
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Eye movement monitoring was used to explore the time course of orthographic learning in adult skilled readers while they read novel words presented in isolation one, three or five times. Offline measures of spelling-to-dictation and orthographic decision were used to measure orthographic memorisation. Further, the participants' visual attention span was estimated. Results showed better memorisation of new words' orthography with additional exposures. An exposure-by-exposure in-depth analysis of eye movements revealed an early sharper decrease for the number of fixations and most measures of processing time. Participants with a higher visual attention span showed better performance in orthographic decision and processing times. The overall findings suggest that orthographic learning occurs from the first exposure and that top-down effects from the newly acquired orthographic knowledge would facilitate processing from the second exposure. Further, time needed for bottom-up information extraction appears to be modulated by visual attention span.
1. Introduction
Memorisation of the orthographic form of thousands of words is critical to become a fluent reader and a good speller (Castles et al., Citation2018; Treiman, Citation2017). Orthographic learning is mainly incidental, occurring with exposure to printed words via reading experience. Despite the key role of orthographic learning in both reading—for the visual recognition of printed words—and writing—for word-specific spelling, we still have little insight into how learning affects new printed word processing and what are the cognitive mechanisms at play. In this paper, we explore the orthographic learning of new words using eye-tracking, which allows studying the learning process as reading unfolds, thus in an online manner. Furthermore, while most previous studies have emphasised the impact of phonological decoding on orthographic learning (e.g.Bowey & Muller, Citation2005; Castles & Nation, Citation2006; Share, Citation1999), we here examine whether the visual attention capacity, as measured through tasks of visual attention span (VA span), has a role on the orthographic learning of novel words.
A diversity of methods has been used to explore orthographic learning. The most popular is the self-teaching paradigm proposed by David Share in his seminal experiments (Share, Citation1999, Citation2004). In this paradigm, participants are administered a learning phase followed by a test phase. During the learning phase, they are asked to read aloud meaningful stories in which target pseudo-words—introduced as names for fictitious places, animals, fruits, etc. —are embedded in short texts. Each story introduces a single target pseudo-word that can be repeated a few times per text. Orthographic learning is assessed during the following test phase that is proposed immediately or some days/months after text reading. Three tasks were initially designed to gauge the acquisition of the target pseudo-word orthographic form: an orthographic choice task, that required identifying the target pseudo-word alongside a homophonic foil (e.g. YAIT-YATE), a naming task, in which the targets (e.g. YAIT) and their foils were randomly displayed and naming reaction times recorded, and a spelling task.
Results of Share's seminal studies showed that orthographic learning occurred after only a few encounters with the novel word. Evidence of orthographic learning has been reported after a single encounter (Nation et al., Citation2007; Share, Citation2004) and one to four encounters appear to be sufficient for relatively durable memorisation of the target specific orthography (Bowey & Muller, Citation2005; Nation et al., Citation2007; Share, Citation1999, Citation2004; Tucker et al., Citation2016). Further, studies revealed that orthographic learning could occur out of context. Effective learning was not only reported for novel words embedded in meaningful texts but also in scrambled passages (Cunningham, Citation2006) or when presented in isolation (Bosse et al., Citation2015; Landi et al., Citation2006; Nation et al., Citation2007; Share, Citation1999; Wang et al., Citation2011). Most previous studies explored incidental orthographic learning in children (from the first grade to later grades). Written word learning was also explored in adults but mainly using intensive repetitions with explicit instruction and/or artificial languages (Taylor et al., Citation2011).
One issue with the orthographic learning paradigm is that it does not straightforwardly provide evidence that learning was effective following exposition to the novel words. The validity and reliability of the tasks used to assess orthographic learning have been debated (Castles & Nation, Citation2008). Among the tasks initially used by Share (Citation1995, Citation1999), the orthographic choice task is one of the most popular, but simultaneous presentation of alternative orthographies in this paradigm may induce strategy-based processing without tapping the word recognition process. Moreover, performance tends to be high and thus not sensitive enough to orthographic learning. In contrast, performance on the spelling task was typically reported as drastically low in children (Bosse et al., Citation2015; Cunningham, Citation2006) and the task not sensitive enough to reflect orthographic learning (Castles & Nation, Citation2008). Some alternative solutions to these more standard tasks have been proposed, like word recognition tasks allowing to measure word length effects (Martens & De Jong, Citation2008) or tasks of matching between a new word and its definition (Joseph et al., Citation2014), but these measures were also found to lack sensitivity.
In the present study, an orthographic decision task inspired from Wang et al. (Citation2011) was administered as a potential new alternative. In this task, targets and homophonic foils were displayed one at a time and participants had to respond either YES if the written form corresponded to the spelling of the learned novel word or NO otherwise. The presentation of a single written form at a time in this orthographic decision task prevents the strategy-based responses reported in the orthographic choice task and more naturally taps the word recognition process. Moreover, response accuracy and reaction times were both recorded to increase task sensitivity. Orthographic learning was further evaluated through a spelling task where participants were asked to spell the target novel words. The use of the spelling task with children was debated, but higher performance and better sensitivity were here expected for adults. This task which requires fully specified orthographic information about the target is particularly relevant to assess target-specific orthographic memorisation. While the memorisation tasks provide offline measures of orthographic learning, eye movements appear as providing insights on the online learning process.
Most research on eye movements in reading have focused on real word processing in text reading (Rayner, Citation1998, Citation2009). Some studies have investigated the effect of a single encounter with pseudo-words on eye movements (Chaffin et al., Citation2001; Lowell & Morris, Citation2014; Wochna & Juhasz, Citation2013). While there was no pseudo-word effect on fixation location (Lowell & Morris, Citation2014), more refixations were reported for pseudo-word processing and extra processing-time was needed for pseudo-words as compared to familiar words. These findings are consistent with reports of word frequency effect on eye movements (Rau et al., Citation2015; Schilling et al., Citation1998; Williams & Morris, Citation2004), suggesting that the pseudo-words were processed as low-frequency words would be.
Only a few studies have investigated how eye movement measures are affected by repeated exposure to the same novel word in conditions of incidental learning. Joseph et al. (Citation2014) explored eye movements while English-speaking adult participants read pseudo-words embedded in sentences. The stimuli were bisyllabic 6-letter pseudo-words that were presented in short stories (i.e. 15 exposures to each of the 16 pseudo-word) during the 5-day sessions of the learning phase. Eye movement tracking revealed an effect of repeated exposure on pseudo-word processing time, shorter first fixation duration and shorter single fixation duration being reported over repeated sessions. Pellicer-Sanchez (Citation2016) also reported significant repeated exposure effects on the number of fixations and total reading time during the incidental learning of 6-letter pseudo-words presented for reading in meaningful contexts. Eye movement variations with repeated exposures were also incidentally observed by Gerbier et al. (Citation2015, Citation2018) but using a reading-while-listening paradigm in sixth-grade French pupils. In this paradigm, participants processed pseudo-words embedded in meaningful texts while listening to the spoken version of the text through headphones. Twelve 2-syllable pseudo-words were presented four times each in different stories. Online eye movement monitoring revealed a decrease of the first fixation duration and a tendency to shift the first fixation location to the right across repetitions.
Overall, eye movement monitoring while reading novel words appears as particularly useful for the real-time study of orthographic learning (Nation & Castles, Citation2017). Most previous studies focused on the effect of the learning context on eye movements, focusing on the order-of-acquisition (Joseph et al., Citation2014), contextual diversity, spacing and retrieval practice (Pagan & Nation, Citation2019) or the diversity of semantic contexts (Joseph & Nation, Citation2018). Only a few studies manipulated the number of exposures and studied eye movement changes throughout exposures (Gerbier et al., Citation2015, Citation2018; Joseph & Nation, Citation2018; Joseph et al., Citation2014). However, these studies provided no in-depth analysis of eye-movement changes from exposure to exposure (see, however, Pellicer-Sanchez, Citation2016). In the present study, we monitored eye movements while participants read novel words that were presented in isolation and which they were exposed to from one to five times. This paradigm allows an exposure-by-exposure tracking of eye-movement changes during novel word orthographic learning, thus providing direct insight on the online learning process. Furthermore, the time course of eye movements on target novel words was compared with that of real words to disentangle repetition effects from orthography learning effects. We reasoned that eye movements may be sensitive to repetition effects, the fact that the same printed items were presented several times during the reading phase. Similar repetition effects were expected on both the novel words and the familiar words but stronger orthographic learning effects were expected for the novel words. As a result, any across-exposure eye movement effect specific to the novel words (a Word Type by Exposure interaction) would be interpreted as evidence in support of orthographic learning.
The self-teaching hypothesis (Share, Citation1995, Citation1999) asserts that phonological decoding is the central mechanism by which orthographic knowledge is acquired. When exposed to a novel word, readers have to decode the word, using their general letter-sound mapping knowledge to generate the novel word's spoken form. The theory posits that every time the novel word is successfully decoded, the reader has the opportunity to memorise its orthographic form. Some computational models that have implemented the self-teaching mechanism (Pritchard et al., Citation2018; Ziegler et al., Citation2014) illustrate the critical role of phonological decoding in the development of orthographic knowledge. This central role is supported by experimental findings showing that accurate decoding is a powerful predictor of incidental orthographic learning (Ricketts et al., Citation2011) and that orthographic learning is lower in conditions of concurrent articulation (de Jong et al., Citation2009; Kyte & Johnson, Citation2009; Share, Citation1999). However, despite the well-documented role of phonological decoding in orthographic knowledge acquisition, there is also evidence that decoding does not guarantee orthographic learning when successful and does not systematically prevent orthography acquisition when unsuccessful (Castles & Nation, Citation2006, Citation2008; Nation et al., Citation2007; Tucker et al., Citation2016).
