
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This paper presents a three-step conceptual framework that can be used to structure the care-related capacity planning process in a nursing home context. The proposed framework provides a sound practical vehicle to organise client-centred care without overstretching available capacity. Within this framework, an MILP for shift scheduling and a Genetic Algorithm (GA) for task-scheduling are proposed. To investigate the performance of the proposed framework, it is benchmarked against the current situation. The results show that considerable improvements can be achieved in terms of efficiency and waiting time. More specifically, it is shown that very modest waiting times can be achieved without exceeding available capacity, despite the fluctuations in care demand across the day.
1. Introduction
The Dutch population is ageing and according to the forecasts this trend is likely to continue for the foreseeable future. It is expected that the percentage of people aged 65 years and over will rise from 19% in 2018 to 29% in 2040. In addition, the total Dutch population aged 80 years and over is expected to reach 10% by 2040, compared with 5% in 2018 (PopulationPyramid, Citation2020; Statistica, Citation2018). The ageing of the Dutch population puts pressure on the financial sustainability of the Dutch long-term care (LTC) system for two main reasons. Firstly, research demonstrates that the risk of poor health and related physical or mental disability increases with age (Meerding et al., Citation1998). On average, elderly people over the age of 85 consume four times as much healthcare per person as those aged between 65 and 75 (NZA, Citation2018). The second reason is that the relative increase in the number of elderly will lead to a substantial increase of the old-age dependency ratio, which measures the number of elderly people at an age when they are generally economically inactive, as share of those of working age.
On top of an increase in demand, the Dutch long-term care labour market is in shortage, and it is expected that the current shortage will increase from over 30,000 in 2015 to more than 90,000 employees in 2030 (Actiz, Citation2021). Consequently, in order to ensure the long-term financial sustainability of the Dutch healthcare system, providers of long-term care are challenged to develop (innovative) strategies and approaches that enable them to meet the (future) needs of their clients in a more efficient manner. In the Netherlands, nursing homes play an important role in the long-term care continuum. A nursing home can be described as a facility with a domestic styled environment that provides 24-hour functional support and care for persons who require assistance with activities of daily living and who often have complex health needs and increased vulnerability (Sanford et al., Citation2015, p. 183). Most nursing home clients are in need of assistance with basic activities of daily living due to physical or psychological disabilities. In everyday practice this means that, in order to live their lives according to their own daily routines, nursing home clients greatly depend on timely delivery of care and support. As such, the coordination and timing of service delivery has a significant impact on their perceived quality of life (Moeke, Citation2016).
Capacity planning plays a vital role in the pursuit of balancing the timely delivery of the required care with the cost of providing that care. When it comes to capacity planning in a nursing home context, the effective and efficient utilisation of the available care workers plays a dominant role. This is due to the fact that care workers are responsible for the daily care and supervision of the residents and their labour costs account for a significant proportion of the total healthcare expenditure (Di Giorgio et al., Citation2014). Hence, the main focus of capacity planning in a nursing home setting is on getting the right number of care workers with the right set of skills on the right job at the right time.
In addition, Dutch nursing homes are, slowly but surely, becoming information-intensive enterprises. Due to the increasing use of electronic health records and other forms of health information technology, nursing homes have access to large amounts of clinical and operational data. This development enhances data-driven decision-making and process improvement. Also, when it comes to capacity planning, nursing homes are starting to recognise data-driven decision-making as essential to improve their (future) operations (Moeke & Bekker, Citation2020). Still, in the current nursing home practice, decisions regarding the allocation of care workers are often addressed without a sound quantitative basis (Bekker et al., Citation2019; Moeke et al., Citation2016).
1.1. Contribution and outline
The main contribution of this paper is that we apply and substantiate a conceptual framework that can be used to structure the care-related capacity planning process in a nursing home context. We do this with the help of empirical data from a real-life case. Using benchmarks that are based on the current situation, we illustrate that substantial improvement can be achieved in terms of efficiency and waiting time. Within the conceptual framework, we envisage the modifications required to existing methods as a secondary, though smaller, contribution. In particular, we present an MILP for shift scheduling, which can be used in a setting with hierarchical qualifications. Furthermore, we develop a Genetic Algorithm (GA) for task scheduling based on the time preferences of the clients and the availability of care workers. The combination of these features is uncommon in the scheduling literature. Also, in our GA, the starting times of tasks (and thus the fitness) are determined using an LP. This differs from traditional GAs.
We note that our focus is on care by appointment. These are care tasks for which, based on the needs and preferences of the client, it is possible to make a fairly detailed planning in advance (Moeke, Citation2016). Examples are giving medicine and help with getting out of bed in the morning.
The remainder of this paper is structured as follows. Section 2 presents related literature. In Section 3, the context related to the real-life case under study is being described. Next, in Section 4, our three-step framework is presented, where Sections 4.1, 4.2 and 4.3 elaborate on the modelling aspects in the different steps of the three-step framework. More specifically, an MILP for shift scheduling and a GA for task-scheduling are proposed in Sections 4.2 and 4.3, respectively. Section 5 presents the numerical results using the real-life case data. In the last section, conclusions are drawn, and implications for practice and future research directions are discussed.
2. Related literature
There are numerous Operations Research (OR) studies on capacity planning in healthcare. However, to date, the area of nursing home care has received hardly any attention. As such, the findings of Hulshof et al. (Citation2012) still hold. They state that “The body of OR/MS literature directed to residential care services is limited”.
2.1. Shift scheduling
In most service systems, demand fluctuates during the course of the day. In order to develop an appropriate shift schedule, first the expected workload needs to be predicted and translated into the required number of employees during the course of a day such that the desired service level is met. Shift scheduling is concerned with apportioning the required staffing levels into shifts that are specified by their start times, lengths, the number, and type of employees, and timing of (lunch) breaks. A shift schedule should adhere to capacity restrictions, service-level requirements, and (working hours) regulations.
Shift scheduling methods have been applied to transportation systems (De Bruecker et al., Citation2018; Ciancio et al., Citation2018; Solos et al., Citation2016), emergency services (Becker et al., Citation2019; Butler & Maydell, Citation1979; Rajagopalan et al., Citation2011), call centres (Bhulai et al., Citation2008; Koole & Van Der Sluis, Citation2003), healthcare systems (Brunner et al., Citation2009; Omar et al., Citation2015; Siferd & Benton, Citation1994) and many other types of service organisations. See also, Erhard et al. (Citation2018) for a rather recent review on physician scheduling. However, the work of (Bekker et al., Citation2019) is the only study we found that examined shift scheduling in a nursing home setting. In their study, they developed a Mixed-Integer Linear Programming (MILP) model using a Lindley-type equation and techniques from stochastic optimisation. The results of their numerical experiments show substantial improvements both in terms of average waiting time as well as in service level. In addition, the proposed shift schedules resulted in a more evenly spread workload for the care workers.
For the purpose of this study, we extend the approach of Bekker et al. (Citation2019) by including differentiated practice. Moreover, we incorporate the assignment of care tasks to shifts (i.e., task assignment).
2.2. Task assignment
Task assignment can be regarded as a subproblem of workforce planning, dealing with “combining individual tasks into task sequences that could usefully be carried out by one person” (Ernst et al., Citation2004, p. 5). In this study, the focus of task assignment lies with assigning care tasks to specific shifts (and thus care workers).
