
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Tower state recognition is of great importance in smart electric power management. Most previous efforts were devoted on the guyed towers and tower structures or materials to monitor the structural stability of towers through sensors fixed on them. Actually, identifying their states as a whole is also needed for remote management. This study addresses the task of tower state recognition in high-resolution remote-sensing images under the framework of deep learning. To achieve this goal, a new remote-sensing image dataset is constructed. Technically then, an ensemble learning strategy is developed to classify the states of the transmission towers. Specifically, MobileNetV3 is taken as the weak classifier as it is simple yet parameter-light in the family of convolutional networks. Along the line of ensemble learning with the principal of Adaboost in machine learning, an Adaboost-style network paradigm, named as Adaboost-MobileNetV3 in this paper, is finally proposed to recognize the states of towers. To evaluate its effectiveness, a series of deep convolutional networks are compared with the proposed network. The extensive comparative experiments indicate that the proposed Adaboost-MobileNetV3 network is suitable for practical tower state recognition, which achieves about 90% accuracy with at least about 4% higher than these compared models.
1. Introduction
Smart inspection for power grids has received growing attention in recent years. Among them, power transmission tower is one of the most critical components to be inspected. Previous methods for this task have been mostly constructed to monitor the towers with sensors, as demonstrated in (Carlos and Kaminski Citation2017; Lu et al. Citation2022). Nowadays, high-resolution remote-sensing (RS) images record large regions with rich details. Beyond with sensors, recognizing the towers in RS images as a whole renders a cheaper way to develop tools of intelligent inspection with machine learning methods.
As surveyed and demonstrated in Matikainen et al. (Citation2016), Dileep (Citation2020), and Li et al. (Citation2022), some approaches have been developed for vision-based transmission tower detection. Our literature investigation indicates that recognizing tower states in RS images, such as ‘normal-tower’, ‘broken-tower’ and ‘buckled-tower’, has not gained enough attention. As RS images contain complex backgrounds, tower-like objects and noise, recognizing towers in RS images is actually a challenging task in practice.
Recently, convolutional neural networks (CNNs) have witnessed the great success in computer vision. Most CNNs for image classification, such as Visual Geometry Group (VGG) network (Simonyan and Zisserman Citation2014), GoogleNet (Szegedy et al. Citation2015), Residual Network (ResNet) (He et al. Citation2016) and Vision Transformer (Dosovitskiy et al. Citation2021), are developed for natural images with large-scale parameters. In addition, some combinations with heterogeneous learners, for examples, CNN with multilayer perceptron (Ahsan et al. Citation2020), CNN with support vector machine (Liu, Xiangbin, and Sun Citation2018), CNN with self-organizing maps (Awad and Lauteri Citation2021), are considered to develop complex models. Those models with huge parameters should be trained with powerful GPUs. Light-weight networks are needed to reduce the cost in real-world applications. However, the classification accuracy, even with the famous yet powerful MobileNetV3, as demonstrated in Howard et al. (Citation2019), is still limited, when it is applied to complex RS images in the wilds. This observation motivates us to ensemble a series of light-weight networks to enhance the performance.
In this study, we propose a new Adaboost-style paradigm with CNNs and Adaboost algorithm in view of ensemble learning. Within this framework, the MobileNetV3 is taken as the weak learner. After a series of weak learners are trained, they are then integrated together which is named as Adaboost-MobileNetV3 for convenience. The proposed method can take the advantages of MobileNetV3 and Adaboost simultaneously, producing a more powerful classifier for the task of tower state recognition.
To sum up, the contributions and main work in this paper are highlighted as follows:
(1) To our best knowledge, this work is the first one to study the task of state recognition of power transmission towers in RS images, which renders practical value for intelligent inspection of power grids with drone/satellite RS.
(2) Based on the empirical observations, an Adaboost-MobileNetV3 model is constructed to improve the recognition accuracy, which is developed according to the principles of ensemble learning and deep learning.
(3) A large-scale image dataset is constructed to support for this issue by identifying four typical classes of tower states: normal-tower, broken-tower, buckled-tower, and non-tower (object like towers but really not).
(4) The Adaboost-MobileNetV3 is compared with a series of existing models, including four plain CNNs, three light-weight CNNs, and two representative ensemble learning approaches, indicating its effectiveness of the proposed method.
