research activities to train and evaluate robots in unique scenarios, such as door opening and object retrieval, following human instructions. iGibson’s notable features include its physics-based rendering, supporting over 500 objects and 15 interactive scenes for more realistic environmental settings compared to game-based simulators. It allows transparent changes to object states and properties, including food states and cleanliness levels. Furthermore, iGibson includes AI robot models like Husky [Citation26], Fetch [Citation27], and TurtleBot2 [Citation28], acting as virtual subjects for household activities, and it supports activity scenarios using real humans through a virtual reality (VR) interface. It has been instrumental in advancing research in point navigation and object navigation challenges.
Lastly, Kolve et al. [Citation25] introduced the AI2-THOR framework, built on the Unity physics engine, to realistically model object properties and scenes. Like iGibson, VirtualHome, AI2-THOR allows changes in object states, enabling actions like picking up, throwing, and pushing objects. It also employs robot models for multi-agent interactions in household tasks. AI2-THOR boasts a substantial number of interactive objects, totalling 3578, with environmental metadata providing 3D bounding boxes and scene bounds to facilitate robot navigation. However, it has limitations in actions and lacks a human avatar.
The features observed among datasets are summarized in Table . These datasets collectively offer diverse options for training and evaluating models in action recognition and related research fields. The features of these synthetic datasets have drawn significant attention when creating activity scenarios for activity simulation tasks.
Table 2. Consistent features observed among the synthetic activity datasets.
3.2.2. Applied synthetic activity datasets in embodied AI research
This section briefly presents research areas that are intensively using synthetic activity datasets. Duan et al. [Citation29] presented that the structure of AI research tasks to become practical technology has increased with more complexity. It has progressed from the bottom of the level of visual navigation, including point navigation [Citation30], object navigation [Citation31], vision, and language navigation [Citation32], to embodied question answering (EQA), including multi-target question answering (MQA) [Citation33] and interactive question answering (IQA) [Citation34]. In this work, the synthetic datasets mentioned in the above section are discussed in which research tasks are utilized. The iGibson dataset [Citation24] is commonly used in point navigation, where a robot agent is instructed to navigate a specific point, and object navigation, where a robot is instructed to navigate a particular class of object. In addition, question answering (QA) requires visual awareness, abilities to understand the language given by humans, and answering questions to train the agent to interact with the real environment. AI2-THOR [Citation25] also has been downloaded to conduct several experiments for a wide range of research. The first exciting research area is object detection in computer vision since many types of objects have been simulated. Visual navigation, vision, and language navigation (VLN), as well as the study of object relationships and affordance concepts, are also usefully applied in particular and very deep analysis. However, many research works using VirtualHome [Citation21], ElderSim [Citation22], and SIMS4ACTION [Citation23] datasets to recognize normal or abnormal human behaviour have yet to emerge. Therefore, the challenging research tasks would be interesting if a dataset such as VirtualHome2KG [Citation9,Citation10] framework is applied. Table summarizes the research areas, the datasets used, and the specific research tasks associated with each dataset in the context of recognition tasks.
Table 3. Applied synthetic activity datasets in AI research tasks.
4. Scenarios preparation for activity dataset in virtual space
In this section, we delve into the process of preparing verbal scenarios for Activities of Daily Living (ADLs) to construct a comprehensive dataset. The subsequent subsections elaborate on critical components, including the introduction of the VirtualHome2KGFootnote3 [Citation9,Citation10] framework employed for the generation of activity data. Figure illustrates a schematic representation of our workflow, where “selection of activities,” “scenarios,” and “activity program structure” serve as inputs. These components undergo a seamless integration facilitated by the VirtualHome2KG framework, generating synthetic activity data as the output. The detailed intricacies of each phase, encompassing environmental settings, statistical distribution for generated image data, and challenges encountered, are expounded upon in their respective subsections.
Figure 2. Overall workflow of activity scenario preparation and simulation task.
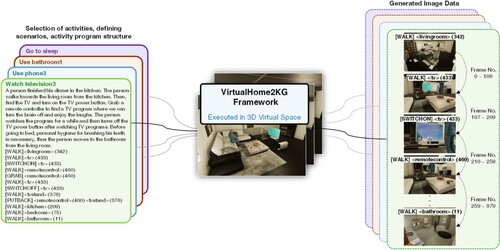
4.1. VirtualHome2KG framework
In this section, we elucidate the process of generating human activity data using the VirtualHome2KG [Citation9,Citation10] framework. To begin, we provide a comprehensive overview of the VirtualHome2KG framework, offering a clear description of its functionalities and components. This introduction serves as a foundation for understanding the subsequent steps involved in generating human activity data within the context of this innovative framework. VirtualHome2KG is a purpose-built framework to construct and enrich Knowledge Graphs (KGs), structured representations of information that depict relationships and connections between entities or concepts. Here, these KGs revolve specifically around daily living activities using virtual environments.