The assignment of tasks to shifts shows similarities with the Unrelated Parallel Machine Scheduling Problem (UPMSP), for which there is a considerable amount of the literature available, see, e.g., Allahverdi et al. (Citation2008). Most studies on machine scheduling focus on minimising the makespan, whereas in this contribution we focus on delivering care as close as possible to the time preference of the nursing home resident (i.e., minimising earliness and lateness). This may be interpreted as parallel machine scheduling with different due dates. We refer to Ark et al. (Citation2022) for a recent study in the case of common due dates; their literature review hardly shows references to studies in which tardiness costs are minimised in the case of different due dates. Another complicating factor in the setting under study is that care workers only work part of the day, leading to the phenomenon of unavailability of “machines”. Finally, we note that the list of solution methods in (Allahverdi et al., Citation2008,) shows that metaheuristics are often used, including genetic algorithms.
Table 1. Qualification levels.
Table 2. Duration of care tasks.
Some prominent task assignment studies involving time windows are Gertsbakh & Stern (Citation1978), Mankowska et al. (Citation2014), and Gertsbakh & Stern (Citation1978) discuss task scheduling with time windows for a homogeneous workforce. The difference is that they do not incorporate penalties for delay. Their objective is to find the minimum required staffing requirements to obtain a feasible schedule. Mankowska et al. (Citation2014) consider a home care setting where care workers visit clients at home and time windows reflect the time preferences of their clients. The objective is to minimise the weighted sum of total travel times, total tardiness, and maximum tardiness. Their solution is based on an ILP for small instances and a heuristic for larger ones.
An elementary difference with home care is that travel times are much less important in a nursing home setting. Consequently, travel times are not part of our objective function, whereas they are crucial in home care. Moreover, compared to home care, the workload across the day can be predetermined, which allows us to decompose the capacity planning process into multiple steps, that is, our three-step framework. Such an approach is not (directly) applicable in a home care setting, as the workload depends on the route. We refer to Fikar & Hirsch (Citation2017) for a rather recent overview on home healthcare to Di Mascolo et al. (Citation2021) for a bibliometric analysis, containing many references. Also, in this domain, metaheuristics is the common solution method, see e.g. Fikar & Hirsch, Citation2017, .
Another distinguishing feature of task scheduling in nursing homes is that qualification levels should be taken into consideration (Bellenguez-Morineau & Néron, Citation2007; Krishnamoorthy et al., Citation2012; Schimmelpfeng et al., Citation2012). However, Bellenguez-Morineau & Néron (Citation2007) focus on the makespan as objective, whereas Krishnamoorthy et al. (Citation2012) consider the minimum workforce for a feasible schedule in case of hard constraints for start times. Finally, Schimmelpfeng et al. (Citation2012) present a task scheduling approach for rehabilitation hospitals with different qualifications and precedence constraints between tasks, but they do not consider time preferences for individual tasks.
The problem studied in Lieder et al. (Citation2015) is most closely related to the problem at hand. They also focus on the assignment of tasks, with different levels of qualification, in a nursing home setting. To optimally solve this scheduling problem, they propose a Mixed Integer Program (MIP) and a Dynamic Programming (DP) approach. However, the state space of the presented DP approach suffers from the curse of dimensionality. As such, the computation time of this approach may become prohibitively long.
2.3. Genetic algorithms
Task assignment, as discussed in Subsection 2.2, typically involves NP-hard problems. As a result, there is a vast amount of the literature considering metaheuristics for solving realistic-sized instances. Genetic algorithms are randomised optimisation algorithms, belonging to the class of metaheuristics. One of their primary properties is that they have the ability to maintain a diverse set of solutions to escape from local optima (Eiben & Smith, Citation2015, Section 3.7). Due to their versatility and adaptability, they can be applied to solve problems in different fields, such as health care (De Carvalho Filho et al., Citation2014), manufacturing (Gen & Lin, Citation2014), design (Hornby et al., Citation2011) and finance (Mahfoud & Mani, Citation2000).
GAs are highly suitable to solve scheduling and task assignment problems, which is supported by a rich literature. For example, Sakawa & Mori (Citation1999) use an GA to solve job-shop scheduling problems in which processing times and due dates are fuzzy. In Wang et al. (Citation2017), an GA is used to solve dynamic scheduling problems in which two types of costs have to be optimised, which thus results in a multi-objective problem.
GAs have also been used to create nurse schedules. For example, Jan et al. (Citation2000) use a genetic algorithm to create monthly nurse schedules. They consider a range of different (hard and soft) constraints, such as nurses’ preferences and the right of having days off. However, they do not consider qualification levels. The constraint closest to this is that the professional level of the nurse is taken into account, but this is only a soft constraint. In Aickelin & Dowsland (Citation2004) a weekly schedule is created for hospital wards up to 30 nurses. They use an GA that solves the unconstrained version of the problem, and then a decoder that creates the feasible schedules. This is different from our approach in which feasible schedules are obtained by the GA and the LP fitness calculation. The combination of GA and mathematical programming is sometimes also referred to as matheuristic. In Amindoust et al. (Citation2021) a genetic algorithm is created that also incorporates a fatigue factor due to the Covid-19 pandemic. They assume that all nurses have identical skills and develop weekly and monthly schedules.
It should be noted that these papers focus on nurses working in hospitals, which is different from nurses working in a nursing home (in terms of activities, duration of activities, spread of activities over the day, etc.). Moreover, most papers focus on weekly and monthly schedules of the nurses, instead of the daily activity schedules that we consider.
2.4. Framework and conclusions
As there are many planning and control decisions in complex (health care) organisations, various frameworks for operations management decisions have been proposed, see, e.g., Hans et al. (Citation2012), Matta et al. (Citation2014), and Vissers et al. (Citation2001). Such frameworks reveal the need to decompose the complex planning process into manageable proportions. The focus of this study is on establishing a blueprint for the shift schedule(s), as well as an operational planning concerning routes for care workers. With the framework of Moeke & Bekker (Citation2020) as starting point, we provide specific methods for each step and verify its value using real-life data.
To summarise this literature section, it can be stated that the literature on planning of nursing home capacity is scarce. Moreover, decisions related to nursing home capacity are involved, as shift and task scheduling are intertwined. Both shift and task scheduling have been addressed in the literature, but the nursing home setting has specific features leading to different problems. For instance, for shift scheduling, there are no papers that address hierarchical shift scheduling in a nursing home context. Moreover, although metaheuristics are common for task assignment problems, the application of an GA in which residents have time preferences and care workers are partly available is not. Finally, incorporating an ILP within the GA differs from traditional GAs.
3. Case description
In this study, the emphasis lies on the capacity planning of a Dutch nursing home department during daytime (7:00–23:00). The concerned department provides 24/7 care and support to 18 clients who are all aged 70 years and over. Although all residents need some assistance with activities of daily living, due to somatic and/or psycho-geriatric illnesses, most of them are still largely self-sufficient. The available amount of capacity, in terms of care hours, largely depends on the so-called Care Intensity Package score (in Dutch “het zorgprofiel”) of the clients. For the clients of this department, there is a budget for 2 hours of care and support per resident during daytime, yielding a total available budget of 36 care hours during daytime per day.
The available care workers are hierarchically divided into distinct qualification levels (QLs). This so-called differentiated practice is based on a distinction in education, responsibility, and complexity of care (Jansen et al., Citation1997). shows the QLs that are relevant for this study and the corresponding tasks. The preferred lengths of shifts during which care workers carry out activities are 4, 6, and 8 hours. In order to make it possible for the clients to live their lives according to their preferences, the aim is to deliver the necessary care as close as possible to their time preferences, i.e., minimising delay. The required care (activities) and corresponding time preferences are inventoried on a regular basis, using a standardised, systematic method. During daytime, there are slightly over 100 care activities per day. For more details about the current situation, we refer to Section 5.
