
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Spatiotemporal movement pattern discovery has stimulated considerable interest due to its numerous applications, including data analysis, machine learning, data segmentation, data reduction, abnormal behaviour detection, noise filtering, and pattern recognition. Trajectory clustering is among the most widely used approaches of extracting interesting patterns in large trajectory datasets. In this paper, regarding the optimal performance of density-based clustering, we present a comparison between eight similarity measures in density-based clustering of moving objects’ trajectories. In particular, Distance Functions such as Euclidean, L1, Hausdorff, Fréchet, Dynamic Time Warping (DTW), Longest Common SubSequence (LCSS), Edit Distance on Real signals (EDR), and Edit distance with Real Penalty (ERP) are applied in DBSCAN on three different datasets with varying characteristics. Also, experimental results are evaluated using both internal and external indices. Furthermore, we propose two modified validation measures for density-based trajectory clustering, which can deal with arbitrarily shaped clusters with different densities and sizes. These proposed measures were aimed at evaluating trajectory clusters effectively in both spatial and spatio-temporal aspects. The evaluation results show that choosing an appropriate Distance Function is dependent on data and its movement parameters. However, in total, Euclidean distance proves to show superiority over the other Distance Functions regarding the Purity index and EDR distance can provide better performance in terms of spatial and spatio-temporal quality of clusters. Finally, in terms of computation time and scalability, Euclidean, L1, and LCSS are the most efficient Distance Functions.
1. Introduction
Remarkable developments in information and communication technologies such as wireless networks and mobile computing devices along with the significant increase in accuracy of positioning services have led to the collection of massive volumes of moving objects’ trace data. Performing data analysis over traces of moving objects, e.g. citizens, vehicles, and animals leads to useful information about movement patterns. Pattern extraction play an essential role in many applications including traffic control, urban planning, smart transportation, and biological studies (Basiri, Amirian, and Mooney Citation2016; Yuan et al. Citation2017; Zheng et al. Citation2009; Mahdavinejad et al. Citation2018) which has captured lots of attention over the last two decades.
The term spatial trajectory refers to a special kind of time series in which the location of a moving object has been captured at specific instances of time (Georgiou et al. Citation2018). Generally, spatial trajectories are represented by a sequence of timestamped locations as follows (Aghabozorgi, Shirkhorshidi, and Wah Citation2015):
where idk is the location identifier, lock is the position at the time tk, and Ak is other descriptive data related to the point.
In order to extract useful patterns out of trajectory data with huge volume, different methods such as clustering and classification are usually applied. Clustering is an unsupervised learning method, associating data in groups (clusters) based on their distance. (Han, Pei, and Kamber Citation2011; Xu and Wunsch Citation2005). The aim of trajectory clustering is categorizing a trajectory dataset in groups of clusters based on their movement characteristics. Trajectories existing in each cluster have similar movement characteristics or behaviour to one another within the same cluster and dissimilar to the trajectories in other clusters (Berkhin Citation2006; Besse et al. Citation2015; Yuan et al. Citation2017).
Generally, two main approaches can be employed for clustering complex data like trajectories. First, defining trajectory-specific clustering algorithms and second, using generic clustering algorithms which utilizes trajectory-specific Distance Functions (DFs). The latter encapsulated the specifics of the trajectory data are in DFs (Andrienko and Andrienko Citation2010). Some generic clustering algorithms like K-means are only able to extract clusters with a convex shape, and they are also unstable against outliers. However, it is clear that trajectory clusters are of arbitrary shape (concave, drawn-out, linear, elongated), and their datasets are much capable of having outliers. One of the most suitable clustering methods for trajectories is density-based clustering (Kriegel et al. Citation2011) which can extract clusters with arbitrary shape and is also tolerant against outliers(Ester et al. Citation1996). Density-Based Spatial Clustering of Applications with Noise (DBSCAN) is one of the most popular methods among this family, which is widely employed in trajectory clustering (Zhao and Shi Citation2019; Cheng et al. Citation2018; Chen et al. Citation2011b; Lee, Han, and Whang Citation2007).
Measuring the similarity is the central core of the clustering problem; therefore, similarity (inverse of distance) should be determined before grouping. Distance definition in spatial trajectories is much more complicated than point data. Trajectories are sequences of points in several dimensions that are not of the same length. Thus, in order to compare two trajectories, a comprehensive approach is needed to fully determine their distance. Depending on the analysis purpose and also the data type, different DFs are presented. The concept of similarity is domain specific, so different DFs is defined in order to address different aspects of similarity such as spatial, spatio-temporal, and temporal.
Spatial similarity is based on spatial parameters like movement path and its shape whereas spatio-temporal similarity is based on movement characteristics like speed, and temporal similarity is based on time intervals and movement duration (Ranacher and Tzavella Citation2014). For instance, in order to extract the movement patterns in trajectories like detecting the transportation mode, besides the trajectories geometry, their movement parameters should also be considered. Accordingly, every distance function is not suitable for all applications, and correct recognition of data and application is crucial.
Among all defined Distance Functions so far, Euclidean, Fréchet, Hausdorff, DTW, LCSS, EDR, and ERP distances are the basic functions in similarity measurements from which so many other functions are generated (Aghabozorgi, Shirkhorshidi, and Wah Citation2015; Wang et al. Citation2013; Ali Abbaspour, Shaeri, and Chehreghan Citation2017).
Validation is widely considered as the most challenging and vital factor in clustering. The present paper aims to evaluate the effect of different DFs in clustering methods, which are based on density in spatial trajectories. Considering the fact that in previous research density-based methods performed better in trajectory clustering than other methods (Birant and Kut Citation2007; Zhang et al. Citation2014), finding a DF with the best efficiency among this type of clustering functions is an essential issue that, no one to the best of our knowledge has studied it. In order to fulfil this aim, the effectiveness of some frequently used DFs is evaluated in DBSCAN clustering algorithm. For the correct selection of similarity functions to be used in DBSCAN, the results of each algorithm are compared to Purity index, Spatial CS measure, and Spatio-temporal to find out to which of the distance functions the DBSCAN algorithm shows a more efficient reaction. The current research attempts to reach the intended results by contributing to the following aspects compared to the previous studies:
Using datasets with different movement parameters and varying complexities for studying the effect of data variety
Studying the effect of different values of noise and outliers
Using both internal and external indicators to evaluate the quality of clustering
Suggesting two modified validation measures for density-based trajectory clustering to meet both spatial and spatio-temporal quality of clusters
Comparing the operational time of different similarity functions and assessing the effect of the increase in the data volume on it.
