
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The European and United States Pharmacopoeia demand a noninferiority study on the detection of microorganisms when an alternate qualitative microbiological method is intended to replace the compendial microbiological method. However, without imposing any modeling assumptions or constraints, noninferiority studies require large numbers of test samples for a proposed noninferiority criterion of 0.7 or higher for each microorganism. When we can assume that the accuracy of the alternate method with respect to the compendial method is homogeneous across microorganisms, a joint statistical analysis of the data from all microorganisms can be used to help reduce the sample size dramatically. For this situation, we provide a test statistic for noninferiority, an optimal spiking experiment, and a sample size calculation approach under only mild modeling assumptions of the microorganism-specific detection proportions. We illustrate our approach on a real dataset and demonstrate good performance of our method using simulation studies.
1 Introduction
According to international guidelines USP < 1223 > and EP 5.1.6, validation of a qualitative rapid microbiological method (RMM) requires an illustration of noninferiority compared to the compendial method (CM) on two validation parameters: specificity and limit of detection. The European (EP) and United States Pharmacopoeia (USP) define specificity as the ability to detect the required range of microorganisms that may be presented in the test sample. They emphasize that extraneous matter in the test system (e.g., growth medium) should not interfere with the test. Thus, specificity is strongly related to false positives. The limit of detection (LOD) is defined in the EP and USP as the lowest number of microorganisms in a test sample that can be detected under the stated experimental conditions with at least 95% confidence. In other areas of science, the LOD is associated with the sensitivity of the test method (e.g., for chemical analyses). The EP also indicates that accuracy can replace the LOD under certain circumstances and they define accuracy as the closeness of test results between the alternative and compendial method.
These three validation parameters are all related to the probability of detecting microorganisms, but they do not provide direct information on the probability of detecting exactly one microorganism. This detection proportion (IJzerman-Boon and Van denHeuvel 2015) will naturally depend on the type of microorganism, the microbiological method, and possibly other types of factors. If this detection proportion is the main parameter that is affecting positive and negative test result, we could just study this one parameter in the validation study. In this setting, we could define accuracy as the ratio of the two detection proportions between the RMM and the CM for each microorganism and ignore the LOD and specificity. The RMM is then considered noninferior with respect to the CM if this accuracy parameter exceeds some predefined amount (say 70%), the so-called noninferiority margin, for each microorganism.
Estimation of this accuracy parameter is not trivial without making modeling assumptions on the probability of detecting microorganisms, since we can not spike test samples with exactly one microorganism. Using a Binomial form for the detection probability, IJzerman-Boon and Van denHeuvel (2015) used maximum likelihood estimation and constructed an approximate 95% confidence interval with good coverage, opening the way for noninferiority studies on this accuracy parameter. However, when only one type of microorganism is being tested, the authors demonstrated that they need approximately 200 test samples per microbiological method to reject the null hypothesis of 100% accuracy in favor of 70% accuracy ( and
). Clearly, designing an experiment with 200 test samples per microbiological method is probably doable when a very small set of microorganisms is being tested in a validation study, but it is not feasible for a large set of microorganisms.
Alternatively, it may be assumed that the accuracy across microorganisms is homogeneous or consistent, while allowing for unique detection proportions for the different microorganisms. When the RMM uses similar principles of detecting microorganisms, this assumption seems warranted. For instance, certain RMM’s use a combination of the detection principle of the compendial method with modern technology (e.g., cameras and specialized software) to detect growth of microorganisms that can not yet be seen with the naked eye), making the method faster in detecting organisms than the compendial method that does not use this modern technology. Under this assumption we may pool all the data from all microorganisms to determine noninferiority of the RMM with respect to the CM across a large set of microorganisms and potentially reduce the total sample size dramatically. This article will study the optimal design for such a noninferiority study and provide a minimum sample size calculation formula that would guarantee noninferiority with a particular power and a specific Type I error rate. Simulation studies will demonstrate the performance of our approach.
Section 2 contains the statistical details on the probability detection model, the formulation of accuracy and noninferiority, our optimal design, and the sample size calculation. In Section 3, we present a simulation study where we studied the performance of our theory for different sets or distributions of detection proportions. Section 4 demonstrates a real case study where we implemented our theory in practice. Then, the final section contains a summary and a discussion.
2 Statistical Methodology
Let be a binary random variable representing the absence and presence of microorganisms in test sample
obtained with microbiological method
(j = 1: CM; j = 2: RMM) for type of microorganism
. We further assume that Xijk
is the true latent or hidden number of microorganisms for type of microorganism i in test sample k that is allocated to method j. We assume that the conditional probability of a positive test result in test sample k, given the true number of microorganism
, is equal to
(1)
(1) where πij
is the so-called detection proportion for type of microorganism i and method j, since it represents the probability of detecting one microorganism (Van den Heuvel and IJzerman-Boon Citation2013; IJzerman-Boon and Van denHeuvel 2015; Manju et al. Citation2019), that is,
. A detection proportion of
implies that microbiological method j is able to detect microorganism i perfectly (i.e., the limit of detection is equal to one), but when πij
is not perfect (
), the microbiological method will detect on average less microorganisms than actually present in a test sample. Model (1) is called the binomial detection mechanism, as proposed by others (Abbott Citation1925; CochranCitation1950; Ridout, Fenlon and Hughes Citation1993; IJzerman-Boon and Van denHeuvel 2015).
We now assume that the detection proportion of the RMM (j = 2) satisfies the following relation with respect to the CM ):
(2)
(2) with
to maintain
for all i. This restriction would be automatically guaranteed when
. The parameter θ can be viewed as the accuracy or recovery of the RMM with respect to the CM on detecting one microorganism in a test sample. It is considered homogeneous or constant over all m different types of microorganisms, while maintaining potentially different detection proportions
for the CM on the set of microorganisms. Under assumption (2) it is more convenient to use the notation
.
The RMM is considered to be noninferior when the accuracy parameter θ is above some predefined noninferiority margin δ, that is, leading to noninferiority hypothesis(3)
(3)
For microbiological methods it is not uncommon to use a noninferiority margin equal to (see Sutton, Knapp and Dabbah) or
(which can be derived from an absolute margin of 0.2 on differences in proportions in USP < 1223 >).
To test this noninferiority hypothesis, m different types of microorganisms are being tested. We will assume that for each type of microorganism a single spike solution is being created from which 2n test samples of equal volume are being collected. These 2n test samples are randomly divided into two groups each with n test samples. One group of n test samples are tested with the RMM and the other group with the CM. We will assume that the total volume of all 2n test samples is relatively small compared to the volume of the spiked solution, so that we can assume that test samples are approximately independent (Cochran Citation1950; Wyshak and Detre Citation1972; Van den Heuvel Citation2011). We further assume that the microorganisms are randomly distributed in the spiked solution, implying that the true number of microorganisms Xijk
in test sample k follows approximately a Poisson distribution with mean spike λ (Cochran Citation1950; Van den Heuvel Citation2011; IJzerman-Boon and Van denHeuvel 2015; Manju et al. Citation2019). Combining these assumptions with binomial detection probability (1), the probability that a test sample is tested positively, also called the positive rate, is then equal to(4)
(4)
Our research question is to optimally test hypothesis (3) using data having probability distribution (4) and with
being treated as nuisance parameters. More specifically, we would like to know how to choose λ and n such that the null hypothesis for a given noninferiority margin δ can be rejected using a Type I error rate of α and a power of
.
