
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Marine big data are characterized by a large amount and complex structures, which bring great challenges to data management and retrieval. Based on the GeoSOT Grid Code and the composite index structure of the MongoDB database, this paper proposes a spatio-temporal grid index model (STGI) for efficient optimized query of marine big data. A spatio-temporal secondary index is created on the spatial code and time code columns to build a composite index in the MongoDB database used for the storage of massive marine data. Multiple comparative experiments demonstrate that the retrieval efficiency adopting the STGI approach is increased by more than two to three times compared with other index models. Through theoretical analysis and experimental verification, the conclusion could be achieved that the STGI model is quite suitable for retrieving large-scale spatial data with low time frequency, such as marine big data.
1. Introduction
With the continuous development and innovation of information technology and monitoring equipment, we could obtain multiscale, real-time, and large-scale observation data of the marine environment quickly and conveniently, which provides a strong support for marine researches. However, with the continuous growth of the data amount and diversified data types, the management and retrieval of marine big data has become increasingly prominent (Guo, Wang, & Liang, Citation2016). The main problems could be summarized as follows.
Firstly, the decentralized management mode indicates that marine data are stored by different departments. Data cannot be managed in a centralized way, and flow with the business, resulting in a set of independent databases in each business system. Secondly, marine big data are typical spatio-temporal big data with multiscale characteristics. The traditional method of defining spatial position by latitude, longitude, and elevation is limited by the storage modes of data management systems. Last but not the least, the efficiency of marine big data query and retrieval needs to be improved. At present, Relational Database is more often used in marine data management, which has low efficiency for query and retrieval of a large amount of marine spatio-temporal data. In contrast, Non-Relational Database (NoSQL) has the characteristics of a simple data model and distributed storage (Ma, Wang, Liu, & Ranjan, Citation2015). However, the NoSQL database has different designs according to the requirements of different application scenarios. It may have good performance in a certain field, but cannot be used in other scenarios.
In recent years, many researches have been carried out in combination with distributed NoSQL data systems such as HBase, Accumulo, Caasandra, etc., which are more suitable for the storage and management requirements of spatio-temporal big data (Song, Liu, & Wang, Citation2016). For example, Nishimura, Das, Agrawal, and El Abbadi (Citation2013) have established a multidimensional index MD-HBase based on the underlying key-value data model, to support the storage management of large-scale data and cope with high concurrent access. At the same time, they built an index layer to support multidimensional query processing requirements, so as to make up for the gap between the scalability and spatio-temporal applicational functionality of the existing NoSQL storage system. Wei, Hsu, Peng, and Lee (Citation2014) have proposed to construct a multidimensional index, namely KR+ Index, and carried out experiments on HBase and Cassandra, and the results have showed that KR+ Index has better performance than MD-HBase. Aiming at the high cost of R-Tree Index construction and maintenance, Zhongliang, Yulong, Baofeng, and Rui (Citation2016) have proposed a spatial index based on an improved quadtree coding method, namely M-Quadree Index, to solve the issue of unbalanced data volume in each subpartition. Van Le and Takasu (Citation2015) have proposed the corresponding index mechanism in HBase based on spatio-temporal coding STcode. Spatio-temporal adjacent data objects will have the same prefix after being encoded by STcode and be stored together in HBase. Similarly, Guan et al. (Citation2017) have extended the GeoHash encoding algorithm which is widely used in key value storage structure, to encode longitude, latitude, and time into a short and unique string, so as to meet the fast update of track data index. Chen, Zhang, Ge, and Xiao (Citation2015) have further studied the indexing mechanism of HBase and proposed the STEHIX index framework. STEHIX implements the local spatio-temporal index for Storefile on each region server by modifying HBase’s internal index architecture. GeoMesa (Hughes et al., Citation2015) is an open-source, large-scale spatial-temporal data storage, index and query component based on NoSQL, which supports the establishment of distributed NoSQL data systems such as Accumulo, HBase, Cassandra and Google BigTable. GeoMesa constructs the index key by GeoHash geocoding and the splitting and combining of the timestamp string (Fox, Eichelberger, Hughes, & Lyon, Citation2013). Similarly, the National Geospatial Intelligence Agency of the US, in collaboration with Radiantblue and Booz Allen Hamilton, has developed a set of class library GeoWave (Whitby, Fecher, & Bennight, Citation2017), which uses the scalability of distributed key value storage to effectively store, retrieve, and analyze a large number of geographic data sets. However, the spatial and time dimensions adopted in most of the above studies do not have the same weights, so it is difficult to provide an effective bottom organization mechanism for the subsequent rapid data access and efficient spatio-temporal applications.