Beyond decoding skills, other factors like prior orthographic knowledge and print exposure do predict the quality of orthography learning (Cunningham, Citation2006; Stanovich & West, Citation1989; Wang et al., Citation2014), suggesting the involvement of additional orthographic (Cunningham et al., Citation2001) or visual-orthographic (Share, Citation2008) processing skills during self-teaching. The impact of visual-orthographic processing on orthographic learning was directly addressed by Bosse et al. (Citation2015) in a self-teaching paradigm. In their study, either the whole letter-string of printed bi-syllable pseudo-words was simultaneously displayed, or the first and second syllables were presented successively one at a time during the learning phase. In both conditions, children were asked to utter the spoken form of the entire pseudo-word after presentation. For the pseudo-words that were accurately decoded, results revealed better orthographic learning when the entire pseudo-word letter-string was simultaneously available for visual processing during the learning phase. Beyond decoding skills, this suggests that orthographic learning further depends on the learner's capacity to attend simultaneously to the whole sequence of letters of the novel word while reading.
A number of previous studies have also provided indirect evidence that orthographic acquisition relates to the capacity for multielement simultaneous processing, that is, the VA span (Bosse et al., Citation2007). Typically, VA span is estimated through tasks of multi-letter or multi-digit oral report but the VA span is not specific to verbal tasks and alphanumeric material. It can be very similarly estimated using non-verbal tasks and non-verbal stimuli, like symbols or pseudo-letters (Chan & Yeung, Citation2020; Lobier et al., Citation2012). Performance on VA span tasks reflects the amount of visual attention capacity available for processing (Dubois et al., Citation2010; Lobier et al., Citation2013), which relates to the dorsal attention network (Lobier et al., Citation2014, Citation2012; Reilhac et al., Citation2013; Valdois et al., Citation2019a, Citation2014). Individuals with higher VA span show more efficient word recognition skills, thus faster reading (Antzaka et al., Citation2017; Bosse & Valdois, Citation2009; Lobier et al., Citation2013; Valdois et al., Citation2019b), more accurate irregular word reading (Bosse & Valdois, Citation2009) and smaller length effects (van den Boer et al., Citation2013); for computational modelling, see Ginestet et al. (Citation2019). Exploration of their eye movements during text reading revealed lesser fixations and larger saccades, suggesting that more letters were simultaneously processed per fixation (Prado et al., Citation2007). Overall, these findings suggest that individuals with higher visual attention capacity may more efficiently identify a higher number of letters simultaneously while reading, which would boost letter-string processing and facilitate orthographic learning. The present study for the first time explored the potential impact of VA span on the incidental orthographic learning of novel words.
Our main purpose was to provide new insights on the process of orthographic learning. Eye movement monitoring was used during the learning phase to track orthographic learning online through the analysis of cross-exposure effects on eye movements. The paradigm we used—repeated exposition to novel words presented without context—offered the opportunity to track the exposure-by-exposure evolution of eye movements for an in-depth analysis of the online learning process. Furthermore, real words were presented mixed to the target pseudo-words during the reading phase and in similar conditions of eye movement recording for a baseline measure to which pseudo-word processing was compared. Any between-exposure variation of eye movements for words was interpreted as mainly reflecting repetition effects. By comparison, any differential effect for the target pseudo-words would be interpreted as evidence of orthographic learning. The off-line tasks were administered after the learning phase to ensure that any variation of eye movements as a function of the number of exposures might be interpreted as reflecting online orthographic learning.
As previously reported in self-teaching paradigms, we expected better performance on the offline measures of orthographic learning (i.e. spelling-to-dictation and orthographic decision tasks) with increased exposure to the target pseudo-words. With respect to the online measures of eye movement, better learning would translate into fewer fixations and shorter processing time across exposures during reading. In line with behavioural evidence that orthographic learning occurs from the first exposure (Share, Citation2004), significant eye movement changes were expected to occur very early, mainly between the first and second exposures. The words of mid-to-high frequency used as baseline were expected to have stable orthographic memories, thus limiting online memorisation effects. Accordingly, interactions between the number of exposures and the item type (words or pseudo-words) are expected on number of fixations and processing time, as a marker of novel word orthographic acquisition clearly different from a simple item repetition effect.
Another goal of the present study was to explore the potential influence of multielement simultaneous processing skills on target pseudo-word processing and orthographic learning, through the administration of offline tasks of VA span. We predicted eye movements and orthographic learning to vary depending on the participants' VA span skills. Participants with higher VA span would be more prone to identify a higher number of letters simultaneously while reading, which would affect both eye movement measures and orthographic learning. We predicted that participants with a higher VA span would show better orthographic learning, thus higher performance in spelling and in orthographic decision. They might further exhibit faster learning over time than lower VA span participants, which might result in faster decrease in number of fixations and processing time across exposures.
2. Method
2.1. Participants
Forty-six undergraduate students () participated in the experiment. All participants were native French-speakers with normal or corrected-to-normal vision and no known learning or reading disorders. None of them showed an abnormally low performance in a spelling-to-dictation control task of 30 irregular real words (
;
; range: 40–90). They received a
compensation for their participation. Informed written consent was obtained from each participant and the study was approved by the ethics committee for research activities involving humans (CERNI number: 2018-Avis-02-06-01) of the Grenoble-Alpes University. It was thus performed in accordance with the ethical standards of the declaration of Helsinki.
2.2. Protocol
Each participant was first engaged in an incidental learning phase followed by a test phase. During the learning phase, they were asked to read aloud real control words and target pseudo-words that were mixed and displayed 1, 3 or 5 times each on the screen while their eye movements were recorded. To ensure incidental learning, no explicit instruction was given to participants to take notice of novel words' orthography: the participants were instructed to read aloud the stimuli and they were not informed that the purpose of the study was to test their orthographic knowledge of the target pseudo-words. Two tasks of spelling-to-dictation and orthographic decision were used in the test phase to estimate their pseudo-word orthographic learning. The two tasks were systematically administered in the same order, spelling-to-dictation first. Global and partial letter-report tasks were further administered to measure the participants' VA span.
2.3. The learning phase
2.3.1. Material
2.3.1.1. Pseudo-words
A list of pseudo-words was designed to be used for implicit learning. Thirty legal bi-syllabic eight-letter pseudo-words were generated by reference to the French lexical database LEXIQUE (New et al., Citation2001). They were built up from existing trigrams (mean ; SD
; range: 327–4144) to have no orthographic neighbours (i.e. none differed from a real word by a single letter). None was homophone to a real word. Each pseudo-word contained at least two ambiguous graphemes, that is, graphemes corresponding to phonemes that could be written in at least two different ways. For example, the target pseudo-word GOUCIONT corresponding to the phonological form / gusjɔ̃ / would be written GOUSSION when following the most frequent phoneme-to-grapheme mappings in French. Moreover, at least another pseudo-word of the list included the same phoneme but corresponding to another ambiguous grapheme that was not the most often associated to this phoneme in French. For example, the phoneme / ɔ̃ /, spelled ONT in GOUCIONT, was spelled OND in TRIMPOND. Furthermore, to prevent any systematic visual exploration strategy during the learning phase, the ambiguous graphemes' positions were varied between items, so that they could be located at the beginning, middle left, middle right or at the end of the pseudo-word letter-string. A critical point in the current study is to ensure that novel words accurate spellings cannot be derived from their phonological form. Therefore, a control experiment was carried out to estimate the probability of accurate by-default spellings. The lists of the target novel words and their homophones were dictated to a group of 30 students, none of them participating to the orthographic learning experiment. On average, 3.1% of the collected spellings were identical to those of the target pseudo-words (3.4% for the homophones). Therefore, significantly higher evidence of correct spellings than the 3.1% spontaneously collected would support orthographic learning.
To investigate the effect of the number of exposures (1, 3 or 5), three different subsets of pseudo-words (noted A, B and C; see Test Lists in A.1) were created. The three lists were matched in orthographic features—position and number of ambiguous graphemes and mean trigram frequency (respectively, 1627.4, 1668.6, 1668.5). They were further matched in “orthographic difficulty”, controlling for the number of possible spellings that complied with the pseudo-word pronunciation.
2.3.1.2 Control words
The 30 control words were 8 letters long with no orthographic neighbours. All were of medium frequency (per million, mean ; SD
). As for pseudo-words, the word list was divided into three sublists (noted A, B and C; see Test Lists in A.2) balanced with respect to their mean frequencies (respectively, 34.44, 36.03, 35.93).
2.3.2. Apparatus
All stimuli were displayed on a computer screen (DELL, Round Rock, TX, USA) using a px resolution and a 60-Hz refresh rate. Stimuli were presented on a black background in white lowercase Courier New font (size 32 px) and experiments were designed with the open-source experiment builder Opensesame (Mathôt et al., Citation2012; v.3.1.2).
