
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Electric vehicles (EVs) have played a significant role in sustainability, and EVs fire accidents have raised doubts in recent years. To solve the mobile analytical equipment limitation in EVs fire accident and help staff receive prompt results at on-spot inspection, we provide a lightweight but accurate Transformer that can ideally adapt to the mobile environment. First, we built on the simple Segformer and extended it to aggregate the representations of amorphous objects, such as fire traces, in image recognition. Second, we used shunt-based self-attention (SSA) to enhance the model for capturing multi-scale contextual information and help distinguish the deformed level of EVs after combustion. Third, we redesigned a simple multi-level information aggregation (MIA) decoder to obtain the relationship between pixels in the channel dimensions by a weighted aggregation. Furthermore, to foster image trace recognition, we put forwards and evaluated the accuracy of models on electric vehicle fire traces (EVFTrace), a dataset of images of burnt EVs. On EVFTrace, the mean intersection over union (mIoU) achieves 72.24%. The float point operations (Flops) and parameters (Params) achieve 114.83 G and 89.5 M. Our model shows excellent efficiency and accuracy for burnt EVs segmentation tasks.
1. Introduction
Vehicles have become vital tools for transportation and travel with the development of the automotive industry. To reduce the oil dependence, Electric vehicles (EVs) have been provided as an ideal alternative in human life to avoid global energy shortage and the concentration of air pollutants for sustainability (X. Sun et al. Citation2019). According to a report from the China Association of Automobile Manufacturers, the ownership of EVs in China has been steadily increasing, and the sales volume of alternative energy EVs had reached 6,887,000 in 2022. In addition, the authorities of most developed countries tend to encourage the use of EVs for sustainability (Sanguesa et al. Citation2021). Compared with traditional vehicles, EVs offer a lower energy cost and higher travelling efficiency in the automotive sector for sustainable development (Agamloh, von Jouanne, and Yokochi Citation2020). In recent years, environmental challenges have prompted social demand for sustainable vehicles, and EVs have played a significant role in smart cities and green transportation (Husain et al. Citation2021). The lithium-ion battery is one of the fundamental components and; however, it is also the main cause of fire incidents (P. Sun et al. Citation2020). Further development of EVs with lithium-ion batteries is indicated for fire safety (Bisschop, Willstrand, and Rosengren Citation2020; Dorsz and Lewandowski Citation2022). According to (Brzezinska and Bryant Citation2022), the thermal runaway and self-ignition of lithium-ion batteries lead to most EV fire accidents. Moreover, compared to gasoline-caused vehicle fire accidents, EVs have raised doubts in terms of fire safety (H. Li et al. Citation2020).
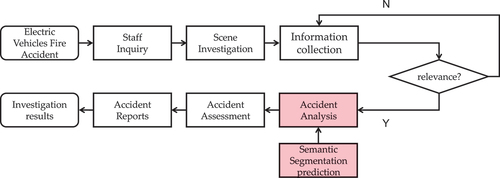
An execution flow of the conventional EVs fire accident investigation is shown in . Investigating and analysing suspicious ignition regions can help locate the critical reason for fire accidents and reduce the negative outcome (Nicholas et al. Citation2010). Furthermore, it can eliminate potential fire hazards and provide additional guidance to fire safety engineers. Recently, more efforts in image recognition have focused on fire risk assessment and hazard analysis, such as real-time image detection (S. Zhang et al. Citation2022). With the salient visual appearance of EVs after combustion such as broken windows, burnt-off paint, battery leakage, and rusted metal, it is feasible to apply semantic segmentation methods for EVs fire accident assessment (Shields and Scheibe Citation2006). In addition, compared with manual on-spot inspection, semantic segmentation is more convenient and efficient for locating the ignition region with less time and labour consumption (Pu and Zhang Citation2022). However, most neural networks in deep learning have high requirements for analytical equipment. With high computational cost and model size, it is difficult for mobile tools to run related neural networks and obtain an ideal result. The limitations of mobile analytical equipment severely restrict the application of semantic segmentation to EVs fire accidents. A well-balanced strategy is necessary to facilitate progress in EVs fire safety research. The execution flow of EVs fire accident investigation is illustrated in .
Figure 1. Execution flow of EVs fire accident investigation.
Most recent semantic segmentation models have rarely been applied for the image recognition of burnt EVs in fire accidents. Meanwhile, the limitation of mobile analytical equipment on EVs fire sites will influence the experimental results of the part model, which includes a high computational cost and model size, such as DeepLabV3+ (Chen et al. Citation2018). However, with the well-maintained appearance of EVs after combustion, it is feasible to locate the ignition regions in the visual images using related segmentation methods. With this scenario, we aim to provide an effective Transformer named multi-scale Segformer (MSegformer) to help the relevant staff of EVs fire investigations receive prompt results. Our model maintains a good balance between computation cost and accuracy for EVs fire segmentation. It is suitable for mobile investigation environments of EVs fire accidents with simple architecture and precise segmentation results. The main contributions of this paper are summarised as follows:
(1) Aiming to the condition that there are rarely public EVs fire accident datasets, we collected images of burnt EVs from the Tianjin Fire Science and Technology Research Institute of M. E. M and labelled these images for pixel-level segmentation tasks.