4. Conceptual framework: a three-step approach
Based on the recent work of Moeke & Bekker (Citation2020), we apply a three-step framework for capacity planning in a nursing home context (see, ). More specifically, we identify the following steps: (1) workload evaluation, (2a) staffing, (2b) shift scheduling, and (3) rostering & tasks assignment.
Figure 1. Stages of the care-related capacity planning process.
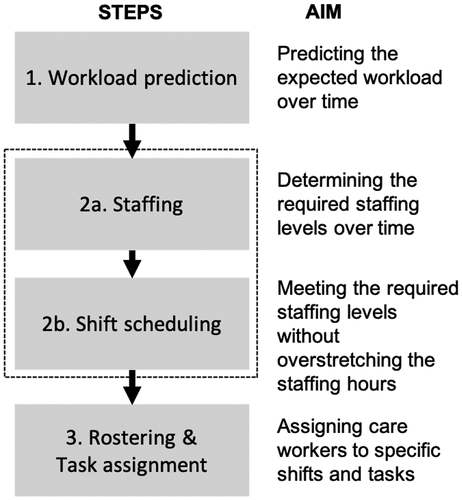
In the first stage (i.e., workload evaluation) the aim is, with the help of historical demand data, to determine the workload over time. This may seem obvious, but practice shows that insight into health care demand is often lacking in long-term care settings. During daytime, the majority of the demand is related to activities of daily living (ADLs). Although there may be strong fluctuations in ADL-related demand, it is possible to collect the time preferences of each client regarding ADLs and estimate the corresponding care durations. Combining the time preference of an activity with the duration provides an estimate of the workload, i.e., the number of care workers required to meet the care demand.
The workload evaluations form the basis for steps 2a and 2b (i.e., staffing and shift scheduling). When it comes to staffing (step 2a) the focus lies on determining the corresponding staffing levels over time in order to meet the demand. The aim of shift scheduling (step 2b) is to determine working shifts (start and end times, breaks, etc.), together with the assignment of the number and type of care workers to each shift, without over-stretching the available staffing hours. In the nursing home setting, we combine staffing and shift scheduling, as the workload can be estimated pretty well during the day time. In other application domains, for example, in call centres, determining staffing levels (step 2a) is done separately due to complexity as a result of uncertainty in demand.
Finally, in step three, the focus lies on assigning care workers to specific shifts and tasks. More specifically, it deals with the following two questions: Which of the available care workers should be assigned to which shift(s)? And, which care tasks should be assigned to which shift(s) in order to meet the demand of the nursing home clients as closely as possible? Assigning care workers to shifts, i.e., rostering, is a classical component in workforce management, see, e.g., Burke et al. (Citation2004); therefore, we focus on the assignment of tasks to shifts (and thus to care workers) in this paper. In the sequel, we elaborate on steps 1, 2, and 3 in Sections 4.1, 4.2, and 4.3, respectively.
4.1. Step 1: workload evaluation
This section concerns step 1 of the conceptual framework visualised in . The key initial step in capacity planning is to obtain insight into the demand (or workload). The dataset that is used to analyse the workload in the current situation consists of the following variables:
• Resident ID – the ID of a specific resident.
• Preferred Activity Time (PAT) – the preferred starting time of the healthcare activity.
• Task description – a brief description of the activity (i.e. healthcare task) entered as free text.
• Qualification Level (QL) – the QL required to perform the task.
• Expected service time – expected duration of the activity in minutes.
Let denote the number of activities. We now define notation of the information that needs to be collected from all clients: (i)
the PAT of activity
, (ii)
the required QL of activity
, and (iii)
the duration of activity
, for
. Based on the input, the first step is to determine the workload
, where
is the number of activities of QL
at time
if each activity would start at their PAT. In particular,
with the indicator function. That is, the workload at time
is the number of residents who need care at time
ignoring capacity constraints. As such, it prescribes the required number of care workers at any time if demand would have been met directly (no waiting is allowed). In the current situation, there are 105 tasks, of which 53 are QL2-tasks and 52 are QL3-tasks.
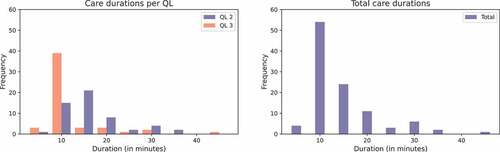
When it comes to the duration of care tasks, in the current situation, the total average (expected) duration for QL2 and QL3-tasks are 16.42 and 12.31 minutes, respectively, with a standard deviation of 6.83 minutes, which are almost the same for both QLs (see also ). As can be observed in most care tasks take between 10 and 15 minutes. Nevertheless, there is some variation in the duration with tasks that may take well over half an hour.
Figure 2. Durations of activities; QL2 and QL3 separate (left) and combined (right).
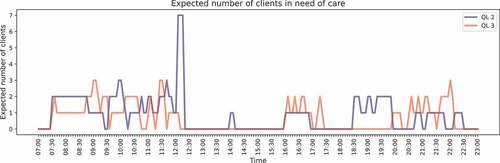
The workload (i.e., the number of residents in need of care) for the current situation is visualised in . It can be observed that the workload is relatively high between 7:30 and 12:30, 18:30 and 23:00. Due to the (predictable) fluctuations in workload across the day, capacity planning is non-trivial and requires a solid quantitative foundation.
Figure 3. Workload evaluation QL2 and QL3 for the current situation (step 1).
4.2. Step 2: shift scheduling with hierarchical qualifications
In this section, we present the shift scheduling model formulation in case of hierarchical qualification levels; that is, we consider step 2 of the framework presented in . The model is applied to a specific nursing home department, but the model can be easily customised by modifying and adding constraints. The model is largely inspired by the MILP formulation in Bekker et al. (Citation2019), but the formulation is extended to allow for different (hierarchical) qualification levels. More specifically, in the shift scheduling phase, we focus on the workload dynamics at an aggregate level. That is, we do not yet distinguish unique care workers or residents, but only consider the total demand and capacity during a time interval. We discretise time and evaluate the aggregate dynamics between epochs and
, for
. In our case study, we choose to consider intervals with a length of 5 minutes.
Note that the total demand follows directly from the workload evaluation in step 1. Therefore, let us now first focus on the capacity for a given combination of shifts. For each QL, there are a limited number of shift types. Here, a shift type refers to the combination of starting time of a shift and the length of the corresponding shift (and may also include breaks). Let
be the total number of shift types for QL
, and let
be the number of care workers with QL
that are scheduled for shift type
. We denote by
that shift type
for QL
works during interval
, and let
otherwise. Hence, via
the user specifies how shift type
for QL
looks like. Then, the available capacity of QL
during interval
is
, for
.
At an aggregate level, the difference between the demand and capacity provides the backlog in the amount of work. Let denote the backlog of activities requiring QL
at the start of interval
. A complication is that care workers of QL
may perform activities requiring QL
. As such, let
denote the total number of care workers that perform activities of QL
during interval
. Observe that
and
are not necessarily equal. Now, the aggregate backlog for QL
satisfies the recursive relation
. Observe that the relation between
, and
,
, and
is linear up to the
operator. Incorporating such a
operator in an MILP is quite standard.
We now specify the MILP for determining a shift scheduling (step 2); the notation is given in .
Table 3. Notation for shift scheduling problem.
