
ABSTRACT
An adequate compute and storage infrastructure supporting the full exploitation of Copernicus and Earth Observation datasets is currently not available in Europe. This paper presents the cross-disciplinary open-source technologies being leveraged in the C-SCALE project to develop an open federation of compute and data providers as an alternative to monolithic infrastructures for processing and analysing Copernicus and Earth Observation data. Three critical aspects of the federation and the chosen technologies are elaborated upon: (1) federated data discovery, (2) federated access and (3) software distribution. With these technologies the open federation aims to provide homogenous access to resources, thereby enabling its users to generate meaningful results quickly and easily. This will be achieved by abstracting the complexity of infrastructure resource access provisioning and orchestration, including discovery of data across distributed archives, away from the end-users. Which is needed because end-users wish to focus on analysing ready-to-use data products and models rather than spending their time on the setup and maintenance of complex and heterogeneous IT infrastructures. The open federation will support processing and analysing the vast amounts of Copernicus and Earth Observation data that are critical for the implementation of the Destination Earth resp. Digital Twins vision for a high precision digital model of the Earth to model, monitor and simulate natural phenomena and related human activities.
1. Introduction
With the exponential increase of Earth Observation (EO) data (Wagemann, Siemen, Seeger, & Bendix, Citation2021), the traditional approach of downloading, processing, and analysing data on local machines severely limits the full exploitation of the rich and diverse data available (Gomes, Queiroz, & Ferreira, Citation2020; Overpeck, Meehl, Bony, & Easterling, Citation2011; Ramachandran et al., Citation2018; Sudmanns et al., Citation2020). Particularly Copernicus, the European Union’s Earth Observation programme, has established itself as one of the key global data sources for a broad range of EO datasets. Its Sentinel missions are providing global coverage at a spatial resolution of up to 10 m, contributing to a data archive that grows by 16 TB per dayFootnote1 (around 4 PB per year) and this amount will increase as more satellites become available.
Since the full exploitation of the massive EO data streams requires that historical and (near) real time analysis ready data are readily available in close proximity to computing resources, there is a trend towards accessing, processing and analysing data on the cloud-based services where the data are stored (Gomes et al., Citation2020).
Cloud platforms offering on-demand computing and distributed storage can be categorised into two distinct categories: (1) closed platforms that aim to bring all data into a central location and provide tools for users to analyse the data close to compute resources; and (2) open architectures that assume data will remain distributed and aim to provide interoperability solutions between different data catalogues and computational tools.
Closed systems, such as Google Earth Engine (GEE; Gorelick et al., Citation2017), have pioneered a vision for cloud-native big Earth data analytics. They have demonstrated that in using the cloud, users do not have to wait for downloads or deal with data-preparation steps. Instead, on these platforms, users have access to comprehensive and user-friendly data catalogues that can be analysed with scalable, on-demand compute resources. However, these closed systems are not open source and often have a limited scope. For example, GEE predominantly supports the analysis of satellite imagery, but there are many other types of Earth System data and analysis methodologies that are not possible on GEE (Abernathey & Hamman, Citation2020).
Today there is a rich set of publicly funded (open) and commercial cloud infrastructures that offer a broad range of tailored services and platforms for managing and analysing big Earth data (Camara et al., Citation2016; Gomes et al., Citation2020; Ramachandran et al., Citation2018). However, these infrastructures and the platforms and services they offer differ in terms of the underlying technologies they utilise, the degree to which they are open and transparent, and the level of abstraction they offer their end-users (Wagemann et al., Citation2021). Specifically in Europe, the processing of EO data and the development of higher-level solutions and services have suffered from a fragmented landscape and a lack of coherent approaches for interoperability and governance, which also leads to data duplication. An adequate compute and storage infrastructure supporting the exploitation of Copernicus and EO datasets is currently not available in Europe. Moreover, a complete global online Sentinel data archive following FAIR (Findable, Accessible, Interoperable, Reusable) best practices for researchers does not exist in Europe and older Sentinel and contributing mission data might only be retrievable from the European Space Agency’s (ESA) cold storage (tape archives). This hinders the work of researchers who often require access to long, historical, EO time series data (e.g. Bauer-Marschallinger et al., Citation2021; Donchyts et al., Citation2016; Pekel, Cottam, Gorelick, & Belward, Citation2016; Wagner et al., Citation2021). As a result, researchers tend to rely on monolithic infrastructures controlled by a single company, such as GEE, Amazon Web Services and, more recently, Microsoft’s Planetary Computer. On these infrastructures, analysis-ready Copernicus and EO data are readily available close to their significant computing resources for processing. Whilst these monolithic infrastructures are to some extent FAIR, particularly around Findability and Accessibility, the solutions deployed there are generally not Interoperable and Reusable since the workflows usually rely on vendor specific tooling or services and hence are difficult to port to other providers.
This paper presents an open compute and data federation as an alternative to closed, monolithic infrastructures for big Earth data analytics. The compute and data federation is being implemented under the C-SCALE projectFootnote2. The progress of the implementation can be monitored by referring to the documented project deliverables and milestones which are published openlyFootnote3.
2. Background and objectives
Europe lacks an adequate, open compute and storage infrastructure, following FAIR practices, that would support the exploitation of Copernicus and EO datasets in scientific and applied (e.g. monitoring and forecasting) applications on continental, regional or global scales.
