
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Convolutional neural network (CNN) is now widely applied in bearing fault diagnosis, but the design of network structure or parameter tuning is time-consuming. To solve this problem, a particle swarm optimization (PSO) algorithm is used to optimize the network structure and a self-adaptive CNN is proposed in this paper. In the proposed method, a theoretical method is used to automatically determine the window size of short-time Fourier transform (STFT). To reduce the computation time, PSO is only applied to obtain the optimal key parameters in CNN with a small number of training samples and a small epoch number. To simplify the CNN structure, a fitness function considering the numbers of kernels and neuron nodes is used in PSO. According to the verification experiments for two well-known public datasets, the proposed method can get higher accuracy than other state-of-art methods. Furthermore, the parameters that are required to be input only involve the bearing parameters, so the proposed method can be applied in industry readily.
1. Introduction
Rolling element bearings have been widely applied and are the most critical components in industrial machinery. According to our literature review, 40–55% of broken machines are caused by bearing faults (Boudinar et al., Citation2016; Hamadache et al., Citation2015; Harmouche et al., Citation2015; Rai & Upadhyay, Citation2016; Sohaib et al., Citation2017). The degradation of bearings can result in unexpected failures of machines, which lead to long downtimes, large economic losses, and serious human injuries. Therefore, the bearing fault diagnosis is regarded as an important tool for identification, prediction, and prevention of failures in rotating machinery.
Fault diagnosis techniques can be generally categorized into model-based, signal-based, knowledge-based, and hybrid fault diagnosis (Gao et al., Citation2015).
In signal-based methods, there are many kinds of signals such as vibration and acoustic signals (Liu et al., Citation2016), electric current (Boudinar et al., Citation2016), temperature (Yuan et al., Citation2018), and wear debris. Among these, the vibration signal is the most widely used approach (Lin & Ye, Citation2019; Sohaib et al., Citation2017). The signal processing methods generally include Fourier Transform (FT), Short-Time Fourier Transform (STFT), Wavelet Transform (WT), Wavelet Package Transform (WPT), Empirical Wavelet Transform (EWT), Hilbert-Huang Transform (HHT), Empirical Mode Decomposition (EMD), Variation Mode Decomposition (VMD), and Ensemble Empirical Mode Decomposition (EEMD). For more details on the advantages and disadvantages of these methods can be seen in Refs (Lin & Ye, Citation2019; Ma et al., Citation2018; Yi et al., Citation2016).
Nowadays, a signal-based method is always integrated with a knowledge-based method, which can be used to optimize the parameters in the signal-based method. For example, the particle swarm optimization (PSO) and quasi-Newton minimization algorithms are applied to seek optimal parameters of continuous wavelet transform models based on impulse modelling (Huo et al., Citation2017). Similarly, PSO is applied for the parameter optimization of VMD (Wang et al., Citation2018; Yi et al., Citation2016; Yuwono et al., Citation2016). On the other hand, the signal-based method can be used for handcrafted feature design and feature extraction, and then the knowledge-based method further makes use of these features to learn fault modes through training with historical data. Here, two kinds of methods, i.e. shallow machine learning and deep learning, are used for knowledge learning.
For the shallow machine learning methods, after the right set of features are designed, these features are fed into some shallow machine learning algorithms. For example, in references EMD-SVM (Zhang, Liang et al. Citation2015), HHT-SVM (Soualhi et al., Citation2015), DWT-KNN (Jung & Koh, Citation2015), WPT-KNN (Wang, Citation2016), WT-Naive Bayes (NB) (Seshadrinath et al., Citation2014), HHT-FFT-PCA (Harmouche et al., Citation2015), and EMD-PSO-SVM (Chen, Tang et al. Citation2014), signal processing methods including EMD, HHT, DWT, WPT, etc are used to extract features and SVM, KNN,NB,PCA are to perform classifications. PSO is used to determine the optimal parameters of SVM (Chen, Tang et al. Citation2014).
In the deep learning methods, Ref (Peng et al., Citation2017) use convolutional neural network (CNN) to diagnose fused signals of two sensors, where FFT is as are preprocessing method. Wavelet scalogram images are fed into CNN to detect faults (Wang et al., Citation2016). Similarly, three time–frequency analysis methods STFT, WT, and HHT are used to generate image representations of the raw signals which are fed into CNN (Verstraete et al., Citation2017). Adaptive overlapping CNN (AOCNN) with a sparse filter is proposed to deal with one-dimensional raw vibration signals directly. The adaptive convolutional layer and the root-mean-square (RMS) pooling layer are proposed to dealt with the shift variant problem (Qian et al., Citation2018). Time-domain and frequency-domain features are extracted from different sensor signals and then fed into multiple two-layer sparse auto encoder (SAE) for feature fusion, which is used to train deep belief network (DBN) for further classification (Chen & Li, Citation2017). A stacked sparse auto encoder is applied to automatically extract the fault features of sound spectrograms with STFT, and softmax regression is adopted as the method of classifying the fault modes (Liu et al., Citation2016). In Ref. (Jia et al., Citation2016), DNN based on a stack auto encoder is applied for roller bearing and planetary gearbox fault diagnosis using frequency spectra. In Ref. (Jiang et al., Citation2018), deep recurrent neural network (DRNN) is used to extract the features from the input spectrum sequences. In Ref. (Lei et al., Citation2016), the features are learnt through sparse filtering in an unsupervised way and then fed to softmax regression for classifying health conditions in a supervised manner (Lei et al., Citation2016).
