
Abstract
Companies may receive forecast upsides that can undermine their ability to support customer demand on time. Therefore, it is critical to include forecast upsides when performing comparative analysis of inventory classification models. This study focuses on this subject. The study includes statistical methods and sensitivity analysis to determine the performance of which MCIC model is statistically significant with respect to inventory and customer orders fill rate. Results show that the PBB-model outperforms other models when forecast upside is present and the result is statistically significant. On the other hand, when no forecast upside is present, the R-model, which does not use descending ranking criteria, outperforms other models, and the difference is statistically significant. We also find that adding descending ranking criteria to the R-model and ZF-model does not improve their Service-Cost Performance Index.
1. Introduction
ABC classification is a well-known method of inventory classification. This classification scheme divides the stock keeping units (SKUs) into a number of classes based on certain criteria. Inventory classification plays an important role in the management of inventory. When classifying inventory, two questions need to be addressed: (1) How many classes must be used? and (2) How do we determine the borders between these classes (Van Kampen, Akkerman, & Pieter van Donk, Citation2012)?
The traditional ABC classification is based on Pareto’s principle. The criterion used is annual dollar usage. This method assumes that 20% of items are responsible for 80% of the annual dollar usage (Chu, Liang, & Liao, Citation2008). Items are then categorized into class A, B, or C. Class A items are considered the most important, will typically contain items that account for 80% of the total annual dollar usage but only make up 20% of the total items. Class B items are considerably less important and typically contain 30% of the total items that are responsible for approximately 15% of the total annual dollar usage. The least important are class C items, which contribute the lowest total annual dollar usage but contain a large number of inventory items. They are responsible for approximately 5% of the annual dollar usage value and contain around 50% of the total number of items. Companies can afford to keep a higher stock of class B and C items than class A items, whereas class A items need to be monitored very closely (Beheshti, Grgurich, & Gilbert, Citation2012).
The traditional method is simple and easy to use. It is argued in the literature that other factors can also play a role in inventory classification which may include lead time, inventory cost, and obsolescence (Torabi, Hatefi, & Pay, Citation2012). Therefore, multi-criteria inventory classification (MCIC) has been used in recent studies in the context of inventory classification.
Multi-criteria ABC classification considers more than one factor or criterion that can impact inventory classification. Criteria used in the literature are cost, lead time, criticality, obsolescence, durability, stockability, order size requirement, commonality, substitutability, and repairability (Guvenir & Erel, Citation1998; Ng, Citation2007; Partovi & Anandarajan, Citation2002; Ramanathan, Citation2006; Torabi et al., Citation2012; Zhou & Fan, Citation2007). The literature shows that many techniques have been used to classify inventory, including matrix-based methodology, cluster analysis, analytic hierarchy process (AHP), genetic algorithm, neural networks, and optimization models.
Companies maintain different varieties of products, namely SKUs. Controlling and giving them equal attention is not easy or productive (Kabir & Akhtar Hasin, Citation2013). Inventory-control policies include maintaining an appropriate safety stock level, customer orders fill rate, and reorder points (Babai, Ladhari, & Lajili, Citation2015; Cohen & Ernst, Citation1988). Inventory classification can help in developing inventory control policies (Guvenir & Erel, Citation1998). For example, since class A consists of a smaller number of items but is responsible for a higher annual dollar usage, it is suggested to maintain a tighter inventory control, which includes regular cycle counting and better forecasting methods for class A items.
It is useful to understand the performance of MCIC models on inventory cost reduction and customer orders fill rate. The customer orders fill rate is defined as the probability of filling an entire customer order within a specified period (Song, Citation1998). Babai et al. (Citation2015) presented a service-cost performance index (SCPI) analysis of four MCIC models (Ng-model, H-model, ZF-model, and R-model). They concluded that the R-model and ZF-model perform better in a combined SCPI. The reason for this is that in the Ng-model and H-model, the criteria are ranked in descending order (). And since the unit cost and higher annual dollar usage are used as the most important criteria, items having a higher unit cost and higher annual dollar usage receive a higher classification (class A or B) in the Ng-model and H-model. When the safety stock costs of all items are summed, this results in a higher total safety stock cost in these models.