From a user point of view, the variety of Earth observation data sources is rich but fragmented. There are different initiatives offering low-level as well as high-level EO data products. There are also initiatives to catalogue these data sources. However, it remains up to the users to understand this fragmented landscape and find out where to source data and how to access them.
The Copernicus Data and Information Access Services (DIASFootnote4) were initiated in response to this gap. Still, limited interoperability, compute and data resources hindered the delivery of a ubiquitous EO “data lake” and the platforms’ scopes tend to focus on data application areas that have an immediate “business” value. As a result only partial Sentinel archives and other contributing mission data related to specific business value application areas are available and there is not a sufficiently large online archive enabling researchers to run generic queries to find ready-to-use datasets near adequate compute resources to analyse them. Furthermore, the lack of open interfaces to access the computing resources needed to analyse Copernicus and EO data increases the complexity of developing data analytics, because they need to be adapted when moving from one platform to another. This in turn prevents the creation of an open library of data analytics that can be freely accessed and deployed on different platforms.
An alternative to (closed) monolithic infrastructures is an open network of data and compute providers, i.e. a federation, interoperating over high-bandwidth internet connections (de La Beaujardière, Citation2019), where multiple providers, the federation members, deliver services without being organised in a strict hierarchical setup. de La Beaujardière (Citation2019) identifies the following critical components to develop in order to replicate the convenience of a monolithic infrastructure platform using open-source software in a federated approach: (1) focus on object storage rather than file downloads as a means to share data (although it should be noted that object storage is not the only solution for effective data sharing); (2) develop scalable, data-proximate, computing solutions such as those used in the cloud; and (3) provide high-level analysis tools enabling researchers to focus on science rather than the complexity of compute and storage resource provisioning and orchestration.
A federated approach to distributed computing has been demonstrated as a feasible approach by the high energy physics community, who conceived the notion of a distributed computing grid in 1999 to analyse the massive volumes of data produced by the Large Hadron Collider at CERN (Bird et al., Citation2014). The federation model alleviates the need for one organisation to shoulder the entire infrastructural burden, allowing each organisation to focus on its strengths and thereby extend their often-limited budgets to support the greater federated goal. Additionally, an open federation of data and computing resources would overcome perceived risks related to resilience, sustainability, and flexibility compared to a single closed platform. It would also be more compatible with the distributed nature of scientific institutions and funding streams.
The European Commission initiated the implementation of the European Open Science Cloud (EOSCFootnote5) to federate existing research data infrastructures to provide capabilities to “access and reuse all publicly funded research data in Europe, across scientific disciplines and countries” and “give the EU a global lead in research data management and ensure that European scientists enjoy the full benefits of data-driven science”.
The EOSC PortalFootnote6 was set up as an access channel to cross-disciplinary services and resources for science. Leveraging the cross-disciplinary technology available through the EOSC Portal, the Copernicus – EOSC Analytics Engine project (C-SCALEFootnote7), initiated in January 2021, aims to seamlessly integrate cross-/inter- disciplinary EOSC services, ensuring interoperability between distributed data catalogues, computational tools and infrastructure. While Copernicus is practically unrivalled as a data source, processing the data and building higher-level solutions and services has suffered from a fragmented landscape and a lack of coherent approaches to interoperability and governance.
The C-SCALE project aims to demonstrate that a shared, open, general-purpose Copernicus access platform is feasible by combining and federating the best-of-breed tools, competences and services from DIAS, the national Collaborative Ground SegmentsFootnote8, academic and national compute infrastructures and EOSC. C-SCALE is federating European digital capabilities, laying the foundation for a European open-source platform for big Copernicus and EO Data Analytics. In doing so, it is the ambition of the C-SCALE federation to enable end-users to discover EO data sources based on the area of their interest, to query for products carried by different providers in a uniform fashion, and to have automated tools within analytics platforms to access such data seamlessly, choosing between available data sources on the grounds of proximity to the processing platform. Additionally, data analytics developed for the C-SCALE federation will be deployable and executable on a vast variety of providers belonging to the federation. This will be facilitated through the adoption of common and EOSC standards which will also facilitate the integration with other analysis platforms. All C-SCALE services will be openly accessible and findable through the EOSC Portal ().
Figure 1. Basic functional framework for the C-SCALE compute and data federation.
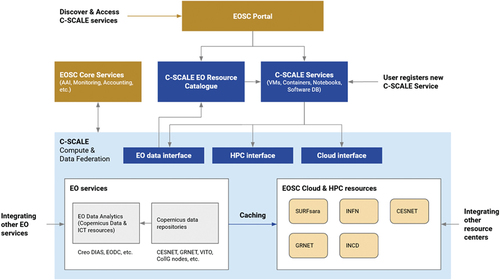
3. Federation components
In the following sections, we summarise the technologies, standards and protocols that the C-SCALE project partners have agreed upon towards implementing an open, interoperable, compute and data federation delivering Copernicus and EO data and services over high-bandwidth internet connections in Europe. More detailed information about the federation design can be found in Šustr, Hermann, Břoušek, and Daems (Citation2021) and Fernández, Oonk, Donvito, and Venekamp (Citation2021).
The federation approach for data is based on the following principles:
EO data will be retrieved directly from the provider that holds them, avoiding bottlenecks and duplication.
The federation will expose a common query interface and dispatches queries “pass-through” to C-SCALE providers.
The redundancy of data and metadata stored anywhere across the federation will be minimised.