(2) Considering the mobile equipment limitations in fire on-spot investigations, we provide a lightweight but accurate Transformer framework that can help staff receive prompt results on fire site. Specifically, for segmented objects burnt EVs and on-spot application environments, we combine a simple Segformer (E. Xie, Wang, Yu, et al. Citation2021) with shunt-based self-attention (SSA) (Ren et al. Citation2022) to aggregate the representations for amorphous objects, such as fire traces, and further capture contextual information from coarse- to fine-grained features.
(3) To overcome the difficulty in deformed object segmentation, we designed a multi-level information aggregation (MIA) decoder to fuse the feature maps in the hierarchy, update the channel weight of pixels by a weighted recalibration, and predict the segmentation masks. The MIA is simple but efficient for segmentation tasks.
2. Related Work
2.1. Semantic segmentation
Semantic segmentation has been exponentially boosted by the concept of fully convolutional networks (FCN) (Long, Shelhamer, and Darrell Citation2015). However, the limited receptive field in the FCN leads to coarse pixel-wise predictions. Subsequently, more recent efforts have focused on solving the problem of context modelling with an FCN. Pyramid scene parsing network (PSPNet) (Zhao et al. Citation2017) utilises a pyramid architecture to obtain multiple features. DeepLabV3+ leverages dilated convolution and a hierarchical decoder to capture long-range dependencies from local to global features. Other methods, such as the attention mechanism and strip pooling (Hou et al. Citation2020), have been developed to refine dense predictions for semantic segmentation.
Trace segmentation is a significant component of semantic segmentation tasks, which requires further context emphasis. To overcome the detailed deficiencies in amorphous object segmentation, such as flame and smoke, the model correspondingly needs to collect rich background information and capture the inherent dependencies. In (X. Li and Zhang Citation2023), the authors combined an edge extraction module based on gradient transformation with DeepLabV3+ to strengthen the edge information of a flame. Following the design of dual-attention network (DANet) (Fu et al. Citation2019; Zeshu et al. Citation2022), and (X. Zhang, Liang, and Zhang Citation2021), two attention modules are appended to extract detailed information of smoke and represent context semantics. However, there is still little exploitation of segmentation models for locating the ignition region of burnt EVs, particularly in mobile scenarios. However, the salient appearances of burnt EVs, such as burnt-off paint and rusted metal, make relevant segmentation tasks possible. Therefore, we attempt to utilise semantic segmentation models to locate ignition regions and provide an alternative ancillary for EVs fire investigation with limited analytical equipment.
2.2. Transformer
Transformer has achieved tremendous success in natural language processing (NLP) (Vaswani et al. Citation2017) and has been viewed as a strong alternative to convolutional networks (ConvNets) in visual image tasks. In ConvNets, the most recent models tend to be increasingly complex to overcome the receptive field limitation. However, unlike the limited convolution kernel in ConvNets, Transformer has a more flexible receptive field for image recognition, which can capture the global spatial contextual information by the encoder. Therefore, it is possible to achieve precise fire segmentation results for burnt EVs with a simple Transformer.
Vision Transformer (ViT) (Dosovitskiy et al. Citation2021) is the first work to validate that a pure Transformer can be applied in image classification and achieve state-of-the-art performance. Recently, variants of ViT such as LocalViT (Y. Li, Zhang, Cao, et al. Citation2023), DeiT (Touvron et al. Citation2021), and CPVT (Chu et al. Citation2023) have further improved image recognition performance. These models tend to divide an image into a series of embedded patches, which are then fed into a standard Transformer. Moreover, for dense prediction in semantic segmentation, pyramid vision Transformer (PVT) (W. Wang, Xie, Li, et al. Citation2021) constructs an FCN-like model to extract multi-level features and learn high-resolution representations. SEgmentation TRansformer (SETR) (Zheng et al. Citation2021) provides a pure Transformer framework to solve the limited receptive field challenge for segmentation tasks. To overcome the difficulty of burnt EVs segmentation in mobile analytical equipment, we propose a simple but effective Transformer framework in Section 3.
2.3. Attention mechanism
The attention mechanism can model long-range dependencies from spatial or channel dimensions and has been widely applied in many tasks. The most recent models in semantic segmentation have exploited the attention mechanism to achieve dense prediction. Squeeze-and-excitation networks (SENet) (Hu, Shen, and Sun Citation2018) adopt SE blocks to recalibrate the weight parameters in the channel dimension. Non-local network (NLNet) (X. Wang, Girshick, Gupta, et al. Citation2018) proposes non-local operations for capturing the global context and exploiting dimension-wise priors. Inspired by them, DANet appends two types of attention mechanisms to aggregate the features and models rich contextual dependencies in spatial and channel dimensions, respectively. In addition, as in (Q. Wang, Wu, Zhu, et al. Citation2020) and (X. Li, Zhong, Wu, et al. Citation2019), more attention modules have been proposed and applied to ConvNets. Transformers also use multi-head self-attention layers to extract pixel-level context information with a sequence of image patches. Therefore, to achieve the ideal performance for burnt EVs segmentation tasks, we combine a Transformer with other attention mechanisms to reinforce the representations in segmented object detail.
3. Methods
Our proposed architecture is built on the recent Segformer and mainly consists of two modules: a hierarchical Transformer encoder with SSA, and an MIA decoder. The MSegformer is illustrated in :
Figure 2. Our proposed MSegformer framework.
