
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
High level of tropospheric ozone concentration, exceeding allowable level has been frequently reported in Malaysia. This study proposes accurate model based on Machine Learning algorithms to predict Tropospheric ozone concentration in major cities located in Kuala Lumpur and Selangor, Malaysia. The proposed models were developed using three-year of historical data for different parameters as input to predict 24-hour and 12-hour of tropospheric ozone concentration. Different Machine Learning algorithms have been investigated, viz. Linear Regression, Neural Network and Boosted Decision Tree. The results revealed that wind speed, humidity, Nitrogen Oxide, Carbon Monoxide and Nitrogen Dioxide have significant influence on ozone formation. Boosted Decision Tree outperformed Linear regression and Neural Network algorithms for all stations. The performance of the proposed model improved by using 12-hours dataset instead of the 24-hour where R2 values were equal to 0.91, 0.88 and 0.87 for the three investigated stations. To assess the uncertainties of the Boosted Decision Tree model, 95% prediction uncertainties (95PPU) d-factors were introduced.95PPU showed about 94.4, 93.4, 96.7% and the d-factors were 0.001015, 0.001016 and 0.001124 which relate to S1, S2 and S3, respectively. The obtained results provide a reliable prediction model to mimic actual ozone concentration in different locations in Malaysia.
1. Introduction
Ozone is a gas made up of three oxygen atoms (O3) where it occurs naturally in small amount in the stratosphere (upper atmosphere) which help to protect life on Earth from the sun's ultraviolet (UV) radiation. Tropospheric Ozone located at lower atmosphere is a major air pollutant in urban areas that include metropolitan cities like Kuala Lumpur, Petaling Jaya and Kelang in Malaysia. When present in sufficient quantity, tropospheric ozone can have severe effects on humans’ health such as respiratory and cardiovascular diseases (Zhan et al., Citation2018). It is imperative to examine both indoor and outdoor ozone concentration to monitor ambient air quality (Shen et al., Citation2017); (Chen et al., Citation2018). Moreover, tropospheric ozone gives negative impact toward crops production and vegetation in general (Antanasijević et al., Citation2019); (Ismail et al., Citation2011). In Malaysia, regulations have been set by the Department of Environment (DOE) known as New Malaysia Ambient Air Quality Standard to limits the emission of air pollutants concentration in such a way that they cannot exceed recommended maximum values since 1989. New Malaysia Ambient Air Quality Standard for ground level ozone, O3 cannot exceed the average of 1-hour time by 2020 standard which will be 200 or average of 8-hour time by 2020 standard of 120
(‘Official Portal of Department of Environment’, Citation2019). Malaysia is a developing country and Kuala Lumpur, Petaling Jaya and Kelang are the major cities thus susceptible to high-ozone concentration generated due to air pollution from fuel combustion, generation of Volatile organic compounds (VOCs) and operation from high industrial zones. Therefore, future increase of ozone concentration need to be carefully monitored (Ezimand & Kakroodi, Citation2019).
Various methods have been initiated for predicting the ozone concentration all over the world such as deterministic (theoretical and detailed atmospheric diffusion model) and statistical regression (Capilla, Citation2016; Gao et al., Citation2018; Hoshyaripour et al., Citation2016). Some methods have been developed based on linear regression concept. Multiple Linear Regression (MLR) is one of the most popular linear regression methods in predicting ozone concentration (Banja et al., Citation2012; Huang et al., Citation2019). However, this model shows drawback to apprehend the nonlinearity and complexity associated with the structure of system (Arsić et al., Citation2020).
Recently Artificial intelligence technique has gained popularity among researchers as a nonlinear approach to solve complex problem to forecast air quality (Abdul-Wahab & Al-Alawi, Citation2002; Alimissis et al., Citation2018). Over the years, improvements have been made toward neural network model to provide a robust prediction model (Biancofiore et al., Citation2015). Recurrent architecture significantly improves the performance of neural predictors by only using meteorological parameters as input data. Moreover, recent study to develop hybrid model based on convolutional neural network and long short-term memory (CNN-LSTM) provided a satisfactory hybrid model for seasonal stability and its prediction performance proved to be superior than multilayer perceptron (MLP) and LSTM (Pak et al., Citation2018). Self-adaptive neuro-fuzzy weighted extreme learning machine to improve prediction accuracy and real-time air pollution concentration prediction has been investigated by (Li et al., Citation2018). On the other hand, recently many researchers implemented Support Vector Machines (SVMs) to predict ozone concentration in an advance time-series manner (Luna et al., Citation2014). The modified SVM-r model is flexible enough to encompass other input variable such as city models or traffic patterns that might enhance prediction. Few studies focused on prediction ozone concentration in urban areas (Abdullah et al., Citation2019; Pawlak & Jarosławski, Citation2019; Shaban et al., Citation2016). However, no one has investigated the robustness of Boosted Decision Tree Regression in predicting ozone concentrations in general and specifically in urban cities.
