
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
With the widespread application of smart home systems, the optimal design of smart home systems has received considerable research attention. This paper puts forward a network smart home system design scheme based on the analysis of the indoor environment and the forecast of the future indoor environment. By building a multi-level network model, an integrated model system from analysis, prediction to decision-making is formed. The swarm intelligent decision-making ability of the networked smart home system is realized by applying a recurrent neural network and a reinforcement learning method. Meanwhile, the indoor simulation environment is built, the indoor environment variables are simulated and the performance of the system is verified by the simulation environment. The simulation results show that the networked smart home system has advantages over the single smart home equipment in the performance of indoor comfort improvement.
1. Introduction
As one of the main application fields of edge computing, the concept of smart home was proposed in the 1980s. The system monitors and manages various communications, home appliances and security equipment, and realizes intelligent management of the home environment. (The concept of smart home was first introduced from the field of edge computing, which is responsible for monitoring and managing various communications among home appliances and security equipment, shed new light into the intellectual management of home environment.) It is generally divided into three phases: smart single product, interconnection and artificial intelligence. It is mainly based on the fourth generation of intelligent products based on all IP technology; technology integration, using short-range real-time communication solutions such as WiFi, Zigbee and so on. In the smart home network environment to provide services through the cloud center, to achieve customized personalized services according to user needs (Al-Ali et al., Citation2017; Ansarey et al., Citation2014; Babou et al., Citation2018; Barsoum & Hasan, Citation2015; Keshtkar & Arzanpour, Citation2017; Xing & Deng, Citation2019). For example, Al-Ali et al. (Citation2017) introduced an energy management system for smart homes and better consumer needs through big data analysis methods and business intelligence. Cheikh et al. (Babou et al., Citation2018) proposed the concept of home edge computing (HEC) in the context of edge computing in the smart home. It is a three-tiered edge computing architecture that provides ultra-low latency for applications to the user's near-end and focuses on handling the problem of overloading data transmission. Utilizing edge computing in the smart home scenario can better meet real-time business needs and bring people a better service experience. The development of smart home systems using edge computing is still in the experimental state.
Machine learning employs the science of artificial intelligence, and its main research object is artificial intelligence, especially how to improve the performance of specific algorithms in experiential learning. Reinforcement learning is an important branch of machine learning, which served to describe and solve the problem that agents use learning strategies to maximize returns or achieve specific goals in their interaction with the environment. The inspiration comes from the behaviourist theory in psychology, that is, how the organism gradually forms expectations of the stimulus under the stimulus of the reward or punishment given by the environment. Since the late 1980s, with growing support from the development of mathematics, reinforcement learning has drawn much attention owing to its ability to learn online and the adaptive ability without a tutor system, and has been applied in many fields, such as handicraft manufacture, robot control, optimization and scheduling, simulations and so on (Hao et al., Citation2018; Mathe et al., Citation2016; Nguyen et al., Citation2019; Sun et al., Citation2018; Yin et al., Citation2018). Research in the past decades investigated various methods, techniques and algorithms used in reinforcement learning, and their defects and problems are gradually revealed. It is the focus of researchers’ discussion and research to find a better way and algorithm to promote the development and wide application of reinforcement learning. Therefore, neural networks and their algorithms have become the focus of many researchers due to their unique generalization and storage capabilities.