The C-SCALE federation aims to make products accessible directly from the hosting providers. Federation services help users locate the right provider and then use the discovered resource as efficiently as possible.
3.1. Federated data discovery
Federated data discovery allows users to identify data archives relevant to their use case and harmonise access to their contents.
Sites participating in the federation rely on their existing storage, lookup and access solutions to offer two functions:
Redistribution of EO products from producers toward user communities
Attribute-based discovery of EO products
The intent is not to replace but rather to configure or extend these solutions to enable integration with the federation. A survey of participating sites and software stacks represented in the emerging federation is given in .
Table 1. EO product redistribution software used by relevant parties, indicating currently supported protocols for data access and lookup. Those are the two most important features to be unified across the federation.
A primary objective of the C-SCALE project is to enable harmonised access to data products across all participants following common authentication schemas (Section 3.2.2), and to provide a common query endpoint to discover federated products with a single call.
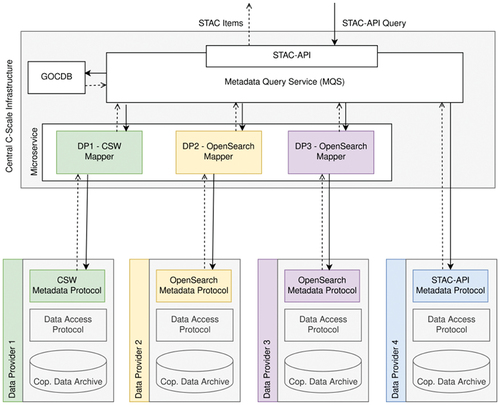
The Metadata Query Service (MQS) is being developed as the central entry point to query metadata across the federation. The MQS will identify all datasets available in the federation given user-defined constraints (hereafter referred to as queryables).
To enable this centralised search functionality the query interfaces of the single data providers will be connected to the central MQS. In this integration, the central service will act as metadata query broker only. Therefore, no caching is performed but rather the queries are only redirected by the integrated query services and then the results are aggregated and returned to the user.
As a central entry point for metadata queries, the MQS must define two interfaces to allow interaction with its user:
Request: query for products (defines the query interface)
Return: match list (defines the return format)
In designing the MQS, the following protocols have been considered in deciding on the most suitable protocol the MQS should expose: OpenSearch, CSW and STAC-APIFootnote9 (Šustr et al., Citation2021).
All three are relevant to products already in use by the EO community. OpenSearch and CSW are implemented by a subset of partners in the data federation (), while openEOFootnote10, an open API to connect R, Python, JavaScript and other clients to big Earth observation cloud back-ends in a simple and unified way (Schramm et al., Citation2021), uses STAC-API. Of the three options, CSW was found to be inferior to both OpenSearch and STAC-API. Despite the fact that CSW is a widely used Open Geospatial Consortium standard, the design of its underlying relational database has become outdated and its stringent, often over-complicated definitions are too detailed for most applications making it difficult to interact with compared to other protocols.
summarises the relative merits of OpenSearch and STAC-API.
Table 2. Pros and cons of OpenSearch and STAC-API.
The choice to use STAC and STAC-API is motivated primarily by its active development and active adoption in the EO community compared to other standards such as OpenSearch or CSW.
STAC defines how geospatial information should be described to facilitate easy indexing and discovery of data. On top of STAC, the STAC-API can be used to query catalogues. The response from STAC-API follows the GeoJSONFootnote11 specification, a well-structured, machine-friendly format for encoding a variety of geographic data structures. Both STAC and STAC-API are structured in a simple base – extension model. This allows for an iterative implementation starting with a minimal working product and then extending the two interfaces depending on external requirements. STAC-API allows searching by collection, ids, time range and spatial extent (bounding box and geometry). These queryables are supported by all members of the data federation. Future extensions of queryables will be based on requirements and the availability of queryables at the different data providers (see Šustr et al., (Citation2021) for more details).
To return all matching datasets available in the federation, the providers’ query interfaces must be integrated with the central MQS. Generally, queries are simply forwarded to data providers, their results are aggregated, and returned back to the user. To avoid querying providers who are unlikely to have any matching products, machine-readable descriptions of available datasets (product types and geographical areas of interest) and data retention policies will be registered in the federation’s service catalogue. The MQS will subsequently be able to reflect that and, for a given query, disregard sources who have declared only completely unrelated datasets.
For a data provider, two options are available to interconnect their query interface with the central MQS:
Expose the described interfaces (STAC/STAC-API).
Implement two additional mapping steps in the backend of the MQS: (a) map the STAC query received through the STAC-API to the data provider’s query interface; and (b) map the data provider’s return format to a list of STAC items. The mapping will be implemented as a Mapper-microservice in the MQS and deployed on the central infrastructure. Different implementations of the Mapper will be required by different data providers as they provide either completely different query interfaces (CSW, OpenSearch, OData) or at least different implementations and queryables.
To catalogue the service endpoints and to describe the site-specific characteristics of the federation providers, the Grid Configuration Database (GOCDBFootnote12) service will be used. GOCDB is used broadly within EOSC to catalogue participating sites and services, including specific service endpoints. GOCDB supports the use of custom attributes and does not require any extension with respect to C-SCALE requirements. The service can be used in its present EOSC-wide deployment. Default attributes will be used where appropriate, and custom attributes will carry the rest of the metadata characterising each given service endpoint within the federation. It is important to reiterate here that metadata kept in GOCDB do not refer to actual data products stored in the federation since it is one of the defining features of C-SCALE that product metadata will not be duplicated elsewhere.