The objective is to minimise the total backlog (Equation1(1)
(1) ). EquationEquation (2)
(2)
(2) gives the available capacity of QL
at time
in terms of the shifts. EquationEquation (3)
(3)
(3) guarantees that the available hours are not exceeded. EquationEquations (4)
(4)
(4) and (Equation5
(5)
(5) ) model the hierarchical qualification levels. The first Equationequation (4)
(4)
(4) dictates that the actual number of care workers performing a level
activity should not exceed the total number of care workers that are qualified to perform that activity. The second Equationequation (5)
(5)
(5) makes sure that the care workers are not simultaneously used for more than one QL. When there are only two QLs (say
and
), the two constraints can be simplified to
The recursive relation for the backlog of level activities is given in EquationEquation (6)
(6)
(6) , whereas EquationEquation (7)
(7)
(7) provides that there is no backlog at the end of the day. Observe that the problem becomes infeasible if the number of available hours is not sufficient. The backlog at the end of the day may also be transformed into a soft constraint by including it in the objective function, but we find that such a situation indicates that there is a structural problem and prefer a hard constraint. EquationEquation (8)
(8)
(8) ensures that the minimum number of required care workers are present. EquationEquation (9)
(9)
(9) provides that backlogs are non-negative, whereas EquationEquation (10)
(10)
(10) and EquationEquation (11)
(11)
(11) make sure that staffing levels and number of shifts scheduled are integer values.
4.3. Step 3: task assignment
We now turn to step 3 of the conceptual framework of . This step is at the operational level rather than at the tactical level, but it is required to determine the performance of a capacity plan in terms of waiting time and overtime.
In the current practice, usually no sophisticated algorithms are applied to assign tasks to workers. Hence, tasks are often assigned in an ad hoc manner, which is very similar to a First Come First Served approach (FCFS). In this paper, a genetic algorithm (GA) is developed that solves the task assignment in a more sophisticated way (see, Subsection 4.3.2). A greedy heuristic, which resembles the current FCFS assignment approach, is also developed in order to compare the performance of the current practice to the performance of the GA (see, Subsection 4.3.1).
To describe the two task assignment algorithms, we need to define some notation first. The shifts are determined from the shift scheduling algorithm presented in the previous section (step 2 of ). Denote by the total number of shifts during the time horizon. Let
and
be the start and end times of shift
, respectively, as determined by the shift scheduling algorithm in step 2. For convenience, we number the shifts in decreasing QL. Let
be the number of shifts that can handle activities of the
th largest QL. Then, an activity with QL
can be handled by shifts
.
4.3.1. Greedy heuristic
In the greedy heuristic, we assign activities directly to the shift that becomes available first. We present a recursive scheme that can be used to determine waiting times and assignment of tasks. The recursion is essentially based on the Kiefer-Wolfowitz recursion for the G/G/s queue. The difference with the G/G/s queue is that we need a multi-class system and that the number of servers vary over time (but we are primarily interested in the deterministic version).
It is convenient to order the activities according to their preferred starting time (in increasing order). Below, when we refer to activity , we understand this activity to be ordered according to the PAT. Denote by
the interarrival time between activities
and
(possibly being equal to
).
Let be the remaining time until shift
becomes available at time
. We extend
to the negative half line and let
denote that shift
is already idle for
time units. Note that
decreases linearly in
and makes a jump when an activity is assigned to shift
. We are particularly interested in
just before PAT instants, i.e., the
th activity observes
, where
. Also, let
denote the availability of shifts just after activity
has been assigned.
Now, we start the recursion at time with
, for
, as shift
will be available at its starting time. Next, use the recursive relation
Observe that shift may be working in overtime after the
th activity in case
, where
. In particular, the overtime is given by
. Now, an activity will be assigned to a compatible shift resulting in the smallest waiting time for this activity. If all shifts have finished, e.g., at the end of the day, then the activity will be assigned to a compatible shift resulting in the smallest overtime. Specifically, activity
will be assigned to shift
with a sufficiently large number. Consequently, just after the assignment, we have
The waiting time of activity is now
.
4.3.2. Genetic algorithm
We now present a more advanced algorithm to allocate care workers to activities and to determine the moment at which activities should be carried out. The objective is to create a feasible task schedule that minimises a weighted combination of the total earliness and waiting time for nursing home residents.
In order to solve the task scheduling problem at-hand, we iteratively carry out a two-step procedure. In each generation of the GA, we first determine which care worker should perform which task in which order. Next, we determine the optimal starting times for the care tasks. For this second step, we use an efficient LP approach, which is not straightforward to incorporate in an GA. To the best of the authors’ knowledge, this the first study in which such an approach is applied. These two steps together yield the fitness of a candidate solution and are used in the GA to find better solutions.
Schedule representation A task schedule is described by a vector representation , where
is the care worker that carries out activity
. For instance, with
and
, the solution
denotes that activities 3 and 6 are carried out by care worker 1, activities 1, 4, and 5 are done by care worker 2 and care worker 3 only takes care of activity 2. During a single shift, activities are carried out in the order of the individual PATs.
Outline GA procedure The outline of the GA is based on Eiben & Smith (Citation2015), Chapter 3, and is presented in Algorithm 1. A population is a collection of schedules. In each iteration of the GA, a collection of children is created by using “crossover” and “mutation” operations on parent solutions. Subsequently, the new generations should consist of better schedules than the old generations. We discuss steps 2–5 of the algorithm in more detail below.
Initialise First, we create a (random) population of initial solutions. This is done by randomly assigning the activities to care workers who work during the preferred time of the activities. We also allow that activities are carried out by care workers that do not work at the preferred time of the activity. An activity is assigned to a care worker who does not necessarily work during the preferred time with a probability of 0.1.
Crossover For a combination of parents, a crossover point is generated at random. A child is created by selecting elements
to
from the mother and elements
to
from the father. The second child inherits elements
to
from the father and elements
to
from the mother. The crossover operation is performed on two parts of the population. First of all, the crossover operation is performed on the best
% of the population. The best solution of the population is combined with the second-best solution; the third-best solution with the fourth-best solution, etcetera. In addition, the crossover operation is performed on combinations of randomly chosen solutions. Each solution can only be chosen once.
Mutate Each solution is mutated. With this mutation operator, each activity is assigned to another randomly selected care worker with probability . Thus, the value of
determines to which extent solutions are mutated; larger values of
imply more mutations. Then, with probability
, the activity is allocated to a care worker that works during the preferred time and has a compatible QL. Here, a compatible QL means that it is equal or larger than the QL required for the activity. Otherwise, a care worker is selected that does not necessarily work during the preferred time while still having a compatible QL.
The mutation operation described above may lead to quite disruptive changes. This is highly valuable for maintaining diversity in the generation, but makes it more difficult to create similar solutions. In the final phase of the search process, smaller adaptations are useful for fine-tuning of the good individuals. Therefore, a second type of mutation is performed on % of the population in each generation. This type of mutation is specifically designed to mutate the first activity in the schedule for which waiting occurs, say activity
, and the neighbouring activities. We take a number
randomly between 1 and 4. The
activities directly before
and the
activities directly after
are mutated in a similar way as described above. That is, each of these activities are assigned to another randomly selected care worked with probability
. With probability
, the activity is allocated to a care worker that works during the preferred time and has a compatible QL. Otherwise, a care worker is selected that does not necessarily work during the preferred time while still having a compatible QL.