Developing an accurate prediction model requires the selection of the input parameters, such as air quality and meteorological data, that have impacts on the changes in ozone concentration (Gómez-Losada et al., Citation2018; Gradišar et al., Citation2016; Ragosta et al., Citation2015; Zhang et al., Citation2019). However, most of the desirable data are often unavailable or incomplete due to the problem of data source retrieval or large missing data (Gómez-Sanchis et al., Citation2006; Hájek & Olej, Citation2012). Therefore, there is need to develop model with high level of precision by using few input parameters.
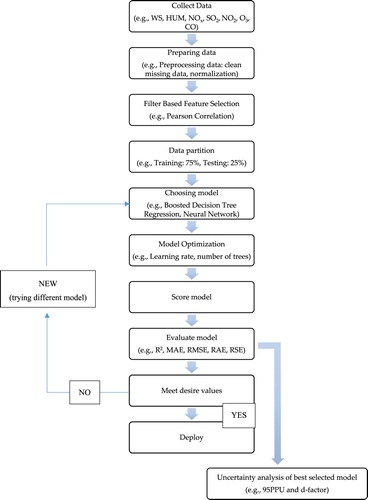
In this study four models – Boosted Decision Tree Regression (BDTR), Neural Network with Gaussian Normalizer, Neural Network with Min–Max Normalizer and Linear Regression – with six different input parameters are investigated. Pearson Correlation Coefficient was used to select proper input parameters to the proposed models. These models then tested at three different location in Malaysia. Two different scenarios were investigated were the accuracy of the proposed model tested by predicting the ozone concentrations for different time horizon, 24-hour and 12-hour. The models’ performances are then compared to evaluate their robustness by implementing various performance. Finally, as for the best model, the uncertainties are assessed by using the indices of bracketed by the 95PPU and d-factor.
2. Materials and methods
2.1. Study area and dataset
The area of investigation covers Kuala Lumpur and Selangor, Malaysia. In Kuala Lumpur the monitoring station is located at SMK. Seri Permaisuri Cheras which is denoted as S1. The Selangor first monitoring station is located at SK. Bandar Utama Petaling Jaya
and known as S2 and second monitoring station of Selangor is located at SMK(P). Raja Zarina Kelang
and denoted as S3. Selangor surrounds the federal territories of Kuala Lumpur and Putrajaya. Hence, both areas of investigation are on the west coast of Peninsular Malaysia (Figure ).
Figure 1. Location of monitoring stations.
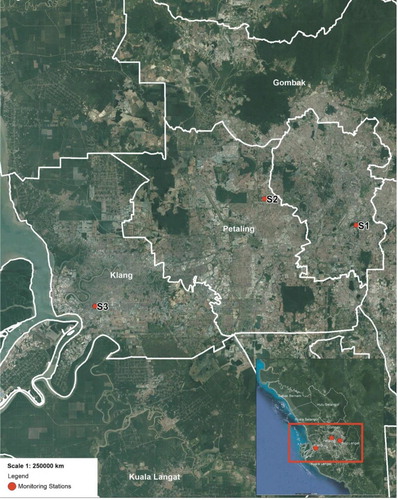
The land surface in Selangor is leveled on the west and hilly on the east. The climate is very much dictated by the surrounding sea and prevailing wind system with tropical rainforest climate, high average temperature and high average rainfall. January is the benchmark of highest precipitation throughout the year whereas the lowest precipitation is on October. Although January has the highest precipitation, the temperature is still moderately high. Hottest temperature is on June reaching up to 37°C and the lowest temperature is on November.
Selangor and Kuala Lumpur are considered as highly populated regions in Malaysia due to the development of Klang Valley, started in 1980. Rapid development is seen over the years in the regions not only focusing on building structures but with good infrastructure facilities. However, driving own vehicle is still preferable by most of the citizens to commute from one place to another.
Monitoring stations provide air quality and meteorological data which were obtained from the Department of Environment (DOE). The original dataset includes hourly average wind speed (WS), Humidity (HUM), Nitrogen Oxide (NOx), Sulphur Dioxide (SO2), Nitrogen Dioxide (NO2), Ozone (O3) and Carbon Monoxide (CO). These datasets are historical data of three years’ observation from 1st of January 2012 until 31st December 2014.
