
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The least-cost path problem is a widely studied problems in geographic information science. In raster space, the problem is to find a path that accumulates the least amount of cost between two locations based on the assumptions that the path is a one-dimensional object (represented by a string of cells) and that the cost (per unit length) is measured on a quantitative scale. Efficient methods are available for solution of this problem when at least one of these assumptions is upheld. This is not the case when the path has a width and is a two-dimensional object called a corridor (represented by a swath of cells) and the cost (per unit area) is measured on an ordinal scale. In this paper, we propose one additional model that characterizes a least-cost corridor on an ordinal-scaled raster cost surface – or a least ordinal-scaled cost corridor for short – and show that it can be transformed into an instance of a multiobjective optimization problem known as the preferred path problem with a lexicographic preference relation and solved accordingly. The model is tested through computational experiments with artificial landscape data as well as real-world data. Results show that least ordinal-scaled cost corridors are guaranteed to contain smaller areas of higher cost than conventional least-cost corridors at the expense of more elongated and winding forms. The least ordinal-scaled cost corridor problem has computational complexity of O(n2.5) in the worst case, resulting in a longer computational time than least-cost corridors. However, this difference is smaller in practice.
1. Introduction
The least-cost path problem is one of the most widely studied problems in geographic information science. It is a source of theoretical exploration and has a variety of practical applications ranging from the placement of highways (Lombard and Church Citation1993; Yu, Lee, and Munro-Stasiuk Citation2003; Scaparra, Church, and Medrano Citation2014) and pipelines (Huber and Church Citation1985; Feldman et al. Citation1995; Bagli, Geneletti, and Orsi Citation2011) to siting for wildlife corridors (Adriaensen et al. Citation2003; Chetkiewicz and Boyce Citation2009; Rayfield, Fortin, and Fall Citation2010). The least-cost path problem and its solution methods are dependent on how the underlying surface is represented. When solved in digital devices, two-dimensional (2D) cost surfaces may be discretized into regions of constant cost and their least-cost paths into polylines. This vector version of the problem is known as the ‘weighted region problem’ (Mitchell and Papadimitriou Citation1991). However, it cannot be solved exactly in polynomial time (De Carufel et al. Citation2012). When a 2D cost surface is discretized into a grid of regular (commonly rectangular, hexagonal, or triangular (Carr, Olsen, and White Citation1992; Birch, Oom, and Beecham Citation2007; Dale Citation2000; Sahr Citation2011)) shaped cells, each of which is assigned a value representing the cost per unit length, we have a raster version of the problem that seeks a path that accumulates the smallest amount of cost while connecting a source cell and a destination cell. Furthermore, vector and raster data may be extended from 2D to three-dimensions (3D). In such cases, a 3D least-cost path problem is considered (Eklund, Kirkby, and Pollitt Citation1996; Scott Citation1994; Wagner and Scott Citation1995).
The 2D raster-based least-cost path problem relies on two (sometimes implicit) assumptions. First, the cost values assigned to the cells are measured on a scale that allows them to be meaningfully multiplied and added. Second, the path is a one-dimensional object, which has length but not width. These assumptions together justify the representation of a path as a sequence of adjacent cells and the calculation of its accumulated cost as the sum of the cost-weighted distance between each pair of consecutive cells (i.e. the product of the distance between the centres of those cells and the mean of their cost values) in that sequence, where two cells are said to be adjacent if they share a cell side or a cell corner, that is, if one can be translated to the other in an orthogonal or diagonal one-cell step.
The two assumptions also motivate an efficient solution method for the problem. It converts a raster cost surface to a graph in which nodes represent cells and arcs represent pairs of adjacent cells, and equates the length of each arc with the cost-weighted distance between the corresponding cells. A least-cost path on the original cost surface corresponds to a shortest path in the derived graph, which can be searched for by any classic shortest path algorithm such as the one by Dijkstra (Citation1959). Dijkstra’s algorithm in its original form has a complexity of O(n2) where n represents the number of nodes (or cells in the present context). It has a better complexity with an advanced data structure such as a priority queue or heap (Ahuja, Magnanti, and Orlin Citation1993), and its actual computation time may be shortened with a heuristic such as A* (Hart, Nilsson, and Raphael Citation1968).
The validity of the quantitative cost assumption may be questioned unless it is certain that the cost values have been measured on a ratio scale, such as travel time per unit distance (Mulrooney et al. Citation2017) or travel cost per unit distance (Hallett and McDermott Citation2011). Significantly, in many applications of the least-cost path problem, cost is estimated by classifying one or more qualitative attributes such as land cover type (Ray, Lehmann, and Joly Citation2002; Chardon, Ariaensen, and Matthysen Citation2003; Driezen et al. Citation2007; Stevenson-Holt et al. Citation2014). Although this process may take advantage of opinions and judgements of experts in the relevant fields (O’Brien et al. Citation2006; Gonzales and Gergel Citation2007; LaRue and Nielsen Citation2008; Chetkiewicz and Boyce Citation2009), it does not necessarily guarantee accurate or consistent results (see Rayfield, Fortin, and Fall (Citation2010), Zeller, McGarigal, and Whiteley (Citation2012), Ligmann-Zielinska and Jankowski (Citation2014) for reviews).
If sufficient information is not available for quantification of cost, one alternative is to measure cost on an ordinal scale and assign each cell a ranking (Graham Citation2001; Rabinowitz and Zeller Citation2010). Numerical values may be used to encode these rankings but they are arbitrary. Thus, if a conventional least-cost path is searched for over such a cost surface, its location or length may not be accurate or consistent because they are affected by the superfluous magnitudes assigned to essentially ordinal-scaled cost values (see Schadt et al. Citation2002; Larkin et al. Citation2004; Driezen et al. Citation2007; Gonzales and Gergel Citation2007; Rayfield, Fortin, and Fall Citation2010; Murekatete and Shirabe Citation2020 for discussions). Such paths would be considered to be derived without attention to the true cost value. For this reason, the currently available methods for delineating least-cost paths would not reasonably apply when the cost values are not certainly measured on a ratio scale. However, one could consider a situation where the cost values are not measured on a ratio scale, but there exist some knowledge how much more preferred one value is than another. As such, there are many variations of this problem that fall between knowing exact ratio scale measurements of cost and using an ordinal scale to rank values as discussed above. For example, O’Brien et al. (Citation2006) used a plus/minus score to score different landcover types with their perceived level of suitability for woodland caribou habitat, and then order them accordingly. In another example, researchers used ranked variables and attributes derived from expert surveys to determine the relative weight of variables and attributes in order to score suitability (LaRue and Nielsen Citation2008). Each variation could potentially necessitate a new problem formulation and solution.
Still, it is possible to consider a variant of the least-cost path problem that addresses the assumption that there is no knowledge of how much one value is preferred over another and does not rely on the availability of quantitative cost. In their attempt to rank-order paths situated on an ordinal-scaled raster cost surface, for example, Murekatete and Shirabe (Citation2020) employed a tie-breaker of two paths that measures, for each path, the (geometric) length of the segment consisting of cells of each cost value and regards the one having the shorter segment of the highest cost value as less cost. If the two paths are tied, the same procedure is performed with the second highest cost value, and if necessary, it is repeated with each of the lower cost values until the tie is broken. This is analogous to the one based on which participating countries in the Olympic Games are ranked in the number of first gold, then silver, and finally bronze medals. With this tie-breaker, the problem can be transformed into a tractable multicriteria shortest path problem (to be reviewed in the next section) and solved as such (Murekatete and Shirabe Citation2020). It was found that their solution intersected fewer cells deemed ‘undesirable’ than the traditional least-cost paths did. Such an approach to the least-cost path problem could provide planners, researchers, and geographers with an additional tool in a set of useful algorithms. For each use case, a user should evaluate the conditions of the problem, the desired outcome, and the significance of potential errors in delineation of a path, and then choose the most appropriate from the available tools.
