
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.Abstract
Information extraction is an important foundation for automated patent analysis. Deep learning methods show promising results for information extraction, the performance of such methods heavily depends on the available corpus. To promote research on Chinese information extraction and evaluate the performance of related systems, we present a novel dataset, named CPIE, and make it publicly available. The dataset consisting of five thousands records of Chinese patent documents. The data were annotated by a tagging team using an on-line annotation tools. The dataset was evaluated using a state-of-the-art information extraction method that involves named entity recognition and relationship classification. The results shed light on new challenges and promote information extraction research.
1. Introduction
Accurate analysis of patent can protect intellectual properties (Park et al., Citation2012), inspire new industry solutions (Cho et al., Citation2018) and make important investment decisions (Zhang et al., Citation2015). Nevertheless, patent analysis is laboursome and time-consuming because that patent documents are lengthy and rich in technical and legal terms (Son et al., Citation2022; Tseng et al., Citation2007). As the number of patents has been increasing dramatically with rapid development in various technology areas in recent years, automated patent analysis technologies are in high demand (Chen et al., Citation2020b; Jiang et al., Citation2022).
One of the primary steps in patent analysis is information extraction that is essential for information storage and retrieval (Grishman, Citation2015). Information extraction aims to extract structured information of interest from unstructured or semi-structured text types (Singh, Citation2018). Statistical learning based information extraction methods have been flourished over the last decades, such as the Conditional Random Field(CRF) (Finkel et al., Citation2005), Hidden Markov Model(HMM) (Seymore et al., Citation1999), Maximum Entropy (MaxEnt) (Mccallum et al., Citation2001) and Support Vector Machine (SVM) (Li et al., Citation2004). Owing to the outperformance of deep learning in various natural language processing tasks, deep learning has gradually become the dominated method for information extraction in recent years (Grishman, Citation2015; Hong et al., Citation2021; Liu et al., Citation2013). More recently, transformer architecture based on the attention mechanism has made it possible to train large models on a large text corpus (Brown et al., Citation2020; Devlin et al., Citation2018; Vaswani et al., Citation2017). These models learn powerful representations and can be fine-tuned in downstream tasks. Some refreshing experimental results have been demonstrated to use GPT for patent classification and generation (Lee, Citation2019; Lee & Hsiang, Citation2020a, Citation2020b).
The performance of deep learning based information extraction heavily depends on the available corpus. Therefore, constructing a large-scale dataset is essential for developing new information extraction methods. Although there are many public news corpus sets, patents and news differ significantly. After literature review and analysis of the text, the characteristics of the Chinese patent text are as follows: (1) Professional vocabulary and unfamiliar vocabulary are more common. (2) Long sentences, complicated and rigorous expressions. (3) Emphasize that the same entity is repetitive. Furthermore, most public patent datasets belong to the English language corpus which is unsuitable for Chinese patent information extraction. To our best knowledge, there is no data set for the study of Chinese patent semantic information extraction. This study introduces a large-scale Chinese patents information extraction dataset, named as CPIE, and makes it publicly available for research use. To further illustrate the challenges of information extraction techniques for Chinese patents, the state-of-art deep learning based information extraction methods are benchmarked as a base line for the CPIE.
The remainder of this paper is organized as follows. Firstly, the construction process of the dataset is detailed in Section Methods. Then, a transformer based information extraction method is evaluated on the CPIE dataset in Section Experiments and Results. The last section concludes the paper with directions for future study.
2. Related works
2.1. Datasets
Numerous annotated corpora for information extraction have been released in the literatures, such as news corpus Conll-2003 (Sang & De Meulder, Citation2003), encyclopaedia corpus LIC-2019 (Language and Intelligence Challenge-2019) (Wu, Citation2019), a biological dataset FOBIE which contains 1500 manually annotated sentences (Kruiper et al., Citation2020) and the DUIE dataset that mainly involves news, entertainment and Baidu user-generated content (Li et al., Citation2019). Nevertheless, most of these shared corpora did not focus on the domain of patent documents. As a combination of technical language and legal language, patents have prominent characteristics being different from generic corpus, where the former is full of jargon, complex, or new technical words (Chen et al., Citation2020a).
