
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This study addresses a flexible job shop scheduling problem considering the energy tax regulations. We introduce two strategies as reactive scheduling to deal with two different kinds of uncertainty. The first uncertainty is about the start and processing times of the jobs with a known probability distribution. The second kind is related to machine breakdowns, modification or cancellation of the orders, and receive new orders without any known probability distribution. Two conflict objective functions are considered as minimising tax cost on surplus energy consumption and minimising total cost of jobs lateness based on soft time-windows. A bi-objective mathematical model is developed to formulate the problem. Since the problem is well-known strongly NP-hard, a new solution approach is introduced based on the NSGA-II algorithm to solve the problem in a reasonable computational time. Some test problems based on a real case study are used to evaluate the performance of the proposed solution approach. The result analysis confirms the effectiveness of the proposed algorithm and its superiority comparing with another algorithm based on the classic NSGA-II. Moreover, sensitivity analysis is done on the main parameters to provide proper managerial suggestions based on the obtained Pareto front solutions.
1. Introduction
Nowadays, all countries in the world are facing a serious challenge such as the energy crisis and environmental pollution. To tackle this common world threat, many efforts have been done on broadening the sources of energy and reducing the consumption/cost of energy (Yang et al. Citation2020). According to a report of the International Energy Agency (IEA), demand for energy consumption in the world will increase by 35% in the upcoming 15 years (Tang, Warkentin, and Wu Citation2019). Due to the limited available energy resources, energy-saving is very important and vital for all countries in the world to achieve sustainable economic growth in all sectors (Cai et al. Citation2019; Long et al. Citation2018). Given that the manufacturing industry is the most important sector in the development of the economy. For this reason, more than 40% of the world’s energy consumption is allocated to them (Danielle et al. Citation2011; Bruzzone et al. Citation2012; Duflou et al. Citation2012; Li and Lin Citation2016). According to the opinion of economists, governments are on the economic growth that has put the tax on energy consumption (van Zon and Yetkiner Citation2003). Governments of developed countries have implemented tax regulations to prevent greenhouse gas emissions and to ensure more energy-saving. Manufacturing industries affected by government energy-saving regulations must pay very high taxes on surplus energy consumption. Therefore, these policies impose many restrictions on many manufacturing industries to reduce energy consumption via optimisation of production scheduling. The make-to-order (MTO) systems based on casting and multi-machine scheduling are a type of these manufacturing industries that almost uses high-powered machines and technology such as induction melting furnaces. In the nowadays-competitive environment, such industries are usually facing some challenges such as high penalty costs of lateness in delivering orders and high tax costs on surplus energy consumption to governments. It is especially vital for managers to minimise these costs and to make a trade-off between these conflict objectives under uncertainty.
Job shop scheduling is one of the most popular scheduling problems in the MTO system. Unexpected disruptions during running original predictive scheduling lead to failure in original scheduling. Such industries are forced to pay very high production costs for facing minor disruptions in the original scheduling because of their higher lateness penalties comparing to other industries. Moreover, machines of such industries use more energy. Therefore, uncertainties during running original predictive scheduling lead to increase costs of energy consumption.
Consequently, in previous years, researchers have found that flexible job shop scheduling (FJSS) can be an efficient method for overcoming the existing uncertainty (Gao, Gen, and Sun Citation2006; Gao et al. Citation2007; Gao, Sun, and Gen Citation2008; Gen, Gao, and Lin Citation2009). Studies of such industries have shown that uncertainty is caused by factors such as job inaccessibility, inadequate estimation of processing time, machine breakdowns, modifications of the orders, and receive new orders (Herroelen and Leus Citation2005).
In this paper, two types of uncertainties are investigated for the FJSS problem with the nature of casting that almost uses high-powered machines. The first type includes the uncertainties with pre-known probability distribution such as inaccessibility of resources and jobs. Such uncertainties may lead to the creation of stochastic parameters and variables especially in the operations start time of jobs. Moreover, uncertainties such as lack of skilled manpower and inadequate estimation of processing time may lead to the creation of stochastic parameters in the operations processing time of jobs. For these parameters, we need to define a probability distribution to present the proper stochastic scheduling (Kall and Wallace Citation1994). For this reason, in the presented mathematical model of this study, the start and processing time of operations are considered as stochastic parameters with a uniform probability distribution.
The second type of uncertainties includes parameters that follow no well-known probability distribution such as machine breakdowns and modification or cancellation of the orders, changing of the delivery dates, and receiving new important orders. Such uncertainties that occur as unexpected disturbances during running original predictive scheduling may lead to failure in initial scheduling. For this purpose, reactive scheduling will be used to deal with these types of disruptions.
To optimise solutions in the face of unexpected events, the best way is to use reactive scheduling and this type of scheduling method is provided as a revised version of real-time scheduling. In the other words, most pre-scheduling activities in real-time scheduling can be defined better through reactive scheduling. Reactive scheduling is divided into two categories (Herroelen and Leus Citation2004): the first category is rescheduling, and the second is scheduling repair. In this paper, we use scheduling repair for responding to disruptions during running the original predictive scheduling. Scheduling repair would be a proper approach to adapt the original scheduling to the new status. This approach attempts to improve the original scheduling so that the best results are achieved in terms of unexpected internal and external disruptions. The best reactive strategies for responding to disruptions are in two ways. Firstly, the system can allocate multiple machines into each operation of jobs, and secondly, the system is able to select the best alternative process for other jobs.
As stated above, this paper provides an appropriate approach to respond to two general types of uncertainties in a stochastic flexible job shop scheduling (SFJSS) problem. Stochastic scheduling is used for responding appropriately to the uncertainties of the first type such as start and processing stochastic time with a uniform probability distribution. Reactive scheduling is used for dealing with the second type of uncertainties such as machine breakdowns and modification or cancellation of the orders, changing of the delivery dates, and receiving important new orders, appropriately. Energy consumption in switching machine modes has considered adjusting the machine’s status in two of the three modes such as processing, idle, and standby. For this purpose, we aim to minimise tax cost on surplus energy consumption and total cost of jobs lateness based on soft time-windows using scheduling repair in the original predictive scheduling, which is failure due to the effect of unexpected disruptions.
The conceptual model of reactive scheduling for disruptions in SFJSS with energy-saving regulations has been shown in .
Figure 1. A schematic view of the proposed approach in this research
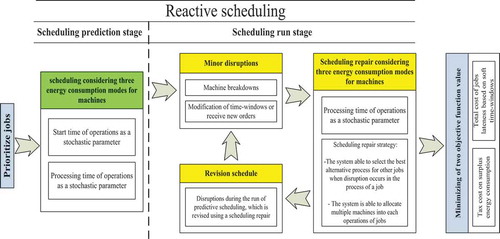
In general, this study attempts to answer the following research question: ‘How can industry owners do to a trade-off between total costs of jobs lateness based on soft time-windows and tax cost on surplus energy consumption with uncertain parameters?’. To better present the place of the main features of this study among previous studies, a comparison has been made in five different aspects.
1.1. Related studies in energy-saving
Studies in this field can be divided into four groups including energy- saving using the turn on/turn off approach, the speed level adjustment approach, peak consumption, and government regulations. In the first group, researchers have used the turn on/turn off approach considering a pre-defined amount for the idle mode to minimise total energy consumption. Researchers proposed a single-machine scheduling problem using a neural network to determine the status of turn-off or idle modes in the time gap between two jobs (Mouzon, Yildirim, and Twomey Citation2007). In 2008, researchers introduced a concept called break-even which is a criterion for determining the turn-off or idle state of the machine (Mouzon and Yildirim Citation2008). Also, the control coefficient of the turn-off machine was provided for the flow shop scheduling problem (Dai et al. Citation2013). Also, other researchers considered energy consumption as an objective function with the possibility of the turn off the machine to energy-saving in single-machine scheduling problems (Che et al. Citation2017). Wu & Sun employed both of the turn on/turn off approach and different speeds for processing to minimise the energy consumption and makespan in a flexible job shop scheduling problem simultaneously (Wu and Sun Citation2018).
In the second group, researchers have tried to minimise total energy consumption using the speed level adjustment approach without affecting the makespan. Then, studies were conducted on two machines with different speeds for flow shop scheduling problems (Mansouri, Aktas, and Besikci Citation2016). Even in 2015, researchers studied the energy consumption of machines in idle and processing modes for the dynamic flow shop scheduling problem when the new job arrival and machine breakdown were under consideration (Dai Citation2015). In the same group, some researchers proposed a teaching-learning-based optimisation (TLBO) to solve the hybrid flow shop scheduling problem which is made up of three subproblems including scheduling, machine assignment, and speed selection (Lei, Gao, and Zheng Citation2017). Similarly, Chen et al. employed a collaborative optimisation algorithm to minimise makespan and total energy consumption simultaneously, in which a speed adjusting strategy for the non-critical operations is designed to improve total energy consumption (Chen, Wang, and Peng Citation2019). Due to the notable influence of the speed change approach on energy-saving, this issue receiving increasing attention in the field of academic during last years (Zhang and Chiong Citation2016; Fu et al. Citation2019; Li, Lei, and Cai Citation2019; Luo, Zhang, and Fan Citation2019; Wu and Che Citation2020).