The validity of the one-dimensional path assumption is another concern. Paths found on raster surfaces often represent real world entities that have significant widths, such as highways (McHarg Citation1969, Gårds and Oscarsson Citation2019), railways (Arulrajah et al. Citation2009; Kalliainen and Kolisoja Citation2013), and pathways for animal movement (Singleton Citation2002; LaRue and Nielsen Citation2008). These examples suggest that some paths are actually two-dimensional objects characterized by their width as well as their length, and therefore should be evaluated in terms of their cost-weighted area in the least-cost path problem, or more fittingly, the least-cost corridor problem.
The least-cost corridor problem has been approached by a variety of methods in the literature. One creates a buffer around a least-cost path by half the desired corridor width (LaRue and Nielsen Citation2008). Another involves smoothing the cost surface using a radius equal to half the desired width and finding a least-cost path on the smoothed cost surface as the centerline of a least-cost corridor on the original cost surface (Huber and Church Citation1985). Yet another resamples the cost surface in order to make the resolution of a cell match the required width (see Gonçalves (Citation2010) for an example). These approaches are straightforward and easy to perform but their accuracy is uncertain. On the other hand, Gonçalves (Citation2010) explicitly modelled a corridor as a ‘wide path’, which is a region swept by a one-dimensional string of cells called ‘path-front’, and converted the least-cost corridor problem into a shortest path problem in a graph where path-fronts (or various forms) are represented as nodes and transitions between path fronts are represented as arcs and solved it as such. This approach effectively finds a least-cost corridor with a specified width, but it quickly becomes inefficient as the width increases (which, in turn, increases the number of forms of path-fronts exponentially). Shirabe (Citation2016) replaced a path front with a two-dimensional group of cells arranged in an octagonal form in sweeping a corridor, which turned out to be a more scalable approach. Although there are a number of approaches to the least-cost corridor problem, as named above, unfortunately there is no exploration in current literature as to whether any of them works when quantitative information on cost is not available.
The purpose of this paper is to propose a model that characterizes a least-cost corridor on an ordinal-scaled raster cost surface and an efficient method for it solution. The rest of the paper is structured as follows. Section 2 reviews two path/corridor optimization problems, on which the design of our model is based, as described in Section 3. The performance of the model was tested through computational experiments with synthetic data and real-world data, and their results are reported in Sections 4 and 5, respectively. Section 6 discusses findings and implications of the experiments and application. Section 7 concludes the paper.
2. Preliminaries
We review two optimization problems that motivate our formulation and solution of the least ordinal-scaled cost corridor problem: the preferred path problem with a lexicographic preference relation and the least-cost corridor problem.
2.1. Preferred path problem with a lexicographic preference relation
Suppose a path, P, in a graph, G, such that each arc (i, j) has an ordered set of q lengths, {, … ,
}. Then, consider an ordered set of q lengths, {
, … ,
}, of P that are defined as follows.
If the multiple lengths of each arc can be reduced to a single length, G becomes a usual graph and affords the classic shortest path problem. Otherwise, we have a multicriteria shortest path problem that may not be tractable unless paths are compared in some special ways.
A ‘lexicographic preference relation’ (Perny and Spanjaard Citation2005) is one such comparison that makes the problem tractable. It defines the order of preference of two paths in the following manner. A path, P, is preferred to another path, Q, if P’s first length is shorter than Q’s. If their first lengths are equal, P is preferred to Q if P’s second length is shorter than Q’s. This tie-breaker is repeated with a subsequent length at a time until the tie is broken. A lexicographic preference relation is formally expressed as follows.
P is preferred to Q if and only if
The ‘preferred path problem’ (Perny and Spanjaard Citation2005) with a lexicographic preference relation is defined accordingly.
Problem 1 generalizes the classic shortest path problem and can be solved by a minor modification of Dijkstra’s algorithm with a complexity of O(n2q), where n is the number of nodes and q is the number of lengths of each arc (see, e.g. Murekatete and Shirabe (Citation2021) for pseudocode).
2.2. Least-cost corridor problem
According to the terminology of Tomlin (Citation1990), a neighbourhood is a set of cells that is arranged in a specified form.
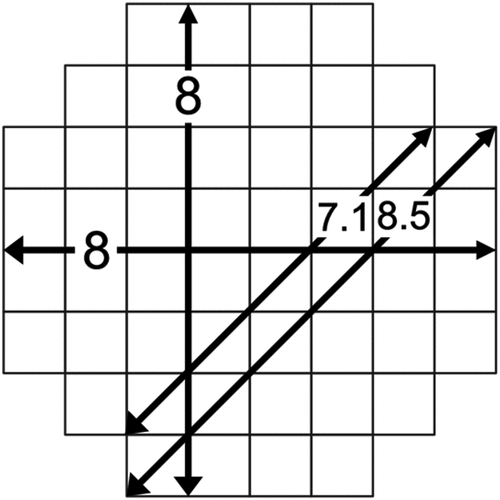
In his formulation of the least-cost corridor problem, Shirabe (Citation2016) constructs neighbourhoods of a ‘(w,d)-form’, that is, a w-by-w block of cells, where w is the desired corridor width in number of cells from which d rows are diagonally removed from each corner. In particular, d is set to the largest integer that is not greater than w in order to minimize the differences in the lateral and diagonal widths of the form and make the form as regular as possible. As illustrated in , given the nature of rectangular cells, the lateral widths are consistently equal to w, whereas the diagonal widths alternate between two values around w.
Figure 1. A neighborhood of the (8,2)-form (set of cells). Measurements of the lateral and diagonal widths are displayed at each of the double arrows.
A corridor is then defined as a sequence of adjacent neighbourhoods of the same (w,d)-form (determined by a specified corridor width) (see for an example), where two neighbourhoods are said to be adjacent to each other if one neighbourhood can be translated to the other in an orthogonal or diagonal one-cell step (see ).
Figure 2. Example of a corridor defined as a sequence of adjacent neighborhoods between two neighborhoods (enclosed by bold lines). All neighborhoods in this example have the same (8,2)-form.
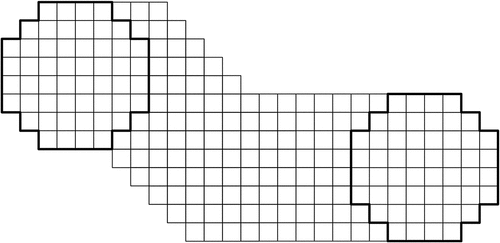
Figure 3. Pairs of a neighborhood (set of empty cells) and each of its adjacent neighborhoods (enclosed by bold lines) and their corresponding crescents (shaded).

The quality of a corridor is evaluated in terms of its cost-weighted area. Let P be a corridor and U(P) be all the cells that are in at least one neighbourhood in P. The cost-weighted area of P, , is defined as:
where ai is the (geometric) area of cell i and fi is the cost per unit area in cell i.
With a corridor and its cost-weighted area defined above, the least-cost corridor problem is defined as follows.