Fortunately, researchers have begun to focus on information extraction from patent documents in recent years. For example, Akhondi et al. released a chemical patent corpus named as CPC-2014 (Akhondi et al., Citation2014), and Pérez-Pérez et al. elaborated a patent corpus for chemical compound and drug named entity recognition (CHEMDNER-patents for short). TFH-2020 collected patents on thin-film magnetic head technology in hard disks from the USPTO database and constructed a patent information extraction dataset containing 15 relational and 17 entity types (Chen et al., Citation2020b). The ChEMU 2020 lab proposed two fundamental information extraction tasks focusing on the chemical reaction processes described in chemical patents (He et al., Citation2021). As a professional and statement-oriented document, the article structure and sentence logic of patent documents are pretty different from news information. Consequently, this study attempts to construct a patent information extraction dataset.
2.2. Patent information extraction
Information extraction is an active area of research in natural language processing. Pipeline way and joint way are mainly ways for information extraction. The former extracts the entities first and then identifies the relationship between them, which makes the information extraction task easy to deal with, and each component can be more flexible. Currently most information extraction methods are presented in a pipeline way. Automatically extracting chemical named entities (Zhang et al., Citation2016) or biomedical named entities (Saad et al., Citation2020) from patents has been extensively investigated. Early techniques for chemical entity extraction, such as dictionary-based methods (Akhondi et al., Citation2016; Hettne et al., Citation2009; Rebholz-Schuhmann et al., Citation2007) and grammar-based methods (Akhondi et al., Citation2015; Liu et al., Citation2012), heavily rely on expert knowledge in the chemical domain. Klinger et al. (Klinger et al., Citation2008) present a machine learning approach based on conditional random fields to find mentions of IUPAC and IUPAC-like names in patents. CPC-2014 has promoted the development of novel chemical text NER methods (Akhondi et al., Citation2016; Leaman et al., Citation2016; Zhang et al., Citation2016). When extracting valuable information from patents, one can readily obtain the relation mentions by a variety of methods, such as SAO (Subject-Action-Object) method (Choi et al., Citation2013; Guo et al., Citation2016), template method (Yoon & Kim, Citation2012).
As an increasing number of annotated patent corpora are released, the applications of deep learning for information extraction in patent texts have emerged. The bidirectional long short-term memory network in conjunction with a CRF layer is utilized to locate chemical named entities on patent documents (Hemati & Mehler, Citation2019; Zhai et al., Citation2019). Chen et al. employed a deep neural network to categorize semantic relations between a pair of entities in patent texts, and analyzed the influence of word embedding and deep learning model (Chen et al., Citation2020b). In fact, word embedding that represents words as dense vectors in a vector space to mirror the semantic meaning of words has a strong influence on many natural language processing tasks, especially for deep learning based methods. Such deep learning based information extraction methods use the traditional word embeddings trained by the word2vec. The contextual word embedding models can learn powerful representations and be fine-tuned on different tasks. Bidirectional Encoder Representations from Transformers (BERT) has shown remarkable improvements across various NLP tasks (Devlin et al., Citation2018). In the patent domain, researchers have fine-tuned BERT for patent classification (Lee & Hsiang, Citation2020b), patent texts generation (Lee, Citation2019; Lee & Hsiang, Citation2020a) and other patent analysis tasks (Choi et al., Citation2019; Risch et al., Citation2020). Chinese-roberta-wwm-ext that improved mask strategy based on BERT takes the advantages of whole word masking at word granularity and RoBERTa model, has shown better performance on Chinese NLP tasks (Cui et al., Citation2021). However, the effectiveness of these contextual word embedding models on patent documents information extraction is still not clear and needs to be investigated.
3. Materials and methods
The present CPIE, a dataset consisting of 5445 granted patents documents collected from China National Intellectual Property Administration (CNIPA) by using FTP. It contains patents across different technological areas filed between 2015 and 2019. Around two sentences are selected manually from the description section of each patent as the raw data. The data are annotated with a tagging team by using an on-line annotation tools and evaluated with popular information extraction models.