We define ‘forecast upside’ as a scenario when actual demand is higher than the forecast. It is also referred to as positive forecast error or just forecast error in this study. When actual customer demand becomes higher than the forecast, it can result in inventory shortages, which will eventually impact the customer orders fill rate. Babai et al. (Citation2015) did not consider a model comparison when forecast upside is present. They also did not include PBB-model in the comparison. Also, it is not evident how the R-model and ZF-model will perform when descending criteria ranking is included in these models, as found with the Ng-model and H-model, and whether there will be any difference in the SCPI. We also do not know if the difference in the performance of the models differs significantly. This study fills these gaps. Since this study focuses more on fulfilling orders fill rate, the study does not include the scenario of forecast downside. In the case of forecast downside, actual customer demand becomes lower than the forecast which creates inventory surplus. This poses a risk of having higher inventory cost than having lower orders fill rate. The contribution of this paper is as follows:
Comparative analysis of the SCPI of MCIC is studied in three different scenarios: (1) when forecast error is not present; (2) when forecast error is present but the same across all classes A, B, and C; and (3) when forecast error is present, but this error is different for classes A, B, and C. Hypothesis testing that assesses the significance of differences between the inventory performance of MCIC models is included. The recent PBB-model (Park, Bae, & Bae, Citation2014), modified R-model, and modified ZF-model are included in the comparison. The modified R-model and modified ZF-model add descending criteria ranking functionality to these models so that criteria can be ranked in descending order. Altogether, we used seven models for comparison: R-model, Ng-model, ZF-model, H-model, PBB-model, modified R-model, and modified ZF-model.
2. Literature review
In today’s world, a moderate-sized company must deal with thousands of inventory items, and inventory classification decisions may become challenging. Different methods and techniques used in the ABC classification of inventory are listed in Table , which is extracted from the work of Van Kampen et al. (Citation2012) and further modified to include more recent studies. This study is focused on optimization models, which will be discussed in detail in the next section.
Table 1. Methods and techniques used in ABC classification (Van Kampen et al., Citation2012).
2.1. Optimization models
Recently, linear optimization models have gained attention in inventory classification. They are similar to DEA like models. In these models, criteria values for each item are converted into a scalar score. The weights for each criterion are generated by DEA like linear optimization models (Ng, Citation2007). Ramanathan (Citation2006) used a weighted linear optimization (WLO) model to rank inventory. He noted that this type of optimization model has an advantage over other techniques because it gives optimal inventory scores without the user having to specify weights. In addition to the R-model, many other models have been proposed.
2.1.1. R-model
Ramanathan (Citation2006) presented a WLO model to use in inventory classification, whereby the weight of each criterion on each item is automatically generated when the model is run. Also, after the model is run, the aggregate inventory score for each inventory item is maximized, which he termed ‘optimal inventory score.’ Based on the scores, items can be classified into classes A, B, or C. The R-model is shown below:(1)
where j = criteria, m = inventory items, N = total number of inventory items, = weight of mth inventory items under criteria j, and
= score of mth inventory items under criteria j.
The objective function gives the optimal inventory score for the mth item. The model is repeatedly solved for each item by changing the objective function. The scores are used to classify the inventory items. The first constraint is a normalization constraint, which ensures that the weighted sum of an inventory item for all jth criteria is not greater than 1. The equation is written for all ‘n’ inventory items. The second constraint ensures that the weight of the jth criteria on the mth inventory item is not negative.
2.1.2. Ng-model
Ng (Citation2007) presented an alternative linear optimization model and also presented a transformation technique, which ensures that results can be obtained without using a linear optimizer. He ranked the criteria in descending order in the Ng-model:(2)
where j = criteria, i = inventory items, = weight of the ith inventory item under criteria j, and
= score of ith inventory item under criteria j.
The objective function is a maximization function. When the model is solved, the objective function maximizes the score for each inventory item. Weights are automatically generated when the model is solved. The first constraint is a normalization constraint, which ensures that summation of the weights received on the ith inventory item by criteria j is equal to 1. The second constraint is a descending ranking of the criteria, which shows that criterion 1 is more important than criterion 2, and criterion 2 is more important than criterion 3. In other words, it can be interpreted in mathematical form as follows: . The advantage of employing the Ng-model is that it lets the user identify which criterion s/he considers more important than others while ranking the inventory items. The R-model does not use this constraint.
2.1.3. ZF-model
Zhou and Fan (Citation2007) pointed out that the R-model will always give an aggregate score of 1 to an item if it scores a higher value than other items in the certain criterion, even if it scores low in other criteria. This can assign that item an A classification. To correct this problem, the authors calculated good and bad indexes for each item using a maximization and minimization linear programming model, respectively. Then these two indexes were combined to produce a composite index. In the minimization problem, aggregate scores of the items are minimized so that each item gets a least-favorable weight for itself. The minimization model is shown below:(3)
where i = inventory items, n = criteria, = score of ith inventory item under criteria n,
= weight of ith inventory item under criteria n, and
= least favorable aggregate score of ith inventory item.
The first constraint ensures that the weighted sum for all items based on the same set of weights must be greater than or equal to 1. The second constraint ensures that the sum of the weights on the ith item is greater than 0. The ZF-model is a WLO model. The objective function scores each inventory, which the authors termed as ‘least favorable’ or ‘bad index.’
They used the R-model for the maximization problem. The resulting scores from the model are referred to as a good index, which ensures that each item receives the most favorable weight for itself that maximizes its score when the model is solved. The model is shown below:(4)
where = most favorable aggregate score of ith inventory item.
Furthermore, the two indexes are combined to produce a ‘composite index’ using the formula shown in Equation (Equation5(5) ).