A corridor, P, has another property, cumulative cost-weighted area, . Letting Ns be the first neighbourhood in P, it is defined as:
where
In EquationEquation (6)(6)
(6) ,
represents the set difference – referred to here as a ‘crescent’ for its shape (see for examples)—of two adjacent neighbourhoods, Ni and Nj, and
denotes its cost-weighted area. It is important to note that if a corridor, P, does not self-intersect, i.e. none of its crescent intersect any other crescent or the first neighbourhood of it, then U(P) =
and
.
The cumulative cost-weighted area and its possible equality to the cost-weighted area motivate the following procedure for solving Problem 2. First, convert the raster cost surface into a graph in which each node represents a neighbourhood and each arc represents a crescent derived from a pair of adjacent neighbourhoods, and assign each arc the cost-weighted area of the corresponding crescent. Then, search the graph for a shortest path between the nodes corresponding to the source neighbourhood and the destination neighbourhood, and select the cells of the corridor that the shortest path corresponds to. Since the number of nodes in the graph is smaller than or equal to the number, n, of cells in the cost surface, the graph search takes O(n2) time if Dijkstra’s algorithm is employed.
The procedure described above does not guarantee to generate a corridor without self-intersection. However, results from the computational experiments by Shirabe (Citation2016) suggest that it is rare to occur.
3. Method
The least-cost corridor problem on an ordinal-scaled cost surface – or the least ordinal-scaled cost corridor problem – is introduced here in terms of formulation and solution.
3.1. Formulation
To evaluate a corridor situated on an ordinal-scaled cost surface, we measure the subarea of it corresponding to each cost value separately, instead of aggregating them. Suppose that the cost surface has q different cost values, which are arranged in the descending order. Let P be a corridor (i.e. a sequence of adjacent neighbourhoods of the same (w,d)-form), Ns be the first neighbourhood of P, and U(P) be all the cells that are in at least one neighbourhood of P. Then, consider the subset of U(P) that consists of only cells with the kth cost value. The (geometric) area of this subset is referred to as the kth area, , of P, and formally defined as:
where ak(i) is the area of cell i with the kth cost value.
Although we do not have quantitative information on the ordinal-scaled cost surface, we know that its kth cost value is higher than its (k + 1)th cost value. Then, we assume the most conservative assumption: the magnitude of the difference between two consecutive cost values is arbitrarily large. This leads us to the following relation for two corridors. A corridor, P, is preferred to another corridor, Q, if P has a smaller 1st area than Q. If the two corridors have equal 1st areas, P is preferred to Q if P has a smaller 2nd area than Q. The tie-breaker is repeated with a subsequent area at a time until the tie is broken. This is a lexicographic preference relation, which is formally defined as:
P is preferred to Q if and only if
Accordingly, the least ordinal-scaled cost corridor problem is formulated as a special case of the preferred path problem with a lexicographic preference relation as follows.
3.2. Solution
To design a method for solving the least ordinal-scaled cost corridor problem presented as Problem 3, we first define the kth cumulative area, , of a corridor, P, as:
where is the kth area of the crescent,
, derived from two adjacent neighbourhoods, Ni and Nj, which is defined as:
As stated in Section 2.2, if a corridor, P, does not self-intersect, then while any two of its first neighbourhood and crescents
(for all
) does not intersect each other, the union of all of them is equal to
, which here implies that P’s kth cumulative area (defined by EquationEquation (10))
(10)
(10) is equal to its kth area (defined by EquationEquation (7))
(7)
(7) for every k.
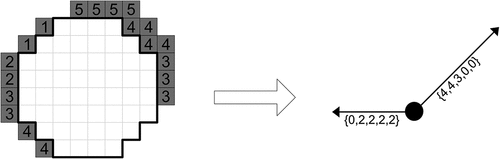
This suggests a possible application of the procedure used for the least-cost corridor problem (Problem 2) that converts the raster cost surface into a graph in which nodes represent neighbourhoods and arcs represent crescents derived from adjacent neighbourhoods. The only difference here is that each arc is assigned an ordered set of q lengths, the kth of which represents the kth area of the corresponding crescent (see for an example). The conversion takes O(nqw) time where n and q are the numbers of cells and of unique values, respectively, of the cost surface and w is the corridor width. This is because for each of n cells, it visits each of a constant number of cells adjacent to that cell, and for each of these visits, it loops through the corresponding crescent whose number of cells is proportional to w, and counts, for each of the q values, the number of cells that have that value.
Figure 4. An example of conversion of crescents (shaded) on a raster cost surface with five different values (5, 4, 3, 2, and 1) to arcs (arrows) of a graph each having five lengths (bracketed). Note that a node (dot) of the graph corresponds to a neighborhood (enclosed by bold line) on the raster cost surface. Note also that the number in each cell in the crescent represents the cost value of that cell.
The graph search takes O(n2q) time, as the number of nodes of the graph is less than or equal to the number of cells of the cost surface, and the number of lengths of each arc of the graph is equal to the number of unique values in the cost surface. It must be acknowledged, however, that the output corridor is not guaranteed to be without self-intersection, so that its kth area is not guaranteed to be equal to the kth length of the most preferred path. Therefore, the presented procedure is a heuristic. In practice, however, resulting corridors are highly unlikely to self-intersect, as demonstrated in the computational experiments reported in the next two sections.
4. Experiments
We conducted two computational experiments. The first experiment (Experiment 1) was designed to examine the qualities of the proposed model of a least ordinal-scaled cost corridor. The second experiment (Experiment 2) was designed to evaluate the computational efficiency of the proposed method for its solution. We included a comparison of the proposed model and the existing least-cost corridor model in both experiments. This is because existing models remain available to be used instead of, alongside, or in connection with the proposed model although cost values may be measured on an ordinal scale.
4.1. Data
4.1.1. Experiment 1
In Experiment 1, we accessed two sets of artificial landscape data created by Seegmiller et al. (Citation2020) for similarly designed experiments with the existing least-cost corridor model. The artificial landscape data was created using the NLMpy PYTHON software package (Etherington et al. Citation2015), which implements a number of algorithms to generate neutral landscape models (NLMs) encoded in raster format with various types of spatial patterns. Each of the two sets comprised 100 NLMs, each consisting of 500 rows and 500 columns and containing fractional values ranging from 0 to 1.
The first set of 100 NLMs was generated with the ‘mid-point displacement method’ (Fournier et al. Citation1982) to simulate real-world surfaces, referred to as ‘cloudy’ (Murekatete and Shirabe Citation2020), whose values change gradually with varying degrees of autocorrelation (see for an example). The frequency distribution of cell values in each cloudy NLM took the form of a bell-shape curve across the value range. The second set of 100 NLMs, referred to as ‘patchy’ (Murekatete and Shirabe Citation2020), was generated with the ‘modified random clusters method’ (Saura and Marténez-Millén Citation2000) to simulate real-world surfaces consisting of regions of constant values (see for an example). The frequency distribution of cell values in each patchy NLM was uniform across the value range.
Figure 5. Examples of (a) cloudy and (b) patchy neutral landscape models. Note that the darker shades represent higher values.

4.1.2. Experiment 2
In Experiment 2, we accessed three additional sets of cloudy NLMs with three different grid sizes, i.e. 250-by-250, 500-by-500, and 750-by-750, from Seegmiller et al. (Citation2021). Each of the three sets comprised 100 NLMs, each containing fractional values ranging from 0 to 1.
4.2. Procedure
In both experiments involved a large number of instances of the least ordinal-scaled cost corridor problem and of the least-cost corridor problem created by systematically varying the number of unique cost values, the corridor width, and the grid size. Details of this procedure are described below.
4.2.1. Experiment 1
In Experiment 1, we performed the following tasks for the set of 100 cloudy NLMs, as well as for the set of 100 patchy NLMs.
