
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
The existing ripeness detection algorithm for strawberries suffers from low detection accuracy and high detection error rate. Considering these problems, we propose an improvement method based on YOLOv5, named MS-YOLOv5. The first step is to reconfigure the feature extraction network of MS-YOLOv5 by replacing the standard convolution with the depth hybrid deformable convolution (Ms-MDconv). In the second step, a double cooperative attention mechanism (Bc-attention) is constructed and implemented in the CSP2 module to improve the feature representation in complex environments. Finally, the Neck section of MS-YOLOv5 has been enhanced to use the fast-weighted fusion of cross-scale feature pyramid networks (FW-FPN) to replace the CSP2 module. It not only integrates multi-scale target features but also significantly reduces the number of parameters. The method was tested on the strawberry ripeness dataset, the mAP reached 0.956, the FPS reached 76, and the model size was 7.44M. The mAP and FPS are 8.4 and 1.3 percentage higher than the baseline network, respectively. The model size is reduced by 6.28M. This method is superior to mainstream algorithms in detection speed and accuracy. The system can accurately identify the ripeness of strawberries in complex environments, which could provide technical support for automated picking robots.
1. Introduction
Strawberries are very popular with consumers because of their high nutritional value (Kowalska et al., Citation2018). Nowadays, strawberry acreage is increasing dramatically and the problem of how to pick them efficiently has become a pressing issue. In most places, strawberry picking is done manually, which requires pickers to use a variety of techniques to ensure that the strawberries they pick meet certain quality standards. This work has undoubtedly driven up labour and material costs. With the development of smart agriculture, robotic picking (Zhou et al., Citation2022) has attracted much attention due to its efficiency, time-saving and cost-saving. Picking robots need to be equipped with relevant object detection methods (Huang & Wu, Citation2023; Mai et al., Citation2020; Qiao et al., Citation2021; Wahjuni & Nurarifah, Citation2023) to achieve the detection of strawberry ripeness. However, these detection methods cannot reach a balance between detection accuracy and speed. The phenomenon of low detection speed and high accuracy (Zhao et al., Citation2022) or high detection speed and low accuracy (Zhang et al., Citation2022) usually occurs, so it is necessary to design a detection method that can combine speed and accuracy.
The lightweight MS-YOLOv5 model proposed in this paper can take into account both model lightness and high detection speed. Our contributions can be summarized as follows:
By reconfiguring the feature extraction network, expand the receptive field to extract multi-scale information and reduce the number of parameters to some extent.
By building a double mechanism of cooperative attention to strengthen the discriminability of object and background information.
We propose a fast fusion network with cross-scale feature weights to adapt to multiscale feature fusion and improve detection accuracy.
The rest of this paper is organized as follows: Section 2 describes the background content related to this research, such as the introduction of traditional object detection and deep learning-based algorithms; Section 3 introduces the method used in our proposed MS-YOLOv5 and describes related details. Section 4 lists the experimental operating environment, experimental parameter settings, comparison results, and visual analysis of the experimental results; Section 5 summarizes and looks at the text.
2. Related work
Object detection methods are generally divided into traditional image detection methods and deep learning detection methods. Deep learning-based detection methods are divided into one-stage and two-stage object detection methods. The primary one-stage methods are YOLOv3-YOLOv8 (Chen et al., Citation2023; Hurtik et al., Citation2022; Li, Li, et al., Citation2022; Vats & Anastasiu, Citation2023; Xing et al., Citation2022; Zhang et al., Citation2023). The primary two-stage detection methods are Faster RCNN (Zhong et al., Citation2022), Libra RCNN (Pang et al., Citation2019), Cascade RCNN (Cai & Vasconcelos, Citation2018), and so on.
Inspired by the traditional image detection method, (Anraeni et al., Citation2021) used RGB feature extraction and the k-nearest neighbour algorithm (k-NN) to identify a strawberry fruit’s ripeness. However, there is still a need to improve the classification accuracy of ripeness. (Pérez-Zavala et al., Citation2018) the HOG (Histogram of Oriented Gradients) and LBP (Local Binary Pattern) features were used to detect fruit clusters and achieved an accuracy of 88.61 percentage points. The precision was not high due to the size of the fruit and the biometric characteristics. (Arefi et al., Citation2011) used the threshold-based analysis method to extract tomato combination features from RGB, HIS, and YIQ space respectively to locate the target. Still, the detection was poor when the tomato fruit was small. (Lu & Sang, Citation2015) used the canny edge algorithm to detect the edge of the chromatic aberration map, enhancing ripened citrus fruits in complex environments. In conclusion, the traditional extraction methods can solve the problem of fruit recognition to a certain extent, the features extracted by these methods need to be artificially designed, which makes it difficult to automatically extract the target information and cannot be balanced regarding the time and effectiveness of the feature extraction.
