
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Recent examples for unplanned external events are the global COVID-19 pandemic, the war in Ukraine, or most recently Hurricane Ian in Puerto Rico. Disruptions due to unplanned external events can lead to violation of assumptions in clinical trials. In certain situations, randomization tests can provide nonparametric inference that is robust to violation of the assumptions usually made in clinical trials. The ICH E9 (R1) Addendum on estimands and sensitivity analyses provides a guideline for aligning the trial objectives with strategies to address disruptions in clinical trials. In this article, we embed randomization tests within the estimand framework to allow for inference following disruptions in clinical trials in a way that reflects recent literature. A stylized clinical trial is presented to illustrate the method, and a simulation study highlights situations when a randomization test that is conducted under the intention-to-treat principle can provide unbiased results.
1 Introduction and Background
1.1 Disruptions in Clinical Trials
Disruptions due to unplanned external events can lead to violation of assumptions in clinical trials. Recently, the COVID-19 pandemic introduced disruptions into many industry-sponsored and academic clinical trials (Bakouny et al. Citation2022; FDA Citation2021; Hawila and Berg Citation2021). Likewise, the war in Ukraine introduced challenges for recruitment in Ukrainian and Russian clinical trial sites (Rubin Citation2022). On a more local scale, severe climate and geological events can cause large-scale disruptions, such as after hurricanes and earthquakes (Dalton Citation2005; “Hurricane Katrina,” Citation2006; Lunt and Heenan Citation2019; Yale University, Citation2022). Patients from communities with higher social vulnerability may be affected disproportionally by a disruption (Joudrey et al. Citation2022).
1.2 Specific Examples
The following specific examples have motivated the considerations presented in this article.
Treatment Effect Drift: Changes in patient’s general health related to the pandemic shut down may lead to a drift in the patient populations baseline composition. This may result in initial trial assumptions being violated, as historical data are less relevant. For example, in a CNS trial studying a major depressive population, differences in the anticipated treatment effect may be smaller than initially anticipated with outside factors (shut-down, curfews, social isolation), taking a toll on the mental state of the entire population. Similarly, outcome trials with mortality as an endpoint will have to address issues of confounding or competing outcomes, as more patients died due to COVID-19. This will reduce the overall study power.
Population Shift: In studies where the safety of a drug is not completely known, women of child-bearing age were discontinued from treatment during the pandemic, due to the inability of the investigator to ensure reliable pregnancy tests were being conducted prior to allowing the patient to continue in the trial.
Change of Care: Due to the war in Ukraine, patients in ongoing clinical trials were either withdrawn from the trials or transferred to other sites in neighboring countries, in cases where the patient was able to move there. In cases where a patient moved from one site to another, the internal reliability of the endpoint assessment may be questionable. For example, in situations where the treatment under study is administered on top of Standard of Care (SOC), what is considered SOC in one country is often very different from the SOC in another country. A patient fleeing from one country to another may be required to change the SOC.
Change in Data Collection: During the COVID-19 shut down and the war in Ukraine, in-person patient visits were converted to phone visits (when possible). This leads to a lower/different data quality of the data collected from these patients and visits, versus patients that had access to in-person visits. For example, in a recent schizophrenia trial, assessments were to be made by well-trained site staff. These assessments included tasks in which the patient had to draw shapes, repeat patterns from memory and other visual and behavioral tasks. During the shutdown, when sites were closed to in-person visits, these assessments were done via video call. However, video calls are imperfect in terms of Wi-Fi quality, situational distraction and general attention, making comparability of assessments done via video versus those done in person questionable.
Change in Availability of Study Medication: Investigative Medicinal Product (IMP) supply issues can lead to a disruption in the planned randomization of patients. The Interactive Response Technology (IRT)/Interactive Voice Response System (IVRS) provides the sponsor with an option to include “forced randomization” within an IRT system. When this option is turned on, and a kit for that treatment arm that a patient is supposed to be randomized to (according to the next entry on the randomization list) is not available, the IRT system skips that entry and assigns the patient to a treatment kit that is actually available at the site. One option of “forced randomization” implemented in the IRT allows the skipped randomization assignments to then “back-filled” by patients at other sites that have that treatment kit available.
This article provides a conceptual framework for using randomization test to address the issues raised in examples 1 and 4–5 in Sections 2–6 and discusses challenges with solving example 2 in the discussion in Section 7. We focus on disruptions that produce intercurrent events. Intercurrent events are events occurring after treatment initiation that affect either the interpretation or the existence of the measurements associated with the clinical question of interest (ICH E9(R1) Citation2021).