2. Method
2.1. Principle of Adaboost-CNN
In machine learning, combining multiple weak classifiers with the Adaboost algorithm, as pointed out by Taherkhani, Cosma, and McGinnity (Citation2020), can yield a single strong classifier in viewpoint of ensemble learning. In this learning setting, weak classifiers are trained sequentially with the weighted training samples. The misclassified samples are given relatively larger sample weights, and each classifier focuses on samples that are currently not trained well. Finally, all of the trained weak classifiers are added together in a way of linearly weighting combination to generate the final strong classifier.
Along the above general Adaboost-based ensemble learning, in parallel, Adaboost-CNN is an integration of CNN and Adaboost techniques. Here, CNN serves as the base classifier, which is sequentially trained for several epochs in each round.
However, traditional CNNs have huge numbers of parameters to be learned. To develop the Adaboost-CNN framework, due to its characteristic of iterative learning, it would be more promising to adopt the light-weight CNNs as the weak learners. These CNNs are generally designed with much less parameters, which facilitates to learn the strong classifiers with comprehensively high accuracy, high efficiency and low resource cost. According, based on our deep investigation, MobileNetV3 is employed as the weak classifier to boost the classification performance of tower state recognition.
2.2. MobileNetv3
We employ the MobileNetV3 (the third version) as the weak classifier to develop the model for tower state recognition. Compared to other CNNs, MobileNetV3, as demonstrated in (Howard et al. Citation2019), has much fewer parameters with lower computational cost, thus is suitable for deploying on resource-constraint edge devices like satellites.
Technically, MobileNetV3 is created with several improvements, including: (1) redesigned computationally-expensive layers; and (2) the Squeeze-and-Excitation (SE) block as bottleneck (the core module in MobileNetV3).
The SE block is employed to built upon a convolutional transformation. Let the output of this block be a feature map , where
and
are its height and width, respectively, and
is the number of the channels. Further let
be the
-th sub-matrix of
. Then, the following shrinking is performed:
where stands for the squeeze operation,
collects the local descriptor that accounts for the statistics of the input, and
is the element of the
-th row and
-th column of matrix
. Further let
. Then, the output of the excitation module can be calculated as
where collects the excitation weights,
and
are parameters to be learned,
is the commonly used sigmoid function, and ReLU(
) is the commonly used function of ‘Rectified Linear Unit’. By combining
and
(the
-th entity of
) together, it yields the output of SE block as follows:
where is a scaling operation to squeeze the feature maps.
The above SE block designed in our framework intrinsically renders a dynamic mechanism that is conditioned on the input feature maps. This can be regarded as a self-attention on the channels of feature maps, which makes it powerful to capture the channel information similar to the attention scheme.
2.3. The model for ensemble learning: Adaboost-MobileNetv3
demonstrates the overall schematic diagram of the Adaboost-MobileNetV3 designed in this work, which takes the MobileNetV3 as the weak classifier.
Figure 1. Overall schematic diagram of the proposed Adaboost-MobileNetV3.
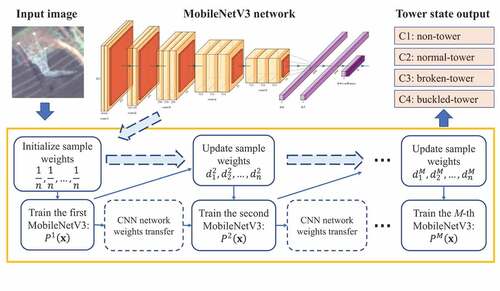
Along the technical line of ensemble learning with Adaboost algorithm, in the first round of training of Adaboost-MobileNetV3, the weights of the training samples are all equally as , where
is the number of training samples. With the initial weights, the first MobileNetV3 network
is trained (here
represents the input image). Specifically, let
be the sample weight of the
-th training sample used by the
-th weak classifier (MobineNetV3 network). Thus, with these notations, accordingly we set initially
. At the (
+1)-th iteration, the weight of the
-th sample, namely,
, is then updated according to the following rule:
where is the number of the classes (here,
),
is the learning rate of Adaboost-MobineNetV3,
is the one-hot based label vector of the
-th training sample,
is the probabilistic output vector from the
-th weak classifier of the
-th training sample
, and
is the total number of iterations.
In addition to updating the sample weights, in our framework, the current weak classifier will be transferred to the next round of network as the base model for further training. In this way, totally weak classifiers are finally obtained sequentially.
During testing phase, all the weak classifiers are combined together in way of linearly weighting to predict the class of the input image
, which is defined as follows:
where is the
-th entity of the probabilistic output vector of the
-th weak classifier, and “
“stands for obtaining the index of the maximum one among the
values with index
. demonstrates the steps of constructing the proposed Adaboost-MobileNetV3.
