
ABSTRACT
Individual reports of language history, use, and proficiency are generally considered sufficient for language profiling. Yet, these variables alone neglect the contribution of contextual linguistic diversity to one’s overall language repertoire. In this study we used the Contextual Linguistic Profile Questionnaire to evaluate whether there is a difference in contextual linguistic diversity between participants across the linguistically dissimilar contexts of South Africa and England. We further assessed whether self-reported lingualism status groups (monolinguals, bilinguals, multilinguals) scored differently on contextual linguistic diversity to evaluate the utility and uniformity of categorical labels across varying contexts, and investigated how codeswitching and socio-economic status contributed to these effects. Our results demonstrated that contextual linguistic diversity differs between nations: South Africans score higher, promotion of multilingualism is dependent on socio-economic status only in England, lingualism status is not contextually comparable when measured categorically, and codeswitching accounts for linguistic features of South Africans.
Introduction
A growing body of literature has highlighted the impact of context on bilingual language use (Beatty-Martínez, Valdés Kroff, & Dussias, Citation2018; Kreiner & Degani, Citation2015; Montrul, Citation2015) and its effects on cognition more broadly (Abutalebi & Green, Citation2016; Freedman et al., Citation2014). It has been well documented that second language (L2) learning imposes almost immediate and long-term changes to the first language (L1), irrespective of whether the L2 is learned early or late in life (Bice & Kroll, Citation2015; Chang, Citation2012; Schmid, Citation2013). However, fewer studies have addressed whether the sociolinguistic context from which speakers are drawn contributes to their language repertoire. This area of research is extended across the language continuum to speakers who may not consider themselves to be bilingual (speakers/learners of two languages) or multilingual (speakers/learners of more than two languages) in the usual senses of the words, but who may be immersed in a linguistically diverse context and gain linguistic information from their environment, without necessarily having an acute awareness of such gains, or the impetus to learn another language.
Contextual diversity can include instances of interpersonal communication where it is not necessary for an interlocutor to attain full comprehension, knowledge, or use of the totality of languages available within their specific context, but where mutual understanding and recognition of meaning may nevertheless be reached. Such situations are largely evident in countries with a colonial past, where English is not always a principal mother tongue, yet occupies a place of prestige and socio-political power (Tsimpli et al., Citation2019). Accordingly, language knowledge can include linguistic information via either active or passive linguistic exposure (Wigdorowitz, Pérez, & Tsimpli, Citation2020). Active linguistic exposure is the direct use, production, and upkeep of language(s) that one employs in their regular communicative endeavors, where the speaker has a conscious representation and has developed some degree of proficiency in each of their languages. In contrast, passive linguistic exposure is the summation of linguistic knowledge as a consequence of implicit and contextual linguistic exposure and input that is derived from the sociolinguistic environment within which the speaker is situated. Passive linguistic exposure is more commonly observed in multilingual societies and settings, where language information is mainly gained implicitly as a consequence of the sociolinguistic milieu.
While active linguistic exposure is the common model used in language research, passive exposure is steadily gaining recognition as an integral feature of one’s language repertoire. For example, ambient exposure to multilingualism in a more multilingual society (southern California compared to central Pennsylvania) predisposes the brain of monolingual adults to learning another language (Bice & Kroll, Citation2019), while adults who are passively exposed to foreign speech sounds manifest an enhancement of auditory discrimination (Kurkela, Hämäläinen, Leppänen, Shu, & Astikainen, Citation2019). In fact, this learning effect seems to extend beyond the auditory domain, as it has been found that primary school children in India coming from monolingual households show an advantage in fluid intelligence as an effect of sociolinguistic diversity in their school and community settings (Tsimpli et al., Citation2020). Moreover, extensive literature has demonstrated that language knowledge is observed in the absence of deliberate learning and, possibly via limited language exposure (Gullberg, Roberts, Dimroth, Veroude, & Indefrey, Citation2010; Oh et al., Citation2020), when participants receive linguistic input from an immersive learning setting rather than a non-immersive one (Kroll, Dussias, & Bajo, Citation2018; Morgan-Short, Steinhauer, Sanz, & Ullman, Citation2012; Pliatsikas, DeLuca, Moschopoulou, & Saddy, Citation2017), and via receptive input in heritage bilingual communities (Sherkina-Lieber, Perez-Leroux, & Johns, Citation2011).
Furthermore, the effects of passive exposure also appear to endure over one’s lifespan. For instance, adults who consistently overheard a language as children were able to learn native-like phonological features of their overheard language despite not retaining explicit knowledge or awareness of the exposed-to language (Au et al., Citation2002; Au, Oh, Knightly, Jun, & Romo, Citation2008; Knightly, Jun, Oh, & Au, Citation2003). Additionally, behavioral and neuroimaging research on functionally monolingual international adoptees allude that even durationally minimal exposure to a language in childhood with no subsequent maintenance or conscious recollection of the language leads to long-term linguistic and neural effects similarly expected in bilinguals who speak the “lost” language (Oh, Au, & Jun, Citation2010; Pierce, Chen, Delcenserie, Genesee, & Klein, Citation2015). Overall, this evidence indicates that passive linguistic exposure has an important effect on one’s language repertoire.
In light of these findings, it is possible that in linguistically diverse, multilingual contexts, where various languages are spoken and displayed across the linguistic landscape (Gorter, Citation2006), at least some linguistic information is cognitively integrated by the people situated within and exposed to such contexts. Consequently, exposure to a linguistically diverse context over a substantial period is imperative to one’s language repertoire, particularly when exploring the holistic linguistic experience of speakers across the continuum of language knowledge.
Context and the lingualism status spectrum
Another area of importance regards the classification of individuals into respective language groups, such as the commonly used descriptors of monolingualism, bilingualism, and multilingualism. We refer to these as an individual’s lingualism status since these describe some continuous stature of language experience. Yet, an obvious caveat observed from the accumulated literature is the lack of clarity and regularity in conceptualizing the lingualism status of participants and the often-imposed categorical grouping of participants into one of these groups (Surrain & Luk, Citation2019). We propose that a categorical classification of one’s lingualism status may pose unique problems to the conception of the individual’s language knowledge and experience, given the limitations of the nature and diversity of language experience imposed by one linguistic label. It is therefore necessary to evaluate whether speakers are homogeneous in their contextual language exposure if they classify themselves with the same linguistic label because, under the conventional view, we would expect monolinguals (extended to bilinguals and multilinguals) from one context to be largely equivalent to monolinguals from another. Yet, are monolinguals in multilingual societies equal to (i) bilinguals/multilinguals within the same sociolinguistic context, or (ii) monolinguals in less linguistically diverse contexts? It is only when contextual linguistic diversity and, in particular, passive linguistic exposure is added to an epistemology of language experience that the prospect of greater understanding about the confounds of one’s language profile is real.
As noted, if monolingualism is a unanimous experience, then it is assumed that those who identify or are classified as monolingual have homogeneous and stable linguistic knowledge. However, such a restricted classification often fails to take contextual linguistic diversity and classificatory norms into account. The categorization of participants into boxed language groups, whether self-reported or designated, may therefore conceal nuances of language knowledge and experience that could alter research findings across various domains. For instance, studies have found differences in electrophysiological responses to language processing across seemingly similar monolingual groups differing in contextual linguistic exposure (Bice & Kroll, Citation2019) and proficiency (Pakulak & Neville, Citation2010). In addition, the situation is further complicated because different linguistic contexts employ unique standards and ideologies as to what counts as monolingualism, bilingualism, and multilingualism, as well as how language knowledge may be integrated as a result of the general linguistic milieu. As is the binary status quo, bilinguals are usually compared to monolingual counterpart “control” groups to assess whether bilingualism has an effect on X behavioral, linguistic, or cognitive outcome. Moreover, the majority of bilingualism research has been conducted within Global North, Western, or Anglosphere contexts, where conceptions of language knowledge and use may have particular meanings distinct from those from other, more linguistically diverse contexts outside of the Global North.
