
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Early stage developability assessments of monoclonal antibody (mAb) candidates can help reduce risks and costs associated with their product development. Forecasting viscosity of highly concentrated mAb solutions is an important aspect of such developability assessments. Reliable predictions of concentration-dependent viscosity behaviors for mAb solutions in platform formulations can help screen or optimize drug candidates for flexible manufacturing and drug delivery options. Here, we present a computational method to predict concentration-dependent viscosity curves for mAbs solely from their sequence—structural attributes. This method was developed using experimental data on 16 different mAbs whose concentration-dependent viscosity curves were experimentally obtained under standardized conditions. Each concentration-dependent viscosity curve was fitted with a straight line, via logarithmic manipulations, and the values for intercept and slope were obtained. Intercept, which relates to antibody diffusivity, was found to be nearly constant. In contrast, slope, the rate of increase in solution viscosity with solute concentration, varied significantly across different mAbs, demonstrating the importance of intermolecular interactions toward viscosity. Next, several molecular descriptors for electrostatic and hydrophobic properties of the 16 mAbs derived using their full-length homology models were examined for potential correlations with the slope. An equation consisting of hydrophobic surface area of full-length antibody and charges on VH, VL, and hinge regions was found to be capable of predicting the concentration-dependent viscosity curves of the antibody solutions. Availability of this computational tool may facilitate material-free high-throughput screening of antibody candidates during early stages of drug discovery and development.
Abbreviations
| cP | = | Centipoise |
| mAb | = | Monoclonal antibody |
| SCM | = | Spatial Charge Map |
| Fv | = | Variable Fragment |
| UF/DF | = | Ultrafiltration/Diafiltration |
| η0 | = | Viscosity of platform formulation buffer |
| η | = | Viscosity of antibody solution |
| c | = | Concentration of an antibody |
| MOE | = | Molecular Operating Environment |
| GB/VI | = | Generalized Born/volume integral |
| RMSG | = | Root mean square gradient |
| MD | = | Molecular dynamics |
| CDR | = | Complementarity determining region |
| Fc | = | Crystalizable portion of the antibody |
| IMGT® | = | The international ImMunoGeneTics information system® |
| e | = | Charge on an electron |
| ZVH | = | Charge on VH region |
| ZVL | = | Charge on VL region |
| ZFc | = | Charge on Fc region |
| ZCL | = | Charge on CL region |
| ZCH1 | = | Charge on CH1 region |
| ZHinge | = | Charge on hinge region |
| ZmAb | = | Total charge on the antibody molecule |
| pISequence | = | Sequence-based pI of the antibody molecule |
| pIStructure | = | Structure-based pI of the antibody molecule |
| APTango | = | Normalized aggregation propensity of the antibody sequence calculated using TANGO |
| APWaltz | = | Normalized aggregation propensity of the antibody sequence calculated using WALTZ |
| vdwA | = | Van der Waals surface area of the antibody molecule |
| ASAhyd | = | Hydrophobic surface area of the antibody molecule |
| ASAhphil | = | Hydrophilic surface area of the antibody molecule |
| DmAb | = | Dipole moment of the antibody molecule |
| ζmAb | = | Zeta potential of the antibody molecule |
| IgG | = | Immunoglobulin G |
| LOO | = | Leave one out |
| D0 | = | diffusion coefficient at the limit concentration → 0 |
Introduction
In recent years, monoclonal antibody (mAb)-based therapeutic products have gained greater representation in the pipelines of pharmaceutical companies. For example, the total number of antibody molecules in clinical pipelines increased from ∼350 in 20131 to ∼470 in 2016.Citation2 MAb-based therapeutics can target a wide variety of disease conditionsCitation3 with high target specificityCitation4 and low non-mechanism toxicity.Citation5 Often, such products need to be administered at high concentrations to improve patient compliance, ease of administration, and to save on treatment costs.Citation6 But, in some cases these high concentration antibody solutions can become highly viscous, leading to challenges in manufacturing, storage and administration. Therefore, low viscosities at high concentrations of antibody solutions are desired for successful product development of mAb-based therapeutics.
Typical approaches to ensure low viscosity of antibody solutions depend upon the stage of drug product development.Citation6 If the product is in late stages of development, then optimization of formulation can be pursued. However, re-formulation requires additional material and resources, which adds to the already high cost of drug product development. Therefore, rationally prioritizing/optimizing antibody candidates at early discovery stages is preferred. At the early stages, material available for experimental testing is limited. Computational tools require no material, and are therefore ideally suited for early stage developability assessments of mAb candidates.
Computational tools for viscosity prediction of small molecules were developed several decades ago,Citation7-9 but only a few studies of biologics have been reported so far in the literature. Li and coworkersCitation10 pioneered the efforts to predict viscosity of highly concentrated mAb solutions using their calculated molecular properties. These authors experimentally measured concentration-dependent viscosity behaviors of 11 different mAbs under standardized conditions and found correlations with computationally estimated molecular descriptors such as charge, zeta-potential and aggregation propensity of variable fragments (Fv regions) of the antibodies. Antibody molecules whose formulations demonstrate high viscosities at 150 mg/mL contain negatively charged patches on their Fv regions. This is because pIs of these Fv regions are lower than the pH of formulation buffer. Sharma and coworkersCitation11 also used computationally estimated molecular descriptors to predict viscosity at 180 mg/mL concentration in different formulation conditions than those used by Li and coworkers.Citation10 These authors also predicted plasma clearance difference between human and cynomolgus monkeys, and chemical stability against tryptophan oxidation and aspartic acid isomerization using molecular dynamics (MD) simulations. In a third study, Trout and coworkersCitation12 developed a spatial charge map (SCM) tool for screening antibody solutions using information about the charge distribution on the Fv portions of mAbs. The authors validated their method using data on mAbs being developed at 3 pharmaceutical companies. Furthermore, Nichols et al.Citation13 used a molecular model of the Fv portion of a viscosity-challenged IgG1λ mAb to rationally design point mutations that improved its viscosity behavior. Recently, Geoghegan et al.Citation14 also demonstrated that rational structure-based re-engineering of the Fv portion of an IgG1 mAb can help mitigate its viscosity and tendencies to form reversible self-associations. These studies demonstrate utility of molecular modeling and simulations toward developability assessments of therapeutic antibody candidates.
The studies described above focused on predicting and improving the viscosity of mAbs at high concentrations using molecular models of the Fv regions only, while the viscosity data were collected using experiments performed on the full-length mAbs. Use of molecular models for Fv regions alone neglects contributions of the constant regions toward concentration-dependent viscosity behaviors of full-length antibodies. The effects on viscosity behaviors due to variations in antibody isotypes are also ignored. In contrast, coarse-grained simulations of antibody solutions performed by Buck et al.Citation15 showed that inter-domain interactions involving both the variable (Fv) and the constant (CL, CH1, and Fc) regions engage in the formation of transient intermolecular networks, and therefore contribute toward increased viscosity of antibody solutions at high concentrations. This observation motivated us to use full-length antibody models in the present investigation.
Knowledge of the viscosity behaviors of antibody solutions not only at one arbitrarily chosen high concentration, but over a wide range of concentrations is desirable during drug development. Antibody solutions are concentrated to different extents during manufacturing, drug substance storage, drug product presentations and administration. Prior knowledge of concentration-dependent viscosity behaviors can be very useful at all these steps. Here, we present an algorithm to predict entire concentration-dependent viscosity curves for different mAbs in the same formulation solely from their amino acid sequences and homology-based structural models. Experimentally determined concentration-dependent viscosity curves for 16 different antibody molecules were combined with molecular descriptors computed from their full-length homology-based structural models to construct this algorithm. While contributions of the electrostatic interactions toward viscosity behaviors of antibody solutions have been emphasized in earlier studies,Citation6,10-13 this analysis demonstrates that hydrophobicity also makes important contributions to protein:protein interactions that eventually lead to high viscosities in certain concentrated antibody solutions.