Initially, an VirtualHome2KG ontologyFootnote4 was designed using the Web Ontology Language (OWL) and proceeded to construct synthetic data (KGs) in alignment with the structure defined by the ontology schema. This ontology effectively captures the intricate interplay between activities and their constituent actions, alongside the sequencing of object states, affordances, and spatiotemporal dynamics. Figure shows a part of the designed class diagram of ontology (Egami et al. [Citation8]). We here present the basic principles of reading the ontology diagram. The classes in the ontology are depicted as rectangles or ovals, representing different types of entities. For instance, classes include ho:Activity, :Action, :Object, :Event, among others. The relationships between classes are illustrated by arrows connecting them. Arrows denote connections and associations between classes, such as an arrow from :Object to :Action signifying a relationship between actions and objects. Annotations in the form of text labels on classes and arrows provide additional information, aiding in clarification and context. In the context of the ontology, we have described:
:Episode—:hasActivity→ho:Activity represents an episode contains one or more activities. :Episode indicates a segment, referring to a series of connected activities. :hasActivity suggests a relationship where an episode encompasses.
ho:Activity—:hasEvent→:Event represents an activity is associated with one or more events. ho:Activity indicates an activity performed by agent (:Character), and it connects to :Event with using the :hasEvent relationship.
:Event—:agent→:Character indicates that an event involves an agent.
:Event—:place→:Room suggests that an event takes place in a particular room. The :place relationship links the event to the room where it occurs.
:Event—:from→:Room and :Event—:to→:Room represent the spatial aspects of an event, specifying the starting :from and ending :to points or the movement from one room to another during the event.
:Event—:mainObject→:Object and :Event—:targetObject→:Object: An event involves a primary object :mainObject and may target another object :targetObject.
:Event—:action→:Action represents that :action relationship shows actions associated with the event. It indicates primitive actions such as WALK, GRAB, EAT, etc.
:Event—:situationBeforeEvent→:Situation and :Event—:situationAfterEvent→ :Situation connect an event to situations, representing the state of the environment or objects before :situationBeforeEvent and after :situationAfterEvent the event occurs.
:Event—:time→time:TemporalEntity, :Event—:time→time:TemporalDuration: Here, the :time relationship associates an event with temporal aspects, linking to a specific time entity or duration. It is also suggested that each event involves a specific interaction with a target object by taking a certain amount of time to complete. For example, the action “SIT on sofa” consists in interacting with the “sofa” object and has a duration associated with it.
rdfs:subClassOf represents way to establish a hierarchy, where subclasses inherit properties and relationships from super classes. For example, in :StartEvent—:rdfs:subClassOf→:Event and EndEvent—:rdfs:subClassOf→:Event, the :StartEvent is a subclass of :Event that shares common attributes with events in general but have specific features that distinguish them as starting events. Similarly, the :EndEvent is also a subclass of :Event that shares common attributes with events but has distinctive features related to ending events.
Figure 3. Part of the designed class diagram of ontology [Citation8].
![Figure 3. Part of the designed class diagram of ontology [Citation8].](/cms/asset/c64a2d72-0c4b-441e-aed3-281c0edea465/tmsi_a_2318848_f0003_oc.jpg)
For interacting with object, :Object class is formed to represent a physical object in environment and :State class to capture the state of an object at a specific time, with its associated :StateType, a size and spatial 3D coordinates of an object (x3do:Shape), and :attribute. Defining next and previous relations of the object states can track temporal changes in the object’s state. In these relations, :StateType class represents a specific state value an object can have, such as OPENED, SWITCHON, CLOSED, etc. The meaningful connections between entities in the ontology are described:
:Object—:affords→:Action and :Object—:attribute→:Attribute represents an object has the potential to afford certain actions and specific attributes. Consider an instance of :Object representing a “sofa,” which may afford the action of “SIT” and processes the attributes like “SITTABLE.” Thus, affordance represents object properties that provide executable actions to agents (e.g. GRABBALE, SITTABLE).
:State—:isStateOf→:Object means that the state of an object can be represented, indicating the condition or status of that object at a specific time. An instance of :State might be “OPEN” state of a “microwave.” The :isStateOf connects this state to the microwave.
:State—:state→:SateType suggests that the state of a microwave could be classified as “OPENED” or “CLOSED.”
:Object—:bbox→:x3do:Shape: Objects have associated shapes, and the :bbox could represent a simplified shape enclosing the object.
:Situation—:partOf→:Object or :State: To incorporate the spatial changes that occur before and after the execution of each event in an activity, the authors constructed the :Situation class. This allows us to capture the context and changes in the environment as actions are performed and to effectively track changes in the state of objects over time. For example, the action “Sit on Sofa” involves the agent interacting with the object “Sofa.” The “Sit on Sofa” action is facilitated by the “SITTABLE” affordance of the sofa, allowing the agent to perform the sitting action. The action might have a pre-defined duration of 30 s, during which the agent remains seated.
This example illustrates how the ontology effectively captures the interaction, state changes, affordances, and attributes associated with an agent’s action, ultimately enriching the simulation with detailed context and realism. The designed ontology has facilitated the creation of KGs focusing on single activities in daily life. However, real-life scenarios involve a sequence of activities. To tackle this, a method was proposed to extract activities from the KGs, ensuring coherence between before and after situations. Using Markov chain modelling, a comprehensive KG representing sequences of daily living episodes was generated [Citation10].