During the reading phase, the participants' eye movements were monitored using a RED250 eye tracker (SMI® company, Teltow, Germany) at a viewing distance of 67 cm. The system was interfaced with a laptop (Latitude E6530, DELL, Round Rock, TX, USA) and gaze position recording was performed by the iViewX software (SMI® company, Teltow, Germany). Each character covered a horizontal visual angle of 0.47, and each 8-letter stimulus covered a 3.76
visual angle. To minimise head movements, participants kept their forehead pressed on a frontal support.
2.3.3. Procedure
A first listening phase without visual display was administered to each participant. The pronunciation of the target pseudo-words was heard through headphones. The “canonical” pronunciation provided through headphones followed the most frequent grapheme-to-phoneme correspondences. Participants were instructed to listen carefully to the pronunciation of the new words (pseudo-words) as they would have to read them aloud in the second phase. The rationale for providing “canonical” pronunciations was to avoid having different participants refer to different pronunciations.
After the initial listening phase, the eye-tracker was calibrated, using a five-point calibration procedure. Then, the learning phase started. Each trial began with the presentation of a fixation cross. Participants were instructed to keep their eyes on the cross; doing so long enough (randomised time ranged from 400 to 600 ms) would trigger the display of the stimulus on the screen.
A stimulus was composed of a control word or a pseudo-word and a digit from 1 to 9 (see ). The two items (word or pseudo-word and digit) were simultaneously presented on the horizontal line, the digit always right of the written item. To avoid any phenomenon of spatial habituation or anticipation, the position of the fixation cross was varied randomly from 204 to 804 px horizontally left to the centre of the screen. The distance between the fixation cross and the letter-string and between the letter-string and the digit was fixed, and set to 9.41 cm (8.03 at a viewing distance of 67 cm).
Figure 1. Experimental design. Top: Illustration of the time course of a trial during the learning phase. Bottom: Distance (in cm, pixels and degrees) between items and reference frame for counting letter positions (illustrated by for the first and
for the last letter). (To view this figure in colour, please see the online version of this journal.)
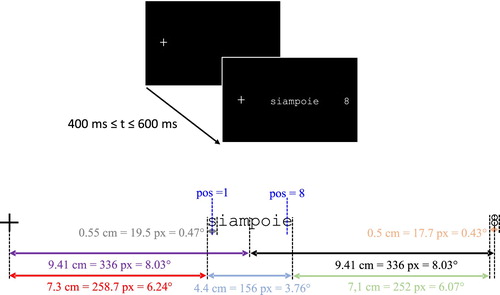
Participants were asked to read aloud as naturally as possible the written word or pseudo-word, then the digit. This induced a processing sequence (fixation cross then item then digit) ensuring a left-to-right scanning on the item while avoiding atypical fixations during first pass on the novel word due to interference with end of processing. Then, they pressed the space bar of the keyboard to trigger the next trial. No feedback was provided during the task. Drift correction and re-calibration of the eye-tracker could be performed at any time by the experimenter if necessary, with drift correction systematically performed every 10 trials.
Ten items, pseudo-words and real words were displayed once each; 10 items were displayed 3 times each and 10 items 5 times; for a total of 180 trials. The trials were presented with a different, random order for each participant. The number of exposures was counterbalanced across subjects, so that, for example, Participant 1 would read the pseudo-words and control words from Lists A, B and C respectively once, three times and five times, whereas Participant 2 would read Lists A, B and C respectively five times, once and three times, etc. The reading task was preceded by four practice trials (see Practice Lists in A.1 and A.2) during which feedback was provided. The participants' naming responses were scored as correct or incorrect.
2.4. Test phase
2.4.1. Unexpected pseudo-word spelling-to-dictation test
Immediately after the learning phase, participants performed a spelling-to-dictation task to measure how well they had memorised the experimental pseudo-words. The oral pronunciation of each pseudo-word was successively presented through headphones, once each, without repetition, and in a random, different order for each participant. Participants had to type each pseudo-word immediately after its pronunciation on the computer keyboard. They were instructed that the pseudo-words were those which they had been previously exposed to and were explicitly asked to spell them as they were spelled during the learning phase. Overall, 30 pseudo-words (see Test Lists in A.1) were written by each participant. No time limit was imposed and participants triggered the next trial at their convenience. No feedback was provided to the participants. Two scores were computed from the participants' spellings. A whole pseudo-word spelling score corresponding to the number of spellings strictly identical to the target orthography and a by-grapheme spelling score corresponding to the number of target graphemes that were accurately spelled. The latter measure was expected to be potentially more sensitive to orthographic learning than the former.
2.4.2. Orthographic decision test
Target pseudo-words' learning was further assessed through an orthographic decision task. In this task, each target pseudo-word was paired with a pseudo-homophone.
2.4.2.1. Stimuli
Thirty pseudo-homophones (see Test List in A.3) were generated following the same criteria as for the pseudo-words. The pseudo-homophones were matched to the pseudo-words in trigram frequency (mean ; SD
; range: 307–3829). The written form of each pseudo-homophone included at least one ambiguous grapheme that differed from that of the related target pseudo-word (e.g. SAITTEAU-CEITTEAU, PHACRAIS-PHACRAIT, SIEMPOIT-SIAMPOIE).
2.4.2.2. Protocol
Each item (target pseudo-word or pseudo-homophone) was successively displayed on the computer screen one at a time. The participants were asked to decide as quickly and as accurately as possible whether the displayed item was spelled as the target pseudo-word or not. Each trial began with a fixation cross displayed at the centre of the computer screen during 500 ms. The fixation cross was immediately replaced by a forward mask composed of 8 hash marks (########) for 500 ms. The target was then displayed, centred on fixation, until the participant's response.
Presentation order was randomised and different for each participant. No feedback was provided to the participants. The two possible response buttons were the left button (for a “Yes” response) and the right button (for a “No” response) of a serial response (SR) box. A total of 60 targets were presented: the 30 target pseudo-words read during the learning task (see Test Lists in A.1) and the 30 pseudo-homophones (see Test List in A.3). The task was preceded by four practice trials (see Practice List in A.1 and A.3) during which feedback was provided. Accuracy and reaction times were recorded.
2.5. VA span tasks
The participants were administered global and partial report tasks to estimate their VA span. The tasks followed the protocol described by Antzaka et al. (Citation2017) which we only summarise in the following. At each trial, a six-consonant string was briefly displayed centred on the fixation point. The consonant string was built-up from 10 consonants (B, P, T, F, L, M, D, S, R, H) with no repeated letter. The consonant string was presented in black uppercase Arial font on a white background. Inter-letter spacing was increased to avoid crowding (0.57 inter-consonant space). Twenty-four strings were successively presented in the global report task, 72 in the partial report task. In both tasks, trials began with a fixation dot displayed at the centre of the screen during 1 s, immediately followed by a blank screen during 50 ms. The 6-consonant string was then displayed for 200 ms.
In the global report task, participants were told to verbally report as many letters as possible immediately after string presentation, regardless of the letter position in the string. In the partial report task, a single vertical bar appeared for 50 ms (1.1 below one of the letter positions) at the offset of the consonant string, indicating the position of the letter to be reported. The experimenter typed the participants' response without providing any feedback. The experimenter then proceeded to the next trial by pressing the Enter key. Both tasks were preceded by 10 practice trials during which feedback was provided. The strings were displayed in a random order that differed for each participant.
Accuracy was recorded for the two tasks of VA span as the number of target letters accurately reported, which induces a maximum score of 144 (for 24 trials × 6 letters per trials) and 72 (one letter per trials) for the global and partial report task respectively. In order to give the same importance to each task, the total score of VA span (, expressed as a percentage) was calculated, for each participant, using the following relation:
(1)
(1)
3. Results
We first consider results of the orthographic memorisation tasks to evaluate the incidental learning of the pseudo-words' orthographic form. Next, we analyse eye movements during the reading phase, focusing on how they are affected by the number of exposures to target pseudo-words. Last, we explore whether and how VA span affected orthographic learning while reading.
3.1. Statistical models
The data were analysed by means of generalised linear mixed effects models (glmer function; R Core Team, Citation2018; RStudio version 1.0.143) for all dependent variables. Participants and items were introduced as random factors. We used the Gamma family and the identity link for reaction times (RT) data (including temporal measures from eye-tracking data), the Poisson family and the identity link for the analysis of the number of fixations and the Binomial family and the logit link for binomial variables such as accuracy. Initially, a maximal random effects structure was specified for all models, which included all subject and item random intercepts and random slopes (Barr et al., Citation2013). If a model failed to converge, we followed Barr et al. (Citation2013) suggestion removing first correlations between random factors then random interactions. When a model still did not converge, we dropped random slopes associated with smaller variance, until the model converged. In all models, contrasts were specified as 0.5/ −0.5, 1/0/ −1 or 2/1/0/ −1 / −2 when independent variables have, respectively, 2, 3 or 5 modalities. Specific details of the models used are provided in Supplementary MaterialFootnote1 (for a quick access, see the .html file from “Statistical_files” folder).
All models related to orthographic memorisation tasks included the number of exposures (3 modalities; 1, 3 and 5 exposures) as fixed factor. In all models related to eye-tracking data, number of exposures (5 modalities; from 1 to 5 exposures), item type and their interaction were specified as fixed factors. In order to distinguish the number of exposure effect from the trial order effect, the order of presentation of items (continuous variable from 1 to 180) was also included in these main models as covariable, except for the analysis of the number of fixations for which the statistical model failed to converge. Finally, we explored the effect of VA span on all the online and offline measures only using pseudo-word data. Two sets of analyses were computed in which VA span was either used as a continuous variable or a discrete variable defining two groups of participants with higher or lower VA span. Results of the two groups are presented in the paper. The number of exposures, VA span group and their interaction were specified as fixed factors. The reported effects of the VA span group on eye movements or offline measures were further found significant when using VA span as a continuous variable. However, the statistical models that used VA span as a continuous variable did not converge for any of the three offline measures (pseudo-word spelling scores, orthographic decision scores and RTs) and one of the online measure (number of fixations).
