
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
The rapid development of intelligent navigation drives the rapid accumulation of ocean data, and the ocean science has entered the era of big data. However, the complexity and variability of the ocean environments make some data unavailable. It makes ocean target detection and the unmanned surface vehicle (USV) intelligent control process in ocean scenarios face various challenges, such as the lack of training data and training environment. Traditional ocean image data collection method used to capture images of complex ocean environments is costly, and it leads to a serious shortage of ocean scene image data. In addition, the construction of an autonomous learning environment is crucial but time-consuming. In order to solve the above problems, we propose a data collection method using virtual ocean scenes and the USV intelligent training process. Based on virtual ocean scenes, we obtain rare images of ocean scenes under complex weather conditions and implement the USV intelligent control training process. Experimental results show that the accuracy of ocean target detection and the success rate of obstacle avoidance of the USV are improved based on the virtual ocean scenes.
1. Introduction
With the development of ocean-observation methods, a mount of multi-source heterogeneous ocean big data are formed and widely used (Woodring et al., Citation2015; Guo, Citation2017a). Many researchers try to solve complex ocean issues, such as ocean target detection (Li, Perrie, He, Lehner, & Brusch, Citation2012; Collins, Denbina, & Atteia, Citation2013) and ship autonomous control (Roberts, Sutton, Zirilli, & Tiano, Citation2003; Dong, Wan, Li, Liu, & Zhang, Citation2015; Zhuo & Hearn, Citation2008) by combining big ocean data with deep learning, and they have made a lot of progress (Guo, Citation2017b).
Deep learning has been applied to many fields (Wang, Yuan, Zhang, Lewis, & Sycara, Citation2019; Wang, Sugumaran, Zhang, & Xu Citation2018; Wang, Luo, & Liu, Citation2015). This technique requires tons of data or interactive experimental environments as training support. Several typical databases such as MS COCO (Lin et al., Citation2014) and ImageNet (Deng et al., Citation2009) at present are commonly used for image training by deep learning. OpenAI developed GYM (Brockman et al., Citation2016) interactive experimental environment for the training agent control and decision. These data sets or interactive experimental environments greatly promote the development of deep learning. In addition, in the field of unmanned driving, many research institutions (Shah, Dey, Lovett, & Kapoor, Citation2018; Kato, Tokunaga, Maruyama, Maeda, & Azumi, Citation2018) have developed virtual unmanned vehicle interaction platforms and verified a large number of deep learning models based on these virtual scenes, making great progress. shows the virtual unmanned vehicle interaction platform of AirSim by Microsoft.
Enough data are available in the common domains. However, there are still insufficient data and inefficient interactive experimental environments in the fields of ocean target detection and ship intelligent control. The reason for insufficient data volume is the constraints of the ocean environment, which makes it impossible to collect enough image data under complex weather conditions. In terms of ship intelligent control, if interactive training environment is directly constructed in the real world, ships will face the risk of damage and loss. In addition, the training cycle is long and the training effect is not guaranteed. Taking the unmanned surface vehicle (USV) as an example, some researchers (Yin & Zhang, Citation2017; Soltan, Ashrafiuon, & Muske, Citation2011) only do experiments on USV intelligent control based on simple virtual 2D scenarios. 3D scenes are closer to the reality and easier to transfer trained models, while 2D scenes don’t have the Z-axis, making the model transfer more difficult.
Aiming to solve the issues on insufficient ocean scene image data and simple ship interactive experimental environment, we construct a 3D virtual ocean environment to implement image data collection and ship intelligent control based on Unity3D. The method is applicable for general ship autonomous control systems. The rest of the paper is organized as follows: In Section 2, the construction of virtual ocean scenes is presented. In Section 3, an ocean scene target detection task combines our collected data and the USV obstacle avoidance training experiments are designed. Finally, in Section 4 and Section 5, the conclusions and future work are presented
Figure 1. Virtual unmanned vehicle interaction platform of AirSim (Shah, Dey, Lovett, & Kapoor, Citation2018)

2. Construction of virtual trainable ocean scenes
This paper uses the Unity3D engine to construct virtual ocean scenes to enrich the data of the ocean target detection model and reduce the cost of collecting samples. The advantages of using Unity3D to construct ocean scenes are as follows. Firstly, Unity3D has a high-performance lighting system. Secondly, it has high level image rendering engine. Thirdly, it has realistic particle system which makes image data more realistic. Lastly, it has powerful terrain editor that can create more complex scenes. Meanwhile, based on virtual ocean scenes and powerful Unity3D engine, we build a realistic physical motion model of the USV. We use Unity Machine Learning Agents Toolkit (ML-Agent) (Juliani et al., Citation2018) to train the USV.
