
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Despite the increasing use of digital media data in communication research, a central challenge persists – retrieving data with maximal accuracy and coverage. Our investigation of keyword-based data collection practices in extant communication research reveals a one-step process, whereas our cross-disciplinary literature review suggests an iterative query expansion process guided by human knowledge and computer intelligence. Hence, we introduce the WordPPR method for keyword selection and text data retrieval, which entails four steps: 1) collecting an initial dataset using core/seed keyword(s); 2) constructing a word graph based on the dataset; 3) applying the Personalized PageRank (PPR) algorithm to rank words in proximity to the seed keyword(s) and selecting new keywords that optimize retrieval precision and recall; 4) repeating steps 1–3 to determine if additional data collection is needed. Without requiring corpus-wide sampling/analysis or extensive manual annotation, this method is well suited for data collection from large-scale digital media corpora. Our simulation studies demonstrate its robustness against parameter choice and its improvement upon other methods in suggesting additional keywords. Its application in Twitter data retrieval is also provided. By advancing a more systematic approach to text data retrieval, this study contributes to improving digital media data retrieval practices in communication research and beyond.
Digital media data refer to “data that are collected, extracted, gathered, or scraped from a web-based platform such as a website, social networking site, mobile application, or another virtual space” (Lukito et al., Citation2023). Such naturally occurring, massive, and nuanced data can help communication researchers gain unprecedented insights into human communication and social interaction, complementing traditional research methods like surveys and experiments. Despite the various sources (e.g., social network sites, discussion forums, and news media sites) and modalities (e.g., texts, visuals, audios, and videos) of digital media data, researchers often follow common analytical steps in practice, which include retrieving data, cleaning and preprocessing data, and applying methods suitable for research objectives (Grimmer & Stewart, Citation2013). The retrieval of a relevant and comprehensive dataset is a critical first step because it significantly impacts downstream analysis and results (Antoniak & Mimno, Citation2021; Kim et al., Citation2016). Yet, this crucial step is often overlooked in digital media research in the field of communication, potentially leading to research limitations (Moreno-Ortiz & García-Gámez, Citation2023).
Take text data, arguably the primary type of digital media data in communication research. Though many advanced Natural Language Processing (NLP) methods have been frequently applied (e.g., BERT developed by Devlin et al., Citation2018), relatively little attention has been paid to the data retrieval step. A prevalent practice in communication research is to use a set of keywords as Boolean search strings, informed by domain expertise or prior literature. However, neither guarantees optimal data quality (Antoniak & Mimno, Citation2021) and problematic keyword selection can lead to biased data collection and compromised research validity (He & Rothschild, Citation2016; Mahl et al., Citation2022).
In this article, we synthesize research from social, computer, and information sciences and propose a new method of keyword selection for text data retrieval. Three key insights from related literature form the bedrock of this method: 1) keywords need to be incrementally expanded to capture multifaceted discourses in digital media spaces (e.g., Krovetz & Croft, Citation1992); 2) the keyword expansion process should harness both human knowledge and computer intelligence (e.g., King et al., Citation2017; Makki et al., Citation2018); and 3) word co-occurrence graphs can effectively represent the semantics of text (Mihalcea & Tarau, Citation2004). Accordingly, we introduce the WordPPR method – an iterative, researcher-driven computational approach to keyword selection for text data retrieval from digital media corpora. This approach incorporates researcher and computer input in an iterative process of (computer) generating, (researcher) evaluating, and (researcher) selecting and expanding keywords. It begins with a set of seed word(s) or phrase(s) identified by the researcher as the starting point, collects data using the seed(s), constructs a word graph based on word co-occurrence, and suggests the most relevant and least ambiguous words or phrases associated with the seed(s) for the researcher to choose from, all of which can be repeated to achieve an optimal level of retrieval precision and recall. Compared to other methods that require processing or sampling an entire corpus or annotating sample data (e.g., Kuzi et al., Citation2016, Linder, Citation2017; Rinke et al., Citation2021), our method is particularly suitable for selecting keywords to collect text data from a massive digital media corpus, as it relies on a local algorithm to incrementally retrieve data.
In what follows, we first highlight the issues with prevailing keyword selection and data retrieval practices in communication research, by presenting a survey of articles from leading communication journals that collect and analyze text data from social media. We then synthesize text data retrieval literature across communication, computer, and information sciences. Next, we introduce the WordPPR method, describe its workflow, and establish its effectiveness using simulations, focusing on its robustness against parameter choice and its performance compared with other methods. Lastly, we demonstrate its application in one social media data retrieval task.
Text data retrieval practices in communication research
Keyword selection is often the basis for text data retrieval, and by extension, measurement construction. Studies across social science disciplines have used keywords for Boolean searches to collect data from social media and other digital media sources to study various topics, such as online public opinion (e.g., Barberá et al., Citation2019; Choi, Citation2014; Zhang et al., Citation2019), digital activism and political protests (e.g., Freelon et al., Citation2016; Jost et al., Citation2018; Suk et al., Citation2023), election or campaign dynamics (e.g., Bovet & Makse, Citation2019; Jungherr, Citation2016), and news media discourses (e.g., Barberá et al., Citation2020; Hart et al., Citation2020; Stryker et al., Citation2006). As Jungherr’s (Citation2016) systematic review of Twitter use in election campaign research emphasizes, the keyword or hashtag list for data collection is crucial because it can affect data quality by introducing false negatives (i.e., content that should be included but is not) and false positive (content that should not be included but is).
However, a systematic approach to keyword selection and text data retrieval remains underutilized in communication research (Mahl et al., Citation2022; Mayr & Weller, Citation2017). Consider, for instance, the articles published in leading communication journals (Journal of Communication, New Media and Society, Journal of Computer-Mediated Communication, and Political Communication, according to the SCImago Journal Rank indicator within the category of “communication” based on their 5-year journal impact factors). After reviewing each publication in all four journals between 2017 and 2021 (N = 1,179), we identified 75 articles that used keywords to collect social media data and found two general approaches to keyword selection and data retrieval: a one-step approach and a multi-step approach.