In this study the datasets were first analyzed then sorted into two categories for three years of historical data used for the areas under investigation. First category was hourly average of 24 h with a total of 1,84,128 data as given in Table . Second category was hourly average daytime only from 6:00 am to 6:00 pm with total of 92,064 data as given in Table .
Table 1. Statistics of 24-hours raw data.
Table 2. Statistics of 12- hour daylight raw data.
In order to get optimum results, any missing data in each column was cleaned by using the function of clean missing data with cleaning mode of replace using Probabilistic principal components analysis (PCA). The cleaned dataset was normalized by using Lognormal transformation method. This is applied though all numeric columns used in the model. Normalization is imperative as part of data preparation to create new values within the general distribution and ratios subsequently maintain the values in the source data. Both dataset categories were split into training set and testing set. With randomly selected data, 75% of the total data were for training and 35% was for testing.
2.2. Input selection for sensitivity test
Filter-based feature selection is an essential step in performing machine-learning algorithm model. It was used to identify the columns in input dataset that have the greatest predictive power. In this study, the Pearson Correlation was used for filter selection metric. Pearson Correlation measures the linear correlation between two variables X and Y that is called Pearson Correlation Coefficient. It is the covariance of the two variables divided by the product of their standard deviations. Any changes of the scale in the two variables will not affect the Pearson Correlation Coefficient.
Pearson Correlation:
(1)
(1)
is the covariance; correlation function, n is the sample size of the data. xi, yi are the individual sample points indexed with i.
and
sample mean.
2.3. Models selections
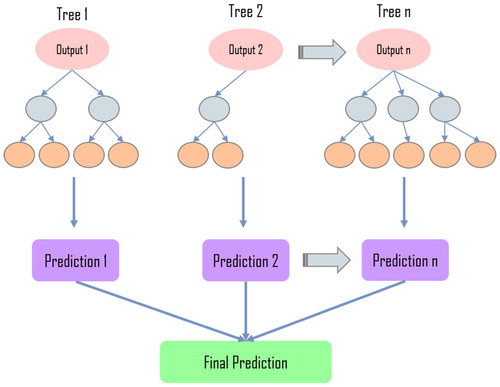
A set of statistical analysis was used to compare the performance of each algorithm. This includes Boosted Decision Tree Regression. Boosted Decision Tree regression is an algorithm used to train the model by implementing MART (Multiple Additive Regression Trees) algorithm. Each tree is dependent on the prior tress, that is how boosting works as shown in Figure . In each step the loss function will be defined to measure the error in order to crrect the next tree till the optimum tree obtained. Therefore, in Boosted Decision Tree regression, prediction is an ensemble of group of weaker prediction models that come together to form a strong prediction model as shown in below formula:
(2)
(2)
(3)
(3) Whereby h(x) is the tree's output, wis the weight,
is the loss function, distance between the truth and the prediction of ith sample.
is a regularization function.
Figure 2. Typical boosted decision tree regression structure.
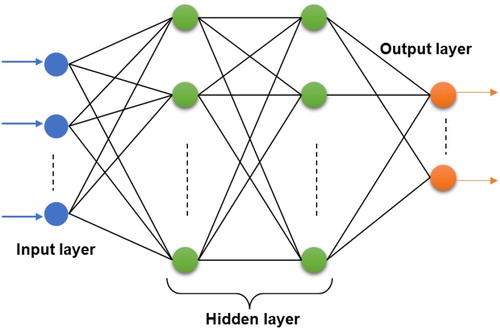
The Neural Network Regression Algorithm was used next. The Neural network is usually used in classification and regression problems. Neural network model consists of three arranged layers as shown in Figure . The principle is that hidden layer will transforms input data into high dimensional space whereby each neuron in the hidden layer apply radial function. All hidden neurons are connected to the output neurons by adjusting output weights at the last layer of output layer (Ali Ghorbani et al., Citation2018; Homsi et al., Citation2019; Qasem et al., Citation2019).
Figure 3. Simple neural network model.
Finally, comparision between the proposed model and Linear Regression Algorithm was carried out in this study. Linear regression shows a linear relationship between one or more independent variables and a numeric dependent variable outcome.
Linear Regression:
(4)
(4) Where
is the slope of line and
is y-intercept for linear relationship between
and x regression.
shows the steps of the proposed method in this study. Several performance indexes used to validate the scored model on how close the computed ozone concentrations to the real values, which can be given as follows:
Coefficient of determination, R2. High R2 value indicate good model performance.
(5)
Figure 4. Flow chart of the prediction methodology of 3-year historical hourly average ozone concentration using machine learning algorithms.