2.1 Maximum Likelihood Estimation
Our test statistic for noninferiority hypothesis (3) will be based on a lower confidence limit (Hahn and Meeker Citation1991; Wellek Citation2010) for the maximum likelihood estimator of θ (or alternatively for a transformation of this estimator). Thus, we need to study the maximum likelihood estimators for θ and πi
first. We do not have to estimate the spike parameter λ since the spike level is normally set by the experimenter (although it is difficult to set this spike level precisely). In the rare case that no information on λ would be available we would estimate the parameter for microorganism i. The interpretation of
is then lost, but we could still estimate the common accuracy θ.
The log-likelihood function for the set of observations under the earlier stated model assumptions is equal to
(5)
(5) where accuracy parameter θj
is given by
when j = 2 and
when j = 1, and where
is the number of positively tested samples for type of microorganism i and method j. The set of likelihood equations for estimation of θ and πi
is then given by
(6)
(6)
In case m = 1, the solution to the set of equations in (6) is given by(7)
(7) assuming that λ is (approximately) known and under restriction of
for
, with
the average number of positively tested samples or the observed positive rate for microorganism i and method j. In case
is equal to a boundary value
, the estimators
and/or
may either not exist or otherwise be unrealistic. For instance, when
both estimators
and
do not exist, while for
only the estimator
does not exist. When
or
, it may lead to the unrealistic estimates
or
, respectively. Thus, when we have only one type of microorganism, we can only allow experiments with data satisfying
, that is, for our approach both positive and negative samples should occur for each method. It implies that the average spike λ should be selected appropriately to avoid these boundary issues as much as possible.
The probability that the observed positive rates for one of the methods is equal to one of the boundaries is given by(8)
(8) with
for measuring microorganism i with the CM and
for the RMM. In this probability is visualized as a function of the sample size for three levels of η. It shows that large sample sizes may be needed to have a low probability that the positive rates are away from the boundary, in particular when η is larger.
Fig. 1 Visualization of the probability of observing only positive or only negative test results.
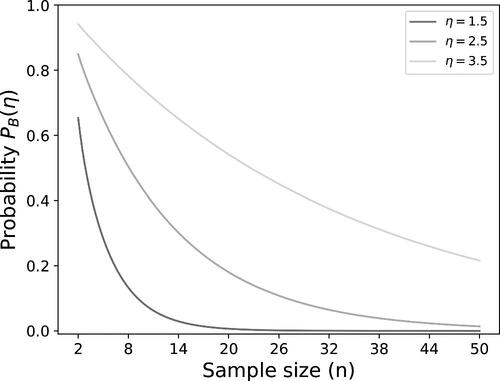
In case m > 1, we may be less stringent on boundary issues when at least one type of microorganism satisfies , with
. Indeed, when the observed positive rates for one type of microorganism are away from the boundary, this microorganism already provides a proper estimate of θ (and its standard error) and therefore, we may allow the observed positive rates of other types of microorganisms to be equal to the boundary. However, we demonstrate in Appendix A that we still must ignore microorganisms when both observed positive rates are equal to the same boundary (
or
) if we wish to obtain proper estimates of θ and πi
(assuming that at least one type of microorganism has data away from the boundaries), but we do not have to exclude data when only one method has an observed positive rate at the boundary.
The Fisher information matrix I is determined by the following moments of the score functions (see Appendix B)
(9)
(9)
Using the inverse of the Fisher information matrix , the asymptotic variance of
can be determined in a closed-form expression (see Appendix B) and it is given by
(10)
(10)
An estimate of this asymptotic variance can be obtained by substituting the ML estimators
and
in (10). Using this estimated asymptotic variance, an asymptotic one-sided confidence limit can be constructed by
(11)
(11) with α being the significance level and zq
the qth quantile of the standard normal distribution. Then the noninferiority hypothesis (3) is rejected when the lower confidence limit is above the noninferiority margin δ, that is,
.
Alternatively, we will use a lower confidence limit on the ML estimator of the logarithmically transformed accuracy with
the natural logarithm, since we expect that the distribution of a logarithmic transformation of an estimator of a ratio (see (2)) may converge faster to a normal distribution than the distribution of the ratio estimator itself. The lower confidence limit on the logarithmic transformed estimator can be obtained with the delta method (Cramér Citation1946), leading to
(12)
(12)
In this case, the noninferiority hypothesis (3) is rejected when this transformed lower confidence limit is above the logarithmically transformed noninferiority margin, that is, . Note that this transformed approach leads to a multiplicative noninferiority test in the original scale of the accuracy and could therefore have a better power than the test based on (11).
2.2 Optimal Spiking Design
For our optimal spiking design, we will focus on an experiment with a single spiked solution for each type of microorganism that is then used to collect 2n samples. Since the detection proportion πi
for microorganism i is typically unknown at the design stage, we would like to determine one optimal level for the mean spike per test sample λ that is used for all microorganisms. In other words, to maximize the power of our noninferiority test in either (11) or in (12), we should minimize the variance in (10) over the mean spike λ, while the detection proportions π1, π2, …, πm
are being unknown and potentially arbitrary.
The variance in (10) can be bounded from below and from above using minima and maxima values of the elements in the sum in (10). Indeed, the sum in (10) is smaller than or equal to m times the maximum element and larger than or equal to m times the minimum element. These boundaries only include a single detection proportion, making the form of the variance in (10) somewhat easier to study. The boundaries for the variance
are given by
Clearly, the maximum and minimum variance are reached at different values of the detection proportion and the two boundaries will become equal to each other when all detection proportions are equal (). The variance of the ML estimator
then reduces to
(13)
(13)
It can be shown that VE
in (13) is a convex function with respect to π, λ, and (Appendix C), which implies that it has a unique minimum for λ. However, the solution for λ would depend on the detection proportion π and the accuracy θ and it does not come in a closed-form expression. On the other hand, we know that the optimal solution for λ is of the form
, since the variance in (13) is a function of
. The solution of the optimal λ0 for the minimum variance in (13) can be found by setting the derivative of (13) with respect to
equal to zero, and thus satisfies the following equation
(14)
(14)
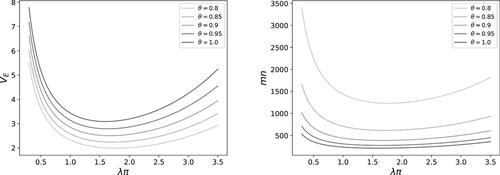
shows the optimal values λ0 for different values of accuracy θ using the Newton–Rhapson procedure (Süli and Mayers Citation2003).
Table 1 Optimal values of λ0 for different levels of accuracy θ and optimal sample sizes mn for 80% power.