Recurrent neural network is an artificial neural network with a tree-like hierarchical structure and the nodes of the network recurse the input information according to their connection order (Tu et al., Citation2016; Wu & Yue, Citation2019; Xu et al., Citation2019; Yan et al., Citation2018; Zhang et al., Citation2017). Wherein, neurons can not only accept the information of other neurons but also accept their information, which forms a network structure with a loop, and subsequently enable the ability of short-term memory neural network. It is a nonlinear dynamic system and can be used to realize associative memory and solve optimization problems by electronic circuits (Haykin, Citation1999; Huaguang & Zhanshan, Citation2009). So far, a large number of researchers have strengthened the effects and applications of reinforcement learning through the characteristics of neural networks (Ding et al., Citation2017; Guo et al., Citation2019; Teich et al., Citation2014). For example, in Guo et al. (Citation2019) and Teich et al. (Citation2014), the authors adopted neural network algorithm as the core adaptive algorithm based on the relationship between the complexity of the smart home environment and non-linear variables, with added wavelet, particle swarm and optimizing neural network algorithms, such as convolution, makes neural network algorithms have better performance in adaptive control systems. Under different processing problem backgrounds, different optimization methods are used to obtain better results. In Ding et al. (Citation2017), the neural network is further studied and explored, and the neural network algorithm based on deep learning is proposed. This algorithm has better performance in controlling system performance and accuracy than ordinary, single or other optimized neural network algorithms. Its advantages lie in multi-layer processing, rich hidden layer mode, complex connection weight relationship, and the large probability simulation which reduces the relationship between various factors and variables in complex and changeable environment. In Xie et al. (Citation2020), Yu et al. (Citation2021), authors have investigated applications of the deep reinforcement learning in smart building energy management with the consideration of different system scales comprehensively. Yu et al. (Citation2019) have researched the problem of minimizing the sum of energy cost and thermal discomfort cost in a long-term time horizon for a sustainable smart home with a heating, ventilation, and air conditioning load and a stochastic program has been proposed to minimize the time average expected total cost.
This paper focuses on the neural network algorithm that serves as the core of the prediction algorithm. The improvement and optimization of the neural network algorithm are proposed based on the prediction results. This research explores the extent to which our designated model of the indoor environment could automatically improve the comfortability of the indoor environment under the simulations. This paper takes the indoor environment analysis and forecasts the future indoor environment changes as the starting point, constructs a multi-level network model, and forms an integrated modelling solution from analysis to prediction and subsequent decision-making. Combining recurrent neural network, network reinforcement learning technology and proposed improvement measures to realize the group intelligent decision-making ability of smart home system.
The mainly contribution of this paper is:
Temperature, humidity, light, dust and wind speed are integrated into the smart home system, so as to improve the overall comfort of the living environment.
Recurrent neural network is used to collect the timing information of environmental variables to improve the intelligence of smart home system.
The rest of this paper is organized as follows. Section 2 analyses the basic problem and constructs the prediction model. Section 3 further analyses the prediction model and integrates it with the reinforcement learning method. Section 4 discusses the details of the algorithm of our models and makes the numerical result in a simulation environment which verifies the performance of the models. Finally, the conclusion is given in Section 5.
2. Analysis of problems and construction of the prediction model
In the indoor environment, human comfort is related to a variety of environmental attributes, including temperature, humidity, somatosensory wind speed, air dust, sunlight, and light intensity in the environment, and densely related to spatial location and time strong dependencies. In this regard, I consider the effects of space position and time, and design temperature, humidity, wind speed, dust, and light intensity as time-varying fields in space, and the corresponding variables are ,
,
,
and
, where
. These variables together affect the physical comfort of the human body, as shown in Figure (a).
Figure 1. (a) Variables affecting human comfort. (b) Directed graph of coupling relationship between different variables.
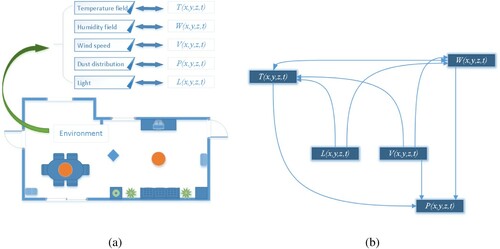
In view of the coupling effects between these variables, for example, the wind speed will affect the interplay of the humidity field and the temperature field. I represent these coupling relationships in Figure (b). respectively are used to represent the intelligent controller's control parameters for temperature, humidity, wind speed, dust and light intensity, then the system model can be established as follows:
(1)
(1) where
and
are undetermined functionals. Under ideal conditions, these undetermined functionals are present with specific expressions. However, the existence and uniqueness of the solution of the equation cannot be guaranteed even if these expressions exist. Moreover, the boundary conditions of indoor environment are often complicated, and difficult to determine the solution of the continuous space problem under the premise of limited sensors (state observation). Therefore, I do not consider the analytical form of the functional groups above, but from the coupling relationship of (1), I parameterize and discretize the abstract system to obtain a new optimization model.