1.3 Randomization Tests
The central question in a clinical trial is whether the outcome of a trial participant would be different from their observed outcome, had they received a different treatment. Consider a clinical trial with N participants and two treatment groups, experimental group A and control group B. The treatment assignment Ti of a participant i is a random variable that takes a value with ti = 0, if participant i is allocated to treatment C, and ti = 1 if the participant is allocated to treatment E. The vector
of treatment assignment is the randomization sequence. A randomization procedure is a probability distribution on the set
. Let the clinical outcome of interest of participant i be denoted by Yi. Randomization tests address this simplest null hypothesis, namely, whether a participant’s observed outcome is independent of the treatment they received:
It can be shown that the vector of observed outcomes is a sufficient statistic for H0 (Lehmann Citation1975; Pesarin Citation2001; Uschner Citation2021).
Let be a statistic that measures the effect of t on y, for example the difference in means test statistic
, where
denotes the mean of y in group t. We often refer to the effect of t on y as the difference between the treatment groups. Let tobs be the actual randomization sequence that was used to assign the participants in the clinical trial that is being analyzed (as opposed to other realizations t of the treatment assignment). Under the null hypothesis H0, the responses are independent of the treatment that a participant received. The distribution of the test statistic
given the value of the observed responses
equals the distribution of
induced by the randomization. Formally, it is
Note that is the probability measure over the set of randomization sequences, generated by the randomization procedure. The null hypothesis H0 is rejected if the probability of observing a result at least as extreme as the observed result,
is lower than a predefined threshold α. The probability p is the p-value of the randomization test. The randomization test p-value can be estimated using Monte Carlo simulations. By drawing at random L sequences ti from
using the sequence probabilities given by the randomization procedure, a consistent estimator for p is given by
where 1(
) is the indicator function.
1.4 Estimands
In 2020, the ICH E9 (R1) addendum was proposed to improve decision making from clinical trials by increasing the clarity of benefits and risks of a treatment for a given medical condition. Specifically, the guideline requires a precise description of the treatment effect and the population to which it applies, specifies the treatments being studied, the primary endpoint including time points of measurements, strategies to address intercurrent events, and a population level summary measure. “As such, an estimand is a precise description of the treatment effect reflecting the clinical question posed by a given clinical trial objective. It summarizes at a population level what the outcomes would be in the same patients under different treatment conditions being compared” (ICH E9(R1), Citation2021). Strategies to address intercurrent events discussed in ICH E9(R1) (Citation2021) include the treatment policy strategy and the hypothetical strategy. We discuss in Section 4 how these strategies can be incorporated in the randomization test.
Note that the population level summary measure is distinct of the conceptual treatment effect. For example, in the setting of a survival endpoint, the treatment effect is more broadly speaking the difference in the distributions of the survival curves, but a population level summary measure could be the median survival time, or the restricted mean survival in each group.
1.5 Randomization Tests and Estimands
Randomization tests address a related and complementary question to that of the estimand. They give an answer to the question: “Given a difference in the distributions of the outcome between treatment groups of this magnitude, what is the probability that this effect should have been observed by chance alone?” (Rosenberger and Lachin Citation2016). Consequently, randomization tests provide a natural framework of inference to follow estimation based on the estimand framework.
To our knowledge, randomization tests have not been connected with the estimand framework as presented in ICH E9 (R1). Embedding randomization tests within the estimand framework will allow disruptions in clinical trials to be addressed in a way that reflects recent literature. (Van Lancker et al., Citation2022)
From the components of the estimand, selecting a population of interest is least aligned with the core principles of randomization tests. Randomization tests are rooted in the Fisherian framework of inference and do not require trial participants to be a random sample from a super population. By virtue of asking what the outcome of a patient would have been, had they been assigned a different treatment, randomization tests apply to the participants in the trial, rather than to a “super population” or hypothetical target population. In the estimand framework, on the other hand, the target population of interest is a core component, and treatment effects can be estimated using the Neyman-Pearson or Bayesian inference frameworks.