(5)
where gI* = maximum value of good index, gl− = minimum value of bad index, bI* = maximum value of bad index, = minimum value of bad index,
= control parameter that is specified by user, and nIi = composite index for an item i. The resulting composite indexes are then used to rank the inventory item to assist in inventory classification.
2.1.4. H-model
Hadi-Vencheh (Citation2010) pointed out that the inventory score of an item from the Ng-model is independent of the weights associated with each criterion. This means that the weight of each criterion becomes irrelevant in determining the aggregate score of an item. Hadi-Vencheh (Citation2010) extended the Ng-model and attempted to correct this issue. He used the sum of the squared weights in the normalization constraint, which converts the model into a non-linear model. The H-model is shown below:(6)
where = relative importance weight attached to jth criteria, and
= score of ith inventory item under criteria j.
The objective function maximizes the aggregate score for each inventory item. Constraint 1 ensures that the sum of the squared values of all weights equals 1. Constraint 2 ensures that the weights are in ascending order. All weights are greater than zero.
2.1.5. PBB-model
Park et al. (Citation2014) proposed an optimization model that gives a cross-efficiency optimal score. First, an optimal inventory score is calculated using the R-model, which the authors termed as WLO model. Then, they introduced another model to achieve the cross-efficiency optimal scores for an item evaluated by another item as shown below:(7)
where urk = weight given to the rth criterion of the kth item (yrk), yrk = score on item k under criterion r, = optimal performance of inventory score as received from R-model, and
= optimal cross-efficiency score for item p evaluated by item k.
2.1.6. Modified R-model
In the modified R-model, we included a descending ranking criteria constraint. While solving the model, criteria with higher importance receive higher weights. All other constraints and the objective function used in the R-model remain unchanged. The modified R-model is shown below:(8)
2.1.7. Modified ZF-model
Similar to the modified R-model, we included a descending order criteria constraint in the modified ZF-model. Due to this constraint, weights are assigned to the criteria based on the importance level when the model is solved. All other constraints and the objective function used in the ZF-model remain unchanged. The modified ZF-model is shown below:(9)
3. Method
We considered the technique ‘optimization models’ in the comparative analysis in this study. Relevant studies are shown in Table . Formulations of the seven models were shown previously in Section 2. Our analysis of the models involves a three-step process. In the first step, each model is run for all inventory items. Criteria used are annual dollar usage, average unit cost, and lead time. Annual dollar usage is considered as the most important, whereas lead time as the least important criterion. We used Lingo optimization software to solve the models. Items are classified into classes A, B, or C. The second step involves evaluation of the SCPI for each model using the safety stock cost and overall fill rate (FRT), as was done by Babai et al. (Citation2015). The notation and formula used are shown in the Appendix. The SCPI of each model is compared in three different categories: First: with no forecast upside. Second: with constant forecast upside across all classes, whereby forecast errors ranging from 15 to 40% are used. Third: with variable forecast error across classes A, B, and C. Forecast error for class A ranges from 20 to 45%, for class B from 25 to 50%, and for class C from 30 to 55%. To assist in the sensitivity analysis, a wide range of forecast error is used at multiple customer service levels (CSLs). We used three CSL categories:
First: Class A = 99% CSL, Class B = 95% CSL, and Class C = 90% CSL
Second: Class A = 95% CSL, Class B = 90% CSL, and Class C = 85% CSL
Third: Class A = 90% CSL, Class B = 85% CSL, and Class C = 80% CSL
The sensitivity analysis will attempt to answer the following questions: Does a model outperform other models for a wide range of forecast errors? Does more than one model outperform other models at different forecast error levels? Do the results differ at different CSLs?
To calculate the positive forecast error, or in other words, to know how much the actual demand is higher than the forecast, we can use the following formula (Hartnett & Romcke, Citation2000):(10)
The third step involves hypothesis testing. We constructed an ANOVA table for randomized block design where inventory performance of items under each model is considered treatment and each block refer to a certain forecast error applied on each item. The structure of the randomized block design (Bhattacharya & Johnson, Citation1977) is shown in Table ; the resulting ANOVA is shown in Table .(11)
(12)
(13)
Table 2. Data structure for randomized block design with b blocks and k treatments.
Table 3. ANOVA table for randomized block design.
Hypothesis testing is set as follows:
Ho: No treatment difference (T1 = T2 = … = Tk)
VS
H1: At least one treatment difference occurs
3.1. Illustrative example 1
We applied methods described in the previous section on two different data-sets: one including 47 inventory items used in the previous literature (Babai et al., Citation2015; Flores, Olson, & Dorai, Citation1992; Ng, Citation2007; Ramanathan, Citation2006) and the other including 10 inventory items used by Park et al. (Citation2014). Experimental results of the first data-set of 47 items will be presented first.
