
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
This paper proposes an approach under the framework of deep learning for the task of identification and extraction of high-voltage transmission wires in power grids based on high-resolution optical remote sensing images. First, the task is defined as a semantic segmentation problem. Based on the recently proposed Swin-Unet framework, an intuitive improvement named ‘Swin-Unet-M’ with a refined linear embedding is proposed, improving the wire segmentation performance. Second, an effective sample synthesis technique is developed to generate training images containing wires. The wire target is randomly merged in background images to generate a rich pseudo-wire segmentation training dataset. Consequently, the cost of manually pixel-wise wire labelling is largely reduced. Experimental results demonstrate that the proposed Swin-Unet-M model can obtain higher segmentation performance and effectively identify and extract the wires in real images.
1. Introduction
The inspection of transmission systems in power grids is related heavily to the safety and stability of power grids, as Zhou et al. (Citation2018a) point out. Power grid companies invest a lot of resources every year for power inspection. At present, however, the power inspection work of high-voltage transmission wires in most countries was mainly done manually, which requires a lot of human or financial resources. Furthermore, its real-time performance is poor, especially in a harsh environment, where the transmission wires could not be checked in time, as demonstrated in (Shimasaki et al. Citation2019; Zhang et al. Citation2020). Technically, in way of sensor imaging, unmanned aerial vehicles (UAVs) that carry cameras can provide accurate environmental perception, further enhancing the drone’s monitoring capabilities. Compared with the imaging methods using airplanes/satellites, UAV-based image acquisition has enormous advantages in practical applications, as Haroun, Deros, and Din (Citation2021) point out.
This paper studies the segmentation method of transmission wires in remote sensing images. Identifying the wires in transmission corridor can conveniently screen the hazards, such as the possible hanging foreign objects in wires, favouring the smart inspection on power grids. Affected by the flying height of drones and the resolution of cameras, the wires often exhibit the following characteristics in images: (1) the wires are generally thin (see ) and affected by the imaging resolution, whose width often occupies only a few pixels, and some wires even appear as hair filaments; (2) the wires are generally lighter in brightness and grey in appearance (see ), and their image brightness values are very similar to those of grey buildings or cement roads. The background information under the wire could also cause aliasing to the imaging spectrum of the wire, due to the unavoidable spectral mixing in remote sensing. For example, when the wire passes over the water, the radiation of wires radiated to the water is often aliased, and the wire target is even submerged from the background, e.g., (; (3) when the drone is flying, it could be easily accompanied by small vibrations, causing the wires to appear bundled in the image, as shown in (. From the figures, it is observed that there exist multiple wire ‘artefacts’ in the image. Additionally, the ambient light and weather conditions during imaging also have certain impacts on wires. In general, identifying wires in high-altitude aerial photography is an urgent and challenging problem to be solved. Consequently, it is of great significance to study the identification of transmission wires on power grids.
Figure 1. Representative samples with different characteristics of transmission wires in high-resolution optical remote sensing images.

With the development of deep learning, convolutional neural networks have shown great potential in computer vision and continue to maintain optimal performance in object classification, segmentation, etc. On one hand, to solve the aforementioned problems and difficulties for the accurate wire segmentation in remote sensing images, this paper proposes a new Swin Transformer based segmentation network named ‘Swin-Unet-M’ with a refined linear embedding, enhancing feature representative capability for thin-and-long objects alike wires. On the other hand, to reduce the manual pixel-wise annotation cost for wire images, an effective approach for wire image composition/synthesis is proposed, and a rich ‘pseudo-wire’ segmentation training dataset is generated. Experimental results demonstrate that the proposed Swin-Unet-M model can effectively identify the wires, on both synthetic and real remote sensing images.
Our contribution mainly lies in three points: (1) As far as we know, our work is the first trial to study the automatic segmentation of transmission wires in high-altitude overhead aerial/satellite remote sensing images, which can favour the intelligent inspection of power grids. (2) An improved pixel-wise wire segmentation model named ‘Swin-Unet-M’, inspired by the U-Net and Swin Transformer architectures, is proposed. (3) An intuitive and effective sample generation technique is developed, which can largely reduce the cost of manual pixel-wise labelling for wire segmentation dataset. Extensive experiments on both synthetic and real wire datasets are promising, demonstrating the efficiency of the proposed model for the task of wire segmentation.
2. The proposed approaches
2.1. Refined linear embedding for wire segmentation
We focus on the two-class (wire or not-wire) pixel-wise segmentation task in remote sensing images. As described above, segmenting the wires with a thin and long shape from complex background is challenging. Although the U-Net architecture and its variants, such as the research works developed in (Ronneberger, Fischer, and Brox Citation2015) and (Zhou et al. Citation2018b), are suitable for this task, owing to its mechanism of multi-scale feature fusion, it does not effectively model the pixel-level relationship that is very important for the segmentation of thin-and-long shape of wires.