In these two kinds of knowledge-based methods, deep learning can auto extract highly representative features while shallow machine learning methods require labour-intensive feature engineering, so it is widely researched all over the world. However, the design of network or parameter tuning is one time-consuming procedure, which affects the performance of the neuron network. For example, lots of existing CNN networks have been designed and applied, and different CNNs (Hoang & Kang, Citation2019; Verstraete et al., Citation2017; Wang et al., Citation2016; Wen et al., Citation2018) consisting of different convolution, pooling, and dense layers are proposed, which result in different performances. On account of this, most current research focuses on the development of the network. In order to design the optimized deep belief network, PSO is used for deciding the optimal network structure, including the optimal number of neurons in each hidden layer, the learning rate, and the momentum (Shao et al., Citation2015). Similarly, the main parameters of the deep CNN model are also determined with the PSO method (Fuan et al., Citation2017). In our method, a two-step training idea is introduced, which is different from that in Ref. (Fuan et al., Citation2017). The first-step is the optimization of the CNN structure, where the fitness function accounts the number of neuron nodes and trains the CNN parameters with a small number of training samples and a small epoch number. The second-step is the final training with the optimized CNN.
Through above literature review, it is obvious that the design of network or tuning parameters is a complex and time-consuming work. To relieve the burden, a Self-Adaptive CNN (SA-CNN) is proposed in this study. Because the PSO has the characteristics of fast convergence speed, small setting parameters and convenient implementation, it is used to optimize the key parameters in CNN (Yuwono et al., Citation2016).
Although CNN can auto extract features, to accelerate the evolution of PSO, signal processing is taken as a preprocessing method to extract basic time–frequency information. Among signal processing methods reviewed before, WT analysis is restricted by mutually selected wavelet basis function and the number of decomposition levels (Wang et al., Citation2018); Empirical wavelet transform (EWT) is restricted on choosing the boundaries of Fourier spectrum appropriately (Yi et al., Citation2016);HHT and EMD exists deficiencies such as model mixing and the end effect (Kumar & Kumar, Citation2019; Wang et al., Citation2018; Yi et al., Citation2016); VMD is not model-adaptive and heavily relies on the penalty parameter selection and the number of components (Wang et al., Citation2018; Yi et al., Citation2016); EEMD is computationally expensive and requires selection of noise parameter (Kumar & Kumar, Citation2019). Most of them are not adaptable and restricted on the selection of parameters. As the simplicity and efficiency of STFT, it is taken as the preprocessing method in this work.
The main contributions of this study are as follows:
STFT is a simple and efficient method to transform time domain signals into time–frequency space. Its limitation is that it gives constant time and frequency resolution once the window size is fixed (Kumar & Kumar, Citation2019). Hence, the setting of the window size is important. In this study, through analysing the characteristics of the bearing fault type, a method of automatically deciding the window size of STFT or its input-size of spectrum is proposed.
PSO is applied to optimize the key parameters of CNN including the kernel number and the number of neuron nodes in CNN. To reduce the computational complexity, a fitness function accounting the number of neuron nodes is provided.
In the implementation of algorithm, to further reduce the time complexity of PSO, a small number of training samples and a small epoch number are used to evaluate the prediction accuracy of each particle. Through a two-step training, a SA-CNN with adaptive input-size for bearing fault diagnosis is proposed.
The rests of this paper are organized as follows. Section II introduces the bearing fault types, the method of automatically deciding parameters in STFT, the optimization with PSO and the implementation of SA-CNN. In Section III, contrastive experiments with two well-known public datasets are conducted and the results are discussed. Finally, Section IV provides some conclusions and suggests topics for future research.
2. Our proposed method
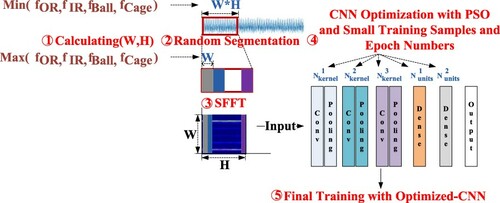
In this study, a self-adaptive CNN method based on STFT (SA-CNN) is proposed for bearing fault diagnosis, as shown in Figure . It has the following five steps: (1) calculating the input size (W, H); (2) randomly segmenting the raw signal to many signal segments with H*W points; (3) applying STFT to every signal segment, where the rectangle window size is W and has no overlapping, and obtaining the power spectrum with time–frequency information; (4) in the first-step training, PSO is used to evolve the CNN parameters, i.e. the numbers of kernels and dense units; (5) in the second-step training, the final training with optimized CNN is used to adjust the neuron weight.
Figure 1. Framework of SA-CNN.
2.1. Bearing fault types
Bearing faults are categorized into two types: generalized roughness fault and single-point fault (Eren, Citation2017; Stack et al., Citation2004).
The generalized roughness fault is a type of failure where the surface of a bearing has degraded considerably over a large area. It is a kind of distributed and noncyclic fault caused by improper lubrication, erosion, or pollution. There is no identifiable characteristic frequency associated with this fault type.
The single-point fault is a kind of single and localized fault caused by a small hole, a pit, or a missing material. As we all know, when a fault in one surfaces of a bearing strike another surface, a force impulse is generated, thus exciting resonances in the bearing and the machine. The successive impacts produce a series of impulse responses, the amplitude of which can be modulated (Ho & Randall, Citation2000). Therefore, the single-point fault creates a periodic impact vibration and produces a characteristic fault frequency.