4.2.1.1. Creation of cost grids
We first divided the value range 0 to 1 defined for all NLMs into five intervals of equal length. Next, we mapped five integer values, representing cost, starting with 1 and ending with 100 with a constant (or as constant as possible) increment to those intervals. Then, we converted each of the 100 NLMs into a cost grid by assigning each cell one of those cost values corresponding to the NLM value of that cell. This resulted in 100 cost grids with five unique cost values ranging from 1 to 100. Similarly, we created four additional sets of 100 cost grids with 10, 20, 50, and 100 unique cost values ranging from 1 to 100. Note that because of the random nature of the NLM creation process, there were some NLMs whose values did not populate all the defined intervals, which caused the resulting cost grids to contain slightly fewer unique values than they were supposed to.
4.2.1.2. Instantiation of problems
We defined 25 problem types by combining each of the five sets of cost grids having 5, 10, 20, 50, and 100 unique values and each of five corridor widths including 5, 10, 20, 40, and 80 cells. These corridor widths were chosen to span five different widths increasing exponentially to represent a large range of different widths. An example is one of finding a corridor with a width of five cells on a cost grid of 100 unique values. For each such problem type, we fixed a source and destination pair at the upper-left and lower-right corners of the grid, and created 100 instances, one for each of the 100 cost grids. This resulted in 2500 problem instances.
4.2.1.3. Solution of problems
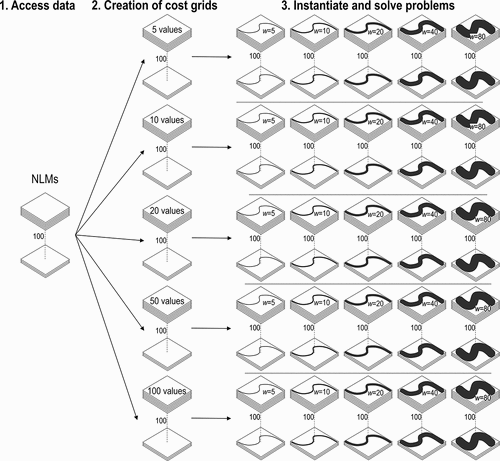
We solved each of the 2500 problem instances as a least ordinal-scaled cost corridor problem with the solution method presented in Section 3 and as a least-cost corridor problem with the solution method reviewed in Section 2. Both solutions involved the routine for converting a cost grid to a graph and Dijkstra’s algorithm (with a priority queue) for searching the graph for a shortest path, which were coded in Java and executed on a 3.40 GHz Intel Core i7–6700 CPU processor with 32.8 GM of Ram. This resulted in 2500 least-cost corridors and 2500 least ordinal-scaled cost corridors. The workflow of the steps outlined above is schematically illustrated in .
Figure 6. Workflow of the three steps for Experiment 1. Step 1 was accessing neutral landscape models (NLM). Step 2 was to convert them to ordinal scaled cost grids with 5, 10, 20, 50, and 100 unique values. Step 3 was to instantiate the problems with corridors with widths of 5, 10, 20, 40, and 80 cells and then solve those problems.
4.2.1.4. Analyses of areas of corridors
For each of the 2500 least ordinal-scaled cost corridors and each of the 2500 least-cost corridors, we calculated the area of it that intersected cells of each unique cost value as well as its total area in terms of number of cells. We did not include the cells in the source or destination in this calculation because they were predetermined and should not affect qualities of the corridor.
4.2.1.5. Analyses of sinuosity of corridors
We also analysed the shape and length of each of the 2500 least ordinal-scaled cost corridors and each of the 2500 least-cost corridors. We had anticipated that both least ordinal-scaled cost corridors and least-cost corridors would tend to twist and turn to avoid costly cells, which were not uniformly distributed. To see if there was any difference between the two types of corridors in this tendency, we calculated the sinuosity of each corridor as the ratio of the length of its centerline to that of the straight line between its source and destination. Given the anticipated sinuosity, we had suspected that corridors might self-intersect. Therefore, we checked for self-intersection in all the corridors.
4.2.2. Experiment 2
In Experiment 2, we first defined 15 problem types in almost the same manner as in Experiment 1, using the same corridor widths but only three numbers, 10, 50, and 100, of unique cost values were considered. Then, we derived a cost grid from each NLM in the three sets of 100 NLMs (each set corresponding to one of three grid sizes) and created an instance of each of the 15 problem types with that cost grid. This resulted in 1500 problem instances for each of the three grid sizes. Then, we solved each problem instance as a least ordinal-scaled cost corridor problem and as a least-cost corridor problem as we did in Experiment 1. For each solution, we measured the time to convert the cost grid to a graph and the time to run the shortest path algorithm in the graph.
5. Results
5.1. Experiment 1
We report results of Experiment 1 with cloudy cost grids and with patchy cost grids separately. To facilitate the presentation, we use the following convention.
The segment of a corridor that consists of cells whose cost values are not in the highest p% but in the highest q(>p)% of a given set of cost values is referred to as the ‘p%-q% segment’ of that corridor. For example, the 0–10% segment of a corridor in a cost grid with 50 unique values consist of cells with cost values of 92, 94, 96, 98, or 100.
The area of the ‘p%-q% segment’ of a corridor is measured in terms of number of cells and called the ‘p%-q% area’ of that corridor.
5.1.1. Cloudy grids
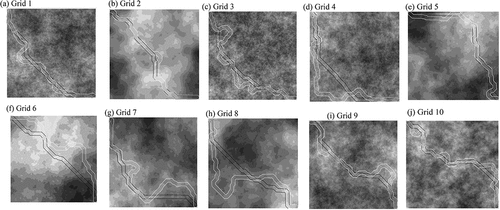
A visual inspection of corridors generated in the experiment suggested that least ordinal-scaled cost corridors tended to take more turns than least-cost corridors to avoid costly cells (see for an example). This was confirmed by the numerical results presented below.
Figure 7. Example of a least ordinal-scaled cost corridor (outlined in white) and a least-cost corridor (outlined in black) with w=20 between their common source and destination generated on a cloudy cost grid with 10 unique values. (a)-(j) represent the first ten cloudy cost grids used in the experiment. Note that the darker shades represent higher cost values.
summarize all the 2500 least ordinal-scaled corridors and the 2500 least-cost corridors, respectively, in terms of the average 0–10% to 90–100% areas of 100 instances of each problem type (specified by the number of unique cost values and the corridor width associated with the corresponding row). For example, the bottom-left cell of ) indicates that the average 0–10% area of the 100 least ordinal-scaled cost corridors with a width of 80 cells in cost grids with 100 unique values was six cells. Note that for those problem types with five unique cost values (corresponding to the first five rows), only five segments (i.e. 0–20% to 80–100% segments) were considered instead of the 10 segments (i.e. 0–10% to 90–100% areas), because each of the five cost values was 20% of the cost value range. For example, the top-right cell of ) indicates that the average 80–100% area of the 100 least-cost corridors with a width of five cells in cost grids with five unique values was 888 cells. The most costly segments of the least ordinal-scaled cost corridors tended to be significantly smaller than that of the least-cost corridors for any problem type (compare each row of the first column in ).
Table 1. Average segment areas of (a) the 100 least ordinal-scaled cost corridors and (b) the 100 least-cost corridors for each problem type on cloudy cost grids.
