
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
A difficulty in variance component estimation (VCE) is that the estimates may become negative, which is not acceptable in practice. This article presents two new methods for non-negative VCE that utilize the expectation maximization algorithm for the partial errors-in-variables model. The former searches for the desired solutions with unconstrained estimation criterion and concludes statistically that the variance components have indeed moved to the edge of the parameter space when negative estimates appear implemented by the other existing VCE methods. We concentrate on the formulation and provide non-negative analysis of this estimator. In particularly, the latter approach, which has greater computational efficiency, would be a practical alternative to the existing VCE-type algorithms. Additionally, this approach is easy to implement, the non-negative variance components are automatically supported by introducing non-negativity constraints. Both algorithms are free from a complex matrix inversion and reduce computational complexity. The results show that our algorithms retrieve well to achieve identical estimates over the other VCE methods, the latter approach can quickly estimate parameters and has practical aspects for the large volume and multisource data processing.
1. Introduction
In geodetic data processing, the least squares (LS) estimates would be incorrect if the coefficient matrix is contaminated with random errors. To avoid lacking good estimation precision, the iterative algorithm of total least squares (TLS) (Golub and Van Loan Citation1980; Schaffrin and Wieser Citation2008; Wang Citation2012; Wang and Zhao Citation2019) has been developed to solve the observation equations with the unknown parameters of interest and all measurements polluted errors. Such a functional model is the errors-in-variables (EIV) model (Fang Citation2011, Citation2013; Amiri-Simkooei and Jazaeri Citation2012; Jazaeri et al. Citation2014). The EIV model ignores the nonrandomness of elements in the coefficient matrix, As a result, the total number of the unknown parameters has been significantly increased. Xu et al. (Citation2012) proposed an extended model in the terminology of partial EIV model to reduce the correction of nonrandom elements and obtained the statistical properties of a (weighted or ordinary) TLS estimator in the case of finite samples. Liu et al. (Citation2013) further analyzed the structure of the partial EIV model and highlighted that this model greatly facilitates the precision estimation of subsequent estimates (Wang and Zhao Citation2018; Wang and Zou Citation2019; Wang and Ding Citation2020).
The functional models and the algorithms for numerically finding the LS or TLS solutions have been extensively studied. In practical applications, the prior stochastic model of observations is often unreliable. This problem has attracted a widely spread attention in the monitoring data sets of surface deformation, such as earthquake, volcanic eruption, crustal movement and groundwater extraction. Knowledge of an appropriate (co)variance matrix is a prerequisite for reasonable parameter estimation and subsequent precision analysis. The unknown variance components can be updated iteratively to weigh the contributions of different data sets, such as observed displacement data of InSAR and GPS, to obtain the final estimates, this is the ubiquitous task of variance component estimation (VCE). There exist several VCE methods to estimate heterogeneous variance components such as the variance component estimation of Helmert type (Helmert Citation1907), best invariant quadratic unbiased estimation (BIQUE) (Koch Citation1999), minimum norm quadratic unbiased estimation (MINQUE) (Xu et al. Citation2006, Citation2007), iterative almost unbiased estimation (IAUE) (Hsu Citation1999; Vergos et al. Citation2012), least squares variance component estimation (LS-VCE) (Teunissen and Amiri-Simkooei Citation2008) and restricted maximum likelihood estimation (REML) (Koch Citation1986). The VCE methods have been widely applied to the so called LS problem, heteroscedasticity of different types of observations is also a typical characteristic for the EIV model or the case of the partial EIV model. In an early work of Amiri-Simkooei (Citation2013), the LS-VCE is applied to the EIV model, this application can generally evaluate the unknown variance components for the observations and the coefficient matrix. Considering that the ill-posed TLS problem usually occurs in geodetic applications, Wang et al. (Citation2019) added the virtual observations and adopted the Helmert method to determine the ridge parameter for the partial EIV model, this ridge parameter is the weight ratio between the different measurements and reduces the influence of the minor disturbance of observations. Wang and Xu (Citation2016) used the ratio of relative weight method for estimating the variance components, they described that the Helmert method applied to the partial EIV model is also feasible.