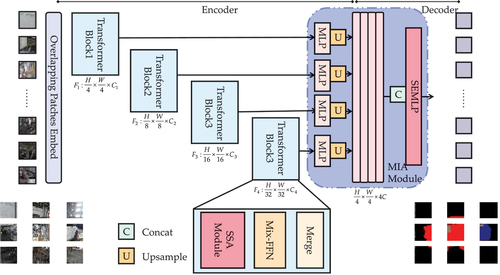
3.1. Segformer architecture
In ConvNets, the limited receptive field is a critical constraint for performance, and researchers have focused on reinforcing the representation with a larger receptive field, such as pyramid pooling module (PPM) or dilated convolution. However, models using these strategies tend to have complex architectures with high computational costs. Considering that researchers need to provide precise results for the on-spot inspection of burnt EVs, it is important to require less computational cost and a smaller model size for the limited analysis equipment on the site of EVs fire accidents. Therefore, we provide a simple but accurate strategy for burnt EVs segmentation. In this strategy, we first split an image into a sequence of patches, and then deploy a simple and lightweight Transformer to encode these patches. Second, we merge these patches to obtain multi-level feature maps. Finally, we fuse these feature maps and decode them using a MIA to predict our segmentation masks.
In our proposed MSegformer, we build on the recent Segformer and modify the encoder and decoder for our segmentation tasks, which require more spatial and channel context information to distinguish the burnt level in the EVs. Segformer designs a Mix Transformer (MiT) encoder for pixel-to-pixel segmentation tasks. With an image size , MiT generates a series of feature maps in the resolution of
and feeds these features into an ALL-MLP (E. Xie, Wang, Yu, et al. Citation2021) layer to fuse multi-level features and predict the segmentation masks.
Specifically, compared with ViT, which divides an image into patches, MiT divides an image into
patches and flattens them as a sequence of patches. Meanwhile, MiT removes positional encoding (PE) and its variants, such as positional encoding generator (PEG), from Transformer encoders. As a substitute for PE, MiT preserves the overlapping region between two adjacent patches to provide the location information. Moreover, a mixed feed-forward network (Mix-FFN) is designed to locate the position and aggregate the representation, while image sizes in the training and valid sets are not consistent. The details are presented in and .
Figure 3. Part of Transformer encoders.
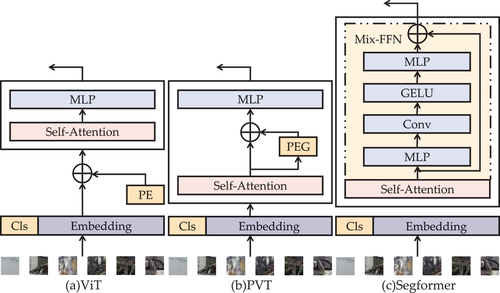
Table 1. Backbones with the SSA modules in MSegformer.
The computational expression of Mix-FFM is given as follows:
where is the input vector,
is the output vector and Gaussian Error Linear Unit (GELU) is the activation function as follows:
3.2. MSegformer encoders
For semantic segmentation, Transformer encoders tend to design a hierarchical architecture to capture multi-level features from coarse to fine, such as PVT, SeMask (Jain et al. Citation2023), and MixFormer (Cui et al. Citation2024).
In PVT, a scaling factor is introduced into the self-attention layers to merge the tokens and obtain a global receptive field, where the keys
and values
are downsampled
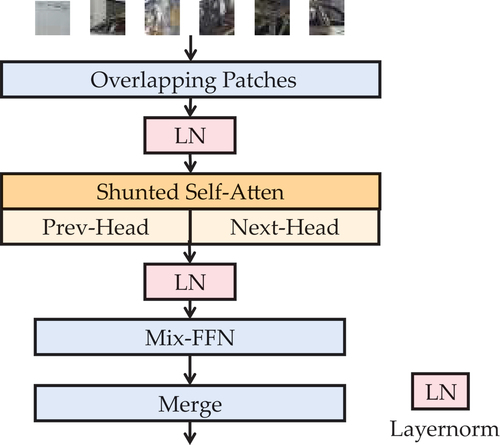
compared to the original modules. However, these strategies tend to merge patches by a fixed and identical factor in the same self-attention layer, without considering the use of different scaling factors in the multi-head self-attention module of the same layer. It inevitably reduces the experimental performance for amorphous objects. In order to learn more coarse- and fine-grained information for EVs fire trace, we introduce the SSA into our Transformer blocks. The SSA module contains several scaling factors in the same self-attention layer. With the key design, it can inject multiple attentions into tokens and merge those tokens to model hybrid-scale receptive fields at per layer. Different from other self-attention layers with identical key and value per layer, SSA conducts token aggregation for the key and value in a self-attention and preserves more detailed features. Benefiting from SSA, our models can capture both local and global spatial features in the same self-attention layer and collect the relationships between objects of various sizes. For burnt EVs segmentation tasks, it is efficient to capture more detailed information for amorphous objects, such as fire traces and deformed EVs after combustion.
For SSA, the multi-head self-attention module is divided into two parts. Further details of the model are shown in , and the expression is as follows:
Figure 4. Transformer blocks in MSegformer encoder.
where is the input sequence of
by a scaling factor
and
is a depth-wise convolution for local aggregation.
The parameters listed in are described in more detail. Specifically, there are six models with Transformer blocks in different numbers, where B0 is the most lightweight and B5 is the most complex. For an image in resolution ,
indicates the depth of layer, with the number of heads
, scaling factor
, channel numbers
, kernel size
, stride
, and padding
. We reserve the self-attention heads of stage1 and stage4 with an identical scaling factor. Furthermore, we vary the scaling factors of self-attention heads in stage2 and stage3, where half is the same and the rest is to
th.