In a study exploring the consequences of context on language use, Beatty-Martínez et al. (Citation2020) compared three groups of ostensibly equivalent, highly proficient Spanish-English bilinguals, situated across three contexts that differed in language practice on lexical production and proactive/reactive inhibitory control. One group lived in Granada, Spain, where Spanish and English are mainly used separately and across specific domains (e.g., Spanish at home, English at school/work, little-to-no codeswitching). The second group lived in San Juan, Puerto Rico, where Spanish and English are more integrated and there is greater flexibility of language choice across domains and more opportunities to codeswitch. The last group consisted of participants born and raised in Spanish-speaking environments who immigrated to the United States during childhood or adolescence and were studying at State College, Pennsylvania. Although English is the dominant language used across domains in this State, there are varied but limited opportunities for Spanish use and codeswitching. Overall, they found that lexical access and how it relates to cognitive control greatly depends on the language practices and demands of the linguistic context. Specifically, accuracy on a picture naming task was modulated by inhibitory control only for the immersed bilinguals in the United States but not the other two groups, suggesting that this group of bilinguals needed to actively monitor their context prior to speaking, as their language choice was facilitated in relation to the language of their interlocutors, which had habitually become English. The authors acknowledged that most studies would normally aggregate such seemingly similar speakers into a single Spanish-English bilingual group, whereby this approach could lead to “a failure to characterize the complexity associated with the context of language use” (Beatty-Martínez et al., Citation2020, p. 15).
Although much work has been done to describe and quantify language experience, there is little uniformity or standard method as to how and by what measure this should be captured. Furthermore, assessment efforts have largely amassed around children’s linguistic knowledge, with far fewer questionnaires available for adults (for a review see Kašćelan et al., Citation2022). Given the expansive interest in multilingualism research, the goal should be attaining language knowledge about the participants that meets a best practice standard, and we propose that this includes a measure that captures sociolinguistic experience along with history, usage, and proficiency indicators. In order to appropriately characterize speakers within dynamic language contexts, it is clear that we need to consider their diverse experiences with respect to contextual language diversity and use (Bice & Kroll, Citation2019; Kroll et al., Citation2018; Tsimpli et al., Citation2020; Wigdorowitz et al., Citation2020). Having a holistic measure of language experience that captures information about sociolinguistic context can, accordingly, indicate where the speaker is linguistically immersed, including how certain languages may be privileged over others, and the flexibility, codeswitching, and exchange of language practices.
One recent questionnaire has been designed to evaluate both contextual and individual linguistic diversity as distinct features comprising the language profile: The Contextual and Individual Linguistic Diversity Questionnaire (CILD-Q; Wigdorowitz et al., Citation2020). The CILD-Q assesses contextual linguistic diversity by three scales: a) Multilingualism in Context, which encompasses the contextual use, societal practice, and community language norms (e.g., codeswitching) of multiple languages in addition to the dominant language within a context including via interlocutors, the media, and across the linguistic landscape (e.g., signage); b) Multilingualism in Practice, which includes individual exposure of linguistic diversity as a feature of spoken engagement that one is either directly or indirectly (i.e., ancillary engagement such as overhearing a conversation) involved in; and c) Linguistic Diversity Promotion, which is the societal and governmental promotion and encouragement of language variation and use within the context. Both Multilingualism in Context and Multilingualism in Practice scales consist of some items about codeswitching. The former reports on codeswitching about the general language situation within the context, while the latter concerns communicative practices of a more personal nature. Moreover, the CILD-Q is part of a larger language profiling questionnaire: The Contextual Linguistic Profile Questionnaire (CLiP-Q), which also captures demographic information, language history, use and proficiency, as well as socio-economic status (SES). As mentioned, apart from contextual linguistic diversity, most of these factors are usually considered in bilingual studies; however, SES has received less attention.
SES is commonly measured as a proxy of parental and/or personal educational attainment, occupation, and/or household assets and income, and it has been consistently found to have a large and sustained impact on language development (Brito & Noble, Citation2014, Citation2018; Letourneau, Duffett-Leger, Levac, Watson, & Young-Morris, Citation2013). Unsurprisingly, individuals from lower SES backgrounds have poorer linguistic outcomes compared to those from higher SES backgrounds, whereby SES is operationalized as the quality and quantity of the childhood linguistic environment (De Cat, Citation2020). Given its ubiquitous influence, Wigdorowitz and colleagues (Citation2020) also acknowledged that any measure of language profiling must include SES indicators if it is to provide a comprehensive overview of the population under investigation. Accordingly, factors that characterize the sociolinguistic context and the nature of language input, including SES, cannot be undervalued when the goal is to obtain a best practice perspective able to tease apart the contributions of contextual and individual language experience in order to attain a comprehensive account of linguistic knowledge and influence.
The present study
This study investigates the importance of contextual linguistic diversity when comparing groups from different sociolinguistic contexts, but where English is the lingua franca. In this way, we recruited participants from South Africa and England. South Africa is more multilingual than England in terms of the number of speakers of multiple languages as well as language policy (Constitution of the Republic of South Africa, Citation1996; Department for Education, Citation2014; Statistics South Africa, Citation2012; The British Academy, Citation2019). Although English is the dominant language in both countries, it is not numerically predominant and may not be the most proficient language of many South Africans, where it is reported as the fourth most common L1 (9.6%) after Zulu (22.7%), Xhosa (16.0%), and Afrikaans (13.5%) (Statistics South Africa, Citation2012). While English is the only de facto official language of England, reported as the main language for 92% of the population (Office for National Statistics, Citation2013), 11 languages have attained official status in South Africa (Mesthrie, Citation2002). In fact, there are more opportunities for active, and crucially passive exposure to multiple languages for South African speakers, whereas the opportunities for widespread and diverse language use are scarcer and more restricted to particular circumstances and engagements (such as amongst family or religious gatherings) in England.
Both groups were assessed on the CLiP-Q (Wigdorowitz et al., Citation2020), a language profiling measure designed to capture imperative information about contextual and individual linguistic diversity (regarding both active and passive linguistic exposure) as well as additional variables associated with explaining linguistic findings, to understand the relationship between contextual linguistic diversity (CILD-Q scales), sociolinguistic context (England vs South Africa), and SES, on the one hand, and contextual linguistic diversity, lingualism status (monolinguals vs bilinguals vs multilinguals), and SES, on the other hand. Finally, we also explored the interplay between sociolinguistic context and lingualism status by analyzing codeswitching practice. The specific research questions and predictions are as follows:
RQ1. (A) Do people who live in a more multilingual context (South Africa) report greater contextual linguistic diversity than those from a less multilingual context (England)? (B) Do individual differences in SES explain these differences? Given that South Africa is a more multilingual country than England, and that South African speakers have more opportunities for passive linguistic exposure than speakers from England, we predict that South Africans will score higher than participants from England in terms of their contextual linguistic diversity overall, and across all three scales of the CILD-Q: Multilingualism in Context, Multilingualism in Practice, and Linguistic Diversity Promotion. We also predict that SES will not differ between countries since our sample broadly represents individuals across a range of socio-economic standing. However, given the prevalence of multilingualism in South Africa, we predict that across the socio-economic spectrum, contextual linguistic diversity will be consistently experienced and promoted irrespective of one’s SES. In contrast, for the England participants, SES could influence the uptake of multilingualism in two possible ways. First, those with lower SES could score highly on contextual linguistic diversity, especially if it is the case that lower SES groups use more than one language, as has been reported in many immigrant populations (Fernández Reino, Citation2019). As a second alternative, participants in England with high SES could score higher on contextual linguistic diversity because of an awareness that foreign language learning is an index of higher education, global advancement, and cognitive benefit (Hogan-Brun, Citation2017). This hypothesis would be particularly associated with higher SES families sending their children to independent/private schools, in which foreign language learning is valued and promoted more than in state schools (Tinsley, Citation2019).
