
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
As the ageing population increases, it is essential to manage human resources with residual life prediction, especially for the ageing population. Thus, this study aims to predict residual life using the available information of health statuses, such as the performances in activities of daily living (ADL) and memory. In this study, the principal components of ADL and memory information are extracted for prediction. The relationship between the principal components and residual life is established based on the concept of the proportional residual, which states that the residual life may be proportional to the changes in ADL and memory performance. A recursive model for residual life prediction is formulated and fitted for the Chinese Health and Nutrition Survey data. Finally, a goodness-of-fit test is conducted, and an example case is presented. The results show that the fitted model in this study is more accurate and precise than the original, unfitted model to estimate the residual life of human beings. This study is advantageous over existing studies in two aspects: (1) the model is formulated using a recursive method based on stochastic filtering; (2) the data include both physical status and mental status.
1. Introduction
Currently, live expectancy surpasses the age of 60 (de Cabo & Mattason, Citation2019; DESA, Citation2007; Fitzmaurice et al., Citation2019; Rudd et al., Citation2020; Word Health Organization, Citation2015). This demographic brings unprecedented opportunities and challenges. Longer life can be an incredibly valuable resource in economic, social, cultural, and familial aspects (Beard & Bloom, Citation2015). However, the healthcare expenditures for older people are increasing over time (Gregersen, Citation2014). The increasing prevalence of chronic diseases associated with ageing that accompanies the growth of the elderly population makes it hard for health and care services to cope (Oliver et al., Citation2014). Previous research shows that the expected cumulative expenditures for healthier elderly persons are similar to those of less healthy individuals (Lubitz et al., Citation2003). This implies that if we can estimate the health status of the aged person, their possible expenditure in a good health condition can be saved. Intuitively, a direct reflection of health status is the residual life. Thus, if a healthcare system wants to manage health better and reduce costs, an effective residual life prediction is needed.
Many researchers have studied life prediction for human beings using life expectancy or mortality (Arora et al., Citation2016; Atance et al., Citation2020; Boudoulas et al., Citation2017; Evans & Soliman, Citation2019; Parker et al., Citation2020; Wandeler et al., Citation2016; Wang et al., Citation2018). Traditional studies investigated this topic from the perspective of disease. Wandeler et al. studied the trends in life expectancy of HIV-positive adults on antiretroviral therapy worldwide (Wandeler et al., Citation2016). Wang et al. proposed a mortality prediction system for heart failure with orthogonal relief and dynamic radius means (Wang et al., Citation2018). Another stream of studies investigated this topic from the perspective of non-disease factors. For instance, Boudoulas et al. reviewed the effect of the evolution of medical science and medical technology on life expectancy (Boudoulas et al., Citation2017). Evans and Soliman presented an ecological study on the relationship between the subjective sense of well-being and life expectancy (Evans & Soliman, Citation2019). Parker et al. provided a systematic review on healthy working life expectancy at age 50 (Parker et al., Citation2020).
Besides traditional statistical studies, some researchers tried to study life expectancy or mortality using mathematical models (Hashir & Sawhney, Citation2020; Li et al., Citation2017; Su et al., Citation2020). For example, Li et al. used machine learning models to predict in-hospital mortality of ST-elevation myocardial infarction patients (Li et al., Citation2017). Su et al. developed a clinical prediction model for the mortality of diabetic adults with COVID-19 in Wuhan, China (Su et al., Citation2020). Hashir and Sawhney attempted to predict mortality with free-text clinical notes (Hashir & Sawhney, Citation2020). However, these mathematical models are limited to a population with a specific disease, while healthcare requires a comprehensive health assessment or residual life prediction for an average person. Some researchers developed models to estimate age-specific mortality for an average person (Cho et al., Citation2020). For instance, Cho et al. proposed an age-structured biomass model with an impulsive dynamic system to estimate age-specific natural mortality (Cho et al., Citation2020), Díaz-Rojo et al. used a multivariate control chart and Lee-Carter models to study mortality changes (Díaz-Rojo et al., Citation2020).
However, both streams of studies have limitations. On the one hand, these traditional studies were carried out with statistical approaches, lacking the support of the change mechanism for life prediction and the results of quantitative analysis cannot be interpreted clearly (Atance et al., Citation2020). These studies cannot be easily used to guide healthcare workers, especially when they want to implement the healthcare policy to older adults, since these studies cannot explain the life prediction mechanism. These mathematical models of age-specific mortality did not utilize other health information except age, reducing the prediction accuracy. For example, aged people with better health status than age match groups may live longer than expected. Herein, it is recommended to utilize health information to adjust the residual life prediction.
Thus, this study proposes a recursive model to estimate the residual life of human beings with the utilization of health information to obtain a comprehensive health assessment (Senne, Citation1972). This estimation is related to the recursive filtering problem (Liu et al., Citation2021; Yang et al., Citation2021). Herein, the proposed model is constructed based on a stochastic filtering model, which was initially proposed by Wang and Christer (Citation2000) for condition-based monitoring maintenance applications and then applied in life prediction for machines with vibration monitoring (Wang et al., Citation2018). This model is essentially a recursive Bayesian algorithm that is advanced in two aspects. First, it can track the subject’s progress and thus predict the outcome without information loss. Second, since the information is fully utilized, the prediction is more accurate and precise. Thus, this method can provide an effective view of the health status observed over one’s lifetime to estimate the residual life for human beings.