3.3. Multi-level information aggregation
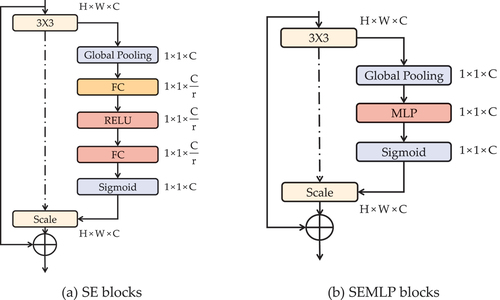
Owing to the flexibility and simplicity of the structure, the SE block is widely integrated into many architectures to aggregate the representation of models, such as (S. H. Xie et al. Citation2021) and (Wentao and Li Citation2021). In the SE block, the feature in the channel dimension is recalibrated by modelling channel-wise dependencies and capturing contextual information. In this procedure, the feature map is squeezed by its spatial dimensions, and the feature relationships of multiple channels are emphasised by the operation of two fully connected (FC) layers. In the first FC layer, there is dimensionality-reduction radio , which can lead to the loss of feature information.
Considering that our segmented objects require more contextual priors, we revise the SE blocks to achieve weighted recalibration with less loss. A more detailed description about the SE block with MLP module (SEMLP) is presented in . To alleviate the loss in the SE block, we consider a multilayer perceptron (MLP) as a substitute for the original two FC layers. It can capture more channel-wise feature information without adding an excessive number of parameters. This structure retains the flexible and simple identities of the base SE blocks and aggregates the representations of our segmented objects. The MLP is expressed as follows:
Figure 5. Comparison of different channel attention mechanisms.
where ,
and
are the weight matrices,
,
, and
are the bias matrices, and Rectified Linear Unit (RELU) is the activation function.
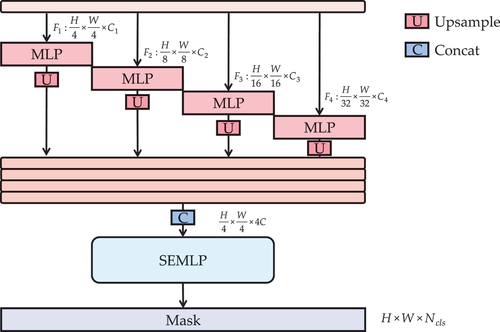
To evaluate the performance of our Transformer encoder, we introduce a simple MIA decoder, which can reshape the 3D feature map to a 2D shape. In Section 3.2, we design a hierarchical encoder to progressively capture multi-scale feature information from coarse- to fine-grained. In this section, we collect the outputs of each level, unify their channel dimensions, resize to th by upsampling, and concatenate them together. Finally, we reinforce the feature maps using SEMLP blocks and fuse features to predict the results for semantic segmentation. The computational expression of the decoder architecture is as follows:
where refers to the label mask for tasks.
With the receptive field limitation, the decoder designs in ConvNets inevitably become complex and heavy to enlarge the receptive field, such as in (Pu and Zhang Citation2022; M. Yang et al. Citation2018), and (K. Yang et al. Citation2019). However, Transformer encoders, which rely on the multi-head self-attention module, have a global receptive field to fulfil the feature extraction from the local to global context and make a simple decoder possible. Compared to these decoders in ConvNets such as PPM and atrous spatial pyramid pooling (ASPP), our MIA decoder can fuse multi-level feature maps in the spatial dimension and implement a channel-wise weighted recalibration in a smaller model size. Detailed descriptions are presented in :
Figure 6. MIA decoder.
4. Experiments
4.1. Experimental setup
We implemented our approach using PyTorch. The CPU was an Intel Xeon Gold 5118 processor (2.30 GHz), the GPU was NVIDIA Tesla P40, and the graphic memory was 24GB. We initialised the encoders using the pre-trained models on ImageNet and performed the exponential learning rate policy with a loss of 1 and weight of auxiliary loss of 0.4. The initial learning rates were set to 2e-2, and the optimiser was stochastic gradient descent (SGD) with a batch size of 2, momentum of 0.9, and weight decay of 1e-4. The models were trained for 20 epochs and 5K iterations per epoch with dropout. We evaluated the results on the Electric Vehicle Fire Trace (EVFTrace) dataset with the mIoU metric. Exceptionally, we report the Flops and Params metric to evaluate the superiority of methods in semantic segmentation in terms of computation cost and model size. Furthermore, we conducted experiments using the Wild PAnoramic Semantic Segmentation (WildPASS) dataset and observed the results. Following (E. Xie, Wang, Yu, et al. Citation2021), Segformer was pre-trained on ImageNet-1K and other models were pre-trained on ImageNet. We fine-tuned these pre-trained models with cross-entropy loss for semantic segmentation tasks.