The one-step approach hinges on researchers, who select keywords based on either their domain knowledge (e.g., An & Mendiola-Smith, Citation2019; Borg et al., Citation2020; Thorsen & Sreedharan, Citation2019) or other resources (such as existing research, authoritative sources, or unspecified sources, e.g., Scherr et al., Citation2018; Vicari, Citation2021). For instance, Stier et al. (Citation2017) use two keywords #ClimateChange and #NetNeutrality to collect tweets, assuming that they capture related policy discourse. The multi-step approach entails separate steps of keyword selection and validation and data collection (Bradshaw et al., Citation2020; Karsgaard & MacDonald, Citation2020). For instance, Bradshaw and colleagues (Citation2020) outline four steps for Twitter data retrieval with hashtags. They commence with an initial manual identification of hashtags pertinent to specific political events. This is followed by a subsequent expansion of the dataset, which detects additional salient hashtags through frequency and co-use analyses. A filtration process is then applied, where only the most central hashtags are retained and those generating minor and ephemeral conversations are discarded. Lastly, a focused set of hashtags generating substantial traffic on Twitter is finalized. Our quantitative analysis of the keyword selection and data collection practices across the 75 articles reveals that the overwhelming majority (84%, N = 63) adopt the one-step approach, lacking documentation of the keyword selection process or assessment of the quality of the keywords and retrieved data (see Appendix A for a detailed report).
Researcher-driven, computational, and iterative keyword selection and expansion
The quality of data retrieval can be evaluated by “retrieval precision” and “retrieval recall” (Kim et al., Citation2016, p. 5; Mahl et al., Citation2022; Stryker et al., Citation2006). Retrieval precision refers to the proportion of relevant content in retrieved data; retrieval recall is a measure of the proportion of total relevant content that is retrieved. The one-step, often researcher-centered approach illustrated above, can suffer from poor recall. He and Rothschild (Citation2016) demonstrate that, compared with a baseline set of tweets about the 2012 U.S. Senate elections collected using only candidate names as the keywords, the set of tweets collected via a multi-step keyword expansion approach is 3.2 times larger and produces different conclusions about sentiments and interactions. In a study of Swedish politics, Lorentzen and Nolin (Citation2017) find that the dataset generated by keywords that capture additional hashtags and participants over time has significantly higher quality than the dataset generated by a static, pre-defined set of keywords, in terms of user characteristics, network features, and tweet types. Also, this approach might not be reliable in the sense that different researchers can select different keyword sets for the same retrieval task, resulting in substantially disparate target content and measurement of the construct of interest (King et al., Citation2017).
Related research in social, computer, and information sciences points to two major directions for maximizing data retrieval quality. First, iterative keyword expansion is critical. Due to lexical ambiguity and variety, expanding a keyword list based on initial seeds can reduce false negatives and increase the completeness of retrieved data (Krovetz & Croft, Citation1992). This idea is reflected in Parekh and colleagues’ (Citation2018) four-phased social media data collection model that includes initialization, expansion, filtering, and validation. By running real data collection experiments, Kuzi et al. (Citation2016) show that their query expansion technique, which takes an entire corpus, applies the Word2Vec term embeddings and identifies terms similar to the initial query term, can boost retrieval performance significantly compared to results based on the initial term only.
Second, it is crucial to integrate human knowledge and computer intelligence. While keyword selection and data collection practices in communication research tend to be researcher-centered, researchers from computer science, information science, and engineering tend to adopt a computer-centered approach to digital media data retrieval, where little human guidance is involved. A computer-centered approach can efficiently and automatically update relevant keywords and track language evolution, allowing researchers to follow rapidly changing online conversations over time (Liu et al., Citation2019). This fully automated approach with little human intervention can also be advantageous in terms of minimizing human bias (Liu et al., Citation2019). In this effort, related work has incorporated natural language processing, deep word embeddings, and clustering algorithms to extract relevant keywords from websites (Lee & Kim, Citation2018), detect online trolls (Liu et al., Citation2019), and capture health outbreaks via real-time Twitter information (Edo-Osagie et al., Citation2020). While efficient, relying on a fully automated model may lack theoretical rigor and increase false positives. Therefore, it is important to combine both computer and human input (Elyashar et al., Citation2021).
Some methods have incorporated iterative keyword expansion and human-computer input, where manual annotation and machine learning are combined. Makki et al. (Citation2018) present an interactive Twitter data retrieval system that prompts researcher feedback (by asking researchers to label the relevance of collected tweets) while minimizing the number of labeling requests. The ReQ-ReC (ReQuery-ReClassify) framework developed by Li et al. (Citation2014) relies on human-guided active learning and features a double-loop system where an outer loop generates queries and an inner loop takes researcher input to train relevance classifiers, a process that can be iterated multiple times to achieve optimal retrieval results. In a similar vein, Linder’s (2017) method follows the steps of collecting an initial dataset with seed keywords, annotating a random sample, training a classification algorithm to suggest keywords, and repeating the previous steps till satisfaction.
King et al. (Citation2017) “human-led and computer-assisted” method for keyword discovery and selection is predicated on the acute observation that humans can be good at “recognizing whether any given word is an appropriate representation of a given concept” (p. 972). This algorithm uses human input as the starting point such that researchers define “a search set” (e.g., the entire corpus or a dataset obtained based on a set of general keywords) as well as “a reference set” known to be relevant to the construct of interest, which is a subset of the search set (e.g., by coming up with keywords or selecting a subset of the already defined keywords). Then, different classifiers are used to divide the search set data into target vs. non-target data by treating the reference set as labeled data. Lastly, two lists of top-ranked keywords, which are the best features of the target and non-target data, respectively, are generated, and researchers select the keywords based on the two lists.
Similarly, Wang et al. (Citation2016) Double Ranking (DR) method starts with a set of seed keywords developed by researchers to first collect a relevant dataset; it then produces a shortlist of candidate keywords by ranking the words in the dataset. Each word in the shortlist is applied to collect more data, and the percentage of documents in the data containing the seed keywords is computed, producing a final list of keywords for researchers to select from. Both the King et al. (Citation2017) and Wang et al. (Citation2016) methods harness human input by asking researchers to adjudicate the appropriateness of keywords, which we draw heavily upon.
Besides the immediately relevant literature on digital media data retrieval, keyword extraction research, which focuses on producing keywords in a target text dataset for a summary representation, provides a third direction. Such keywords can be identified based on simple statistical measures, such as term frequency (TF) and term frequency-inverse document frequency (TF-IDF) (Qaiser & Ali, Citation2018). Linguistic knowledge can improve the quality of keyword extraction, such as focusing on noun phrase chunks in text (Hulth, Citation2003). Pointwise Mutual Information and Information Retrieval (PMI-IR) can effectively quantify the similarity between two words and words with high PMI can be considered as keywords for a text dataset (Turney, Citation2001). Mihalcea and Tarau’s (Citation2004) TextRank provides a key intuition for our research. TextRank is a graph-based ranking method that treats text units in a document as nodes in the graph and the relations between text units (determined by word co-occurrence within delimited windows) as edges. It ranks the text units by running a graph-ranking algorithm. Abilhoa and De Castro (Citation2014) build on this graph-based approach and develop the Twitter Keyword Graph that takes tweets as input, builds a graph based on word co-occurrence, and ranks words by centrality measures.