First, is not interfered by other variables, so to simplify the expression, let
,
, and by discretizing each variables, it yields the state sequence
and control sequence
. According to Figure (b), the topological relationship among the variables can be described by the coupling matrix as follows:
where each
is an undetermined matrix and 0 is zero matrix. So far, I use recurrent neural network (Tu et al., Citation2016; Wu & Yue, Citation2019; Xu et al., Citation2019; Yan et al., Citation2018; Zhang et al., Citation2017 to describe the model (1) as below,
(2)
(2) where
,
and
are initial conditions. Also
and
is the outdoor light intensity. RNN is a recurrent neural network. Define comfort function
, whose value represents the level of comfort. Our goal is to maintain the level of comfort in the limited time
, i.e.
3. Further analysis of the prediction model and reinforcement learning integration
I integrate autonomy as an important design concept into the establishment of the model in system (2), that is, all variables that may be related to the time are embedded into the system (2) as state variables or intrinsic parameters, such as the outdoor light intensity. For outdoor temperature, it varies from day to night. By arranging sensors outdoors, the outdoor temperature is introduced into the system as a multi-dimensional variable . That is to say,
is a high-dimensional state variable, its dimension is equal to the total number of temperature sensors, some of which are placed outdoors. It is why
in coupling matrix
is an undetermined matrix. And
represent self-coupling matrices of
respectively. The rest in
represents the coupling between variables. So far, in order to be more precise, the first equation in (2) needs to be modified, because the outdoor state is not affected by the control parameters, so I do direct sum decomposition for the state variable
,
, where
represents indoor state and
represents the outdoor state. The control variables can only affect the indoor state variables, and the comfort degree is only related to the indoor state variables. So, let
. And in the optimization model, the lower bound condition is not conducive to the later solution process, and the original intention of designing the lower bound is to maintain the comfort at a higher level. Therefore, referring to the risk theory, I can substitute the lower bound process by combining a concave function
, so that in the later optimization process, the comfort can reach a higher level, and at the same time reduce its volatility. Therefore, the model can be modified to
(3)
(3) where
,
,
,
and
are external inputs.
is a positive integer large enough to represent the duration. The function
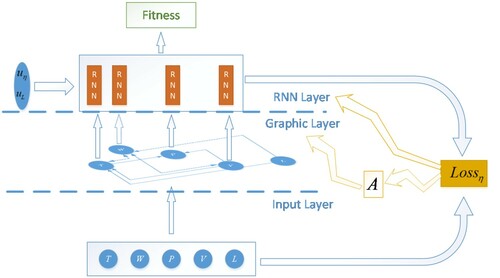
can be directly modelled according to the indoor structure, window opening position, light source position and wall reflection, which will not be described here. The RNN layer is composed of four RNNs, which are independent of each other, which are applied to the coupling matrix
to form state output. Let the observation value sequence of indoor state be
, so I can define the loss function as follows:
where
is parameters of neutral network. Sum the loss functions of different strategies, and minimize the target
as shown in Figure .
Figure 2. Three-layer network structure of the system.
Next, I will use the theory and method of reinforcement learning to optimize the control strategy. Reinforcement learning is developed from dynamic programming equation. This means that the learning system obtains the mapping relationship between the state and the behaviour through the interaction with the external environment, and the learning goal is to optimize the value of reward function. Q-learning used here is a classical reinforcement learning algorithm. First define the function Q,
According to (3), is a Markov decision process (MDP) (Chen et al., Citation2017; Doshi-Velez, Citation2009; Li, Citation2019; Qiao et al., Citation2018; Xie et al., Citation2020; Yu et al., Citation2019; Yu et al., Citation2021; Zheng & Cho, Citation2011. So according to the principle of dynamic principle (Redouane & Cherif, Citation2018; Zheng et al., Citation2008, the Bellman equation holds as below,
where
is the learning rate and by defining the loss function,
and combining with the system (3), the flow chart of the whole algorithm is shown in Figure .