Each row of conveys that both the least ordinal-scaled cost corridors and the least-cost corridors generally had left-skewed distributions of segment areas, and their average 0;.–10% (or 0–20%) areas were disproportionally small. Another similarity of the two types of corridors was that each of their average segment areas (except the 0–10% area of the least ordinal-scaled cost corridors) increased with corridor width, but it remained almost the same even as the number of unique values increased. The former can be seen by scanning any five rows having the same number of unique values, and the latter by scanning any five rows having the same corridor width. A notable difference, on the other hand, was that the least ordinal-scaled cost corridors generally had a smaller average 0–10% (or 0–20%) area but larger average 40–50% (or 40–60%), … , 90–100% (or 80–100%) areas than the least-cost corridors.
presents the average sinuosity of the 100 least ordinal-scaled cost corridors and of the 100 least-cost corridors, respectively, for each of the 25 problem types on cloudy cost grids. The former was higher than the latter for all problem types. The average sinuosity of both types of corridors generally decreased with corridor width (to a smaller degree with the least-cost corridors). The number of unique cost values, however, had mixed effects. While the average sinuosity of the least ordinal-scaled cost corridors increased with number of unique cost values, that of the least-cost corridors decreased with it but only slightly.
Table 2. Average sinuosities of (a) the 100 least ordinal-scaled cost corridors and (b) the 100 least-cost corridors for each problem type on cloudy cost grids.
Lastly, none of the 2500 least ordinal-scaled corridors and the 2500 least corridors self-intersected.
5.1.2. Patchy grids
A visual comparison of least ordinal-scaled cost corridors and least-cost corridors (see as an example) suggested that the former turned more to avoid costly cells. To show this numerically, as done with those generated in cloudy cost grids, the 100 least ordinal-scaled cost corridors and the 100 least-cost corridors were summarized in terms of the average 0–10% (or 0–20%) to 90–100% (80–100%) areas () and of the average sinuosity () for each of the 25 problem types.
Figure 8. Example of a least ordinal-scaled cost corridor (outlined in white) and a least-cost corridor (outlined in black) with w=20 between their common source and destination generated on a patchy cost grid with 10 unique values. (a)-(j) represent the first ten patchy cost grids used in the experiment. Note that the darker shades represent higher cost values.

Table 3. Average segment areas of (a) the 100 least ordinal-scaled cost corridors and (b) the 100 least-cost corridors for each problem type on patchy cost grids.
Table 4. Average sinuosities of (a) the 100 least ordinal-scaled cost corridors and (b) the 100 least-cost corridors for each problem type on patchy cost grids.
Each row of shows that for both the least ordinal-scaled cost corridors and least-cost corridors, the average 0–10% (or 0–20%) area was smallest and increased from left to right across the columns. Notably, the least ordinal-scaled cost corridors generally had a smaller average 0–10% (or 0–20%) area and larger average 40–50% (or 40–60%), … , 90–100% (or 80–100%) areas than the least-cost corridors. As for the effects of the two defining parameters of a problem type, all the average segment areas increased with corridor width and changed only slightly with number of unique cost values, for both types of corridors.
indicate that the least ordinal-scaled cost corridors had a larger average sinuosity than the least-cost corridors for all problem types, and that the average sinuosity of both types of corridors generally decreased with as the corridor width increased but did not change much with number of unique cost values. The most costly segments of the least ordinal-scaled cost corridors tended to be significantly smaller than that of the least-cost corridors for any problem type (compare each row of the first column in ).
Lastly, none of the 2500 least ordinal-scaled corridors and the 2500 least corridors self-intersected.
5.2. Experiment 2
present the average running times for converting a cost grid to a graph and searching the graph for a shortest path to find a least ordinal-scaled cost corridor and a least-cost corridor, respectively, for the 100 instances of each of the 15 problem types (specified by the number of unique cost values and the corridor width associated with the corresponding row). Note that the former running time is referred to here as ‘G2 G’ time and the latter as ‘SP’ time.
Table 5. Average running times for grid to graph conversion and shortest path search in seconds of (a) the 100 least ordinal-scaled cost corridors and (b) the 100 least-cost corridors for each problem type and grid size.
For all problem types, the least ordinal-scaled cost corridors had longer average G2 G time and SP time than the least-cost corridors. Still, their computational behaviours were similar in the following aspects. First, their average G2 G times increased almost linearly with grid size and corridor width. Second, their average SP times increased faster than linearly with grid size and decreased with increasing corridor width but only slightly. A major difference between the two types of corridors was that while both average G2 G time and SP time for the least ordinal-scaled cost corridors increased almost linearly with number of unique cost values, those for the least-cost corridors were not affected by it.
Finally, it is worth mentioning that for both types of corridors the G2 G time significantly dominated the SP time.
6. Demonstration
With the goal of demonstrating the proposed model’s practical value, we applied it to a 2019 study by Gärds and Oscarsson (Citation2019), which explored the possibility of alternative alignment of the existing highway between two Swedish cities, Jönköping and Huskvarna. The major task was to identify a promising location for a right-of-way of 400 metres required for a highway route between two specified locations.
6.1. Data
In the study, waterbodies, slope, proximity to buildings, and land cover were found relevant factors to placement of the highway, which led to four respective raster cost surfaces created as follows.
Waterbody cost surface – derived from a land cover map, where water bodies were masked, and near shore and rivers were assigned cost values between 0 and 1.
Slope cost surface – derived from an elevation map, classified into six slope ranges, with each given a score of 0, 3, 5, 7, 10, and 25 based on the per cent slope and its relevant slope criteria. Those scores were then transformed to a standardized cost between 0 and 1 using a linear scaling method.
Land cover cost surface – derived from a land cover map with 11 land cover types. The values were reclassified to combine similar land cover types, resulting in six land covers. The land cover classes were then ranked in order of preference for construction and assigned cost between 0 and 1.
Proximity to buildings cost surface – derived from a map of building footprints. Euclidean distance from buildings was calculated, and the distance was classified into four bins. Each bin was given an ordered score between 0 and 3 based on the relevant proximity to building criteria. Finally, the scores were transformed to a standardized cost between 0 and 1 using a linear scaling method.
All the four cost surfaces had the same spatial extent (1320 rows and 700 columns) and resolution (20 metres) and were combined into a single composite cost surface by calculating a weighted sum of their cost values on a cell-by-cell basis. The weight of each cost surface was determined by applying the analytical hierarchy process (see Eastman, Kyem, and Toledano Citation1993 for an outline of its procedure) to the relative importance of each factor perceived by the involved planners. The cost surface contained 69 different values ranging from 0 to 820, and as seen in , their distribution was heavily skewed to the left.
Table 6. Frequency distribution of cost values over the study area.
6.2. Problem
Given the cost surface with a resolution of 20 metres and the two terminal locations, the task of aligning the highway right-of-way of 400 metres was seen as a problem of finding a least-cost corridor with a width of 20 cells between two terminal neighbourhoods. In the original study, the cost values were assumed to be measured on a ratio scale. In this demonstration, we were interested in how different a solution might result if this assumption were to be violated.
Thus, we solved the highway alignment problem as a least ordinal-scaled cost corridor problem and as a least-cost corridor problem using the methods described in the preceding sections. Then, we evaluated the two output corridors in terms of their segment areas (i.e. the 0–10% segment to the 90–100% segment) and sinuosity.
