
 ?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.
?Mathematical formulae have been encoded as MathML and are displayed in this HTML version using MathJax in order to improve their display. Uncheck the box to turn MathJax off. This feature requires Javascript. Click on a formula to zoom.ABSTRACT
Effective and timely diagnosis and treatment of ocular diseases is essential for swift recovery of the patients. Among ocular diseases, cataract and glaucoma are the most prevalent globally and need adequate attention. The present paper aims to develop an optimised deep learning based convolutional neural network (CNN) for the multi-classification of ocular diseases (normal, glaucoma and cataract). Three pre-trained CNNs (SqueezeNet, Darknet-53, EfficientNet-b0) were optimised concerning batch size (6/8/10) & optimiser type (SGDM, RMSProp, Adam) for obtaining maximum possible accuracy in the detection of multiple ocular diseases (cataract & glaucoma). Darknet-53 (batch size-6, optimiser type-Adam) gave the highest accuracy of 99.4% for a test sample of 1000 images. The performance metrics of Darknet-53 have been computed using a confusion matrix. Confusion matrix is also applied to calculate accuracy, sensitivity, specificity, f1 score and receiver operating curve (ROC). Through comparative performance analysis of the three CNNs, SqueezeNet, Darknet-53 and EfficientNet-b0 achieved the highest accuracy of 95%, 99.4% and 90%, respectively. The results indicate the importance of batch size and optimiser type on the performance of CNN models.
1. Introduction
According to the World Health Organization, globally more than 400 million people are suffering from eye diseases such as cataract, glaucoma, etc. (World report on vision, World Health Organization Citation2019). Often these ocular diseases are present in latent condition in the patients, i.e. the patients themselves are usually oblivious to the exacerbation of the asymptomatic pathological conditions (Robinson Citation2001). Thus, reliable and timely diagnosis of eye diseases is of critical importance for their effective treatment. While there exist several eye diseases of concern in today’s times, among them, cataract and glaucoma are one of the most commonly observed conditions which may lead to total blindness or visual impairment (Abbas et al. Citation2022; Tognetto et al. Citation2022). In low- to middle-income countries, cataract forms almost half the total reported cases of ocular diseases (Guergueb and Akhloufi Citation2023). In Europe, the prevalence of cataract has been estimated to be as high as 74% in elderly people of >70 years of age (Prokofyeva et al. Citation2013). Cataract surgery in the apt time is the most effective intervention for treating the patients diagnosed with cataract. Similarly, glaucoma is one of the foremost causes of irreversible loss of eyesight around the world, with predictions estimating >110 million cases by the year 2040 (Tham et al. Citation2014).
The right diagnosis at the opportune time is essential for effective and economical treatment of any diseases. In this scenario, artificial intelligence (AI) and deep learning-based techniques have been extensively explored recently for the diagnosis of ocular conditions with the help of fundus images of eye, which are 2D projected images of the eye (Li et al. Citation2021; Taylor et al. Citation2021). During the pandemic (COVID-19) which impacted the health sector globally by testing the potential of health infrastructure, it was realised that AI is a potent tool that could bring huge relief to people without access to proper hospitals/quality healthcare systems for diagnosis of their medical condition and further proceed for the course of appropriate medical treatment. It is imperative to note in the case of diagnosis of ocular conditions such as glaucoma and cataracts that it is very challenging for doctors to identify using medical images as they may lack clarity or might have low contrast, etc, whereas AI programs tested on thousands of medical images have higher accuracy in the diagnosis of medical diseases. The currently used conventional methods are therefore challenging due to the intricate attributes which need to be carefully identified by the medical doctors through visual inspection (Zangalli et al. Citation2011; Divya and Jacob Citation2018; Barros et al. Citation2020). In this context, AI can enable the development of easily accessible screening tools for identification of the condition in ageing populations of developed countries as well as developing countries with limited number of medical doctors for large populations (Benet and Pellicer-Valero Citation2021; Wang et al. Citation2021; Zhang et al. Citation2023).
Several researchers have attempted to develop deep learning-based convolutional neural network (CNN) approaches for the correct identification and classification of the type of ocular diseases using fundus images. provides a brief list of studies on application of deep learning techniques on automated identification and/or classification of cataract and glaucoma among other ocular diseases. A common research gap observed is the need for a study on the multi-classification of glaucoma and cataract, which are the foremost among the commonly occurring ocular diseases reported. Furthermore, the previous works have not investigated the effects of batch size and optimiser type on the network performance, which are imperative to optimise the network parameters for greater accuracy of prediction (Sarki et al. Citation2020; Tong et al. Citation2020; Deepak and Bhat Citation2023a). The primary target of the present work is to develop an effective CNN model for the identification of cataract and glaucoma conditions, which has not been addressed in the literature (Kumar and Gupta Citation2023).
Table 1. Identification/classification of cataract and glaucoma using deep learning methods.
In the previous literature, most studies have failed to correlate the impact of batch and optimiser type on the overall network performance. This research work details the optimisation of these network parameters (batch size/network type) for enhancing the accuracy of prediction which is clear from the results. Considering this goal, this research work has focused on the optimisation of deep neural networks using different batch sizes (10/8/6) and optimisers, viz., adaptive momentum (Adam), root mean square propagation (RMSprop) and standard gradient descent with momentum (SGDM), for achieving the best the network performance for the correct identification of fundus images among three classes – normal, cataract and glaucoma.
2. Methodology
2.1. Proposed methodology
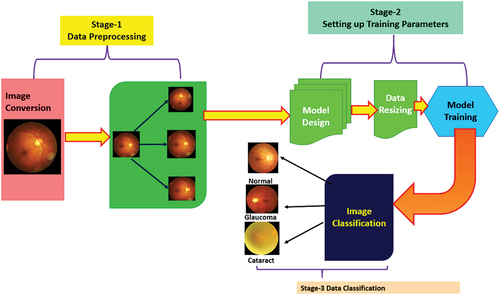
In this paper, optimised deep neural networks have been trained using ocular images for performing the multiclass classification of ocular diseases by testing three-pretrained optimised CNN as depicted in . The pretrained networks include SqueezeNet, Darknet-53 and EfficientNet-b0 which have been optimised with respect to the batch size and optimiser type for achieving the best possible accuracy in multiclassification of ocular diseases (Cataract & Glaucoma).