Inspired by deep learning object detection methods (Li, Wang, et al., Citation2022), used deep convolution and mixed attention mechanism methods to improve YOLOv4 and effectively reduce the size of the model. The mAP of the DAC-YOLOv4 is 72.7 percentage points, but the detection speed is only 20 FPS. (Gai et al., Citation2023) combined DenseNet interlayer density with CSP-Darknet53 to improve feature extraction for precision detection of small targets and masked fruit. (Latha et al., Citation2022) used the YOLOv4-tiny model to implement various fruits and vegetables for detection, achieving a mean inference speed of 18 ms but an accuracy of 51 percentage points. (Chen et al., Citation2022) improved the detection rate by adding attention and depth-separable convolution modules to the detection head and neck, respectively. Although the detection time of this model is 0.06 s, the model size of 187 MB is not suitable for use in embedded devices. (An et al., Citation2022) proposed a YOLOX-inspired SDNet model. They improved the convolution module in the YOLOX feature extraction network while adding an attention module and replacing the SIoU loss function. The SDNet achieved a precision of 94.26 percentage points and a recall of 90.72 percentage points. (Wang & He, Citation2021) used a channel pruning method for the YOLOv5s and refined the pruned model for rapid fruit detection, which can simplify the model while ensuring accuracy. (Li et al., Citation2023) used the YOLOv5 for parasite detection while introducing an attention mechanism to improve the detection accuracy of the model, with 96.51 percentage points accuracy and detection times up to 7.7 ms. Although these methods can realize the detection of fruit, they still have certain limitations to the detection of multi-target fruit in natural planting environments. Therefore, it is necessary to design an algorithm with high detection accuracy and speed for multiple targets in a complex environment.
3. MS-YOLOv5 detection method
Strawberry images can be particularly challenging to analyze due to the small size of the objects and the potential for target occlusion. To address these challenges, this study proposes an MS-YOLOv5 strawberry ripeness detection method with depth hybrid deformable convolution, double cooperative attention mechanism, and fast fusion of cross-scale feature weights. The network structure of MS-YOLOv5 is shown in Figure .
Figure 1. Improved diagram of the framework network structure for MS YOLOv5.
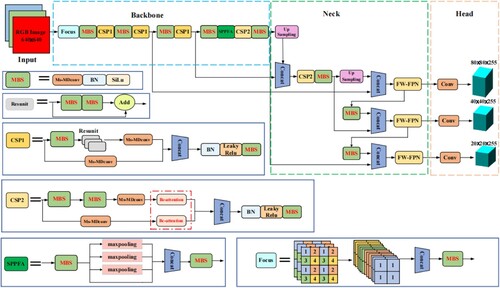
There are three enhancement strategies on the baseline YOLOv5 network: (1) Reconfiguration of the lightweight CSP-Darknet-53 feature extraction network in the MBS module by mixing multiple depth deformable convolution kernels (Ms-MDconv) into one convolution operation to replace the original standard convolution, thereby taking full advantage of deformable convolution. This makes the network lighter by quickly extracting multi-scale features from the target and obtaining more feature information about small objects. (2) Since the target features are not obvious due to the target occlusion and complex background, to improve the detection accuracy of the model, we add BC-attention behind the depth hybrid deformable convolution in module CSP2. It can enrich the target feature information as well as the localization information to obtain richer semantic information about the target. (3) We incorporate a fast-weighted feature pyramid network (FW-FPN) in the Neck part of MS-YOLOv5, which is designed to fuse target information from different feature layers to obtain desirable results.