This paper continues as follows: after the introduction, Section 2 gives a brief overview of the literature review. Theoretical foundations and suggested method are detailed in Section 3. Section 4 begins by describing the data under study and continues with examining the applied framework on this data. Finally, the paper is ended with some conclusions and suggestions in Section 5.
2. Literature review
Up to now, numerous Distance Functions have been proposed that each one makes use of a different definition of similarity in trajectories. The most basic Distance Function is Euclidean distance. Clarke (Citation1976), Richalet et al. (Citation1978), and Takens (Citation1980) have made use of this distance for studying the similarity in trajectories. Myers, Rabiner, and Rosenberg (Citation1980) pioneered in employing DTW, another important DF, to compute the time series distance. Besides, Kruskal (Citation1983) and Picton et al. (Citation1988) exploited this algorithm for measuring the spatial trajectory distance. Concerning the nature of spatio-temporal data, which contains noise and outliers, developing DFs which were more robust against these errors was reasonable. Therefore, some DFs were proposed based on the LCSS by Kearney and Hansen (Citation1990) and Vlachos, Kollios, and Gunopulos (Citation2002a).
In addition to the research mentioned above in suggesting new DFs, several studies were also conducted on comparing and evaluating the similarity functions. Wang et al. (Citation2013) widely investigated the weaknesses and strengths of six DFs including Euclidean, DTW, PDTW, EDR, ERP, and LCSS distances for the measurement of trajectory similarity by applying different transformations. They have identified DTW as the superior DF, and LCSS as the only resistant DF against noise and inconstant sampling rate. However, the effect of distance functions in trajectory clustering is not investigated.
Despite the considerable amount of literature on defining Distance Functions and evaluating them, not much is known about the performance of DFs in spatial trajectory clustering. Atev, Miller, and Papanikolopoulos (Citation2010) compared the performance of their suggested edited Hausdorff function to two basic DFs, DTW and LCSS, in trajectory clustering by hierarchical and spectral methods and concluded that their proposed function has superiority over those two basic DFs. However, the effect of other important Distance Functions like Euclidean distance, L1 Norm, Hausdorff, Fréchet, EDR, and ERP in clustering has not been addressed. Besse et al. (Citation2016) conducted an assessment of the performance of their suggested DF (SSPD) and some known DFs (DTW, LCSS, ERP, Hausdorff, Fréchet, Discrete Fréchet, and OWD) in two clustering methods of hierarchical and affinity propagation. They claimed that the best results had been achieved from OWD, and on the other hand, LCSS had shown a weak performance.
Much work on the evaluation of geometrical similarity function has been carried out, yet there are still some critical issues about movement similarity parameters like velocity, acceleration, direction, and complexity. For many application domains, however, the geometrical similarity is insufficient for an in-depth understanding of the motion of moving objects. For instance, in order to group the pedestrians in a sidewalk and to distinguish the ones who walk from the ones who run, the use of geometrical similarity will not lead to consistent results, and it is crucial to consider the speed similarity and speed changes during time. Each type of measures has advantages and disadvantages, and that which one is better suited in the domain of density-based trajectory clustering is the central question that is addressed in this paper.
Our paper aims to present a comprehensive comparison of the performance of the similarity functions in trajectory clustering and on data with different complexities which contain noise and outliers based on three criteria: clustering quality, our proposed velocity coefficient, and the computational time, which has not been addressed in previous studies.
3. Methodology
In this section, we propose a framework that summarizes the whole procedure of evaluating the performance of Distance Functions in density-based clustering, as shown in .
Figure 1. A general flowchart for assessment of distance functions in density-based clustering.
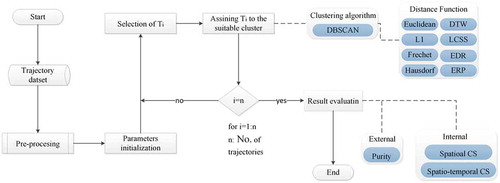
In the initial stage of the process, experimental data with different movement characteristics are selected in order to do the secondary analysis. In the pre-processing stage, noise and outliers with different values are applied to the original data in order to evaluate the effect of the error on the performance of Distance Functions in density-based trajectory clustering. The process of trajectory clustering with DBSCAN algorithm using Euclidean, L1, Hausdorff, Fréchet, DTW, LCSS, EDR, and ERP distances is presented in the following part. In the next step, the efficiency of each DF in density-based clustering is evaluated using internal and external indicators and the computational time.
3.1. Distance functions
3.1.1. Euclidean distance
The Euclidean distance is a traditional distance which is employed in various areas of data mining like determining the trajectory similarity. Among all advantages of this DF, the simplicity of implementation, low computation time, and not requiring the initial parameter can be mentioned. However, its result is considerably sensitive to the presence of noise and outliers. Moreover, it requires trajectories to be the same length and be sampled at fixed time intervals. (Pfeifer and Deutrch Citation1980; Priestley Citation1980). To overcome these stated drawbacks, other DFs were defined that will be discussed later. Given two trajectories Li and Lj of length n in p dimension, the Euclidean distance between them, DE (Li, Lj), is defined as Formula 2.
where, is the mth dimension of the kth point of Li.
3.1.2. Norm L1
Norm L1 is similar to the Euclidean distance except that it is more robust to noise. Lp-norms are easy to compute. However, they cannot handle local time-shifting, which is essential in trajectory similarity measurement. The calculation of this distance is detailed in Equation (3). Parameters used in this equation are defined in the same way as Equation (2) (Jajuga Citation1987).