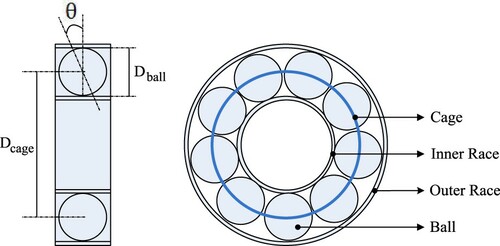
Since rolling-element bearings are constituted by an inner race, an outer race, a cage and balls, the single-point fault includes four types: cage fault, outer race fault, inner race fault and ball bearing fault, as shown in Figure (Hamadache et al., Citation2015). Their corresponding characteristic fault frequencies are given by Equations (1–4) separately, where is the number of balls in one bearing,
and
are the diameters of ball and cage respectively,
is the contact angle,
is the shaft speed, and
is the sample frequency (Aimer et al., Citation2019; Eren, Citation2017).
(1)
(1)
(2)
(2)
(3)
(3)
(4)
(4)
Figure 2. Bearing Components.
In addition, bearing characteristic fault frequencies can be grouped into four different zones: low frequency zone (shaft speed zone), bearing defect frequency zone, bearing nature resonance frequency zone, and high frequency zone in Figure (El-Thalji & Jantunen, Citation2015).
Figure 3. Bearing frequency zones.
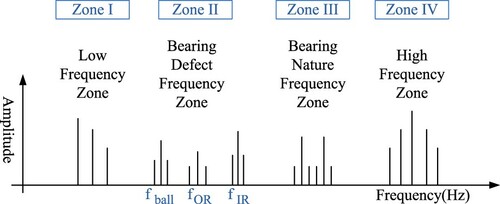
Bearing defect frequency zone (Zone II) include two parts. The first part is the low-frequency event which originates from the entry of the ball/roller in the vicinity of defect. This event gives peak in the bearing fault frequency zone. The second part is the high-frequency event, which is the result of the impact of rolling element on the trailing edge of the defect. The defect frequency zone can be derived from Equations (1–4) (Eren, Citation2017; Kumar & Kumar, Citation2019). To be notice, this study mainly focuses on the single-point fault or Zone II because the defect frequency will be used to auto decide the parameters related with STFT.
In signal-based methods, the major disadvantage of the time–frequency approach is that the computation time increases with both the number of samples and the number of sought harmonics. Equations (1–4) enable us to know in advance the frequency bands where the fault signature is likely to appear. Therefore, it can reduce the length of the spectrum and consequently the computation time (Aimer et al., Citation2019; Boudinar et al., Citation2016) to process the data on these predictable fault frequencies band instead of those on all the spectra.
2.2. STFT with auto-decided parameters
In Figure , when a raw signal is input, it will be segmented into many signal segments and every segment is applied with STFT. Therefore, the length of one signal segment and the window size are required to be fixed. As described in Figure in Section 2.1, the bearing defect frequency zone contains lower frequency components and higher frequency components. To prevent any information loss of the lowest frequency component, the time of sampling L points must be longer than the multiple periods of the lowest frequency component, as in Equation (5). Correspondingly, L can be determined by Equation (6). Similarly, to capture the highest frequency component in the bearing defect frequency zone, the time of sampling W points must be longer than the multiple periods of the highest frequency component, as shown in Equation (7). Thus, W can be given by Equation (8). For Equations (5–8), is required.
(5)
(5)
(6)
(6)
(7)
(7)
(8)
(8)
(9)
(9)
After L samples are randomly extracted from the raw signal, they will be split into H frames, every of which has a fixed window size of W with no overlapping. Every frame with W samples is processed through FFT as Equation (10). Equation (12) is the normalization of the power spectrum. Since the power spectrum is symmetrical, only the single-sided data are fed into CNN, i.e. a matrix [H, W/2] is fed into CNN.
(10)
(10)
(11)
(11)
(12)
(12) where
, and
.
2.3. Optimized CNN structure through PSO
2.3.1. Fixed CNN structure
Figure illustrates the proposed CNN structure. Three successive convolution and pooling layers are used to extract high level features. The ReLU is taken as the activation function and the max pooling layer is for preserving the maximum coefficients that contain the main information of fault features. The last three dense layers construct an MLP as a classifier.
Figure 4. The proposed CNN structure.
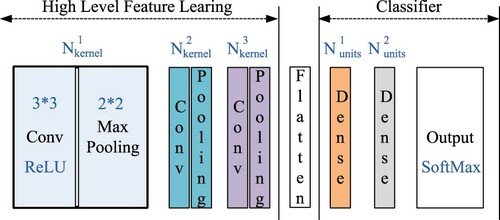
According to the universal approximation theorem, three-layer neuron network, with a sufficient number of hidden-layer units, can approximate any continuous function. But in practice learning, the hidden-layer units are hard to be determined. Feeding the auto extracted features with three-layer CNN into three-layer MLP can make MLP structure as simple as possible and PSO is used to find the optimal network structure, which maybe a wise solution.
In CNN, the loss function uses the categorical cross entropy loss (Zhang & Sabuncu, Citation2018); the optimizer is the Adam method because its hyper-parameters have intuitive interpretations and typically require little tuning (Kingma & Ba, Citation2015).
2.3.2. Binary PSO
In PSO, each particle has its own position x and velocity v and maintains a record of the position of its previous best performance . A global best position
is maintained by the algorithm. The
represents potential solutions while the global best position is the global optimum solution.
