
ABSTRACT
The existing flaws in both conducting and reporting of research have been outlined and criticized in the past. Weak research design, poor methodology, lack of fresh ideas and poor reporting are the main points to blame. Issues have been continually raised on the types of results published, review process, sponsorship, notion, ethics, and incentives in publishing, the role of regulatory agencies and stakeholders, the role of funding, and the cooperation between funders and academic institutions and the training of both clinicians and methodologists or statisticians. As a result, there is loss of the utmost goal: the production of robust research to form recommendations to support pragmatic decision in a real-world context. We propose the construction of a model based on artificial intelligence that could assist stakeholders, clinicians, and patients to guide conducting the best quality of research. We briefly describe the levels of the workflow, including the input and output data collection, the feature extraction/selection, the architecture, and parameterization of the model, along with its training, operation, and refinement.
Introduction
The optimal delivery of health care requires four elements: research, practice, evaluation, and policy development. The quality of the former has been constantly the target of scientific interest, where Randomized Controlled Trials (RCTs) and systematic reviews (SRs) have both occupied the top of the hierarchy of evidence. But, both of them are problematic: the former are extremely time and money consuming, while the latter are numerous, often carrying the questioned quality of the original trials: different approaches through the combination of production of primary data, teamwork, replication, and meta-analyses, have been proposed (Panagiotou et al. Citation2013).
The existing flaws in both conducting and reporting have been outlined and criticized in the past (Ioannidis Citation2005; Goodman and Greenland Citation2007), while, later on, potential solutions of future prospects have been recorded (Ioannidis Citation2014; Wang Citation2016). The fearing statement of these and other reports was that as much as half of the scientific literature may be wrong. Weak research design, poor methodology, lack of fresh ideas to drive innovation and poor reporting often are the main points to blame (Ioannidis Citation2005, Citation2014; Goodman and Greenland Citation2007; McElreath and Smaldino Citation2015; Wang Citation2016). Also, the procedures of evaluating both research and researchers are passing through lengthy CVs and social pressure to paper count (Smaldino and McElreath Citation2016): quantitative metrics, such as publication rates and impact factors have been the norm (van Diest et al. Citation2001).
In parallel, the number of publications is rising (Larsen and von Ins Citation2010): there are more opportunities for collaboration and multi-author papers, an intense competition for academic positions, publication of the largest possible number of results instead of the most rigorous ones, and an endless competition for grants, promotions, and prestige (van Diest et al. Citation2001; Larsen and von Ins Citation2010; Ioannidis et al. Citation2014).
In addition, issues have been continually raised on the types of results published (publishing everything vs. selective publishing with respect to cost-benefit and time), review process, sponsorship, notion, ethics, and incentives in publishing, access of patients to published and unpublished results, amount of research published in other than English languages and not indexed in the basic databases, the role of regulatory agencies and stakeholders, the role of funding, and the cooperation between funders and academic institutions and the training of especially clinicians and practicing scientists on one hand and methodologists or statisticians on research practices and real-world study aims and final endpoints, on the other (van Diest et al. Citation2001; Ioannidis Citation2005, Citation2014; Goodman and Greenland Citation2007; Larsen and von Ins Citation2010; Cyranoski et al. Citation2011; McElreath and Smaldino Citation2015; Wang Citation2016).
As a result, there is loss of the utmost goal: the production of robust research to form recommendations to support pragmatic decision in a real-world context.
The utilization of some rapidly evolving fields, such as computer-based prediction models and Artificial Intelligence (AI) systems conforms to the tendency toward automation of the procedures performed in any modern medical field, replacing the use of the human brain in specific tasks. Such systems are already implemented in the modern scientific era with numerous examples, including cancer research, neurology, cardiology, imaging, drug design, and immune therapies, among others (Siristatidis et al. Citation2010; Hamet and Tremblay Citation2017). These models/systems have demonstrated usefulness in performing associations between the analyzed factor/s [or causative source(s)] and results [such as treatment outcome(s)]. Artificial Neural Networks (ANNs), the basic components of AI, exhibit remarkable information processing abilities pertinent mainly to nonlinearity, high level of parallelism, some fault tolerance capability, as well as learning capability followed by generalization and self-adapting prospects (Hamet and Tremblay Citation2017). Their special characteristics lie through a ‘learning through training’ model, resembling the capacity of the brain to learn, assimilate and recall this knowledge in anticipation of a future event, while via trained learning, they self-adapt and change their structural characteristics to accumulate the knowledge (Goodman and Greenland Citation2007; Hamet and Tremblay Citation2017). The reduction of cost, the combination of hardware specifically designed for AI implementation, the improvement of evaluation, at the stages of data acquisition, interpretation, and decision-making are important features, among others (Monroe Citation2018).