3.1.3. Hausdorff distance
Hausdorff distance is another function for calculating the closeness of two trajectories or a subset of them. Two trajectories are defined as close if each one of the first trajectory points is proximate to at least one point of the second trajectory (Wei et al. Citation2013). To calculate the Hausdorff distance, Equation (4) is used (Chen et al. Citation2011a).
where h(Li, Lj) is calculated from Equation (5).
In Equation (5), euc (a, b) is the Euclidean distance between the sampled points a and b which belong to trajectories Li and Lj respectively.
3.1.4. Fréchet distance
This function emphasizes on the location as well as the order of points in the sequence for measuring the similarities. Fréchet distance searches all the points in both trajectories to find the longest Euclidean distance between two trajectories (Alt and Godau Citation1995). Fréchet distance between two trajectories Li and Lj are given by Equation (6) (Khoshaein Citation2013).
where ||c|| is calculated by Equation (7).
where Li and Lj are two trajectories of m and n lengths and K = min(m,n). and
are the kth points of Li and Lj trajectories, respectively.
3.1.5. DTW
DTW is a popular DF for finding the optimal queueing between two time series, and it is employed for evaluating the similarity in trajectories having even different lengths. Its primary purpose is to find the path w between two trajectories with the lowest cost. Compared to Euclidean distance and norm L1, among the advantages of this method, more stability because of independence from local time shifting as well as finding the optimal path even with temporal stretch and the different sampling rate can be mentioned (Kruskal Citation1983; Myers, Rabiner, and Rosenberg Citation1980). DTW distance between two trajectories Li and Lj of lengths m and n, respectively, is defined by Equation (8) (Berndt and Clifford Citation1994).
where, R(Li) and R(Lj) are the remained trajectory from Li and Lj, respectively, after removing their initial points.
3.1.6. LCSS
The LCSS is a variation of the Edit Distance which calculates the size of the longest similar substring in two trajectories. This function contains two threshold values of σ and ɛ, which are used in x and y directions respectively. When the difference between x and y of two points in two trajectories is less than the threshold extent, these pairs of points are assumed similar, and LCSS is increased by one unit. Unlike Euclidean and DTW, LCSS attempts to match two trajectories by enabling them to stretch, without rearranging the sequence of the elements, however allowing some elements to be unmatched, which makes it very robust to noise (Vlachos, Kollios, and Gunopulos Citation2002b). LCSS distance between two trajectories Li and Lj are given by Equation (9) (Rick Citation2000).
where ε and σ are the required initial parameters of the equation which should be determined by the user. and
are x and y coordinate of the first point of Li respectively where
and
are x and y coordinates of the first point of Lj respectively.
3.1.7. EDR
EDR is a similarity measure based on Edit Distance on strings, which seeks the minimum number of edit operations (e.g. replace, insert, or delete) required to change one trajectory to another. EDR is able to deal with three common problems in previous DFs, including noise, shifts, and data scaling. Given two trajectories Li and Lj of lengths n and m, respectively, EDR distance between Li and Lj is defined as follows (Chen, Tamer Özsu, and Oria Citation2005):
where the function is computed using Equation (11).
3.1.8. ERP
ERP is a commonly used metric DF in similarity evaluation, which borrows ideas from both norm L1 and Edit Distance. Functions which are based on Lp-norms are metric; however they do not support local time shifting. On the other hand, functions based on edit distance are non-metric, but they are able to cope with local time shifting (Chen et al., Citation2005, 107). Given two trajectories Li and Lj, ERP distance between Li and Lj is:
where the function is given by Equation (12). Constant value gap can be assumed (0, 0).
3.2. Density-based clustering
For three main reasons, density-based algorithms are appropriate choices for trajectory clustering. First, in many real-world applications, captured trajectories inevitably contain some noise and outliers, but as they do not affect the total density of the data, density-based clustering will perform more effectively. Second, in many applications such as analysis of the birds’ movement, the forms of clusters do not follow any particular shape. Therefore, using methods such as K-means which are only able to extract clusters with spherical shape will not yield satisfactory results. On the other hand, using density-based methods which are capable of extracting clusters of arbitrary shape is more reasonable. Third, the number of clusters is not usually previously known. Some of the clustering algorithms require the number of clusters as the input parameter, but density-based algorithms do not suffer from this limitation. . demonstrate how the DBSCAN algorithm works for trajectory clustering.
Figure.2. DBSCAN algorithm for trajectory clustering.
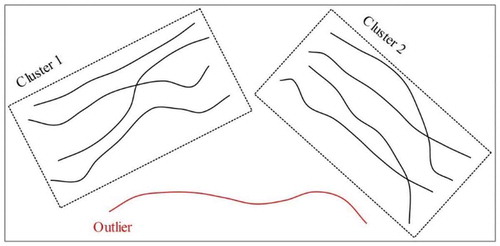
3.2.1. DBSCAN algorithm
DBSCAN is one of the most used clustering algorithms, which is based on the notion of density (Ester et al. Citation1996). The algorithm clusters a set of objects in groups where the density of objects is high and recognizes the ones out of the dense area as outliers. These techniques do not require the number of clusters to be given as an input parameter and also do not make any assumptions about the density within the clusters. The basic idea of using DBSCAN for trajectory clustering is that considering a similarity function (such as Euclidean or DTW), each trajectory existing in a cluster should have at least minTr number of trajectories in its neighbourhood within a radius of Eps.
Given the trajectory dataset TD and distance function dis: TD TD
,in the following, we will introduce the definitions involving the basic idea of using DBSCAN in the trajectory clustering task.
Eps-neighbourhood of trajectory Ti
TD is defined by
Ti is directly density-reachable to To with respect to Eps, minTr and DF if Ti
For a given Eps, minTr and DF, trajectory Tp is density-reachable from a trajectory Tq if there exists a series of trajectories T1, …, Tn, T1 = Tq, Tn = Tp in the condition that Tk is directly density-reachable to Tk+1.
Trajectories Ti and Tj are density-connected for a given Eps, minTr and DF, if there is a trajectory To such that both Ti and Tj are density-reachable from it.