The above information is summarised in , a schematic of the Metadata Query Service Architecture.
Figure 2. Metadata query service architecture.
3.2. Federated access
Data shared through the federation are mostly open-access EO products, and the authentication of users accessing products in the federation is motivated primarily by the need to keep track of usage of the data by users representing different communities and different scientific and professional disciplines. Whilst federation-wide user authentication is a topic already addressed in EOSC, providing adequate centralised services ready to be deployed, it has not yet been tested specifically for EO-related workflows. Harmonised access to a federated compute and data infrastructure is critical for interoperability between providers to support federated big data analytics where data is distributed across providers.
The EOSC Authorisation and Authentication Infrastructure (AAIFootnote13) will be used for user authentication and authorisation. The EOSC AAI brings together identity providers (IdPs), the EOSC service providers and intermediary identity management proxies, such as EGI Check-inFootnote14, IAMFootnote15 and eduTEAMSFootnote16 (to name a few). To authenticate users, C-SCALE sites set up OpenID Connect (OIDC) authentication with EGI Check-in, a proxy service that operates as a central hub to connect federated IdPs with service providers following the AARC blueprint architectureFootnote17 ().
Figure 3. Federated access in C-SCALE is achieved via EGI Check-in and SRAM. Both serve as community Authentication and Authorisation Infrastructures (Community AAI in the above) and are compliant with the AARC blueprint architecture. The above figure was taken from the EOSC-hub project documentationFootnote18.
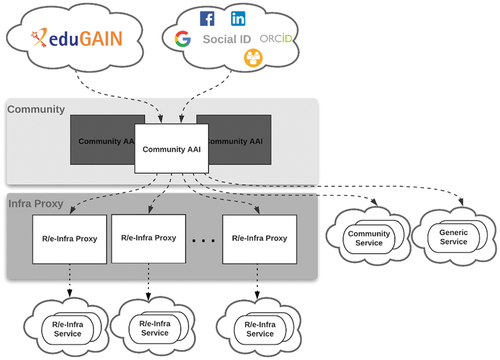
For user registration, approval, and group-based authorisation, EGI Check-in integrates with PerunFootnote19 to provide advanced identity management. EGI Check-in then uses data from Perun for authorisation and attribute release.
To support processing Copernicus and EO data, compute resources need to be integrated with the data federation. The C-SCALE federation brings together High Performance (HPC), High Throughput (HTC) and cloud compute providers.
Cloud-based providers use HTTP/REST-based APIs that can be protected with OIDC, and similarly to the data federation EGI Check-in will be used to integrate the cloud compute providers in the federation. However, HPC/HTC systems typically rely on LDAP-based identity management that synchronise user information at the nodes of the system, including the ssh public keys that allow users to connect to the system without an account password or passphrase. The only AAI intermediary identity management proxy with LDAP support to propagate user information and a Technology Readiness Level (≥8) at the time of design of the C-SCALE federation was the SURF Research Access Management (SRAMFootnote20). Hence, SRAM is currently the only mature AAI choice for LDAP-based integration of HPC and HTC providers. SRAM also supports SAML and OIDC, and C-SCALE is currently investigating how best to couple EGI Check-in and SRAM towards facilitating harmonised access across federated cloud and HPC/HTC systems.
The different compute providers may have very different internal and external network setups and policies and hence a wide variety in connectivity. Cloud and HTC systems, designed for data-intensive processing, typically have high bandwidth connectivity to the outside world. While HPC systems focus on compute-intensive processing and aim to deliver a high speed, internal network between the worker nodes, they typically do not allow external connectivity from the processing nodes and sometimes also have limited bandwidth from the login nodes to the outside world. Additionally, HTC/HPC systems focus on a managed cluster approach and hence provide access to a very large set of uniformly managed compute nodes that are optimized for complex, massive sets of calculations and data processing.
These differences for HPC and HTC systems have consequences for data logistics that impact their interaction with the data federation components, leading to further developments to support the most appropriate data query and retrieval strategy for each use case. In general, use cases can retrieve and store their data in the home and project spaces created for each use case. Depending on the network setup and storage medium of the data required by a use case, on-the-fly data staging and transport may also be possible and in fact be efficient on certain systems in the federation.
3.3. Software distribution
In a distributed and federated computing environment, users need solutions to efficiently manage and distribute their software across multiple providers. C-SCALE does not prescribe a single mechanism or solution to distribute software but provides users with the features of the EGI Applications Database (AppDBFootnote21; ) as a production-grade, central service to store and provide information about software solutions.
Figure 4. Federated software distribution in C-SCALE.
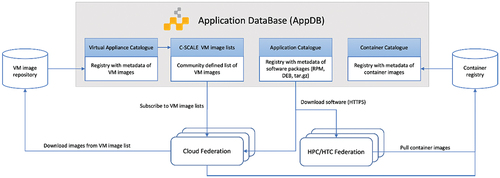
There are three main kinds of software artifacts considered in C-SCALE:
Virtual Machine Images providing the starting root volume of the disk for a Virtual Machine to run.