Post-hoc comparisons were performed using Tukey contrasts in orthographic memorisation tasks—spelling-to-dictation and orthographic decision. Based on expectations that orthographic learning would occur very early after the first exposure, analyses modelling local interactions between the first and second exposure and between the second and third exposure were computed for all the eye-tracking measures, using similar generalised linear mixed effects models than previously described, excluding the order of presentation of items as covariable.
The whole statistical models were performed on the data from 42 participants, due to the exclusion of four participants following clean-up of eye movement data (see Section 3.3.1).
3.2. Performance in orthographic memorisation
Results from both the target pseudo-word spelling-to-dictation and orthographic decision tasks are summarised in . Results showed a significant main effect of the number of exposures on performance in the spelling-to-dictation task either considering the whole word scoring () or the by-grapheme scoring (
). The pseudo-words were more accurately spelled when they had been more often encountered during the reading phase. While performance on the whole pseudo-word spelling score significantly improved between the first and fifth exposures to the same pseudo-word (
), a significant effect of exposure on the by-grapheme score was observed from the third exposure (
). None of the other contrasts was significant. We further checked whether whole pseudo-word spelling performance differed from by-default spellings at the first exposure. Comparison of participants performance after a single exposure (11.4%) significantly differed from by-default spelling performance of people who were never exposed to the novel words (3.1%;
. The overall results suggest that incidental orthographic learning was effective during the reading phase.
Table 1. Performance on the target pseudo-words (mean and standard deviation) as a function of the number of exposures for the spelling-to-dictation and the orthographic decision tasks.
With respect to the orthographic decision task, trials with log-duration more than 2.5 standard deviations from the mean were excluded from analyses (1.35% of the trials). Both the percentage of correct responses and RTs obtained in the orthographic decision task are presented in . In the absence of orthographic learning, choices in orthographic decision were expected to be merely random (around 50%). A one-sample t-test showed that the proportion of correct choices (combining all exposure levels) was significantly above chance for the target pseudo-words () but not for their homophones (
). The above-chance-level performance on the targets was found for both the three-exposure (
) and five-exposure (
) conditions.
Further analyses were performed on response accuracy and RTs but only for the target pseudo-words, due to random performance on the homophones. An effect of the number of exposures was expected on the two measures if orthographic learning occurred during the reading phase. Indeed, target pseudo-words were recognised more accurately () and faster (
) across exposures. Post-hoc comparisons show that the number-of-exposures effect was significant on both response accuracy and RTs from one to three exposures (accuracy:
p < .001; RTs:
) and only on RTs from three to five exposures (accuracy:
; RTs:
). Above-chance-level performance on the target pseudo-words and more efficient pseudo-word recognition (accuracy and RTs) across exposures both support that orthographic learning did occur during the reading phase. Evidence for significant learning effects after only three exposures suggest that three or perhaps two exposures are sufficient for orthographic learning.
3.3. Analyses of eye movements during the learning phase
3.3.1. Data cleaning
Although we recorded eye-tracking data for the two eyes, only data from the right eye were analysed. Parsing raw data from the eye-tracker (i.e. event detection) was done using the BeGaze software (SMI® company, Teltow, Germany). The High-Speed algorithm was used, keeping default parameter values: minimum saccadic duration was 22 ms, peak speed threshold of a saccade was 40/s and minimum fixation duration was 50 ms. A custom-designed software was further used to select the relevant fixations for subsequent analyses. Visual inspection of the vertical coordinates of each participant led to remove those fixations located too far from the horizontal line. Using this method, we removed 1.71% of the total number of fixations (835 fixations out of 48,865 fixations). To explore eye movements during online orthographic learning, we focused the analyses on the oculomotor events occurring during the first-pass of letter-string processing. The oculomotor events were taken into account for further analyses if occurring within an area of interest defined as follows: fixations further than 30 px (0.72
) to the left of the left boundary of the first letter, or further than 30 px (0.72
) to the right of the right boundary of the last letter, were excluded from analyses.
For all analyses, trials that showed more than one blink on the target pseudo-word were excluded. We further excluded trials with more than eight saccades or nine fixations that were considered as extreme outliers according to a quartile-based criterion (more saccades than ). Trials with total log-duration further than 2.5 standard-deviations from the mean were further excluded (range: 79–2402 ms). Finally, trials containing at least one fixation log duration greater than 2.5 standard deviation from the mean (i.e. more than 1055 ms) were excluded from the analyses. The whole data from four participants were discarded due to the low percentage of trials remaining after data cleaning (
). Overall, 90.66% of the trials (6854 out of 7560 trials, see for details) from 42 participants were kept for further analyses. Learning effects were first explored on the whole population before focusing on potential differential effects depending on the participants' VA span abilities.
Table 2. Number and percentage of trials per item type and exposure (in columns: W for words, PW for pseudo-words and exp1 to exp5 for the five exposures) and number of fixations (in rows). The total indicates the number and percentage of trials kept after removing outliers.
Reading scores revealed that, on average, participants correctly (i.e. using the canonical pronunciation, that is to say, the pronunciation heard during the initial presentation phase) read more than 85% of the target pseudo-words, whatever the number of exposures. summarises results for the different eye movement measures of interest across exposures: number of fixations, total fixation duration, single fixation duration, duration of the first-of-two fixation, duration of the second-of-two fixation. The number of fixations corresponds to the total number of fixations before leaving the word. Total Fixation Duration is the sum of all fixation durations starting with the first fixation on the word and ending with the first forward saccade towards the digit. Total reading time thus includes both first-pass fixation durations and the duration of within-word short regressions. The experimental paradigm prevented the occurrence of long regressions since the participants were instructed to read the word then the digit and press the key to start the next trial as soon as possible. Single fixation duration is measured on words that received only one fixation during reading. The two last measures are taken from words that received only two fixations. The durations of the first and second of two fixations were separately analysed. Most previous studies (e.g. Pagan & Nation, Citation2019) that distinguished single fixation trials from multiple fixation trials focused on the analysis of the first-of-multiple fixation while ignoring the number and duration of subsequent fixations. We here decided to restrict the analysis to a more homogeneous corpus of trials, considering trials with exactly one or two fixations. As shown in , two-fixation trials predominated in the corpus, representing 38.9% and 45.0% trials on pseudo-words and words respectively. Focusing on two-fixation trials allowed an in-depth analysis of both the first and second fixation duration. Further analyses were run using the first-of-multiple fixation duration measure. Results were identical to those reported for the first-of-two-fixation duration, except when otherwise reported in the text.
Figure 2. Eye movement measures recorded during the reading task as a function of the number of exposures. (A) Number of fixations, (B) Total fixation duration, (C) Single fixation duration, (D) First-of-two fixation duration and (E) Second-of-two fixation duration. All times are in ms and vertical bars are for standard errors.
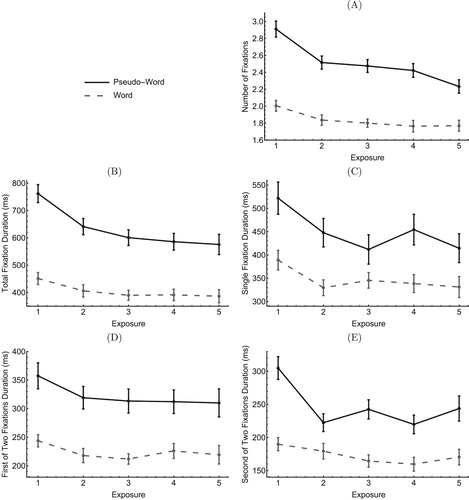
For all eye movement measures, results are provided for the target pseudo-words and the control words as a function of the number of exposures. A differential exposure effect for the target pseudo-words and control words was expected as a marker of new word orthographic learning. As performance on memorisation tasks provided evidence for effective orthographic learning occurring across the first three exposures, we were in particular attentive to differences in oculomotor measures between the first and second or third exposure.
3.3.1.1. Number of fixations
As shown in (A), the number of fixations recorded during the reading phase varied depending on item type (main effect: ) and number of exposures (main effect:
). More importantly, the item-type by number-of-exposure interaction was significant (
), showing a steeper decrease in number of fixations across exposures for pseudo-words than for words. Post-hoc analyses showed that the number of fixations more sharply declined for the pseudo-words than for words between the first and second exposures (
; nonsignificant interaction between the second and third exposures:
).
3.3.1.2 Total Fixation Duration
Total Fixation Duration for target pseudo-words and control words, as a function of the number of exposures, is plotted in (B). The two main effects of item-type () and number-of-exposures (
) were significant, as well as the interaction between these two factors (
) showing steeper total fixation duration decrease with increased exposure for pseudo-words than for words. Post-hoc analyses showed a sharper total fixation duration decline for pseudo-words than for words between the first and second exposures (
) as well as between the second and third exposure (
).