In the third group, some approaches for energy-saving in peak consumption have been considered. In this type of scheduling, attempts have been made to shift operations of jobs to off-peak times to reduced energy consumption. The turn off of machines at the off-peak in flexible production systems was investigated for energy-saving (Pach et al. Citation2014). In the same year, researchers investigated the same problem in which energy prices were multiple at different times and this approach was applied to a single machine scheduling problem (Shrouf et al. Citation2014). Also, a bi-objective mixed integer programming mathematical model was proposed by researchers at different energy prices in the single machine batch scheduling problem (Cheng et al. Citation2017). As a new study, researchers tackled the scheduling problems under Time-of-Use (TOU) tariffs to minimise the total power cost by appropriately scheduling the jobs in a way that the overall completion time not be exceeded from a predetermined production deadline (Cheng, Chu, and Zhou Citation2018).
In the fourth group, researchers applied different energy-saving approaches based on government regulations such as subsidies and tax rules. The effect of the energy-saving approach has been analysed by implementing various subsidy regulations (preferential tax, price subsidy, sales, and investment subsidy) on the amount of production and profit (Zhang et al. Citation2014). Two competitive supply chains were investigated by researchers. Thus, they analysed four competitive combinations of the supply chain with four government sub-objectives function (energy-saving, net income, social welfare, and sustainable development) (Hafezalkotob Citation2017).
In general, compared with the four aforementioned groups, it can be concluded that machines in the MTO systems especially based on casting are rarely turned off but the amount of energy consumption in switching the idle and standby modes of machines is significant. Furthermore, the cost of government taxes on surplus energy consumption in such manufacturing industries is notable. It is also notable that, a few researchers have investigated the energy consumption issue considering machine switching in flexible job shop scheduling problems under government tax regulations. Therefore, this issue is the first main feature studied in this paper.
1.2. Related studies in reactive scheduling
Unexpected disruptions during production that do not follow a certain probability distribution lead to failure in the original predictive scheduling and reactive scheduling is the best approach to reconsider in the original predictive scheduling. Researchers have considered a reactive scheduling problem in a stochastic environment. They analysed several scheduling policies in the conditions of machines’ inaccessibility for a classic job shop system (Sabuncuoglu and Bayiz 2000). One year later, the researchers proposed a reaction scheduling problem with the simultaneous application of average job’s tardiness and average job’s cost (Chryssolouris and Subramaniam Citation2001). Then, reactive job shop policies were considered in the condition of lack of access to machines and It was also suggested that time be revised based on a concept of control limits (Suwa and Sandoh Citation2007). In 2008, a reactive flexible job shop scheduling problem was considered for optimisation of lead time (Wu Citation2008). An event-oriented policy was considered to be reactive to the scheduling of the job shop with the stochastic arrival of jobs with machines inaccessibility. They also measured the performance of a multi-objective function, including tardiness of jobs and makespan (Adibi et al., Citation2010).
It can be concluded based on the previous studies that, a few researchers have conducted reactive scheduling problems considering machine breakdowns, changing the delivery dates, and conducting a new order based on a mathematical model. Therefore, this issue is the second main feature that is studied in this paper.
1.3. Related studies in stochastic scheduling
Stochastic scheduling is used to schedule jobs under the uncertainties that occur during production and follow a pre-known probability distribution. A flexible job shop scheduling problem was conducted under uncertainty and dynamic jobs arriving as well as sequences-dependent setup time of machines and some dispatch rules were introduced that are typically incorporated into two new methods in a simulated model (Kianfar, Fatemi Ghomi, and Oroojlooy Jadid Citation2012). Then, researchers solved the problem of dynamic flow shop scheduling when new jobs have arrived and machines are not available (Dai Citation2015).
The above studies have shown that four fields are usually considered for stochastic scheduling in flow shop and job shop such as starting time (Inaccessibility to machines or jobs), processing time (changes in time, special changes), machine breakdowns, and urgent jobs. In this paper, both of two approaches i.e., reactive scheduling and stochastic scheduling are considered in this study to investigate as a mathematical model for job shop scheduling problems. Therefore, this issue is one of the unique features studied in this paper.
1.4. Related studies considering similar objective functions
Creating a balance between different objectives is the inevitable challenge for the MTO systems. This paper aims to optimise two important conflict objective functions include the tax cost on surplus energy consumption and total cost of jobs lateness simultaneously. Such objective functions in flexible job shop scheduling problems have less attention paid by researchers. Mouzon proposed a model to minimise total energy consumption and delay for single machines (Mouzon and Yildirim Citation2008). A paper published in 2015 looked at minimising energy consumption with a maximum of limited tardiness in a single-machine problem (Che et al. Citation2015). Zhang et al. proposed a model to minimise the total tardiness and the energy consumption for a flexible job shop scheduling problem (Zhang and Chiong Citation2016). As another instance, Luo et al. developed a new decoding method and two Pareto-based mechanisms to obtain active schedules for a flexible job shop considering two aforementioned objectives (Luo, Zhang, and Fan Citation2019). Recently, researchers investigated the FJSS problem to minimise the makespan and the total energy consumption simultaneously while the total tardiness has been considered as a constraint. In this work, the authors used a chance-constrain approach to describe decision-makers’ awareness of total tardiness (Fu et al. Citation2019).
1.5. Related studies considering the solution algorithms
Most GA-based developed solution algorithms are mainly constructed based on three operators of selection, crossover, and mutation in combination with other heuristic and meta-heuristic algorithms. Studies were conducted in 2010 to minimise the maximum fuzzy completion time based on an efficient decomposed-integration GA (Lei Citation2010). A genetic algorithm was designed for strategic scheduling of cycle-driven in the case of a flexible job shop dynamic scheduling (Liu et al. Citation2011). A genetic simulated annealing algorithm was introduced in the flexible flow shop scheduling problem (Dai et al. Citation2013). In 2015, to manage the release time, the researchers looked at two meta-heuristic algorithms such as GA and PSO (Rey et al. Citation2015). A hybrid genetic algorithm integrating the local search was proposed to minimise the total tardiness and energy consumption (Zhang and Chiong Citation2016). In later years, researchers established a model to compute the energy consumption of machine tools at different machining stages and developed a green scheduling heuristic method to optimise makespan (He et al. Citation2015). Thereinafter, researchers used a hybrid GA and glow-worm swarm optimisation algorithm with a green transport heuristic strategy (GA-GSO-GTHS) (Liu, Guo, and Wang Citation2019). For the multi-objective flexible job-shop scheduling problems, the authors considered the transportation constraints and proposed an enhanced genetic algorithm to solve the multi-objective optimisation model with energy consumption and makespan (Dai et al. Citation2019). Meanwhile, researchers proposed a bi-objective ant colony optimisation to minimise the total energy consumption and makespan for an energy-aware batch scheduling problem (Jia et al. Citation2019).
Due to the bi-objective problem of this paper, the NSGA-II has been used in the development of the algorithm based on GA. In the proposed algorithm, another new operator called the ‘Floating Operator’ is utilised in addition to classic operators which may have many applications, especially in stochastic scheduling and reactive scheduling. In general, the studies conducted in the five fields mentioned can be shown in .
Figure 2. A framework of fields studied in this research
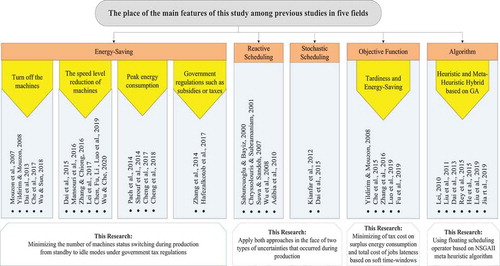
In summary, the majority of the scheduling problems in the energy-saving field are investigated in a single machine environment for each processing stage. However, there is usually more than one machine as parallel in some critical processing stages to increase flexibility such as the FJSS problem and less work has been done on such multi-machine problems. In such cases, no study has applied reactive scheduling and stochastic scheduling simultaneously to tackle both of the two main types of uncertainties. Furthermore, in the previous studies, less attention has been paid to two conflicting objectives include minimising tax cost on surplus energy consumption and minimising the total cost of jobs lateness based on a soft time-windows. Therefore, this study aims to minimise these two objective functions in a flexible job shop scheduling problem with a soft time-windows for a due date under uncertainty and a casting factory is studied as a real-world case study. In this way, a new mathematical model is introduced that can solve the problem with small dimensions, and a meta-heuristic algorithms based on a non-dominated sorting approach are developed to solve the large-sized instances in a reasonable time. So, we can summarise the contributions of this study in three categories as below:
Deciding on the best state of energy consumption in switching machine modes to reduce the costs imposed by government tax regulations: We usually have a high amount of energy dissipation in switching the modes of machines used in MTO systems based on casting. This is because of high-powered machines have been used such as induction melting furnaces. Increasing the number of machines status switching during production from standby to idle modes dramatically increases energy consumption. In such cases, tax costs on surplus energy consumption imposed on industry owners. Therefore, a new model is introduced to minimise tax costs on surplus energy consumption by adjusting machines on the best mode.
Introducing a new mathematical model for simultaneous use of reactive scheduling and stochastic scheduling approaches to reduce costs arising from government tax regulations and lateness based on delivery soft time-windows: Jobs scheduling in a flexible job shop problem is very difficult when industry owners are facing some known and unknown uncertainties during production. Applying the two approaches of reactive scheduling and stochastic scheduling to deal with each of the uncertainties in the framework of an exact mathematical model is one of the main features of the study in this research. It should be explained that few studies in this area have just proposed simulation approaches without any exact model. The proposed model in this study can provide the optimum solution with the minimum tax cost on surplus energy consumption and total cost of jobs lateness based on soft time-windows whenever any disruption has happened.