Figure 1. Ocular disease classification using CNN.
Transfer learning is basically leveraging and transferring the knowledge acquired from one task and applying it to solve other linked tasks. Consequently, this helps in overpowering the isolated learning technique of the traditional design of conventional deep learning and machine learning algorithms. The transfer learning concept in machine learning has great advantages such as training model efficiently and saving resources required for training deep learning models. Transfer learning implements CNN models that have already been trained on challenging datasets such as ImageNet (Soekhoe et al. Citation2016; Alzubaidi et al. Citation2020; Morid et al. Citation2021; Gupta et al. Citation2022). The transfer learning approach is effective as the CNN was trained on large number of photos and require the model to make predictions on a relatively large number of classes, consequently the model learns to efficiently extract features from images to perform well on the current classification problem (CitationTransfer learning and its application in computer vision). It is important to note that the fine-tuning of hyperparameters of CNN model such as batch size (6/8/10), learning rate (optimised at 0.0001) and solver type (SGDM/RMSprop/Adam) are essential for improved classification accuracy of the CNN model. This is being addressed in the present work.
2.2. Dataset
Ocular Disease Intelligent Recognition (ODIR) is an ophthalmic database consisting of patients with colour fundus photographs from left and right eyes, age and diagnostic keywords from doctors. The ODIR dataset publicly available in Kaggle repository consisting of 5,000 patients with colour fundus images and age, including photographs of both left and right eye, is used for training the deep learning models (https://www.kaggle.com/datasets/andrewmvd/ocular-disease-recognition-odir5k). This is a real-life set of information of patients collected by Shanggong Medical Technology Co., Ltd. from different medical centres/hospitals in China. In these organisations, fundus images were captured by different cameras available in the market, such as Kowa Canon and Zeiss ensuing into varied resolutions of images. In this research work, we have focused on three different ocular conditions for training the deep learning-based CNN network which includes Normal, Diabetes and Glaucoma. Here, 80% of the data was kept for training, i.e. 4000 images and 20% was kept for testing, i.e. 1000 images comprising 333 normal eye, 333 glaucoma eye, 334 cataract eye images to maintain the data balance during prediction of classes.
To limit the possibility of data leakage and over-fitting, two cross-validation techniques have been implemented during model training. Apart from randomised data partitioning as training and validation, leave-one-out cross-validation is adopted to enhance the computations take place multiple times to lower the risk of either over-fitting or under-fitting the model.
2.3. Data augmentation
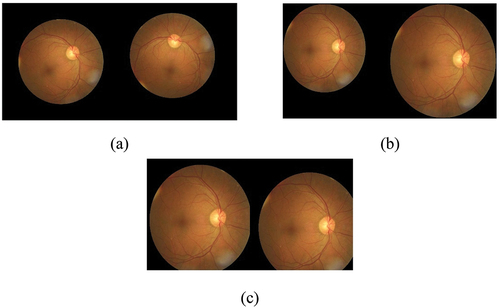
The data augmentation has been done using scaling (1–2), rotation (−90° to + 90°) using the bilinear method and translate (shifting 10 to 70 pixels) in both X and Y directions. The sample images after data augmentation are shown in . During data augmentation, the dataset of ocular images increased by 10%.
Figure 2. Data augmentation by (a) rotation 30° & 70°, (b) 1.4 & 1.8, (c) 10, 25 & 40, 60.
3. Deep neural network optimizers
3.1. Stochastic gradient descent with momentum (SGDM)
The SGDM optimiser oscillates and descends towards the optimal solution for minimising a loss function using the steepest path. To reduce these oscillations which occur due to the computations of the training algorithm for mini batches of the training dataset, a ‘momentum’ term γ is added in the solution update formula. The SGDM with an update of momentum is expressed as (Asaoka et al. Citation2019)
where is the parameter set corresponding to the
iteration, and the learning rate
states the initial learning rate for all deep learning net algorithms. The impact of the learning rate differs for the different optimisation algorithms (Bishop Citation2006). The momentum term determines the contribution value of the previous gradient to the current iteration.
3.2. Root mean square propagation (RMSprop)
While the previous optimiser, SGDM applies a single learning rate for all the parameters, the RMSprop algorithm enhances the performance of a network by using varying learning rates that differ in accordance with the parameter set and adapt to the loss function optimisation status. The RMSprop uses this technology and changes the average of the element-wise squares of the parameter gradients as (Deepak and Bhat Citation2023a)
where β2 signifies the decay rate of the moving average. The value of β2 can be quantified by using the squared gradient decay factor. RMSprop normalises each parameter independently by applying the moving average where there is element-wise division, given by
When there are large gradients involved the RMSprop decreases the learning rate while also increasing the learning rate for smaller gradients. ɛ is a constant term added to avoid division by zero (Bishop Citation2006; Deepak and Bhat Citation2023a).
3.3. Adaptive moment estimation (Adam)
Adam applies a parameter update that is similar to RMSprop, albeit there is an additional momentum term. The resultant term produces a moving average elementwise of both the parameter gradients and their squared values (Deepak and Bhat Citation2023a)
The values of β1 and β2 decay rates can be measured using the squared gradient decay factor and gradient decay factor. Further, Adam applies the moving averages on the gradient of the parameters along with their squares to update the parameters of the network as (Deepak and Bhat Citation2023a)
If gradients are found comparable over numerous iterations, then the gradient’s moving average facilitates the updates of parameters to obtain momentum in a particular direction. However, if the gradients are noisy, then the gradient’s moving average value reduces, thereby reducing the parameter update value (Kingma and Ba Citation2014).