A cluster C is a non-empty subset of TD, for every Tp, Tq: if Tp
3.3. Motivation of using clustering validation indices
In distance-based trajectory clustering, the quality of clustering is generally affected by choice of the Distance Function. It is necessary to assess the efficiency of different DFs for both spatial and spatio-temporal aspects. Different partitions generated by the clustering algorithm from the same data are not equally useful and can sometimes be misleading. Therefore, assessment and validation of the results is a crucial task and at the same time a difficult one. Each clustering method results in a unique grouping of objects and also requires unique computation time. Computation time and clustering quality are among the most frequently used measuring criteria for evaluation of the clustering methods. In case of large high-dimensional datasets like trajectories visual perception of the clusters structure is unable to assess the quality of a clustering, and proper clustering validation indices should be employed.
In general, there are two main approaches to evaluate the clustering results: internal and external criteria. An external validation index uses prior knowledge, whereas an internal index is only based on information from the data. In this paper, we use both internal and external approaches.
3.3.1. External validation measure
External clustering validation approaches compare clustering results with externally given cluster labels. In other words, these indices measure the degree to which cluster labels affirm ground truth. Assume that the trajectory dataset TD, and true clustering classes C = {c1,c2, …, cJ} are available. We use Purity as a common external validation index to evaluate clusters Cʹ = {cʹ1,cʹ2, …, cʹK} as follows:
3.3.2. Internal validation measure
In real-world applications, there are no predefined classes in the clustering process. Consequently, external measures are not practical to determine whether the found cluster has a satisfactory configuration. Internal criteria measure the quality of clustering without any external information using only information intrinsic to the data. Examples include Dunn’s measure (Dunn Citation1974), Silhouette (Rousseeuw Citation1987), and Davies-Bouldin’s measures (Davies and Bouldin Citation1979). However, many of the current validation criteria are developed for the evaluation of convex shaped clusters and have major issues with trajectory clusters which are usually dense and arbitrarily shaped. CS index is a validation measure that can handle this issue and shows superiority to other indices in term of coping with clusters of different densities, sizes, and shapes (RamakrishnaMurty, Murthy, and Prasad Reddy; Chou, Su, and Lai Citation2004). Having a TD dataset partitioned as C = {C1,C2, …, CK}, CS measure is computed using the following equation:
where Ri is the representative trajectory for the cluster Ci and dis is the similarity function of the trajectories.
The trajectory clustering aims to describe the trajectory dataset as a group of clusters based on their movement characteristics. The reason for defining different distance functions is the different definitions of similarity in different applications and various aspects of similarity, such as spatial and spatio-temporal. Therefore, in order to address this issue, two spatial and spatio-temporal indicators are applied to evaluate the results more precisely.
3.3.2.1. Spatial
In some applications, in order to extract and discover useful information, it is very limiting to investigate trajectories which have the same path and are captured in a similar time. Spatial similarity only considered spatial closeness of trajectories, and ignore their temporal dimension. Accordingly, it does not address the similarity of movement parameters like velocity and acceleration. In this study, in order to investigate the quality of clustering from the spatial aspect, the Euclidean distance is chosen to be the dis(Ti, Tj) in Equation (14), because it is a fast function and it can also evaluate the spatial closeness of trajectories effectively.
3.3.2.2. Spatio-temporal
The aim of spatio-temporal similarity is considering both the spatial and temporal dimensions of trajectories and their other dynamic characteristics such as velocity (Pelekis et al. Citation2007). In applications such as smart transportation which is aimed at discovering the pattern of vehicles on the roads, and also the traffic anomaly detection, it is important to pay attention to the density of trajectories and their speed changes. Hence, the quality assessment of clustering result considering only the spatial closeness of trajectories inside clusters is not enough. To evaluate the clustering quality from a spatio-temporal point of view and using CS indicator, we formulate dis(Ti, Tj) in Equation (14) as detailed below:
Showing each trajectory Ti as a vector of velocities Vi = {v1, v2, …, vm} such that vp is the velocity in i th point of trajectory Ti.
Using linear interpolation to equalize the length of vectors Vi and Vj.
Utilizing Euclidean distance to calculate the distance between two velocity borders after equalizing the lengths.
The less the value of Spatial and Spatio-temporal CS, the higher is the quality of the clustering in terms of velocity similarity of cluster members with each other.
4. Implementation and evaluation
In the current paper, the CVRR trajectory Analysis dataset provided by the Computer Vision and Robotics Department of the University of California, San Diego is used for the trajectory clustering task (Morris and Trivedi Citation2011). It consists of five different simulated scenes, among which i5, cross, and labomni are employed in this study and are illustrated in . Their trajectories contain only the spatial information, and velocity must be inferred. I5 is a highway trajectory in both directions including 806 trajectories, cross is a four-way traffic intersection which includes 1900 trajectories, and labomni contains 209 trajectories of humans walking through a lab. In order to properly investigate the clustering performance of different DFs, noise with Gaussian distribution and a Signal-to-Noise Ratio (SNR) of 2 and 5 and outlier data with 1% and 2% have been added to these two datasets. . summarizes, for each data, important movement parameters.
Figure 3. Trajectory datasets (a) cross, (b) i5, and (c) labomni.

Table 1. The characteristics of the data under study.
4.1. Pre-processing
Lengths of trajectories vary significantly, not only because of inconsistent sampling rates but also because of the gap(s) caused by sensor failures. In Euclidian and L1 distances, trajectories are required to be the same length.
Therefore, linear interpolation can be used as the pre-processing operation to transform trajectories to similar lengths. The value of non-acquisition point p at the time t can be estimated by Eq. 18.
where p1, p2, t1, and t2 are the first point before P, the first point after P, the acquisition time of p1 and acquisition time of p2, respectively.
4.2. Effectiveness of CS measure
In this part, the effectiveness of the proposed indicators for trajectory clustering is investigated. Three different trajectory datasets (.) are clustered using the DBSCAN algorithm with the different number of clusters, and the value of Spatial CS in different K’s are shown in . As it is evident from the table, this indicator has performed successfully in finding the appropriate number of clusters in three cases: clusters with different shapes, clusters with different shapes and sizes, and clusters with different shapes and densities.
