
Abstract
When we examine the National Land Cover Database 2006 (NLCD 2006) in a small scale, we find out that there are only 4.5 ha (50 pixels) of emergent herbaceous wetlands in Athens-Clarke County, Georgia. In order to testify that it is not simply due to mapping error or uncertainty, we propose a geographic knowledge discovery (GKD) process based on NLCD. The GKD process consists of data preparation, data preprocessing, feature extraction and knowledge consolidation. A case study ‘What geomorphological characteristics accommodate emergent herbaceous wetlands in North Georgia’ is presented to illustrate the process. Geomorphological characteristics refer to digital elevation model (DEM) and eight DEM-derived variables, which are proxies to geomorphological conditions. Geographic data are inherently spatial dependent and heterogeneous and such properties are considered in data preparation. In feature extraction, the goal of the study and the nature of the data are taken into consideration to select a suitable algorithm. In knowledge consolidation, three steps of validation – with statistics, cross-validation and field survey – are presented. The proposed methods can be extended to GKD from NLCD for other purposes. The GKD results testify that the small area of emergent herbaceous wetlands in Athens-Clarke County, Georgia, is not due to mapping error or uncertainty. The case study also proves that See5 algorithm performs very well to extract the learned knowledge. The procedure that we propose with NLCD can be applied to other environmental monitoring purpose.
1. Introduction
In 2000, the US Geological Survey (USGS) EROS Data Center released the 1992 National Land Cover Dataset (NLCD) (Vogelmann et al. Citation2001). It is the first 30 m × 30 m land cover product for the continental United States, though the overall accuracies at Level II and Level I are only 58% and 80%, respectively (Wickham et al. Citation2010). After the initial NLCD 1992, newer versions of NLCD 2001 and NLCD 2006 are released. NLCD 2001 is built upon the success of NLCD 1992 by incorporating Alaska, Hawaii, and Puerto Rico into the product (Homer et al. Citation2007). It introduces a database concept to land cover mapping through inclusion of percentages of urban impervious surface and forest canopy cover, and improves the methods used for land cover classification with improved overall accuracies at Level II and Level I of 78.7% and 85.3%, respectively (Wickham et al. Citation2010). NLCD 2006 is built upon NLCD 2001 by incorporating land cover and impervious surface change for the continental United States (Xian and Homer Citation2010). The accuracy assessment of NLCD 2006 was conducted by selecting a stratified random sample of pixels with the reference classification interpreted from multi-temporal high resolution digital imagery (Wickham et al. Citation2013). The Level II () and Level I overall accuracies for NLCD 2006 are 78% and 84%, respectively, with Level II user’s accuracies exceeding 80% for water, high density urban, all upland forest classes, shrub land and cropland (Wickham et al. Citation2013). However, when we examine the NLCD products in a finer scale, we see that there are only 4.5 ha (50 pixels) of Class 95, emergent herbaceous wetlands in NLCD 2006 of Athens-Clarke County, Georgia. Why the area of Class 95 here is so small? We are interested in finding out whether this particular land cover class does have a small area in the county or is caused by mapping error or uncertainty. The investigation process leads to a geographic knowledge discovery (GKD) procedure.
Table 1. NLCD 2006 Level II class codes and definitions (Web Reference 1).
On the other hand, we see accuracy assessment of NLCD products is an established protocol of the NLCD mapping process and has been conducted widely with different sampling (Stehman et al. Citation2003; Wickham, Stehman, Smith, Wade, and Yang Citation2004) at different scales with diversified ground truth references (Stehman and Selkowitz Citation2010; Stehman et al. Citation2008; Wickham, Stehman, Smith, and Yang Citation2004). Results indicate that NLCD products are consistent in spatial patterns, with great overall accuracies nationwide. Moreover, compared to the raw data of Landsat imagery, NLCD products concern specific features/classes and contain specialized domain knowledge. They are created by experts’ joint efforts from Environmental Protection Agency (EPA), National Oceanic and Atmospheric Administration (NOAA), United States Forest Service (USFS), USGS, Bureau of Land Management (BLM), National Park Service (NPS), National Aeronautics and Space Administration (NASA), US Fish and Wildlife Service (USFWS), National Agricultural Statistics Service (NASS) and US Army Corps of Engineers through systematic modelling processes and thus convey update knowledge about detailed land use status nationwide.