Results
In this report, we describe our attempts to predict concentration-dependent viscosity curves for mAbs solely from their sequence and structural attributes. To enable this, concentration-dependent viscosity curves for 16 different antibodies were determined experimentally under standardized conditions as described earlier.Citation10 Next, homology-based structural models of all 16 antibodies in our data set were built and used for calculation of hydrophobic and electrostatic properties for these antibodies. The sequence-based analyses for calculating aggregation propensities were also performed.
Observations from concentration-dependent viscosity curves for 16 mAbs
Concentration-dependent viscosity curves for 16 mAbs formulated in the same buffer were analyzed using Eqs Equation2(2)
(2) and Equation3
(3)
(3) (see Materials and Methods section for details). Briefly, the relationship between solution viscosity and solute concentration is exponential (Eq. Equation2
(2)
(2) ), which can be linearized via logarithmic manipulation (Eq. Equation3
(3)
(3) ). Here, the experimental data on each antibody () were used to obtain the values of intercept (lnA) and slope (B) via linear regression of Eq. Equation3
(3)
(3) . These values are presented in .
Table 1. Concentration dependent viscosity data on 16 mAbs used in this study.Footnote*
Table 2. Experimentally observed values of parameters A and B for the 16 mAbs.Footnote*
Parameter A is nearly constant
Most antibodies in the current data set have similar values for the intercept, lnA ( and ). The average value for intercept (lnA) is −0.58±0.26 (range: −0.17 to −1.34). Upon taking the antilog, the average value for parameter A is 0.58±0.13 (range: 0.26–0.84; standard deviation to mean ratio = 22%). Two antibodies, mAbs 14 and 15 show significantly different values for parameter A than the remaining 14 mAbs (A = 0.84 for mAb 14 and 0.26 for mAb 15). If these 2 outliers are removed, the average value for parameter A for the remaining 14 mAbs becomes 0.58±0.079 (range = 0.46–0.72; standard deviation to mean ratio = 13%). These observations suggest that the intercept for the antibodies studied here is nearly constant. As noted by Li et al.,Citation10 parameter A is the intrinsic relative viscosity of an antibody dissolved in infinitely dilute solution. The intrinsic relative viscosity of a solute (mAb in our case) is related to diffusion coefficient of the solute via the Stokes-Einstein equation,Citation10 which also considers the solute's molecular size. Even though the antibodies studied in this work differ from one another in terms of the number of residues, germlines and isotypes, they all have overall similar molecular shapes and sizes. Therefore, it is expected that they have similar intrinsic relative viscosity values (intercept, lnA). To further explore the connection between lnA and D0, we determined the D0 values for the antibodies, except mAb4, used in this study via the dynamic light scattering experiments.Citation13 The D0 value for mAb4 was not determined because material was not available. The measured D0 values for all mAbs, except for mAb14, fall in the range 4.0–4.6 × 10−7 cm2/s (). These values are similar to those reported in the literature. For example, Saltzman et al.Citation16 reported the D0 value for a mAb to be 4.4 ± 1.3 × 10−7 cm2/s, while Connolly et al.Citation17 reported a range of 3.9–4.8 × 10−7cm2/s. The average measured D0 values for the mAbs included in this study (excluding mAb14) is 4.4 ± 0.17 × 10−7 cm2/s with a standard deviation to mean ratio = 3.9%. Therefore, the measured D0 values behave similarly to the lnA values.
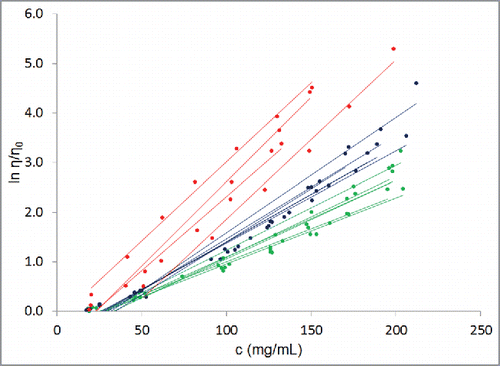
Figure 1. Experimentally determined concentration-dependent viscosity behaviors for the 16 antibodies in our database (). Dots are experimentally obtained data points while lines are least square fits to the data using equation Equation3(3)
(3) . c is the concentration of the antibody in the solution, η is the viscosity of the solution, and η0 is the viscosity of the platform formulation buffer. All the antibody molecules show exponential dependence of viscosity on concentration, as is clear from the R2 values in . As a guide to the eye, well-behaved antibodies are shown in green, poorly-behaved antibodies are shown in red, and rest of the antibodies are shown in blue.
The greater than average A value for mAb14 (A = 0.84 for mAb14) is consistent with a slower diffusion coefficient for this mAb under the dilute conditions. The D0 (diffusion coefficient at the limit concentration → 0) value for this mAb, measured using DLS experiments, is 2.6 × 10−7 cm2/s, which is significantly smaller than those for the other mAbs in this study (). On the other hand, the smaller than average value of the parameter A for mAb15 (A = 0.26) does not correspond to a relatively larger value for D0. The measured D0 value for mAb15 is 4.3×10−7 cm2/s, which is similar to D0 values for the other mAbs (). These observations suggest that the relationship between D0 and the parameter A may not be a simple one. More experimental data are needed to understand this relationship before it can be used for the prediction of parameter A. At present, we have used the average value of A while predicting the antibody viscosity curves (described below).
Parameter B varies significantly
In comparison to ln A, the values for the slope parameter B show larger variations from antibody to antibody ( and ). Parameter B varies by ∼260%, ranging from 0.0133 for mAbs 1 and 2 to 0.0341 for mAb16 in our data set (). The average value for the parameter B is 0.021±0.007 (standard deviation to mean ratio = 33%). The first quartile, median, and third quartile B values are 0.0159, 0.0192, and 0.0233, respectively. The interquartile range between first and third quartile is 0.0074. The variation in parameter B does not shrink when the data on mAbs 14 and 15 is excluded (Average B = 0.0198±0.0059; range = 0.0133–0.0341; standard deviation to mean ratio = 30% for the remaining 14 mAbs). The observation of large variations in values of parameter B is important because the slope governs the rate of increase in logarithm of relative viscosity with antibody concentration. In other words, it determines the curvature of the exponential concentration-dependent viscosity curve. In physical chemistry, the curvature is a measure of solute:solute interactions in a solution.Citation10,17,18 Moreover, Connolly et al. have provided experimental evidence that the curvature is related to diffusion interaction parameter (kD), which is a measure of antibody:antibody interactions in solution.Citation17 Therefore, large variations in the values of slope (parameter B) suggest that antibody self-associations are formed to different extents in different antibody solutions at the same solute (antibody) concentration. Because all the antibodies in this study had the same formulation, the differences in their viscosity behaviors (different B values) must arise from the differences in their molecular sequence and structural attributes.
Taken together, these observations show that it is feasible to estimate entire concentration-dependent viscosity curve for an antibody dissolved in a platform formulation provided that the value of its slope can be derived from sequence-structural attributes of the antibody. In the next section, several different molecular properties of antibodies will be examined for correlations with the parameter B and the prediction of parameter B.