Mean absolute error, MAE measures accuracy of continuous variables.
Root mean square error, RMSE whereby
Relative absolute error, RAE. The relative absolute error is the normalized value by dividing the total absolute error to the simple predictor total absolute error.
Relative square error, RSE. The relative square error is the normalized value by dividing the total square error to the simple predictor total square error.
2.4. Uncertainty analysis of best selected model
Uncertainty analysis attempts to measure the output variance due to input variability. It is carried out to define the range of possible outcomes based on input uncertainty and to examine the impact of the model's lack of knowledge or errors. This study employ the technique, 95% of projected uncertainties (95PPU), advocated by Abbaspour (Noori et al., Citation2010). 95PPU is computed by percentiles of 2.5% XL and 97.5% XU.
(10)
(10) Whereby k is the number of observed data at testing stages. Based on Eq. (10), the value of ‘Bracketed by 95PPU’ is maximum (or 100%) when all measured data at testing stages are inserted between the XL and XU. The acceptable range of the measured data should fall between 80–100% in the 95PPU level. However, in case of some regions where data are poor, 50% of data in 95PPU would be appropriate (Noori et al., Citation2010). In addition, d-factor parameter is used to estimate the average width of confidence interval band as shown in Eq. (11).
(11)
(11)
is the standard deviation of the measured data (x) and
is the average distance between the upper and lower bands as in Eq. (12).
(12)
(12)
3. Results and discussion
The study aimed to explore the capability of different machine learning algorithm models for the prediction of hourly average ozone concentration at any desirable time in Kuala Lumpur and Selangor. Then all these models were optimized by analyzing the prediction accuracy in terms of performance indexes.
3.1. Pearson correlation coefficient
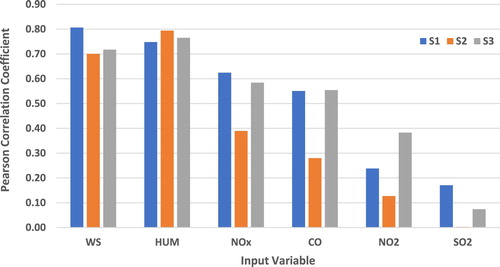
Pearson Correlation Coefficient is used to measure how related each of the parameters to the dependent variable. Based on Figure , it can be seen that there are four parameters that have high correlation with dependent variable which is Ozone. For example, at S1, the highest Pearson correlation coefficient found to be with wind speed followed by humidity, nitrogen oxide and finally carbon monoxide. Such correlation is reported by other studies which found Ozone concentration to be affected by the wind velocity in terms of horizontal transport and vertical mixing (‘Official Portal of Department of Environment’, Citation2019); (Fang et al., Citation2019). At S2 and S3 the result show that humidity is the highest parameter correlated with dependent variable followed by wind speed, nitrogen oxide and last carbon monoxide. Nitrogen dioxide shows the lowest correlation with dependent variable at all monitoring stations. Finally, Sulphur dioxide shows the least correlation with almost no impact with the output variable especially for the model at S2.
Figure 5. Bar chart of Pearson correlation coefficient of input variable with output variable, O3 (6:00 am – 6:00 pm).
3.2. Models performance at each monitoring stations
Table indicates the performance indices for training dataset of the four models based at three monitoring stations for both scenarios 24-hour and daytime 12-hour. The Boosted Decision Tree Regression model shows that when only 12- hour daytime is considered instead of 24-hour dataset, high level of coefficient of determination (R2) values were obtained for all stations. The 12- hour daytime dataset R2 value for S1 is 0.91977, for S2 is 0.88439 and for S3 is 0.87859 whilst 24-hour dataset has R2 of 0.85985 for S1, 0.78897 for S2 and 0.80631 for S3. The presence of sunlight during the day hence help ozone formation. This explains why 12-hour daytime models outperformed the 24-hour models. Other performance indices such as the Mean absolute error (MAE), Root Mean square error (RMSE), Relative Absolute error (RAE) and Relative Square Error (RSE) confirmed the accuracy of the proposed model as presented in Table .
Table 3. Performance indexes of training dataset.
Moreover, the Boosted Decision Tree Regression models outperformed all other models including the Neural Network regression with Gaussian Normalizer, Linear Regression and Neural Network with Min–Max Normalizer. In terms of accuracy, Neural Network with Gaussian Normalizer represents the second best then followed by the Linear Regression and finally Neural Network Regression. The Min–max Normalizer was the lowest in its accuracy to predict 12-hour daytime Ozone concentrations.
