
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Chinese Herbal Medicine (CHM) classification is a promising research issue in Intelligent Medicine. However, the small available Chinese Herbal datasets and the traditional CHM classification model lead to huge challenge for obtaining the promising classification results. To tackle the above challenges, a novel large CHM classification (CHMC) dataset has been firstly established, which includes 100 classes with about 10,000 samples. This dataset contains a wide range of medicinal materials and natural background. Further, the promising EfficientNetB4 model is proposed to perform the CHM classification. EfficientNet can uniformly scales up the depth, width and resolution of the model, which will obtain better accuracy as it balance all dimensions of the network, including depth, width, and resolution, respectively. To validate the superiority of the EfficientNet and the effectiveness of CHMC dataset, extensive experiments have been conducted, verifying that the EfficientNetB4 is optimal for CHM classification, with 5% improvement of the existing model. In addition, this model has achieved state-of-the art CHM classification performance, with TOP-1 accuracy of 83.1%, and TOP-5 accuracy of 92.50%.
1. Introduction
Chinese Herbal Medicine (CHM) with a long-term development history, which has broad applications and attracted much attention from academia and industry fields. It plays a critical role in human being health. For example, CHM has made outstanding contributions to the effective fight against the novel coronavirus pneumonia in China. Consequently, accurate classification of CHM is essential in promoting the development of medical treatment.
Tremendous research efforts have been conducted classifying the CH. Luo et al. (Citation2013) proposed a novel processing technique of the Locally Linear Embedding algorithm (LLE) and Linear Discriminant Analysis (LDA) to perform the CHM classification, which could handle the high-dimensional nonlinear data of CHM. However, the dataset they used only contains six classes that is quite small. Zhang et al. (Citation2013) utilized a supervised local projection strategy to identify the leaves of plant and achieved superior classification performance. A Support Vector Machine (SVM) with Fourier characteristics and morphometric methods have been employed to classify the medicines in two test sets, including 26 and 17 classes, respectively (Unger et al., Citation2016). Specifically, one class contains about 10 samples and achieves the corresponding accuracy of 73.21% and 84% in each issue. Dehan et al. (Citation2014) also adopted two approaches PCA and SVM, and conducted a comparison experiment. It is figured out that the SVM can obtain superior results. In 2016, the SOM algorithm has been utilized to identify CHM images (Wang et al., Citation2016). Although excellent performance are obtained, the scale of the dataset is relatively small, and there are not many classes of images. Liu et al. (Citation2018) utilized GoogleNet for the CHM classification. Unfortunately, the dataset in this work is relatively large (50 classes), but still cannot meet our requirements. Further, the model they used is out of date.
As above stated, although extensive methods have been developed to address CHM classification, it has not achieved the promising results. The reason can be concluded as follows: (1) the existing CHM data sets are small; (2) most CHM classification models are traditional with poor performance. To overcome the above-mentioned problem, we established a novel large CHM classification (CHMC) dataset via crawler technology. This dataset contains 100 classes, and each class contains 100 samples on average. Thus, the dataset includes 10,000 images in total. Among them, 8000 samples are utilized for training and the rest for testing. Moreover, CHMC has rich variety of medicinal materials. Specifically, concerning the natural attributes of medicinal materials: CHMC involves botanical medicine (rice bud, cockscomb, cinnamon twig, hematoxylin), animal medicine (sea cuttlebone, sea dragon, earth dragon, corrugated fruit, scorpion) and mineral medicine (red stone fat, Alum). Moreover, considering the medicinal part: CHMC contains roots (asarum, ginseng), bark (cork, pomegranate peel), seeds (lotus seeds, wild jujube kernels, orange cores), etc. Furthermore, the most samples in CHMC have nature backgrounds, which can promote real-world applications.