The optimal spike λ can be selected approximately when there would be knowledge on the average detection proportion for the CM, because the first-order approximation of
in (10) is equal to
. Thus, the first-order approximation of the variance in (10) is given by (13) with the detection proportion π replaced by
. If however information on the (average) detection proportion is lacking, then it should be noted that what is actually needed, is some knowledge on the product
. This can be obtained for a particular organism by performing a pilot experiment in which a laboratory uses a compendial enumeration method to estimate
of the spike λ for microorganism i, assuming that the detection proportion
for the compendial enumeration method. If the latter assumption is not fulfilled, then λi
actually estimates the product
, which can be used to design the study.
A minimum sample size mn that provides power for testing hypothesis (3) using the proposed confidence limit in (11), can be calculated with the well-known sample size formula for a simple hypothesis test based on normality (Donner, Birkett and Buck Citation1981; Hsieh Citation1988; Julious Citation2004)
(15)
(15)
When we would use the logarithmically transformed test statistic in (12), the corresponding sample size formula would be equal to (15) with replaced by
. Since
for all positive x, we obtain that
for all
. Hence, the sample size will be smaller for the logarithmically transformed test statistic compared to the nontransformed test statistic when the accuracy is beyond the noninferiority margin. Or in other words, the logarithmically transformed test will have more power than the nontransformed test when applied to the same dataset.
Several sample sizes mn are presented in for different values of accuracy θ for a selected noninferiority margin of . It demonstrates that the total sample size can stay below 400 test samples when the true accuracy is at least 0.9 and an optimal spike can be selected. However, the sample sizes are calculated under ideal settings (an optimal spike and equal detection proportions) and it requires an evaluation when the settings would be different in practice. shows that the variance (13) and the sample size (15) may substantially change with the value
, especially for values below 1 or above 3, which may be an issue when exact information on the average detection proportion is lacking. In the following section we will conduct simulations to better understand the influence of unequal detection proportions on our testing procedure.
Fig. 2 The variance VE
(with mn = 1) and the sample size mn (,
) as a function of
for different values of θ.
3 Simulation
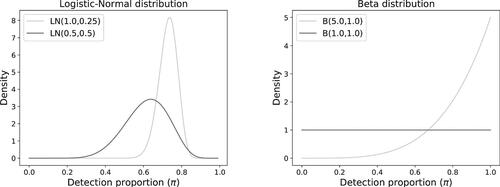
To simulate data for our (optimal) spiking experiment, we need to select different detection proportions for the CM. We will follow two different approaches. First of all, we will assume that the detection proportions are drawn randomly from a probability distribution. This means that for each simulation run we draw a new set of detection proportions. We used the logistic-normal and the beta B(a, b) distribution. For the logistic-normal distribution, the detection proportion for the CM is set to
, with Zi
drawn from a normal distribution,
, and for the beta distribution the detection proportion is set to
, with
. For both distributions, we used two different settings:
and
, and
and (1, 1), respectively. The density functions for these choices of distributions are given in . The mean detection proportions
for these four distributions are equal to 0.73, 0.62, 0.83, and 0.5, respectively. Second, we will consider different sets of fixed detection proportions. For these settings, the proportions will remain the same for each simulation run. One set of detection proportions consists of the quantiles
, with F one of the logistic-normal or beta distributions and m the number of microorganisms. The second set of detection proportions consists of a small detection proportion between 0.1 and 0.2 and the other detection proportions above 0.5 such that the average of the detection proportions is equal to the mean detection of one of the four distributions F. For this settings we only consider m = 5 different types of microorganisms. For the distribution
, the detection proportions are chosen equal to 0.15, 0.75, 0.83, 0.91, and 0.99, with an average of
. For the distribution
, the detection proportions are chosen equal to 0.15, 0.7, 0.725, 0.75, and 0.775, with an average of
. For the beta distribution B(5, 1), the detection proportions are selected equal to 0.2, 0.975, 0.983, 0.991, and 0.999 with an average of
and, finally, for the distribution B(1, 1) the detection proportions are selected equal to 0.15, 0.5, 0.56, 0.62, and 0.68, with an average of
.
Fig. 3 Density functions for the simulation of detection proportions (left: logistic-normal; right: beta).
3.1 Simulation of Spiking Experiment
We select different numbers for the types of microorganism () and use three levels for the homogeneous accuracy (
). We also choose
equal to the noninferiority margin
to investigate the Type I error. After selecting m and θ, we draw the detection proportions π11, π21, …,
for the CM using one of the four distributions for the random case. For the fixed setting of detection proportions, we just use the set of values we indicated above. Moreover we determine
for the RMM. Then, the sample size n is taken such that mn is equal to the optimal sample size in using test statistic
. In case n would not be an integer we rounded n to the nearest integer value larger than n. Then, for each microorganism i and method j, we simulated the numbers of microorganisms
, …,Xijn
in the n test samples using a Poisson(λ) distribution, with λ being the average number of microorganisms in the test samples (
). These numbers of microorganisms are assumed to be independent. Then, the observed binary outcomes
, …, Yijn
, are independently generated with a Bernoulli distribution using the conditional distribution
, with
if j = 1 and
if j = 2. This procedure is repeated 1000 times, to obtain multiple simulated spiking experiments under the same settings and investigate the power of our test statistics. The simulation of this spiking experiment was conducted with SAS software, version 9.4.
3.2 Analysis of Simulated Spiking Experiment
For each simulated dataset, we calculated the observed positive rate for microorganism i and method j. To be able to estimate the parameters θ and πi
and to conduct the noninferiority tests for each simulated spiking experiment, we first had to clean the data and eliminate types of microorganisms with observed positive rates at the boundary. Any type of microorganism with either only negative (
) or otherwise only positive samples (
) were removed from the data when we had at least one type of microorganism with data
(Appendix A). Information on the number of microorganisms that were available for the analysis will be reported.
It is expected that the detection proportions that are randomly drawn for each simulation run will typically result in less extreme results than for the fixed settings. The reason is that in the fixed settings several proportions are really close to one (especially for the distributions B(5, 1) and ), which may result in positive rates for microorganisms equal to the boundary one for the corresponding microorganisms. Thus, the consequence is that more datasets may be eliminated in the fixed settings compared to the random settings.
After eliminating microorganisms, the model parameters are estimated and the noninferiority tests are performed. In practice, laboratories are often able to provide an estimate of the spike λ for microorganism i using a compendial enumeration method. This estimate can be used in the analysis by substituting λ by this estimate. In the simulation study we used
as proxy, with
the simulated average in the test sample. The analysis of the data was conducted with SAS software, version 9.4, using procedure NLMIXED. Both the Type I error and the power of the noninferiority test will be reported.