We address this point as follows: A sponsor designs and runs a clinical trial to address a clinical question of interest. A benefit of the experimental treatment over the control treatment is hypothesized with respect to a specific clinical outcome within a group of patients with certain clinical characteristics, such as disease status, comorbidities, willingness to participate in research, etc. These patients meet the inclusion and exclusion criteria of a trial and are eligible to participate and be randomized. As such, they present the target population of the clinical trial and it is expected that the probabilistic behavior of the clinical outcome in the sample is similar to the group of patients defined by the inclusion and exclusion criteria. Therefore, randomization test-based inference is expected to be applicable to patients with characteristics similar to the trial participants. For the randomization test, the outcomes of the patients in the target population do not need to follow any specific (parametric) distribution, and the trial participants are not required to be a random sample from the target population. We assume that there is a statistic S that captures the difference between the treatment groups. To integrate the randomization test into the estimand framework, we choose to be the target of estimation for the specific trial objective, but we do not require its distribution to follow a certain form. The inference using the randomization test is conditional on the sample observed in the trial. As such, the randomization test provides inference about the population of the trial, which is the group of patients enrolled into the study, and relies on effective implementation of inclusion and exclusion criteria and replication of the results with external data (e.g., from additional clinical trials) to ensure that conclusions are generalizable to the larger target population.
The population-level summary measure is another component of the estimand that is not closely aligned with the randomization-test following the Fisherian paradigm of inference. To address this point, we use summary measures conditional on the data that were observed in the study, aligned with the formulation of the sample average treatment effect (SATE) in formula (1) of Ding and Li (Citation2018).
2 Motivating Example
In this section, we describe the properties of a simplified, hypothetical trial in exercise and nutrition science and illustrate different ways in which it might have been affected by the pandemic, inspired by the PLAN study (Epstein et al. Citation2021).
Consider a single-blind randomized controlled trial of two weight loss interventions on obesity. One intervention is standard of care plus a drug; the other is standard of care plus a lifestyle intervention. The primary outcome is change in BMI from baseline to 24 months after enrollment. The primary objective of the trial is to investigate whether one of the two treatments is superior to the other, and to assess the magnitude of the difference of change in BMI between the treatments. In this situation, the estimand of primary interest can be defined in the Fisherian framework as follows:
The target population is defined by the inclusion and exclusion criteria of the trial, albeit conditional on the enrolled participants.
The primary outcome of interest is the change in BMI from enrollment to 24 months after follow-up in the group of enrolled participants. BMI is assessed in clinic every three months from beginning to end of follow-up.
The randomized treatment is the treatment of interest.
The intercurrent events and their strategies are:
Withdrawal from treatment due to reasons associated with the treatment: treatment policy strategy.
Withdrawal from treatment unrelated to treatment: hypothetical strategy.
The population summary measure is the difference in means of the primary outcome between the two treatment groups after 24 months of treatment conditional on observed outcomes of the enrolled study participants.
2 Impact of the pandemic:
The planning and the enrollment for the trial have started prior to the pandemic, but not all participants were recruited at the start of the pandemic. During the course of the trial, the trial protocol needed to be amended for the impact of the pandemic, and the following intercurrent events were added due to the pandemic:
Measurement of the primary outcome in clinic is replaced with at-home measurement of the primary outcome: Treatment policy strategy
The study drug is replaced with a different drug because of supply chain-issues: Hypothetical strategy
In some situations, for example when the disruption occurred late in the timeline of the trial, investigators and sponsors may decide to ignore the impact of the pandemic and analyze the trial under the intention-to-treat principle as if the disruption had not occurred. In other situations, one may be more interested in assessing the intervention in the new reality of a world that has learned to live with the effects of the pandemic. In even other cases, one might want to assess the evidence from the trial separately for the different phases of the trial, and potentially combine the evidence in a stratified way.
In the following section, we describe three possible estimands and corresponding inferential strategies using the randomization test to account for the different COVID-19 related intercurrent events.
3 Randomization test and Estimands to Address Disruptions
Following the ICH E9 (R1) Addendum and the notation in Van Lancker et al. (Citation2022), we describe estimands with respect to their five attributes: population, treatment, endpoint, intercurrent event, and population summary measure. The super population is the set of potential subjects who meet the inclusion and exclusion criteria of the trial as defined by the trial protocol at the time of enrollment of the participant at participating clinics. The plan is to recruit N subjects from the super population that will form the trial or sample population Θ. Participants are randomized to receive either the experimental treatment or a control treatment. Recall that the experimental treatment is denoted by T = 1, control by T = 0. Let the endpoint Yl denote the random variable that measures the outcome at time l in the participant follow up . In the situation of the weight loss example, Yl is the change in BMI from baseline to time t. An intercurrent event will be denoted by Cl, where Cl = 1 if the intercurrent event happened prior to time l, and affects outcomes from time l onwards, otherwise
. For the weight loss example in the previous section, the two intercurrent events unrelated to the pandemic and the two intercurrent events related to the pandemic will be the elements of
In a global trial, the intercurrent event could be generalized to reflect different times of onset across the countries that participate in the trial. The target of estimation and inference is the population level summary measure
.