Container images provide a filesystem that contains all the software dependencies needed for an application to run. Several container image formats are available: Open Container InitiativeFootnote22 supported by docker and most of the container runtimes and Singularity Image FormatFootnote23, supported by Singularity. Container images can be fetched from container repositories such as Docker HubFootnote24 or stored in a distributed software repository such as CVMFSFootnote25. For managed HPC/HTC systems, software containers must be run in user space, thus specific container runtimes (e.g. Singularity and udocker) are available instead of docker.
Native software binaries that can be installed directly on the system. HPC/HTC systems allow only the installation of software within user space. The use of virtual environments (e.g. virtualenv and conda) provide software installation completely in user-space without root privileges on HPC/HTC.
AppDB offers support for native software products and Virtual Machine images with an open browsable catalogue with information on the software metadata that facilitates reusing and sharing software across user communities. Support for container images is currently under development and available as a beta featureFootnote26. The C-SCALE federation will work with user communities to create a collection of software in AppDB that will include those applications required by the use cases.
HPC systems in general have stricter software policies and re-compilation of the applications with the libraries and configuration of each specific system is highly recommended to ensure optimal performance on the hardware. Partners providing HPC systems in C-SCALE will support recompilation of the applications where appropriate. This is especially relevant for parallel applications (e.g. MPI), where the correct tuning can have a considerable impact on the performance of the applications.
External software distribution solutions are also available for use within the C-SCALE federation, although they may not have direct support by the providers within the federation. A few publicly available, external solutions that we can mention here are: B2SHAREFootnote27, ZenodoFootnote28, GitHubFootnote29, SingularityHubFootnote30 and Docker HubFootnote31.
3.4. Workflows
The purpose of the federation is to support analytics of Copernicus and EO data facilitating both interactive user access and automated workflows. shows the sequence diagram of a basic use case where an automated job queries the federation for products and access matching products for processing.
Figure 5. Basic use case sequence diagram.
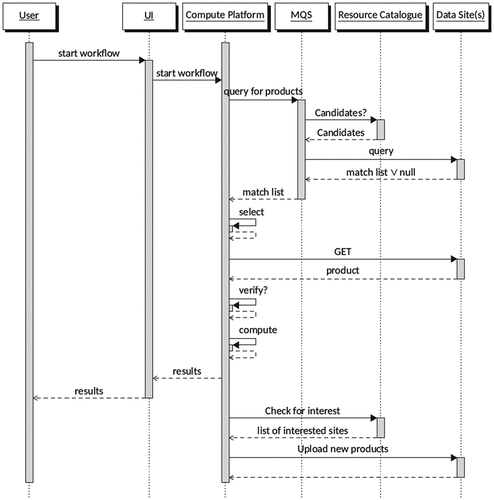
In this basic use case, the user initiates the workflow through a user interface by querying for products to analyse. A wide range of conditions (queryables) are supported, including specific product identifiers, a range of spatial, temporal, provenantial and other criteria. It uses the catalogue of service endpoints in GOCDB to identify which sites host the requested products and forwards the query only to those sites. The request returns a list of products, complete with download locations, for processing on compute resources. Where duplicate datasets are identified, the user may decide which data sources to include in the workflow based on available bandwidth or similar criteria.
It is anticipated that most use cases require downloading the required products to local scratch storage for efficient analysis. This local scratch storage may (or not) reside within the same infrastructure holding the data. Hence the next step in the workflow is to download the matching products, or a user-defined subset of these. Products are downloaded directly from the federation data sites for analysis, relying on the URLs returned by the MQS.
As an optional final step, if the results of the analysis are of interest to other users or federation members, they may be uploaded to a federation member for retention.
The workflow of the basic use case described above may be modified to best suit the community needs. For example, users may interact with the MQS directly if they only wish to perform queries to obtain results. This would enable 3rd party downstream service providers to develop, for example, STAC-enabled user tools or graphical user interfaces, leveraging the template queries with the standard programmatic interfaces of the MQS. Modifications to the basic workflow will be implemented in collaboration with the users, depending on their requirements.
4. Summary and conclusion
The C-SCALE project is presented as one initiative towards implementing an open federation of compute and data providers interoperating over high-bandwidth internet connections as an alternative to monolithic infrastructures for processing and analysing Copernicus and EO data critical for the development of a high precision digital model of the Earth to model, monitor and simulate natural phenomena and related human activities (Destination EarthFootnote32).
The following open-source technologies and services were presented as key components to implement and further develop towards replicating the convenience of a monolithic infrastructure platform using open-source software in a federated approach:
Metadata Query Service: a STAC and STAC-API to identify all datasets available in the federation given user-defined constraints.
Grid Configuration Database: a catalogue of service endpoints describing site-specific characteristics of the federation providers.
OpenID Connect (OIDC) authentication with EGI Check-in to access data and cloud computing providers, combined with Perun for advanced identity management.
LDAP based identity management using SRAM to access HPC and HTC systems.
Applications Database as a service to store and provide information about software solutions deployed in the federation.
The resultant C-SCALE service offering follows the EOSC “free at the point of use” approach, meaning that services for researchers are either offered for free by their corresponding national infrastructure or the services are funded through a project and are reimbursed through the European Commissions’ Virtual Access mechanism. Towards long term sustainability, the federation partners are developing a hybrid pricing model combining a commercial pay per use and public funding model depending on the use case and its Technology Readiness Level. For example, it is envisaged that a commercial pay per use model would be implemented for use cases that generate income and hence can support the sustainability of the federation.