Prediction of the parameter B
Germlines and isotypes do not correlate with viscosity behaviors of mAbs
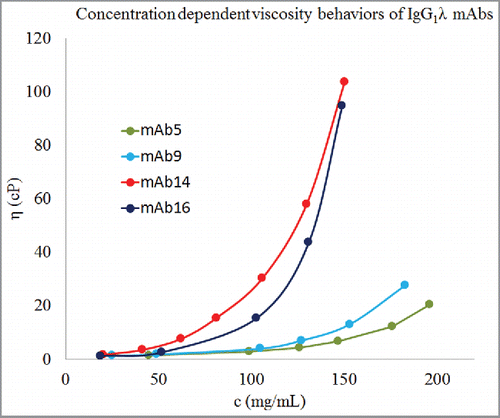
The isotypes, germlines of the variable regions, and experimentally derived values for parameters A and B for the 16 mAbs studied here are shown in . It can be seen that the data set of 16 mAbs contains antibodies of diverse isotypes and germlines. However, there is no correlation between germlines/isotypes and parameter B. For example, 4 mAbs (mAb5, mAb9, mAb14, and mAb16) are of isotype IgG1λ, but their concentration-dependent viscosity behaviors are significantly different from one another. mAb5 and mAb9 show lower viscosity in comparison to mAb14 and mAb16 (see ). Similarly, mAb6 and mAb15 have the same heavy chain germline, IGHV3–23*04, but mAb15 shows considerably poorer concentration-dependent viscosity behavior than mAb6. These observations are consistent with those made by Li et al.,Citation10 and suggest that the viscosity behaviors of antibody molecules are encoded in their amino acid sequences at a finer level than germlines or isotypes.
Figure 2. Concentration-dependent viscosity behaviors of 4 antibodies of IgG1λ isotype. Dots represent experimental data, c is concentration in mg/mL, and η is viscosity in cP. Lines are guide to the eye. These 4 mAbs of the same isotype show different concentration-dependent viscosity behaviors. mAb5 and mAb9 have considerably lower viscosity behaviors than mAb14 and mAb16. Therefore, viscosity behaviors of antibody molecules are encoded in their amino acid sequences at a finer level than isotypes.
No single molecular descriptor is capable of predicting parameter B reliably
Full-length homology-based structural models were built for all 16 antibodies in our data set by following the procedures described in the methods section. These models were used to compute several descriptors, e.g., charge, pI, zeta-potential, dipole moments, hydrophobic surface area, hydrophilic surface area, according to the methods described by Long et al.Citation19 These descriptors represent both electrostatic and hydrophobic properties of the mAbs. Amino acid sequences of the mAbs were also used to compute additional descriptors such as aggregation propensity. The Methods sections presents all the descriptors calculated for each antibody. The square of linear correlation coefficient (R2) values for linear correlation coefficients obtained from regressions between parameter B and various descriptors calculated from homology models and amino acid sequences of the 16 mAbs are shown in . Plots showing the linear relationships between the slope parameter B and the descriptors are also shown in Fig. S1 of the Supporting Information. Student's t-tests were performed to determine if these linear relationships obtained from analyses of the 16 mAbs are statistically significant and will also be present in larger data sets. The descriptors whose correlations with the parameter B show R2 values > 0.18 (r < −0.42 or r > +0.42) are statistically significant at a 95% confidence level, and the descriptors whose correlations with the parameter B show R2 values > 0.38 (r < −0.62 or r > 0.62) are statistically significant at a 99.5% confident level (see materials and methods). No single descriptor shows strong linear correlation with the parameter B that is significant at 99.5% confidence level (). However, aggregation propensity calculated using WALTZ, hydrophobic and van der Waals surface areas, charges on VH and VL regions, total charge on the full-length antibody, ZmAb, sequence- and structure-based pIs, and dipole moment of the full-length antibody with the parameter B show statistically significant linear correlations with the parameter B, at 95% confidence level ().
Table 3. Correlation coefficient (R), square of correlation coefficient (R2) obtained from a linear regression between experimentally derived value of parameter B and each computationally estimated descriptor. The results from t-tests for the significance of the correlations are also shown and significant correlations are highlighted. Footnote*
The correlation between APWaltz and B is particularly interesting, considering that the aggregation process can involve non-native molecular conformations.Citation20 In our experience, aggregation and viscosity, particularly at high concentrations, are related (our unpublished experimental data). In some cases, antibodies that demonstrate high viscosity are also more aggregation prone, but this is not a perfect trend. In highly concentrated antibody solutions, it is conceivable that a certain extent of conformational diversity around the native state of the antibody molecular structure exists.Citation21 These near-native antibody molecules could form weak intermolecular interactions and then networks leading to increased viscosity.Citation15 If the antibody concentration continues to rise, these interactions could trigger aggregation and precipitation of the antibody molecules. However, it is difficult to quantify conformational diversity in antibody molecules at high concentrations in the absence of multi-copy atomistic simulations of antibody solutions. Such simulations are computationally very expensive and out of the scope of this investigation.
In summary, these results show that concentration-dependent viscosity behaviors of antibody solutions depend on several factors and individual descriptors show only weak correlations with parameter B. This is a reasonable observation from the physical perspective because intermolecular interactions, underpinning solution behaviors of antibodies, are defined by several hydrophobic and electrostatic properties of the individual antibodies.Citation6
Multivariate analysis of parameter B
Several independent mathematical models using all or subsets of the descriptors were built and compared for their abilities to predict the parameter B. Different mathematical models were compared for their adjusted R2, RMSE, p-values, as well as performance on leave-one-out (LOO) analysis. The best performing model is discussed below in this section and a subset of the remaining models is listed in Section 5 of the Supporting Information. The final model selected by stepwise linear regression routine in the software MATLABCitation22 as the best performing model for the prediction of parameter B is shown in the Eq. 1.(1)
(1)
where x3, x5, x7, and x13 have the same meaning as in . That is, x3 is the net charge on VH domain (ZVH), x5 is the net charge on the Hinge region (ZHinge), x7 is the net charge on the VL domain (ZVL), and x13 is the solvent accessible hydrophobic surface area of the full-length antibody (ASAhyd). The coefficients of this final model are listed Table S1. The Eq. Equation1(1)
(1) is presented in Wilkinson notation.Citation23 Briefly, x3*x7 means x3 + x7 + x3 × x7 in this notation. All the intermediate steps taken by MATLABCitation22 to reach Eq. Equation1
(1)
(1) are listed in Table S2 of Supporting Information.
Equation Equation1(1)
(1) was found to be the best performing mathematical model for prediction of the parameter B from molecular descriptors because: 1) it shows high value for adjusted R2; 2) it has low root mean square error (RMSE); 3) it has low p-value; and most importantly, 4) it performs very well in LOO cross-validations. An R2 of 0.885 and adjusted R2 of 0.754 were obtained for this model. The F-statistic and p-value for the model in Eq. Equation1
(1)
(1) are 6.75 and 0.0104, respectively. Therefore, the null hypothesis that Eq. Equation1
(1)
(1) is not capable of predicting the parameter B, is rejected at 95% level of confidence (p-value <0.05). The RMSE for the Eq. Equation1
(1)
(1) is 0.00344, which is an order of magnitude lower than experimental values of parameter B. Furthermore, LOO cross-validations were performed by excluding one antibody molecule from the training set at a time to assess the robustness of the model. This exercise was repeated 16 times by leaving out the experimental data on a different mAb each time. During the LOO cross-validations, the adjusted R2 values ranged from 0.676 to 0.891 and the R2 values ranged from 0.861 to 0.953. The RMSEs ranged from 0.00216 to 0.0037, while the p-values of F-tests for significance in linear relationship ranged from 0.00184 to 0.0385. These results show that Eq. Equation1
(1)
(1) represents a statistically significant predictive model between the computationally obtainable descriptors and the slope parameter B. It is pertinent to note here that the total number of different viscosity measurements were 105 () and each value of the parameter B represents the entire concentration-dependent viscosity curve for an antibody.