3.3 Simulation Results
In this section, we only report the results of the detection proportions that were drawn randomly from the four distributions for each simulation run. The results of the fixed detection proportions are reported in Appendix D. The conclusions for these different ways of selecting detection proportions are not fundamentally different. The Type I error rates between these two approaches are very comparable, but the power values are somewhat lower in the fixed settings for higher values of the spike level λ. This can be fully explained by the higher numbers of datasets that must be eliminated (as we described in Appendix A). Our sample sizes are calculated under the assumption that none of the data is being eliminated. Thus, if then substantial amounts of data must be removed because they cannot contribute to the estimation of the parameters, the sample sizes have been underestimated, leading to lower powers that may drop below 80%.
shows the average, the minimum, the maximum, and the 5% quantile of the numbers of microorganisms that were not removed from the simulated spiking experiment (m = 15, ) for the four distributional choices and for two levels of accuracy. For the other chosen settings, all with lower m, λ, and θ, less data had to be removed since these settings had a lower chance of obtaining boundary values (see (8)).
Table 2 Summary statistics of the included number of microorganisms for random detection proportions.
It shows that it is unlikely to remove more than 6 types of microorganisms in a spiking experiment with 15 microorganisms (i.e., a quantile of 9 for distribution B(5, 1)), but in most settings it is expected to remove substantially less data. Clearly, the relative small sample size of n = 15, calculated for an accuracy of θ = 1, is more likely to provide data at the boundaries frequently when the average spike would be larger (see (8) and ), but this is less of an issue when the sample size is larger and the accuracy is smaller, for example, when n = 26 and .
The performance of the two noninferiority tests is provided in . provides the simulated Type I error rate, while the other three figures provide the power of the tests for different levels of accuracy (at significance ). In each figure we show the results of the four choices of distribution functions for the detection proportions and the three settings for the number of microorganisms (
) with the corresponding sample sizes n.
Fig. 4 Type I error rate of the two noninferiority test () as a function of λ for different distributions and number of microorganisms when detection proportions are selected randomly.
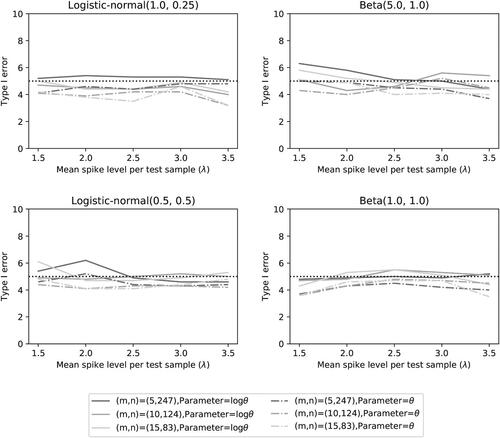
Fig. 5 Power of the two noninferiority tests () as a function of λ for different distributions and number of microorganisms when detection proportions are selected randomly.
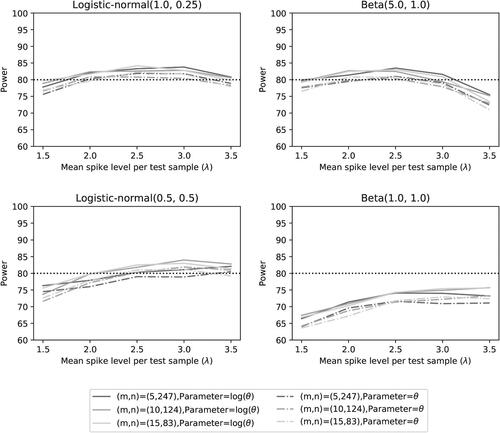
Fig. 6 Power of the two noninferiority tests () as a function of λ for different distributions and number of microorganisms when detection proportions are selected randomly.
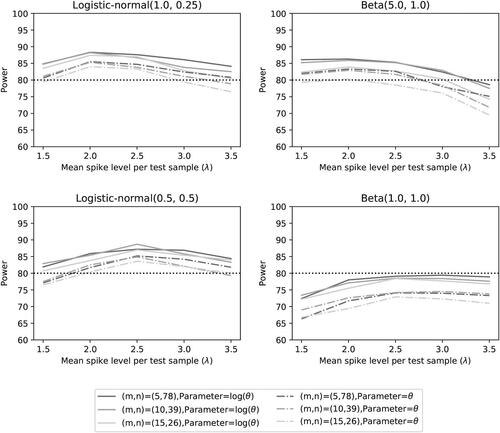
Fig. 7 Power of the two noninferiority tests (θ = 1) as a function of λ for different distributions and number of microorganisms when detection proportions are selected randomly.
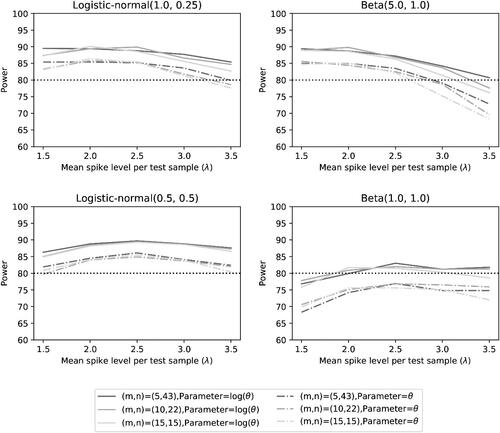
shows that the significance level of 5% is nicely achieved. This may not be a surprise, since we used a sample size mn that was calculated under assumption that the accuracy is equal to . The fluctuations of the Type I error rates seem to be random and unrelated to the choices of distributions.
The results on power demonstrate that the noninferiority test is more powerful than
(as expected). For the first three distributions, a power of 80% is achieved for
in most settings when the average spike λ can be maintained within 2 to 3 colony forming units per test sample (CFU/sample). This does not always occur for test
, even though we used the sample size calculation for this test. Spiking levels at
and/or
CFU/sample may diminish the power, depending on the mean detection proportion of the distribution in combination with the accuracy. Indeed, the distributions with lower mean detection proportions (
) and B(1, 1)) seem to benefit from a somewhat higher spike, in particular when the accuracy is lower. This is not surprising since the first-order approximation of variance
in (10) is equal to VE
in (13) with π replaced by
(see Section 2.2). The two distributions with a higher mean detection proportion seem to do better for lower spike levels, but a level of 1.5 CFU/sample still seems to be too low. This is not surprising either, since a spike lower than 1.593 would be less optimal even when the mean detection proportion would be equal to one (see ).
A power of 80% does not seem to be attained for any spike level when the accuracy is and the detection proportions follow a uniform distribution (B(1, 1)). We think this may be caused by detection proportions close to zero. The variance VE
for the accuracy estimator for detection proportions close to zero would have extreme standard errors (see ). Thus, just one small detection proportion may affect the power of the test negatively. For lower values of θ this effect is enhanced compared to accuracies closer to one.
The form of the density for the detection proportions also seems to affect the power of the noninferiority test on accuracy, which is probably caused by the likelihood of a small detection proportion. The distributions and B(1, 1) do not just have a lower mean, they also show more variability, with a higher probability of generating small detection proportions. Based on our past experiences with the CM, we expect that the
and
are more realistic distributions on detection proportions in practice than the other two. Having detection proportions below 0.3 for microorganisms with the CM seems less likely, unless the microorganism is highly stressed and unwilling to grow.