A typical problem in estimation principles of variance components is that not all existing VCE methods produce positive estimates. Lee and Khuri (Citation2001), therefore, investigated the probability of the occurrence of negative estimates, it actually depends on the design used and the true values of the variance components themselves. Thompson (Citation1962) analyzed the influence of the VCE methods, it may lead to negative variance components. Moghtased-Azar et al. (Citation2014) presented an alternative method for non-negative VCE, and reparameterized the variance components by a positive-valued function, this method succeeded to overcome the phenomenon of negative variance in each iteration, but its convergence may be slow or divergent due to the presence of an extremely inappropriate stochastic model. Based on the LS-VCE method, Amiri-Simkooei (Citation2016) deduced a non-negative least squares variance component estimation (NNLS-VCE) approach using the sequential coordinate-wise non-negative least squares (NNLS) of Franc et al. (Citation2005), this approach provides the precision of variance component estimates that is never worse than the unconstraint algorithms. However, it is essentially a non-negative constraint approach and the statistic information is not easily available. Jennrich and Sampson (Citation1976) recommended replacing the negative variance components with a certain positive value or adding non-negativity constraints to the VCE method.
As a result, to obtain the non-negative estimation, some kinds of constraints, such as equality and inequality constraints, are imposed to the estimators (Jennrich and Sampson Citation1976; Groeneveld 1994; Moghtased-Azar et al. Citation2014; Amiri-Simkooei Citation2016). These participation constraints are rooted in a prior information inherent to the variance components, consequently, the estimation of parameters with large bias may be improved. Nevertheless, compared with a great number of publications on non-negative VCE methods and publications, statistical aspects of the non-negative variance component estimators have not received due attention, in particular, in the case of a non-negative estimator without any constraints. On the other hand, the existing non-negative VCE methods either take a positive estimate or estimate it to zero, it lacks a uniform standard. Unlike the VCE methods, the shortcomings of these methods with the constraints cannot give a reasonable explanation and derivation for the problem of the negative variance. To find a more intuitive and reliable procedure, the algorithm of expectation maximization (EM) is developed here.
The EM algorithm was originally proposed by Dempster et al. (Citation1977) and has been extensively studied (Lange et al. Citation1989; Peng Citation2009; Gupta and Chen Citation2010; Koch Citation2013). Variance component estimation derived by the EM algorithm for the linear mixed model is routinely applied to biological or longitudinal data. Laird and Ware (Citation1982) applied two-stage random-effects models for maximum likelihood estimation using two probability distributions, the first one for response vectors of different individuals belong to a single family and the second one for random-effects parameters, which are to be specified as the latent variables, that vary across individuals. Calvin (Citation1993) extended the method of Laird and Ware (Citation1982), and developed an EM algorithm for REML estimation of the multivariate mixed model where the variance component matrices are estimated with unbalanced data. This algorithm is reasonably quick for moderately sized data. Foulley et al. (Citation2000) investigated the class of random-effects components, and estimated the parameters associated with random coefficient factors separately from those pertaining to the stationary time processes and measurement errors. In the geodetic literature, the EM algorithm is often adopted to solve the mean shift model or variance inflation model for robust estimation (Peng Citation2009; Koch Citation2013; Koch and Kargoll Citation2013). Based on the time series data sets and EM algorithm, Kargoll et al. (Citation2018) investigated the random deviations associated with the autoregressive process, they also deduced an iteratively reweighted LS approach capable of adaptive robust adjustment of parameters. Unfortunately, the EM algorithm can be slow to converge. Thus, various modifications of the EM algorithm, such as expectation conditional maximization (ECM) and an extension of the ECM algorithm, namely, the ECM either (ECME), were proposed to accelerate convergence in this setting (Little and Rubin Citation2002; Mclachlan and Krishnan Citation2008).
The traditional solutions for the EM algorithm are usually applied to the linear model for VCE or robust estimation. In this article, we have derived two non-negative VCE approaches, namely the EM algorithm VCE (EM-VCE) and the modified EM algorithm of non-negative VCE (EM-NN-VCE), for the more general partial EIV model. Although, the coefficient matrix without random effects has been considered by Laird and Ware (1982) , estimation via the EM algorithm with a random coefficient matrix and measurement errors will be derived here. More importantly, we will extend the analysis of non-negativity for EM-VCE solutions. Unlike all the methods of TLS, the random errors of the coefficient matrix will be introduced as the latent variables or missing data, and based on conditional expectations. The missing data are determined to facilitate the problem of the maximization. Both algorithms are free from a complex matrix inversion and the parameters and variance components are jointly estimated. The latter, which exhibits less computational burden, would be a practical alternative to the existing VCE-type algorithms. Additionally, the feasibility and superiority of the proposed algorithms over the methods of REML, positive-valued functions non-negative VCE (PVFs-VCE) and NNLS-VCE will be verified by numerical examples.
This article is organized as follows: Section 2 introduces the structural information of the partial EIV model and briefly describes the maximization problems of this model. In Section 3, we deduce the EM algorithm variance component estimation (EM-VCE) for the partial EIV model, the non-negativity of EM-VCE and the modified version of non-negative VCE are further presented. In Section 4, we perform two numerical examples to simultaneously estimate the variance components and fixed parameters using the proposed algorithms and control methods. Finally, some conclusions are made in Section 5.