Using floating scheduling operator based on NSGA-II meta-heuristic algorithm: Given that the floating operator is applied to the body of the sub chromosome, it allows the algorithm to perform the best local search in the local feasible spaces. In other words, the operator allows operations of the job to be floating within a certain range and find the best value of objective functions in local feasible spaces. This algorithm has been developed based on NSGA-II, which uses three operators including selection, crossover, and mutation to find the feasible spaces and the best local search can be done in the same space using the floating operator.
The remaining sections of this paper are organised as follows: the problem is described in the form of a case study in section 2. In section 3, the mathematical model is presented. The solution approach is presented in section 4. Then, the proposed model is investigated using data from a real case study in a factory with a casting process. In the following, computational result and sensitivity analysis is presented in section 5. Finally, the paper is concluded with different dimensions of the problem in section 6 as the last section.
2. Problem description in the form of a case study
Reactive flexible job shop scheduling problem with energy-saving in a stochastic environment can be described as follows: There are jobs to do in this problem and the
th job consists of a maximum of
operations, which are processed using the
parallel machines in the
th stage. Parallel machines consume the same amount of energy at each stage in three statuses: processing mode, idle mode, and standby mode. In addition, the parallel machines have the same speed level. The machines never turn off due to the high cost of restarting. Therefore, the machines between the two consecutive operations are only in two statuses of idle mode or standby mode. It is worth mentioning that the machines in each stage use a certain amount of energy to status switching from standby to idle modes and on the contrary. The machine keeps in idle mode when the energy consumption between two consecutive operations in the idle mode is less than the required energy for switching from standby to idle mode. Otherwise, it is wise to machine adjust in standby mode to reduce energy consumption. Each operation of each job is assigned just to one machine in needed stages. The operations sequence of a job has already have been specified and cannot be changed. Start time and processing time are considered stochastic with a uniform probability distribution. There are two types of disruption during production including machine breakdowns and modification or cancellation of the orders, changing of the delivery time-windows, and receiving important new orders.
The first task of this problem is to create the best allocation of machines to operations by observing the priority of operations on the machine and the sequence of operations on the jobs. For this purpose, jobs should be delivered to the customers in the least possible deviation from the soft time-windows even in an uncertain environment. The second task of this problem is to decide about the best adjustment of the machine’s status switching between two consecutive operations to reduce energy consumption within the framework of government regulations. This problem is conducted in this study considering two conflict objective functions as total costs of jobs lateness based on soft time-windows and tax cost on surplus energy consumption.
The main features of this problem are defined with inspiration from a casting industry as a real case study. The considered casting factory manufactures a variety of parts for the automotive industries as an MTO system using different processes including induction melting furnace, machining, milling, and sandblast. In the B16 department of this factory, ball bearing parts are custom manufacturing and repairing for all types of automobiles. The factory has seven machines in total in which, the casting stage has two parallel machines with different energy consumption and after that there is the machining stage with three parallel machines with different energy consumption. Furthermore, there is one machine for each of the millings and sandblast stages. In the first half of August 2019, this factory received orders to build three parts and repair two parts in the ball bearing sector.
A contract has been concluded with the customers, who the orders will be delivered in a soft time-windows according to the . The contract concluded by the department of commerce provides penalties for job lateness outside the time-windows. In , the upper bound and the lower bound of the delivery time window of the th job have been presented as
and
respectively in the original scheduling
. Also, the items
and
indicate the amount of penalty for delivery earlier and later than the specified time window of
th job respectively.
Table 1. Delivery time-windows and lateness penalty of the jobs based on original scheduling ()
For example, as is evident in this table, there is a 140$ penalty per hour for the lateness in delivery the job 1. While delivering this product earlier than the specified lower bound in the time-window (18) will impose 100$ per hour. The production planning department is going to a proper schedule with a minimum of total tax cost on surplus energy consumption and total cost of jobs lateness based on soft time-windows per hour. The real-time occurrence of the original predictive scheduling is shown in based on the scheduling of the Company’s production planning department. The start time and the processing time are determined as stochastic (with uniform distribution). According to , the operation 1 of the first job is assigned to , which means the first machine in the first stage. The process starts at 1 o’clock randomly, and the processing time takes 5 hours randomly. In addition, the operation process takes 10 hours after breakdowns and repairing the machine.
Table 2. The real-time occurrence of the original predictive scheduling (Start and processing stochastic time)
The power consumption of the machines at each stage in three modes such as processing, idle, and standby as well as the power consumption of each machine to switch from standby to idle modes based on the energy label of the machines in kw/h are illustrated in . In , the item shows the power consumption of the
th machine in the
h stage for switching from standby to idle mode.
Table 3. Machine parameters in energy consumption (kw/h)
For example, it can be found from this table that the power consumption of machine 1 in the fourth stage (M41) is 1220 kw/h, 953 kw/h, and 20 kw/h in the processing mode, idle mode, and the standby mode respectively. In addition, the power consumption of the mentioned machine is equivalent to 5,000 kw/h for switching from standby to idle modes. According to calculations based on government tax regulations, the maximum amount of power consumption is 200,000 kw/h for producing the five aforementioned parts and surplus energy consumption causes a tax cost of 3000$ per hour. However, two kinds of disruptions happen at 10 o’clock during the real-time occurrence of the original predictive scheduling. The first disruption happened because some preventive maintenance modifications were not implemented on some machines; the machines are damaged and are out of the production circuit for a certain period. The inaccessibility time of each machine based on the first disruption is shown in .
Table 4. Duration of inaccessibility on machines in each stage ()
The second disruption is that the customers called and asked the factory to change the delivery time window in lieu of paying the factory according to . In , the items and
show the upper bound and the lower bound of the delivery time window for the
th job in the reactive scheduling
, respectively.
Table 5. Delivery time-windows and lateness penalty of the jobs based on reactive scheduling ()
In the next section, a new mathematical model is introduced to response to unexpected disruptions and uncertainties during production using strategies of scheduling repair and energy consumption in switching machine modes.
3. Mathematical model for reactive scheduling in SFJSS problem
In this section, a new mathematical model is proposed to deal with the two types of mentioned uncertainties during production. So, the model is proposed based on the repair strategy and stochastic scheduling approach. Meanwhile, minimising the total cost of jobs lateness as well as minimising the tax cost on surplus energy consumption is considered as two objectives. In the following, first, the main assumptions of the considered problem are presented and then, notations and mathematical model of the problem is introduced as a mixed-integer programming (MIP) model.
The operations sequence of a job has already been specified and cannot be changed
Each operation of each job is assigned just to one machine in needed stages.
Each machine can only process one operation of a job at a certain moment
Sequences of jobs on machines are prioritised.
Once start, the process cannot be interrupted.
Setup times are independent and considered as a section of processing time.
Start time and processing time are considered stochastic with a uniform probability distribution
Also, the following notations are used to formulate the considered problem:
Table
The proposed mathematical model
The first objective function of the mathematical model can be seen in Equationequation (1)(1)
(1) , which seeks to minimise the total cost of job lateness penalties based on the time window. The second objective function of the mathematical model can be seen in Equationequation (2)
(2)
(2) , which seeks to minimise tax cost on surplus energy consumption within the framework of government regulations. In Equationequations (3)
(3)
(3) , (Equation4
(4)
(4) ), and (Equation5
(5)
(5) ) the energy consumption of each machine in each stage is calculated in modes of processing, idle, and standby, respectively. EquationEquation (6)
(6)
(6) indicates the distance between two consecutive operations of
and
on each machine in each stage in the idle mode in three different conditions such as both of them in the original scheduling, one of them in the original scheduling and the other in reactive scheduling and both of them in reactive scheduling. EquationEquation (7)
(7)
(7) is mentioned to the distance between two consecutive operations of
and
on each machine in each stage in the standby mode in three different conditions such as both of them in the original scheduling, one of them in the original scheduling and the other in reactive scheduling and both of them in reactive scheduling. In Equationequations (8)
(8)
(8) to (10) are shown the distance between two consecutive operations of
and
on each machine in each stage in three different conditions such as both of them in the original scheduling, one of them in the original scheduling and the other in reactive scheduling and both of them in reactive scheduling. In Equationequations (11)
(11)
(11) to (14) assumption (5) of the mathematical model are considered and these equations indicate that the disturbances occurred during processing time or after the processing time has elapsed. Switching the status of each machine in each stage for stability in the best mode of energy consumption between idle and standby with the aim of energy-saving is shown through Equationequations (15)
(15)
(15) to (24). When two operations of
and
achieve a common stage simultaneously, which of them is the priority? so this is expressed as Equationequation (25)
(25)
(25) . In Equationequations (26)
(26)
(26) to (31) the two operations of
and
are identified that are consecutive. According to Equationequation (32)
(32)
(32) , each machine in each stage is assigned to the operation of
when the operation mentioned requires the same stage. EquationEquations (33)
(33)
(33) to (35) indicate which operation of each job is starting to process in original scheduling and which of them will start in reactive scheduling. The sequences of operations on the jobs are determined via Equationequations (36)
(36)
(36) and (Equation37
(37)
(37) ). In Equationequations (38)
(38)
(38) to (42) are emphasised on prioritising between two operations of
and
in three different conditions such as both of them in the original scheduling, one of them in the original scheduling and the other in reactive scheduling and both of them in reactive scheduling. According to Equationequation (43)
(43)
(43) , each operation of each job can be processed by only one machine in each stage. EquationEquations (44)
(44)
(44) to (45) ensure that operations that start in original scheduling should not be considered in reactive scheduling. EquationEquations (46)
(46)
(46) to (49) indicate which operation of which jobs have been assigned to which machine in each stage. EquationEquations (50)
(50)
(50) to (52) represent the decision variables and their possible values.