With the above solutions the federation aims to provide homogenous access to resources, thereby enabling its users to generate meaningful results quickly and easily. This will be achieved by abstracting the complexity of infrastructure resource access provisioning and orchestration, including discovery of data across distributed archives, away from the end-users. Today, Copernicus and EO data are distributed in a relatively raw manner, partly even being served in the sensor track geometry (satellite swath), that requires specific sensor expertise and time-consuming and error-prone processing even for EO expert users. Hence, an additional objective is to provide access to optimised low-level data, in terms of filetype and standardised formats, as well as higher level analysis ready data, including on-demand solutions to generate analysis ready data where these are not readily available.
The above will be achieved by working closely with research communities who, through use cases, will co-design, test, pilot, identify limitations and refine components of the C-SCALE compute and data federation to iteratively build a federation addressing user needs. Users and use cases will benefit from EOSC generic services, facilitating cross-disciplinary pollination of technologies and collaboration opportunities with other big data science domains that offer their services on EOSC, such as high energy physics, astrophysics and bioinformatics. By collaborating with the infrastructure and technology providers, users will be exposed to new state-of-the-art open source solutions for science, receive support for the development of scalable cloud agnostic and interoperable solutions, and have access to a large repository of Copernicus data with fast access to computing resources.
summarises the current use cases and the scope of the challenges they are trying to overcome. Additional use cases will be onboarded through an open call for use casesFootnote33 that will expand the user community and further enable the co-design of C-SCALE components. Community needs and requirements will be identified from the use cases. In implementing their workflows, the use cases provide feedback to the infrastructure providers on how to improve the usability and functional design of the federation components. Feedback will be given through the User ForumFootnote34, and in doing so, user feedback is taken into consideration, ensuring that the federation offers services aligned with user needs. The user community is invited to contribute to the C-SCALE developments by submitting applications to the open call and contributing to the discussions on the User Forum.
Table 3. Summary of use cases and the challenges they are trying to overcome.
In deploying the six use cases (), the user community has already identified some limitations that need to be addressed. For example:
Not all Copernicus and EO datasets and tools of interest to the use cases are readily available on the compute and data federation.
Some tools depend on complex deployment solutions, such as Kubernetes clusters, which are difficult to maintain.
Access to resources is not (yet) completely harmonised, see discussion in Section 3.2.2 related to using EGI Check-in to access cloud systems and SRAM to access HTC/HPC systems.
Access to resources is not automated, requiring communication around requirements between providers and users, which generally slows down the resource provisioning.
These limitations are being addressed collaboratively with the users and infrastructure providers working closely together to find appropriate solutions to support the use case requirements.
In conclusion, while the C-SCALE project has a moderate budget and its participants represent only a portion of the Copernicus and EO stakeholders, this initiative is aiming to lay the foundation for a federated compute and data infrastructure supporting EO and Copernicus data analytics with platform services co-designed by the community.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data that support the findings of this study are openly available in https://zenodo.org/ at https://zenodo.org/communities/c-scale/.
Additional information
Funding
Notes on contributors
Björn Backeberg
Björn Backeberg is physical oceanographer with 10+ years of experience in research and development focusing on numerical modelling, satellite remote sensing and data assimilation towards the development of decision support tools for stakeholders and end-users. More recently he has focussed on building capacity in cloud computing technologies towards producing regional and global scale data analytics. He has a PhD in numerical ocean modelling from the University of Cape Town, where he also worked as a Research Officer before moving to the Council for Scientific and Industrial Research (CSIR). As in Principal Researcher in the CSIR’s Coastal Systems Research Group, he played a strategic leadership role, developing, conceptualising and leading large R&D and industrial projects. He has a broad network of international collaborators, including the Nansen Environmental and Remote Sensing Center in Bergen, Norway, where he holds an adjunct research position. In this capacity, from 2013-2018, he served as Director of the Nansen-Tutu Centre, a South African - Norwegian joint venture in marine environmental research and training. More recently he worked at the EGI Foundation, a pan-European federation of cloud providers delivering advanced computing services for research. He currently works at the Deltares Software Centre where he assists with the development and implementation of new innovative capabilities in Deltares’ simulation software and data analysis tools. This includes building capacity towards adopting cloud computing technologies in producing regional and global scale data analytics and decision support tools.
Zdeněk Šustr
Zdeněk Šustr is a researcher, developer and development team manager at CESNET. He has been involved with European high-throughput computing projects for over a decade, witnessing the shift from grid to cloud computing paradigm, starting with the EGEE series, over the EMI and EGI series of projects, INDIGO-DataCloud, to the current DEEP-HybridDataCloud and the EOSC group of projects. Since 2016 he acts on behalf of CESNET as the technology partner of the Czech Collaborative Ground Segment under ESA’s Sentinels Collaborative Ground Segment. Since Spring 2018 he represents CESNET in its role as the Czech DataHub Relay in the Sentinel’s Collaborative Ground Segment. Together with his team he also develops open source management and integration tools to enrich the Sentinel DataHubs ecosystem of Earth observation products and services.
Enol Fernández
Enol Fernández is a Cloud Solutions Manager at the EGI Foundation working on the definition of the EGI Cloud federation architecture and its innovation roadmap. He also supports the EGI Community Team in the co-design and implementation of solutions for meeting the computing requirements of their research platforms and applications. Previously, he worked in the User Community Support Team of EGI and as middleware developer and providing support to user communities at UAB and CSIC in the context of distributed computing European projects. He holds a PhD in Computer Science from Universitat Autòmoma de Barcelona and a Computing Engineering Degree from Universidad de La Laguna.