Evaluate In the evaluation step, the fitness is calculated of all newly created solutions. The fitness consists of two elements: (i) total waiting time and earliness corresponding to PATs, and (ii) total overtime of care workers. Note that the schedule representation determines which activity is carried out by which care worker and in which order, but not the time at which the activity should be performed. The time at which activities are performed are, however, required to determine the quality of the schedule. We employ an LP model to determine these activity times.
In the following, we introduce the LP model that is applied to determine the starting time of all activities. Let be the number of activities that is carried out by care worker
, and we drop the shift number from the notation for now. During the shift, the objective is to minimise the weighted sum of earliness and tardiness. Let
and
denote the corresponding weights. Define the decision variables
as the starting time of the
-th activity,
. Observe that the waiting time of the
-th activity is
. We use the auxiliary variables
,
, to linearise the model. Similarly, the earliness of the
-th activity is
, for which we use the auxiliary variables
for
. This gives rise to the following simple LP:
Note that the LP has to be solved quite often, i.e., for each shift and each individual. However, solving this LP is very fast. Moreover, once the LP has been solved, its solution is saved, so that it can be re-used in a later generation if the same LP has to be solved again.
Select A new generation is selected by roulette wheel selection from the previous generation and the newly generated offspring population. Solutions are selected based on their fitness. A higher fitness corresponds to a higher probability of being part of the next generation.
Parameter tuning An important element of an GA is the tuning of its parameters. In the developed algorithm, five parameters should be set: ,
,
,
and
. Tuning the parameters of an GA is a cumbersome process, as the combination of parameters influences the performance of the GA. As it is computationally impossible to consider all parameter combinations (for each parameter combination the GA would have to be run multiple times), we use a search algorithm, namely Hyperopt (Bergstra et al., Citation2013). This algorithm, specifically developed for hyperparameter tuning, searches the total parameter space in a sophisticated way. We use the TPE algorithm, as the fitness evaluations are computationally costly and thus a small evaluation budget is available. We refer the interested reader to Bergstra et al. (Citation2011) for details about the TPE algorithm.
5. Numerical experiments
The aim of this section is to provide insight in the potential benefits of using the capacity planning process as described in Section 4. To do so, we compare the performance of three different planning strategies under different scenarios. The main characteristics of the applied strategies are presented in . Strategies A and B make use of the shift scheduling approach as presented in Section 4.2. Strategy C, on the other hand, resembles current practice. In order to create shift schedules that resemble current practice as closely as possible, we used worker-to-resident ratios that are based on a study of the Dutch Institute for Health Services Research (NIVEL), see, Hingstman et al. (Citation2012) or Bekker et al. (Citation2019). Specifically, we used an ILP in the spirit of Section 4.2 to choose shifts such that the worker-to-resident ratios across the day, as published by NIVEL, are matched as closely as possible. For the assignment of tasks, strategy A makes use of the GA that is presented in Section 4.3.2, whereas strategies B and C use the greedy heuristic (see, Section 4.3.1). The greedy heuristic closely resembles the way in which tasks are assigned in the current practice.
Table 4. Overview of the applied planning strategies.
Regarding the numerical experiments, it should be noted that the GA involves randomness, that is, the solutions will differ each time the algorithm is run. Therefore, for each experiment, the algorithm is run 100 times to obtain insight in the variability of the fitness.
5.1. Scenarios & base case
For the purpose of this numerical experiment, the performance of the three planning strategies has been compared under different scenarios. Regarding the scenarios, a change in the following aspects have been taken into account: (1) the number of clients (i.e., the effect of less or more clients), (2) qualification levels (i.e., the effect of working with or without QLs), and (3) utilisation of care workers (i.e., the effect of a higher average workload per care worker). provides a detailed overview of how the changes in the aforementioned aspects have been operationalised into (sub-)scenarios. The current practice situation (see, Section 3) is represented by the following sub-scenario: Base case QL U. In other words, a situation with 18 clients in care (i.e., base case), where QLs are used and in which the average utilisation is 70%. Some additional characteristics of the current situation are:
Table 5. Overview of aspects examined in the scenario analysis, with in grey the characteristics of the current practice situation.
• Number of tasks per day: 53 and 52 for QL2 and QL3.
• Available capacity per day: 18 h for both QL2 and QL3.
• Available shift lengths: 4, 6, and 8 h.
• Utilisation per QL: 81% and 59% for QL2 and QL3.
An overview of the main characteristics of the U QL-version of the base case, scenario 1 and scenario 2 can be found in .
Table 6. Main characteristics of the U QL-version of the base case, scenario 1 and scenario 2.
5.2. Running time & parameter tuning
In terms of computational time, we note that the computation times for planning strategies B and C (see, ) are negligible; in some cases, the MILP (i.e., the shift scheduling of step 2) takes several seconds. Planning strategy A requires more computational budget, due to the (more advanced) GA used for assigning the tasks in step 3. One run of the GA takes between 1.92 and 14.49 minutes with a population of 200 schedules and 100 generations, depending on the experiment.Footnote1
The computation time of the parameter optimisation of the GA is considerable (around 24 h) and therefore it is preferred to only perform this optimisation once (i.e., not for each new sub-scenario again). Extensive testing indicates that running the parameter optimisation on sub-scenario Base case U QL creates an algorithm that is sufficiently versatile and yields good results on the other sub-scenarios. This is shown for three different sub-scenarios in . To create these figures, the GA was run 100 times on a certain sub-scenario with two parameter settings: the first parameter setting obtained from a parameter optimisation on the Base Case U QL sub-scenario and the second parameter setting obtained from a parameter optimisation on the specific sub-scenario. Clearly, the results obtained by running the GA with the Base Case U QL sub-scenario parameters results in equal or even better fitness values than the results obtained with the parameters for each specific sub-scenario. Thus, by using the parameters of the Base Case U QL sub-scenario, an algorithm is created that can be applied in diverse settings while keeping the running time and results acceptable, as only one parameter optimisation has to be done in total, instead of one per sub-scenario. The output of the parameter optimisation for the Base Case U QL scenario can be found in . These parameters have been used to generate the results in the following subsections. Interestingly, both the values for and
are high, which means that a large percentage of the best population is used in the crossover population and that an activity has a large probability to be allocated to a care worker that works during the preferred time and has a compatible QL.
Figure 4. The minimum fitness for three scenarios and two parameter settings.
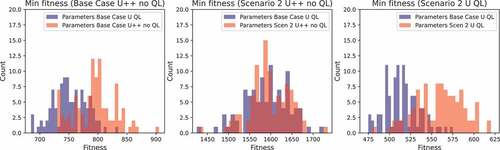
Table 7. The used parameters found by running the parameter optimisation on base case U QL.
5.3. Experiments with QLs
Regarding the results of the numerical experiments, we distinguish between working with QL (i.e., this section) and working without QLs (Section 5.4). Furthermore, the base case (see, Section 5.1) will serve as our primary example. As previously discussed, three experiments with different utilisation levels are considered (“U”, “U+”, and “U++”). The performance of each of the presented planning strategy is being discussed following the three steps as presented in Section 4.
5.3.1. Planning strategy A
Step 1: We refer to for the evolution of the workload across the day. There is a considerable amount of variability in the workload across the day, which corresponds to the natural rhythm in daily living. Note that step 1 is equal for all three utilisation levels.
Step 2: The shifts that are obtained using the shift scheduling algorithm can be found in . Observe that most of the capacity is used in the morning, which is also in line with the workload across the day that follows from step 1 (). Observe that in case of the “U+” and “U++” scenarios, no care workers are scheduled during the afternoon (12:30–15:00, 13:30–16:30, respectively). This follows from the fact that the amount of overcapacity is small (high utilisation) and there are only a few healthcare tasks during this time interval. Hence, care workers can then be used more efficiently during the busier hours. The shifts for scenarios 1 and 2 can be found in the appendix (see ).