7. Results
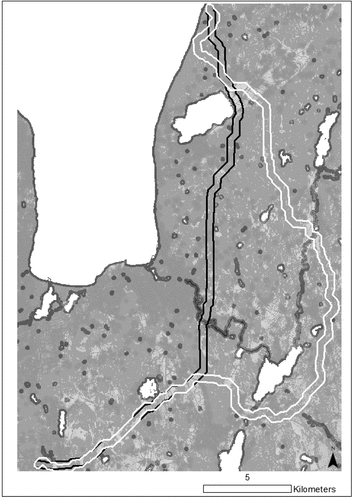
shows the least ordinal-scaled cost corridor and the least-cost corridor generated. When visually inspected, we saw that the former had many small turns, as well as one large turn avoiding a stretch of more costly cells. This differed from the least-cost corridor, which had few small turns and no large turns. This was reflected in the sinuosities of the two corridors: 1.75 for the least ordinal-scaled cost corridor and 1.22 for the least-cost corridor.
Figure 9. The least ordinal-scaled cost corridor (outlined in white) and the least-cost corridor model (outlined in black) between the two terminal locations. Note that the darker shades represent higher cost values, and white represents prohibited areas.
presents the 0–10% to 90–100% areas of the two corridors. Both corridors avoided costly cells, as the least ordinal-scaled cost corridor completely avoided those cells with the top 20% highest cost values and the least-cost corridor contained only two such cells. A major difference was that the least ordinal-scaled cost corridor did not contain a single cell until the 30–40% value range, whereas the least-cost corridor already contained cells in the more costly value ranges. However, the former had a larger area overall than the latter, by 1.44 times.
Table 7. Areas of segments of the least ordinal-scaled cost corridor and the least-cost corridor.
As for the computational cost, the grid-to-graph conversion took 31.61 and 23.51 s for the least ordinal-scaled cost corridor model and the least-cost corridor model, respectively. A larger difference was seen in the shortest path search, as the former model took 7.22 and the latter model took 0.91 s.
8. Discussion
8.1. Qualities
The results presented in suggest that the proposed least ordinal-scaled cost corridor model produces corridors which avoid high-cost cells. The area of least ordinal-scaled cost corridors containing cells with the 10% most costly values is small in absolute and proportional terms, making up a significantly smaller proportion of the corridors than the rest of values in the cost surface. While this is also true for least-cost corridors, the area of least ordinal-scaled cost corridors containing the most costly values tends to be smaller than that of least-cost corridors (the 0–10% areas and 10–20% areas in ).
It was found that the overall areas of least ordinal-scaled cost corridors were larger than those of least-cost corridors. This was most likely because the former corridors took more turns to sidestep high-cost cells, which resulted in a higher sinuosities (see ) and larger areas of cells with less costly values (see ). An implication of this is that if the foremost desire is to minimize values which are ordered as more costly than others, the least ordinal-scaled cost corridors will be preferable to least-cost corridors, but at the cost of the corridor potentially being longer overall. Without knowing the differences in cost values, however, it is not certain that longer least ordinal-scaled cost corridors will cost more than their least-cost counterparts.
There were no instances of self-intersection in the experiments or the demonstration, despite the increase in sinuosity in the least ordinal-scaled cost corridors. However, it is not certain that self-intersection will never happen. This is because as the number of unique values increases, least ordinal-scaled cost corridors may take more turns and have a higher sinuosity, as seen with those corridors found in cloudy cost surfaces (see ). The chance of a corridor self-intersecting increases with its sinuosity. Therefore, we may not see self-intersecting corridor on cost surfaces with small number of unique values, such as those derived from land cover data, which are unlikely to go beyond the number tested in this paper. For example, the United Nations Food and Agriculture Organization’s Land Cover Classification System has identified just 22 land cover classes for the entire globe (Di Gregorio and Jansen Citation2005), and the United States Geological Survey defines 16 land cover classes in the National Land Cover Database for the United States (Yang et al. Citation2018).
Another finding was that the ability to avoid high-cost cells was affected by the frequency distribution of values in the cost surface (as observed by Murekatete and Shirabe (Citation2018) with least-cost paths). This was well illustrated by the least ordinal-scaled cost corridors found on cloudy cost surfaces that contained a smaller area in the least costly value range (see the second-to-last column of each row in )). The same was seen with the least ordinal-scaled cost corridor found in the demonstration (see the second-to-last column of ). This might seem counterintuitive because avoiding more costly cells would normally result in a larger area of less costly cells. The unexpectedly small area of less costly cells in those corridors is explained by the fact that the corresponding cost surfaces had a significantly small number of less costly cells.
8.2. Efficiency
Both the grid-to-graph (G2 G) conversion and the shortest path (SP) search for least ordinal-scaled cost corridors took longer than those for least-cost corridors. The time it takes for the G2 G conversion time for both the least ordinal-scale cost corridors and the least-cost corridors increased almost linearly with the number of nodes in the graph. This can be explained by their computational complexities of the G2 G conversion, which are O(nqw) and O(nw) for least ordinal-scaled cost corridor and the least-cost corridor, respectively, where n is the number of cells in the cost surface, q is the number of unique values, and w is the corridor width. Similarly, the SP time for both least ordinal-scaled cost corridors and least-cost corridors increased faster than linearly with the number of nodes in the graph. This can be explained again by their computational complexities of the SP search, which are O(n2q) and O(n2) for the least ordinal-scaled cost corridor and least-cost corridor, respectively. However, both G2 G time and SP time for least ordinal-scaled cost corridors became longer as the number of unique values in the cost surface increased, whereas those for least-cost corridors did not, which was expected given the presence and absence of q in their respective complexities. What was unexpected, however, was that the SP search for both least ordinal-scaled cost corridors and least-cost corridors had slightly smaller running times as the width of the corridors grew. This is explained by the fact that as the width of the corridor increases, there are fewer valid neighbourhoods in the raster cost surface, and therefore fewer nodes in the graph.
Given the additional dependence on the number of unique values in the cost surface (q) in both the G2 G conversion and SP search, the running time of least ordinal-scaled cost corridors runs the risk of becoming significantly longer if the number of unique values in the cost surface becomes too large. As discussed above, it is expected that many cost surfaces are derived from land cover maps, and therefore the number of values in a cost surface will remain the same even as the size of the surface grows. This does not rule out cases in which the cost surface has been derived from more than one factor and may result in a larger number of unique values, similar to those in the application demonstration.
The G2 G conversion dominates the processing time for least ordinal-scaled cost corridors and least-cost corridors in this study. However, in a similar experiment by Shirabe (Citation2016), the average running time for the G2 G conversion for a least-cost corridor was not much. For example, it was 0.27 s when the dimensions of the cost surface were 500-by-500, there were 100 unique cost values, and the corridor width was 80, compared to 13.81 s in Experiment 2. This led us to believe the longer running times of the G2 G conversions in Experiment 2 was most likely because our implementation of the models was not optimal. This suggests that the running time of the G2 G conversion could be significantly reduced.
Though we have identified the problem on a two-dimensional raster grid with rectangular (square) cells, and developed the algorithm accordingly, this problem is potentially seen on other data types. For example, in future work we could see adapting the heuristic for vector data or raster grids with other shapes of cells. Additionally, we could extend the 3D least-cost corridor introduced in Seegmiller (Citation2021) using a 3D neighbourhood form to a 3D least ordinal-scaled cost corridor. Finally, to further test the method currently proposed, we may consider using a parallel algorithm with openMP or GPU in the future.
9. Conclusions
We have introduced a new variant of the least-path problem called ‘the least ordinal-scaled cost corridor problem’, in which the values of a cost surface are not quantitatively measured and a path has width as well as length. We have formulated it as a special case of the preferred path problem with a lexicographic preference relation and solved it as such. Through computational experiments, we have found that least ordinal-scaled cost corridors effectively avoid costly cells, but at the expense of elongating their forms and increasing the running time in comparison to least-cost corridors. As demonstrated with a real-world example of highway alignment, the least ordinal-scaled cost corridor problem holds promise as an alternative to existing optimal routing models when there is not full information on the data and cost evaluation involves high degrees of subjectivity and uncertainty.