Marine big data are kinds of spatial data which contain both temporal and spatial information, and have a variety of attribute types. It will inevitably encounter a series of problems such as spatial information positioning, large data volume, complex structure, and so on. Therefore, a suitable spatio-temporal index model combined with a NoSQL database is needed, to realize efficient organization and management of marine big data. This paper proposed a Spatial-temporal Grid Index Model (STGI) based on GeoSOT Grid Code, which is suitable for the MongoDB database and adopts a secondary index structure. Several groups of comparative experiments for this model are carried out, and the feasibility and efficiency of this new STGI model in retrieving marine big data are finally proved.
2. GeoSOT grid code methods
GeoSOT (Geographical coordinate grid Subdivision by One-dimension-integer and Two to nth power) subdivision theory () proposed by Cheng, Tong, Chen, and Zhai (Citation2016) has offered an efficient and scientific way of dividing the whole Earth seamlessly and overlappingly with multiple scales. Recently, it has been widely used and verified in spatial data management (Lu, Cheng, Jin, & Ma, Citation2013), urban component management (Zhang, Cheng, & Miao, Citation2019), massive trajectory data (Qian et al., Citation2019), remote-sensing image data organization (Wang, Cheng, Wu, Wu, & Teng, Citation2015), and other GIS applicational scenarios (Li, Pu, Cheng, & Chen, Citation2019). According to the GeoSOT subdivision theory, subdivision grids cover the complete Earth space without any leaks or overlaps. Meanwhile, different level grids form a recursive hierarchical tiling structure. To perform recursive subdivision and to form grid cells of the whole degree, whole minute, and whole second, the spatial subdivision domain is extended to an integer power of 2 as needed. Specifically, the subdivision domain extends three times on the 0th, 9th, and 15th layers, corresponding to the initial space, 1°, and 1ʹ (Li, Cheng, Chen, & Meng, Citation2016). Each grid on the Earth could be given a unique computable grid code, which is used as the location identifier (Wang, Ma, Yan, Chang, & Zomaya, Citation2018). This geospatial grid code could be recognized as a discrete code corresponding to the existing longitude and latitude scheme.
Figure 1. GeoSOT subdivision theory and grid code
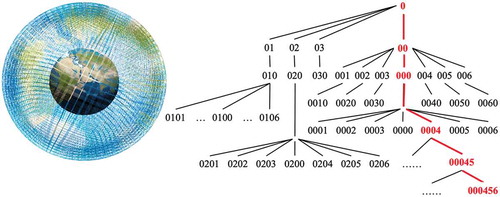
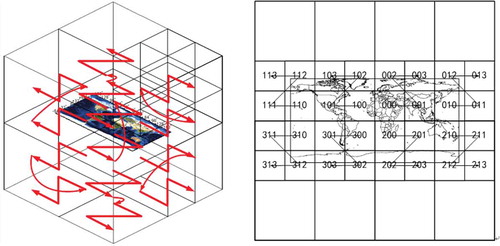
GeoSOT grid codes are not random at the same subdivision level. They are sorted according to the Z-order three-dimensional space-filling curve instead (). Hence, grid codes of neighboring grids have close values. Each level of grid codes adopts Z-order coding on the basis of the previous level. The encoding length of the GeoSOT grid is equal to the number of its grid level, from 1 bit to 32 bits. Finally, high-dimensional spatial information is converted to a one-dimensional spatial grid code, which is more convenient for the storage and query of spatial big data.
Figure 2. The Z-order filling curve of GeoSOT grid code
3. Spatio-temporal grid index (STGI)
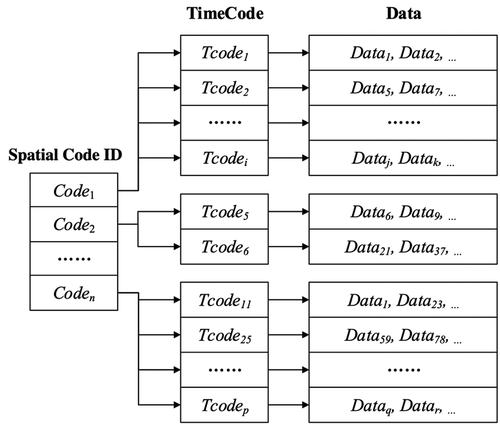
The Spatio-temporal Grid Index model could be constructed as in . Codei is the ith GeoSOT Grid Code for spatial information, and Tcodei is the ith time code using a timestamp, while Datai represents the spatial data or entity.