2.1. Ocean scene construction and image dataset collection
Data augmentation is widely used to provide more training data for deep neural network. For example, random cropping and image mirroring are commonly used in classification models trained on natural images. State-of-the-art model trained on specific dataset (e.g. MINST) use some distortions such as scale variation, translation and rotation (Simard, Steinkraus, & Platt, Citation2003; Wan, Zeiler, Zhang, Le Cun, & Fergus, Citation2013) in image classification. These methods obviously enlarge the amount of dataset. Recent work has focused on learning data augmentation strategies directly from data itself (Cubuk, Zoph, Mane, Vasudevan, & Le, Citation2019; Zoph et al., Citation2019). In this paper, we intend to collect ocean image data by constructing a virtual ocean scene to solve the problem of insufficient image data in ocean scenes. By finding valuable image sample data in the virtual ocean scene, the problem of insufficient sample detection of ocean targets can be solved effectively. This greatly reduces the cost of image data collection.
In order to ensure that the collected data are closer to reality, we use the Unity3D engine to achieve realistic ocean scenes. Based on the advantages of Unity3D, we have greatly restored the ocean scenes that is easily disturbed in the real world from several dimensions, such as lighting, shadows and reflections. In addition, in order to enrich the ocean scenes, we integrate the Unity3D weather-maker component from the Unity store. Based on this component, we get the ocean scene under different weather conditions and we can get high-value images of complex ocean scene to complete our collection goal.
Various types of ships such as passenger ship, cargos and yachts build in the ocean scene (). These ships are common in ocean image data sets, but the data of ships that incorporate complex weather is very scarce which is the focus of our collection. It should be noted that all the images are collected on the wave-free sea.
The USV is controlled to achieve ocean scene image collection. The USV is equipped with a monocular image sensor which can automatically capture an ocean scene image sample every 5 seconds. The image sensor of the USV will store the perceived image data into the database every 5 seconds by using a Unity script. shows the image data we collect at different position or different weather. We combine the camera component of Unity3D to design the image sensor of the USV.
Figure 2. The operation interface of ocean scene image data collection based on Unity3D

Based on the weather-maker component from the Unity store, we collect data from four types of typical ocean scenes: normal (sunny), dusk, cloudy and night. at different times of the day. The times when the data were collected are presented in using solid circles. shows the number of different types of ships collected datum under different weather conditions. In this table, others represent common obstacles(e.g. buoys) in the sea. The resolution of the images is 1024*768 pixels.
Figure 3. Image data collection of ocean scenes on sunny, dusk and cloudy days. The image includes a variety of ships with obvious light changes. These image data samples are difficult to obtain in real scenario

Table 1. Data collected in different scenes at different time
Table 2. The number of different types of ships collected datum under different weather conditions
2.2. Construction of the USV intelligent control training environment
To make the USV of the ability to handle a wide variety of complex tasks and deal with more challenges from the sea, USV must have the autonomous intelligent control capacities. As mentioned above, traditional USV training methods are expensive, so we propose to designe the experimental environment based on the virtual ocean scenes constructed by Unity3D for autonomous intelligent control of USV.
There are two key factors in building the autonomous control experiment environments of intelligent USV. One is how to build a realistic physical motion model of USV, and the other is how to make USV trainable in the virtual ocean scenes. For building the realistic physical motion model of USV, we designed the thruster and rudder based on the basic structure of USV by the powerful physical engine of Unity3D. Compared to cars, the USV has two control commands: steering and thrusting. It should be noted that the USV does not have a brake and generally USES the water friction to implement brake. Unlike driving a car, the USV steering is a discrete control that can reduce rudder area and increase the service life of rudder as long as possible in reality. The maximum angle of the rudder is also limited. The thrusting controls increase and decrease thrust. Based on the USV features mentioned above, shows the steering and thrusting controls we design. We set a thrust thresholdwith value of 250 horsepower for USV; and if the thrust reaches this threshold, it will not increase any more. shows the major components of USV.