Moreover, this study also makes innovation in terms of information utilized. The previous research works of residual life prediction for the elderly are usually based only on the physiological conditions of the elderly, ignoring the influence of mental factors. To provide a more accurate prediction of the remaining life of the elderly, mental factors, such as the performance in memory, were introduced within the physical health indicators, such as the performance in Activities in Daily Life (ADL) in this study. In other words, the filtering approach is adapted to use both disability and cognitive impairment information, which have been proved to associate closely with later life loss (Jagger et al., Citation2007; Spiers et al., Citation2005; Stuck et al., Citation1999). The level of disability can be reflected by the performance in ADL (Covinsky et al., Citation2003; Dunlop et al., Citation1997; Katz, Citation1983), while the decline of cognitive function can be reflected by the memory impairment (Brewer et al., Citation2005; McGuire et al., Citation2006). Therefore, ADL and memory performance changes can be used as early indicators of mortality risk to estimate the residual life.
People may question why medical history, especially related to severe diseases, is not employed to predict the residual life in this study. For this issue, this study has four concerns. First, the medical history is not easily collected since people may be reluctant to talk about this sensitive topic. Second, only a fraction of people have access to their medical history, so that the application of the method utilizing medical history is limited. Third, medical history information is also difficult to be unified because patients are treated in different medical institutions or doctors with different treatment plans. Last, the medical history cannot reflect some sub-health status conditions without the diagnosis of disease, and these sub-health status conditions may also cause a reduction of residual life.
The remainder of this paper is arranged as follows. Section 2 presents the introduction and the initial process of data and variables used. Section 3 gives the model formulation process. Section 4 fits the proposed model according to the Chinese Health and Nutrition Survey (CHNS) data, a nationally representative survey in China. Section 5 provides a case study to illustrate the proposed model. Section 6 discusses, and Section 7 concludes this study, respectively.
2. Data and variables
This study uses longitudinal data from the Chinese Health and Nutrition Survey (CHNS) conducted by the Carolina Population Centre at the University of North Carolina at Chapel Hill, U.S.A., and the National Institute of Nutrition and Food Safety at the Chinese Centre for Disease Control and Prevention. CHNS started in 1989, and there were eight follow-up surveys between 1991 and 2011. CHNS used a multi-stage, random cluster method to draw samples from 19,000 participants from 4400 households in nine provinces, which made these samples substantially varied in geography, economic development, public resources, and health indicators (Popkin et al., Citation2009).
The general retirement age in China is around 55; thus, the ADL and memory tests are designed for adults aged 55 and older in the CHNS questionnaire. Therefore, the elderly is defined as adults older than 55 years old when their follow-up began, and in this study, all the analyses were performed for this population only. Excluding participants with invalid, erroneous, and incomplete cases on variables of concern, the total number of samples in our analyses is 10,986. Among them, 1746 samples recorded the age of death (complete), while the other samples are still alive at the last survey (censored), as shown in Table .
Table 1. Sample statistics.
From 2000 to 2011, ADL and memory were analysed separately in the CHNS questionnaire. The first section used ADL to understand the various life difficulties caused by health and physical limitations, as shown in Table . Respondents answered the question, ‘Do you have any difficulty doing this?’ for activities shown in Table . Possible answers were: 1 no difficulty; 2 have some difficulty but can still do it; 3 need help to do it; 4 cannot do it at all.
Table 2. ADL.
The second part was a memory test, as shown in Table . It began with the question, ‘How is your memory?’, followed by ‘In the past twelve months, how has your memory changed?’ Next, the participants were asked to memorize and repeat ten words. After counting backward from 20 to 1, the participants were asked to repeat those ten words. The questions are shown in Table .
Table 3. Memory.
Twenty-five variables can be extracted from these 25 questions, and these require at least 25 parameters to be estimated from the data, which is a demanding task even if they are not correlated. The fact is that some of them may be highly correlated or even useless to the following analyses. Hence, the relationships among the 25 variables need to be examined first to reduce the parameters. We used Principal Component Analysis (PCA) to examine the variables. PCA can transform the original set of variables to a new set of uncorrelated variables, named principal components, which are linear combinations of the original variables (Li & Liu, Citation2020; Miao & Lv, Citation2020; Samuel & Cao, Citation2016). Generally, a few principal components account for most of the variation in the original information and will be intuitively meaningful and useful in subsequent analyses where we can operate with a largely reduced number of variables. The process of PCA is as follows.
Let be the set of m random variables that represent the m observed original variables data. Using PCA, an m-dimensional uncorrelated variable vector,
, is obtained, whose variances decrease in sequence from the first. Each
is taken to be a linear combination of
, so that
(1)
(1) where
is a vector of constants. Equation (1) contains an arbitrary scale factor. After imposing the condition,
, the overall transformation is ensured to be orthogonal and the distances are preserved. Then the variance of each
,
is given by
(2)
(2) where
is the covariance matrix of
and
are the eigenvalues of the covariance matrix of
.
The first principal component, , is found by choosing
to maximize the variance of
subject to the constraint that
. Thus,
is believed to have the largest possible variance for all combinations of the form of Equation (1). Similarly,
is the second principal component found by choosing
, so that it has the second-largest possible variance and is uncorrelated with
. Principal components
are all derived, uncorrelated, and with decreasing variances. Then, using
in Equation (1),
and the variance
can be obtained. Because the ADL and memory reflect physical and mental health, respectively, the PCA is performed for the two parts separately. Variances of these principal components are shown in Figure .