The population summary measure of the estimand corresponding to the intention-to-treat principle is given by
The super population consists of all subjects that were eligible for the trial at the moment of their enrollment.
The inference using the randomization test is conditional on the sample observed in the trial Θ, which affects the definition of θITT. Let be the outcome and treatment assignment of participant i, respectively, and
the sample sizes in group E and C after N participants have been enrolled. The sample statistic corresponding to the ITT estimand is
Note that in the introduction.
Based on this framework, we now discuss different estimands that may be of interest in the situation of the motivating example.
Estimand 1 is the effect of the treatment for the overall population Θ, but assuming that all participants can come to the clinic to get their BMI measured, and the study drug is still available,
By we denote the counterfactual outcome under treatment t, where we intervene and set the COVID-19 related intercurrent events to zero. This can be implemented in different ways, as described by Van Lancker et al. (Citation2022).
For the randomization test, the p-value conditional on the absence of administrative challenges is given by
Alternatively, we can use multiple imputation to impute missing participant outcomes after the onset of the pandemic, as well as combine p-values from different imputed datasets (Ivanova et al. Citation2022).
Estimand 2 is the effect in the post-pandemic population , but similar to Estimand 1, assuming that participants are not faced by operational challenges,
Again, we can either use a conditional randomization test to condition on the observed outcomes, or use multiple imputation to insert the missing counterfactual outcomes.
Estimand 3 is the effect in a post-pandemic world, but assuming that all BMI measurements are conducted at home:
As for Estimands 1 and 2, we have the option of either a conditional randomization test or multiple imputation.
We summarize the main differences between the estimands in :
Table 1 Differences between proposed estimands with respect to estimand attributes.
4 Strategies to Address Missing Values for Hypothetical Estimands in the Randomization Test
4.1 Intention to Treat Analysis (Treatment Policy Strategy)
In the case of intercurrent event , the participant outcomes are observed, but affected by a time trend. In this situation, the unconditional randomization test will provide unbiased results, because the null hypothesis
continues to be true. In that situation, we can conduct the randomization test without any changes to the testing procedure. Here, we are dropping the index l to denote the primary outcome at the end of the follow up time,
.
4.2 Conditional Randomization Tests
To calculate the p-value conditional on the absence of the intercurrent event, we restrict the reference set to sequences where the treatment assignment for a participant i is the same as the assignment i in the observed randomization sequence. This effectively excludes values that were measured after the onset of the disruption from the inference, and can lead to reduced power if the proportion of values after the beginning of onset of the disruption is large (Heussen et al. Citation2023).
4.3 Multiple Imputation
Ivanova et al. (Citation2022) recently presented a multiple imputation framework for randomization tests in clinical trials. The imputation framework of that test can be modified for the situation of intercurrent events, where missing counterfactual values for the intercurrent event can be imputed in a suitable way. For example, baseline and longitudinal covariates as well as longitudinal outcome values of earlier time points could be used to impute missing outcomes at the time point of interest. The imputation model can follow the same considerations as for the population-based inference, see Van Lancker et al., (Citation2022): If the data after the onset of the intercurrent event are considered to be similar to those prior to the onset, that is, the outcomes can be assumed to come from the same distribution prior and after the onset of the pandemic, the missing data can be imputed under the assumption that they are missing at random (MAR), and their distribution is estimated based on the observed data prior to onset of the intercurrent event. If the data after the onset of the intercurrent event is deemed to be different from the observed data, such as in the case of the intercurrent events 3 and 4 of the motivating example, an alternative imputation model under the missing-not-at-random (MNAR) assumption may be used, reflecting the estimand under the hypothetical strategy. An imputation strategy under the MNAR assumption might entail incorporating additional assumptions regarding the missing data, for example based external information regarding the correlation of in-clinics versus at home visits. Heussen et al. (Citation2023) examines the performance of randomization and population based tests under different missing data mechanisms.
4.4 Post-Stratification
Another natural way of handling an intercurrent event imposed by a trial disruption at the analysis stage is post-stratification. Post-stratification is an inferential procedure applicable to estimation and testing that does not belong to the framework of the estimand. Still, post-stratification is commonly proposed to deal with issues of protocol change. While estimands are defined before data collection and before estimation, estimators can be defined later. We will address post-stratification as a separate concept in Section 5.4.