4. Convolutional neural networks
In this research work, we compare three different types and sizes of CNN networks to understand their ability to predict the medical conditions accurately. SqueezeNet is 18 layers deep and uses lesser parameters in comparison to other pretrained networks such as AlexNet/GoogleNet while not compromising on the network accuracy; hence, it was chosen. In comparison of RestNet-50 based on residual connections, the Darknet-53 network makes the addition of output x to output f(x) and applies ReLU activation as the final model output. By direct passing of input x to the output, then final output f(x) = x; when the f(x) value is 0 then H(x) = x, the results of residual approaches 0 and there is the convergence of the training model. This Darknet-53 structure guarantees that the network would converge despite the existence of numerous layers and the model could be trained easily. Hence, as the network becomes deeper, the expression of features is enhanced while it also maintains the recognition precision. Furthermore, the convolution 1 × 1 present in the residual network decreases the channel of each convolution, which consequently reduces the number of parameters. Also, the amount of computation is reduced to a significant extent which leads to the convergence of the model. Although few studies have attempted to further include convolution kernels, here we investigated the base version of the DarkNet-53 model for the sake of simplicity (He et al. Citation2024). EfficientNet-b0 is known to have better network performance than other CNN models such as GoogleNet, AlexNet as it implements mobile inverted bottleneck convolution (MBConv) which enhances its accuracy and reduces the size of parameters. Therefore, SqueezeNet, DarkNet and EfficientNet-b0 were chosen for the study.
4.1. SqueezeNet
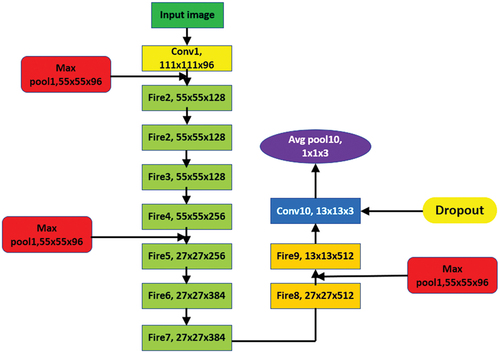
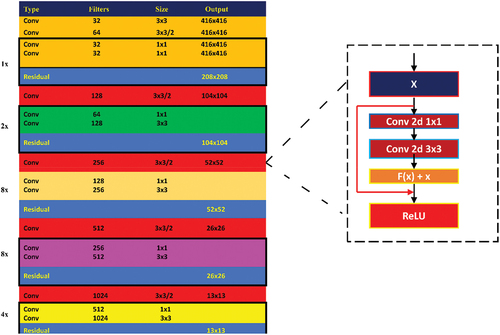
SqueezeNet comprises the fire-protection module () which reduces the parameters of the network by replacing 3 × 3 filter with 1 × 1 filter, hence decreasing the input channels to 3 × 3 filter. It keeps the downsampling later in the network so that larger activation maps can be covered in the convolution layers. Scaling of the model is performed through deep compression. Compared to AlexNet, a popularly used CNN model, SqueezeNet uses 50 times smaller number of parameters while not compromising on accuracy and the modal volume is compressed by 510 times the original volume (Iandola et al. Citation2016). The architecture of SqueezeNet network is shown in .
Figure 3. Fire protection module in SqueezeNet architecture.
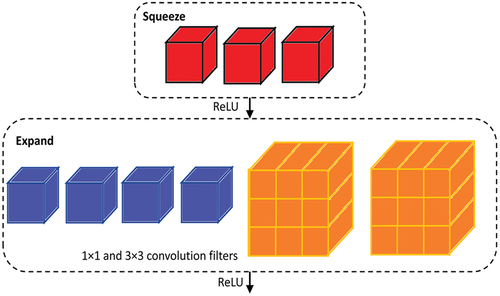
Figure 4. Overall architecture of SqueezeNet.
4.2. DarkNet-53
As Darknet-53 is a deep network, there is an issue of gradient divergence which is addressed using residual networks that help the network learn efficiently (He et al. Citation2016). The schematic diagram of Darknet-53 is shown in . The digits 1, 2, 4 and 8 in the leftmost column (see ) represent the number of residual components that are repeated. The residual connection consists of two convolutional layers. The first convolutional layer with 1 × 1 kernel size and second convolution layer with 3 × 3 kernel size.
Figure 5. Schematic diagram of DarkNet-53.
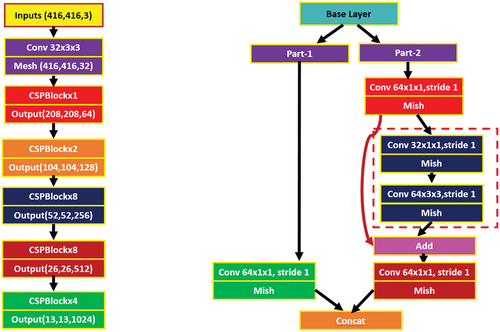
shows the detailed architecture of DarkNet-53. The network makes addition of output x to output f(x) and applies ReLU activation as the final model output (Ioffe and Szegedy Citation2015). By direct passing of input x to the output, then final output f(x) = x; when the f(x) value is 0 then H(x) = x, the results of residual approaches 0 and there is the convergence of the training model (see ). This structure will guarantee that the network would converge despite the existence of numerous layers and the model could be trained easily. Hence, as the network becomes deeper, the expression of features is enhanced while it also maintains the recognition precision. Furthermore, the convolution 1 × 1 present in the residual network decreases the channel of each convolution, which consequently reduces the number of parameters. Also, the amount of computation is reduced to a significant extent which leads to the convergence of the model.
Figure 6. Architecture of DarkNet-53 network.