Figure 3. Spatio-temporal grid index structure
3.1. Grid level selection
From the GeoSOT subdivision theory, the whole Earth is divided according to the spatial domain. If the grid size is too large, a grid would contain multiple objects and each object would contain multiple data. It makes the storage format too cumbersome and increases the difficulties of attribute retrieval. If the grid size is too small, the data attributes contained in multiple grids will be duplicated, resulting in the redundancy and a waste of storage space, and the retrieval efficiency would be greatly reduced as well. Therefore, when considering actual application requirements, we need to select a suitable grid level to contain each data and make the redundancy as less as possible. In this work, the grid level with a higher accuracy than the experimental data is chosen. As shown in , the black box represents the actual geographical area, while the red box represents the grid size selected according to the range domain. Although some redundant data are generated, we could greatly improve the index structure without loss of accuracy and attribute information.
Figure 4. Example of grid-level selection

3.2. Metadata table structure
Marine data are stored in the MongoDB database. As a document-oriented NoSQL database, MongoDB has great flexibility in the structure of stored data. It could store data according to different attribute values and different structures. Moreover, the data structure is not fixed and attribute columns could be increased or decreased according to the application demands. In this paper, a unique global spatial identification code, that is, GeoSOT Grid Code, is added to each marine data and a time identification code is attached according to the time. The spatial code, time code, and each attribute value of marine data constitute a document record. Then a spatio-temporal secondary index could be created on the spatial code and time code columns to build a composite index in MongoDB. Especially, the spatial code is selected as the primary index while the time code as the secondary index.
The metadata table structure of marine big data in the database is shown in .
Table 1. Metadata table structure
3.3. Query operation
The basic retrieval idea of STGI is that, firstly according to the target retrieval spatial range, all the voxels containing the region are recorded to form a set of spatial voxels filling the query range. Then, combined with the time set composed of the target time range, each eligible data is retrieved through a spatial and temporal composite index. This data information set is the result of range retrieval.
The process of range retrieval by STGI is defined as follows:
Define as the operation of combining two groups of codes. If the point
in the point set P of the target space, is located in the subdivision volume element
, that is
, then
is the spatial retrieval volumn element of the point
. If the time
in the target time range set
, drops in the time range set
, that is
, then
is the retrievable time. When
and
is satisfied at the same time, an index that meets the query condition could be obtained through the composite index. Then the index set of
is composed of all the indexes that meet the criteria in the space set
and time set
. Through the index set, the spatio-temporal data information in a certain time period of the target elevation and polygon range could be retrieved.
4. Experiments
The purpose of this experiment is to verify the feasibility and efficiency of STGI proposed on the basis of the GeoSOT Grid Code through comparisons with other spatio-temporal index models. Index models used in this experiment include:
Traditional ObjectID primary index model;
A secondary index model of latitude, longitude, height, and time “lat_lon_height+time”;
A quaternary index model of latitude, longitude, height, and time “lat+lon+height+time”;
A primary index model of latitude, longitude, height combined with time “lat_lon_height_time”;
“Spatial-temporal Grid,” a primary index model originated from the spatio-temporal one-dimensional code;
STGI, a secondary index model created on Spatial Code and Time Code columns, proposed in this paper.
4.1. Experimental environment
The configuration information of our experimental platform could be referred to in and . In addition, in order to facilitate the operation and visualization of the MongoDB database, this experiment uses the database management tool Robo 3T.
Table 2. Hardware environment configuration
Table 3. Software environment configuration
4.2. Experimental data
Experimental data include ocean current, ocean wave, sea surface temperature, wind force, and so on, all of which take 0.5° as the longitude and latitude interval of point data. In order to make the source data meet the requirements of this experiment, it is necessary to preprocess these data. The specific steps are as follows:
Step 1: The format of source data is the NC file. In order to facilitate the file display and processing, first, convert them into txt files.