3.1. Reconfiguration of feature extraction networks
The input feature map is sampled at a fixed location by a standard convolutional kernel, and the max-pooling layer continuously reduces the size of the feature map to generate a spatially location-constrained region of interest (RoI). This results in the same receptive field size at different locations, making it difficult to extract features at different target scales and with different deformation targets. Therefore, we use deep deformable convolution for feature extraction. Compared with the original feature extraction network, it does not need to extract the feature sequentially according to the stride but can automatically adjust the scale and receptive field for the feature according to the feature shape of the target. Deep deformable convolution feature extraction is more targeted, most of the irrelevant feature information is eliminated, and the number of parameters can be reduced. Deep deformable convolution can be adapted to a specific scale and receptive field, but it cannot cover all scales. On this basis, we propose depth hybrid deformable convolution. By changing the offset, multiple deformable convolution kernels are mixed on the same convolution to achieve strawberry image extraction, so as to obtain more scale target features. Although the depth hybrid deformable convolution increases the number of parameters compared to a single deformable convolution, it is much less than the original feature extraction network. The depth hybrid deformable convolution is shown in Figure .
Figure 2. Depth hybrid deformable convolution.
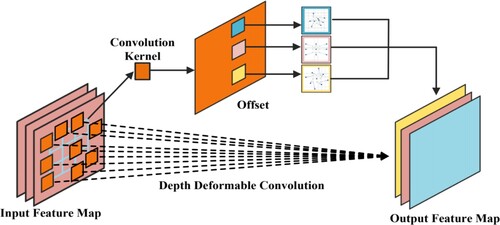
From Figure , a depth deformable convolution with a mixture of different offsets can automatically adapt to scale and rotation transformations of the target based on its size and shape. The input feature map (H × W × N) is passed through a convolution kernel to produce a feature map of (H × W × 2N), where 2 means that there are offsets in both x and y directions. The ordinary convolutional network operation is shown in Equation (1), and the depth hybrid deformable convolution adds an offset to the ordinary convolutional network as shown in Equation (2).
(1)
(1)
(2)
(2) In the equation above, x is the input value, y(L0) and y(
) are the output value resulting from the calculation of L0, w is the weight matching the input,
is an offset made to
, R is a grid of acceptance surface, as shown below.
(3)
(3)
3.2. Double cooperative attention mechanism
The background in the strawberry images is so complex that the features cannot be distinguished, especially unripe strawberries and leaves both with the same colour, which are likely to be misidentified. We introduce an attention mechanism that enriches the features of the strawberry itself, weakens the background information, and enhances the feature representation of the target. SENet (Hu et al., Citation2018) can adaptively learn the channel weights and focus on the more useful channel information. However, SENet’s attention mechanism typically focuses only on the channel dimension and cannot effectively capture attention in the spatial dimension. Inspired by SENet’s attention mechanism, a double cooperative attention mechanism is constructed based on SENet’s enhancement, which cooperatively performs feature weighting operations through channel and spatial dependencies to improve the perception of target features. Firstly, the attention mechanism compresses spatial information and then adopts an incentive channel strategy to obtain rich information about the target channel; secondly, it adds a PA module that conveys more precise spatial information about the target in the spatial dimension by obtaining attention in the spatial dimension. The double mechanism of cooperation is shown in Figure .
Figure 3. Double cooperative attention mechanism.

Figure shows that X and U are the inputs and outputs of Ftr, respectively, the module that improves on SENet is the network structure after U. We do the spatial information compression operation on U (i.e. Fsq(.)) and then, in concert with Position Attention (PA), an enhancement of the localization information. Due to the scale being applied to the entire channel, the target important channel features are enhanced by controlling the scale size and weakening the background information, making the extracted features more informative. The spatial information is averaged into a single value before a global average pooling precedes the Fsq(.) operation to filter the spatial distribution information to exploit the correlation between channels. The scale is then calculated based on the global channel information, making the calculation more accurate. The 1 × 1 × C data is output from the spatial information compression operation. The channel information excitation is applied (i.e. Fex(.)) and finally normalized using a Sigmoid function and multiplying the value as scale onto the C channels of U as the input to the following module, where U is calculated as follows.
(4)
(4) The compressed channel information function is a unitary mapping of computation by mapping the characteristics of the input X∈R H0×W0×C0 to those of U∈R H1×W1×C1. In Equation (4), v denotes the set of learned feature filter kernels, where vn refers to the parameters of the n filter and then outputs as U = [u1, u2, … , un][n] shown. z∈Rn compresses the dimension of the space U by average pooling, H is the height of the feature map, W is the width, and Fsq(.) of z is computed in the following manner.