Description of methods
A workflow of such a system could comprise the following levels ():
Figure 1. A proposed workflow of the ANN approach.
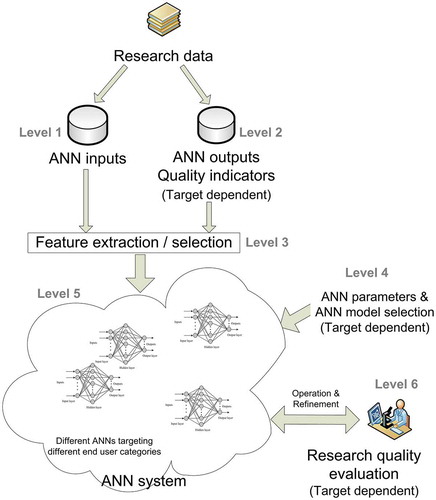
Level 1: Input data collection
Data from the bibliographic research of major databases, such as the Cochrane Central Register of Controlled Trials, MEDLINE, EMBASE, and CINAHL, Thomson Reuters Web of Science, along with trial registers for ongoing and registered trials, conference abstracts in the Web of Science and Google Scholar for gray literature, professional societies, organizations, and individuals will be collected. Of them, features that can lead to the evaluation of their quality will be extracted, serving as the ANN inputs (Eysenbach Citation2011; Levitt and Thelwall Citation2011; Cottrell EK Citation2015; Chavda and Patel Citation2016; Maggio et al. Citation2017; Braithwaite et al. Citation2019; Higgins et al. Citation2019; Leatherdale Citation2019; Sterne et al. Citation2019). In order to condense them into a fine-structured set, algorithms will be used. A list of characteristics with the potential to serve as ANN inputs is presented in .
Table 1. List of characteristics with the potential to serve as ANN inputs.
Level 2: Output data collection
The ANN system outputs are quality scores, i.e., measures of quality indicators (for example, using a scale from 1 to 100). Notably, these data will be dependent on the target population; in specific, these outputs and/or scores are different according to the target population, i.e., clinicians, patients, or stakeholders, and will be used only for the initial ANN construction phase (). These data will be collected through Internet publications and relevant reports or personal or web-based questionnaires depending on the issue raised or the populations implicated (stakeholders, clinicians, or patients). Of note, the ANN could predict either all metrics separately or in groups, according to the issue raised and its programming.
Table 2. List of outputs and/or scores according to the target population, used for the initial ANN construction phase.
Level 3: Feature extraction/selection
Mathematical models, such as information gain, correlation coefficient scores, chi-square tests, and recursive feature elimination algorithms, among others, will be applied in the data of the two previous levels. The aim of this process is to identify the most important characteristics to be used as inputs for ANN construction (Setiono and Liu Citation1997; Kwak and Choi Citation2002). As this step is related to the training of the ANN, the data processed are those relevant to training, which are characterized as ‘important’. Notably, these data are associated, for example, with high-quality metrics. In addition, even the ‘non-important’ input features can be selected. Markedly, ANNs have the capability to isolate and avoid using or using only a part of such data that are not related to the set output.
Level 4: Architecture and parameterization
In this step, the ANN architecture is being selected and parameterized. A different ANN will be used for each individual target group (patients, clinicians, stakeholders/organizations/scientific communities). Furthermore, the parameterization will be dependent on the ANN model/s of choice, while ANN characteristics will be selected, such as size, training algorithms, iterations, and definition of criteria for the stop of training.
Level 5: Training
This is performed using data from Levels 1 and 2, being selected at Level 3. Firstly, during this process, the ANN ‘learns’ from the data inserted, while, simultaneously, can incorporate knowledge on unknown data, i.e., data not included in the training set, a characteristic so-called ‘generalization’ (Haykin Citation1999). Secondly, the proposed ANN would have a ‘cyclic nature and function’, i.e., the system should be able to be trained again to accumulate new knowledge and/or adjust existing knowledge from previous training processes, a process so-called ‘continual learning’ (Parisi et al. Citation2019; Zeng et al. Citation2019).
Level 6: Operation – refinement
The trained ANN system will be used in an operational manner (routine) for evaluating research quality, separately for each individual target group. In addition, data collection will be continually renewed via automated searches, with subsequent extraction of new data, which will – probably replace the initial selected, based on low-performance indices of the ANN and new groups interested – and inserted. Thus, new training cycles can be performed during the operational period, in an attempt to develop and refine the system. Importantly, in this level, the user input is expected to ‘judge’ the ANN performance, serving as a guide to refine its training (https://doi.org/10.1097/MD.0000000000006612). In addition, further information will be gathered from the patients themselves, as a supplementary form of feedback, in an effort to refine the accuracy of the system. At this point, standardized criteria of effectiveness should be applied in order to avoid subjective interpretations and contradictory results.