Our WordPPR method for keyword selection is built on the three major recommendations from social, computer, and information sciences reviewed above: iteratively expanding keywords to account for lexical variety, integrating both human knowledge and computer intelligence, and representing the order and semantics of text using a word co-occurrence graph. Like many hybrid methods, it consists of the general steps of developing, applying, and validating keywords. The most important feature distinguishing our method from others is its computational efficiency. This method is efficient for and compatible with very large corpora, like the entire data stream from a mainstream social media platform. This is because the WordPPR is a local algorithm that incrementally retrieves documents topically relevant to the seed word(s). Therefore, the computational and memory cost is only impacted by the retrieved documents (which is a relatively small subset of the entire corpus). Some keyword selection methods require processing a complete corpus or a random sample of it for developing and validating keywords (see King et al., Citation2017; Kuzi et al., Citation2016). For example, Rinke et al. (Citation2021) expert-informed topic modeling (EITM) performs topic modeling under expert guidance and selects documents with high cumulative probabilities of belonging to relevant topics. However, this method only works when the global dataset is available. It is unfeasible if a researcher needs to build keywords for a massive corpus that is too large to draw a sample from, let alone analyze it. Furthermore, some methods require a non-trivial amount of manual annotation of sample data to determine its relevance (e.g., Makki et al., Citation2018; Linder, Citation2017), a process that can be labor-intensive and time-consuming. The human input part of the WordPPR method requires researchers to produce seed keywords and select additional ones from the computer-generated list, which emphasizes human supervision but places a much lighter burden on researchers. In addition, we will demonstrate that the WordPPR method can provide consistent sets of candidate keywords under some basic statistical assumptions and achieve better performance than similar methods.
What is the WordPPR method?
The WordPPR method () consists of four steps: 1) collecting an initial dataset using core/seed keyword(s); 2) constructing a word graph based on the dataset; 3) applying the Personalized PageRank (PPR) algorithm to rank words in proximity to the seed keyword(s) and selecting new keywords that optimize retrieval precision and recall; 4) repeating steps 1–3 to determine if additional data collection is needed.
Figure 1. The workflow of the WordPPR method.
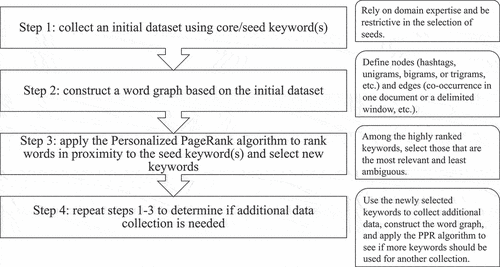
The first step takes human judgment as the initial input, where the researcher determines one or a few core keyword(s) specific to the research topic. This requires researchers to gain a domain-specific understanding of the topic and even to collaborate with domain experts to define the seed keyword(s). Also, the researcher should be restrictive so as to reduce the noise introduced by keywords that are frequently used in unrelated contexts. After selecting the core keyword(s), the researcher can retrieve data (e.g., social media posts) containing the keyword(s) from a database.
The second step centers around constructing a word graph based on the collected data. There are different ways to construct the word graph, but the underlying principle is to treat words (e.g., hashtags, unigrams, bigrams, or trigrams, etc.) as nodes and the relationships between words as edges. After standard preprocessing (e.g., removing stopwords and stemming or lemmatizing words), the edge between two words can be established via co-occurrence in one document (e.g., a social media post) or within a delimited window in the document.
In the third step, the PPR algorithm is applied to the word graph to generate additional keywords closest to the initial keyword(s), as measured by the algorithm. This idea is similar to that in many of the existing query-building systems, like the “word movers’ distance” measure that uses word embeddings to quantify the similarity between new documents and the prototype document (Elyashar et al., Citation2021). PPR is a variant of Google’s PageRank (Page et al., Citation1998), which ranks the nodes in a network by their “relational closeness” to the given seed node(s). The PPR vector, (where
is the number of candidate keywords), quantifies such closeness for every node and is defined to be the stationary distribution (i.e., the converging probability distribution of a stochastic process) of the following personalized random walk (a stochastic process). The random walk starts at a given seed node. At any step, the random walker teleports to the seed node with probability
, or randomly goes to one of the adjacent nodes from the current node with probability
. Here,
is called the teleportation constant. If
= 0, PPR is equivalent to a random walk on the graph (Pearson, Citation1905). See Appendix B for a detailed description of PPR. In the section below, we provide a mathematical description of the WordPPR algorithm.
The WordPPR algorithm
The WordPPR algorithm applies PPR to the co-occurrence graph of words, which is undirected and weighted (the directed version can be constructed similarly). Throughout this article, we assume that a given word graph is connected. Selecting the “closest” words to a given word from a word graph is analogous to a targeted sampling of nodes in a graph with a seed node, for which PPR provides a consistent estimate under the stochastic block model (Chen et al., Citation2020; Karrer & Newman, Citation2011).
To construct the word graph (, Step a), we use a set of documents in the data collected via an initial keyword search. Let
be the document-term matrix where
if word
occurs in document
(and 0 otherwise), and
is the number of unique words in all documents. We define the adjacency matrix
of the word co-occurrence graph as
. So,
is the number of documents in which word
and
co-occur. Note that
is usually sparse in practice (containing less than 1% non-zeros in the example below).
Table 1. The WordPPR Algorithm.
Next, we calculate the PPR vector, , using the initial keywords as the seeds (, Step b). This step essentially defines the Markov transition matrix that represents PPR on the word graph and calculates the principal left eigenvector of this matrix (Haveliwala, Citation2002; Jeh & Widom, Citation2003). When the
is sparse, the principal eigenvector can be calculated efficiently (e.g., using the “Spectra” or “ARPACK” library). To use PPR in WordPPR, we compute a frequency measure and an exclusivity measure for each word in the collected data (, Step c). Frequency (i.e., simply word frequency) ensures that a given candidate word is capable of including a sufficiently large number of new documents (on top of existing documents obtained using the seed keywords, thus contributing to “retrieval recall”). Exclusivity seeks to locate words that appear mostly in the target topic and infrequently in other topics. This measure ensures that a given candidate word primarily adds useful documents (and not polluting the existing document set, thus contributing to “retrieval precision”). To measure the frequency and exclusivity of words, we define the following two quantities
:
for any word , where
is the teleportation constant used for calculating PPR vector
(a commonly used default value is 0.25), and
is the
th element in
, and
is the degree of word
(i.e., the total number of words that co-occurred with word
). In this definition,
is a consistent estimator for word frequency, and
for word exclusivity (see more details in next section).