Moreover, in order to obtain effective CHM classification performance, we have proposed to utilizing promising EfficientNet model to conduct CHM classification. Conventional convolutional Neural Networks (ConvNets) are commonly proposed at a fixed resource cost, and then scaled up for suppressing performance if more resources are obtainable. For example, ResNet (He et al., Citation2016) can be scaled up from ResNet-18 to ResNet-200 through utilizing more layers. The most commonly used approach is to scale up ConvNets by their width (Zagoruyko & Komodakis, Citation2016) or depth (He et al., Citation2016). Another research line is to scale up models via image resolution (Huang et al., Citation2018). Although these models have achieved better performance than their corresponding baseline model without scaling up, they only scale one of the three dimensions – width, depth, and image resolution. Though two or three dimensions can be scaled arbitrarily, arbitrary scaling needs tedious manual adjustments and still often leads to sub-optimal accuracy and efficiency. EfficientNet can uniformly scale the model in all dimensions and can carefully balance the network width, depth, and resolution, respectively.
Above all, our contributions can be summarized as follows:
We first establish a novel large CHMC dataset for CHM classification with 100 categories and 10,000 samples. CHMC contains rich variety of medicinal materials, including botanical medicine, animal medicine, mineral medicine, roots, bark, and seeds part medicine. Furthermore, most samples in CHMC have complex and close to natural background.
We first propose to leverage the EfficientNet model which has powerful classification capabilities to conduct CHM classification. Through a simple but extremely effective compound coefficient, EfficientNet can consistently scale all dimensions, including width, depth, and resolution, and obtain much better efficiency and accuracy than other models. Specifically, EfficientNetB4 achieves the best result for CHM classification, with 5% improvement of the existing model. Additionally, EfficientNetB4 has obtained the state-of-the-art CHM classification performance, with TOP-1 accuracy of 83.1%, and TOP-5 accuracy of 92.50%.
Extensive ablation studies have been designed and executed to validate the performance of EfficientNet model and the effectiveness of the dataset. Concretely, these studies include the evaluation of various models, the evaluation of ResNet model with different layers, the evaluation of different EfficientNet variants, the evaluation of ResNet50 and EfficienetNetB4, and the evaluation of different dataset scales.
The reminder of this paper is organized as follows. Section 2 briefly reviews some related works. In Section 3, we describe the construction of the dataset and the EfficientNet model in detail. Experimental results are illustrated in Section 4 and some discussions are presented in Section 5. Finally, we conclude this paper in Section 6.
2. Related works
In this section, we will review some works closely related to this study, including deep neural networks. In recent years, deep convolutional neural networks (Krizhevsky et al., Citation2012; LeCun et al., Citation1989) have established a series of milestones for image classification (Krizhevsky et al., Citation2012; Zeiler & Fergus, Citation2014). Concretely, AlexNet (Krizhevsky et al., Citation2012), consisted of eight layers, won the 2012 ImageNet competition. This network started a new era of deep learning. Afterward, as the network becomes deeper, the performance of the convolutional neural network continues to make breakthroughs. In 2014, the GoogleNet (Szegedy et al., Citation2014) with 22 layers, won the ImageNet competition and obtained 74.8% top-1 accuracy. The key to this model is its inception module. Moreover, VGG (Simonyan & Zisserman, Citation2014), with two variants, VGG16 and VGG19, ranked second in the competition of the same year. Although above-mentioned networks have achieved promising classification results, they cannot be extended to deeper layers due to gradient explosion or dispersion problems. To tackle this problem, He et al. (Citation2016) have developed ResNet framework, which with 152 layers on the ImageNet dataset and with a depth of up to 100 and 1000 layers on CIFAR10. The ResNet has won the 2015 ImageNet competition. In 2017, SENet (Hu et al., Citation2017) has become the champion of the ImageNet competition and its top-1 accuracy was 82.7%.