Gennadii Donchyts
Gennadii Donchyts is an expert in remote sensing, geospatial processing, and software development. During his career, he worked on multiple international research and consultancy projects, focusing on solving complex multi-disciplinary challenges and designing new algorithms for better management and visualization of scientific data. Dr. Donchyts participated in various international projects, financed by TACIS, UNDP, EURATOM, INTAS, CRDF, DANCEE, SIDA, USAID, which required profound knowledge of the modern software development techniques, database design and various agile software and project management methods, including SCRUM (Certified Scrum Master), Test-Driven Development, and eXtreme Programming. Before starting his Ph.D., he has been a technical lead of a team, working on the development of a new integrated modeling software of Deltares (Delta Shell). In recent years, his main focus has shifted to the development of new methods for the quantification of surface water dynamics from Earth Observation data at a planetary scale. The latter involves the processing of multitemporal, multisensory, and multi-petabyte satellite data using the Google Earth Engine platform. Dr. Donchyts participates in many research projects focusing on large-scale EO data processing, development of web and Cloudbased software solutions for large-scale geospatial data processing and visualization.
Arjen Haag
Arjen Haag is a hydrologist and remote sensing analyst with a special interest in understanding high river discharges and floods. He combines hydrological knowledge with modelling, GIS analysis, data-driven approaches and satellite observations, on topics ranging from water resource management to flood forecasting. He is working at the department of Operational Water Management and Early Warning, while maintaining close ties with other relevant departments. Arjen has a bachelor’s degree in civil engineering, with a minor on remote sensing and geospatial processing, and completed his master’s degree in hydrology at Utrecht University. For his bachelor thesis he updated a data-driven model used operationally at Rijkswaterstaat, the Dutch Directorate-General for Public Works and Water Management. For his MSc thesis he created a fully two-way coupled setup between a global hydrological model and a detailed hydraulic model, allowing exchange of information during model runs. This was used as a starting point for a now completed PhD research. Since then, he has increased his expertise in all fields, specifically flood risk and hydrological forecasting. Additionally, he improved his knowledge of remote sensing and became an expert in the use of Google Earth Engine, a planetary-scale platform for earth science data & analysis. Recently, he has also added artificial intelligence (machine learning, deep learning) to his toolkit, applying this on large geospatial datasets including those obtained from earth observation. At Deltares, he does projects all across the globe, many of which focus on early warning and disaster response, as well as more long-term planning and adaptation. He has helped set up flood forecasting system using the Delft-FEWS platform in various countries, as well as transboundary river basin systems, and built operational earth observation tools for flood mapping and other water-related applications.
Gerben Venekamp
J. B. Raymond Oonk is a senior advisor at SURF in the Netherlands. He works in the distributed data processing (DDP) group and leads an innovation team on big data science driven technologies. Together with the DDP group, he is responsible for the Data Processing and the Custom Cloud Solutions services at SURF. Raymond coordinates large (inter)national data-intensive processing projects focusing primarily on the Astronomy, High Energy Physics and Geosciences domains. Before joining SURF, Raymond was a researcher at the National Institute for Radio Astronomy and at Leiden University. Raymond holds a Ph.D. (2011) in Astronomy from Leiden University. He has supervised 3 MSc students, 5 PhD students, 1 Postdoc and has served as the co-promotor for 3 PhD students.
Gerben Venekamp is an advisor at SURF in the Netherlands within the Trust & Identity group. After obtaining hist MSc in Artificial Intelligence he worked for almost eight years on identities and access to local resources in Grid Computing (European Data Grid, EGEE and EGEE II). After that he moved to the field of smart energy and worked in various European projects on issues related to the energy transition. In 2016 he moved to SURF and started to work on Authentication and Authorization Infrastructures (AAI). He helped piloting the predecessor of SRAM. Currently Gerben is working with a number of SURF’s own research services to connect them to SRAM.
Benjamin Schumacher
Benjamin Schumacher is an environmental geographer at EODC with experience in developing, handling, and analysing results of algorithms connected with Big Data. Conducted research at the University of Marburg in environmental and climate data analysis, statistical and dynamical downscaling and remote sensing as well as geo-data base management. Finished Master’s Thesis with UCAR in Christchurch NZ, concerning the recyclable amount of water and local moisture pathways at Mt Kilimanjaro, Tanzania which has been published in the International Journal of Climatology. Currently working on the PhD Project “Evolution Evolution of micrometeorological observations: Instantaneous spatial and temporal wind velocity from thermal image processing” at the School of Earth and Environment, University of Canterbury, New Zealand. Scientifically interested in Big Data and climate change analysis for sustainable development of planet earth.
Stefan Reimond
Stefan Reimond is a software, data and operations engineer at EODC in Vienna. Together with his team, he is responsible for the technical realisation of national and international science and technology projects focusing on the development of services for users of Earth Observation data. His work covers the development, implementation and deployment of software components with a strong data-oriented focus and their operation and management using state-of-the art DevOps tools. He also supports the project management team in the reporting and documentation phase for meeting milestones and deliverables during the project life cycle. Stefan holds a MSc in Geodesy from Graz University of Technology. He has previously worked as a research assistant in the Planetary Geodesy research group at the Austrian Academy of Sciences' (ÖAW) Space Research Institute (IWF), where he focused on advanced modelling techniques to further exploit space gravimetry data.