We assumed a holding cost 20% of the average unit cost and a standard deviation of 2.62% of the annual forecasted demand, as used by Babai et al. (Citation2015). We evaluated two cases: first, when forecast error is present and does not vary across classes A, B, and C; and second, when forecast error varies across classes A, B, and C.
Case 1: When forecast error is present and does not vary across classes A, B, and C
We extracted Table from the work of Babai et al. (Citation2015), modified it by adding a 15% forecast error, recalculated values for the new annual demand by using Equation (Equation10(10) ), and determined the calculated revised (new) stock cost and overall FRT by using Equations (Equation15
(15) ) and (Equation16
(16) ). They are included in the Appendix. The analysis is shown in the shaded portion of Table , where CSLs of 99, 95, and 90% are used for classes A, B, and C, respectively.
Table 1 Safety stock cost and overall FRT for H-model without forecast error and at 15% forecast error (CSL is 99%, 95%, and 90% for classes A, B, and C, respectively).
Table
Table
Table shows the safety stock cost and overall FRT for the H-model when there is no forecast error (non-shaded region), and also when the forecast error is 15% across all items (shaded region). When summed, the total safety stock cost for all 47 items is found to be $999.80 with no forecast error, and $1149.78 with 15% forecast error. The overall FRT with and without forecast error is calculated by Equation (Equation16(16) ):
Overall FRT (from H-model) = 1401/1415 = 0.9904
Overall FRT (from H-model) with 15% forecast error = 1610/1627 = 0.9895
The same calculations are performed for the other six models and shown in Table . Table includes a positive forecast error across six different forecast error levels, ranging from 15 to 40%. The given forecast error is constant across all items. For example, at 15% forecast error, all items received a 15% forecast error, regardless of which class they belong to. It can be seen that the R-model results in the lowest safety stock when there is no forecast error. This is similar to the findings of Babai et al. (Citation2015). However, when forecast error is present, the PBB-model results in the lowest safety stock cost. These results will be discussed in detail in the next section. In order to be consistent and make the comparison simple, the values are normalized on a scale from 0 to 1 and shown in Table .
Table 5. Safety stock cost and FRT of various MCIC models without forecast error and when forecast error varies across classes A, B, and C.
Table 6. Summary of safety stock cost and customer orders fill rate for MCIC models at 15% forecast error.
In the case of safety stock cost, a normalized value of 0 corresponds to the highest safety cost. We call this ‘x,’ and the remaining values are percentages of ‘x.’ In the case of achieved FRT, a normalized value of 1 corresponds to the highest FRT. We call this ‘y,’ and the remaining values are a percentage of ‘y.’ These two normalized values are summed for each model and are called the SCPI. This normalized scale allows the comparison of the models on a single scale. The higher the value of SCPI, the better is the model. This index makes it easier to compare the inventory performance of the models. The model that results in the highest SCPI score outperforms the other models. Table presents a summary of the various forecast error levels. It can be seen that the PBB-model received the highest SCPI.
Table 7. SCPI at various forecast error levels and CSL of 99, 95, and 90%, for classes A, B, and C, respectively.
3.1.1. ANOVA and testing hypothesis for example 1 Case 1: when forecast error is present and does not vary across classes A, B, and C
The purpose of the hypothesis testing is to determine if there is a significant difference in the SCPI among the different MCIC models. Using the method explained previously in Section 3, we created an ANOVA table when forecast error is present and does not vary across classes A, B, and C, as shown in Table .
Table 8. ANOVA for service-cost inventory performance of MCIC models when forecast error does not vary.
The hypotheses are set as follows:
Ho: No significant difference of SCPI among different MCIC methods
VS
H1: Significant difference of SCPI among MCIC methods exists
The interpretation of these results is as follows: We reject the null hypothesis when Fratio for treatment or MST/MSE > Fα (k–1, (b–1) (k–1)).We find that F0.95 (6,30) = 2.4205 and Fratio for treatment = 311341.3, we reject the null hypothesis, and we conclude that the treatment difference exists at the 95% confidence interval. In other words, the SCPI of all MCIC methods is not statistically equal. In order to find which MCIC method is significantly different, we constructed multiple t confidence intervals for pairwise comparisons of treatment means using Bonferroni’s method (Mendenhall, Sincich, & Boudreau, Citation2016). Bonferroni’s formula is given as:(14)
where p = number of sample (treatment) means in the experiment, g = number of pairwise comparison [g = p (p–1)/2], α = error rate, ν = number of df associated with MSE, S = , and Bij = critical value for each treatment pair (ij).
A treatment difference exists when the difference between the treatment means (y.i–y.j) is greater than Bij. These calculations are shown in the Appendix. We find that the mean of treatment 3 significantly exceeds all other treatments. In other words, treatment 3 significantly outperforms other treatments. This is shown in Figure in the Appendix.