3.3.1.3. Fixation Duration in Single Fixation Trials
The analysis of single fixation duration according to item-type and number-of-exposures was performed on the 1941 trials (25.7 of data) having a single fixation (see for details). Results are presented in (C). The analysis showed longer single fixation duration for pseudo-words than for words (
) and a significant main duration decrease across exposures (
). The item-type by number-of-exposure interaction was significant (
), suggesting that the duration of single fixations decreased more sharply for pseudo-words than for words across exposures. Local interaction analyses reveal a similar decrease of fixation duration for words and pseudo-words between the first and second exposures (
) but a sharper decrease on target pseudo-words between the second and third exposures (
).
3.3.1.4. Fixation Duration in Two-Fixation Trials
Two-fixation trials represent 2878 trials or 38.1% of data (see for details). (D,E) illustrate the number-of-exposure effect on target pseudo-words and control words for the first and second fixation of the two-fixation trials respectively. Results showed that the first-of-two fixation duration lasted longer for pseudo-words than for words () and duration decreased across exposures (
p < .001). The item-type by number-of-exposure interaction was significant (
p = .003) suggesting a sharper decrease of the first-of-two fixation duration for pseudo-words than for words. Post-hoc analyses showed that none of the local interactions between the first and second (
) or second and third (
) exposure was significant.
Analysis of the second-of-two fixation duration showed a main effect of item-type () and number-of-exposures (
), and a significant interaction between item-type and number-of-exposures (
p < .001). However, there was a significant local interaction between the first and second exposures (
) but not between the second and third exposures (
p = .338), showing sharper decline of the second-of-two fixation duration between the first two exposures to target pseudo-words.
3.4. Analysis of potential VA span effect
We further evaluated the potential influence of the participants' VA span abilities on orthographic learning (spelling-to-dictation and orthographic decision) and eye movement measures for target pseudo-words. For this purpose, participants were split into two groups with higher or lower VA span, using the median value (see Equation Equation1(1)
(1) for
calculation;
). The two groups were characterised by a mean VA span performance of 71.8% (
) and 84.8% (
) respectively. Results from all tasks as a function of VA span Group are provided in Supplementary Material (see “Appendix” file).
We first checked whether orthographic learning was more effective depending on the participants' VA span. Results from the spelling-to-dictation task revealed no significant Group effect on any of the two measures of whole word () and by-grapheme accurate spellings (
). There was no significant interaction between the Group and the Number of Exposure for either the whole pseudo-word (
) or by-grapheme spellings (
). Similarly, no significant Group effect (
) and no interaction (
) were found in orthographic decision accuracy. However, there was a significant VA span Group effect on RTs (
). The higher the participants' VA span score, the shorter the RTs. The VA span Group by Number of Exposure interaction was significant (
) but none of the local interactions (all ps>.05), suggesting sharper decrease of orthographic decision RTs across exposures for participants with higher VA span.
For eye movements, there was a significant main effect of VA span group on all the eye movement measures, except the number of fixations (). The total fixation duration was significantly shorter for the higher VA span group (
). The main effect of VA span Group on the duration of fixations in single (
) and two fixation (first-of-two fixation:
; second-of-two fixation:
) trials was also significant, showing shorter durations in the group with higher VA span. However, none of the Group by Exposure interaction was significant (all ps>.05), suggesting that the two VA span groups showed very similar decrease in fixation duration over exposures. Note that the analyses using VA span as a continuous variable revealed a significant VA span by Exposure interaction, but only for the second-of-two fixation duration that decreased more sharply for participants with higher VA span (
).
4. Discussion
In this study, we investigated orthographic learning of new words using eye-tracking. Through a paradigm inspired from the self-teaching paradigm initiated by Share (Citation1999), French-speaking skilled readers were exposed to novel words, presented in isolation for one, three or five exposures. A conventional spelling-to-dictation task and an original orthographic decision task were used to measure orthographic learning after the reading phase. Further, VA span tasks were administered to investigate the potential impact of visual attention capacity on the processing of new words while reading and as a result, on the orthographic learning process.
Evidence from the two memorisation tasks and eye-movement measures is in line with previous reports, suggesting that the paradigm we used was appropriate to explore orthographic learning. Such evidence is threefold. First, results from the offline orthographic memorisation tasks—higher number of target graphemes in pseudo-word spelling and shorter RTs in orthographic decision—suggest that orthographic learning began very early during processing, namely across the three first exposures to the novel word. Fast orthographic learning is convergent with findings in previous research (Nation et al., Citation2007; Share, Citation2004).
Second, in line with the previous eye-tracking studies that compared word and pseudo-word processing (Lowell & Morris, Citation2014; Rayner, Citation2009), we show that the number of fixations is higher for pseudo-words than for words. As previously reported by Pellicer-Sanchez (Citation2016), the item-type effect is quite consistent across exposures and extends to all the eye movement measures. Third, we show that the higher the number of exposures to the target pseudo-word, the lower the processing time. There is strong agreement that visual processing of a new word is influenced by the number of encounters with this word (Joseph & Nation, Citation2018; Joseph et al., Citation2014). However, variations in the oculomotor measures carried out on real words also suggest some sensitivity to the number of exposures. Given the range of frequency of our control words, it seems difficult to assimilate these variations to any orthographic learning. This effect may be more likely due to repeated reading of the same set of well-known words in a short time, inducing familiarisation to the set of stimuli through repetition. If that were the case, such a process could also account for some of the variations of the oculomotor measures for the pseudo-words. The use of control words is thus critical to disentangle repetition effects from learning effects. Comparison of exposure effects on words and pseudo-words in the current study revealed higher decrease in processing time—as evidenced by the number of fixations and total fixation duration—over exposures for pseudo-words than for words. This finding clearly shows that a repetition effect cannot account alone for the oculomotor behaviour observed on pseudo-words. Evidence for differential processing time during pseudo-word processing attests that decreased processing time with increasing exposures does reflect orthographic learning. In the following, we focus on the novelty of the current findings, underlying the relevance of the orthographic decision task and exposure-by-exposure track of eye-movements during the learning phase to reveal orthographic learning. We last discuss how VA span influences the learning process.
4.1. The measures of orthographic learning
A first main contribution of the current study is to provide novel ways of measuring orthographic learning. Based on previous work of Wang et al. (Citation2011), Tamura et al. (Citation2017) and Wang et al. (Citation2013), we designed a new orthographic decision task as an alternative to the standard but more debated task of orthographic choice (Castles & Nation, Citation2008; Tucker et al., Citation2016). Instead of using a multiple choice paradigm as in the standard task, targets and homophonic foils were presented one-at-a-time to prevent strategic influences, like responses based on phonological and/or orthographic comparison. It was assumed that the processing of isolated items, targets or foils, in orthographic decision would more directly trigger the recognition system and would increase sensitivity to orthographic learning. Current evidence suggests that the novel orthographic decision task likely reflects orthographic learning. First, better and faster target pseudo-word recognition was reported across exposures. Second, reported effects on both accuracy and RTs between the first and third exposure suggest good task sensitivity to the early steps of orthographic learning. Last, significant changes between the third and fifth exposures suggest sensitivity all along the learning process. The orthographic decision task thus appears as a promising offline alternative to track the evolution of implicit learning during reading. Whether the novel orthographic decision task challenges the widely used orthographic choice task warrants further investigation, through direct comparison of performance in the two tasks. Future studies would further explore whether the orthographic decision paradigm is appropriate to measure orthographic learning in children.
Orthographic learning was further assessed in our adult participants through a spelling-to-dictation task. As previously reported for children (Bosse et al., Citation2015; Cunningham, Citation2006), the task was difficult even for adult participants who showed relatively low performance when considering the number of target pseudo-words that were accurately spelled as a whole. Although spelling performance significantly improved after five exposures, only about a quarter of the pseudo-words were accurately spelled. This suggests that memorisation of the perfect whole spelling of a new eight-letter word is a long process that is not completed after five exposures to the new written form. However, the fact that more target graphemes were accurately spelled after three exposures to the pseudo-words provides evidence of early orthographic learning. This finding suggests that orthographic representations of the novel words become more and more precise over exposures, even if the exact pseudo-word spelling is not yet stabilised after five encounters. Overall, the spelling-to-dictation task seems appropriate to explore orthographic learning in adult participants and task sensitivity is improved when using a fine-grain scoring based on target graphemes.
4.2. Exposure-by-exposure time course of orthographic learning
A second main contribution of our work is to provide insights on the time course of orthographic learning through the exposure-by-exposure analysis of eye movements during the learning phase. Although changes in eye movements across different phases of repeated print exposure to novel words were examined in previous research (Joseph & Nation, Citation2018; Joseph et al., Citation2014), our study is one of the very first (Pellicer-Sanchez, Citation2016) to provide an exposure-by-exposure, in-depth analysis of this online process. The current findings suggest such analysis is particularly relevant and informative. While the offline measures of orthographic memorisation suggest relative quick learning of the novel words (after only a few exposures), the exposure-by-exposure exploration of the learning process likely highlights very early evidence of orthographic learning. Such exploration further allows investigating whether and how the different eye movement measures respond to additional exposures during incidental learning.