Mean Intersection over Union (mIoU) is set as the metric of this paper to evaluate the accuracy of our method. The details are as follows:
Additionally, to demonstrate the lightness and simplicity of our method in this paper, we add the float point operations (Flops) and parameters (Params) as the metrics in the evaluation. The details are as follows:
4.2. Dataset in Experiments
4.2.1. EVFTrace dataset
To foster research and facilitate a credible evaluation of alternative energy electric vehicle fire accident segmentation, we introduce the EVFTrace dataset. Unlike datasets such as PASCAL VOC or Cityscapes that focus on intact electric vehicle images, EVFTrace includes burnt electric vehicle images collected from the Tianjin Fire Science and Technology Research Institute of M. E. M. It includes electric vehicle images in different categories and under various conditions. The image size is approximately . Overall, we gathered 1455 images of burned electric vehicles, which were shot from multiple views and precisely annotated for semantic segmentation into four classified regions: background, intact, mild, and severe. The detailed descriptions are shown in . The finely annotated images were divided in a 4:1 radio for the training and validation sets. We used six strategies for data augmentation to enhance generalization ability, such as random rotation and random cropping. shows the proportion of pixels in the different classes, and shows images and labelled masks in the EVFTrace dataset.
Figure 7. Details of original images and labels in EVFTrace dataset.
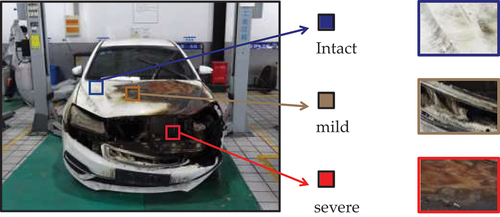
Table 2. Proportion of pixel numbers in different classes.
Figure 8. Images in the EVFTrace dataset with labels.

4.2.2. WildPASS dataset
The WildPASS dataset was annotated by Yang et al. (K. Yang et al. Citation2021), and was built for the panoramic segmentation of urban street scenes. The photos were collected from different angles with a total of eight classes of segmented objects. Among them, there were 500 original cases, which were divided into training and validation sets in a 4:1 radio. We used the same strategies as those used for the data augmentation. The samples in the WildPASS dataset are shown in .
Figure 9. Images from the WildPASS dataset.

4.3. Comparison experiments
We now compare our results with those of several mainstream networks for semantic segmentation on the EVFTrace and WildPASS datasets. Specifically, we include PSPNet, DeepLabV3+, UperNet (Xiao et al. Citation2018), SPNet, CPNet (Yu et al. Citation2020), MobileNetV2 (Sandler et al. Citation2018), EfficientNet-B7 (Tan and Le Citation2019) and NLNet, SETR, and Segformer-B5, where ConvNets use ResNet-101 (He et al. Citation2016) and ResNet-50 as the encoders.
The experimental results are summarised in , including the IoU of each class and the total mIoU. It can be observed that our method, MSegformer-B5, outperforms other related methods on the EVFTrace dataset and is significantly more accurate and efficient. MSegformer-B5 achieves a 72.24% mIoU with a 1.76% mIoU better than SETR and a 0.97% mIoU better than Segformer-B5. Furthermore, compared to ConvNets, our approach also shows an ideal prediction for burnt EVs segmentation tasks. shows the visualisation results of comparison experiments in more detail. They indicate that our approach achieves optimal results for the burnt EVs segmentation tasks on EVFTrace dataset in terms of accuracy.
Table 3. Results of comparison experiments in EVFTrace Dataset.
Figure 10. Visualization results of comparison experiments in EVFTrace Dataset.

In addition, we used the WildPASS dataset to validate the superiority of our approach. The results are summarised in , in which the mIoU for PSPNet, DenseASPP, SwaftNet (K. Yang et al. Citation2020), and DANet are from (K. Yang et al. Citation2021). According to , our Transformer approach presents a significant improvement over ConvNets.
Table 4. Results of comparison experiments in WildPASS Dataset.
Additionally, to demonstrate the performance and efficiency of our approach, we computed the metrics of Flops and Params for different methods, and the results are shown in . Models in Transformers usually use multi-head self-attention modules in the encoder, which naturally produce many parameters through the matrix operations of patches. However, our approach still has a lower computational cost and model size than many other methods, such as PSPNet (ResNet-101) and NLNet.
Table 5. Results related to model size and computational cost.
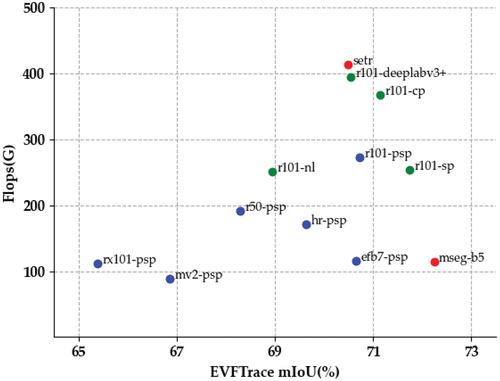
As shown in , on the EVFTrace dataset, MSegformer-B0 yields 7.27 G Flops and 3.79 M Params with 68.29% mIoU. In addition, MSegformer-B5 yields 114.83 G Flops and 89.5 M Params with 72.24% mIoU. Furthermore, our approach performed better for mIoU, Flops and Params compared to the ConvNets. With the aim of burnt EVs segmentation tasks, our approach achieves optimal results in terms of computational cost and model size on the EVFTrace dataset. To further contrast our model design, we provide a visualisation in . It provides a clearer presentation that our approach has a well-balanced condition for computation cost and model size compared to other methods.
Figure 11. Model efficiency vs. Performance on EVFTrace dataset.
4.4. Ablation experiments
To evaluate the impact of each module in our approach for semantic segmentation of burnt EVs in this study, we employed four sets of ablation experiments with different strategies. Our approach consists of three parts: backbone framework, SSA module and MIA decoder. Specifically, we selected Segformer-B5 as the backbone of our experiments. shows more details of the ablation experiments, and the visualisation results for the EVFTrace dataset are shown in .