After the training of all models using training dataset, the unseen data were used to test the models. Table displays the performance indices for testing dataset for the four models based on the three monitoring stations. Again, boosted decision tree regression model exhibits higher R2 values for 12-hour daytime dataset compared to 24-hour dataset of all stations. Daytime dataset R2 value of S1 is 0.87350, for S2 is 0.82166 and for S3 is 0.81143, whereas 24-hour dataset R2 value of S1 is 0.83670, for S2 is 0.74163 and for S3 is 0.76737. The difference between daytime and 24-hour R2 value is noticeably high thus prove daytime data significantly improve prediction model capability.
Table 4. Performance indexes for testing dataset.
Moving on to other models that include Neural Network Regression with Gaussian Normalizer, Linear Regression and Neural Network Regression with Min–Max Normalizer exhibit the same trend as the Boosted decision tree Regression which is for daytime dataset has higher R2 values compared to 24-hour dataset. Performance indexes such as the MAE, RMSE, RAE and RSE also show lower values. Therefore, according to Table , it can be concluded that the Boosted Decision Tree Regression represents the best model for daylight compared to other models. The rank from highest to lowest performance for the other models is similar with the training dataset given in Table . The Neural Network with Gaussian Normalizer is ranked as the second-best model followed by Linear Regression and Neural Network with Min–Max Normalizer was the lowest.
Over the years, there has been many studies done to design the best model to predict ozone concentration. The most popular methods are Support Vector Machine (SVM) by (Luna et al., Citation2014), the typical artificial neural network by (Gao et al., Citation2018). Based on past research by (Gao et al., Citation2018) the performance index for ANN modeling in testing phase was R2 equal to 0.859 whilst the proposed model of BDTR in this study shown R2 equal to 0.920 and 0.874 for training and testing, respectively. The finding of this study reveals that the BDTR outperformed ANN and it can be used as reliable model in predicting the concentrations of Ozone in urban cities.
3.3. Taylor diagram
Taylor diagram provides a summary of how fit the patterns match of their correlation, root-mean-square difference and variance ratio [34]. Construction of Taylor diagram is based on the formula as follows:
(13)
(13) Whereby the R is the correlation coefficient, N is the number of discrete points,
are two variables,
is the standard deviation of f and r and
are the mean values of
.
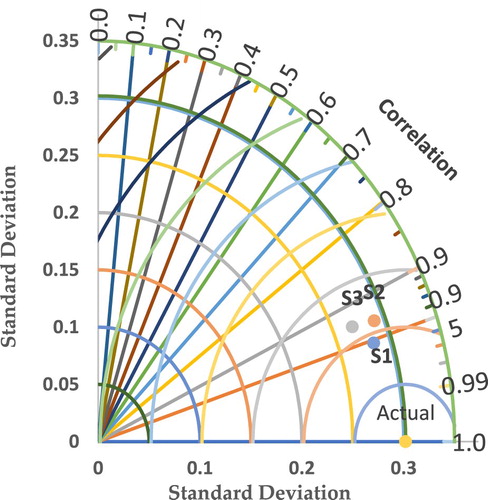
Figure illustrates the relationship between the standard deviation and correlation (R) of predicted ozone and actual ozone at each location for all models. It can be seen that in all stations the proposed model M1 has a better correlation with the actual ozone compared with other models. In addition, the standard deviation for the predicted ozone from M1 is closer to standard deviation of actual ozone which indicates that the proposed model is consistent in predicting the value of concentration for entire population of the data as shown in Figure .
Figure 6. Taylor diagram measures of model correlation and standard deviation with actual ozone.
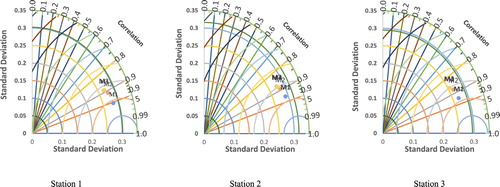
Figure 7. Taryor diagram for Boosted Decision Tree Regression on each site.