As a nationally covered, current, consistent and public domain data set on the US land cover, NLCD products have been regarded as knowledge and applied to local, state and federal scales. The knowledge of NLCD is valuable in at least three ways. First, it is consolidated by the tank of experts and follows the same protocol across time. It is very unlikely that a single research group has the budget, time and human resources to redo the similar procedures of the whole country with the similar (if no better than) accuracies. On the other hand, obeying the same product protocol, it stimulates studies considering environmental and civil monitoring over decades. Second, it has the potential to guide the land use map updates. Updating land use maps via conventional field survey is time consuming and expensive. Although land use stresses the human use of the land, land cover emphasizes the biophysical status of the earth’s surface, land cover can guide land use mapping. Using NLCD as a guideline, it will cost less to find the target area and then using field survey for verification. Finally, the knowledge of NLCD products, once extracted and formulated, can be tight or loose coupled with GIS mapping and modelling without major additional efforts since it is already in a commonly used format.
Data mining and knowledge discovery has been successfully used to extract information from geographic data (Miller and Han Citation2009). In recent decade, the presence of higher performance computers in conjunction with the availability and accessibility of more geospatial data make it possible to discover knowledge from geospatial data. In this paper, in order to find out possible reasons why Class 95 in NLCD 2006 of Athens-Clarke County, Georgia, is so sparse, we present a knowledge discovery procedure using machine learning to extract the knowledge embedded in the NLCD 2006 product. We use a subset of NLCD 2006 in North Georgia area, to see how geomorphological characteristics derived from Digital Elevation Models (DEM) accommodate Emergent Herbaceous Wetlands (NLCD Level II, Class 95).
2. Methods: GKD
Knowledge discovery from database (KDD) can be defined as ‘the non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns in data’ (Fayyad, PiatetskyShapiro, and Smyth Citation1996, 40–41). Following the intelligence hierarchy of data-information-evidence-knowledge-wisdom, which is well accepted in GIScience (Longley et al. Citation2010), KDD is more than data mining as it involves obtaining information through data mining and distilling the information into knowledge through interpretation and interrogation with experts’ knowledge. KDD is beyond traditional statistics-based methods as it does not require either strict assumptions or a priori information. GKD is a unique type of KDD because (1) it should be considered in the frameworks of topology and geometry, as geographic information is inherently interdependent in dimensions; (2) it requires considering spatial dependency and heterogeneity, which are the fundamental natures of geographic data; (3) it follows sophisticated spatial-temporal objects and rules, which are more complicated than the object-relationship data prototype in non-geographic databases; and (4) it needs to accommodate diversified geospatial data types (Miller and Han Citation2009). GKD procedure includes four major steps: data preparation, data preprocessing, feature extraction and knowledge consolidation. The four steps are elaborated in the following subsections using the North Georgia NLCD 2006 data in this project.
2.1. Data preparation: scale and purpose
Geographic data inherently enjoy the properties of spatial dependency and heterogeneity. Spatial dependency is the tendency that objects exhibit similar attributes as they are geographically nearer – the essential idea depicted in Tobler’s First Law of Geography. Spatial heterogeneity refers to most geographic processes that are non-stationary. Due to the uniqueness of geographic locations, global estimates from the geographic database cannot accurately describe geospatial phenomenon in local scales. In order to extract knowledge from NLCD 2006 concerning emergent herbaceous wetlands in North Georgia, we subset the downloaded NLCD 2006 product (Web Reference 2) into a regional scale – North Georgia and North Georgia only (). The boundary data of North Georgia are obtained from Georgia GIS Clearinghouse (Web Reference 3).
Figure 1. A subset of NLCD 2006 product of North Georgia area.
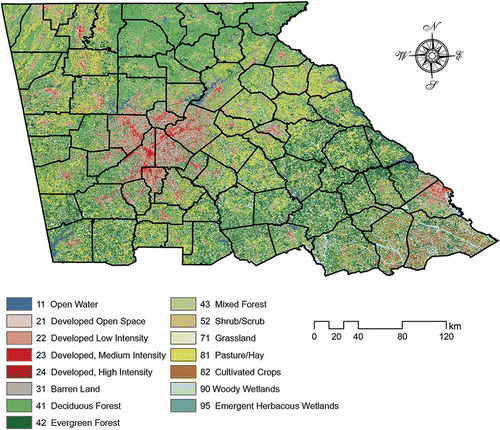
Emergent herbaceous wetlands refer to places where perennial herbaceous vegetation accounts for greater than 80% of vegetative cover and the soil or substrate is periodically saturated with or covered with water. The formation of emergent herbaceous wetlands is related to various environmental factors other than soils and hydrology, including climate, biology, geomorphology, vegetation and human activities (Batzer and Sharitz Citation2006). Geomorphology characteristics or topography features are relatively stable across time and DEM are often used as proxies of geomorphological characteristics, landscape features and land cover (Wood Citation1996). Given the abundance of available and accessible DEM data, we choose to use DEM and DEM-derived Geomorphological Characteristics (details are shown in Section 3) to finish the GKD task. National Elevation Dataset of 3, 10 and 30 metre spatial resolution are accessible at Web Reference 4. To accommodate the spatial resolution of NLCD 2006 product, the National Elevation Dataset of North Georgia at 30 metre is downloaded.