5 Computational Implementation of the Strategies
Recent publications have focused on Monte Carlo simulations to estimate the randomization p-value as an efficient and versatile alternative to large-sample approximations based on the central limit theorem (see Section 1.3). By restricting the sequence probabilities further (e.g., conditional on an ancillary statistic), the reference set is reduced to sequences relevant to the target estimand. This reference set will generally include fewer sequences than the full unrestricted (i.e., unconditional) reference set of all possible treatment allocation sequences induced by the implemented randomization procedure. A major statistical/computational challenge here is to sample relevant randomization sequences from the conditional set to estimate the randomization-based p-value with due precision. The question of choosing the number of sequences in the Monte Carlo reference set has been addressed in the literature (Plamadeala and Rosenberger Citation2012; Zhang & Rosenberger, Citation2011 Heussen et al., Citation2023). By restricting the sequence probabilities further (e.g., conditional on an ancillary statistic), the reference set is reduced to sequences relevant to the target estimand (discussed in more detail below).
5.1 Unconditional Randomization Test for the ITT Estimand
In the unconditional randomization test, each randomization sequence is sampled with the probability arising from the randomization procedure. In order to achieve a precision of for the estimate of the p-value, L = 2500 sequences need to be sampled (Rosenberger and Lachin Citation2016; Zhang and Rosenberger Citation2011). In practice,
sequences are recommended to achieve
.
5.2 Conditional reference set
The conditional reference set consists of all sequences of the full reference set that fulfill certain conditions. For example, Cox (Citation1982) suggested restricting the reference set to sequences that have the same final imbalance as the observed randomization sequence, while Plamadeala and Rosenberger (Citation2012) conditioned on balance at interim looks throughout the allocation process. Wang, Rosenberger and Uschner (Citation2020) used conditional randomization tests to achieve pairwise comparisons, and Uschner (Citation2021) used the technique to achieve unbiased randomization tests.
In general, there are two approaches for creating the conditional reference set (Plamadeala and Rosenberger Citation2012). The first approach consists of generating sequences from the full reference set and discarding sequences that do not meet the criteria for conditioning. Depending on the restriction imposed by the criteria and the randomization procedure, this approach may entail generating many million more sequences than required for the unconditional randomization test; see in Plamadeala and Rosenberger (Citation2012).
The second approach consists of sampling directly from the conditional reference set by iterating through the allocation path using importance sampling (Mehta, Patel, and Senchaudhuri Citation1988). This approach can become computationally challenging if the randomization distribution is complex, for example, in the case of the maximal procedure (Berger, Ivanova, and Knoll Citation2003), or if the condition is complicated, such as in Uschner (Citation2021).
In cases where the trial was randomized using the permuted block design, and we would like to condition on a simple pattern, such as those introduced by an intercurrent event, direct sampling from the conditional reference set is straightforward. It consists of holding the positions of allocations that are affected by the intercurrent event fixed, and permuting the remaining allocations, just taking into account the restriction of balance at the end of a block.
5.3 Multiple Imputation
The multiple imputation strategy consists of creating m imputed datasets in case both counterfactual outcomes for a participant are missing, assuming that the null hypothesis that there is no treatment effect is true. To calculate the observed test statistic, we can combine the estimates of the m completed datasets, and standardize it by its variance according to D. B. Rubin (Citation1987). We obtain the average within imputation variance as
and the variability across samples by
, yielding a variance of
of Θ, allowing us to compute the observed test statistic Sobs based on Θ and
. This observed test statistic will then be compared to the
test statistics
based on
and
for each combination of the m imputed datasets and L randomization sequences (
. Ivanova et al. (Citation2022) showed that this method preserves the error rates of the randomization test.
5.4 Post-Stratification
In this strategy, a separate p-value can be computed independently for each phase of the pandemic. In fact, if an unplanned intercurrent event introduces a protocol change, the randomization process can be restarted after the intercurrent event, resulting in independent randomization sequences for the pre- and post-disruption phases. In the simplest setting, the intercurrent event is independent of the outcome and the treatment assignment. Then the p-values from both phases can be combined in a straightforward way, for example, using Fisher’s combination test. In case a dependence is possible, it needs to be assessed carefully, and suitable methods of combination of inference need to be chosen.
6 What Unconditional Randomization Tests Can and Cannot Do
If there are no missing participant outcomes under the null hypothesis, and the intercurrent event is independent of the treatment assignment, the unconditional randomization test is robust to the intercurrent event in terms of Type I error control and power. We assess the effect of disruptions on the test decision of the randomization test using a simulation study.
6.1 Simulation study Settings
We model the outcome using a normal distribution
where δ is the treatment effect and
represents a mean shift due to a trial disruption. We model the effect
based on a step trend (Tamm and Hilgers Citation2014),
(1)
(1)
This example reflects the case of the intercurrent event of type C3 above, where all the participant outcomes after the start of the pandemic are measured at home instead of in clinic.