3.4. Optimization of Boosted Decision Tree Regression (BDTR)
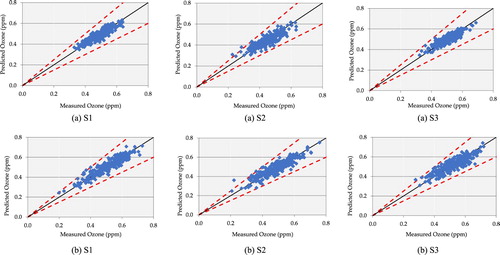
The proposed BDTR models were then optimized in order to improve the model accuracy by tuning the hyper-parameter such as learning rate and number of trees. Figure reveals the relationship between the performance of the models represented by the correlation coefficient, the learning rate, and the number of trees at the three locations. The best correlation coefficient was obtained when the learning rate is 0.8 for the three investigated locations during the training phase where it was equal to 0.97213 at S1, 0.95835 at S2 and 0.95748 at S3. While the optimum number of trees was found when the learning rate is high for all the locations and it is exponentially decreased until a lowest value is achieved. Figure presents the scatterplots of predicted versus measured ozone concentrations. It can be seen that the optimized Boosted Decision Tree Regression models is capable to precisely mimicking the actual data during the testing phase for all locations of 24-hour and 12-hour scenarios.
Figure 8. Correlation Coefficient Vs Number of Trees Vs Learning Rate: S1, S2 and S3.
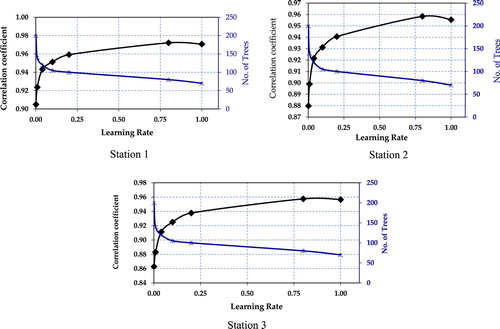
Figure 9. Scatter plot of predicted versus measured ozone for: (a) 24-hour testing dataset and (b) daylight testing dataset for.
3.5. Uncertainty analysis of Boosted Decision Tree Regression model
Uncertainty analysis of the best model Boosted Decision Tree was calculated 95PPU and d-factor. Table represents the uncertainty analysis results for the stations using the 12-hour testing dataset.
Table 5. Uncertainty analysis of BDTR model.
The values bracketed by 95PPU indicate that about 94.4%, 93.4% and 96.7% of data for the best Boosted Decision Tree model relate to S1, S2 and S3, respectively. Moreover, the d-factor has values of 0.001015, 0.001016 and 0.001124 for S1, S2 and S3, respectively. From this results it can be concluded that the proposed model showed outstanding performance for predicting the ozone concentration in this study area. However, in order to generalize the performance of the proposed model to another study area required further analysis for the historical records of the ozone concentration. This is due to the fact that each case study has its own pattern of the ozone concentration pattern that might need further adjustment in the model architecture.
4. Conclusions
The capability of the Boosted Decision Tree Regression model was assessed based on the available historical data measured from 2012 to 2014. The proposed Boosted Decision Tree Regression models were then optimized based on the learning rate and total number of trees constructed. The study showed that Boosted Decision Tree outperformed Linear regression and Neural Network algorithms for all stations. The performance of the proposed model improved by using 12-hours dataset instead of the 24-Hours where R2 values were equal to 0.91977, 0.88439 and 0.87859 for the three stations, respectively. The findings provide a promising base for conducting further investigations on the robustness of the Boosted Decision Tree Regression model for ozone concentration prediction in different time horizon. Additionally, the reliability of the Boosted Decision Tree Regression was evaluated based on uncertainty estimation using 95PPU and d-factor indices. It is seen that the Boosted Decision Tree model has an acceptably low degree of uncertainty. In this study, high level of accuracy was obtained using only few meteorological variables (such as wind speed, humidity, Nitrogen Oxide, Carbon Monoxide and Nitrogen Dioxide) as input to the proposed model. However, further studies might be needed to improve the proposed model by introducing more input parameters which have not been investigated due to the lack of such information. In addition, introducing more advanced optimization algorithm to be integrated with the Boosted Decision Tree Regression models might improve the prediction accuracy and accelerate the convergence rate.