2.2. Data preprocessing: compilation to a GIS database
Date preprocessing generally involves ‘cleaning’ the selected data and noise removal to eliminate duplicate records and handle missing data fields. In our case, we first mosaicked 27 tiles of DEM of Georgia. Second, eight DEM-derived geomorphological metrics, namely aspect, profile convexity, plan convexity, longitudinal convexity, cross-sectional convexity, minimum curvature, maximum curvature and slope (percent) are generated (details in Section 3). Third, all the layers abovementioned and the selected NLCD 2006 product are re-projected to the spatial reference of NAD_1983_UTM_Zone_17N. Finally, all the source data are put into GIS database.
2.3. Feature extraction: the outcome of data mining
Feature extraction through data mining refers to the application of low-level functions for revealing hidden information in a database (Klösgen and Zytkow Citation2002). It is the core part of GKD. Various data mining algorithms have been developed, including decision trees, naïve Bayesian classification, artificial neural networks, support vector machines, random forests and so forth (Miller and Han Citation2009; Tayyebi and Pijanowski Citation2014; Ziegler and König Citation2014). However, choosing a suitable learning algorithm for a specific GKD task is determined at least by the data source and knowledge representation.
Decision trees, named after their tree-like graphic representation of results, are decision support tools that generate an assignment for each data item with respect to a set of known classes. Decision trees are widely applied in geography, especially in GKD (Ai et al. Citation2013; Champagne et al. Citation2014; Chee and Elith Citation2012; Costa et al. Citation2014; Lam Citation2012; Li, Wang, and Wang Citation2005; Qi and Zhu Citation2003; Wan, Lei, and Chou Citation2012; Wu et al. Citation2009). GKD with decision trees usually requires less assumption about parameters and data distribution; plus it is capable to handle a certain level of noise. More importantly, the conditional logic and representation of decision trees are easy to understand.
In our study, See5 algorithm (Quinlan Citation1986, Citation1993, Citation2004) is applied to generate decision trees from training data for the following three reasons. First, See5 implements decision tree in rulesets, which is generally easier to understand than trees since each rule describes a specific context associated with a class. Moreover, a ruleset generated from a tree usually has fewer rules than that tree with leaves, which increases comprehensibility. Second, See5 employs adaptive boosting (Freund and Schapire Citation1996). Boosting refers to generating several rulesets rather than just one. When a new case is to be classified, each classifier votes for its predicted class and the votes are counted to determine the final class. Trials over numerous data sets show that on average 10-classifier boosting reduces the error rate for test cases by about 25% (Quinlan Citation1993, Citation2004). Finally, See5 implements fuzzy threshold, which is more tolerant to the noise and uncertainty in thresholds.
2.4. Knowledge consolidation
The final step of GKD is to validate and consolidate the knowledge from extracted features. In our study, the learned rulesets are first testified using independent samples from the same database to ensure the learning accuracies. Second, we also run different boosting scenarios to further validate the data mining results. Once the accuracy meets the demand, further verification by field survey are conducted with selected areas. Finally, the learned rulesets are approximately ready to be interpreted and documented.
Abovementioned steps are the basic process of GKD in our study. The actual process can contain iterations and trails and errors. We emphasize that the four steps are integral and of equal importance, though most previous studies on GKD primarily focused on data mining algorithms.