4.2. Selection of activities
Daily activities vary from person to person, but there are common examples that many people engage in on a regular basis. Examples include “getting out of bed and brushing teeth,” “preparing and eating meals,” “working or studying,” “leisure,” “engaging in physical exercise,” “socializing with pets, and winding down before bedtime.” In this study, we consider these activities to be essential parts of our daily routines, helping us maintain a balanced and productive life. When selecting daily activities to simulate, we drew inspiration from VirtualHome [Citation21], adopting its some activity names and program structure as a foundation. However, it’s important to note that our simulations diverge from VirtualHome [Citation21] regarding scenarios, interactive objects, and step-by-step actions. These divergences result from our unique and thoughtful considerations, resulting in simulations that offer a distinctive experience. Specifically, we select 11 categories [Citation21] of everyday household tasks that happen in a real-life environment. To enhance clarity, Table comprehensively describes the categories, accompanied by their corresponding brief descriptions and exemplary activities.
Table 4. Selected categories of daily living activities and their general description.
Next, we discuss the representation of abnormal activities. Egami et al. [Citation8] classified risk factors into three categories to construct KGs such as dangerous action (i.e. Go up or down the steps), dangerous interactions (i.e. reach an object that is in the high place), and dangerous spatial relationship (i.e. an object is placed on an aisle) based on the reports of safety engineering experts, data provided by the Tokyo Fire Department, and accidental falls in elderly homes. To simulate abnormal activity in virtual space, the possible activities are selected according to the surveys [Citation8]. Some of the activities are considered based on the publications of the Canadian Institutes of Health Research [Citation35]. Table provides simulated abnormal activities occurred in home environments.
Table 5. Selected abnormal activities occurred in home environments.
4.3. Creation of scenarios and activity programs
To simulate the natural activity of daily living, we adhere to two essential criteria for scenario preparation. The first criterion ensures that the action steps are capable of meaningfully describing the activity. In the case of “Clean_television,” the main action must convey the concept of cleaning, and the target object must be clearly identified as a television. With these criteria in mind, we create a scenario and activity program using VirtualHome2KG. The framework utilizes the capabilities of the VirtualHome platform to simulate a diverse range of daily living activities within 3D virtual environments. The structure of an activity comprises three integral components: the activity name, the scenario that defines the context of the activity, and the program outlining the step-by-step instructions on how to execute the activity. For instance, a scenario of an activity named “Clean_television” is described below: “Walk to the kitchen and look at the TV. Find and grab a towel to clean the TV. Wipe down the television using that towel.” An activity program is defined as a sequential arrangement of actions, each associated with an object’s name and its corresponding object ID as shown in equation (1).
(1)
(1) where stept means the steps of action over time t, actiont means performed actions over time t, objectt,n represents an interacted object by a virtual agent, and idt,n is a unique counter of an object over time t which could be distinguished from multiple instances of objects in an environment. In “Clean_television” activity, the “[WIPE]” action is used to interpret the cleaning action, and the “towel” is the cleaning material that fulfils the meaningful representation of the cleaning activity. This program embodies the process of cleaning a television and can be executed in different virtual environments. It encapsulates the key steps and actions required to perform this common household task effectively. In this way, we have prepared over 600 daily activity scenarios in total.
The second criterion, which is crucial in creating scenarios for simulating natural activities, involves aligning the steps of actions with the object’s affordance. In this context, affordance refers to an object’s inherent properties and functions. To illustrate this concept, let’s consider an example related to a “bed.” A “bed” primarily affords actions such as lying down and sitting on it. These actions align with the bed’s intended use and functionality. However, if a virtual human is standing on a bed, it may be considered an abnormal action because it deviates from the typical affordance of a bed. To determine whether this situation is normal or abnormal, people can observe the factors: Why is the virtual human standing on the bed? It could be for reaching something high on a shelf, changing a lightbulb, or any other specific purpose. By considering these factors how the action aligns with the object’s affordance, we can determine whether the situation is normal or abnormal. This consideration allows us to create scenarios that reflect real-world behaviours and interactions, ensuring that virtual humans’ actions are consistent with the properties of the objects and environments they interact with. This paper mainly focuses on the “Fall” as a target abnormal action that interoperates with an object’s properties, such as “Fall while standing at somewhere height.” We have prepared a total of more than 100 abnormal activity scenarios. Our simulated activity’s scenariosFootnote5 are available under the VirtualHome2KG framework.
4.4. Properties of the simulated activity data
We present the properties of simulated activity data, encompassing key elements such as the environmental setting, scenario components, recording of generated image data, and the unique challenges.