Figure 4. Major components of the unmanned surface vessel
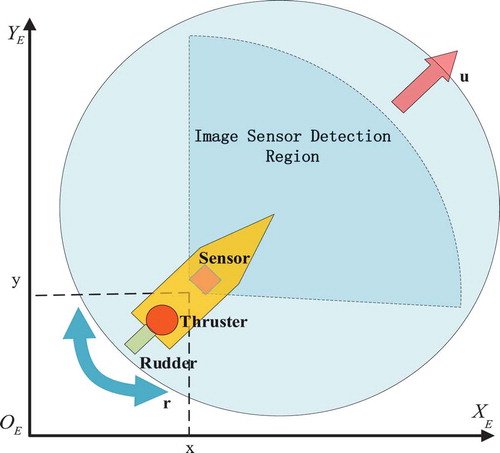
Table 3. The control commands of USV
In order to train USV in virtual ocean scenes, we utilize the Unity Machine Learning Agents Toolkit (ML-Agents) (Juliani et al., Citation2018). ML-Agents is an open-source Unity plugin that enables games and simulations to serve as environments for training intelligent agents. Agents can be trained using reinforcement learning, imitation learning, neuro evolution or other machine learning methods through a simple-to-use Python API. It also provides implementations (based on TensorFlow Abadi et al., Citation2016) of state-of-the-art algorithms to enable game developers and hobbyists to easily train intelligent agents for 2D, 3D and VR/AR games. These trained agents can be used for multiple purposes, including controlling Non-Player Character behavior (in a variety of settings such as multi-agent and adversarial), automatically testing of game builds and evaluating different game design decisions before its release . In this paper, ML-Agents is used to train USV for complex tasks such as obstacle avoidance. The ML-Agents toolkit is mutually beneficial for both game developers and AI researchers as. Because it provides a central platform where advances in AI can be evaluated on Unity’s rich environments and then made accessible to the wider research and game developer communities.
Based on USV physical motion model and the ML-agent training framework, we can design various tasks for USV, and USV has acquired the ability to handle complex tasks through long-term continuous training ().
Figure 5. Typical application scenarios in Unity3D ML-Agents toolkit
3. Experimental results
In Section 2, we introduced virtual ocean scenes that can train USV, and the image data collected under complex weather conditions in virtual ocean scenes. In this section, the collected image data and common standard data will be combined to evaluate the effectiveness of the detection model trained. Additionally, we also perform the obstacle avoidance training experiments for USV in complex scenarios based on ML-Agent.
3.1. Ocean scene target detection
In the field of maritime object detection, a certain amount of real data can be obtained; but it is insufficient for detection tasks in complex weather conditions. Traditional data augmentation can hardly augment the diversity of global features, so we try to utilize virtual ocean scenes data as augmentation data. In Section 2.1, we utilize Unity3D to build virtual ocean scenes in order to generate various synthetic boat data. The most common boats (such as container ship, passenger ship, sailing boat, etc.) are placed in the virtual ocean scene at random positions and orientations. The components of virtual sea scene and boat models are freely available online in Unity3D shop and the scene is a non-photorealistic simulator environment. For a particular weather condition, domain randomization is also used to perturb parameters in environment in order to make network focus on the essential features of the images and have better generalization in real data. In the field of ocean object detection, the test data include a variety of weather conditions. Samples with these global features are insufficient in training data and hard to obtain in reality. Traditional data augmentation methods are hard to generate samples in different global features, so we use virtual ocean scenes to synthesize data. shows the statistical information of boat data under different weather conditions in PASCAL VOC (Everingham, Van Gool, Williams, Winn, & Zisserman, Citation2010) dataset. The number of different weather samples is maldistribution . Most training and test boat class data are in normal weather despite a bit of backlight. Comparing to the images collected under normal weather, the images collected under dusk weather are more helpful for improving the accuracy.