Table 8. Shifts for base case experiments with QLs (Step 2).
Step 3: In this step, we need to assign tasks to care workers, from which we may determine the waiting time of clients and possible tardiness of care workers. We do so by using the developed GA. As previously indicated, the population size is set to 200, and the number of generations is set to 100. We report the fitness of the best individual of the final generation, hereafter referred to as the minimum fitness. As a GA is a randomised algorithm, we run the GA 100 times. presents the mean minimum fitness per generation together with a 95% confidence interval. Clearly, the strongest reduction in the minimum fitness is obtained in the first few generations. reports the mean (minimum) fitness together with its standard deviation.
Figure 5. The mean minimum fitness per generation together with a 95% empirical confidence interval.
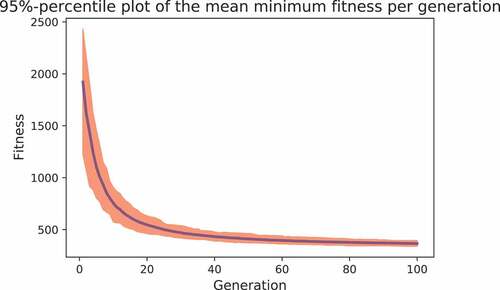
Table 9. Results for strategy A, with QLs, based on 100 runs.
An utilisation of 70% (over the two QL’s) leads to acceptable waiting times of a few minutes on average. For instance, in the base case, the total waiting time is 345.5 minutes over 105 activities yielding 3.29 minutes on average. Observe that the fitness strongly increases with utilisation. For the base case and utilisations over 80% (scenario “U++”), the overtime amounts to 210 minutes in total and excessive waiting occurs (approximately 1810 minutes in total, yielding a fitness of about 2020). Hence, due to the variability in healthcare tasks across the day, it seems difficult to operate at high utilisations. This is recognised in practice, where nursing homes work with an utilisation of about 70%.
Furthermore, from the experiments, we see some differences between the fitness of the 200 individuals of the final generation (not reported here for conciseness). This shows that there is some diversity within the final generation. From the standard deviations in , we see a quite stable performance of the best individual.
5.3.2. Planning strategies B and C
We now compare the results of planning strategy A with strategies B and C. As there is no structural monitoring of the workload across the day, step 1 does typically not occur in the current situation (i.e., planning strategy C).
Step 2: For the planning strategy B, we use the MILP of Subsection 4.2 resulting in the same shifts as in . Regarding strategy C, the aim was to determine shifts such that the current worker-to-resident ratios across the day are maintained as closely as possible. We refer to Hingstman et al. (Citation2012) and Bekker et al. (Citation2019) for these ratios that tend to lead to a rather stable capacity across the day, with a small peak during the morning. As the workload deviates from this pattern, there seems to be much room for improvement here.
Step 3: For both strategies B and C, the greedy algorithm of Subsection 4.3.1 is used to assign tasks to care workers. We determined the total waiting and overtime for both strategies, yielding the corresponding fitness. Moreover, to compare the performance with strategy A, we define the relative difference for strategy with strategy A as
where denotes the (mean) fitness of strategy
. The results can be found in . Clearly, an enormous gain in performance can be achieved by determining shifts of care workers (step 2). The fitness values of strategy C are multiple hundreds of percents off from the fitness of strategy A; for instance, for the base case under sub-scenario “U” the performance of strategy C is 748% worse than strategy A. This reveals the huge efficiency potential in nursing home care. Strategy B clearly outperforms strategy C, revealing the importance of a good shift schedule. However, using the GA (i.e., strategy A) still reduces the fitness by tens of percents compared to strategy B. Hence, in the base case under sub-scenario “U” strategy B still performs 23% worse than strategy A. In particular, if the utilisation becomes higher (scenario “U++”), the benefits of the GA become larger. This may be explained by the fact that the impact of scheduling decisions becomes larger due to the tight capacity.
Table 10. Benchmark results, with QL.
5.4. Experiments without QLs
For the experiments presented in this subsection, we neglect QLs and assume that every care worker is qualified to handle every activity, that is, every care worker is assumed to have the highest QL. Again, the base case will serve as our primary example, and we consider as in 5.3 three levels of utilisation.
5.4.1. Planning strategy A
Step 1: The workload is now just the sum of the workloads of the two QLs as displayed in , and again equal for all utilisation levels. Note that the workload during the morning and evening becomes more stable during these periods by neglecting QLs. But still, there is considerable variability across the day.
Step 2: The results of the shift scheduling algorithm can be found in . As expected, most of the capacity is assigned to the morning again in all experiments, with 3–4 out of 6 care workers between 11:00 and 13:00 hours. However, compared to the situation with QLs, a small part of the capacity is shifted from the morning to the afternoon. When combining the work of the QLs, it can be seen from that 3 care workers during 7:30–11:00 hours are tight, but are just enough to handle the aggregated demand. The shifts for scenarios 1 and 2 can be found in the appendix (see ).
Step 3: The GA is again used to assign activities to care workers in this step. The mean minimum over 100 evaluations can be found in , together with the standard deviations. is similar to , but without the distinction in QLs. Comparing the two tables, it evidently holds that discarding QLs substantially improves performance. Moreover, we see that for higher utilisations, the reduction in fitness value is typically larger when discarding QLs, for example, for the base case the reductions are about 18%, 42%, and 63% for scenarios “U”, “U+”, and “U++”, respectively. This can be explained by the fact that discarding QLs provides more flexibility in task assignment, which may be more beneficial in scenarios with high utilisations. We like to note that the precise percentages clearly depend on the situation, with the workload pattern as a predominant factor. Finally, as we also concluded with QLs, we see a quite stable performance of the minimum fitness of the GA again, as can be concluded from the relatively small standard deviation .
5.4.2. Planning strategies B and C
Again, we compare the results of planning strategy A with strategies B and C to gain insight into the impact of QLs.
Step 2: We determined the shifts of care workers using the same methods as for the case with QLs. That is, for strategy B the shifts are based on the MILP after incorporating the aggregated workload across the day, yielding . The shifts for planning strategy C are based on the same worker-to-resident ratios again. As expected, regarding strategy C the shifts do not well align with the workload pattern.
Step 3: We compare the fitness of the two benchmark strategies B and C in with strategy A; again shows the relative difference in fitness between the benchmark strategies B and C, and strategy A. The difference is enormous again, where clearly huge gains can be achieved by choosing shifts in a more appropriate manner. Comparing the
of strategy B with that of A, we still see significant gains in performance ranging from 9% to 45%. However, the added value of the GA is not as large as in the case with QL. This can be explained from the observation that without QLs, simple heuristic rules work better. For instance, there is no need for care workers of QL3 to make a trade-off whether they should now carry out a type-2 activity or remain idle for a future type-3 activity.
Table 11. Shifts per scenario (step 2), without QLs.
Table 12. Results for strategy A, without QLs, based on 100 runs.
Table 13. Benchmark results, without QL.