RQ2. (A) Is lingualism status contextually consistent when assessing linguistic diversity in South Africa and England? (B) Do individual differences in SES contribute to any possible differences? Given that contextual linguistic diversity is a phenomenon comprising active and passive linguistic input as derived from the sociolinguistic milieu, we consider it distinct from lingualism status, and therefore predict that self-reported monolinguals from South Africa will score closely to their bilingual and multilingual counterparts on the CILD-Q, who at the same time, are expected to attain close scores (overall and across the three scales), due to the great contextual linguistic diversity of this country. In contrast, because England is less linguistically diverse, we predict a larger difference between monolinguals and bilinguals/multilinguals. Regarding the last two groups, it is less clear whether bilinguals and multilinguals will differ from one another, since these participants usually have explicit knowledge of more than one language, and therefore do experience overt linguistic diversity. Therefore, as with South Africans, we do not expect differences on contextual linguistic diversity between bilinguals and multilinguals from England. Finally, whether individual differences in SES should play a role regarding lingualism status in each country remains completely exploratory.
RQ3. Does codeswitching contribute to the effects of contextual linguistic diversity in South Africa and England across lingualism status groups? As mentioned above, only two of the three CILD-Q scales have items that refer to codeswitching: Multilingualism in Context (MIC) and Multilingualism in Practice (MIP). Recall, MIC reports on the global practice of codeswitching within the context, and in contrast, MIP concerns communicative practices of a more personal nature. Accordingly, the codeswitching analysis focuses on these two scales, distinguishing between non-codeswitching and codeswitching items. Our predictions are as follows. Regarding MIC, we predict that monolingual, bilingual, and multilingual South Africans will score higher on both codeswitching and non-codeswitching items than counterpart lingualism groups from England, given that individuals living in multilingual contexts will be exposed, purely as a consequence of their natural language environment, to more linguistic variation than individuals living in predominantly unilingual contexts. In contrast, for the MIP scale, differences across countries are exclusively expected in the codeswitching items. Specifically, given that this scale relates more directly to one’s personal language experience, we predict that South African monolinguals will score higher on codeswitching items than monolinguals from England, since codeswitching is a positive and acceptable linguistic attribute for South Africans across the lingualism spectrum (Mesthrie, Citation2002). It is less clear whether bilinguals and multilinguals will differ in their codeswitching practice across South Africa and England since these participants report to have access to more than one language and may engage directly or overhear others engaging in codeswitching. Despite this, we expect South African bilinguals and multilinguals to score higher on codeswitching items than the same groups from England.
Methods
Participants
The country that the participants reported to have lived in for the longest amount of time guided the classification of the sample into their respective South African and England groups. An initial sample of 353 participants accessed the CLiP-Q but were removed if they had incomplete or anomalous responses, leaving a sample of 269 participants (South Africans = 67.29%, significantly older than England participants). To address the unequal sample size and reduce the age disparity, we computed a propensity score match with age as the matching variable. Matching yielded a final sample of 176 (88 participants across each group; South Africans: Mage = 28.53, SD = 7.81, female = 84.1%, male = 15.9%; England: Mage = 22.80, SD = 6.10, female = 62.5%, male = 36.4%, non-binary = 1.1%). English was reported as the most proficient language of 144 participants and the second most proficient language of 28 participants, with all participants reporting daily English exposure (see for English proficiency ratings). Furthermore, English was reported as the primary medium of instruction for the majority of participants across primary (70.35%) and secondary (70.86%) school settings. Through self-report, our sample was divided into 63 monolinguals (19 South Africa, 44 England), 55 bilinguals (37 South Africa, 18 England), and 58 multilinguals (32 South Africa, 26 England).
Table 1. Means (and standard deviations) for self-rated English (L1 or L2) proficiency for South African and England participants
Materials
Contextual Linguistic Profile Questionnaire (CLiP-Q)
The CLiP-Q (Wigdorowitz et al., Citation2020) is a holistic language profiling measure which captures information that has been found to be imperative to language profiling research. The questionnaire includes the following sections:
A. Demographic information. Participants report the country they have lived in over the majority of their lives, which leads them to answer country-specific demographic questions about their nationality, country and province/region of birth and current residence, total years lived in reported country, age, gender, and ethnicity.
B. Contextual and Individual Linguistic Diversity Questionnaire (CILD-Q). As mentioned above, the CILD-Q differentiates linguistic diversity within the individual and as a feature of their contextual exposure in relation to the country participants report to have lived in over the majority of their lives (i.e., where they have received the greatest sociolinguistic exposure). Because of its dominance, English is the reference language used to frame the questions. Participants respond, on a Likert scale ranging from 1 (strongly disagree) to 5 (strongly agree), to 18 items that have been found to reliably measure three scales pertaining to contextual linguistic diversity: Multilingualism in Context (MIC), Multilingualism in Practice (MIP), and Linguistic Diversity Promotion (LDP; see description above and for CILD-Q items). Higher mean scores reflect greater general exposure and mixing of different languages from that of English across spoken and written domains (MIC), greater individual and conversational exposure to linguistic diversity (including engagement in code-switching; MIP), and higher governmental and societal encouragement of language diversity (LDP). Item order is randomized across participants.
Table 2. Means (and standard deviations) of CILD-Q items across nationality groups
C. Language history, use, and proficiency. This section is concerned with individual accounts of language history, use, and proficiency and is divided into two components. The first gathers information about general language background including all spoken and written languages, home and most comfortable language, formally and informally learned languages, medium of schooling, exposure to English, and lingualism status self-classification. The second component asks questions about participants’ first, second, and third most proficient languages, with repeated questions for each language. Information is obtained about age milestones (e.g., acquisition, writing); years of language use; ability in speaking, understanding, reading, and writing; extent of language use with interlocutors, across activities, and when engaging in personal states (e.g., thinking); and degree of cultural association. Lastly, an open-ended question is presented probing participants for any additional language background and usage information they deem to be noteworthy.
D. Socio-economic status (SES). A composite SES score is computed from variables associated with SES, including an index of household assets (home security, computer, paid TV subscription, internet access, car, and domestic worker and/or gardener; 0 = no, 1 = yes, summed), annual household income (value range according to tax brackets; 1 = Less than R195,850/£11,850 to 6 = R1,500,001/£150,001 and above), self, maternal, and paternal level of education (1 = lower than or up to Grade 11/less than or up to GCSE to 6 = PhD). Scores from each variable were averaged to create a composite SES score ranging from 1 (low SES) to 6 (high SES).
Taken together, the four sections of the CLiP-Q provide a comprehensive linguistic profile of adults situated across various sociolinguistic contexts.
Procedure
Ethical clearance was granted from the University of Cambridge Research Ethics Committee prior to conducting the research. The CLiP-Q was distributed online across the researchers’ networks (e.g., listservs, social media sites) via Qualtrics and took around 30 minutes to complete. Participation was voluntary and informed consent was requested once participants were informed of the study overview, inclusion criteria, and ethical guidelines.