4.3. EfficientNet-b0 (EffNet-b0)
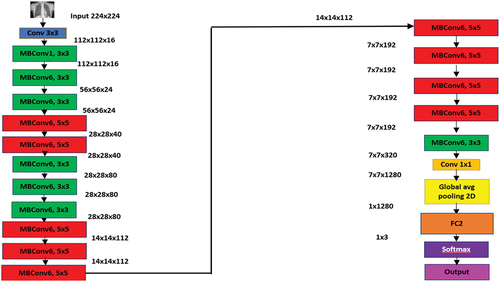
EfficientNet-b0 is a deep neural network consisting of 83 layers. EffNet-b0 is a base network which takes 224 × 224 pixels size as input images (Tan and Le Citation2019). It is known for the implementation of mobile inverted bottleneck convolution (MBConv) which is equivalent to MobileNetV2; however, it is larger due to the higher floating-point operation per second (FLOP) budget. EffNet-b0 is comparatively more efficient and accurate in comparison to the existing CNN network models while also reducing the size of parameters and FLOP by their order of magnitude. EffNet-b0 employs Swish which is a product of sigmoid and linear activation, whereas the other existing CNN models apply ReLU which acts as an activation function (Hridoy et al. Citation2021). EffNet-b0 uses lesser trainable parameters as it deploys an inverted residual block. The overall architecture of EfficientNet-b0 is shown in .
Figure 7. Overall architecture of EfficientNet-b0.
5. Results
5.1. Optimized CNN models: effect of batch size, data augmentation and type of optimizer
The accuracy of the three pretrained CNN investigated in this study, viz., SqueezeNet, DarkNet-53 and EffNet-b0 have been applied with different batch size − 6/8/10 and optimiser type – SGDM/RMSProp/Adam for classification of ocular diseases (test dataset of 100 images), while keeping the validation frequency = 5, maximum epochs = 8 and learning rate = 0.0001 constant. The best network classification results for each CNN network type are shown in , which clearly prove that Darknet-53 (batch size-6, optimiser-SGDM) with an accuracy of 99.4% outperformed SqueezeNet (batch size-6, optimiser-Adam) with an accuracy of 95% and EfficientNet-b0 (batch size-6, optimiser-SGDM) with an accuracy of 90%.
Figure 8. Ocular disease classification using SqueezeNet (batch size-6, optimizer-Adam) (with augmented image data).
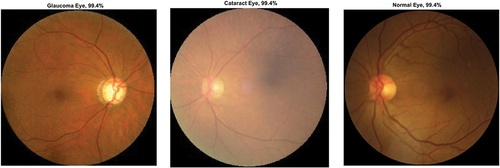
Figure 9. Ocular disease classification using darknet-53 (batch size-6, optimizer-sgdm) (with augmented image data).
Figure 10. Ocular disease classification using EfficientNet-b0 (batch size-6, optimizer-sgdm) (with augmented image data).
The evaluation metrics of CNN model for assessing performance are based on the confusion matrix parameters. The parameters for evaluation include Precision, f1 score, Accuracy, Recall, specificity and false-negative rate. However, DarkNet-53 network makes addition of output x to output f(x) and applies ReLU activation as the final model output. This structure guarantees that the network would converge despite the existence of numerous layers and the model could be trained easily. As DarkNet-53 maintains recognition precision, it performs the best in comparison SqueezeNet and EfficientNet-b0.
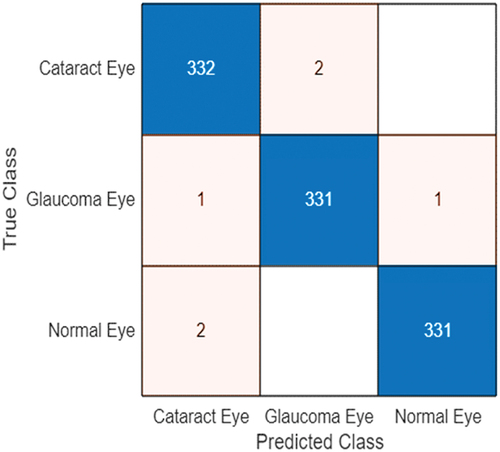
The consolidated accuracy obtained using Darknet-53 for ocular disease classification as normal, cataract or glaucoma in comparison to SqueezeNet and EfficientNet-b0 for various batch size 6/8/10 & optimiser type-SGDM/RMSProp/Adam is shown in . The highest accuracy was obtained for Darknet-53 (batch size-6/optimiser-sgdm) as 99.4%. The confusion matrix corresponding to the optimised DarkNet-53 model is shown in .
Figure 11. Effect of batch size and optimizer type on the ocular disease classification accuracy for various deep learning-based CNN (with data augmentation).
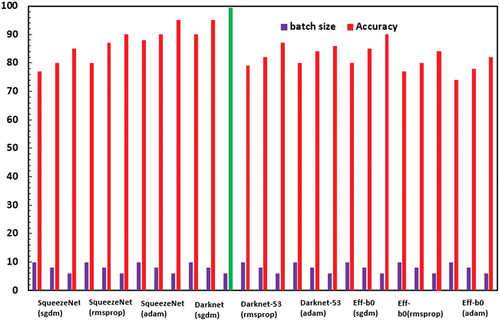
Figure 12. Confusion matrix for darknet-53 (batch size-6, optimizer-SGDM) with 99.4% accuracy.
The effect of data augmentation on the classification accuracy of the optimised models is depicted in . Consistently around 3–4% improvement in accuracy is observed with data augmentation. The details of the optimised CNN networks are presented in .
Figure 13. Accuracy with and without data augmentation for the different CNN networks.
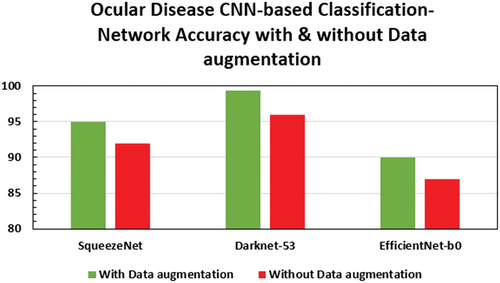
Table 2. Accuracy of various optimised networks.