6. Conclusions & discussion
We presented a three-step conceptual framework that can be used to structure the care-related capacity planning process in a nursing home context. More specifically, we identified the following steps: (1) workload evaluation, (2a) staffing, (2b) shift scheduling, and (3) rostering & tasks assignment. For step 2b (shift scheduling) we presented an MILP, which can be used in a setting with hierarchical qualifications. In addition, for the task assignment in step 3 we proposed a modified genetic algorithm, which determines optimal starting times of activities using an LP next to the assignment of activities to care workers. By benchmarking the proposed framework against the current situation, it is shown that enormous improvements can be achieved in terms of efficiency and waiting time. Specifically, it can be observed that appropriate shift scheduling is crucial to match the available capacity with demand. However, using a generic algorithm for task assignment also provides considerable improvements. The numerical experiments show that applying the proposed framework results in an average waiting time of only a few minutes for an average occupancy of near 70%, despite the considerable variability in demand across the day. For utilisations of over 80%, the waiting and overtime seem to increase rapidly. As such, this study reveals the potential of efficiently organising client-centred care using an appropriate optimisation framework.
The proposed framework provides a sound practical vehicle to organise client-centred care without overstretching available capacity. From a practical point of view, we see that it is difficult for nursing homes to give preferences of clients a more prominent place. This requires registration of client preferences, which is not yet common. Also, we like to stress that the shift schedule and activity planning provides a blueprint for practice. Events happening during the day may require care workers to deviate from the activity plan.
An appealing feature of the three-step framework is that the capacity-planning process can be divided into separate steps. These separate steps provide more insight in the process and will be easier to implement in practice. For instance, in view of the autonomy of the care worker, we envisage that in practice it will be simpler to modify the shifts schedule than the task assignment. Also, the decomposition better allows for modifications in the separate steps. The take assignment results with a genetic algorithm are very promising. An interesting topic for further research is to compare the performance of the GA algorithm with other optimisation procedures. Moreover, the results can be improved by integrating steps 2 and 3, but this will make the optimisation model more complex and the advantage of decomposing the capacity planning process will be lost. Finally, it is of interest to apply this framework to situations where intra- and extramural care are combined.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Notes
1. Experiments have been carried out on an 2.7 GHz Quad-Core Intel Core i5 with 16GB of RAM.
References
- Actiz. (2021). Infographic arbeidsmarkt VVT.
- Aickelin, U., & Dowsland, K. (2004). An indirect genetic algorithm for a nurse scheduling problem. Computers Operations Research, 31(5), 761–778. https://doi.org/10.1016/S0305-0548(03)00034-0
- Allahverdi, A., Ng, C., Cheng, T. E., & Kovalyov, M. Y. (2008). A survey of scheduling problems with setup times or costs. European Journal of Operational Research, 187(3), 985–1032 https://doi.org/10.1016/j.ejor.2006.06.060
- Amindoust, A., Asadpour, M., & Shirmohammadi, S. (2021). A hybrid genetic algorithm for nurse scheduling problem considering the fatigue factor. Journal of Healthcare Engineering, 2021, 1–11. https://doi.org/10.1155/2021/5563651
- Ark, O. A., Schutten, M., & Topan, E. (2022). Weighted earliness/tardiness parallel machine scheduling problem with a common due date. Expert Systems with Applications, 187, 115916. https://doi.org/10.1016/j.eswa.2021.115916
- Becker, T., Steenweg, P. M., & Werners, B. (2019). Cyclic shift scheduling with on-call duties for emergency medical services. Health Care Management Science, 22(4), 676–690. https://doi.org/10.1007/s10729-018-9451-9
- Bekker, R., Moeke, D., & Schmidt, B. (2019). Keeping pace with the ebbs and flows in daily nursing home operations. Health Care Management Science, 22(2), 350–363. https://doi.org/10.1007/s10729-018-9442-x
- Bellenguez-Morineau, O., & Néron, E. (2007). A branch-and-bound method for solving multi-skill project scheduling problem. RAIRO-Operations Research-Recherche Opérationnelle, 41(2), 155–170. https://doi.org/10.1051/ro:2007015
- Bergstra, J., Bardenet, R., Bengio, Y., & Kégl, B. (2011, December 12 - 15). Algorithms for hyper-parameter optimization. In Proceedings of the 24th International Conference on Neural Information Processing Systems (NIPSS’ 11). (pp. 2546–2554).Granada, Spain: Curran Associates Inc.
- Bergstra, J., Yamins, D., & Cox, D. D. (2013, June 16-21). Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Proceedings of the 30th International Conference on Machine Learning (ICML 2013). Atlanta, GA, USA. 28, 115–123. JMLR.org.
- Bhulai, S., Koole, G., & Pot, A. (2008). Simple methods for shift scheduling in multiskill call centers. Manufacturing & Service Operations Management, 10(3), 411–420. https://doi.org/10.1287/msom.1070.0172
- Brunner, J. O., Bard, J. F., & Kolisch, R. (2009). Flexible shift scheduling of physicians. Health Care Management Science, 12(3), 285–305. https://doi.org/10.1007/s10729-008-9095-2
- Burke, E. K., De Causmaecker, P., Berghe, G. V., & Van Landeghem, H. (2004). The state of the art of nurse rostering. Journal of Scheduling, 7(6), 441–499. https://doi.org/10.1023/B:JOSH.0000046076.75950.0b
- Butler, D., & Maydell, U. (1979). Manpower scheduling in the Edmonton police department. INFOR: Information Systems and Operational Research, 17(4), 366–372. https://doi.org/10.1080/03155986.1979.11731754
- Ciancio, C., Laganà, D., Musmanno, R., & Santoro, F. (2018). An integrated algorithm for shift scheduling problems for local public transport companies. Omega, 75, 139–153. https://doi.org/10.1016/j.omega.2017.02.007
- De Bruecker, P., Beliën, J., De Boeck, L., De Jaeger, S., & Demeulemeester, E. (2018). A model enhancement approach for optimizing the integrated shift scheduling and vehicle routing problem in waste collection. European Journal of Operational Research, 266(1), 278–290. https://doi.org/10.1016/j.ejor.2017.08.059
- de Carvalho Filho, A. O., de Sampaio, W. B., Silva, A. C., de Paiva, A. C., Nunes, R. A., & Gatass, M. (2014). Automatic detection of solitary lung nodules using quality threshold clustering, genetic algorithm and diversity index. Artificial Intelligence in Medicine, 60(3), 165–177. https://doi.org/10.1016/j.artmed.2013.11.002
- Di Giorgio, L., Filippini, M., & Masiero, G. (2014). Implications of global budget payment system on nursing home costs. Health Policy, 115(2), 237–248. https://doi.org/10.1016/j.healthpol.2014.01.017
- Di Mascolo, M., Martinez, C., & Espinouse, M.-L. (2021). Routing and scheduling in home health care: A literature survey and bibliometric analysis. Computers & Industrial Engineering, 158, 107255. https://doi.org/10.1016/j.cie.2021.107255
- Eiben, A. E., & Smith, J. E. (2015). Introduction to evolutionary computing. Springer.
- Erhard, M., Schoenfelder, J., Fügener, A., & Brunner, J. O. (2018). State of the art in physician scheduling. European Journal of Operational Research, 265(1), 1–18. https://doi.org/10.1016/j.ejor.2017.06.037
- Ernst, A. T., Jiang, H., Krishnamoorthy, M., & Sier, D. (2004). Staff scheduling and rostering: A review of applications, methods and models. European Journal of Operational Research, 153(1), 3–27. https://doi.org/10.1016/S0377-2217(03)00095-X
- Fikar, C., & Hirsch, P. (2017). Home health care routing and scheduling: A review. Computers & Operations Research, 77, 86–95. https://doi.org/10.1016/j.cor.2016.07.019
- Gen, M., & Lin, L. (2014). Multiobjective evolutionary algorithm for manufacturing scheduling problems: State-of-the-art survey. Journal of Intelligent Manufacturing, 25(5), 849–866. https://doi.org/10.1007/s10845-013-0804-4
- Gertsbakh, I., & Stern, H. I. (1978). Minimal resources for fixed and variable job schedules. Operations Research, 26(1), 68–85. https://doi.org/10.1287/opre.26.1.68
- Hans, E.W., van Houdenhoven, M., & Hulshof, P. J. H. (2012). A framework for healthcare planning and control. In R. Hall (Eds.), Handbook of healthcare system scheduling (pp. 303–320). Springer.