The output includes two empirical cumulative distribution functions (ECDFs) applied to the values of and
. To leverage the frequency and exclusivity of words, Airoldi and Jonathan (Citation2016) adopt the harmonic mean of the word’s rank in the distribution of
and
and define a hybrid measure of words:
where parameter can be interpreted as the weight for exclusivity (which defaults to 0.5). summarizes the procedure of WordPPR. Researchers can peruse the suggested top words ranked by the FREX measure and select all the keywords specific to the topic of interest. Here, researchers can inspect a large number of top words to increase the chance of discovering relevant words and in the meantime prioritize the precision of each selected keyword to reduce the noise introduced in the collected dataset.
With the newly selected keywords from step three, the researcher in the fourth step can repeat steps one to three, i.e., retrieving a new dataset, constructing a word graph based on the new dataset, and applying the WordPPR algorithm to generate a new list of keywords for the researcher to choose from. If the researcher cannot find new and meaningful keywords from the list, the data collection process can be terminated, and the first and second rounds of collected data can be combined and cleaned for downstream analysis. Otherwise, the researcher can repeat steps one to three till no additional keywords and data can be added.
Why does the WordPPR method work? Two validations
After explaining what WordPPR is, we turn to the mathematical evidence for why WordPPR works. Chen (Citation2021) demonstrates that if the corpus is generated from the latent Dirichlet allocation (LDA) model (Blei et al., Citation2003), then ranking words by the vector output by WordPPR is statistically consistent with ranking words by the frequency measure, and ranking words by the
vector is consistent with ranking words by the exclusivity measure. In what follows, we provide two simulation studies to validate the robustness of the WordPPR method and its comparability with other methods.
Robustness of the WordPPR method
This first simulation study establishes that under the ideal LDA corpus WordPPR can recommend highly accurate keywords for text data retrieval from a given corpus. We performed this simulation in three steps: we first generated text data with LDA (represented by a document-term matrix); then we applied one iteration of the WordPPR algorithm; and finally, we assessed the accuracy of returned keywords in terms of frequency and exclusivity.
Each row of is the word distribution of a topic and is generated from the Dirichlet distribution,
Dirichlet
for
, where the elements in
are sampled from the exponential distribution, Exponential
. We experimented with corpus size (i.e., the number of documents)
and the expected document length
. In addition, we studied the effect of teleportation constant with
. For each combination of parameters, we simulated the document-term matrix for 30 times and evaluated the WordPPR algorithm independently.
To evaluate words ranked by and
(i.e., the two output vectors of WordPPR), the accuracy in terms of frequency and exclusivity is defined as follows. Let
be the set of top
words ranked by
, then the accuracy in frequency is defined as
Similarly, the accuracy in exclusivity for the top
words ranked by
is defined as
, where
represents the proportion of topic 1 in all the occurrences of each word. In this simulation, we set
,
.
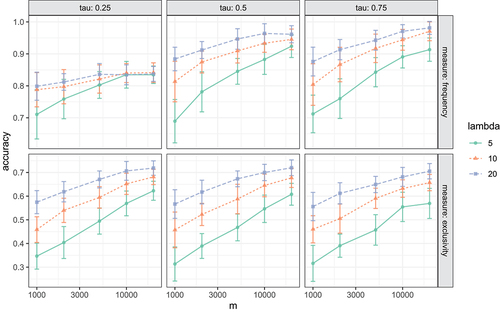
displays the accuracy of WordPPR’s frequency and exclusivity estimates, for five different document sample sizes (“,” x-axis), three different expected document lengths (“lambda,” colors and shapes), and three different teleportation constants (“tau,” panel columns). The results uniformly show that WordPPR can identify both frequent and exclusive words with high accuracy. Moreover, both the increase in the number of sample documents and the increase in the expected document length improve the accuracy of WordPPR. In addition, the choice of teleportation constant appears to have little effect on the accuracy of WordPPR, except in the top left panel, suggesting that WordPPR is robust against a wide range of parameter settings.
Figure 2. Accuracy of the frequency and exclusivity measures of the WordPPR algorithm for five document sample sizes (“,” x-axis), three document lengths (“lambda,” colors and shapes), and three teleportation constants (“tau,” panel columns). Each point represents the average accuracy of including the top 25 words. The error bars indicate two times the standard deviation of accuracy across 30 repeated experiments.
Comparison with other methods
The second simulation study compares WordPPR with several existing keyword selection techniques and shows that WordPPR can achieve superior performance in terms of producing the first round of additional keywords. The simulation was conducted in three steps: we first generated text data with a mixture of curated LDA and then applied one iteration of WordPPR and other methods, including term frequency (TF), term frequency-inverse document frequency (TFIDF), the non-personalized version of WordPPR (TextRank; Mihalcea & Tarau, Citation2004), Double Ranking (Entropy, Wang et al., Citation2016), discriminatory power (DiscPower, King et al., Citation2017). Finally, we assessed the accuracy of returned keywords in terms of sensitivity and specificity (i.e., receiver operating characteristic, ROC).
First, we sampled 15,000 text documents from the LDA with 10 underlying topics and 1000 unique words, where the first topic was assumed to be the target topic. For each topic , we generated the word distribution
from the Dirichlet distribution,
Dirichlet
, where
was sampled from the exponential distribution, Exponential
. Some existing methods require additional sets of documents. The target set should contain the documents that the researcher sees as relevant to the target topic, for example, by searching the initial keywords in the corpus. The general set should be a random document sample of the corpus. To generate the target set (5,000 documents), we set the topic distribution to be
. To generate the general set (10,000 documents), we set the topic distribution to be
. The expected document length in both target and general sets was set to 25. For all documents, we also added a very small probability (0.001) of random bit flipping to simulate typos.