Data analysis
Linear mixed-effects models (LME) were conducted in R using the “lme4” package (Bates et al., Citation2020), which accounts for both fixed and random effects. LME models can estimate participant and item-level data under one analytic framework, which increases the generalizability of the results (Baayen, Davidson, & Bates, Citation2008). Participants and items were computed as random factors in all models. In addition, fixed factors varied according to the research question. For instance, to address RQ1, Model 1 included nationality (England vs South Africa), CILD-Q scales (MIC vs MIP vs LDP) and SES fixed factors, whereas to address RQ2, Models 2 and 3 included the fixed factors of lingualism status (monolingual vs bilingual vs multilingual), CILD-Q scales (MIC vs MIP vs LDP) and SES, for the South African and England samples separately. SES was considered as a continuous variable, using centered values. In all cases, the dependent variable was the mean score (from 1 to 5) obtained from the CILD-Q.
To determine the optimal structure for the random and fixed components of each LME model, the procedure, as outlined by Zuur, Ieno, Walker, Saveliev, and Smith (Citation2009) was followed. We first looked for the best random structure using restricted maximum likelihood, while the full fixed structure (i.e., a three-way interaction in all cases) was retained (Barr, Levy, Scheepers, & Tily, Citation2013). More specifically, the random structure was tested by running an ANOVA between all possible models containing the various combinations of intercepts and/or slopes, using nationality and lingualism status as random slopes, while keeping the full fixed structure (see Pérez, Joseph, Bajo, & Nation, Citation2016, for the same rationale). The model containing the lowest AIC and BIC values was selected.
Once the best random structure was identified, we then tried to obtain the best fixed structure. To do this, we ran stepwise model comparisons from the most complex model (i.e., three-way interaction) to the simplest model (i.e., main effect), by selecting the significant χ2 test for the log-likelihood, using maximum likelihood. Third, χ2 and p values were provided by the ANOVA function of the “lmerTest” package using Satterthwaite’s approximation for denominator degrees of freedom (Kuznetsova, Brockhoff, Christensen, & Jensen, Citation2020). It was also important to evaluate the effect size of the significant effects, in order to describe the proportion of the total variability attributed to the factor, and in this way, provide an indication of the practical significance of the result. Partial eta squared (ηp2) was calculated using the “eta_sq” function of the “sjstats” package (Lüdecke, Citation2020). To qualify the two-way interactions, the “testInteractions” function of the “phia” package (De Rosario-Martínez, Citation2015) and “lsmeans” function of the “lsmeans” package (Lenth, Citation2018) were used for post-hoc analyses with Bonferroni correction where necessary. For the three-way interactions, we divided the data into subsets according to the levels of the CILD-Q scales and fitted adjusted LME for these subsets.
Finally, to address RQ3, we ran independent samples t-tests with a Bonferroni correction, comparing lingualism status (monolingual vs bilingual vs multilingual) across nationality (South Africa vs England) in all crossed conditions including either MIC or MIP scales and non-codeswitching and codeswitching items.
Results
Results of the LME analysis are presented in three main sections with a focus on the fixed effects output. Summary details regarding model fit and random effects of the significant models are provided in the Appendix. We first evaluated whether participants from South Africa and England differed in their contextual linguistic diversity and whether possible differences were explained by SES (RQ1). Secondly, we evaluated whether there were differences of lingualism status within each country and, once more, if individual differences in SES explained their effects (RQ2). Finally, we explored the role of codeswitching in the MIC and MIP scales to investigate differences in lingualism status across South Africa and England (RQ3). Means and standard deviations for item-level data are provided in , while means and standard error values for CILD-Q scores across nationality groups as a factor of linguistic status are provided in .
Table 3. Means (and standard errors) for CILD-Q scores across nationality groups as a factor of lingualism status and CILD-Q scale
Contextual linguistic diversity across countries
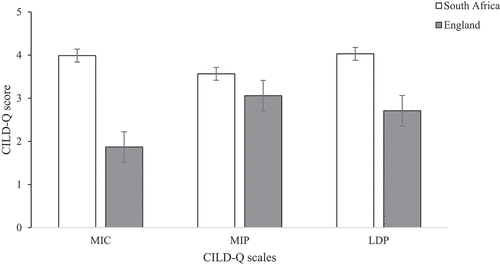
Regarding differences between countries (Model 1, see Appendix), our LME model showed a significant main effect of nationality, F(1,187.46) = 13.96, p < .001, ηp2 = .07, where as expected, participants from South Africa (M = 3.85, SE = .12) scored higher on the CILD-Q than participants from England (M = 2.50, SE = .17). In addition, the two-way interaction of nationality × scale was marginally significant, F(2,184.82) = 2.99, p = .05, ηp2 = .03, where pairwise comparisons with Bonferroni correction showed that South Africans scored higher than participants from England across two CILD-Q scales: MIC, t(125.4) = 11.51, p < .001; and LDP, t(29.2) = 5.18, p < .001. No difference was found in the MIP scale (p = .19; see ). To further clarify this interaction, a second pairwise comparison was run dividing by nationality. This analysis demonstrated that the three scales did not differ from one another for the South African group (ps > .55), but they did for the England group. Post hoc analyses showed that this group had lower scores in MIC compared to MIP, t(24.1) = −4.19, p < .01, but no differences were found between MIC and LDP, nor between MIP and LDP (ps > .15).
Figure 1. Bar graph with mean and standard error values of CILD-Q scores, representing the two-way interaction between nationality and CILD-Q scales (MIC = Multilingualism in Context; MIP = Multilingualism in Practice; LDP = Linguistic Diversity Promotion).
More importantly, the previous interaction was qualified by a three-way interaction with SES: nationality × scale × SES, F(2,174.67) = 3.83, p < .05, ηp2 = .04. To understand this interaction, a subset was performed by dividing by scale. This division produced a non-significant interaction of nationality × SES for both the MIC and MIP scales (ps > .45). In contrast, the same interaction was significant in the LDP scale, F(1,175.98) = 5.37, p < .05, where pairwise comparisons showed that SES explained differences in LDP in England, χ2(1) = 6.15, p < .05, but not SA (p = .88). Specifically, England participants with higher SES scored higher in LDP, while those with lower SES scored lower in this scale (see ). No other effects were significant (all ps > .12).
Figure 2. Scatter linear graph with mean CILD-Q scores, representing the interaction between nationality and SES across the three scales: Multilingualism in Context (Figure 2a); Multilingualism in Practice (Figure 2b), and Linguistic Diversity Promotion (Figure 2c).
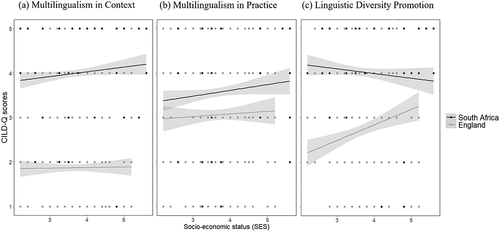
Altogether, our findings regarding contextual linguistic diversity across countries suggest that compared to England participants, South Africans had greater exposure to linguistic diversity within their contextual confounds and the promotion of linguistic diversity across governmental and societal strata was larger. In addition, contextual linguistic diversity was experienced consistently for South Africans, but the England group varied in how they experienced it. In fact, individual differences in SES showed that contextual linguistic diversity depends on this factor, but only in England which is a less linguistically diverse context. That is, in England, SES appeared to influence whether there was promotion and endorsement of multilingualism, but for South Africans, multilingualism was promoted regardless of one’s socio-economic standing.
Contextual linguistic diversity across lingualism status
Taking into account the unequal sample sizes between the two countries across the lingualism conditions, a separate model for each nationality was run to evaluate differences across lingualism status. No significant effects were found in the South African group (Model 2; all ps > .14). Regarding differences across lingualism status for England (Model 3, see Appendix), our LME manifested a significant effect of scale, F(2,23.82) = 10.51, p < .001, ηp2 = .47, where pairwise comparisons demonstrated differences between participants across the scales. England participants scored significantly lower on MIC in comparison to MIP, t(25) = 4.12, p < .01, and LDP, t(23.7) = 2.53, p < .05. In contrast, no difference was found between MIP and LDP (p = .59; see England scale scores in ). No other main or interaction effect was significant (all ps > .13).