4.4.1. Environmental setting
The VirtualHome2KG framework [Citation9,Citation10], is implemented through the utilization of Extended-VirtualHome.Footnote6 This extended platform, derived from VirtualHome [Citation21] and based on VirtualHome v2.2, incorporates some additional functions to enhance its capabilities. VirtualHome platform [Citation21] typically incorporates over 150 cameras in each scene. These cameras offer three dynamic views: top view, first-person view, and third-person view. In our current work, we select to generate image data using the first-person and third-person perspectives. However, these views might obscure human-object interactions and limit the visibility of the full-bodied virtual human. To address this, we add static camera views as illustrated in Figure , with four cameras in each room’s corner (e.g. living room, bedroom, kitchen, and bathroom) across all scenes, ensuring comprehensive data coverage. In Extended-VirtualHome, significant improvements have been made regarding camera perspective and the ability to capture actions. The field of view has been expanded to 70 degrees, providing a broader view of the environment. This version employs five points of view: one first-person view, one third-person view, and three additional points of view (POV) strategically selected using suitable cameras. Moreover, it enables actions to be performed using room transitions, enhancing the realism and complexity of simulations by allowing seamless movement between rooms.
Figure 4. Static camera settings installed in each room’s corner.
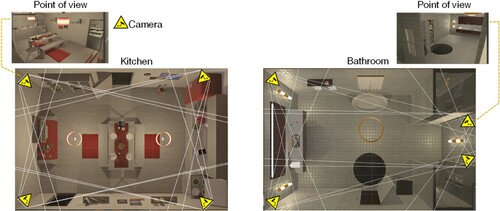
4.4.2. Scenario components
In our scenario components, we employed one virtual human for dataset generation sessions. One vital application of daily living activity detection is the monitoring of older patients. Thus, the virtual human’s walking characteristics were programmed to simulate a non-fast walking pace like older adults. This virtual human’s actions were recorded in rooms with both lighting on and off conditions. The virtual human’s behaviour was guided by an activity program outlining their expected interactions with objects across seven scenes. The selection of objects for interaction was determined based on the specific requirements of each activity. For example, in the leisure activity of “watching television,” the virtual human interacted with objects like the television and remote control as required by the activity’s parameters.
4.4.3. Recording generated image data
During the execution of scenarios and activity programs, videos are generated at a rate of 30 frames per second, with an RGB image size of 640 × 480, which aligns with the standard resolution commonly used in real-world scenarios. The dataset comprises two modalities for image generation: RGB and 3D skeleton (pose). Notably, the virtual skeleton data is directly extracted from the 3D Unity platform, but it is available for a single view only. It is worth noting that the limitation arises when aligning the skeleton data with the agent in each video scene, as the skeleton posture and position may not be identical for each camera view. However, the use of virtual skeleton data offers distinct advantages, including the ability to provide complete pose data even when certain body parts are obscured from view. This advantage proves valuable when developing and accessing algorithms for tasks such as action recognition, posture estimation, or activity monitoring, as it enables a more comprehensive understanding of human body movements and interactions in scenarios. Additionally, the Extended-VirtualHome generates JSON data files containing 2D bounding boxes of objects in images at five-frame intervals. This information provides spatial context and object localization data, enhancing its utility for computer vision and machine learning applications.
Our activity scenarios are carried out by multi-view settings, where multiple cameras capture the activities. Furthermore, the scenarios are meticulously designed to incorporate detailed room transition descriptions, enabling seamless action movement between rooms. This deliberate preparation enhances the overall realism and complexity of simulations. Next, we present the statistics related to the distribution of activities in the scenarios. Figure illustrates the distribution of actions and objects in different activity categories for seven scenes. In this context, “occurrences” refers to the frequency or number of times a particular action or object was observed within each category, serving as a measure of prevalence. In the “Abnormal” category, the highest occurrences of the “WALK” action suggest that falls commonly occur during dynamic activities involving walking; this is due to the agent losing balance or encountering obstacles while in motion. The presence of high occurrences of objects such as “sofa” and “bed,” along with occurrences in the “bedroom,” “bathroom,” indicates behaviours associated with falls. “sofa” and “bed” emerge as crucial supportive objects for “Fall while sitting down or lowering,” “Fall while getting up or rising” and fall while walking forward somewhere else. Additionally, the prominence of falls in the “bedroom” and “bathroom” emerges as a common location for falls, contributing to the high occurrences in these rooms. In the “EatingDrinking” category, the data in Figure reveals that the action with the highest occurrence is “WALK.” This finding suggests that, in the depicted scenarios, an agent is frequently observed walking while eating or drinking. The prevalence of the “WALK” action is linked to contextual factors inherent in the scenarios or data collection. For instance, it is plausible that the scenarios include situations where the agent is commonly seen walking from one location to another with food or beverages. Similarly, the object “waterglass” also serves as a symbolic representation of beverages in general, encompassing not only water but also other drinks like juice or milk. If the categorization includes different beverages under the “EatingDrinking” category, the versatile use of water glasses for various drinks could contribute to its high occurrence. In the “HouseCleaning” category, the data reveals that the action with the highest occurrences is “WALK,” suggesting that walking is a prevalent activity during house cleaning scenarios. This observation indicates that the agent is frequently observed moving around while engaging in various cleaning tasks within a household setting. Additionally, the notable occurrences of cleaning materials such as “sponge,” “towel,” and “sink” suggest the key objects involved in the cleaning process. The “sponge” and “towel” are common tools used for wiping and cleaning surfaces, while the “sink” points to the location where cleaning activities related to dishwashing or other tasks occur.
Figure 5. Alignment of objects and actions with activity categories – Abnormal, EatingDrinking, and HouseCleaning.