Step 2: Extract each type of file in the Python compilation environment. Convert the longitude, latitude, elevation, and time information into the 11th level spatial grid code (the plane grid size is 16′ and the field is “SpatialGrid”) and time code (the field is “time”), and then attach the data attribute information to facilitate the subsequent index establishment. Export to the JSON file.
Step 3: Merge different types of data according to spatial grid code and time code as shown in . Export to JSON file to facilitate file processing and database import.
Step 4: Build the comparison files. Add new fields to the JSON files exported in step 3 according to the comparative index models. Add “lat_lon_height,” “lat_lon_height_time,” “Spatial-temporal Grid,” and other fields. A total of 1,215,759 document records are generated and exported to the JSON file.
Step 5: In order to test the performance of different index models under large data volume, the time range by 10 times is expanded, and a total 12,157,590 pieces of data are generated to expand the data volume.
In this experiment, the “lat_lon_height” field is encoded by an 18-bit string in the format of , which represents latitude, longitude, and height, respectively. “lat_lon_height_time” field is encoded by a 32-bit string in the format of
. “Spatial-temporal Grid” adopts 46-bit string encoding, that is, to combine 33-bit one-dimensional spatial grid code in the 11th level and 13-bit time code.
4.3. Range query experiments
This range query experiment is carried out to test the query speed of all marine data related to a polygon query region with different time ranges. The query conditions are set as shown in . Randomly select a rectangular area on the earth, the size of which is 1°×1°, 2°×2°, 3°×3°, and 4°×4°, respectively, while the query time range is 10, 30, and 50 time points, respectively. Record the time consumption of different rectangular regions in different time ranges. Queries would be carried out 10 times in each group and the average consumption time is taken as the result. illustrates the range query results retrieved using different index models.
Table 4. Range query experiments in different time ranges (unit: ms)
4.4. Analysis and discussions
4.4.1. STGI vs “lat_lon_height+time”
Both “lat_lon_height+time” and STGI models have secondary indexes in their structures and take “time” filed as the secondary level. However, they choose different spatial encoding methods, resulting in obvious performance differences when retrieving large amounts of marine data.
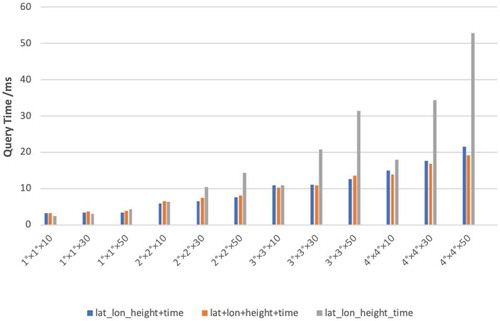
Figure 5. STGI vs “lat_lon_height+time.”
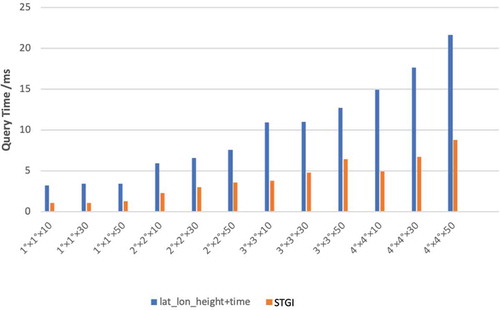
As could be seen from , the STGI model shows higher retrieval efficiency under different query conditions. Especially when the query area and data volume increase, the STGI model could save more time and show greater advantages. Although the space encoding length of the STGI model is longer, the performance of STGI is 2.56 times higher than that of the traditional “lat_lon_height+time” model. Hence, geospatial grid code has more advantages than the traditional method of longitude, latitude, and height in accelerating spatio-temporal information retrieval.
4.4.2. STGI vs Primary Index Model
One of the main characteristics of MongoDB is that it could establish a composite index, which could enhance the relevance of retrieval fields and accelerate the retrieval. STGI and “Spatial-temporal Grid” index models adopt the same spatial coding method and different index structures. STGI model separates the space field and time field, and establishes secondary index, while “Spatial-temporal Grid” model combines space and time fields into one to establish a primary index.