Figure 4. Demonstration of trajectories with (a) different shapes (b) different shapes and sizes (c) different shapes and densities.
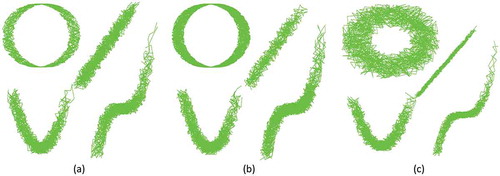
Table 2. Numerical value of spatial CS measure in different cases.
4.3. Parameter analysis
Despite all the advantages of the DBSCAN algorithm, it suffers from sensitivity to the input parameters. However, without understanding the characteristics of the trajectory dataset, determining an appropriate value for this parameter is a challenging task. For example, with a given minTr, if a low value of Eps is considered, many of the trajectories will be recognized as outliers and on the other hand considering a high value for Eps will result in containing the outliers in the clusters that lead to the integration of small clusters forming big ones. These clustering results might be inappropriate to conclude from about the data. Considering this, we conduct the experiment with different values of Eps and MinTr in order to investigate the input parameter effects on clustering outcomes. In the figure below the values for two spatial and spatio-temporal indicators for different values of Eps and MinTr in the labomni clustering and with EDR distance is shown which can be used to choose appropriate values for these parameters.
4.4. Clustering results
For the purpose of evaluating similarity functions’ performance in density-based trajectory clustering, different DFs, and DBSCAN algorithm are run on a core i5 computer with 8G RAM. Setting the parameters of DBSCAN is one of the challenges of these algorithms. To obtain the desired number of clusters for each dataset, each DF with different values of Eps and MinTr was executed, and the best results were considered in this paper.
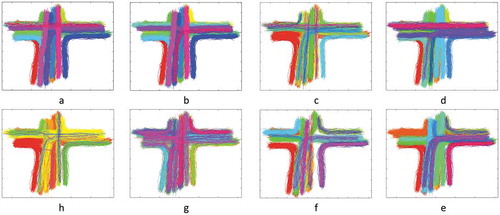
In ., clustering results for different methods on the cross data are depicted, and each group is shown with a different colour. Trajectories which are assigned to no clusters denote noises and are shown by black circles. Due to the space limitations, i5 and labomni results are not discussed in this paper. It is observed from the figures below that trajectories with the same path are placed in the same group. Clusters with different shape, despite using the same clustering method, shows the effect of the used DF on the geometrical shape of clusters.
Figure 5. Determine the input parameters of DBSCAN algorithm using (a) Spatial CS measure and (b) Spatio-temporal CS measure.
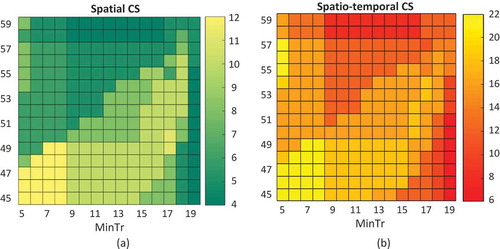
Figure 6. Clustering results with DBSCAN algorithm using (a) Euclidean, (b) L1, (c) Fréchet, (d) Hausdorff, (e) LCSS, (f) DTW, (g) ERP, (h) EDR.
4.4.1 Purity for original data
In , Purity index for different similarity functions are illustrated. According to the results, for each dataset, a different similarity function has shown the best performance, which indicates the dependence of the optimum similarity function on the data. In i5, Hausdorff distance with the purity index value of 0.6166, in cross, the Euclidean distance with the purity index value of 0.9153 and in labomni, the Fréchet distance with the purity index value of 0.9091 have obtained the most suitable results. Considering all three datasets together, the Euclidean distance with the average value of 0.7447 for purity index has had a stronger performance among the mentioned DFs in density-based clustering of trajectories.
Table 3. Purity value for different distances.
4.4.2 Purity in the presence of error
Some errors are inevitable in capturing the trajectory points’ locations using measurement devices like GPS. The errors appear as two major forms of noise and outliers. Thus, it is essential to pay attention to these two errors in trajectory clustering. In order to conduct experiments considering the effect of errors on the performance of DFs; at first step, noise with Signal to Noise Ratio of 2 and 5 was added to all three datasets. In and , the error percentage resulted from imposing noise and outlier, respectively, on the results in . is illustrated. According to the results, the noise did not affect the results of L1 and LCSS distances, whereas DTW has been affected the most. Among all three datasets, i5 has been the most sensitive against noise.
Figure 7. Error caused by imposing noise on original data.
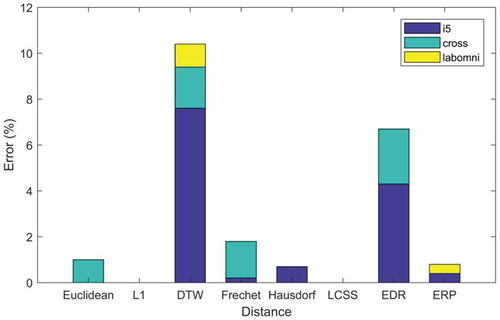
Figure 8. Error caused by imposing noise on original data.
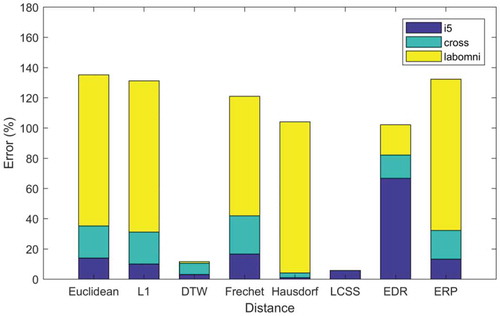
In the next step, 1% and 2% of outliers were added to the three datasets, and the results are shown in As it is observable from this figure, the presence of outliers severely affects the results. Hence, using proper preprocessing techniques to eliminate outliers is necessary. Additionally, because of LCSS distance’s nature, it has shown to be more resistant to outliers than other DFs. The quality of results using LCSS for cross and labomni datasets in case of containing outliers have not changed from than that of containing any outliers. Another surprising point is the low sensitivity of DTW results against outliers, whereas it has been undertaking the most from noise. On the other hand, L1, which had a satisfactory performance in the case of containing noise, showed highly dependent and sensitive to outliers. The main conclusion of the above experiments is that despite the functional abilities of the DBSCAN algorithm in handling noise, it cannot perform satisfactorily against outliers in most DFs. However, LCSS distance has proved to be remarkably resistant to both noise and outliers.