Figure 1. Variances of principal components.
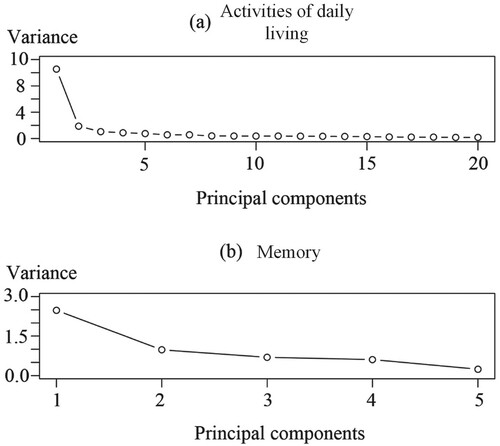
After calculating the eigenvalues and the principal components, the first few components are examined to determine if they account for a large proportion of the total variance. This study selects the components that account for more than 70% of cumulative variance. Figure shows that the first principal components of both ADL and memory account for the overwhelming majority (over 70%) of the total variation in the original information. To balance between the number of components and the amount of original information, two principal components are used in subsequent analyses: the first principal components of ADL denoted as , and the first principal components of memory denoted as
. The PCA transforming parameters of the two first principal components are shown in Tables and .
3. Model formulation
3.1. Residual life prediction
Typically, deteriorating health means the reduction of residual life. Since health status is an ambiguous concept difficult to quantify, the residual life can be used as a health indicator. In this case, the health status information, including ADL and memory, is used to monitor our model. Generally, physical health is strongly associated with ADL, while mental health is positively related to memory; therefore, people in a feebler health status usually exhibit deteriorative performance in ADL and memory. Thus, there is a stochastic relationship between health status monitoring data and the unobserved actual health status.
In this study, a new filtering methodology with a recursive nature is adopted. The model use all past information about ADL and memory as covariates to predict residual life. From the PCA analyses, two principal components are shown to contain most of the initially observed information, and therefore, can be used to represent the original ADL and memory data. In practice, the first principal component means a weighted average of the original information where the weights are obtained by maximizing the variance. Let denote the first principal components calculated based on the observed ADL at the time of the
survey,
let
denote the residual life of the participant at
, provided that this individual has survived to
, and let
denote the history values of
, where
.
is defined in the same pattern. Then the objective is to establish the Probability Distribution Function (PDF) of
given
and
, i.e.
.
The relationship between residual lives at times and
can be expressed as
(3)
(3) Equation (3) shows that
must be conditional on
so that
. Our model assumes that after obtaining the health status information (ADL and memory) at time
, the residual life distribution estimated is altered by the difference between the actual and expected health status decrements over
. A similar concept has been used in accelerated life models where the survival function is accelerated by a deterministic constant (Crowder et al., Citation1991). Then
is given by
(4)
(4) where
denotes the actual health status decrement and
denotes the expected health status decrement over
. Both
and
may not be observed directly, but they can be indicated by
and
as
. Here,
and
denote expected
and
, while
,
and
are functions
,
respectively and
, where
and
are parameters to be specified.
The form of function is chosen based on the proportional hazard model. This model is a semi-parametric model with good performance in analysing and explaining the hazard for different values of the concerned variables. The form of function
can be easily extended to other cases.
To calculate and
, we need first quantify the relationships between expected health status information (
and
) and survival time (
) which also is the age when the participant was surveyed. We employed linear regression to quantify this relationship since the parameter estimation and prediction of linear regression are efficient, and the parameter in linear regression is easy to interpret. Thus, the two relationships can be expressed as
and
, where
,
,
and
are parameters. The form of the two relationships can be extended to other cases.
Then Equation (4) can be expressed as
(5)
(5) which is a proportional function. If the health status is stable without deterioration, so that
and
, then the residual life prediction should also be stable and
. Otherwise, residual life prediction will vary proportionally with
and
. By specifying an initial PDF of
,
, and using the fact that
(6)
(6) and Equation (5), after some recursive manipulations, it can be shown that the PDF of
conditional on
and
, and
can be expressed as
(7)
(7) Equation (7) shows an advantage of this model:
is conditional on all past
and
,
, rather than just the current
and
. If all
and
, this equation then returns to the conventional conditional survival PDF. If all observed data conform to the expected mean, then
as there is no evidence of deviation from the original prediction. Only in some cases when
or
,
revised accordingly. However, it should be noted that this is not the case in using the proportional hazard model, where the hazard can only return to the baseline hazard if all
and
. There is no difficulty in extending the model to use more principal components. However, for the balance between the accuracy and the number of parameters estimated, this study focuses on the case where only the two most important principal components are used.
For the initial residual life distribution , an appropriate choice is the Weibull distribution,
, where
is the scale parameter and
is the shape parameter. The Weibull distribution is a widely used survival analysis distribution. The closed-form of the survival function and the wide variety of shapes exhibited by density functions make the Weibull distribution a particularly convenient generalization of the exponential distribution. It can be used to flexibly describe time distribution, especially when the hazard rate may increase, decrease, or remain invariant.