Although the deeper the network, the better the performance, but in some real application scenarios such as mobile or embedded devices, such a large and complex model is quite difficult to be applied. Thus, the research work (Howard et al., Citation2017) proposes the mobile model MobileNet. The essential of this network is the utilization of decomposable depthwise separable convolution, which cannot only reduce the computational complexity of the model, but also greatly reduce the model size. Moreover, Xception (Chollet, Citation2016) is another improvement of Inception v3 proposed by Google after Inception. It mainly uses depthwise separable convolution, similar to that of MobileNet, to replace the convolution operation in the original Inception v3. Xception obtained the comparable classification performance on the ImageNet dataset with Inception v3.
Moreover, numerous researchers proposed to scale up ConvNets to pursue superior accuracy. However, most of their work consider depth, width, and resolution separately. To further achieve enhanced performance, the work (Tan & Le, Citation2019) systematically explores model scaling and demonstrates that carefully balancing network width, depth, and resolution can result in better results, then develops a novel model called EfficientNet.
Although convolutional neural networks have made a series of breakthroughs in recognition tasks, we are not sure that which model is optimal for our scenario. Therefore, exploring an optimal model for solving our scenario is becoming a key issue in this paper.
3. Methods
3.1. Dataset construction
This section elaborates the process of dataset construction in detail, including the data collection, cleaning, and preprocessing.
3.1.1. Data collection and cleaning
In the normal process of collecting medicinal materials, the ones of similar function are usually stored together. Therefore, the pictures of the same medicinal material collected in pharmacies and other occasions are very similar, with less diversity. Besides, the generalization ability of the trained model is poor, and it is prone to overfitting. Aiming to increase the diversity and richness of the samples, we utilize crawling strategy to collect a series of pictures of medicine images, under natural conditions with complex backgrounds, and cleaned them as necessary. The cleaned data is divided into the training set and test set, with a ratio 4:1. In the cleaning process, we choose images according to the proportion of the medicine in the image, the ones with a small proportion are deleted. To ensure the feasibility of data, our collection process is partitioned into three stages, with data categories ranging from less to more, specifically 29 categories, 50 categories, and 100 categories. After processing, each category contains 100 images. Some illustrative images are shown in Figure .
Figure 1. Example of CHM classification dataset.

Furthermore, a wide variety of medicinal materials are collected. From the natural attributes of medicinal materials: it involves botanical medicine (rice bud, cockscomb, cinnamon twig, hematoxylin), animal medicine (sea cuttlebone, sea dragon, earth dragon, corrugated fruit, scorpion) and mineral medicine (red stone fat, Alum), as shown in Figure ; from the medicinal part: it related to roots (asarum, ginseng), bark (cork, pomegranate peel), seeds (lotus seeds, wild jujube kernels, orange cores), etc., as shown in Figure .
Figure 2. Examples of CHM with different natural attributes. (a) Animal medicine, (b) Mineral medicine and (c) Botanical medicine.

Figure 3. Examples of different medicinal parts of Chinese medicinal materials. (a) Root Part, (b) Bark part and (c) Seed Part.

3.1.2. Data preprocessing
The major task in the data preprocessing stage is data augmentation. In this stage, we adopt several most commonly used data augmentation strategies, including rotation, translation, and shearing, for CHM data augmentation.
3.2. Problem formulation
Assume CHMC dataset has N samples from C classes, the corresponding label set is denoted as
with
.
The sample is sent into a network F with several phases with convolutional operation or pooling/fc operation. The network contains p phases and the
has
layers with operator
. Finally, F obtains the logit
for sample
.
(1)
(1)
(2)
(2)
(3)
(3) where F denotes the classification network,
indicates the logit for sample
from F,
represents the
has
layers and each layer with operator
, ⊙ indicates the composition operations between a series of layers.
The predicted probability of class c for sample
from network is calculated as
(4)
(4) where the logit
is obtained from the ‘softmax’ layer of Network for
.
The network can be trained through the conventional cross entropy loss L in classification tasks, which can be obtained by the following equation.
(5)
(5) where
is the true label for
,
is an indicator, if
,
,
,
, L denotes the cross entropy error between the correct labels and the predicted values, which can enforce the model to predict the correct results for the training samples.