The velocity v and the position x of each particle at the next iteration (t + 1) are calculated based on the values at current iteration (t). Each iteration comprises the evaluation of each particle, which is discussed in ‘(3) fitness evaluation’; each particle adjusts its own velocity in the direction of and
. Equation (15) is used for binary encoding.
(13)
(13)
(14)
(14)
(15)
(15)
(16)
(16) where w is called the ‘inertia weight’, which controls the impact of the previous velocity of the particle on its current one;
and
are positive constants with default values called ‘acceleration coefficients’;
,
and rand() are random numbers uniformly distributed in the interval [0.0, 1.0] (Kennedy & Eberhart Citation1997; Ziani et al., Citation2017).
2.3.3. Fitness evaluation
Let all the kernel size be F, all the padding size be P, all the stride step be S, and all the pooling size be D. Then, the output size of one successive convolution and pooling layer can be expressed as:
(17)
(17)
(18)
(18)
The encoding information in each particle includes and
, where
,
is the number of classes and
is the number of bits in every dimension. Then, the fitness score can be expressed as Equation (20).
(19)
(19)
(20)
(20) where acc is the prediction accuracy of CNN. It is noted that, to reduce the time complexity of PSO, a small number of training samples
and a small epoch number
are used to evaluate the prediction accuracy of each particle. Equation (19) is to ensure the simplicity of the network structure to reduce the time complexity.
2.4. Implementation of SA-CNN
In Figure , steps (1-2) are used to automatically decide the parameters of W and H used in STFT; steps (3.1-3.2) are implemented to preprocess STFT to generate the power spectrum matrix; step 3.3 is to optimize the CNN structure.
Figure 5. Procedure of SA-CNN.

3. Experiments
Two public famous fault diagnosis datasets, i.e. the Case Western Reserve University’s (CWRU) bearing dataset (Loparo & Loparo, Citation2013), and the Machinery Failure Prevention Technology (MFPT) society bearing fault dataset (Bechhoefer, Citation2016), are used to investigate the effectiveness of the proposed method. In every experiment, let the default batch size be 100 and the epoch number be 50. All results are obtained by running the algorithm for ten times with one GPU. The default proportion of the training data in the whole dataset Pt is 0.8. All prediction accuracies are from the results with the testing dataset.
3.1. CWRU bearing dataset
Two-horsepower reliance electric motors are used for the acquisition of accelerometer data on both the drive end (DE) and fan end (FE) bearings, as shown in Figure . In the experiment, artificial single-point faults are seeded in the bearing’s inner raceway (IR), outer raceway (OR), and rolling element (ball) (BF) with an electro discharge machining (EDM) operation. The vibration signal is sampled at 12 kHz through accelerometers attached at the 12 o’clock position to the DE of the motor.
Figure 6. Test bed for CWRU dataset.

Vibration data are recorded under various engine loads (0–3 hp) running at 1730, 1750, 1772, and 1797 RPM. The depth of the motor shaft bearings with faults ranges from 0 to 0.028 in. (0, 0.007, 0.014, 0.021, 0.028 in.), and the fault orientation includes the inner race, rolling element, and outer race. As shown in Table , all these data have one normal class and 15 fault classes without considering the different RPMs. Notably, in this study, some classes (bold and italic fonts) are merged as one value in the last column of Table . Hence, there are totally 12 classes of data to be classified. In this experiment, 10000 data samples are randomly extracted from the raw data file with the same probability.
Table 1. Classes in CWRU dataset.
3.1.1. Comparison of the results from different methods
In this experiment, SA-CNN is compared with many deep learning methods including deep recurrent neural network (DRNN) (Jiang et al., Citation2018), sparse filter (Lei et al., Citation2016), CNN-Vibration image (Wen et al., Citation2018), CNN-PSO-WP (Fuan et al., Citation2017), CNN-Wavelet/STFT (Verstraete et al., Citation2017), HCNN (Wen et al., Citation2019b), and an optimized deep belief network with PSO (DBN-PSO) (Shao et al., Citation2015).
As can be seen from Table , our proposed SA-CNN method achieves an accuracy of 99.96% after running for ten times. Figure shows one of the classification confusion matrixes. Furthermore, in our method, the number of classes to be classified is 12, which is more than that in other methods except DRNN (with an accuracy of 96.53%). Therefore, our method is more efficient than the other methods. ‘SA-CNN-E2E’ algorithm, called SA-CNN-End-to-End, means that there is no preprocessor of STFT before feeding into CNN. It get 99.60% accuracy, so the preprocessor of STFT is valuable to improve the algorithm performance.
Figure 7. A classification confusion matrix (DE_time).
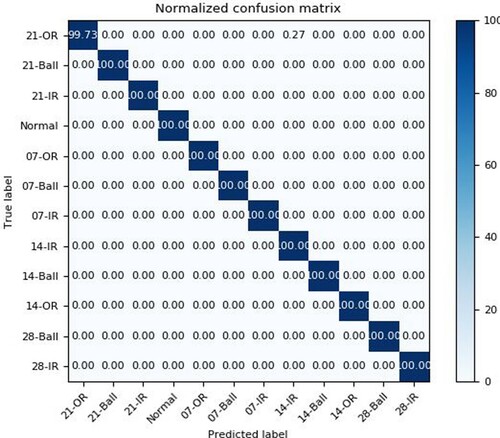
Table 2. Comparison with CWRU dataset (,
, DE_time, %).