Figure 6. STGI vs primary index model
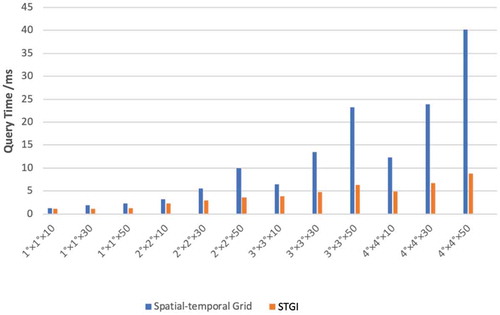
As shown in , when the query area and data volume were small, such as in a rectangular area of 1°×1°, both STGI and “Spatial-temporal Grid” index models showed good retrieval performances, and the time consumption was less than 5 ms. However, when the query area and data volume increase, the query time of the latter model increases greatly, while the STGI model showed better stability.
Figure 7. Query time ratios of two index models
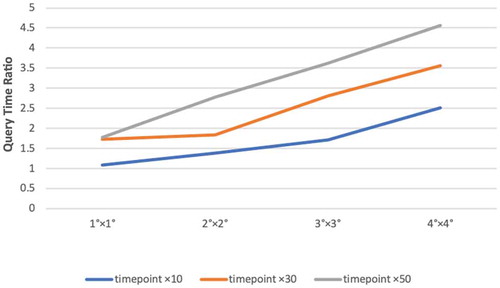
shows the rule that query time ratios of two index models change with the size of the query area. When the number of time points is the same and the query area increases, query time ratios of two models increase obviously. This indicates STGI could improve the retrieval efficiency much more significantly when the data volume increases. Therefore, the secondary index adopted by STGI could show greater advantages in processing ten million marine spatio-temporal data. The main reason is that GeoSOT Grid Code makes spatial adjacent objects similar in code values; hence, it has excellent performances as a spatial index. However, the “Spatial-temporal Grid” model combines spatial code and time code into one-dimensional code, which destroys code similarity and leads to its worse efficiency compared with STGI. Therefore, it is clear that the applicable condition of the STGI model is for spatial data with low time frequency. In addition, when usingthe primary index, spatial, and temporal information need to be combined into one string of code, making its length too long. As encoding is in the form of strings, the longer the string, is the greater the impact brings on the retrieval efficiency.
4.4.3. Comparisons of index models with different levels
When building the index models, both the excellent performance and the actual demands should be considered together. MongoDB composite index could be used to build a multilevel index. However, it is not that the higher level of the index, the better, especially considering the space and data structure complexity of index building. indicates that the primary index (gray column) consumes the most time, while the secondary index (blue column) and quaternary index (orange column) have no obvious differences in query speed. Therefore, we should make the structure of the index model as simple as possible when the query efficiency is guaranteed.
Figure 8. Comparisons of index models with different levels
From the quantitative comparisons from the figure above, the conclusions could be achieved as follows:
The average retrieval efficiency of the STGI model is 2.56 times higher than that of the “lat_lon_height+time” model.
The average retrieval efficiency of the STGI model is 2.63 times higher than that of the “lat+lon+height+time” model.
The average retrieval efficiency of the STGI model is 3.80 times higher than that of the “lat_lon_height_time” model. The improvement effect is more obvious with the increase of data volume.
The average retrieval efficiency of the STGI model is 2.45 times higher than that of the “Spatial-temporal Grid” model. The improvement effect is more obvious with the increase of data volume.
Hence, the STGI model is quite suitable for large-scale spatial data with low time frequency, such as marine big data.
5. Conclusions
This work proposed a spatio-temporal index model STGI for marine big data management, which realized the combination of the GeoSOT Grid Code and MongoDB composite index. Data containing spatial and temporal information could be associated through the STGI model, which innovated the traditional retrieval method by queries of latitude, longitude, and height. A number of comparative experiments with other index models were designed to verify the retrieval efficiency of STGI model for massive marine data. The retrieval efficiency adopting the STGI approach was increased by more than two to three times compared with other index models.
Compared with the traditional coding method of latitude, longitude, and height, GeoSOT Grid Code can improve the performance of the spatio-temporal index model more obviously as a superior spatial index. Moreover, the secondary index structure is more effective than primary and quaternary index structures in the storage of massive spatio-temporal data. STGI model adopts the structure of superior grid coding and secondary index, and the advantage combinations of them could lead to its higher retrieval efficiency.
In the future work, more types and structures of data need to be involved to enhance the applicability of the STGI model for multisource heterogeneous marine big data.
Supplemental Material
Download MS Word (32.1 KB)Data availability statement
For the moment, the data from the project are not publicly available. The data that support the findings of this study will be available on request from the authors.