To investigate the case of the heterogeneous treatment effect, as it would be the situation in case of intercurrent events of type C4, where one of the randomized treatments is affected by supply chain issues where the other is not, we assume that there is an interaction between treatment and the intercurrent event. In our model of Yi, we replace the step trend with a trend that affects only one treatment group,
The simulation study uses the following parameters shown in . The treatment effect δ was chosen to reflect the null hypothesis that T and Y are independent in one scenario, and as effect size needed to achieve 80% power to detect a constant additive treatment effect in the other.
Table 2 Simulation parameters.
6.2 Results of the Simulation Study
and show Type I error probability and power of the randomization test in case of a step trend and a heterogeneous treatment effect, respectively, introduced by the trial using Random Allocation Rule (.
Fig. 1 Rejection probability under the null hypothesis ( for increasing trend effect; Left hand side: Model (1), right hand side: Model (2).
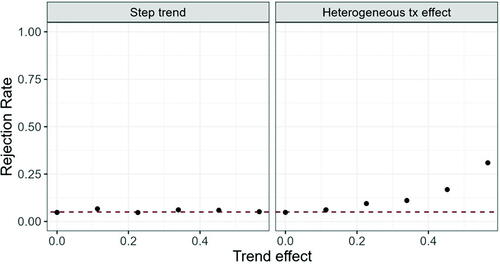
Fig. 2 Rejection probability under the alternative ( for increasing trend effect; Left hand side: Model (1), right hand side: Model (2).
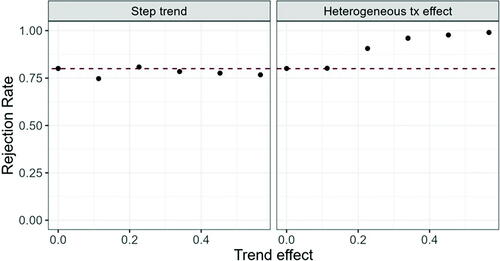
We can see that the Type I error probability and power are maintained at the nominal level in case of the step trend introduced in Model (1), but inflated in case of a heterogeneous treatment effect when the heterogeneity is large. The same behavior is observed for other randomization procedures (data not shown).
7 Conclusions and Discussion
We describe how randomization tests can be used to address intercurrent events arising from a trial disruption. The presented strategies provide a high degree of flexibility for inference following estimation based on the estimand framework. In addition, we show that the randomization test based on the ITT estimand maintains the nominal error rates in case the intercurrent events are independent of the treatment assignment mechanism. The proposed strategies can serve as a primary analysis of the treatment effect in a clinical trial, or as a sensitivity analysis that does not rely on parametric assumptions regarding the distribution of the outcomes. Carter et al. (Citation2023) have found that regulatory agencies request the use of randomization tests in situations where a violation of the assumptions was observed.
To our knowledge, this is the first article that connects the estimand framework with randomization-based inference. Traditionally, randomization-based inference focuses on inference conditional on the population that has enrolled in the clinical trial. The estimand framework, in contrast, takes the perspective from the design stage of a clinical trial, and focuses on formulating treatment contrasts of interest a priori. In that sense, randomization-based inference and the estimand framework complement each other.
An important limitation of the randomization-based approach is that its validity stems from a sharp null hypothesis of equality of potential outcomes under the different treatment conditions. A sharp null, also called Fisher’s null hypothesis, implies a population average null, also called Neyman’s null, and is more restrictive. In a seeming paradox of finite populations, Neyman’s test of the average null can be more powerful to detect a constant treatment effect than Fisher’s test of the sharp null (Ding Citation2017). Design-based alternatives to Fisher’s Test exist which impute a nonconstant null and test Neyman’s average treatment effect (Imbens and Menzel Citation2018). As testing for the population average effect is the far more common approach in clinical trials, testing for the sharp null is often harder to communicate to practicioners.
Several questions remain open: An interesting extension beyond the scope of the current manuscript is to embed the presented approach in the causal-inference literature. Additionally, it is unclear how inference after changes in patient populations after the intercurrent event should be interpreted: For example, changes in patient populations may occur, because participants at a higher risk from COVID-19 may choose to avoid participation in trials, because some sites stop enrollment due to site closures, because some measurements cannot be observed for a certain proportion of participants at the start of the pandemic, for example, pregnancy test, or a general shift in the assumed baseline occurs at time of disruption, for example mental health disorders increase. From the randomization-based perspective, the trial results are applicable to the participating study population, and generalizability to external populations comes from careful choice of inclusion and exclusion criteria, as well as replication of the trial results in other populations.