2. Partial EIV model
The partial EIV model proposed by Xu et al. (Citation2012) is expressed as
(1)
(1)
where
denotes the
vector of observations,
represents the
coefficient matrix with errors,
is the true matrix of
denotes the
vector of fixed parameters,
represents the
identity matrix,
is the
constant vector consisting of nonrandom elements and zeros of
represents the
deterministic matrix related to
is the
vector composed of random elements of
denotes the true vector of
represents the
vector of observation errors and
is the
error vector of the independent random elements of
stands for the Kronecker product (Grafarend and Schaffrin Citation1993),
denotes the operator that stacks one column of a matrix underneath the previous one, and
is the opposite of the
operator which reshapes the vector into the original matrix.
We assume that the random error vectors and
are independent of each other. Then the stochastic model of the partial EIV model is defined as
(2)
(2)
where and
are the variance-covariance matrices corresponding to
and
the EquationEquation (1)
(1)
(1) is deformed as follows
(3)
(3)
This eliminates the unknown parameter vector in EquationEquation (1)
(1)
(1) , and the stochastic properties of the variables in that vector are expressed in the coefficient matrix. In probability statistics,
and
are the two-dimensional random variables that follow the normal distribution,
is also a random variable with
If we define the equation
then, the first and second central moments of the random variable
are given as
(4)
(4)
(5)
(5)
where
is expressed as
Considering that the observation vector
and the coefficient matrix
have different variance components under certain circumstances, we set the variance-covariance matrices
and
in EquationEquation (2)
(2)
(2) , where
and
are the known cofactor matrices. Then, define the parameters as
and assume
the likelihood function
is identical to the probability density function
of
and can be expressed as
(6)
(6)
To facilitate the calculation, we take logarithms of the exponential likelihood function in EquationEquation (6)(6)
(6) simultaneously on both sides
(7)
(7)
The matrix is a nonlinear function of the unknown parameters
Taking the partial derivatives with respect to the parameters in EquationEquation (7)
(7)
(7) , which will involve nonlinear objective functions with the observation errors and coefficient matrix errors. Thus, the iterative form after derivation is more complicated.
3. Non-negative VCE for the partial EIV model
3.1. Formulation of EM-VCE
Facing the thorny task of maximizing likelihood function we introduce appropriate latent variables or missing data to bring the maximization problems into an equivalent and easy-to-handle form. Latent variables are treated as unobserved data that can be attributed to conditional expectations, and such a latent variable plays an auxiliary role in the framework of maximum likelihood estimation. A general technique for addressing the problems of various missing data is the EM algorithm (Dempster et al. 1977). It can avoid involving the inverse of the matrix and the iterative process is stable; thus, it is frequently utilized as an iterative optimization method for maximum likelihood estimation or residual (restricted) maximum likelihood estimation. From the EM algorithm, a random log-likelihood function
is given with the unknown parameters
involving
denotes the complete data,
is the observations or incomplete data and
represents the latent variables or missing data. The parameters
can be estimated as
(8)
(8)
where
is the iteration step,
is the maximum number of iterations. To emphasize that the preceding conditional expectation is a function of the unknown parameters
involving parameters
we let
be the domain of missing data
The conditional expectation in EquationEquation (8)
(8)
(8) is denoted by the
function
such that
(9)
(9)
where
is the joint probability density function,
indicates the conditional probability density function of missing data
based on the observations
and the parameters
The EM algorithm performs two steps in each iteration, the E-step determines the conditional expectation of the missing data and the M-step is to maximize the conditional expectation with respect to the unknown parameters
As for the maximum likelihood estimation for the partial EIV model using the EM algorithm, the random error vector is deemed to be the missing data,
is treated as the incomplete data; then the complete data will be
Since the independent and random properties of the variables, we could find the complete data
Thereby, the stochastic model can be expressed as
(10)
(10)
According to Mclachlan and Krishnan (Citation2008), the likelihood function of is represented as
(11)
(11)
Then, the log-likelihood function is written as
(12)
(12)
Taking the particularity of the inversion of the block matrix and the determinant into account via Searle et al. (Citation1992), we obtain
(13)
(13)
(14)
(14)
Substituting EquationEquations (13)(13)
(13) and Equation(14)
(14)
(14) into EquationEquation (12)
(12)
(12) , the log-likelihood function is rewritten as
(15)
(15)
From EquationEquation (14)(14)
(14) , the aforementioned equation would be further simplified as follows
(16)
(16)
From the preceding derivation, the log-likelihood function of the complete data may be divided into
(17)
(17)
Unlike the definition of the log-likelihood function in EquationEquation (7)(7)
(7) , the log-likelihood function
consists of two marginal distributions.