Acknowledgments
The authors thank the editor and anonymous reviewers for their valuable and constructive comments on earlier drafts of the article. Any errors remain, of course, the sole responsibility of the authors. This work was supported by the Swedish Research Council Formas under Grant 942-2015-1513.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Adriaensen, F., J. P. Chardon, G. De Blust, E. Swinnen, S. Villalba, H. Gulinck, and E. Matthysen. 2003. “The Application of ‘Least-Cost’modelling as a Functional Landscape Model.” Landscape and Urban Planning 64 (4): 233–247. doi:10.1016/S0169-2046(02)00242-6.
- Ahuja, R. K., T. L. Magnanti, and J. B. Orlin. 1993. Network Flows: Theory, Algorithms, and Applications. Englewood Cliffs, NJ: Prentice Hall.
- Arulrajah, A., A. Abdullah, M. W. Bo, and A. Bouazza. 2009. “Ground Improvement Techniques for Railway Embankments.” Proceedings of the Institution of Civil Engineers-Ground Improvement 162 (1): 3–14. doi:10.1680/grim.2009.162.1.3.
- Bagli, S., D. Geneletti, and F. Orsi. 2011. “Routing for Power Lines Through Least Cost Path Analysis and Multicriteria Evaluation to Minimize Environmental Impacts.” Environmental Impact Assessment Review 31 (3): 234–239. doi:10.1016/j.eiar.2010.10.003.
- Birch, C. P., S. P. Oom, and J. A. Beecham. 2007. “Rectangular and Hexagonal Grids Used for Observation, Experiment and Simulation in Ecology.” Ecological Modelling 206 (3–4): 347–359. doi:10.1016/j.ecolmodel.2007.03.041.
- Carr, D. B., A. R. Olsen, and D. White. 1992. “Hexagon Mosaic Maps for Display of Univariate and Bivariate Geographical Data.” Cartography and Geographic Information Systems 19 (4): 228–236. doi:10.1559/152304092783721231.
- Chardon, J. P., F. Ariaensen, and E. Matthysen. 2003. “Incorporating Landscape Elements into a Connectivity Measure: A Case Study of the Speckled Wood Butterfly (Parage Aegeria L.).” Landscape Ecology 18: 561–573. doi:10.1023/A:1026062530600.
- Chetkiewicz, C., and M. Boyce. 2009. “Use of Resource Selection Functions to Identify Conservation Corridors.” The Journal of Applied Ecology 46 (5): 1036–1047. doi:10.1111/j.1365-2664.2009.01686.x.
- Dale, M. R. 2000. Spatial Pattern Analysis in Plant Ecology. Cambridge, United Kingdom: Cambridge University Press.
- De Carufel, J. L., C. Grimm, A. Maheshwari, M. Owen, and M. Smid, 2012. Unsolvability of the Weighted Region Shortest Path Problem. European Workshop on Computational Geometry (EuroCG), 65–68.
- Di Gregorio, A., and L. J. M. Jansen. 2005. Land Cover Classification System Classification Concepts and User Manual Software Version (2). 8 EaNRS (ed). Rome: Food and Agriculture Organization of the United Nations.
- Dijkstra, E. W. 1959. “A Note on Two Problems in Connection with Graphs.” Numerische Mathematik 1 (1): 269–271. doi:10.1007/BF01386390.
- Driezen, K., F. Adriaensen, C. Rondinini, C. P. Doncaster, and E. Matthysen. 2007. “Evaluating Least-Cost Model Predictions with Empirical Dispersal Data: A Case-Study Using Radiotracking Data of Hedgehogs (Erinaceus Europaeus).” Ecological modelling 209 (2–4): 314–322. doi:10.1016/j.ecolmodel.2007.07.002.
- Eastman, J., P. Kyem, and J. Toledano 1993. “A Procedure for Multi-Objective Decision Making in GIS Under Conditions of Conflicting Objectives.” In European Conference on Geographical Information Systems, Genoa, Italy, 438–447.
- Eklund, P. W., S. Kirkby, and S. Pollitt, 1996. “A Dynamic Multi-Source Dijkstra’s Algorithm for Vehicle Routing.” In 1996 Australian New Zealand Conference on Intelligent Information Systems. Proceedings. ANZIIS 96, Adelaide, SA, Australia, 329–333.
- Etherington, T. R., E. P. Holland, D. O’Sullivan, and T. Poisot. 2015. “NLMpy: A Python Software Package for the Creation of Neutral Landscape Models Within a General Numerical Framework.” Methods in Ecology and Evolution 6 (2): 164–168. doi:10.1111/2041-210X.12308.
- Feldman, S. C., R. E. Pelletier, E. Walser, J. C. Smoot, and D. Ahl. 1995. “A Prototype for Pipeline Routing Using Remotely Sensed Data and Geographic Information System Analysis.” Remote Sensing of Environment 53 (2): 123–131. doi:10.1016/0034-4257(95)00047-5.
- Fournier, A., D. Fussel, and L. Carpenter. 1982. “Random Midpoint Displacement Method. Computer Rendering of Stochastic Models.” Communications of the ACM 25.
- Gärds, J., and M. Oscarsson, 2019. Exploring the Use of GIS-Based Least-Cost Corridors for Designing Alternative Highway Alignments. Bachelor thesis, Sweden: KTH Royal Institute of Technology. URN:urn: nbn:se:kth:diva-254595. http://kth.diva-portal.org/smash/record.jsf?pid=diva2%3A1333968&dswid=−1412
- Gärds, J., and M. Oscarsson, 2019. Exploring the use of GIS-based least-cost corridors for designing alternative highway alignments. Bachelor thesis, KTH Royal Institute of Technology, Sweden. URN.
- Gonçalves, A. B. 2010. “An Extension of GIS-Based Least-Cost Path Modelling to the Location of Wide Paths.” International Journal of Geographical Information Science 24 (7): 983–996. doi:10.1080/13658810903401016.
- Gonzales, E. K., and S. E. Gergel. 2007. “Testing Assumptions of Cost Surface Analysis—A Tool for Invasive Species Management.” Landscape Ecology 22 (8): 1155–1168. doi:10.1007/s10980-007-9106-6.
- Graham, C. 2001. “Factors Influencing Movement Patterns of Keel-Billed Toucans in a Fragmented Tropical Landscape in Southern Mexico.” Conservation Biology 15 (6): 1789–1798. doi:10.1046/j.1523-1739.2001.00070.x.
- Hallett, L. F., IV, and D. McDermott. 2011. “Quantifying the Extent and Cost of Food Deserts in Lawrence, Kansas, USA.” Applied Geography 31 (4): 1210–1215. doi:10.1016/j.apgeog.2010.09.006.
- Hart, P. E., N. J. Nilsson, and B. Raphael. 1968. “A Formal Basis for the Heuristic Determination of Minimum Cost Paths.” IEEE Transactions on Systems Science and Cybernetics 4 (2): 100–107. doi:10.1109/TSSC.1968.300136.
- Huber, D. L., and R. L. Church. 1985. “Transmission Corridor Location Modeling.” Journal of Transportation Engineering 111 (2): 114–130. doi:10.1061/(ASCE)0733-947X(1985)111:2(114).
- Kalliainen, A., and P. Kolisoja, 2013. A New Method to Determine the Desired Minimum Railway Embankment Dimensions. In Proceedings of the International Conferences on the Bearing Capacity of Roads, Railways and Airfields, Trondheim, Norway, 349–358.