We plan to address these issues in the future.
Acknowledgments
The authors thank the National Institute of Statistical Sciences for facilitating this work on Randomization Tests to Address Disruptions in Clinical Trials, which is part of the Ingram Olkin Forum Series on Unplanned Clinical Trial Disruptions. The authors would also like to recognize the organizers of this forum series (those who are not an author on this article): Nancy Flournoy and James Rosenberger. The authors thank Victoria P. Johnson and Abigail Yuqun Luo for their review of and helpful comments on the article.
Disclosure Statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Bakouny, Z., Labaki, C., Bhalla, S., Schmidt, A. L., Steinharter, J. A., Cocco, J., Tremblay, D. A., Awad, M. M., Kessler, A., Haddad, R. I., Evans, M., Busser, F., Wotman, M., Curran, C. R., Zimmerman, B. S., Bouchard, G., Jun, T., Nuzzo, P. V., Qin, Q., Hirsch, L., Feld, J., Kelleher, K. M., Seidman, D., Huang, H., Anderson-Keightly, H. M., El Zarif, T., Alaiwi, S. A., Champagne, C., Rosenbloom, T. D., Stewart, P. S., Johnson, B. E., Trinh, Q., Tolaney, S. M., Galsky, M. D., Choueiri, T. K., and Doroshow, D. B. (2022), “Oncology Clinical Trial Disruption during the COVID-19 Pandemic: A COVID-19 and Cancer Outcomes Study,” Annals of Oncology, 33, 836–844. DOI: 10.1016/j.annonc.2022.04.071.
- Berger, V., Ivanova, A., and Knoll, D. (2003), “Minimizing Predictability While Retaining Balance through the Use of Less Restrictive Randomization Procedures,” Statistics in Medicine, 22, 3017–3028. DOI: 10.1002/sim.1538.
- Carter, K., Scheffold, A. L., Renteria, J., Berger, V. W., Luo, Y. A., Chipman, J. J., and Sverdlov, O. (2023), “Regulatory Guidance on Randomization and the Use of Randomization Tests in Clinical Trials: A Systematic Review,” Statistics in Biopharmaceutical Research. DOI: 10.1080/19466315.2023.2239521.
- Cox, D. R. (1982), “A Remark on Randomization in Clinical Trials,” Utilitas Mathematica, 21A, 245–252.
- Dalton, R. (2005), “New Orleans Researchers Fight to Salvage Work from Submerged Labs,” Nature, 437, 300–300. DOI: 10.1038/437300a.
- Ding, P. (2017), “A Paradox from Randomization-Based Causal Inference,” Statistical Science, 32, 331–345. DOI: 10.1214/16-STS571.
- Ding, P., and Li, F. (2018), “Causal Inference: A Missing Data Perspective,” Statistical Science, 33, 214–237. DOI: 10.1214/18-STS645.
- Epstein, L. H., Schechtman, K. B., Kilanowski, C., Ramel, M., Moursi, N. A., Quattrin, T., Cook, S. R., Eneli, I. U., Pratt, C., Geller, N., Campo, R., Lew, D., and Wilfley, D. E. (2021), “Implementing Family-Based Behavioral Treatment in the Pediatric Primary Care Setting: Design of the PLAN Study,” Contemporary Clinical Trials, 109, 106497. DOI: 10.1016/j.cct.2021.106497.
- FDA (2021), “FDA Guidance on Conduct of Clinical Trials of Medical Products During the COVID-19 Public Health Emergency,” available at https://www.fda.gov/regulatory-information/search-fda-guidance-documents/fda-guidance-conduct-clinical-trials-medical-products-during-covid-19-public-health-emergency
- Hawila, N., and Berg, A. (2021), “Assessing the Impact of COVID-19 on Registered Interventional Clinical Trials,” Clinical and Translational Science, 14, 1147–1154. DOI: 10.1111/cts.13034.
- Heussen, N., Hilgers, R.-D., Rosenberger, W. F., Tan, X., and Uschner, D. (2023), “Randomization-Based Inference for Clinical Trials with Missing Outcome Data,” Statistics in Biopharmaceutical Research. DOI: 10.1080/19466315.2023.2250119.
- Hurricane Katrina: What Have We Learned? (2006), Applied Clinical Trials. Available at https://www.appliedclinicaltrialsonline.com/view/hurricane-katrina-what-have-we-learned
- ICH E9(R1) (2021), “E9(R1) Statistical Principles for Clinical Trials: Addendum: Estimands and Sensitivity Analysis in Clinical Trials,” U.S. Food and Drug Administration; FDA. Available at https://www.fda.gov/regulatory-information/search-fda-guidance-documents/e9r1-statistical-principles-clinical-trials-addendum-estimands-and-sensitivity-analysis-clinical
- Imbens, G., and Menzel, K. (2018), “A Causal Bootstrap,” working paper no. 24833; working paper series. National Bureau of Economic Research. DOI: 10.3386/w24833.