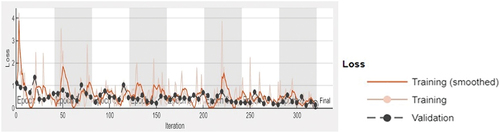
The accuracy and loss function plot of the Darknet-53 (batch size-6, optimiser-SGDM) obtained during the training process in MATLAB 2023 is shown in , respectively. The superiority of DarkNet-53 for eye disease identification has also been observed in other works (Thanh et al. Citation2020; Pal et al. Citation2020). The obtained results indicate that the optimised DarkNet-53 may be employed to develop mobile or desktop-based applications for multi-class diagnosis of ocular conditions (normal, cataract and glaucoma) with reasonable reliability subject to the ethical and other established standards of the medical community. Also, this paves the way for future research for sub-classification of eye-diseases and investigations on diagnosis of other types of ocular diseases.
Figure 14. 99.4% accuracy of darknet-53 (batch size-6, optimizer-SGDM) obtained during the training process.
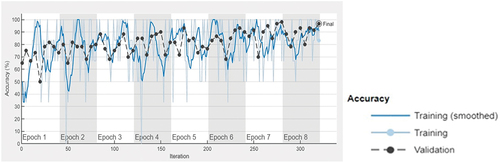
Figure 15. Loss function of the optimized darknet-53 model (batch size-6, optimizer-SGDM) obtained during the training process.
5.2. Performance metrics calculation
The performance metrics give a deeper understanding of the prediction of the network in comparison to the accuracy performance metric. Classification accuracy is a critical area of research in the field of deep learning modelling (Li et al. Citation0000, Citation2019; Deepak and Bhat Citation2023b; Wang et al. Citation2024; Lu et al. Citation2024; Bhat and Deepak Citation2024). From the confusion matrix obtained for the classification performance of the optimised DarkNet-53 model, the parameters like Precision, f-1 score, Accuracy, Recall and specificity (Bustos et al. Citation2020; Chakraborty and Kishor Citation2022) have been computed as shown in , which shows that the performance metric values of Darknet-53 have been listed.
Table 3. Performance metrics of the optimised darknet-53 (batch size-6, optimiser-SGDM).
The formulae used to compute the performance metrics are shown in Eqs. (7–11)
In medical analysis, it is important that the number of false-negative cases is to be kept very minimal. The false-negative rate is computed using Eq. (12).
where TP – true positive, TN – true negative, FP – false positive, FN – false negative, FNR – false-negative rate. Therefore, based on the confusion matrix shown in , the FNR for the cataract, glaucoma and normal classes are 0.59%, 0.60% and 0.60%, respectively. Thereby, the overall FNR for the eye disease classification using the optimised Darknet-53 is 0.60%, which is very minimal. This is crucial for biomedical image medical classification, which would limit the number of false negatives which may prove perilous for the patients.
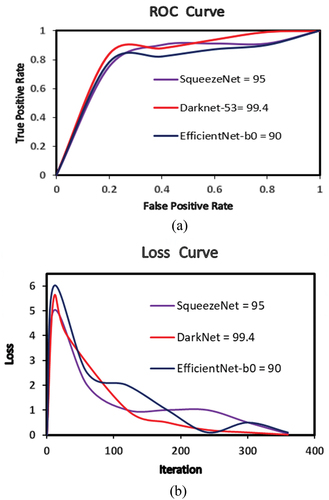
The receiver operating characteristics (ROC) curve is a significant performance assessment tool in case of multiclassification problems. ROC is regarded as a probability curve and demonstrates capability of model to differentiate between the classes at several threshold settings. To compare the relationship between true-positive and false-positive rates for the best models for classification of eye images and their receiver operating characteristic (ROC) curve is shown in .
Figure 16. (a) Receiver operating curve and (b) loss curve for the best accuracy CNNs.
The present work holds significant scientific implications. By employing deep learning techniques, particularly convolutional neural networks (CNNs), for the multiclassification of ocular diseases through transfer learning, the study presents important results in the field of medical image analysis and diagnosis. The utilisation of transfer learning enables the models to leverage pre-trained knowledge from large datasets, enhancing their accuracy and efficiency in detecting various ocular conditions. This advancement is crucial as it can potentially revolutionise the way ocular diseases are diagnosed, providing more accurate and timely assessments for patients. Furthermore, the research contributes to the growing body of literature on deep learning applications in healthcare, showcasing the potential of AI-driven solutions to address complex medical challenges. Particularly, the effect of batch size and type of optimiser on the accuracy of CNN predictions is an important highlight of this paper. Overall, this paper not only offers valuable insights into ocular disease detection but also underscores the transformative impact of deep learning methodologies in medical diagnostics. A key area of future research in ocular disease identification is the utilisation of image-preprocessing techniques such as colour correction, colour space selection, noise reduction and contrast enhancement on the retinal images (Pandey et al. Citation2023). This can help in improving the performance and reliability of disease identification obtained through CNNs.
The complexity of the deep learning model architecture, particularly the convolutional neural network (CNN), including the number of layers, type of layers (convolutional, pooling, fully connected) and the depth of the network, affects computational requirements and performance. In this regard, the utilisation of transfer learning, where pre-trained models are fine-tuned on a specific task, can affect the complexity. Transfer learning can reduce the computational burden by leveraging knowledge gained from pre-trained models, thus requiring fewer training iterations (Salehi et al. Citation2023). The effects of batch size and optimisers which are considered in this study can aid in handling the complexity of developing deep learning models of disease identification through image analysis.