Case 2: When forecast error is present and varies across classes A, B, and C
In this case, we evaluate the MCIC inventory performance when the positive forecast error is unique for classes A, B, and C but different across these classes. We can construct Table for safety stock cost and overall FRT. The values are calculated with CSLs of 99, 95, and 90% for classes A, B, and C, respectively. Results are shown in Table and Figure . Table shows that the PBB-model results in the highest SCPI at all forecast error levels. A similar result is shown in Figure .
Table 9. Safety stock cost and overall FRT for MCIC models when forecast error varies, and CSL is 99, 95, and 90% for classes A, B, and C, respectively.
Figure 1. Graphical analysis of service-cost performance index (SCPI).
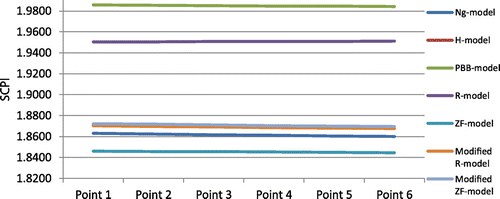
Point 1: A = 0.2, B = 0.25, C = 0.3; Point 2: A = 0.25, B = 0.30, C = 0.35; Point 3: A = 0.30, B = 0.35, C = 0.40; Point 4: A = 0.35, B = 0.40, C = 0.45
Point 5: A = 0.40, B = 0.45, C = 0.50; Point 6: A = 0.45, B = 0.50, C = 0.55
3.1.2. ANOVA and testing hypothesis for example 1 Case 2: when forecast error is present and varies across classes A, B, and C
The ANOVA when the forecast error is different across classes A, B, and C is shown in Table .
Table 10. ANOVA for service-cost performance index of MCIC models when forecast error varies across classes A, B, and C.
The hypotheses are set as follows:
Ho: No significant difference of SCPI among different MCIC methods
VS
H1: Significant difference of SCPI among MCIC methods exists
The interpretation of these results is as follows: We find that the Fratio for treatment = 60554.694, which is greater than F0.95 (6,30) = 2.4205, we reject the null hypothesis, and we conclude that a treatment difference exists at the 95% confidence interval at variable forecast error levels across classes A, B, and C. In other words, the SCPI of all MCIC methods is not statistically equal. We also constructed multiple t confidence intervals for pairwise comparisons of treatment means using Bonferroni’s method (Mendenhall et al., Citation2016). We find that the mean of treatment 3 (PBB-model) significantly exceeds that of all other treatments. This is shown in Figure in the Appendix. It can be concluded that the PBB-model significantly outperforms other models.
3.2. Illustrative example 2
The data used for example 2 is from Park et al. (Citation2014) and consists of ten inventory items. Safety stock cost and overall FRT are calculated both for Cases 1 and 2. In Case 1, forecast error does not vary across classes A, B, and C. In Case 2, forecast error varies across classes A, B, and C. Results are transformed into a SCPI. Results for Cases 1 and 2 for example 2 are shown in the Appendix (A3 and A4).
3.2.1. ANOVA and testing hypothesis for example 2 Case 1: when forecast error does not vary across classes A, B, and C
Hypothesis testing is performed in this section, and ANOVA results are shown in Table .
Table 11. ANOVA for service-cost performance index of MCIC models when forecast error does not vary across classes A, B, and C.
The hypotheses are set as follows:
Ho: No significant difference of SCPI among different MCIC methods
VS
H1: Significant difference of SCPI among MCIC methods exists
The interpretation of these results is as follows: We find that F0.95 (6,30) = 2.4205 < Fratio for treatments = 346275.1, we reject the null hypothesis, and we conclude that a treatment difference exists at the 95% confidence interval at non-variable forecast error levels across classes A, B, and C. This shows that the SCPI of all MCIC methods is not statistically equal. We also create multiple t confidence intervals for pairwise comparisons of treatment means. Treatment means are compared with critical values of each treatment pair (Bij). We find that the mean of treatment 3 (PBB-model) significantly exceeds that of all other treatments. In other words, the PBB-model significantly outperforms the other models. This is shown in Figure in the Appendix.
3.2.2. ANOVA and testing hypothesis for example 2 Case 2: when forecast error varies across classes A, B, and C
We performed hypothesis testing, and the ANOVA is shown in Table .
Table 12. ANOVA for service-cost performance index of MCIC models when forecast error varies across classes A, B, and C.
The hypotheses are set as follows:
Ho: No significant difference of SCPI among different MCIC methods
VS
H1: Significant difference of SCPI among MCIC methods exists
The interpretation of these results is as follows: We find that F0.95 (6,30) = 2.4205 < Fratio for treatments = 40597.619, we reject the null hypothesis, and we conclude that a treatment difference exists at the 95% confidence interval at variable forecast error levels across classes A, B, C. This means that the SCPI of all MCIC methods is not statistically equal. We also construct multiple t confidence intervals for pairwise comparisons of treatment means using Bonferroni’s method (Mendenhall et al., Citation2016). We find that the mean of treatment 3 (PBB-model) significantly exceeds that of all other treatments. In other words, the PBB-model significantly outperforms other models. This is shown in Figure in the Appendix.