Discussion
In the field of research, a construction of such an AI model, based on a supervised learning ANN could assist stakeholders, clinicians, and patients to guide conducting the best quality of research. For example, an adequate input data set could be composed of all the above-mentioned parameters and be complemented by feature extraction and selection algorithms. Both selection of the appropriate ANN model and definition of its parameters and characteristics, along with the evaluation of the system performance, would subsequently depend on the target population that the information will be addressed to. Thus, the inputs are the characteristics gathered from various sources indicated, such as bibliometrics, altmetrics, and quality assessment tools and the outputs are the final target addressed for stakeholders, clinicians, and patients. Finally, the training and self-adaptation of the system would depend on the target group that will be used for and the questions posed. The final aim is to obtain a robust AI-assisted way of judging and thus leading research.
A typical example of such a system was reported by our team, some months ago. The constructed ANN was based on statistically significant variables with the outcome of live birth, representing a stable and efficient system with increased performance indices. Validation of the system allowed an insight of its clinical value as a supportive tool in medical decisions, and overall provides a reliable approach in the routine practice of IVF units in a user-friendly environment. Of note, the rather small standard deviation in the performance indices between the training and test sets throughout the validation process indicated a stable performance of the constructed ANN (Vogiatzi et al. Citation2019).
Of course, limitations exist and lie on a ‘non human way’ of leading human acts, the lack of reasoning, since ANNs have no mechanism to justify their output, the possible lack of qualitative assessment and the objectivity of the collection of the primary data sets, on which the ANN would base its outcome, along with the clear definition and choice of the quality metrics, named here as outputs.
Compared to the existing relevant approaches, our proposed ANN system displays numerous advantages, such as the quality metrics linked to the need of specific target groups, the capability for continuous and augmenting learning and adaptation, through the inclusion of new data and the users’ feedback, and the lack of need to design human understandable algorithms and metrics, to obtain a quality score: instead, the ANN, operating as a black box, self-adapts and provides quality metrics according to the user needs.
In conclusion, this ANN system is not just a re-iteration of parameters already used to assess research and researchers. We propose the combination of high validity current quality metrics adapted to the individual needs of patients, clinicians, and stakeholders. To the authors’ belief, the implementation of such a system, apart from being feasible, offers the capability of combining current quality inputs and outputs, targeting to the goal of the production of robust research. In this context, features that could add to its refinement and improvement are the technologies of big data, the cloud, and the interoperability offered by operators of systems, which could help not only to the data collection but also to its operation, as a product.
Author contributions
Conceived the idea and drafted the paper: CS; co-drafted the paper and wrote the technical parts: AP.
Acknowledgments
The authors wish to thank Paraskevi Vogiatzi for her ideas for writing the manuscript.
Disclosure statement
Authors have no competing interest.
References
- Braithwaite J, Herkes J, Churruca K, Long JC, Pomare C, Boyling C, Bierbaum M, Clay-Williams R, Rapport F, Shih P, et al. 2019. Comprehensive Researcher Achievement Model (CRAM): a framework for measuring researcher achievement, impact and influence derived from a systematic literature review of metrics and models. BMJ Open. 9(3):e025320. doi:10.1136/bmjopen-2018-025320
- Chavda J, Patel A. 2016. Measuring research impact: bibliometrics, social media, altmetrics, and the BJGP. Brit J Gen Prac. 66(642):e59–61. doi:10.3399/bjgp16X683353.
- Cottrell EKWE, Kato E, Uhl S, Belinson S, Chang C, Hoomans T, Meltzer DO, Noorani H, Robinson KA, Motu’apuaka M, et al. 2015. Defining the benefits and challenges of stakeholder engagement in systematic reviews. Compa Eff Res. 2015(5):13–19.
- Cyranoski D, Gilbert N, Ledford H, Nayar A, Yahia M. 2011. Education: the PhD factory. Nature. 472(7343):276–279. doi:10.1038/472276a.
- Eysenbach G. 2011. Can Tweets predict citations? Metrics of social impact based on Twitter and correlation with traditional metrics of scientific impact. J Med Internet Res. 13(4):e123. doi:10.2196/jmir.2012.
- Goodman S, Greenland S. 2007. Why most published research findings are false: problems in the analysis. PLoS Med. 4(4):e168.eng. doi:10.1371/journal.pmed.0040168.