The mathematical model (Eq. Equation1(1)
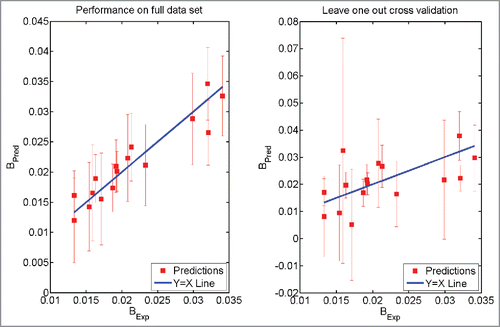
(1) ) derived here was used to make predictions for parameter B. shows a comparison between predicted and experimentally observed values for parameter B. The R2 value for correlation between experimental and predicted values for parameter B is 0.8718 with RMSE 0.002276. The t-value is 9.70 and p-value is 2.0934 × 10−8. shows the comparison between predicted and experimentally observed values for B-parameter by LOO cross-validation analyses. In this case, the R2 value for correlation between experimental and predicted values for parameter B is 0.2864 with RMSE 0.0073. The t-value is 2.3570 and p-value is 0.0157. Both these figures show that the agreements between predictions from the mathematical model derived in this work and the experimental values are statistically significant at 95% confidence (both the p-values < 0.05) level.
Figure 3. Prediction using Eq. Equation1(1)
(1) . The model was trained on the full data set (Left Panel). The model was trained after leaving one antibody molecule out of the data set (Right Panel). The error bars have the same size as 95% confidence intervals. BExp refers to the experimentally obtained values of the parameter B while BPred refers to the prediction made using Eq. 1.
To further test the validity of the mathematical model, predicted concentration-dependent viscosity curves were constructed for all 16 antibodies using average values for the intercept (lnA) and the predicted values for parameter B. These curves were then compared with experimentally obtained viscosity curves in each case. show comparisons between experimental and predicted concentration-dependent viscosity curves for 3 representative mAbs that demonstrate good (low viscosities at high concentrations, mAb3), moderate (moderate viscosities at high concentrations, mAb9) and poor (high viscosities at high concentrations, mAb16) concentration-dependent viscosity behaviors. show that predictions are in reasonable agreement with experimentally observed viscosity behaviors. Moreover, experimentally observed viscosity behaviors are always within the error bars of the predicted viscosity behaviors. We note that for mAb3, the agreement between predicted viscosity behaviors and experimentally observed viscosity behavior is relatively less accurate at concentrations higher than 150 mg/mL. In our training data set experimental measurements on antibody solutions greater than 150 mg/mL are sparse. This is because it is often difficult to perform experiments at such high concentrations particularly when antibody solutions are highly viscous. Therefore, it is expected that predictions become relatively less accurate at concentrations above 150 mg/mL in some cases. The comparisons between predicted and experimentally obtained viscosity curves for the remaining 13 antibodies are shown in the Section 3 of Supplementary Information. These figures show that the mathematical model derived in our study can reasonably predict the concentration-dependent viscosity behaviors of all the 16 antibodies in the data set. Moreover, we note that for the poorly behaved antibody molecules the differences between predictions using the average value of the parameter A and the experimentally obtained values of the parameter A tend to be high (mAb14 and mAb15 in Fig. S2).
Figure 4. Comparison of experimentally observed and predicted concentration-dependent viscosity behaviors of 3 representative antibodies. The parameter B is obtained after training Eq. Equation1(1)
(1) on the complete data set. The parameter A is taken as the average of A values for all the antibodies (i.e., 0.58, as listed in ). An antibody with low viscosity (mAb3), an antibody with moderate viscosity (mAb9), and an antibody with high viscosity (mAb16) are shown in this figure. Dashed lines are predictions made using one standard deviation about the predicted value of B. Similar concentration-dependent viscosity behavior curves can be constructed for any antibody in the database after the parameter B is predicted using Eq. Equation1
(1)
(1) . Further examples for predicted concentration-dependent viscosity behaviors are provided in Section 3 in Supporting Information.
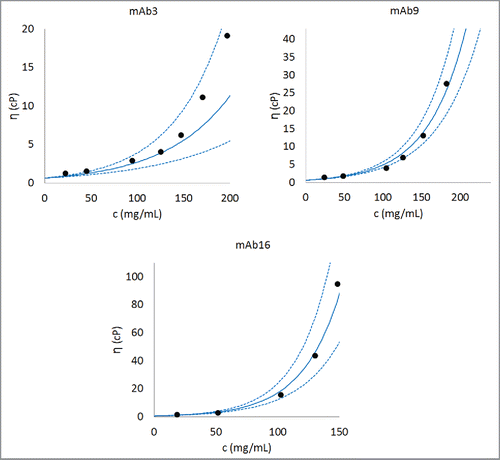
Figure 5. Prediction of concentration-dependent viscosity behavior of an antibody currently under development at Pfizer. The experimental data are shown as black circles and the predictions are shown as curve. The parameter B was predicted using Eq. Equation1(1)
(1) . This predicted value of B and average value of A () was used for creating the concentration-dependent viscosity curves from Eq. Equation2
(2)
(2) . For comparison predictions using the real value of A for TestmAb (0.73) are also shown. Equation Equation1
(1)
(1) is correctly able to predict the concentration-dependent viscosity behavior of TestmAb. Moreover, the agreement between predicted and experimentally observed viscosity behavior improves when the real value of A for TestmAb is used. The dotted red lines are viscosity predictions using the real value of A for TestmAb (0.73) and within one standard deviation about the predicted value of B.
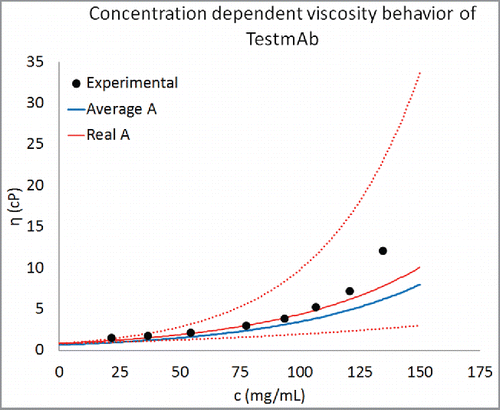
Further test of predictability of Eq. Equation1 (1) (1)
(1) (1)
Equation Equation1(1)
(1) was tested further by predicting concentration-dependent viscosity behavior of an antibody molecule (TestmAb) that was not part of the 16 mAbs used for developing the predictive model described in Eq. Equation1
(1)
(1) (i.e., TestmAb is not listed in ). TestmAb is an IgG1κ Pfizer proprietary antibody currently in drug product development. The heavy chain of TestmAb is 86% to 95% similar to the IgG1 heavy chains and the light chain is 77% to 92% similar to the kappa light chains in our training data set of 16 mAbs. Its concentration-dependent viscosity behavior was measured in platform formulation and the values of the parameters A and B were calculated using Eq. Equation1
(1)
(1) . The calculated values of parameters A and B for this antibody are 0.73 and 0.0179, respectively. A homology model for this antibody was built following the same procedure as for the 16 mAbs in the training data set (described in Methods section). Descriptors listed in were calculated from this homology model and Eq. Equation1
(1)
(1) was used to predict the parameter B. The predicted value of B was 0.0166 with 1 standard deviation error bar of 0.008. Equation Equation1
(1)
(1) was used to construct the concentration-dependent viscosity behavior of TestmAb from the predicted B and average value of A (i.e., 0.58, as listed in .) and real value of A (0.73). The result of this analysis is presented in . It is clear from that Eq. Equation1
(1)
(1) is capable of predicting the concentration-dependent viscosity behavior of TestmAb. However, the predictability improved significantly when the real value of A (0.73) was used. Even using the real A, the experimental and predicted viscosity values still show differences at concentrations above 100 mg/mL. However, these differences fall within the error limits (dotted red lines in ), obtained from uncertainties in the B-value estimates. In summary, the ability of Eq. Equation1
(1)
(1) to correctly predict the concentration-dependent viscosity behavior of an antibody molecule that was not in the training data set provides greater support for the validity of the scheme developed here. Further testing of this predictive method is currently underway in our laboratory.