- Ivanova, A., Lederman, S., Stark, P. B., Sullivan, G., and Vaughn, B. (2022), “Randomization Tests in Clinical Trials with Multiple Imputation for Handling Missing Data,” Journal of Biopharmaceutical Statistics, 32, 441–449. DOI: 10.1080/10543406.2022.2080695.
- Joudrey, P. J., Kolak, M., Lin, Q., Paykin, S., Anguiano, V., Jr,., and Wang, E. A. (2022), “Assessment of Community-Level Vulnerability and Access to Medications for Opioid Use Disorder,” JAMA Network Open, 5, e227028. DOI: 10.1001/jamanetworkopen.2022.7028.
- Lehmann, E. (1975), Nonparametrics: Statistical Methods Based on Ranks, San Francisco: Holden-Day.
- Lunt, H., and Heenan, H. (2019), “Mitigating the Impact of Disasters and Emergencies on Clinical Trials Site Conduct: A Site Perspective following Major and Minor Unforeseen Events,” Contemporary Clinical Trials Communications, 16, 100487. DOI: 10.1016/j.conctc.2019.100487.
- Mehta, C. R., Patel, N. R., and Senchaudhuri, P. (1988), “Importance Sampling for Estimating Exact Probabilities in Permutational Inference,” Journal of the American Statistical Association, 83, 999–1005. DOI: 10.1080/01621459.1988.10478691.
- Pesarin, F. (2001), Multivariate Permutation Tests: With Applications in Biostatistics, Chichester: Wiley. Available at https://books.google.com/books?id=iKprQgAACAAJ
- Plamadeala, V., and Rosenberger, W. F. (2012), “Sequential Monitoring with Conditional Randomization Tests,” The Annals of Statistics, 40, 30–44. DOI: 10.1214/11-AOS941.
- Rosenberger, W. F., and Lachin, J. M. (2016), Randomization in Clinical Trials—Theory and Practice. Wiley Series in Probability and Statistics (2nd ed.), Hoboken, NJ: Wiley.
- Rubin, R. (2022), “Clinical Trials Disrupted during War in Ukraine,” JAMA, 327, 1535–1536. DOI: 10.1001/jama.2022.5571.
- Rubin, D. B. (1987), Multiple Imputation for Nonresponse in Surveys, pp. i–xxix, New York: Wiley. DOI: 10.1002/9780470316696.fmatter.
- Tamm, M., and Hilgers, R.-D. (2014), “Chronolgical Bias in Randomized Clinical Trials under Different Type of Unobserved Time Trends,” Methods of Information in Medicine, 53, 501–510. DOI: 10.3414/ME14-01-0048.
- Uschner, D. (2021), “Randomization Based Inference in the Presence of Selection Bias,” Statistics in Medicine, 40, 2212–2229. DOI: 10.1002/sim.8898.
- Van Lancker, K., Tarima, S., Bartlett, J., Bauer, M., Bharani-Dharan, B., Bretz, F., Flournoy, N., Michiels, H., Parra, C. O., Rosenberger, J. L., and Cro, S. (2022), “Estimands and their Estimators for Clinical Trials Impacted by the COVID-19 Pandemic: A Report from the NISS Ingram Olkin Forum Series on Unplanned Clinical Trial Disruptions,” arXiv: 2202.03531. DOI: 10.48550/arXiv.2202.03531.
- Yale University. (2022), “Disasters Could Disrupt Care For Opioid Use Disorder in Most Vulnerable Communities: Medical Services Often Don’t Go Where They Are Most Needed,” ScienceDaily, available at https://www.sciencedaily.com/releases/2022/04/220419140737.htm
- Wang, Y., Rosenberger, W. F., and Uschner, D. (2020), “Randomization Tests for Multiarmed Randomized Clinical Trials,” Statistics in Medicine, 39, 494–509. DOI: 10.1002/sim.8418.
- Zhang, L., and Rosenberger, W. F. (2011), “Adaptive Randomization in Clinical Trials,” in Design and Analysis of Experiments, Vol. 3: Special Designs and Applications, ed. K. Hinkelmann, pp. 251–282, Hoboken, NJ: Wiley. Available at https://books.google.com/books?id=gKEpcJnqOc8C