3.2. Parameter estimation
There are three sets of parameters estimated in our model, as shown in Table . The first set includes the Weibull distribution that includes the scale parameter
and the shape parameter
. If there are enough residual life data, the two parameters can be estimated using the maximum likelihood method. From the available information sources, among the
participants’ life data,
of them are complete life data, and the
of them are censored data, then the likelihood function is
, where
is the PDF of lifetime,
is the survival function,
is the final lifespan of the
th participants, and
is the last survey time of the
th censored participant. The estimated values of the scale parameter
and the shape parameter
can be obtained by maximizing the likelihood function.
Table 4. Parameter estimated.
The second set is within the linear regression for the relationships between health status information and survival time, including ,
,
, and
. The estimation for this parameter set is conducted based on the available data. In practice, the parameters in the second set can also be adjusted by health workers’ experience.
The third set includes the parameters and
which govern the relation between
and
and they are called governor parameters. The two parameters are the core parameters in the proposed model, and they are estimated by the following method.
For any participant, the following events have been observed at each survey: if the participant is alive; or
, where
is the lifespan and
is the time of the last survey before
. The likelihood function of all observed events for a participant is
(8)
(8) Note that these events are all conditioned on the participant having survived up to the time of the events, so the events are statistically independent. Using Equation (7) after some manipulations, the likelihood function for a single participant over his or her lifetime can be expressed as
(9)
(9) The likelihood function for h participants is given by
(10)
(10) where
is the lifespan of the
th participant,
is the time of the
th survey of the
th participant,
and
are the first principal components of the
th participant at
, and
is the number of surveys before the death of the
th participant.
Equation (10) represents the probability that all the events reflected by the data happened. Herein, once we have the first two sets of parameters, the values of and
can be estimated by maximizing the logarithm of Equation (10).
4. Model fitting
4.1. Fitting the model to the data
In this section, the model introduced above is fitted to the health status data from the CHNS. To keep as much as the original information as possible, both the complete and censored samples are used; 9566 randomly selected samples were to fit the model and the remaining 1420 samples were used to test the fitted model. Since the ADL and memory test information are only collected from people aged 55 and older, all the fitting analyses are limited to this population. Participants observed after the age of 55, and
. For simplicity, the survival time
is calculated from age 55, that is
.
For the initial residual life distribution , where
, the scale parameter
and the shape parameter
of the Weibull distribution are estimated using the maximum likelihood method based on data from 9566 samples. Incorporating the Weibull distribution into the likelihood function can beexpressed as
(11)
(11) where
is the life span of the
th complete participant and
is the last survey time of the
th censored participant. Taking the logarithm on both sides of Equation (11), it can be transformed to
(12)
(12) By maximizing Equation (12), the estimates of
and
are
and
, respectively; by inverting the information matrix, the variances and covariance of estimated parameters
and
can be approximated, then
,
and
. The variances and the covariance of the estimated
and
are minimal compared with their estimated values, which means that they are stable and probably uncorrelated.
The health status information and survival time relationships are expressed as and
. The results of the regression show that
,
,
and
and all the regression parameters are significant (P-Value
). In other words, with age (survival time) increase, the ADL and memory will deteriorate.
Next, parameters and
can be estimated using the maximum likelihood method as
(13)
(13) where
and
. Using Equation (7),
, and taking ln on both sides of Equation (13), it can be expressed as
(14)
(14) where
and
. By maximizing Equation (14), the estimated values of
and
, given that
and
are substituted by their estimated values
and
. The variance of the estimated parameter
is calculated by
.
and
can also be calculated in the same way. Then we have
,
and
. For
, the calculated variances and co-variances are extremely small compared with the estimated values, so that they are stable and uncorrelated.
The residual life of a participant at time is predicted based upon estimated model parameters and the information of first two principal components. The
is expressed by the following function:
(15)
(15) This equation shows a life mechanism that predicts how residual life is influenced by the deviation between the expected and real components’ information, while increasing health status deterioration indicates a relatively shorter residual life.
4.2. Goodness-of-fit
To assess the model fit, 1420 samples were chosen as test set and the chi-square goodness-of-fit test was used to carry out the test (Fisher, Citation1922; Pearson, Citation1992). This study of the chi-squared test is not applied since there is only one observation for each distribution
. It is feasible to carry out the chi-squared test in this situation by partitioning each distribution
into some intervals with equal probability; then
will have an equal probability to be in any one of the intervals. This effectively transforms
into a uniform distribution. Specifically,
is partitioned into
cells here so that each cell had an equal probability,
. Under the hypothesized distribution, each observation cell is examined. After this transformation, all
follow an identical uniform distribution, the number of observations
per cell counted and compared with the expected values followed by goodness-of-fit test.
However, for the censored participants, their real residual life cannot be known at each survey. For these samples, is calculated and the
is assumed to have an equal probability of being in any one of the
cells covered by
. In this case, all the numbers of observations in these
cells increase by
.
The null hypothesis is that the elderly’s residual life
follows the stated probability distribution
. Since all parameters in
are already estimated by the other 9566 randomly selected samples, the hypothesis here is simple. To do the test, we need to decide the number of partitions, namely,
. It is recommended that for a sample of size
(large) and significance level
, one should use approximately
(D’Agostino & Stephens, Citation1986). Then the expected number of observations in each cell is
and finally, the sum of standard deviation can be expressed by
(16)
(16)
In this study, , thus choosing
is reasonable. Then the degree of freedom is
, the equal probability of each cell
is
and the expected number of observations in each cell is
. Substituting these values into Equation (16), the sum of standard deviation is 32.43. On the other hand, if we choose a significance level of 0.05, referring to the
table, the critical value is
. As 32.43 is smaller than 48.60, the hypothesis is true, so that there is no evidence to reject the established model.