Acknowledgments
The authors would like to acknowledge the Ministry of Higher Education Malaysia providing a fundamental research grant scheme No: FRGS/1/2018/TK10/UNITEN/03/2. In addition, the authors would like to thank the Malaysian Meteorological Department (MetMalaysia) for providing relevant data.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Abdul-Wahab, S. A., & Al-Alawi, S. M. (2002). Assessment and prediction of tropospheric ozone concentration levels using artificial neural networks. Environmental Modelling and Software, 17(3), 219–228. https://doi.org/10.1016/S1364-8152(01)00077-9
- Abdullah, S., Nasir, N. H. A., Ismail, M., Ahmed, A. N., & Jarkoni, M. N. K. (2019). Development of ozone prediction model in urban area. International Journal of Innovative Technology and Exploring Engineering, 8(10), 2263–2267. https://doi.org/10.35940/ijitee.J1127.0881019
- Ali Ghorbani, M., Kazempour, R., Chau, K.-W., Shamshirband, S., & Ghazvinei, P. T. (2018). Forecasting pan evaporation with an integrated artificial neural network quantum-behaved particle swarm optimization model: A case study in Talesh, Northern Iran. Engineering Applications of Computational Fluid Mechanics, 12(1), 724–737. https://doi.org/10.1080/19942060.2018.1517052
- Alimissis, A., Philippopoulos, K., Tzanis, C. G., & Deligiorgi, D. (2018). Spatial estimation of urban air pollution with the use of artificial neural network models. Atmospheric Environment, 191, 205–213.https://doi.org/10.1016/j.atmosenv.2018.07.058
- Antanasijević, D., Pocajt, V., Perić-Grujić, A., & Ristić, M. (2019). Urban population exposure to tropospheric ozone: A multi-country forecasting of SOMO35 using artificial neural networks. Environmental Pollution, 244, 288–294. https://doi.org/10.1016/j.envpol.2018.10.051
- Arsić, M., Mihajlović, I., Nikolić, D., Živković, Ž., & Panić, M. (2020). Prediction of ozone concentration in ambient air using multilinear regression and the artificial neural networks methods. Ozone: Science & Engineering, 42(1), 79–88. https://doi.org/10.1080/01919512.2019.1598844
- Banja, M., Papanastasiou, D. K., Poupkou, A., & Melas, D. (2012). Development of a short-term ozone prediction tool in tirana area based on meteorological variables. Atmospheric Pollution Research, 3(1), 32–38.https://doi.org/10.5094/APR.2012.002
- Biancofiore, F., Verdecchia, M., Di Carlo, P., Tomassetti, B., Aruffo, E., Busilacchio, M., Bianco, S., Di Tommaso, S., & Colangeli, C. (2015). Analysis of surface ozone using a recurrent neural network. Science of the Total Environment, 514, 379–387. https://doi.org/10.1016/j.scitotenv.2015.01.106
- Capilla, C. (2016). Prediction of hourly ozone concentrations with multiple regression and multilayer perceptron models. International Journal of Sustainable Development and Planning, 11(4), 558–565. https://doi.org/10.2495/sdp-v11-n4-558-565
- Chen, S., Mihara, K., & Wen, J. (2018). Time series prediction of CO2, TVOC and HCHO based on machine learning at different sampling points. Building and Environment, 146, 238–246. https://doi.org/10.1016/j.buildenv.2018.09.054
- Ezimand, K., & Kakroodi, A. A. (2019). Prediction and spatio – Temporal analysis of ozone concentration in a metropolitan area. Ecological Indicators, 103, 589–598. https://doi.org/10.1016/j.ecolind.2019.04.059
- Fang, C., Wang, L., & Wang, J. (2019). Analysis of the spatial–temporal variation of the surface ozone concentration and its associated meteorological factors in Changchun. Environments, 6(4), 46. https://doi.org/10.3390/environments6040046
- Gao, M., Yin, L., & Ning, J. (2018). Artificial neural network model for ozone concentration estimation and Monte Carlo analysis. Atmospheric Environment, 184, 129–139. https://doi.org/10.1016/j.atmosenv.2018.03.027
- Gómez-Losada, Á., Asencio–Cortés, G., Martínez–Álvarez, F., & Riquelme, J. C. (2018). A novel approach to forecast urban surface-level ozone considering heterogeneous locations and limited information. Environmental Modelling and Software, 110, 52–61. https://doi.org/10.1016/j.envsoft.2018.08.013
- Gómez-Sanchis, J., Martín-Guerrero, J. D., Soria-Olivas, E., Vila-Francés, J., Carrasco, J. L., & del Valle-Tascón, S. (2006). Neural networks for analysing the relevance of input variables in the prediction of tropospheric ozone concentration. Atmospheric Environment, 40(32), 6173–6180. https://doi.org/10.1016/j.atmosenv.2006.04.067
- Gradišar, D., Grašič, B., Zlata Božnar, M., Mlakar, P., & Kocijan, J. (2016). Improving of local ozone forecasting by integrated models. Environmental Science and Pollution Research, 23(18), 18439–18450. https://doi.org/10.1007/s11356-016-6989-2
- Hájek, P., & Olej, V. (2012). Ozone prediction on the basis of neural networks, support vector regression and methods with uncertainty. Ecological Informatics, 12, 31–42. https://doi.org/10.1016/j.ecoinf.2012.09.001
- Homsi, R., Shiru, M. S., Shahid, S., Ismail, T., Harun, S. B., Al-Ansari, N., Chau, K.-W., & Yaseen, Z. M. (2019). Precipitation projection using a CMIP5 GCM ensemble model: A regional investigation of Syria. Engineering Applications of Computational Fluid Mechanics, 14(1), 90–106. https://doi.org/10.1080/19942060.2019.1683076
- Hoshyaripour, G., Brasseur, G., Andrade, M. F., Gavidia-Calderón, M., Bouarar, I., & Ynoue, R. Y. (2016). Prediction of ground-level ozone concentration in São Paulo, Brazil: Deterministic versus statistic models. Atmospheric Environment, 145, 365–375. https://doi.org/10.1016/j.atmosenv.2016.09.061
- Huang, Y., Yang, Z., & Gao, Z. (2019). Contributions of indoor and outdoor sources to ozone in residential buildings in Nanjing. International Journal of Environmental Research and Public Health, 16(14), 2587. https://doi.org/10.3390/ijerph16142587
- Ismail, M., Suroto, A., Ibrahim, T. A. E., & Abdullah, A. M. (2011). Tropospheric ozone trend in the Muda irrigation area, Kedah. Journal of Physical Science, 22(2), 87–99.