Given that the proposed model is a mixed-integer nonlinear programming (MINLP). For this purpose, the model must be linearised and converted to MIP model. To achieve this goal, some equations must be rewritten, which is linearised using the following equations:
Two Equationequations (1)(1)
(1) and (Equation2
(2)
(2) ) make the objective functions to be nonlinear that can be rewritten as two transformed to linear equations using (53) and adding a new variable and two auxiliary constraints (Bagheri and Bashiri Citation2014).
To linearise the equation with some multiplied binary variables, Equationequation (54)(54)
(54) is used.
EquationEquation (55)(55)
(55) is used to linearise the equations in which that a binary variable is multiplied by an integer variable.
According to the above changes, Equationequations (1)(1)
(1) and (Equation2
(2)
(2) ) are linearised using (53). The Equationequations (8)
(8)
(8) , (Equation46
(46)
(46) ), (Equation47
(47)
(47) ), and (Equation48
(48)
(48) ) will be linear using (54). Due to Equationequation (55)
(55)
(55) , the Equationequations (6)
(6)
(6) and (Equation7
(7)
(7) ) in the proposed model will be linearised. Finally, two Equationequations (9)
(9)
(9) and (Equation10
(10)
(10) ) are linearised using Equationequations (54)
(54)
(54) and (Equation55
(55)
(55) ).
After linearising the proposed mathematical model, we will present the role of the ‘floating operator’ in the developed NSGA-II algorithm in order to save energy and then to solve and compare the mentioned model using the solver of CPLEX in GAMS 23 and MATLAB in the form of a case study.
4. The proposed solution approach based on NSGA-II
The flexible job shop scheduling problem with more than two jobs is NP-Hard (Ho and Tay Citation2004). In such high-complexity problems, heuristic and meta-heuristic algorithms are always used to provide near solutions in a reasonable time (Wu and Wu Citation2017). Researchers have shown that NSGA-II developed based on a genetic algorithm is highly effective in optimising multi-objective problems (Deb et al. Citation2002). In this section, a new solution approach based on NSGA-II is proposed to solve the considered problem with large-sized instances. The structure of the chromosome in the proposed algorithm is divided into two parts: the first part consists of the main chromosome and the second part consists of a sub chromosome that is created based on the main chromosome. In this developed algorithm, after the selection of parent chromosomes, two classical operators including crossover and mutation are applied to the main chromosome. In this meta-heuristic algorithm, a new operator is introduced called ‘floating operator’. This operator plays a vital role in reducing energy consumption. In the flexible job shop scheduling problem, some operations do not have a free float. As a result, the postponement of such operations will deliver jobs outside the soft time-windows. Thus, total costs of jobs lateness penalties will increase. But some operations have a floating distance. Therefore, the movement of these operations in the floating distance does not affect on the delivery time. The floating operator will move operations of jobs within the range of the floating distance based on a floating parameter. This operator will reduce taxes on surplus energy consumption while maintaining the lowest level of jobs’ lateness penalty cost. The floating operator is designed for the best local search, which is applied on the sub chromosomes.
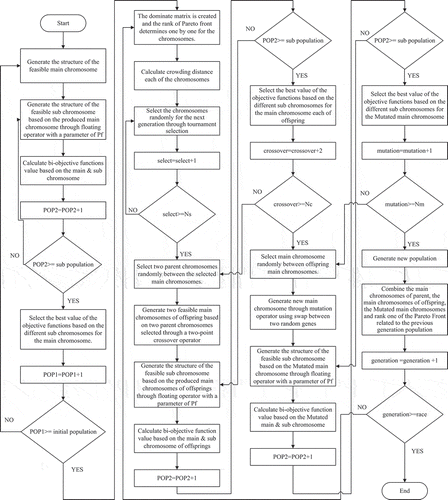
A new solution procedure is developed in this section based on the basic idea of the NSGA-II approach to deal with all features of the considered problem. The main steps of the proposed solution method are as follows: At first, an initial population is generated from the feasible main chromosome. A population of sub chromosomes is generated for each of the main chromosomes using a floating operator and the best sub chromosome for the main chromosome is selected based on the calculation of bi-objective functions value. Then, the dominate matrix is created and the rank of the Pareto front is determined for each chromosome with the computing of the crowding distance. Eventually, the next generation is selected through tournament selection. The population of feasible main chromosomes of offsprings is created using the crossover of main chromosomes of parents’ population and generate new main chromosome of offsprings through mutation operator using swap between two random genes. Finally, the best sub chromosome is selected for the main chromosome of each offspring and a new population is being produced. The algorithm is iterated until the termination condition is satisfied. The main sections of the proposed solution approach can be described based on the as follows:
Encoding of the main chromosome structure: In order to better explanation of this structure, it is implemented on a case study presented in section 2 of this paper. Solution representation of the main chromosome structure consists of a row vector with number of gens. Genes are encoded based on the corresponding number of jobs. The
th job number in the main chromosome structure must be repeated
operations and it is not allowed to repeat more or less than
. In this structure, the preserving strategy is used to make the main chromosome feasible. The structure of the main chromosome is divided into two parts such as original scheduling and reactive scheduling. The original scheduling is executed based on the initial predictive scheduling by the factory but reactive scheduling is executed based on strategies of scheduling repair. For example, in the order of 5 jobs is received by the factory. The number of genes in the main chromosome is 16 based on the total number of operations. According to this case study, the time of occurrence of disruptions is 10 o’clock. Therefore, the stochastic start time of those operations of jobs has been done before 10 o’clock according to the initial predictive scheduling and this part is always constant in all main chromosomes. While the second part of these main chromosomes is different. In this part, a random number is selected from the set of jobs for each gene. For this purpose, if the
th selected number is repeated less than or equal to
in previous genes. Then, the
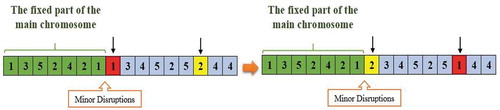
th job number will be encoded in the relevant gene, otherwise, another random number is generated. The method of encoding the main chromosome structure is shown in .
Figure 3. Encoding of the main chromosome structure
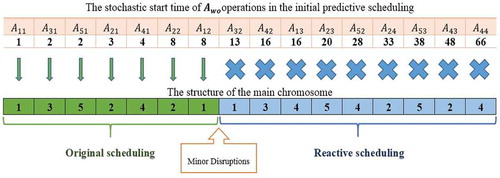
As can be seen in , the start time of seven genes from the structure of the main chromosome that are marked in green is less than 10 o’clock. For this purpose, the numbers of jobs are transferred exactly to the corresponding gene. It is noteworthy that the blue genes are not executed according to the initial predictive scheduling. The encoding of such genes is based on a random selection of th job from the
set with respect to the allowable repetition limit
. For example, the first job has three operations. Thus, the number one is repeated three times in the structure of the main chromosome.
Encoding of the sub-chromosome structure: The sub chromosomes have a matrix structure. It is said that its matrix structure consists of nine rows and the number of columns is equal to the columns of the main chromosome structure. The structure of sub chromosomes is similar to main chromosomes consists of two parts such as original scheduling and reactive scheduling. The sub chromosome is encoded based on the main chromosome. Each row of this matrix represents a series of codes, which are described as follows: in row one, the number of operations is encoded based on the number of jobs in the main chromosome. It is shown that the number of stages in the second row is based on the encoding of row one related to the sub chromosome and the main chromosome. The third row depends on the encoding of the previous two rows of the sub chromosome and main chromosome, which indicates the allocation number of the machines. In the stages where there are parallel machines, the machine numbers are randomly selected and placed in the corresponding gene. The iteration number of the machine allocation number is shown in the fourth row, which is encoded based on the third row. The codes in the fifth row indicate the scheduling period of the operations of jobs. Therefore, operations of jobs receive code 1 that is in the original scheduling. The sixth row is the start time of operations if they have received code 1 in the fifth row. Therefore, their start time is based on the initial predictive scheduling. Otherwise, the start time will be generated by observing the constraints of the mathematical model. Genes take value 1 if the machine is in an idle mode between and
in the seventh row. Sequential operations assigned to a machine are identified using the fourth row. The interval between two consecutive operations is calculated based on the sixth row and the stochastic parameter of processing time. Thereupon, the status of machines between them is defined as standby mode and idle mode. In the eighth row, genes take value 1 if the
is complete before disruption time in the original scheduling
. In the ninth row, genes taking value 1 if the
is complete before disruption time and inaccessible to the machine in the original scheduling
. Thus, two rows of eight and nine are calculated based on the sixth row and the stochastic parameter of processing time. The matrix structure of the subchromosome based on the real data from a case study is shown in .
Figure 4. Encoding of the sub chromosome structure
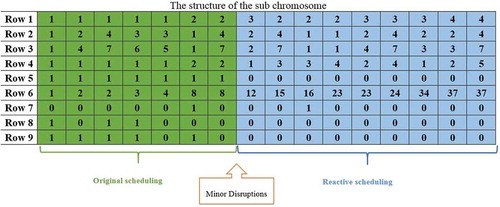
The genes shown in green are fixed for all the sub chromosomes. It is worth noting that the first three rows of the sub chromosome and main chromosome can be reached to the binary variable . From the 4th row, the value for binary variables
and
can be extracted along with the first three rows of subchromosome and main chromosome. Also, the binary variable
can be seen in the fifth row of the sub chromosome using the first row of the sub chromosome and main chromosome. The integer variable
is shown in the sixth row along with the first row of the sub chromosome and main chromosome. The binary variables
,
and
are shown in the seventh, eighth, and ninth rows, respectively.