(5)
(5)
(6)
(6) The extraction operation equation is shown in (6), where
(vector multiplication to obtain a C/T dimensional vector, dimensionality reduction),
(vector multiplication to obtain a C dimensional vector, dimensionality increase), δ is the Relu function, while σ is the Sigmoid function and the σ(.) represents the second fully connected layer. Finally, the output
is obtained by multiplying the scalar Sn with the feature Un, as shown in the following equation.
(7)
(7) Whereas the augmented SENet can gain richer information about the characteristics of the target channel, this does not increase the spatial information of the target. Meanwhile, the ability to locate the target is poor, which tends to cause the detector to learn more background information and not make good use of the detector’s performance. Therefore, enriching target features through position and channel attention can yield more information on the channel and position, hence improving the network’s detection performance. PA (Position Attention) is a positional attention module capable of embedding spatial information about the target in the pathway and generating a coordinate perception attention map. The structure of the PA attention mechanism is shown in Figure .
Figure 4. PA attention mechanism module.
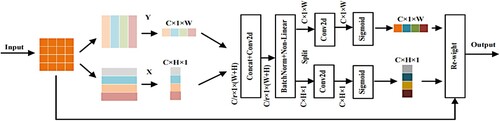
Consistent with the discussion above, this paper includes the location information of the attention mechanism embedded in the attention of the channel to compensate for the location information lost by the global pooling of the network. This module generates two independently oriented feature maps using two one-dimensional global pooling of the input features along the vertical direction Y and the horizontal direction X, respectively. Two feature maps with location information are separately weighted and encoded into two attention maps, each of which captures the long-range correlation dependencies of the input feature map along a spatial direction. The coordinate information is integrated into the channel attention maps to store the location information in the generated channel attention maps. The two one-dimensional global pooling operations gave the input X. The module uses two spatial extents of the convolution kernel of the pooling layer (H, 1) or (1, W) to encode each channel along the horizontal coordinate and the vertical coordinate, respectively. The output equation for the channel q at h is shown below.
(8)
(8) Similarly, the following equation gives the channel output q at w.
(9)
(9) This module generates directional feature maps by clustering features along two spatial directions. It enables the network to localize the target of interest more accurately by retaining valid information about the precise location. In this paper, the double mechanism of cooperative attention proposed is that the channel attention mechanism and the spatial attention mechanism work together. Thus, not only the channel information of the target can be noticed, but also the target’s location information can be strongly perceived.
3.3. Fast-weighted fusion of cross-scale feature pyramid networks
In response to the variable size of strawberry scales and the fact that unripe strawberries are typically difficult to detect, we constructed a pyramid network of fast-weighted features (FW-FPN). By transferring rich semantic information from higher layers to lower layers, resulting in a high-resolution feature map with strong semantics, we gain more information about the characteristics of small targets to improve the correct detection rate of small targets. To fuse features of different resolutions, the usual method for fusing multi-scale target features is to make their resolutions equal in terms of the number of channels, then perform a summation calculation over the channels and assign the correct weight value to the different input features. The fast-weighted feature pyramid network is shown in Figure .
Figure 5. Fast-weighted feature pyramid network.
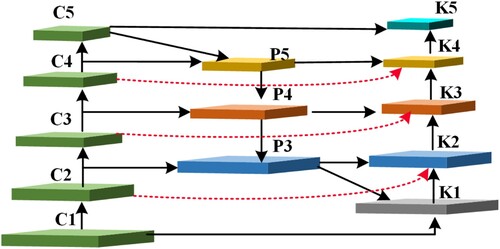
C1-C5 shown in Figure are the feature maps at different scales extracted from the original network by CSP-Darknet53. The C4 module modified the feature channels by 1 × 1 convolution, with the number of modified channels equivalent to C5. We fused the C5 module with the C4 module for feature fusion to obtain P5, the C3 module was fused with the P5 module by 1 × 1 convolution to obtain P4, and the C2 module was fused with the P4 module by 1 × 1 convolution to obtain P3. During the top-down feature extraction process, it is highly likely that the feature information from the bottom layer will be absent. Thus, to make up for this, we incorporate three cross-layer connections (illustrated by the red arrows). The K2 module is obtained through a 1 × 1 convolution of the C2 and K1 modules and fused with the P3 module. The K3 module is obtained through a 1 × 1 convolution of the C3 and K2 modules and fused with the P4 module. The K4 module is obtained through a 1 × 1 convolution of the C4 and K3 modules and fused with the P5 module.