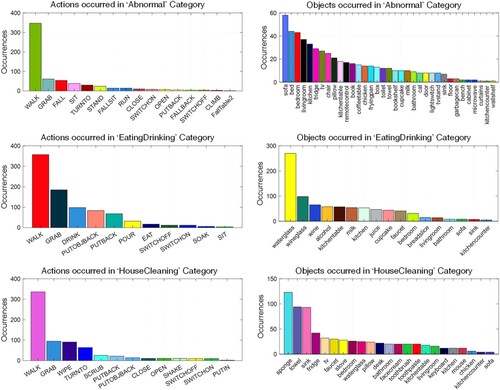
Our scenarios also incorporate objects and actions that align with their respective activity categories. For instance, in the “EatingDrinking” category, items like milk, cupcake, and juice are associated with actions like grabbing, eating, and drinking, respectively. Hence, objects related to food and beverages, including alcohol, juice, milk, wine, cupcakes, water glasses, and wine glasses, are categorized under “EatingDrinking.” Likewise, actions such as drinking, eating, pouring, and grabbing are also encompassed within the “EatingDrinking” category. Thus, our scenarios are valuable because they reflect the objects and actions commonly encountered in everyday human activities. In Figure , we observe the distribution of activities measured in the number of action steps within a scenario. The shortest activity, “Relax on sofa,” in leisure category typically involves just three steps, such as [WALK] <living room> (1), [WALK] <sofa> (1), and [SIT] <sofa> (1). On the other hand, the longest activity, “Clean kitchen,” consists of multiple composite tasks like “Clean sink,” “Clean fridge,” “Clean kitchen table,” and “Clean stove,” each comprising a series of intricate actions. Likewise, when we examine the duration of each activity, it becomes evident that activities with longer action sequences result in longer overall durations for those activities. These long-tail distributions are the characteristic features of real-world scenarios. Our simulated activity’s video dataFootnote7 is available under the VirtualHome2KG and Figures and display RGB video results based on the given normal and abnormal scenarios, respectively. The availability of 3D skeleton (pose) data is imminent in our repository.
Figure 6. Distribution of activities measured in the number of action steps in scenarios.
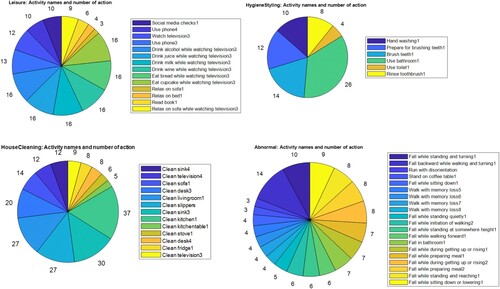
Figure 7. Some simulated daily activities in the virtual homes, exploring various scenarios and interactions.
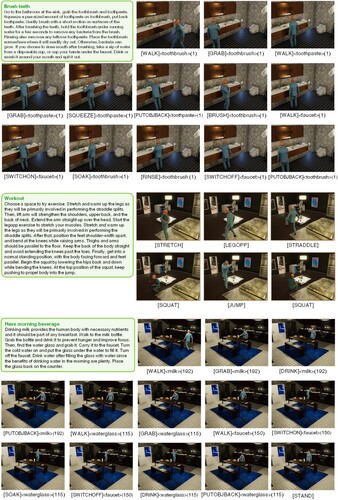
Figure 8. Some simulated abnormal activities in the virtual homes, exploring unexpected risky situations.

4.4.4. Challenges
We present challenging activity scenarios that demand models to navigate complex situations. Composite activities: The scenarios encompass both particular activities (e.g. Use toilet, Hand washing), as well as composite activities (e.g. Use bathroom) involving the execution of multiple particular activities, such as “Use toilet,” “Hand washing,” “Preparing for brushing teeth,” “Brush teeth,” and “Rinse toothbrush.” These composite scenarios are crucial for forming realistic simulations, as they replicate real-world situations where multiple actions are often interrelated and must be considered in tandem. Abnormal activities: The challenges of abnormal fall scenarios in various settings are multifaceted and demand specialized solutions. Falls occur in specific contexts, such as getting up or rising from a seated position and preparing meals, which pose unique challenges. These scenarios often involve movements and environmental factors that can make fall detection and response more intricate. Falls during activities like sitting down or lowering oneself, standing and reaching for objects, and turning while standing are particularly challenging to detect accurately, as they require systems to differentiate between regular movements and falls. Additionally, falls at elevated locations, such as standing at heights, introduce added complexities and risks. Ensuring privacy, real-time response, and integration with healthcare systems are common challenges across these scenarios. Moreover, tailoring fall detection solutions to address the distinct characteristics of each scenario while minimizing false alarms remains an ongoing and critical challenge in fall detection and prevention. These multifaceted challenges underscore the importance of innovative, context-aware approaches to enhance the safety and well-being of individuals in various fall-prone situations.