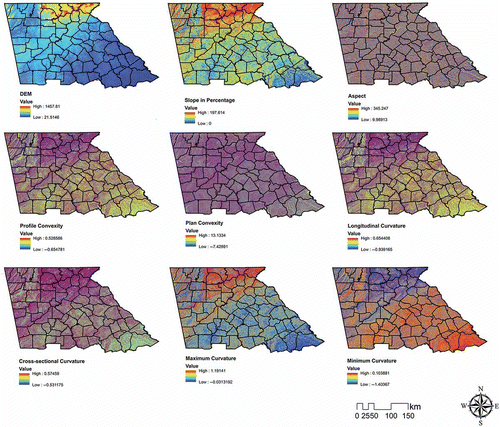
3. DEM and DEM-derived geomorphological characteristics
There are numerous ways to define DEM. Mathematically, one representation of DEM can be simplified as in Equation (1), where DEM (z) is defined as a regular two-dimensional matrix (i.e. x and y) of heights sampled above some datum that describes a surface (Wood Citation1996).
Table 2. Definitions and expressions DEM-derived geomorphological characteristics (GC).
Figure 2. DEM and DEM-derived geomorphological characteristics for the study area.
4. A case study: what geomorphological characteristics accommodate emergent herbaceous wetlands in North Georgia?
What wetlands to the earth is what the kidneys to human beings. Wetlands are critical to both the balanced ecosystems and our welfares. There have been intense discussions of wetlands-related issues in the ecological society. The 100th anniversary of the British Ecological Society in 2013 provides to identify 100 important questions from the 754 questions submitted from 388 ecology experts of fundamental importance in pure ecology (Sutherland et al. Citation2013). Wetlands-related problem are identified in both ‘ecosystems and functions’ and ‘human impacts and global change’ panels of the 100 questions; while the GKD procedure that we present can be an additive to the ‘methods’ panel to solve those 100 fundamental ecological problems.
Emergent herbaceous wetlands (Class 95) are crucial because they can be regarded as indicators that suggest subtle environmental changes, though they are usually ephemeral compared to woody wetlands (Class 90). Therefore, the primary goal of our study is to get the knowledge that what geomorphological characteristics accommodate emergent herbaceous wetlands rather than woody wetlands in North Georgia through GKD.
The study area of North Georgia consists of 76 counties (), with 79,426 points (30 m × 30 m) of emergent herbaceous wetlands and 284,378 points (30 m × 30 m) of woody wetlands. A requirement of See5 algorithm is to set a certain number of labelled samples. Each labelled sample is a recording containing all variables and one label. In our study, variables are all relevant geomorphological characteristics, i.e. DEM, slope, aspect, cross-sectional convexity, profile convexity, longitudinal convexity, plan convexity, maximum curvature and minimum curvature; while the label is either ‘Class 90’ or ‘Class 95’. Then, a labelled sample database is constructed with 786 (approximately 2.1‰) randomly selected records. They are divided equally – half of them are set as labelled samples for constructing the See5 learning algorithm and the other half of them are used to validate the learning results.
5. GKD results and discussion of the case study
We set nine scenarios with the boosting number of 10, 20, 30, 40, 50, 60, 70, 80 and 90. A general assumption is that the noise that might be presented in NLCD 2006 product or DEM (and/or the geomorphological characteristics derived from DEM) is neglected. First, we try to evaluate the learned knowledge from See5 algorithm with both labelled samples and validation samples in nine scenarios, without considering the benefits of boosting. Second, the adjusted results by boosting are assessed. Third, the kappa coefficients of each learning scenario are presented. Fourth, the knowledge of relatively importance of ‘what geomorphological characteristics accommodate emergent herbaceous wetlands in North Georgia’ is generated. Finally, we select a county of North Georgia – Athens-Clarke county– as a sample field survey to demonstrate the process of testifying and consolidating the knowledge with ground truth.
An example result of rulesets by See5 algorithm is shown in , where the boosting number is set to 90. There are four mutually exclusive rules in the rulesets. The order of rules does not count. For each rule, the parameters in the parenthesis summarize its performance. In (N) or (N/M), N denotes the number of labelled samples covered by the rule; M denotes the number of labelled samples which should not belong to the rule, however is predicted by the rule; the number in the square brackets shows the confident level with which the rule of prediction is made.
Table 3. An example of rulesets-based learning results by labelled samples.
Then learning outcomes of the nine scenarios without the benefits of boosting are assessed with both labelled samples themselves and validation samples (). We see the average errors concerning both labelled samples and validation samples are no more than 4.1%, which indicates that on average the learning algorithm in this GKD process is over 95.9%.
Table 4. Nine scenarios of See5 learning algorithm without boosting.
As mentioned in Section 2, one advantage of See5 algorithm is its adaptive boosting feature, in which generally more rulesets are constructed to make it more robust. shows the evaluation of See5 performance from labelled samples themselves and validation samples with different boosting numbers.