6. Conclusions
Three pretrained CNNs, viz., SqueezeNet, DarkNet-53 and EfficientNet-b0 were optimised with respect to their batch size − 6/8/10 and optimiser type – SGDM/RMSProp/Adam for the best accuracy and performance metrics for multi-classification of ocular diseases (glaucoma and cataract). It was found that DarkNet-53 with batch size − 6 and optimiser – Adam achieved the highest accuracy of 99.4%, precision − 99.39%, Recall − 99.40%, f1-score − 99.39%, Specificity − 99.69% and overall FNR of 0.60%. The results establish the importance of investigating the effect of batch size and optimiser type for the development of best suited CNN models for specific applications. Sub-classes of various other ocular diseases would be considered for multi-classification using deep learning-based CNN models in future studies.
Future research direction would be to implement and train deep learning-based CNN for other types of ocular conditions such as cataract, age-related macular degeneration, hypertension, pathological myopia and other diseases/abnormalities. Also, development of MATLAB-based app would be done for facilitating self-diagnosis by patients using ocular images. Thus, enabling reliable and quality healthcare solutions for all patients.
Author contributions
Both authors contributed to the conception and design. Dr. G Divya Deepak conducted the optimisation of the CNN models. The first draft of the manuscript was written by Dr. G Divya Deepak. It was revised by Dr. Subraya Krishna Bhat and Dr. G Divya Deepak. Both authors read and approved the final manuscript.
Statement of informed consent
The dataset used in this study is from a public database. No identifying details are shown in the present paper.
Acknowledgements
The authors acknowledge the infrastructural and moral support provided by Manipal Academy of Higher Education to conduct this research. The authors express their indebtedness to the reviewers for taking their valuable time to provide valuable suggestions and comments, which have enriched the quality of the present work.
Disclosure statement
No potential conflict of interest was reported by the author(s).
Additional information
Funding
Notes on contributors
G Divya Deepak
Dr. G Divya Deepak is an Assistant Professor-Selection Grade in the Department of Mechanical and Industrial Engineering at Manipal Institute of Technology, India. He has done his Masters from University of Windsor, Canada. His Ph.D research work is in the field of atmospheric pressure cold plasma jets for biomedical applications (in collaboration with Central Electronics Engineering Research Institute,Pilani (CSIR-CEERI) Govt of India). His current research interests include the topics related to Dielectric barrier discharge based cold plasma jets, Application of Machine Learning/Deep Learning Techniques for Biomedical Image Processing and Advanced Manufacturing Methods.
Subraya Krishna Bhat
Dr. Subraya Krishna Bhat is an Assistant Professor in the Department of Mechanical and Industrial Engineering at Manipal Institute of Technology, India. He obtained his PhD in the area of Cardiovascular Biomechanics from Kyushu Institute of Technology, Japan being a recepient of the prestigious MEXT scholarship from the government of Japan for his doctoral reasearch. His current research interests include the topics related to Biomechanics/Continuum Mechanics, Application of Machine Learning/Deep Learning Techniques for Biomedical Data and Advanced Manufacturing Methods.
References
- Abbas Q, Qureshi I, Yan J, Shaheed K. 2022. Machine learning methods for diagnosis of eye‑related diseases: a systematic review study based on ophthalmic imaging modalities. Arch Computat Methods Eng. 29(6):3861–13. doi: 10.1007/s11831-022-09720-z.
- Abu-Ein AA, Tahat NM, Al-Smadi MM, Al-Nawashi MM, Al-Nawashi M. 2022 Dec 2. Combining artificial intelligence and image processing for diagnosing diabetic retinopathy in retinal fundus images. Int J Onl Eng. 18(13):131–151. doi: 10.3991/ijoe.v18i13.33985.
- Acharya RU, Yu W, Zhu K, Nayak J, Lim T-C, Chan JY. 2010. Identification of cataract and post-cataract surgery optical images using artificial intelligence techniques. J Med Syst. 34(4):619–628. doi: 10.1007/s10916-009-9275-8.
- Ahn JM, Kim S, Ahn K-S, Cho S-H, Lee KB, Kim US, Bhattacharya S. 2018. A deep learning model for the detection of both advanced and early glaucoma using fundus photography. PLoS One. 13(11):0207982. doi: 10.1371/journal.pone.0207982.
- Alzubaidi L, Fadhel MA, Al-Shamma O, Zhang J, Santamaría J, Duan Y, Oleiwi SR. 2020. Towards a better understanding of transfer learning for medical imaging: a case study. Appl Sci. 10(13):4523. doi: 10.3390/app10134523.
- An G, Omodaka K, Hashimoto K, Tsuda S, Shiga Y, Takada N, Kikawa T, Yokota H, Akiba M, Nakazawa T. 2019. Glaucoma diagnosis with machine learning based on optical coherence tomography and color fundus images. J Healthc Eng. 2019:1–9. doi: 10.1155/2019/4061313.
- Asaoka R, Tanito M, Shibata N, Mitsuhashi K, Nakahara K, Fujino Y, Kiuchi Y. 2019. Validation of a deep learning model to screen for glaucoma using images from different fundus cameras and data augmentation. Ophthalmol Glaucoma. 2(4):224–231. doi: 10.1016/j.ogla.2019.03.008.
- Barros DM, Moura JC, Freire CR, Taleb AC, Valentim RA, Morais PS. 2020. Machine learning applied to retinal image processing for glaucoma detection: review and perspective. Biomed Eng Online. 19(1):1–21. doi: 10.1186/s12938-020-00767-2.
- Benet D, Pellicer-Valero OJ. 2021. Artificial intelligence: the unstoppable revolution in ophthalmology. Surv Ophthalmol. 67(1):252–270. doi: 10.1016/j.survophthal.2021.03.003.
- Bhat SK, Deepak GD. 2024. Predictive modelling and optimization of double ring electrode based cold plasma using artificial neural network. Int J Eng. 37(1):83–93. doi: 10.5829/IJE.2024.37.01A.08.