For WordPPR, we set the teleportation constant to be (see above for analysis that shows that WordPPR is robust against choices of
) and experimented with three weights of the exclusivity parameter
(referred to as WordPPR.3, WordPPR.5, and WordPPR.7 respectively). Although WordPPR only requires a target set of documents, our experiment indicates that including both target and general sets can generate comparably satisfactory results. For TF, TFIDF, and TextRank, we combined target and general sets. For Double Ranking of Wang et al. (Citation2016), since the re-ranking step is not feasible, we skipped it and focused on its computational metric based on entropy. In calculating Entropy, we treated the target set and general set as the “current set” and “random (or reference) set” described in Wang et al. (Citation2016) respectively. For DiscPower, we treated the target set and general set as the “reference set” and “search set” described in King et al. (Citation2017) respectively.
To evaluate keyword rankings, we defined the “ground-truth” set of keywords that a word must satisfy two criteria to be included: (1) word
is frequent to topic 1 (the target topic) and (2) word
is exclusive to topic 1. Mathematically, we quantify (1) as “
is greater than the 10th percentile of all the elements in
.” For (2), define
with
. Note that
is the proportion of each word’s frequency exclusive to topic 1. With that, we quantify (2) as “
is greater than the 10th percentile of all the elements in
.” Combining (1) and (2) resulted in ~50 “ground-truth” keywords, and we used these to calculate the sensitivity and specificity of each tested method. displays the performance (ROC) of all eight methods. lists the Area Under the ROC Curve (AUC), which is an aggregate measure of performance. As shown, WordPPR outperforms the other existing methods in ranking keywords, with overall higher sensitivity and specificity. Upon repeating the above simulation 30 times, we consistently observed the same result. The AUC of WordPPR is significantly higher than the others (paired t-test, at the 0.01 significance level). In addition, comparing across different
values of WordPPR, we observed small to minimal variation in AUC (yet all outperforming other methods), suggesting that the performance of WordPPR is relatively stable when varying the weight of exclusivity.
Figure 3. Comparison of different keyword ranking methods (TF, TFIDF, TextRank, entropy, DiscPower, and WordPPR) based on the ROC curve.
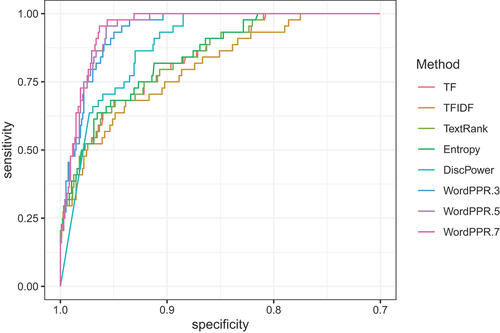
Table 2. Comparison of different keyword ranking methods based on the AUC measure (area under the ROC curve).
How to apply the WordPPR method? An application
To illustrate the workflow and effectiveness of the WordPPR method, we applied it to the collection of #MeToo-related tweets on Twitter. In October 2017, actress Alyssa Milano tweeted to encourage survivors of sexual violence to share their stories using the phrase “me too” in response to the allegations against Harvey Weinstein. Soon, #MeToo was used to call for recognition of the issue and solidarity with victims, which ultimately coalesced into digital connective action (Suk et al., Citation2021). Beyond the outpouring of stories among sexual violence survivors, the #MeToo movement has kept growing, as activists continue to lead the movement and workplace policy changes have been implemented. Furthermore, #MeToo received waves of attention from politicians and political parties, especially during the Brett Kavanaugh confirmation period and the 2020 US election campaign, when then-Supreme Court nominee Kavanaugh and Presidential candidate Biden were accused of sexual misconduct. In this case study, we define the scope of the data collection to be tweets about the #MeToo movement from October 2017 to December 2020. A longitudinal examination of the movement can demonstrate whether the WordPPR method is suitable to generate a selection of keywords that reflect multiple developments of the movement over several years.
For this application, we relied on the Twitter API product track for academic research, which provided unprecedented access to all publicly available tweets. In the first step, we selected “#metoo” (not case-sensitive) as the keyword for the first round of data retrieval because the movement was propelled by this hashtag. It is a reasonable assumption that the majority of the tweets containing this hashtag are central to the #MeToo conversation. We collected 13,180,909 tweets containing this hashtag from October 1, 2017, to December 31, 2020.
In the second step, we constructed a word graph based on a 10% random sample of the collected tweets. After standard preprocessing (removing stopwords, lemmatizing words, and removing infrequent words), we extracted both hashtags and bigrams in unique tweets and created a word graph where each hashtag or bigram is a node and each edge represents co-occurrence in the same tweet. We included hashtags because they represent key strands of conversations and debates on Twitter, a feature emphasized in Makki and colleagues’ Active Tweet Retrieval Visualization framework (2018). Bigrams were chosen to reduce ambiguity introduced by unigrams. According to Krovetz and Croft (Citation1992), “words are ambiguous and this ambiguity can cause documents to be retrieved that are not relevant” (p.116), and the solution to this ambiguity problem is to use phrases instead of single words Citation1992.
The PPR algorithm was then applied to the word graph, resulting in a list of keywords ranked by frequency, exclusivity, and FREX (). We relied on the composite FREX measure and qualitatively evaluated the top 100 hashtags/bigrams with the highest FREX measures. It can be seen that FREX is a more effective measure than mere word frequency because some frequent words are downranked by FREX. For example, relevant keywords like “sexually abuse” (total frequency of 823), “#ibelieveher” (frequency of 864), and “#metoounlessitsbiden” (frequency of 858) are not ranked highly by frequency despite their significant relevance to the research context. The FREX measure, therefore, helps researchers efficiently distinguish keywords specific to the research topic from frequent keywords without contextual relevance (e.g., #news, #women).
Table 3. Top 100 hashtags and bigrams related to #MeToo using the WordPPR algorithm: round one of data collection.
In step 4, we collected 69,915,400 tweets from the same Twitter endpoint access using the new keywords. displays the new top 100 words based on the word graph constructed from a 10% random sample of the second round of data collection. As can be seen in , the newly suggested words have no significant relevance to the research context to warrant another round of data collection. Therefore, after repeating steps 2 and 3, our data collection stopped, yielding a total of 83,096,309 unique tweets using the following list of keywords: #metoo, #timesup, sexual harassment, sexual assault, sexually assault, sexual abuse, #believewomen, #believesurvivors, #sexualharassment, sexual misconduct, sexual predator, sexual violence, sexually harass, #churchtoo, #sexualassault, #rape, #whyididntreport, #metoomovement, #mentoo, #rapeculture,” #believeallwomen, #metoounlessitsbiden, #ibelieveher, #ibelievetarareade, #sexualabuse, sexually abuse. To assess the amount of noise in the dataset, one author coded 500 tweets randomly drawn from the dataset for relevance to #MeToo and found only 8 out of 500 to be clearly irrelevant. In Appendix C, we also presented keywords suggested by other methods (TF, TFIDF, Entropy, Discriminatory Power, and TextRank) and discussed the effectiveness of the WordPPR method.