Steps of selection operator: In this part of the algorithm, the best chromosomes are selected through the Parto Front ranking criteria and crowding distance criteria using the value calculation of the two objective functions. The number of chromosomes selected from the initial population is calculated as (56).
where is the selection coefficient and
denoted the number of the initial population. The steps of tournament selection can be described as follows:
Step1: Calculate the value of two objective functions for all chromosomes
Step2: Determine the rank of the Pareto front through the dominate matrix. It is worth noting that, among the values of the different functions of a chromosome, at least one function has a lower value than the other chromosomes.
Step3: Calculate the crowding distance for each of the chromosomes within a Pareto front. For this purpose, we arrange the chromosomes within a Pareto front from the lowest to the highest based on the first objective function. Set the value of the first and last points of the Pareto front to infinity. The crowding distance between the middle points of the Pareto Front is calculated based on the following equationEquation;(57)
(57)
In relation (57), the value of is the crowding distance of a point
. In addition,
is the value of the first objective function at the last point of the Pareto front and
is the value of the first objective function at the first point of the Pareto front. Finally, the same definitions apply to
and
for the value of the second objective function.
After performing the above three steps, we randomly select two chromosomes from the initial population. Then, the chromosomes with the least rank are selected as many as need to participate in the next population. But if two chromosomes have the same rank of the Pareto front, the chromosome is passed on to the next generation with a higher crowding distance.
Steps of crossover operator: This operator is applied to the parent’s main chromosomes. Given that the original scheduling part is fixed for all the main chromosomes of parents. For this purpose, the two-point crossover method has been used to produce the main chromosomes of offsprings. The number of the parent’s main chromosomes involved in the crossover operator is calculated by Equationequation (58)(58)
(58) .
where is the crossover coefficient. The steps of the two-point method in the crossover operator are as follows:
Step1: Random selection of two parent’s main chromosomes obtained from the selection operator
Step2: Selecting two genes to apply the two-point method of the crossover operator on the parent’s main chromosomes. It is worth noting that the first point must be set on the first gene of reactive scheduling after the occurrence of disruptions. Then, the second point is randomly selected between the first point and the last gene.
Step3: Perform the transplant operation between the two selected points in the second step on the two parent’s main chromosomes selected in the first step. It is noteworthy that the crossover operator creates infeasible main chromosomes of offsprings. For this purpose, if the th transferred number of parents is repeated less than or equal to
in previous genes of offsprings. Then, the
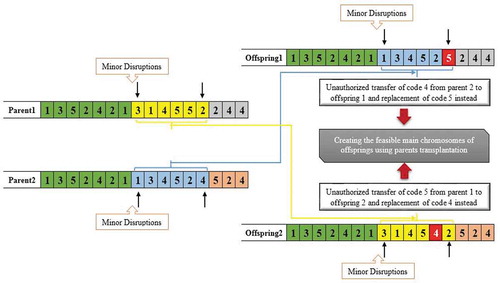
th job number will be encoded in the relevant gene of offsprings. Otherwise, the corresponding gene remains empty. Finally, the code for jobs that are less repetitive than the allowable limit is included in the empty gene. A schematic view of the crossover operator can be seen in .
Figure 5. Encoding of offspring’s main chromosomes using crossover operator
Steps of mutation operator: In order to prevent premature convergence of solutions, the mutation operator uses the method of the swap between two genes to produce a new main chromosome. The operator mentioned is shown in . The number of the offspring’s main chromosomes involved in the mutation operator is calculated by
Figure 6. Encoding of offspring’s main chromosomes using mutation operator
where is the mutation coefficient. The steps of the swap method in the mutation operator are as follows:
Step1: Random selection of offspring’s main chromosomes obtained from the crossover operator
Step2: Random selection of two genes from the main chromosome of the offspring between the first gene of reactive scheduling after the occurrence of disruptions and the last gene.
Step3: Code swap between two genes from the main chromosome of the offspring.
A summary of performance of the mutation operator has been presented in .
Steps of the floating operator: This operator is applied on sub chromosomes of the main chromosomes to enhance the power of the algorithm exploration. In this study, the floating operator has been used as an efficient method to reduce energy consumption in the framework of soft time-windows. This intelligent operator significantly reduces energy consumption using creating a float on the start time of operations. In such a way that the best status of the machine determines between the two modes of idle and standby with the best duration to stay in the above mode. Thus, this operator will reduce taxes on surplus energy consumption while maintaining the lowest level of total costs of jobs lateness penalties. The floating value is calculated based on the parameter . The steps of the floating method in the floating operator are as follows:
Step1: Determining operations of jobs that have a free float using Equationequation (60)(60)
(60) .
The free float between two consecutive operations of
and
is equal to zero. Thus, there is no free float between the two operations. Otherwise, there is free float.
Step2: Creating a float between two consecutive operations based on the parameter . Thus, the parameter
is calculated as follows:
Step3: Apply the floating operator on the start time of the operations of the jobs in row 6 of the sub chromosomes and row 7 being affected based on row 6. shows that how the floating operator performs in the proposed solution approach.
Figure 7. A schematic view of the performance of the floating operator
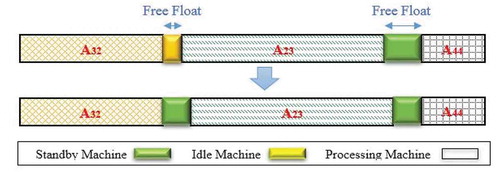
For example, creating a floating time unit at the start time of operation has changed the machine’s status from idle mode to standby mode, which consumes less energy than before.
The steps of the floating scheduling operator are shown in . The NSGA-II using the floating scheduling operator has better quality solutions than the NSGA-II in Wu and Sun (Citation2018) because it has a higher intelligence in a local search.
Figure 8. Flow chart of the proposed floating scheduling operator based on pNSGA-II algorithm
In the next section, a numeric example is investigated to be solved using the proposed solution approach and to analyse the performance of the floating parameter. Moreover, the performance of the proposed NSGA-II (pNSGA-II) algorithm using floating operator has been compared with the NSGA-II algorithm in Wu and Sun (Citation2018) based on the solutions obtained from the augmented ε-constraint method.
5. Numerical analysis based on real data from a case study
All the experiments are performed on a PC with the following specifications: Intel Core (TM) 2 Duo CPU, T6570 @ 2.10 GHz, 2.00 G RAM, Win7 32 bit. For coding the proposed algorithm, Matlab software was used. These experiments were performed on real data from a case study described in Section 2 of this paper. The performance of the pNSGA-II as a Pareto-based evolutionary algorithms is strongly dependent on its parameters. We tried to tune the algorithm parameters by the Taguchi method in the design of the experiment. So, for each parameter, three different levels are defined to evaluate the influence of relevant parameters on algorithm performance. The proposed algorithm consists of 7 parameters. Each parameter was tested at three levels: low, medium, and high by the Taguchi analysis method. Test values and the final value of each parameter have been presented in .
Table 6. Parameters setting of pNSGA-II algorithm
Due to the result of , the required parameters for the proposed algorithm are set as follows. The population size of the main chromosomes is considered to be 245. Also, the population size of the sub chromosomes is considered to be 34. The probabilities of selection (), crossover (
) and mutation (
) are set as 0.60, 0.72 and 0.5, respectively. The float operator is applied to the sub chromosomes with a
parameter equal to 1. The iteration has been set to 7 in order to discover the appropriate solution space and avoid long computational time. Tuning results of the parameters based on the design of experiments (DOE) is illustrated in .
Figure 9. A demonstration of the design of experiments using Taguchi analysis
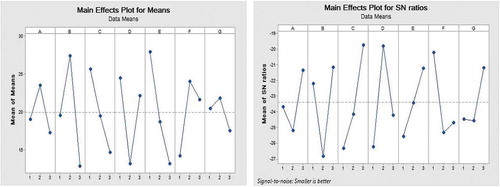
shows the result of the three-level plan of the Taguchi test for the seven aforementioned parameters. The population size of the main chromosomes, the population of the sub chromosomes, the selection probability, the crossover probability, the mutation probability, the float operator, and the number of generations (iterations) have been denoted by A to G, respectively. The experimental design values of each parameter have been presented in in the appendix.
Given that the proposed NSGA-II enhanced using a floating scheduling operator is expected to have a more accurate local search, the performance of this algorithm is compared to the NSGA-II introduced by Wu and Sun (Citation2018). This comparison is performed in terms of three well-known indicators considering the optimum Pareto front provided by the mathematical model.
The first indicator used in this evaluation is the Error Ratio (ER). The number of solutions on the final Pareto front is compared to the real Pareto front
as the exact solutions. The ER indicator is calculated by
where indicates the total number of solutions on the
. Furthermore, error solutions are expressed on the
with
. If the
solution of the
coincides with solution of the
,
takes value 0. Otherwise, it takes value 1. The lower values of
demonstrates that the
obtained by the meta-heuristic algorithm has less error than the
provided by the exact method.