4.4.5. Ethical considerations
Ethical considerations are the cornerstone of our work when preparing scenarios for our human activity dataset. Our unwavering commitment is to create virtual human activity scenarios that mirror real-life interactions and adhere to the highest ethical standards. Fundamental to this commitment is our dedication to respecting the cultural, social, and ethical values held by individuals and communities. Our foremost objective is to carefully curate scenarios that avoid any potential to promote harm or perpetuate biases, ensuring that our virtual environments remain safe, inclusive, and free from content that could be harmful or prejudiced. By rigorously upholding these ethical principles, we aim to provide a dataset that not only reflects the richness of human activities but also fosters an environment of respect, empathy, and fairness for all users and participants.
5. Evaluation on simulated activities
To assess the feasibility of our concept in recognizing ADLs through the simulated activity data, we employ a comprehensive method dedicated to detecting abnormal activities.
5.1. Abnormal activity detection
We utilized human skeleton data from the VirtualHome2KG based on our simulated activity scenarios. We used Virtual Grounding Point Calculation [Citation17], which is employed to extract a virtual grounding point (VGP) from human skeleton data to analyse stability and posture during activities. The feature representation is illustrated in Figure . Initially, it involves calculating the base of support (BoS) for a standing human body based on the positions of critical skeletal points, such as the toes. Subsequently, the body’s centre of mass (CoM) is determined, typically found along the vertical axis, providing insights into stability during different activities. A vertical line is then drawn from the head to the BoS, facilitating alignment of the vertical axis with the base of support. The point where this line intersects with the BoS is computed, revealing crucial details about the relationship between the CoM and BoS. An intersection point is calculated to form the VGP, representing a significant point on the ground indicative of stability and posture. Finally, the distance (d) between the CoM and VGP is computed using the Euclidean distance as shown in Equation (2), offering valuable information about how posture changes during activities like standing, walking, or falling.
(2)
(2) where d means Euclidean distance between the centre of mass (CoM) and virtual grounding point (VGP).
Figure 9. Illustration of feature extraction: construction of virtual ground point (VGP) and posture deformities are estimated by calculating angles involving three points in the upper body of skeleton image.
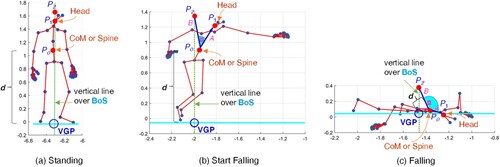
For the next feature, posture deformities are estimated by calculating angles involving three points in the upper body of the skeleton image: the head (P1), spine (P0), and a point (P2) on the vertical line over the base of support (BoS), as illustrated in Figure . The objective is to identify unusual postures, particularly during falls or moments of instability, where the angles between these three points may exceed 90 degrees. For instance, when a person falls or assumes an abnormal posture, the angle between the spine and head can widen beyond 90 degrees. This can occur as the spine arches backward or twists unnaturally due to losing balance, significantly if the person tilts their head backward during the fall. The degree (θ) between three points is calculated as shown in Equation (3) to quantify these angles and estimate posture deformities.
(3)
(3) Here, θ represents the angle, π is the mathematical constant pi, tan−1denotes the arctangent function, Ax and Ay represent the x and y components of vector A (a vector from the head (P1) to spine (P0)), similarly, Bx and By represent the x and y components of vector B (a vector from a point (P2) on the vertical line over BoS to spine (P0)).
5.2. Experimental results and discussion
The study utilizes the VirtualHome2KG dataset, which simulates abnormal activities in seven scenes using a single virtual agent. Within this context, 19 scenarios, including the abnormal action “fall,” are randomly selected and examined. The work focuses on two key features for representation: firstly, the distance (d) between the centre of mass (CoM) and the Virtual Grounding Point (VGP), and secondly, the angular orientation (θ) derived from three upper body points. Analysis of CoM and VGP changes reveals that the distance between them shortens when a person initiates a fall. To distinguish between abnormal and normal states, a threshold of less than one (positive) is set for the optimal distance. During falls or unusual postures, the angle (θ) between three points – head, spine, and a point of the vertical line over the BoS – can exceed 90 degrees. To assess the effectiveness of these features, four possible outcomes are defined: detected abnormal state, undetected abnormal state, normal state, and misdetected normal state, as outlined in reference [Citation16]. Table provides a detailed performance evaluation for each scenario, including precision (PRC), recall (RCL), and accuracy (ACC) for both distance (d) and angular orientation (θ) features. Here, the scene specifies the scene in which the activity is simulated.
Table 6. Performance evaluation on some simulated abnormal activity data.
The comprehensive evaluation of scene-specific performance across simulated activities reveals notable patterns. In scenarios involving falls, whether in the bathroom or when getting up or rising, the method demonstrates a high precision, suggesting that it is likely to be correct when the method identifies a fall. However, there is a need to extend the investigation of scenarios for “Falls during getting up or rising,” as performance variability across scenes emphasizes the challenges associated with transitions from sitting to standing. This analysis could help refine the methodology for optimal performance in various scenarios that involve common human movements. Analysing “Falls while preparing meals” unveils performance variability, with scene 6 showcasing effectiveness in capturing falls during meal preparation. Additionally, scenarios related to “Falls while standing and turning” display varying performance, with scene 3 consistently excelling. Examining factors contributing to the success of scene 3 informs potential enhancements for capturing falls during activities involving turning motions. While the results are promising in simulated environments, further validation and testing in real-world scenarios could be extended in future work. Factors such as lighting conditions, variations in human anatomy, and different real-world home settings might impact the method’s performance. This study’s focus on static representations prompts consideration for incorporating temporal aspects and dynamic movements. Exploring the impact of dynamic sequences in fall detection scenarios could guide future model enhancements.