Table 6. Comparison of segmentation performance of different modules in EVFTrace Dataset.
Figure 12. Visualization results of ablation experiments in EVFTrace Dataset.

The segmented visualisation results in show that the background regions and burnt EVs with our approach are similar with the annotation mask than other methods. For instance, our method segments the broken window of burnt EVs in the column 2 as a severe region, which is segmented as a mild region by Segformer.
shows that our method performs optimally with a 72.24% mIoU, which is 0.97%, 0.52%, and 0.26% mIoU higher than other models. The results from Segformer, Segformer + MIA, and our approach show that our approach can inject multiple receptive fields into tokens, merge tokens to preserve fine-grained object features, capture multi-scale feature maps in per self-attention layer and aggregate the performance for amorphous objects. Furthermore, the results from Segformer, Segformer + SSA, and our approach show that our approach can model channel dimensional relationships between objects of different sizes and reinforce the representation in segmented prediction tasks.
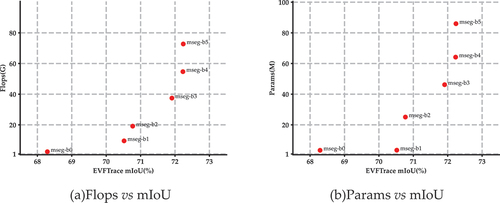
Furthermore, to compute the effect of the depth of the encoder on the results, we employed six sets of experiments from B0 to B5. The experimental results are shown in and visualised in .
Table 7. Results of MSegformer encoders in EVFTrace Dataset.
Figure 13. Performance vs. Model efficiency with MSegformer encoders on EVFTrace.Dataset.
5. Conclusions
Currently, there are still rare applications for semantic segmentation research on EVs fire recognition. However, with a well-maintained appearance and structure after combustion, the bodies of EVs tend to be recognised as a significant guideline for the investigation and analysis of ignition points. To address these scenarios, we collected images of burned EVs and built the EVTFrace dataset. Considering the mobile equipment limitations on the EVs fire site, to help relevant staff receive prompt investigation results, we propose a simple and lightweight MSegformer model. In this study, we implemented and compared the proposed approach with several mainstream models. Our approach achieves an optimal result with 72.24% mIoU, 114.83 G Flops and 89.5 M Params. The results show that compared to ConvNets and other Transformers with the common multi-head self-attention layer, our approach with the SSA and MIA modules can capture object features at hybrid scales in the same self-attention layer, collect these features, unify their channel dimensions, reinforce these feature maps with a weighted recalibration, and show a more ideal performance for burnt EVs. Comprehensive experimental results demonstrate the superiority of our models in terms of accuracy, computational cost, and model size for burnt EVs segmentation tasks.
For our proposed model, there are still several improvement points for the future. First, the number of images of burnt EVs in our dataset is limited, and no pixel-level labelled dataset in the field of EVs fire accident is publicly available. It inevitably influences the experimental results. To overcome this problem, the collection of images of burnt EVs is necessary and effective for further research. Second, owing to the specialised limitations, our perspectives are restricted by the knowledge in computer vision. However, it is significantly feasible to combine with relevant knowledge in other fields, such as automation, to enhance the application in flexible scenarios.
Author contributions
Conceptualisation, M.L.; methodology, M.L.; software, M.L.; validation, M.L. and X.W.; formal analysis, M.L. and X.W.; investigation, M.L. and X.W.; data curation, X.W.; writing – original draft preparation, M.L.; writing – review and editing, X.W.; visualisation, M.L.; supervision, X.W. All authors have read and agreed to the published version of the manuscript. Agreement to be accountable for all aspects of the work in ensuring that questions related to the accuracy or integrity of any part of the work are appropriately investigated and resolved.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are available from the corresponding author, M.L., upon reasonable request. Please email [email protected] for the web link and verification code.
Additional information
Notes on contributors
Mengqi Lei
Mengqi Lei obtained a bachelor’s degree in Electronic Science and Technology at the School of Microelectronics in Tianjin University. She is currently studying for her master’s degree in Electronic and Information Engineering at the School of Microelectronics in Tianjin University.
Xin Wang
Xin Wang obtained a bachelor’s degree in Electronic and Information Engineering at the School of Microelectronics in Heibei University of Technology. She has obtained a master’s degree in Electronic and Information Engineering at the School of Microelectronics in Tianjin University.
References
- Agamloh, E., A. von Jouanne, and A. Yokochi. 2020. “An Overview of Electric Machine Trends in Modern Electric Vehicles.” Machines 8 (2): 20. https://doi.org/10.3390/machines8020020.
- Bisschop, R., O. Willstrand, and M. Rosengren. 2020. “Handling Lithium-Ion Batteries in Electric Vehicles: Preventing and Recovering from Hazardous Events.” Fire Technology 56 (6): 2671–2694. https://doi.org/10.1007/s10694-020-01038-1.
- Brzezinska, D., and P. Bryant. 2022. “Performance-Based Analysis in Evaluation of Safety in Car Parks Under Electric Vehicle Fire Conditions.” Energies 15 (2): 649. https://doi.org/10.3390/en15020649.
- Chen, L. C., Y. Zhu, G. Papandreou, and S. George. 2018. “Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation.” In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 801–818. https://doi.org/10.1007/978-3-030-01234-2_49.