3.1. Label definition
The goal of information extraction is to extract a pair of predefined entity relations between entities from the unstructured text. An entity refers to the names of people, places, organizations and other entities of interest in text documents, which can be defined according to the actual task needs. In this study, 8 types of entities and 5 types of semantic relations are defined to describe the structure of the invention after a literature review and expert consultation. The entity types and semantic relations are listed respectively in Table . Considering that the label definition is directional, entities are classified into head entities and tail entities. The corresponding relations are shown in Figure .
Figure 1. The correspondence between entity and relation.

Table 1. Entity types and relation types.
The result of the information extraction is represented as a set of SPO triples which is composed of a head entity type, a relation and a tail entity type:
3.2. Data annotation
3.2.1. Sample statistics
A lot of off-the-shelf annotation tools can be used for general NLP tasks. Table compares the convenience and functional characteristics of brat (http://brat.nlplab.org/index.html), Baidu EasyData (https://ai.baidu.com/easydata/), YEDDA (https://github.com/jiesutd/YEDDA) and Doccano (https://github.com/doccano/doccano). Compared to other off-line annotation tools, EasyData is an on-line annotation tool that is of simple to use. Furthermore, EasyData can realize automatic data deduplication and team multi-person labelling that is very suitable for processing large-scale corpus. As a consequence, EasyData was selected to annotate the entity relation in this study.
Table 2. Comparison of annotation tools.
A tagging team consisting of 30 members was trained with the usage of labelling tool and the rule of information extraction through a combination of offline lecture and online learning documents. The original corpus was uploaded to the EasyData platform, which automatically distributes the corpus to each annotation member equally. The annotation results were cross-checked with another annotation member and some poor-quality samples were re-labelled. The data annotation was completed after half a month, which was the first Chinese patent semantic information extraction dataset, named as CPIE.
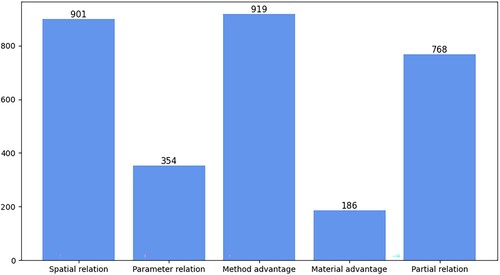
CPIE involves 1080 samples, and each sample consists of an original text and one or more pairs of SPO triples. The statistics of entity labels and relation labels in the CPIE are shown in Figures and respectively. A total of 6256 entity mentions are obtained where the most significant type is component that accounts for 26.7% and then followed by effect, method and location. Intuitively, the description of an invention’s method and its effect is the main content in a patent specification. As shown in Figure , the largest proportion in all relation labels is the method advantage, followed by the spatial relation, because these two relations devote to describe the methods and location.
Figure 2. Statistics of entity labels.
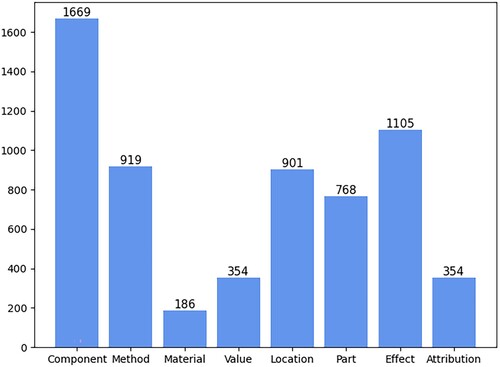
Figure 3. Statistics of relation labels.
3.2.2. Annotation examples
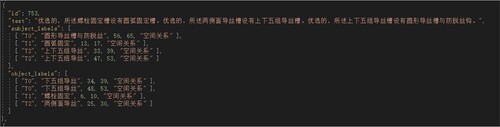
The final goal is SPO triad extraction, thus the sequence annotated BIO labels are typed on the SUBJECT and OBJECT labels. Combining the BIO classification with the entity type classification, and finally the two categories SUBJECT and OBJECT are obtained. Before the experiment, the dataset was pre-processed by categorizing the entities with SUBJECT and OBJECT labels in each sample and recording their indexes at the starting and ending positions in the sequence, as shown in Figure .