Table 4. The proportion of diverse weather conditions in PASCAL VOC dataset
We compare the results of training common object detection deep neural networks with and without our collected virtual ocean scenes data augmentation on Pascal VOC dataset. Note that our method makes it easier to improve the accuracy with a small amount of augment data. We only perform data augmentation for the ship classification task. The PascalVOC 2007 test data are used for testing. Detection performance is evaluated using average precision (AP) (Everingham et al., Citation2015), with detections judged to be true/false positives by measuring bounding box overlap with intersection over union (IoU) at least 0.5. We train detection model YoloV2 (Redmon & Farhadi, Citation2017). shows that adding virtual ocean scenes data to training data improves the accuracy.
Table 5. Compare the accuracy of boat class with/without 500 virtual ocean scenes data on Pascal 07 and Pascal 07 + 12 dataset. The virtual ocean scenes images are collected in Unity3D
3.2. USV autonomous obstacle avoidance
In Section 2.2, USV intelligent control is constructed into training environment with the Unity Machine Learning Agents Toolkit. In this part, we propose to train the USV in a virtual ocean environment to verify the accuracy of the algorithm by using deep reinforcement learning (Kaelbling, Littman, & Moore, Citation1996; Schulman, Wolski, Dhariwal, Radford, & Klimov, Citation2017). Traditional methods usually model the USV motion and the environment in a mathematical way that needs perceptual information and prior knowledge (Lisowski & Smierzchalski, Citation1970; Naeem, Sutton, & Chudley, Citation2006; Johansen, Perez, & Cristofaro, Citation2016). Unfortunately, in reality, it is difficult to provide sufficient perceptual information as well as prior knowledge due to complex marine environments, resulting in inaccurate modeling. To address these issues, we utilize a partially observable Markov decision process (POMDP) to model the USV obstacle avoidance problem, and propose a vision-based USV reinforcement learning obstacle avoidance algorithm (VURLOA). In order to reduce the training cost and ensure the safety of USV, we carry out the training method in virtual ocean environment. The above-mentioned vision sensor and convolutional neural networks (Krizhevsky, Sutskever, & Hinton, Citation2012) are employed to obtain obstacles’ characteristics, and we use the time difference sailing distance to design a series of reward functions for obstacle avoidance and sailing. shows the entire framework of POMDP modeled USV obstacle avoidance.
Figure 6. POMDP modeled USV obstacle avoidance overall pipeline
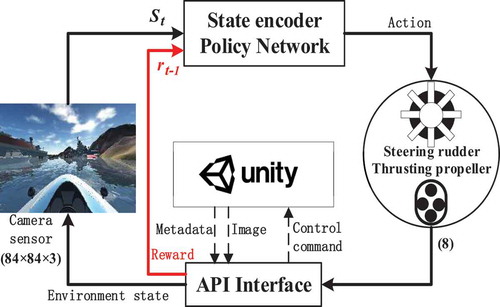
Figure 7. Comparison among the results using our VURLOA algorithm, random policy and CDRLOA algorithm (Cheng & Zhang, Citation2017) average sailing speed during the USV obstacle avoidance training
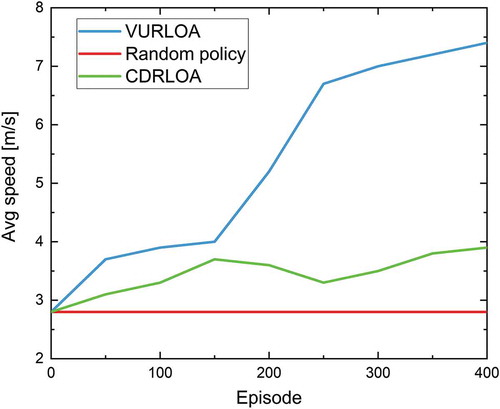
Figure 8. Comparison among the results using our VURLOA algorithm, random policy and CDRLOA algorithm (Cheng & Zhang, Citation2017)
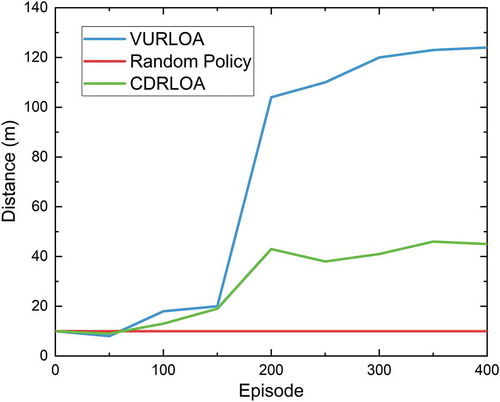
To verify the advancement of our algorithm, we use the speed and travel distance of USV as a measure. Here, we mainly compare with Yin Cheng et al. (Cheng & Zhang, Citation2017) who designed a concise deep reinforcement learning obstacle avoidance (CDRLOA) algorithm. We train our algorithm with different reward function and random control policy in 400 episodes. Then we count the advantages of each algorithm in terms of average speed and navigation distances. shows the comparison results of average speed. In this figure, we can see that our algorithm has a significant improvement in average speed during the training process. The maximum of the average speed is 7.3 m/s, which is derived from our algorithm. This means that the USV reaches the target position in a short time. Other algorithms cannot effectively get high speed in the training. In contrast, the average speed keeps less then 2.8 m/s using random policy and the maximum is only 4 m/s using reward function from Cheng and Zhang’s algorithm.