- Bishop CM. 2006. Pattern recognition and machine learning. New York, NY: Springer.
- Bustos A, Pertusa A, Salinas J-M, de la Iglesia-Vayá M. 2020. PadChest: a large chest X-ray image dataset with multi-label annotated reports. Med Image Anal. 66:101797. doi: 10.1016/j.media.2020.101797.
- Chakraborty C, Kishor A. 2022 Dec. Real-time cloud-based patient-centric monitoring using computational health systems. IEEE Trans Comput Social Syst. 9(6):1613–1623. doi:10.1109/TCSS.2022.3170375
- Chen X, Xu Y, Wong DWK, Wong TY, Liu J. 2015. Glaucoma detection based on deep convolutional neural network. In: 2015 37th Annual international conference of the IEEE engineering in medicine and biology society (EMBC); Milan, Italy. p. 715–718.
- Deepak GD, Bhat SK. 2023a. Optimization of deep neural networks for multiclassification of dental X-rays using transfer learning. Comput Meth Biomech Biomed Eng Imaging Vis. 1–20. Online. doi: 10.1080/21681163.2023.2272976.
- Deepak GD, Bhat SK. 2023b. Predictive modeling and optimization of pin electrode based cold plasma using machine learning approach. Multiscale and Multidiscip Model Exp Des. doi: 10.1007/s41939-023-00321-2.
- Diaz-Pinto A, Morales S, Naranjo V, Köhler T, Mossi JM, Navea A. 2019. Cnns for automatic glaucoma assessment using fundus images: an extensive validation. Biomed Eng Online. 18(1):1–19. doi: 10.1186/s12938-019-0649-y.
- Divya L, Jacob J. 2018. Performance analysis of glaucoma detection approaches from fundus images. Proc Comput Sci. 143:544–551. doi: 10.1016/j.procs.2018.10.429.
- Gao X, Lin S, Wong TY. 2015. Automatic feature learning to grade nuclear cataracts based on deep learning. IEEE Trans Biomed Eng. 62(11):2693–2701. doi: 10.1109/TBME.2015.2444389.
- Gharaibeh N, Abu-Ein A, Nahar KM. 2021. A hybrid SVM NAÏVE-BAYES Classifier for bright lesions recognition in eye fundus images. Int J Electr Eng Inform. 13(3):530–545.
- Gharaibeh N, Abu-Ein AA, Nahar KM, Abu-Ain WA, Al-Nawashi MM. 2023. Swin transformer-based segmentation and multi-scale feature pyramid fusion module for Alzheimer’s disease with machine learning. Int J Online Biomed Eng. 19(4):22–50.
- Gharaibeh N, Al-Naami B, Nahar KM. 2018. An effective image processing method for detection of diabetic retinopathy diseases from retinal fundus images. Int J Signal Imag Syst Eng. 11(4):206–216.
- Guergueb T, Akhloufi MA. 2023. A review of deep learning techniques for glaucoma detection. SN Comput Sci. 4(3):274. doi: 10.1007/s42979-023-01734-z.
- Gupta J, Pathak S, Kumar G. 2022. Deep learning (CNN) and transfer learning: a review. J Phys Conf Ser. 2273(1):012029. doi: 10.1088/1742-6596/2273/1/012029.
- He Z, Jia D, Zhang C, Li Z, Wu N. 2024. An automatic Darknet-based immunohistochemical scoring system for IL-24 in lung cancer. Eng Appl Artif Intell. 128:107485.
- He K, Zhang X, Ren S, Sun J. 2016. Deep residual learning for image recognition. In IEEE conference on computer vision and pattern Recognitio; Jun 770778; New York, NY, USA: IEEE.
- Hridoy RH, Akter F, Mahfuzullah M, Ferdowsy F. 2021. A computer vision-based food recognition approach for controlling. In 2021 International Conference on Information Technology (ICIT); Amman, Jordan.
- Iandola FN, Han S, Moskewicz MW, Ashraf K, Dally WJ, Keutzer K. 2016. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv, arXiv: 1602 07360. 1–17.
- Ioffe S, Szegedy C. 2015. Batch normalization accelerating deep network training by reducing internal covariate shift. In Proceedings International Conference on Machine Learning; 448456; Heidelberg, Germany: Springer.
- Kim D, Jun TJ, Eom Y, Kim C, Kim D. 2019. Tournament based ranking CNN for the cataract grading. Proceeding Annual International Conference of the IEEE Engineering in Medicine and Biology Society; Berlin, Germany. p. 1630–1636.
- Kingma D, Ba J. 2014. Adam: a method for stochastic optimization. arXiv preprint arXiv:14126980. 1–15.
- Kumar Y, Gupta S. 2023. Deep transfer learning approaches to predict glaucoma, cataract, choroidal neovascularization, diabetic macular edema, DRUSEN and Healthy Eyes: an experimental review. Arch Computat Methods Eng. 30(1):521–541. doi: 10.1007/s11831-022-09807-7.
- Li W, Gu C, Chen J, Ma C, Zhang X, Chen B, Wan S. DLS-GAN: generative adversarial nets for defect location sensitive data augmentation. IEEE Trans Autom Sci Eng. doi: 10.1109/TASE.2023.3309629
- Li W, Liu X, Liu J, Chen P, Wan S, Cui X. 2019. On improving the accuracy with auto-encoder on conjunctivitis. Appl Soft Comput. 81:105489.
- Li T, Bo W, Hu C, Kang H, Liu H, Wang K, Fu H. 2021. Applications of deep learning in fundus images: a review. Med Image Anal. 69:101971. doi: 10.1016/j.media.2021.101971.
- Lu H, Jin T, Wei H, Nappi M, Li H, Wan S. 2024. Soft-orthogonal constrained dual-stream encoder with self-supervised clustering network for brain functional connectivity data. Expert Syst Appl. 244:122898.