Obviously, with the benefit of adaptive boosting, in most cases the errors in labelled samples trend towards 0, whose average is only 0.2. Considering the validation samples, the overall accuracy is 96.91%, which is slightly larger than that without boosting. By assessing the labelled samples which generate the See5 results and the validation samples with and without boosting, the overall accuracy tells the effectiveness about See5. Then kappa coefficient () is produced for further analysis. Unlike overall accuracy ( and ), kappa coefficients are commonly used to discriminate categorical data, comparing the accuracy with cases generated from random assignment of labelled samples. This provides another angle to see the algorithm’s performance. We see in different scenarios that the kappa coefficient ranges from 71.3% to 86.9%, with an average of 78.7%, which is a pretty good result.
Table 6. See5 learning algorithm evaluations with adaptive boosting.
Table 5. Kappa coefficient for each scenario.
As an integral part of GKD process, we want to know what is the relative importance order of different geomorphological characteristics accommodate emergent herbaceous wetlands in North Georgia and consolidate it into knowledge for future reference. Hence, a comprehensive comparison and rank of the frequency and the relative weight of each geomorphological characteristic are shown in . Frequency denotes the times of presence of the geomorphological characteristic in nine scenarios. However, in each scenario, every geomorphological characteristic is not equally contributed to the final rulesets; it is necessary to calculate their importance globally. Therefore, adjusted weight is computed by weighting each variable’s contribution in the total nine scenarios. To some degree, we see that the overall rank patterns generated from both frequency and adjusted weights are consistent with each other: DEM is the leading contributor to the knowledge of accommodating emergent herbaceous wetlands in North Georgia, followed by slope and aspect. Then it comes to plain convexity, minimum curvature and maximum curvature. The least contributing geomorphological characteristic here is the plan convexity, with the least ranks in both metrics. One interesting phenomenon is that considering longitudinal convexity and cross-sectional convexity, they do contribute in the majority of scenarios, with 6 and 7 times out of 9, respectively; however, each time the degree of their contribution is trivial, with the adjusted weight of 7.54% and 7.20%, respectively.
Table 7. Rank of geomorphological characteristics in the GKD process.
Considering statistical results from to , plus the expertise from wetland ecology professionals, the learned knowledge with 24 rules that what geomorphological characteristics accommodate emergent herbaceous wetlands in North Georgia is consolidated ().
Table 8. Consolidated knowledge of rulesets.
Finally, we used our knowledge from the GKD process to testify at subset of study area – Athens-Clarke County. In , we extract the location information from all the 50 points of emergent herbaceous wetlands in NLCD 2006 product, shown in crosses. We then find out that the entire 50 points satisfy our learned knowledge in . With scrutiny, we take two more steps verifications. First, one tile of the National Agriculture Imagery Program (NAIP) in 2009 (1 metre spatial resolution) is downloaded as background image for visual interpretation.
Figure 3. Sites of emergent herbaceous wetlands in Athens-Clarke County, Georgia.
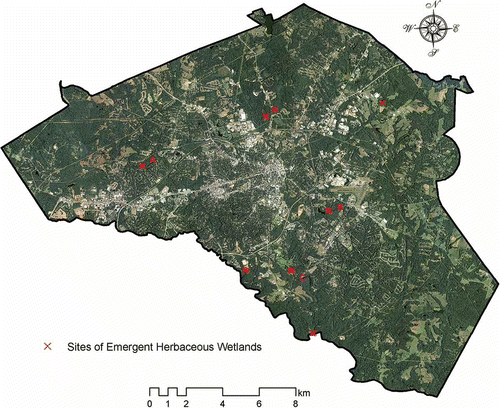
Even from high-resolution remote sensed imagery, we cannot easily identify the emergent herbaceous wetlands from their surrounding forests, as they are quite similar visually. Noting that the 50 points are grouped into 8 regions, an alternative way of verification is taken. We tried to reach each of the 8 regions; however, 5 out of them are private lands, which we were not able to step into. The three sites (i.e. A, B and C in ) that we accessed are composed with 5, 7 and 8 points, respectively. All photos () are taken on 24 February 2013.
Figure 4. Photos for the three sites.