- Li, Y., Jiang, P., She, Q., & Lin, G. (2018). Research on air pollutant concentration prediction method based on self-adaptive neuro-fuzzy weighted extreme learning machine. Environmental Pollution, 241, 1115–1127. https://doi.org/10.1016/j.envpol.2018.05.072
- Luna, A. S., Paredes, M. L. L., de Oliveira, G. C. G., & Corrêa, S. M. (2014). Prediction of ozone concentration in tropospheric levels using artificial neural networks and support vector machine at Rio de Janeiro, Brazil. Atmospheric Environment, 98, 98–104.https://doi.org/10.1016/j.atmosenv.2014.08.060
- Noori, R., Hoshyaripour, G., Ashrafi, K., & Araabi, B. N. (2010). Uncertainty analysis of developed ANN and ANFIS models in prediction of carbon monoxide daily concentration. Atmospheric Environment, 44(4), 476–482. https://doi.org/10.1016/j.atmosenv.2009.11.005
- “Official Portal of Department of Environment.” (2019).
- Pak, U., Kim, C., Ryu, U., Sok, K., & Pak, S. (2018). A hybrid model based on convolutional neural networks and long short-term memory for ozone concentration prediction. Air Quality, Atmosphere and Health, 11(8), 883–895. https://doi.org/10.1007/s11869-018-0585-1
- Pawlak, I., & Jarosławski, J. (2019). Forecasting of surface ozone concentration by using artificial neural networks in rural and urban areas in Central Poland. Atmosphere, 10(2), 52. https://doi.org/10.3390/atmos10020052
- Qasem, S. N., Samadianfard, S., Kheshtgar, S., Jarhan, S., Kisi, O., Shamshirband, S., & Chau, K.-W. (2019). Modeling monthly pan evaporation using wavelet support vector regression and wavelet artificial neural networks in arid and humid climates. Engineering Applications of Computational Fluid Mechanics, 13(1), 177–187. https://doi.org/10.1080/19942060.2018.1564702
- Ragosta, M., D’Emilio, M., & Giorgio, G. A. (2015). Input strategy analysis for an air quality data modelling procedure at a local scale based on Neural Network. Environmental Monitoring and Assessment, 187(5). https://doi.org/10.1007/s10661-015-4556-9
- Shaban, K. B., Kadri, A., & Rezk, E. (2016). Urban air pollution monitoring system with forecasting models. IEEE Sensors Journal, 16(8), 2598–2606. https://doi.org/10.1109/JSEN.2016.2514378
- Shen, J., Chen, J., Zhang, X., Zou, S., & Gao, Z. (2017). Outdoor and indoor ozone concentration estimation based on artificial neural network and single zone mass balance model. Procedia Engineering, 205, 1835–1842. https://doi.org/10.1016/j.proeng.2017.10.253
- Zhan, Y., Luo, Y., Deng, X., Grieneisen, M. L., Zhang, M., & Di, B. (2018). Spatiotemporal prediction of daily ambient ozone levels across China using random forest for human exposure assessment. Environmental Pollution, 233, 464–473. https://doi.org/10.1016/j.envpol.2017.10.029
- Zhang, J., Wang, C., Qu, K., Ding, J., Shang, Y., Liu, H., & Wei, M. (2019). Characteristics of ozone pollution, regional distribution and causes during 2014–2018 in Shandong Province, East China. Atmosphere, 10(9), 501. https://doi.org/10.3390/atmos10090501