Taken together, self-reported monolinguals, bilinguals, and multilinguals did not differ from one another in terms of their contextual linguistic diversity in South Africa or England.
Contextual linguistic diversity and codeswitching
Finally, to explore whether some of the differences found across nations and/or lingualism status were a result of items that refer specifically to codeswitching, we ran independent t-tests comparing South Africa and England participants across monolinguals, bilinguals, and multilinguals in all crossed conditions including either MIC or MIP scales and non-codeswitching and codeswitching items (see ). A Bonferroni correction for the two types of items separately, set the alpha at .008.
Table 4. Mean, standard deviation, p-value (t-test comparison) and g-value (Hedges’ g effect size) for non-codeswitching and codeswitching item clusters of Multilingualism in Context (MIC) and Multilingualism in Practice (MIP) across nationality groups, as a factor of lingualism status
Results showed that codeswitching played a role depending on the CILD-Q scale. South Africans scored higher than England participants on both codeswitching and non-codeswitching items in the MIC scale (all ps < .001). Therefore, codeswitching alone did not account for the differences observed in contextual exposure to multilingualism. In contrast, codeswitching explained differences between countries in the MIP scale. That is, there were no significant differences between the two nations across the three lingualism status groups for the non-codeswitching items (all ps > .43), whereas codeswitching items revealed differences between lingualism groups across the two countries. More specifically, monolinguals and multilinguals in South Africa scored higher than their England counterparts on the codeswitching items (ps = .05 and < .001, respectively, after Bonferroni correction); in contrast the bilingual groups did not manifest significant differences across countries on codeswitching items (p = .19). These findings indicate that codeswitching was a feature of direct communicative practices of South Africans who self-identified as monolinguals or multilinguals compared to the same populations in England. On the contrary, codeswitching did not seem to be a feature more greatly experienced by South African bilinguals than England bilinguals, suggesting that bilingualism was more similarly defined across the two countries, with equivalent opportunities of codeswitching.
Discussion
A core aim of sociolinguistic research is to, systematically and accurately, describe and quantify language experience. Typically, this is carried out using a language profiling measure where linguistic information of input and usage, age of acquisition and exposure, and proficiency is captured (de Bruin, Citation2019). Language profiling is largely the first point of data collection in empirical studies aimed at investigating differences across designated language groups. Such information gleaned for these measures plays a vital role in the description, division, and comparison of participants (Luk & Bialystok, Citation2013; Silva-Corvalán & Treffers-Daller, Citation2015). Therefore, it is essential that a language profile measure incorporates a broad and valid range of linguistic information that can be used, at minimum, as a baseline for describing an individual’s language experience. Accordingly, it was important to assess, using a holistic language profile measure, whether exposure to a predominantly multilingual or unilingual context (where English is the lingua franca), affects linguistic knowledge overall, as well as whether self-classification of lingualism status is contextually consistent, taking socio-economic status and codeswitching behavior into account.
Contextual linguistic diversity across contexts
First, we tried to understand whether people who live in a more multilingual context (South Africa) report greater contextual linguistic diversity than those from a less multilingual context (England; RQ1A). Unsurprisingly, the results show that the sociolinguistic context of where people are immersed does contribute to their linguistic experience overall even when the prominent language across the contexts is the same. In line with our hypothesis, South Africans reported greater overall contextual linguistic diversity, and more specifically, higher multilingual exposure (MIC) and multilingual endorsement (LDP), in comparison to participants from England. Though, it is noteworthy that the differences between nationality groups did not emerge for communicative engagement (MIP; see ). In this way, we can be confident that contextual linguistic diversity is greatly influenced by exposure to multilingual content within one’s environment – whether through the media, on signage, or as a factor of creative and intermingled language practices at the community level – in addition to the value placed on multilingualism from society and the government. The lack of difference between South Africa and England participants on MIP could be due to the fact that this scale relates more to active instances of communicative engagement between interlocutors, where an individual may be privy to an exchange either through directly partaking in it or being an overhearer. In this way, for participants who are exposed to additional languages other than English, their exposure here is more explicit, obvious, and may involve unique strategies of communication (such as codeswitching), and as such, this is reflected in the smaller mean differences between the nationality groups. Nonetheless, future research should clarify this interpretation.
In addition, South Africans scored similarly across all of the CILD-Q scales, but in England, participants scored greater on communicative multilingualism (MIP) in comparison to contextual multilingualism (MIC). This suggests that contextual linguistic diversity is more consistently experienced and pervasive in South Africa, while in England this is not the case. In both countries English attains societal language dominance status since it is the lingua franca and privileged in terms of use across pedagogy, government, business, and media. Yet, since South Africa is a unique setting of widespread linguistic fusion, which hosts numerous languages and a diverse array of dialects, we argue that the country’s speakers are ubiquitously exposed, both actively and passively, to linguistic diversity in a way distinct from those situated in England. For instance, a South African adult has undoubtedly been surrounded by speakers and content of different languages to that of their L1 (more so, on average, than speakers situated in England), but may not use or have acute knowledge of most or any of these languages. Their knowledge here may be predominantly an awareness of linguistic diversity, but perhaps without actual receptive or productive ability in an additional language, albeit their language skills “may vary along a continuum from zero to full ability” (Tsimpli et al., Citation2020, p. 2). Therefore, the context of language use is an imperative aspect to consider when comparisons are to be drawn about individuals situated in different sociolinguistic settings.
The interplay of multilingual promotion and socio-economic status
We next wanted to address whether SES contributed to the effects of contextual linguistic diversity in South Africa and England (RQ1B). Indeed, we found that the results appear to be dependent on SES, but only in England which is a less linguistically diverse context in both number of speakers of multiple languages as well as policy. In England, SES appears to influence whether there is promotion and endorsement of multilingualism, with those of a higher socio-economic standing acknowledging a greater uptake and acceptance of multilingualism than those of a lower socio-economic standing. A possible explanation for this finding can be linked to the notion of what Hogan-Brun (Citation2017) calls Linguanomics (the economics of language), whereby multilingualism is viewed as an economic asset and prospect of human capital, as measured both tangibly (e.g., teaching, translation) and intangibly (e.g., culture, identity, human rights).
Our results suggest that those of a high socio-economic standing in England perceive multilingualism as being adequately promoted by the people and country more generally, while those of lower economic advantage perceive multilingualism as being promoted less adequately. It is not the case that the lingualism status of the participants are influencing this finding, since the distribution of those with low SES scores (< 3.5; monolinguals = 22, bilinguals = 7, multilinguals = 14) are fairly equal to those of high SES scores (≥ 3.5; monolinguals = 22, bilinguals = 11, multilinguals = 12). Rather, the perception of multilingual endorsement is greater for participants with more economic resources, who may therefore have access to such resources through education or other privileged means. Compare, for instance, access to language education in state-funded versus independent schools across England. Although there has been a steady decline in language education across both school sectors, language learning remains more of a pedagogical priority and viable subject option for students attending independent schools (Collen, Citation2020; Tinsley, Citation2019). This disparate priority may be one of the factors that accounts for the observed results, since 41% of the sample reported to attend an independent or grammar secondary school, and of those that did attend a state school, 42% had received some secondary education in a medium of instruction other than English. Having the economic and social means to gain experience with language education may, therefore, foster the view that multilingualism is promoted within the country.