leads to a maximization problem, which is easier to address than the original problems described with EquationEquations (6)
(6)
(6) and Equation(7)
(7)
(7) . The E-step is to obtain the conditional expectation of the observations and random elements of the coefficient matrix. Thus, there is
(18)
(18)
Obviously, estimating variance components via maximum likelihood estimation requires the conditional distributions and
Diffey et al. (Citation2017) noted that the loss of freedom is derived from unconsidered parameters
the estimates of variance components will be biased. However, the estimates using the REML are unbiased. The approach of linear transformation transforms the vector
into the new vector
Namely:
(19)
(19)
where
is a nonsingular matrix,
and
are the
and
transformation matrices with full column rank. Also,
and
are required. To obtain the conditional distributions in EquationEquation (18)
(18)
(18) , the statistical information of new observations
and
is of the form
(20)
(20)
The two conditional distributions are simplified into
(21)
(21)
(22)
(22)
where
then
is obtained
(23)
(23)
The expectation formula of the quadratic form is
(24)
(24)
where
is the known matrix,
and
are the expectation and covariance matrix of random variable
The preceding formula is equally appropriate for the conditional expectation. Thus, the
function can be obtained using the EquationEquations (16)
(16)
(16) and Equation(24)
(24)
(24) , such that
(25)
(25)
(26)
(26)
where
(27)
(27)
(28)
(28)
Set the partial derivatives of the function in EquationEquations (25)
(25)
(25) and Equation(26)
(26)
(26) with respect to the variance factors
and
equal to
it can be formulated as
(29)
(29)
(30)
(30)
Combining the stochastic information of the incomplete data and
yields
(31)
(31)
where is the expectation involving a given observation vector
Wang et al. (Citation2016) indicated that the matrix
is reconstructed when the vector
of the iteration step
is known, and the parameters
would be estimated with the indirect adjustment. It is equivalent to directly setting the partial derivative with respect to the parameters
from EquationEquation (16)
(16)
(16) , which is derived as
(32)
(32)
Fang et al. (Citation2017) deduced the TLS solution with the same form of EquationEquation (32)(32)
(32) by the Bayesian inference and programed the iterative process for the EIV model. They found that its computation efficiency is low. Thus, we start from EquationEquations (3)
(3)
(3) and Equation(31)
(31)
(31) , the error vector
is written as
(33)
(33)
Substitute the equation into EquationEquation (32)
(32)
(32) , the least-squares solution may be reconfigured as
(34)
(34)
EquationEquation (34)(34)
(34) is an alternative form of the estimates
with higher computational efficiency that the EM-VCE would be adopted. Also, the flowchart of the EM-VCE algorithm for the partial EIV model is depicted in .
3.2. Non-negativity of EM-VCE
The existing VCE methods such as the Helmert method, BIQUE, MINQUE, LS-VCE and REML, always have the potential to yield negative variances, which is in conflict with the fact that the variance components satisfy There are many reasons for the existence of negative variances (Sjöberg Citation2011; Moghtased-Azar et al. Citation2014; Amiri-Simkooei Citation2016; El Leithy et al. Citation2016): (1) a set of improper initial guess, namely, a badly chosen set for the initial variance components; (2) low redundancy in the functional model, which is insufficient redundant observations. In fact, the precision of VCE can be improved by increasing the number of redundant observations; and (3) an improper stochastic model. To illustrate the non-negativity of the variance components using the EM algorithm in Searle et al. (Citation1992), we start from EquationEquation (23)
(23)
(23) and combine it with the structure of the covariance matrix
when
That is
(35)
(35)
Based on the matrix inversion formula we obtain
(36)
(36)
Inserting EquationEquation (36)(36)
(36) into EquationEquation (30)
(30)
(30) , the second term of EquationEquation (30)
(30)
(30) is simplified as
(37)
(37)
Taking the matrix into account with
the following equation is established
(38)
(38)
where is the invertible matrix. The
and
are positive definite matrices from the properties of the positive definite; hence
(39)
(39)
The first term of EquationEquation (30)(30)
(30) is substituted into EquationEquation (28)
(28)
(28) to obtain
(40)
(40)
where is a symmetric and positive definite matrix,
In the iteration step
once any positive value of
is given and the EquationEquation (39)
(39)
(39) is taken into account. The EquationEquation (30)
(30)
(30) will be rewritten as
(41)
(41)
Through induction, the non-negative estimates of each iteration are ensured in the aforementioned process. is still a positive definite matrix, then
would be guaranteed. However, in actual situations, the variance components may converge to zero. According to Zhou et al. (2015), the EM algorithm, to some extent, acts like an interior point method, approaching the optimum from within the feasible region. The non-negativity of the variance factor
of the observations is similar to the variance factor
Given any positive value of
the estimate
has the same property.