3.3. EfficientNet
3.3.1. Compound scaling
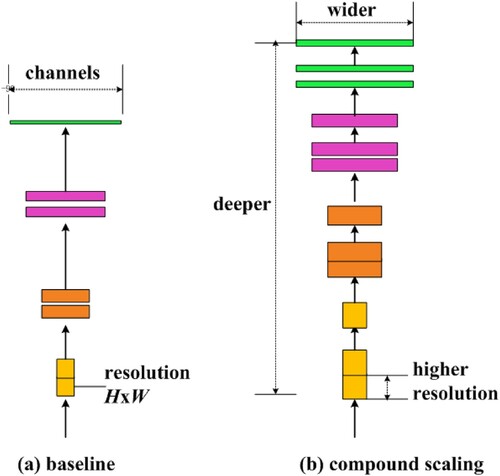
The key idea of EfficientNet (Tan & Le, Citation2019) is to leverage a novel compound scaling strategy to uniformly scaling the width, depth and resolution of network, aiming at pursuring enhanced classification results with more resources available. This model scaling strategy is presented in Figure (b). Figure (a) illustrates a baseline network example with smaller width, depth, and resolution. Among it, the H and W denote the shape of the input tensor.
Figure 4. Model scaling of EfficientNet. (a) An example of baseline network. (b) Compound scaling approach that consistently scales all three dimensions, including width, depth, and resolution with a fixed ratio.
EfficientNet utilize a compound coefficient ϕ to consistently scales the width, depth, and resolution of network in the following way as in Tan and Le (Citation2019):
(6)
(6) where α, β, and γ are constants. ϕ is a coefficient specified by user that determines how many more resources are accessible for model scaling, while α, β, and γ denote how to distribute these excess resources to network depth, width, and resolution respectively.
3.3.2. EfficientNet structure
Table presents the structure of EfficientNet-B0 as in Tan and Le (Citation2019). The key building block of EfficientNet-B0 is mobile inverted bottleneck MBConv (Sandler et al., Citation2018; Tan et al., Citation2019), with added squeeze-and-excitation optimization (Hu et al., Citation2017).
Table 1. Comparison of various models based on 29 types of CHM.
Beginning with the baseline EfficientNetB0 and utilizing the compound scaling method can scale up the network to different larger and superior variants, from EfficientNetB1-EfficientNetB4. The detailed ,
and
of EfficientNetB0-EfficientNetB4 is listed in Table .
Table 2. The compound scales for different EfficientNets.
3.3.3. Model training
For a fair comparison, the models in the experiment uniformly adopt SGD to update the parameters. At the same time, the epochs are 50 and the batch_size is 8. In addition, the Bayesian search is selected as the main strategy of hyperparameter search in this paper.
3.3.4. Evaluation criteria
In order to verify the performance of the model, we utilize the following evaluation criteria, including top1 accuracy, top5 accuracy, precision, recall, and .
Among them, the top1 accuracy refers to the accuracy of the first ranking category in accordance with the actual results and the top5 accuracy refers to the accuracy of the top five categories containing actual results. The , it indicates how many of the predicted samples are correctly predicted.
, which denotes how many samples are correctly predicted in terms of the original samples.TP/FP/FN indicates the number of True positive/False positive/False negative samples. The
, it is an index utilized in statistics to measure the accuracy of the classification model. F1 score takes the precision and recall of the classification model into account simultaneously, and it is the harmonic average of the precision and recall.
4. Experiments
In this section, we will describe our experiments in detail. Extensive experiments are conducted for exploring the availability of dataset and the efficiency of the optimal model.
4.1. Evaluation of various models
To explore the performances of CHM classification in various models, we compare various popular deep neural networks based on 29 classes of CHM. The comparison models include Resnet, SE-Resnet, MobileNet, EfficientNet, with results presented in Table . Table illustrates that the EfficienetNetB4 model obtains the best results, validating the effectiveness of EfficienetNetB4 model in CHM classification.
Table 3. Comparison of various models based on 29 types of CHM.