Physical insights gained from the mathematical model for prediction of parameter B
The mathematical model described above is phenomenological in nature. However, it does lead to improved understanding of the molecular origins of protein:protein interactions that underpin concentration-dependent viscosity behaviors of antibody solutions. Most importantly, no descriptor alone can fully explain concentration-dependent viscosity behavior of antibody molecules, and therefore models that utilize a broader set of physical descriptors may achieve greater success in explaining molecular origins of concentration-dependent viscosity behaviors of antibody molecules. The profile-based scheme is one such method that seeks to qualitatively explain concentration-dependent viscosity behavior by striking a balance between electrostatic interactions and hydrophobic interactions. Moreover, quantitative methods developed by Li et al.Citation10 and Sharma et al.Citation11 used this balance while predicting the viscosity of antibody solutions at higher concentrations by using electrostatic and hydrophobic interactions originating from the Fv portions of the antibody molecules.
Consistent with earlier studies that relied on molecular models of the Fv regions,Citation10,11 the model presented in Eq. Equation1(1)
(1) also suggests that net values of the charge on the VH and VL domains in the Fv regions play important roles in determining concentration-dependent viscosity behaviors of the antibody solution. In addition to the charge on Fv region, a role for hydrophobicity in viscosity behaviors of antibodies is also suggested by inclusion of hydrophobic surface area of the full-length antibody in the model (see Eq. Equation1
(1)
(1) ). This new finding justifies use of full-length antibody structural models in this work because large solvent-exposed hydrophobic patches (> 100 Å2) were found on both the variable and the constant regions of antibody molecules in our database. Our earlier reportCitation10 did discuss a role for hydrophobicity, but hydrophobic surface area was not explicitly included in the previous model. While both hydrophobicity and electrostatics contribute to intermolecular interactions, and therefore viscosity behaviors of antibody solutions, none of the currently available experimental methods is capable of separating their individual percent contributions. It may be feasible to estimate these percentages and identify the nature of dominant interactions via multi-copy antibody atomistic simulations. However, such simulations are extremely computationally expensive and out of the scope of this investigation.
Moreover, the effect of the heavy chain isotype of an antibody molecule on its viscosity behavior was also incorporated in this model through the charge on the hinge region. The isotypes IgG1, IgG2, and IgG4 have different amino acid sequences and disulfide bond patterns in their hinge regions as is shown in .Citation24
Figure 6. Hinge region sequence alignment of human IgG1, IgG2, and IgG4 antibodies. Note that number of charged residues in the hinge regions of different isotypes is different.

Discussion
Antibody-based therapeutics are an important segment of the drug development pipelines of biopharmaceutical companies. To increase patient compliance, adherence, and ease of administration, subcutaneous administration of highly concentrated (typically above 100 mg/mL) antibody solutions is preferred.Citation6 However, the undesirably high viscosity (viscosity greater than 20 cP) demonstrated by certain antibody solutions can lead to challenges in manufacturing and administration, and thereby delay the progression of a drug candidate through development.Citation6 Methods to forecast concentration-dependent viscosity behavior of antibody solutions are required for proactive elimination or optimization of antibody-based drug candidates that are likely to show undesirably high viscosities at high concentrations. Here, we developed a computational scheme to predict concentration-dependent viscosity behavior of mAb solutions solely from their molecular sequence and structural attributes. It correlates experimentally observed viscosity behaviors of mAbs with computationally estimated molecular descriptors from their homology-based structural models. This scheme can be used early in the discovery and formulation development stages where material available for experimental testing is scarce. The computational approaches such as the one we developed do not need any material and can be used to prioritize antibody candidates based on their predicted concentration-dependent viscosity behaviors, even before any material becomes available to perform experiments.
In our previous work,Citation10 we developed a scheme to predict viscosity of antibody solutions at a given concentration using the properties of the Fv region. We found that the computationally estimated charge on the Fv region of an antibody can be used to predict viscosity of antibody solutions at 150 mg/mL. In addition to this, we also rationalized the differences in viscosity behaviors of antibody molecules by developing a qualitative profile-based screening method. Here, we made 2 significant improvements over our previous work. First, we are now able to predict the viscosity behaviors of antibody solutions at all concentrations. Second, the calculations of the macromolecular descriptors now utilize the homology models of full-length antibodies. To our knowledge, this study is the first reported attempt to quantitatively predict the entire concentration-dependent viscosity curves for mAbs. The utility of full-length antibody models in viscosity prediction is reflected in the finding that total hydrophobic surface area is an important component of the model. This implies that hydrophobic effects are important aspects of protein:protein interactions that contribute toward viscosity behaviors of the mAbs. This model also explicitly takes into account the charge on the hinge region of the antibodies to account for presence of antibodies with different isotypes in our data set. These insights could not have been gained from use of molecular models for just the Fv portions.Citation10,11
Although the current model is significantly improved, the scheme presented here has the following 5 limitations, and therefore, scope for further improvements. First, a bigger and more diversified training data set is needed to increase the robustness of the scheme. Only 16 antibody molecules, most of them well behaved, were used in this analysis. While this is an improvement over the 11 mAbs used in our previous effort, the number of antibodies whose concentration-dependent viscosity curves have been determined under standardized experimental conditions and procedures remains small. Second, in this work, we relied on physically intuitive correlations between computationally estimated molecular descriptors and experimentally observed viscosity behaviors of antibody solutions. We realize that many other more sophisticated statistical and machine learning methods, such as support vector machine, principal component regression, random forest regression, least absolute shrinkage and selection operator (LASSO) regression, partial least squares regression, could have been also used in this work and mathematical models derived from these methods could have been compared with one another. However, this is out of scope for the current work. Third, homology-based molecular models of full-length antibodies were constructed and used to obtain values for various descriptors of the molecular properties used in this work. However, mAbs are inherently dynamic macromolecules. Therefore, use of average values for these descriptors derived from conformational ensembles of the mAbs may have improved the performance of this scheme. The conformational ensembles for protein molecules can be obtained via MD simulations, but such simulations of full-length antibody molecules are computationally time consuming and resource intensive at present. For example, in our ongoing unpublished work, atomistic representation of a full-length antibody molecule in explicit solvent led to approximately 900,000 atoms in the simulation box and the simulation required approximately 2 days to complete one nanosecond run, using a 2 femtosecond time-step on a 12 CPU machine supported with 2 K5000 NVIDIA graphics processing units (GPUs). Wang and coworkersCitation25 also reported that 1.5 computer days were needed to complete one nanosecond of MD simulations on a murine antibody on a 32 CPU cluster. At this time, we found use of energy minimized homology structures as a reasonable first step toward the prediction of concentration-dependent viscosity behaviors of the mAb solutions. The fourth limitation is that the mathematical model obtained for viscosity prediction in one platform formulation condition is not transferrable across different formulations. Analogous schemes for each different formulation need to be derived so that they can accurately account for inclusion/exclusion of various formulation components, along with the change in buffers and pH. A step-by-step guide to develop a viscosity prediction algorithm for a different formulation is provided in . The fifth limitation is that our analysis is based on correlations observed among molecular descriptors and viscosity of antibody solutions. While the correlations are physically meaningful, they do not imply causal relationships. Therefore, we caution that phenomenological models alone may be insufficient to conclusively prove or disprove potential hypotheses regarding the molecular origins of high viscosity in concentrated antibody solutions. Moreover, viscosity, solubility, and aggregation are interrelated phenomena because they all arise from protein:protein interactions. Molecular descriptors calculated here may correlate with more than one of these phenomena.
Table 4. Steps followed in this scheme to develop viscosity prediction algorithm. Analogous schemes can be used to develop predict viscosity behaviors of antibodies for different formulations (different buffers, excipients and pH).