The initial SiLu network utilizes a Sigmoid activation function which computes the contribution of each input feature for boosting computational speed, quicker model convergence, and more stable training. The computational formulas for SiLu and Hard-Swish are presented below.
(10)
(10)
(11)
(11)
4. Experimental results and analysis
4.1. Experimental environment
The experimental operating system for this study was Ubuntu 20.04; the CPU was Intel® Xeon® CPU E5-2678 v3 @ 2.50 GHz * 2, Python was 3.9, the deep learning framework was Pytorch 1.11.0, CUDA version 11.1, the training network size was 640 × 640, and the number of iterations was 300. A training batch size of 16, a momentum of 0.9, a learning rate of 0.01, and a weight decay of 0.0001.
4.2. Dataset acquisition
The dataset used in this paper was 640 × 640, consisting of 3468 strawberry images. It used the LabelImg tool in VOC format, which contains information about the target’s category and location. Table shows the division of the dataset in the experiments.
Table 1. Division of the dataset in the experiments.
The original images were subjected to light and dark transformations, flips, and scale transformations to make the model more robust and generalized. To avoid overfitting to some extent, we increased the dataset to 9536 images. The effect of data augmentation is shown in Figure .
Figure 6. Data enhancement of original images.

We have defined samples of ripe and unripe strawberries to help readers understand our dataset more intuitively, as shown in Figure .
Figure 7. Display of ripe and unripe strawberries in the dataset.

4.3. Results analysis
4.3.1. Indicators of experimental evaluation
One way to better assess the detection accuracy of the model is to evaluate the performance of each category in the model using the Average Precision (AP), which is often closely related to Recall and Precision. This experiment divides maturity into ripe and unripe, and the two AP categories are first summed and then averaged to get the mean Average Precision (mAP). The recall and precision formulas are given below.
(12)
(12)
(13)
(13) Where TP indicates the number of positive samples detected correctly, FN is the number of negative samples detected as errors, and FP presents the number of negative samples detected correctly. The equations for AP and mAP are given below.
(14)
(14)
(15)
(15) Finally, Frame Per Second (FPS), model complexity (FLOPS), and model size were introduced to evaluate the model’s superiority.
4.3.2. Ablation experiments
To test the effectiveness of the model enhancement, we perform ablation experiments using YOLOv5 as the base network for the enhancement. As ablation comparison experiments, we use a reconfiguration feature extraction network, double cooperative attention, and a fast-weighted feature pyramid network. The ablation results are shown in Table . We have designated depth hybrid deformable convolution as module A, double cooperative attention as module B, and fast-weighted feature pyramid network as module C.
Table 2. Ablation experiments of MS-YOLOv5.
The ablation experiments in Table show that the improved depth hybrid deformable convolution module, double cooperative attention, and fast fusion of cross-scale feature weights can efficiently improve the detection accuracy of the model as follows:
Depth hybrid deformable convolution: by replacing the standard convolution of the original network with depth deformable convolution and mixing depth deformable convolution of different scales acting in the same convolution kernel. As shown in Table , the mAP was 90.6 percentage points and the recall rate was 88.5 percentage points, an improvement of 3.4 and 2.5 percentage points, respectively, over the baseline network. The model size was also reduced by 2.72M, indicating that the use of mixed-depth deformable convolution can effectively expand the receptive field, extract more information from the target features, and reduce the number of parameters by a certain amount to reduce the model size and improve the detection speed.
Double cooperative attention mechanism: to help the detector distinguish the target from the background, feature fusion is achieved by channel attention in cooperation with spatial attention. When comparing the ablation experiments, several parameters are introduced that can improve the performance of the detector. 2.7 percentage points can still be improved based on the introduction of the depth hybrid deformable convolution module, and the experiments show that the detector’s performance can be fully exploited.
Fast-weighted fusion of cross-scale feature pyramid networks: since strawberries contain large, medium, and small scales, the original network could not be better for multi-scale feature fusion, so fast fusion of cross-scale feature weights is proposed. Experimental results show that this module can improve the mAP by up to 2.3 percentage points, improving the target detection rate, and is lighter than the feature pyramid network of the original network.