Figure 4. Example of a sample (Named entity identification).
Relation extraction is seen as a classification subtask in this study, the subtask uses a pre-training model, which improved mask strategy based on bert. The model uses Whole Word Masking (WWM) at word granularity, in Whole Word Masking, if a sub-word, which is part of a complete word, is masked, other parts of the same word are also masked. In the input layer, the model is similar to bert and consists of three parts: token_ids, attention_masks and token_type_ids.
In the relational classification subtask, each sample is split by relational label and marked with an index of the starting and ending position of the entity pair corresponding to that label in the sequence, as shown in Figure .
Figure 5. Example of a sample (Relationship classification).

3.3. Framework for patent information extraction
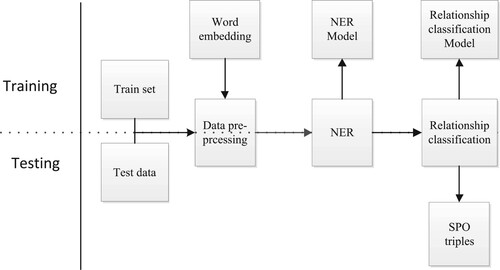
To evaluate the performance of the CPIE dataset, a pipeline-style framework for patent information extraction is proposed, which is based on a transformer pre-training model. The framework is divided into two functionally independent subtasks: named entity recognition (NER) and relationship classification. These subtasks are clearly defined and functionally independent, which are detailed in the following sub-sections. The structure of the pipeline relationship extraction framework is illustrated in Figure . Data pre-processing is conducted either in training or inference steps, which involves deleting stop word and word embedding. The information extraction model is trained on the annotated dataset and then used to extract valuable information from the input text.
Figure 6. Flowchart of the patent information extraction.
3.3.1. NER
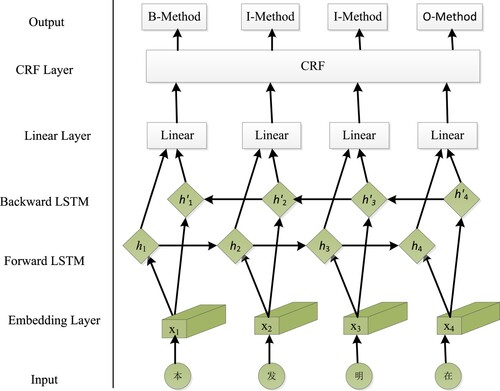
NER is conducted as a sequence-labelling problem, in which ‘B’ is attached to the tokens as the beginning of entities, ‘I’ to those as the inside of entities and ‘O’ for non-entity tokens. Here, the BIO classification and the entity type classification are combined, and finally all entities are classified into two categories: SUBJECT and OBJECT. In order to implement NER easily and accurately, BiLSTM is combined with the traditional machine learning method CRF. As shown in Figure , the text sequences are transformed as embeddings using the pre-training model chinese-roberta-wwm-ext and fed into BiLSTM network after splitting and converting into token_ID. Finally, the predicted labels are obtained by the CRF layer. The model of BiLSTM and CRF are trained in an end-to-end style with the help of gradient back propagation.
Figure 7. The framework of the BiLSTM based NER method.
3.3.2. Relationship extraction
Relation extraction is considered as a classification subtask in this study. Entity pairs are generated which one is acquired from SUBJECT and another one is acquired from OBJECT. Subsequently, entity pairs with all possible combinations are fed into the relational classification model which results in an SPO triple containing an entity of type SUBJECT, an entity of type OBJECT and a predicted relationship.
The relation classification is conducted with the Bert and BiLSTM network (Shi & Lin, Citation2019). Firstly, the input sequence (CLS) sentence (SEP) subject (SEP) object (SEP) is constructed. Then, entity mentions in the sentence are replaced with masks to prevent over-fitting, comprised of argument type (Subject or Object) and entity type (such as Method and Component), e.g. SUBJ-COMP, denoting that the subject entity is a component. The input is then fed into the BERT encoder to obtain the contextual representation that is concatenated with position embeddings and passed into the BiLSTM layer. The final hidden states in each direction of the BiLSTM are used for prediction with a one-hidden-layer multilayer perceptron.