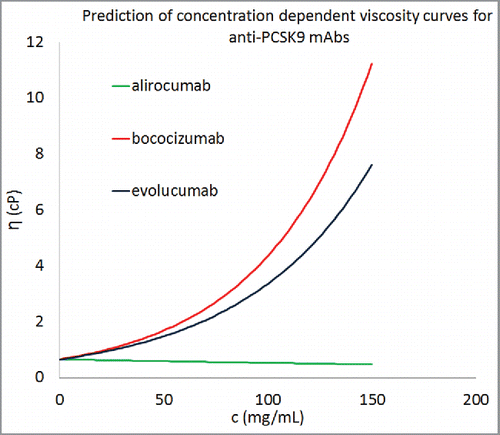
In spite of these limitations, this work presents a consistent scheme and promises improvements as greater experimental data becomes available. Here, our quest for developing highly accurate viscosity prediction algorithms was tempered by the practical immediate need for such predictive tools. However, we have explored how this scheme might be used to provide an additional input during the developability assessment of antibody molecules. As an example, 3 antibodies that target proprotein convertase subtilisin/kexin type 9 (alirocumab (Sanofi-Aventis and Regeneron Pharmaceuticals, Praluent), bococizumab (Pfizer, PF-04950615), and evolucumab (Amgen, Repatha)), were chosen for a hypothetical developability assessment for viscosity behaviors. Molecular descriptors of these antibodies were calculated using the same procedure as described in the previous sections. The predicted viscosity curves for the 3 antibodies, if they were formulated in the same way as the 16 mAbs in our data set, are shown in . All 3 antibodies are predicted to demonstrate low viscosities at 150 mg/mL, but the trends suggest that concentrating 2 of them further (> 200 mg/mL) leads to unacceptably high viscosities. It must be emphasized that these viscosity curves are hypothetical and actual viscosities for these antibody products at high concentrations may vary significantly since their formulations are different. Notwithstanding this, describes how Eq. Equation1(1)
(1) can be used to forecast and compare concentration-dependent viscosity behaviors of multiple antibody candidates, against a given target antigen, under standardized formulation conditions. This information, if available at the early stages of biologic drug development, can be used as an additional input to the lead candidate selection/optimization process. Such an input becomes invaluable if the target product profile involves high concentration drug product development. Therefore, the scheme developed here can provide a time- and cost-effective screening technique for formulation development of antibody-based therapeutics.
Figure 7. Concentration-dependent viscosity curves for 3 commercially developed antibody molecules using the descriptors from homology models. Equation Equation1(1)
(1) was used to predict the parameter B for these antibody molecules and average values of A was taken from . All 3 antibody molecules were predicted to show viscosity less than 20 cP at concentrations greater than 150 mg/mL.
Materials and methods
Five of 16 drug product development-stage Pfizer proprietary antibodies used in this study are IgG1κs, 4 are IgG1λs, 4 are IgG2κs, and 3 are IgG4κs.
Experimental methods
Experimental data on concentration-dependent viscosity curves for 16 Pfizer proprietary antibodies under platform formulation was collected by following the procedures described earlier.Citation10 Experimental data on concentration-dependent diffusion behaviors of antibody molecules under platform formulation were collected using dynamic light scattering in a manner described by Nichols et al.Citation13
Mathematical modeling
Concentration-dependent viscosity behavior
The following equation was used for mathematical modeling of concentration-dependent viscosity behavior of antibody molecules:Citation10(2)
(2)
This equation can be linearized as follows:(3)
(3)
Where η is the viscosity of an antibody solution with concentration c; is the viscosity of the platform buffer; ln A and B are intercept and slope of the linear regression.
The experimental data (presented in ) was used to obtain the values of A and B for each antibody.
Concentration-dependent diffusion behavior
The experimentally observed concentration-dependent diffusion behaviors were fit to the following equation proposed by Harding et. al.Citation26 to calculate D0:(4)
(4)
Where kD is the diffusion interaction parameter, c is the concentration of the antibody molecules, Dc is the diffusion coefficient of antibody molecules at concentration c, and D0 is the diffusion coefficient of the antibody molecules in the limit of zero concentration. This equation assumes a linear relationship between diffusion coefficient and concentration, and is usually valid for antibody solutions with antibody concentration lower than 10 mg/mL. All antibodies in our data set exhibited linear relationship between Dc and c. The linear relationship improved considerably after one outlier Dc was removed from the linear fits for mAb6, mAb9, mAb10. The D0 values thus calculated are listed in .
Computational methods
Homology modeling
The software Molecular Operating Environment (MOE)Citation27 from Chemical Computing Group (Montreal, Canada) was used for constructing homology-based models of full-length antibody structures and for computing molecular properties from these structural models.Citation27 Amber10:EHT force field as implemented in MOECitation27 was used. Protein internal and external dielectrics were set to 4 and 80, respectively. Homology-based structural models for Fabs were built first. These models were then used to build chimeric templates for full-length antibody structural models. Antibody modeler in MOECitation27 was used for building homology models of the Fabs, while protein modeler in MOECitation27 was used for building the full-length antibody models.
Homology modeling of fabs
Homology-based structural models for Fab regions were built using MOE antibody modeler by searching for appropriate templates frameworks in the antibody database. The templates for CDR loops were manually assigned. The maximum number of main chain models was set to 25 and the number of side chain models per main chain was also set to 25. Up to 625 intermediate models were built for each Fab. GB/VI solvation was used for ranking the intermediate models for each Fab. The model with the best GB/VI score was chosen for each Fab. In the next step, the Fab models with the best GB/VI scores were energy minimized.
Homology modeling for full-length models for the antibodies
As stated earlier, the isotypes, IgG1, IgG2, and IgG4 are represented in the data set of 16 mAbs studied here. Therefore, the following crystal structures for full-length antibodies available in the Protein Data Bank (http://www.rcsb.org/pdb/home/home.do) were used for constructing chimeric templates for homology-based models for full-length antibodies: 1HZHCitation28 for IgG1 mAbs, 1IGTCitation29 for IgG2 mAbs and 5DK330 for IgG4 antibodies. Note that 1IGT is the crystal structure for a murine IgG2a antibody. To our knowledge, no crystal structures for a human or humanized IgG2 mAb are publicly available.
The procedure to build chimeric templates published by Guo et al.Citation31 was followed with some modifications. In each case, the chimeric templates were constructed by superposing the previously built Fab models on both the Fabs present in the crystal structures of the full-length antibodies. The sequence identities between target antibodies and chimeric templates were as follows: > 98% for IgG1 heavy chains, > 99% for IgG1 light chains, > 77% for IgG2 heavy chains, > 99% for IgG2 light chains, > 99% for IgG4 heavy chains and 100% for IgG4 light chains. For each target full-length antibody, the query coverage of the chimeric template was almost 100%. The sequence identity for IgG2 heavy chains was lower because IGT is a murine IgG2a antibody. It has a different disulfide bonding pattern than a human IgG2 antibody because murine IgG2a antibodies have 3 disulfide bonds in their hinge regions, while human IgG2 antibodies have 4 disulfide bonds (for further details, see Fig. S2 in Wang et al.Citation32 and Fig. S6 in Supporting Information.) Moreover, for IgG2 molecules, the disulfide bond between Cys128 of the heavy chain (the first Cys of the CH1 domain) and the Cys214 of the light chain (the last Cys of the light chain) in 1IGT was preserved while building the chimeric template by grafting the residues near Cys128 in the heavy chain of 1IGT onto the Fab of the chimeric molecule. Each chimeric template was then used to build the full-length antibody structure in MOE.Citation27 The number of main chain models was set to 100 and number of sidechain models was set to 10. Therefore, 1000 intermediate models were made for each molecule and ranked according to their GB/VI implicit solvation energies in MOE.Citation27 The model with the best GB/VI implicit solvation energy was selected as the final model. The final model for each mAb was further optimized via energy minimizations to an RMSG below 0.00001 kcal mol−1 Å−2. An extra step was taken in the case of IgG2 molecules before energy minimization. As noted above, 1IGT has a different disulfide bond structure than a human antibody. Because of this, homology modeling for IgG2 molecules resulted in unpaired cysteines in the hinge region. These cysteines were paired by building disulfide bonds manually before energy minimizing the structure.