4.3.3. Comparing different attention mechanisms
It is also worth noting that the results of using different attention mechanisms within the algorithm are different; therefore, to test the superiority of our proposed augmented attention mechanism, the results of the comparison with the SENet, CA (Hou et al., Citation2021), and mainstream CBAM (Woo et al., Citation2018) attention mechanisms are shown in Table .
Table 3. Comparison table of YOLOv5 with different attention mechanisms.
Table shows that YOLOv5 combined with BC-attention improves the detection accuracy of the model. The model is better at detecting the ripeness of strawberries, demonstrating the superiority of our method. Visualizations of the different attention mechanisms are shown in Figure , which may reflect where the model should focus more.
Figure 8. Visualization of the effects of applying different attentional mechanisms to the features of YOLOv5.

4.3.4. Comparison experiments of different advanced methods
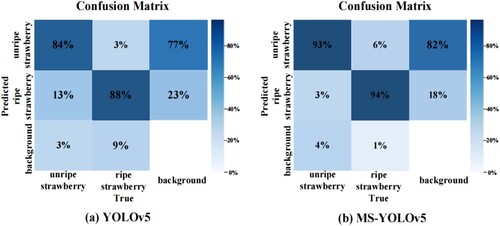
To quantify the detection and misdetection rates of this network, we plotted a confusion matrix according to the detection outcome, as shown in Figure . It can reflect missed and inaccurate detection rates in the model predictions. The confusion matrix shows that the background and target false detection rates for this network have improved, which fully validates the nature of this network in more detail.
Figure 9. Confusion matrix comparison between MS-YOLOv5 and YOLOv5.
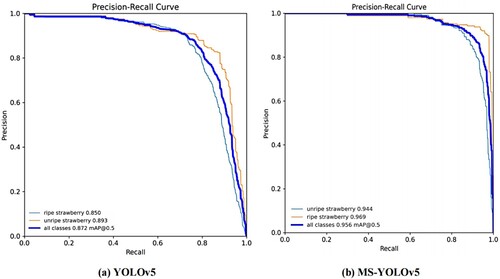
To qualitatively analyze the superiority of this network model, Precision_Recall curves were plotted against the log of the training process log and compared based on the baseline network, as shown in Figure . The area enclosed by the Precision_Recall curve is more significant than that of the baseline network, indicating that the MS-YOLOv5 network is superior in the accuracy of detection.
Figure 10. Precision_Recall comparison between MS-YOLOv5 and YOLOv5.
The results of this method are compared with other state-of-the-art detection methods on the strawberry ripeness dataset. The evaluation of MS-YOLOv5’s comparative tests is mainly compared from multiple perspectives, such as detection accuracy and detection speed, and the table of comparative tests is shown in Table .
Table 4. Table comparing MS-YOLOv5 with state-of-the-art methods.
As can be seen in Table , the YOLOv5 method incorporates depth hybrid deformable convolution, double cooperative attention mechanism, and fast fusion of cross-scale feature weighting, achieving the best results in many aspects, such as detection accuracy and speed. In the strawberry ripeness dataset, the mAP of MS-YOLOv5 was 1.9 and 0.4 percentage points higher than YOLOv7 and YOLOv8. MS-YOLOv5 has a detection rate of up to 76, slightly higher than the YOLOv5, which can meet the requirements of real-time control. In summary, MS-YOLOv5 shows a significant performance improvement in terms of detection accuracy and speed.
4.4. Visualization of MS-YOLOv5 model detection results
The results of the detection effect under different conditions between YOLOv5 and MS-YOLOv5 are shown in Figure . As can be seen in Figure , the MS-YOLOv5 model is more accurate than the YOLOv5 model in detecting objects with occluded objects, multiple targets, and small target objects in the datasets over the course of training. The improved MS-YOLOv5 model, when tested with YOLOv5, significantly reduces the occurrence of false detections, which can improve the statistics of strawberry ripeness.
Figure 11. Detection effect under different conditions between YOLOv5 and MS-YOLOv5.