The analysis of eye movements in our adult participants revealed early changes with additional exposure on the three measures of number of fixation, second of two fixation duration and single fixation duration. A sharper duration decline was observed between the first and second exposures to the novel word for the two former measures and between the second and third exposures for the latter. As a direct consequence, a sharp decrease of total fixation duration was observed between both the first and second, and second and third exposures. Thus specific changes in time processing for pseudo-words that can be attributed to orthographic learning occur during the very first stages of the learning process. These findings support prior evidence of rapid orthographic learning (Cunningham, Citation2006; Share, Citation2004). Robust learning starts after just one exposure not only in transparent languages as Hebrew (Share, Citation2004) but also in nontransparent languages as English (Cunningham, Citation2006) or French (current data). Rapid and automatic orthographic learning thus appears as a property of the learning system that is independent of language transparency. Current findings further confirm that early orthographic learning can occur in the absence of semantic context (Landi et al., Citation2006; Nation et al., Citation2007).
Another originality of the current work was to capitalise on the predominance of two fixation trials for an analysis of both the first and second fixations in conditions where novel words were fixated twice and only twice. Most previous studies in the field analysed the duration of the first of multiple fixations without providing insights on later processing (Bertram, Citation2011), see however Mousikou and Schroeder (Citation2019) for an attempt in an eye tracking study on morphological processing. An analysis of the first-of-multiple fixation duration was actually carried out in the present study; results were not reported here as they were very similar to those reported for the first-of-two fixation. Focusing on two fixations trials revealed an effect of orthographic learning not only on the first-of-two fixation duration but further on the duration of the second-of-two fixation.
Interestingly, only the second fixation duration showed a sharp decrease between the first and second exposures. In contrast, the duration of the first fixation gradually declined across exposures without any specific effect emerging from the first three encounters with the novel word. In this regard, the first-of-two-fixation duration measure differs from the other eye-movement measures that all showed earlier significant changes. Although further studies are needed to check the robustness of this finding and better understand why orthographic learning may rapidly affect the duration of the second- but not the first-of-two fixation, a potential sketch emerges from the overall data. At the first encounter, thus in the absence of lexical representation, only a few pseudo-words (12%) were processed within a single fixation, suggesting that, for most pseudo-words, only insufficient or partial letter identity information could be extracted within a unique fixation. As previously suggested (Lowell & Morris, Citation2014), long processing time for pseudo-words at the first encounter is likely to reflect time needed for bottom-up information extraction on letter identity and for encoding the new letter-string into memory. As a result, the large variation observed in number of fixations and processing time between the first and second exposures may primarily reflect improved letter identification at the second exposure, due to top-down influence from the newly acquired orthographic representation. However, top-down information at the second encounter was not sufficient to significantly decrease single fixation duration, and such a decrease was only observed between the second and third exposures. As for the number of fixations, very early decrease in duration for the second-of-two fixation suggests that this measure is particularly sensitive to the existence of a newly created orthographic representation of the pseudo-word, which is not the case for the first-of-two-fixation duration. This might suggest that the second-of-two fixation, that was required to complete letter identity processing during orthographic encoding at the first encounter, would be mainly used later on and from the second exposure to check matching with the newly created representation. In contrast, the first-of-two fixation may be empowered to progressively evolve into being a single fixation. More and more letters are likely to be processed more efficiently, thus faster, during this first fixation as the quality of orthographic representation improves across exposures.
Overall, the exposure-by-exposure analysis of eye movements during the learning phase appears as particularly useful to better understand the critical links between eye-movement patterns and the orthographic learning process. However, the current findings suggest that independent analyses of how the different eye-movement measures evolve over exposures provides only piecemeal information on the learning process. In particular, we lack a dynamic model providing insights on how the number of fixations and fixation duration interacts during orthographic learning. Moreover, contrary to previous research that minimised the impact of visual processing on learning (Perry et al., Citation2019; Pritchard et al., Citation2018; Share, Citation1999; Ziegler et al., Citation2014), current findings clearly argue for a major role of visual processing on new orthographic knowledge acquisition.
4.3. Does VA span affect orthographic learning?
Another novelty of the current study was to explore whether differences in VA span do affect orthographic learning. For this purpose, our set of participants was split into two groups with higher or lower VA span skills. Comparison of the two groups' performance on the offline measure of orthographic decision revealed that adult readers with a higher VA span recognised novel word spellings faster than their lower VA span peers. More importantly, RTs were found to decline more steeply across exposures in the higher VA span group, suggesting higher improvement of recognition skills with additional exposures in this group. The higher VA span group further showed shorter processing times on all the fixation duration measures, but the number-of-exposure effect on processing time was similar in the two groups. However, the analysis using VA span as a continuous variable revealed that the duration of the second-of two fixation more sharply declined across exposures in participants with higher VA spans.
A more unexpected finding is the absence of VA span group effect on the number of fixations during target pseudo-word processing. A relationship between VA span and the number of fixations was previously reported (Prado et al., Citation2007). We thus expected adult participants with lower VA span abilities to process fewer letters simultaneously at each fixation, which should have resulted in more fixations. However, previous evidence that the number of fixation varied depending on VA span abilities was reported in dyslexic children with a VA span deficit, while our participants have no history of dyslexia and no VA span deficit. As expert readers, they were probably able to process enough letters at each fixation whatever the variations in their VA span.
The role of VA span in orthographic learning requires further investigations. Nevertheless, the current findings suggest that the amount of visual attention available for multiletter simultaneous processing may increase the quality of novel word orthographic representations that will be established in memory. The rationale for such an assumption is that the more attention is allocated to the novel word, the faster is letter identity processing, which boosts relevant letter information encoding and facilitates orthographic learning. In line with this assumption, there is evidence that participants with higher VA spans show faster processing time from the first encounter, thus faster letter identity processing and faster orthographic encoding. However, if related to more efficient orthographic learning, processing time should decrease more sharply over exposures in participants with higher than lower VA span. There is some evidence that this might be the case for the second-of-two-fixation duration but not for the other measures of total fixation duration, single fixation duration or first-of-two-fixation duration. Thus VA span might more specifically affect the processing time measure that was previously found to be the most sensitive to early orthographic learning. If higher VA span abilities do contribute to stabilise more precise orthographic representations of the pseudo-words across exposures, we would expect more pseudo-words to be processed through a single fixation over time. In agreement with this expectation, post-hoc analyses revealed that participants with higher VA span abilities processed more pseudo-words in a single fixation after five encounters.Footnote2 Evidence from second-of-two-fixation duration and single fixation trials suggests better quality of orthographic representations in the higher VA span group, which might account for faster recognition of pseudo-word spellings over exposures in the orthographic decision task. We would further expect better learning to progressively affect recognition accuracy in orthographic decision and pseudo-word spelling performance. Such effects were not observed after five exposures and might require a higher number of exposures to the target pseudo-words. Assuming that higher VA span contributes to improve orthographic learning would further predict a relationship between VA span performance and lexical orthographic knowledge. Post-hoc correlation analysis supports this relationship, showing that the higher the VA span, the higher was the number of irregular words that were accurately spelled by our participants (Pearson's correlation ). Overall, the current study provides a number of tiny but convergent evidence that the amount of visual attention available for novel word processing may contribute to orthographic learning. While the current findings align with previous evidence that readers with higher VA span read faster (Antzaka et al., Citation2017; Bosse & Valdois, Citation2009; Lobier et al., Citation2013), show lower length effects in real word reading (van den Boer et al., Citation2013) and have better spelling performance (van den Boer & Elsje, Citation2015), further studies are required to comfort and clarify the role of VA span in orthographic learning.
Evidence for a potential contribution of visual attention span to orthographic learning would have strong practical and theoretical implications. At the practical level, intensive training using VA span targeted intervention programs, like COREVA (Valdois et al., Citation2014) or MAEVA (Zoubrinetzky et al., Citation2019), has proven successful to improve VA span with positive transfer to reading performance. Further research is required to explore whether similar trainings may further improve orthographic learning skills and, as a consequence, spelling performance. Evidence that VA span contributes to orthographic learning should further have implications for models of learning to read. Current models (Pritchard et al., Citation2018; Ziegler et al., Citation2014) emphasise the impact of phonological decoding on orthographic learning while minimising the role of visual processing in this learning process. As acknowledged by Pritchard et al. (Citation2018), these models do not incorporate the sophisticated mechanisms of visual processing postulated by word recognition models, as the gradient of acuity (Whitney, Citation2001), lateral interferences (Davis, Citation2010; Gomez et al., Citation2008) or a visual attention component (Ans et al., Citation1998; Ginestet et al., Citation2019; Mozer & Behrmann, Citation1990). Evidence that visual attention contributes to orthographic learning would require the development of new models including both well-defined processes of phonological decoding, and fully specified mechanisms of visual processing, including a visual attention mechanism. Furthermore, while current models adopt a one-shot approach to learning, creating a fully specified orthographic word node after only a single exposure, current eye movement data rather suggest that orthographic learning is a gradual process that extends over multiple exposures. A challenge for future orthographic learning and reading acquisition models is to better fit the human data that describes the online dynamics of the learning process.
Acknowledgments
This work has been supported by a French Ministry of Research (MESR) grant to EG and the French government as part of the e-FRAN “FLUENCE” project funded by the “Investissement d'Avenir” program handled by the “Caisse des Dépôts et Consignations”.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Correction Statement
This article has been republished with minor changes. These changes do not impact the academic content of the article.
Notes
1 Open access availability for Supplementary Material files: https://osf.io/fa87h/?view_only=1df862ea1d0745698400c6c946eb7d26
2 Post-hoc analyses of variance (ANOVAs) showed that the Group-by-Exposure interaction on the number of single fixation trials was not significant (). However, contrast analyses revealed a higher rate of single fixation trials in the higher than lower VA span Group at the fifth encounter (15.38% vs. 8.75%,
), while no significant difference between groups was found at the first encounter (7.69% vs. 6.23%,
).