5. Case study
In this section, a participant was chosen as an example to exhibit the fitted model. The participant was first surveyed when he was 61 years old and the subsequent surveys were carried out at the ages of 65, 68, 72, and 74. Finally, he passed away just ten months after the last survey. The residual life distribution of the participant was predicted after each survey based on his ADL and memory information using the model fitted in Section 6.
To illustrate the effectiveness of the proposed model, two perspectives of comparisons are provided based on this example: (1) the fitted model itself, including the comparisons for the result from the initial distribution (Weibull distribution) before using the proposed model and the result from using exponential distribution instead of Weibull distribution as the initial distribution in the fitted model; (2) the proposed model vs. other prediction methods, including the comparisons for the result from multiple regression and the result from the life table.
5.1. The proposed model
To provide the effectiveness in terms of the proposed model itself, we calculate the results from two methods: (1) the initial distribution using the Weibull distribution without the stochastic filtering; (2) exponential distribution as the initial distribution that is using exponential distribution to replace the Weibull distribution as the initial distribution.
5.1.1. Comparison with initial distribution (Weibull distribution)
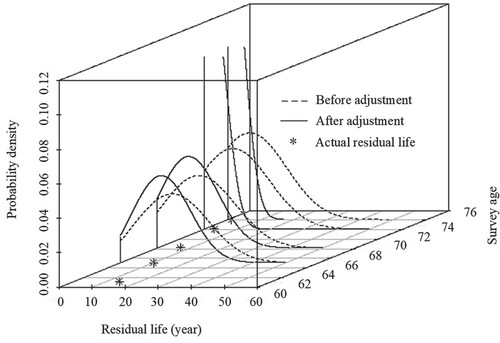
This comparison shows the difference between the results from the fitted model and the initial distribution (before adjustment, Weibull distribution), as shown in Figure . The residual life prediction using the fitted model in this study is more accurate than the initial distribution in general. The Mean Square Error (MSE) is also calculated. The MSE using our model is 6.2, and without it is 66.3. This proves that the fitted model provides a more reasonable prediction distribution. In addition, with increasing survey times and information amount, the fitted model is more precise and stable. The fitted model work only after the second survey because both and
used in this model need at least two observations to calculate.
Figure 2. Comparison of the predicted residual life distribution based on the fitted model and the initial distribution. (Note: the distribution curves of the fourth and fifth predictions are too centralized to be shown in the plot, so the last two curves are interrupted; the following figures also have the similar situations).
5.1.2. Comparison with exponential distribution as the initial distribution
The exponential distribution is widely used to depict the residual life, especially those whose residual life is irrelevant to their history. Thus, this comparison shows the difference between the results from the fitted model with the Weibull or the exponential distribution as the initial distribution, as shown in Figure .
Figure 3. Comparison of the predicted residual life distribution based on the fitted model with Weibull distribution and the fitted model with exponential distribution.
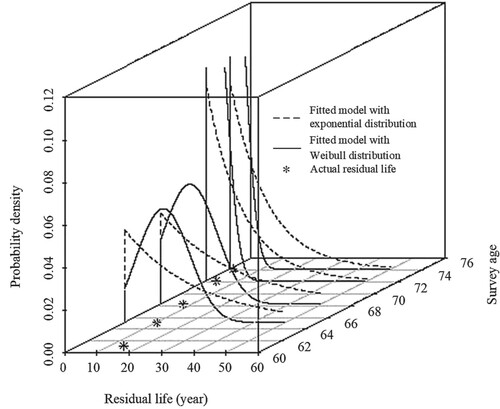
In this study, the exponential distribution is fitted with the same data from the Weibull distribution, which is , where
. The residual life prediction using the fitted model with Weibull distribution is more accurate than with an exponential distribution. This proves that using the Weibull distribution in the fitted model provides a more reasonable prediction than the exponential distribution.
5.2. The proposed model vs. other prediction methods
To further illustrate the proposed model’s effectiveness, we further provide the results from other methods of residual life prediction as comparative studies. Among the life prediction methods for human beings, regression analysis and life table are the two most commonly used methods. Regression analysis is a classical and straightforward statistical method to conduct prediction, especially for predicting with a large amount of data. The life table is a statistical table reflecting the death of a group of people (usually 10,000 people), compiled according to the age-specific mortality. The comparisons of the proposed model using multiple regression and life table are presented below.
5.2.1. Comparison with multiple linear regression
The formula of the multiple linear regression is , where
is the constant,
is the random error following
,
and
are the coefficients of the first principle components of ADL and memory, respectively. Using the same data as in the fitting for the proposed model, the values of
,
,
and
can be estimated to 6.55318, 0.26129, 0.07349, and 0.25761, respectively. Then we used this multiple linear regression model to predict the residual life,
. According to the linear regression, the prediction distribution is a normal distribution
. Finally, we compared the difference between the results from the fitted model and the multiple regression, as shown in Figure .
Figure 4. Comparison of the predicted residual life distributions from the proposed model and multiple linear regression.