6. Conclusions and future work
Examining the NLCD 2006 in a small scale, we find out that there are only 4.5 ha (50 pixels) of emergent herbaceous wetlands in Athens-Clarke County, Georgia. In order to testify that it is not simply due to mapping error or uncertainty, this paper introduced a GKD process from NLCD. A case study ‘What geomorphological characteristics accommodate emergent herbaceous wetlands in North Georgia’ using NLCD 2006 and DEM was then presented as an illustration to this process. The GKD results testify that the small area of emergent herbaceous wetlands in Athens-Clarke County, Georgia, is not due to mapping error or uncertainty with statistical validation, cross-validation and field validation. Moreover, each release of the Multi Resolution Land Characteristics (MRLC) consortium NLCD has represented an advance in Landsat-based land cover mapping. NLCD is consolidated by the tank of experts and follows the same protocol across time. Additionally, it has the potential to guide the land use map updates. Finally, the knowledge of NLCD products, once extracted and formulated, can be used for mapping and modelling automatically.
The GKD process we proposed includes four components: data preparation, data preprocessing, feature extraction and finally knowledge consolidation with detailed illustration in the case study. In data preparation, the study purpose and scale determine what portion of data should be applied, since geographic data inherently enjoy the properties of spatial dependency and heterogeneity. During the data preprocessing stage, it is very critical to filter the outliers and clean the data, then compile them into a GIS database for effective management with efficiency. In the feature extraction stage, when choosing from diverse machine learning algorithms, the goal of the study and the nature of the data applied should be always taken into consideration. Here we used See5 algorithm, because (1) the rulesets representation are easier to understand and consolidate into knowledge for documentation; (2) adaptive boosting can actually improve the performance of GKD; and (3) the application of fuzzy thresholds highly simulates the real situation in the fields. Due to the spatial dependent nature of geographic data, it is critical to follow a probability sampling scheme such as random sampling, systematic sampling and stratified sampling, when selecting labelled samples for training and validating in the feature extraction stage. In the final state – knowledge consolidation – we propose the following three validations before documenting the knowledge: first, test the learned knowledge statistically (in the case study, we compared the overall accuracy in nine different scenarios with and without adaptive boosting and kappa coefficients); second, cross-validate the learned knowledge with other sources of geospatial information (in the case study, we made visual comparisons with high-resolution remote sensed imagery); finally, verification with ground truth – to see is to believe.
A new Comprehensive Change Detection Method (CCDM) is designed as a key component for the development of NLCD 2011, providing critical information on location, magnitude and direction of potential change areas, and serving as a basis for further characterizing land cover changes for the nation (Jin et al. Citation2013). At the same time, how to assess NLCD products is a long standing effort, such as how to prioritize among many accuracy assessment objectives in the face of cost constraints (Stehman et al. Citation2008), how to scale the information in error matrices to estimate the accuracy of land cover proportions over much larger areas (Stehman Citation2009), and the role of the spatial unit that is used to assess agreement (Stehman and Wickham Citation2011).
In the future, we are planning to use finer resolution DEM data, such as 10 metre resolution DEM form aerial photos and 1 metre DEM from LiDAR cloud points, and try to incorporate DEM derived topographical features, i.e. ridge, peak, pass, plane, channel and pit (Wood Citation1996) into the current GKD process. We will also compare NLCD 2011 with global land cover mapping data (Gong et al. Citation2013) and then adopt them into the GKD process to obtain more knowledge and benefit from NLCD products.
Web Reference (Last visited: 1 January 2014)
Product Legend of the National Land Cover Database 2006 (NLCD 2006), Sioux Falls, SD, USA. Accessed December 2013. http://www.mrlc.gov/nlcd06_leg.php
Product Overview of the National Land Cover Database 2006 (NLCD 2006), Sioux Falls, SD, USA. Accessed December 2013. http://www.mrlc.gov/nlcd2006.php
Georgia GIS Clearinghouse for Map Data & Aerial Photography, GA, USA. Accessed December 2013. https://data.georgiaspatial.org/
United States Department of Agriculture (USDA) Natural Resources Conservation Service, Geospatial Data Gateway, Washington, DC, USA. Accessed December 2013. http://datagateway.nrcs.usda.gov
References
- Ai, L., N. F. Fang, B. Zhang, and Z. H. Shi. 2013. “Broad Area Mapping of Monthly Soil Erosion Risk Using Fuzzy Decision Tree Approach: Integration of Multi-Source Data within GIS.” International Journal of Geographical Information Science 27 (6): 1–17. doi:10.1080/13658816.2012.752095.
- Batzer, D. P., and R. R. Sharitz. 2006. Ecology of Freshwater and Estuarine Wetlands. Berkeley: University of California Press.