- Hamet P, Tremblay J. 2017. Artificial intelligence in medicine. Metabolism. 69S:S36–S40.
- Haykin SS. 1999. Neural networks: a comprehensive foundation. 2nd ed. Upper Saddle River (N.J.): Prentice Hall.
- Higgins JPTTJ, Chandler J, Cumpston M, Li T, Page MJ, Welch VA, editors. 2019. Cochrane Handbook for Systematic Reviews of Interventions version 6.0 (updated July 2019). Cochrane. www.training.cochrane.org/handbook
- Ioannidis JP. 2005. Why most published research findings are false. PLoS Med. 2(8):e124.eng. doi:10.1371/journal.pmed.0020124.
- Ioannidis JP. 2014. How to make more published research true. PLoS Med. 11(10):e1001747. doi:10.1371/journal.pmed.1001747.
- Ioannidis JP, Boyack KW, Klavans R. 2014. Estimates of the continuously publishing core in the scientific workforce. PLoS One. 9(7):e101698. doi:10.1371/journal.pone.0101698.
- Kwak N, Choi CH. 2002. Input feature selection for classification problems. IEEE Trans Neural Net Pub IEEE Neural Net Cou. 13(1):143–159. doi:10.1109/72.977291.
- Larsen PO, von Ins M. 2010. The rate of growth in scientific publication and the decline in coverage provided by Science Citation Index. Scientometrics. 84(3):575–603. doi:10.1007/s11192-010-0202-z.
- Leatherdale ST. 2019. Natural experiment methodology for research: a review of how different methods can support real-world research. Int J Soc Res Methodol. 22(1):19–35. doi:10.1080/13645579.2018.1488449.
- Levitt JM, Thelwall M. 2011. A combined bibliometric indicator to predict article impact. Inf Process Manag. 47(2):300–308. doi:10.1016/j.ipm.2010.09.005.
- Maggio LA, Meyer HS, Artino AR Jr. 2017. Beyond citation rates: a real-time impact analysis of health professions education research using altmetrics. Acad Med. 92(10):1449–1455. doi:10.1097/ACM.0000000000001897.
- McElreath R, Smaldino PE. 2015. Replication, communication, and the population dynamics of scientific discovery. PLoS One. 10(8):e0136088. doi:10.1371/journal.pone.0136088.
- Monroe D. 2018. Chips for artificial intelligence. Commun ACM. 61(4):15–17. doi:10.1145/3185523.
- Panagiotou OA, Willer CJ, Hirschhorn JN, Ioannidis JP. 2013. The power of meta-analysis in genome-wide association studies. Annu Rev Genomics Hum Genet. 14:441–465. doi:10.1146/annurev-genom-091212-153520.
- Parisi GI, Kemker R, Part JL, Kanan C, Wermter S. 2019. Continual lifelong learning with neural networks: A review. Neural Net. 113:54–71. doi:10.1016/j.neunet.2019.01.012.
- Setiono R, Liu H. 1997. Neural-network feature selector. IEEE Trans Neural Net Pub IEEE Neural Net Cou. 8(3):654–662. doi:10.1109/72.572104.
- Siristatidis CS, Chrelias C, Pouliakis A, Katsimanis E, Kassanos D. 2010. Artificial neural networks in gynaecological diseases: current and potential future applications. Med Sci Mon. 16(10):RA231–236.
- Smaldino PE, McElreath R. 2016. The natural selection of bad science. R Soc Open Sci. 3(9):160384. doi:10.1098/rsos.160384.
- Sterne JAC, Savovic J, Page MJ, Elbers RG, Blencowe NS, Boutron I, Cates CJ, Cheng HY, Corbett MS, Eldridge SM, et al. 2019. RoB 2: a revised tool for assessing risk of bias in randomised trials. BMJ. 366:l4898. doi:10.1136/bmj.l4898.
- van Diest PJ, Holzel H, Burnett D, Crocker J. 2001. Impactitis: new cures for an old disease. J Clin Pathol. 54(11):817–819. doi:10.1136/jcp.54.11.817.
- Vogiatzi P, Pouliakis A, Siristatidis C. 2019. An artificial neural network for the prediction of assisted reproduction outcome. J Assist Reprod Genet. 36(7):1441–1448. doi:10.1007/s10815-019-01498-7.
- Wang YX. 2016. Systemic review and meta-analysis of diagnostic imaging technologies. Quant Imaging Med Surg. 6(5):615–618. doi:10.21037/qims.2016.10.08.
- Zeng G, Chen Y, Cui B, Yu S. 2019. Continual learning of context-dependent processing in neural networks. Nature Mac Intel. 1(8):364–372. doi:10.1038/s42256-019-0080-x.