4. Experiment and results
4.1. Hyper-parameters
The CPIE dataset was divided into a training set, a validation set and a test set with a ratio of 7:2:1, containing 756, 216 and 108 samples respectively. The Coda and Corpus data used to support the findings of this study are available at https://github.com/mripet/CPIE/tree/main.
According to the length of original text, the maximum length of input sentence is determined to be 512 characters where the characters exceed the maximum sentence length are discarded. The sentence including less than 512 characters is filled with unique tokens. Mask is also performed on the characters randomly with a probability of 15%, and Mask – Attention is sent to the model together.
With the aim of training models, the learning rate size was set to 0.002, and the training batch was set to 8. The network was trained for 15 epochs. The algorithm was developed using pyTorch1.6.0 (https://pytorch.org/) for the Python 3.8 environment (Python Software Foundation, Wilmington, DE, USA) on a NVIDIA GeForce GTX 2060 (Nvidia, Santa Clara, CA, USA) with 8GB GPU memory.
4.2. NER results
Table compares the performance of the Bi-LSTM models with chinese-bert-base and chinese-roberta-wwm-ext for each type of entity with precision, recall and F1-score. Besides, the support degree that is the number of each type of entities is listed on the right side in Table . Both models performed with a low precision for the NER task since that the training samples are not sufficient to contain the terminologies. Additionally, it can be observed that chinese-roberta-wwm-ext is 0.03–0.06 higher than chinese-bert-base in all metrics which benefits from whole word masking technique and RoBERTa method (Liu et al., Citation2019).
Table 3. NER results of Bi-LSTM models.
Table 4. RE experimental results.
4.3. Relationship extraction results
The relational classification models performed relatively well on the test set. As shown in Table , the macro average of Precision, Recall and F1-score were 0.91, 0.88 and 0.89, respectively. The model classifies the parameter relation with a higher precision than other relation types. The model classification for the method advantage has the lowest precision among all the relation types. Intuitively, method advantage is very intractable because the various expression and implicit description. The parameter relation classification is easier because the feature of the numerical value is clearly distinguishable from other features. Furthermore, parameter relation is a broad category including many kinds of numerical relationships. The partial relation has the largest number of support because a large portion of the patents involve the description of devices.
4.4. SPO triples extraction
In the test set with a total of 1039 SPO triples, 1089 SPO triples were obtained in total after the pipeline framework, of which 74 were correct. The specific metrics are shown in Table . It is nothing to that an exact match strategy is adopted for result evaluation where a correct identification only happens when an extracted entity is exactly matched with gold standard in annotated corpus.
Table 5. SPO experimental results.
Here, the entity pairs with all possible combinations are fed into the relational classification model which results in the underperformance of the SPO triples recognition. For example, a sentence involving 4 entities of SUBJECT type and 4 entities of OBJECT type, which would predicate 16 SPO triples for this sentence. Actually, a total of 3 triads have been manually labelled for such sentence. Therefore, entity pair selection is necessary to filter out entity pairs which are obviously impossible to form an interested semantic relation. Nevertheless, few methods have been reported to end this.
In addition, the final accuracy of the pipeline-style framework will be influenced by the accuracy of all subtask models. Errors in entity prediction are propagated to the relational classification task, leading to errors in the final triple predictions.
5. Conclusions
A Chinese patent semantic information extraction dataset was constructed and released, which fills the blank of lacking patent semantic information extraction dataset in the Chinese corpus. The CPIE provides data and test benchmarks for domestic counterparts to perform patent text information extraction. An information extraction algorithm comprising of NER and relational classification is used as a benchmark to complete the information extraction experiment. Besides, NER and RE models based on the transformer pre-training model are evaluated on the constructed data set separately. Experiments show that the relation classification subtask can be conducted with a high accuracy whereas the BiLSTM has a poor performance for the NER subtask.