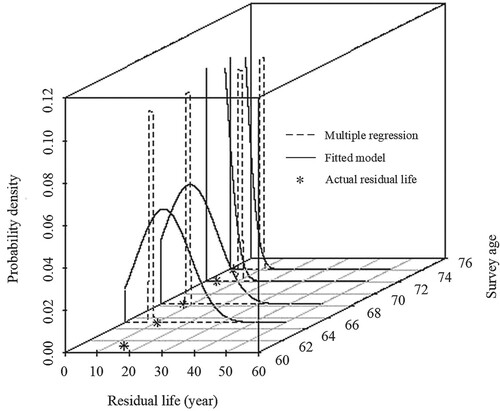
The residual life prediction using the proposed model is more accurate than using multiple linear regression, especially at the last two survey times when more historical health information was collected and integrated into the model.
5.2.2. Comparison with life table
Since the survey data ended in 2011, we use the 2010 life table of the Chinese population, as shown in Table . To provide a comparison, a normal distribution, based on a Life Table, is presented. The expectation is the residual life from the Life Table, while the standard deviation is set as 1 since the expected residual life is updated with age annually. Thus, we compare the difference between the fitted model and life table results, respectively, as shown in Figure .
Figure 5. Comparison of the predicted residual life distribution based on the fitted model with Weibull distribution and the fitted model with exponential distribution.
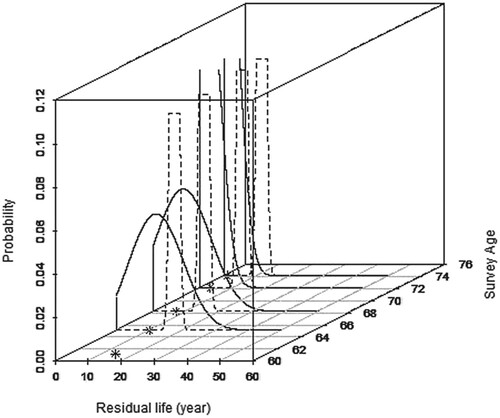
Table 5. Life table of Chinese population in 2010.
Our results show that the residual life prediction using the proposed model is more accurate than using a life table. Generally, residual life prediction from the life table is longer, and the proposed model can update the prediction according to the historical health information compared with the life table.
6. Discussion
The proposed model in this study is based on the stochastic filtering theory, which solves drawbacks of quantitative analysis of the previous statistical models. The proposed model can use time-series data through a recursive method to constantly update the prediction and improve its reliability. In terms of the data, ADL and memory were used to extract an indicator that comprehensively reflects people’s health status. This method is different from the previous health assessment using biochemical indicators. The information we used is a more comprehensive reflection of health level, emphasizing the ability to live. This method is more conducive to promotion and application, especially in economically underdeveloped areas with poor medical conditions.
According to the research results, ADL and memory are adequate information for calculating the remaining human life. With the deterioration of health, residual life will decrease, and at the same time, ADL and memory will worsen. If ADL and memory reflect the acceleration of this trend, residual life will also be accelerated until the end of life. This implies that society should pay more attention to people’s ADL and memory to guard against health deterioration. In addition, for health management agencies and insurance companies, ADL and memory should also become important references for guiding work.
7. Conclusions
This study presents an improved method to estimate the residual life of the elderly by using a recursive model. Compared to the previous study model, the proposed model is developed to integrate the health information extracted from ADL and memory, which is the progressive feature of this study. This paper provides a physiologic relationship between the health status and ADL and memory. When memory is introduced as a mental factor, the usage and feasibility of the stochastic filtering are further verified. As ageing is an increasingly serious issue in many countries, the government and the public should pay attention to the ADL and memory of the elderly.
There are two possible limitations of the proposed method. On the one hand, the method is a little complex in terms of its mathematical calculation. However, this limitation can be addressed by developing this method into algorithms and models embedded in the software. On the other hand, the accuracy and precision of the prediction by this method increases with the quantity of historical information, so that this method requires an effective health information recording system or organization.
This article can be extended in a few directions. One direction is to extend the method for the application to the young population. Another direction is to apply this method to other survey data where the health information may be different. Also, it is also meaningful to study the optimization of health behaviour based on the prediction of the proposed method.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Arora, A., Spatz, E., Herrin, J., Riley, C., Roy, B., Kell, K., Coberley, C., Rula, E., & Krumholz, H. M. (2016). Population well-being measures help explain geographic disparities in life expectancy at the county level. Health Affairs, 35(11), 2075–2082. https://doi.org/https://doi.org/10.1377/hlthaff.2016.0715
- Atance, D., Debón, A., & Navarro, E. (2020). A Comparison of forecasting mortality models using resampling methods. Mathematics, 8(9), 1550. https://doi.org/https://doi.org/10.3390/math8091550
- Beard, J., & Bloom, D. (2015). Towards a comprehensive public health response to population ageing. The Lancet, 385(9968), 658–661. https://doi.org/https://doi.org/10.1016/S0140-6736(14)61461-6
- Boudoulas, K. D., Triposkiadis, F., Stefanadis, C., & Boudoulas, H. (2017). The endlessness evolution of medicine, continuous increase in life expectancy and constant role of the physician. Hellenic Journal of Cardiology, 58(5), 322–330. https://doi.org/https://doi.org/10.1016/j.hjc.2017.05.001
- Brewer, W. J., Francey, S. M., Wood, S. J., Pantelis, H. J., Phillips, L. J., Yung, A. R., Anderson, V. A., & McGorry, P. D. (2005). Memory impairments identified in people at ultra-high risk for psychosis who later develop first-episode psychosis. American Journal of Psychiatry, 162(1), 71–78. https://doi.org/https://doi.org/10.1176/appi.ajp.162.1.71
- Cho, G., Kim, D., Jung, S., Jung, I. H., & Kim, S. (2020). Estimating age-specific natural mortality for sandfish in the eastern coastal waters of Korea. Mathematics, 8(9), 1612. https://doi.org/https://doi.org/10.3390/math8091612
- Covinsky, K. E., Palmer, R. M., Fortinsky, R. H., Counsell, S. R., Stewart, A. L., Kresevic, D., & Burant, C. J. (2003). Loss of independence in activities of daily living in older adults hospitalized with medical illnesses: Increased vulnerability with age. Journal of the American Geriatrics Society, 51(4), 451–458. https://doi.org/https://doi.org/10.1046/j.1532-5415.2003.51152.x
- Crowder, M. J., Kimber, A. C., Smith, R. L., & Sweeting, T. J. (1991). Statistical analysis of reliability data. Chapman and Hall.