shows the comparison results of navigating distance in the form of box plots. This figure demonstrates that our algorithm has a significant improvement in navigating distance during the training process. In contrast, the obstacles cannot be effectively avoided using the other two algorithms. The navigated distance is about 10 m using random policy and the maximum is 45 m using reward function from Cheng and Zhang’s algorithm. All the obstacles can be avoided by using our algorithm and the maximum of the navigated distance can reach over 120 m. In contrast, the obstacles cannot be effectively avoided using the other two algorithms. The navigated distance is about 10 m using random policy and the maximum is 45 m using reward function from Cheng and Zhang’s algorithm.
We verified the obstacle avoidance algorithm of the USV through a virtual environment, and the experimental results mentioned above fully verify the superiority and efficiency of our algorithm. Based on this training environment, various algorithms can be trained for complex control problems to judge the effectiveness of the algorithm.
4. Conclusions
Ocean big data are developing rapidly. However, there are some problems in ocean target detection and the USV intelligent control, such as insufficient data and invalid training environment. In this paper, (i) the 3D virtual ocean scenes were built based on Unity3D. (ii) We collected ocean image data under complex weather in 3D virtual scene and augmented target detection samples. (iii) The USV intelligent control training environment were constructed by introducing the Unity Machine Learning Agents Toolkit. From the experimental results, the accuracy of the ocean target detection model is improved through data augmentation, and we provide a control policy for maneuvering the USV that can help USV reach the destination in a short time and avoid collisions.
5. Future work
In this paper, the augmentation of image data under complex weather conditions and the intelligent control training of the USV are realized by constructing ocean virtual scenes. In the future, based on the advantages of virtual scenes, will conduct experiments in more complex scenes,especially considering the waves. (i) More virtual sensors are developed based on Unity3D engine such as lidar sensors and sonar sensors to realize different types of data augmentation. (ii) Intelligent control training for complex ocean tasks is no longer limited to the USV, but provides multi-ship type training. (iii) The collaborative experiments considering different conditions of weather and sea surface will be conducted is formed by incorporating drones into ocean virtual scenes. It will be helpful to obtain more abundant scene information (iv) Based on (iii), the newly generated algorithm can be trained and verified.
Disclosure statement
No potential conflict of interest was reported by the authors.
Data availability statement
The data referred to in this paper is not publicly available at the current time.
Additional information
Funding
Notes on contributors

Wei Wang
Wei Wang received the B.Eng. degrees in the School of Computer Science and Technology, Fuyang Normal University, China, in 2012. Received the M.Eng degree in the School of Information Engineering and Automation, Kunming University of Science and Technology, in 2016. He is currently working toward the Ph.D. degree at the School of Computers, Shanghai University, China. His research interests include deep reinforcement learning, Intelligent unmanned system.

Yang Li
Yang Li received the B.Eng. degrees from the School of Computer Science and Technology, Anhui University, China, in 2017. He is currently working toward the Ph.D. degree at the School of Computers, Shanghai University, China. His research interests include deep reinforcement learning, multi-agent reinforcement learning, and multi-agent system.