3.1.2. Spectrum image
According to Equations (1–9) and the parameter settings (,
,
,
,
,
,
, and
), we can get the characteristic vibration frequencies as follows:
As Table shows, the spectrum images with STFT according to equations (10-12) are easy to be discriminated by human eyes. Table lists all error results found in the experiment and the corresponding activation maps (Selvaraju et al., Citation2017). In these activation maps, the maximum coefficients are always mapped to high temperatures in the heat map. In Table , 21-OR and 14-IR are the most difficult to be discriminated. Moreover, 14-IR and 14-OR, or 21-Ball and 07-OR are similar in the high temperature area if the location is not considered. The main reason is that: the convolutional units of various layers of CNNs actually behave as object detectors (Zhou et al., Citation2015), but this ability is lost when fully-connected layers are used for classification (Zhou et al., Citation2016).
Table 3. Signal and spectrum.
Table 4. Class activation mapping.
3.1.3. Performance and parameters
As the CNN structure is optimized with PSO, the time complexity needs to be considered carefully. For analysing the performance with different parameters, our method is implemented with different combinations between and
In Tables and , the combinations of and
can get better prediction accuracies, but their time complexity is not the minimum value. Hence, there is a balance choice between time complexity and prediction accuracy. Of course, the time complexity should be considered only in the beginning of the CNN optimization with PSO, and it will be the same as existing CNN methods once the optimized CNN is fixed.
Table 5. Prediction accuracies with different parameters (DE_time, %).
Table 6. Time complex with CWRU dataset (DE_time).
Furthermore, according to Table , is the main factor that leads to the higher time complexity.
3.1.4. Evolution of CNN with PSO
Figure depicts the curves related with the converge speed, which is proportional to and
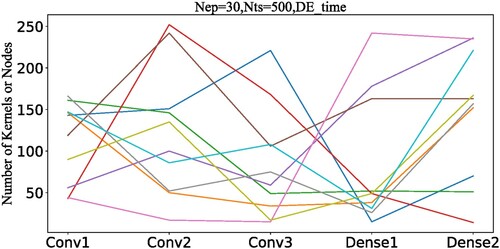
. The bottom figure is a partially enlarged figure. The fitness value −1 means that the prediction accuracy is 100% according to Equation (20). After the fitness value reaches to −1, the converging speed becomes slowly because of the huge searching space. Furthermore, the optimization of CNN is a multi-optimization problem as the CNN structure from different running results is different (Figure ).
Figure 8. Fitness curves (bottom: partially enlarged figure).
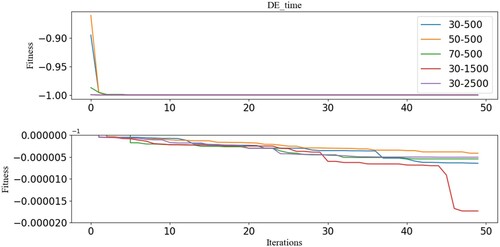
Figure 9. Network structure.
3.1.5. Effect of STFT
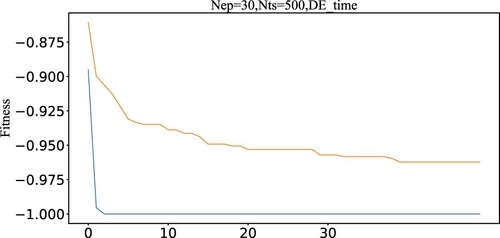
As Figure shown, with the preprocessing of STFT, the fitness can be quickly converged to −1.0. Therefore, signal processing taken as a preprocessing method to extract basic time–frequency information can accelerate the evolution of PSO and improve the algorithm performance.
Figure 10. Fitness curve.
3.2. MFPT bearing dataset
This MFPT dataset is recorded from a bearing test rig (normal bearing data, an outer race fault under various loads, and an inner race fault under various loads), and includes four sets of bearing vibration data: (1) a baseline set under the load of 270 lbs, which is sampled at 97656 Hz for 6 s; (2) an outer race fault set including three outer race faults (ThreeOR) under the load of 270 lbs, which are sampled at 97656 Hz for 6 s; (3) seven additional outer race faults (SevenOR) under various loads of 25, 50, 100, 150, 200, 250, and 300 lbs, which are sampled at 48828 Hz for 3 s; and (4) seven inner race faults (SevenIR) under various loads of 25, 50, 100, 150, 200, 250, and 300 lbs, which are sampled at 48828 Hz for 3 s. In the experiments, 10000 data samples are randomly extracted from the raw data file with the same probability.
3.2.1 Spectrum image
According to Equations (1–9) and the parameter settings (,
,
,
,
,
, and
), we can get the characteristic vibration frequencies as follows:
Table gives the signals and spectrum images used by our method according to Equations (10–12). It seems that the spectrum imaged can be readily discriminated by human eyes.
Table 7. Signals and spectra.
3.2.2. Comparison of the results from different methods
In Table , it can be seen that our proposed method achieves an accuracy of 99.99% for 4 classes and 100% for 3 class classification. By contrast, CNN using the time–frequency information of wavelet or spectrogram does not perform well because of the non-optimized CNN structure and the parameters used in signal processing (Verstraete et al., Citation2017; Wen et al., Citation2019).
Table 8. Comparison with MFPT dataset (Pt=0.8, %).