Figure 3. The algorithm framework.
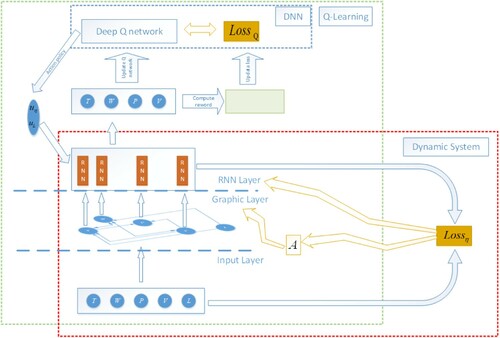
So, I give the total loss function of the model, is
4. Details of algorithm and numerical result in the simulation environment
In the established simulation environment, I summarize the algorithm framework as follows:
Initialize the state space sequence and clear the system time
Initialize DQN
Enter the status into DQN, use ϵ-greed strategy to generate control strategy, and use control strategy to generate several control sets
Match the control set with the state, enter it into the system (3), update the prediction state, and update the simulation state in the simulation system, and return to step 3 until the system time reaches the set time
Calculate Loss, use backpropagation to optimize the network
Return to step 1 until the
converges or reaches the set number of trainings.
In the training, the initial temperature indoor is 0 and the initial humidity is 80, and P is 30. is the square root function and
is the
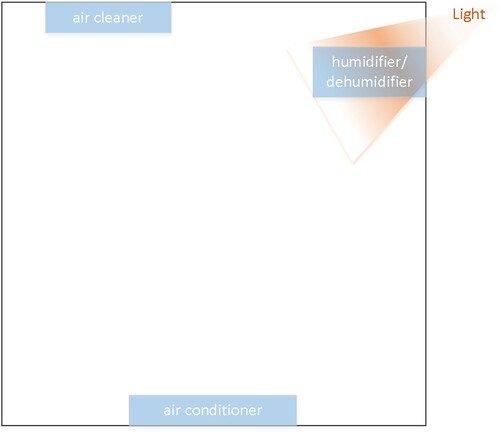
distance from the state to the ideal state. The number of temperature observer, humidity observer and dust observer are set to be 1, the light intensity is set to a constant value, and the wind speed is measured using equipment to set the wind speed, as shown in Figure . In the environment, the intelligent networking equipment includes air conditioner, humidifier/dehumidifier and air cleaner. The simulation works on a computer with Intel Core i7-10700, 64G memory and an NVIDIA 2080ti graphics card. The soft environment is Python/Pytorch.
Figure 4. Distribution of networked home intelligent devices in the simulation environment.
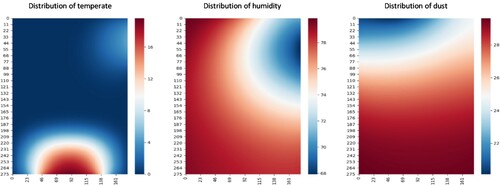
When the equipment is just started, the indoor environment variable distribution is shown in Figure .
Figure 5. Distribution of indoor environment variables when the equipment is just started.
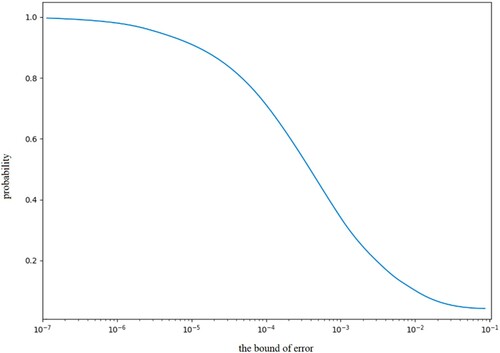
The learning rate of algorithm training is set as 0.05, the number of times of the outermost cycle training is 100,000, and thegrowth of the rewards during the training process is shown in Figure . After 100,000 times of training, the reward is stable at about 0.75 from 0.5 at the beginning. At this time, the probability that the error of the environmental state value in the prediction system exceeds 10% is less than 0.7%, the probability that the error exceeds 5% is less than 1.7%, and the probability that the error exceeds 1% is less than 7.2%. The relationship between the error bound and probability of the prediction exceeding the error bound is shown in Figure .