- D’Agostino, R. B., & Stephens, M. A. (1986). Goodness-of-fit-techniques. Marcel Dekker.
- de Cabo, R., & Mattason, M. P. (2019). Effects of intermittent fasting on health, aging, and disease. New England Journal of Medicine, 381(26), 2541–2551. https://doi.org/https://doi.org/10.1056/NEJMra1905136.
- DESA. (2007). Development in an ageing world. World economic and social survey (pp. v–viii). United Nations. http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=2302B1B61C64FB890F208EB0DD218401?doi=10.1.1.177.2319&rep=rep1&type=pdf
- Díaz-Rojo, G., Debón, A., & Mosquera, J. (2020). Multivariate control chart and Lee–Carter models to study mortality changes. Mathematics, 8(11), 2093. https://doi.org/https://doi.org/10.3390/math8112093
- Dunlop, D., Hughes, S., & Manheim, L. (1997). Disability in activities of daily living: Patterns of change and a hierarchy of disability. American Journal of Public Health, 87(3), 378–383. https://doi.org/https://doi.org/10.2105/AJPH.87.3.378
- Evans, G. F., & Soliman, E. Z. (2019). Happier countries, longer lives: An ecological study on the relationship between subjective sense of well-being and life expectancy. Global Health Promotion, 26(2), 36–40. https://doi.org/https://doi.org/10.1177/1757975917714035
- Fisher, R. (1922). On the interpretation of χ2 from contingency tables, and the calculation of P. Journal of the Royal Statistical Society, 85(1), 87–94. https://doi.org/https://doi.org/10.2307/2340521
- Fitzmaurice, C., Abate, D., Abbasi, N., Abbastabar, H., Abd-Allah, F., Abdel-Rahman, O., Abdelalim, A., Abdoli, A., Abdollahpour, I., Abdulle, A. S. M., Abebe, N. D., Abraha, H. N., Abu-Raddad, L. J., Abualhasan, A., Adedeji, I. A., Advani, S. M., Afarideh, M., Afshari, M., Aghaali, M., & Agius, D. (2019). Global, regional, and national cancer incidence, mortality, years of life lost, years lived with disability, and disability-adjusted life-years for 29 cancer groups, 1990 to 2017 a systematic analysis for the Global Burden of Disease Study. JAMA Oncology, 5(12), 1749–1768. https://doi.org/https://doi.org/10.1001/jamaoncol.2019.2996
- Gregersen, F. (2014). The impact of ageing on health care expenditures: A study of steepening. The European Journal of Health Economics, 15(9), 979–989. https://doi.org/https://doi.org/10.1007/s10198-013-0541-9
- Hashir, M., & Sawhney, R. (2020). Towards unstructured mortality prediction with free-text clinical notes. Journal of Biomedical Informatics, 108, 103489. https://doi.org/https://doi.org/10.1016/j.jbi.2020.103489
- Jagger, C., Matthews, R., Matthews, F., Robinson, T., Robine, J. M., Brayne, C., & Medical Research Council Cognitive Function and Ageing Study Investigators. (2007). The burden of diseases on disability-free life expectancy in later life. The Journals of Gerontology Series A: Biological Sciences and Medical Sciences, 62(4), 408–414. https://doi.org/https://doi.org/10.1093/gerona/62.4.408
- Katz, S. (1983). Assessing self-maintenance: Activities of daily living, mobility, and instrumental activities of daily living. Journal of the American Geriatrics Society, 31(12), 721–727. https://doi.org/https://doi.org/10.1111/j.1532-5415.1983.tb03391.x
- Li, R., & Liu, Y. (2020). Sparse representation-based classification for the planetary gearbox with improved KPCA and dictionary learning. Systems Science & Control Engineering, 8(1), 369–379. https://doi.org/https://doi.org/10.1080/21642583.2020.1777218
- Li, X., Liu, H. F., Yang, J. G., Xie, G. T., Xu, M. L., & Yang, Y. J. (2017). Using machine learning models to predict in-hospital mortality for ST-elevation myocardial infarction patients. Studies in Health Technology and Informatics, 245, 476–480. https://doi.org/https://doi.org/10.3233/978-1-61499-830-3-476
- Liu, D., Wang, Z. D., Liu, L. R., & Alsaadi, F. E. (2021). Recursive filtering for stochastic parameter systems with measurement quantizations and packet disorders. Applied Mathematics and Computation, 398, 125960. https://doi.org/https://doi.org/10.1016/j.amc.2021.125960
- Lubitz, J., Cai, L., Kramarow, E., & Lentzner, H. (2003). Health, life expectancy, and health care spending among the elderly. New England Journal of Medicine, 349(11), 1048–1055. https://doi.org/https://doi.org/10.1056/NEJMsa020614
- McGuire, L., Ford, E., & Ajani, U. (2006). Cognitive functioning as a predictor of functional disability in later life. The American Journal of Geriatric Psychiatry, 14(1), 36–42. https://doi.org/https://doi.org/10.1097/01.JGP.0000192502.10692.d6
- Miao, C., & Lv, Z. (2020). Nonlinear chemical processes fault detection based on adaptive kernel principal component analysis. Systems Science & Control Engineering, 8(1), 350–358. https://doi.org/https://doi.org/10.1080/21642583.2020.1768173
- Oliver, D., Foot, C., & Humphries, R. (2014). Making our health and care systems fit for an ageing population. King’s Fund.