- Maheshwari S, Kanhangad V, Pachori RB. 2020. CNN-based approach for glaucoma diagnosis using transfer learning and LBP-based data augmentation. arXiv Preprint. http://arxiv.org/abs/2002.08013.
- Morid MA, Borjali A, Fiol GD. 2021. A scoping review of transfer learning research on medical image analysis using ImageNet. Comput Biol Med. 128:104115. doi: 10.1016/j.compbiomed.2020.104115.
- Pal P, Kundu S, Kumar Dhara A. 2020. Detection of red lesions in retinal fundus images using YOLO V3. Curr Indian Eye Res J Ophthalmic Res Group. 7:49.
- Pandey AK, Singh SP, Chakraborty C. 2023. Retinal image preprocessing techniques: acquisition and cleaning perspective. Internet Technol Lett. e437. doi: 10.1002/itl2.437.
- Phan S, Satoh S, Yoda Y, Kashiwagi K, Oshika T. 2019. Evaluation of deep convolutional neural networks for glaucoma detection. Jpn J Ophthalmol. 63(3):276–283. doi: 10.1007/s10384-019-00659-6.
- Prokofyeva E, Wegener A, Zrenner E. 2013. Cataract prevalence and prevention in Europe: a literature review. Acta Ophthalmol. 91(5):395–405. doi: 10.1111/j.1755-3768.2012.02444.x.
- Robinson B. 2001. Prevalence of asymptomatic eye disease in an optometric population. Optom Vis Sci. 78(12):250. doi: 10.1097/00006324-200112001-00395.
- Salehi AW, Khan S, Gupta G, Alabduallah BI, Almjally A, Alsolai H, Siddiqui T, Mellit A. 2023. A study of CNN and transfer learning in medical imaging: advantages, challenges, future scope. Sustainability. 15(7):5930. doi: 10.3390/su15075930.
- Sarki R, Ahmed K, Wang H, Zhang Y. 2020. Automatic detection of diabetic eye disease through deep learning using fundus images: a survey. IEEE Access. 8:151133–151149. doi: 10.1109/ACCESS.2020.3015258.
- Soekhoe D, van der Putten P, Plaat A. 2016. On the impact of data set size in transfer learning using deep neural networks. In: Boström H, Knobbe A, Soares C Papapetrou P, editors. Advances in intelligent data analysis XV. IDA 2016. Lecture notes in computer science. Vol. 9897. Cham: Springer. doi: 10.1007/978-3-319-46349-0_5.
- Tan M, Le Q. 2019. EfficientNet: rethinking model scaling for convolutional neural networks. arXiv, arXiv: 1905 11946. 1–11.
- Taylor M, Liu X, Denniston A, Esteva A, Ko J, Daneshjou R, Chan A-W. 2021. Raising the bar for randomized trials involving artificial intelligence: the SPIRIT-AI and CONSORT-AI guidelines. J Invest Dermatol. 141(9):2109–2111. doi: 10.1016/j.jid.2021.02.744.
- Tham YC, Anees A, Zhang L, Goh JHL, Rim TH, Nusinovici S, Hamzah H, Chee M-L, Tjio G, Li S, et al. 2021. Referral for disease-related visual impairment using retinal photograph-based deep learning: a proof-of-concept, model development study. Lancet Digit Heal. 3(1):e29–40. doi:10.1016/S2589-7500(20)30271-5.
- Tham Y-C, Li X, Wong TY, Quigley HA, Aung T, Cheng C-Y. 2014. Global prevalence of glaucoma and projections of glaucoma burden through 2040: a systematic review and meta-analysis. Ophthalmology. 121(11):2081–2090. doi: 10.1016/j.ophtha.2014.05.013.
- Thanh THP, Thuy TPT, Hieu TN and Nguyen MS. 2020. “A real-time classification of glaucoma from retinal fundus images using AI technology”. 2020 International Conference on Advanced Computing and Applications (ACOMP); 114–121; Quy Nhon, Vietnam. doi: 10.1109/ACOMP50827.2020.00024.
- Tognetto D, Giglo R, Vinciguerra AL, Milan S, Rejdak R, Rejdak M, Zaluska-Ogryzek K, Zweifel S, Toro MD. 2022. Artificial intelligence applications and cataract management: a systematic review. Surv Opthalmol. 67(3):817–829. doi: 10.1016/j.survophthal.2021.09.004.
- Tong Y, Lu W, Yu Y, Shen Y. 2020. Application of machine learning in ophthalmic imaging modalities. Eye and Vis. 7(1):1–15. doi: 10.1186/s40662-020-00183-6.
- Transfer learning and its application in computer vision: a review, Chandeep Sharma, Sayonee Parikh, Conference: Transfer Learning and its application in Computer Vision. 2022 Mar. Waterloo, Canada.
- Wang H, Zhang D, Feng J, Cascone L, Nappi M, Wan S. 2024. A multi-objective segmentation method for chest X-rays based on collaborative learning from multiple partially annotated datasets. Inf Fusion. 102:102016.
- Wang SH, Nayak DR, Guttery DS, Zhang X, Zhang YD. 2021. COVID-19 classification by CCSHNet with deep fusion using transfer learning and discriminant correlation analysis. Inf Fusion. 68:131–148. doi: 10.1016/j.inffus.2020.11.005.
- World report on vision, World Health Organization. 2019. https://www.who.int/publications/i/item/9789241516570. Accessed on 10 Nov 2023.
- Zangalli C, Gupta SR, Spaeth GL. 2011. The disc as the basis of treatment for glaucoma. Saudi J Ophthalmol. 25(4):381–387. doi: 10.1016/j.sjopt.2011.07.003.
- Zhang Y, Khan MA, Zhu Z, Wang S. 2023. Snelm: squeezenet-guided elm for COVID-19 recognition. Comput Syst Sci Eng. 46(1):13–26. doi: 10.32604/csse.2023.034172.