Xiangfeng Luo
Xiangfeng Luo is a professor in the School of Computers, Shanghai University, China. Currently, he is a visiting professor at Purdue University, USA. His main research interests include Web Wisdom, Cognitive Informatics, and Text Understanding. He has authored or co-authored more than 100 publications and his publications have appeared in IEEE Trans. on Systems, Man, and Cybernetics-Part C, IEEE Trans. on Automation Science and Engineering, IEEE Trans. on Learning Technology, etc. He has served as the Guest Editor of ACM Transactions on Intelligent Systems and Technology. Dr. Luo has also served on the committees of a number of conferences/workshops, including Program Co-chair of ICWL 2010 (Shanghai), WISM 2012 (Chengdu), CTUW2011 (Sydney) and PC member for more than 40 conferences and workshops.

Shaorong Xie
Shaorong Xie received the B.Eng. and M.Eng. degrees in mechanical engineering from Tianjin Polytechnic University, Tianjin, China, in 1995 and 1998, respectively, and the Dr. Eng. degree in mechanical engineering from the Institute of Intelligent Machines at Tianjin University and the Institute of Robotics and Automatic Information System, Nankai University, Tianjin, China, in 2001. She is a Professor with the School of Mechatronic Engineering and Automation, Shanghai University, Shanghai, China. Her research areas include advanced robotics technologies, bionic control mechanisms of eye movements, and image monitoring systems.
References
- Abadi, M., Barham, P., Chen, J., Chen, Z., Davis, A., Dean, J., … & Kudlur, M. (2016). Tensorflow: A system for large-scale machine learning. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI’16) (pp. 265–283), Savannah, GA, USA.
- Brockman, G., Cheung, V., Pettersson, L., et al., Openai gym[J]. arXiv preprint arXiv:1606.01540, (2016).
- Collins, M. J., Denbina, M., & Atteia, G. (2013). On the reconstruction of quad-pol SAR data from compact polarimetry data for ocean target detection. IEEE Transactions on Geoscience and Remote Sensing, 51(1), 591–600.
- Cubuk, E. D., Zoph, B., Mane, D., Vasudevan, V., & Le, Q. V. (2019). Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE conference on computer vision and pattern recognition. (pp. 113–123), Long Beach, CA.
- Deng, J., Dong, W., Socher, R., Li, L. J., Li, K., & Li, F. F. (2009). ImageNet: A large-scale hierarchical image database. In Proceeding of IEEE computer vision and pattern recognition (pp. 248–255), Fontainebleau MiamiBeach.
- Dong, Z., Wan, L., Li, Y., Liu, T., & Zhang, G. (2015). Trajectory tracking control of underactuated USV based on modified backstepping approach. International Journal of Naval Architecture and Ocean Engineering, 7(5), 817–832.
- Everingham, M., Eslami, S. M. A., Van Gool, L., Williams, C. K. I., Winn, J., & Zisserman, A. (2015). The Pascal visual object classes challenge: A retrospective. International Journal of Computer Vision, 111(1), 98–136.
- Everingham, M., Van Gool, L., Williams, C. K. I., Winn, J., & Zisserman, A. (2010). The Pascal visual object classes (VOC) challenge. International Journal of Computer Vision, 88(2), 303–338.
- Guo, H. (2017a). Big Earth data: A new frontier in Earth and information sciences. Big Earth Data, 1(1–2), 4–20.
- Guo, H. (2017b). Big data drives the development of Earth science. Big Earth Data, 1(1–2), 1–3.
- Johansen, T. A., Perez, T., & Cristofaro, A. (2016). Ship collision avoidance and COLREGS compliance using simulation-based control behavior selection with predictive hazard assessment. IEEE Transactions on Intelligent Transportation Systems, 17(12), 3407–3422.
- Juliani, A., Berges, V. P., Vckay, E., Gao, Y., Henry, H., Mattar, M., & Lange, D. (2018). Unity: A general platform for intelligent agents. arXiv Prepr. arXiv1809.02627.