- Parker, M., Bucknall, M., Jagger, C., & Wilkie, R. (2020). Extending working lives: A systematic review of healthy working life expectancy at age 50. Social Indicators Research, 150(1), 337–350. https://doi.org/https://doi.org/10.1007/s11205-020-02302-1
- Pearson, K. (1992). On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonably supposed to have arisen from random sampling. In S. Kotz & N. L. Johnson (Eds.), Breakthroughs in statistics. Springer series in statistics (perspectives in statistics) (pp. 11–28). Springer.
- Popkin, B. M., Du, S., Zhai, F., & Zhang, B. (2009). Cohort profile: The China health and nutrition survey – Monitoring and understanding socio-economic and health change in China, 1989–2011. International Journal of Epidemiology, 39(6), 1435–1440. https://doi.org/https://doi.org/10.1093/ije/dyp322
- Rudd, K. E., Johnson, S. C., Agesa, K. M., Shackelford, K. A., Tsoi, D., Kievlan, D. R., Colombara, D. V., Ikuta, K. S., Kissoon, N., Finfer, S., Fleischmann-Struzek, C., Machado, F. R., Reinhart, K. K., Rowan, K., Seymour, C. W., Watson, R. S., West, T. E., Marinho, F., Hay, S. I., … Naghvi, M. (2020). Global, regional, and national sepsis incidence and mortality, 1990-2017: Analysis for the Global Burden of Disease Study. The Lancet, 395(10219), 200–211. https://doi.org/https://doi.org/10.1016/S0140-6736(19)32989-7
- Samuel, R. T., & Cao, Y. (2016). Nonlinear process fault detection and identification using kernel PCA and kernel density estimation. Systems Science & Control Engineering, 4(1), 165–174. https://doi.org/https://doi.org/10.1080/21642583.2016.1198940
- Senne, K. (1972). Stochastic processes and filtering theory – Andrew H. Jazwinski. IEEE Transactions on Automatic Control, 17(5), 752–753. https://doi.org/https://doi.org/10.1109/TAC.1972.1100136
- Spiers, N. A., Matthews, R. J., Jagger, C., Matthews, F. E., Boult, C., Robinson, T. G., & Brayne, C. (2005). Diseases and impairments as risk factors for onset of disability in the older population in England and Wales: Findings from the Medical Research Council Cognitive Function and Ageing study. The Journals of Gerontology Series A: Biological Sciences and Medical Sciences, 60(2), 248–254. https://doi.org/https://doi.org/10.1093/gerona/60.2.248
- Stuck, A. E., Walthert, J. M., Nikolaus, T., Büla, C. J., Hohmann, C., & Beck, J. C. (1999). Risk factors for functional status decline in community-living elderly people: A systematic literature review. Social Science & Medicine, 48(4), 445–469. https://doi.org/https://doi.org/10.1016/S0277-9536(98)00370-0
- Su, M. H., Yuan, J., Peng, J. R., Wu, M. J., Yang, Y. S., & Peng, Y. G. (2020). Clinical prediction model for mortality of adult diabetes inpatients with COVID-19 in Wuhan, China: A retrospective pilot study. Journal of Clinical Anesthesia, 66, 109927. https://doi.org/https://doi.org/10.1016/j.jclinane.2020.109927
- Wandeler, G., Johnson, L. F., & Egger, M. (2016). Trends in life expectancy of HIV-positive adults on antiretroviral therapy across the globe: Comparisons with general population. Current Opinion in HIV and AIDS, 11(5), 492–500. https://doi.org/https://doi.org/10.1097/COH.0000000000000298
- Wang, W., & Christer, A. (2000). Towards a general condition based maintenance model for a stochastic dynamic system. Journal of the Operational Research Society, 51(2), 145–155. https://doi.org/https://doi.org/10.1057/palgrave.jors.2600863
- Wang, Z., Yao, L. J., Li, D. D., Ruan, T., Liu, M., & Gao, J. (2018). Mortality prediction system for heart failure with orthogonal relief and dynamic radius means. International Journal of Medical Informatics, 115, 10–17. https://doi.org/https://doi.org/10.1016/j.ijmedinf.2018.04.003
- World Health Organization (2015). World health statistics. WHO Press.
- Yang, H., Wang, Z. D., Shen, Y. X., & Alsaadi, F. E. (2021). Self-triggered filter design for a class of nonlinear stochastic systems with Markovian jumping parameters. Nonlinear Analysis-Hybrid Systems, 40, 101022. https://doi.org/https://doi.org/10.1016/J.NAHS.2021.101022