Figure 6. The growth of the rewards during the neural network in training.
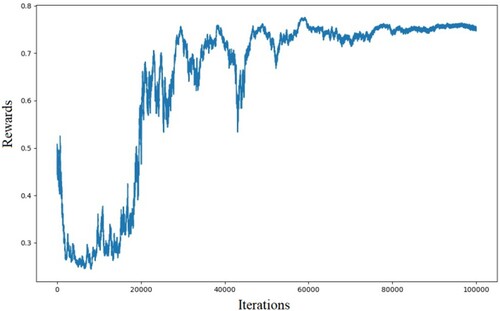
Figure 7. The curve of the relationship between the error bound and probability of the prediction exceeding the error bound.
After training, the effect of the networked smart home system in the simulation system is shown in Figure , and the changes and comparison of indoor temperature, humidity and micro dust of the networked smart home system are shown in Figure .
Figure 8. Distribution of indoor environment variables after a period of control.
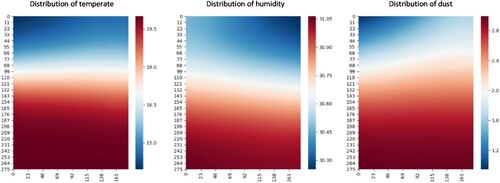
Figure 9. Comparison of indoor temperature, humidity and dust change between networked smart home system and single smart home equipment.
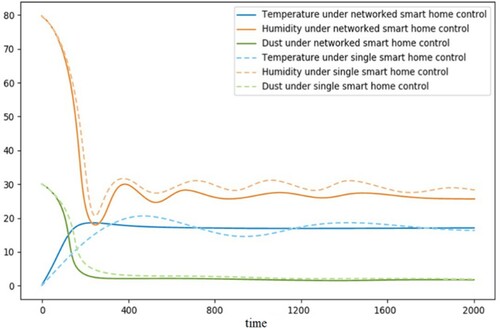
It can be seen from Figure that after 800 simulation time units, the indoor environment variables of networked smart home system are basically controlled within a suitable range. Compared with the single smart home equipment, the network smart home system has advantages.
In addition, I make a comparison between our method and some typical method in Table , and the adjustment time cost by different methods to reach the % zone of the comfort state is investigated. The experimental results show that our method has certain advantages in the speed of comfort adjustment.
Table 1. The adjustment time cost by different methods to reach the % zone of the comfort state.
5. Conclusion
In this paper, a kind of network smart home system has been established. Through the construction of multi-level network model, an integrated scheme from analysis to final decision-making has been formed to realize the group intelligent decision-making ability of smart home system. After integrating recurrent neural network, graph structure layer and reinforcement learning technology, the intelligent home network system with independent intelligent decision-making ability has been realized after training. The simulation results have shown that the system has advantages over the single smart home equipment in the performance of indoor comfort improvement.
In the future work, the LSTM or GRU can be put into the network instead of common GNN, it may achieve better results. In addition, the indoor temperature and humidity suitable for sleep and dining may be different, which is also the question needs to study in the future.
Acknowledgements
This work is jointly supported by the Key Project of University Outstanding Young Talents Support Program of Anhui Province(gxyqZD2017140), the Scientific and Technological Innovation Team Construction Project of Wuhu Institute of Technology of China (Wzykj2018A03, Wzykjtd202005), the Key Project of Natural Science Research of Anhui Higher Education Institutions of China (KJ2019A0974,KJ2020A0911).