4 Case Study
Our approach has been implemented in practice, where a specific RMM was compared to the CM. The company who performed the validation study decided to test m = 16 different types of microorganism and used noninferiority margin . Although there is no reason to assume that the RMM is inferior to the CM, the accuracy will be considered less than 1 to avoid being too optimistic. It was assumed that the accuracy was in the range
. This leads to a sample size in the range of
, using test statistic
and . It was therefore decided to take n = 30 test samples per microorganism and method, allowing for a true accuracy of just below 0.9. The optimal λ0 should be chosen between 1.634 and 1.721 CFU/sample. Assuming that the mean detection proportion may be close to 0.5, since a few difficult to test microorganisms are being tested, a spike λ in the range of 3 CFU/sample was recommended.
The collected number of positive test samples for the noninferiority study are given in . The company also provided an estimated or predicted spike level based on the compendial enumeration method.
Table 3 Numbers of positive test samples out of 30 test samples from a real noninferiority study.
The model and methodology as explained in Section 2 was used to estimate the accuracy and the detection proportions for all microorganisms with the CM. We used the estimated spike levels provided by the company in the analysis, but we obtained the same conclusion on the accuracy when we ignored this information. If the estimated spike would be somewhat too low (or underestimated), we would obtain estimates for the detection proportions that may be larger than one. This is not an issue when interest is in the estimation and testing of the accuracy, it merely shows that the predicted spike level was not accurately determined. The SAS code is provided in Appendix E.
The estimates of the individual detection proportions and their 95% confidence intervals are given in . The estimate of the logarithmically transformed accuracy with its 90% confidence interval is given by –0.156 . Since the noninferiority margin in the log scale is equal to
, we reject the null hypothesis on inferiority and conclude that the RMM is most likely noninferior to the CM. The estimate of the accuracy with its 90% confidence interval is
.
Table 4 Estimated detection proportions with their 95% confidence intervals.
5 Discussion and Conclusion
We have provided an optimal framework for a noninferiority study on detection of microorganisms between two qualitative microbiological methods where we have assumed that the accuracy or recovery parameter is homogeneous across all types of microorganisms. We provided the optimal average spike level for the test samples taken from a single solution experiment and presented a sample size formula. Our simulation study showed that the proposed noninferiority tests have a power that is close to or better than the requested power. We recommend to use the logarithmically transformed accuracy test in the analysis, but a sample size calculation that is conducted for the accuracy test in the original scale. The reason for this discrepancy is that our calculations are somewhat optimistic since they are calculated under ideal circumstances.
The main benefit of our approach is the potential of a substantial reduction in sample sizes. IJzerman-Boon and Van denHeuvel (2015) showed that a sample size of 200 test samples per microbiological method for one microorganism is necessary to obtain 80% power for a traditional hypothesis test on accuracy when the true accuracy is 70%. For a homogeneous accuracy setting, this number could theoretically be reduced to 213 test samples for all microorganisms together, when the number of microorganisms is limited to 7. The reason for this limit is that with less than 30 test samples per microorganism, there is a risk that the collected data on a microorganism is not suitable for noninferiority testing, because the positive rates likely become equal to zero or one, excluding this microorganism from participating in the noninferiority study. Our case study demonstrated that a sample size of 30 test samples per method for each microorganism is attainable and worked nicely and we recommend not to go lower due to this risk of observing boundary values. This is still a reduction in sample sizes of about 85% with current status quo.
Our analysis also demonstrated that an optimal average spike is somewhere in between 2 and 3 CFU/sample when the detection proportions are larger than 0.5 and not all equal to one. This is in line with the official guidelines (USP < 1223 > 2015), who propose to choose a spike level such that the positive rate for the compendial is between 50 to 75%, even though higher spike levels have been recommended in the past. However, our noninferiority test is different from these guidelines, which proposes to use the most probable number (MPN) that is calculated from multiple dilutions or a noninferiority test on the positive rates. The MPN is less powerful than our test statistic and the second test statistic is highly sensitive to the spike and may falsely result in noninferiority when spike levels are selected somewhat higher (IJzerman-Boon, Manju, and Van denHeuvel 2020).
The disadvantage of our approach is that it is not known whether we may assume a homogeneous accuracy in practice. When the rapid and the compendial method have the same detection principles or mechanisms, but the rapid method is just faster than the compendial method in establishing a decision, it may not be unrealistic that there exists a consistent ratio between the two methods on detecting a single organism across different types of microorganisms. However, when detection mechanisms between the rapid and compendial method are truly different it is unknown if a common accuracy is realistic. Note that different detection proportions for detecting different organisms can be assumed for a common or homogeneous accuracy as well as for heterogeneous accuracies. In case the assumption of a common accuracy is false or there exists doubt on the assumption, different microorganisms may possibly be grouped based on their expectation of equal accuracy, but with different accuracies across groups. If certain groups can be formed, then our noninferiority framework can be applied to these groups separately and still result in lower sample sizes. In the near future, we are planning to study statistical tests that could evaluate the assumption of a homogeneous accuracy or otherwise determine the influence of heterogeneous accuracies on the noninferiority of the rapid method compared to the compendial method for a particular organism. This may complement the work we provided here. It should be noted that in the presented case study the likelihood ratio test for testing the null hypothesis of one common accuracy was not rejected (p = 0.794), suggesting that homogeneity of accuracy was reasonable, but the power (and Type I error) of the likelihood ratio test still need evaluation.
Supplemental Material
Download Zip (4.2 KB)Additional information
Funding
Notes
1 This equation actually has a solution whenever the observed positive rates and
are not equal to the same boundary value as we will see for the second equation in (A.1) in Scenarios 2 to 5. Thus, one of the positive rates is allowed to be equal to the boundary, as long as the other is not. However, characteristics of the solution depend on whether or not the positive rates are at a boundary zero or not.
Related Research Data
References
- Abbott, W. S. (1925), “A Method of Computing the Effectiveness of an Insecticide,” Journal of Economic Entomology, 18, 265–267. DOI: 10.1093/jee/18.2.265a.
- Cochran, W. G. (1950), “Estimation of Bacterial Densities by Means of the “Most Probable Number”,” Biometrics, 6, 105–116. DOI: 10.2307/3001491.
- Cramér, H. (1946), Mathematical Methods of Statistics, Princeton, NJ: Princeton University Press.
- Donner, A., Birkett, N., and Buck, C. (1981), “Randomization by Cluster: Sample Size Requirements and Analysis,” American Journal of Epidemiology, 114, 906–914. DOI: 10.1093/oxfordjournals.aje.a113261.
- EP 5.1.6. (2017), European Pharmacopoeia 9.2. Alternative Methods for Control of Microbiological Quality, EDQM: Strasbourg, pp. 4339–4348.
- Hahn, G. J., and Meeker, W. Q. (1991), Statistical Intervals: A Guide for Practitioners, New York: Wiley.
- Hsieh, F. Y. (1988), ‘Sample Size Formulae for Intervention Studies With The Cluster as Unit of Randomization,” Statistics in Medicine, 7, 1195–1201. DOI: 10.1002/sim.4780071113.