Computation of molecular descriptors
The structural model for each mAb was protonated to pH 5.8 and salt concentration of 10 mM, and was again energy minimized to an RMSG below 0.00001 kcal mol−1 Å−2. These models were used to compute several molecular descriptors, such as charge, pI, ξ-potential, dipole moment, solvent exposed polar and nonpolar surface areas for each mAb. The protein properties were calculated using MOE Protein Properties module at pH 5.8 and 10 mM salt concentrations (refer to MOE help pages and Long et. al.Citation19 for further description of the computed protein properties). The formulation buffer used in the experiments contained no salt. However, a low ionic strength was used in the calculations to take into account any residual ions that may have been carried over from the purification trains. In addition to the protein properties computed using MOE protein properties module, the charges on residues were summed up to obtain charges on different regions of the mAbs, namely, VH, VL, CL, CH1, Hinge, and Fc. These charges were calculated within the context of the full-length models and are therefore different in magnitudes from the values of charges calculated based on the models of the individual regions outside the context of the mAb structure. The definitions for different antibody regions were taken from a review by Padlan.Citation33 These regions were automatically identified for all antibodies using an in-house script written in Python (https://www.python.org/). In addition to the above described structure-based properties, aggregation propensities for each antibody heavy and light chain in our data set were calculated using WALTZCitation34 at a pH of 5.8 and 10 mM salt concentration. APWaltz, aggregation propensity of an antibody based on WALTZ scores, was calculated in a manner similar to Eq. Equation4(4)
(4) in Li et al.,Citation10 i.e., by adding the aggregation propensities of heavy and light chains of the antibody and then by dividing it with the number of residues in the antibody. APTango was calculated following the same procedure after obtaining aggregation propensities using the software TANGO.Citation35
Identification of germlines and isotypes
The germlines of both the chains of the antibody molecules in this database were identified using IgBLAST,Citation36 which is based on the IMGT® classification system (http://www.imgt.org). The heavy chain and light chain isotypes were identified manually according to the definitions given in the review by Padlan.Citation33
t-test for significance in correlation
t-tests were performed to determine if the correlations (R2) between the parameter B and the computationally estimated descriptors are statistically significant. A significant correlation is more likely to hold for larger data sets. These tests were performed in the manner described in Kumar et al.Citation37 Briefly, t values were calculated first as follows:(5)
(5)
Where n is the total number of antibodies in the data set, i.e., 16. From these t values, the values of cumulative distribution function of the Student's t distribution for 16 (n = 16) degrees of freedom were calculated using the function tcdf() in the software MATLAB.Citation22 These calculated values of cumulative distribution function were subtracted from 1 to calculate the p value. A p value of 0.05 is significant at 95% confidence level. The |R| and t value of 0.423 and 1.7467, respectively, correspond to a p value = 0.05 when n = 16. Therefore, |R| ≥ 0.423 is statistically significant at a 95% confidence level.
F-test for linear regression
F-tests were performed to evaluate goodness of the linear fit. These tests were automatically performed in the software MATLAB.Citation22 A significant p value means that the linear relationship is significant and the goodness of fit is high. In the F-test, F-statistic is calculated as follows:Citation38(6)
(6)
Where, RSSNull, RSSAlt, dNull, and dAlt are residual sum of squares of the null model, residual sum of squares of the alternative model, degree of freedom of the null model, and degree of freedom of the alternative model, respectively. The null model is a model that has no descriptors in it, i.e., the null model is a constant term. The alternative model is the model that is being tested. If the F-statistics is high and the corresponding p-value is low, then the hypothesis that the null model is better than the alternative model is rejected. Further details about the implementation of F-test in the software MATLAB,Citation22 can be found in a tutorial on the software's website (http://www.mathworks.com/help/stats/f-statistic-and-t-statistic.html?requestedDomain=www.mathworks.com).
Prediction of B from computationally estimated molecular descriptors
Stepwise linear regression was performed to identify an equation that uses the smallest number of computationally estimated descriptors to reliably predict the parameter B. These analyses were performed in the software MATLAB.Citation22 Adjusted R2 was used as a criterion to add or remove a term from the model to avoid over-fitting the data because adjusted R2 penalizes a model for adding a new term, and it only increases when the goodness of fit is statistically significant.Citation39 The starting model was a constant term. Descriptors were added or removed by using the default settings for adjusted R2 in the software MATLAB.Citation22
Disclosure of potential conflicts of interest
DST, LL, MPB, NGL, CTB, and SK are employees of Pfizer Inc. SKS is an employee of Lonza AG. The authors declare no potential conflict of interest.
Supplemental_Figure_1___Tables_1-2.docx
Download MS Word (1 MB)Acknowledgments
The authors thank numerous Pfizer colleagues for their inputs at various stages of this work. Dr. Brajesh Rai is thanked for his advice and discussions on data analysis. DST thanks Pfizer Postdoctoral program for financial support.
References
- Reichert JM. Which are the antibodies to watch in 2013? mAbs 2013; 5:1-4; PMID:23254906; http://dx.doi.org/10.4161/mabs.22976
- Reichert JM. Antibodies to watch in 2016. mAbs 2016; 8:197-204; PMID:26651519; http://dx.doi.org/10.1080/19420862.2015.1125583
- Ecker DM, Jones SD, Levine HL. The therapeutic monoclonal antibody market. MAbs 2015; 7:9-14; PMID:25529996; http://dx.doi.org/10.4161/19420862.2015.989042
- Brady JL, Harrison LC, Goodman DJ, Cowan PJ, Hawthorne WJ, O'Connell PJ, Sutherland RM, Lew AM. Preclinical screening for acute toxicity of therapeutic monoclonal antibodies in a hu-SCID model. Clin Trans Immunol 2014; 3:e29; PMID:25587392; http://dx.doi.org/10.1038/cti.2014.28
- Brennan FR, Morton LD, Spindeldreher S, Kiessling A, Allenspach R, Hey A, Muller PY, Frings W, Sims J. Safety and immunotoxicity assessment of immunomodulatory monoclonal antibodies. MAbs 2010; 2:233-55; PMID:20421713; http://dx.doi.org/10.4161/mabs.2.3.11782
- Tomar DS, Kumar S, Singh SK, Goswami S, Li L. Molecular basis of high viscosity in concentrated antibody solutions: Strategies for high concentration drug product development. mAbs 2016; 8:216-28; PMID:26736022; http://dx.doi.org/10.1080/19420862.2015.1128606
- Druin ML, Kreps SI. Prediction of viscosity of liquid hydrocarbons. Ind Eng Chem Fund 1970; 9:79-83; http://dx.doi.org/10.1021/i160033a012