- Chu, X., Z. Tian, and B. Zhang. 2023. “Conditional Positional Encodings for Vision Transformers.” In International Conference on Learning Representations, Kigali, Rwanda, 2102.10882.
- Cui, Y., C. Jiang, G. Wu, and L. Wang. 2024. “Mixformer: End-To-End Tracking with Iterative Mixed Attention.” IEEE Transactions on Pattern Analysis and Machine Intelligence 46 (6): 4129–4146. https://doi.org/10.1109/TPAMI.2024.3349519.
- Dorsz, A., and M. Lewandowski. 2022. “Analysis of Fire Hazards Associated with the Operation of Electric Vehicles in Enclosed Structures.” Energies 15 (1): 11. https://doi.org/10.3390/en15010011.
- Dosovitskiy, A., L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, et al. 2021. “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale.” In International Conference on Learning Representations, Vienna, Austria.
- Fu, J., J. Liu, and H. Tian. 2019. “Dual Attention Network for Scene Segmentation.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 3141–3149. https://doi.org/10.1109/CVPR.2019.00326.
- He, K., X. Zhang, S. Ren, and S. J. Shaoqing. 2016. “Deep Residual Learning for Image Recognition.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 770–778. https://doi.org/10.1109/CVPR.2016.90.
- Hou, Q., L. Zhang, and J. Feng. 2020. “Strip Pooling: Rethinking Spatial Pooling for Scene Parsing.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 4002–4011. https://doi.org/10.1109/CVPR42600.2020.00406.
- Husain, I., G. Md Sariful, E. Su, G.-J. Yu, W. Chowdhury, S. Xue, L. Rahman, and D. Sahu Raj. 2021. “Electric Drive Technology Trends, Challenges, and Opportunities for Future Electric Vehicles.” Proceedings of the IEEE 109 (6): 1039–1059. https://doi.org/10.1109/JPROC.2020.3046112.
- Hu, J., L. Shen, and G. Sun. 2018. “Squeeze-And-Excitation Networks.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 7132–7141. https://doi.org/10.1109/CVPR.2018.00745.
- Jain, J., A. Singh, N. Orlov, N. Huang, Z. Li, J. Walton, and S. Shi Humphrey. 2023. “Semask: Semantically Masked Transformers for Semantic Segmentation.” In IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Paris, France, 752–761. https://doi.org/10.1109/ICCVW60793.2023.00083.
- Li, H., W. Peng, X. Yang, H. Chen, J. Sun, and Q. Wang. 2020. “Full-Scale Experimental Study on the Combustion Behavior of Lithium Ion battery Pack Used for Electric vehicle.Fire Technol.” Fire Technology 56 (6): 2545–2564. https://doi.org/10.1007/s10694-020-00988-w.
- Li, X., and R. Zhang. 2023. “Laboratory Flame Image Segmentation and Recognition by Fusing Infrared and Visible Light.” Chinese Journal of Liquid Crystals & Displays 38 (9): 1262–1271. https://doi.org/10.37188/CJLCD.2022-0357.
- Li, Y., K. Zhang, J. Cao, R. Timofte, M. Magno, L. Benini, and L. Van Goo. 2023. “Localvit: Bringing Locality to Vision Transformers.” In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Detroit, MI, USA, 9598–9605. https://doi.org/10.1109/IROS55552.2023.10342025.
- Li, X., Z. Zhong, J. Wu, and J. Yang. 2019. “Expectation-Maximization Attention Networks for Semantic Segmentation.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea (South), 9166–9175. https://doi.org/10.1109/ICCV.2019.00926.
- Long, J., E. Shelhamer, and T. Darrell. 2015. “Fully Convolutional Networks for Semantic Segmentation.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 3431–3440. https://doi.org/10.1109/CVPR.2015.7298965.
- Nicholas, J. S., H. William, E. G. Gregory, L. H. Ronald, and M. K. Patrick. 2010. “Vehicle Fire Burn Pattern Study.” In Proceedings of the International Symposium on Fire Investigation Science and Technology, Ottawa, Ontario. Boston, MA, 533–44.
- Pu, J., and W. Zhang. 2022. “Electric Vehicle Fire Trace Recognition Based on Multi-Task Semantic Segmentation.” Electronics 1738 (11): 11. https://doi.org/10.3390/electronics11111738.
- Ren, S., D. Zhou, S. He, S. Feng, and J. Wang. 2022. “Shunted Self-Attention via Multi-Scale Token Aggregation.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 10843–10852. https://doi.org/10.1109/CVPR52688.2022.01058.
- Sandler, M., A. Howard, M. Zhu, M. Zhmoginov, and C. Andrey. 2018. “Mobilenetv2: Inverted Residuals and Linear Bottlenecks.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 4510–4520. https://doi.org/10.1109/CVPR.2018.00474.
- Sanguesa, J. A., V. Torres-Sanz, P. Garrido, F. J. Martinez, and J. M. Marquez-Barja. 2021. “A Review on Electric Vehicles: Technologies and Challenges.” Smart Cities 4 (1): 372–404. https://doi.org/10.3390/smartcities4010022.
- Shields, L. E., and R. R. Scheibe. 2006. “Computer-Based Training in Vehicle Fire Investigation Part 2: Fuel Sources and Burn Patterns.” SAE Technical Paper 2006–01–0548. https://doi.org/10.4271/2006-01-0548.