Table 4. Top 100 hashtags and bigrams related to #MeToo using the WordPPR algorithm: round two of data collection.
Discussion
With widely available digital media data, significant advancement in computational methods, and the immense potential they hold to enhance communication research, our research community needs to pay more attention to the first step of data retrieval in research that harnesses digital media data and computational methods. In their paper that reviews lexicon selection for measuring bias and stereotypes, Antoniak and Mimno (Citation2021) advocate that “[seeds] and their rationales need to be tested and documented, rather than hidden in code or copied without examination.” This article echoes their call. The same principle applies to the keyword selection process for digital media data collection: keywords used for data collection must be systematically selected, documented, and evaluated.
Since Boolean searches are predominantly applied in our field, we explore the question of how to generate search keywords that can produce a high-quality dataset. After reviewing studies published in leading communication journals over 5 years, we observe a heavy reliance on the one-step keyword selection approach, which can lead to biased and incomplete data. Synthesizing cross-disciplinary research on data retrieval, we distill three key insights: 1) keywords need to be incrementally expanded to capture multifaceted discourses, 2) the keyword expansion process should tap into both human knowledge and computer intelligence, and 3) the word co-occurrence graph can effectively represent the order and semantics of text. These ideas are crystallized in our researcher-driven, computer-assisted, iterative, and graph-based keyword selection method, the WordPPR method.
The WordPPR method requires researchers to first identify core seed words, then collect data with them and feed the data into the WordPPR algorithm, and lastly select additional keywords from the list of keywords suggested by the algorithm. The three steps could be repeated until reaching data saturation. This method is computationally efficient because it does not require analyzing an entire corpus or randomly sampling it. It is particularly advantageous when researchers have to deal with massive data coming from a global social media stream (for example, Twitter’s global stream, which easily goes over hundreds of millions of tweets within 1 day) or data spanning an extensive period. Another advantage of this method is that, unlike other methods, it does not require intensive human labor that is usually in the form of manual annotation of sample data. Instead, human supervision is utilized to select seed word(s) and evaluate additional keywords (as in King et al., Citation2017; Wang et al., Citation2016). Therefore, it is an efficient method in terms of both computational cost and human labor. In addition, our two extensive simulation studies demonstrate that under the LDA assumption, the WordPPR method can identify all keywords that define a given topic and achieve better performance than similar methods.
Applying this method in the #MeToo case further demonstrates its effectiveness in identifying keywords and its applicability to data collection from massive corpora. Given that the entire Twitter corpus is too large to analyze or sample, the WordPPR method allows us to zero in on the core data and then incrementally collect additional relevant data efficiently. In our case, the first round of data collection suggests highly relevant and comprehensive keywords for the second round collection, without requiring any additional iteration.
Moreover, our WordPPR method addresses important validity concerns that are central to social science research. For content validity, our method emphasizes an iterative keyword expansion process that harnesses both human knowledge and computational intelligence, aiming to capture the multiple layers inherent in a given discourse from a digital media source. It also emphasizes the role of the researcher’s judgment in the initial seed word selection and subsequent evaluation, which is informed by theoretical guidance and conceptualization. With regard to criterion validity, our method aligns with and improves existing methods. Our simulation analysis indicates that our method generates results that are highly comparable, and in some aspects, superior to those produced by existing methods.
Through the application and validation, we show the importance of the “human-led and computer-assisted” and iterative model for digital data retrieval. In particular, our WordPPR method can be an effective way to reduce researcher bias yet harness researcher knowledge to guide keyword expansion, ultimately increasing the accuracy and completeness of the collected dataset. This workflow can apply to all languages and potentially different sources and types of digital media. Though we only surveyed related research practices in the field of communication and used the findings to illustrate the oversimplified keyword selection approach, this problem might not be limited to communication research. Furthermore, the development of the WordPPR method has drawn research from multiple disciplines, holding the potential to inspire researchers in other disciplines like information and computer sciences. We hope that future research using digital media data can strengthen the data collection process by considering the WordPPR method. Our method code and application code have been made publicly and freely available online.
Given the rapid advancement in the capacities and applications of large language models (LLMs) (Wei et al., Citation2022), there lies the potential for them to augment the WordPPR method. For example, LLMs could be employed to suggest seed keywords given a meticulously constructed research topic prompt. Furthermore, they might be utilized to extract additional keywords from a representative sample of the initial dataset. It is imperative for future investigations to systematically delve into the integration of LLMs within the realms of keyword selection and data collection.
With digital media data becoming a prevalent and rich source of research data for communication researchers, the importance of applying a systematic way of selecting keywords and retrieving text data cannot be understated. This process should not solely fall on researchers or computers. Instead, an iterative process where human researchers and computer intelligence interact can reduce human bias, augment human capacity, and produce an accurate and complete dataset that maximizes the validity of research findings.
Acknowledgement
We thank our reviewers, the editors, Dr. Karl Rohe, Dr. Nojin Kwak, and Dr. Dhavan Shah for their helpful feedback. We also thank Rui Wang, Dongdong Yang, and Xinxia Dong for assistance with the journal article coding.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The method and application code files as well as the supplementary materials are available at https://osf.io/pcybz/.
Additional information
Notes on contributors
Yini Zhang
Yini Zhang (Ph.D., University of Wisconsin–Madison) is an assistant professor in the Department of Communication at the University at Buffalo, State University of New York. She studies social media, media ecosystem, and political communication, using computational methods.
Fan Chen
Fan Chen (Ph.D., University of Wisconsin–Madison) is a Data Scientist at Google. He studies and develops statistical methods for social media, genomics, and advertisement data. The bulk of this work was completed while he was a Ph.D. student at the University of Wisconsin–Madison.
Jiyoun Suk
Jiyoun Suk (Ph.D., University of Wisconsin-Madison) is an assistant professor in the Department of Communication at the University of Connecticut. She studies the role of networked communication in shaping social trust, activism, and polarization, using computational methods.
Zhiying Yue
Zhiying Yue (Ph.D., University at Buffalo) is a postdoctoral researcher at the Digital Wellness Lab, Boston Children’s Hospital, and Harvard Medical School. Her research interests generally focus on individuals’ social media use and psychological well-being.