3.3. Modified version of EM-VCE
In the implement of EM-VCE, this approach requires a few more iterations. Thus, a modified algorithm to improve the convergence longs to be presented. The Fisher–Score algorithm is an iterative method for a nonlinear function model in Zhao et al. (Citation2019). The information matrix does not require evaluating the quadratic form of the observations in the Hessian matrix. This algorithm converges quickly and has strong robustness to the initial guess over the Newton–Rapson algorithm. To obtain a more general derivation of the partial EIV model, the statistical information of its observations and coefficient matrix is expressed as
(42)
(42)
where is a positive or semi-definite matrix corresponding to the variance factor
Calculating the partial derivatives from the EquationEquations (25)–(28), it can be obtained as
(43)
(43)
Taking the second partial derivative of the function with respect to
which means taking the first partial derivative for
of EquationEquation (43)
(43)
(43) . That is
(44)
(44)
Take the expectation of the EquationEquation (44)(44)
(44) to obtain
(45)
(45)
The Fisher–Score algorithm changes the information matrix of the Newton–Rapson algorithm with the expectation of the information matrix. Thus, the iterative formulae of the modified EM-VCE are
(46)
(46)
(47)
(47)
Obviously, the value of the molecular part of the second term of EquationEquations (46)(46)
(46) and Equation(47)
(47)
(47) is not always greater than or equal to zero. When a positive value
is given as the initial guess, only the denominator of the fraction of the initial iteration is greater than zero. As the iterative process proceeds,
may cause a nonpositive definite matrix
which implies that a negative variance appears. Therefore, according to Sun et al. (Citation2003), adding the non-negativity constraints will make it possible to estimate non-negative variance components with
for the modified version. This will mainly constrain one of the elements and will not affect the estimation of the remaining elements, which ensures the non-negative estimates.
4. Numerical results and analysis
To verify the feasibility and effectiveness of the proposed algorithms, two examples, i.e. linear regression and the four-parameter planar coordinate transformation, are employed. Seven algorithms, namely, the LS method, TLS method, REML (Koch Citation1986), positive-valued functions non-negative variance component estimation (Moghtased-Azar et al. Citation2014), non-negative least squares variance component estimation (Amiri-Simkooei Citation2016) and the two proposed approaches are used to estimate the variance components for the partial EIV model. All seven algorithms adopted in this article are shown in .
Table 1. The design of seven algorithms.
4.1. Linear regression
The linear regression model is
(48)
(48)
where represents the coordinates in a planar coordinate system,
and
are the corresponding coordinate errors and
and
are the linear regression model parameters.
To extract random and nonrandom elements from the coefficient matrix, the matrix forms and
are given as
(49)
(49)
where is a
matrix whose internal elements are all zero, and
is a
matrix whose internal elements are all one.
With the simulated data, 20 values are generated at equal intervals between 0.9 and 11 for the true vector of the coordinates. The true values of parameters for the linear regression model are
then, the true vector
of coordinates is obtained. Furthermore, random errors with a mean value of
and the covariance matrices of
and
are added into the true value
of 20 sets of the coordinates. The simulated coordinates and the corresponding weights are shown in . For the purpose of comparing the relative performance of different VCE methods, this example is used to estimate the variance components in the presence of positive variances. In other words, the new proposed method must have the ability to estimate the variance components, which lays a foundation for the following research on negative variances.
Table 2. Coordinate observations and corresponding weights.
With the given simulated data, the parameters and variance components are estimated using seven schemes with the convergence threshold of the results are listed in .
Table 3. Linear regression results with different methods.
and
are the variance component estimates for the observations and coefficient matrix errors, respectively.
indicates the norm between the parameter estimate and the true value. MAE is the mean absolute error and describes the precision of the model-prediction. The weighted form of mean absolute error is
where
represents the individual model-prediction error and
is the individual weight of observations. As seen from , there is a considerable difference for the parameters
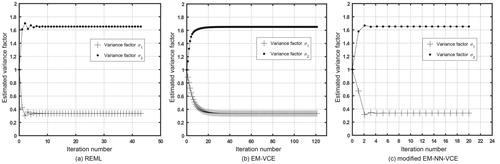
estimated depending on whether the VCE methods is considered. The parameters based on the VCE are closer to the true values. Additionally, the MAE of estimation results by the VCE methods is also smaller in comparison to the methods of LS and TLS. Regarding the number of iterations, Scheme 4 has 38, while Scheme 3 and 5 have 43. Regarding the two proposed approaches, the convergence of Scheme 6 is relatively slow and the iteration number is 121. However, Scheme 7 requires only 20 iterations, which is more efficient. The convergence of the VCE for Schemes 3, 6 and 7 is given in . According to the results of this example, the EM-VCE and the modified EM-NN-VCE accord with the three previous VCE methods.