4. Results and discussion
In the illustrative Examples 1 and 2 presented in Section 3, we analyzed the safety stock cost and overall FRT of MCIC models at CSLs of 99, 95, and 90% for classes A, B, and C, respectively. We found that the PBB-model outperformed other models. In order to determine if the same result is true at other CSLs, we constructed Tables and , in order to compare the results at other CSLs for both data-sets.
Table 13. Service-cost performance index for MCIC models – first data-set of 47 items.
Table 14. Service-cost performance index for MCIC models – second data-set of 10 items.
Results of both data-sets at various CSLs show that the PBB-model displays better service-cost performance both with non-variable and variable forecast error compared to other MCIC models. The lowest safety stock cost and highest overall FRT is achieved from the PBB-model when forecast error is present, and the difference is statistically significant at 95% confidence level. However, with no forecast error, the R-model results in a better SCPI in the first data-set, as was also seen by Babai et al. (Citation2015), but in the second data-set, the R-model was second after the PBB-model. We cannot conclude that the R-model will always result in better service-cost performance when the forecast error is not present. Since Babai et al. (Citation2015) did not include the PBB-model in their study, the effect of the PBB-model on the comparative analysis is unknown. Babai et al. (Citation2015) claimed that models that do not use descending ranking criteria result in better service-cost performance with no forecast error. This finding does not change since the PBB-model also does not use descending ranking criteria.
According to Babai et al. (Citation2015), the R-model outperforms other models, since it does not impose descending ranking order among criteria. To further investigate this, we included descending ranking orders between criteria both in the R-model and the ZF-model, and referred to this as the modified R-model and modified ZF-model. We found that adding descending ranking criteria does not increase the performance of the models, but rather decreases the performance. This also complements the findings of Babai et al. (Citation2015).
Although the PBB-model does not use descending ranking criteria, it does use a different approach than the R-model. It not only uses self-evaluation, as in the case of the R-model, but it also cross-evaluates other items while giving an optimal score to an item. When the PBB-model is solved for a given inventory item, it maximizes the inventory score of that item while simultaneously minimizing the scores of other competing items. Thus, the scores of items are further refined because they go through two different evaluations. Therefore, classification of items is much more stable so it minimizes the effect of forecast error on the SCPI. This can be seen, when forecast error is present in the PBB-model, and it performs better than the other models at all forecast error levels.
This study recommends the PBB-model over other MCIC models for inventory classification. The only problem with using the PBB-model is its extensive calculations, which uses two models – one for self-evaluation and the other for peer-evaluation. Results of the first model are used in solving the second model. This increases the number of calculations and adds complexities. But in this age, a software program could be developed to facilitate the calculation of the models and make them less time-consuming.
The performance metrics used in this study are order FRT and safety stock cost in combination, for comparing the performance of models. However, when the performance metrics change, the results of the comparative analysis might change. Other models may show better performances. For example, if order FRT is the only consideration, Ng-model, modified R-model, and modified ZF-model show better performances as can be seen in Table and Figure .
5. Conclusion
This study provides a comprehensive comparison of service-cost performance of seven MCIC models in three different scenarios: (1) when there is no forecast upside; (2) when forecast upside is present, but does not vary across classes A, B, and C; and (3) when forecast upside is present and varies across classes A, B, and C. We find that at no forecast upside, models that do not use descending ranking criteria (R-model, PBB-model, ZF-model) show a higher SCPI than models that use descending ranking criteria (Ng-model and H-model). In both Cases 2 and 3, when forecast upside is present, the PBB-model outperforms other MCIC models, and the result is statistically significant.
A service-cost performance evaluation of the MCIC models provides an understanding of how the models would behave in different forecast scenarios. When companies are not able to improve the accuracy of their forecast, they would like to use an inventory classification method that minimizes the risk of an increase in inventory cost and at the same time increases the fill rate of orders.
For future research, the performance of MCIC models could be further evaluated by changing the criteria used in the models and see if the comparative results change, that is, whether a given MCIC model would outperform with variable criteria sets. The bootstrap approach can also be employed in this regard. Also, a scenario of forecast downside can be considered in future research.
Disclosure statement
No potential conflict of interest was reported by the authors.
References
- Arikan, F., & Citak, S. (2017). Multiple criteri a inventory classification in an electronics firm. International Journal of Information Technology & Decision Making, 1–17.
- Babai, M. Z., Ladhari, T., & Lajili, I. (2015). On the inventory performance of multi-criteria classification methods: Empirical investigation. International Journal of Production Research, 53, 279–290.10.1080/00207543.2014.952791
- Beheshti, H. M., Grgurich, D., & Gilbert, F. W. (2012). ABC inventory management support system with a clinical laboratory application. Journal of Promotion Management, 18, 414–435. 10.1080/10496491.2012.715502
- Bhattacharyya, G. K. & Johnson, R. A. (1977). Statistical concepts and methods, Vol. 106. New York: Wiley.