A wide range of patent fields are involved in the corpus, which leads to the dispersion of sample features. Therefore, it is necessary to narrow the fields of patent corpus and construct specific datasets for different fields to improve the quality of patent corpus. Additionally, a joint framework for information extraction could be attempted to eliminate the effects of error propagation.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Data availability statement
The data can be available from the corresponding author upon reasonable request.
Additional information
Funding
References
- Akhondi, S. A., Hettne, K. M., van der Horst, E., van Mulligen, E. M., & Kors, J. A. (2015). Recognition of chemical entities: Combining dictionary-based and grammar-based approaches. Journal of Cheminformatics, 7(Suppl 1). https://doi.org/10.1186/1758-2946-7-S1-S10
- Akhondi, S. A., Klenner, A. G., Tyrchan, C., Manchala, A. K., Boppana, K., Lowe, D., Zimmermann, M., Jagarlapudi, S. A., Sayle, R., & Kors, J. A. (2014). Annotated chemical patent corpus: A gold standard for text mining. PLoS One, 9(9), e107477. https://doi.org/10.1371/journal.pone.0107477
- Akhondi, S. A., Pons, E., Afzal, Z., van Haagen, H., Becker, B. F., Hettne, K. M., van Mulligen, E. M., & Kors, J. A. (2016). Chemical entity recognition in patents by combining dictionary-based and statistical approaches. Database, 2016, baw061. https://doi.org/10.1093/database/baw061
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D., Wu, J., Winter, C., ... Amodei, D. (2020). Language models are few-shot learners. In NIPS '20: Proceedings of the 34th International Conference on Neural Information Processing Systems (pp. 1877–1901). ACM.
- Chen, L., Xu, S., Shang, W., Wang, Z., Wei, C., & Xu, H. (2020a). What is special about patent information extraction? In Proceedings of the EEKE 2020 - Workshop on Extraction and Evaluation of Knowledge Entities from Scientific Documents (pp. 63–72).
- Chen, L., Xu, S., Zhu, L., Zhang, J., Lei, X., & Yang, G. (2020b). A deep learning based method for extracting semantic information from patent documents. Scientometrics, 125(1), 289–312. https://doi.org/10.1007/s11192-020-03634-y
- Cho, H. P., Lim, H., Lee, D., Cho, H., & Kang, K.-I. (2018). Patent analysis for forecasting promising technology in high-rise building construction. Technological Forecasting and Social Change, 128, 144–153. https://doi.org/10.1016/j.techfore.2017.11.012
- Choi, S., Kim, H., Yoon, J., Kim, K., & Lee, J. Y. (2013). An SAO-based text-mining approach for technology roadmapping using patent information. R&D Management, 43(1), 52–74. https://doi.org/10.1111/j.1467-9310.2012.00702.x
- Choi, S.-J., Lee, H., Park, E., & Choi, S. (2019). Deep patent landscaping model using transformer and graph embedding. ArXiv 2019, https://arxiv.org/abs/1903.05823
- Cui, Y., Che, W., Liu, T., Qin, B., & Yang, Z. (2021). Pre-training with whole word masking for Chinese bert. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29, 3504–3514. https://doi.org/10.1109/TASLP.2021.3124365
- Devlin, J., Chang, M.-W., & Lee, K. (2018). Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. ArXiv 2018, https://arxiv.org/abs/1810.04805
- Finkel, J. R., Grenager, T., & Manning, C. (2005). Incorporating non-local information into information extraction systems by Gibbs sampling. In Proceedings of the Proceedings of the 43rd Annual Meeting of the Association for Computational Linguistics.