Contrastively, for South Africans, multilingualism appears to be promoted by society and the government regardless of one’s socio-economic standing. That is, across the low to high socio-economic spectrum, participants equally agree that multilingualism is encouraged. This may be largely influenced by language policies that have been implemented to safeguard multilingualism (e.g., National Language Policy Framework, South African Department of Arts and Culture, Citation2003), the pedagogical necessity for a multilingual nation, as well as a pledge of inclusiveness and fair representation, including that of language equity in post-apartheid South Africa (Plüddemann, Citation2015; Weideman, Read, & du Plessis, Citation2021). Given that this finding is particularly novel, we encourage further research to investigate these results in more depth to unpack the influence of SES on multilingual promotion.
Contextual linguistic diversity and lingualism status
We next investigated whether lingualism status was contextually consistent when assessing contextual linguistic diversity in South Africa and England separately (RQ2). We found that self-reported monolinguals, bilinguals, and multilinguals did not differ from one another in terms of their contextual linguistic diversity in South Africa or England. That is, South African/England self-described monolinguals scored closely to South African/England self-described bilinguals and multilinguals on the CILD-Q, and likewise, the bilinguals and multilinguals scored closely to one another. In line with our hypotheses, a null result of lingualism status on contextual linguistic diversity was present in the South African group, but our findings partially differed from our second hypothesis, where we predicted England monolinguals to score lower than their bilingual and multilingual counterparts given that this is a less linguistically diverse context. In fact, what we did find was a null result for lingualism status on contextual linguistic diversity for England too.
Interestingly, these results suggest that, on the one hand, regardless of the individual lingualism status descriptor one identifies with, their sociolinguistic context is shown to be a consistent contributor to language experience. Contextual linguistic diversity is therefore an imperative variable to consider over-and-above lingualism status, since it is not always possible to show categorical differences across groups that classify themselves under separate linguistic labels. Importantly though, Tsimpli et al. (Citation2020, p. 2) notes that “linguistic diversity at the societal level may or may not translate as multilingualism at the individual level.” There is thus a distinction between active and passive language exposure, but where both contribute holistically to the language repertoire.
On the other hand, this is an illuminating finding, adding evidence to the growing body of literature questioning the appropriateness of a categorical notation of language experience. Recently, bilingualism has been disputed as a categorical variable; no definitive experiential threshold suddenly transforms an individual from a monolingual to a bilingual (Luk & Bialystok, Citation2013; Marian & Hayakawa, Citation2021; Takahesu Tabori et al., Citation2018). Rather, language experience is much more complex and multifaceted than the oftentimes reductionist approach it is condensed to. In this sense, our study provides substantial and supplementary evidence supporting this claim, and therefore offers the opportunity to explore similar questions where lingualism status is treated on a continuum, rather than categorically.
Clearly, the conceptions of lingualism categories are not as bounded as have been previously assumed (for a review see Surrain & Luk, Citation2019). We have shown that self-descriptions of lingualism status in one context can appear similar, thereby providing further evidence illustrating how heterogeneous language groups are, even if people identify themselves under the same linguistic label (also see Beatty-Martínez et al., Citation2020; Bice & Kroll, Citation2019; de Bruin, Citation2019). Accordingly, the more linguistic information we can attain from an individual, the better scope we will have at making some group classifications. We should therefore strive toward a graded approach that positions speakers on a continuum from less multilingual toward more multilingual (Gullifer et al., Citation2018; Gullifer & Titone, Citation2020; Luk & Bialystok, Citation2013; Marian & Hayakawa, Citation2021), specifically with an acknowledgment of their contextual linguistic experience (Wigdorowitz et al., Citation2020).
Contextual linguistic diversity and codeswitching
Lastly, we aimed to investigate whether codeswitching contributed to the effects of contextual linguistic diversity in South Africa and England across lingualism status groups (RQ3). In line with our hypotheses, we found that codeswitching did not account for the differences across groups in the MIC scale (which addresses more of the general consensus of language use within the context), where all South African lingualism groups scored higher than the same groups from England across items that both contained and did not contain codeswitching. In contrast, codeswitching, as a direct communicative practice, accounted for the higher MIP scores reported by South African multilinguals and monolinguals (this scale refers more specifically to one’s personal language practice and engagements). We therefore cannot overlook the fact that there may be a difference in codeswitching practice between South African and England so-called multilinguals, and especially monolinguals. This finding is striking if we assume that monolinguals have access to one language only and codeswitching is generally a proposed bilingual phenomenon (e.g., Beatty-Martínez, Navarro-Torres, & Dussias, Citation2020) that requires access to more than one language.
In addition, there was no difference in MIP codeswitching items for the bilingual groups across the two contexts, nor were there any differences for lingualism groups across the nations on MIP items that did not refer to codeswitching. The fact that codeswitching explained the higher MIP scores reported by multilingual and monolingual South Africans but not for the bilingual group across the contexts may also suggest that bilingualism is a more concretely defined notion of language knowledge when contrasted with monolingualism and multilingualism, and can be taken to refer specifically to the knowledge of two languages. In contrast, monolingualism and multilingualism are more nuanced notions of language and may be broadly influenced by linguistic (e.g., number of languages spoken, proficiency) and non-linguistic (e.g., community-based norms) factors. Alternatively, these findings further illustrate the problematic categorization of language knowledge as encompassed within a single lingualism group, as mentioned above.
Essentially, the main point of interest is how speakers have perceived themselves in linguistic terms. If it is expected that a typical monolingual or multilingual would not engage in codeswitching because this phenomenon is considered a “bilingual” practice, then it is surprising that South African multilinguals and monolinguals report codeswitching more so than their England counterparts. The sociolinguistic context of where individuals are situated is then clearly an essential contributor to one’s language repertoire. More precisely, individuals situated in multilingual contexts have language experiences that are different from individuals situated in unilingual contexts, even though they may classify themselves under the same linguistic label. Codeswitching is a common communicative practice in South Africa (Slabbert & Finlayson, Citation1999), observed across formal and informal settings (Mabule, Citation2019; Rose & Van Dulm, Citation2011) and in different communities (McCormick, Citation2002; Slabbert & Finlayson, Citation2002), suggesting that it is a widespread and pervasive part of many peoples’ language repertoires. In England, however, it is less common, where it mainly, if at all, occurs within immigrant or heritage communities (Promprakai, Citation2018). Furthermore, attitudes and community-based norms facilitating (or impeding) codeswitching are also important to consider (Beatty-Martínez et al., Citation2020). In multilingual societies, speakers’ intentions to codeswitch may therefore be driven by pragmatic and interactional opportunities irrespective of one’s lingualism status.
Conclusions
While individual reports of language history, use, and proficiency have generally been considered sufficient for language profiling, these variables alone neglect contextual linguistic experience as a factor that contributes to one’s overall language repertoire. We have demonstrated that a language profiling measure, such as the CLiP-Q, that captures variables pertinent to language knowledge and experience overall should be a goal toward best practice. When conclusions are to be drawn about the role of factors that contribute to linguistic experience and knowledge, it is imperative that researchers are cognizant of the types of information they have acquired. A full picture cannot be drawn if it lacks an inspection of the sociolinguistic experience and exposure of those being evaluated, given how important sociolinguistic context is to one’s linguistic repertoire. Fundamentally, we argue that contextual linguistic diversity can influence one’s sensitivity to sociolinguistic variation that may be devoid of actual awareness or use of multiple languages, and furthermore, it can shape the status of languages within the socio-cultural context. The nature of contextual linguistic diversity has a profound effect on the linguistic knowledge and use of inhabitants of these contexts. This sociolinguistic factor should be prioritized if research in the language sciences is to make progress.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abutalebi, J., & Green, D. W. (2016). Neuroimaging of language control in bilinguals: Neural adaptation and reserve. Bilingualism: Language and Cognition, 19(4), 689–698. doi:10.1017/S1366728916000225
- Au, T. K.-F., Knightly, L. M., Jun, S.-A., & Oh, J. S. (2002). Overhearing a language during childhood. Psychological Science, 13(3), 238–243. doi:10.1111/1467-9280.00444
- Au, T. K.-F., Oh, J. S., Knightly, L. M., Jun, S.-A., & Romo, L. F. (2008). Salvaging a childhood language. Journal of Memory and Language, 58(4), 998–1011.