- Champagne, C., H. McNairn, B. Daneshfar, and J. Shang. 2014. “A Bootstrap Method for Assessing Classification Accuracy and Confidence for Agricultural Land Use Mapping in Canada.” International Journal of Applied Earth Observation and Geoinformation 29: 44–52. doi:10.1016/j.jag.2013.12.016.
- Chee, Y. E., and J. Elith. 2012. “Spatial Data for Modelling and Management of Freshwater Ecosystems.” International Journal of Geographical Information Science 26 (11): 2123–2140. doi:10.1080/13658816.2012.717628.
- Costa, H., H. Carrão, F. Bação, and M. Caetano. 2014. “Combining Per-Pixel and Object-Based Classifications for Mapping Land Cover over Large Areas.” International Journal of Remote Sensing 35 (2): 738–753. doi:10.1080/01431161.2013.873151.
- Fayyad, U., G. PiatetskyShapiro, and P. Smyth. 1996. “From Data Mining to Knowledge Discovery in Databases.” AI Magazine 17 (3): 37–54.
- Freund, Y., and R. E. Schapire. 1996. “Experiments with a New Boosting Algorithm.” Paper presented at the Machine Learning-International Workshop then Conference, Bari, July 3–6.
- Gong, P., J. Wang, L. Yu, Y. Zhao, Y. Zhao, L. Liang, J. Chen, et al. 2013. “Finer Resolution Observation and Monitoring of Global Land Cover: First Mapping Results with Landsat TM and ETM+ Data.” International Journal of Remote Sensing 34 (7): 2607–2654. doi:10.1080/01431161.2012.748992.
- Homer, C., J. Dewitz, J. Fry, M. Coan, N. Hossain, C. Larson, and J. Wickham. 2007. “Completion of the 2001 National Land Cover Database for the Counterminous United States.” Photogrammetric Engineering and Remote Sensing 73 (4): 337.
- Jin, S., L. Yang, P. Danielson, C. Homer, J. Fry, and G. Xian. 2013. “A Comprehensive Change Detection Method for Updating the National Land Cover Database to Circa 2011.” Remote Sensing of Environment 132: 159–175. doi:10.1016/j.rse.2013.01.012.
- Klösgen, W., and J. Zytkow. 2002. Handbook of Knowledge Discovery and Data Mining. Oxford: Oxford University Press.
- Lam, N. S.-N. 2012. “Geospatial Methods for Reducing Uncertainties in Environmental Health Risk Assessment: Challenges and Opportunities.” Annals of the Association of American Geographers 102 (5): 942–950. doi:10.1080/00045608.2012.674900.
- Li, L., J. Wang, and C. Wang. 2005. “Typhoon Insurance Pricing with Spatial Decision Support Tools.” International Journal of Geographical Information Science 19 (3): 363–384. doi:10.1080/13658810412331317742.
- Longley, P. A., M. F. Goodchild, D. J. Maguire, and D. W. Rhind. 2010. Geographic Information Systems and Science. 3rd ed. Hoboken, NJ: John Wiley & Sons.
- Miller, H. J., and J. Han. 2009. Geographic Data Mining and Knowledge Discovery. Boca Raton, FL: CRC Press LLC.
- Qi, F., and A. X. Zhu. 2003. “Knowledge Discovery from Soil Maps Using Inductive Learning.” International Journal of Geographical Information Science 17 (8): 771–795. doi:10.1080/13658810310001596049.
- Quinlan, R. 1986. “Induction of Decision Trees.” Machine Learning 1 (1): 81–106. doi:10.1007/BF00116251.
- Quinlan, R. 1993. C4. 5: Programs for Machine Learning (Vol. 1). San Francisco, CA: Morgan Kaufmann Publishers.
- Quinlan, R. 2004. “Data Mining Tools See5 and C5.0.” Accessed December 31, 2013. http://www.rulequest.com/index.html
- Stehman, S. V. 2009. “Sampling Designs for Accuracy Assessment of Land Cover.” International Journal of Remote Sensing 30 (20): 5243–5272. doi:10.1080/01431160903131000.
- Stehman, S. V., and D. J. Selkowitz. 2010. “A Spatially Stratified, Multi-Stage Cluster Sampling Design for Assessing Accuracy of the Alaska (USA) National Land Cover Database (NLCD).” International Journal of Remote Sensing 31 (7): 1877–1896. doi:10.1080/01431160902927945.
- Stehman, S. V., and J. D. Wickham. 2011. “Pixels, Blocks of Pixels, and Polygons: Choosing a Spatial Unit for Thematic Accuracy Assessment.” Remote Sensing of Environment 115 (12): 3044–3055. doi:10.1016/j.rse.2011.06.007.