3.3. Discussion
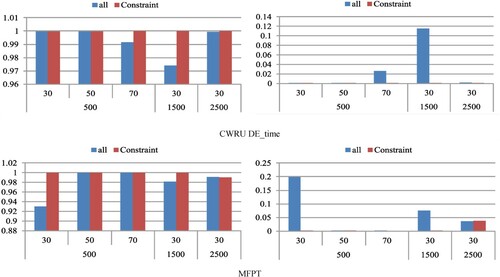
All results within the ten running times are merged into Tables and , which provides the probability of achieving an accuracy of 100% with stable standard deviations. In Table , larger leads to higher stability and larger probability, whereas larger
leads to worse performance of the method. For example, when
and
is increased, the value of ‘std’ decreases and the value of ‘probability’ mostly increases; when
and
is increased, the value of ‘std’ mostly increases. This is because that larger
makes PSO require more time to converge to the stable level. Therefore,
is a main factor to be tuned. Notably, according to section 3.1.3, larger
may lead to more training time. In Table , larger ‘batch_size’ make the prediction accuracy less ‘std’ and more stable.
Table 9. Prediction accuracies with different parameters (%).
Table 10. The influence of different batch size (%).
In Figure , the left figures (no any constraint) have more numbers near zero, and the network structure converges to simpler network structure with less neuron nodes because the fitness function considers the simplicity of network structure in Equation (19). Consequently, the simple network structure may lead to worse performance in terms of both prediction accuracy and its standard deviation, as shown in Figure .
Figure 11. Comparison of network structure.
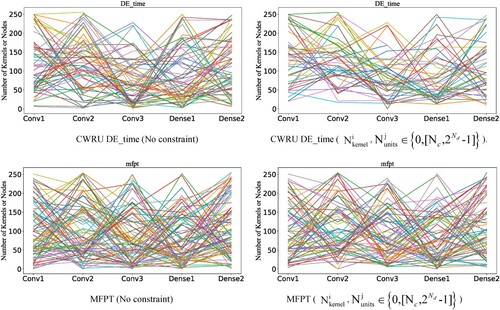
Figure 12. Comparison of network structure (Left: prediction accuracy; right: standard deviation).
4. Conclusions
In summary, a self-adaptive CNN method (SA-CNN) with two-step training is proposed on account of the time-consuming problem in the design of a CNN structure or its parameter tuning. To reduce the time complexity, two main mechanisms are used. First, the CNN structure is fixed, and only its key parameters including the kernel number and the number of neuron nodes are optimized by PSO. Second, a small number of training samples and a small epoch number are used to evaluate the prediction accuracy. Based on the given the bearing parameters, SA-CNN can automatically decide the parameters of W and H used in STFT, and adjust CNN into an optimized structure. Therefore, the proposed method can be easily applied in industry. Through the experiments with two famous public datasets, CWRU and MFPT, it is demonstrated that the SA-CNN method can achieve better results than other state-of-art methods and the preprocessing of STFT can accelerate the evolution speed of PSO. In the future, the location of high temperature area in the rotating machinery will be considered to improve the prediction accuracy; meanwhile, it is necessary to take both fault patterns and fault deterioration into account.
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China (61502423), Zhejiang Provincial Natural Science Foundation (LY16G020012), and Zhejiang Province Public Welfare Technology Application Research(LGF19F010-002, LGF20F010004, LGG21F030014:The Research on Cold-Start Fault Diagnosis Method Based on Immune Algorithm and Deep Learning).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Aimer, A. F., Boudinar, A. H., Benouzza, N., et al. (2019). Bearing fault diagnosis of a PWM inverter fed-induction motor using an Improved short time Fourier Transform. Journal of Electrical Engineering & Technology, 1–10. https://doi.org/https://doi.org/10.1007/s42835-019-00096-y
- Bechhoefer, E. (2016). A quick introduction to bearing envelope analysis. MFPT Data, http://www.mfpt.org/FaultData/Fault-Data.htm.Set
- Boudinar, A. H., Benouzza, N., Bendiabdellah, A., & Khodja, M.-E.-A. (2016). Induction motor bearing fault analysis using a root-MUSIC method. IEEE Transactions on Industry Applications, 52(5), 3851–3860. https://doi.org/https://doi.org/10.1109/TIA.2016.2581143
- Chen, Z., & Li, W. (2017). Multisensor feature fusion for bearing fault diagnosis using sparse autoencoder and deep belief network. IEEE Transactions on Instrumentation and Measurement, 66(7), 1693–1702. https://doi.org/https://doi.org/10.1109/TIM.2017.2669947
- Chen, F., Tang, B., Song, T., & Li, L. (2014). Multi-fault diagnosis study on roller bearing based on multi-kernel support vector machine with chaotic particle swarm optimization. Measurement, 47, 576–590. https://doi.org/https://doi.org/10.1016/j.measurement.2013.08.021
- El-Thalji, I., & Jantunen, E. (2015). Fault analysis of the wear fault development in rolling bearings. Engineering Failure Analysis, 57, 470–482. https://doi.org/https://doi.org/10.1016/j.engfailanal.2015.08.013
- Eren, L. (2017). Bearing fault detection by one-dimensional convolutional neural networks. Mathematical Problems in Engineering. https://doi.org/https://doi.org/10.1155/2017/8617315.