- Katritzky AR, Chen K, Wang Y, Karelson M, Lucic B, Trinajstic N, Suzuki T, Schüürmann G. Prediction of liquid viscosity for organic compounds by a quantitative structure–property relationship. J Phys Org Chem 2000; 13:80-6; ; http://dx.doi.org/10.1002/(SICI)1099-1395(200001)13:1<80::AID-POC179>3.0.CO;2-8
- Ivanciuc O, Ivanciuc T, Filip PA, Cabrol-Bass D. Estimation of the liquid viscosity of organic compounds with a quantitative structure−property model. J Chem Inform Comput Sci 1999; 39:515-24; ; http://dx.doi.org/10.1021/ci980117v
- Li L, Kumar S, Buck PM, Burns C, Lavoie J, Singh SK, Warne NW, Nichols P, Luksha N, Boardman D. Concentration dependent viscosity of monoclonal antibody solutions: explaining experimental behavior in terms of molecular properties. Pharm Res 2014; 31:3161-78; PMID:24906598; http://dx.doi.org/10.1007/s11095-014-1409-0
- Sharma VK, Patapoff TW, Kabakoff B, Pai S, Hilario E, Zhang B, Li C, Borisov O, Kelley RF, Chorny I, et al. In silico selection of therapeutic antibodies for development: viscosity, clearance, and chemical stability. Proc Natl Acad Sci U S A 2014; 111:18601-6; PMID:25512516; http://dx.doi.org/10.1073/pnas.1421779112
- Agrawal NJ, Helk B, Kumar S, Mody N, Sathish HA, Samra HS, Buck PM, Li L, Trout BL. Computational tool for the early screening of monoclonal antibodies for their viscosities. mAbs 2016; 8:43-8; PMID:26399600; http://dx.doi.org/10.1080/19420862.2015.1099773
- Nichols P, Li L, Kumar S, Buck PM, Singh SK, Goswami S, Balthazor B, Conley TR, Sek D, Allen MJ. Rational design of viscosity reducing mutants of a monoclonal antibody: hydrophobic versus electrostatic inter-molecular interactions. MAbs 2015; 7:212-30; PMID:25559441; http://dx.doi.org/10.4161/19420862.2014.985504
- Geoghegan JC, Fleming R, Damschroder M, Bishop SM, Sathish HA, Esfandiary R. Mitigation of reversible self-association and viscosity in a human IgG1 monoclonal antibody by rational, structure-guided Fv engineering. mAbs 2016; 8:941-50; PMID:27050875; http://dx.doi.org/10.1080/19420862.2016.1171444
- Buck PM, Chaudhri A, Kumar S, Singh SK. Highly viscous antibody solutions are a consequence of network formation caused by domain-domain electrostatic complementarities: insights from coarse-grained simulations. Mol Pharm 2015; 12:127-39; PMID:25383990; http://dx.doi.org/10.1021/mp500485w
- Saltzman WM, Radomsky ML, Whaley KJ, Cone RA. Antibody diffusion in human cervical mucus. Biophys J 1994; 66:508-15; PMID:8161703; http://dx.doi.org/10.1016/S0006-3495(94)80802-1
- Connolly BD, Petry C, Yadav S, Demeule B, Ciaccio N, Moore JM, Shire SJ, Gokarn YR. Weak interactions govern the viscosity of concentrated antibody solutions: high-throughput analysis using the diffusion interaction parameter. Biophys J 2012; 103:69-78; PMID:22828333; http://dx.doi.org/10.1016/j.bpj.2012.04.047
- Creighton TE. The physical and chemical basis of molecular biology. Helvetian Press 2010.
- Long WF, Labute P. Calibrative approaches to protein solubility modeling of a mutant series using physicochemical descriptors. J Comput-Aided Mol Des 2010; 24:907-16; PMID:20842408; http://dx.doi.org/10.1007/s10822-010-9383-z
- Roberts CJ. Protein aggregation and its impact on product quality. Curr Opin Biotechnol 2014; 30:211-7; PMID:25173826; http://dx.doi.org/10.1016/j.copbio.2014.08.001
- Sarangapani Prasad S, Hudson Steven D, Jones Ronald L, Douglas Jack F, Pathak Jai A. Critical examination of the colloidal particle model of globular proteins. Biophys J 2015; 108:724-37; PMID:25650939; http://dx.doi.org/10.1016/j.bpj.2014.11.3483
- The MathWorks, Inc., Natick, Massachusetts, United States. MATLAB 2013a.
- Wilkinson GN, Rogers CE. Symbolic description of factorial models for analysis of variance. J Roy Stat Soc C (Applied Statistics) 1973; 22:392-9; http://dx.doi.org/10.2307/2346786
- Liu H, May K. Disulfide bond structures of IgG molecules. mAbs 2012; 4:17-23; PMID:22327427; http://dx.doi.org/10.4161/mabs.4.1.18347
- Wang X, Kumar S, Buck PM, Singh SK. Impact of de-glycosylation and thermal stress on conformational stability of a full length murine IgG2a monoclonal antibody: Observations from molecular dynamics simulations. Proteins: Structure, Function, and Bioinformatics 2013; 81:443-60; PMID:23065923; http://dx.doi.org/10.1002/prot.24202
- Harding SE, Johnson P. The concentration-dependence of macromolecular parameters. Biochem J 1985; 231:543-7; PMID:4074322; http://dx.doi.org/10.1042/bj2310543.
- Chemical Computing Group Inc. SSW, Suite #910, Montreal, QC, Canada, H3A 2R7. Mol Operating Environ 2014. 09. 2016
- Saphire EO, Parren PW, Pantophlet R, Zwick MB, Morris GM, Rudd PM, Dwek RA, Stanfield RL, Burton DR, Wilson IA. Crystal structure of a neutralizing human IGG against HIV-1: a template for vaccine design. Science 2001; 293:1155-9; PMID:11498595; http://dx.doi.org/10.1126/science.1061692
- Harris LJ, Larson SB, Hasel KW, McPherson A. Refined Structure of an Intact IgG2a Monoclonal Antibody. Biochemistry 1997; 36:1581-97; PMID:9048542; http://dx.doi.org/10.1021/bi962514+
- Scapin G, Yang X, Prosise WW, McCoy M, Reichert P, Johnston JM, Kashi RS, Strickland C. Structure of full-length human anti-PD1 therapeutic IgG4 antibody pembrolizumab. Nat Struct Mol Biol 2015; 22:953-8; PMID:26595420; http://dx.doi.org/10.1038/nsmb.3129
- Guo J, Kumar S, Prashad A, Starkey J, Singh SK. Assessment of physical stability of an antibody drug conjugate by higher order structure analysis: Impact of thiol- maleimide chemistry. Pharm Res 2014; 31:1710-23; PMID:24464270; http://dx.doi.org/10.1007/s11095-013-1274-2
- Wang X, Kumar S, Singh SK. Disulfide scrambling in IgG2 monoclonal antibodies: Insights from molecular dynamics simulations. Pharm Res 2011; 28:3128-44; PMID:21671135; http://dx.doi.org/10.1007/s11095-011-0503-9
- Padlan EA. Anatomy of the antibody molecule. Mol Immunol 1994; 31:169-217; PMID:8114766; http://dx.doi.org/10.1016/0161-5890(94)90001-9
- Maurer-Stroh S, Debulpaep M, Kuemmerer N, de la Paz ML, Martins IC, Reumers J, Morris KL, Copland A, Serpell L, Serrano L, et al. Exploring the sequence determinants of amyloid structure using position-specific scoring matrices. Nat Meth 2010; 7:237-42; PMID:20154676; http://dx.doi.org/10.1038/nmeth.1432
- Fernandez-Escamilla AM, Rousseau F, Schymkowitz J, Serrano L. Prediction of sequence-dependent and mutational effects on the aggregation of peptides and proteins. Nat Biotechnol 2004; 22:1302-6; PMID:15361882; http://dx.doi.org/10.1038/nbt1012
- Ye J, Ma N, Madden TL, Ostell JM. IgBLAST: an immunoglobulin variable domain sequence analysis tool. Nucleic Acids Res 2013; 41:W34-W40; PMID:23671333; http://dx.doi.org/10.1093/nar/gkt382
- Kumar S, Tsai CJ, Nussinov R. Temperature Range of Thermodynamic Stability for the Native State of Reversible Two-State Proteins. Biochemistry 2003; 42:4864-73; PMID:12718527; http://dx.doi.org/10.1021/bi027184+
- Weisberg S. Weights, Lack of Fit, and More. Applied Linear Regression: John Wiley & Sons, Inc., 2005:96-114; http://dx.doi.org/10.1002/0471704091
- Chatterjee S, Hadi AS. Variable Selection Procedures. Regression Analysis by Example: John Wiley & Sons, Inc., 2006:281-315.