Charis Chatzikyriakou
Charis Chatzikyriakou obtained her MSc (2017) in Civil Engineering, and more specifically in Geoscience and Remote Sensing, at Delft University of Technology, NL. She focused on Airborne and Terrestrial Laser Scanning, Satellite Image Processing, Terrestrial and Satellite Geodesy amongst other fields. After her studies, she worked as a Project Manager at Terra Drone Europe B.V., where she managed the geo-data acquisition and processing in photogrammetric and LiDAR national and international projects. Charis now works as a Project Manager at EODC and is responsible for the acquisition and implementation of EC, ESA and national projects in the field of Earth Observation data and services, including task coordination, tracking and control, financial management, scientific and financial reporting.
Notes
9. Spatial Temporal Asset Catalog: https://stacspec.org/.
10. https://openeo.org/.
11. https://geojson.org/.
12. https://goc.egi.eu/.
28. https://zenodo.org/.
29. https://github.com/.
References
- Abernathey, R., & Hamman, J. (2020). Closed platforms vs. open architectures for cloud-native earth system analytics. Blog post. Retrieved from https://medium.com/pangeo/closed-platforms-vs-open-architectures-for-cloud-native-earth-system-analytics-1ad88708ebb6
- Bauer-Marschallinger, B., Cao, S., Navacchi, C., Freeman, V., Reuß, F., Geudtner, D., & Wagner, W. (2021). The normalised Sentinel-1 Global Backscatter Model, mapping Earth’s land surface with C-band microwaves. Scientific Data, 8(1), 277. doi:10.1038/s41597-021-01059-7
- Bird, I., Buncic, P., Carminati, F., Cattaneo, M., Clarke, P., Fisk, I., … Mount, R. (2014). Update of the computing models of the WLCG and the LHC experiments. Retrieved from http://cds.cern.ch/record/1695401/files/LCG-TDR-002.pdf
- Camara, G., Fernando Assis, L., Ribeiro, G., Reis Ferreira, K., Llapa, E., & Vinhas, L. (2016). Big earth observation data analytics: Matching requirements to system architectures. In Proceedings of the 5th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data (BigSpatial ’16) (pp. 1–6). New York, NY: Association for Computing Machinery. doi:10.1145/3006386.3006393
- de La Beaujardière, J. (2019). A geodata fabric for the 21st century. EOS, 100. doi:10.1029/2019EO136386
- Donchyts, G., Baart, F., Winsemius, H., Gorelick, N., Kwadijk, J., & van de Giesen, N. (2016). Earth’s surface water change over the past 30 years. Nature Climate Change, 6(9), 810–813. doi:10.1038/nclimate3111
- Fernández, E., Oonk, R., Donvito, G., & Venekamp, G. (2021). (C-SCALE) initial design of the compute federation. doi:10.5281/zenodo.5084884.
- Gomes, V. C. F., Queiroz, G. R., & Ferreira, K. R. (2020). An overview of platforms for big earth observation data management and analysis. Remote Sensing, 12(8), 1253. doi:10.3390/rs12081253
- Gorelick, N., Hancher, M., Dixon, M., Ilyushchenko, S., Thau, D., & Moore, R. (2017). Google earth engine: Planetary-scale geospatial analysis for everyone. Remote Sensing of Environment, 202, 18–27. doi:10.1016/j.rse.2017.06.031
- Overpeck, J. T., Meehl, G., Bony, S., & Easterling, D. R. (2011). Climate data challenges in the 21st century. Science, 331(6018), 700–702. doi:10.1126/science.1197869
- Pekel, J.F., Cottam, A., Gorelick, N., & Belward, A. S. (2016). High-Resolution mapping of global surface water and its long-term changes. Nature, 540(7633), 418–422. doi:10.1038/nature20584
- Ramachandran, R., Lynnes, C., Baynes, K., Murphy, K., Baker, J., Kinney, J., … Smith, M. J. (2018). Recommendations to improve downloads of large earth observation data. Data Science Journal, 17. doi:10.5334/dsj-2018-002
- Schramm, M., Pebesma, E., Milenkovic, M., Foresta, L., Dries, J., Jacob, A., … Reiche, J. (2021). The openEO API - Harmonising use of earth observation cloud services using virtual data cube functionalities. Remote Sensing, 13(6), 1125. doi:10.3390/rs13061125
- Sudmanns, M., Tiede, D., Lang, S., Bergstedt, H., Trost, G., Augustin, H., … Blaschke, T. (2020). Big Earth data: Disruptive changes in Earth observation data management and analysis? International Journal of Digital Earth, 13(7), 832–850. doi:10.1080/17538947.2019.1585976
- Šustr, Z., Hermann, S., Břoušek, P., & Daems, D. (2021). C-SCALE Copernicus data access and querying design. doi:10.5281/zenodo.5045317
- Wagemann, J., Siemen, S., Seeger, B., & Bendix, J. (2021). A user perspective on future cloud-based services for big Earth data. International Journal of Digital Earth, 14(12), 1758–1774. doi:10.1080/17538947.2021.1982031
- Wagner, W., Bauer-Marschallinger, B., Navacchi, C., Reuß, F., Cao, S., Reimer, C., … Briese, C. (2021). A sentinel-1 backscatter datacube for global land monitoring applications. Remote Sensing, 13(22), 4622. doi:10.3390/rs13224622