6. Conclusion
In this work, we conducted a comprehensive survey of existing ADLs datasets, encompassing both real-world and virtual spaces. This exploration allowed us to discern the strengths and weaknesses inherent in these datasets, ultimately guiding us towards our central objective of generating a context-rich activity dataset. Leveraging the knowledge gleaned from our survey, we meticulously crafted scenarios that mirror people’s daily activities. Additionally, we incorporated abnormal scenarios, which play a critical role in elderly care. Our utilization of the VirtualHome2KG framework proved instrumental in generating video data accompanied by rich metadata, enhancing the versatility of our dataset for research purposes, particularly in action recognition and abnormal action detection tasks. Our evaluation employed human skeleton data, with features like the Virtual Grounding Point and angular orientation, to distinguish normal and abnormal conditions. In summary, our dataset and methodologies contribute significantly to activity recognition and simulation. This resource enables the development of innovative algorithms for fall detection, action recognition, and activity monitoring in virtual and real-world contexts, fostering advancements in understanding human behaviour. In the future, we will focus on the daily life cycle and extend our work of simulating lifelog activity scenarios that can provide more meaningful context.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors

Swe Nwe Nwe Htun
Swe Nwe Nwe Htun received the PhD degree in the Materials and Informatics at the Interdisciplinary Graduate School of Agriculture and Engineering, University of Miyazaki, Japan in 2020. She is currently a Post-Doctoral Researcher with the National Institute of Advanced Industrial Science and Technology (AIST), Japan. Her research interests include image search engines, image recognition and understanding human behaviour.

Shusaku Egami
Shusaku Egami received the PhD degree in engineering from The University of Electro-Communications, Tokyo, Japan, in 2019. He is currently a Senior Researcher with the National Institute of Advanced Industrial Science and Technology (AIST), Japan. He is also a part-time Lecturer with Hosei University, Tokyo, and a Collaborative Associate Professor with The University of Electro-Communications. His research interests include semantic web, ontologies, and knowledge graphs.

Ken Fukuda
Ken Fukuda received the PhD degree in information science from The University of Tokyo, in 2001. As a PhD student, he received the Research Fellowship for Young Scientists. He joined the National Institute of Advanced Industrial Science and Technology (AIST), as a Research Scientist, in 2001. He was a Visiting Lecturer with The University of Tokyo and a Visiting Associate Professor with Waseda University. Since then, he has led multiple national and international projects, covering a broad range of interdisciplinary research from life science to service science. He is currently leading the Data-Knowledge Integration Team, Artificial Intelligence Research Center, AIST. He is also a Collaborative Professor with The University of Electro-Communications. His research interests include knowledge representation, knowledge graphs, data-knowledge integration, and human–robot interaction.
Notes
References
- Padmakumar A, Thomason J, Shrivastava A, et al. TEACh. Task-driven embodied agents that chat. AAAI Conference on Artificial Intelligence; 2021.
- Wright J. Tactile care, mechanical hugs: Japanese caregivers and robotic lifting devices. Asian Anthropol. 2018;17:24–39. doi:10.1080/1683478X.2017.1406576
- Pillai S, Leonard JJ. Monocular SLAM supported object recognition. 2015 Robotics: Science and Systems Conference; 2015 July.
- Sigurdsson GA, Varol G, Wang X, et al. Hollywood in homes: crowdsourcing data collection for activity understanding. In: Leibe B, Matas J, Sebe N, et al., editors. Computer vision – ECCV; Lecture notes in computer science, Vol. 9905. Cham: Springer. doi:10.1007/978-3-319-46448-0_31
- Das S, Dai R, Koperski M, et al. Toyota smarthome: real-world activities of daily living. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV); Seoul, Korea (South); 2019. p. 833–842. doi:10.1109/ICCV.2019.00092
- Shahroudy A, Liu J, Ng T, et al. NTU RGB+D: a large scale dataset for 3D human activity analysis. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2016. p. 1010–1019.
- Rai N, Chen H, Ji J, et al. Home action genome: cooperative compositional action understanding. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); Nashville, TN; 2021. p. 11179–11188. doi:10.1109/CVPR46437.2021.01103
- Egami S, Ugai T, Oono M, et al. Synthesizing event-centric knowledge graphs of daily activities using virtual space. IEEE Access. 2023;11:23857–23873. doi:10.1109/ACCESS.2023.3253807
- Egami S, Nishimura S, Fukuda K. VirtualHome2KG: constructing and augmenting knowledge graphs of daily activities using virtual space. International Semantic Web Conference (ISWC) Posters, Demos, and Industry Tracks; 2021.