- Boylan, J. E., Syntetos, A. A., & Karakostas, G. C. (2008). Classification for forecasting and stock control: A case study. Journal of the Operational Research Society, 59, 473–481.10.1057/palgrave.jors.2602312
- Canen, A. G., & Galvão, R. D. (1980). An application of ABC analysis to control imported material. Interfaces, 10, 22–24.10.1287/inte.10.4.22
- Canetta*, L., Cheikhrouhou, N., & Glardon, R. (2005). Applying two-stage SOM-based clustering approaches to industrial data analysis. Production Planning & Control, 16, 774–784.10.1080/09537280500180949
- Chen, Y., Li, K. W., Kilgour, D. M., & Hipel, K. W. (2008). A case-based distance model for multiple criteria ABC analysis. Computers & Operations Research, 35, 776–796.10.1016/j.cor.2006.03.024
- Chrisman, J. J. (1985). Basic production techniques for small manufacturers: II inventory control methods and MRP. Product Inventory Mngt, 26, 48–64.
- Chu, C. W., Liang, G. S., & Liao, C. T. (2008). Controlling inventory by combining ABC analysis and fuzzy classification. Computers & Industrial Engineering, 55, 841–851.10.1016/j.cie.2008.03.006
- Cohen, M. A., & Ernst, R. (1988). Multi-item classification and generic inventory stock control policies. Production and Inventory Management Journal, 29, 6–8.
- D’Alessandro, A. J., & Baveja, A. (2000). Divide and conquer: Rohm and Haas’ response to a changing specialty chemicals market. Interfaces, 30(6), 1–16.10.1287/inte.30.6.1.11627
- Ernst, R., & Cohen, M. A. (1990). Operations related groups (ORGs): A clustering procedure for production/inventory systems. Journal of Operations Management, 9, 574–598.10.1016/0272-6963(90)90010-B
- Flores, B. E., Olson, D. L., & Dorai, V. K. (1992). Management of multicriteria inventory classification. Mathematical and Computer Modelling, 16, 71–82.10.1016/0895-7177(92)90021-C
- Gajpal, P. P., Ganesh, L. S., & Rajendran, C. (1994). Criticality analysis of spare parts using the analytic hierarchy process. International Journal of Production Economics, 35, 293–297.10.1016/0925-5273(94)90095-7
- Ghobbar, A. A., & Friend, C. H. (2002). Sources of intermittent demand for aircraft spare parts within airline operations. Journal of Air Transport Management, 8, 221–231.10.1016/S0969-6997(01)00054-0
- Guvenir, H. A., & Erel, E. (1998). Multicriteria inventory classification using a genetic algorithm. European Journal of Operational Research, 105, 29–37.10.1016/S0377-2217(97)00039-8
- Hadi-Vencheh, A. (2010). An improvement to multiple criteria ABC inventory classification. European Journal of Operational Research, 201, 962–965.10.1016/j.ejor.2009.04.013
- Hartnett, N., & Romcke, J. (2000). The predictability of management forecast error: A study of Australian IPO disclosures. Multinational Finance Journal, 4, 101–132.10.17578/4
- Hatefi, S. M., & Torabi, S. A. (2010). A common weight MCDA–DEA approach to construct composite indicators. Ecological Economics, 70, 114–120.10.1016/j.ecolecon.2010.08.014
- Huiskonen, J. (2001). Maintenance spare parts logistics: Special characteristics and strategic choices. International Journal of Production Economics, 71, 125–133.10.1016/S0925-5273(00)00112-2
- Kabir, G., & Akhtar Hasin, M. A. (2013). Multi-criteria inventory classification through integration of fuzzy analytic hierarchy process and artificial neural network. International Journal of Industrial and Systems Engineering, 14, 74–103.10.1504/IJISE.2013.052922
- Keshavarz Ghorabaee, M., Zavadskas, E. K., Olfat, L., & Turskis, Z. (2015). Multi-criteria inventory classification using a new method of evaluation based on distance from average solution (edas). Informatica, 26, 435–451.10.15388/Informatica.2015.57
- Lolli, F., Ishizaka, A., & Gamberini, R. (2014). New AHP-based approaches for multi-criteria inventory classification. International Journal of Production Economics, 156, 62–74.10.1016/j.ijpe.2014.05.015
- Mendenhall, W. M., Sincich, T. L., & Boudreau, N. S. (2016). Statistics for engineering and the sciences. CRC Press.10.1201/9781315382494
- Molenaers, A., Baets, H., Pintelon, L., & Waeyenbergh, G. (2012). Criticality classification of spare parts: A case study. International Journal of Production Economics, 140, 570–578.10.1016/j.ijpe.2011.08.013
- Munna, M. M., Rahman, M. H., & Roney, M. F. S. (2015). Comparative analysis for multicriteria inventory classification of Unilever Brothers Ltd. Using AHP and Fuzzy AHP models. Int. J. Mech. Eng. Autom, 2, 377–382.