- IJzerman-Boon, P. C., Manju, M. A., and Van den Heuvel, E. R. (2020), “Non-Inferiority Testing for Qualitative Microbiological Methods: Assessing and Improving the Approach in USP <1223> ,” Manuscript in Preparation.
- IJzerman-Boon, P. C., and Van den Heuvel, E. R. (2015), “Validation of Qualitative Microbiological Test Methods,” Pharmaceutical Statistics, 14, 120–128. DOI: 10.1002/pst.1663.
- Julious, S. A. (2004), ‘Sample Sizes for Clinical Trials With Normal Data,” Statistics in Medicine, 23, 1921–1986. DOI: 10.1002/sim.1783.
- Lu, T. T., and Shiou, S. H. (2002), “Inverses of 2 × 2 Block Matrices,” Computers & Mathematics with Applications, 43, 119–129.
- Manju, M. A., Van den Heuvel, E. R., and IJzerman-Boon, P. C. (2019), “A Comparison of Spiking Experiments to Estimate the Detection Proportion of Qualitative Microbiological Methods,” Journal of Biopharmaceutical Statistics, 29, 30–55. DOI: 10.1080/10543406.2018.1452027.
- Ridout, M. S., Fenlon, J. S., and Hughes, P. R. (1993), “A Generalized One-Hit Model for Bioassays of Insect Viruses,” Biometrics, 49, 1136–1141. DOI: 10.2307/2532255.
- Süli, E. and Mayers, D. F. (2003), An Introduction to Numerical Analysis, Cambridge: Cambridge University Press.
- Sutton, S. V. W., Knapp, J. E., and Dabbah, R. (2001), “Activities of the USP Microbiology Subcommittee of Revision During the 1995–2000 Revision Cycle,” PDA Journal of Pharmaceutical Science and Technology, 55, 33–48.
- USP <1223> (2015), United States Pharmacopoeia 40. Validation of Alternative Microbiological Methods, Rockville, MD: U.S. Pharmacopoeial Convention, pp. 1756–1770.
- Van den Heuvel, E. R. (2011), “Estimation of the Limit of Detection for Quantal Response Bioassays,” Pharmaceutical Statistics, 10, 203–212. DOI: 10.1002/pst.435.
- Van den Heuvel, E. R. and IJzerman-Boon, P. C. (2013), “A Comparison of Test Statistics for the Recovery of Rapid Growth-Based Enumeration Tests,” Pharmaceutical Statistics, 12, 291–299. DOI: 10.1002/pst.1581.
- Wellek, S. (2010), Testing Statistical Hypotheses of Equivalence and Noninferiority, Boca Raton, FL: CRC Press.
- Wyshak, G., and Detre, K. (1972), ‘Estimating the Number of Organisms in Quantal Assays,” Applied Microbiology, 23, 784–790. DOI: 10.1128/am.23.4.784-790.1972.
Appendix A
Here, we discuss maximum likelihood estimation of the model parameters θ and π1, π2, …, πm
for model (4) based on data , where part of the data may be at the boundary value (
), but at least one type of microorganism has data that is not at the boundary (
,
). We illustrate this for just two microorganisms, where one microorganism may have observed boundary values (i = 1) and the other microorganism has not (i = 2). We may assume λ = 1, because we could just replace
by a new parameter ηi
that should be estimated instead. The likelihood equations from (6) are then reduced to the following three equations:
(A.1)
(A.1)
The proof is built up in the following way. First, we demonstrate that the MLE’s do not exist when and
are at the same boundary. For all remaining settings the MLE’s do exist. To demonstrate that claim, we first discuss the solution
for π2 using the third equation in (A.1). We show its existence for each θ and study
as function of θ, to determine certain characterizations we need later in the proof. Then we study
in the second equation of (A.1) for different data scenarios of
and
. In these scenarios we also study the solution
for the first equation in (A.1) when the solutions
and
are substituted.
The same boundary values for the first microorganism
In case and
, the second equation in (A.1) reduces to
, which results in the unrealistic estimator of
. When
and
, the second equation in (A.1) becomes equal to
, which has no finite solution for the detection proportion π1. Thus, it is obvious that a microorganism can not have two observed positive rates at the same boundary. Therefore, microorganisms with either
and
or
and
should be removed from the spiking experiment. For all other settings we will demonstrate that the set of equations in (A.1) has solutions for θ, π1, and π2.
Solution detection proportion for the second microorganism
The third equation in (A.1) has a unique solution for π2 when the observed positive rates satisfy and
and when
is fixedFootnote1. The function
is a continuous decreasing function in
, since both parts are decreasing functions. It converges to
when π2 converges to 0 and when π2 converges to
, the function converges to
. Thus, there is just one unique solution
that solves the third equation in (A.1). It should be noted that
, with
. Hence, if both methods are equal, that is, θ = 1, then the detection proportion π2 for the second microorganism is estimated based on the average positive rates
of the two methods.
Due to the continuity of the function in π2 and θ, the function
is continuous in θ. Furthermore, when θ converges to zero,
would converge to infinity when π2 would be fixed. Thus, π2 needs to increase to compensate for this increase and to become or maintain a solution for the third equation in (A.1). This leads to
and
. Furthermore, we obtain that
, from the observation that
after rewriting the third inequality in (A.1).
We will now demonstrate that when
. We only need to address the situation where
, since otherwise
is trivially obtained. When
is true, we obtain the following inequality
(A.2)
(A.2) since
is a decreasing function in π2. Now assume that also the alternative inequality
is true, then we would obtain the inequality
(A.3)
(A.3)
again using that
is a decreasing function in π2. Rewriting the third equation in (A.1) as
and using inequalities (A.2) and (A.3), we obtain the following contradiction:
Thus, must be an increasing function in θ.
Finally, rewriting the third equation and letting θ converge to infinity, we obtain(A.4)
(A.4)
Since is an increasing function in θ, it either converges to infinity or to some finite value. In both cases the left-hand side in (A.4) is a finite value. Thus, the right-hand side in (A.4) must be a finite value too. If we define
as this finite limit, we obtain that
, with
. Note that ξ2 can not be equal to zero. To demonstrate this, lets assume
. In this case, we would have that the expression on the left-hand side in (A.4) would be positive for any value of θ, since
is an increasing function,
is a decreasing function, and its limit is equal to zero. Thus, the expression in the left-hand side of (A.4) approaches
from above. We would also have that
, since
. In combination with the fact that
, this means that we can find a value θ such that the expression on the right-hand side in (A.4) becomes negative, since
. Since the equality in (A.4) should hold for any value of θ and not just for the limits, we have created a contradiction. Thus, the value ξ2 must be negative.
Solution detection proportion for the first microorganism
We will now study the solution π1 from the second equation in (A.1) as a function of θ, assuming that and
are not both equal to the same boundary. We will make use of the same reasoning as for π2 where possible. We will study the different settings for
and
and show that the first equation in (A.1) also has a solution in
after we substituted the solutions
and
in the first equation of (A.1).