- Baayen, R. H., Davidson, D. J., & Bates, D. M. (2008). Mixed-effects modeling with crossed random effects for subjects and items. Journal of Memory and Language, 59(4), 390–412. doi:10.1016/j.jml.2007.12.005
- Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68(3), 255–278. doi:10.1016/j.jml.2012.11.001
- Bates, D., Maechler, M., Bolker, B., Walker, S., Christensen, R. H. B., Singmann, H., Dai, B. et al. (2020). Package “lme4.” R Package Version 1.1-23, R Core Team. https://cran.r-project.org/web/packages/lme4/lme4.pdf
- Beatty-Martínez, A. L., Navarro-Torres, C. A., & Dussias, P. E. (2020). Codeswitching: A bilingual toolkit for opportunistic speech planning. Frontiers in Psychoogy, 11, 1699. doi:10.3389/fpsyg.2020.01699
- Beatty-Martínez, A. L., Navarro-Torres, C. A., Dussias, P. E., Bajo, M. T., Guzzardo Tamargo, R. E., & Kroll, J. F. (2020). Interactional context mediates the consequences of bilingualism for language and cognition. Journal of Experimental Psychology. Learning, Memory, and Cognition, 46(6), 1022–1047. doi:10.1037/xlm0000770
- Beatty-Martínez, A. L., Valdés Kroff, J. R., & Dussias, P. E. (2018). From the field to the lab: A converging methods approach to the study of codeswitching. Languages, 3(2), 1–19. doi:10.3390/languages3020019
- Bice, K., & Kroll, J. F. (2015). Native language change during early stages of second language learning. NeuroReport, 26(16), 966–971. doi:10.1097/WNR.0000000000000453
- Bice, K., & Kroll, J. F. (2019). English only? Monolinguals in linguistically diverse contexts have an edge in language learning. Brain and Language, 196, 104644. doi:10.1016/j.bandl.2019.104644
- The British Academy. (2019). Languages in the UK: A call for action. London, UK. https://www.thebritishacademy.ac.uk/sites/default/files/Languages-UK-2019-academies-statement.pdf
- Brito, N. H., & Noble, K. G. (2014). Socioeconomic status and structural brain development. Frontiers in Neuroscience, 8, 1–12. doi:10.3389/fnins.2014.00276
- Brito, N. H., & Noble, K. G. (2018). The independent and interacting effects of socioeconomic status and dual-language use on brain structure and cognition. Developmental Science, 21(6), e12688. doi:10.1111/desc.12688
- Chang, C. B. (2012). Rapid and multifaceted effects of second-language learning on first- language speech production. Journal of Phonetics, 40(2), 249–268. doi:10.1016/j.wocn.2011.10.007
- Collen, I. (2020). Language Trends 2020: Language teaching in primary and secondary schools in England. British Council. https://www.britishcouncil.org/sites/default/files/language_trends_2020_0.pdf
- Constitution of the Republic of South Africa. (1996). Constitution of the Republic of South Africa, 1996. https://www.wipo.int/edocs/lexdocs/laws/en/za/za107en.pdf
- de Bruin, A. (2019). Not all bilinguals are the same: A call for more detailed assessments and descriptions of bilingual experiences. Behavioral Sciences, 9(3), 1–13. doi:10.3390/bs9030033
- De Cat, C. (2020). Predicting language proficiency in bilingual children. Studies in Second Language Acquisition, 42(2), 279–325. doi:10.1017/S0272263119000597
- De Rosario-Martínez, H. 2015. Package “phia.” R Package Version 0.2-1, R Core Team https://cran.r-project.org/web/packages/phia/phia.pdf
- Department for Education. (2014). The national curriculum in england–framework document. UK. https://assets.publishing.service.gov.uk/government/uploads/system/uploads/attachment_data/file/381344/Master_final_national_curriculum_28_Nov.pdf
- Fernández Reino, M. (2019). English language use and proficiency of migrants in the UK. UK: COMPAS, University of Oxford. Migration Observatory briefing. https://migrationobservatory.ox.ac.uk/wp-content/uploads/2019/07/Briefing-English-language-use-and-proficiency-1.pdf
- Freedman, M., Alladi, S., Chertkow, H., Bialystok, E., Craik, F. I., Phillips, N. A. et al. (2014). Delaying onset of dementia: Are two languages enough? Behavioural Neurology, 2014(808137), 1–8. doi:10.1155/2014/808137
- Gorter, D. (Ed.). (2006). Linguistic landscape: A new approach to multilingualism. Clevedon, Buffalo, Toronto: Multilingual Matters.
- Gullberg, M., Roberts, L., Dimroth, C., Veroude, K., & Indefrey, P. (2010). Adult language learning after minimal exposure to an unknown natural language. Language Learning, 60(2), 5–24. doi:10.1111/j.1467-9922.2010.00598.x
- Gullifer, J. W., Chai, X. J., Whitford, V., Pivneva, I., Baum, S., Klein, D., & Titone, D. (2018). Bilingual experience and resting-state brain connectivity: Impacts of L2 age of acquisition and social diversity of language use on control networks. Neuropsychologia, 117, 123–134. doi:10.1016/j.neuropsychologia.2018.04.037
- Gullifer, J. W., & Titone, D. (2020). Characterizing the social diversity of bilingualism using language entropy. Bilingualism: Language and Cognition, 23(2), 283–294. doi:10.1017/S1366728919000026
- Hogan-Brun, G. (2017). Linguanomics: What is the market potential of multilingualism? London, UK: Bloomsbury Publishing Plc.
- Kašćelan, D., Prévost, P., Serratrice, L., Tuller, L., Unsworth, S., & De Cat, C. (2022). A review of questionnaires quantifying bilingual experience in children: Do we document the same constructs? Bilingualism: Language and Cognition, 25(1), 29–41. doi:10.1017/S1366728921000390
- Knightly, L. M., Jun, S.-A., Oh, J. S., & Au, T. K.-F. (2003). Production benefits of childhood overhearing. The Journal of the Acoustical Society of America, 114(1), 465–474. doi:10.1121/1.1577560
- Kreiner, H., & Degani, T. (2015). Tip-of-the-tongue in a second language: The effects of brief first-language exposure and long-term use. Cognition, 137, 106–114. doi:10.1016/j.cognition.2014.12.011
- Kroll, J. F., Dussias, P. E., & Bajo, M. T. (2018). Language use across international contexts: Shaping the minds of L2 speakers. Annual Review of Applied Linguistics, 38, 60–79. doi:10.1017/S0267190518000119
- Kurkela, J. L. O., Hämäläinen, J. A., Leppänen, P. H. T., Shu, H., & Astikainen, P. (2019). Passive exposure to speech sounds modifies change detection brain responses in adults. NeuroImage, 188, 208–216. doi:10.1016/j.neuroimage.2018.12.010
- Kuznetsova, A., Brockhoff, P. B., Christensen, R. H. B., & Jensen, S. P. 2020. Package “lmerTest.” R Package Version 3.1-2, R Core Team https://cran.r-project.org/web/packages/lmerTest/lmerTest.pdf
- Lenth, R. (2018). Package “lsmeans.” R package version 2.30-0. R Core Team. https://cran.r-project.org/web/packages/lsmeans/lsmeans.pdf
- Letourneau, N. L., Duffett-Leger, L., Levac, L., Watson, B., & Young-Morris, C. (2013). Socioeconomic status and child development: A meta-analysis. Journal of Emotional and Behavioral Disorders, 21(3), 211–224. doi:10.1177/1063426611421007
- Lüdecke, D. (2020). Package “sjstats.” R package version 0.18.0. R Core Team. https://cran.r-project.org/web/packages/sjstats/sjstats.pdf
- Luk, G., & Bialystok, E. (2013). Bilingualism is not a categorical variable: Interaction between language proficiency and usage. Journal of Cognitive Psychology, 25(5), 605–621. doi:10.1080/20445911.2013.795574
- Mabule, D. R. (2019). Code-switching as a form of communication: Insights from a South African public hearing discussion. South African Journal of African Languages, 39(1), 67–75. doi:10.1080/02572117.2019.1572324
- Marian, V., & Hayakawa, S. (2021). Measuring bilingualism: The quest for a “bilingualism quotient.” Applied Psycholinguistics, 42(2), 527–548. doi:10.1017/S0142716420000533
- McCormick, K. (2002). Code-switching, mixing and convergence in Cape Town. In R. Mesthrie (Ed.), Language in South Africa (pp. 216–234). Cambridge, UK: Cambridge University Press.