- Grishman, R. (2015). Information extraction. IEEE Intelligent Systems, 30(5), 8–15. https://doi.org/10.1109/MIS.2015.68
- Guo, J., Wang, X., Li, Q., & Zhu, D. (2016). Subject–action–object-based morphology analysis for determining the direction of technological change. Technological Forecasting and Social Change, 105, 27–40. https://doi.org/10.1016/j.techfore.2016.01.028
- He, J., Nguyen, D. Q., Akhondi, S. A., Druckenbrodt, C., Thorne, C., Hoessel, R., Afzal, Z., Zhai, Z., Fang, B., Yoshikawa, H., Albahem, A., Cavedon, L., Cohn, T., Baldwin, T., & Verspoor, K. (2021). ChEMU 2020: Natural language processing methods Are effective for information extraction from chemical patents. Frontiers in Research Metrics and Analytics, 6, 654438. https://doi.org/10.3389/frma.2021.654438
- Hemati, W., & Mehler, A. (2019). LSTMVoter: Chemical named entity recognition using a conglomerate of sequence labeling tools. Journal of Cheminformatics, 11(1), 3. https://doi.org/10.1186/s13321-018-0327-2
- Hettne, K. M., Stierum, R. H., Schuemie, M. J., Hendriksen, P. J., Schijvenaars, B. J., Mulligen, E. M., Kleinjans, J., & Kors, J. A. (2009). A dictionary to identify small molecules and drugs in free text. Bioinformatics (Oxford, England), 25(22), 2983–2991. https://doi.org/10.1093/bioinformatics/btp535
- Hong, Z., Ward, L., Chard, K., Blaiszik, B., & Foster, I. (2021). Challenges and advances in information extraction from scientific literature: A review. JOM Journal of the Minerals Metals and Materials Society, 73(11), 3383–3400. https://doi.org/10.1007/s11837-021-04902-9
- Jiang, S., Sarica, S., Song, B., Hu, J., & Luo, J. (2022). Patent data for engineering design: A critical review and future directions. Journal of Computing and Information Science in Engineering, 22, 1–48. https://doi.org/10.1115/1.4054802.
- Klinger, R., Kolářik, C., Fluck, J., Hofmann-Apitius, M., & Friedrich, C. M. (2008). Detection of IUPAC and IUPAC-like chemical names. Bioinformatics (Oxford, England), 24(13), i268–i276. https://doi.org/10.1093/bioinformatics/btn181
- Kruiper, R., Vincent, J. F., Chen-Burger, J., Desmulliez, M. P., & Konstas, I. (2020). A scientific information extraction dataset for nature inspired engineering. ArXiv 2020, https://arxiv.org/abs/2005.07753
- Leaman, R., Wei, C.-H., Zou, C., & Lu, Z. (2016). Mining chemical patents with an ensemble of open systems. Database, 2016, baw065. https://doi.org/10.1093/database/baw065
- Lee, J.-S. (2019). PatentTransformer: A framework for personalized patent claim generation. In Proceedings of the JURIX (Doctoral Consortium).
- Lee, J.-S., & Hsiang, J. (2020a). Patent claim generation by fine-tuning OpenAI GPT-2. World Patent Information, 62, 101983. https://doi.org/10.1016/j.wpi.2020.101983
- Lee, J.-S., & Hsiang, J. (2020b). Patent classification by fine-tuning BERT language model. World Patent Information, 61, 101965. https://doi.org/10.1016/j.wpi.2020.101965
- Li, Y., Bontcheva, K., & Cunningham, H. (2004). SVM based learning system for information extraction. In Proceedings of the International Conference on Deterministic & Statistical Methods in Machine Learning.
- Li, S., He, W., Shi, Y., Jiang, W., Liang, H., Jiang, Y., Zhang, Y., Lyu, Y., & Zhu, Y. (2019). Duie: A large-scale Chinese dataset for information extraction. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing (pp. 791–800).
- Liu, H., Christiansen, T., Baumgartner, W. A., Jr., & Verspoor, K. (2012). Biolemmatizer: A lemmatization tool for morphological processing of biomedical text. Journal of Biomedical Semantics, 3(1), 3, https://doi.org/10.1186/2041-1480-3-3.
- Liu, Y., Ott, M., Goyal, N., Du, J., Joshi, M., Chen, D., Levy, O., Lewis, M., Zettlemoyer, L., & Stoyanov, V. (2019). RoBERTa: A robustly optimized BERT pretraining approach. ArXiv 2019, https://arxiv.org/abs/1907.11692
- Liu, C., Sun, W., Chao, W., & Che, W. (2013). Convolution neural network for relation extraction. In Proceedings of the International Conference on Advanced Data Mining and Applications (pp. 231–242).