- Hingstman, T., Langelaan, M., & Wagner, C. (2012). De dagelijkse bezetting en kwaliteit van zorg in instellingen voor langdurige zorg [Daily utilization and quality of care in long-term care institutions]. NIVEL.
- Hornby, G., Lohn, J., & Linden, D. (2011). Computer-automated evolution of an x-band antenna for nasa’s space technology 5 mission. Evolutionary Computing, 19(1), 1–23. https://doi.org/10.1162/EVCO_a_00005
- Hulshof, P., Kortbeek, N., Boucherie, R., Hans, E., & Bakker, P. (2012). Taxonomic classification of planning decisions in health care: A structured review of the state of the art in OR/MS. Health Systems, 1(2), 129–175. https://doi.org/10.1057/hs.2012.18
- Jan, A., Yamamoto, M., & Ohuchi, A. (2000). Evolutionary algorithms for nurse scheduling problem. In Proceedings of the 2000 Congress on Evolutionary Computation (CEC00). La Jolla, CA, USA, 1, 196–203.IEEE.
- Jansen, P. G., Kerkstra, A., Abu-saad, H. H., & van der Zee, J. (1997). Differentiated practice and specialization in community nursing: A descriptive study in the Netherlands. Health & Social Care in the Community, 5(4), 219–226. https://doi.org/10.1111/j.1365-2524.1997.tb00117.x
- Koole, G., & Van Der Sluis, E. (2003). Optimal shift scheduling with a global service level constraint. IIE Transactions, 35(11), 1049–1055. https://doi.org/10.1080/07408170304398
- Krishnamoorthy, M., Ernst, A. T., & Baatar, D. (2012). Algorithms for large scale shift minimisation personnel task scheduling problems. European Journal of Operational Research, 219(1), 34–48. https://doi.org/10.1016/j.ejor.2011.11.034
- Lieder, A., Moeke, D., Koole, G., & Stolletz, R. (2015). Task scheduling in long-term care facilities: A client-centered approach. Operations Research for Health Care, 6, 11–17. https://doi.org/10.1016/j.orhc.2015.06.001
- Mahfoud, S., & Mani, G. (2000). Financial forecasting using genetic algorithms. Applied Artificial Intelligence, 10(6), 543–565. https://doi.org/10.1080/088395196118425
- Mankowska, D. S., Meisel, F., & Bierwirth, C. (2014). The home health care routing and scheduling problem with interdependent services. Health Care Management Science, 17(1), 15–30. https://doi.org/10.1007/s10729-013-9243-1
- Matta, A., Chahed, S., Sahin, E., & Dallery, Y. (2014). Modelling home care organisations from an operations management perspective. Flexible Services and Manufacturing Journal, 26(3), 295–319. https://doi.org/10.1007/s10696-012-9157-0
- Meerding, W. J., Bonneux, L., Polder, J. J., Koopmanschap, M. A., & van der Maas, P. J. (1998). Demographic and epidemiological determinants of healthcare costs in Netherlands: Cost of illness study. BMJ, 317(7151), 111–115. https://doi.org/10.1136/bmj.317.7151.111
- Moeke, D. (2016). Towards high-value (d) nursing home care: Providing client-centred care in a more efficient manner. Available at SSRN 3116326.http://dx.doi.org/10.2139/ssrn.3116326
- Moeke, D., & Bekker, R. (2020). Capacity planning in healthcare: Finding solutions for healthy planning in nursing home care. In L. T. Løvseth, & A. H. de Lange (Eds.), Integrating the organization of health services, worker wellbeing and quality of care (pp. 171–195). Springer.
- Moeke, D., van de Geer, R., Koole, G., & Bekker, R. (2016). On the performance of small-scale living facilities in nursing homes: A simulation approach. Operations Research for Health Care, 11, 20–34. https://doi.org/10.1016/j.orhc.2016.10.001
- NZA. (2018). Monitor zorg voor ouderen 2018. Nederlandse Zorgautoriteit.
- Omar, E.-R., Garaix, T., Augusto, V., & Xie, X. (2015). A stochastic optimization model for shift scheduling in emergency departments. Health Care Management Science, 18(3), 289–302. https://doi.org/10.1007/s10729-014-9300-4
- PopulationPyramid. (2020). Population pyramids of the world from 1950 to 2100. https://www.populationpyramid.net
- Rajagopalan, H. K., Saydam, C., Sharer,E., Setzler, H. (2011). Ambulance deployment and shift scheduling: An integrated approach. Journal of Service Science and Management, 4(1), 66. https://doi.org/10.4236/jssm.2011.41010
- Sakawa, M., & T, Mori. (1999). An efficient genetic algorithm for job-shop scheduling problems with fuzzy processing time and fuzzy duedate. Computers Industrial Engineering, 36(2), 325–341. https://doi.org/10.1016/S0360-8352(99)00135-7
- Sanford, A., Orrell, M., Tolson, D., Abbatecola, A., Arai, H., Bauer, J., Cruz-Jentoft, A., Dong, B., Ga, H., Goel, A., Hajjar, R., Holmerova, I., Katz, P. R., Koopmans, R. T. C. M., Rolland, Y., Visvanathan, R., Woo, J., Morley, J. E., & Vellas, B. (2015). An international definition for €nursing home. Journal of the American Medical Directors Association, 16(3), 181–184. https://doi.org/10.1016/j.jamda.2014.12.013
- Schimmelpfeng, K., Helber, S., & Kasper, S. (2012). Decision support for rehabilitation hospital scheduling. OR Spectrum, 34(2), 461–489. https://doi.org/10.1007/s00291-011-0273-0
- Siferd, S. P., & Benton, W. (1994). A decision modes for shift scheduling of nurses. European Journal of Operational Research, 74(3), 519–527. https://doi.org/10.1016/0377-2217(94)90228-3
- Solos, I. P., Tassopoulos, I. X., & Beligiannis, G. N. (2016). Optimizing shift scheduling for tank trucks using an effective stochastic variable neighbourhood approach. International Journal Artificial Intelligence, 14(1), 1–26.
- Statistica (2018). Netherlands: Population, by age 2018.
- Vissers, J., Bertrand, J., & De Vries, G. (2001). A framework for production control in health care organizations. Production Planning & Control, 12(6), 591–604. https://doi.org/10.1080/095372801750397716
- Wang, D., Liu, F., & Jin, Y. (2017). A multi-objective evolutionary algorithm guided by directed search for dynamic scheduling. Computers Operations Research, 79, 279–290. https://doi.org/10.1016/j.cor.2016.04.024
Appendix A.
Shifts scenarios 1 and 2
Table A1. Shifts for each experiment for scenario 1, with QLs.
Appendix
Table A2. Shifts for each experiment for scenario 1, without QLs.
Appendix
Table A3. Shifts for each experiment for scenario 2, with QLs.
Appendix
Table A4. Shifts for each experiment for scenario 2, without QLs.