- Mesthrie, R. (Ed.). (2002). Language in South Africa. Cambridge, UK: Cambridge University Press.
- Montrul, S. (2015). Dominance and proficiency in early and late bilingualism. In C. Silva-Corvalán & J. Treffers-Daller (Eds.), Language dominance in bilinguals: Issues of measurement and operationalization (pp. 15–35). Cambridge, UK: Cambridge University Press.
- Morgan-Short, K., Steinhauer, K., Sanz, C., & Ullman, M. T. (2012). Explicit and implicit second language training differentially affect the achievement of native-like brain activation patterns. Journal of Cognitive Neuroscience, 24(4), 933–947. doi:10.1162/jocn_a_00119
- Office for National Statistics. (2013). Language in England and Wales: 2011. https://www.ons.gov.uk/peoplepopulationandcommunity/culturalidentity/language/articles/languageinenglandandwales/2013-03-04
- Oh, J., Au, T., & Jun, S. (2010). Early childhood language memory in the speech perception of international adoptees. Journal of Child Language, 37(5), 1123–1132. doi:10.1017/S0305000909990286
- Oh, Y., Todd, S., Beckner, C., Hay, J., King, J., & Needle, J. (2020). Non‑māori‑speaking new zealanders have a māori proto‑lexicon. Scientific Reports, 10(1), 22318. doi:10.1038/s41598-020-78810-4
- Pakulak, E., & Neville, H. J. (2010). Proficiency differences in syntactic processing of monolingual native speakers indexed by event-related potentials. Journal of Cognitive Neuroscience, 22(12), 2728–2744. doi:10.1162/jocn.2009.21393
- Pérez, A., Joseph, H. S. S. L., Bajo, T., & Nation, K. (2016). Evaluation and revision of inferential comprehension in narrative texts: An eye movement study. Language, Cognition and Neuroscience, 31(4), 549–566. doi:10.1080/23273798.2015.1115883
- Pierce, L. J., Chen, J.-K., Delcenserie, A., Genesee, F., & Klein, D. (2015). Past experience shapes ongoing neural patterns for language. Nature Communications, 6(1), 10073. doi:10.1038/ncomms10073
- Pliatsikas, C., DeLuca, V., Moschopoulou, E., & Saddy, J. D. (2017). Immersive bilingualism reshapes the core of the brain. Brain Structure & Function, 222(4), 1785–1795. doi:10.1007/s00429-016-1307-9
- Plüddemann, P. (2015). Unlocking the grid: Language-in-education policy realisation in post-apartheid South Africa. Language and Education, 29(3), 186–199. doi:10.1080/09500782.2014.994523
- Promprakai, N. (2018). Dispelling myths of first-generation immigrant code-switching: Evidence from Thai marriage migrants in England. Newcastle University. https://theses.ncl.ac.uk/jspui/bitstream/10443/4239/1/Promprakai%2C%20N.%202018.pdf
- Rose, S., & Van Dulm, O. (2011). Functions of code switching in multilingual classrooms. Per Linguam, 22(2), 1–13. doi:10.5785/22-2-63
- Schmid, M. S. (2013). First language attrition. Linguistic Approaches to Bilingualism, 3(1), 94–115. doi:10.1075/lab.3.1.05sch
- Sherkina-Lieber, M., Perez-Leroux, A., & Johns, A. (2011). Grammar without speech production: The case of Labrador Inuttitut heritage receptive bilinguals. Bilingualism: Language and Cognition, 14(3), 301–317. doi:10.1017/S1366728910000210
- Silva-Corvalán, C., & Treffers-Daller, J. (2015). Language dominance in bilinguals: Issues of measurement and operationalization. Cambridge, UK: Cambridge University Press.
- Slabbert, S., & Finlayson, R. (1999). A socio-historical overview of codeswitching studies in the African languages. South African Journal of African Languages, 19(1), 60–72. doi:10.1080/02572117.1999.10587383
- Slabbert, S., & Finlayson, R. (2002). Code-switching in South African townships. In R. Mesthrie (Ed.), Language in South Africa (pp. 235–257). Cambridge, UK: Cambridge University Press.
- South African Department of Arts and Culture. (2003). National Language Policy Framework. http://www.dac.gov.za/sites/default/files/LPD_Language%20Policy%20Framework_English_0.pdf
- Statistics South Africa. (2012). Census 2011: Census in brief ( Census No. 03-01–41). http://www.statssa.gov.za/census/census_2011/census_products/Census_2011_Census_in_brief.pdf
- Surrain, S., & Luk, G. (2019). Describing bilinguals: A systematic review of labels and descriptions used in the literature between 2005–2015. Bilingualism: Language and Cognition, 22(2), 401–415. doi:10.1017/S1366728917000682
- Takahesu Tabori, A. A., Mech, E. N., & Atagi, N. (2018). Exploiting language variation to better understand the cognitive consequences of bilingualism. Frontiers in Psychology, 9(1686), 1–7. doi:10.3389/fpsyg.2018.01686
- Tinsley, T. (2019). Language trends 2019: Language teaching in primary and secondary schools in England survey report. UK: British Council. https://www.britishcouncil.org/sites/default/files/language-trends-2019.pdf
- Tsimpli, I. M., Mukhopadhyay, L., Treffers-Daller, J., Alladi, S., Marinis, T., Panda, M., Sinha, P. (2019). Multilingualism and multiliteracy in primary education in India: A discussion of some methodological challenges of an interdisciplinary research project. Research in Comparative and International Education, 14(1), 54–76. doi:10.1177/1745499919828908
- Tsimpli, I. M., Vogelzang, M., Balasubramanian, A., Marinis, T., Alladi, S., Reddy, A., & Panda, M. (2020). Linguistic diversity, multilingualism, and cognitive skills: A study of disadvantaged children in India. Languages, 5(1), 10. doi:10.3390/languages5010010
- Weideman, A., Read, J., & du Plessis, T. (Eds.). (2021). Assessing academic literacy in a multilingual society: Transition and transformation. Bristol, Blue Ridge Summit: Multilingual Matters.
- Wigdorowitz, M., Pérez, A. I., Tsimpli, I. M. (2020). A holistic measure of contextual and individual linguistic diversity. International Journal of Multilingualism, 1–19. doi:10.1080/14790718.2020.1835921. Advanced online publication.
- Zuur, A. F., Ieno, E. I., Walker, N. J., Saveliev, A. A., & Smith, G. M. (2009). Mixed effects models and extensions in ecology with R. New York: Springer.
Appendix. Significant Linear Mixed-Effect (LME) models: Fixed and random effects
Model 1. LME on the CILD-Q scores including the fixed factors of nationality, scale, and SES
Model 3. LME on the CILD-Q scores including the fixed factors of lingualism status, scale and SES (England)