Figure 1. Flowchart showing the implementation of the EM-VCE method for the partial EIV model.
Figure 2. The convergence of the estimates of two variance factors and
for the linear regression. (a) Variance factors
and
estimated by the REML method; (b) Variance factors
and
estimated by the EM-VCE method; and (c) Variance factors
and
estimated by the modified EM-NN-VCE method.
4.2. Planar coordinate transformation
To further demonstrate the validity of the proposed algorithms in the presence of negative variance, a planar coordinate transformation model is adopted as follows:
(50)
(50)
where are the coordinates of the start coordinate system,
are the coordinates of the target coordinate system.
and
are the errors of the corresponding coordinates. Subscripts
expresses the
coordinates, and
and
are the coordinate transformation parameters.
Considering the planar coordinate transformation for the partial EIV model, the vector and the fixed matrix
associated with the coefficient matrix are
(51)
(51)
where and
are the
zero matrices,
and
Given 15 sets of true values of the start coordinate system and 4 transformation parameters, the true coordinates of the target coordinate system are obtained from connecting two sets of coordinate systems. Then, we add random errors with a mean of and the covariance matrices of
and
to the two coordinate systems. A set of coordinates containing errors is listed in .
Table 4. Coordinate simulation values of two sets of coordinate systems.
Assuming that the true values of the transformation parameters are the weights of two sets of coordinate systems are as follows
In , a negative variance component appears by Scheme 3. Scheme 5 imposes non-negativity constraints based on the LS-VCE theory, the variance factors are non-negative. Scheme 4 fails to converge due to its improper stochastic model. Also, Scheme 3 lacks good estimation results in , the MAE is even worse than the LS and TLS. The MAE of estimation results by the non-negative VCE methods is negligible due to a small amplitude of the variance component obtained. In this article, the convergence threshold of Scheme 5 is set as the variance components are close to those of Schemes 5 and 7. The convergence of the variance components of Schemes 3, 5 and 7 is shown in . Nineteen iterations are needed for the REML. However, only 10 and 11 iterations are required for the NNLS-VCE and the modified EM-NN-VCE, respectively.
Figure 3. The convergence of the estimates of two variance factors (left column) and
(right column) for the coordinate transformation. (a) Variance factor
estimated by the REML method; (b) Variance factor
estimated by the REML method; (c) Variance factor
estimated by the NNLS-VCE method; (d) Variance factor
estimated by the NNLS-VCE method; (e) Variance factor
estimated by the modified EM-NN-VCE method; and (f) Variance factor
estimated by the modified EM-NN-VCE method.
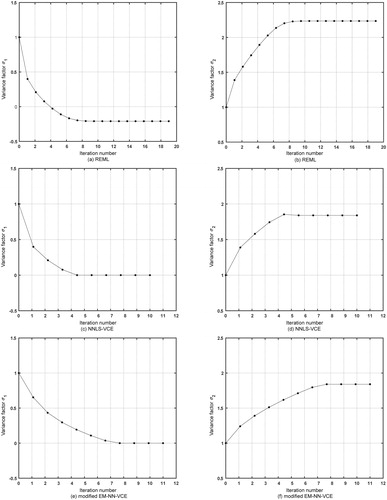
Table 5. Coordinate transformation results with different methods.
In , different convergence thresholds are set for Scheme 6. As the threshold decreases, both variance components converge to a certain trend value. The variance factor estimated approaches zero. The variance factor
also converges to a positive value. This approach guarantees the non-negativity of the variance components. In fact, when the variance factor
approaches zero, the likelihood function
of the complete data
will approach infinity. In that case, the variance component estimated by EM-VCE tend to converge slowly, maximizing the likelihood function is actually an ill-posed problem. Thereby, an approximate value with zero for variance component is feasible, the EM-VCE could be applied to verify the justification of the existing non-negative VCE methods.
Table 6. Results of Scheme 6 with different convergence thresholds.