- Fuan, W., Hongkai, J., Haidong, S., Wenjing, D., & Shuaipeng, W. (2017). An adaptive deep convolutional neural network for rolling bearing fault diagnosis. Measurement Science and Technology, 28(9), 095005. https://doi.org/https://doi.org/10.1088/1361-6501/aa6e22
- Gao, Z., Ding, S. X., & Cecati, C. (2015). Real-time fault diagnosis and fault-tolerant control. IEEE Transactions on Industrial Electronics, 62(6), 3752–3756. https://doi.org/https://doi.org/10.1109/TIE.2015.2417511
- Hamadache, M., Lee, D., & Veluvolu, K. C. (2015). Rotor speed-based bearing fault diagnosis (RSB-BFD) under variable speed and constant load. IEEE Transactions on Industrial Electronics, 62(10), 6486–6495. https://doi.org/https://doi.org/10.1109/TIE.2015.2416673
- Harmouche, J., Delpha, C., & Diallo, D. (2015). Improved fault diagnosis of ball bearings based on the global spectrum of vibration signals. IEEE Transactions on Energy Conversion, 30(1), 376–383. https://doi.org/https://doi.org/10.1109/TEC.2014.2341620
- Ho, D., & Randall, R. B. (2000). Optimisation of bearing diagnostic techniques using simulated and actual bearing fault signals. Mechanical Systems and Signal Processing, 14(5), 763–788. https://doi.org/https://doi.org/10.1006/mssp.2000.1304
- Hoang, D. T., & Kang, H. J. (2019). Rolling element bearing fault diagnosis using convolutional neural network and vibration image. Cognitive Systems Research, 53, 42–50. https://doi.org/https://doi.org/10.1016/j.cogsys.2018.03.002
- Huo, Z., Zhang, Y., Francq, P., Shu, L., & Huang, J. (2017). Incipient fault diagnosis of roller bearing using optimized wavelet transform based multi-speed vibration signatures. IEEE Access, 5, 19442–19456. https://doi.org/https://doi.org/10.1109/ACCESS.2017.2661967
- Jia, F., Lei, Y., Lin, J., Zhou, X., & Lu, N. (2016). Deep neural networks: A promising tool for fault characteristic mining and intelligent diagnosis of rotating machinery with massive data. Mechanical Systems and Signal Processing, 72-73, 303–315. https://doi.org/https://doi.org/10.1016/j.ymssp.2015.10.025
- Jiang, H., Li, X., Shao, H., & Zhao, K. (2018). Intelligent fault diagnosis of rolling bearings using an improved deep recurrent neural network. Measurement Science and Technology, 29(6), 065107. https://doi.org/https://doi.org/10.1088/1361-6501/aab945
- Jung, U., & Koh, B.-H. (2015). Wavelet energy-based visualization and classification of high-dimensional signal for bearing fault detection. Knowledge and Information Systems, 44(1), 197–215. https://doi.org/https://doi.org/10.1007/s10115-014-0761-z
- Kennedy, J., & Eberhart, R. C. (1997). A discrete binary version of the particle swarm optimisation algorithm. In James M. Tien (Ed.), Proceedings of the IEEE International Conference on neural networks (pp. 4104–4108). IEE.
- Kingma, D. P., & Ba, J. (2015). Adam: A method for stochastic optimization. International Conference on learning representations.
- Kumar, A., & Kumar, R. (2019). Role of signal processing, modeling and decision making in the diagnosis of rolling element bearing defect: A review. Journal of Nondestructive Evaluation, 38(1). https://doi.org/https://doi.org/10.1007/s10921-018-0543-8
- Lei, Y., Jia, F., Lin, J., Xing, S., & Ding, S. X. (2016). An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Transactions on Industrial Electronics, 63(5), 3137–3147. https://doi.org/https://doi.org/10.1109/TIE.2016.2519325
- Lin, H. C., & Ye, Y. C. (2019). Reviews of bearing vibration measurement using fast Fourier transform and enhanced fast Fourier transform algorithms. Advances in Mechanical Engineering, 11(1). https://doi.org/https://doi.org/10.1177/1687814018816751.
- Liu, H., Li, L., & Ma, J. (2016). Rolling bearing fault diagnosis based on STFT-deep learning and sound signals. Shock and Vibration. https://doi.org/https://doi.org/10.1155/2016/6127479.