3. Dataset
In this study, we constructed a dataset of tower images with four classes: (C1) non-tower, (C2) normal-tower, (C3) broken-tower, and (C4) buckled-tower. As mentioned before, C1 labels the objects like towers but really not. shows some examples.
Figure 2. Example images in each class in the dataset. There are four classes: (C1) non-tower, (C2) normal-tower, (C3) broken-tower, and (C4) buckled-tower.

This dataset is constructed from 36 high-resolution RS images of high-altitude overhead flying drones or satellites including WorldView-2, WorldView-3, QuickBird, and Gaofen-2. The width and height of these ‘big’ images range from 12,330 to 130,438 pixels. The resolution of aerial images captured from drones ranges from 0.03 m to 0.1 m. The resolutions of satellite images obtained by WorldView-2, WorldView-3, QuickBird and Gaofen-2, are 0.48 m, 0.28 m, 0.61 m and 0.78 m, respectively.
4. Experimental evaluation
4.1. Comparison approaches
As we argued in subsection 2.2 that the MobileNetV3 is a light-weighted network, it is necessary to investigate its ability of feature learning for the task of tower state classification. This is due to the fact that the core of any CNNs is to learn features in a data-driven way. Adaboost and Random Forest are employed as classifiers to fulfill this task, which are two popularly-used framework for data classification in ensemble learning. To this end, the following feature extraction techniques are conducted:
(1) HoG: it serves as a hand-crafted feature extraction method, yielding two methods: ‘HoG+Adaboost’ (HoG-AB) and ‘HoG+Random Forest’ (HoG-RF).
(2) ResNet50: it serves as a data-driven feature learning method with powerful backbone CNN, yielding two methods: ‘ResNet50+Adaboost’ (ResNet50-AB) and ‘ResNet50+Random Forest’ (ResNet50-RF).
(3) MobileNetV3: it serves as a data-driven feature learning method with light-weight CNN, yielding two methods: ‘MobileNetV3+Adaboost’ (MBNetV3-AB) and ‘MobileNetV3+Random Forest’ (MBNetV3-RF).
In experiments, the open-source scikit-image library is used to extract the HoG features. The input images were first resized to pixels. The number of orientations in HoG is set to eight, the cell size is taken as
pixels, and the number of cells in each block is set to 1. For each image, the dimension of HoG feature is
. For ResNet-50 and MobileNetV3 networks, the deep features from the global average pooling layer were extracted, with the dimensions 2048 and 960, respectively.
Then, seven remarkable CNNs are employed to conduct the experimental comparison. Considering the requirement of high classification accuracy and low computational cost for smart power inspection, we paid more attention to evaluating efficient CNNs, which are divided into plain CNNs and light-weight CNNs as follows:
(1) VGG16: baseline model popularly-used in computer vision.
(2) ResNet50: powerful backbone model popularly-used in computer vision.
(3) ResNest50: a powerful CNN. As demonstrated in (Xie et al. Citation2017), it has a homogeneous, multi-branch architecture by repeating residual blocks.
(4) RegNetX: a powerful CNN. As demonstrated in (Radosavovic et al. Citation2020), it is constructed on ResNet with parameterization on the neural cells.
(5) SEResNet: a powerful light-weight CNN constructed on squeeze-and-excitation operators and residual blocks, as demonstrated in (Hu, Shen, and Sun Citation2018).
(6) ShuffleNetV2: a powerful light-weight CNN developed with channel split operators to balance between speed and computation complexity (Ma et al. Citation2018).
(7) MobileNetV3: a powerful light-weight CNN created with several platform-aware network improvements, as demonstrated in (Howard et al. Citation2019).
4.2. Experimental settings
In the experiments, the popularly used Stochastic Gradient Descent (SGD) optimization algorithm is employed to train the proposed Adaboost-MobileNetV3. The batch size is set to 128. Like many existing CNNs, the initial learning rate is empirically set to . The number of weak classifiers for Adaboost-MobileNetV3 is set to 5. In each round of MobileNetV3 training, the number of epochs is set to 60. Thus, the total number of training epochs is set to 300. After each round of training, the sample weights are re-computed according to the training errors of the current model. In this process, if the error is equal to zero, the training will be early stopped.
All the models are trained on the collected tower state recognition with the training and evaluation subsets reported in . For the seven CNNs described in subsection 4.1, we adopted their corresponding pre-trained networks on the ImageNet 2012 classification dataset and fine-tuned them on our data set for tower state recognition.