- Mccallum, A., Freitag, D., & Pereira, F. (2001). Maximum entropy Markov models for information extraction and segmentation. icml.
- Park, H., Yoon, J., & Kim, K. (2012). Identifying patent infringement using SAO based semantic technological similarities. Scientometrics, 90(2), 515–529. https://doi.org/10.1007/s11192-011-0522-7
- Rebholz-Schuhmann, D., Kirsch, H., Arregui, M., Gaudan, S., Riethoven, M., & Stoehr, P. (2007). EBIMed–text crunching to gather facts for proteins from Medline. Bioinformatics (Oxford, England), 23(2), e237–e244. https://doi.org/10.1093/bioinformatics/btl302
- Risch, J., Alder, N., Hewel, C., & Krestel, R. (2020). PatentMatch: A dataset for matching patent claims & prior art. ArXiv 2020, https://arxiv.org/abs/2012.13919v1
- Saad, F., Aras, H., & Hackl-Sommer, R.. (2020). Improving named entity recognition for biomedical and patent data using Bi-LSTM deep neural network models. In E. Métais, F. Meziane, H. Horacek, & P. Cimiano (Eds.), Natural Language Processing and Information Systems. NLDB 2020. Lecture Notes in Computer Science (Vol. 12089, pp. 25–36). Springer. https://doi.org/10.1007/978-3-030-51310-8_3
- Sang, E. F., & De Meulder, F. (2003). Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. ArXiv 2003, https://arxiv.org/abs/cs/0306050
- Seymore, K., McCallum, A., & Rosenfeld, R. (1999). Learning hidden Markov model structure for information extraction. In Proceedings of the AAAI-99 Workshop on Machine Learning for Information Extraction (pp. 37–42).
- Shi, P., & Lin, J. (2019). Simple BERT models for relation extraction. ArXiv 2019. https://doi.org/10.48550/arXiv.1904.05255. https://arxiv.org/abs/1904.05255
- Singh, S. (2018). Natural language processing for information extraction.
- Son, J., Moon, H., Lee, J., Lee, S., Park, C., Jung, W., & Lim, H. (2022). AI for patents: A novel yet effective and efficient framework for patent analysis. IEEE Access, 10, 59205–59218. https://doi.org/10.1109/ACCESS.2022.3176877
- Tseng, Y.-H., Lin, C.-J., & Lin, Y.-I. (2007). Text mining techniques for patent analysis. Information Processing & Management, 43(5), 1216–1247. https://doi.org/10.1016/j.ipm.2006.11.011
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł, & Polosukhin, I.. (2017). Attention is all you need. In I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, & R. Garnett (Eds.), Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4–9, 2017, Long Beach, CA, USA (pp. 5998–6008). http://arxiv.org/abs/1706.03762
- Wu, H. (2019). Report of 2019 language & intelligence technique evaluation. Baidu Corporation.
- Yoon, J., & Kim, K. (2012). Trendperceptor: A property-function based technology intelligence system for identifying technology trends from patents. Expert Systems with Applications, 39(3), 2927–2938. https://doi.org/10.1016/j.eswa.2011.08.154
- Zhai, Z., Nguyen, D. Q., Akhondi, S., Thorne, C., Druckenbrodt, C., Cohn, T., Gregory, M., & Verspoor, K. (2019). Improving chemical named entity recognition in patents with contextualized word embeddings, Florence, Italy, August (pp. 328–338).
- Zhang, L., Li, L., & Li, T. (2015). Patent mining: A survey. ACM Sigkdd Explorations Newsletter, 16(2), 1–19. https://doi.org/10.1145/2783702.2783704
- Zhang, Y., Xu, J., Chen, H., Wang, J., Wu, Y., Prakasam, M., & Xu, H. (2016). Chemical named entity recognition in patents by domain knowledge and unsupervised feature learning. Database (Oxford), 2016, baw049. https://doi.org/10.1093/database/baw049.