The second indicator used in this evaluation is the Generational Distance (GD). The distance of each solution from the is calculated from all
solutions of the
and the sum of the shortest distances is obtained by
According to this relation, the GD metric indicates a shorter distance between the and the
. In other words, decreasing the value of the GD indicator represents the increase in the quality of the solutions on the
.
The third important indicator for evaluating the proposed algorithm is the Overall Non-Dominated Vector Generation Ratio (ONVGR) that is calculated as (64).
where the total number of solutions on and
are shown with
and
respectively. When ONVGR = 1, it shows that the same number of solutions have been found in both
and
. However, it does not infer that
. This metric requires the optimum Pareto front as
. In order to evaluate the performance of the pNSGA-II algorithm, the proposed optimisation method is compared to NSGA-II in Wu and Sun (Citation2018), and the augmented ε-constraint method. In , the Pareto front of the NSGA-II algorithm in Wu and Sun (Citation2018), and the pNSGA-II algorithm is carefully evaluated based on the optimal Pareto front. Therefore, the results of this evaluation are reported in based on three important indicators such as ER, GD, and ONVGR.
Figure 10. Evaluation of the Pareto front related to the pNSGA-II algorithm
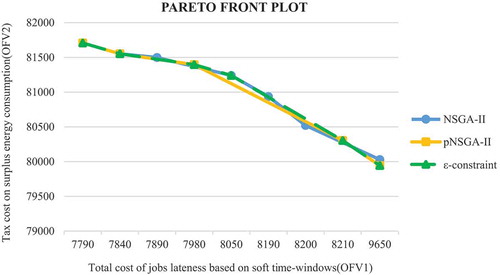
Table 7. Comparison the result of solving the small- and medium-sized cases
As can be seen in , the Pareto front of pNSGA-II corresponds to the real Pareto front provided by the ε-constraint method. reports the result of two algorithms in comparison to the result of the exact solution provided by the augmented ε-constraint in terms of CPU time, ER, GD, and ONVGR for 6 cases of small size and 4 cases of medium size. For all cases, the total number of machines and the total number of stages are 7 and 4, respectively. All experiments are conducted 30 runs and the best results have been reported for 10 cases.
As shown in , the pNSGA-II algorithm performs better than the NSGA-II algorithm in terms of CPU time and evaluation indicators in small- and medium-sized cases. It is important to note that determining the floating parameter is very important because increasing the value of the floating parameter does not indicate better performance in the proposed NSGA-II algorithm. Therefore, an optimal value of the parameter is required. In , sensitivity analysis on the GD indicator is performed based on changes in the
parameter.
Figure 11. Sensitivity analysis on the floating parameter in the pNSGA-II algorithm
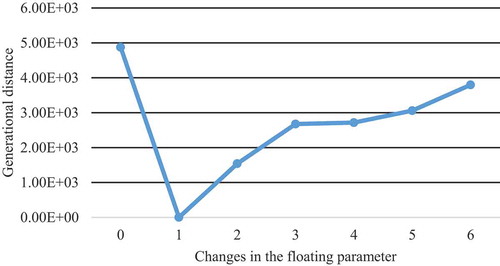
In , the average performance of five runs for the GD indicator is considered for each floating parameter setting. As the figure shows, increasing the floating parameter from 1 to 6 makes the GD indicator worse. Therefore, the adjusted value for the floating parameter (i.e., 1) is the best value to solve the problem in this case study.
In order to better demonstrate the performance of the pNSGA-II algorithm, we solved six cases of large size. Due to the complexity of the case, it is impossible to obtain the optimum Pareto set in a reasonable time for real-world instances. Hence, some other comparison metrics should be used for result analysis that does not require to the optimum Pareto solutions. In this way, two popular indicators are illustrated and used to evaluate the efficiency of two algorithms in solving the case in real-world dimensions. The first indicator is the Overall Non-dominated Vector Generation (ONVG). The ONVG is a popular metric that presents the number of non-dominated solutions provided by an algorithm.
The second indicator used in this evaluation is Diversification (D). Diversification is another important metric in evolutionary the performance of multi-objective optimisation algorithms in which the Pareto optimal set is not known. The diversification mechanism in the algorithm is based on the extent of the solutions on the , which is calculated as the following :
Moreover, demonstrates the distance between the two non-dominated solutions
and
on a
that is calculated as Euclidean distance. Therefore, increasing diversification leading to a widespread of solutions in the parametric space. In , the evaluation output is reported based on the CPU time and value of the indicators including D and ONVG for 6 cases of large size.
Table 8. Result comparison in solving the large-sized instances
How to contract with the customer is always very important in a make-to-order (MTO) system. Another important challenge for managers is to reduce the contract-related costs, especially under uncertainty and disruptions. Both of the jobs lateness costs and tax costs on surplus energy consumption are dependent on the soft time-windows. Therefore, determining proper soft time-windows for the due date is important to reduce energy consumption costs in such industries and to make production profitable. In this way, a sensitivity analysis has been done on the time window changes. and demonstrate the different conditions of Pareto front solutions according to changes in soft time-windows based on the Hypervolume indicator. The Hypervolume indicator is well known as an interesting indicator in tackling the bi-objective optimisation problems since it is a refinement of the Pareto dominance relation. This indicator guides to exploration of the objective space regions based on a reference point and at the same time have the property of being a refinement of the Pareto dominance relation (Auger et al. Citation2012).
Table 9. Sensitivity analysis on soft time-windows based on hypervolume indicator
Figure 12. Sensitivity analysis on the soft time-windows based on hypervolume indicator
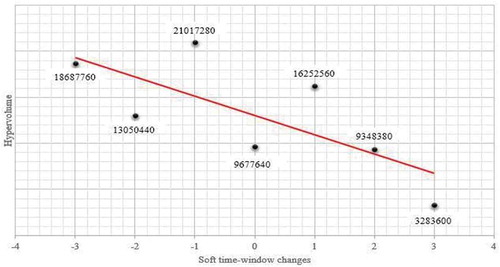
The value of the Hypervolume indicator has been reported in according to the changes of soft time-windows from −3 to +3. In addition, represents the reduction rate of the Hypervolume indicator as to the upper and lower bounds of the time-window increase.
To ensure that the result of the pNSGA-II is significantly better than the NSGA-II, some statistical tests are performed on the results obtained from 30 times run for each instance. To this end, the two-sample T-test has been done on the equality hypothesis (H0: against H1:
). However
and
are average of indicators of the pNSGA-II and NSGA-II, respectively, in 30 times solving of each instance. shows a summary result of these tests. Observing the result, the pNSGA-II significantly outperformed the NSGA-II in terms of GD in solving the case with 10 different dimensions.
Table 10. Statistical test on equality of means GD metric for two algorithms
Similarly, this statistical test was performed on the diversification indicator (). More values of this metric indicate better performance of the relevant algorithm. Therefore, the two-sample T-test has been done on the equality hypothesis as (H0:
against H1:
). While,
and
are average of indicator
calculated for the pNSGA-II and NSGA-II, respectively, in 30 times solving of each instance.
The result of this test has been addressed in . Calculating this indicator doesn’t require the optimum solutions and so, we performed this assessment for large-sized instances. Due to this result, the pNSGA-II has significantly outperformed the NSGA-II in solving five test cases of six instances.
Table 11. Statistical test on equality of means D metric for two algorithms
In summary, The p-values of the statistical tests have been reported in . As a result, the rationale of the proposed algorithm better performance is mainly because of enhancing the algorithm to a greedy heuristic local search in the algorithm which makes it more powerful to explore better much more efficiently in a proper direction which is achieved by the floating operator added in the proposed NSGA-II algorithm.
6. Conclusion
In this paper, the problem of flexible job shop scheduling was investigated under two types of uncertainties during production. We adjusted the problem for a real case study in the casting-based industry that almost uses high-powered machines to provide the optimal energy consumption. The problem was described clearly with the parameters and decision variables and then, a new bi-objective mathematical model was introduced to formulate it. Then, the non-linear model was modified to a linear MIP version. This model was developed for make-to-order (MTO) production systems with high-powered machines under uncertainty. The problem was conducted considering two conflicting objective functions of jobs lateness total costs and tax costs on surplus energy consumption. Two strategies were proposed including stochastic scheduling and reactive scheduling relevant to two different kinds of uncertainties with a known probability distribution and without any known probability distribution. A new solution approach was introduced based on the NSGA-II using a proposed floating operator. This operator causes enhancing the algorithm exploration to perform better local search throughout feasible solution space. In other words, the operator allows operations of the job to be floating within a certain range and find the best value of the objective function in local feasible spaces. It was shown that the proposed algorithm provided a set of solutions on the Pareto front close to the result of the exact method that was obtained using an augmented ε-constraint method. Moreover, the results demonstrated that the proposed solution approach outperforms the NSGA-II algorithm in Wu and Sun (Citation2018).
To ensure the significant difference between the pNSGA-II and the NSGA-II, some statistical tests were performed on two indicators of DG and D. To this end, each of the 16 test cases was solved 30 times and equality of means was investigated using a two-sample T-test. The results demonstrated outperforming the pNSGA-II in solving 15 test cases out of a total of 16 instances.
In summary, the results of this research can lead to better management approaches in how to make a contract with the customers. However, the bargaining power with the customer in order to get more time to deliver orders can significantly reduce late penalties. On the other hand, it can also lead to a decrease in the energy consumption of machines. The solutions provided by the model indicated that how we can reduce total production costs by readjusting the soft time-windows range. It is worth noting that using a floating operator in the NSGA-II algorithm, makes the algorithm smart to do a local search heuristically in the feasible space.