5. Conclusion
In this experiment, the MS-YOLOv5 model is proposed for strawberry ripeness detection to improve the detection accuracy and speed. To highlight the difference between the background and target features, our method further enhances the target features and localization information. For the detection of strawberry ripeness, the improved model achieves a mAP of 95.6 percentage points, an accuracy improvement of 8.4 percentage points over the original method. Here, we carried out ablation and comparison experiments on the improved method, which showed that it is superior to state-of-the-art detection methods such as YOLOv7 and YOLOv8 regarding model size, detection accuracy, and detection speed. The MS-YOLOv5 model offers strong technical support for the real-time identification of strawberry ripening. However, its precision and speed in detection suffer when numerous categories and targets are present in the dataset. This demonstrates that our detector is amicable for the identification of a limited number of targets, which suggests an area for enhancement.
Availability of data and materials
The data used to support the findings of this study are available from the corresponding author upon request.
Disclosure statement
No potential conflict of interest was reported by the authors.
Additional information
Funding
References
- An, Q., Wang, K., Li, Z., Song, C., Tang, X., & Song, J. (2022). Real-time monitoring method of strawberry fruit growth state based on YOLO improved model. IEEE Access, 10, 124363–124372. https://doi.org/10.1109/ACCESS.2022.3220234
- Anraeni, S., Indra, D., Adirahmadi, D., & Pomalingo, S. (2021). Strawberry ripeness identification using feature extraction of RGB and K-nearest neighbor. In 2021 3rd East Indonesia conference on computer and information technology (EIConCIT) (pp. 395–398). IEEE.
- Arefi, A., Motlagh, A. M., Mollazade, K., & Teimourlou, R. F. (2011). Recognition and localization of ripen tomato based on machine vision. Australian Journal of Crop Science, 5(10), 1144–1149.
- Cai, Z., & Vasconcelos, N. (2018). Cascade R-CNN: Delving into high quality object detection. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 6154–6162). IEEE.
- Chen, J., Bai, S., Wan, G., & Li, Y. (2023). Research on YOLOv7-based defect detection method for automotive running lights. Systems Science & Control Engineering, 11(1), 2185916. https://doi.org/10.1080/21642583.2023.2185916
- Chen, W., Lu, S., Liu, B., Chen, M., Li, G., & Qian, T. (2022). CitrusYOLO: A algorithm for citrus detection under orchard environment based on YOLOV4. Multimedia Tools and Applications, 81(22), 31363–31389. https://doi.org/10.1007/s11042-022-12687-5
- Gai, R., Chen, N., & Yuan, H. (2023). A detection algorithm for cherry fruits based on the improved YOLO-v4 model. Neural Computing and Applications, 35(19), 13895–13906. https://doi.org/10.1007/s00521-021-06029-z
- Hou, Q., Zhou, D., & Feng, J. (2021). Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 13713–13722). IEEE.
- Hu, J., Shen, L., Albanie, S., Sun, G., & Wu, E. (2018). Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7132–7141). IEEE.
- Huang, M. L., & Wu, Y. S. (2023). GCS-YOLOV4-Tiny: A lightweight group convolution network for multi-stage fruit detection. Mathematical Biosciences and Engineering, 20(1), 241–268. https://doi.org/10.3934/mbe.2023011
- Hurtik, P., Molek, V., Hula, J., Vajgl, M., Vlasanek, P., & Nejezchleba, T. (2022). Poly-YOLO: Higher speed, more precise detection and instance segmentation for YOLOv3. Neural Computing and Applications, 34(10), 8275–8290. https://doi.org/10.1007/s00521-021-05978-9
- Kowalska, J., Kowalska, H., Marzec, A., Brzeziński, T., Samborska, K., & Lenart, A. (2018). Dried strawberries as a high nutritional value fruit snack. Food Science and Biotechnology, 27(3), 799–807. https://doi.org/10.1007/s10068-018-0304-6
- Latha, R. S., Sreekanth, G. R., Rajadevi, R., Nivetha, S. K., Kumar, K. A., Akash, V., Bhuvanesh, S., & Anbarasu, P. (2022). Fruits and vegetables recognition using YOLO. In 2022 international conference on computer communication and informatics (pp. 1–6). IEEE.
- Li, C., Li, L., Jiang, H., Weng, K., Geng, Y., Li, L., Ke, Z., Li, Q., Cheng, M., Nie, W., Li, Y., Zhang, B., Liang, Y., Zhou, L., Xu, X., Chu, X., Wei, X., & Wei, X. (2022). YOLOv6: A single-stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976.