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
References
- Al-Ali, A. R., Zualkernan, I. A., Rashid, M., Gupta, R.,Alikarar, M. (2017). A smart home energy management system using IoT and big data analytics approach. IEEE Trans Consum Electr, 63(4), 426–434. https://doi.org/https://doi.org/10.1109/TCE.2017.015014
- Ansarey, M., Shariat Panahi, M., Ziarati, H., Mahjoob, M. (2014). Optimal energy management in a dual-storage fuel-cell hybrid vehicle using multi-dimensional dynamic programming. Journal Power Sources, 250, 359–371. https://doi.org/https://doi.org/10.1016/j.jpows-our.2013.10.145
- Babou, C. S. M., Fall, D., Kashihara, S., INiang, I., Kadobayashi, Y. (2018). Home edge computing (HEC): Design of a new edge computing technology for achieving ultra-low latency, edge computing–EDGE. Springer.
- Barsoum, A. F., & Hasan, M. A. (2015). Provable multicopy dynamic data possession in cloud computing systems. IEEE Trans Inf Forensics Security, 10(3), 485–497. https://doi.org/https://doi.org/10.1109/TIFS.2014.2384391
- Chen, Q., Guo, X., & Bai, H. (2017). Semantic-based topic detection using Markov decision processes. Neurocomputing, 242, 40–50. https://doi.org/https://doi.org/10.1016/j.neucom.2017.02.020
- Ding, C. X., Sun, Y., & Zhu, Y. G. (2017). A NN-based hybrid intelligent algorithm for a discrete nonlinear uncertain optimal control problem. Neural Processing Letters, 45(2), 457–473. https://doi.org/https://doi.org/10.1007/s11063-016-9536-8
- Doshi-Velez, F. (2009). The infinite partially observable markov decision process. In Proceedings of 23rd Annual Conference on Neural Information Processing Systems. Vancouver, British Columbia, Canada., 22, 477–485.
- Guo, S. K., Liu, Y. Q., Chen, R., Sun, X., & Wang, X. X. (2019). Improved smote algorithm to deal with imbalanced activity classes in smart homes. Neural Processing Letters, 50(2), 1503–1526. https://doi.org/https://doi.org/10.1007/s11063-018-9940-3
- Hao, J., Bouzouane, A., & Gaboury, S. (2018). Recognizing multi-resident activities in non-intrusive sensor-based smart homes by formal concept analysis. Neurocomputing, 318, 75–89. https://doi.org/https://doi.org/10.1016/j.neucom.2018.08.033
- Haykin, S. (1999). Neural networks-A comprehensive foundation, 2nd edition. Prentice-Hall.
- Huaguang, Z., & Zhanshan, W. (2009). New delay-dependent criterion for the stability of recurrent neural networks with time-varying delay. Science China Information Sciences, 52(6), 942–948. https://doi.org/https://doi.org/10.1007/s11432-009-0100-2
- Keshtkar, A., & Arzanpour, S. (2017). An adaptive fuzzy logic system for residential energy management in smart grid environments. Applied Energy, 186, 68–81. https://doi.org/https://doi.org/10.1016/j.apenergy.2016.11.028
- Li, Z. (2019). An adaptive overload threshold selection process using Markov decision processes of virtual machine in cloud data center. Cluster Computing, 22(S2), 3821–3833. https://doi.org/https://doi.org/10.1007/s10586-018-2408-4
- Mathe, S., Pirinen, A., & Sminchisescu, C. (2016). Reinforcement learning for visual object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2894–2902.