- Egami S, Nishimura S, Fukuda K. A framework for constructing and augmenting knowledge graphs using virtual space: towards analysis of daily activities. In: 2021 IEEE 33rd Int. Conf. on Tools with Artificial Intelligence (ICTAI); 2021. p. 1226–1230. doi:10.1109/ICTAI52525.2021.00194
- Htun SNN, Egami S, Fukuda K. A survey and comparison of activities of daily living datasets in real-life and virtual spaces. In: 2023 IEEE/SICE International Symposium on System Integration (SII); Atlanta, GA; 2023. p. 1–7. doi:10.1109/SII55687.2023.10039226
- Beddiar DR, Nini B, Sabokrou M, et al. Vision-based human activity recognition: a survey. Multimed Tools Appl. 2020;79:30509–30555. doi:10.1007/s11042-020-09004-3
- Sharma V, Gupta M, Pandey AK, et al. A review of deep learning-based human activity recognition on benchmark video datasets. Appl Artif Intell. 2022;36(1):2093705. doi:10.1080/08839514.2022.2093705
- Olugbade T, Bieńkiewicz M, Barbareschi G, et al. Human movement datasets: an interdisciplinary scoping review. ACM Comput Surv 2023;55(6):1–29, Article no. 126. doi:10.1145/3534970
- Fukuda K, Ugai T, Oono M, et al. Daily activity data generation in cyberspace for semantic AI technology and HRI simulation. 40th Annual Meeting of the Japan Robotics Society of Japan; 2022 Sept; 3J1-03.
- Htun SNN, Zin TT, Hama H. Virtual grounding point concept for detecting abnormal and normal events in home care monitoring systems. Appl Sci. 2020;10:3005. doi:10.3390/app10093005
- Htun SNN, Egami S, Duan Y, et al. Abnormal activity detection based on place and occasion in virtual home. In: 15th International Conference on Genetic and Evolutionary Computing (ICGEC 2023); Kaohsiung, Taiwan; 2023 Oct 6–8; Vol. 2, Lecture notes in electrical engineering, Vol. 1114. Springer.
- Tayyub J, Hawasly M, Hogg DC, et al. CLAD: a complex and long activities dataset with rich crowdsourced annotations; ArXiv, abs/1709.03456; 2017.
- Vaquette G, Orcesi A, Lucat L, et al. The daily home life activity dataset: a high semantic activity dataset for online recognition. In: 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017); 2017. p. 497–504.
- Zhang Q, Lin W, Chan AB. Cross-view cross-scene multi-view crowd counting. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021. p. 557–567.
- Puig X, Ra KK, Boben M, et al. VirtualHome: simulating household activities via programs. In: 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition; 2018. p. 8494–8502.
- Hwang H, Jang C, Park G, et al. ElderSim: a synthetic data generation platform for human action recognition in eldercare applications. IEEE Access. 2023;11:9279–9294. doi:10.1109/ACCESS.2021.3051842
- Roitberg A, Schneider D, Djamal A, et al. Let’s play for action: recognizing activities of daily living by learning from life simulation video games. In: 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS); Prague, Czech Republic; 2021. p. 8563–8569. doi:10.1109/IROS51168.2021.9636381
- Li C, Martín-Martín R, Lingelbach M, et al. iGibson 2.0: object-centric simulation for robot learning of everyday household tasks; ArXiv, abs/2108.03272; 2021.
- Kolve E, Mottaghi R, Han W, et al. AI2-THOR: an interactive 3D Environment for visual AI; ArXiv, abs/1712.05474; 2017.
- HUSKY unmanned ground vehicle [Internet]; [cited 2023 Apr 20]. Available from: https://clearpathrobotics.com/husky-unmanned-ground-vehicle-robot/
- Fetch robotics [Internet]; [cited 2023 Apr 20]. Available from: https://fetchrobotics.com/
- TurtleBot2 [Internet]; [cited 2023 Apr 20]. Available from: https://www.turtlebot.com/turtlebot2/
- Duan J, Yu S, Li T, et al. A survey of embodied AI: from simulators to research tasks. IEEE Trans Emerging Topics Comput Intell. 2022;6:230–244. doi:10.1109/TETCI.2022.3141105
- Pérez-D’Arpino C, Liu C, Goebel P, et al. Robot navigation in constrained pedestrian environments using reinforcement learning; arXiv preprint arXiv:2010.08600; 2020.
- Shen B, Xia F, Li C, et al. Igibson 1.0: a simulation environment for interactive tasks in large realistic scenes. 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS); 2020.
- Anderson P, Wu Q, Teney D, et al. Vision-and-language navigation: interpreting visually-grounded navigation instructions in real environments. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018. p. 3674–3683.
- Yu L, Chen X, Gkioxari G, et al. Multi-target embodied question answering. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019; Long Beach, CA; 2019 Jun 16–20. p. 6309–6318.
- Gordon D, Kembhavi A, Rastegari M, et al. IQA: visual question answering in interactive environments. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition; 2018. p. 4089–4098.
- Robinovitch SN, Feldman F, Fabio YY, et al. Video capture of the circumstances of falls in elderly people residing in long-term care: an observational study. Lancet. 2013;381:47–54. doi:10.1016/S0140-6736(12)61263-X