- Larkin, J. L., D. S. Maehr, T. S. Hoctor, M. A. Orlando, and K. Whitney. 2004, January. “Landscape Linkages and Conservation Planning for the Black Bear in West-Central Florida.” Animal Conservation Forum 7 (1): 23–34. Cambridge University Press. doi:10.1017/S1367943003001100.
- LaRue, M. A., and C. K. Nielsen. 2008. “Modelling Potential Dispersal Corridors for Cougars in Midwestern North America Using Least-Cost Path Methods.” Ecological Modelling 212 (3–4): 372–381. doi:10.1016/j.ecolmodel.2007.10.036.
- Ligmann-Zielinska, A., and P. Jankowski. 2014. “Spatially-Explicit Integrated Uncertainty and Sensitivity Analysis of Criteria Weights in Multicriteria Land Suitability Evaluation.” Environmental Modelling & Software 57: 235–247. doi:10.1016/j.envsoft.2014.03.007.
- Lombard, K., and R. L. Church. 1993. “The Gateway Shortest Path Problem: Generating Alternative Routes for a Corridor Location Problem.” Geographical Systems 1: 25–45.
- McHarg, I. L. 1969. Design with Nature, 197. New York: American Museum of Natural History.
- Mitchell, J. S. B., and C. H. Papadimitriou. 1991. “The Weighted Region Problem: Finding Shortest Paths Through a Weight Planar Subdivision.” Journal of the ACM 38 (1): 18–73.
- Mulrooney, T., K. Beratan, C. McGinn, and B. Branch. 2017. “A Comparison of Raster-Based Travel Time Surfaces Against Vector-Based Network Calculations as Applied in the Study of Rural Food Deserts.” Applied Geography 78: 12–21. doi:10.1016/j.apgeog.2016.10.006.
- Murekatete, R. M., and T. Shirabe. 2018. “A Spatial and Statistical Analysis of the Impact of Transformation of Raster Cost Surfaces on the Variation of Least-Cost Paths.” International Journal of Geographical Information Science 32 (11): 2169–2188. doi:10.1080/13658816.2018.1498504.
- Murekatete, R., and T. Shirabe. 2020. “An Experimental Analysis of Least-Cost Path Models on Ordinal-Scaled Raster Surfaces.” International Journal of Geographical Information Science 1–25. doi:10.1080/13658816.2020.1753204.
- Murekatete, R. M., and T. Shirabe. 2021. “An Experimental Analysis of Least-Cost Path Models on Ordinal-Scaled Raster Surfaces.” International Journal of Geographical Information Science 35 (8): 1545–1569.
- O’Brien, D., M. Manseau, A. Fall, and M. J. Fortin. 2006. “Testing the Importance of Spatial Configuration of Winter Habitat for Woodland Caribou: An Application of Graph Theory.” Biological Conservation 130 (1): 70–83. doi:10.1016/j.biocon.2005.12.014.
- Perny, P., and O. Spanjaard. 2005. “A Preference-Based Approach to Spanning Trees and Shortest Paths Problems.” European Journal of Operational Research 162 (3): 584–601. doi:10.1016/j.ejor.2003.12.013.
- Rabinowitz, A., and K. A. Zeller. 2010. “A Range-Wide Model of Landscape Connectivity and Conservation for the Jaguar, Panthera Onca.” Biological Conservation 143: 939–945. doi:10.1016/j.biocon.2010.01.002.
- Rayfield, B., M. J. Fortin, and A. Fall. 2010. “The Sensitivity of Least Cost Habitat Graphs to Relative Cost Surface Values.” Landscape Ecology 25 (4): 519–532. doi:10.1007/s10980-009-9436-7.
- Ray, N., A. Lehmann, and P. Joly. 2002. “Modeling Spatial Distribution of Amphibian Populations: A GIS Approach Based on Habitat Matrix Permeability.” Biodiversity and Conservation 11: 2143–2165. doi:10.1023/A:1021390527698.
- Sahr, K. 2011. “Hexagonal Discrete Global Grid Systems for Geospatial Computing.” Archiwum Fotogrametrii, Kartografii i Teledetekcji 22: 363–376.
- Saura, S., and J. Martínez‐millán. 2000. “Landscape Patterns Simulation with a Modified Random Clusters Method.” Landscape ecology 15: 661–678.
- Scaparra, M. P., R. L. Church, and F. A. Medrano. 2014. “Corridor Location: The Multi-Gateway Shortest Path Model.” Journal of Geographical Systems 16 (3): 287–309. doi:10.1007/s10109-014-0197-8.
- Schadt, S., F. Knauer, P. Kaczensky, E. Revilla, T. Wiegand, and L. Trepl. 2002. “Rule‐based Assessment of Suitable Habitat and Patch Connectivity for the Eurasian Lynx.” Ecological Applications 12 (5): 1469–1483. doi:10.1890/1051-0761(2002)012[1469:RBAOSH]2.0.CO;2.
- Scott, M. S., 1994. “The Development of an Optimal Path Algorithm in Three-Dimensional Raster Space.” Doctoral diss., University of South Carolina.
- Seegmiller, L., T. Shirabe, and C. D. Tomlin. 2021. “A Method for Finding Least-Cost Corridors with Reduced Distortion in Raster Space.” International Journal of Geographical Information Science 35 (8): 1570–1591.
- Shirabe, T. 2016. “A Method for Finding a Least-Cost Wide Path in Raster Space.” International Journal of Geographical Information Science 30 (8): 1469–1485. doi:10.1080/13658816.2015.1124435.
- Singleton, P. H. 2002. Landscape Permeability for Large Carnivores in Washington: A Geographic Information System Weighted-Distance and Least-Cost Corridor Assessment. 549 Vol. Corvallis, Oregon: US Department of Agriculture, Forest Service, Pacific Northwest Research Station.
- Stevenson-Holt, C. D., K. Watts, C. C. Bellamy, O. T. Nevin, A. D. Ramsey, and B. L. Allen. 2014. “Defining Landscape Resistance Values in Least-Cost Connectivity Models for the Invasive Grey Squirrel: A Comparison of Approaches Using Expert-Opinion and Habitat Suitability Modelling.” Plos One 9 (11): e112119. doi:10.1371/journal.pone.0112119.
- Tomlin, C. D. 1990. Geographic Information Systems and Cartographic Modeling. Englewood Cliffs, NJ: Prentice-Hall.
- Wagner, D. F., and M. S. Scott. 1995, February. “Improving the Performance of Raster GIS: A Comparison of Approaches to Parallelization of Cost Volume Algorithms.” In AutoCarto-Conference, Charlotte, North Carolina, 164–176.
- Yang, L., S. Jin, P. Danielson, C. Homer, L. Gass, S. M. Bender, A. Case, et al. 2018. “A New Generation of the United States National Land Cover Database: Requirements, Research Priorities, Design, and Implementation Strategies.” ISPRS Journal of Photogrammetry and Remote Sensing 146: 108–123. doi:10.1016/j.isprsjprs.2018.09.006.
- Yu, C., J. A. Y. Lee, and M. J. Munro-Stasiuk. 2003. “Extensions to Least-Cost Path Algorithms for Roadway Planning.” International Journal of Geographical Information Science 17 (4): 361–376. doi:10.1080/1365881031000072645.
- Zeller, K. A., K. McGarigal, and A. R. Whiteley. 2012. “Estimating Landscape Resistance to Movement: A Review.” Landscape Ecology 27: 777–797. doi:10.1007/s10980-012-9737-0.