4.2. The necessity of hyperparameter search
To evaluate the effectiveness of hyperparameter search, Baysian strategy has been employed to search the optimal hyperparameter for different promising models, including MobileNetV3_large_x1_0, Xception71, ResNet50_vd and EfficientNetB4, respectively. The comparison results of models with different parameters are shown in Figure (a) is about learning rate hyperparameter, and Figure (b) is about weight decay hyperparameter. Specifically, the search ranges of learning_rate and weight_decay hyperparameters are determined by the algorithm.
Figure 5. Comparison results of hyperparameter search. (a) Comparison results on Learning_rate hyperparameter for different models. (b) Comparison results on Weight_decay hyperparameter for various models.
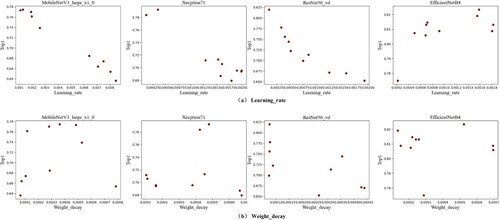
Figure illustrates that after hyperparameter search, the performance of model will be greatly improved, which validates the effectiveness of hyperparameter search.
4.3. Evaluation of different dataset scales
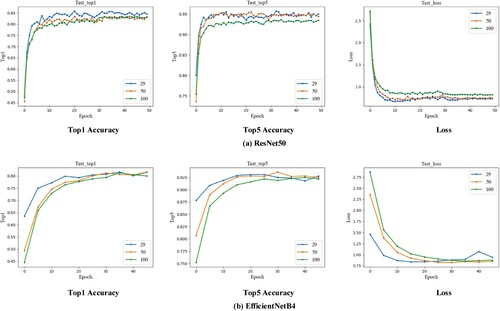
In order to verify the feasibility of the dataset we collected, we established it step by step. Meanwhile, we validate the performance of dataset with different scales. The reason is that when the dataset scale becomes larger and the performance is still remain comparable with those of small-scale dataset, we can believe that the large dataset we constructed is valid. To be specific, we explore three different dataset scales, including 29, 50, 100 classes of CHM. Furthermore, our experiments are based on the relatively optimal ResNet50 and EfficientNetB4 models respectively. The comparison results are reported in Figure . Figure illustrates that for different sample scales, the models obtain comparable performances in terms of top1 accuracy, top5 accuracy and loss, which verifies that the data we collect is valid, even when the scale is expanded to 100 categories. Furthermore, in subsequent experiments, we will employ 100 types of data by default.
Figure 6. Performance comparison of different sample scales, including 29, 50, and 100 classes of CHMs, based on ResNet50 and EfficientNetB4.
4.4. Evaluation of ResNet model with different layers
ResNet is a relatively popular classification model. To verify the performance of the different ResNet variants on the CHM data, we compared the residual model with different layers, including ResNet18, ResNet34, ResNet50, ResNet101, ResNet152, respectively. The comparison results are reported in Figure which illustrates that for ResNet18, ResNet34 and ResNet50, the deeper the layer, the better the performance. However, the ResNet101 and ResNet152 obtain worse results than that of ResNet50, which may be because of the data scale we established is still small when applying the ResNet model. In a word, the ResNet50 is the optimal choice among the ResNet model variants for our situation.
Figure 7. Performance comparison of ResNet models with different layers.

4.5. Evaluation of different EfficientNet variants
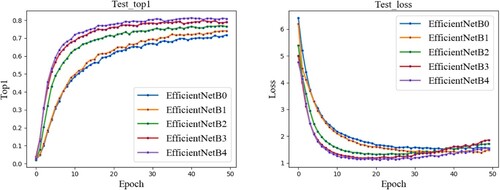
EfficientNet is recently the promising classification model. To validate the performance of the different EfficientNet variants on the CHM classification data, we compared the EfficientNet with different variants, including EfficientNetB0 EfficientNetB4, respectively. The comparison results are shown in Figure which indicates that the EfficientNetB4 obtains the optimal results.