- Nguyen, N. D., Nguyen, T., & Nahavandi, S. (2019). Multi-agent behavioral control system using deep reinforcement learning. Neurocomputing, 359, 58–68. https://doi.org/https://doi.org/10.1016/j.neucom.2019.05.062
- Qiao, Y., Si, Z., Zhang, Y., Abdesslem, F. B., Zhang, X., Yang, J. (2018). A hybrid markov-based model for human mobility prediction. Neurocomputing, 278, 99–109. https://doi.org/https://doi.org/10.1016/j.neucom.2017.05.101
- Redouane, B., & Cherif, B. M. (2018). Learning-based symbolic assume-guarantee reasoning for Markov decision process by using interval Markov process. Innovations System Software Eng, 14(3), 229–244. https://doi.org/https://doi.org/10.1007/s11334-018-0316-7
- Sun, X., Wu, P., & Hoi, S. C. H. (2018). Face detection using deep learning: An improved faster RCNN approach. Neurocomputing, 299, 42–50. https://doi.org/https://doi.org/10.1016/j.neucom.2018.03.030
- Teich, T., Roessler, F., Kretz, D., Franke, S. (2014). Design of a prototype neural network for smart homes and energy efficiency. Procedia Engineering, 69, 603–608. https://doi.org/https://doi.org/10.1016/j.proeng.2014.03.032
- Tu, Z. W., Cao, J. D., Alsaedi, A., Alsaadi, F. E., & Hayat, T. (2016). Global Lagrange stability of complex-valued neural networks of neutral type with time-varying delays. Complexity, 21(S2), 438–450. https://doi.org/https://doi.org/10.1002/cplx.21823
- Wu, Y. F., & Yue, D. (2019). Robust adaptive neural network control for a class of multiple-input multiple-output nonlinear time delay system with hysteresis inputs and dynamic uncertainties. Asian Journal Control, 21(5), 2330–2339. https://doi.org/https://doi.org/10.1002/asjc.1831
- Xie, W., Xie, D., Zou, Y., Zhang, D., Sun, Z., & Zhang, L. (2020). Deep reinforcement learning for smart home energy management. IEEE Internet of Things Journal, 7(4), 2751–2762. https://doi.org/https://doi.org/10.1109/JIOT.2019.2957289
- Xing, M. L., & Deng, F. Q. (2019). Tracking control for stochastic multi-agent systems based on hybrid event-triggered mechanism. Asian Journal Control, 21(5), 2352–2363. https://doi.org/https://doi.org/10.1002/asjc.1823
- Xu, Q. Y., Zhang, Y. J., & Xiao, S. Y. (2019). Event-triggered guaranteed cost consensus of networked singular multi-agent systems. Asian Journal Control, 21(5), 2425–2440. https://doi.org/https://doi.org/10.1002/asjc.1848
- Yan, M. M., Qiu, J. L., Chen, X. Y., Chen, X., Yang, C. D., Zhang, A. C., & Alsaadi, F. (2018). The global exponential stability of the delayed complex-valued neural networks with almost periodic coefficients and discontinuous activations. Neural Processing Letters, 48(1), 577–601. https://doi.org/https://doi.org/10.1007/s11063-017-9736-x
- Yin, Z., He, W., Yang, C., Sun, C. (2018). Control design of a marine vessel system using reinforcement learning. Neurocomputing, 311, 353–362. https://doi.org/https://doi.org/10.1016/j.neucom.2018.05.061
- Yu, L., Jiang, T., & Zou, Y. (2019). Online energy management for a sustainable smart home with an HVAC load and random occupancy. IEEE Transactions on Smart Grid, 10(2), 1646–1659. https://doi.org/https://doi.org/10.1109/TSG.2017.2775209
- Yu, L., Qin, S., Zhang, M., Shen, C., Jiang, T., & Guan, X. (2021). A review of deep reinforcement learning for smart building energy management. IEEE Internet of Things Journal, 8(15), 12046–12063. https://doi.org/https://doi.org/10.1109/JIOT.2021.3078462
- Zhang, D., Kou, K. I., Liu, Y., Cao, J. (2017). Decomposition approach to the stability of recurrent neural networks with asynchronous time delays in quaternion field. Neural Networks, 94, 55–66. https://doi.org/https://doi.org/10.1016/j.neunet.2017.06.014
- Zheng, L., & Cho, S. Y. (2011). A modified memory-based reinforcement learning method for solving POMDP problems. Neural Processing Letters, 33(2), 187–200. https://doi.org/https://doi.org/10.1007/s11063-011-9172-2
- Zheng, L., Cho, S. Y., & Quek, C. (2008). A memory-based reinforcement learning algorithm for partially observable Markovian decision processes. In: Proceedings of IEEE world congress on computational intelligence. Hong Kong, pp. 800–805.