References
- Abilhoa, W. D., & De Castro, L. N. (2014). A keyword extraction method from twitter messages represented as graphs. Applied Mathematics and Computation, 240, 308–325. https://doi.org/10.1016/j.amc.2014.04.090
- Airoldi, E. M., & Bischof, J. M. (2016). Improving and evaluating topic models and other models of text. Journal of the American Statistical Association, 111(516), 1381–1403.
- An, Z., & Mendiola-Smith, L. (2019). Connections to neighborhood storytellers and community-oriented emotional disclosure on Twitter during an emergency event. New Media & Society, 22(8), 1359–1377. https://doi.org/10.1177/1461444819878818
- Antoniak, M., & Mimno, D. (2021, August). Bad seeds: Evaluating lexical methods for bias measurement. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) (pp. 1889–1904).
- Barberá, P., Boydstun, A. E., Linn, S., McMahon, R., & Nagler, J. (2020). Automated text classification of news articles: A practical guide. Political Analysis, 29(1), 19–42. https://doi.org/10.1017/pan.2020.8
- Barberá, P., Casas, A., Nagler, J., Egan, P. J., Bonneau, R., Jost, J. T., & Tucker, J. A. (2019). Who leads? Who follows? Measuring issue attention and agenda setting by legislators and the mass public using social media data. American Political Science Review, 113(4), 883–901. https://doi.org/10.1017/s0003055419000352
- Blei, D., Edu, B., Ng, A., Jordan, M., & Edu, J. (2003). Latent Dirichlet Allocation. Journal of Machine Learning Research, 3, 993–1022.
- Borg, K., Lindsay, J., & Curtis, J. (2020). When news media and social media meet: How Facebook users reacted to news stories about a supermarket plastic bag ban. New Media & Society. 146144482095668. https://doi.org/10.1177/1461444820956681
- Bovet, A., & Makse, H. A. (2019). Influence of fake news in Twitter during the 2016 US presidential election. Nature communications, 10(1), 7.
- Bradshaw, S., Howard, P. N., Kollanyi, B., & Neudert, L. M. (2020). Sourcing and automation of political news and information over social media in the United States, 2016-2018. Political Communication, 37(2), 173–193. https://doi.org/10.1080/10584609.2019.1663322
- Chen, F. (2021). Spectral Methods for Social Media Data Analysis. The University of Wisconsin-Madison.
- Chen, F., Zhang, Y., & Rohe, K. (2020). Targeted sampling from massive block model graphs with personalized PageRank. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(1), 99–126. https://doi.org/10.1111/rssb.12349
- Choi, S. (2014). The two-step flow of communication in twitter-based public forums. Social Science Computer Review, 33(6), 696–711. https://doi.org/10.1177/0894439314556599
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Edo-Osagie, O., De La Iglesia, B., Lake, I., & Edeghere, O. (2020). A scoping review of the use of twitter for public health research. Computers in Biology and Medicine, 122, 103770. https://doi.org/10.1016/j.compbiomed.2020.103770
- Elyashar, A., Plochotnikov, I., Cohen, I.-C., Puzis, R., & Cohen, O. (2021). The state of mind of health care professionals in light of the COVID-19 pandemic: Text analysis study of Twitter discourses. Journal of Medical Internet Research, 23(10), e30217. https://doi.org/10.2196/30217
- Freelon, D., McIlwain, C. D., & Clark, M. D. (2016). Beyond the hashtags: #Ferguson, #Blacklivesmatter, and the online struggle for offline justice. SSRN Electronic Journal. https://doi.org/10.2139/ssrn.2747066
- Grimmer, J., & Stewart, B. M. (2013). Text as data: The promise and pitfalls of automatic content analysis methods for political texts. Political Analysis, 21(3), 267–297. https://doi.org/10.1093/pan/mps028
- Hart, P. S., Chinn, S., & Soroka, S. (2020). Politicization and polarization in COVID-19 news coverage. Science Communication, 42(5), 679–697. https://doi.org/10.1177/1075547020950735
- Haveliwala, T. H. (2002, May). Topic-sensitive pagerank. In Proceedings of the 11th international conference on World Wide Web (pp. 517–526).
- He, R., & Rothschild, D. (2016). Selection bias in documenting online conversations. Working paper. https://researchdmr.com/EntityDetection
- Hulth, A. (2003). Improved automatic keyword extraction given more linguistic knowledge. In Proceedings of the 2003 conference on Empirical methods in natural language processing (pp. 216–223).
- Jeh, G., & Widom, J. (2003, May). Scaling personalized web search. In Proceedings of the 12th international conference on World Wide Web (pp. 271–279).
- Jost, J. T., Barberá, P., Bonneau, R., Langer, M., Metzger, M., Nagler, J., Sterling, J., & Tucker, J. A. (2018). How social media facilitates political protest: Information, motivation, and social networks. Political Psychology, 39(39), 85–118. https://doi.org/10.1111/pops.12478
- Jungherr, A. (2016). Twitter use in election campaigns: A systematic literature review. Journal of Information Technology & Politics, 13(1), 72–91. https://doi.org/10.1080/19331681.2015.1132401
- Karrer, B., & Newman, M. E. J. (2011). Stochastic blockmodels and community structure in networks. Physical Review E, 83(1). https://doi.org/10.1103/physreve.83.016107
- Karsgaard, C., & MacDonald, M. (2020). Picturing the pipeline: Mapping settler colonialism on instagram. New Media & Society, 22(7), 1206–1226. https://doi.org/10.1177/1461444820912541
- Kim, Y., Huang, J., & Emery, S. (2016). Garbage in, garbage out: Data collection, quality assessment and reporting standards for social media data use in health research, infodemiology and digital disease detection. Journal of Medical Internet Research, 18(2), e41. https://doi.org/10.2196/jmir.4738
- King, G., Lam, P., & Roberts, M. E. (2017). Computer-assisted keyword and document set discovery from unstructured text. American Journal of Political Science, 61(4), 971–988. https://doi.org/10.1111/ajps.12291
- Krovetz, R., & Croft, W. B. (1992). Lexical ambiguity and information retrieval. ACM Transactions on Information Systems (TOIS), 10(2), 115–141. https://doi.org/10.1145/146802.146810
- Kuzi, S., Shtok, A., & Kurland, O. (2016, October). Query expansion using word embeddings. In Proceedings of the 25th ACM international on conference on information and knowledge management (pp. 1929–1932).
- Lee, D., & Kim, K. (2018). Web site keyword selection method by considering semantic similarity based on word2vec. The Journal of Society for E-Business Studies, 23(2), 83–96.