4.4.3. Spatial and spatio-temporal CS
In the following part, a comparison between the similarity functions using indicators which were introduced in section 3.3.2 has been made and discussed. As can be observed from , in total, EDR has achieved the best results regarding the spatial similarity with the average spatial CS value of 28.50. It means that using this distance in applications in which only the spatial closeness of trajectories is important will be more optimum than other similarity functions. L1, Euclidean, Fréchet, ERP, LCSS, and Hausdorff have achieved the next ranks in the best DFs. On the other hand, considering Spatio-temporal CS measure, EDR again has obtained the best result than other distance with the average spatio-temporal CS value of 40.86. After EDR distance, Fréchet, DTW, LCSS, L1, ERP, and Euclidean distances have shown higher ranks concerning the value of Spatio-temporal CS measure.
Table 4. Numerical value of spatial and spatio-temporal CS measure in different distances.
Another salient point in Table is that for the cluster members, Euclidean and L1 distances have shown a satisfactory performance regarding the spatial closeness and a weak performance with regard to the spatio-temporal similarity. This denotes that using these DFs can only achieve acceptable results only in cases in which the temporal dimension of trajectories is ignored, and therefore adding time will not yield satisfactory outcomes. By getting along well with the time shift, EDR and Fréchet distances, have obtained the first and the second ranks respectively in density-based trajectory clustering regarding the velocity similarity of cluster members with each other. Taking into account the optimum performance of EDR, the clustering quality in a different number of clusters is depicted in .
4.4.4. Computation time
pinpoints the efficiency of different DFs in terms of computation time. As illustrated in this figure, by increasing the data size, the running time of all algorithms is increased. However, this increase is less significant in Euclidean, L1 Norm, and LCSS methods than other methods. This mentions a lower dependence of these methods on the increase of the data volume. By increasing data volume by four times, the running time is multiplied about ten times for Euclidean, L1 Norm, and LCSS and about 17 times for other DFs.
Figure 9. CS measure for different number of clusters.
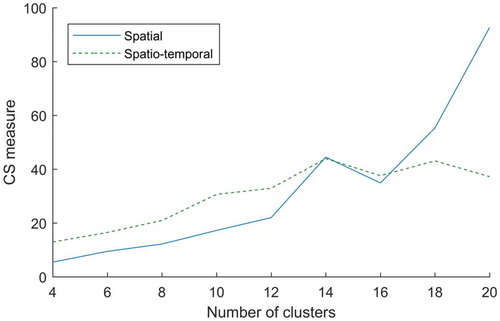
Figure 10. Performance comparison of different distance functions in clustering with the DBSCAN algorithm.
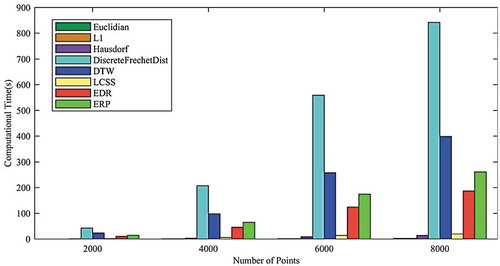
It is observable that the running time of clustering using the Euclidean and L1 Norm is less than 10 seconds, which is insignificant comparing to other methods. The high running time of Fréchet is another critical point in this graph. With a data volume of 2000 points, running time of clustering using Fréchet is 50 seconds, and with increasing the data volume by four times, it will increase to 800 seconds. After Fréchet distance, DTW is proving to be costly and time-consuming.
5. Conclusion
As stated in the introduction, density-based methods are best suited for arbitrarily-formed clusters among the various kinds of existing clustering methods. Therefore, our main objective was to evaluate the effectiveness of well-known Distance Functions in density-based clustering of trajectories from two spatial and spatio-temporal aspects. In this paper, we evaluated the performance of different DFs in the presence of two common types of error (noise and outlier). Choosing an appropriate DF in density-based trajectory clustering is a challenging task, and as can be observed from the experimental results, it depends on both data and movement parameters of. Hence, considering the Purity index, the best three results for i5, cross, and labomni dataset are achieved by Hausdorf, Euclidean, and Fréchet distances, respectively.
Besides, considering the fact that trajectory datasets usually have many noise and outliers. This experiment shows that density-based clustering algorithms are marginally affected by noise regardless of the utilized Distance Function. However, the presence of outliers severely influences the results of most of the DFs. LCSS and in the next rank, DTW have proven to be highly resistant against outliers in the trajectory datasets.
In this experiment, we find that although Lp-norm distances are fast and easy to compute, there are two major problems in utilizing them for density-based clustering of trajectories. First, results achieved from these DFs are highly influenced by the presence of noise and outliers, although L1 is less affected than Euclidean distance. Second, due to not supporting local time shifts, the quality of clustering is deficient from spatio-temporal aspect comparing to the spatial point of view. In order to deal with the first problem, in this study using LCSS distance is suggested for density-based clustering of trajectories. Unlike Lp-norm distance, LCSS permits some elements to remain unmatched. Hence in case of unreliability about the preprocessing procedures using LCSS is recommended. Besides, our experiment states the superiority of LCSS over DTW, ERP, EDR, Fréchet, and Hausdorff distances in terms of computation time and scalability. Despite the ability of this distance function to cope with errors, LCSS is a coarse measure, as it does not differentiate between trajectories in density-based trajectory clustering. As can be seen from the results,it performed poorly in both Purity and CS measures. Different speeds of the moving objects may lead to local time shifts in trajectories. DTW, LCSS, and EDR have been proposed to address this problem. However, in this experiment, we find that despite the promising result of EDR and at the next rank DTW, LCSS could not yield satisfactory results regarding velocity similarity of cluster members. After EDR, Fréchet distance has obtained one of the best performances due to the consideration of the order of points in trajectories besides their geometry. As can be seen from , Fréchet has performed more satisfactorily in labomni than the other two datasets because of its complexity of data.