- Loparo, K. A., & Loparo, K. A. (2013). Bearing data center. Case Western Reserve University, http://csegroups.case.edu/bearingdatacenter/pages/welcome-case-western-reserve-university-bearing-datacenter-website
- Ma, J., Wu, J., & Wang, X. (2018). Incipient fault feature extraction of rolling bearings based on the MVMD and Teager energy operator. ISA Transactions, 80, 297–311. https://doi.org/https://doi.org/10.1016/j.isatra.2018.05.017
- Peng, Y., Wen, Z., Li, D., & Shang, Z. (2017). A new deep learning model for fault diagnosis with good anti-noise and domain adaptation ability on raw vibration signals. Sensors, 17(2), 387–425. https://doi.org/https://doi.org/10.3390/s17020387
- Qian, W., Li, S., Wang, J., et al. (2018). An intelligent fault diagnosis framework for raw vibration signals: Adaptive overlapping convolutional neural network. Measurement Science and Technology, 29(9). https://doi.org/https://doi.org/10.1088/1361-6501/aad101
- Rai, A., & Upadhyay, S. H. (2016). A review on signal processing techniques utilized in the fault diagnosis of rolling element bearings. Tribology International, 96, 289–306. https://doi.org/https://doi.org/10.1016/j.triboint.2015.12.037
- Selvaraju, R. R., Cogswell, M., Das, A., et al. (2017). Grad-cam: Visual explanations from deep networks via gradient-based localization. Proceedings of the IEEE International Conference on Computer Vision, 618–626. doi: https://doi.org/10.1109/ICCV.2017.74
- Seshadrinath, J., Singh, B., & Panigrahi, B. K. (2014). Vibration analysis based interturn fault diagnosis in induction machines. IEEE Transactions on Industrial Informatics, 10(1), 340–350. https://doi.org/https://doi.org/10.1109/TII.2013.2271979
- Shao, H., Jiang, H., Zhang, X., & Niu, M. (2015). Rolling bearing fault diagnosis using an optimization deep belief network. Measurement Science and Technology, 26(11). https://doi.org/https://doi.org/10.1088/0957-0233/26/11/115002
- Sohaib, M., Kim, C. H., & Kim, J. M. (2017). A hybrid feature model and deep-learning-based bearing fault diagnosis. Sensors, 17(12), 2876. https://doi.org/https://doi.org/10.3390/s17122876
- Soualhi, A., Medjaher, K., & Zerhouni, N. (2015). Bearing health monitoring based on Hilbert–huang transform, support vector machine, and regression. IEEE Transactions on Instrumentation and Measurement, 64(1), 52–62. https://doi.org/https://doi.org/10.1109/TIM.2014.2330494
- Stack, J. R., Habetler, T. G., & Harley, R. G. (2004). Fault classification and faultsignature production for rolling element bearings in electric machines. IEEE Transactions on Industry Applications, 40(3), 735–739. https://doi.org/https://doi.org/10.1109/TIA.2004.827454
- Verstraete, D., Ferrada, A., Droguett, E. L., et al. (2017). Deep learning enabled fault diagnosis using time-frequency image analysis of rolling element bearings. Shock and Vibration. https://doi.org/https://doi.org/10.1155/2017/5067651
- Wang, D. (2016). K-nearest neighbors based methods for identification of different gear crack levels under different motor speeds and loads: Revisited. Mechanical Systems and Signal Processing, 70-71, 201–208. https://doi.org/https://doi.org/10.1016/j.ymssp.2015.10.007
- Wang, X. B., Yang, Z. X., & Yan, X. A. (2018). Novel particle swarm optimization-based variational mode decomposition method for the fault diagnosis of complex rotating machinery. IEEE/ASME Transactions on Mechatronics, 23(1), 68–79. doi: https://doi.org/10.1109/ISFA.2016.7790137
- Wang, J., Zhuang, J., Duan, L., & Cheng, W. (2016). A multi-scale convolution neural network for featureless fault diagnosis. Proceedings of the International Symposium on Flexible Automation, 65–70. doi: https://doi.org/10.1109/ISFA.2016.7790137
- Wen, L., Gao, L., & Li, X. (2019a). A New Snapshot Ensemble convolutional neural network for fault diagnosis. IEEE Access, 1–11. https://doi.org/https://doi.org/10.1109/access.2019.290329
- Wen, L., Li, X., & Gao, L. (2019b). A New Two-level Hierarchical diagnosis network based on convolutional neural network. IEEE Transactions on Instrumentation and Measurement, 1–9. https://doi.org/https://doi.org/10.1109/TIM.2019.2896370
- Wen, L., Li, X., Gao, L., & Zhang, Y. (2018). A new convolutional neural network-based data-driven fault diagnosis method. IEEE Transactions on Industrial Electronics, 65(7), 5990–5998. https://doi.org/https://doi.org/10.1109/TIE.2017.2774777
- Yi, C., Lv, Y., & Dang, Z. (2016). A fault diagnosis scheme for rolling bearing based on particle swarm optimization in variational mode decomposition. Shock and Vibration. https://doi.org/https://doi.org/10.1155/2016/9372691
- Yuan, Z., Zhang, L., & Duan, L. (2018). A novel fusion diagnosis method for rotor system fault based on deep learning and multi-sourced heterogeneous monitoring data. Measurement Science and Technology, 29(11). https://doi.org/https://doi.org/10.1088/1361-6501/aadfb3
- Yuwono, M., Qin, Y., Zhou, J., Guo, Y., Celler, B. G., &Su, S. W. (2016). Automatic bearing fault diagnosis using particle swarm clustering and hidden Markov model. Engineering Applications of Artificial Intelligence, 47, 88–100. https://doi.org/https://doi.org/10.1016/j.engappai.2015.03.007
- Zhang, X., Liang, Y., Zhou, J., & Zang, Y. (2015). A novel bearing fault diagnosis model integrated permutation entropy, ensemble empirical mode decomposition and optimized SVM. Measurement, 69, 164–179. https://doi.org/https://doi.org/10.1016/j.measurement.2015.03.017
- Zhang, Z., & Sabuncu, M. (2018). Generalized cross entropy loss for training deep neural networks with noisy labels. Advances in Neural Information Processing Systems, 8778–8788. https://dl.acm.org/doi/https://doi.org/10.5555/3327546.3327555
- Zhou, B., Khosla, A., Lapedriza, A., et al. (2016). Learning deep features for discriminative localization. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
- Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., & Torralba, A. (2015). Object detectors emerge in deep scene cnns. International Conference on Learning Representations.
- Ziani, R., Felkaoui, A., & Zegadi, R. (2017). Bearing fault diagnosis using multiclass support vector machines with binary particle swarm optimization and regularized Fisher’s criterion. Journal of Intelligent Manufacturing, 28(2), 405–417. https://doi.org/https://doi.org/10.1007/s10845-014-0987-3