5. Conclusions
In some geodetic applications, the problem of negative variances may appear in the process of correcting the stochastic model with variance factors. Many attempts have been made to counteract this effect, such as PVFs-VCE and NNLS-VCE, this problem may be avoided by introducing the positive-valued functions or non-negativity constraints. To investigate the properties of solutions from the statistics, an unconstrained approach is required. Based on the standard theories of the EM algorithm, we develop two new methods of non-negative VCE for the partial EIV model, an iterative algorithm of TLS is obtained simultaneously. The EM-VCE can statistically demonstrate that the problem of maximum likelihood estimation is essentially an ill-posed problem in the presence of negative estimates and variance component estimates move to the edge of the parameter space. A modified version of VCE is also presented to improve the computational efficiency and has access to the non-negative estimates. Both algorithms are free from a complex matrix inversion. Finally, two numerical examples, i.e. linear regression and the four-parameter planar coordinate transformation, are employed to verify the feasibility of the proposed algorithms. The results of linear regression show that the proposed algorithms can achieve the more reasonable fixed parameter estimates compared with the algorithms of LS and TLS. The variance component estimates are identical to the algorithms of REML, PVFs-VCE and NNLS-VCE, the modified EM algorithm, namely, EM-NN-VCE, which is nearly fifty percent faster. Two variance factors of the latter example were simultaneously estimated to be non-negative by the proposed algorithms. This study provides a statistical explanation for the justifiability of the existing non-negative VCE methods.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Amiri-Simkooei AR. 2013. Application of least squares variance component estimation to errors-in-variables models. J Geod. 87(10–12):935–944.
- Amiri-Simkooei AR. 2016. Non-negative least-squares variance component estimation with application to GPS time series. J Geod. 90(5):451–466.
- Amiri-Simkooei AR, Jazaeri S. 2012. Weighted total least squares formulated by standard least squares theory. J Geod Sci. 2(2):113–124.
- Calvin JA. 1993. REML estimation in unbalanced multivariate variance components models using an EM algorithm. Biometrics. 49(3):691–701.
- Dempster AP, Laird NM, Rubin DB. 1977. Maximum likelihood from incomplete data via the EM algorithm. J R Stat Soc Ser B. 39(1):1–38.
- Diffey SM, Smith AB, Welsh AH, Cullis BR. 2017. A new REML (parameter expanded) EM algorithm for linear mixed models. Aust N Z J Stat. 59(4):433–448.
- El Leithy HA, Abdel Wahed ZA, Abdallah MS. 2016. On non-negative estimation of variance components in mixed linear models. J Adv Res. 7(1):59–68.
- Fang X. 2011. Weighted total least squares solutions for applications in geodesy. Hanover, Germany: Leibniz Universität Hannover.
- Fang X. 2013. Weighted total least squares: necessary and sufficient conditions, fixed and random parameters. J Geod. 87(8):733–749.
- Fang X, Li B, Alkhatib H, Zeng W, Yao Y. 2017. Bayesian inference for the errors-in-variables model. Stud Geophys Geod. 61(1):35–52.
- Foulley JL, Jaffrézic F, Robert-Granié C. 2000. EM-REML estimation of covariance parameters in Gaussian mixed models for longitudinal data analysis. Genet Sel Evol. 32(2):129–141.
- Franc V, Hlaváč V, Navara M. 2005. Sequential coordinate-wise algorithm for the non-negative least squares problem. In: Gagalowicz A, Philips W (eds) Computer analysis of images and patterns, Lecture Notes in Computer Science. p. 407–414.
- Golub GH, Van Loan CF. 1980. An analysis of the total least squares problem. SIAM J Numer Anal. 17(6):883–893.
- Grafarend EW, Schaffrin B. 1993. Ausgleichungsrechnung in linearen modellen. Mannheim, Germany: BI-Wissenschaftsverlag.
- Groeneveld E. 1994. A reparameterization to improve numerical optimization in multivariate REML (co)variance component estimation. Genet Sel Evol. 26(6): 537–545.
- Gupta MR, Chen Y. 2010. Theory and use of the EM algorithm. FNT Signal Process. 4(3):223–296.
- Helmert FR. 1907. Die Ausgleichungsrechnung nach der Methode der kleinsten Quadrate. Berlin, Germany: Zweite Auflage, Teubner, Leipzig.
- Hsu R. 1999. An alternative expression for the variance factors in using iterated almost unbiased estimation. J Geod. 73(4):173–179.
- Jazaeri S, Amiri-Simkooei AR, Sharifi MA. 2014. Iterative algorithm for weighted total least squares adjustment. Surv Rev. 46(334):19–27.
- Jennrich RI, Sampson PF. 1976. Newton-Raphson and related algorithms for maximum likelihood variance component estimation. Technometrics. 18(1):11–17.
- Kargoll B, Omidalizarandi M, Loth I, Paffenholz J-A, Alkhatib H. 2018. An iteratively reweighted least-squares approach to adaptive robust adjustment of parameters in linear regression models with autoregressive and t-distributed deviations. J Geod. 92(3):271–297.
- Koch KR. 1986. Maximum likelihood estimate of variance components. Bull Geod. 60(4):329–338.