References
- Ans, B., Carbonnel, S., & Valdois, S. (1998). A connectionist multiple-trace memory model for polysyllabic word reading. Psychological Review, 105(4), 678–723. https://doi.org/10.1037/0033-295X.105.4.678-723
- Antzaka, A., Lallier, M., Meyer, S., Diard, J., Carreiras, M., & Valdois, S. (2017). Enhancing reading performance through action video games: The role of visual attention span. Scientific Reports, 7(1), 14563. https://doi.org/10.1038/s41598-017-15119-9
- Barr, D. J., Levy, R., Scheepers, C., & Tily, H. J. (2013). Random effects structure for confirmatory hypothesis testing: Keep it maximal. Journal of Memory and Language, 68(3), 255–278. https://doi.org/10.1016/j.jml.2012.11.001
- Bertram, R. (2011). Eye movements and morphological processing in reading. The Mental Lexicon, 6(1), 83–109. https://doi.org/10.1075/ml
- Bosse, M.-L., Chaves, N., Largy, P., & Valdois, S. (2015). Orthographic learning during reading: The role of whole-word visual processing. Journal of Research in Reading, 38(2), 141–158. https://doi.org/10.1111/j.1467-9817.2012.01551.x
- Bosse, M.-L., Tainturier, M. J., & Valdois, S. (2007). Developmental dyslexia: The visual attention span deficit hypothesis. Cognition, 104(2), 198–230. https://doi.org/10.1016/j.cognition.2006.05.009
- Bosse, M.-L., & Valdois, S. (2009). Influence of the visual attention span on child reading performance: A cross-sectional study. Journal of Research in Reading, 32(2), 230–253. https://doi.org/10.1111/jrir.2009.32.issue-2
- Bowey, J., & Muller, D. (2005). Phonological recoding and rapid orthographic learning in third-graders' silent reading: A critical test of the self-teaching hypothesis. Journal of Experimental Child Psychology, 92(2), 203–219. https://doi.org/10.1016/j.jecp.2005.06.005
- Castles, A., & Nation, K. (2006). How does orthographic learning happen? In S. Andrews (Ed.), From Inkmarks to Ideas: Current Issues in Lexical Processing (pp. 151–179). Psychology Press.
- Castles, A., & Nation, K. (2008). Learning to be a good orthographic reader. Journal of Research in Reading, 31(1), 1–7. https://doi.org/10.1111/jrir.2008.31.issue-1
- Castles, A., Rastle, K., & Nation, K. (2018). Ending the reading wars: Reading acquisition from novice to expert. Psychological Science in the Public Interest, 19, 5–51. https://doi.org/10.1177/1529100618772271
- Chaffin, R., Morris, R., & Seely, R. E. (2001). Learning new word meanings from context: A study of eye movements. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27(1), 225–235. https://doi.org/10.1037/0278-7393.27.1.225
- Chan, K. S., & Yeung, P. -S. (2020). Prediction of Chinese reading fluency by verbal and non-verbal visual attention span measures. Frontiers in Psychology, 10, 3049. https://doi.org/10.3389/fpsyg.2019.03049
- Cunningham, A. E. (2006). Accounting for children's orthographic learning while reading text: Do children self-teach? Journal of Experimental Child Psychology, 95, 56–77. https://doi.org/10.1016/j.jecp.2006.03.008
- Cunningham, A. E., Perry, K. E., & Stanovich, K. E. (2001). Converging evidence for the concept of orthographic processing. Reading and Writing: An Interdisciplinary Journal, 14, 549–568. https://doi.org/10.1023/A:1011100226798
- Davis, C. J. (2010). The spatial coding model of visual word identification. Psychological Review, 117(3), 713. https://doi.org/10.1037/a0019738
- de Jong, P. F., Bitter, D. J., van Setten, M., & Marinus, E. (2009). Does phonological recoding occur during silent reading and is it necessary for orthographic learning? Journal of Experimental Child Psychology, 104(3), 267–282. https://doi.org/10.1016/j.jecp.2009.06.002
- Dubois, M., Kyllingsbæk, S., Prado, C., Musca, S. C., Peiffer, E., Lassus-Sangosse, D., & Valdois, S. (2010). Fractionating the multi-character processing deficit in developmental dyslexia: Evidence from two case studies. Cortex, 46, 717–738. https://doi.org/10.1016/j.cortex.2009.11.002
- Gerbier, E., Bailly, G., & Bosse, M.-L. (2015). Using Karaoke to enhance reading while listening: Impact on word memorization and eye movements (pp. 59–64). ISCA Workshop on Speech and Language Technology in Education (SLaTE) Conference 2015, Leipzig, Germany. https://hal.archives-ouvertes.fr/hal-01192870
- Gerbier, E., Bailly, G., & Bosse, M.-L. (2018). Audio-visual synchronization in reading while listening to texts: Effects on visual behavior and verbal learning. Computer Speech and Language, 47, 79–92. https://doi.org/10.1016/j.csl.2017.07.003
- Ginestet, E., Phénix, T., Diard, J., & Valdois, S. (2019). Modeling the length effect for words in lexical decision: The role of visual attention. Vision Research, 159, 10–20. https://doi.org/10.1016/j.visres.2019.03.003
- Gomez, P., Ratcliff, R., & Perea, M. (2008). The overlap model: A model of letter position coding. Psychological Review, 115(3), 577–601. https://doi.org/10.1037/a0012667
- Joseph, H., & Nation, K. (2018). Examining incidental word learning during reading in children: The role of context. Journal of Experimental Child Psychology, 166, 190–211. https://doi.org/10.1016/j.jecp.2017.08.010
- Joseph, H., Wonnacott, E., Forbes, P., & Nation, K. (2014). Becoming a written word: Eye movements reveal order of acquisition effects following incidental exposure to new words during silent reading. Cognition, 133(1), 238–248. https://doi.org/10.1016/j.cognition.2014.06.015
- Kyte, C. S., & Johnson, C. J. (2009). The role of phonological recoding in orthographic learning. Journal of Experimental Child Psychology, 93(2), 166–185. https://doi.org/10.1016/j.jecp.2005.09.003
- Landi, N., Perfetti, C. A., Bolger, D. J., Dunlap, S., & Foorman, B. R. (2006). The role of discourse context in developing word form representations: A paradoxical relation between reading and learning. Journal of Experimental Child Psychology, 94(2), 114–133. https://doi.org/10.1016/j.jecp.2005.12.004
- Lobier, M., Dubois, M., & Valdois, S. (2013). The role of visual processing speed in reading speed development. PloS One, 8(4), e58097. https://doi.org/10.1371/journal.pone.0058097
- Lobier, M., Peyrin, C., Pichat, C., Le Bas, J.-F., & Valdois, S. (2014). Visual processing of multiple elements in the dyslexic brain: Evidence for a superior parietal dysfunction. Frontiers in Human Neuroscience, 8, 479. https://doi.org/10.3389/fnhum.2014.00479
- Lobier, M., Zoubrinetzky, R., & Valdois, S. (2012). The visual span deficit in dyslexia is visual and not verbal. Cortex, 48, 768–773. https://doi.org/10.1016/j.cortex.2011.09.003
- Lowell, R., & Morris, R. K. (2014). Word length effects on novel words: Evidence from eye movements. Attention, Perception, & Psychophysics, 76(1), 179–189. https://doi.org/10.3758/s13414-013-0556-4
- Martens, V. E., & De Jong, P. F. (2008). Effects of repeated reading on the length effect in word and pseudoword reading. Journal of Research in Reading, 31(1), 40–54. https://doi.org/10.1111/jrir.2008.31.issue-1
- Mathôt, S., Schreij, D., & Theeuwes, J. (2012). Opensesame: An open-source, graphical experiment builder for the social sciences. Behavior Research Methods, 44(2), 314–324. https://doi.org/10.3758/s13428-011-0168-7
- Mousikou, P., & Schroeder, S. (2019). Morphological processing in single-word and sentence reading. Journal of Experimental Psychology: Learning, Memory, and Cognition, 45(5), 881–903. https://doi.org/10.1037/xlm0000619
- Mozer, M. C., & Behrmann, M. (1990). On the interaction of selective attention and lexical knowledge: A connectionist account of neglect dyslexia. Journal of Cognitive Neuroscience, 2(2), 96–123. https://doi.org/10.1162/jocn.1990.2.2.96
- Nation, K., Angell, P., & Castles, A. (2007). Orthographic learning via self-teaching in children learning to read English: Effects of exposure, durability, and context. Journal of Experimental Child Psychology, 96(1), 71–84. https://doi.org/10.1016/j.jecp.2006.06.004
- Nation, K., & Castles, A. (2017). Putting the learning into orthographic learning. In K. Cain, D. L. Compton, & R. K. Parrila (Eds.), Theories of Reading Development (pp. 147–168). John Benjamins Publishing Company.