Table 1. Dataset: each class is split into training, validation and test subset. Here, ‘#’ stands for ‘the total number of’. For example, ‘# training’ means the total number of the training samples.
Totally, in this work, six well-known evaluation metrics in pattern classification are adopted to evaluate the performance, including the Precision, Recall, F1-score, Overall Accuracy (Accuracy), Macro Average Accuracy (Macro average) and the weighted average accuracy (Weighted average). The first three scores are evaluated class by class, while the last three scores are computed on all of the classes.
4.3. Experimental results
4.3.1. Comparisons with Adaboost and random forest
According to the description in subsection 4.1, in this group of experiments, we conducted the evaluations with six methods, including HoG-AB, HoG-RF, ResNet50-AB, ResNet50-RF, MBNetV3-AB, and MBNetV3-RF.
shows the classification results. In each approach, the scores of Precision, Recall, and F1-score are reported class by class, and the scores of Accuracy, Macro average and Weighted average are demonstrated as average on all of the classes. From this table, we have the following observations. First, the CNN-based deep feature extraction methods have much better overall performance than the hand-designed Histogram of Gradient (HoG) method. Second, the features extracted with light-weight MobileNetV3 render more promising results over those with the plain ResNet50. For instance, either with Adaboost or with random forest classification, the overall accuracies obtained with MobileNetV3 features are consistently higher than those with ResNet-50 features. This indicates its high discriminative capability of MobileNetV3 network, and also renders the evidence that the MobileNetV3 network is a suitable model for real-world applications.
Table 2. Evaluation of the results of the tower extraction from the test dataset using methods based on Adaboost and Random Forest.
4.3.2. Comparisons with plain CNNs and light-weight CNNs
According to the description in subsection 4.1, in this group of experiments, we conducted the evaluations with Plain CNNs and Light-weighted CNNs, including VGG16, ResNet50, ResNext, RegNetX, SEResNet, ShuffleNetV2, MobileNetV3 and the proposed Adaboost-MobileNetV3. The training process is carried out by using similar settings in each network to obtain results that can be fairly compared. The experimental settings are described in detail in subsection 4.2.
reports the comparison results with six metrics for each method. It is seen that most methods achieve good results on this data set. In particular, the proposed method Adaboost-MobileNetV3 achieves significantly the best performance.
Table 3. Comparison between the tower extraction results obtaining with CNNs and the proposed method. The bold digits indicate the highest scores.
Specifically, according to the accuracy of each class in , the CNNs obtain much higher classification metrics on the largely-concerned C3 and the C4 classes, with F1 scores more than . For the C1 class, all the methods achieve F1 scores higher than
, and the proposed method obtains the best F1 score of
. As demonstrated in , for the C2 class, the classification performances of all methods are relatively low, compared to other classes. For this class, the proposed method also achieves the best result, with much higher F1 score than that ranking at the second one.
The inferior classification results indicate that the normal towers in C2 classes are difficult to classify correctly. Due to space limited, reports only the confusion matrixes on the test data with the proposed method. From the confusion matrixes of these methods, we observed that the samples in C2 class are often wrongly classified to other objects. The reason lies in that, some objects look like towers with similar visual appearances in the RS images with relatively low resolution.
Table 4. Confusion matrix of Adaboost-MobileNetV3 (AB-MBV) on test data set.
As a conclusion, our experiments suggest that the MobileNetV3 is promising in real-time applications with high accuracy. The main reason lies in that, within the Adaboost framework, this network is light-weight, which is very suitable to be employed as weak classifiers, while the other heavy-weight neural networks could not be trained efficiently and sufficiently due to their much more parameters.
5. Conclusion
In this paper, we has presented a deep learning approach for transmission tower state recognition. To this end, a data set is first constructed for this task. The proposed model is developed on the light-weight MobileNetV3 and Adaboost algorithm, which yields an ensemble learning framework named as Adaboost-MobileNetV3 for this task. The comparative experimental results indicate that our method achieves the over-all enhancement on the six metrics of performance with an overall accuracy above .
Based on the evaluation results, it is suggested that our model is suitable for practical use, owing to its high classification accuracy and low computational cost. However, the accuracy could be further improved by either adopting the more powerful CNNs or collecting more labelled data of towers. In practice, prior knowledge, such as the geographical regions, and GPS information of the towers, and so on, can be employed together with our method to enhance the performance of identifying normal or non-normal towers.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- Ahsan Md Manjurul, Tasfiq E. Alam, Theodore Trafalis, Pedro Huebner . 2020. “Deep MLP-CNN Model Using Mixed-Data to Distinguish Between COVID-19 and Non-COVID-19 Patients.” Symmetry 12 (9): 1526. doi:10.3390/sym12091526.