Figure 8. Performance comparison of different EfficientNet variants.
4.6. Evaluation of ResNet50 and EfficienetNetB4
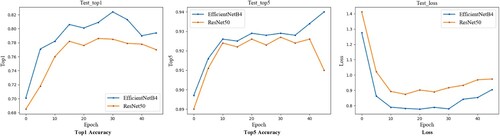
Based on the above sections, we conclude that ResNet50 and EfficientNetB4 are the optimal two models in their corresponding counterpart. In order to figure out the better one of these two models, we compared them and presented the results in the Figure . Figure illustrates that EfficientNetB4 is superior to that of ResNet50 in terms of top1, top5 and loss evaluation criteria.
Figure 9. Performance comparison of ResNet50 and EfficientNetB4.
5. Discussions
CHM classification is essential to intelligent medical, assisting people to better collect, identify, and process CHM. Furthermore, it can better treat diseases such as the new coronavirus. However, CHM classification has not achieved promising performance. Reasons can be concluded as follows, first, the classification of CHM requires very professional knowledge, and there are few people with this ability. Furthermore, the previous Chinese herbal datasets are small, and the recognition model employed is not optimal.
To tackle the above-mentioned problems, a novel larger CHM dataset, with 100 categories, has been established. This dataset is more feasible in terms of backgrounds and involved fields. Specifically, most examples in this dataset contains wild and complex backgrounds. Further, this dataset contains plant, animal and mineral medicinal materials, and also includes root, bark and seed medicinal materials.
In order to ensure that the established dataset is effective, we set up it gradually, from small to large, ranged from 29 categories, 50 categories, and 100 categories. Section 4.3 validate the performance of them. The results demonstrate that different scale datasets obtain promising and comparable performance, which verifies the feasibility of our novel dataset when its scale up to 100 categories.
Furthermore, we explore the effectiveness of using Bayesian hyperparameter search strategies in training in order to improve CHM classification performance. Section 4.2 demonstrates that the results of model will be greatly improved after the hyperparameter search, which verifies the effectiveness of the hyperparameter search.
To explore the effectiveness of EfficientNet for CHM classification, we design the experiments from four aspects: (1) the evaluation of different models, (2) the evaluation of ResNet model with different layers, (3) the evaluation of different EfficientNet variants and (4) the evaluation of ResNet50 and EfficienetNetB4. According to the evaluation of different models, we figured out that the ResNet50 and EfficientNetB4 models achieve superior results on 29 categories CH dataset. In order to further assess the ResNet and EfficientNet models in their corresponding counterparts, the (2) and (3) experiments are carried out, which further validate the superiorities of ResNet50 and EfficientNetB4 in their corresponding families (ResNet18–ResNet 152 and EfficientNetB0–EfficientB4). The (4) experiments are finally utilized to figure out the most optimal model, which reports that the EfficientNetB4 is the best model for CHM classification.
6. Conclusions
This paper establishes a novel relatively large CHM dataset with natural and complex backgrounds, which contains 100 categories and 10,000 samples in total. Furthermore, we first propose to apply the excellent EfficientNet to perform CHM classification task. Numerous experiments have been carried out to validate the availability of the established dataset and the effectiveness of EfficientNet. Experimental results demonstrate that EfficientNetB4 is the superior classification model and obtains state-of-the-art CHM classification performance, far beyond other models (ResNet, SE-ResNet, MobileNet, and Xception et.) in terms of all evaluation criteria. Future work will be explored in the aspects of construction of a larger CHM dataset with more categories, and more effective methods for classifying CHMs.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Chollet, F. (2016). Xception: Deep Learning with Depthwise Separable Convolutions. In Computer vision and pattern recognition(CVPR). IEEE. arxiv:1610-02357. IEEE
- Dehan, L., Jia, W., Yimin, C., & Hamid, G. (2014). Classification of Chinese Herbal medicines based on SVM. In 2014 International conference on information science, electronics and electrical engineering. IEEE. https://doi.org/https://doi.org/10.1109/InfoSEEE.2014.6948152. IEEE
- He, K. m., Zhang, X. Y., Ren, S. Q, & Sun, J. (2016). Deep residual learning for image recognition. In 2016 IEEE conference on computer vision and pattern recognition(CVPR). IEEE. (pp. 770–778).
- Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., & Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. Preprint, arXiv:1704.04861.
- Hu, J., Shen, Li., Albanie, S., Sun, Gang., & Wu, E. (2017). Squeeze-and-excitation networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 99. https://doi.org/https://doi.org/10.1109/TPAMI.2019.2913372
- Huang, Y., Cheng, Y., Bapna, A., Firat, O., Chen, M. X., Chen, D., Lee, H., Ngiam, J., Le, Q. V., Wu, Y., & Chen, Z. (2018). Gpipe: Efficient training of giant neural networks using pipeline parallelism. Preprint, arXiv:1808.07233.
- Krizhevsky, A., Sutskever, I., & Hinton, G. (2012). ImageNet classification with deep convolutional neural networks. In Conference on Neural Information Processing Systems(NIPS) . MIT Press. (pp. 1097–1105).
- LeCun, Y., Boser, B., Denker, J. S., Henderson, D., Howard, R. E., Hubbard, W., & Jackel, L. D. (1989). Backpropagation applied to handwritten zip code recognition. Neural computation, 1(4), 541–551. https://doi.org/https://doi.org/10.1162/neco.1989.1.4.541
- Liu, S. P., Chen, W. Y., & Dong, X. J. (2018). Automatic classification of Chinese herbal based on deep learning method. In 2018 14th International conference on natural computation, fuzzy systems and knowledge discovery (ICNC-FSKD). Springer.
- Luo, D. H., Fan, D. J., Yu, H., & Li, Z. M. (2013). A new processing technique for the identification of Chinese herbal medicine. In Fifth international conference on computational and information sciences. IEEE.
- Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., & Chen, L. C. (2018). Inverted residuals and linear bottlenecks. In Computer vision and pattern recognition (CVPR). IEEE.
- Simonyan, K., & Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. In Computer vision and pattern recognition (CVPR). IEEE.
- Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., & Rabinovich, A. (2014). Going deeper with convolutions. In Computer vision and pattern recognition (CVPR). IEEE.
- Tan, M., Chen, B., Pang, R., Vasudevan, V., Sandler, M., Howard, A., & Le, Q. V. (2019). MnasNet: Platform-aware neural architecture search for mobile. In Computer vision and pattern recognition (CVPR). IEEE.
- Tan, M., & Le, Q. V. (2019). EfficientNet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning (ICML). ACM.
- Unger, J., Merhof, D., & Renner, S. (2016). Computer vision applied to herbarium specimens of German trees: Testing the future utility of the millions of herbarium specimen images for automated identification. BMC Evolutionary Biology, 16(1), Article number: 248. https://doi.org/https://doi.org/10.1186/s12862-016-0827-5
- Wang, M., Li, L., Yu, C., Yan, A., Zhao, Z., Zhang, G., Jiang, M., Lu, A., & Gasteiger, J. (2016). Classification of mixtures of Chinese herbal medicines based on a self-organizing map (SOM). Molecular Informatics, 35(3–4), 109–115. https://doi.org/https://doi.org/10.1002/minf.201500115
- Zagoruyko, S., & Komodakis, N. (2016). Wide residual networks. In British Machine vision conference (BMVC). Springer.
- Zeiler, M. D., & Fergus, R. (2014). Visualizing and understanding convolutional networks. In European conference on computer vision (ECCV). Springer.
- Zhang, S. W., Li, Y. K., Dong, T. B., & Zhang, X. P. (2013). Label propagation based supervised locality projection analysis for plant leaf classification. Pattern Recognition, 46(7), 1891–1897. https://doi.org/https://doi.org/10.1016/j.patcog.2013.01.015