- New, B., Pallier, C., Ferrand, L., & Matos, R. (2001). Une base de données lexicales du français contemporain sur internet : LEXIQUE™. L'année Psychologique, 101(3), 447–462. https://doi.org/10.3406/psy.2001.1341
- Pagan, A., & Nation, K. (2019). Learning words via reading: Contextual diversity, spacing and retrieval effects in adults. Cognitive Science, 43. https://doi.org/10.1111/cogs.12705
- Pellicer-Sanchez, A. (2016). Incidental L2 vocabulary acquisition from and while reading: An eye-tracking study. Studies in Second Language Acquisition, 38(1), 97–130. https://doi.org/10.1017/S0272263115000224
- Perry, C., Zorzi, M., & Ziegler, J. C. (2019). Understanding dyslexia through personalized large-scale computational models. Psychological Science, 30(3), 386–395. https://doi.org/10.1177/0956797618823540
- Prado, C., Dubois, M., & Valdois, S. (2007). The eye movements of dyslexic children during reading and visual search: Impact of the visual attention span. Vision Research, 47, 2521–2530. https://doi.org/10.1016/j.visres.2007.06.001
- Pritchard, S. C., Coltheart, M., Marinus, E., & Castles, A. (2018). A computational model of the self-teaching hypothesis based on the dual-route cascaded model of reading. Cognitive Science, 1–49. https://doi.org/10.1111/cogs.12571
- Rau, A. K., Moll, K., Snowling, M. J., & Landerl, K. (2015). Effects of orthographic consistency on eye movement behavior: German and English children and adults process the same words differently. Journal of Experimental Child Psychology, 130, 92–105. https://doi.org/10.1016/j.jecp.2014.09.012
- Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124(3), 372–422. https://doi.org/10.1037/0033-2909.124.3.372
- Rayner, K. (2009). The 35th Sir Frederick Bartlett lecture: Eye movements and attention in reading, scene perception, and visual search. The Quarterly Journal of Experimental Psychology, 62(8), 1457–1506. https://doi.org/10.1080/17470210902816461
- R Core Team (2018). R: A language and environment for statistical computing. R Foundation for Statistical Computing.
- Reilhac, C., Peyrin, C., Démonet, J.-F., & Valdois, S. (2013). Role of the superior parietal lobules in letter-identity processing within strings: fMRI evidence from skilled and dyslexic readers. Neuropsychologia, 51, 601–612. https://doi.org/10.1016/j.neuropsychologia.2012.12.010
- Ricketts, J., Bishop, D. V., Pimperton, H., & Nation, K. (2011). The role of self-teaching in learning orthographic and semantic aspects of new words. Scientific Studies of Reading, 15(1), 47–70. https://doi.org/10.1080/10888438.2011.536129
- Schilling, H. E., Rayner, K., & Chumbley, J. I. (1998). Comparing naming, lexical decision, and eye fixation times: Word frequency effects and individual differences. Memory & Cognition, 26(6), 1270–1281. https://doi.org/10.3758/BF03201199
- Share, D. L. (1995). Phonological recoding and self-teaching: Sine qua non of reading acquisition. Cognition, 55(2), 151–218. https://doi.org/10.1016/0010-0277(94)00645-2
- Share, D. L. (1999). Phonological recoding and orthographic learning: A direct test of the self-teaching hypothesis. Journal of Experimental Child Psychology, 72(2), 95–129. https://doi.org/10.1006/jecp.1998.2481
- Share, D. L. (2004). Orthographic learning at a glance: On the time course and developmental onset of self-teaching. Journal of Experimental Child Psychology, 87(4), 267–298. https://doi.org/10.1016/j.jecp.2004.01.001
- Share, D. L. (2008). Orthographic learning, phonological recoding and self-teaching. Advances in Child Development and behavior, 31–82. https://doi.org/10.1016/S0065-2407(08)00002-5
- Stanovich, K. E., & West, R. F. (1989). Exposure to print and orthographic processing. Reading Research Quarterly, 24(4), 402–433. https://doi.org/10.2307/747605
- Tamura, N., Castles, A., & Nation, K. (2017). Orthographic learning, fast and slow: Lexical competition effects reveal the time course of word learning in developing readers. Cognition, 163, 93–102. https://doi.org/10.1016/j.cognition.2017.03.002
- Taylor, J. S. H., Plunkett, K., & Nation, K. (2011). The influence of consistency, frequency, and semantics on learning to read: An artificial orthography paradigm. Journal of Experimental Psychology: Learning, Memory and Cognition, 37(1), 60–76. https://doi.org/10.1037/a0020126
- Treiman, R. (2017). Learning to spell: Phonology and beyond. Cognitive Neuropsychology, 34(3–4), 83–93. https://doi.org/10.1080/02643294.2017.1337630
- Tucker, R., Castles, A., Laroche, A., & Deacon, H. (2016). The nature of orthographic learning in self-teaching: Testing the extent of transfer. Journal of Experimental Child Psychology, 145, 79–94. https://doi.org/10.1016/j.jecp.2015.12.007
- Valdois, S., Lassus-Sangosse, D., Lallier, M., Moreaud, O., & Valdois, S. (2019a). What does bilateral damage of the superior parietal lobes tell us about visual attention disorders in developmental dyslexia? Neuropsychologia, 130, 78–91. https://doi.org/10.1016/j.neuropsychologia.2018.08.001
- Valdois, S., Peyrin, C., Lassus-Sangosse, D., Lallier, M., Démonet, J.-F., & Kandel, S. (2014). Dyslexia in a french-spanish bilingual girl: Behavioural and neural modulations following a visual attention span intervention. Cortex, 53, 120–145. https://doi.org/10.1016/j.cortex.2013.11.006
- Valdois, S., Roulin, J.-L., & Bosse, M. L. (2019b). Visual attention modulates reading acquisition. Vision Research, 165, 152–161. https://doi.org/10.1016/j.visres.2019.10.011
- van den Boer, M., de Jong, P. F., & van Meeteren, M. M. H. (2013). Modeling the length effect: Specifying the relation with visual and phonological correlates of reading. Scientific Studies of Reading, 17(4), 243–256. https://doi.org/10.1080/10888438.2012.683222
- van den Boer, M., & Elsje, v. B. (2015). The specific relation of visual attention span with reading and spelling in dutch. Learning and Individual Differences, 39, 141–149. https://doi.org/10.1016/j.lindif.2015.03.017
- Wang, H.-C., Castles, A., Nickels, L., & Nation, K. (2011). Context effects on orthographic learning of regular and irregular words. Journal of Experimental Child Psychology, 109(1), 39–57. https://doi.org/10.1016/j.jecp.2010.11.005
- Wang, H.-C., Marinus, E., Nickels, L., & Castles, A. (2014). Tracking orthographic learning in children with different profiles of reading difficulty. Frontiers in Human Neuroscience, 8(468). https://doi.org/10.3389/fnhum.2014.0046
- Wang, H.-C., Nickels, L., Nation, K., & Castles, A. (2013). Predictors of orthographic learning of regular and irregular words. Scientific Studies of Reading, 17(5), 369–384. https://doi.org/10.1080/10888438.2012.749879
- Whitney, C. (2001). How the brain encodes the order of letters in a printed word: the SERIOL model and selective literature review. Psychonomic Bulletin & Review, 8(2), 221–43. https://doi.org/10.3758/BF03196158
- Williams, R., & Morris, R. (2004). Eye movements, word familiarity, and vocabulary acquisition. European Journal of Cognitive Psychology, 16(1-2), 312–339. https://doi.org/10.1080/09541440340000196
- Wochna, K. L., & Juhasz, B. J. (2013). Context length and reading novel words: An eye-movement investigation. British Journal of Psychology, 104(3), 347–363. https://doi.org/10.1111/bjop.2013.104.issue-3
- Ziegler, J. C., Perry, C., & Zorzi, M. (2014). Modelling reading development through phonological decoding and self-teaching: Implications for dyslexia. Philosophical Transactions of the Royal Society of London B: Biological Sciences, 369(1634), 20120397. https://doi.org/10.1098/rstb.2012.0397
- Zoubrinetzky, R., Collet, G. M., Nguyen Morel, M. A., Valdois, S., & Serniclaes, W. (2019). Remediation of allophonic perception and visual attention span in developmental dyslexia: A joint assay. Frontiers in Psychology, 10, 1502. https://doi.org/10.3389/fpsyg.2019.01502
Appendix. Lists of items
Pseudo-words used in the learning phase, the spelling-to-dictation of pseudo-words and the orthographic decision: Test List A: broufand, chaiquau, deinrint, faingion, gouciont, nauplois, ploitart, quinsard, speirain, tramoint; Test List B: ceitteau, chanquet, coirtint, drottont, flommais, glounein, priquoin, quarlant, siampoie, trimpond; Test List C: bussiond, cherrein, ciercard, claffand, fentroit, phacrait, prinnant, scrodain, tauppart, trancare. Practice List: bloutint, fraquaud.
Control words used in the learning phase: Test List A: uniforme, portrait, enceinte, mouchoir, surprise, complice, scandale, chanteur, immeuble, avantage; Test List B: physique, revanche, horrible, boutique, sensible, fauteuil, chocolat, mensonge, solution, voyageur; Test List C: prochain, grandeur, nocturne, lointain, religion, empereur, division, quartier, province, jugement. Practice List: candidat, charmant.
Homophones used in the orthographic decision: Test List: broufant, cheicaud, dainrein, phingion, goussion, nopploie, ploittar, quainsar, spairint, trammoin, saitteau, chenquai, quoirtin, drautond, flaummet, glounnin, pricoint, quarland, siempoit, trimppon, busciont, chairain, siercart, claphant, phantroi, phacrais, prinnand, scraudin, thauppar, trenquar. Practice List: bloutain, phracaut.