- Stehman, S. V., J. D. Wickham, J. H. Smith, and L. Yang. 2003. “Thematic Accuracy of the 1992 National Land-Cover Data for the Eastern United States: Statistical Methodology and Regional Results.” Remote Sensing of Environment 86 (4): 500–516. doi:10.1016/S0034-4257(03)00128-7.
- Stehman, S. V., J. D. Wickham, T. G. Wade, and J. H. Smith. 2008. “Designing a Multi-Objective, Multi-Support Accuracy Assessment of the 2001 National Land Cover Data (NLCD 2001) of the Conterminous United States.” Photogrammetric Engineering and Remote Sensing 74 (12): 1561–1571. doi:10.14358/PERS.74.12.1561.
- Sutherland, J. S., P. F. Freckleton, H. C. J. Godfray, R. B. Beissinger, B. Benton, D. C. Cameron, G. Carmel, et al. 2013. “Identification of 100 Fundamental Ecological Questions.” Journal of Ecology 101 (1): 58–67. doi:10.1111/1365-2745.12025.
- Tayyebi, A., and B. C. Pijanowski. 2014. “Modeling Multiple Land Use Changes Using ANN, CART and MARS: Comparing Tradeoffs in Goodness of Fit and Explanatory Power of Data Mining Tools.” International Journal of Applied Earth Observation and Geoinformation 28: 102–116. doi:10.1016/j.jag.2013.11.008.
- Vogelmann, J. E., S. M. Howard, L. M. Yang, C. R. Larson, B. K. Wylie, and N. Van Driel. 2001. “Completion of the 1990s National Land Cover Data Set for the Conterminous United States from Landsat Thematic Mapper Data and Ancillary Data Sources.” Photogrammetric Engineering and Remote Sensing 67 (6): 650–662.
- Wan, S., T.-C. Lei, and T.-Y. Chou. 2012. “A Landslide Expert System: Image Classification through Integration of Data Mining Approaches for Multi-Category Analysis.” International Journal of Geographical Information Science 26 (4): 747–770. doi:10.1080/13658816.2011.613397.
- Wickham, J. D., S. V. Stehman, J. A. Fry, J. H. Smith, and C. G. Homer. 2010. “Thematic Accuracy of the NLCD 2001 Land Cover for the Conterminous United States.” Remote Sensing of Environment 114 (6): 1286–1296. doi:10.1016/j.rse.2010.01.018.
- Wickham, J. D., S. V. Stehman, L. Gass, J. Dewitz, J. A. Fry, and T. G. Wade. 2013. “Accuracy Assessment of NLCD 2006 Land Cover and Impervious Surface.” Remote Sensing of Environment 130: 294–304. doi:10.1016/j.rse.2012.12.001.
- Wickham, J. D., S. V. Stehman, J. H. Smith, T. G. Wade, and L. Yang. 2004. “A Priori Evaluation of Two-Stage Cluster Sampling for Accuracy Assessment of Large-Area Land-Cover Maps.” International Journal of Remote Sensing 25 (6): 1235–1252. doi:10.1080/0143116031000149998.
- Wickham, J. D., S. V. Stehman, J. H. Smith, and L. Yang. 2004. “Thematic Accuracy of the 1992 National Land-Cover Data for the Western United States.” Remote Sensing of Environment 91 (3–4): 452–468. doi:10.1016/j.rse.2004.04.002.
- Wood, J. D. 1996. “The Geomorphological Characterisation of Digital Elevation Models.” PhD thesis, University of Leicester. http://www.soi.city.ac.uk/~jwo/phd
- Wu, S.-S., X. Qiu, E. L. Usery, and L. Wang. 2009. “Using Geometrical, Textural, and Contextual Information of Land Parcels for Classification of Detailed Urban Land Use.” Annals of the Association of American Geographers 99 (1): 76–98. doi:10.1080/00045600802459028.
- Xian, G., and C. Homer. 2010. “Updating the 2001 National Land Cover Database Impervious Surface Products to 2006 using Landsat Imagery Change Detection Methods.” Remote Sensing of Environment 114 (8): 1676–1686. doi:10.1016/j.rse.2010.02.018.
- Ziegler, A., and I. R. König. 2014. “Mining Data with Random Forests: Current Options for Real-World Applications.” Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 4 (1): 55–63. doi:10.1002/widm.1114.