- Kaelbling, L. P., Littman, M. L., & Moore, A. W. (1996). Reinforcement learning: A survey. Journal of Artificial Intelligence Research, 4, 237–285.
- Kato, S., Tokunaga, S., Maruyama, Y., Maeda, S., & Azumi, T. (2018). Autoware on board: Enabling autonomous vehicles with embedded systems. In 2018 ACM/IEEE 9th International Conference on Cyber-Physical Systems (ICCPS), Porto, Portugal.
- Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems (pp. 1097–1105), Harrahs and Harveys, Lake Tahoe.
- Li, H., Perrie, W., He, Y., Lehner, S., & Brusch, S. (2012). Target detection on the ocean with the relative phase of compact polarimetry SAR. IEEE Transactions on Geoscience and Remote Sensing, 51(6), 3299–3305.
- Lin, T. Y., Maire, M., Belongie, S., et al.,Microsoft coco: Common objects in context[C]//European conference on computer vision. Springer, Cham (2014): 740–755.
- Lisowski, J., & Smierzchalski, R. (1970). Methods to assign the safe manoeuvre and trajectory avoiding collision at sea. WIT Transactions on the Built Environment, 12, 12.
- Naeem, W., Sutton, R., & Chudley, J. (2006). Modelling and control of an unmanned surface vehicle for environmental monitoring. In UKACC International Control Conference (pp. 1–6), Universities of Glasgow and Strathclyde.
- Redmon, J., & Farhadi, A. (2017). YOLO9000: Better, faster, stronger. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7263–7271), Honolulu, Hawaii.
- Roberts, G. N., Sutton, R., Zirilli, A., & Tiano, A. (2003). Intelligent ship autopilots—A historical perspective. Mechatronics, 13(10), 1091–1103.
- Schulman, J., Wolski, F., Dhariwal, P., Radford, A., & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv Prepr. arXiv1707.06347.
- Shah, S., Dey, D., Lovett, C., & Kapoor, A. (2018). AirSim: High-fidelity visual and physical simulation for autonomous vehicles. In Field and service robotics (pp. 621–635). Springer.
- Simard, P. Y., Steinkraus, D., Platt, J. C. (2003). Best practices for convolutional neural networks applied to visual document analysis. Icdar, 3, 2003.
- Soltan, R. A., Ashrafiuon, H., & Muske, K. R. (2011). ODE-based obstacle avoidance and trajectory planning for unmanned surface vessels. Robotica, 29(5), 691–703.
- Wan, L., Zeiler, M., Zhang, S., Le Cun, Y., & Fergus, R. (2013) Regularization of neural networks using dropconnect. In International conference on machine learning (pp. 1058–1066), Atlanta.
- Wang, X., Luo, X., & Liu, H. (2015). Measuring the veracity of web event via uncertainty. Journal of Systems and Software, 102, 226–236.
- Wang, X., Sugumaran, V., Zhang, H., & Xu, Z. (2018). A capability assessment model for emergency management organizations. Information Systems Frontiers, 20(4), 653–667.
- Wang, X., Yuan, S., Zhang, H., Lewis, M., & Sycara, K. (2019). Verbal explanations for deep reinforcement learning neural networks with attention on extracted features. In 2019 28th IEEE International Conference on Robot and Human Interactive Communication (RO-MAN) (pp. 1–7), Le Meridien, Windsor Place, New Delhi, India.
- Woodring, J., Petersen, M., Schmeiβer, A., Patchett, J., Ahrens, J., & Hagen, H. (2015). In situ eddy analysis in a high-resolution ocean climate model. IEEE Transactions on Visualization and Computer Graphics, 22(1), 857–866.
- Cheng, Y., & Zhang, W. (2017). Concise deep reinforcement learning obstacle avoidance for underactuated unmanned marine vessels. Neurocomputing, 272, 63–73.
- Zhuo, Y., & Hearn, G. E. (2008). Ship intelligent autopilot in narrow water. In Proceedings of the 27th China control conference, Yun An Conference Resort, Kunming, Yunan Province, China.
- Zoph, B., Cubuk, E. D., Ghiasi, G., Lin, T.-Y., Shlens, J., & Le, Q. V. (2019). Learning data augmentation strategies for object detection. arXiv Prepr. arXiv1906.11172.