We propose that further research investigate the effect of geometrical transformations, changes in the acquisition rate of the points, and time shift on the performance of different DFs. Moreover, depending on the intended application, it is possible to benefit from different data with more different characteristics than the data used in this study.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Aghabozorgi, S., A. S. Shirkhorshidi, and T. Y. Wah. 2015. “Time-series clustering–A Decade Review.” Information Systems 53: 16–38. doi:10.1016/j.is.2015.04.007.
- Ali Abbaspour, R., M. Shaeri, and A. Chehreghan. 2017. “A Method for Similarity Measurement in Spatial Trajectories.” Spatial Information Research 25 (3): 491–500. doi:10.1007/s41324-017-0115-5.
- Alt, H., and M. Godau. 1995. “Computing the Fréchet Distance between Two Polygonal Curves.” International Journal of Computational Geometry & Applications 5 (01n02): 75–91. doi:10.1142/S0218195995000064.
- Andrienko, G., and N. Andrienko. 2010. “Interactive Cluster Analysis of Diverse Types of Spatiotemporal Data.” Acm Sigkdd Explorations Newsletter 11 (2): 19–28. doi:10.1145/1809400.
- Atev, S., G. Miller, and N. P. Papanikolopoulos. 2010. “Clustering of Vehicle Trajectories.” IEEE Transactions on Intelligent Transportation Systems 11 (3): 647–657. doi:10.1109/TITS.2010.2048101.
- Basiri, A., P. Amirian, and P. Mooney. 2016. “Using Crowdsourced Trajectories for Automated OSM Data Entry Approach.” Sensors 16 (9): 1510. doi:10.3390/s16122100.
- Berkhin, P. 2006. “A Survey of Clustering Data Mining Techniques.” In: Kogan J., Nicholas C., Teboulle M. (eds)., Grouping Multidimensional Data, 25–71. Springer, Berlin: Springer.
- Berndt, D. J., and J. Clifford. 1994. “Using Dynamic Time Warping to Find Patterns in Time Series.” Paper presented at the KDD workshop.
- Besse, P., B. Guillouet, J.-M. Loubes, and F. Royer. 2015. “Review and Perspective for Distance Based Trajectory Clustering.” ARXIV.
- Besse, P. C., B. Guillouet, J.-M. Loubes, and F. Royer. 2016. “Review and Perspective for Distance-based Clustering of Vehicle Trajectories.” IEEE Transactions on Intelligent Transportation Systems 17 (11): 3306–3317. doi:10.1109/TITS.2016.2547641.
- Birant, D., and A. Kut. 2007. “ST-DBSCAN: An Algorithm for Clustering Spatial–Temporal Data.” Data & Knowledge Engineering 60 (1): 208–221. doi:10.1016/j.datak.2006.01.013.
- Chen, J., R. Wang, L. Liu, and J. Song. 2011a. “Clustering of Trajectories Based on Hausdorff Distance.” Paper presented at the Electronics, Communications and Control (ICECC), 2011 International Conference on Ningbo, China.
- Chen, J., R. Wang, L. Liu, and J. Song. 2011b. “Clustering of Trajectories Based on Hausdorff Distance.” Paper presented at the 2011 International Conference on Electronics, Communications and Control (ICECC), Ningbo, China.
- Chen, L., M. Tamer Özsu, and V. Oria. 2005. “Robust and Fast Similarity Search for Moving Object Trajectories.” Paper presented at the Proceedings of the 2005 ACM SIGMOD international conference on Management of data, New York, USA.
- Cheng, Z., L. Jiang, D. Liu, and Z. Zheng. 2018. “Density Based Spatio-temporal Trajectory Clustering Algorithm.” Paper presented at the IGARSS 2018-2018 IEEE International Geoscience and Remote Sensing Symposium Valencia.
- Chou, C.-H., M.-C. Su, and E. Lai. 2004. “A New Cluster Validity Measure and Its Application to Image Compression.” Pattern Analysis and Applications 7 (2): 205–220. doi:10.1007/s10044-004-0218-1.
- Clarke, F. H. 1976. “Optimal Solutions to Differential Inclusions.” Journal of Optimization Theory and Applications 19 (3): 469–478. doi:10.1007/BF00941488.
- Davies, D. L., and D. W. Bouldin. 1979. “A Cluster Separation Measure.” IEEE Transactions on Pattern Analysis and Machine Intelligence PAMI-1 (2): 224–227. doi:10.1109/TPAMI.1979.4766909.
- Dunn, J. C. 1974. “Well-separated Clusters and Optimal Fuzzy Partitions.” Journal of Cybernetics 4 (1): 95–104. doi:10.1080/01969727408546059.
- Ester, M., H.-P. Kriegel, J. Sander, and X. Xiaowei 1996. “A Density-based Algorithm for Discovering Clusters in Large Spatial Databases with Noise.” Paper presented at the Kdd HINNEBURG.
- Georgiou, H., S. Karagiorgou, Y. Kontoulis, N. Pelekis, P. Petrou, D. Scarlatti, and Y. Theodoridis. 2018. “Moving Objects Analytics: Survey on Future Location & Trajectory Prediction Methods.” arXiv Preprint arXiv:1807.04639.
- Han, J., J. Pei, and M. Kamber. 2011. Data Mining: Concepts and Techniques. Elsevier.
- Jajuga, K. 1987. “A Clustering Method Based on the L1-norm.” Computational Statistics & Data Analysis 5 (4): 357–371. doi:10.1016/0167-9473(87)90058-2.
- Kearney, J. K., and S. Hansen. 1990. Stream Editing for Animation. Department of Computer Science University of Iowa.