Scenario 1 { }
}
This is the exact same situation as for π2 and we thus obtain the same characteristics for as for
. Since
converges to infinity when θ converges to zero (since
), we can find a value θ0 such that
for
. For this value, it follows for the left-hand side of the first equation in (A.1) that
(A.5)
(A.5)
Additionally, similar to (A.4) for the second microorganism, converges to
when θ converges to infinity. Thus, we can find a θ1 such that we have the opposite inequality in (A.5). This implies that there exists a
that would give equality in (A.5), since
is a continuous function in θ.
Scenario 2 {}
The second equation in (A.1) becomes equal to and leads immediately to the solution of
. This solution satisfies the same characteristics as the solution from Scenario 1. Indeed,
is an increasing function in θ with
and
, which could be infinite when
. Furthermore, the solution
converges to infinity when θ converges to zero. To demonstrate the existence of θ, we can use the same reasoning as in Scenario 1. There is again a θ0 such that inequality in (A.5) holds true, making use of
, and
converges to zero when θ converges to zero. There also exists a
such that the inequality in (A.5) is reversed when θ0 is replaced by θ1. Indeed,
converges to
and
converges to 1.
Scenario 3 {}
The second equation in (A.1) becomes equal to and leads immediately to the solution of
. This solution is somewhat different from the solution in Scenario 1, since
due to
. Furthermore, we have that
is an increasing function in θ with
but with
. We now need to show that there exists a solution θ such that
(A.6)
(A.6)
Since is finite,
converges to infinity when θ converges to zero, and
converges to zero when θ converges to zero, we can select a θ0 such that the left side in (A.6) with θ replaced by θ0 is larger than the right-hand side in (A.6) with θ replaced by θ0. Furthermore, we may find a θ1 such that the left side in (A.6) is lower than one, since
converges to one when θ increases and
, while the right side is always larger than one. Thus, there exist a
that would give equality in (A.6).
Scenario 4 {}
Note that we may assume here that , since the combination
and
has been addressed in Scenario 3. Since the arguments for finding solution π2 is unaffected by
when
, the solution
also exists for situation
and
. We need to investigate if the same characteristics holds for
as for
. The continuity of
,
, and being a nondecreasing function is not affected by
when
. Furthermore, for the asymptotics of
we did not need that
, thus we also have
, with
. The complication is to demonstrate that
when
. Rewriting the second equation in (A.1) and making use of
, we obtain
This equality can only hold when . Thus, the proof now follows Scenario 1.
Scenario 5 {}
Note that we may assume here that , since the combination
and
has been addressed in Scenario 2. For the solution of π1, we may follow the proof of finding solution π2 completely. The existence of
, the continuity of
,
,
and
being a nondecreasing function in θ are all unaffected by
. With
, it follows that
. Now using the proof of Scenario 1 for finding the solution θ, we also demonstrate the existence of
in this scenario.
Appendix B
We will demonstrate that the variance of the maximum likelihood estimator is given by (10). Note that the log-likelihood function is given in (5) and that the score functions are given in (6). They can be obtained by just taking simple derivatives with respect to the parameters. Here, we will calculate the variances and covariances of the score functions and then calculate the inverse Fisher information to determine the variance of
.
First note that the expected value of the score functions are zero, since }], with
if j = 1 and
if j = 2. Thus, the variance of
is now determined by
since the variance of
is equal to
. The variance of
is given by
since the variance of
is equal to
. Since
and
are independent and data from different microorganisms are independent, the covariance between
and
is now obtained as
and the covariance between
and
with
, is obviously zero.
The Fisher information matrix can now be written as(B.1)
(B.1) with
Clearly, I11 and I22 are nonsingular and invertible. Since is also invertible, the inverse of I can be written as (Lu and Shiou Citation2002)
The variance of the MLE of θ is therefore given by , the first (top-left) element of the inverse Fisher information matrix. We now obtain that
If we now introduce , we obtain that
,
and the term within the sum of
can be rewritten into
Then we obtain that
This leads to the variance in (10).
Appendix C
We will study the convexity of variance VE
in (13) as a function of . This is the same as studying this variance as a function of
when λ = 1. Since mn is a constant, we could also assume that it is equal to one. Thus, we will study the function
(C.1)
(C.1)
To demonstrate that this function is convex, we will study the first and second derivative. The first derivative is equal to(C.2)
(C.2) and its second derivative is equal to
(C.3)
(C.3)
where
and
. The function g(x) is an increasing function, since its derivative is
and this function is always positive for any x. Since
, we also obtain that g(x) > 0 when x > 0. This implies that the second derivative in (C.3) is positive for
. Hence, the variance VE
is a convex function in
, λ, and π.
Appendix D
Here we present the results of the simulation study for the case where detection proportions were selected as fixed parameters for simulation runs under the same simulation settings.
When the detection proportions are fixed at the quantiles of one of the four distribution functions, shows the summary statistics for the available number of microorganisms in an experiment with m = 15, and two accuracies
and θ = 1. The results show that for distribution B(5, 1), 5% of the simulation runs have less than 9 organisms, while we started with m = 15 microorganisms and for a few simulations the complete experiment was invalidated based on the criteria in Appendix A. As we mentioned before, the relatively large detection proportions for this distribution function provide a high probability that the number of positive samples for both methods are at the same upper boundary, making the data useless for our estimation procedure.
Table 5 Summary statistics of the included number of microorganisms for fixed detection proportions based on quantile of the four distributions.
shows that the Type I error rate is close to the nominal value of . The issues of eliminating data (also for settings with large numbers of organisms removed) do not seem to affect the Type I error a lot. show similar powers to the setting with the detection proportions randomly drawn from the distribution (cf. ). The random settings remove almost the same amount of data from an experiment as the fixed settings, which explains the similarity in power. The power values are at some settings below 80%, since the sample size calculation did not take into account the loss of data.
Fig. 8 Type I error rate of the two noninferiority tests () as a function of λ for the different number of microorganisms when detection proportions are fixed at the quantiles of a distribution.
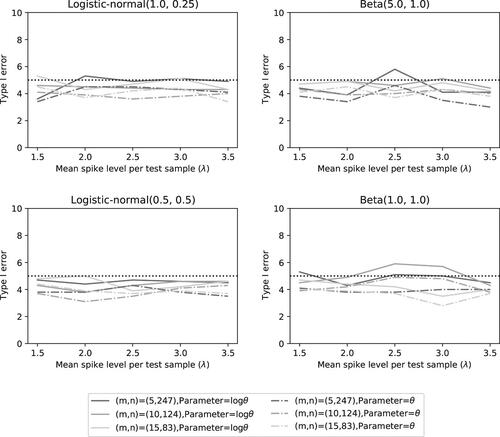
Fig. 9 Power of the two noninferiority tests () as a function of λ for the different number of microorganisms when detection proportions are fixed at the quantiles of a distribution.