Recently, Liu et al. (Citation2021) proposed the Swin Transformer architecture, achieving the state-of-the-art performance on various vision tasks. More recently, Cao et al. (Citation2021) adopted the Swin Transformer block as an basic unit to build an U-Net alike architecture for medical image segmentation. Considering that the wires are of thin and long shapes and the complex backgrounds in remote sensing images, attention-based modelling that lays on the level of pixels could be promising to address this issue. This offers a chance to combine U-Net and Swin-Transformer together for our task. Although these models, including U-Net and Swin-Transformer, can work well in their own situations, simply integrating them together with vertical package will not yield good performances. This observation motivates us to design improved modules to enhance their ability with a natural architectural design with tricks of multi-scale feature fusion and low-level attention on shifted window.
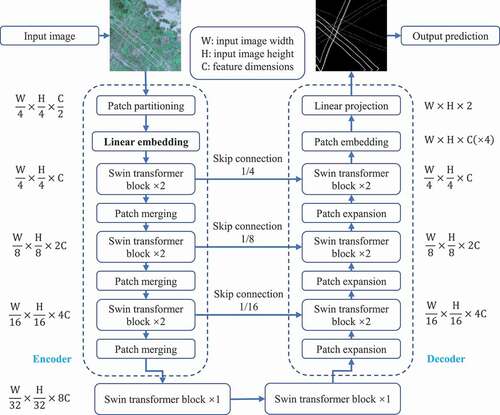
The overall architecture of the ‘Swin-Unet’ model is illustrated in , which mainly consists of three parts: encoder, bottleneck, and decoder. For the encoder, input images are split into non-overlapping patches with patch size of as sequence embedding. A linear embedding layer is applied to project the features into arbitrary dimension. These transformed patch tokens are passed into subsequent Swin Transformer blocks and patch merging layers to generate hierarchical feature representations. The patch merging layer is responsible for downsampling and increasing feature dimension, which is similar to the pooling layer in traditional U-Net alike networks. In the bottleneck, two Swin Transformer blocks are used to construct the bottleneck to learn the deep representation and the outputs are fed into the decoder.
Figure 2. Flowchart of the Swin-Unet-M model for wire segmentation.
The Swin Transformer block proposed in Liu et al. (Citation2021) consists of a shifted window based multi-head self-attention module, followed by a 2-layer multi-layer perceptron (MLP) with Gaussian error linear unit (GELU) nonlinearity in between. A LayerNorm (LN) layer is applied before each multi-head self-attention (MSA) module and each MLP, and a residual connection is applied after each module. Let be the input features of Swin Transformer block, the output feature
is computed as
where and
are the output features of SW-MSA and W-MSA for block
, respectively. W-MSA and SW-MSA are window-based multi-head self-attention mechanisms using regular and shifted window partitioning strategy, respectively. Similar to previous works based on vision transformers, Swin Transformer introduces a relative position bias using a small-size matrix
to compute the self-attention:
where are the query, key matrix and value matrix in Transformer module,
is the query/key dimension, and
is the number of image patches in rows and columns. With the shifted window partitioning approach, the connections between neighbouring non-overlapping windows from the previous layer are effectively captured, which have been proved to be effective, as Liu et al. (Citation2021) demonstrated.
Our task is to recognize the wires in remote sensing images. As aforementioned, the wire is generally thin in the original image and might only occupy a few pixels, which poses difficulties and challenges for accurate segmentation. However, note that in the original ‘Linear Embedding’ block of the encoder of Swin-Unet, the input image is directly processed by a convolution operation with kernel size of and stride of
. Consequently, the original wire information might be blurred in the output features, leading to difficulties for the network to recover the wire details in the output.
To better keep the wire information and enhance the feature representation for segmentation, an improvement module with tricks of ‘Linear Embedding’ of Swin-Unet is developed, that is, using two consecutive convolution blocks with smaller kernel sizes and strides, each of convolution layer followed by a max pooling layer. With the two consecutive convolution-maxpooling operations, the output features of ‘Refined Linear Embedding’ will keep the wire information as much as possible and facilitate its feature recovery in the decoder. We name the new model as ‘Swin-Unet-M’. The main difference between Swin-Unet and Swin-Unet-M is summarized in .