- Koch KR. 1999. Parameter estimation and hypothesis testing in linear models. Berlin, Germany: Springer-Verlag.
- Koch KR. 2013. Robust estimation by expectation maximization algorithm. J Geod. 87(2):107–116.
- Koch KR, Kargoll B. 2013. Expectation maximization algorithm for the variance-inflation model by applying the t-distribution. J Appl Geod. 7(3):217–225.
- Laird NM, Ware JH. 1982. Random-effects models for longitudinal data. Biometrics. 38(4):963–974.
- Lange KL, Little RJA, Taylor JMG. 1989. Robust statistical modeling using the t distribution. J Am Stat Assoc. 84(408):881–896.
- Lee J, Khuri AI. 2001. Modeling the probability of a negative ANOVA estimate of a variance component. CSAB. 51(1–2):31–45.
- Little RJA, Rubin DB. 2002. Statistical analysis with missing data. 2nd ed. Hoboken (NJ): Wiley.
- Liu JN, Zeng WX, Xu PL. 2013. Overview of total least squares methods. Geom Inform Sci. 38(5):505–512.
- Mclachlan GJ, Krishnan T. 2008. The EM algorithm and extensions. 2nd ed. Hoboken (NJ): Wiley.
- Moghtased-Azar K, Tehranchi R, Amiri-Simkooei AR. 2014. An alternative method for non-negative estimation of variance components. J Geod. 88(5):427–439.
- Peng J. 2009. Jointly robust estimation of unknown parameters and variance components based on expectation-maximization algorithm. J Surv Eng. 135(1):1–9.
- Schaffrin B, Wieser A. 2008. On weighted total least-squares adjustment for linear regression. J Geod. 82(7):415–421.
- Searle SR, Casella G, McCulloch CE. 1992. Variance components. New York (NY): Wiley.
- Sjöberg LE. 2011. On the best quadratic minimum bias non-negative estimator of a two-variance component model. J Geod Sci. 1(3):280–285.
- Sun Y, Sinha BK, Rosen DV, Meng Q. 2003. Nonnegative estimation of variance components in multivariate unbalanced mixed linear models with two variance components. J Stat Plan Infer. 115(1):215–234.
- Teunissen PJG, Amiri-Simkooei AR. 2008. Least-squares variance component estimation. J Geod. 82(2):65–82.
- Thompson WA, Jr. 1962. The problem of negative estimates of variance components. Ann Math Statist. 33(1):273–289.
- Vergos GS, Tziavos IN, Sideris MG. 2012. On the determination of sea level changes by combining altimetric, tide gauge, satellite gravity and atmospheric observations. Heidelberg, Berlin: Springer.
- Wang L. 2012. Properties of the total least squares estimation. Geod Geodyn. 3(4):39–46.
- Wang L, Ding R. 2020. Inversion and precision estimation of earthquake fault parameters based on scaled unscented transformation and hybrid PSO/Simplex algorithm with GPS measurement data. Measurement. 153:107422.
- Wang L, Wen G, Zhao Y. 2019. Virtual observation method and precision estimation for ill-posed partial EIV model. J Surv Eng. 145(4):04019010.
- Wang L, Xu G. 2016. Variance component estimation for partial errors-in-variables models. Stud Geophys Geod. 60(1):35–55.
- Wang L, Yu H, Chen X. 2016. An algorithm for partial EIV model. Acta Geod Cartographica Sin. 45(1):22–29.
- Wang L, Zhao Y. 2018. Scaled unscented transformation for nonlinear error propagation:accuracy, sensitivity and applications. J Surv Eng. 144(1):04017022.
- Wang L, Zhao Y. 2019. Second order approximating function method for precision estimation of total least squares. J Surv Eng. 145(1):04018011.
- Wang L, Zou C. 2019. Accuracy analysis and applications of Sterling interpolation method for nonlinear function error propagation. Measurement. 146:55–64.
- Xu P, Liu Y, Shen Y, Fukuda Y. 2007. Estimability analysis of variance and covariance components. J Geod. 81(9):593–602.
- Xu P, Liu J, Shi C. 2012. Total least squares adjustment in partial errors-in-variables models: algorithm and statistical analysis. J Geod. 86(8):661–675.
- Xu P, Shen Y, Fukuda Y, Liu Y. 2006. Variance component estimation in linear inverse ill-posed models. J Geod. 80(2):69–81.
- Zhao J, Guo F, Li Q. 2019. Fisher-Score algorithm of WTLS estimation for PEIV model. Geom Inform Sci Wuhan Univ. 44(2):59–65.
- Zhou H, Hu L, Zhou J, Lange K. 2015. MM algorithms for variance components models. J Comput Graph Stat. arXiv: 1509. 07426.