Disclosure statement
No potential conflict of interest was reported by the authors.
Supplementary material
Supplemental data for this article can be accessed here.
Additional information
Funding
Notes on contributors

Tengteng Qu
Tengteng Qu received her B.E. degree in surveying engineering in 2011 and the Ph.D. degree in photogrammetry engineering and remote sensing in 2017 from Tongji University. Since 2018, she has worked as Postdoc in College of Engineering, Peking University, China, and Research Assistant Professor in Peking University Collaborative Innovation Center for Geospatial Big Data. Her research interests focus on geospatial big data, SAR remote sensing and geohazard monitoring. Since 2019, she has served as a standard expert of geographic information in IEEE Standards Association, Open Geospatial Consortium (OGC) and the International Organization for Standardization (ISO).

Lizhe Wang
Lizhe Wang is the Dean and “ChuTian” Chair Professor at School of Computer Science, China University of Geosciences. His research interests include remote sensing data processing, Digital Earth. He is a fellow of the Institution of Engineering and Technology and British Computer Society.

Jian Yu
Jian Yu received the B.E. degree in Energy and Power Engineering from Peking University, Beijing, China in 2019. Currently, he is pursuing the Ph.D. degree in Aerospace Engineering at Peking University, Beijing, China. Since 2019, he has studied the application of Grid-based Situation Awareness Map in the field of autonomous driving. His research interests include autonomous driving, artificial intelligence and spatio-temporal subdivision grid.

Jining Yan
Jining Yan received his PhD in signal and information processing in the University of Chinese Academy of Sciences. He is an associate professor of School of Computer Science, China University of Geosciences. His research interests include remote sensing data processing, time-series analysis and change detection, cloud computing in remote sensing and applied oceanography.

Guilin Xu
Guilin Xu received his B.Sc. degree in applied geophysics in 1990 and the Ph.D. degree in 2004 from China University of Geosciences (Wuhan). He served as the President of Guangxi Academy of Oceanography from 2014 to 2017. Since 2017, he has been the Director of Key Laboratory of Ministry of Education, and Administrative Office of Scientific and Technological Research in Nanning Normal University, China. His research interests include smart ocean, marine economy and marine big data, ecological environment monitoring and planning of land and resources.

Meng Li
Meng Li received the B.E. degree in Engineering of Surveying and Mapping from Wuhan University, Hubei, China in 2017, and the M.S. degree in Aerospace Engineering from Peking University, Beijing, China in 2020. From 2017 to 2020, she studied moving target spatio-temporal coordinate models and spatio-temporal grid code. Her research interests include spatio-temporal subdivision grid and spatio-temporal data organization.

Chengqi Cheng
Chengqi Cheng received his B.Sc. and M.Sc. degrees in earth sciences in 1982 and 1985 respectively from Nanjing University, China. He received the Ph.D. degree in urban and environmental sciences from Peking University in 1989. Now he serves as the Director of Institute for Aeronautics and Astronautics Information Engineering of Peking University, and also the Vice Dean of Advanced Technology Academy of Peking University. His research interests include geographic information engineering, the organization theories and methods of spatial information, and global subdivision theory. Since 2018, he has served as a standard expert of geographic information in Open GeospatialConsortium (OGC) and the International Organization for Standardization (ISO).

Kaihua Hou
Kaihua Hou received the B.E. degree in Aerospace Engineering in 2016 from Peking University, China. Currently he is pursuing the Ph.D. degree in Aerospace Engineering in Peking University. Since 2016, he has focused on the research of network geographical identification. His research interests include geographical information engineering and spatio-temporal subdivision grid.

Bo Chen
Bo Chen received his B.E. degree in aerial photogrammetry in 2002, and Ph.D. degree in photogrammetric engineering and remote sensing in 2008 from Information Engineering University. Since 2016, he has been a Research Associate Professor in the Department of Aeronautics and Astronautics in Peking University, China. His research interests include organization of geospatial big data, global subdivision and geocode methods, and spatial information engineering.
References
- Chen, X., Zhang, C., Ge, B., & Xiao, W. (2015). Spatio-temporal queries in HBase. In 2015 IEEE International Conference on Big Data (Big Data) (pp. 1929–1937). Santa Clara, CA: IEEE.
- Cheng, C., Tong, X., Chen, B., & Zhai, W. (2016). A subdivision method to unify the existing latitude and longitude grids. ISPRS International Journal of Geo-Information, 5(9), 161.