- Awad, M. M., and M. Lauteri. 2021. “Self-Organizing Deep Learning (SO-UNet)—A Novel Framework to Classify Urban and Peri-Urban Forests.” Sustainability 13 (10): 1–5548. doi:10.3390/su13105548.
- Carlos, T. B., and J. Kaminski Jr. 2017. “Dynamic Response Due to Cable Rupture in a Transmission Lines Guyed Towers.” Procedia Engineering 199: 116–121. doi:10.1016/j.proeng.2017.09.173.
- Dileep, G. 2020. “A Survey on Smart Grid Technologies and Applications.” Renewable Energy 146: 2589–2625. doi:10.1016/j.renene.2019.08.092.
- Dosovitskiy, A., L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, et al. 2021. “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.” In International Conference on Learning Representations, Vienna, Austria, 3-7, May.
- He, K., X. Zhang, S. Ren, and J. Sun. 2016. “Deep Residual Learning for Image Recognition.” In IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, Nevada, USA, 26 June - 1 July, 770–778.
- Howard, A., M. Sandler, G. Chu, L.C. Chen, B. Chen, M. Tan, W. Wang, et al. 2019. “Searching for MobileNetv3.” In IEEE/CVF Conference on Computer Vision, Seoul, Korea, 27 October - 2 November, 1–8.
- Hu, J., L. Shen, and G. Sun. 2018. “Squeeze-And-Excitation Networks.” In IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, Utah, USA, 18-22, June, 7132–7141.
- Li, J., Y. Li, H. Jiang, and Q. Zhao. 2022. “Hierarchical Transmission Tower Detection from High-Resolution SAR Image.” Remote Sensing 14 (3): 1–625. doi:10.3390/rs14030625.
- Liu, T., Y. Xiangbin, and B. Sun. 2018. “Combining Convolutional Neural Network and Support Vector Machine for Gait-Based Gender Recognition.” In Chinese Automation Congress, Xi’an, Beijing, 23-25, November, 3477–3481.
- Lu, Z., H. Gong, Q. Jin, H. Qingwu, and S. Wang. 2022. “A Transmission Tower Tilt State Assessment Approach Based on Dense Point Cloud from UAV-Based LiDar.” Remote Sensing 14 (2): 1–408. doi:10.3390/rs14020408.
- Matikainen, L., M. Lehtomaki, E. Ahokas, J. Hyyppa, M. Karjalainen, A. Jaakkola, A. Kukko, and T. Heinonen. 2016. “Remote Sensing Methods for Power Line Corridor Surveys.” Isprs Journal of Photogrammetry and Remote Sensing 119: 10–31. doi:10.1016/j.isprsjprs.2016.04.011.
- Ma, N., X. Zhang, H.T. Zheng, and J. Sun. 2018. “Shufflenet V2: Practical Guidelines for Efficient CNN Architecture Design.” In European Conference on Computer Vision (ECCV), Munich, Germany, 8 - 14 September, 116–131.
- Radosavovic, I., R. Prateek Kosaraju, R. B. Girshick, H. Kaiming, and P. Dollár. 2020. “Designing Network Design Spaces.” IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14-19, June 10425–10433.
- Simonyan, K., and A. Zisserman. 2014. “Very Deep Convolutional Networks for Large-Scale Image Recognition.” arXiv:1409.1556. doi:10.48550/arXiv.1409.1556. Accessed 3 January 2023.
- Szegedy, C., W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. 2015. “Going Deeper with Convolutions.” In IEEE/CVF Conference on Computer Vision and Pattern Recognition, Boston, USA, 8-10 June, 1–8.
- Taherkhani, A., G. Cosma, and T. M. McGinnity. 2020. “AdaBoost-CNN: An Adaptive Boosting Algorithm for Convolutional Neural Networks to Classify Multi-Class Imbalanced Datasets Using Transfer Learning.” Neurocomputing 404: 351–366. doi:10.1016/j.neucom.2020.03.064.
- Xie, S., R. Girshick, P. Dollár, T. Zhuowen, and H. Kaiming 2017. “Aggregated Residual Transformations for Deep Neural Networks.” In IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, Hawaii, USA, 21-26 July, 1492–1500.