- Khoshaein, V. 2013. “Trajectory Clustering Using a Variation of Fréchet Distance.” (Doctoral dissertation, University of Ottawa). Citeseer.
- Kriegel, H., P. Kröger, J. Sander, and A. Zimek. 2011. “Density‐based Clustering.” Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 1 (3): 231–240.
- Kruskal, J. B. 1983. “An Overview of Sequence Comparison: Time Warps, String Edits, and Macromolecules.” SIAM Review 25 (2): 201–237. doi:10.1137/1025045.
- Lee, J.-G., J. Han, and K.-Y. Whang. 2007. “Trajectory Clustering: A Partition-and-group Framework.” Paper presented at the Proceedings of the 2007 ACM SIGMOD international conference on Management of data.
- Mahdavinejad, M. S., M. Rezvan, M. Barekatain, P. Adibi, P. Barnaghi, and A. P. Sheth. 2018. “Machine Learning for Internet of Things Data Analysis: A Survey.” Digital Communications and Networks 4 (3): 161–175. doi:10.1016/j.dcan.2017.10.002.
- Morris, B. T., and M. M. Trivedi. 2011. “Trajectory Learning for Activity Understanding: Unsupervised, Multilevel, and Long-term Adaptive Approach.” IEEE Transactions on Pattern Analysis and Machine Intelligence 33 (11): 2287–2301. doi:10.1109/TPAMI.2011.64.
- Myers, C., L. Rabiner, and A. Rosenberg. 1980. “Performance Tradeoffs in Dynamic Time Warping Algorithms for Isolated Word Recognition.” IEEE Transactions on Acoustics, Speech, and Signal Processing 28 (6): 623–635. doi:10.1109/TASSP.1980.1163491.
- Pelekis, N., I. Kopanakis, G. Marketos, I. Ntoutsi, G. Andrienko, and Y. Theodoridis. 2007. “Similarity Search in Trajectory Databases.” Paper presented at the 14th International Symposium on Temporal Representation and Reasoning (TIME’07).
- Pfeifer, P. E., and S. J. Deutrch. 1980. “A Three-stage Iterative Procedure for Space-time Modeling Phillip.” Technometrics 22 (1): 35–47. doi:10.2307/1268381.
- Picton, T., M. Hunt, R. Mowrey, R. Rodriguez, and J. Maru. 1988. “Evaluation of Brain-stem Auditory Evoked Potentials Using Dynamic Time Warping.” Electroencephalography and Clinical Neurophysiology/Evoked Potentials Section 71 (3): 212–225. doi:10.1016/0168-5597(88)90006-8.
- Priestley, M. B. 1980. “State‐dependent Models: A General Approach to Non‐linear Time Series Analysis.” Journal of Time Series Analysis 1 (1): 47–71. doi:10.1111/j.1467-9892.1980.tb00300.x.
- Ranacher, P., and K. Tzavella. 2014. “How to Compare Movement? A Review of Physical Movement Similarity Measures in Geographic Information Science and Beyond.” Cartography and Geographic Information Science 41 (3): 286–307. doi:10.1080/15230406.2014.890071.
- Richalet, J., A. Rault, J. L. Testud, and J. Papon. 1978. “Model Predictive Heuristic Control.” Automatica (journal of IFAC) 14 (5): 413–428. doi:10.1016/0005-1098(78)90001-8.
- Rick, C. 2000. “Efficient Computation of All Longest Common Subsequences.” Paper presented at the Scandinavian Workshop on Algorithm Theory. Berlin, Heidelberg: Springer.
- Rousseeuw, P. J. 1987. “Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis.” Journal of Computational and Applied Mathematics 20: 53–65. doi:10.1016/0377-0427(87)90125-7.
- Takens, F. 1980. “Motion under the Influence of a Strong Constraining Force.” In Global Theory of Dynamical Systems, 425–445. Berlin, Heidelberg: Springer.
- Vlachos, M., G. Kollios, and D. Gunopulos. 2002a. “Discovering Similar Multidimensional Trajectories.” Paper presented at the Data Engineering, 2002. Proceedings. 18th International Conference on data engineering, San Jose, CA, USA, USA..
- Vlachos, M., G. Kollios, and D. Gunopulos. 2002b. “Discovering Similar Multidimensional Trajectories.” Paper presented at the Proceedings 18th international conference on data engineering, San Jose, CA, USA.
- Wang, H., S. Han, K. Zheng, S. Sadiq, and X. Zhou. 2013. “An Effectiveness Study on Trajectory Similarity Measures.” Paper presented at the Proceedings of the Twenty-Fourth Australasian Database Conference-Volume, 137, Adelaide, Australia.
- Wei, L.-X., X.-H. He, Q.-Z. Teng, and M.-L. Gao. 2013. “Trajectory Classification Based on Hausdorff Distance and Longest Common Subsequence.” Dianzi Yu Xinxi Xuebao(Journal of Electronics and Information Technology) 35 (4): 784–790.
- Xu, R., and D. Wunsch. 2005. “Survey of Clustering Algorithms.” IEEE Transactions on Neural Networks 16 (3): 645–678. doi:10.1109/TNN.2005.845141.
- Yuan, G., P. Sun, J. Zhao, L. Daxing, and C. Wang. 2017. “A Review of Moving Object Trajectory Clustering Algorithms.” Artificial Intelligence Review 47 (1): 123–144. doi:10.1007/s10462-016-9477-7.
- Zhang, X., H. Liu, X. Zhang, and X. Liu. 2014. “Novel Density-Based Clustering Algorithms for Uncertain Data.” Neural Networks 93 (2017): 240-255.
- Zhao, L., and G. Shi. 2019. “A Trajectory Clustering Method Based on Douglas-Peucker Compression and Density for Marine Traffic Pattern Recognition.” Ocean Engineering 172: 456–467. doi:10.1016/j.oceaneng.2018.12.019.
- Zheng, Y., L. Zhang, X. Xie, and M. Wei-Ying. 2009. “Mining Interesting Locations and Travel Sequences from GPS Trajectories.” Paper presented at the Proceedings of the 18th international conference on World wide web, Madrid, Spain.