- Fox, A., Eichelberger, C., Hughes, J., & Lyon, S. (2013). Spatio-temporal indexing in non-relational distributed databases. In 2013 IEEE International Conference on Big Data (pp. 291–299). Silicon Valley, CA: IEEE.
- Guan, X., Bo, C., Li, Z., & Yu, Y. (2017). ST-hash: An efficient spatiotemporal index for massive trajectory data in a NoSQL database. In 2017 25th International Conference on Geoinformatics (pp. 1–7). Buffalo, NY: IEEE.
- Guo, H., Wang, L., & Liang, D. (2016). Big earth data from space: A new engine for Earth science. Science Bulletin, 61(7), 505–513.
- Hughes, J. N., Annex, A., Eichelberger, C. N., Fox, A., Hulbert, A., & Ronquest, M. (2015). Geomesa: A distributed architecture for spatio-temporal fusion. In Geospatial Informatics, Fusion, and Motion Video Analytics V (Vol. 9473, p. 94730F). Baltimore, MD: International Society for Optics and Photonics.
- Li, S., Cheng, C., Chen, B., & Meng, L. (2016). Integration and management of massive remote-sensing data based on GeoSOT subdivision model. Journal of Applied Remote Sensing, 10(3), 034003.
- Li, S., Pu, G., Cheng, C., & Chen, B. (2019). Method for managing and querying geo-spatial data using a grid-code-array spatial index. Earth Science Informatics, 12(2), 173–181.
- Lu, N., Cheng, C., Jin, A., & Ma, H. (2013). An index and retrieval method of spatial data based on GeoSOT global discrete grid system. In 2013 IEEE International Geoscience and Remote Sensing Symposium-IGARSS (pp. 4519–4522). Melbourne, VIC: IEEE.
- Ma, Y., Wang, L., Liu, P., & Ranjan, R. (2015). Towards building a data-intensive index for big data computing–a case study of remote sensing data processing. Information Sciences, 319, 171–188.
- Nishimura, S., Das, S., Agrawal, D., & El Abbadi, A. (2013). MD-HBase: Design and implementation of an elastic data infrastructure for cloud-scale location services. Distributed and Parallel Databases, 31(2), 289–319.
- Qian, C., Yi, C., Cheng, C., Pu, G., Wei, X., & Zhang, H. (2019). Geosot-based spatiotemporal index of massive trajectory data. ISPRS International Journal of Geo-Information, 8(6), 284.
- Song, W., Liu, P., & Wang, L. (2016). Sparse representation-based correlation analysis of non-stationary spatiotemporal big data. International Journal of Digital Earth, 9(9), 892–913.
- Van Le, H., & Takasu, A. (2015). A scalable spatio-temporal data storage for intelligent transportation systems based on hbase. In 2015 IEEE 18th International Conference on Intelligent Transportation Systems (pp. 2733–2738). Las Palmas, Spain: IEEE.
- Wang, L., Cheng, C., Wu, S., Wu, F., & Teng, W. (2015). Massive remote sensing image data management based on HBase and GeoSOT. In 2015 IEEE international geoscience and remote sensing symposium (IGARSS) (pp. 4558–4561). Milan, Italy: IEEE.
- Wang, L., Ma, Y., Yan, J., Chang, V., & Zomaya, A. Y. (2018). pipsCloud: High performance cloud computing for remote sensing big data management and processing. Future Generation Computer Systems, 78, 353–368.
- Wei, L. Y., Hsu, Y. T., Peng, W. C., & Lee, W. C. (2014). Indexing spatial data in cloud data managements. Pervasive and Mobile Computing, 15, 48–61.
- Whitby, M. A., Fecher, R., & Bennight, C. (2017). Geowave: utilizing distributed key-value stores for multidimensional data. Lecture Notes in Computer Science, 105–122.
- Zhang, H., Cheng, C., & Miao, S. (2019). A precise urban component management method based on the GeoSOT grid code and BIM. ISPRS International Journal of Geo-Information, 8(3), 159.
- Zhongliang, F. U., Yulong, H. U., Baofeng, W. E. N. G., & Rui, P. E. N. G. (2016). M-quadtree index: A spatial index method for cloud storage environment based on modified quadtree coding approach. Acta Geodaetica et Cartographica Sinica, 45(11), 1342.