As an interesting future study, it is worthwhile to develop the problem by considering release time and machine eligibility. Moreover, exploring other efficient hybrid solution algorithms may enhance the performance of the solution approach which can be recommended as a direction for further work.
Disclosure Statement
The authors do hereby declare that there is no conflict of interests of other works regarding the publication of this paper.
Additional information
Funding
Notes on contributors

Behnam Ayyoubzadeh
Behnam Ayyoubzadeh is currently a Ph.D. candidate from the Islamic Azad University, North Tehran Branch since 2018. He received his B.Sc. in Industrial Engineering from the Islamic Azad University, Karaj Branch in 2011. Also, He received his M.Sc. in Industrial Engineering from the Islamic Azad University, Karaj Branch in 2013. His main areas of research are the modelling of scheduling (especially job shop) and production planning and control. He published more than 10 papers in reputable academic journals and conferences.

Sadoullah Ebrahimnejad
Sadoullah Ebrahimnejad is an Associate Professor of Industrial Engineering at Islamic Azad University – Karaj Branch in Iran. He received his B.Sc. degree from Iran University of Science & Technology in 1986, M.Sc. degree from Amirkabir University of Technology in 1993, and Ph.D. degree from Islamic Azad University - Science & Research Branch in Tehran in 2001. His research interests are Fuzzy MADM/MODM, SCM, Operations management, Optimization models, Risk management, Multi-criteria network optimization. He published more than 90 papers in reputable academic journals and conferences.

Mahdi Bashiri
Mahdi Bashiri holds a BSc in Industrial Engineering from Iran University of Science and Technology, MSc and PhD from Tarbiat Modares University. He is a recipient of the 2013 young national top scientist award from the Academy of Sciences of the Islamic Republic of Iran. He has served as a professor of Industrial Engineering at Shahed University and an assistant professor in Business analytics at Coventry University. His research interests are sustainable supply chain network design, heuristic and matheuristic algorithms, and decision making. He has published more than 190 papers in reputable academic journals and conferences.

Vahid Baradaran
Vahid Baradaran received his Ph.D. degree from Tarbiat Modares University in the industrial engineering field in 2010. He is an associate professor at Islamic Azad University, Tehran North Branch. Since he worked in university, he taught many courses in Operation Research, Statistics, Decision Making, Multivariate Statistical Analysis, and Data Mining in Master Science, and PhD courses.

Seyed Mohammad Hassan Hosseini
Seyed Mohammad Hassan Hosseini is currently principal and assistant professor of Industrial Engineering College at Shahrood University of Technology, where he has been since 2013. He received a B.Sc. from Iran University of Science and Technology in 2000, and an M.Sc. from the Amirkabir University of Technology. He received his Ph.D. in Industrial Engineering from the Payam-e-Noor University of Tehran in 2012. From 2002 to 2008 he worked at Iran Khodro Company (IKCO) as the most famous car manufactures in Middle East as an expert of quality control and also CRM department.
His main areas of research are the modelling of scheduling (especially flow shop) and production planning and control, quality engineering and management, and decision making techniques. He has published over than 40 papers in different international journals such as Journal of applied mathematical modelling, The International Journal of Advanced Manufacturing Technology, International Journal of Industrial Engineering Computations, International Journal of Supply and Operations Management, Journal of Optimization in Industrial Engineering, Journal of Industrial and Systems Engineering, Journal of applied mathematics and computations, Environment Systems and Decisions, International Journal of Productivity and Quality Management and so on.
As of 2014, Google Scholar reports over than 200 citations to his work. He has given numerous invited talks and tutorials, and is a founder of and consultant to companies involved in car making.
References
- Adibi, M. A., M. Zandieh, and M. Amiri. 2010. “Multi-objective scheduling of dynamic job shop using variable neighborhood search.” Expert Systems with Applications 37 (1): 282–287. doi:10.1016/j.eswa.2009.05.001.
- Auger, A., J. Bader, D. Brockhoff, and E. Zitzler. 2012. “Hypervolume-based multiobjective optimization: Theoretical foundations and practical implications.” Theoretical Computer Science 425 (March 2012): 75–103. doi:10.1016/j.tcs.2011.03.012.
- Bagheri, M., and M. Bashiri. 2014. “A new mathematical model towards the integration of cell formation with operator assignment and inter-cell layout problems in a dynamic environment.” Applied Mathematical Modelling 38 (4): 1237–1254. doi:10.1016/j.apm.2013.08.026.
- Bruzzone, A. A. G., D. Anghinolfi, M. Paolucci, and F. Tonelli. 2012. “Energy-aware scheduling for improving manufacturing process sustainability: A mathematical model for flexible flow shops.” CIRP Annals - Manufacturing Technology 61 (1): 459–462. doi:10.1016/j.cirp.2012.03.084.
- Cai, S., X. Long, L. Li, H. Liang, Q. Wang, and X. Ding. 2019. “Determinants of intention and behavior of low carbon commuting through bicycle-sharing in China.” Journal of Cleaner Production 212 (March 2019): 602–609. doi:10.1016/j.jclepro.2018.12.072.
- Che, A., K. Lv, E. Levner, and V. Kats 2015. “Energy consumption minimization for single machine scheduling with bounded maximum tardiness.” ICNSC 2015–2015 IEEE 12th International Conference on Networking, Sensing and Control Taiwan, 146–150. doi:10.1109/ICNSC.2015.7116025.
- Che, A., X. Wu, J. Peng, and P. Yan. 2017. “Energy-efficient bi-objective single-machine scheduling with power-down mechanism.” Computers and Operations Research 85 (September 2017): 172–183. doi:10.1016/j.cor.2017.04.004.
- Chen, J., L. Wang, and Z. Peng. 2019. “A collaborative optimization algorithm for energy- efficient multi-objective distributed no-idle fl ow-shop scheduling.” Swarm and Evolutionary Computation 50 (November2019): 100557. doi:10.1016/j.swevo.2019.100557.
- Cheng, J., F. Chu, M. Liu, P. Wu, and W. Xia. 2017. “Bi-criteria single-machine batch scheduling with machine on/off switching under time-of-use tariffs.” Computers and Industrial Engineering 112 (October 2017): 721–734. doi:10.1016/j.cie.2017.04.026.
- Cheng, J., F. Chu, and M. Zhou. 2018. “An Improved Model for Parallel Machine Scheduling Under Time-of-Use Electricity Price.” IEEE Transactions on Automation Science and Engineering 15 (2): 896–899. doi:10.1109/TASE.2016.2631491.
- Chryssolouris, G., and V. Subramaniam. 2001. “Dynamic scheduling of manufacturing job shops using genetic algorithms.” Journal of Intelligent Manufacturing 12 (3): 281–293. doi:10.1023/A:1011253011638.
- Dai, M. 2015. “Research on Energy-efficient Process Planning and Scheduling.” Doctor of Philosophy. Nanjing University of Aeronautics and Astronautics.
- Dai, M., D. Tang, A. Giret, and M. A. Salido. 2019. “Multi-objective optimization for energy-efficient flexible job shop scheduling problem with transportation constraints.” Robotics and Computer Integrated Manufacturing 59 (October 2019): 143–157. doi:10.1016/j.rcim.2019.04.006.
- Dai, M., D. Tang, A. Giret, M. A. Salido, and W. D. Li. 2013. “Energy-efficient scheduling for a flexible flow shop using an improved genetic-simulated annealing algorithm.” Robotics and Computer-Integrated Manufacturing 29 (5): 418–429. doi:10.1016/j.rcim.2013.04.001.
- Danielle, M. Tendall and Claudia R. Binder. 2011. “Nuclear Energy in Europe: Uranium Flow Modeling and Fuel Cycle Scenario Trade-Offs from a Sustainability Perspective.” Environmental Science & Technology 45 (6): 2442–2449. doi:10.1021/es103270a.
- Deb, K., A. Pratap, S. Agarwal, and T. Meyarivan. 2002. “A fast and elitist multiobjective genetic algorithm: NSGA-II.” IEEE Transactions on Evolutionary Computation 6 (2): 182–197. doi:10.1109/4235.996017.
- Duflou, J. R., J. W. Sutherland, D. Dornfeld, C. Herrmann, J. Jeswiet, S. Kara, M. Hauschild, and K. Kellens. 2012. “Towards energy and resource efficient manufacturing: A processes and systems approach.” CIRP Annals - Manufacturing Technology 61 (2): 587–609. doi:10.1016/j.cirp.2012.05.002.
- Fu, Y., G. Tian, A. M. Fathollahi-fard, A. Ahmadi, and C. Zhang. 2019. “Stochastic multi-objective modelling and optimization of an energy-conscious distributed permutation flow shop scheduling problem with the total tardiness constraint.” Journal of Cleaner Production 226 (July 2019): 515–525. doi:10.1016/j.jclepro.2019.04.046.
- Gao, J., M. Gen, and L. Sun. 2006. “Scheduling jobs and maintenances in flexible job shop with a hybrid genetic algorithm.” Journal of Intelligent Manufacturing 17 (4): 493–507. doi:10.1007/s10845-005-0021-x.
- Gao, J., M. Gen, L. Sun, and X. Zhao. 2007. “A hybrid of genetic algorithm and bottleneck shifting for multiobjective flexible job shop scheduling problems.” Computers and Industrial Engineering 53 (1): 149–162. doi:10.1016/j.cie.2007.04.010.