Table 1. The differences between Swin-Unet and Swin-Unet-M in ‘Linear Embedding’ module. Conv means the convolutional layer, means the kernel size,
means the stride,
means the padding size. Maxpool denotes the maxpooling layer.
means the batch size.
denotes the feature dimension (
in this study).
Due to the data imbalance in wire and non-wire pixel samples, a hybrid loss is adopted for network training. Specifically, a linear combination of weighted binary cross-entropy loss and dice loss is adopted for both the Swin-Unet and Swin-Unet-M networks, , where the cross-entropy loss
is defined as
where denotes the probability of pixel
belongs to non-wire or wire class,
indicates the ground truth label,
is the class weight,
is a trade-off parameter to balance the contributions of both losses,
is the total number of pixels. The dice loss
is
To sum up, our proposed Swin-Unet-M model adopts two consecutive convolutional blocks with small kernels in the shallow layers, and retains as much of the wire pixel information as possible for subsequent feature extraction in the encoder and the reconstruction in the decoder. Consequently, the proposed model is expected to have powerful capability of segmenting the thin and long shape of objects in images and achieve better performance than the conventional Swin-Unet and U-Net-alike models.
2.2. Pseudo-wire data generation
The pixel-wise manually labelling of wires in remote sensing images is time-consuming. With careful observations on these images, we have the following findings: (1) the wire is thin and does not have complex textures or characteristic structures like human faces, (2) the wire object itself is generally with a cylinder shape, which is unrelated to the viewpoint of the imaging camera. These aspects inspire us to propose an effective method of image composition to construct the wire segmentation dataset.
The flow chart of the proposed approach is shown in the . First, a small number of easy-to-label wire pixels for fine-scale annotation of artificial wires is selected, then the colour statistics of wires according to the labelling information is extracted, and the typical colour values of wires through pixel clustering is obtained. Meanwhile, the area of wires in the corridor of wire in the image is labelled. This labelling method can largely reduce the time for labelling the wire in a pixel-wise way.
Figure 3. Flow chart of the proposed synthetic wire sample generation.
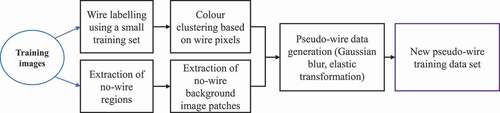
After obtaining the typical colour values of the wire, the next step is to generate the wire. A background patch from one image is randomly selected and a straight line is drawn. The colour value of drawn line is randomly sampled within of the typical colour values. Meanwhile, the corresponding wire mask image (i.e., the ground truth) can be generated according to the position where the line is drawn. In order to generate more realistic wire data, random Gaussian blur or Elastic geometric transformation proposed by Yan and Tokuda (Citation1993) is performed on the synthetic image after the straight wire line is drawn. Elastic geometric transformation is also applied to the ground truth mask image. In this way, a large number of wire segmentation images containing ‘wires’ can be generated. Several representative examples including the synthetic images and ground truth are shown in the first two columns of .
Figure 4. Visualization of segmentation results on synthetic test set. The images from left to right of each row are: original image, ground truth, the results obtained using FCN-Unet, Deeplab-Unet, PSP-Unet, Swin-Unet, and Swin-Unet-M.

3. Experiments
3.1. Datasets and experimental settings
In this study, the experimental data included 19 aerial remote sensing images taken from high-altitude drones, which mimics the satellite imaging but with much higher spatial resolution. 13 images of them were selected to construct the training set, and the remaining six images were used as the test set. The width and height of these images range from 12,330 to 130,438, with the resolution ranging from 0.03 m to 0.05 m.
In order to evaluate the performance of wire segmentation, five trials were independently conducted. In each trial, a test set was also synthesized for quantitative evaluation. The background images on this test set are all extracted from the big image in the original test set. In the synthesized dataset, the size of background images is all set to pixels. Finally, the synthetic training and testing dataset in each trial contains a total of 3670 and 332 samples, respectively.
Three remarkable U-Net networks have been evaluated for the task of wire segmentation following the best practices in the open-source mmsegmentationFootnote1 framework. FCN-Unet is the original fully convolutional U-Net network with simple convolution, max-pooling and up-sampling layers. Deeplab-Unet is an U-Net architecture equipped with the cascade multi-scale context modules and spatial pyramid pooling module described by Chen et al. (Citation2018). PSP-Unet developed in Zhao et al. (Citation2017) is built upon the pyramid scene parsing network. During training, we randomly crop different sizes of patches (i.e., ,
and
pixels) and fed them into these networks for training. The stochastic gradient descent (SGD) algorithm is used, the batch size is 4, the initial learning rate is 0.01, and the number of training steps is 40,000. During testing, the sliding window technique is adopted to obtain the probabilistic maps and generate predictions.