- Nan-fang, C. U. I., & Xue, L. U. O. (2004). ABC classfication based on AHP in servicing spare part [J]. Industrial Engineering and Management, 6, 33–36.
- Ng, W. L. (2007). A simple classifier for multiple criteria ABC analysis. European Journal of Operational Research, 177, 344–353.10.1016/j.ejor.2005.11.018
- Onwubolu, G. C., & Dube, B. C. (2006). Implementing an improved inventory control system in a small company: A case study. Production Planning & Control, 17, 67–76.10.1080/09537280500366001
- Park, J., Bae, H., & Bae, J. (2014). Cross-evaluation-based weighted linear optimization for multi-criteria ABC inventory classification. Computers & Industrial Engineering, 76, 40–48.10.1016/j.cie.2014.07.020
- Partovi, F. Y., & Anandarajan, M. (2002). Classifying inventory using an artificial neural network approach. Computers & Industrial Engineering, 41, 389–404.10.1016/S0360-8352(01)00064-X
- Portougal, V. (2002). Demand forecast for a catalog retailing company. Production and Inventory Management Journal, 43, 29.
- Ramanathan, R. (2006). ABC inventory classification with multiple-criteria using weighted linear optimization. Computers & Operations Research, 33, 695–700.10.1016/j.cor.2004.07.014
- Song, J. S. (1998). On the order fill rate in a multi-item, base-stock inventory system. Operations Research, 46, 831–845.10.1287/opre.46.6.831
- Syntetos, A. A., Boylan, J. E., & Croston, J. D. (2005). On the categorization of demand patterns. Journal of the Operational Research Society, 56, 495–503.10.1057/palgrave.jors.2601841
- Torabi, S. A., Hatefi, S. M., & Pay, B. S. (2012). ABC inventory classification in the presence of both quantitative and qualitative criteria. Computers & Industrial Engineering, 63, 530–537.10.1016/j.cie.2012.04.011
- Van Kampen, T. J., Akkerman, R., & Pieter van Donk, D. (2012). SKU classification: A literature review and conceptual framework. International Journal of Operations & Production Management, 32, 850–876.10.1108/01443571211250112
- Yu, M. C. (2011). Multi-criteria ABC analysis using artificial-intelligence-based classification techniques. Expert Systems with Applications, 38, 3416–3421.10.1016/j.eswa.2010.08.127
- Zhou, P., & Fan, L. (2007). A note on multi-criteria ABC inventory classification using weighted linear optimization. European Journal of Operational Research, 182, 1488–1491.10.1016/j.ejor.2006.08.052
Appendix
The total cost of safety stock and overall FRT is given by (Babai et al., Citation2015) as:(15)
(16)
where
N = Number of SKUs in the inventory system
CT = Total safety stock cost for all inventory items
ki = Safety factor for item i against the Customer Service Level (CSL)
hi = Unit inventory holding cost of item i
Di = Mean annual demand of item i
= Standard deviation of annual demand for item i
Li = Lead time of item i
Qi = Order quantity of item i
FRi = Fill rate of item i
FRT = Overall fill rate of the inventory system
G(x) = Loss function of the standard normal distribution
Figure A1. Comparison of treatment differences for sample data-set 1 for Case 1.
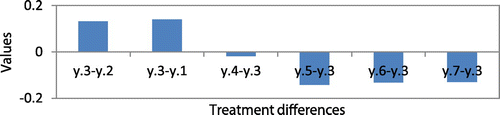
Figure A2. Comparison of treatment differences for sample data-set 1 for Case2.
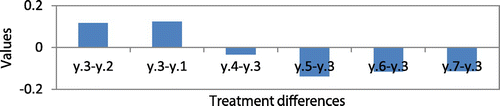
Figure A3. Comparison of treatment differences for sample data-set 2 for Case1.
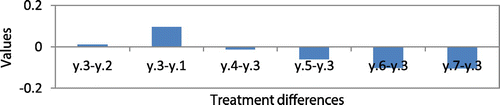
Figure A4. Comparison of treatment differences for sample data-set 2 for Case2.
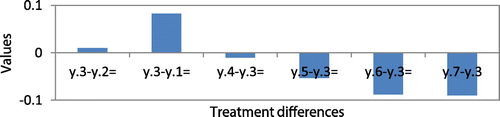
Table A1. ANOVA for 47 items for Case 1 when forecast error is present and does not vary across classes A, B, and C.
Table A2. Comparing treatment means for 47 items for Case 1.
Table A3. Service-cost performance index of MCIC models for example 2 and Case 1: when forecast error does not vary across classes A, B, and C (CSLs of 99, 95, and 90% for classes A, B, and C, respectively).
Table A4. Service-cost performance index of MCIC models for example 2 and Case 2: when forecast error varies across classes A, B, and C (CSLs of 99, 95, and 90% for classes A, B, and C, respectively).