- Gao, J., L. Sun, and M. Gen. 2008. “A hybrid genetic and variable neighborhood descent algorithm for flexible job shop scheduling problems.” Computers and Operations Research 35 (9): 2892–2907. doi:10.1016/j.cor.2007.01.001.
- Gen, M., J. Gao, and L. Lin. 2009. “Multistage-based genetic algorithm for flexible job-shop scheduling problem.” Studies in Computational Intelligence 187: 183–196. doi:10.1007/978-3-540-95978-6_13.
- Hafezalkotob, A. 2017. “Competition, cooperation, and coopetition of green supply chains under regulations on energy saving levels.” Transportation Research Part E: Logistics and Transportation Review 97 (January 2017): 228–250. doi:10.1016/j.tre.2016.11.004.
- He, Y., Y. Li, T. Wu, and J. W. Sutherland. 2015. “An energy-responsive optimization method for machine tool selection and operation sequence in fl exible machining job shops.” Journal of Cleaner Production 87 (January 2015): 245–254. doi:10.1016/j.jclepro.2014.10.006.
- Herroelen, W., and R. Leus. 2004. “Robust and reactive project scheduling: A review and classification of procedures.” International Journal of Production Research 42 (8): 1599–1620. doi:10.1080/00207540310001638055.
- Herroelen, W., and R. Leus. 2005. “Project scheduling under uncertainty: Survey and research potentials.” European Journal of Operational Research 165 (2): 289–306. doi:10.1016/j.ejor.2004.04.002.
- Ho, N. B., and J. C. Tay 2004. “GENACE: An efficient cultural algorithm for solving the flexible job-shop problem.” Proceedings of the 2004 Congress on Evolutionary Computation, CEC2004, USA, 2( July 2004), 1759–1766. doi:10.1109/cec.2004.1331108.
- Jia, Z., Y. Wang, C. Wu, Y. Yang, and X. Zhang. 2019. “Multi-objective energy aware batch scheduling using ant colony optimization algorithm.” Computers & Industrial Engineering 131 (May 2019): 41–56. doi:10.1016/j.cie.2019.03.033.
- Kall, P., and S. W. Wallace. 1994. John Wiley and Sons Ltd: Stochastic programming.
- Kianfar, K., S. M. T. Fatemi Ghomi, and A. Oroojlooy Jadid. 2012. “Study of stochastic sequence-dependent flexible flow shop via developing a dispatching rule and a hybrid GA.” Engineering Applications of Artificial Intelligence 25 (3): 494–506. doi:10.1016/j.engappai.2011.12.004.
- Lei, D. 2010. “A genetic algorithm for flexible job shop scheduling with fuzzy processing time.” International Journal of Production Research 48 (10): 2995–3013. doi:10.1080/00207540902814348.
- Lei, D., L. Gao, and Y. Zheng. 2017. “A Novel Teaching-Learning-Based Optimization Algorithm for Energy-Efficient Scheduling in hybrid flow shop.” IEEE Transactions on Engineering Management 65 (2): 330–340. doi:10.1109/TEM.2017.2774281.
- Li, K., and B. Lin. 2016. “Impact of energy conservation policies on the green productivity in China’s manufacturing sector: Evidence from a three-stage DEA model.” Applied Energy 168 (April 2016): 351–363. doi:10.1016/j.apenergy.2016.01.104.
- Li, M., D. Lei, and J. Cai. 2019. “Two-level imperialist competitive algorithm for energy-ef fi cient hybrid fl ow shop scheduling problem with relative importance of objectives.” Swarm and Evolutionary Computation 49 (September 2019): 34–43. doi:10.1016/j.swevo.2019.05.006.
- Liu, A.-J., Y. Yang, Q.-S. Xing, H. Lu, Y.-D. Zhang, Z.-Y. Zhou, G.-H. Wu, and X.-H. Zhao. 2011. “Dynamic scheduling on multi-objective flexible job shop.” Computer Integrated Manufacturing Systems 17: 2629–2637.
- Liu, Z., S. Guo, and L. Wang. 2019. “Integrated green scheduling optimization of flexible job shop and crane transportation considering comprehensive energy consumption.” Journal of Cleaner Production 211 (February 2019): 765–786. doi:10.1016/j.jclepro.2018.11.231.
- Long, X., C. Wu, J. Zhang, and J. Zhang. 2018. “Environmental efficiency for 192 thermal power plants in the Yangtze River Delta considering heterogeneity: A metafrontier directional slacks-based measure approach.” Renewable and Sustainable Energy Reviews 82 (February 2018): 3962–3971. doi:10.1016/j.rser.2017.10.077.
- Luo, S., L. Zhang, and Y. Fan. 2019. “Energy-efficient scheduling for multi-objective flexible job shops with variable processing speeds by grey wolf optimization.” Journal of Cleaner Production 234 (October 2019): 1365–1384. doi:10.1016/j.jclepro.2019.06.151.
- Mansouri, S. A., E. Aktas, and U. Besikci. 2016. “Green scheduling of a two-machine flowshop: Trade-off between makespan and energy consumption.” European Journal of Operational Research 248 (3): 772–788. doi:10.1016/j.ejor.2015.08.064.
- Mouzon, G., and M. B. Yildirim. 2008. “A framework to minimise total energy consumption and total tardiness on a single machine.” International Journal of Sustainable Engineering 1 (2): 105–116. doi:10.1080/19397030802257236.
- Mouzon, G., M. B. Yildirim, and J. Twomey. 2007. “Operational methods for minimization of energy consumption of manufacturing equipment.” International Journal of Production Research 45 (18–19): 4247–4271. doi:10.1080/00207540701450013.
- Pach, C., T. Berger, Y. Sallez, T. Bonte, E. Adam, and D. Trentesaux. 2014. “Reactive and energy-aware scheduling of flexible manufacturing systems using potential fields.” Computers in Industry 65 (3): 434–448. doi:10.1016/j.compind.2013.11.008.
- Pach, C., T. Berger, Y. Sallez, T. Bonte, E. Adam, and D. Trentesaux. 2014. “Reactive and energy-aware scheduling of flexible manufacturing systems using potential fields.” Computers in Industry 65 (3): 434–448. doi:10.1016/j.compind.2013.11.008.
- Rey, G. Z., A. Bekrar, D. Trentesaux and B,-H. Zhou. 2015. “Solving the flexible job-shop just-in-time scheduling problem with quadratic earliness and tardiness costs.” The International Journal of Advanced Manufacturing Technology 81: 1871–1891. doi:10.1007/s00170-015-7347-0.
- Shrouf, F., J. Ordieres-Meré, A. García-Sánchez, and M. Ortega-Mier. 2014. “Optimizing the production scheduling of a single machine to minimize total energy consumption costs.” Journal of Cleaner Production 67 (March 2014): 197–207. doi:10.1016/j.jclepro.2013.12.024.
- Suwa, H., and H. Sandoh. 2007. “Capability of cumulative delay based reactive scheduling for job shops with machine breakdowns.” Computers and Industrial Engineering 53 (1): 63–78. doi:10.1016/j.cie.2007.04.002.
- Tang, Z., M. Warkentin, and L. Wu. 2019. “Understanding employees’ energy saving behavior from the perspective of stimulus-organism-responses.” Resources, Conservation and Recycling 140 (January 2019): 216–223. doi:10.1016/j.resconrec.2018.09.030.
- van Zon, A., and I. H. Yetkiner. 2003. “An endogenous growth model with embodied energy-saving technical change.” Resource and Energy Economics 25 (1): 81–103. doi:10.1016/S0928-7655(02)00018-0.
- Wu, X. 2008. “Research on flexible job shop dynamic scheduling problem.” Journal of System Simulation 20 (14): 3828–3832.
- Wu, X., and Y. Sun. 2018. “A Green Scheduling Algorithm for Flexible Job Shop with Energy-Saving Measures.” Journal of Cleaner Production 172 (January 2018): 3237–3248. doi:10.1016/j.jclepro.2017.10.342.
- Wu, X., and S. Wu. 2017. “An elitist quantum-inspired evolutionary algorithm for the flexible job-shop scheduling problem.” Journal of Intelligent Manufacturing 28 (6): 1441–1457. doi:10.1007/s10845-015-1060-6.
- Wu, X., and A. Che. 2020. “Energy-efficient no-wait permutation flow shop scheduling by adaptive multi-objective variable neighborhood search.” Omega 94 (July 2020): 102117. doi:10.1016/j.omega.2019.102117.
- Yang, T., L. Zhao, W. Li, and A. Y. Zomaya. 2020. “Reinforcement learning in sustainable energy and electric systems : A survey.” Annual Reviews in Control 49: 145–163. doi:10.1016/j.arcontrol.2020.03.001.
- Zhang, H., L. Li, P. Zhou, J. Hou, and Y. Qiu. 2014. “Subsidy modes, waste cooking oil and biofuel: Policy effectiveness and sustainable supply chains in China.” Energy Policy 65 (February 2014): 270–274. doi:10.1016/j.enpol.2013.10.009.
- Zhang, R., and R. Chiong. 2016. “Solving the energy-efficient job shop scheduling problem: A multi-objective genetic algorithm with enhanced local search for minimizing the total weighted tardiness and total energy consumption.” Journal of Cleaner Production 112 (January 2016): 3361–3375. doi:10.1016/j.jclepro.2015.09.097.
Appendix
Table A1. Design summary
Table A2. Experimental design levels based on Taguchi analysis
Table A3. Response table for signal to noise ratios (smaller is bettter)
Table A4. Response table for means