- Sun, P., R. Bisschop, H. Niu, and X. Huang. 2020. “A Review of Battery Fires in Electric Vehicles.” Fire Technology 56 (4): 1361–1410. https://doi.org/10.1007/s10694-019-00944-3.
- Sun, X., Z. Li, X. Wang, and C. Li. 2019. “Technology Development of Electric Vehicles: A Review.” Energies 2020 (1): 13, 90. https://doi.org/10.3390/en13010090.
- Tan, M., and Q. Le. 2019. “Efficientnet: Rethinking Model Scaling for Convolutional Neural Networks.” In International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 6105–6114.
- Touvron, H., M. Cord, M. Douze, M. Massa, and F. Sablayrolles. 2021. “Training Data-Efficient Image Transformers & Distillation Through Attention.” In International Conference on Machine Learning. PMLR, Vienna, Austria, 10347–10357.
- Vaswani, A., N. Shazeer, and N. Parmar. 2017. “Attention Is All You Need.” In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 5998–6008.
- Wang, X., R. Girshick, A. Gupta, and A. He. 2018. “Non-Local Neural Networks.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 7794–7803.
- Wang, J., K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Tan, and M. Wang. 2020. “Deep High-Resolution Representation Learning for Visual Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence.” IEEE Transactions on Pattern Analysis & Machine Intelligence 43 (10): 3349–3364. https://doi.org/10.1109/TPAMI.2020.2983686.
- Wang, Q., B. Wu, P. Zhu, P. Li, P. Zuo, and W. Hu. 2020. “ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 11531–11539. https://doi.org/10.1109/CVPR42600.2020.01155.
- Wang, W., E. Xie, X. Li, and X. Fan. 2021. “Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions.” In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 548–558. https://doi.org/10.1109/ICCV48922.2021.00061.
- Wentao, L. I., and P. Li. 2021. “Small Objects Detection Algorithm with Multi-Scale Channel Attention Fusion Network.” Journal of Frontiers of Computer Science and Technology 15 (12): 2390.
- Xiao, T., Y. Liu, B. Zhou, and J. Bolei. 2018. “Unified Perceptual Parsing for Scene Understanding.” In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 432–448. https://doi.org/10.1007/978-3-030-01228-1_26.
- Xie, E., W. Wang, Z. Yu, Z. Anandkumar, and A. Alvarez. 2021. “SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers.” In Advances in Neural Information Processing Systems 34 pre-proceedings, 12077–12090. Vol. 34.
- Xie, S. H., W. Z. Zhang, P. Cheng, and Z.-X. Yang. 2021. “Fire Smoke Detection Model Based on YOLOv4 with Channel Attention.” Chinese Journal of Liquid Crystals & Displays 36 (10): 1445–1453. https://doi.org/10.37188/CJLCD.2020-0312.
- Yang, K., X. Hu, H. Chen, H. Xiang, and K. Wang. 2020. “DS-PASS: Detail-Sensitive Panoramic Annular Semantic Segmentation Through SwaftNet for Surrounding Sensing.” In IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 457–464. https://doi.org/10.1109/IV47402.2020.9304706.
- Yang, K., X. Hu, B. L. M, E. Romera, and K. Wang. 2019. “Pass: Panoramic Annular Semantic Segmentation.” IEEE Transactions on Intelligent Transportation Systems 21 (10): 4171–4185. https://doi.org/10.1109/TITS.2019.2938965.
- Yang, M., K. Yu, C. Zhang, and L. Chi. 2018. “Denseaspp for Semantic Segmentation in Street Scenes.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 3684–3692. https://doi.org/10.1109/CVPR.2018.00388.
- Yang, K., J. Zhang, S. Reiß, S. Hu, and X. Stiefelhagen. 2021. “Capturing Omni-Range Context for Omnidirectional Segmentation.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 1376–1386. https://doi.org/10.1109/CVPR46437.2021.00143.
- Yu, C., J. Wang, C. Gao, C. Yu, and G. Shen. 2020. “Context Prior for Scene Segmentation.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 12413–12422. https://doi.org/10.1109/CVPR42600.2020.01243.
- Zeshu, D., Y. Feiniu, and X. Xue. 2022. “Improved Spatial and Channel Information Based Global Smoke Attention Network.” Journal of Beijing University of Aeronautics & Astronautics 48 (8): 1471–1479. https://doi.org/10.13700/j.bh.1001-5965.2021.0549.
- Zhang, X., Y. Liang, and W. Zhang. 2021. “Real-Time Smoke Segmentation Algorithm Fused with Global and Local Representation.” Journal of Xidian University 55 (12): 2334–2341. https://doi.org/10.3785/j.issn.1008-973X.2021.12.013.
- Zhang, S., Q. Yang, Y. Gao, and D. Gao. 2022. “Real-Time Fire Detection Method for Electric Vehicle Charging Stations Based on Machine Vision.” World Electric Vehicle Journal 13 (2): 23. https://doi.org/10.3390/wevj13020023.
- Zhao, H., J. Shi, and X. Qi. 2017. “Pyramid Scene Parsing Network.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 6230–6239. https://doi.org/10.1109/CVPR.2017.660.
- Zheng, S., J. Lu, and H. Zhao. 2021. “Rethinking Semantic Segmentation from a Sequence-To-Sequence Perspective with Transformers.” In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 6877–6886. https://doi.org/10.1109/CVPR46437.2021.00681.