For the Swin-Unet and Swin-Unet-M, we follow the hyperparameter settings used in Cao et al. (Citation2021): and
in loss
are empirically set to 0.4 and 180, respectively. The batch size during training is
, the SGD optimizer with momentum
and weight decay
is adopted to train the models. The pre-trained weights on ImageNet are used to initialize the model parameters Cao et al. (Citation2021). During network training, the early-stop technique is adopted to select the final optimal model.
In this task, only two classes of wire foreground and background are included, resulting in a binary segmentation problem. Dice coefficient (DSC) and average Intersection Over Union (mIoU) are two common evaluation metrics. DSC measures the region overlap of two segmentations, and IoU is known as Jaccard distance. Their mean and standard deviation values on five independent trials were reported.
3.2. Results and analysis
All results for the three U-Nets are reported in . First, the highest DSC is , obtained from the FCN-Unet, and the corresponding IoU is
. The overall difference among the three U-Nets is not significant, in either DSCs or mIoUs. Second, with different size of input patches, the performance of each model are different. Basically, larger the size of input patch is, the better performance the trained model can have. The reason is that, with larger size of input image patch, the networks can have more context information and can discriminate more background pixels from wire pixels.
Table 2. Wire segmentation performance of three typical U-Net architectures with three different patch sizes (i.e., ,
, and
pixels).
reports the segmentation performance of Swin-Unet and the proposed Swin-Unet-M. In our experiments, similar to the experimental setting presented in Cao et al. (Citation2021), we randomly crop image patches with size of pixels from the input images and fed them into Swin-Unet and Swin-Unet-M. Multiple models were trained with different initial base learning rates (LR). From , all evaluation metrics are constantly higher than those in . First, both Swin-Unet and the proposed Swin-Unet-M can achieve better performances over the traditional U-Nets, which shows the efficiency of Swin Transformer based U-Net architecture on the task of wire segmentation. Second, compared to the Swin-Unet, the proposed Swin-Unet-M have better evaluation results. Especially, the trained Swin-Unet-M model with a learning rate of
has achieved the best mean DSC of
.
Table 3. Wire segmentation performance of the Swin-Unet and Swin-Unet-M with different learning rates (LR). The bold numbers mean the best result.
shows the wire segmentation results on the synthetic test set. As illustrated, the wire segmentation method based on Swin-Unet-M proposed in this paper can segment the composite wires in these images. From , it is found that some background areas, which contain vegetation or composite buildings, have certain side effects on correct wire identification within the area. The wires in can be correctly identified, but the model also recognizes some road background as wires.
shows the wire prediction results of the U-Nets, Swin-Unet and Swin-Unet-M on the real images. Note that all these images do not have ground truth labelling and not used for training. The models are all trained on the synthetic wire dataset. It can be seen that these models can identify the wires in real images very well, which indicates their good generalization capability, and also suggests the efficiency of the proposed sample generation technique. Especially for the images with obvious wires but simple background, the recognition results looks good, as shown in (. Moreover, from , we can see our Swin-Unet-M achieves much better results regarding to the recognition of wire pixels, while the conventional U-Nets wrongly recognize the pixels belongs to tower as wires. This provides positive evidences on the powerful representative capability of Swin Transformer based architectures over the convolutional ones. Also, the promising segmentation results on real images shows the effectiveness of the proposed pseudo-wire synthesis technique. However, for those images with complicated background and thin/blurred wires, as shown in , the segmentation performance seems very limited. These results illustrate the challenges of wire segmentation, providing us the possible research directions in future.
Figure 5. Visualization of segmentation results on four real images. The images from left to right of each row are: original image and the results obtained using FCN-Unet, Deeplab-Unet, PSP-Unet, Swin-Unet and the proposed Swin-Unet-M, respectively.

For Swin-Net and Swin-Unet-M, the mean inference time on an input image with size of 512 undefined pixels are 0.1664 and 0.1817 s, respectively. The Swin-Unet-M has a slightly more inference time compared to the original Swin-Unet.
To sum up, the proposed approaches have two advantages. First, the wire data synthetic technique facilitates generating large wire segmentation data set and can largely reduce the manual pixel-wise labelling cost. From our experiments, the trained models on the synthetic wire images can effectively recognize the wires in real images, as shown in . Second, the Swin-Unet-M model can obtain better wire segmentation performance, compared to the common U-Nets and the original Swin-Unet, showing powerful capability of segmenting the thin and long shape of wires, in either synthetic or real images. However, there are still some room or drawbacks to be improved. First, in terms of wire data generation, the pixel colour clustering is adopted to generate candidate wire colour clusters that are used to draw pseudo-wire lines in background images. How to better model the wire lines with more styles is still an open challenge. Take the figures in as example, the real image usually contains some complex artefacts of wires, how to efficiently model these types of wire style is challenging. Second, for the proposed Swin-Unet-M model, although the refined linear embedding can effectively retain the pixel-wise wire information for subsequent feature extraction, it needs more computation cost, compared to the original Swin-Unet. How to effectively reduce the network computation cost with light-weight architectures while keeping high segmentation accuracy would be an interesting research subject.