- Linder, F. (2017). Improved data collection from online sources using query expansion and active learning. Available at SSRN 3026393.
- Liu, B., Wang, Z., Zhu, W., Sun, Y., Shen, Z., Huang, L., Li, Y., Gong, Y., & Ge, W. (2019). An ultra-low power always-on keyword spotting accelerator using quantized convolutional neural network and voltage-domain analog switching network-based approximate computing. Institute of Electrical and Electronics Engineers Access, 7, 186456–186469. https://doi.org/10.1109/access.2019.2960948
- Li, C., Wang, Y., Resnick, P., & Mei, Q. (2014, July). ReQ-ReC: High recall retrieval with query pooling and interactive classification. In Proceedings of the 37th international ACM SIGIR conference on Research & development in information retrieval (pp. 163–172).
- Lorentzen, D. G., & Nolin, J. (2017). Approaching completeness: Capturing a hashtagged Twitter conversation and its follow-on conversation. Social science computer review, 35(2), 277–286.
- Lukito, J., Brown, M. A., Dahlke, R., Suk, J., Yang, Y., Zhang, Y., Chen, B., Kim, S. J., & Soorholtz, K. (2023). The State of Digital Media Data Research, 2023. Media & Democracy Data Coop. http://dx.doi.org/10.26153/tsw/46177
- Mahl, D., von Nordheim, G., & Guenther, L. (2022). Noise pollution: A multi-step approach to assessing the consequences of (not) validating search terms on Automated Content Analyses. Digital Journalism, 11(2), 298–320. https://doi.org/10.1080/21670811.2022.2114920
- Makki, R., Carvalho, E., Soto, A. J., Brooks, S., Oliveira, M. C. F. D., Milios, E., & Minghim, R. (2018). Atr-vis: Visual and interactive information retrieval for parliamentary discussions in twitter. ACM Transactions on Knowledge Discovery from Data (TKDD), 12(1), 1–33. https://doi.org/10.1145/3047010
- Mayr, P., & Weller, K. (2017). Think before you collect: Setting up a data collection approach for social media studies. The SAGE Handbook of Social Media Research Methods, 107–124.
- Mihalcea, R., & Tarau, P. (2004, July). Textrank: Bringing order into text. In Proceedings of the 2004 conference on empirical methods in natural language processing (pp. 404–411).
- Moreno-Ortiz, A., & García-Gámez, M. (2023). Strategies for the analysis of large social media corpora: Sampling and keyword extraction methods. Corpus Pragmatics, 7(3), 241–265. https://doi.org/10.1007/s41701-023-00143-0
- Page, L., Brin, S., Motwani, R., & Winograd, T. (1998). The pagerank citation ranking: Bring order to the web. Technical report, Stanford University.
- Parekh, D., Amarasingam, A., Dawson, L., & Ruths, D. (2018). Studying jihadists on social media: A critique of data collection methodologies. Perspectives on Terrorism, 12(3), 5–23.
- Pearson, K. (1905). The problem of the random walk. Nature, 72(1867), 342–342. https://doi.org/10.1038/072342a0
- Qaiser, S., & Ali, R. (2018). Text mining: Use of TF-IDF to examine the relevance of words to documents. International Journal of Computer Applications, 181(1), 25–29. https://doi.org/10.5120/ijca2018917395
- Rinke, E. M., Dobbrick, T., Löb, C., Zirn, C., & Wessler, H. (2021). Expert-Informed Topic Models for document set discovery. Communication Methods and Measures, 16(1), 39–58. https://doi.org/10.1080/19312458.2021.1920008
- Scherr, S., Haim, M., & Arendt, F. (2018). Equal access to online information? Google’s suicide-prevention disparities may amplify a global digital divide. New Media & Society, 21(3), 562–582. https://doi.org/10.1177/1461444818801010
- Stier, S., Schünemann, W. J., & Steiger, S. (2017). Of activists and gatekeepers: Temporal and structural properties of policy networks on twitter. New Media & Society, 20(5), 1910–1930. https://doi.org/10.1177/1461444817709282
- Stryker, J. E., Wray, R. J., Hornik, R. C., & Yanovitzky, I. (2006). Validation of database search terms for content analysis: The case of cancer news coverage. Journalism & Mass Communication Quarterly, 83(2), 413–430. https://doi.org/10.1177/107769900608300212
- Suk, J., Abhishek, A., Zhang, Y., Ahn, S. Y., Correa, T., Garlough, C., & Shah, D. V. (2021). # MeToo, networked acknowledgment, and connective action: How “empowerment through empathy” launched a social movement. Social Science Computer Review, 39(2), 276–294. https://doi.org/10.1177/0894439319864882
- Suk, J., Zhang, Y., Yue, Z., Wang, R., Dong, X., Yang, D., & Lian, R. (2023). When the personal becomes political: Unpacking the dynamics of sexual violence and gender justice discourses across four social media platforms. Communication Research, 50(5), 610–632. https://doi.org/10.1177/00936502231154146
- Thorsen, E., & Sreedharan, C. (2019). #endmaleguardianship: Women’s rights, social media and the Arab public sphere. New Media & Society, 21(5), 1121–1140. https://doi.org/10.1177/1461444818821376
- Turney, P. D. (2001). Mining the web for synonyms: PMI-IR versus LSA on TOEFL. In Machine Learning: ECML 2001: 12th European Conference on Machine Learning Freiburg, Germany, September 5–7, 2001 Proceedings 12 (pp. 491–502). Springer Berlin Heidelberg.
- Vicari, S. (2021). Is it all about storytelling? Living and learning hereditary cancer on twitter. New Media & Society, 23(8), 2385–2408.
- Wang, S., Chen, Z., Liu, B., & Emery, S. (2016). Identifying search keywords for finding relevant social media posts. Proceedings of the AAAI Conference on Artificial Intelligence, 30(1). https://doi.org/10.1609/aaai.v30i1.10387
- Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., Chi, E. H., Hashimoto, T., Vinyals, O., Liang, P., Dean, J., & Fedus, W. (2022). Emergent abilities of large language models. arXiv preprint arXiv:2206.07682.
- Zhang, Y., Shah, D., Foley, J., Abhishek, A., Lukito, J., Suk, J., Kim, S. J., Sun, Z., Pevehouse, J., & Garlough, C. (2019). Whose lives matter? Mass shootings and social media discourses of sympathy and policy, 2012–2014. Journal of Computer-Mediated Communication, 24(4), 182–202. https://doi.org/10.1093/jcmc/zmz009