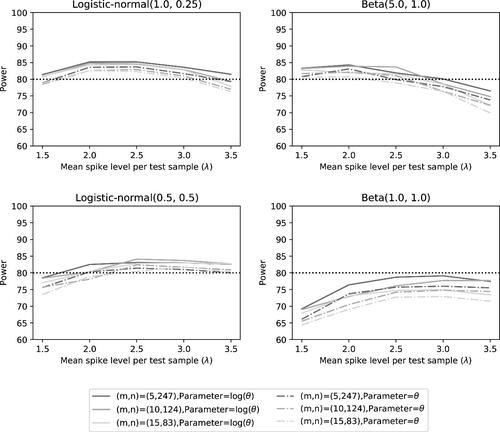
Fig. 10 Power of the two noninferiority tests () as a function of λ for the different number of microorganisms when detection proportions are fixed at the quantiles of a distribution.
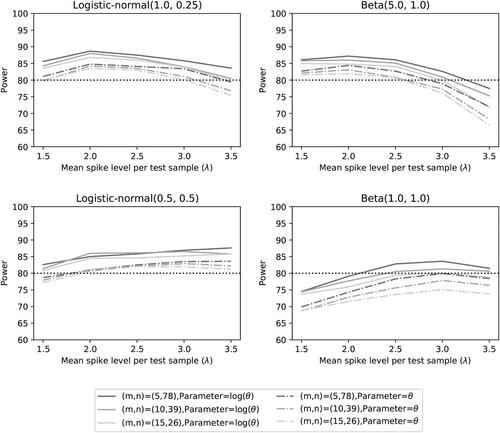
Fig. 11 Power of the two noninferiority tests (θ = 1) as a function of λ for the different number of microorganisms when detection proportions are fixed at the quantiles of a distribution.
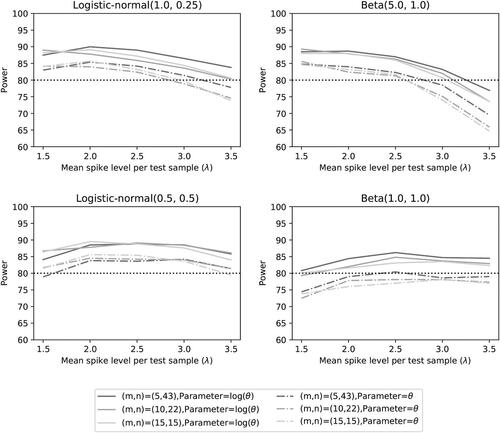
For the case of one small detection proportion and four larger detection proportions, we see similar results as for the detection proportions selected at the quantiles. The summary statistics can be found in , the Type I error can be found in , while the power can be found in .
Fig. 12 Type I error rate of the two noninferiority tests () as a function of λ for the number of microorganisms m = 5 when detection proportions are fixed with one small value and an average equal to the distribution mean.
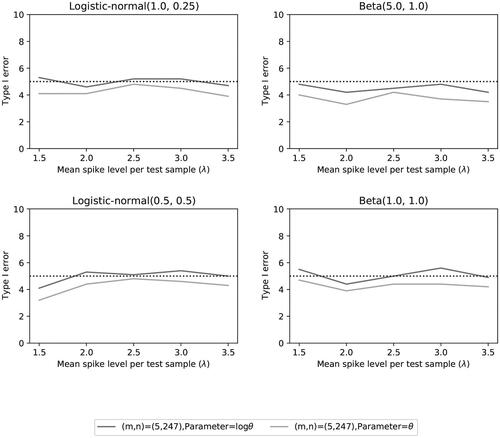
Fig. 13 Power of the two noninferiority tests () as a function of λ for the number of microorganisms m = 5 when detection proportions are fixed with one small value and an average equal to the distribution mean.
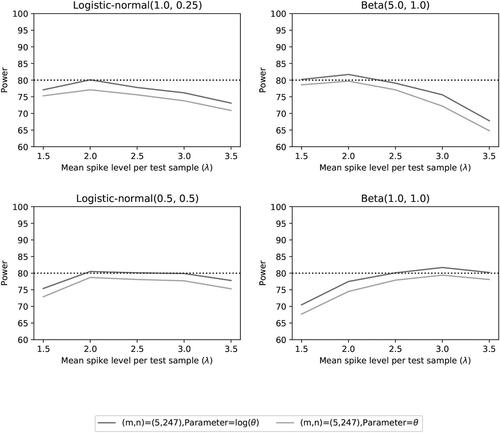
Fig. 14 Power of the two noninferiority tests () as a function of λ for the number of microorganisms m = 5 when detection proportions are fixed with one small value and an average equal to the distribution mean.
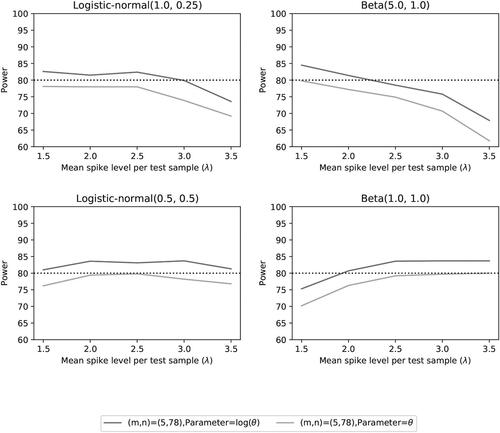
Fig. 15 Power of the two noninferiority tests (θ = 1) as a function of λ for the number of microorganisms m = 5 when detection proportions are fixed with one small value and an average equal to the distribution mean.
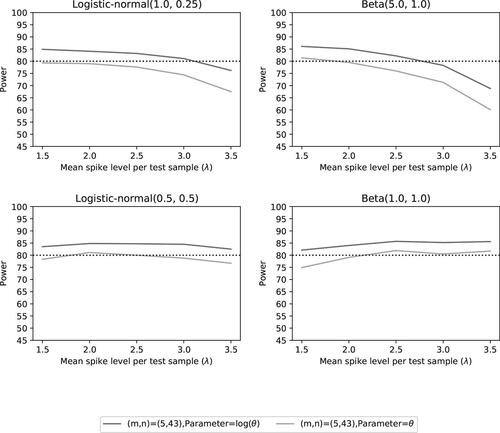
Table 6 Summary statistics of the included number of microorganisms for fixed detection proportions with one small value and an average equal to the distribution mean.
Appendix E
PROC NLMIXED DATA = VALIDATION QPOINTS = 20 DF= 10000; PARMS %DO I = 1%TO 16; DET&I = 0.8%END; LOGTHETA=-0.1; %DO I = 1%TO 16; IF MICROORGANISM =&I THEN DO; PC = 1-EXP(-DET&I.*LAMBDA_HAT); PR = 1-EXP(-EXP(LOGTHETA)*DET&I.* LAMBDA_HAT); END; %END; P = (METHOD=’C’)*PC + (METHOD=’R’)*PR; MODEL Y ∼ BINARY(P); ESTIMATE ’LOG ACCURACY’ LOGTHETA ALPHA = 0.1; RUN;
CODE 1. The SAS code for estimating the detection proportions and the common accuracy.