4. Conclusion
This paper investigated the automatic segmentation of transmission wires in remote sensing images. First, an intuitive wire segmentation model named Swin-Unet-M with a refined linear embedding was proposed for improved performance. Second, an effective but straightforward synthetic image composition technique for wire datasets was developed, practically reducing the labelling cost. Third, extensive experiments based on the synthetic wire dataset were conducted, and several well-known U-Net models were evaluated. Compared to the traditional U-Net-based methods, the proposed Swin-Unet-M can perform better. In addition, experimental results on real images suggested that the proposed model is also powerful to extract real wires in images.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes
References
- Cao, H., Y. Wang, J. Chen, D. Jiang, X. Zhang, Q. Tian, and M. Wang. 2021. “Swin-Unet: Unet-Like Pure Transformer for Medical Image Segmentation.” Accessed 12 May 2021. https://arxiv.org/abs/2105.05537
- Chen, L.-C., Y. Zhu, G. Papandreou, F. Schroff, and H. Adam. 2018. ”Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation.” In Computer Vision – ECCV 2018, edited by V. Ferrari, M. Hebert, C. Sminchisescu, and Y. Weiss, 833–851. Cham: Springer International Publishing.
- Haroun, F. M. E., S. N. M. Deros, and N. M. Din. 2021. “Detection and Monitoring of Power Line Corridor from Satellite Imagery Using RetinaNet and K-Mean Clustering.” IEEE Access 9: 116720–116730. doi:https://doi.org/10.1109/ACCESS.2021.3106550.
- Liu, Z., Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo. 2021. “Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows.” 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 9992–10002. Los Alamitos, CA: IEEE Computer Society, October.
- Ronneberger, O., P. Fischer, and T. Brox. 2015. ”U-Net: Convolutional Networks for Biomedical Image Segmentation.” Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015, Lecture Notes in Computer Science, 234–241. Cham: Springer International Publishing.
- Shimasaki, H., S. Ryuhei, H. Takano, and H. Taoka. 2019. “A Study on Maintenance Decision Support for Power Grid Components Using Their Inspection and Maintenance Records.” Journal of International Council on Electrical Engineering 9 (1): 38–44. doi:https://doi.org/10.1080/22348972.2019.1612976.
- Yan, R., and N. Tokuda. 1993. ”Analysis and Recognition of Medical Images: 1. Elastic Deformation Transformation.” In Communicating with Virtual Worlds, edited by N. M. Thalmann and D. Thalmann, 580–593. Tokyo: Springer Japan.
- Zhang, S., Z. Lei, Y. Liu, W. Yang, Q. Zhao, S. Yang, and P. Xu. 2020. “Analysis of Intelligent Inspection Program for UAV Grid Based on AI.” 2020 IEEE International Conference on High Voltage Engineering and Application (ICHVE) Beijing, China, 1–4.
- Zhao, H., J. Shi, X. Qi, X. Wang, and J. Jia. 2017. “Pyramid Scene Parsing Network.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Los Alamitos, CA, USA, 6230–6239.
- Zhou, Z., C. Zhang, C. Xu, F. Xiong, Y. Zhang, and T. Umer. 2018a. “Energy-Efficient Industrial Internet of UAVs for Power Line Inspection in Smart Grid.” IEEE Transactions on Industrial Informatics 14 (6): 2705–2714. doi:https://doi.org/10.1109/TII.2018.2794320.
- Zhou, Z., M. M. Rahman Siddiquee, N. Tajbakhsh, and J. Liang. 2018b. “Unet++: A Nested U-Net Architecture for Medical Image Segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support,Stoyanov, Danail, Taylor, Zeike, Carneiro, Gustavo, Syeda-Mahmood, Tanveer, Martel, Anne, Maier-Hein, Lena, Tavares, João Manuel R.S., Bradley, Andrew, Papa, João Paulo, Belagiannis, Vasileios, Nascimento, Jacinto C., Lu, Zhi, Conjeti, Sailesh, Moradi, Mehdi, Greenspan, Hayit, Madabhushi, Anant (Eds.), 3–11. Cham: Springer.