- Li, K., Wang, J., Jalil, H., & Wang, H. (2023). A fast and lightweight detection algorithm for passion fruit pests based on improved YOLOv5. Computers and Electronics in Agriculture, 204, 107534. https://doi.org/10.1016/j.compag.2022.107534
- Li, Y., Wang, J., Wu, H., Yu, Y., Sun, H., & Zhang, H. (2022). Detection of powdery mildew on strawberry leaves based on DAC-YOLOv4 model. Computers and Electronics in Agriculture, 202, 107418. https://doi.org/10.1016/j.compag.2022.107418
- Lu, J., & Sang, N. (2015). Detecting citrus fruits and occlusion recovery under natural illumination conditions. Computers and Electronics in Agriculture, 110, 121–130. https://doi.org/10.1016/j.compag.2014.10.016
- Mai, X., Zhang, H., Jia, X., & Meng, M. Q. H. (2020). Faster R-CNN with classifier fusion for automatic detection of small fruits. IEEE Transactions on Automation Science and Engineering, 17(3), 1555–1569.
- Pang, J., Chen, K., Shi, J., Feng, H., Ouyang, W., & Lin, D. (2019). Libra R-CNN: Towards balanced learning for object detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 821–830). IEEE.
- Pérez-Zavala, R., Torres-Torriti, M., Cheein, F. A., & Troni, G. (2018). A pattern recognition strategy for visual grape bunch detection in vineyards. Computers and Electronics in Agriculture, 151, 136–149. https://doi.org/10.1016/j.compag.2018.05.019
- Qiao, L., Chen, Y., Cheng, Z., Xu, Y., Niu, Y., Pu, S., & Wu, F. (2021). Mango: A mask attention guided one-stage scene text spotter. Proceedings of the AAAI Conference on Artificial Intelligence, 35(3), 2467–2476. https://doi.org/10.1609/aaai.v35i3.16348
- Vats, A., & Anastasiu, D. C. (2023). Enhancing retail checkout through video inpainting, YOLOv8 detection, and DeepSort tracking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5529–5536). IEEE.
- Wahjuni, S., & Nurarifah, H. (2023). Faster RCNN based leaf segmentation using stereo images. Journal of Agriculture and Food Research, 11, 100514. https://doi.org/10.1016/j.jafr.2023.100514
- Wang, D., & He, D. (2021). Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosystems Engineering, 210, 271–281. https://doi.org/10.1016/j.biosystemseng.2021.08.015
- Woo, S., Park, J., Lee, J. Y., & Kweon, I. S. (2018). CBAM: Convolutional block attention module. In V. Ferrari, M. Hebert, C. Sminchisescu, & Y. Weiss (Eds.), Proceedings of the European conference on computer vision (pp. 3–19). Springer.
- Xing, Z., Chen, X., & Pang, F. (2022). DD-YOLO: An object detection method combining knowledge distillation and Differentiable Architecture Search. IET Computer Vision, 16(5), 418–430. https://doi.org/10.1049/cvi2.12097
- Zhang, J., Wan, G., Jiang, M., Lu, G., Tao, X., & Huang, Z. (2023). Small object detection in UAV image based on improved YOLOv5. Systems Science & Control Engineering, 11(1), 2247082. https://doi.org/10.1080/21642583.2023.2247082
- Zhang, Y., Yu, J., Chen, Y., Yang, W., Zhang, W., & He, Y. (2022). Real-time strawberry detection using deep neural networks on embedded system (RTSD-net): An edge AI application. Computers and Electronics in Agriculture, 192, 106586. https://doi.org/10.1016/j.compag.2021.106586
- Zhao, S., Liu, J., & Wu, S. (2022). Multiple disease detection method for greenhouse-cultivated strawberry based on multiscale feature fusion Faster R_CNN. Computers and Electronics in Agriculture, 199, 107176. https://doi.org/10.1016/j.compag.2022.107176
- Zhong, S., Xu, W., Zhang, T., & Chen, H. (2022). Identification and depth localization of clustered pod pepper based on improved Faster R-CNN. IEEE Access, 10, 93615–93625. https://doi.org/10.1109/ACCESS.2022.3203106
- Zhou, H., Wang, X., Au, W., Kang, H., & Chen, C. (2022). Intelligent robots for fruit harvesting: Recent developments and future challenges. Precision Agriculture, 23(5), 1856–1907. https://doi.org/10.1007/s11119-022-09913-3